
Abstract
We designed a superposition calculus for a clausal fragment of extensional polymorphic higher-order logic that includes anonymous functions but excludes Booleans. The inference rules work on \(\beta \eta \)-equivalence classes of \(\lambda \)-terms and rely on higher-order unification to achieve refutational completeness. We implemented the calculus in the Zipperposition prover and evaluated it on TPTP and Isabelle benchmarks. The results suggest that superposition is a suitable basis for higher-order reasoning.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Superposition [6] is widely regarded as the calculus par excellence for reasoning about first-order logic with equality. To increase automation in proof assistants and other verification tools based on higher-order formalisms, we propose to generalize superposition to an extensional, polymorphic, clausal version of higher-order logic (also called simple type theory). Our ambition is to achieve a graceful extension, which coincides with standard superposition on first-order problems and smoothly scales up to arbitrary higher-order problems.
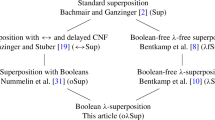
Bentkamp et al. [12] designed a family of superposition-like calculi for a \(\lambda \)-free clausal fragment of higher-order logic, with currying and applied variables. We adapt their extensional nonpurifying calculus to support \(\lambda \)-terms (Sect. 3). Our calculus does not support interpreted Booleans. It is conceived as the penultimate milestone toward a superposition calculus for full higher-order logic. If desired, Booleans can be encoded in our logic fragment using an uninterpreted type and uninterpreted “proxy” symbols corresponding to equality, the connectives, and the quantifiers.
Designing a higher-order superposition calculus poses three main challenges:
-
1.
Standard superposition is parameterized by a ground-total simplification order \(\succ \), but such orders do not exist for \(\lambda \)-terms equal up to \(\beta \)-conversion. The relations designed for proving termination of higher-order term rewriting systems, such as HORPO [40] and CPO [22], lack many of the desired properties (e.g., transitivity, stability under grounding substitutions).
-
2.
Higher-order unification is undecidable and may give rise to an infinite set of incomparable unifiers. For example, the constraint
 admits infinitely many independent solutions of the form \(\{ y \mapsto \lambda x.\; {\textsf {f}}^{\,\,n} \, x \}.\)
admits infinitely many independent solutions of the form \(\{ y \mapsto \lambda x.\; {\textsf {f}}^{\,\,n} \, x \}.\) -
3.
In first-order logic, to rewrite into a term s using an oriented equation \(t \approx t'\), it suffices to find a subterm of s that is unifiable with t. In higher-order logic, this is insufficient. Consider superposition from \({\textsf {f}} \> {\textsf {c}} \approx {\textsf {a}}\) into \(y \> {\textsf {c}} \not \approx y \> {\textsf {b}}\). The left-hand sides can obviously be unified by \(\{y \mapsto {\textsf {f}}\}\), but the more general unifier \(\{y \mapsto \lambda x.\> z\> x\> ({\textsf {f}}\> x)\}\) also gives rise to a subterm \({\textsf {f}} \> {\textsf {c}}\) after \(\beta \)-reduction. The corresponding inference generates \(z\> {\textsf {c}}\> {\textsf {a}} \not \approx z\> {\textsf {b}} \>({\textsf {f}}\> {\textsf {b}})\).
 admits infinitely many independent solutions of the form
admits infinitely many independent solutions of the form To address the first challenge, we adopt the \(\eta \)-short \(\beta \)-normal form to represent \(\beta \eta \)-equivalence classes of \(\lambda \)-terms. In the spirit of Jouannaud and Rubio’s early joint work [39], we state requirements on the term order only for ground terms (i.e., closed monomorphic \(\beta \eta \)-equivalence classes); the nonground case is connected to the ground case via stability under grounding substitutions. Even on ground terms, we cannot obtain all desirable properties. We sacrifice compatibility with arguments (the property that \(s' \succ s\) implies \(s'\>t \succ s\>t\)), compensating with an argument congruence rule (ArgCong), as in Bentkamp et al. [12].
For the second challenge, we accept that there might be infinitely many incomparable unifiers and enumerate a complete set (including the notorious flex–flex pairs [37]), relying on heuristics to postpone the combinatorial explosion. The saturation loop must also be adapted to interleave this enumeration with the theorem prover’s other activities (Sect. 6). Despite its reputation for explosiveness, higher-order unification is a conceptual improvement over \({\textsf {SK}}\) combinators, because it can often compute the right unifier. Consider the conjecture \(\exists z. \> \forall x\> y.\> z\> x\> y \approx {\textsf {f}}\> y\> x\). After negation, clausification, and skolemization (which are as for first-order logic), the formula becomes \(z\> ({\textsf {sk}}_{\textsf {x}}\> z) \> ({\textsf {sk}}_{\textsf {y}}\> z) \not \approx {\textsf {f}}\> ({\textsf {sk}}_{\textsf {y}}\> z) \> ({\textsf {sk}}_{\textsf {x}}\> z)\). Higher-order unification quickly computes the unique unifier: \(\{z \mapsto \lambda x\> y.\> {\textsf {f}}\>y\>x\}\). In contrast, an encoding approach based on combinators, similar to the one implemented in Sledgehammer [52], would blindly enumerate all possible \({\textsf {SK}}\) terms for z until the right one, \({\textsf {S}}\> ({\textsf {K}}\> ({\textsf {S}}\> {\textsf {f}}))\> {\textsf {K}}\), is found. Given the definitions \({\textsf {S}}\> z\> y\> x \approx z\> x\> (y\> x)\) and \({\textsf {K}}\> x\> y \approx x\), the E prover [59] in auto mode needs to perform 3757 inferences to derive the empty clause.
For the third challenge, the idea is that, when applying \(t \approx t'\) to perform rewriting inside a higher-order term s, we can encode an arbitrary context as a fresh higher-order variable z, unifying s with \(z\>t\); the result is \((z\>t')\sigma \), for some unifier \(\sigma \). This is performed by a dedicated fluid subterm superposition rule (FluidSup).
Functional extensionality is also considered a quintessential higher-order challenge [14], although similar difficulties arise with first-order sets and arrays [34]. Our approach is to add extensionality as an axiom and provide optional rules as optimizations (Sect. 5). With this axiom, our calculus is refutationally complete w.r.t. extensional Henkin semantics (Sect. 4). Our proof employs the new saturation framework by Waldmann et al. [71] to derive dynamic completeness of a given clause prover from ground static completeness.
We implemented the calculus in the Zipperposition prover [28] (Sect. 6). Our empirical evaluation includes benchmarks from the TPTP [64] and interactive verification problems exported from Isabelle/HOL [23] (Sect. 7). The results clearly demonstrate the calculus’s potential. The 2020 edition of the CADE ATP System Competition (CASC) provides further confirmation: Zipperposition finished 20 percentage points ahead of its closest rival [63]. This suggests that an implementation inside a high-performance prover such as E [59] or Vampire [48] could fulfill the promise of strong proof automation for higher-order logic (Sect. 8).
An earlier version of this article was presented at CADE-27 [11]. This article extends the conference paper with more explanations, detailed soundness and completeness proofs, including dynamic completeness, and new optional inference rules. We have also updated the empirical evaluation and extended the coverage of related work. Finally, we tightened side condition 4 of FluidSup, making the rule slightly less explosive.
2 Logic
Our extensional polymorphic clausal higher-order logic is a restriction of full TPTP THF [16] to rank-1 (top-level) polymorphism, as in TH1 [41]. In keeping with standard superposition, we consider only formulas in conjunctive normal form, without explicit quantifiers or Boolean type. We use Henkin semantics [15, 31, 35], as opposed to the standard semantics that is commonly considered the foundation of the HOL systems [33]. Both semantics are compatible with the notion of provability employed by the HOL systems. But by admitting nonstandard models, Henkin semantics is not subject to Gödel’s first incompleteness theorem, allowing us to claim refutational completeness of our calculus.
Syntax We fix a set \(\Sigma _\mathsf {ty}\) of type constructors with arities and a set \(\mathscr {V}_\mathsf {ty}\) of type variables. We require at least one nullary type constructor and a binary function type constructor \({\rightarrow }\) to be present in \(\Sigma _\mathsf {ty}\). A type \(\tau ,\upsilon \) is either a type variable \(\alpha \in \mathscr {V}_\mathsf {ty}\) or has the form \(\kappa (\bar{\tau }_n)\) for an n-ary type constructor \(\kappa \in \Sigma _\mathsf {ty}\) and types \(\bar{\tau }_n\). We use the notation \(\bar{a}_n\) or \(\bar{a}\) to stand for the tuple \((a_1,\dots ,a_n)\) or product \(a_1 \times \dots \times a_n\), where \(n \ge 0\). We write \(\kappa \) for \(\kappa ()\) and \(\tau \rightarrow \upsilon \) for \({\rightarrow }(\tau ,\upsilon )\). Type declarations have the form \(\varvec{\Pi }\bar{\alpha }_m.\tau \) (or simply \(\tau \) if \(m = 0\)), where all type variables occurring in \(\tau \) belong to \(\bar{\alpha }_m\).
We fix a set \(\Sigma \) of (function) symbols \({\textsf {a}}, {\textsf {b}}, {\textsf {c}}, {\textsf {f}}, {\textsf {g}}, {\textsf {h}}, \dots \), with type declarations, written as \({\textsf {f}}:\varvec{\Pi }\bar{\alpha }_m.\tau \) or \({\textsf {f}}\), and a set \(\mathscr {V}\) of term variables with associated types, written as \({\textit{x}}:\tau \) or \({\textit{x}}\). The notation \(t :\tau \) will also be used to indicate the type of arbitrary terms t. We require the presence of a symbol of type \(\varvec{\Pi }\alpha .\alpha \) and of a symbol \(\mathsf {diff}:\varvec{\Pi }\alpha ,\beta .(\alpha \rightarrow \beta )\rightarrow (\alpha \rightarrow \beta )\rightarrow {\alpha }\) in \(\Sigma \). We use \(\mathsf {diff}\) to express the polymorphic functional extensionality axiom. A signature is a pair \((\Sigma _\mathsf {ty},\Sigma )\).
Next, we define terms on three layers of abstraction: raw \(\lambda \)-terms, \(\lambda \)-terms (as \(\alpha \)-equivalence classes of raw \(\lambda \)-terms), and terms (as \(\beta \eta \)-equivalence classes of \(\lambda \)-terms).
The raw \(\lambda \)-terms over a given signature and their associated types are defined inductively as follows. Every \(x : \tau \in \mathscr {V}\) is a raw \(\lambda \)-term of type \(\tau \). If \({\textsf {f}}:\varvec{\Pi }\bar{\alpha }_m.\tau \in \Sigma \) and \(\bar{\upsilon }_m\) is a tuple of types, called type arguments, then \({\textsf {f}}{\langle {\bar{\upsilon }_m}\rangle }\) (or \({\textsf {f}}\) if \(m = 0\)) is a raw \(\lambda \)-term of type \(\tau \{\bar{\alpha }_m \mapsto \bar{\upsilon }_m\}\). If \(x :\tau \) and \(t:\upsilon \), then the \(\lambda \)-expression \(\lambda x.\> t\) is a raw \(\lambda \)-term of type \(\tau \rightarrow \upsilon \). If \(s:\tau \rightarrow \upsilon \) and \(t:\tau \), then the application \(s\>t\) is a raw \(\lambda \)-term of type \(\upsilon \).
The function type constructor \(\rightarrow \) is right-associative; application is left-associative. Using the spine notation [26], raw \(\lambda \)-terms can be decomposed in a unique way as a nonapplication head t applied to zero or more arguments: \(t \> s_1\dots s_n\) or \(t \> \bar{s}_n\) (abusing notation).
A raw \(\lambda \)-term s is a subterm of a raw \(\lambda \)-term t, written \(t = t[s]\), if \(t = s\), if \(t = (\lambda x.\>u[s])\), if \(t = (u[s])\>v\), or if \(t = u\>(v[s])\) for some raw \(\lambda \)-terms u and v. A proper subterm of a raw \(\lambda \)-term t is any subterm of t that is distinct from t itself.
A variable occurrence is free in a raw \(\lambda \)-term if it is not bound by a \(\lambda \)-expression. A raw \(\lambda \)-term is ground if it is built without using type variables and contains no free term variables.
The \(\alpha \)-renaming rule is defined as  , where y does not occur free in t and is not captured by a \(\lambda \)-binder in t. Raw \(\lambda \)-terms form equivalence classes modulo \(\alpha \)-renaming, called \(\lambda \)-terms. We lift the above notions on raw \(\lambda \)-terms to \(\lambda \)-terms.
, where y does not occur free in t and is not captured by a \(\lambda \)-binder in t. Raw \(\lambda \)-terms form equivalence classes modulo \(\alpha \)-renaming, called \(\lambda \)-terms. We lift the above notions on raw \(\lambda \)-terms to \(\lambda \)-terms.
A substitution \(\rho \) is a function from type variables to types and from term variables to \(\lambda \)-terms such that it maps all but finitely many variables to themselves. We also require that it is type correct—i.e., for each \(x:\tau \in \mathscr {V}\), \(x\rho \) is of type \(\tau \rho \). The letters \(\theta ,\pi ,\rho ,\sigma \) are reserved for substitutions. Substitutions implicitly \(\alpha \)-rename \(\lambda \)-terms to avoid capture; for example, \((\lambda x.\> y)\{y \mapsto x\} = (\lambda x'\!.\> x)\). The composition \(\rho \sigma \) applies \(\rho \) first: \(t\rho \sigma = (t\rho )\sigma \). The notation \(\sigma [\bar{x}_n \mapsto \bar{s}_n]\) stands for the substitution that replaces each \(x_i\) by \(s_i\) and that otherwise coincides with \(\sigma \).
The \(\beta \)- and \(\eta \)-reduction rules are specified on \(\lambda \)-terms as  and
and  . For \(\beta \), bound variables in t are implicitly renamed to avoid capture; for \(\eta \), the variable x must not occur free in t. The \(\lambda \)-terms form equivalence classes modulo \(\beta \eta \)-reduction, called \(\beta \eta \)-equivalence classes or simply terms.
. For \(\beta \), bound variables in t are implicitly renamed to avoid capture; for \(\eta \), the variable x must not occur free in t. The \(\lambda \)-terms form equivalence classes modulo \(\beta \eta \)-reduction, called \(\beta \eta \)-equivalence classes or simply terms.
Convention 1
When defining operations that need to analyze the structure of terms, we will use the \(\eta \)-short \(\beta \)-normal form \(t{\downarrow }_{\beta \eta }\), obtained by applying  and
and  exhaustively, as a representative of the equivalence class t. In particular, we lift the notions of subterms and occurrences of variables to \(\beta \eta \)-equivalence classes via their \(\eta \)-short \(\beta \)-normal representative.
exhaustively, as a representative of the equivalence class t. In particular, we lift the notions of subterms and occurrences of variables to \(\beta \eta \)-equivalence classes via their \(\eta \)-short \(\beta \)-normal representative.
Many authors prefer the \(\eta \)-long \(\beta \)-normal form [37, 39, 51], but in a polymorphic setting it has the drawback that instantiating a type variable with a functional type can lead to \(\eta \)-expansion. We reserve the letters s, t, u, v for terms and x, y, z for variables.
An equation \(s \approx t\) is formally an unordered pair of terms s and t. A literal is an equation or a negated equation, written \(\lnot \; s \approx t\) or \(s \not \approx t\). A clause \(L_1 \vee \dots \vee L_n\) is a finite multiset of literals \(L_{\!j}\). The empty clause is written as \(\bot \).
A complete set of unifiers on a set X of variables for two terms s and t is a set U of unifiers of s and t such that for every unifier \(\theta \) of s and t there exists a member \(\sigma \in U\) and a substitution \(\rho \) such that \(x\sigma \rho = x\theta \) for all \(x \in X.\) We let \({{\,\mathrm{CSU}\,}}_X(s,t)\) denote an arbitrary (preferably minimal) complete set of unifiers on X for s and t. We assume that all \(\sigma \in {{\,\mathrm{CSU}\,}}_X(s,t)\) are idempotent on X—i.e., \(x\sigma \sigma = x\sigma \) for all \(x \in X.\) The set X will consist of the free variables of the clauses in which s and t occur and will be left implicit.
Given a substitution \(\sigma \), the \(\sigma \)-instance of a term t or clause C is the term \(t\sigma \) or the clause \(C\sigma \), respectively. If \(t\sigma \) or \(C\sigma \) is ground, we call it a \(\sigma \)-ground instance.
Semantics A type interpretation \(\mathscr {I}_{\mathsf {\mathrm{ty}}}= (\mathscr {U}, \mathscr {J}_\mathsf {ty})\) is defined as follows. The universe \(\mathscr {U}\) is a nonempty collection of nonempty sets, called domains. The function \(\mathscr {J}_\mathsf {ty}\) associates a function \(\mathscr {J}_\mathsf {ty}(\kappa ) : \mathscr {U}^n \rightarrow \mathscr {U}\) with each n-ary type constructor \(\kappa \), such that for all domains \(\mathscr {D}_1,\mathscr {D}_2\in \mathscr {U}\), the set \(\mathscr {J}_\mathsf {ty}(\rightarrow )(\mathscr {D}_1,\mathscr {D}_2)\) is a subset of the function space from \(\mathscr {D}_1\) to \(\mathscr {D}_2\). The semantics is standard if \(\mathscr {J}_\mathsf {ty}(\rightarrow )(\mathscr {D}_1,\mathscr {D}_2)\) is the entire function space for all \(\mathscr {D}_1,\mathscr {D}_2\).
A type valuation \(\xi \) is a function that maps every type variable to a domain. The denotation of a type for a type interpretation \(\mathscr {I}_{\mathsf {\mathrm{ty}}}\) and a type valuation \(\xi \) is defined by \(\smash {\llbracket \alpha \rrbracket _{\mathscr {I}_{\mathsf {\mathrm{ty}}}}^{\xi }}=\xi (\alpha )\) and \(\smash {\llbracket \kappa (\bar{\tau })\rrbracket _{\mathscr {I}_{\mathsf {\mathrm{ty}}}}^{\xi }}= \mathscr {J}_\mathsf {ty}(\kappa )(\smash {\llbracket \bar{\tau }\rrbracket _{\mathscr {I}_{\mathsf {\mathrm{ty}}}}^{\xi }})\). We abuse notation by applying an operation on a tuple when it must be applied elementwise; thus, \(\smash {\llbracket \bar{\tau }_n\rrbracket _{\mathscr {I}_{\mathsf {\mathrm{ty}}}}^{\xi }}\) stands for \(\smash {\llbracket \tau _1\rrbracket _{\mathscr {I}_{\mathsf {\mathrm{ty}}}}^{\xi }},\dots , \smash {\llbracket \tau _n\rrbracket _{\mathscr {I}_{\mathsf {\mathrm{ty}}}}^{\xi }}\). A type valuation \(\xi \) can be extended to be a valuation by additionally assigning an element \(\xi (x)\in \smash {\llbracket \tau \rrbracket _{\mathscr {I}_{\mathsf {\mathrm{ty}}}}^{\xi }}\) to each variable \(x :\tau \). An interpretation function \(\mathscr {J}\) for a type interpretation \(\mathscr {I}_{\mathsf {\mathrm{ty}}}\) associates with each symbol \({\textsf {f}}:\varvec{\Pi }\bar{\alpha }_m.\tau \) and domain tuple \(\bar{\mathscr {D}}_m\in \mathscr {U}^m\) a value \(\mathscr {J}({\textsf {f}},\bar{\mathscr {D}}_m) \in \smash {\llbracket \tau \rrbracket _{\mathscr {I}_{\mathsf {\mathrm{ty}}}}^{\xi }}\), where \(\xi \) is the type valuation that maps each \(\alpha _i\) to \(\mathscr {D}_i\).
The comprehension principle states that every function designated by a \(\lambda \)-expression is contained in the corresponding domain. Loosely following Fitting [31, Sect. 2.4], we initially allow \(\lambda \)-expressions to designate arbitrary elements of the domain, to be able to define the denotation of a term. We impose restrictions afterward using the notion of a proper interpretation. A \(\lambda \)-designation function \(\mathscr {L}\) for a type interpretation \(\mathscr {I}_{\mathsf {\mathrm{ty}}}\) is a function that maps a valuation \(\xi \) and a \(\lambda \)-expression of type \(\tau \) to elements of \(\smash {\llbracket \tau \rrbracket _{\mathscr {I}_{\mathsf {\mathrm{ty}}}}^{\xi }}\). A type interpretation, an interpretation function, and a \(\lambda \)-designation function form an (extensional) interpretation \(\mathscr {I}= (\mathscr {I}_{\mathsf {\mathrm{ty}}},\mathscr {J},\mathscr {L})\). For an interpretation \(\mathscr {I}\) and a valuation \(\xi \), the denotation of a term is defined as \(\smash {\llbracket x\rrbracket _{\mathscr {I}}^{\xi }} =\xi (x)\), \(\smash {\llbracket {\textsf {f}}{\langle {\bar{\tau }_m}\rangle }\rrbracket _{\mathscr {I}}^{\xi }} =\mathscr {J}({\textsf {f}},\smash {\llbracket \bar{\tau }_m\rrbracket _{\mathscr {I}_{\mathsf {\mathrm{ty}}}}^{\xi }})\), \(\smash {\llbracket s\>t\rrbracket _{\mathscr {I}}^{\xi }} =\smash {\llbracket s\rrbracket _{\mathscr {I}}^{\xi }} (\smash {\llbracket t\rrbracket _{\mathscr {I}}^{\xi }})\), and \(\smash {\llbracket \lambda x.\> t\rrbracket _{\mathscr {I}}^{\xi }} =\mathscr {L}(\xi ,\lambda x.\> t)\). For ground terms t, the denotation does not depend on the choice of the valuation \(\xi \), which is why we sometimes write \(\smash {\llbracket t\rrbracket _{\mathscr {I}}^{}}\) for \(\smash {\llbracket t\rrbracket _{\mathscr {I}}^{\xi }}\).
An interpretation \(\mathscr {I}\) is proper if \(\smash {\llbracket \lambda x.\>t\rrbracket _{\mathscr {I}}^{\xi }}(a) = \smash {\llbracket t\rrbracket _{\mathscr {I}}^{\xi [x\mapsto a]}}\) for all \(\lambda \)-expressions \(\lambda x.\>t\), all valuations \(\xi \), and all a. If a type interpretation \(\mathscr {I}_{\mathsf {\mathrm{ty}}}\) and an interpretation function \(\mathscr {J}\) can be extended by a \(\lambda \)-designation function \(\mathscr {L}\) to a proper interpretation \((\mathscr {I}_{\mathsf {\mathrm{ty}}},\mathscr {J},\mathscr {L})\), then this \(\mathscr {L}\) is unique [31, Proposition 2.18]. Given an interpretation \(\mathscr {I}\) and a valuation \(\xi \), an equation \(s\approx t\) is true if \(\smash {\llbracket s\rrbracket _{\mathscr {I}}^{\xi }}\) and \(\smash {\llbracket t\rrbracket _{\mathscr {I}}^{\xi }}\) are equal and it is false otherwise. A disequation \(s\not \approx t\) is true if \(s \approx t\) is false. A clause is true if at least one of its literals is true. A clause set is true if all its clauses are true. A proper interpretation \(\mathscr {I}\) is a model of a clause set N, written  , if N is true in \(\mathscr {I}\) for all valuations \(\xi \).
, if N is true in \(\mathscr {I}\) for all valuations \(\xi \).
Axiomatization of Booleans Our clausal logic lacks a Boolean type, but it can easily be axiomatized as follows. We extend the signature with a nullary type constructor \({\textit{bool}} \in \Sigma _\mathsf {ty}\) equipped with the proxy constants \({\textsf {t}}, {\textsf {f}} : {\textit{bool}}\), \({\textsf {not}} : {\textit{bool}} \rightarrow {\textit{bool}}\), \({\textsf {and}}, {\textsf {or}}, {\textsf {impl}}, {\textsf {equiv}} : {\textit{bool}} \rightarrow {\textit{bool}} \rightarrow {\textit{bool}}\), \({\textsf {forall}}, {\textsf {exists}} : \varvec{\Pi }\alpha . \,(\alpha \rightarrow {\textit{bool}}) \rightarrow {\textit{bool}}\), \({\textsf {eq}} : \varvec{\Pi }\alpha . \,\alpha \rightarrow \alpha \rightarrow {\textit{bool}}\), and \({\textsf {choice}} : \varvec{\Pi }\alpha .\, (\alpha \rightarrow {\textit{bool}}) \rightarrow \alpha \), characterized by the axioms
This axiomatization of Booleans can be used in a prover to support full higher-order logic with or without Hilbert choice, corresponding to the TPTP THF format variants TH0 (monomorphic) [66] and TH1 (polymorphic) [41]. The prover’s clausifier would transform the outer first-order skeleton of a formula into a clause and use the axiomatized Booleans within the terms. It would also add the proxy axioms to the clausal problem. As an alternative to this complete axiomatization, Vukmirović and Nummelin [70] present a possibly refutationally incomplete calculus extension with dedicated rules to support Booleans. This approach works better in practice and contributed to Zipperposition’s victory at CASC 2020.
3 The Calculus
The Boolean-free \(\lambda \)-superposition calculus presented here is inspired by the extensional nonpurifying Boolean-free \(\lambda \)-free higher-order superposition calculus described by Bentkamp et al. [12]. The text of this and the next section is partly based on that paper and the associated journal submission [10] (with Cruanes’s permission). The central idea is that superposition inferences are restricted to unapplied subterms occurring in the first-order outer skeleton of clauses—that is, outside \(\lambda \)-expressions and outside the arguments of applied variables. We call these “green subterms.” Thus, \({\textsf {g}} \approx (\lambda x.\> {\textsf {f}}\>x\>x)\) cannot be used directly to rewrite \({\textsf {g}}\> {\textsf {a}}\) to \({\textsf {f}}\> {\textsf {a}}\> {\textsf {a}}\), because \({\textsf {g}}\) is applied in \({\textsf {g}}\> {\textsf {a}}\). A separate inference rule, ArgCong, takes care of deriving \({\textsf {g}}\>x \approx {\textsf {f}}\>x\>x\), which can be oriented independently of its parent clause and used to rewrite \({\textsf {g}}\> {\textsf {a}}\) or \({\textsf {f}}\> {\textsf {a}}\> {\textsf {a}}\).
Definition 2
(Green positions and subterms) A green position of a term (i.e., of a \(\beta \eta \)-equivalence class) is a finite sequence of natural numbers defined inductively as follows. For any term t, the empty tuple \(\varepsilon \) is a green position of t. For all symbols \({\textsf {f}}\in \Sigma \), types \(\bar{\tau }\), and terms \(\bar{u}\), if p is a green position of \(u_i\) for some i, then i.p is a green position of \({\textsf {f}}{\langle {\bar{\tau }}\rangle }\> \bar{u}\).
The green subterm of a term at a given green position is defined inductively as follows. For any term t, t itself is the green subterm of t at green position \(\varepsilon \). For all symbols \({\textsf {f}}\in \Sigma \), types \(\bar{\tau }\), and terms \(\bar{u}\), if t is a green subterm of \(u_i\) at some green position p for some i, then t is the green subterm of \({\textsf {f}}{\langle {\bar{\tau }}\rangle }\>\bar{u}\) at green position i.p. We denote the green subterm of s at the green position p by \(s|_p\).
In \({\textsf {f}}\> ({\textsf {g}}\> {\textsf {a}})\> (y\> {\textsf {b}})\> (\lambda x.\> {\textsf {h}}\> {\textsf {c}}\> ({\textsf {g}}\> x))\), the proper green subterms are \({\textsf {a}}\), \({\textsf {g}}\> {\textsf {a}}\), \(y\> {\textsf {b}}\), and \(\lambda x.\> {\textsf {h}}\> {\textsf {c}}\> ({\textsf {g}}\> x)\). The last two of these do not look like first-order terms, and hence their subterms are not green.
Definition 3
(Green contexts) We write  to express that u is a green subterm of t at the green position p and call
to express that u is a green subterm of t at the green position p and call  a green context. We omit the subscript p if there are no ambiguities.
a green context. We omit the subscript p if there are no ambiguities.
In a \(\beta \eta \)-normal representative of a green context, the hole never occurs applied. Therefore, inserting a \(\beta \eta \)-normal term into the context produces another \(\beta \eta \)-normal term.
Another key notion is that of a fluid term. Fluid terms are certain variable-headed terms and \(\lambda \)-expressions into which the calculus must rewrite to be refutationally complete. Fluid terms trigger the FluidSup rule, which complements the familiar superposition rule Sup.
Definition 4
(Fluid terms) A term t is called fluid if (1) \(t{\downarrow }_{\beta \eta }\) is of the form \(y\>\bar{u}_n\) where \(n \ge 1\), or (2) \(t{\downarrow }_{\beta \eta }\) is a \(\lambda \)-expression and there exists a substitution \(\sigma \) such that \(t\sigma {\downarrow }_{\beta \eta }\) is not a \(\lambda \)-expression (due to \(\eta \)-reduction).
Case (2) can arise only if t contains an applied variable. Intuitively, fluid terms are terms whose \(\eta \)-short \(\beta \)-normal form can change radically as a result of instantiation. For example, \(\lambda x.\> y\> {\textsf {a}}\> (z\> x)\) is fluid because applying \(\{z \mapsto \lambda x.\>x\}\) makes the \(\lambda \) vanish: \((\lambda x.\> y\> {\textsf {a}}\> x) = y\> {\textsf {a}}\). Similarly, \(\lambda x.\> {\textsf {f}}\>(y\>x)\>x\) is fluid because \((\lambda x.\> {\textsf {f}}\>(y\>x)\>x)\{y \mapsto \lambda x.\>{\textsf {a}}\} = (\lambda x.\> {\textsf {f}}\>{\textsf {a}}\>x) = {\textsf {f}}\>{\textsf {a}}\).
3.1 The Core Inference Rules
The calculus is parameterized by a strict ground term order, a strict term order, a nonstrict term order, and a selection function. A strict ground term order \(\succ \) needs to enjoy certain properties for our completeness proof to work. A strict term order \(\succ \) underapproximates the lifting of a strict ground term order to the nonground level. To gain some precision in the side conditions of our rules, we introduce a nonstrict term order \(\succsim \) that can compare more terms than the reflexive closure \(\succeq \) of a strict term order \(\succ \). The selection function resembles the selection function of first-order superposition, with a minor restriction concerning literals containing applied variables.
Definition 5
(Strict ground term order) A strict ground term order is a well-founded strict total order \(\succ \) on ground terms satisfying the following criteria, where \(\succeq \) denotes the reflexive closure of \(\succ \):
-
green subterm property:
 ;
; -
compatibility with green contexts:\(s' \succ s\) implies
 .
.
 ;
; .
.Given a strict ground term order, we extend it to literals and clauses via the multiset extensions in the standard way [6, Sect. 2.4].
Two properties that are not required are compatibility with \(\lambda \)-expressions (\(s'\succ s\) implies \((\lambda x. \> s') \succ (\lambda x.\> s)\)) and compatibility with arguments (\(s' \succ s\) implies \(s'\>{t} \succ s\>{t}\)). The latter would even be inconsistent with totality. To see why, consider the symbols \({\textsf {c}} \succ {\textsf {b}} \succ {\textsf {a}}\) and the terms \(\lambda x.\> {\textsf {b}}\) and \(\lambda x.\> x\). Owing to totality, one of the terms must be larger than the other, say, \((\lambda x.\> {\textsf {b}}) \succ (\lambda x.\> x)\). By compatibility with arguments, we get \((\lambda x.\> {\textsf {b}})\> {\textsf {c}} \succ (\lambda x.\>x)\> {\textsf {c}}\), i.e., \({\textsf {b}} \succ {\textsf {c}}\), a contradiction. A similar line of reasoning applies if \((\lambda x.\> {\textsf {b}}) \prec (\lambda x.\> x)\), using \({\textsf {a}}\) instead of \({\textsf {c}}\).
Definition 6
(Strict term order) A strict term order is a relation \(\succ \) on terms, literals, and clauses such that the restriction to ground entities is a strict ground term order and such that it is stable under grounding substitutions (i.e., \(t \succ s\) implies \(t\theta \succ s\theta \) for all substitutions \(\theta \) grounding the entities t and s).
Definition 7
(Nonstrict term order) Given the reflexive closure \(\succeq \) of a strict ground term order \(\succ \), a nonstrict term order is a relation \(\succsim \) on terms, literals, and clauses such that \(t \succsim s\) implies \(t\theta \succeq s\theta \) for all \(\theta \) grounding the entities t and s.
Although we call them orders, a strict term order \(\succ \) is not required to be transitive on nonground entities, and a nonstrict term order \(\succsim \) does not need to be transitive at all. Normally, \(t \succeq s\) should imply \(t \succsim s\), but this is not required either. A nonstrict term order \(\succsim \) allows us to be more precise than the reflexive closure \(\succeq \) of \(\succ \). For example, we cannot have \(y\>{\textsf {b}} \succeq y\>{\textsf {a}}\), because \(y\>{\textsf {b}} \not = y\>{\textsf {a}}\) and \(y\>{\textsf {b}} \not \succ y\>{\textsf {a}}\) by stability under grounding substitutions (with \(\{y \mapsto \lambda x.\>{\textsf {c}}\}\)). But we can have \(y\>{\textsf {b}} \succsim y\>{\textsf {a}}\) if \({\textsf {b}} \succ {\textsf {a}}\). In practice, \(\succ \) and \(\succsim \) should be chosen so that they can compare as many terms as possible while being computable and reasonably efficient.
Definition 8
(Maximality) An element x of a multiset M is \(\unrhd \)-maximal for some relation \(\unrhd \) if for all \(y \in M\) with \(y \unrhd x\), we have \(y \unlhd x\). It is strictly \(\unrhd \)-maximal if it is \(\unrhd \)-maximal and occurs only once in M.
Definition 9
(Selection function) A selection function is a function that maps each clause to a subclause consisting of negative literals, which we call the selected literals of that clause. A literal  must not be selected if \(y\> \bar{u}_n\), with \(n > 0\), is a \(\succeq \)-maximal term of the clause.
must not be selected if \(y\> \bar{u}_n\), with \(n > 0\), is a \(\succeq \)-maximal term of the clause.
The restriction on the selection function is needed for our proof, but it is an open question whether it is actually necessary for refutational completeness.
Our calculus is parameterized by a strict term order \(\succ \), a nonstrict term order \(\succsim \), and a selection function \(\textit{HSel}\). The term orders \(\succ \) and \(\succsim \) must be based on the same strict ground term order \(\succ \). The calculus rules depend on the following auxiliary notions.
Definition 10
(Eligibility) A literal L is (strictly) \(\unrhd \)-eligible w.r.t. a substitution \(\sigma \) in C for some relation \(\unrhd \) if it is selected in C or there are no selected literals in C and \(L\sigma \) is (strictly) \(\unrhd \)-maximal in \(C\sigma .\) If \(\sigma \) is the identity substitution, we leave it implicit.
Definition 11
(Deep occurrence) A variable occurs deeply in a clause C if it occurs inside a \(\lambda \)-expression or inside an argument of an applied variable.
For example, x and z occur deeply in \({\textsf {f}}~x \> y \approx y \> x \mathrel \vee z \not \approx (\lambda w.\>z\>{\textsf {a}})\), whereas y does not occur deeply. In particular, a variable occurring as a nongreen subterm is not necessarily a deeply occurring variable, as exemplified by y. This definition aims to capture all variables with an occurrence under a \(\lambda \)-expression in some ground instances of C.
The first rule of our calculus is the superposition rule. We regard positive and negative superposition as two cases of a single rule

