
Abstract
We present fast methods for filtering voltage measurements and performing optimal inference of the location and strength of synaptic connections in large dendritic trees. Given noisy, subsampled voltage observations we develop fast l 1-penalized regression methods for Kalman state-space models of the neuron voltage dynamics. The value of the l 1-penalty parameter is chosen using cross-validation or, for low signal-to-noise ratio, a Mallows’ C p -like criterion. Using low-rank approximations, we reduce the inference runtime from cubic to linear in the number of dendritic compartments. We also present an alternative, fully Bayesian approach to the inference problem using a spike-and-slab prior. We illustrate our results with simulations on toy and real neuronal geometries. We consider observation schemes that either scan the dendritic geometry uniformly or measure linear combinations of voltages across several locations with random coefficients. For the latter, we show how to choose the coefficients to offset the correlation between successive measurements imposed by the neuron dynamics. This results in a “compressed sensing” observation scheme, with an important reduction in the number of measurements required to infer the synaptic weights.















Similar content being viewed by others



Notes
1 Available at http://neuromorpho.org.
2 We omit from here on the indices \(j,j'\) in W ij and \(M_{ij,i'j'}\) to simplify the notation.
3 This is a recasting of Lemma 4 in Efron et al. (2004).
4 We have verified, through Monte Carlo simulations similar to those in Zou et al. (2007), that this result also holds in the positive constrained case.
References
Barbour, B., Brunel, N., Hakim, V., Nadal, J.-P. (2007). What can we learn from synaptic weight distributions? TRENDS in Neurosciences, 30(12), 622–629.
Bloomfield, S., & Miller, R. (1986). A functional organization of ON and OFF pathways in the rabbit retina. Journal of Neuroscience, 6(1), 1–13.
Candes, E., Romberg, J., Tao, T. (2006). Stable signal recovery from incomplete and inaccurate measurements. Communications on Pure and Applied Mathematics, 59(8), 1207–1223.
Candès, E., & Wakin, M. (2008). An introduction to compressive sampling. IEEE Signal Processing Magazine, 25(2), 21–30.
Canepari, M., Djurisic, M., Zecevic, D. (2007). Dendritic signals from rat hippocampal CA1 pyramidal neurons during coincident pre- and post-synaptic activity: a combined voltage- and calcium-imaging study. Journal of Physiology, 580(2), 463–484.
Canepari, M., Vogt, K., Zecevic, D. (2008). Combining voltage and calcium imaging from neuronal dendrites. Cellular and Molecular Neurobiology, 28, 1079–1093.
Djurisic, M., Antic, S., Chen, W.R., Zecevic, D. (2004). Voltage imaging from dendrites of mitral cells: EPSP attenuation and spike trigger zones. Journal of Neuroscience, 24(30), 6703–6714.
Djurisic, M., Popovic, M., Carnevale, N., Zecevic, D. (2008). Functional structure of the mitral cell dendritic tuft in the rat olfactory bulb. Journal of Neuroscience, 28(15), 4057–4068.
Dombeck, D.A., Blanchard-Desce, M., Webb, W.W. (2004). Optical recording of action potentials with second-harmonic generation microscopy. Journal of Neuroscience, 24(4), 999–1003.
Durbin, J., Koopman, S., Atkinson, A. (2001). Time series analysis by state space methods (Vol. 15). Oxford: Oxford University Press.
Efron, B. (2004). The estimation of prediction error. Journal of the American Statistical Association, 99(467), 619–632.
Efron, B., Hastie, T., Johnstone, I., Tibshirani, R. (2004). Least angle regression. Annals of Statistics, 32, 407–499.
Fisher, J.A.N., Barchi, J.R., Welle, C.G., Kim, G.-H., Kosterin, P., Obaid, A.L., Yodh, A.G., Contreras, D., Salzberg, B.M. (2008). Two-photon excitation of potentiometric probes enables optical recording of action potentials from mammalian nerve terminals in situ. Journal of Neurophysiology, 99(3), 1545–1553.
Friedman, J., Hastie, T., Höfling, H., Tibshirani, R. (2007). Pathwise coordinate optimization. The Annals of Applied Statistics, 1(2), 302–332.
Friedman, J., Hastie, T., Tibshirani, R. (2008). The elements of statistical learning. Springer.
Gelman, A., Carlin, J., Stern, H., Rubin, D. (2004). Bayesian data analysis. CRC press.
