
Abstract
Conventional protein:ligand crystallographic refinement uses stereochemistry restraints coupled with a rudimentary energy functional to ensure the correct geometry of the model of the macromolecule—along with any bound ligand(s)—within the context of the experimental, X-ray density. These methods generally lack explicit terms for electrostatics, polarization, dispersion, hydrogen bonds, and other key interactions, and instead they use pre-determined parameters (e.g. bond lengths, angles, and torsions) to drive structural refinement. In order to address this deficiency and obtain a more complete and ultimately more accurate structure, we have developed an automated approach for macromolecular refinement based on a two layer, QM/MM (ONIOM) scheme as implemented within our DivCon Discovery Suite and "plugged in" to two mainstream crystallographic packages: PHENIX and BUSTER. This implementation is able to use one or more region layer(s), which is(are) characterized using linear-scaling, semi-empirical quantum mechanics, followed by a system layer which includes the balance of the model and which is described using a molecular mechanics functional. In this work, we applied our Phenix/DivCon refinement method—coupled with our XModeScore method for experimental tautomer/protomer state determination—to the characterization of structure sets relevant to structure-based drug design (SBDD). We then use these newly refined structures to show the impact of QM/MM X-ray refined structure on our understanding of function by exploring the influence of these improved structures on protein:ligand binding affinity prediction (and we likewise show how we use post-refinement scoring outliers to inform subsequent X-ray crystallographic efforts). Through this endeavor, we demonstrate a computational chemistry ↔ structural biology (X-ray crystallography) "feedback loop" which has utility in industrial and academic pharmaceutical research as well as other allied fields.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Thanks in large part to their speed and lower cost, virtual screening, docking, and scoring have become integral to the drug discovery process as these methods have become critical tools in the structure based drug design (SBDD) toolbox [1,2,3,4,5,6,7,8]. Unfortunately, these methods are often unable to correctly capture and sample structural water [9,10,11], tautomeric states [12, 13], and conformational strain [14], which leads to problems with binding mode and binding affinity prediction [15,16,17,18,19,20]. Furthermore, these problems are compounded with scoring function errors [21, 22] and inaccurate protein:ligand complex structure determination [23,24,25], which together negatively impact their performance in industrial drug discovery efforts. In this paper, we demonstrate a computational chemistry ↔ structural biology (X-ray crystallography) feedback loop which uses a physics-based score function as an indicator of problems in experimental structure, and we show how we can use improved refinement methods to address these structural problems (and vice versa).
X-ray crystallography is a ubiquitous technique which is used throughout the SBDD process to determine the three-dimensional (3D) atomic structure of biomolecular systems which drive lead optimization and drug design. It is the quality of these structural models which often dictates the success of high-throughput screening, docking, and scoring (e.g. rank ordering) of candidate drug molecules and subsequent lead optimization and rational drug design. Due to advances in data collection, processing, structure solution, and refinement automation, X-ray crystallography has become relatively routine in the pharmaceutical space. Unfortunately even with these advances, surveys have shown that protein X-ray models are still found to have significant atomic coordinate uncertainties and other structural errors which impact their use in pharmaceutical research [26, 27]. In particular, amino acid, ligand, and fragment R-groups containing amides, rings, and other similarly "flippable" species are particularly susceptible to uncertainties in the placement since light elements (e.g. nitrogen, oxygen, and carbon) are typically indistinguishable in macromolecular X-ray crystallography. Those structural errors have been known to negatively impact ligand binding affinity prediction [26] and X-ray model quality impacts the overall success of the SBDD effort [25, 28,29,30]. In addition to limitations in the X-ray experimental, conventional stereochemical-restraints used in traditional X-ray model refinement are highly approximate in that they do not account for interactions such as electrostatics, hydrogen bonds, dispersion, charge transfer, and polarization [31,32,33]. Moreover, these restraints consist of a detailed description of the unbound molecular geometry for each ligand in the structure provided in the form of Crystallographic Information File (CIF). Unfortunately, creation of accurate CIF’s is a nontrivial task and often their use leads to inaccuracies in bound ligand structures [32] due to poor or incomplete a priori understanding of in situ bound bond lengths and angles which arises from the absence of intermolecular interactions in conventional X-ray refinement functionals [29, 34,35,36]. Ultimately, conventionally refined structures are subject to the principle "garbage in/garbage out" and an incorrect ligand description (e.g. CIF) often leads to an inaccurate final geometry [32].
In order to address this limitation and generate X-ray structures which are better prepared for use in SBDD protocols, in previous work, we built on our DivCon, linear-scaling, semiempirical quantum mechanics (SE-QM) [37,38,39] package and we introduced an automated region quantum mechanics (QM) refinement technique which replaces conventional stereochemical-restraints—both for the ligand(s) and for the surrounding active site(s)—with a far more complete SE-QM based energy functional "in real time" during refinement process [36, 39]. Outside of this (these) QM region(s), protein receptor residues and non-active site waters are treated with a molecular mechanics (MM) potential leading to a single QM/MM Hamiltonian, based on the ONIOM formalism [40], which is applied across the entire structure [35]. Together, this Hamiltonian is able to capture critical intra-molecular and inter-molecular interactions, including dispersion, hydrogen bonds, electrostatics, polarization, charge transfer, metal coordination [3, 7, 8, 41, 42], which are neglected in conventional X-ray crystallographic refinement workflows. With this protocol in place, DivCon-based X-ray refinement explicitly disregards any (potentially flawed) information provided by CIF yielding more accurate ligand and active site geometry. Specifically, we have demonstrated that our DivCon, QM/MM refinement applied to the Astex Diverse Set [17] yields significant improvement not only for ligand structure but also for the entire protein:ligand complex structure [35].
In the present work, we applied this QM/MM refinement protocol to the set of structures from the Community Structure Activity Resource (CSAR) data set originally released in 2012 [43]. The CSAR set is a well curated set which includes carefully determined experimental binding affinities and which was specifically developed for the purpose of providing structures to improve available docking/scoring functions. For that reason, we chose the set to explore how our QM/MM refinement method enhances the quality of the protein:ligand geometry and how these improvements in quality also impact our ability to use physics-based functions to predict binding affinity. Furthermore, we are able to demonstrate that we can use binding affinity prediction outliers that remain even after Phenix/DivCon (QM/MM) refinement to indicate those cases which we can improve with subsequent analysis and manual, experimental density driven manipulation. Finally, in order to explore the impact of tautomer/protomer states on binding affinity prediction, we applied our XModeScore [44, 45] method to the set. This method employs the same QM/MM X-ray refinement discussed above and couples it with rigorous experimental density analysis to determine the correct protonation states (or modes) of residues and bound ligands and fragments. We hope that these enhanced structures, available in the Supplementary Information, aid in the development of next generation docking/scoring functions.
