
Abstract
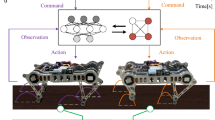
RoboCup 3D Soccer Simulation is a robot soccer competition based on a high-fidelity simulator with autonomous humanoid agents, making it an interesting testbed for robotics and artificial intelligence. Due to the recent success of Deep Reinforcement Learning (DRL) in continuous control tasks, many teams have been using this technique to develop motions in Soccer 3D. This article focuses on learning humanoid robot behaviors: completing a racing track as fast as possible and dribbling against a single opponent. Our approach uses a hierarchical controller where a model-free policy learns to interact model-based walking algorithm. Then, we use DRL algorithms for an agent to learn how to perform these behaviors. Finally, the learned dribble policy was evaluated in the Soccer 3D environment. Simulated experiments show that the DRL agent wins against the hand-coded behavior used by the ITAndroids robotics team in 68.2% of dribble attempts.
Similar content being viewed by others

Availability of data and material
No extra data or material is available.
Code Availability
The source code for the client is available at:
References
Simspark. http://simspark.sourceforge.net/wiki/index.php/Main_Page (2004)
Abdolmaleki, A., Simões, D., Lau, N., Reis, L.P., Neumann, G., Sarıel, S., Lee, D.D. Behnke, S., Sheh, R. (eds.): Learning a humanoid kick with controlled distance. Springer International Publishing, Cham (2017)
Abrel, M., Reis, L.P., Lau, N.: Learning to run faster in a humanoid robot soccer environment through reinforcement learning. In: Proceedings of the 2019 RoboCup Symposium. RoboCup, Australia (2019)
Al-Shedivat, M., Bansal, T., Burda, Y., Sutskever, I., Mordatch, I., Abbeel, P.: Continuous adaptation via meta-learning in nonstationary and competitive environments. arXiv:1710.03641(2017)
Alcaraz-Jiménez, J., Herrero-Perez, D., Barberá, H: A closed-loop dribbling gait for the standard platform league (2014)
Bansal, T., Pachocki, J., Sidor, S., Sutskever, I., Mordatch, I.: Emergent complexity via multi-agent competition. arXiv:1710.03748 (2017)
Barto, A.G., Sutton, R.S., Anderson, C.W.: Neuronlike adaptive elements that can solve difficult learning control problems (1983)
Bengio, Y., Courville, A.C., Vincent, P.: Unsupervised feature learning and deep learning: A review and new perspectives. arXiv:1206.5538 (2012)
Bengio, Y., Louradour, J., Collobert, R., Weston, J.: Curriculum learning. In: Proceedings of the 26th Annual International Conference on Machine Learning, ICML ’09, pp. 41–48. ACM, New York (2009), https://doi.org/10.1145/1553374.1553380
Bergstra, J., Bengio, Y.: Random search for hyper-parameter optimization. J. Mach. Learn. Res. 13, 281–305 (2012). http://dl.acm.org/citation.cfm?id=2188385.2188395
Carvalho Melo, D., Quartucci Forster, C.H., Omena de Albuquerque Máximo, M.R.: Learning when to kick through deep neural networks. In: 2019 Latin American Robotics Symposium (LARS), 2019 Brazilian Symposium on Robotics (SBR) and 2019 Workshop on Robotics in Education (WRE), pp. 43–48 (2019)
Carvalho Melo, L., Omena Albuquerque Máximo, M.R.: Learning humanoid robot running skills through proximal policy optimization. In: 2019 Latin American Robotics Symposium (LARS), 2019 Brazilian Symposium on Robotics (SBR) and 2019 Workshop on Robotics in Education (WRE), pp. 37–42 (2019)
Depinet, M., MacAlpine, P., Stone, P. Bianchi, R.A.C., Akin, H.L., Ramamoorthy, S., Sugiura, K. (eds.): Keyframe sampling, optimization, and behavior integration: Towards long-distance kicking in the Robocup 3D simulation league. Springer, Berlin (2015)
Dhariwal, P., Hesse, C., Plappert, M., Radford, A., Schulman, J., Sidor, S., Wu, Y., Openai baselines. https://github.com/openai/baselines (2017)
Duan, Y., Chen, X., Houthooft, R., Schulman, J., Abbeel, P.: Benchmarking deep reinforcement learning for continuous control. arXiv:1604.06778 (2016)
Farchy, A., Barrett, S., MacAlpine, P., Stone, P.: Humanoid robots learning to walk faster: From the real world to simulation and back. In: Proc. of 12Th Int. Conf. on Autonomous Agents and Multiagent Systems (AAMAS). AAMAS, Saint Paul (2013)