Geman, S., Bienenstock, E., Doursat, R. (1992). Neural networks and the bias/variance dilemma. Neural Computation, 4(1), 1–58.
Gobel, W., & Helmchen, F. (2007). New angles on neuronal dendrites in vivo. Journal of Neurophysiology, 98(6), 3770–3779.
Hines, M. (1984). Efficient computation of branched nerve equations. International Journal of Bio-Medical Computing, 15(1), 69–76.
Huber, P. (1964). Robust estimation of a location parameter. The Annals of Mathematical Statistics, 35(1), 73–101.
Huggins, J., & Paninski, L. (2012). Optimal experimental design for sampling voltage on dendritic trees. Journal of Computational Neuroscience (in press).
Huys, Q., Ahrens, M., Paninski, L. (2006). Efficient estimation of detailed single-neuron models. Journal of Neurophysiology, 96, 872–890.
Huys, Q., & Paninski, L. (2009). Model-based smoothing of, and parameter estimation from, noisy biophysical recordings. PLOS Computational Biology, 5, e1000379.
Iyer, V., Hoogland, T.M., Saggau, P. (2006). Fast functional imaging of single neurons using random-access multiphoton (RAMP) microscopy. Journal of Neurophysiology, 95(1), 535–545.
Knopfel, T., Diez-Garcia, J., Akemann, W. (2006). Optical probing of neuronal circuit dynamics: genetically encoded versus classical fluorescent sensors. Trends in Neurosciences, 29, 160–166.
Kralj, J., Douglass, A., Hochbaum, D., Maclaurin, D., Cohen, A. (2011). Optical recording of action potentials in mammalian neurons using a microbial rhodopsin. Nature Methods.
Larkum, M.E., Watanabe, S., Lasser-Ross, N., Rhodes, P., Ross, W.N. (2008). Dendritic properties of turtle pyramidal neurons. Journal of Neurophysiology, 99(2), 683–694.
Lin, Y., & Zhang, H. (2006). Component selection and smoothing in multivariate nonparametric regression. The Annals of Statistics, 34(5), 2272–2297.
Mallows, C. (1973). Some comments on Cp. Technometrics, pp. 661–675.
Milojkovic, B.A., Zhou, W.-L., Antic, S.D. (2007). Voltage and calcium transients in basal dendrites of the rat prefrontal cortex. Journal of Physiology, 585(2), 447–468.
Mishchenko, Y., & Paninski, L. (2012). A Bayesian compressed-sensing approach for reconstructing neural connectivity from subsampled anatomical data. Under review.
Mishchenko, Y., Vogelstein, J., Paninski, L. (2011). A Bayesian approach for inferring neuronal connectivity from calcium fluorescent imaging data. Annals of Applied Statistics, 5, 1229–1261.
Mitchell, T.J., & Beauchamp, J.J. (1988). Bayesian variable selection in linear regression. Journal of the American Statistical Association, 83(404), 1023–1032.
Nikolenko, V., Watson, B., Araya, R., Woodruff, A., Peterka, D., Yuste, R. (2008). SLM microscopy: Scanless two-photon imaging and photostimulation using spatial light modulators. Frontiers in Neural Circuits, 2, 5.
Nuriya, M., Jiang, J., Nemet, B., Eisenthal, K., Yuste, R. (2006). Imaging membrane potential in dendritic spines. PNAS, 103, 786–790.
Pakman, A., & Paninski, L. (2013). Exact hamiltonian Monte Carlo for truncated multivariate gaussians. Journal of Computational and Graphical Statistics, preprint arXiv:1208.4118.
Paninski, L. (2010). Fast Kalman filtering on quasilinear dendritic trees. Journal of Computational Neuroscience, 28, 211–28.
Paninski, L., & Ferreira, D. (2008). State-space methods for inferring synaptic inputs and weights. COSYNE.
Paninski, L., Vidne, M., DePasquale, B., Ferreira, D. (2012). Inferring synaptic inputs given a noisy voltage trace via sequential Monte Carlo methods. Journal of Computational Neuroscience (in press).
Peterka, D., Takahashi, H., Yuste, R. (2011). Imaging voltage in neurons. Neuron, 69(1), 9–21.