Materials and methods
Structure preparation and refinement
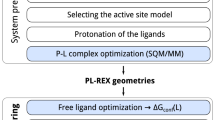
The 55 X-ray coordinate and structure factor files corresponding to five different kinase targets in the 2012 CSAR set were downloaded from the Protein Database (PDB). This set, listed in detail in Table 1 and Table S1, consists of cyclin-dependent kinase 2 (CDK2) with 15 ligands, checkpoint kinase 1 (CHK1) with 16 ligands, mitogen-activated protein kinase 1 (ERK2) with 12 ligands, urokinase-type plasminogen activator (uPA) with 7 ligands, and spleen tyrosine kinase (Syk) with 5 ligands. Hydrogen atoms were added to protein residues, water molecules, and ligands using Protonate3D [46] as implemented in the Molecular Operating Environment (MOE) v2019.0102 package from Chemical Computing Group, Inc.[47]. The default Protonate3D settings of pH, temperature, and ion concentration (Salt) of 7, 300 K, and 0.1 mol/L respectively were selected and all atoms were allowed to "Flip" so some HIS, ASN, and GLN residues may have flipped during the protonation process (see Supplementary Information for all prepared structures used in this paper). In cases with residues with alternative conformations, the default MOE protocol is to maintain the conformation ‘A’ and remove all other alternative states and this protocol was also used in the current structure preparation. It is important to note that original published CIF information was used during ligand protonation only if the CIF a) is available for the relevant ligand within the library provided in the PHENIX package, and b) passes a heavy atom graph match and other integrity checks adopted by MOE. Finally, each structure was crystallographically refined using the ONIOM QM/MM method incorporated into PHENIX package [31] as described in our previous work [35, 36].
Briefly, Phenix/DivCon employs an automated two-layer QM/MM calculation as depicted schematically in Fig. 1. With this approach, any ligand(s) along with any surrounding active site residues are treated using the PM6 semiempirical QM Hamiltonian [48, 49] and the rest of the protein is described with AMBERff14 MM forcefield [50]—both as implemented in our DivCon Discovery Suite v.DEV-671 [39]. The two layer ONIOM QM/MM energy is computed using the subtractive scheme according to the following equation [35, 40],
where \({E}_{all}^{MM}\) is MM energy calculated for the entire system, \({E}_{region}^{MM}\) is the MM energy for the region, and \({E}_{region}^{QM}\) is the energy of the region computed with the QM method. The QM/MM gradients are computed using the similar expression (2).
Finally, the overall refinement target Etotal in PHENIX is presented as,
where Wxray and Wgeom are weights assigned X-ray data and geometry (stereochemistry) restraints respectively, and wcxscale is the additional scale factor implemented in PHENIX [51]. In our work, Wgeom is typically set to one while Wxray is a variable weight determined using an automatic procedure in PHENIX [52]. For QM/MM X-ray refinement the energy of stereochemical restraints Egeom is replaced with \({E}_{ONIOM}^{QM/MM}\) computed using Eq. (1). Gradients on each atom are derived as follows (4),
where \(\left( {\nabla{\mathbf{x}}_{i} } \right)_{{{\text{Xray}}}}\), is referred to X-ray density gradients and \(\nabla {\mathbf{x}}_{ONIOM}^{QM/MM}\) are the ONIOM gradients determined using Eq. (2) meaning that all conventional-PHENIX stereochemical restraint gradients are replaced with QM/MM gradients [35].

Schematic view of the QM/MM two-layer (ONIOM) concept depicting two ligand QM regions with the balance of the receptor treated as a MM layer. This method can support any number of QM regions and may even treat the entire structure as a QM structure
To calculate these energies and gradients, for the MM portions of the structure, the AMBERff14 force field MM parameters were assigned automatically utilizing an automatic molecular perception algorithm [35] implemented in the DivCon Discovery Suite v.DEV.671. The QM regions on the other hand were extended to include all protein, water, and cofactor (if any) residues within 3.0 Å around ligands that are specified in Table 1 for each PDB. For those cases in which PHENIX-provided restraint libraries were missing or deficient, a fresh CIF file for each ligand or cofactor in each structure was generated using MOE. Finally, each Phenix/DivCon QM/MM refinement was conducted on each structure using DivCon Discovery Suite build-DEV.671 [39] "plugin" to the Phenix version phenix-1.17-3644 package [31, 35]. For comparison, conventional Phenix refinements were also carried out with the same input files, and identical default phenix.refine settings were chosen for both QM/MM and conventional refinements.
Tautomer/protomer state determination
After completing the first round of X-ray crystallographic refinement using Phenix/DivCon, our XModeScore [44, 45] method was subsequently employed to determine the most likely tautomer/protomer state in the context of the experimental density and a second set of ONIOM QM/MM refinements were completed with these new states. Briefly, the XModeScore procedure utilizes two components: the post-QM/MM refinement local ligand strain energy (LLSE)—calculated in this case using the aforementioned PM6 Hamiltonian—and the Z-score of the experimental (X-ray) difference density called ZDD discussed in [53]. When LLSE and ZDD are determined for the set of tautomers/protomers (or flip-states, binding modes, etcetera), the XModeScore of the i-tautomer form can be calculated according to (5),
where m is the mean value and s is the standard deviation of the corresponding array of data (ZDD or LLSE). Therefore, the protomer/tautomer with the highest Scorei corresponds to the tautomeric form ‘i’ that best fits both LLSE (calculated energy) and ZDD (experimental density) criteria. The details of how these two criteria are summarized below.
Local ligand strain energy
The LLSE, as opposed to the global ligand strain, is used in XModeScore in order to measure the relative ligand strains based on the very small, localized conformational changes due changes in tautomer/protomer states, rotamer flip states, and so on. The LLSE or EStrain is the difference between the energy of the protein-bound ligand conformation and the isolated ligand conformation and is computed according to the Eq. (6),
where ESinglePoint is the single-point energy computed for the ligand X-ray geometry, and EOptimized is the energy of the optimized ligand that or the local minimum [54]. All LLSE calculations in this project were calculated using the PM6 Hamiltonian [48, 49] as implemented in DivCon.
Ligand strain is generally thought of as a measure of how much strain the ligand must accept or accommodate in order to bind with the protein of interest. Colloquially, in our experience, we think of strain being caused by three different components: Method Induced Strain (MIS) which is the strain attributed to the refinement method itself (e.g. inaccurate CIF parameters, pair potential approximations, protein:ligand interactions, and so on); Docking Induced Strain (DIS) which is the strain associated with initial placement of the ligand within the experimental density; and Target Induced Strain (TIS) or—ideally—a minimal, naturally occurring strain caused by interactions between the protein and ligand. Often it is difficult to "tease out" which components are causing the greatest impact on the calculation of ligand strain. For example, in practice when calculating ligand strain, TIS and MIS often appear to overlap significantly: is the calculated strain naturally occurring or is it due to inaccuracies in protein:ligand pair potential and so on? Given the fact that the present study does not involve re-docking or other hand re-placement of the ligand unless otherwise indicated, the final reported strain is generally limited to the same radius of convergence of the (published) input ligand coordinates. Therefore, we did not endeavor to answer this question and instead we focused on how much an improved potential (i.e. QM/MM in this case) alone addresses the strain with the assumption being that any remaining strain is primarily a mixture of (naturally occurring) TIS and (artificial) DIS. In fact, in cases where higher than expected local ligand strain is reported upon completion of QM/MM X-ray refinement, this is likely an indicator that additional sampling is warranted and underscores how these tools can be used in support of the aforementioned computational chemistry ↔ structural biology (X-ray crystallography) feedback loop.