where \(\mathrel {\dot{\approx }}\) denotes either \(\approx \) or \(\not \approx \). The following side conditions apply:
-
1.
u is not fluid;
-
2.
u is not a variable deeply occurring in C;
-
3.
variable condition: if u is a variable y, there must exist a grounding substitution \(\theta \) such that \(t\sigma \theta \succ t'\sigma \theta \) and \(C\sigma \theta \prec C''\sigma \theta \), where \(C'' = C\{y\mapsto t'\}\);
-
4.
\(\sigma \in {{\,\mathrm{CSU}\,}}(t,u)\);
-
5.
\(t\sigma \not \precsim t'\sigma \);
-
6.
 ;
; -
7.
\(C\sigma \not \precsim D\sigma \);
-
8.
\(t \approx t'\) is strictly \(\succsim \)-eligible in D w.r.t. \(\sigma \);
-
9.
 is \(\succsim \)-eligible in C w.r.t. \(\sigma \), and strictly \(\succsim \)-eligible if it is positive.
is \(\succsim \)-eligible in C w.r.t. \(\sigma \), and strictly \(\succsim \)-eligible if it is positive.
 ;
; is
is There are four main differences with the statement of the standard superposition rule: Contexts \(s[~]\) are replaced by green contexts  . The standard condition \(u \notin \mathscr {V}\) is generalized by conditions 2 and 3. Most general unifiers are replaced by complete sets of unifiers. And \(\not \preceq \) is replaced by the more precise \(\not \precsim \).
. The standard condition \(u \notin \mathscr {V}\) is generalized by conditions 2 and 3. Most general unifiers are replaced by complete sets of unifiers. And \(\not \preceq \) is replaced by the more precise \(\not \precsim \).
The second rule is a variant of Sup that focuses on fluid green subterms:

with the following side conditions, in addition to Sup’s conditions 5 to 9:
-
1.
u is either a fluid term or a variable deeply occurring in C;
-
2.
z is a fresh variable;
-
3.
\(\sigma \in {{\,\mathrm{CSU}\,}}(z\>t{,}\;u)\);
-
4.
\((z\>t')\sigma \not = (z\>t)\sigma \).
The equality resolution and equality factoring rules are almost identical to their standard counterparts:

For ERes: \(\sigma \in {{\,\mathrm{CSU}\,}}(u,u')\) and \(u \not \approx u'\) is \(\succsim \)-eligible in C w.r.t. \(\sigma \). For EFact: \(\sigma \in {{\,\mathrm{CSU}\,}}(u,u')\), \(u\sigma \not \precsim v\sigma \), and \(u \approx v\) is \(\succsim \)-eligible in C w.r.t. \(\sigma \).
Argument congruence, a higher-order concern, is embodied by the rule

where \(n > 0\) and \(\sigma \) is the most general type substitution that ensures well-typedness of the conclusion. In particular, if s accepts k arguments, then ArgCong yields k conclusions—one for each \(n \in \{1,\ldots , k\}\)—where \(\sigma \) is the identity substitution. If the result type of s is a type variable, ArgCong yields infinitely many additional conclusions—one for each \(n > k\)—where \(\sigma \) instantiates the result type of s with \(\alpha _1 \rightarrow \cdots \rightarrow \alpha _{n-k} \rightarrow \beta \) for fresh \(\bar{\alpha }_{n-k}\) and \(\beta \). Moreover, the literal \(s \approx s'\) must be strictly \(\succsim \)-eligible in C w.r.t. \(\sigma \), and \(\bar{x}_n\) is a tuple of distinct fresh variables.
The rules are complemented by the polymorphic functional extensionality axiom:
From now on, we will omit the type arguments to \(\mathsf {diff}\) since they can be inferred from the term arguments.
3.2 Rationale for the Rules
The calculus realizes the following division of labor: Sup and FluidSup are responsible for green subterms, which are outside \(\lambda \)s, ArgCong effectively gives access to the remaining positions outside \(\lambda \)s, and the extensionality axiom takes care of subterms inside \(\lambda \)s. The following examples illustrate these mechanisms. The unifiers below were chosen to keep the clauses reasonably small.
Example 12
The clause \({\textsf {g}}\approx {\textsf {f}}\) cannot superpose into \({\textsf {g}}\>{\textsf {a}}\>{\textsf {b}} \not \approx {\textsf {f}}\>{\textsf {a}}\>{\textsf {b}}\) because \({\textsf {g}}\) occurs in a nongreen context. Instead, we refute these two clauses as follows:

The ArgCong inference adds two arguments to \({\textsf {g}}\), yielding the term \({\textsf {g}}\,\>x_1\>\,x_2\), which is unifiable with the green subterm \({\textsf {g}}\;{\textsf {a}}\; {\textsf {b}}\). Thus we can apply Sup to the resulting clause.
Example 13
Applied variables give rise to subtle situations with no counterparts in first-order logic. Consider the clauses \({\textsf {f}}\>{\textsf {a}} \approx {\textsf {c}}\) and \({\textsf {h}}\>(y\>{\textsf {b}})\>(y\>{\textsf {a}}) \not \approx {\textsf {h}}\>({\textsf {g}}\>({\textsf {f}}\>{\textsf {b}}))\>({\textsf {g}}\>{\textsf {c}})\), where \({\textsf {f}}\>{\textsf {a}} \succ {\textsf {c}}\). It is easy to see that the clause set is unsatisfiable, by grounding the second clause with \(\theta = \{y \mapsto \lambda x.\> {\textsf {g}}\>({\textsf {f}}\>x)\}\). However, to mimic the superposition inference that can be performed at the ground level, it is necessary to superpose at an imaginary position below the applied variable y and yet above its argument \({\textsf {a}}\), namely, into the subterm \({\textsf {f}}\>{\textsf {a}}\) of \({\textsf {g}}\>({\textsf {f}}\>{\textsf {a}}) = (\lambda x.\> {\textsf {g}}\>({\textsf {f}}\>x))\>{\textsf {a}} = (y\>{\textsf {a}})\theta \). We need FluidSup:

FluidSup’s variable z effectively transforms \({\textsf {f}}\>{\textsf {a}} \approx {\textsf {c}}\) into \(z\>({\textsf {f}}\>{\textsf {a}}) \approx z\>{\textsf {c}}\), whose left-hand side can be unified with \(y\>{\textsf {a}}\) by taking \(\{y \mapsto \lambda x.\> z\>({\textsf {f}}\>x)\}\).
Example 14
The clause set consisting of \({\textsf {f}}\>{\textsf {a}} \approx {\textsf {c}}\), \({\textsf {f}}\>{\textsf {b}} \approx {\textsf {d}}\), and \({\textsf {g}}\>{\textsf {c}} \not \approx y\>{\textsf {a}} \mathrel \vee {\textsf {g}}\>{\textsf {d}} \not \approx y\>{\textsf {b}}\) has a similar flavor. ERes applies on either literal of the third clause, but the computed unifier, \(\{y \mapsto \lambda x.\> {\textsf {g}}\>{\textsf {c}}\}\) or \(\{y \mapsto \lambda x.\> {\textsf {g}}\>{\textsf {d}}\}\), is not the right one. Again, we need FluidSup:

Again, the FluidSup inference uses the unifier \(\{y \mapsto \lambda x.\> z\>({\textsf {f}}\>x)\} \in {{\,\mathrm{CSU}\,}}(z\>({\textsf {f}}\>{\textsf {a}}), y\>{\textsf {a}})\).
Example 15
Third-order clauses containing subterms of the form \(y\>(\lambda x.\> t)\) can be even more stupefying. The clause set consisting of \({\textsf {f}}\> {\textsf {a}} \approx {\textsf {c}}\) and \({\textsf {h}}\> (y\> (\lambda x.\> {\textsf {g}}\> ({\textsf {f}}\> x))\> {\textsf {a}})\> y \not \approx {\textsf {h}}\> ({\textsf {g}}\> {\textsf {c}})\> (\lambda w\>x.\> w\>x)\) is unsatisfiable. To see why, apply \(\theta = \{y \mapsto \lambda w\>x.\> w\>x\}\) to the second clause, yielding \({\textsf {h}}\> ({\textsf {g}}\> ({\textsf {f}}\> {\textsf {a}}))\> (\lambda w\>x.\> w\>x) \not \approx {\textsf {h}}\> ({\textsf {g}}\> {\textsf {c}})\> (\lambda w\>x.\> w\>x)\). Let \({\textsf {f}}\> {\textsf {a}} \succ {\textsf {c}}\). A Sup inference is possible between the first clause and this ground instance of the second one:

But at the nonground level, the subterm \({\textsf {f}}\> {\textsf {a}}\) is not clearly localized: \({\textsf {g}}\> ({\textsf {f}}\> {\textsf {a}}) = (\lambda x.\> {\textsf {g}}\> ({\textsf {f}}\> x))\> {\textsf {a}} = (\lambda w\>x.\> w\>x)\> (\lambda x.\> {\textsf {g}}\> ({\textsf {f}}\> x))\> {\textsf {a}} = (y\> (\lambda x.\> {\textsf {g}}\> ({\textsf {f}}\> x))\> {\textsf {a}})\theta \). The FluidSup rule can cope with this using the unifier \(\{y \mapsto \lambda w\>x.\> w\>x{,}\; z \mapsto {\textsf {g}}\} \in {{\,\mathrm{CSU}\,}}(z\> ({\textsf {f}}\> {\textsf {a}}),\> y\> (\lambda x.\> {\textsf {g}}\> ({\textsf {f}}\> x))\> {\textsf {a}})\):

Example 16
The FluidSup rule is concerned not only with applied variables but also with \(\lambda \)-expressions that, after substitution, may be \(\eta \)-reduced to reveal new applied variables or green subterms. Consider the clause set consisting of \({\textsf {f}}\> {\textsf {a}} \approx {\textsf {c}}\) and \({\textsf {h}}\> (\lambda u.\> y\> u\> {\textsf {b}}) \> (\lambda u.\> y\> u\> {\textsf {a}}) \not \approx {\textsf {h}}\> ({\textsf {g}}\>({\textsf {f}}\>{\textsf {b}}))\> ({\textsf {g}}\>{\textsf {c}})\), where \({\textsf {f}}\> {\textsf {a}} \succ {\textsf {c}}\). Applying the substitution \(\{y \mapsto \lambda u'\> v.\> {\textsf {g}}\> ({\textsf {f}}\>v)\> u' \}\) to the second clause yields \({\textsf {h}}\> (\lambda u.\> {\textsf {g}}\> ({\textsf {f}}\> {\textsf {b}})\> u) \> (\lambda u.\> {\textsf {g}}\> ({\textsf {f}}\> {\textsf {a}})\> u) \not \approx {\textsf {h}}\> ({\textsf {g}}\>({\textsf {f}}\>{\textsf {b}}))\> ({\textsf {g}}\>{\textsf {c}})\) after \(\beta \)-reduction and \({\textsf {h}}\> ({\textsf {g}}\> ({\textsf {f}}\> {\textsf {b}})) \> ({\textsf {g}}\> ({\textsf {f}}\> {\textsf {a}})) \not \approx {\textsf {h}}\> ({\textsf {g}}\>({\textsf {f}}\>{\textsf {b}}))\> ({\textsf {g}}\>{\textsf {c}})\) after \(\beta \eta \)-reduction. A Sup inference is possible between the first clause and this new ground clause:

Because it also considers \(\lambda \)-expressions, the FluidSup rule applies at the nonground level to derive a corresponding nonground clause using \(\{ y \mapsto \lambda u'\> v.\> z\>({\textsf {f}}\>v)\>u' \} \in {{\,\mathrm{CSU}\,}}(z\>({\textsf {f}}\> {\textsf {a}}),\> \lambda u.\> y\> u\> {\textsf {a}})\):

Example 17
Consider the clause set consisting of the facts \(C_{\text {succ}} = {\textsf {succ}}\>x \not \approx {\textsf {zero}}\), \(C_{\text {div}} = n \approx {\textsf {zero}} \mathrel \vee {\textsf {div}}\;n\;n \approx {\textsf {one}}\), \(C_{\text {prod}} = {\textsf {prod}}\; K\;(\lambda k.\>{\textsf {one}}) \approx {\textsf {one}}\), and the negated conjecture \(C_{\text {nc}} = {\textsf {prod}}\; K\;(\lambda k.\> {\textsf {div}}\; ({\textsf {succ}}\; k)\; ({\textsf {succ}}\; k)) \not \approx {\textsf {one}}\). Intuitively, the term \({\textsf {prod}}\;K\;(\lambda k.\; u)\) is intended to denote the product \(\smash {\prod _{k\in K} u}\), where k ranges over a finite set K of natural numbers. The calculus derives the empty clause as follows:

Since the calculus does not superpose into \(\lambda \)-expressions, we need to use the extensionality axiom to refute this clause set. We perform a FluidSup inference into the extensionality axiom with the unifier \(\{ \beta \mapsto \iota ,\> z' \mapsto \lambda x.\>x,\> n \mapsto w\>(\mathsf {diff}{\langle {\alpha ,\iota }\rangle }\> (\lambda k.\>{\textsf {div}}\>(w\>k)\>(w\>k))\> z),\> y \mapsto \) \(\lambda k.\>{\textsf {div}}\>(w\>k)\>(w\>k) \} \in {{\,\mathrm{CSU}\,}}(z'\>({\textsf {div}}\>n\>n){,}\; y\>(\mathsf {diff}{\langle {\alpha ,\beta }\rangle }\> y\> z))\). Then we apply ERes with the unifier \(\{z \mapsto \lambda k.\>{\textsf {one}}\} \in {{\,\mathrm{CSU}\,}}({\textsf {one}}{,}\; z\>(\mathsf {diff}{\langle {\alpha ,\iota }\rangle }\> (\lambda k.\>{\textsf {div}}\>(w\>k)\>(w\>k))\> z))\) to eliminate the negative literal. Next, we superpose into \(C_{\text {succ}}\) with the unifier \(\{ \alpha \mapsto \iota ,\> w \mapsto {\textsf {succ}},\> x \mapsto \mathsf {diff}{\langle {\alpha ,\iota }\rangle }\> (\lambda k.\>{\textsf {div}}\>(w\>k)\>(w\>k))\>(\lambda k.\>{\textsf {one}})\} \in {{\,\mathrm{CSU}\,}}(w\>(\mathsf {diff}{\langle {\alpha ,\iota }\rangle }\>(\lambda k.\>{\textsf {div}}\>(w\>k)\>(w\>k))\>(\lambda k.\>{\textsf {one}})), \>{\textsf {succ}}\>x)\). To eliminate the trivial literal, we apply ERes. We then apply a Sup inference into \(C_{\text {nc}}\) and superpose into the resulting clause from \(C_{\text {prod}}\). Finally we derive the empty clause by ERes.
Because it gives rise to flex–flex pairs—unification constraints where both sides are variable-headed—FluidSup can be very prolific. With variable-headed terms on both sides of its maximal literal, the extensionality axiom is another prime source of flex–flex pairs. Flex–flex pairs can also arise in the other rules (Sup, ERes, and EFact). Due to order restrictions and fairness, we cannot postpone solving flex–flex pairs indefinitely. Thus, we cannot use Huet’s pre-unification procedure [37] and must instead choose a full unification procedure such as Jensen and Pietrzykowski’s [38], Snyder and Gallier’s [61], or the procedure that has recently been developed by Vukmirović, Bentkamp, and Nummelin [68]. On the positive side, optional inference rules can efficiently cover many cases where FluidSup or the extensionality axiom would otherwise be needed (Sect. 5), and heuristics can help postpone the explosion. Moreover, flex–flex pairs are not always as bad as their reputation; for example,  admits a most general unifier: \(\{y \mapsto \lambda w\> x.\> y'\,w\> x\> {\textsf {c}}\>{\textsf {d}}{,}\; z \mapsto y'\, {\textsf {a}}\>{\textsf {b}}\}\).
admits a most general unifier: \(\{y \mapsto \lambda w\> x.\> y'\,w\> x\> {\textsf {c}}\>{\textsf {d}}{,}\; z \mapsto y'\, {\textsf {a}}\>{\textsf {b}}\}\).
The calculus is a graceful generalization of standard superposition, except for the extensionality axiom. From simple first-order clauses, the axiom can be used to derive clauses containing \(\lambda \)-expressions, which are useless if the problem is first-order. For instance, the clause \({\textsf {g}}\>x \approx {\textsf {f}}\>x\>x\) can be used for a FluidSup inference into the axiom (Ext) yielding the clause \(w\>t\>({\textsf {f}}\>t\>t)\not \approx z\>t \mathrel \vee (\lambda u.\>w\>u\>({\textsf {g}} u)) \approx z\) via the unifier \(\{ \alpha \mapsto \iota ,\> \beta \mapsto \iota ,\> x \mapsto t,\> v \mapsto \lambda u.\> w\>t\>u,\> y \mapsto \lambda u.\>w\>u\>({\textsf {g}}\>u) \} \in {{\,\mathrm{CSU}\,}}(v\>({\textsf {g}}\>x),\>y\>(\mathsf {diff}{\langle {\alpha ,\beta }\rangle }\>y\>z))\) where \(t = \mathsf {diff}{\langle {\iota ,\iota }\rangle }\>(\lambda u.\>w\>u\>({\textsf {g}}\>u))\>z\), the variable w is freshly introduced by unification, and v is the fresh variable introduced by FluidSup (named z in the definition of the rule). By ERes, with the unifier \(\{ z \mapsto \lambda u.\> w\>u\>({\textsf {f}}\>u\>u) \}\in {{\,\mathrm{CSU}\,}}(w\>t\>({\textsf {f}}\>t\>t),\>z\>t)\), we can then derive \((\lambda u.\> w\>u\>({\textsf {g}}\>u)) \approx (\lambda u.\> w\>u\>({\textsf {f}}\>u\>u))\), an equality of two \(\lambda \)-expressions, although we started with a simple first-order clause. This could be avoided if we could find a way to make the positive literal \(y \approx z\) of (Ext) larger than the other literal, or to select \(y \approx z\) without losing refutational completeness. The literal \(y \approx z\) interacts only with green subterms of functional type, which do not arise in first-order clauses.
3.3 Soundness
To show soundness of the inferences, we need the substitution lemma for our logic:
Lemma 18
(Substitution lemma) Let \(\mathscr {I}= (\mathscr {I}_{\mathsf {\mathrm{ty}}},\mathscr {J},\mathscr {L})\) be a proper interpretation. Then
for all terms t, all types \(\tau \), and all substitutions \(\rho \), where \(\xi '(\alpha ) = \smash {\llbracket \alpha \rho \rrbracket _{\mathscr {I}_{\mathsf {\mathrm{ty}}}}^{\xi }}\) for all type variables \(\alpha \) and \(\xi '(x) = \smash {\llbracket x\rho \rrbracket _{\mathscr {I}}^{\xi }}\) for all term variables x.
Proof
First, we prove that \(\smash {\llbracket \tau \rho \rrbracket _{\mathscr {I}_{\mathsf {\mathrm{ty}}}}^{\xi }} = \smash {\llbracket \tau \rrbracket _{\mathscr {I}_{\mathsf {\mathrm{ty}}}}^{\xi '}}\) by induction on the structure of \(\tau \). If \(\tau = \alpha \) is a type variable,
If \(\tau = \kappa (\bar{\upsilon })\) for some type constructor \(\kappa \) and types \(\bar{\upsilon }\),
Next, we prove \(\smash {\llbracket t\rho \rrbracket _{\mathscr {I}}^{\xi }} = \smash {\llbracket t\rrbracket _{\mathscr {I}}^{\xi '}}\) by induction on the structure of a \(\lambda \)-term representative of t, allowing arbitrary substitutions \(\rho \) in the induction hypothesis. If \(t = y\), then by the definition of the denotation of a variable
If \(t = {\textsf {f}}{\langle {\bar{\tau }}\rangle }\), then by the definition of the term denotation
If \(t = u\>v\), then by the definition of the term denotation
If \(t = \lambda z.\>u\), let \(\rho '(z)=z\) and \(\rho '(x)=\rho (x)\) for \(x\ne z\). Using properness of \(\mathscr {I}\) in the second and the last step, we have
Lemma 19
If \(\mathscr {I}\models C\) for some interpretation \(\mathscr {I}\) and some clause C, then \(\mathscr {I}\models C\rho \) for all substitutions \(\rho \).
Proof
We have to show that \(C\rho \) is true in \(\mathscr {I}\) for all valuations \(\xi \). Given a valuation \(\xi \), define \(\xi '\) as in Lemma 18. Then, by Lemma 18, a literal in \(C\rho \) is true in \(\mathscr {I}\) for \(\xi \) if and only if the corresponding literal in C is true in \(\mathscr {I}\) for \(\xi '\). There must be at least one such literal because \(\mathscr {I}\models C\) and hence C is in particular true in \(\mathscr {I}\) for \(\xi '\). Therefore, \(C\rho \) is true in \(\mathscr {I}\) for \(\xi \). \(\square \)
Theorem 20
(Soundness) The inference rules Sup, FluidSup, ERes, EFact, and ArgCong are sound (even without the variable condition and the side conditions on fluidity, deeply occurring variables, order, and eligibility).
Proof
We fix an inference and an interpretation \(\mathscr {I}\) that is a model of the premises. We need to show that it is also a model of the conclusion.
From the definition of the denotation of a term, it is obvious that congruence holds in our logic, at least for subterms that are not inside a \(\lambda \)-expression. In particular, it holds for green subterms and for the left subterm t of an application \(t\>s\).
By Lemma 19, \(\mathscr {I}\) is a model of the \(\sigma \)-instances of the premises as well, where \(\sigma \) is the substitution used for the inference. Let \(\xi \) be a valuation. By making case distinctions on the truth under \(\mathscr {I},\xi \) of the literals of the \(\sigma \)-instances of the premises, using the conditions that \(\sigma \) is a unifier, and applying congruence, it follows that the conclusion is true under \(\mathscr {I},\xi \). Hence, \(\mathscr {I}\) is a model of the conclusion. \(\square \)
As in the \(\lambda \)-free higher-order logic of Bentkamp et al. [10], skolemization is unsound in our logic. As a consequence, axiom (Ext) does not hold in all interpretations, but the axiom is consistent with our logic, i.e., there exist models of (Ext).
3.4 The Redundancy Criterion
A redundant clause is usually defined as a clause whose ground instances are entailed by smaller (\(\prec \)) ground instances of existing clauses. This would be too strong for our calculus, as it would make most clauses produced by ArgCong redundant. The solution is to base the redundancy criterion on a weaker ground logic—ground monomorphic first-order logic—in which argument congruence and extensionality do not hold. The resulting notion of redundancy gracefully generalizes the standard first-order notion.
We employ an encoding  to translate ground higher-order terms into ground first-order terms.
to translate ground higher-order terms into ground first-order terms.  indexes each symbol occurrence with the type arguments and the number of term arguments. For example,
indexes each symbol occurrence with the type arguments and the number of term arguments. For example,  and
and  . In addition,
. In addition,  conceals \(\lambda \)-expressions by replacing them with fresh symbols. These measures effectively disable argument congruence and extensionality. For example, the clause sets \(\{{\textsf {g}} \approx {\textsf {f}}{,}\; {\textsf {g}}\>{\textsf {a}} \not \approx {\textsf {f}}\> {\textsf {a}}\}\) and \(\{{\textsf {b}} \approx {\textsf {a}}{,}\; (\lambda x.\; {\textsf {b}}) \not \approx (\lambda x.\; {\textsf {a}})\}\) are unsatisfiable in higher-order logic, but the encoded clause sets \(\{{\textsf {g}}_0 \approx {\textsf {f}}_0{,}\; {\textsf {g}}_1({\textsf {a}}_0) \not \approx {\textsf {f}}_1({\textsf {a}}_0)\}\) and \(\{{\textsf {b}}_0 \approx {\textsf {a}}_0{,}\; {\textsf {lam}}_{\lambda x.\; {\textsf {b}}} \not \approx {\textsf {lam}}_{\lambda x.\; {\textsf {a}}}\}\) are satisfiable in first-order logic, where \({\textsf {lam}}_{\lambda x.\>t}\) is a family of fresh symbols.
conceals \(\lambda \)-expressions by replacing them with fresh symbols. These measures effectively disable argument congruence and extensionality. For example, the clause sets \(\{{\textsf {g}} \approx {\textsf {f}}{,}\; {\textsf {g}}\>{\textsf {a}} \not \approx {\textsf {f}}\> {\textsf {a}}\}\) and \(\{{\textsf {b}} \approx {\textsf {a}}{,}\; (\lambda x.\; {\textsf {b}}) \not \approx (\lambda x.\; {\textsf {a}})\}\) are unsatisfiable in higher-order logic, but the encoded clause sets \(\{{\textsf {g}}_0 \approx {\textsf {f}}_0{,}\; {\textsf {g}}_1({\textsf {a}}_0) \not \approx {\textsf {f}}_1({\textsf {a}}_0)\}\) and \(\{{\textsf {b}}_0 \approx {\textsf {a}}_0{,}\; {\textsf {lam}}_{\lambda x.\; {\textsf {b}}} \not \approx {\textsf {lam}}_{\lambda x.\; {\textsf {a}}}\}\) are satisfiable in first-order logic, where \({\textsf {lam}}_{\lambda x.\>t}\) is a family of fresh symbols.
Given a higher-order signature (\(\Sigma _\mathsf {ty},\Sigma )\), we define a ground first-order signature (\(\Sigma _\mathsf {ty},\Sigma _{\mathrm{GF}})\) as follows. The type constructors \(\Sigma _\mathsf {ty}\) are the same in both signatures, but \({\rightarrow }\) is uninterpreted in first-order logic. For each ground instance \({\textsf {f}}{\langle {\bar{\upsilon }}\rangle } : \tau _1\rightarrow \cdots \rightarrow \tau _n\rightarrow \tau \) of a symbol \({\textsf {f}} \in \Sigma \), we introduce a first-order symbol \(\smash {{\textsf {f}}^{\bar{\upsilon }}_{\!j}} \in \Sigma _{\mathrm{GF}}\) with argument types \(\bar{\tau }_{\!j}\) and return type \(\tau _{\!j+1} \rightarrow \cdots \rightarrow \tau _n \rightarrow \tau \), for each j. Moreover, for each ground term \(\lambda x.\>t\), we introduce a symbol \({\textsf {lam}}_{\lambda x.\>t} \in \Sigma _{\mathrm{GF}}\) of the same type.
Thus, we consider three levels of logics: the higher-order level \({\mathrm{H}}\) over a given signature (\(\Sigma _\mathsf {ty},\Sigma )\), the ground higher-order level \({\mathrm{GH}}\), which is the ground fragment of \({\mathrm{H}}\), and the ground monomorphic first-order level \({\mathrm{GF}}\) over the signature (\(\Sigma _\mathsf {ty},\Sigma _{\mathrm{GF}})\) defined above. We use  ,
,  , and
, and  to denote the respective sets of terms,
to denote the respective sets of terms,  ,
,  , and
, and  to denote the respective sets of types, and
to denote the respective sets of types, and  ,
,  , and
, and  to denote the respective sets of clauses. Each of the three levels has an entailment relation
to denote the respective sets of clauses. Each of the three levels has an entailment relation  . A clause set \(N_1\) entails a clause set \(N_2\), denoted
. A clause set \(N_1\) entails a clause set \(N_2\), denoted  , if every model of \(N_1\) is also a model of \(N_2\). For \({\mathrm{H}}\) and \({\mathrm{GH}}\), we use higher-order models; for \({\mathrm{GF}}\), we use first-order models. This machinery may seem excessive, but it is essential to define redundancy of clauses and inferences properly, and it will play an important role in the refutational completeness proof (Sect. 4).
, if every model of \(N_1\) is also a model of \(N_2\). For \({\mathrm{H}}\) and \({\mathrm{GH}}\), we use higher-order models; for \({\mathrm{GF}}\), we use first-order models. This machinery may seem excessive, but it is essential to define redundancy of clauses and inferences properly, and it will play an important role in the refutational completeness proof (Sect. 4).
The three levels are connected by two functions  and
and  :
:
Definition 21
(Grounding function  on terms and clauses) The grounding function
on terms and clauses) The grounding function  maps terms
maps terms  to the set of their ground instances—i.e., the set of all
to the set of their ground instances—i.e., the set of all  where \(\theta \) is a substitution. It also maps clauses
where \(\theta \) is a substitution. It also maps clauses  to the set of their ground instances—i.e., the set of all
to the set of their ground instances—i.e., the set of all  where \(\theta \) is a substitution.
where \(\theta \) is a substitution.
Definition 22
(Encoding
 on terms and clauses) The encoding
on terms and clauses) The encoding
 is defined recursively as
is defined recursively as