Pnevmatikakis, E.A., & Paninski, L. (2012). Fast interior-point inference in high-dimensional sparse, penalized state-space models. Proceedings of the 15th International Conference on Artificial Intelligence and Statistics (AISTATS) 2012, La Palma, Canary Islands. Volume XX of JMLR: W&CP XX.
Pnevmatikakis, E.A., Kelleher, K., Chen, R., Saggau, P., Josić, K., Paninski, L. (2012a). Fast spatiotemporal smoothing of calcium measurements in dendritic trees, submitted. PLoS Computational Biology, 8, e1002569.
Pnevmatikakis, E.A., Paninski, L., Rad, K.R., Huggins, J. (2012b). Fast Kalman filtering and forward-backward smoothing via a low-rank perturbative approach. Journal of Computational and Graphical Statistics (in press).
Press, W., Teukolsky, S., Vetterling, W., Flannery, B. (1992). Numerical recipes in C. Cambridge: Cambridge University Press.
Reddy, G.D., & Saggau, P. (2005). Fast three-dimensional laser scanning scheme using acousto-optic deflectors. Journal of Biomedical Optics, 10(6), 064038.
Sacconi, L., Dombeck, D.A., Webb, W.W. (2006). Overcoming photodamage in second-harmonic generation microscopy: Real-time optical recording of neuronal action potentials. Proceedings of the National Academy of Sciences, 103(9), 3124–3129.
Sjostrom, P.J., Rancz, E.A., Roth, A., Hausser, M. (2008). Dendritic excitability and synaptic plasticity. Physiological Reviews, 88(2), 769–840.
Smith, C. (2013). Low-rank graphical models and Bayesian analysis of neural data: PhD Thesis, Columbia University.
Song, S., Sjöström, P.J., Reigl, M., Nelson, S., Chklovskii, D.B. (2005). Highly nonrandom features of synaptic connectivity in local cortical circuits. PLoS Biology, 3(3), e68.
Studer, V., Bobin, J., Chahid, M., Mousavi, H., Candes, E., Dahan, M. (2012). Compressive fluorescence microscopy for biological and hyperspectral imaging. Proceedings of the National Academy of Sciences, 109(26), E1679–E1687.
Takahashi, N., Kitamura, K., Matsuo, N., Mayford, M., Kano, M., Matsuki, N., Ikegaya, Y. (2012). Locally synchronized synaptic inputs. Science, 335(6066), 353–356.
Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society. Series B, 58, 267–288.
Vucinic, D., & Sejnowski, T.J. (2007). A compact multiphoton 3d imaging system for recording fast neuronal activity. PLoS ONE, 2(8), e699.
Yuan, M., & Lin, Y. (2006). Model selection and estimation in regression with grouped variables. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 68(1), 49–67.
Zou, H., & Hastie, T. (2005). Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 67(2), 301–320.
Zou, H., Hastie, T., Tibshirani, R. (2007). On the degrees of freedom of the lasso. The Annals of Statistics, 35(5), 2173–2192.
Acknowledgments
This work was supported by an NSF CAREER grant, a McKnight Scholar award, and by NSF grant IIS-0904353. This material is based upon work supported by, or in part by, the U. S. Army Research Laboratory and the U. S. Army Research Office under contract number W911NF-12-1-0594. JHH was partially supported by the Columbia College Rabi Scholars Program. AP was partially supported by the Swartz Foundation. The computer simulations were done in the Hotfoot HPC Cluster of Columbia University. We thank E. Pnevmatikakis for helpful discussions and comments.
Conflict of interests
The authors declare that they have no conflict of interest.
Author information
Authors and Affiliations
Corresponding author
Additional information
Action Editor: Misha Tsodyks
Appendices
Appendix A: The quadratic function and the LARS+ algorithm
In this appendix we provide the details of the algorithm used to obtain the solution \(\hat W^{ij}(\lambda )\) for all λ, where \(i=1\ldots N\) indicates the neuron compartment and \(j=1\ldots K\) the presynaptic stimulus associated with the weight. To simplify the notation, define
where these expressions are related by
Let us first obtain an explicit expression for \(Q(W)\). Recall from Section 2 that
Since \(Q(W,V)\) is quadratic and concave in V, we can expand it around its maximum \(\hat {V}(W)\) as
where the NT × NT Hessian
does not depend on Y or W, as is clear from Eq. A.4. Inserting the expansion (A.5) in the integral Eq. A.3 and taking the log, we get
where \(c= -\frac 12 \log |-H_{VV}| + \frac {TN}{2}\log 2\pi \) is independent of W.