Z-score of the difference density (ZDD)
In 2012, Tickle [53] described a novel quality indicator—the real-space Z-score of difference density or ZDD—in order to measure the accuracy of an X-ray model. ZDD is in contrast to the conventional Real Space Correlation Coefficient (RSCC) which correlates with both accuracy and precision of the model and is therefore often unable to measure model inaccuracy. A detailed mathematical description of ZDD can be found in [44, 53], but briefly, the Z-score for a point difference density value is expressed by Eq. (7),
where \(\sigma \left(\Delta \rho \left({\varvec{r}}\right)\right)\) is the standard deviation of the difference density and corresponds to the random error of the model and is pure precision, while the Z-score of the difference density is a measure of the residual, non-random error and is pure accuracy. In order to limit the noise found in the final value, we assume that the difference density Z values should approach a normal distribution of random errors with zero mean and unit standard deviation. The presence of negative peaks or positive peaks, which significantly deviate from the expected distribution, indicates one or more problems with the model. One can then calculate the standard chi-square (c2) statistic for a subset of the negative density values and the positive density values, and find the subset of values of \({x}_{\left(i\right)}^{2}\) which maximize the probability pmax over k,
where the function P is the lower normalized gamma function representing the cumulative distribution function (CDF) of \(\chi _{k}^{2}\). The second function, I, is also computed as the complement and this becomes the normalized incomplete beta function (CDF of a normal order statistic) [55] which accounts for the ‘multiple comparisons’ correction [56]. The ZDD is then evaluated as the two-tailed normal Z-score which corresponds to the maximal value pmax over k of the cumulative probability of \({\chi }_{k}^{2}\) derived from (8),
where the function F is the CDF of the normal distribution, \(2F\left(\left|Z\right|\right)-1\) is the CDF of the half-normal distribution of the absolute value of a normal variate Z, and F−1 is the inverse function or the value of Z corresponding to a given probability. Once these calculations are performed, we obtain a set of negative density values and a set of positive density values. The ZDD− corresponds to incorrectly positioned atoms while the ZDD+ is due to missing atoms. In order to calculate ZDD, the ZDD- and ZDD+ metrics are taken together as defined in (10).
Finally, with LLSE and ZDD in place, in order to calculate XModeScore, multiple tautomer/protomer states are generated and crystallographically refined (using QM/MM refinement) and the LLSE and ZDD are calculated for each state. As with the refinement settings noted above, the XModeScore jobs were based on the QM/MM X-ray refinements with the QM regions defined using a 3 Å radius.
Calculated (predicted) protein:ligand binding affinity
To evaluate the theoretical binding affinity between each ligand and its corresponding protein target, we employed the Generalized-Born Volume Integral/Weighted Surface Area (GBVI/WSA) score function [57] as implemented in MOE2019.01. In all cases in which this score is discussed in this work, the score as calculated on each protein:ligand pose "in place" without performing any docking or subsequent MOE-based structure minimization. The AMBER10 potential coupled with atomic charges and ligand parameters calculated using Extended Hückel Theory (Amber10:EHT) as implemented in MOE was used for all MOE-based calculations. It is notable that the GBVI/WSA score function was chosen instead of a quantum mechanics-based score function, like QMScore [58], to demonstrate that X-ray structures determined with Phenix/DivCon (a QM/MM functional) may be used—without modification—with a classical/traditional score function. For the sake of comparison, the alternative score functions available in the MOE v2019.0102 platform were also summarized including London dG (LDG), ASE Score (ASE), Affinity dG (ADF), and Alpha HB (AHB).
Overall crystallographic structure quality metrics: MolProbity score and Clashscore
MolProbity is included as a module in the PHENIX package and the method incorporates several model validation tools encompassing multiple quality criteria [59]. Specifically, the MolProbity score (MPScore) is a logarithm-based score which combines three key component metrics including Ramachadran plot statistics, rotamer outliers, and clashscore [60]. The lower the MPScore the better the model. The Clashscore, which is a sub-score of the MPScore, is also reported and corresponds to the number of clashes per 1000 atoms. The Clashscore is determined through nonbonded atom contacts and is calculated within the program Probe using a rolling probe algorithm [61]. A clash is counted when the Probe-generated dot surface around one atom overlaps with the dot surface surrounding another atom by an amount greater than 0.4 Å [27]. The higher the number of clashes, the more the model may be adopting a "high energy" or unlikely conformation [59].
Results and discussion
QM/MM vs conventional X-ray refinement of CSAR set
Protein (target) structure quality metrics
As shown in Supplementary Table S2, the application of the QM/MM method only insignificantly affects R-factors that measure the overall agreement between the crystal model and the experimental structure factors. For example, average Rfree after QM/MM and conventional refinements for the CSAR set are virtually identical (0.206 ± 0.01 and 0.205 ± 0.01, respectively), and the average QM/MM Rwork of 0.173 ± 0.008 is only marginally higher than the value after the conventional refinement (0.170 ± 0.007). This observation would suggest that there is slightly less crystallographic model overfitting in the QM driven refinements, but overall, this is congruent with our previous research [36] and it shows that the QM/MM refinement does not damage the models being considered and these models are in fact X-ray structures. The MolProbity score and clashscore are used to characterize of the overall quality of protein structures [29, 35, 59, 62], and these metrics show that the Phenix/DivCon refinement is superior and addresses clashes which the conventional refinement does not appear to address (Table 1). In particular, the clashscore of QM/MM refined structures (0.72 ± 0.23) is, on average, 2 × lower (better) than after the conventional refinement (1.56 ± 0.37). A recent survey of PDB structures [63] indicates that the average clashscore of all structures deposited after 2010 is about 5 with the range of 1–99% of all clashscore values being from 0 to 50. It is notable that in our previous work we observed a larger (4.5-fold) improvement in clashscore for the Astex set as a result of QM/MM refinement as compared to the conventional protocol [35]. Such a discrepancy can likely be attributed to the nature of these two sets. While the Astex set is a highly diverse protein set, the CSAR benchmark is a curated set which only contains 5 different protein targets bound to a variety of ligands. Furthermore, given the stated goals of the original investigators who developed the CSAR set, they may have been more cognizant of potential clashes and addressed them prior to publication (even within the confines of the original, conventional refinement process they had at their disposal).
Ligand structure quality metrics
The local ligand strain method is used to explore refined ligand structural models [24, 29, 64, 65], and LLSE is used to evaluate the quality of the region refinement [35, 36, 66]. In the present study, we find that the average local ligand strain energies calculated over 55 ligands of the CSAR set after Phenix/DivCon refinement is 10.45 ± 3.28 kcal/mol and this observation is similar to the average found in our previous work (9.95 ± 3.77 kcal/mol) for the Astex set after our QM/MM refinement [35]. The average local ligand strain energy of the CSAR ligands after the conventional refinement is 28.53 ± 5.76 kcal/mol or about 2.8-fold higher than in the QM/MM Phenix/DivCon refinement. Again this finding is consistent with the previously observed average improvements in the ligand strain energy by ~ 3.5-fold after QM driven refinements in our previous studies [36]. The strain energy histogram (Fig. 2) shows a clear peak for QM/MM strain energies that covers the bins 1–3 that comprise 44 QM structures in the range from 0 to 15 kcal/mol. The strain energy distribution of PHENIX refined ligands have a peak around 20 kcal/mol with a long tail that covers the range up to 50 + kcal/mol. Given that this ~ threefold improvement in strain is solely attributable to the use of QM/MM refinement, the balance of the LLSE is likely due to a mixture of DIS and TIS and subsequent efforts could include ligand (and active site) sampling to further minimize the strain.

