
Abstract
This paper presents a novel approach to the visualization of research domains in science and technology. The proposed methodology is based on the use of bibliometrics; i.e., analysis is conducted using information regarding trends and patterns of publication rather than the actual content. In particular, we explore the use of term co-occurrence frequencies as an indicator of semantic closeness between pairs of terms. To demonstrate the utility of this approach, a number of visualizations are generated for a collection of renewable energy related keywords. As these keywords are regarded as manifestations of the associated research topics, we contend that the proposed visualizations can be interpreted as representations of the underlying technology landscape.







Similar content being viewed by others
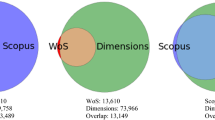
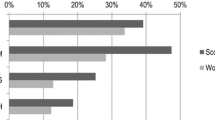
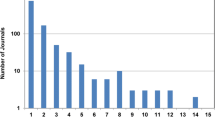
Notes
Year 2005. Source: Energy Information Administration, DOE, US Government.
References
Antolín, G., Tinaut, F. V., Briceño, Y., Castaño, V., Pérez, C., & Ramírez, A. I. (2002). Optimisation of biodiesel production by sunflower oil transesterification. Bioresource Technology, 83(2), 111–114.
Anuradha, K., & Urs, S. (2007). Bibliometric indicators of indian research collaboration patterns: A correspondence analysis. Scientometrics, 71(2), 179–189.
Baek, N. C., Shin, U. C., & Yoon, J. H. (2005). A study on the design and analysis of a heat pump heating system using wastewater as a heat source. Solar Energy, 78(3), 427–440.
Bengisu, M., & Nekhili, R. (2006). Forecasting emerging technologies with the aid of science and technology databases. Technological Forecasting and Social Change, 73(7), 835–844.
Bishop, C. (1995). Neural networks for pattern recognition. London: Oxford University Press.
Bishop, C. (2006). Pattern recognition and machine learning. Information science and statistics. Singapore: Springer.
Börner, K., Dall’Asta, L., Ke, W., & Vespignani, A. (2005). Studying the emerging global brain: Analyzing and visualizing the impact of co-authorship teams. Complexity, 10(4), 57–67.
Braun, T., Schubert, A. P., & Kostoff, R. N. (2000). Growth and trends of fullerene research as reflected in its journal literature. Chemical Reviews, 100(1), 23–38.
Chiu, W.-T., & Ho, Y.-S. (2007). Bibliometric analysis of tsunami research. Scientometrics, 73(1), 3–17.
Cilibrasi, R., & Vitanyi, P. (2006). Automatic extraction of meaning from the web. In IEEE international symp. information theory.
Cilibrasi, R. L., & Vitanyi, P. M. B. (2007). The Google similarity distance. IEEE Transactions on Knowledge and Data Engineering, 19(3), 370–383.
Daim, T. U., Rueda, G., Martin, H., & Gerdsri, P. (2006). Forecasting emerging technologies: Use of bibliometrics and patent analysis. Technological Forecasting and Social Change, 73(8), 981–1012.
Daim, T. U., Rueda, G. R., & Martin, H. T. (2005). Technology forecasting using bibliometric analysis and system dynamics. In Technology management: A unifying discipline for melting the boundaries (pp. 112–122).
de Miranda, C., Dos, G. M., & Filho, L. F. (2006). Text mining as a valuable tool in foresight exercises: A study on nanotechnology. Technological Forecasting and Social Change, 73(8), 1013–1027.
Ding, Y., Chowdhury, G., & Foo, S. (2001). Bibliometric cartography of information retrieval research by using co-word analysis. Information Processing & Management, 37(6), 817–842.
Elnekave, M. (2008). Adsorption heat pumps for providing coupled heating and cooling effects in olive oil mills. International Journal of Energy Research, 32(6), 559–568.
Glänzel, W., & Schubert, A. (2005). Analysing scientific networks through co-authorship. In Handbook of quantitative science and technology research (pp. 257–276).
Hansel, A., & Lindblad, P. (1998). Towards optimization of cyanobacteria as biotechnologically relevant producers of molecular hydrogen, a clean and renewable energy source. Applied Microbiology and Biotechnology, 50(2), 153–160.
Igami, M. (2008). Exploration of the evolution of nanotechnology via mapping of patent applications. Scientometrics, 77(2), 289–308.
Janssens, F., Leta, J., Glänzel, W., & De Moor, B. (2006). Towards mapping library and information science. Information Processing & Management, 42(6), 1614–1642.
Kajikawa, Y., & Takeda, Y. (2008). Structure of research on biomass and bio-fuels: A citation-based approach. Technological Forecasting and Social Change, 75(9), 1349–1359.
Kajikawa, Y., Yoshikawa, J., Takeda, Y., & Matsushima, K. (2007). Tracking emerging technologies in energy research: Toward a roadmap for sustainable energy. Technological Forecasting and Social Change, 75(6), 771–782.
Kim, M.-J. (2007). A bibliometric analysis of the effectiveness of Korea’s biotechnology stimulation plans, with a comparison with four other Asian nations. Scientometrics, 72(3), 371–388.