Since \(\hat {V}(W)\) is the maximum of \(Q(W,V)\), its value is the solution of \(\nabla _{V} Q(W,V)=0\), given by
where
as follows from Eq. A.4. It is useful to expand \(Z(W)\) as
where the coefficients \(Z_{0}, Z_{ij} \in \mathbb {R}^{NT}\) can be read out from Eq. A.10 and are independent of W. This in turn gives an expansion for \(\hat {V}\) in Eq. A.9 as
where
are independent of W. Note that \(\hat {V}_{0}\) has components
where each \((\hat {V}_{0})_{t}\) is an N-vector, and similarly for each \(\hat {V}_{ij}\).
To obtain the explicit form of \(Q(W)\) one can insert the expansion Eq. A.12 for \(\hat {V}(W)\) in Eq. A.8. But it is easier to notice first, using the chain rule, that
where the second term in Eq. A.16 is zero since \(\hat {V}(W)\) is the maximum for any W. Thus once \(\hat V\) is available, the gradient of Q w.r.t. W is easy to compute, since multiplication by the sparse cable dynamics matrix A is fast. We can now insert Eq. A.12 into the much simpler expression (A.18) to get
with \(i,i' = 1\ldots N\) and \(j,j' = 1 \ldots K\) and coefficients
where \(\delta _{ii^{\prime }}\) is Kronecker’s delta. The desired expression for \(Q(W)\) follows by a simple integration of Eq. A.19 and gives the quadratic expression
where \(i = 1\ldots N, j = 1\ldots K\). Note that the costly step, computationally, is the linear matrix solve involving H VV in Eqs. A.13–A.14 to obtain the components of \(\hat V\), which are then used in Eqs. A.20–A.21 to obtain \(p_{ij}\) and \(M_{ij,i'j'}\) in \(O(T)\) time. Note that we do not need the explicit form of \(H^{-1}_{VV}\), only its action on the vectors \(Z_{0}, Z_{ij}\).
Matrix form of coefficients
For just one presynaptic signal (K = 1), we can express the coefficients of the log-likelihood Eq. A.22 in a compact form by defining the matrices
and \(C^{-1}_{yT} = C^{-1}_{y} I_{ST}\), where \(I_{N}\) and \(I_{ST}\) are identity matrices of the indicated dimensions. Using these matrices, the expansion (A.12) for the estimated voltages is
with
where Y in Eq. A.27 is
The coefficients of the quadratic log-likelihood in Eq. A.22 can now be expressed as
and
where we defined \(||U||^2= \sum\limits _{t=1}^{T-1} U_{t}^{2}\). Note that this form makes evident that M is symmetric and negative semidefinite, which is not obvious in Eq. A.21. In matrix form, the OLS solution is given by
where in the last line we used the identity
1.1 A.1 LARS-lasso
We will restate here the LARS-lasso algorithm from (Efron et al. 2004) for a generic concave quadratic function \(Q(W)\). We are interested in solvingFootnote 2
where
As we saw in Eq. 2.11, the solution for \(\hat W\) is a piecewise linear function of λ, with components becoming zero or non-zero at the breakpoints.
As a function of \(W^{i}\), \(L(W,\lambda )\) is differentiable everywhere except at \(W^i=0\). Therefore, if \({W}^{i}\) is non-zero at the maximum of \(L(W,\lambda )\), it follows that
or equivalently
which implies
For λ = ∞, one can ignore the first term in Eq. A.41, so the solution to Eq. A.40 is clearly \(W^{i} =0\). One can show that this holds for all \(\lambda > \lambda _{1}\), where
Suppose, without loss of generality, that the maximum in Eq. A.45 occurs for \(i=1\). The condition Eq. A.43 will now be satisfied for non-zero \(W^{1}\), so we decrease λ and let \(W^{1}\) change as
while the other \(W^{i}\)s are kept to zero. To find \(a^{1}\), insert Eq. A.47 in Eq. A.43,
from which we get \(a_1= -{r_{1}}/(\lambda _{1} M_{11}).\) Proceeding in this way, and denoting by \(\textbf {W}_{p}(\gamma )\) the vector of weights after the p-th breakpoint, in general we will have, after p steps
and we let γ grow until either of these conditions occurs:
-
1.