Histogram of Ligand Strain Energy (LLSE) distributions for ligands from 55 CSAR structures refined using QM/MM method and conventional PHENIX. The lower the LLSE the less strain the ligand must accommodate to fit within its associated active site
In our previous results with the Astex Diverse Set, we showed that ligand ZDD remained essentially unchanged between QM-driven refinement and conventional refinement [35]; however, the current study with the CSAR set shows better distribution of the ligand ZDD values after the Phenix/DivCon refinement. The histogram for ZDD (Fig. 3) indicates that the population of the 1st bin (0–2 ZDD units) contains 1.5 times more QM/MM refined structures versus Phenix alone. Furthermore, the average ZDD for the ligands in QM/MM-refined structures (3.23 ± 1.37 units) is two times lower (better) than after the conventional refinement alone (6.55 ± 2.01 units). As an example, consider the refinement of CDK2 in complex with inhibitor 60 K (PDB entry 4FKU). The difference density map after the conventional refinement exhibits both positive and negative peaks around the phenyl ring of the ligand (Fig. 4b) resulting in a ZDD of 14.0. When Phenix/DivCon refinement was performed however, this process leads to an appropriate shift and rotation of the ligand such that those peaks are properly accommodated and removed by the model. As a result, the difference density peaks around the phenyl ring are not observed on the QM/MM difference map (Fig. 4a) leading to a corresponding ZDD decrease (improvement) to 4.7.

Histogram of Ligand Z-score of the difference density (ZDD) distributions for ligands from 55 CSAR structures refined using QM/MM method and conventional PHENIX. The lower the ZDD the more accurate the model versus the experimental density

The σA-weighted mFo-DFc difference electron density map drawn at 3σ level around the ligand (ligand ID 60 K) in the PDB structure 4FKU refined with QM/MM (a) and conventional (b). The σA-weighted 2mFo-DFc electron density map is contoured at 1 σ. C is provided as an overlay of the two conformations
Impact of improved refinement on binding affinity prediction
In addition to standard crystallographic and chemical metrics described above, we used the GBVI/WSA score available in MOE to evaluate the impact of these improved structures on our ability to accurately predict binding affinity. While correlating predicted binding affinities with experimental binding affinities is a trivial (if often fraught) task in SBDD, it has not generally used in the context of structure evaluation. For each of the five CSAR targets considered (CDK2, CHK1, ERK2, uPA, and Syk) and for each of the X-ray refinements performed, the correlations between experimental binding affinity (− logK) and computationally predicted GBVI/WSA scores were explored and these results are presented in Figs. 5, 6, 7, and 8 (lines/dots/equations/correlations shown in Red compared to those in Black which correspond to the QM/MM and conventional refinements respectively) and summarized in Table 1. The ERK2 and CHK1 sets exhibit the highest correlation among the CSAR proteins based on QM/MM refined structures (Red dots/lines on Figs. 5, 6, 7, and 8) with R2 ranging between 0.75 and 0.76. On the other hand, the five structures of the Syk set produce only poor correlation with the experimental values but the R2 (0.27) after the QM/MM refinement is still higher as compared to the conventionally refined set (0.05). Nevertheless, the Pearson correlation coefficient remains negative (− 0.51) even for the QM refined structures, and we decided not to pursue this data set any further. The R2 values for uPA are similar after the two types of refinements and CHK1 shows a moderate improvement when refined with QM/MM (Figs. 7 and 8). The most significant differences between Phenix/DivCon and conventionally refined structures are observed for the CDK2 and ERK2 sets (Figs. 5 and 6). For conventional structures of the CDK2 set, Fig. 5 (Black dots/lines) shows a scattered relationship between GBVI/WSA score and experimental binding affinity with virtually no correlation to the experimental − logK (R2 = 0.25). After QM/MM refinement however, the relationship yields a clear trendline with a significant R2 correlation of 0.60 (Red dots/lines on Fig. 5). The analysis of the model versus density for the 15 CDK2 structures indicates that the average ZDD (4.9 units) for QM/MM structures is 2 × lower (better) than that of the conventional structures (9.1 units). For example, these structural changes lead to improved ZDD’s for the CDK2 structure 4FKU (Fig. 4). When performing a predicted vs. experimental affinity outlier analysis, one of the worst offenders is 4FKS (Fig. 5) with the residual of 1.36. A superimposition of the refined structures indicates a different orientation of the benzyl moiety after QM/MM X-ray refinement (Fig. 9) which results in a significantly lower (better) ZDD around the ligand (3.86 units) compared to the ZDD yielded by the conventional refinement (16.63 units). This improved X-ray model leads to a decrease of GBVI/WSA score from − 5.70 to − 7.50 kcal/mol which shifts the predicted value of 4FKS practically to the trendline leading to the significantly improved correlation (0.60 versus 0.25). This improvement in binding affinity prediction is observed based on QM/MM refinement alone.

The regression lines of the correlation between experimental affinity (− logK) and computationally predicted GBVI/WSA scores for the 15 protein:ligand CDK2 complexes for PHENIX structures (Black), QM/MM structures (Red), hand-modified QM/MM structures (Green), and QM/MM refined structures with XModeScore chosen tautomers (Blue). Points involving structures discussed in the paper are labeled

The regression lines of correlation between experimental affinity (− logK) and computationally predicted GBVI/WSA scores for the 12 protein:ligand ERK2 complexes for PHENIX structures (Black), QM/MM structures (Red), and QM/MM refined structures with XModeScore chosen tautomers (Blue). Points involving structures discussed in the paper are labeled

The regression lines of correlation between experimental affinity (− logK) and computationally predicted GBVI/WSA scores for the 7 protein:ligand uPA complexes for PHENIX structures (Black), QM/MM structures (Red), hand-modified QM/MM structures (Green), and QM/MM refined structures with XModeScore chosen tautomers (Blue). Points involving structures discussed in the paper are labeled

The regression lines of correlation between experimental affinity (− logK) and computationally predicted GBVI/WSA scores for the protein target CHK1 for PHENIX structures (Black), QM/MM structures (Red), and QM/MM refined structures with XModeScore chosen tautomers (Blue). Points involving structures discussed in the paper are labeled

The σA-weighted mFo-DFc difference electron density map drawn at 3σ level around the ligand (ligand ID 46 K) in the PDB structure 4FKS refined with QM/MM (green) (a) and conventional (yellow) (b), as well as the superimposition of the two structures (c). The σA-weighted 2mFo-DFc electron density map is contoured at 1σ
Impact of structure modification
Up to this point in the discussion, any improvements in predicted versus experimental binding affinity correlation are attributable solely to the addition of a more complete functional (i.e. PM6/AMBERff14) to the X-ray refinement processes and no other "by hand" modification of the structures was performed. One could say that these improvements are reached within limited radius of convergence inherent to an optimization/refinement process. However, given the improved models leading to improved correlations, outliers which remain after refinement can be indicative of structural issues which can be "fed back" to the X-ray crystallography effort. Once we are sure that the structures are chemically correct within the limits of the starting model placement, outliers can often be attributed to actual structural problems in the model. We therefore used the correlations shown in Figs. 5, 6, 7, and 8 (black lines/dots for conventional refinement and red lines/dots for QM/MM refinement) and noted those cases which diverged appreciably and manually studied each case to see if there were obvious structural problems (e.g. missing bridging waters, questionable "flip" states, misplaced atom positions, and so on) in the original PDB model. For the sake of simplicity, we focused on the protein structure regions around the ligand (the active site of each model) and obvious structural defects which were clearly justified by positive/negative peaks of the difference electron density even after QM/MM refinement and we did not perform any further sampling (e.g. model building, simulated annealing, docking, etcetera). These cases are explored in detail in the sections below and are depicted in Figs. 5, 6, 7, and 8 (lines/dots/equations/correlations shown in Green).