Farchy, A., Barrett, S., MacAlpine, P., Stone, P.: Humanoid Robots Learning to Walk Faster: From the Real World to Simulation and Back. In: Proc. of 12Th Int. Conf. on Autonomous Agents and Multiagent Systems (AAMAS) (2013)
Florensa, C., Held, D., Wulfmeier, M., Abbeel, P.: Reverse curriculum generation for reinforcement learning. arXiv:1707.05300 (2017)
Frans, K., Ho, J., Chen, X., Abbeel, P., Schulman, J.: Meta learning shared hierarchies. arXiv:1710.09767 (2017)
Gabel, T., Riedmiller, M., Trost, F.: A Case Study on Improving Defense Behavior in Soccer Simulation 2D: The NeuroHassle Approach, pp. 61–72. Springer, Berlin (2009)
Google: Protocol buffers. https://developers.google.com/protocol-buffers/ (2017)
Haarnoja, T., Zhou, A., Abbeel, P., Levine, S.: Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor (2018)
Hausknecht, M., Stone, P.: Deep reinforcement learning in parameterized action space. In: Proceedings of the International Conference on Learning Representations (ICLR). ICLR, San Juan (2016)
Heess, N., TB, D., Sriram, S., Lemmon, J., Merel, J., Wayne, G., Tassa, Y., Erez, T., Wang, Z., Eslami, S.M.A., Riedmiller, M., Silver, D.: Emergence of locomotion behaviours in rich environments (2017)
Kajita, S., Kanehiro, F., Kaneko, K., Yokoi, K., Hirukawa, H.: The 3D linear inverted pendulum mode: A simple modeling for a biped walking pattern generation. In: Proceedings of the 2001 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, Hawaii (2001)
Kim, J., Kim, B., Yoon, J., Lee, M., Jung, S.Y., Choi, J.: Robot soccer using deep q network. In: 2018 International Conference on Platform Technology and Service (Platcon), pp. 1–6 (2018)
Kitano, H., Asada, M., Kuniyoshi, Y., Noda, I., Osawa, E., Matsubara, H.: Robocup: A challenge problem for ai. AI Magazine 18(1), 73 (1997). https://doi.org/10.1609/aimag.v18i1.1276. https://aaai.org/ojs/index.php/aimagazine/article/view/1276
Leottau, D.L., del Solar, J.R., MacAlpine, P., Stone, P.: A study of layered learning strategies applied to individual behaviors in robot soccer. In: Almeida, L., Ji, J., Steinbauer, G., Luke, S. (eds.) RoboCup-2015: Robot Soccer World Cup XIX, Lecture Notes in Artificial Intelligence. Springer, Berlin (2016)
Leottau, L., Celemin, C., del solar, J.R.: Ball dribbling for humanoid biped robots: A reinforcement learning and fuzzy control approach (2014)
Lillicrap, T.P., Hunt, J.J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., Silver, D., Wierstra, D.: Continuous control with deep reinforcement learning. arXiv:1509.02971 (2015)
MacAlpine, P., Barrett, S., Urieli, D., Vu, V., Stone, P.: Design and optimization of an omnidirectional humanoid walk: A winning approach at the roboCup 2011 3D simulation competition. In: Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence (AAAI). AAAI, Toronto (2012)
MacAlpine, P., Stone, P.: Overlapping layered learning. Artificial Intelligence 254, 21–43 (2018). https://doi.org/10.1016/j.artint.2017.09.001. https://www.sciencedirect.com/science/article/pii/S0004370217301066
MacAlpine, P., Stone, P.: Overlapping layered learning. Artificial Intelligence 254, 21–43 (2018). https://doi.org/10.1016/j.artint.2017.09.001. https://www.sciencedirect.com/science/article/pii/S0004370217301066
MacAlpine, P., Stone, P.: UT Austin Villa: RoboCup 2017 3D simulation league competition and technical challenges champions. In: Sammut, C., Obst, O., Tonidandel, F., Akyama, H. (eds.) RoboCup 2017: Robot Soccer World Cup XXI, Lecture Notes in Artificial Intelligence. Springer, Berlin (2018)
Matiisen, T., Oliver, A., Cohen, T., Schulman, J.: Teacher-student curriculum learning. arXiv:1707.00183 (2017)
Maximo, M.R., Colombini, E.L., Ribeiro, C.H.: Stable and fast model-free walk with arms movement for humanoid robots. Int. J. Adv. Robot. Syst 14(3), 1729881416675135 (2017). https://doi.org/10.1177/1729881416675135
Maximo, M.R.O.A.: Omnidirectional Zmp-based walking for a humanoid robot. Master’s thesis, Instituto Tecnológico de Aeronáutica (2015)