If this happens we let \(W^{k+1}\) become active. Define
and continue with \(k+1\) components as:
To find the new velocity a, insert \(\textbf {W}_{p+1}(\gamma )\) into Eq. A.43 to get
In this equation we need \(sign(a^{k+1})\), which, as we show in Section A.3, coincides with that of the derivative computed in Eq. A.53,
-
2.
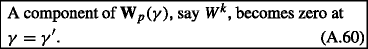
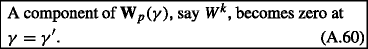
If this happens, \(W^{k}\) must drop from the active set because the path of \(\textbf {W}_{p}(\gamma )\) was obtained assuming a definite sign for \(W^{k}\) in Eq. A.43. So we define
drop \(W^{k}\) from the active set and continue with \(k-1\) active components as:
To find the new a, inserting \(\textbf {W}_{p+1}(\gamma )\) into Eq. A.43 gives
from which a can be solved.
As each a is found, we decrease λ by increasing \(\gamma \), and check again for either cases 1 or 2 until we reach λ = 0, at which point all directions will be active and the weights will correspond to the global maximum of Q(W).
Having presented the algorithm, let us discuss its computational cost. To obtain \(p_{i}\) we need to act with \(H_{VV}^{-1}\) on \(Z_{0}\) (see Eqs. A.13 and A.20). Similarly, for each new active weight \(W^{k+1}\) the \((k+1)\)-th column of M is needed in Eq. A.58, which comes from acting with \(H_{VV}^{-1}\) on \(Z_{k+1}\) (see Eqs. A.14 and A.21). The action of \(H_{VV}^{-1}\) has a runtime of O(TN 3), but in Appendix C we show how to reduce it to \(O(TNS^2)\) with a low-rank approximation. For the total computational cost, we have to add the runtime of solving Eq. A.58. Since at each breakpoint the matrix in the left-hand side of Eq. A.58 only changes by the addition of the \((k+1)\)th row and column, the solution takes \(O(k^2)\) instead of \(O(k^3)\) (Efron et al. 2004). Running the LARS algorithm through k steps, the total cost is then \(O(kTNS^{2} + k^3)\) time.
1.2 A.2 Enforcing a sign for the inferred weights
We can enforce a definite sign for the non-zero weights by a simple modification of the LARS-lasso. Assuming for concreteness an excitatory synapse, the solution to Eq. A.40 for all λ and subject to
can be obtained by allowing a weight to become active only if its value along the new direction is positive. The enforcement of this condition for the linear regression case was discussed in Efron et al. (2004). In our formulation of the LARS-lasso algorithm, the positivity can be enforced by requiring that the first weight becomes active when
and by replacing the condition that triggers the introduction of new active weights, denoted above as condition 1, by
-
1.


By requiring the derivative along \(W^{k+1}\) to be positive at the moment of joining the active set, we guarantee that \(W^{k+1}\) will be positive due to the result of Section A.3.
When λ reaches zero, the weights, some of which may be zero, are the solution to the quadratic program
We will refer to the LARS-lasso algorithm with the modification Eq. A.67 as LARS+. In practice, the measurements can be so noisy that the algorithm may have to be run assuming both non-negative and non-positive weights, and the nature of the synapse can be established by comparing the likelihood of both results at their respective maxima. More generally, if \(K>1\) we have to estimate the sign of each presynaptic neuron; this can be done by computing the likelihoods for each of the \(2^{K}\) possible sign configurations. This exhaustive approach is tractable since we are focusing here on the small-K setting; for larger values of K, approximate greedy approaches may be necessary (Mishchenko et al. 2011).
1.3 A.3 The sign of a new active variable
Property the sign of a new variable \(W^{k+1}\) which joins the active group is the sign of \(\nabla _{k+1} Q(W)\) at the moment of joining.