uPA structures
An analysis of the uPA correlation plots for structures after the QM/MM refinement (Fig. 7) indicates that 4FUD and 4FU9 are the worst outliers on the graph. Unfortunately, the electron density map of the 4FUD outlier provides no clear opportunities to modify the input structure. On the other hand, as depicted in Fig. 10a, there are several questionable peaks of electron difference density observed even after the initial QM/MM refinement of 4FU9. First, the small peak of the positive difference density around the atom N18 suggests that there is an alternative protonation state of the ligand 675. This conclusion was later confirmed by XModeScore (see below). Second, the water molecule (Wat526) in the vicinity of the ligand exhibited a large peak of the negative electron density, and hence we can likely exclude this water molecule from the model. Third, the succinate molecule, Sin304, which comes from the crystallization buffer, was added to the model with the occupancy 0.5. However, a significant amount of positive electron density was observed around that molecule suggesting that we should increase the occupancy of Sin304 to 1.0. When these changes were made, the new QM/MM refinement leads to a better difference density distribution in the binding pocket (Fig. 10b), and ZDD around the ligand 675 decreases (improves) from 2.2 to 1.3 units, and the GBVI/WSA score for the ligand 675 decreases from − 7.11 to − 6.40 kcal/mol. This shift leads to a significant improvement in correlation for the uPA set (the R2 moves from 0.61 to 0.74). Furthermore, the residual of the 4FU9 data point improved from − 0.75 to − 0.15.

Positive (green) and negative (red) peaks of the σA-weighted mFo-DFc difference electron density map around the ligand (ligand ID 675) and Wat526 in the binding pocket of the protein target uPA in the PDB structure 4FU9 refined with QM/MM before (a) and after (b) the manual fit. The σA-weighted 2mFo-DFc electron density map is contoured at 1 σ
CDK2 structures
As shown in Fig. 5, the structures 4EK5 and 4FKO yield binding affinity predictions (GBVI/WSA score) which deviate significantly from the prediction versus experiment trendline for both conventional refinement and QM/MM refinement and yield residuals of 0.69 and − 0.95 respectively. Upon further review of the QM/MM X-ray refined structure 4EK5, the alternative 'A' conformations of the side chains of the residues Leu32, Lys33, and Lys89 (which the reader will recall are kept by default during the structure preparation step) are not in the agreement with the electron density. Instead, the alternative 'B' conformations in the deposited 4EK5 structure show a better agreement with density. Also, two water molecules (Wat581 and Wat631) show no electron density peaks to justify their placement. A similar situation is observed in the QM/MM refined 4FKO in which the 'B' conformations of the side chains of the residues Val29, Leu78, Lys89, and Met91 were fit to the density, and Wat599 does not have a supporting density peak. These changes were subsequently made to the input structures, and new Phenix/DivCon X-ray refinements were performed leading to significant changes in the final structures. In particular, in the structure 4EK5, the amid group of the ligand 03 K becomes more coplanar with the phenyl group to which it is connected (the corresponding torsion angle is − 11.1° in the new-QM/MM X-ray refined structure as compared to its value of − 16.5° in the original-QM/MM refined structure). Such a rotation might be attributed to the removal of Wat631 in the vicinity of the amid group which may have reduced a steric barrier. In both structures, the ZDD of each ligand decreases (improves) in the new-QM/MM structure while the strain energy remains relatively unchanged. Changes in the GBVI/WSA score were in the range 0.2–0.5 while the overall correlation R2 for the CDK2 set increased from 0.60 to 0.71. The residuals 4EK5 and 4FKO also improve to 0.49 and − 0.54 respectively.
Impact of protomer/tautomer selection: XModeScore results
The XModeScore method [44,45] incorporates both a statistical analysis of the difference density distribution and the local ligand strain energy in order to correctly determine "flip" states and protomer/tautomer states of ligands. As a final step in the process, each of the QM/MM refined structures in the previous step (with any manual modifications noted) were submitted to XModeScore analysis in order to determine proper tautomer/protomer states. The final XModeScore results for all CSAR structures are given in Supplementary Table S3. The results for several CSAR sets presented below demonstrate how the correct choice of ligand tautomer/protomer impacts the predictability of the GBVI/WSA score function. See Figs. 5, 6, 7, and 8 (lines/dots/equations/correlations shown in Blue correspond to XModeScore results).
CDK2 structures
As indicated in Table 2, the default protonation states for ligands in 11 out or 15 CDK2 structures prevail as the best tautomeric forms as determined by XModeScore. However, for four structures (4FKP, 4FKQ, 4FKW and 4FKG), XModeScore results show that the best tautomer is different from the one in the initially protonated structures. For example, the best tautomer of the ligand LS5 (PDB 4FKP) is different by the deprotonation of the nitrogen atom of the amino(imino)methylamino group that change GBVI/WSA score by − 0.1 kcal/mol. Similar magnitudes of the change for the scoring function are observed for 4FKQ and 4FKW (Tables 1, 2). The largest structural changes are observed for the ligand 4CK in 4FKG. The default protonation resulted in the protonated carboxyl group –COOH; however, the preferred state of 4CK as determined by XModeScore has a negatively charged carboxyl group which leads to an XModeScore of 1.94 while the default state is assigned a worse score of − 1.08. The tautomer with the unprotonated carboxyl shifts towards Lys89 during the new-QM/MM X-ray refinement, and with some changes in the side chain conformation of Lys89, a stronger H-bond is formed with a OAC4CK-NZLys89 distance of 2.82 Å (versus 3.08 Å in the original-QM/MM refined version with the default tautomer). The interaction diagram for the ligand 4CK (Fig. 11) graphically depicts the strong H-bond mentioned above as well as a more ordered water structure around the tautomer with the unprotonated carboxyl group. Furthermore, the ZDD score is slightly better for the "winning" tautomer, and the calculated binding affinity (GBVI/WSA score) increased from − 6.76 kcal/mol in the original-QM/MM refined structure to − 7.07 kcal/mol in the new-QM/MM refined structure. Taking into account the new GBVI/WSA score values for 4 structures mentioned above the CDK2 set exhibits slightly better correlation (R2 = 0.73) versus the previously noted R2 = 0.71 with the default protonation. It should be noted that the manually manipulated structures were also included in this analysis (Fig. 5: Blue dots/lines).