Maximo, M.R.O.A., Ribeiro, C.H.C.: ZMP-based humanoid walking engine with arms movement and stabilization. In: Proceedings of the 2016 Congresso Brasileiro de Automática (CBA), SBA. Vitória, Brazil (2016)
de Medeiros, T.F., de Máximo, A., M.R.O., Yoneyama, T.: Deep reinforcement learning applied to ieee very small size soccer strategy. In: 2020 Latin American Robotics Symposium (LARS), 2020 Brazilian Symposium on Robotics (SBR) and 2020 Workshop on Robotics in Education (WRE), pp. 1–6 (2020), https://doi.org/10.1109/LARS/SBR/WRE51543.2020.9306954
Melo, D., Soares, E.E., Moreira, E., Muniz, F., Marra, G., Nahum, G., Lopes, H., Saraiva, J.L., José Otávio Vidal, J.F., Melo, L., Maximo, M.: Itandroids soccer3d team description paper 2017. https://www.robocup2017.org/file/symposium/soccer_sim_3D/ITAndroids3D_TDP.pdf (2017)
Melo, D.C., Máximo, M. R. O. A., da Cunha, A.M.: Push recovery strategies through deep reinforcement learning. In: 2020 Latin American Robotics Symposium (LARS), 2020 Brazilian Symposium on Robotics (SBR) and 2020 Workshop on Robotics in Education (WRE), pp. 1–6 (2020), https://doi.org/10.1109/LARS/SBR/WRE51543.2020.9306967
Melo, L.C.: Imitation Learning and Meta-Learning for Optimizing Humanoid Robot Motions. Master’s Thesis, Instituto tecnológico de aeronáutica, são josé dos Campos, SP Brazil (2019)
Melo, L.C., Maximo, M.R.O.A., da Cunha, A.M.: Bottom-up meta-policy search. In: Proceedings of the Deep Reinforcement Learning Workshop of NeurIPS 2019 (2019)
Melo, L.C., Melo, D.C., Maximo, M.R.O.A.: Learning humanoid robot running motions with symmetry incentive through proximal policy optimization. Journal of Intelligent &, Robotic Systems 102(3), 54 (2021). https://doi.org/10.1007/s10846-021-01355-9
Mnih, V., Badia, A.P., Mirza, M., Graves, A., Lillicrap, T.P., Harley, T., Silver, D., Kavukcuoglu, K.: Asynchronous methods for deep reinforcement learning. arXiv:1602.01783 (2016)
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A.A., Veness, J., Bellemare, M.G., Graves, A., Riedmiller, M., Fidjeland, A.K., Ostrovski, G., Petersen, S., Beattie, C., Sadik, A., Antonoglou, I., King, H., Kumaran, D., Wierstra, D., Legg, S., Hassabis, D.: Human-level control through deep reinforcement learning. Nature 518(7540), 529–533 (2015). https://doi.org/10.1038/nature14236. Letter
Muniz, F., Maximo, M.R., Ribeiro, C.H.: Keyframe movement optimization for simulated humanoid robot using a parallel optimization framework. In: 2016 XIII Latin American Robotics Symposium and IV Brazilian Robotics Symposium (LARS/SBR), pp. 79–84 (2016), https://doi.org/10.1109/LARS-SBR.2016.20
Muzio, A., Melo, D., Henrique, E., Muniz, F., Marzzo, I., Saraiva, J.L., Melo, L., Aguiar, L.G., Maximo, M., Bertolino, M.: Itandroids soccer3d team description paper 2016. http://www.robocup2016.org/media/symposium/Team-Description-Papers/Simulation3D/RoboCup_2016_Sim3D_TDP_ITAndroids3D.pdf/ (2016)
Muzio, A.F.V.: Curriculum-based Deep Reinforcement Learning Applied to Humanoid Robots. Master’s Thesis, Instituto tecnológico de aeronáutica, são josé dos Campos, SP Brazil (2018)
Muzio, A.F.V., Maximo, M.R.A., Yoneyama, T.: Deep reinforcement learning for humanoid robot dribbling. In: 2020 Latin American Robotics Symposium (LARS), 2020 Brazilian Symposium on Robotics (SBR) and 2020 Workshop on Robotics in Education (WRE), pp. 1–6 (2020), https://doi.org/10.1109/LARS/SBR/WRE51543.2020.9307084
Obst, O., Murray, J., Boedecker, J., Rollmann, M., Ebrahimi, M., Vatankhah, H., van Dijk, S., Yuan, X.: Simspark effectors. https://gitlab.com/robocup-sim/SimSpark/wikis/Effectors (2004)
ODE: Open dynamics engine (ode). http://www.ode.org/ (2004)
Peng, X.B., Berseth, G., Yin, K., van de Panne, M.: Deeploco: Dynamic locomotion skills using hierarchical deep reinforcement learning. ACM Transactions on Graphics Proc SIGGRAPH 36(4), 2017 (2017)
Peng, X.B., Chang, M., Zhang, G., Abbeel, P., Levine, S.: Mcp: Learning composable hierarchical control with multiplicative compositional policies. In: Wallach, H., Larochelle, H., Beygelzimer, A., D’Alché-Buc, F., Fox, E., Garnett, R. (eds.) Advances in Neural Information Processing Systems, vol. 32, pp. 3681–3692. Curran Associates Inc (2019). http://papers.nips.cc/paper/8626-mcp-learning-composable-hierarchical-control-with-multiplicative-compositional-policies.pdf