Proof
Remember that the matrix \(M_{ii'}\) is negative definite and, in particular, its diagonal elements are negative
As we saw in Section A.1, if the first variable to become active is
with
we have
and using Eq. A.69 and \(\lambda _{1} >0\) we get
as claimed. Suppose now that there are k active coordinates and our solution is
Define
and note that
Suppose a new variable \(W^{k+1}\) enters the active set at \(\gamma =\gamma '\) such that
It is easy to see that when taking \(\gamma \) all the way to \(\lambda _{p}\), the sign of \(c_{k+1}(\gamma )\) does not change
since the \(c_{j}(\gamma )\) (\( j=1, \ldots k\)) go faster towards zero than \(c_{k+1}(\gamma )\). To make the variable \(W^{k+1}\) active, define
and continue with \(k+1\) components as:
To find a, impose on Eq. A.81 the conditions (A.43) that give
where \(\textbf {p} = (p_{1} , \ldots , p_{k+1})^{T}\), \(\textbf {M}_{(k+1,k+1)}\) is the \((k+1) \times (k+1)\) submatrix of \(M_{ij}\), and
Since Eq. A.83 holds for any \(\gamma \), we get the two equations
and
where \(\textbf {M}_{(k+1,k)}\) is obtained from \(\textbf {M}_{(k+1,k+1)}\) by eliminating the last column. Inserting Eq. A.85 into Eq. A.86 we get
where 0 has k elements. Since the \((k+1)\)-th element of the second term in Eq. A.89 is zero, we get
Since \(\textbf {M}^{-1}_{(k+1, k+1)}\) is negative definite, we have \(\left(\textbf {M}^{-1}_{(k+1, k+1)} \right )_{(k+1)(k+1)} <0\), so using Eq. A.78, the result
follows. □
Appendix B: The C p criterion for low SNR
In the limit of very low signal-to-noise ratio, we can ignore the dynamic noise term in Eq. 2.1 and consider
Let us assume that the number of presynaptic neurons is K = 1 to simplify the formulas. The results can be easily extended to the general case. We can combine the above equations as
where we defined
and the matrix X is given by the product
where B was defined in Eq. A.25 and
Equation (B.3) corresponds to a standard linear regression problem and the l 1-penalized posterior log-likelihood to maximize is now
The solution \(\hat W(\lambda )\) that maximizes Eq. B.7 is obtained, as in the general case, using the LARS/LARS+ algorithm, and the fitted observations are given by
One can show that each row in \(C \hat W(\lambda )\) corresponds to the \(C_{V} \rightarrow 0\) limit of the expected voltage \(\hat V_{t}(\lambda )\) defined in Eq. 2.11. Given an experiment \((Y,U)\), consider the training error
and the in-sample error
In \(\text {Err}_{\text in}(\lambda )\), we compute the expectation over new observations \(\tilde Y\) for the same stimuli \(U_{t}\) and compare them to the predictions \(\hat Y(\lambda )\) obtained with the initial experiment \((Y,U)\). Thus, \(\text {Err}_{\text in}(\lambda )\) gives a measure of the generalization error of our results. \(\text {Err}_{\text in}(\lambda )\) itself cannot be computed directly, but we can compute its expectation with respect to the original observations Y. For this, let us consider first the difference between \(\text {Err}_{\text in}\) and err, called the optimism (Friedman et al. 2008). Denoting the components of Y with an index i, it is easy to verify that the expected optimism with respect to Y is
For the general case \(K \geq 1\), we will have \(X \in \mathbb {R}^{ST \times NK}\). Let us assume that ST > NK and that X is full rank, that is, rank\((X) = NK\). Then in Zou et al. (2007) it was shown that if we define \(d(\lambda )= || \hat W(\lambda )||_{0}\) as the number of non-zero components in \(\hat W(\lambda )\), we haveFootnote 4
Thus \(2 d(\lambda ) \, C_{y} \) is an unbiased estimate of \(\omega (\lambda )\), and is also consistent (Zou et al. 2007). With this result, and using err\((\lambda )\) as an estimate of \(\langle \text {err}(\lambda ) \rangle \), we obtain an estimate of the average generalization error \(\langle \text {Err}_{\text in}(\lambda ) \rangle \) as
This quantity can be used to select the best λ as that value that minimizes \(C_{p}(\lambda )\). Since the first term is a non-decreasing function of λ (Zou et al. 2007), it is enough to evaluate \(C_{p}(\lambda )\) for each d at the smallest value of λ at which there are d active weights in \(W(\lambda )\). With a slight abuse of notation, the resulting set of discrete values of Eq. B.15 will be denoted as C p (d).
Appendix C: The low-rank block-Thomas algorithm
In this appendix we will present a fast approximation technique to perform multiplications by the inverse Hessian \(H_{VV}^{-1}\). The NT × NT Hessian H VV in Eq. A.6 takes the block-tridiagonal form
where we have set \(C_{V} = I\) to simplify the notation. We will restore it below to a generic value.