Ligand Interaction diagram for the ligand ID 4CK in the PDB structure 4FKG after the QM/MM and conventional PHENIX refinements. Arrows added to underscore significant structural and interaction changes
uPA structures
As was discussed above we changed the tautomeric state of the ligand 675 in the structure 4FU9 based upon the manual examination of the electron density map alone (Fig. 10). XModeScore calculations confirm that this tautomer—with the fully protonated amino(imino)methyl group—is the most favorable one (Fig. 10b) having an XModeScore of 1.28 while the default ligand state depicted on Fig. 10a has the score of − 2.43. Furthermore, according to XModeScore results, the best tautomer of the ligand 2UP in the structure 4FU8 also represents the state with the fully protonated the amino(imino)methyl group. The Phenix/DivCon refinement using this ligand protonation led to the change of GBVI/WSA score from − 5.52 to − 5.29 kcal/mol (Tables 1, 2). Finally, in the structure 4FUC we discovered that the default protonation state of the ligand 239 with the charged \({\text{NH}}_{3}^{+}\) group has a worse XModeScore score than that of the uncharged state having the \({\text{NH}}_{2}\) group. While the latter ligand state weakens the H-bond interaction between the ammonia group and Asp50 (the distance N38239-OD2Asp50 equals to 2.95 Å in the new-QM/MM structure versus 2.79 Å in the original-QM/MM structure), the new-QM/MM refinement shows that it exhibits better agreement with the experimental density as evidenced by a smaller ZDD value (1.97 units) compared to its magnitude in the original-QM/MM structure (4.42 units) (Fig. 12). Furthermore, a large residual negative density peak seen only in the structure with the \({\text{NH}}_{3}^{+}\) group protonation supports that conclusion. Overall, the correlation R2 coefficient for the uPA set shifted significantly from 0.74 to 0.81 when the updated GBVI/WSA score values for these two structures are substituted for the original values in the correlation analysis (Fig. 7: Blue dots/lines).

The σA-weighted mFo-DFc difference electron density map peaks drawn at 3σ level around the ligand (ligand ID 239) in the PDB structure 4FUC refined with QM/MM for the default (a) and XModeScore best tautomers (b). The σA-weighted 2mFo-DFc electron density map is contoured at 1 σ
CHK1 structures
Finally, for the CHK1 set, two structures (4FTC and 4FSR) were found to have alternative tautomer states which yield better XModeScore's versus than the original states (Table 2, Fig. 8). Specifically, for ligand H6K of PDB 4FTC, the hydrogen atom should be placed on the other nitrogen of pyrazole ring. Both the ZDD value and strain energy associated with the new tautomer is lower (Tables 1, 2) and the GBVI/WSA score became more negative by 0.2 kcal/mol. It is notable that the original protonation state of H6K matches the deposited CIF for this ligand. Overall, using the tautomers determined by XModeScore for 4FTC and 4FSR led to a slightly improved correlation for the CHK1 set (the R2 went from 0.75 to 0.77).
Impact of scoring function choice on binding affinity results
For simplicity and brevity, all of the analyses in the present work focused on the impact of X-ray refinement using the default/recommended score function in MOE: GBVI/WSA. Tables 3 and 4 are also included in order to provide the analogous results using the alternative score functions available in MOE and to compare the various functions available in the platform. We generally observe that GBVI/WSA provides the most consistent performance in two ways: GBVI/WSA is more likely to yield significant correlations for each case, and it appears to be more sensitive to the impact of improved structure. There are some cases in which the London dG (uPA) and Alpha HB (CDK2 and ERK2) score functions also perform well. However, often these functions perform similarly regardless of what manipulations are performed suggesting that—if our goal is to have a strong computational chemistry ↔ structural biology (X-ray crystallography) "feedback loop"—these other scores may be less useful.
Conclusions
There are many structural metrics used to evaluate the quality of protein structures and hence the performance of a given crystallographic method. These metrics include overall R factors (Rfree and Rwork), MolProbity statistics [59], local ligand strain energy as well as more sophisticated computed Z-score of the difference density or ZDD [44]. Using these metrics, we have demonstrated that Phenix/DivCon (QM/MM) X-ray refinement [35, 36] yields superior quality protein:ligand complex structures as compared to conventional PHENIX refinement when challenged with the X-ray models available in popular and well curated Community Structure Activity Resource (CSAR) benchmark set. Furthermore, we have shown that XModeScore [44, 45]—which couples model strain with model experimental density agreement—can be used to successfully determine the correct tautomer/protomer states of the ligands (and active sites) of interest. In this work we also showed that when provided with more accurate QM/MM refined X-ray models, we can use conventional score functions (such as the GBVI/WSA score function found in MOE) to "flag" X-ray models for further crystallographic consideration. Specifically, we used the correlation between the experimentally determined binding affinities of the ligands available in the CSAR protein set and the predicted GBVI/WSA scores calculated based on the refined structures as an additional metric to indicate those cases which provide opportunities for further X-ray density-driven manipulation. Upon subsequent QM/MM refinement, these new X-ray structures give rise to better predicted versus experiment correlation coefficients suggesting that not only were these structures more accurate (as measured by the aforementioned crystallographic metrics), but they were more chemically descriptive of the key protein:ligand interactions important to the SBDD effort. Through this protocol, we have shown that score function predictability, and likely by extension overall SBDD performance, can be greatly enhanced by choosing the correct conformations of the receptor side chains, positions of water molecules as well as the correct protonation/tautomeric state of the ligand. With the proper, QM/MM based refinement tools, this synergistic approach can be replicated within industrial and academic pharmaceutical laboratories.
Going forward, we will continue the development of the Phenix/DivCon (and BUSTER/DivCon) method through the addition of two key improvements. First, the QM method used exclusively in the present work was the PM6 Hamiltonian as originally published [48, 49] and subsequently implemented by QuantumBio staff in the DivCon Discovery Suite. We will explore the impact of the PM6-D3H4 hydrogen bonding and dispersion correction approach added to PM6 by Řezáč and Hobza [67, 68]. Second, since the initial ligand positions were not resampled and all X-ray refinement was performed on the original ligand poses (unless otherwise indicated), the refinements as presented were limited to the same radius of convergence of the published structure. Therefore, only the local ligand strain energy or LLSE is reported in order to better gauge the impact of the change of functional alone. In future work, in order to mitigate the docking (placement) induced strain and to more accurately measure the global ligand strain, this approach will be coupled with the MovableType Conformational Search (MTCS) and Docking (MTDock) fast free energy methods recently implemented in QuantumBio's software [69,70,71].
Supplementary information
All resulting PDB and MTZ files are provided in the following file: https://downloads.quantumbioinc.com/media/tutorials/MT/csar_paper.tar.gz.