King, D. A. (2004). The scientific impact of nations. Nature, 430(6997), 311–316.
Kostoff, R. N. (2001). Text mining using database tomography and bibliometrics: A review. Technological Forecasting and Social Change, 68, 223–253.
Losiewicz, P., Oard, D., & Kostoff, R. (2000). Textual data mining to support science and technology management. Journal of Intelligent Information Systems, 15(2), 99–119.
Manning, C., Raghavan, P., & Schütze, H. (2008). Introduction to information retrieval (Vol. 1). Cambridge: Cambridge University Press.
Martino, J. (1993). Technological forecasting for decision making. McGraw-Hill Engineering and Technology Management Series.
Mcdowall, W., & Eames, M. (2006). Forecasts, scenarios, visions, backcasts and roadmaps to the hydrogen economy: A review of the hydrogen futures literature. Energy Policy, 34(11), 1236–1250.
Morel, C., Serruya, S., Penna, G., & Guimarães, R. (2009). Co-authorship network analysis: A powerful tool for strategic planning of research, development and capacity building programs on neglected diseases. PLoS Neglected Tropical Diseases, 3(8), e501.
Porter, A. (2005). Tech mining. Competitive Intelligence Magazine, 8(1), 30–36.
Porter, A. (2007). How “tech mining” can enhance R&D management. Research Technology Management, 50(2), 15–20.
Porter, A., & Rafols, I. (2009). Is science becoming more interdisciplinary? Measuring and mapping six research fields over time. Scientometrics, 81(3), 719–745.
Porter, A., Roper, A., Mason, T., Rossini, F., & Banks, J. (1991). Forecasting and management of technology. New York: Wiley-Interscience.
Saitou, N., & Nei, M. (1987). The neighbor-joining method: A new method for reconstructing phylogenetic trees. Molecular Biology and Evolution, 4(4), 406–425.
Saka, A., & Igami, M. (2007). Mapping modern science using co-citation analysis. In IV ’07: Proceedings of the 11th international conference information visualization, Washington, DC, U.S.A. (pp. 453–458). Los Alamitos: IEEE Computer Society.
Sammon, J. (1969). A nonlinear mapping for data structure analysis. IEEE Transactions on Computers, 100(18), 401–409.
Smalheiser, N. R. (2001). Predicting emerging technologies with the aid of text-based data mining: The micro approach. Technovation, 21(10), 689–693.
Small, H. (2006). Tracking and predicting growth areas in science. Scientometrics, 68(3), 595–610.
Takeda, Y., & Kajikawa, Y. (2009). Optics: A bibliometric approach to detect emerging research domains and intellectual bases. Scientometrics, 78(3), 543–558.
Takeda, Y., Mae, S., Kajikawa, Y., & Matsushima, K. (2009). Nanobiotechnology as an emerging research domain from nanotechnology: A bibliometric approach. Scientometrics, 80(1), 23–38.
Upham, S., & Small, H. (2010). Emerging research fronts in science and technology: Patterns of new knowledge development. Scientometrics, 83(1), 15–38.
Van Der Heijden, K. (2000). Scenarios and forecasting—Two perspectives. Technological Forecasting and Social Change, 65, 31–36.
Woon, W., & Madnick, S. (2009). Asymmetric information distances for automated taxonomy construction. Knowledge and Information Systems, 21, 91–111. doi:10.1007/s10115-009-0203-5.
Woon, W. L., Zeineldin, H., & Madnick, S. (2011). Bibliometric analysis of distributed generation. Technological Forecasting and Social Change, 78(3), 408–420.
Zhu, D., & Porter, A. (2002). Automated extraction and visualization of information for technological intelligence and forecasting. Technological Forecasting and Social Change, 69(5), 495–506.
Acknowledgements
We would like to thank the Masdar Institute of Science and Technology (MIST) and the Masdar Initiative for their support of this work.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: Renewable energy related keywords
1.1 A.1 Keywords from Kajikawa et al.
Combustion, coal, battery, petroleum, fuel cell, wastewater, heat pump, engine, solar cell, power system.
1.2 A.2 Author keywords
Biomass, CDS, CDTE, energy efficiency, gasification, global warming, least-cost energy policies, power generation, populus, qtl, renewable energy, review, sustainable farming and forestry, adsorption, alternative fuel, arabidopsis, ash deposits, bio-fuels, biodiesel, biomass, biomass-fired power boilers, carbon nanotubes, chemicals, co-firing, coal, corn stover, electricity, emissions, energy balance, energy conversion, energy economy and management, energy policy, energy sources, enzymatic digestion, fast pyrolysis, fuels, gas engines, gas storage, gasification, genome sequence, genomics, high efficiency, hydrolysis, inorganic material, investment, landfill, model plant, natural gas, poplar, pretreatment, pyrolysis, renewable energy, renewables, sugars, sunflower oil, thermal conversion, thermal processing, thin films, transesterification.