It will be convenient, following (Paninski 2010), to adopt for \(C_{0}\), the covariance of the initial voltage \(V_{1}\), the value
(note that the dynamics matrix A is stable here, ensuring the convergence of this infinite sum). This is the stationary prior covariance of the voltages V t in the absence of observations y t , and with this value for \(C_{0}\), the top left entry in the first matrix in Eq. C.1 simplifies to \(-C_{0}^{-1}-A^TA = -I\).
We want to calculate
where \(\mathbf {b}\) can be an arbitrary NT-dimensional vector and each \(b_{i}\) and \(x_{i}\) is a column vector with length N. We can calculate this using the block Thomas algorithm for tridiagonal systems of equations (Press et al. 1992), which in general requires \(O(N^3T)\) time and \(O(N^2T)\) space, as shown in Algorithm 1.

We can adapt this algorithm to yield an approximate solution to Eq. C.3 in \(O(TNS^2)\) time by using low-rank perturbation techniques similar to those used in Paninski (2010), Huggins and Paninski (2012), and Pnevmatikakis et al. (2012b). The first task is to calculate \(\alpha _{1}^{-1}\). Using the Woodbury matrix lemma, we get
where
and
Note that the simple expression (C.6) for \(\alpha _{1}^{-1}\) follows from the form we chose in Eq. C.2 for \(C_{0}\). Plugging \(\alpha _{1}^{-1}\) into the Algorithm 1’s expression for \(\gamma _{1}\) gives
To continue the recursion for the other \(\alpha _{i}^{-1}\)s, the idea is to approximate these matrices as low-rank perturbations to \(-I\),
where \(D_{i}\) is a small \(d_{i} \times d_{i}\) matrix with \(d_{i} \ll N\) and \(L_{i} \in \mathbb {R}^{N \times d_{i}}\). This in turn leads to a form similar to Eq. C.10 for \(\gamma _{i}\),
Therefore we can write
This expression justifies our approximation of \(\alpha _{i}^{-1}\)s as a low rank perturbation to \(-I\): the term \(B_{i}^{T} C_{y}^{-1}B_{i}\) is low rank because the number of measurements is \(S \ll N\), and the second term is low rank because the condition \(eigs(A)<1\) tends to suppress at step i the contribution of the previous step encoded in \(L_{i-1} D_{i-1} L_{i-1}^{T}\). See Pnevmatikakis et al. (2012b) for details.
To apply Woodbury we choose a basis for the two non-identity matrices,
and write
where
Applying Woodbury gives
We obtain \(L_{i}\) and \(D_{i}\) by truncating the SVD of the expression on the right-hand side: in Matlab, for example, do
then choose \(L_{i}\) as the first \(d_{i}\) columns of \(L'\) and \(D_{i}\) as the square of the first \(d_{i}\) diagonal elements \(D'\), where \(d_{i}\) is chosen to be large enough (for accuracy) and small enough (for computational tractability).
We must handle \(\alpha _{T}^{-1}\) slightly differently because of the boundary condition. Making use of the fact that \(C_{0}^{-1} = I - AA^{T}\) and the Woodbury identity, we get
where
and
Multiplications by \(\alpha _{T}^{-1}\) are efficient since we can multiply by \(C_{0}\) in \(O(N)\) time, expoiting the sparse structure of A (see Paninski (2010) for details). It is unnecessary to control the rank because we will only be performing one multiplication with \(\alpha _{T}^{-1}\) and calculating the SVD is a relatively expensive operation.
The updates for calculating \(y_{i}\) and \(x_{i}\) are straightforward:
Algorithm 2 summarizes the full procedure. One can verify that the total computational cost scales like \(O(TNS^2)\) (see Pnevmatikakis et al. (2012b) for details).

Finally, note that for repeated calls to \(H^{-1}_{VV}\mathbf {b}\), we can compute the matrices \(L_{i},D_{i}\) once and store them. For the case when \(C_{V}\) is not the identity we can apply a linear whitening change of variables \(V'_{t} = C_{V}^{-1/2} V_{t} \). We solve as above except we make the substitution \(B_{t} \to B_{t} C_{V}^{1/2}\) and our final solution now has the form
Rights and permissions
About this article
Cite this article
Pakman, A., Huggins, J., Smith, C. et al. Fast state-space methods for inferring dendritic synaptic connectivity. J Comput Neurosci 36, 415–443 (2014). https://doi.org/10.1007/s10827-013-0478-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10827-013-0478-0