using
\(\eta \)-short
\(\beta \)-normal representatives of terms. The encoding  is extended to map from
is extended to map from  to
to  by mapping each literal and each side of a literal individually.
by mapping each literal and each side of a literal individually.
Schematically, the three levels are connected as follows:

The mapping  is clearly bijective. Using the inverse mapping, the order \(\succ \) can be transferred from
is clearly bijective. Using the inverse mapping, the order \(\succ \) can be transferred from  to
to  and from
and from  to
to  by defining \(t \succ s\) as
by defining \(t \succ s\) as  and \(C \succ D\) as
and \(C \succ D\) as  . As with standard superposition, \(\succ \) on clauses is the multiset extension of \(\succ \) on literals, which in turn is the multiset extension of \(\succ \) on terms, because
. As with standard superposition, \(\succ \) on clauses is the multiset extension of \(\succ \) on literals, which in turn is the multiset extension of \(\succ \) on terms, because  maps the multiset representations elementwise.
maps the multiset representations elementwise.
For example, let  . Then
. Then  contains, among many other clauses,
contains, among many other clauses,  , where \(\theta = \{y \mapsto \lambda x.\>{\textsf {f}}\>x\>x\}\). On the \({\mathrm{GF}}\) level, this clause corresponds to
, where \(\theta = \{y \mapsto \lambda x.\>{\textsf {f}}\>x\>x\}\). On the \({\mathrm{GF}}\) level, this clause corresponds to  .
.
A key property of  is that green subterms in
is that green subterms in  correspond to subterms in
correspond to subterms in  . This allows us to show that well-foundedness, totality on ground terms, compatibility with contexts, and the subterm property hold for \(\succ \) on
. This allows us to show that well-foundedness, totality on ground terms, compatibility with contexts, and the subterm property hold for \(\succ \) on  .
.
Lemma 23
Let  . We have
. We have  . In other words, s is a green subterm of t at green position p if and only if
. In other words, s is a green subterm of t at green position p if and only if  is a subterm of
is a subterm of  at position p.
at position p.
Proof
Analogous to Lemma 3.17 of Bentkamp et al. [10]. \(\square \)
Lemma 24
Well-foundedness, totality, compatibility with contexts, and the subterm property hold for \(\succ \) in  .
.
Proof
Analogous to Lemma 3.19 of Bentkamp et al. [10], using Lemma 23. \(\square \)
The saturation procedures of superposition provers delete clauses that are strictly subsumed by other clauses. A clause C subsumes D if there exists a substitution \(\sigma \) such that \(C\sigma \subseteq D\). A clause C strictly subsumes D if C subsumes D, but D does not subsume C. For example, \(x \approx {\textsf {c}}\) strictly subsumes both \({\textsf {a}} \approx {\textsf {c}}\) and \({\textsf {b}} \not \approx {\textsf {a}} \mathrel \vee x \approx {\textsf {c}}\). The proof of refutational completeness of resolution and superposition provers relies on the well-foundedness of the strict subsumption relation. Unfortunately, this property does not hold for higher-order logic, where \({\textsf {f}}\>x\>x \approx {\textsf {c}}\) is strictly subsumed by \({\textsf {f}}\>(x\>{\textsf {a}})\>(x\>{\textsf {b}}) \approx {\textsf {c}}\), which is strictly subsumed by \({\textsf {f}}\>(x\>{\textsf {a}}\>{\textsf {a}}')\>(x\>{\textsf {b}}\>{\textsf {b}}') \approx {\textsf {c}}\), and so on. To prevent such infinite chains, we use a well-founded partial order \(\sqsupset \) on  . We can define \(\sqsupset \) as
. We can define \(\sqsupset \) as  , where
, where  stands for “subsumed by” and \(D >_\text {size} C\) if either \(\textit{size}(D) > \textit{size}(C)\) or \(\textit{size}(D) = \textit{size}(C)\) and D contains fewer distinct variables than C; the \(\textit{size}\) function is some notion of syntactic size, such as the number of constants and variables contained in a clause. This yields for instance \({\textsf {a}} \approx {\textsf {c}} \sqsupset x \approx {\textsf {c}}\) and \({\textsf {f}}\>(x\>{\textsf {a}}\>{\textsf {a}}) \approx {\textsf {c}} \sqsupset {\textsf {f}}\>(y\>{\textsf {a}}) \approx {\textsf {c}}\). To justify the deletion of subsumed clauses, we set up our redundancy criterion to cover subsumption, following Waldmann et al. [71].
stands for “subsumed by” and \(D >_\text {size} C\) if either \(\textit{size}(D) > \textit{size}(C)\) or \(\textit{size}(D) = \textit{size}(C)\) and D contains fewer distinct variables than C; the \(\textit{size}\) function is some notion of syntactic size, such as the number of constants and variables contained in a clause. This yields for instance \({\textsf {a}} \approx {\textsf {c}} \sqsupset x \approx {\textsf {c}}\) and \({\textsf {f}}\>(x\>{\textsf {a}}\>{\textsf {a}}) \approx {\textsf {c}} \sqsupset {\textsf {f}}\>(y\>{\textsf {a}}) \approx {\textsf {c}}\). To justify the deletion of subsumed clauses, we set up our redundancy criterion to cover subsumption, following Waldmann et al. [71].
We define the sets of redundant clauses w.r.t. a given clause set as follows:
-
Given
 and
and  , let \(C\in \textit{GFRed}_{\mathrm{C}}(N)\) if \(\{D \in N \mid D \prec C\}\models C\).
, let \(C\in \textit{GFRed}_{\mathrm{C}}(N)\) if \(\{D \in N \mid D \prec C\}\models C\). -
Given
 and
and  , let \(C\in \textit{GHRed}_{\mathrm{C}}(N)\) if
, let \(C\in \textit{GHRed}_{\mathrm{C}}(N)\) if  .
. -
Given
 and
and  , let
, let  if for every
if for every  , we have
, we have  or there exists \(C' \in N\) such that \(C \sqsupset C'\) and
or there exists \(C' \in N\) such that \(C \sqsupset C'\) and  .
.
 and
and  , let
, let  and
and  , let
, let  .
. and
and  , let
, let  if for every
if for every  , we have
, we have  or there exists
or there exists  .
.For example, \({\textsf {h}}\>{\textsf {g}}\>x \approx {\textsf {h}}\>{\textsf {f}}\>x\) is redundant w.r.t. \({\textsf {g}}\approx {\textsf {f}}\), but \({\textsf {g}}\>x \approx {\textsf {f}}\>x\) and \((\lambda x.\>{\textsf {g}}) \approx (\lambda x.\>{\textsf {f}})\) are not, because  translates an unapplied \({\textsf {g}}\) to \({\textsf {g}}_0\), whereas an applied \({\textsf {g}}\) is translated to \({\textsf {g}}_1\) and the expression \(\lambda x.\>{\textsf {g}}\) is translated to \({\textsf {lam}}_{\lambda x.\>{\textsf {g}}}\). These different translations prevent entailment on the \({\mathrm{GF}}\) level. For an example of subsumption, we assume that \({\textsf {a}} \approx {\textsf {c}} \sqsupset x \approx {\textsf {c}}\) holds, for instance using the above definition of \(\sqsupset \). Then \({\textsf {a}} \approx {\textsf {c}}\) is redundant w.r.t. \(x \approx {\textsf {c}}\).
translates an unapplied \({\textsf {g}}\) to \({\textsf {g}}_0\), whereas an applied \({\textsf {g}}\) is translated to \({\textsf {g}}_1\) and the expression \(\lambda x.\>{\textsf {g}}\) is translated to \({\textsf {lam}}_{\lambda x.\>{\textsf {g}}}\). These different translations prevent entailment on the \({\mathrm{GF}}\) level. For an example of subsumption, we assume that \({\textsf {a}} \approx {\textsf {c}} \sqsupset x \approx {\textsf {c}}\) holds, for instance using the above definition of \(\sqsupset \). Then \({\textsf {a}} \approx {\textsf {c}}\) is redundant w.r.t. \(x \approx {\textsf {c}}\).
Along with the three levels of logics, we consider three inference systems : \(\textit{HInf}\), \(\textit{GHInf}\), and \(\textit{GFInf}\). \(\textit{HInf}\) is the inference system described in Sect. 3.1. For uniformity, we regard the extensionality axiom as a premise-free inference rule Ext whose conclusion is axiom (Ext). The rules of \(\textit{GHInf}\) include Sup, ERes, and EFact from \(\textit{HInf}\), but with the restriction that premises and conclusion are ground and with all references to \(\succsim \) replaced by \(\succeq \). In addition, \(\textit{GHInf}\) contains a premise-free rule GExt whose infinitely many conclusions are the ground instances of (Ext), and the following ground variant of ArgCong:

where \(s \approx s'\) is strictly \(\succeq \)-eligible in \(C' \mathrel \vee s \approx s'\) and \(\bar{u}_n\) is a nonempty tuple of ground terms.
\(\textit{GFInf}\) contains all Sup, ERes, and EFact inferences from \(\textit{GHInf}\) translated by  . It coincides with standard first-order superposition.
. It coincides with standard first-order superposition.
Each of the three inference systems is parameterized by a selection function. For \(\textit{HInf}\), we globally fix one selection function \(\textit{HSel}\). For \(\textit{GHInf}\) and \(\textit{GFInf}\), we need to consider different selection functions. We write \(\textit{GHInf}^\textit{GHSel}\) for \(\textit{GHInf}\) and \(\textit{GFInf}^\textit{GFSel}\) for \(\textit{GFInf}\) to make the dependency on the respective selection functions \(\textit{GHSel}\) and \(\textit{GFSel}\) explicit. Let  denote the set of all selection functions on
denote the set of all selection functions on  such that for each clause in
such that for each clause in  , there exists a clause
, there exists a clause  with
with  and corresponding selected literals. For each selection function \(\textit{GHSel}\) on
and corresponding selected literals. For each selection function \(\textit{GHSel}\) on  , via the bijection
, via the bijection  , we obtain a corresponding selection function on
, we obtain a corresponding selection function on  , which we denote by
, which we denote by  .
.
We extend the functions  and
and  to inferences:
to inferences:
Notation 25
Given an inference \(\iota \), we write \(\textit{prems}(\iota )\) for the tuple of premises, \(\textit{mprem}(\iota )\) for the main (i.e., rightmost) premise, and  for the conclusion.
for the conclusion.
Definition 26
(Encoding  on inferences) Given a Sup, ERes, or EFact inference \(\iota \in \textit{GHInf}\), let
on inferences) Given a Sup, ERes, or EFact inference \(\iota \in \textit{GHInf}\), let  denote the inference defined by
denote the inference defined by  and
and  .
.
Definition 27
(Grounding function  on inferences) Given an inference \(\iota \in \textit{HInf}\), and a selection function
on inferences) Given an inference \(\iota \in \textit{HInf}\), and a selection function  , we define the set
, we define the set  of ground instances of \(\iota \) to be all inferences \(\iota '\in \textit{GHInf}^\textit{GHSel}\) such that \(\textit{prems}(\iota ') = \textit{prems}(\iota )\theta \) and \(\textit{concl}(\iota ') = \textit{concl}(\iota )\theta \) for some grounding substitution \(\theta \).
of ground instances of \(\iota \) to be all inferences \(\iota '\in \textit{GHInf}^\textit{GHSel}\) such that \(\textit{prems}(\iota ') = \textit{prems}(\iota )\theta \) and \(\textit{concl}(\iota ') = \textit{concl}(\iota )\theta \) for some grounding substitution \(\theta \).
This will map Sup and FluidSup to Sup, EFact to EFact, ERes to ERes, Ext to GExt, and ArgCong to GArgCong inferences, but it is also possible that  is the empty set for some inferences \(\iota \).
is the empty set for some inferences \(\iota \).
We define the sets of redundant inferences w.r.t. a given clause set as follows:
-
Given \(\iota \in \textit{GFInf}^\textit{GFSel}\) and
 , let \(\iota \in \textit{GFRed}_{\mathrm{I}}^\textit{GFSel}(N)\) if \(\textit{prems}(\iota ) \mathrel \cap \textit{GFRed}_{\mathrm{C}}(N) \not = \varnothing \) or \(\{D \in N \mid D \prec \textit{mprem}(\iota )\} \models \textit{concl}(\iota )\).
, let \(\iota \in \textit{GFRed}_{\mathrm{I}}^\textit{GFSel}(N)\) if \(\textit{prems}(\iota ) \mathrel \cap \textit{GFRed}_{\mathrm{C}}(N) \not = \varnothing \) or \(\{D \in N \mid D \prec \textit{mprem}(\iota )\} \models \textit{concl}(\iota )\). -
Given \(\iota \in \textit{GHInf}^\textit{GHSel}\) and
 , let \(\iota \in \textit{GHRed}_{\mathrm{I}}^\textit{GHSel}(N)\) if
, let \(\iota \in \textit{GHRed}_{\mathrm{I}}^\textit{GHSel}(N)\) if-
\(\iota \) is not a GArgCong or GExt inference and
 ; or
; or -
\(\iota \) is a GArgCong or GExt inference and \(\textit{concl}(\iota )\in N\mathrel \cup \textit{GHRed}_{\mathrm{C}}(N)\).
-
-
Given \(\iota \in \textit{HInf}\) and
 , let \(\iota \in \textit{HRed}_{\mathrm{I}}(N)\) if
, let \(\iota \in \textit{HRed}_{\mathrm{I}}(N)\) if  for all
for all  .
.
 , let
, let  , let
, let  ; or
; or , let
, let  for all
for all  .
.Occasionally, we omit the selection function in the notation when it is irrelevant. A clause set N is saturated w.r.t. an inference system and the inference component \(\textit{Red}_{\mathrm{I}}\) of a redundancy criterion if every inference from clauses in N is in \(\textit{Red}_{\mathrm{I}}(N).\)
3.5 Simplification Rules
The redundancy criterion \((\textit{HRed}_{\mathrm{I}}, {\textit{HRed}}_{\mathrm{C}})\) is strong enough to support most of the simplification rules implemented in Schulz’s first-order prover E [57, Sects. 2.3.1 and 2.3.2], some only with minor adaptations. Deletion of duplicated literals, deletion of resolved literals, syntactic tautology deletion, negative simplify-reflect, and clause subsumption adhere to our redundancy criterion.
Positive simplify-reflect and equality subsumption are supported by our criterion if they are applied in green contexts  instead of arbitrary contexts \(u[\,]\). Semantic tautology deletion can be applied as well, but we must use the entailment relation of the GF level—i.e., only rewriting in green contexts can be used to establish the entailment. Similarly, rewriting of positive and negative literals (demodulation) can only be applied in green contexts. Moreover, for positive literals, the rewriting clause must be smaller than the rewritten clause—a condition that is also necessary with the standard first-order redundancy criterion but not always fulfilled by Schulz’s rule. As for destructive equality resolution, even in first-order logic the rule cannot be justified with the standard redundancy criterion, and it is unclear whether it preserves refutational completeness.
instead of arbitrary contexts \(u[\,]\). Semantic tautology deletion can be applied as well, but we must use the entailment relation of the GF level—i.e., only rewriting in green contexts can be used to establish the entailment. Similarly, rewriting of positive and negative literals (demodulation) can only be applied in green contexts. Moreover, for positive literals, the rewriting clause must be smaller than the rewritten clause—a condition that is also necessary with the standard first-order redundancy criterion but not always fulfilled by Schulz’s rule. As for destructive equality resolution, even in first-order logic the rule cannot be justified with the standard redundancy criterion, and it is unclear whether it preserves refutational completeness.
As a representative example, we show how demodulation into green contexts can be justified. The justification for the other simplification rules is similar.
Lemma 28
Demodulation into green contexts is a simplification:

where \(t\sigma \succ t'\sigma \) and \(C \succ (t\approx t')\sigma \). It adheres to the redundancy criterion \(\textit{HRed}_\mathrm{C}\)—i.e., the deleted premise C is redundant w.r.t. the conclusions.
Proof
Let N be the set consisting of the two conclusions. We must show that \(C \in {\textit{HRed}}_{\mathrm{C}}(N)\). Let \(C\theta \) be a ground instance of C. By the definition of \({\textit{HRed}}_{\mathrm{C}}\), it suffices to show that  . By the definition of \(\textit{GHRed}_{\mathrm{C}}\), we must therefore show that
. By the definition of \(\textit{GHRed}_{\mathrm{C}}\), we must therefore show that  . By the definition of \(\textit{GFRed}_{\mathrm{C}}\), this is equivalent to proving that the clauses in
. By the definition of \(\textit{GFRed}_{\mathrm{C}}\), this is equivalent to proving that the clauses in  that are smaller than
that are smaller than  entail
entail  .
.
By compatibility with green contexts and stability under grounding substitutions of \(\succ \), the condition \(t\sigma \succ t'\sigma \) implies that  is a clause in
is a clause in  that is smaller than
that is smaller than  . By stability under grounding substitutions, \(C \succ (t\approx t')\sigma \) implies that
. By stability under grounding substitutions, \(C \succ (t\approx t')\sigma \) implies that  is another clause in
is another clause in  that is smaller than
that is smaller than  . By Lemma 23, green subterms on the \({\mathrm{GH}}\) level correspond to subterms on the \({\mathrm{GF}}\) level. Thus,
. By Lemma 23, green subterms on the \({\mathrm{GH}}\) level correspond to subterms on the \({\mathrm{GF}}\) level. Thus,  by congruence. \(\square \)
by congruence. \(\square \)
3.6 A Derived Term Order
We stated some requirements on the term orders \(\succ \) and \(\succsim \) in Sect. 3.1 but have not shown how to fulfill them. To derive a suitable strict term order \(\succ \), we propose to encode \(\eta \)-short \(\beta \)-normal forms into untyped first-order terms and apply an order \(\succ _{\mathsf {fo}}\) of first-order terms such as the Knuth–Bendix order [45] or the lexicographic path order [43].
The encoding, denoted by  , indexes symbols with their number of term arguments, similarly to the
, indexes symbols with their number of term arguments, similarly to the  encoding. Unlike the
encoding. Unlike the  encoding,
encoding,  translates \(\lambda x :\tau .\; t\) to
translates \(\lambda x :\tau .\; t\) to  and uses De Bruijn [25] symbols to represent bound variables. The
and uses De Bruijn [25] symbols to represent bound variables. The  encoding replaces fluid terms t by fresh variables \(z_{t}\) and maps type arguments to term arguments, while erasing any other type information. For example,
encoding replaces fluid terms t by fresh variables \(z_{t}\) and maps type arguments to term arguments, while erasing any other type information. For example,  . The use of De Bruijn indices and the monolithic encoding of fluid terms ensure stability under both \(\alpha \)-renaming and substitution.
. The use of De Bruijn indices and the monolithic encoding of fluid terms ensure stability under both \(\alpha \)-renaming and substitution.
Definition 29
(Encoding  ) Given a signature \((\Sigma _\mathsf {ty},\Sigma )\),
) Given a signature \((\Sigma _\mathsf {ty},\Sigma )\),  encodes types and terms as terms over the untyped first-order signature \(\Sigma _\mathsf {ty}\uplus \{{\textsf {f}}_k \mid {\textsf {f}}\in \Sigma ,\>k\in \mathbb {N}\} \uplus \{{\textsf {lam}}\}\uplus \{\smash {{\textsf {db}}^i_k}\mid i,k\in \mathbb {N}\}\). We reuse higher-order type variables as term variables in the target untyped first-order logic. Moreover, let \(z_{t}\) be an untyped first-order variable for each higher-order term t. The auxiliary function
encodes types and terms as terms over the untyped first-order signature \(\Sigma _\mathsf {ty}\uplus \{{\textsf {f}}_k \mid {\textsf {f}}\in \Sigma ,\>k\in \mathbb {N}\} \uplus \{{\textsf {lam}}\}\uplus \{\smash {{\textsf {db}}^i_k}\mid i,k\in \mathbb {N}\}\). We reuse higher-order type variables as term variables in the target untyped first-order logic. Moreover, let \(z_{t}\) be an untyped first-order variable for each higher-order term t. The auxiliary function  replaces each free occurrence of the variable x by a symbol
\({\textsf {db}}^i\), where i is the number of
\(\lambda \)-expressions surrounding the variable occurrence. The type-to-term version of
replaces each free occurrence of the variable x by a symbol
\({\textsf {db}}^i\), where i is the number of
\(\lambda \)-expressions surrounding the variable occurrence. The type-to-term version of
 is defined by
is defined by
 and
and
 . The term-to-term version is defined by
. The term-to-term version is defined by