1.3 A.3 Keyword plus
16s ribosomal-rna, activation, active-site, adsorption, agrobacterium-mediated transformation, anabaena-variabilis, anacystis-nidulans, aqueous ammonia, bidirectional hydrogenase, biomass conversion processes, briquettes, canopy structure, catalysts, cds, cdte, cells, cellulases, cellulose, ch4, chalcopyrite, charge-transfer dynamics, chemical heat pipe, co2, cocombustion, combustion, composites, conversion, corn stover, coupled electron-transfer, devolatilization, diesel-power-plant, differentiation, dye, efficiency, electrocatalytic hydrogen evolution, electrochemical reduction, electrodes, electron-transfer, elemental sulfur, energy, enzymatic-hydrolysis, families, fermi-level equilibration, films, fimi, flash pyrolysis, fluidized-bed, fuel, fuel-cell vehicles, fuels, functionalized gold nanoparticles, gasification, gasoline, gel electrolyte, gene-transfer, genetic-linkage maps, glycosyl hydrolases, grain morphology, graphite nanofibers, herbaceous biomass, homogeneous catalysis, hybrid poplar, hydrogen, hydrogen-peroxide, hydrogen-production, hydrolysis, ignition, infrastructure, kinetics, light interception, lignin removal, lignocellulosic materials, lime pretreatment, liquefaction, liquid, liquids, mechanisms, metal-complexes, metals, molecular-genetics, monte-carlo simulations, mutagenesis, nanocrystalline semiconductor-films, nickel, nitrogen-fixation, open-top chambers, oxidative addition, partial oxidation, particles, photoelectrochemical cells, photoelectrochemical properties, photoinduced electron-transfer, photonic crystals, photoproduction, photosystem-ii, physisorption, place-exchange-reactions, pores, pressure cooking, products, proton reduction, pulverized coal, pyrolysis, rapd markers, recombination, recycled percolation process, ruthenium polypyridyl complex, seawater, sediment, sensitized nanocrystalline TiO2, sensitizers, short-rotation, solar furnace, solar-cells, sp strain atcc-29133, sputtering deposition method, step gene replacement, surface-plasmon resonance, synergism, synthesis gas, system, TiO2 films, TiO2 thin-films, titanium-dioxide films, transgenic poplar, transport, trichoderma-reesei qm-9414, values, walled carbon nanotubes, waste paper, water-oxidation, wheat-straw mixtures, wood.
Appendix B: Additional visualizations
1.1 B.1 Author keywords
In this appendix, alternative visualizations/clusterings generated using the author-generated keywords are presented. As mentioned in Section 4.1, two alternative forms are presented here. The first, which is shown in Fig. 8, uses Sammon Mapping to generate a topographic representation of the inter-keyword distances. Secondly, k-means clusters were generated using the Jaccard distance, which was described in Section 3.1. This is presented in Table 3. We note that:
-
(1)
As discussed in Section 4.1, as well as by the labeling of highly similar clusters found in Fig. 8, the different visualizations were broadly in agreement with the earlier results as to the overall structure of the research landscape.
-
(2)
However, at the same time, the representations are not identical; this is not surprising since most of these methods are non-linear and would result in distortion and “stretching” of the visualization space.
-
(3)
While the results were consistent with the earlier results, we felt that the visualizations obtained using the Google distance followed by hierarchical clustering or k-means tended to be clearer.
-
(4)
For e.g., the Sammon map shown in Fig. 8 is quite difficult to read except under very high magnification. This is a result of the Sammon mapping technique which, by definition, places similar nodes very close to each other in the visualization space; in many cases this resulted in overlapping terms, while on the other hand large sections of the visualization space remained relatively sparse.
-
(5)
Also, when using the Jaccard distance the clusters tended to be more unbalanced. For e.g. in Table 3, we see that many of the keywords have been lumped together in cluster JK1. This implies that the mapping induced by the Jaccard distance was not able to achieve a good uniform “spread” of the keywords.

Sammon map of author keywords data. Thematic clusters have been highlighted, and where possible have been linked to clusters found in the hierarchical maps
1.2 B.2 Keyword plus
Similar trends were observed here as with the previous sub-section. Again, the broad structure of the research landscape seems to have been preserved. As before, Sammon Mapping (shown in Figs. 9 and 10) resulted in a somewhat cluttered representation of the landscape, while application of the k-means algorithm to the Jaccard distances again resulted in a less uniform distribution of keywords amongst clusters, where it can be seen that there are a significant number of clusters with only one keyword or phrase (nine such clusters were found in Table 4, as compared to only one such cluster in Table 2).

Sammon map of keyword plus terms, set 1. Thematic clusters have been highlighted, and where possible have been linked to clusters found in the hierarchical maps

Sammon map of author keyword plus terms, set 2. Thematic clusters have been highlighted, and where possible have been linked to clusters found in the hierarchical maps
Rights and permissions
About this article
Cite this article
Woon, W.L., Madnick, S. Semantic distances for technology landscape visualization. J Intell Inf Syst 39, 29–58 (2012). https://doi.org/10.1007/s10844-011-0182-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10844-011-0182-3