References
Muller-Dethlefs K, Hobza P (2000) Noncovalent interactions: a challenge for experiment and theory. Chem Rev 100:143–168
Riley KE, Pitonak M, Cerny J, Hobza P (2010) On the structure and geometry of biomolecular binding motifs (hydrogen-bonding, Stacking, X-H...pi): WFT and DFT calculations. J Chem Theory Comput 6:66–80
Raha K, Peters MB, Wang B, Yu N, WollaCott AM, Westerhoff LM, Merz KM (2007) The role of quantum mechanics in structure-based drug design. Drug Discov Today 12:725–731
Kuntz ID (1992) Structure-based strategies for drug design and discovery. Science 257:1078
Jorgensen WL (2004) The many roles of computation in drug discovery. Science 303:1813
Jorgensen WL (2009) Efficient drug lead discovery and optimization. Acc Chem Res 42:724–733
Zhang XH, Gibbs AC, Reynolds CH, Peters MB, Westerhoff LM (2010) Quantum mechanical pairwise decomposition analysis of protein kinase B inhibitors: validating a new tool for guiding drug design. J Chem Inf Model 50:651–661
Diller DJ, Humblet C, Zhang XH, Westerhoff LM (2010) Computational alanine scanning with linear scaling semiempirical quantum mechanical methods. Proteins 78:2329–2337
Young T, Abel R, Kim B, Berne BJ, Friesner RA (2007) Motifs for molecular recognition exploiting hydrophobic enclosure in protein–ligand binding. Proc Natl Acad Sci USA 104:808–813
Luccarelli J, Michel J, Tirado-Rives J, Jorgensen WL (2010) Effects of water placement on predictions of binding affinities for p38alpha MAP kinase inhibitors. J Chem Theory Comput 6:3850–3856
Michel J, Tirado-Rives J, Jorgensen WL (2009) Energetics of displacing water molecules from protein binding sites: consequences for ligand optimization. J Am Chem Soc 131:15403–15411
Martin YC (2009) Let’s not forget tautomers. J Comput Aided Mol Des 23:693–704
Pospisil P, Ballmer P, Scapozza L, Folkers G (2003) Tautomerism in computer-aided drug design. J Recept Signal Transduct Res 23:361–371
Tirado-Rives J, Jorgensen WL (2006) Contribution of conformer focusing to the uncertainty in predicting free energies for protein−ligand binding. J Med Chem 49:5880–5884
Warren GL, Andrews CW, Capelli A-M, Clarke B, LaLonde J, Lambert MH, Lindvall M, Nevins N, Semus SF, Senger S, Tedesco G, Wall ID, Woolven JM, Peishoff CE, Head MS (2006) A critical assessment of docking programs and scoring functions. J Med Chem 49:5912–5931
Moustakas DT, Lang PT, Pegg S, Pettersen E, Kuntz ID, Brooijmans N, Rizzo RC (2006) Development and validation of a modular, extensible docking program: DOCK 5. J Comput Aided Mol Des 20:601–619
Hartshorn MJ, Verdonk ML, Chessari G, Brewerton SC, Mooij WTM, Mortenson PN, Murray CW (2007) Diverse, high-quality test set for the validation of protein–ligand docking performance. J Med Chem 50:726–741
Verdonk ML, Cole JC, Hartshorn MJ, Murray CW, Taylor RD (2003) Improved protein–ligand docking using GOLD. Proteins 52:609–623
Schneider G (2010) Virtual screening: an endless staircase? Nat Rev Drug Discov 9:273–276
Michel J, Essex JW (2010) Prediction of protein-ligand binding affinity by free energy simulations: assumptions, pitfalls and expectations. J Comput Aided Mol Des 24:639–658
Merz KM (2010) Limits of free energy computation for protein−ligand interactions. J Chem Theory Comput 6:1769–1776
Faver JC, Benson ML, He X, Roberts BP, Wang B, Marshall MS, Kennedy MR, Sherrill CD, Merz KM (2011) Formal estimation of errors in computed absolute interaction energies of protein−ligand complexes. J Chem Theory Comput 7:790–797
Nissink JWM, Murray C, Hartshorn M, Verdonk ML, Cole JC, Taylor R (2002) A new test set for validating predictions of protein-ligand interaction. Proteins 49:457–471
Perola E, Charifson PS (2004) Conformational analysis of drug-like molecules bound to proteins: an extensive study of ligand reorganization upon binding. J Med Chem 47:2499–2510
Warren GL, Do TD, Kelley BP, Nicholls A, Warren SD (2012) Essential considerations for using protein-ligand structures in drug discovery. Drug Discovery Today 17:1270–1281
Davis AM, Teague SJ, Kleywegt GJ (2003) Application and limitations of X-ray crystallographic data in structure-based ligand and drug design. Angew Chem Int Ed 42:2718–2736
Davis IW, Leaver-Fay A, Chen VB, Block JN, Kapral GJ, Wang X, Murray LW, Arendall WB, Snoeyink J, Richardson JS, Richardson DC (2007) MolProbity: all-atom contacts and structure validation for proteins and nucleic acids. Nucleic Acids Res 35:W375–W383
Cerutti DS, Freddolino PL, Duke RE, Case DA (2010) Simulations of a protein crystal with a high resolution X-ray structure: evaluation of force fields and water models. J Phys Chem B 114:12811–12824
Janowski PA, Moriarty NW, Kelley BP, Case DA, York DM, Adams PD, Warren GL (2016) Improved ligand geometries in crystallographic refinement using AFITT in PHENIX. Acta Cryst Sect D 72:1062–1072
Reynolds CH, Ringe D, Merz JKM, Petsko GA, Ringe D (2010) X-ray crystallography in the service of structure-based drug design. Drug Design: Structure- and Ligand-Based Approaches. Cambridge University Press, Cambridge, pp 17–29
Adams PD, Afonine PV, Bunkoczi G, Chen VB, Davis IW, Echols N, Headd JJ, Hung LW, Kapral GJ, Grosse-Kunstleve RW, McCoy AJ, Moriarty NW, Oeffner R, Read RJ, Richardson DC, Richardson JS, Terwilliger TC, Zwart PH (2010) PHENIX: a comprehensive Python-based system for macromolecular structure solution. Acta Cryst Sect D 66:213–221
Kleywegt GJ (2007) Crystallographic refinement of ligand complexes. Acta Cryst Sect D 63:94–100
Kleywegt GJ, Henrick K, Dodson EJ, van Aalten DMF (2003) Pound-wise but penny-foolish: how well do micromolecules fare in macromolecular refinement? Structure 11:1051–1059
Read RJ, Adams PD, Arendall WB III, Brunger AT, Emsley P, Joosten RP, Kleywegt GJ, Krissinel EB, Lutteke T, Otwinowski Z, Perrakis A, Richardson JS, Sheffler WH, Smith JL, Tickle IJ, Vriend G, Zwart PH (2011) A new generation of crystallographic validation tools for the protein data bank. Structure 19:1395–1412
Borbulevych O, Martin RI, Westerhoff LM (2018) High-throughput quantum-mechanics/molecular-mechanics (ONIOM) macromolecular crystallographic refinement with PHENIX/DivCon: the impact of mixed Hamiltonian methods on ligand and protein structure. Acta Cryst Sect D 74:1063–1077
Borbulevych OY, Plumley JA, Martin RI, Merz KM Jr, Westerhoff LM (2014) Accurate macromolecular crystallographic refinement: incorporation of the linear scaling, semiempirical quantum-mechanics program DivCon into the PHENIX refinement package. Acta Cryst Sect D 70:1233–1247
Dixon SL, Merz KM (1996) Semiempirical molecular orbital calculations with linear system size scaling. J Chem Phys 104:6643–6649
Dixon SL, Merz KM (1997) Fast, accurate semiempirical molecular orbital calculations for macromolecules. J Chem Phys 107:879–893
QuantumBio Inc. (2020) DivCon Discovery Suite, http://www.quantumbioinc.com
Vreven T, Morokuma K, Farkas Ö, Schlegel HB, Frisch MJ (2003) Geometry optimization with QM/MM, ONIOM, and other combined methods. I Microiterations and constraints. J Comput Chem 24:760–769
Raha K, van der Vaart AJ, Riley KE, Peters MB, Westerhofft LM, Kim H, Merz KM (2005) Pairwise decomposition of residue interaction energies using semiempirical quantum mechanical methods in studies of protein–ligand interaction. J Am Chem Soc 127:6583–6594
van der Vaart A, Merz KM (1999) Divide and conquer interaction energy decomposition. J Phys Chem A 103:3321–3329
Dunbar JB Jr, Smith RD, Damm-Ganamet KL, Ahmed A, Esposito EX, Delproposto J, Chinnaswamy K, Kang Y-N, Kubish G, Gestwicki JE, Stuckey JA, Carlson HA (2013) CSAR data set release 2012: ligands, affinities, complexes, and docking decoys. J Chem Inf Model 53:1842–1852
Borbulevych O, Martin RI, Tickle IJ, Westerhoff LM (2016) XModeScore: a novel method for accurate protonation/tautomer-state determination using quantum-mechanically driven macromolecular X-ray crystallographic refinement. Acta Cryst Sect D 72:586–598
Westerhoff, LM, Borbulevych, OY and Martin, RI (2020) Quantum mechanical/X-ray crystallography diagnostic for proteins. QuantumBio, Inc. US Patent 10,614,909
Labute P (2009) Protonate3D: Assignment of ionization states and hydrogen coordinates to macromolecular structures. Proteins 75:187–205
Chemical Computing Group ULC (2019) Molecular Operating Environment (MOE) v. 2019.02 CCG, 1010 Sherbrooke St. West, Suite #910, Montreal, QC, Canada, H3A 2R7: Montreal, QC.