For example, let \(s = \lambda y.\>{\textsf {f}}\> y\> (\lambda w.\> {\textsf {g}}\>(y\> w))\) where y has type \(\kappa \rightarrow \kappa \) and w has type \(\kappa \). We have  and
and  . Neither s nor \(\lambda w.\> {\textsf {g}}\>(y\> w)\) are fluid. Hence, we have
. Neither s nor \(\lambda w.\> {\textsf {g}}\>(y\> w)\) are fluid. Hence, we have  .
.
Definition 30
(Derived strict term order) Let the strict term order derived from \(\succ _{\mathsf {fo}}\) be \(\succ _{{\lambda }}\) where \(t \succ _{{\lambda }}s\) if  .
.
We will show that the derived \(\succ _{{\lambda }}\) fulfills all properties of a strict term order (Definition 6) if \(\succ _{\mathsf {fo}}\) fulfills the corresponding properties on first-order terms. For the nonstrict term order \(\succsim \), we can use the reflexive closure \(\succeq _{{\lambda }}\) of \(\succ _{{\lambda }}\).
Lemma 31
Let \(\succ _{\mathsf {fo}}\) be a strict partial order on first-order terms and \(\succ _{{\lambda }}\) the derived term order on \(\beta \eta \)-equivalence classes. If the restriction of \(\succ _{\mathsf {fo}}\) to ground terms enjoys well-foundedness, totality, the subterm property, and compatibility with contexts (w.r.t. first-order terms), the restriction of \(\succ _{{\lambda }}\) to ground terms enjoys well-foundedness, totality, the green subterm property, and compatibility with green contexts (w.r.t. \(\beta \eta \)-equivalence classes).
Proof
Transitivity and irreflexivity of \(\succ _{\mathsf {fo}}\) imply transitivity and irreflexivity of \(\succ _{{\lambda }}\).
Well-foundedness: If there existed an infinite chain \(t_1 \succ _{{\lambda }}t_2 \succ _{{\lambda }}\cdots \) of ground terms, there would also be the chain  , contradicting the well-foundedness of \(\succ _{\mathsf {fo}}\) on ground \(\lambda \)-free terms.
, contradicting the well-foundedness of \(\succ _{\mathsf {fo}}\) on ground \(\lambda \)-free terms.
Totality: By ground totality of \(\succ _{\mathsf {fo}}\), for any ground terms t and s we have  ,
,  , or
, or  . In the first two cases, it follows that \(t \succ _{{\lambda }}s\) or \(t\prec _{\lambda }s\). In the last case, it follows that \(t = s\) because
. In the first two cases, it follows that \(t \succ _{{\lambda }}s\) or \(t\prec _{\lambda }s\). In the last case, it follows that \(t = s\) because  is clearly injective.
is clearly injective.
Green subterm property: Let s be a term. We show that \(s \succeq _{{\lambda }}s|_p\) by induction on p, where \(s|_p\) denotes the green subterm at a green position p. If \(p = \varepsilon \), this is trivial. If \(p = p'.i\), we have \(s \succeq _{{\lambda }}s|_{p'}\) by the induction hypothesis. Hence, it suffices to show that \(s|_{p'} \succeq _{{\lambda }}s|_{p'.i}\). From the existence of the green position \(p'.i\), we know that \(s|_{p'}\) must be of the form \(s|_{p'} = {\textsf {f}}{\langle {\bar{\tau }}\rangle }\>\bar{u}_k\). Then \(s|_{p'.i} = u_i\). The encoding yields  and hence
and hence  by the ground subterm property of \(\succ _{\mathsf {fo}}\). Hence, \(s|_{p'} \succeq _{{\lambda }}s|_{p'.i}\) and thus \(s \succeq _{{\lambda }}s|_{p}\).
by the ground subterm property of \(\succ _{\mathsf {fo}}\). Hence, \(s|_{p'} \succeq _{{\lambda }}s|_{p'.i}\) and thus \(s \succeq _{{\lambda }}s|_{p}\).
Compatibility with green contexts: By induction on the depth of the context, it suffices to show that \(t \succ _{{\lambda }}s\) implies \({\textsf {f}}{\langle {\bar{\tau }}\rangle }\>\bar{u}\>t\>\bar{v} \succ _{{\lambda }}{\textsf {f}}{\langle {\bar{\tau }}\rangle }\>\bar{u}\>s\>\bar{v}\) for all t, s, \({\textsf {f}}\), \(\bar{\tau }\), \(\bar{u}\), and \(\bar{v}\). This amounts to showing that  implies
implies  , which follows directly from ground compatibility of \(\succ _{\mathsf {fo}}\) with contexts and the induction hypothesis. \(\square \)
, which follows directly from ground compatibility of \(\succ _{\mathsf {fo}}\) with contexts and the induction hypothesis. \(\square \)
Lemma 32
Let \(\succ _{\mathsf {fo}}\) be a strict partial order on first-order terms. If \(\succ _{\mathsf {fo}}\) is stable under grounding substitutions (w.r.t. first-order terms), the derived term order \(\succ _{{\lambda }}\) is stable under grounding substitutions (w.r.t. \(\beta \eta \)-equivalence classes).
Proof
Assume \(s \succ _{{\lambda }}s'\) for some terms s and \(s'\). Let \(\theta \) be a higher-order substitution grounding s and \(s'\). We must show \(s\theta \succ _{{\lambda }}s'\theta \). We will define a first-order substitution \(\rho \) grounding  and
and  such that
such that  and
and  . Since \(s \succ _{{\lambda }}s'\), we have
. Since \(s \succ _{{\lambda }}s'\), we have  . By stability of \(\succ _{\mathsf {fo}}\) under grounding substitutions,
. By stability of \(\succ _{\mathsf {fo}}\) under grounding substitutions,  . It follows that
. It follows that  and hence \(s\theta \succ _{{\lambda }}s'\theta \).
and hence \(s\theta \succ _{{\lambda }}s'\theta \).
We define the first-order substitution \(\rho \) as \(\alpha \rho = \alpha \theta \) for type variables \(\alpha \) and  for terms u. Strictly speaking, the domain of a substitution must be finite, so we restrict this definition of \(\rho \) to the finitely many variables that occur in the computation of
for terms u. Strictly speaking, the domain of a substitution must be finite, so we restrict this definition of \(\rho \) to the finitely many variables that occur in the computation of  .
.
Clearly  for all types \(\tau \) occurring in the computation of
for all types \(\tau \) occurring in the computation of  and
and  . Moreover,
. Moreover,  for all t occurring in the computation of
for all t occurring in the computation of  and
and  , which we show by induction on the definition of the encoding. If \(t=x\) or if t is fluid,
, which we show by induction on the definition of the encoding. If \(t=x\) or if t is fluid,  . If \(t = {\textsf {f}}{\langle {\bar{\tau }}\rangle }\>\bar{u}\), then
. If \(t = {\textsf {f}}{\langle {\bar{\tau }}\rangle }\>\bar{u}\), then  . If \(t = (\lambda x :\tau .\;u)\) and t is not fluid, then
. If \(t = (\lambda x :\tau .\;u)\) and t is not fluid, then  . \(\square \)
. \(\square \)
4 Refutational Completeness
Besides soundness, the most important property of the Boolean-free \(\lambda \)-superposition calculus introduced in Sect. 3 is refutational completeness. We will prove static and dynamic refutational completeness of \(\textit{HInf}\) w.r.t. \((\textit{HRed}_{\mathrm{I}}, {\textit{HRed}}_{\mathrm{C}})\), which are defined as follows. For the precise definitions of inference systems and redundancy criteria, we refer to Waldmann et al. [71].
Definition 33
(Static refutational completeness) Let \(\textit{Inf}\) be an inference system, and let \((\textit{Red}_{\mathrm{I}}, \textit{Red}_{\mathrm{C}})\) be a redundancy criterion. The inference system \(\textit{Inf}\) is statically refutationally complete w.r.t. \((\textit{Red}_{\mathrm{I}}, \textit{Red}_{\mathrm{C}})\) if we have \(N \models \bot \) if and only if \(\bot \in N\) for every clause set N that is saturated w.r.t. \(\textit{Inf}\) and \(\textit{Red}_{\mathrm{I}}\).
Definition 34
(Dynamic refutational completeness) Let \(\textit{Inf}\) be an inference system, and let \((\textit{Red}_{\mathrm{I}}, \textit{Red}_{\mathrm{C}})\) be a redundancy criterion. Let \((N_i)_i\) be a finite or infinite sequence over sets of clauses. Such a sequence is a derivation if \(N_i \setminus N_{i+1} \subseteq \textit{Red}_{\mathrm{C}}(N_{i+1})\) for all i. It is fair if all \(\textit{Inf}\)-inferences from clauses in the limit inferior \(\bigcup _i \bigcap _{\!j \ge i} N_{\!j}\) are contained in \(\bigcup _i \textit{Red}_{\mathrm{I}}(N_i)\). The inference system \(\textit{Inf}\) is dynamically refutationally complete w.r.t. \((\textit{Red}_{\mathrm{I}}, \textit{Red}_{\mathrm{C}})\) if for every fair derivation \((N_i)_i\) such that \(N_0 \models \bot \), we have \(\bot \in N_i\) for some i.
4.1 Outline of the Proof
The proof proceeds in three steps, corresponding to the three levels \({\mathrm{GF}}\), \({\mathrm{GH}}\), and \({\mathrm{H}}\) introduced in Sect. 3.4:
-
1.
We use Bachmair and Ganzinger’s work on the refutational completeness of standard (first-order) superposition [6] to prove static refutational completeness of \(\textit{GFInf}\).
-
2.
From the first-order model constructed in Bachmair and Ganzinger’s proof, we derive a clausal higher-order model and thus prove static refutational completeness of \(\textit{GHInf}\).
-
3.
We use the saturation framework by Waldmann et al. [71] to lift the static refutational completeness of \(\textit{GHInf}\) to static and dynamic refutational completeness of \(\textit{HInf}\).
In the first step, since the inference system \(\textit{GFInf}\) is standard ground superposition, we can make use of Bachmair and Ganzinger’s results. Given a saturated clause set  with \(\bot \not \in N\), Bachmair and Ganzinger prove refutational completeness by constructing a term rewriting system \(R_N\) and showing that it can be viewed as an interpretation that is a model of N. This first step deals exclusively with ground first-order clauses.
with \(\bot \not \in N\), Bachmair and Ganzinger prove refutational completeness by constructing a term rewriting system \(R_N\) and showing that it can be viewed as an interpretation that is a model of N. This first step deals exclusively with ground first-order clauses.
In the second step, we derive refutational completeness of \(\textit{GHInf}\). Given a saturated clause set  with \(\bot \not \in N\), we use the first-order model
with \(\bot \not \in N\), we use the first-order model  of
of  constructed in the first step to derive a clausal higher-order interpretation that is a model of N. Under the encoding
constructed in the first step to derive a clausal higher-order interpretation that is a model of N. Under the encoding  , occurrences of the same symbol with different numbers of arguments are regarded as different symbols—e.g.,
, occurrences of the same symbol with different numbers of arguments are regarded as different symbols—e.g.,  and
and  . All \(\lambda \)-expressions \(\lambda x.\>t\) are regarded as uninterpreted symbols \({\textsf {lam}}_{\lambda x.\>t}\). The difficulty is to construct a higher-order interpretation that merges the first-order denotations of all \({\textsf {f}}_i\) into a single higher-order denotation of \({\textsf {f}}\) and to show that the symbols \({\textsf {lam}}_{\lambda x.\>t}\) behave like \(\lambda x.\>t\). This step relies on saturation w.r.t. the GArgCong rule—which connects a term of functional type with its value when applied to an argument x—and on the presence of the extensionality rule GExt.
. All \(\lambda \)-expressions \(\lambda x.\>t\) are regarded as uninterpreted symbols \({\textsf {lam}}_{\lambda x.\>t}\). The difficulty is to construct a higher-order interpretation that merges the first-order denotations of all \({\textsf {f}}_i\) into a single higher-order denotation of \({\textsf {f}}\) and to show that the symbols \({\textsf {lam}}_{\lambda x.\>t}\) behave like \(\lambda x.\>t\). This step relies on saturation w.r.t. the GArgCong rule—which connects a term of functional type with its value when applied to an argument x—and on the presence of the extensionality rule GExt.
In the third step, we employ the saturation framework by Waldmann et al. [71] , which is based on Bachmair and Ganzinger’s framework [7, Sect. 4], to prove refutational completeness of \(\textit{HInf}\). Both frameworks help calculus designers prove static and dynamic refutational completeness of nonground calculi. In addition, the framework by Waldmann et al. explicitly supports the redundancy criterion defined in Sect. 3.4, which can be used to justify the deletion of subsumed clauses. Moreover, their framework provides completeness theorems for prover architectures, such as the DISCOUNT loop.
The main proof obligation we must discharge to use the framework is that there should exist nonground inferences in \(\textit{HInf}\) corresponding to all nonredundant inferences in \(\textit{GHInf}\). We face two specifically higher-order difficulties. First, in standard superposition, we can avoid Sup inferences into variables x by exploiting the clause order’s compatibility with contexts: If \(t' \prec t\), we have \(C\{x \mapsto t'\} \prec C\{x \mapsto t\}\), which allows us to show that Sup inferences into variables are redundant. This technique fails for higher-order variables x that occur applied in C, because the order lacks compatibility with arguments. This is why our Sup rule must perform some inferences into variables. The other difficulty also concerns applied variables. We must show that any nonredundant Sup inference in level \({\mathrm{GH}}\) into a position corresponding to a fluid term or a deeply occurring variable in level \({\mathrm{H}}\) can be lifted to a FluidSup inference. This involves showing that the z variable in FluidSup can represent arbitrary contexts around a term t.
For the entire proof of refutational completeness, \(\beta \eta \)-normalization is the proverbial barking dog that never bites. On level \({\mathrm{GH}}\), the rules Sup, ERes, and EFact preserve \(\eta \)-short \(\beta \)-normal form, and so does first-order term rewriting. Thus, we can completely ignore  and
and  . On level \({\mathrm{H}}\), instantiation can cause \(\beta \)- and \(\eta \)-reduction, but this poses no difficulties thanks to the clause order’s stability under grounding substitutions.
. On level \({\mathrm{H}}\), instantiation can cause \(\beta \)- and \(\eta \)-reduction, but this poses no difficulties thanks to the clause order’s stability under grounding substitutions.
4.2 The Ground First-Order Level
We use Bachmair and Ganzinger’s results on standard superposition [6] to prove refutational completeness of \({\mathrm{GF}}\). In the subsequent steps, we will also make use of specific properties of the model Bachmair and Ganzinger construct. The basis of Bachmair and Ganzinger’s proof is that a term rewriting system R defines an interpretation  such that for every ground equation \(s \approx t\), we have
such that for every ground equation \(s \approx t\), we have  if and only if \(s \mathrel {\leftarrow \rightarrow }_R^* t\). Formally,
if and only if \(s \mathrel {\leftarrow \rightarrow }_R^* t\). Formally,  denotes the monomorphic first-order interpretation whose universes \(\mathscr {U}_\tau \) consist of the R-equivalence classes over
denotes the monomorphic first-order interpretation whose universes \(\mathscr {U}_\tau \) consist of the R-equivalence classes over  containing terms of type \(\tau \). The interpretation
containing terms of type \(\tau \). The interpretation  is term-generated—that is, for every element a of the universe of this interpretation and for any valuation \(\xi \), there exists a ground term t such that
is term-generated—that is, for every element a of the universe of this interpretation and for any valuation \(\xi \), there exists a ground term t such that  . To lighten notation, we will write R to refer to both the term rewriting system R and the interpretation
. To lighten notation, we will write R to refer to both the term rewriting system R and the interpretation  .
.
The term rewriting system is constructed as follows:
Definition 35
Let  . We first define sets of rewrite rules \(E_N^C\) and \(R_N^C\) for all \(C\in N\) by induction on the clause order. Assume that \(E_N^D\) has already been defined for all \(D \in N\) such that \(D \prec C.\) Then \(R_N^C = \bigcup _{D \prec C} E_N^D.\) Let
. We first define sets of rewrite rules \(E_N^C\) and \(R_N^C\) for all \(C\in N\) by induction on the clause order. Assume that \(E_N^D\) has already been defined for all \(D \in N\) such that \(D \prec C.\) Then \(R_N^C = \bigcup _{D \prec C} E_N^D.\) Let  if the following conditions are met:
if the following conditions are met:
-
(a)
\(C = C' \vee s \approx t\);
-
(b)
\(s \approx t\) is \(\succsim \)-maximal in C;
-
(c)
\(s \succ t\);
-
(d)
\(C'\) is false in \(R_N^C\);
-
(e)
s is irreducible w.r.t. \(R_N^C.\)
Then C is said to produce  . Otherwise, \(E_N^C = \emptyset \). Finally, \(R_N = \bigcup _{D} E_N^D.\)
. Otherwise, \(E_N^C = \emptyset \). Finally, \(R_N = \bigcup _{D} E_N^D.\)
Based on Bachmair and Ganzinger’s work, Bentkamp et al. [10, Lemma 4.4 and Theorem 4.5] prove the following properties of \(R_N\):
Lemma 36
Let \(\bot \not \in N\) and  be saturated w.r.t. \(\textit{GFInf}\) and \(\textit{GFRed}_{\mathrm{I}}\). If \(C = C' \vee s \approx t \in N\) produces
be saturated w.r.t. \(\textit{GFInf}\) and \(\textit{GFRed}_{\mathrm{I}}\). If \(C = C' \vee s \approx t \in N\) produces  , then \(s \approx t\) is strictly \(\succeq \)-eligible in C and \(C'\) is false in \(R_N\).
, then \(s \approx t\) is strictly \(\succeq \)-eligible in C and \(C'\) is false in \(R_N\).
Theorem 37
(Ground first-order static refutational completeness) The inference system \(\textit{GFInf}\) is statically refutationally complete w.r.t. \((\textit{GFRed}_{\mathrm{I}}, \textit{GFRed}_{\mathrm{C}})\). More precisely, if  is a clause set saturated w.r.t. \(\textit{GFInf}\) and \(\textit{GFRed}_{\mathrm{I}}\) such that \(\bot \not \in N\), then \(R_N\) is a model of N.
is a clause set saturated w.r.t. \(\textit{GFInf}\) and \(\textit{GFRed}_{\mathrm{I}}\) such that \(\bot \not \in N\), then \(R_N\) is a model of N.
4.3 The Ground Higher-Order Level
In this subsection, let \(\textit{GHSel}\) be a selection function on  , let
, let  be a clause set saturated w.r.t. \(\textit{GHInf}^\textit{GHSel}\) and \(\textit{GHRed}_{\mathrm{I}}^\textit{GHSel}\) such that \(\bot \not \in N\). Clearly,
be a clause set saturated w.r.t. \(\textit{GHInf}^\textit{GHSel}\) and \(\textit{GHRed}_{\mathrm{I}}^\textit{GHSel}\) such that \(\bot \not \in N\). Clearly,  is then saturated w.r.t.
is then saturated w.r.t.  and
and  .
.
We abbreviate  as \(R\). Given two terms
as \(R\). Given two terms  , we write \(s\sim t\) to abbreviate
, we write \(s\sim t\) to abbreviate  , which is equivalent to
, which is equivalent to  .
.
Lemma 38
For all terms \(t,s:\tau \rightarrow \upsilon \) in  , the following statements are equivalent:
, the following statements are equivalent:
-
1.
\(t\sim s\);
-
2.
\(t\>(\mathsf {diff}\>t\>s)\sim s\>(\mathsf {diff}\>t\>s)\);
-
3.
\(t\>u\sim s\>u\) for all
 .
.
 .
.Proof
(3) \(\Rightarrow \) (2): Take \(u := \mathsf {diff}\>t\>s\).
(2) \(\Rightarrow \) (1): Since N is saturated, the GExt inference that generates the clause \(C = t\>(\mathsf {diff}\>t\>s) \not \approx s\>(\mathsf {diff}\>t\>s) \mathrel \vee t \approx s\) is redundant—i.e., \(C \in N \mathrel \cup \textit{GHRed}_{\mathrm{C}}(N)\)—and hence  by Theorem 37 and the assumption that \(\bot \not \in N\). Therefore, it follows from \(t\>(\mathsf {diff}\>t\>s)\sim s\>(\mathsf {diff}\>t\>s)\) that \(t\sim s\).
by Theorem 37 and the assumption that \(\bot \not \in N\). Therefore, it follows from \(t\>(\mathsf {diff}\>t\>s)\sim s\>(\mathsf {diff}\>t\>s)\) that \(t\sim s\).
(1) \(\Rightarrow \) (3): We assume that \(t\sim s\)—i.e.,  . By induction on the number of rewrite steps between
. By induction on the number of rewrite steps between  and
and  and by transitivity of \(\sim \), it suffices to show that
and by transitivity of \(\sim \), it suffices to show that  implies \(t\>u\sim s\>u\). If the rewrite step
implies \(t\>u\sim s\>u\). If the rewrite step  is not at the top level, then neither \(s{\downarrow }_{\beta \eta }\) nor \(t{\downarrow }_{\beta \eta }\) can be \(\lambda \)-expressions. Therefore, \((s{\downarrow }_{\beta \eta })\>(u{\downarrow }_{\beta \eta })\) and \((t{\downarrow }_{\beta \eta })\>(u{\downarrow }_{\beta \eta })\) are in \(\eta \)-short \(\beta \)-normal form, and there is an analogous rewrite step
is not at the top level, then neither \(s{\downarrow }_{\beta \eta }\) nor \(t{\downarrow }_{\beta \eta }\) can be \(\lambda \)-expressions. Therefore, \((s{\downarrow }_{\beta \eta })\>(u{\downarrow }_{\beta \eta })\) and \((t{\downarrow }_{\beta \eta })\>(u{\downarrow }_{\beta \eta })\) are in \(\eta \)-short \(\beta \)-normal form, and there is an analogous rewrite step  using the same rewrite rule. It follows that \(t\>u\sim s\>u\). If the rewrite step
using the same rewrite rule. It follows that \(t\>u\sim s\>u\). If the rewrite step  is at the top level,
is at the top level,  must be a rule of \(R\). This rule must originate from a productive clause of the form
must be a rule of \(R\). This rule must originate from a productive clause of the form  . By Lemma 36,
. By Lemma 36,  is strictly \(\succeq \)-eligible in
is strictly \(\succeq \)-eligible in  w.r.t.
w.r.t.  , and hence \(t \approx s\) is strictly \(\succeq \)-eligible in C w.r.t. \(\textit{GHSel}\).
, and hence \(t \approx s\) is strictly \(\succeq \)-eligible in C w.r.t. \(\textit{GHSel}\).
Thus, the following GArgCong inference \(\iota \) applies:

By saturation, \(\iota \) is redundant w.r.t. N—i.e., \(\textit{concl}(\iota )\in N \mathrel \cup \textit{GHRed}_{\mathrm{C}}(N)\). By Theorem 37 and the assumption that \(\bot \not \in N\),  is then true in \(R\). By Lemma 36,
is then true in \(R\). By Lemma 36,  is false in \(R\). Therefore,
is false in \(R\). Therefore,  must be true in \(R\). \(\square \)
must be true in \(R\). \(\square \)
Lemma 39
Let  and \(\theta \), \(\theta '\) grounding substitutions such that \(x\theta \sim x\theta '\) for all variables x and \(\alpha \theta = \alpha \theta '\) for all type variables \(\alpha \). Then \(s\theta \sim s\theta '\).
and \(\theta \), \(\theta '\) grounding substitutions such that \(x\theta \sim x\theta '\) for all variables x and \(\alpha \theta = \alpha \theta '\) for all type variables \(\alpha \). Then \(s\theta \sim s\theta '\).
Proof
In this proof, we work directly on \(\lambda \)-terms. To prove the lemma, it suffices to prove it for any \(\lambda \)-term s. Here, for \(\lambda \)-terms \(t_1\) and \(t_2\), the notation \(t_1\sim t_2\) is to be read as \(t_1{\downarrow }_{\beta \eta }\sim {t_2}{\downarrow }_{\beta \eta }\) because  is only defined on \(\eta \)-short \(\beta \)-normal terms.
is only defined on \(\eta \)-short \(\beta \)-normal terms.
Definition We extend the syntax of \(\lambda \)-terms with a new polymorphic function symbol \(\oplus :\varvec{\Pi }\alpha .\,\alpha \rightarrow \alpha \rightarrow \alpha \). We will omit its type argument. It is equipped with two reduction rules:  and
and  . A \(\beta \oplus \)-reduction step is either a rewrite step following one of these rules or a \(\beta \)-reduction step.
. A \(\beta \oplus \)-reduction step is either a rewrite step following one of these rules or a \(\beta \)-reduction step.
The computability path order \(\succ _{\textsf {CPO}}\) [22] guarantees that
-
\(\oplus \>t\>s \succ _{\textsf {CPO}} s\) by applying rule \(@\rhd \);
-
\(\oplus \>t\>s \succ _{\textsf {CPO}} t\) by applying rule \(@\rhd \) twice;
-
\((\lambda x.\>t)\>s \succ _{\textsf {CPO}} t[x\mapsto s]\) by applying rule \(@\beta \).
Since this order is moreover monotone, it decreases with \(\beta \oplus \)-reduction steps.
The order is also well-founded; thus, \(\beta \oplus \)-reductions terminate. And since the \(\beta \oplus \)-reduction steps describe a finitely branching term rewriting system, by Kőnig’s lemma [44], there is a maximal number of \(\beta \oplus \)-reduction steps from each \(\lambda \)-term.
Definition A \(\lambda \)-term is term-ground if it does not contain free term variables. It may contain polymorphic-type arguments.
Definition We introduce an auxiliary function \(\mathscr {S}\) that essentially measures the size of a \(\lambda \)-term but assigns a size of 1 to term-ground \(\lambda \)-terms.
We prove \(s\theta \sim s\theta '\) by well-founded induction on s, \(\theta \), and \(\theta '\) using the left-to-right lexicographic order on the triple \(\bigl (n_1(s), n_2(s), n_3(s)\bigr )\in \mathbb {N}^3\), where
-
\(n_1(s)\) is the maximal number of \(\beta \oplus \)-reduction steps starting from \(s\sigma \), where \(\sigma \) is the substitution mapping each term variable x to \(\oplus \>x\theta \>x\theta '\);
-
\(n_2(s)\) is the number of free term variables occurring more than once in s;
-
\(n_3(s) = \mathscr {S}(s)\).
Case 1: The \(\lambda \)-term s is term-ground. Then the lemma is trivial.
Case 2: The \(\lambda \)-term s contains \(k \ge 2\) free term variables. Then we can apply the induction hypothesis twice and use the transitivity of \(\sim \) as follows. Let x be one of the free term variables in s. Let \(\rho = \{x \mapsto x\theta \}\) the substitution that maps x to \(x\theta \) and ignores all other variables. Let \(\rho ' = \theta '[x\mapsto x]\).
We want to invoke the induction hypothesis on \(s\rho \) and \(s\rho '\). This is justified because \(s\sigma \) \(\oplus \)-reduces to \(s\rho \sigma \) and to \(s\rho '\sigma \). These \(\oplus \)-reductions have at least one step because x occurs in s and \(k \ge 2\). Hence, \(n_1(s)>n_1(s\rho )\) and \(n_1(s)>n_1(s\rho ')\).
This application of the induction hypothesis gives us \(s\rho \theta \sim s\rho \theta '\) and \(s\rho '\theta \sim s\rho '\theta '\). Since \(s\rho \theta = s\theta \) and \(s\rho '\theta ' = s\theta '\), this is equivalent to \(s\theta \sim s\rho \theta '\) and \(s\rho '\theta \sim s\theta '\). Since moreover \(s\rho \theta ' = s\rho '\theta \), we have \(s\theta \sim s\theta '\) by transitivity of \(\sim \). The following illustration visualizes the above argument:

Case 3:The \(\lambda \)-term s contains a free term variable that occurs more than once. Then we rename variable occurrences apart by replacing each occurrence of each free term variable x by a fresh variable \(x_i\), for which we define \(x_i\theta = x\theta \) and \(x_i\theta ' = x\theta '\). Let \(s'\) be the resulting \(\lambda \)-term. Since \(s\sigma = s'\sigma \), we have \(n_1(s)=n_1(s')\). All free term variables occur only once in \(s'\). Hence, \(n_2(s)>0=n_2(s')\). Therefore, we can invoke the induction hypothesis on \(s'\) to obtain \(s'\theta \sim s'\theta '\). Since \(s\theta = s'\theta \) and \(s\theta ' = s'\theta '\), it follows that \(s\theta \sim s\theta '\).
Case 4:The \(\lambda \)-term s contains only one free term variable x, which occurs exactly once.
Case 4.1:The \(\lambda \)-term s is of the form \({\textsf {f}}{\langle {\bar{\tau }}\rangle }\>\bar{t}\) for some symbol \({\textsf {f}}\), some types \(\bar{\tau }\), and some \(\lambda \)-terms \(\bar{t}\). Then let u be the \(\lambda \)-term in \(\bar{t}\) that contains x. We want to apply the induction hypothesis to u, which can be justified as follows. Consider the longest sequence of \(\beta \oplus \)-reductions from \(u\sigma \). This sequence can be replicated inside \(s\sigma =({\textsf {f}}{\langle {\bar{\tau }}\rangle }\>\bar{t})\sigma \). Therefore, the longest sequence of \(\beta \oplus \)-reductions from \(s\sigma \) is at least as long—i.e., \(n_1(s)\ge n_1(u)\). Since both s and u have only one free term variable occurrence, we have \(n_2(s) = 0 = n_2(u)\). But \(n_3(s) > n_3(u)\) because u is a term-nonground subterm of s.
Applying the induction hypothesis gives us \(u\theta \sim u\theta '\). By definition of  , we have
, we have  and analogously for \(\theta '\), where m is the length of \(\bar{t}\). By congruence of \(\approx \) in first-order logic, it follows that \(s\theta \sim s\theta '\).
and analogously for \(\theta '\), where m is the length of \(\bar{t}\). By congruence of \(\approx \) in first-order logic, it follows that \(s\theta \sim s\theta '\).
Case 4.2:The \(\lambda \)-term s is of the form \(x\>\bar{t}\) for some \(\lambda \)-terms \(\bar{t}\). Then we observe that, by assumption, \(x\theta \sim x\theta '\). By applying Lemma 38 repeatedly, we have \(x\theta \>\bar{t}\sim x\theta '\>\bar{t}\). Since x occurs only once, \(\bar{t}\) is term-ground and hence \(s\theta = x\theta \>\bar{t}\) and \(s\theta ' = x\theta '\>\bar{t}\). Therefore, \(s\theta \sim s\theta '\).
Case 4.3:The \(\lambda \)-term s is of the form \(\lambda z.\>u\) for some \(\lambda \)-term u. Then we observe that to prove \(s\theta \sim s\theta '\), it suffices to show that \(s\theta \>(\mathsf {diff}\>s\theta \>s\theta ')\sim s\theta ' \>(\mathsf {diff}\>s\theta \>s\theta ')\) by Lemma 38. Via \(\beta \eta \)-conversion, this is equivalent to \(u\rho \theta \sim u\rho \theta '\) where \(\rho = \{z\mapsto \mathsf {diff}\>(s\theta {\downarrow }_{\beta \eta })\>(s\theta '{\downarrow }_{\beta \eta })\}\). To prove \(u\rho \theta \sim u\rho \theta '\), we apply the induction hypothesis on \(u\rho \).
It remains to show that the induction hypothesis applies on \(u\rho \). Consider the longest sequence of \(\beta \oplus \)-reductions from \(u\rho \sigma \). Since \(z\rho \) starts with the \(\mathsf {diff}\) symbol, \(z\rho \) will not cause more \(\beta \oplus \)-reductions than z. Hence, the same sequence of \(\beta \oplus \)-reductions can be applied inside \(s\sigma = (\lambda z.\>u)\sigma \), proving that \(n_1(s) \ge n_1(u\rho )\). Since both s and \(u\rho \) have only one free term variable occurrence, \(n_2(s) = 0 = n_2(u\rho )\). But \(n_3(s) = \mathscr {S}(s) = 1 + \mathscr {S}(u)\) because s is term-nonground. Moreover, \(\mathscr {S}(u)\ge \mathscr {S}(u\rho )=n_3(u\rho )\) because \(\rho \) replaces a variable by a ground \(\lambda \)-term. Hence, \(n_3(s) > n_3(u\rho )\), which justifies the application of the induction hypothesis.
Case 4.4:The \(\lambda \)-term s is of the form \((\lambda z.\>u)\>t_0\>\bar{t}\) for some \(\lambda \)-terms u, \(t_0\), and \(\bar{t}\). We apply the induction hypothesis on \(s' = u\{z \mapsto t_0\}\>\bar{t}\). To justify it, consider the longest sequence of \(\beta \oplus \)-reductions from \(s'\sigma \). Prepending the reduction  to it gives us a longer sequence from \(s\sigma \). Hence, \(n_1(s) > n_1(s')\). The induction hypothesis gives us \(s'\theta \sim s'\theta '\). Since \(\sim \) is invariant under \(\beta \)-reductions, it follows that \(s\theta \sim s\theta '\). \(\square \)
to it gives us a longer sequence from \(s\sigma \). Hence, \(n_1(s) > n_1(s')\). The induction hypothesis gives us \(s'\theta \sim s'\theta '\). Since \(\sim \) is invariant under \(\beta \)-reductions, it follows that \(s\theta \sim s\theta '\). \(\square \)
We proceed by defining a higher-order interpretation \(\mathscr {I}^{\smash {{\mathrm{GH}}}}=(\mathscr {U}^{{\mathrm{GH}}},\mathscr {J}_\mathsf {ty}^{{\mathrm{GH}}},\mathscr {J}^{{\mathrm{GH}}},\mathscr {L}^{{\mathrm{GH}}})\) derived from \(R\). The interpretation \(R\) is an interpretation in monomorphic first-order logic. Let \(\mathscr {U}_\tau \) be its universe for type \(\tau \) and \(\mathscr {J}\) its interpretation function.
To illustrate the construction, we will employ the following running example. Let the higher-order signature be \(\Sigma _\mathsf {ty}= \{\iota , \rightarrow \}\) and \(\Sigma = \{{\textsf {f}}:\iota \rightarrow \iota ,\> {\textsf {a}} :\iota ,\> {\textsf {b}} :\iota \}\). The first-order signature accordingly consists of \(\Sigma _\mathsf {ty}\) and  . We write [t] for the equivalence class of
. We write [t] for the equivalence class of  modulo \(R\). We assume that \([{\textsf {f}}_0] = [{\textsf {lam}}_{\lambda x.\>x}]\), \([{\textsf {a}}_0] = [{\textsf {f}}_1({\textsf {a}}_0)]\), and \([{\textsf {b}}_0] = [{\textsf {f}}_1({\textsf {b}}_0)]\), and that \({\textsf {f}}_0\), \({\textsf {lam}}_{\lambda x.\>{\textsf {a}}}\), \({\textsf {lam}}_{\lambda x.\>{\textsf {b}}_0}\), \({\textsf {a}}_0\), and \({\textsf {b}}_0\) are in disjoint equivalence classes. Hence, \(\mathscr {U}_{\iota \rightarrow \iota } = \{ [{\textsf {f}}_0], [{\textsf {lam}}_{\lambda x.\>{\textsf {a}}}], [{\textsf {lam}}_{\lambda x.\>{\textsf {b}}}], \dots \}\) and \(\mathscr {U}_{\iota } = \{ [{\textsf {a}}_0], [{\textsf {b}}_0] \}\).
modulo \(R\). We assume that \([{\textsf {f}}_0] = [{\textsf {lam}}_{\lambda x.\>x}]\), \([{\textsf {a}}_0] = [{\textsf {f}}_1({\textsf {a}}_0)]\), and \([{\textsf {b}}_0] = [{\textsf {f}}_1({\textsf {b}}_0)]\), and that \({\textsf {f}}_0\), \({\textsf {lam}}_{\lambda x.\>{\textsf {a}}}\), \({\textsf {lam}}_{\lambda x.\>{\textsf {b}}_0}\), \({\textsf {a}}_0\), and \({\textsf {b}}_0\) are in disjoint equivalence classes. Hence, \(\mathscr {U}_{\iota \rightarrow \iota } = \{ [{\textsf {f}}_0], [{\textsf {lam}}_{\lambda x.\>{\textsf {a}}}], [{\textsf {lam}}_{\lambda x.\>{\textsf {b}}}], \dots \}\) and \(\mathscr {U}_{\iota } = \{ [{\textsf {a}}_0], [{\textsf {b}}_0] \}\).
When defining the universe \(\mathscr {U}^{{\mathrm{GH}}}\) of the higher-order interpretation, we need to ensure that it contains subsets of function spaces, since \(\mathscr {J}_\mathsf {ty}^{{\mathrm{GH}}}(\rightarrow )(\mathscr {D}_1,\mathscr {D}_2)\) must be a subset of the function space from \(\mathscr {D}_1\) to \(\mathscr {D}_2\) for all \(\mathscr {D}_1,\mathscr {D}_2\in \mathscr {U}^{{\mathrm{GH}}}\). But the first-order universes \(\mathscr {U}_\tau \) consist of equivalence classes of terms from  w.r.t. the rewriting system \(R\), not of functions.
w.r.t. the rewriting system \(R\), not of functions.
To repair this mismatch, we will define a family of functions \(\mathscr {E}_\tau \) that give a meaning to the elements of the first-order universes \(\mathscr {U}_{\tau }\). We will define a domain \(\mathscr {D}_\tau \) for each ground type \(\tau \) and then let \(\mathscr {U}^{{\mathrm{GH}}}\) be the set of all these domains \(\mathscr {D}_\tau \). Thus, there will be a one-to-one correspondence between ground types and domains. Since the higher-order and first-order type signatures are identical (including \({\rightarrow }\), which is uninterpreted in first-order logic), we can identify higher-order and first-order types.
We define \(\mathscr {E}_\tau \) and \(\mathscr {D}_{\tau }\) in a mutual recursion. To ensure well-definedness, we must simultaneously show that \(\mathscr {E}_\tau \) is bijective. We start with nonfunctional types \(\tau \): Let \(\mathscr {D}_\tau = \mathscr {U}_{\tau }\) and let  be the identity. Clearly, the identity is bijective. For functional types, we define
be the identity. Clearly, the identity is bijective. For functional types, we define

To verify that this equation is a valid definition of \(\mathscr {E}_{\tau \rightarrow \upsilon }\), we must show that
-
every element of \(\mathscr {U}_{\tau \rightarrow \upsilon }\) is of the form
 for some term s;
for some term s; -
every element of \(\mathscr {D}_\tau \) is of the form
 for some term u;
for some term u; -
the definition does not depend on the choice of such s and u;
-
 for all s.
for all s.
 for some term s;
for some term s; for some term u;
for some term u; for all s.
for all s.The first claim holds because R is term-generated and  is a bijection. The second claim holds because R is term-generated and
is a bijection. The second claim holds because R is term-generated and  and \(\mathscr {E}_{\tau }\) are bijections. To prove the third claim, we assume that there are other ground terms t and v such that
and \(\mathscr {E}_{\tau }\) are bijections. To prove the third claim, we assume that there are other ground terms t and v such that  and
and  . Since \(\mathscr {E}_{\tau }\) is bijective, we have
. Since \(\mathscr {E}_{\tau }\) is bijective, we have  . Using the \(\sim \)-notation, we can write this as \(u\sim v\). Applying Lemma 39 to the term \(x\>y\) and the substitutions \(\{x\mapsto s, y\mapsto u\}\) and \(\{x\mapsto t, y\mapsto v\}\), we obtain \(s\>u\sim t\>v\)—i.e.,
. Using the \(\sim \)-notation, we can write this as \(u\sim v\). Applying Lemma 39 to the term \(x\>y\) and the substitutions \(\{x\mapsto s, y\mapsto u\}\) and \(\{x\mapsto t, y\mapsto v\}\), we obtain \(s\>u\sim t\>v\)—i.e.,  . Thus, the definition of \(\mathscr {E}_{\tau \rightarrow \upsilon }\) above does not depend on the choice of s and u. The fourth claim is obvious from the definition of \(\mathscr {D}_{\tau \rightarrow \upsilon }\) and the third claim.
. Thus, the definition of \(\mathscr {E}_{\tau \rightarrow \upsilon }\) above does not depend on the choice of s and u. The fourth claim is obvious from the definition of \(\mathscr {D}_{\tau \rightarrow \upsilon }\) and the third claim.
It remains to show that \(\mathscr {E}_{\tau \rightarrow \upsilon }\) is bijective. For injectivity, we fix two terms  such that for all
such that for all  , we have
, we have  . By Lemma 38,
. By Lemma 38,  , which shows that \(\mathscr {E}_{\tau \rightarrow \upsilon }\) is injective. For surjectivity, we fix an element \(\varphi \in \mathscr {D}_{\tau \rightarrow \upsilon }\). By definition of \(\mathscr {D}_{\tau \rightarrow \upsilon }\), there exists a term s such that
, which shows that \(\mathscr {E}_{\tau \rightarrow \upsilon }\) is injective. For surjectivity, we fix an element \(\varphi \in \mathscr {D}_{\tau \rightarrow \upsilon }\). By definition of \(\mathscr {D}_{\tau \rightarrow \upsilon }\), there exists a term s such that  for all u. Hence,
for all u. Hence,  , proving surjectivity and therefore bijectivity of \(\mathscr {E}_{\tau \rightarrow \upsilon }\). Below, we will usually write \(\mathscr {E}\) instead of \(\mathscr {E}_\tau \) since the type \(\tau \) is determined by \(\mathscr {E}_\tau \)’s first argument.
, proving surjectivity and therefore bijectivity of \(\mathscr {E}_{\tau \rightarrow \upsilon }\). Below, we will usually write \(\mathscr {E}\) instead of \(\mathscr {E}_\tau \) since the type \(\tau \) is determined by \(\mathscr {E}_\tau \)’s first argument.
In our running example, we thus have \(\mathscr {D}_\iota = \mathscr {U}_\iota = \{ [{\textsf {a}}_0], [{\textsf {b}}_0] \}\) and \(\mathscr {E}_\iota \) is the identity  . The function \(\mathscr {E}^0_{\iota \rightarrow \iota }\) maps \([{\textsf {f}}_0]\) to the identity
. The function \(\mathscr {E}^0_{\iota \rightarrow \iota }\) maps \([{\textsf {f}}_0]\) to the identity  ; it maps \([{\textsf {lam}}_{\lambda x.\>{\textsf {a}}}]\) to the constant function
; it maps \([{\textsf {lam}}_{\lambda x.\>{\textsf {a}}}]\) to the constant function  ; and it maps \([{\textsf {lam}}_{\lambda x.\>{\textsf {b}}}]\) to the constant function
; and it maps \([{\textsf {lam}}_{\lambda x.\>{\textsf {b}}}]\) to the constant function  . The swapping function \([{\textsf {a}}_0] \mapsto [{\textsf {b}}_0], [{\textsf {b}}_0] \mapsto [{\textsf {a}}_0]\) is not in the image of \(\mathscr {E}^0_{\iota \rightarrow \iota }\). Therefore, \(\mathscr {D}_{\iota \rightarrow \iota }\) contains only the identity and the two constant functions, but not this swapping function.
. The swapping function \([{\textsf {a}}_0] \mapsto [{\textsf {b}}_0], [{\textsf {b}}_0] \mapsto [{\textsf {a}}_0]\) is not in the image of \(\mathscr {E}^0_{\iota \rightarrow \iota }\). Therefore, \(\mathscr {D}_{\iota \rightarrow \iota }\) contains only the identity and the two constant functions, but not this swapping function.
We define the higher-order universe as \(\mathscr {U}^{{\mathrm{GH}}}= \{\mathscr {D}_{\tau }\mid \tau \text { ground}\}\). Moreover, we define \(\mathscr {J}_\mathsf {ty}^{{\mathrm{GH}}}(\kappa )(\mathscr {D}_{\bar{\tau }}) = \mathscr {U}_{\kappa (\bar{\tau })}\) for all \(\kappa \in \Sigma _\mathsf {ty}\), completing the type interpretation \(\mathscr {I}_{\mathsf {\mathrm{ty}}}^{\mathrm{GH}}= (\mathscr {U}^{{\mathrm{GH}}},\mathscr {J}_\mathsf {ty}^{{\mathrm{GH}}})\). We define the interpretation function as \(\mathscr {J}^{{\mathrm{GH}}}({\textsf {f}},\mathscr {D}_{\bar{\upsilon }_m}) =\mathscr {E}(\mathscr {J}({\textsf {f}}_0^{\bar{\upsilon }_m}))\) for all \({\textsf {f}}:\varvec{\Pi }\bar{\alpha }_m.\tau \).
In our example, we thus have \(\mathscr {J}^{{\mathrm{GH}}}({\textsf {f}}) = \mathscr {E}([{\textsf {f}}_0])\), which is the identity on  .
.
Finally, we need to define the designation function \(\mathscr {L}^{{\mathrm{GH}}}\), which takes a valuation \(\xi \) and a \(\lambda \)-expression as arguments. Given a valuation \(\xi \), we choose a grounding substitution \(\theta \) such that  for all type variables \(\alpha \) and all variables x. Such a substitution can be constructed as follows: We can fulfill the first equation in a unique way because there is a one-to-one correspondence between ground types and domains. Since \(\mathscr {E}^{-1}(\xi (x))\) is an element of a first-order universe and \(R\) is term-generated, there exists a ground term t such that \(\smash {\llbracket t\rrbracket _{R}^{\xi }}=\mathscr {E}^{-1}(\xi (x))\). Choosing one such t and defining
for all type variables \(\alpha \) and all variables x. Such a substitution can be constructed as follows: We can fulfill the first equation in a unique way because there is a one-to-one correspondence between ground types and domains. Since \(\mathscr {E}^{-1}(\xi (x))\) is an element of a first-order universe and \(R\) is term-generated, there exists a ground term t such that \(\smash {\llbracket t\rrbracket _{R}^{\xi }}=\mathscr {E}^{-1}(\xi (x))\). Choosing one such t and defining  gives us a grounding substitution \(\theta \) with the desired property.
gives us a grounding substitution \(\theta \) with the desired property.
We define  . To prove that this is well-defined, we assume that there exists another substitution \(\theta '\) with the properties \(\smash {\mathscr {D}_{\alpha \theta '}}=\xi (\alpha )\) for all \(\alpha \) and
. To prove that this is well-defined, we assume that there exists another substitution \(\theta '\) with the properties \(\smash {\mathscr {D}_{\alpha \theta '}}=\xi (\alpha )\) for all \(\alpha \) and  for all x. Then we have \(\alpha \theta = \alpha \theta '\) for all \(\alpha \) due to the one-to-one correspondence between domains and ground types. We have
for all x. Then we have \(\alpha \theta = \alpha \theta '\) for all \(\alpha \) due to the one-to-one correspondence between domains and ground types. We have  for all x because \(\mathscr {E}\) is injective. By Lemma 39 it follows that
for all x because \(\mathscr {E}\) is injective. By Lemma 39 it follows that  , which proves that \(\mathscr {L}^{{\mathrm{GH}}}\) is well-defined.
, which proves that \(\mathscr {L}^{{\mathrm{GH}}}\) is well-defined.
In our example, for all \(\xi \) we have \(\mathscr {L}^{{\mathrm{GH}}}(\xi ,\lambda x.\> x) = \mathscr {E}([{\textsf {lam}}_{\lambda x.\>x}]) = \mathscr {E}([{\textsf {f}}_0])\), which is the identity. If \(\xi (y) = [{\textsf {a}}_0]\), then \(\mathscr {L}^{{\mathrm{GH}}}(\xi ,\lambda x.\> y) = \mathscr {E}([{\textsf {lam}}_{\lambda x.\>{\textsf {a}}}])\), which is the constant function \(c \mapsto [{\textsf {a}}_0]\). Similarly, if \(\xi (y) = [{\textsf {b}}_0]\), then \(\mathscr {L}^{{\mathrm{GH}}}(\xi ,\lambda x.\> y)\) is the constant function \(c \mapsto [{\textsf {b}}_0]\).
This concludes the definition of the interpretation \(\mathscr {I}^{\smash {{\mathrm{GH}}}}=(\mathscr {U}^{{\mathrm{GH}}},\mathscr {J}_\mathsf {ty}^{{\mathrm{GH}}},\mathscr {J}^{{\mathrm{GH}}},\mathscr {L}^{{\mathrm{GH}}})\). It remains to show that \(\smash {\mathscr {I}^{\smash {{\mathrm{GH}}}}}\) is proper. In a proper interpretation, the denotation \(\smash {\llbracket t\rrbracket _{\mathscr {I}^{\smash {{\mathrm{GH}}}}}^{}}\) of a term t does not depend on the representative of t modulo \(\beta \eta \), but since we have not yet shown \(\mathscr {I}^{\smash {{\mathrm{GH}}}}\) to be proper, we cannot rely on this property. For this reason, we use \(\lambda \)-terms in the following three lemmas and mark all \(\beta \eta \)-reductions explicitly.
The higher-order interpretation \(\mathscr {I}^{\smash {{\mathrm{GH}}}}\) relates to the first-order interpretation \(R\) as follows:
Lemma 40
Given a ground \(\lambda \)-term t, we have  .
.
Proof
By induction on t. Assume that  for all proper subterms s of t. If t is of the form \({\textsf {f}}{\langle {\bar{\tau }}\rangle }\), then
for all proper subterms s of t. If t is of the form \({\textsf {f}}{\langle {\bar{\tau }}\rangle }\), then