Plappert, M., Houthooft, R., Dhariwal, P., Sidor, S., Chen, R.Y., Chen, X., Asfour, T., Abbeel, P., Andrychowicz, M.: Parameter space noise for exploration. arXiv:1706.01905 (2017)
Robotics, S.: Nao robot. https://www.ald.softbankrobotics.com/en/robots/nao (2018)
Schulman, J., Levine, S., Moritz, P., Jordan, M.I., Abbeel, P.: Trust region policy optimization. arXiv:1502.05477 (2015)
Schulman, J., Moritz, P., Levine, S., Jordan, M.I., Abbeel, P.: High-dimensional continuous control using generalized advantage estimation. In: Bengio, Y. (ed.) 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings. arXiv:1506.02438 (2016)
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv:1707.06347 (2017)
Schwab, D.: Robot deep reinforcement learning: Tensor state-action spaces and auxiliary task learning with multiple state representations. Ph.D. thesis, Carnegie Mellon University (2020)
Silver, D., Lever, G., Heess, N., Degris, T., Wierstra, D., Riedmiller, M.: Deterministic policy gradient algorithms. In: Proceedings of the 31st International Conference on International Conference on Machine Learning - vol 32, ICML’14, pp. I–387–I–395. JMLR.org. http://dl.acm.org/citation.cfm?id=3044805.3044850 (2014)
Spitznagel, M., Weiler, D., Dorer, K.: Deep reinforcement multi-directional kick-learning of a simulated robot with toes. In: 2021 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), pp. 104–110 (2021), https://doi.org/10.1109/ICARSC52212.2021.9429811
Stoecker, J.: Roboviz. https://github.com/magmaOffenburg/RoboViz (2011)
Sutton, R.S., Barto, A.G.: Introduction to Reinforcement Learning, 1st edn. MIT Press, Cambridge (1998)
Urieli, D., MacAlpine, P., Kalyanakrishnan, S., Bentor, Y., Stone, P.: On optimizing interdependent skills: A case study in simulated 3d humanoid robot soccer. In: Tumer, K., Yolum, P., Sonenberg, L., Stone, P. (eds.) Proc. of 10th Int. Conf. on Autonomous Agents and Multiagent Systems (AAMAS), vol. 2, pp. 769–776. IFAAMAS (2011)
Wang, Z., Bapst, V., Heess, N., Mnih, V., Munos, R., Kavukcuoglu, K., de Freitas, N.: Sample efficient actor-critic with experience replay. arXiv:1611.01224 (2016)
Watkins, C.J.C.H.: Learning from delayed rewards. Ph.D. thesis, King’s College (1989)
Wiliams, R.J.: Simple statistical gradient-following algorithms for connectionist reinforcement learning (1992)
Zaremba, W., Sutskever, I.: Learning to execute. arXiv:1410.4615 (2014)
Acknowledgements
The authors acknowledge the ITAndroids’ Soccer3D team for developing the code base used in this work. Moreover, we would like to thank ITAndroids’ sponsors: Altium, Cenic, Intel, ITAEx, Mathworks, Metinjo, Micropress, Polimold, Rapid, Solidworks, ST Microelectronics, WildLife, and Virtual Pyxis.
Funding
Alexandre Muzio received an Master’s scholarship from CAPES (number 88882.161989/2017-01). Takashi Yoneyama is partially funded by CNPq – National Research Council of Brasil through the grant 304134/2-18-0.
Author information
Authors and Affiliations
Contributions
All authors have contributed to the concept and design of the research. Alexandre Muzio is the main contributor: he developed the RL formulations, implemented the source code, and executed the experiments. Marcos Maximo and Takashi Yoneyama assumed advisor roles during the research, discussing ideas and providing insights when needed. Marcos Maximo prepared this manuscript based on material previously written by Alexandre Muzio. Takashi Yoneyama further contributed by revising the text. The final manuscript was revised and approved by all authors.
Corresponding author
Ethics declarations
Conflict of Interests
The authors declare that they have no conflicts of interest/competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Muzio, A.F.V., Maximo, M.R.O.A. & Yoneyama, T. Deep Reinforcement Learning for Humanoid Robot Behaviors. J Intell Robot Syst 105, 12 (2022). https://doi.org/10.1007/s10846-022-01619-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10846-022-01619-y