Stewart JJP (2009) Application of the PM6 method to modeling proteins. J Mol Model 15:765–805
Rezac J, Fanfrlik J, Salahub D, Hobza P (2009) Semiempirical quantum chemical PM6 method augmented by dispersion and H-bonding correction terms reliably describes various types of noncovalent complexes. J Chem Theory Comput 5:1749–1760
University of California, San Francisco (2010) AMBER 11
Afonine PV, Grosse-Kunstleve RW, Echols N, Headd JJ, Moriarty NW, Mustyakimov M, Terwilliger TC, Urzhumtsev A, Zwart PH, Adams PD (2012) Towards automated crystallographic structure refinement with phenix.refine. Acta Cryst Sect D 68:352–367
Adams PD, Pannu NS, Read RJ, Brunger AT (1997) Cross-validated maximum likelihood enhances crystallographic simulated annealing refinement. Proc Natl Acad Sci USA 94:5018–5023
Tickle I (2012) Statistical quality indicators for electron-density maps. Acta Cryst Sect D 68:454–467
Fu Z, Li X, Merz KM (2012) Conformational analysis of free and bound retinoic acid. J Chem Theory Comput 8:1436–1448
Gibbons JD, Chakraborti S (2010) Nonparametric statistical inference. Chapman and Hall/CRC, London, p 650
Yuriev E, Ramsland PA (2013) Latest developments in molecular docking: 2010–2011 in review. J Mol Recognit 26:215–239
Corbeil CR, Williams CI, Labute P (2012) Variability in docking success rates due to dataset preparation. J Comput Aided Mol Des 26:775–786
Raha K, Merz KM (2005) Large-scale validation of a quantum mechanics based scoring function: predicting the binding affinity and the binding mode of a diverse set of protein–ligand complexes. J Med Chem 48:4558–4575
Chen VB, Arendall WB, Headd JJ, Keedy DA, Immormino RM, Kapral GJ, Murray LW, Richardson JS, Richardson DC (2010) MolProbity: all-atom structure validation for macromolecular crystallography. Acta Cryst Sect D 66:12–21
MacCallum JL, Hua L, Schnieders MJ, Pande VS, Jacobson MP, Dill KA (2009) Assessment of the protein-structure refinement category in CASP8. Proteins 77:66–80
Word JM, Lovell SC, LaBean TH, Taylor HC, Zalis ME, Presley BK, Richardson JS, Richardson DC (1999) Visualizing and quantifying molecular goodness-of-fit: small-probe contact dots with explicit hydrogen atoms. J Mol Biol 285:1711–1733
Zheng M, Reimers JR, Waller MP, Afonine PV (2017) Q|R: quantum-based refinement. Acta Cryst Sect D 73:45–52
Gore S, Sanz GarcÃa E, Hendrickx PMS, Gutmanas A, Westbrook JD, Yang H, Feng Z, Baskaran K, Berrisford JM, Hudson BP, Ikegawa Y, Kobayashi N, Lawson CL, Mading S, Mak L, Mukhopadhyay A, Oldfield TJ, Patwardhan A, Peisach E, Sahni G, Sekharan MR, Sen S, Shao C, Smart OS, Ulrich EL, Yamashita R, Quesada M, Young JY, Nakamura H, Markley JL, Berman HM, Burley SK, Velankar S, Kleywegt GJ (2017) Validation of structures in the protein data bank. Structure 25:1916–1927
Fu Z, Li X, Merz KM (2011) Accurate assessment of the strain energy in a protein-bound drug using QM/MM X-ray refinement and converged quantum chemistry. J Comput Chem 32:2587–2597
Mobley DL, Dill KA (2009) Binding of small-molecule ligands to proteins: “what you see”; is not always “what you get.” Structure 17:489–498
Borbulevych, OY, Plumley, JA and Westerhoff, LM (2012) Systematic study of the ligand strain energy derived from the quantum mechanics crystallographic refinement using the linear scaling program DivCon integrated into the PHENIX package. Abstr Pap Am Chem Soc: 478.
Rezac J, Hobza P (2012) Advanced corrections of hydrogen bonding and dispersion for semiempirical quantum mechanical methods. J Chem Theory Comput 8:141–151
Vorlova B, Nachtigallova D, Jiraskova-Vanickova J, Ajani H, Jansa P, Rezac J, Fanfrlik J, Otyepka M, Hobza P, Konvalinka J, Lepsik M (2015) Malonate-based inhibitors of mammalian serine racemase: kinetic characterization and structure-based computational study. Eur J Med Chem 89:189–197
Zheng Z, Borbulevych OY, Liu H, Deng J, Martin RI, Westerhoff LM (2020) MovableType Software for Fast Free Energy-Based Virtual Screening: Protocol Development, Deployment, Validation, and Assessment. J Chem Inf Model. https://doi.org/10.1021/acs.jcim.0c00618
Pan L-L, Zheng Z, Wang T, Merz KM (2015) Free energy-based conformational search algorithm using the movable type sampling method. J Chem Theory Comput 11:5853–5864
Zheng Z, Ucisik MN, Merz KM (2013) The movable type method applied to protein–ligand binding. J Chem Theory Comput 9:5526–5538
Acknowledgements
The authors wish to acknowledge the continued support of the PHENIX Consortium, in particular Drs Nigel Moriarty, Pavel Afonine and Paul Adams, for maintaining the application programming interface (API) "hooks" to our software within the PHENIX distribution and for helpful discussion and feedback. The authors also wish to acknowledge the continued support of our clients and users. We would also like to thank Chemical Computing Group (in particular Alain Deschenes, Chris Williams, Paul Labute and the entire CCG support team) for their continued support with MOE best practices and with the Scientific Vector Language. Finally, the authors would like to thank Dr. Heather Carlson and her group for their hard work in the preparation and publication of the CSAR benchmark set we utilized for this work. The DivCon plugin to PHENIX and BUSTER along with the patented XModeScore tool is provided by QuantumBio Inc. and it is available at https://www.quantumbioinc.com/products/software_licensing
Funding
The research reported in this publication was supported by the National Institute of General Medical Sciences of the National Institutes of Health under Small Business Innovative Research (SBIR) Award Nos. R43GM113555, R44GM079899, and R44GM121162. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Borbulevych, O.Y., Martin, R.I. & Westerhoff, L.M. The critical role of QM/MM X-ray refinement and accurate tautomer/protomer determination in structure-based drug design. J Comput Aided Mol Des 35, 433–451 (2021). https://doi.org/10.1007/s10822-020-00354-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10822-020-00354-6