If t is an application \(t = t_1\>t_2\), where \(t_1\) is of type \(\tau \rightarrow \upsilon \), then

If t is a \(\lambda \)-expression, then

where \(\theta \) is a substitution such that \(\mathscr {D}_{\alpha \theta }=\xi (\alpha )\) and  . \(\square \)
. \(\square \)
We need to show that the interpretation \(\mathscr {I}^{\smash {{\mathrm{GH}}}}=(\mathscr {U}^{{\mathrm{GH}}},\mathscr {J}_\mathsf {ty}^{{\mathrm{GH}}},\mathscr {J}^{{\mathrm{GH}}},\mathscr {L}^{{\mathrm{GH}}})\) is proper. In the proof, we will need to employ the following lemma, which is very similar to the substitution lemma (Lemma 18), but we must prove it here for our particular interpretation \(\mathscr {I}^{\smash {{\mathrm{GH}}}}\) because we have not shown that \(\mathscr {I}^{\smash {{\mathrm{GH}}}}\) is proper yet.
Lemma 41
(Substitution lemma) We have \(\smash {\llbracket \tau \rho \rrbracket _{\mathscr {I}_{\mathsf {\mathrm{ty}}}^{\mathrm{GH}}}^{\xi }} = \smash {\llbracket \tau \rrbracket _{\mathscr {I}_{\mathsf {\mathrm{ty}}}^{\mathrm{GH}}}^{\xi '}}\) and  for all \(\lambda \)-terms t, all
for all \(\lambda \)-terms t, all  and all grounding substitutions \(\rho \), where
and all grounding substitutions \(\rho \), where  for all type variables \(\alpha \) and \(\xi '(x) = \smash {\llbracket x\rho \rrbracket _{\mathscr {I}^{\smash {{\mathrm{GH}}}}}^{\xi }}\) for all term variables x.
for all type variables \(\alpha \) and \(\xi '(x) = \smash {\llbracket x\rho \rrbracket _{\mathscr {I}^{\smash {{\mathrm{GH}}}}}^{\xi }}\) for all term variables x.
Proof
We proceed by induction on the structure of \(\tau \) and t. The proof is identical to the one of Lemma 18, except for the last step, which uses properness of the interpretation, a property we cannot assume here. However, here, we have the assumption that \(\rho \) is a grounding substitution. Therefore, if t is a \(\lambda \)-expression, we argue as follows:

The step \(*\) is justified as follows: We have  by the definition of \(\mathscr {L}^{{\mathrm{GH}}}\), if \(\theta '\) is a substitution such that \(\smash {\mathscr {D}_{\alpha \theta '}}=\xi '(\alpha )\) for all \(\alpha \) and
by the definition of \(\mathscr {L}^{{\mathrm{GH}}}\), if \(\theta '\) is a substitution such that \(\smash {\mathscr {D}_{\alpha \theta '}}=\xi '(\alpha )\) for all \(\alpha \) and  for all x. By the definition of \(\xi '\) and by Lemma 40, \(\rho \) is such a substitution. Hence,
for all x. By the definition of \(\xi '\) and by Lemma 40, \(\rho \) is such a substitution. Hence,  . \(\square \)
. \(\square \)
Lemma 42
The interpretation \(\mathscr {I}^{\smash {{\mathrm{GH}}}}\) is proper.
Proof
We must show that \(\smash {\llbracket (\lambda x.\>t)\rrbracket _{\mathscr {I}^{\smash {{\mathrm{GH}}}}}^{\xi }}(a) = \smash {\llbracket t\rrbracket _{\mathscr {I}^{\smash {{\mathrm{GH}}}}}^{\xi [x\mapsto a]}}\) for all \(\lambda \)-expressions \(\lambda x.\>t\), all valuations \(\xi \), and all values a.

\(\square \)
Lemma 43
\(\mathscr {I}^{\smash {{\mathrm{GH}}}}\) is a model of N.
Proof
By Lemma 40, we have  for all
for all  . Since \(\mathscr {E}\) is a bijection, it follows that any (dis)equation
. Since \(\mathscr {E}\) is a bijection, it follows that any (dis)equation  is true in \(\mathscr {I}^{\smash {{\mathrm{GH}}}}\) if and only if
is true in \(\mathscr {I}^{\smash {{\mathrm{GH}}}}\) if and only if  is true in \(R\). Hence, a clause
is true in \(R\). Hence, a clause  is true in \(\mathscr {I}^{\smash {{\mathrm{GH}}}}\) if and only if
is true in \(\mathscr {I}^{\smash {{\mathrm{GH}}}}\) if and only if  is true in \(R\). By Theorem 37 and the assumption that \(\bot \notin N\), the interpretation \(R\) is a model of
is true in \(R\). By Theorem 37 and the assumption that \(\bot \notin N\), the interpretation \(R\) is a model of  — that is, for all clauses \(C\in N\),
— that is, for all clauses \(C\in N\),  is true in \(R\). Hence, all clauses \(C\in N\) are true in \(\mathscr {I}^{\smash {{\mathrm{GH}}}}\) and therefore \(\mathscr {I}^{\smash {{\mathrm{GH}}}}\) is a model of N. \(\square \)
is true in \(R\). Hence, all clauses \(C\in N\) are true in \(\mathscr {I}^{\smash {{\mathrm{GH}}}}\) and therefore \(\mathscr {I}^{\smash {{\mathrm{GH}}}}\) is a model of N. \(\square \)
We summarize the results of this subsection in the following theorem:
Theorem 44
(Ground static refutational completeness) Let \(\textit{GHSel}\) be a selection function on  . Then the inference system \(\textit{GHInf}^\textit{GHSel}\) is statically refutationally complete w.r.t. \((\textit{GHRed}_{\mathrm{I}}, \textit{GHRed}_{\mathrm{C}})\). In other words, if
. Then the inference system \(\textit{GHInf}^\textit{GHSel}\) is statically refutationally complete w.r.t. \((\textit{GHRed}_{\mathrm{I}}, \textit{GHRed}_{\mathrm{C}})\). In other words, if  is a clause set saturated w.r.t. \(\textit{GHInf}^\textit{GHSel}\) and \(\textit{GHRed}_{\mathrm{I}}^\textit{GHSel}\), then \(N \models \bot \) if and only if \(\bot \in N\).
is a clause set saturated w.r.t. \(\textit{GHInf}^\textit{GHSel}\) and \(\textit{GHRed}_{\mathrm{I}}^\textit{GHSel}\), then \(N \models \bot \) if and only if \(\bot \in N\).
The construction of \(\mathscr {I}^{\smash {{\mathrm{GH}}}}\) relies on specific properties of \(R\). It would not work with an arbitrary first-order interpretation. Transforming a higher-order interpretation into a first-order interpretation is easier:
Lemma 45
Given a clausal higher-order interpretation \(\mathscr {I}\) on \({\mathrm{GH}}\), there exists a first-order interpretation \(\mathscr {I}^{\mathrm{GF}}\) on \({\mathrm{GF}}\) such that for any clause  the truth values of C in \(\mathscr {I}\) and of
the truth values of C in \(\mathscr {I}\) and of  in \(\mathscr {I}^{\mathrm{GF}}\) coincide.
in \(\mathscr {I}^{\mathrm{GF}}\) coincide.
Proof
Let \(\mathscr {I}= (\mathscr {I}_{\mathsf {\mathrm{ty}}},\mathscr {J},\mathscr {L})\) be a clausal higher-order interpretation. Let \(\mathscr {U}^{\mathrm{GF}}_\tau = \smash {\llbracket \tau \rrbracket _{\mathscr {I}_{\mathsf {\mathrm{ty}}}}^{}}\) be the first-order type universe for the ground type \(\tau \). For a symbol \(\smash {{\textsf {f}}^{\bar{\upsilon }}_{\!j}} \in \Sigma _{\mathrm{GF}}\), let \(\mathscr {J}^{\mathrm{GF}}(\smash {{\textsf {f}}^{\bar{\upsilon }}_{\!j}}) = \smash {\llbracket {\textsf {f}}{\langle {\bar{\upsilon }}\rangle }\rrbracket _{\mathscr {I}}^{}}\) (up to currying). For a symbol \({\textsf {lam}}_{\lambda x.\>t} \in \Sigma _{\mathrm{GF}}\), let \(\mathscr {J}^{\mathrm{GF}}({\textsf {lam}}_{\lambda x.\>t}) = \smash {\llbracket \lambda x.\>t\rrbracket _{\mathscr {I}}^{}}\). This defines a first-order interpretation \(\mathscr {I}^{\mathrm{GF}}= (\mathscr {U}^{\mathrm{GF}},\mathscr {J}^{\mathrm{GF}})\).
We need to show that for any  , \(\mathscr {I}\models C\) if and only if
, \(\mathscr {I}\models C\) if and only if  . It suffices to show that
. It suffices to show that  for all terms
for all terms  . We prove this by induction on the structure of the \(\eta \)-short \(\beta \)-normal form of t. If t is a \(\lambda \)-expression, this is obvious. If t is of the form \({\textsf {f}}{\langle {\bar{\upsilon }}\rangle }\>\bar{s}_{\!j}\), then
. We prove this by induction on the structure of the \(\eta \)-short \(\beta \)-normal form of t. If t is a \(\lambda \)-expression, this is obvious. If t is of the form \({\textsf {f}}{\langle {\bar{\upsilon }}\rangle }\>\bar{s}_{\!j}\), then  and hence
and hence  . \(\square \)
. \(\square \)
4.4 The Nonground Higher-Order Level
To lift the result to the nonground level, we employ the saturation framework of Waldmann et al. [71]. It is easy to see that the entailment relation \(\models \) on \({\mathrm{GH}}\) is a consequence relation in the sense of the framework. We need to show that our redundancy criterion on \({\mathrm{GH}}\) is a redundancy criterion in the sense of the framework and that  is a grounding function in the sense of the framework:
is a grounding function in the sense of the framework:
Lemma 46
The redundancy criterion for \({\mathrm{GH}}\) is a redundancy criterion in the sense of Sect. 2 of the saturation framework.
Proof
We must prove the conditions (R1) to (R4) of the saturation framework. Adapted to our context, they state the following for all clause sets  :
:
-
(R1)
if \(N \models \bot \), then \(N \setminus \textit{GHRed}_{\mathrm{C}}(N) \models \bot \);
-
(R2)
if \(N \subseteq N'\), then \(\textit{GHRed}_{\mathrm{C}}(N) \subseteq \textit{GHRed}_{\mathrm{C}}(N')\) and \(\textit{GHRed}_{\mathrm{I}}(N) \subseteq \textit{GHRed}_{\mathrm{I}}(N')\);
-
(R3)
if \(N' \subseteq \textit{GHRed}_{\mathrm{C}}(N)\), then \(\textit{GHRed}_{\mathrm{C}}(N) \subseteq \textit{GHRed}_{\mathrm{C}}(N \setminus N')\) and \(\textit{GHRed}_{\mathrm{I}}(N) \subseteq \textit{GHRed}_{\mathrm{I}}(N \setminus N')\);
-
(R4)
if \(\iota \in \textit{GHInf}\) and \(\textit{concl}(\iota ) \in N\), then \(\iota \in \textit{GHRed}_{\mathrm{I}}(N)\).
The proof is analogous to the proof of Lemma 4.12 of Bentkamp et al. [10], using Lemma 45. \(\square \)
Lemma 47
The grounding functions  for
for  are grounding functions in the sense of Sect. 3 of the saturation framework.
are grounding functions in the sense of Sect. 3 of the saturation framework.
Proof
We must prove the conditions (G1), (G2), and (G3) of the saturation framework. Adapted to our context, they state the following:
-
(G1)
 ;
; -
(G2)
for every
 , if
, if  , then \(C = \bot \);
, then \(C = \bot \); -
(G3)
for every \(\iota \in \textit{HInf}\),
 .
.
 ;
; , if
, if  , then
, then  .
.Clearly, \(C = \bot \) if and only if  if and only if
if and only if  , proving (G1) and (G2). For every \(\iota \in \textit{HInf}\), by the definition of
, proving (G1) and (G2). For every \(\iota \in \textit{HInf}\), by the definition of  , we have
, we have  , and thus (G3) by (R4). \(\square \)
, and thus (G3) by (R4). \(\square \)
To lift the completeness result of the previous subsection to the nonground calculus \(\textit{HInf}\), we employ Theorem 14 of the saturation framework, which, adapted to our context, is stated as follows. The theorem uses the notation \(\textit{Inf}(N)\) to denote the set of \(\textit{Inf}\)-inferences whose premises are in N, for an inference system \(\textit{Inf}\) and a clause set N. Moreover, it uses Herbrand entailment  on
on  , which is defined so that
, which is defined so that  if and only if
if and only if  .
.
Theorem 48
(Lifting theorem) If \(\textit{GHInf}^\textit{GHSel}\) is statically refutationally complete w.r.t. \((\textit{GHRed}_{\mathrm{I}}^\textit{GHSel}, \textit{GHRed}_{\mathrm{C}})\) for every  , and if for every
, and if for every  that is saturated w.r.t. \(\textit{HInf}\) and \(\textit{HRed}_{\mathrm{I}}\) there exists a
that is saturated w.r.t. \(\textit{HInf}\) and \(\textit{HRed}_{\mathrm{I}}\) there exists a  such that
such that  , then also \(\textit{HInf}\) is statically refutationally complete w.r.t. \((\textit{HRed}_{\mathrm{I}}, {\textit{HRed}}_{\mathrm{C}})\) and
, then also \(\textit{HInf}\) is statically refutationally complete w.r.t. \((\textit{HRed}_{\mathrm{I}}, {\textit{HRed}}_{\mathrm{C}})\) and  .
.
Proof
This is almost an instance of Theorem 14 of the saturation framework. We take  for \(\mathbf{F} \),
for \(\mathbf{F} \),  for \(\mathbf{G} \), and
for \(\mathbf{G} \), and  for Q. It is easy to see that the entailment relation \(\models \) on \({\mathrm{GH}}\) is a consequence relation in the sense of the framework. By Lemmas 46 and 47, \((\textit{GHRed}_{\mathrm{I}}^\textit{GHSel}, \textit{GHRed}_{\mathrm{C}})\) is a redundancy criterion in the sense of the framework, and
for Q. It is easy to see that the entailment relation \(\models \) on \({\mathrm{GH}}\) is a consequence relation in the sense of the framework. By Lemmas 46 and 47, \((\textit{GHRed}_{\mathrm{I}}^\textit{GHSel}, \textit{GHRed}_{\mathrm{C}})\) is a redundancy criterion in the sense of the framework, and  are grounding functions in the sense of the framework, for all
are grounding functions in the sense of the framework, for all  . The redundancy criterion \((\textit{HRed}_{\mathrm{I}},{\textit{HRed}}_{\mathrm{C}})\) matches exactly the intersected lifted redundancy criterion
. The redundancy criterion \((\textit{HRed}_{\mathrm{I}},{\textit{HRed}}_{\mathrm{C}})\) matches exactly the intersected lifted redundancy criterion  of the saturation framework. Theorem 14 of the saturation framework states the theorem only for \({\sqsupset } = \varnothing \). By Lemma 16 of the saturation framework, it also holds if \({\sqsupset } \not = \varnothing \). \(\square \)
of the saturation framework. Theorem 14 of the saturation framework states the theorem only for \({\sqsupset } = \varnothing \). By Lemma 16 of the saturation framework, it also holds if \({\sqsupset } \not = \varnothing \). \(\square \)
Let  be a clause set saturated w.r.t. \(\textit{HInf}\) and \(\textit{HRed}_{\mathrm{I}}\). We assume that \(\textit{HSel}\) fulfills the selection restriction that a literal
be a clause set saturated w.r.t. \(\textit{HInf}\) and \(\textit{HRed}_{\mathrm{I}}\). We assume that \(\textit{HSel}\) fulfills the selection restriction that a literal  must not be selected if \(y\> \bar{u}_n\), with \(n > 0\), is a \(\succeq \)-maximal term of the clause, as required in Definition 9. For the above theorem to apply, we need to show that there exists a selection function
must not be selected if \(y\> \bar{u}_n\), with \(n > 0\), is a \(\succeq \)-maximal term of the clause, as required in Definition 9. For the above theorem to apply, we need to show that there exists a selection function  such that all inferences \(\iota \in \textit{GHInf}^\textit{GHSel}\) with
such that all inferences \(\iota \in \textit{GHInf}^\textit{GHSel}\) with  are liftable or redundant. Here, for \(\iota \) to be liftable means that \(\iota \) is a
are liftable or redundant. Here, for \(\iota \) to be liftable means that \(\iota \) is a  -ground instance of a \(\smash {\textit{HInf}}\)-inference from N; for \(\iota \) to be redundant means that
-ground instance of a \(\smash {\textit{HInf}}\)-inference from N; for \(\iota \) to be redundant means that  .
.
To choose the right selection function  , we observe that each ground clause
, we observe that each ground clause  must have at least one corresponding clause \(D\in N\) such that C is a ground instance of D. We choose one of them for each
must have at least one corresponding clause \(D\in N\) such that C is a ground instance of D. We choose one of them for each  , which we denote by
, which we denote by  . Then let \(\textit{GHSel}\) select those literals in C that correspond to literals selected by \(\textit{HSel}\) in
. Then let \(\textit{GHSel}\) select those literals in C that correspond to literals selected by \(\textit{HSel}\) in  . With respect to this selection function \(\textit{GHSel}\), we can show that all inferences from
. With respect to this selection function \(\textit{GHSel}\), we can show that all inferences from  are liftable or redundant:
are liftable or redundant:
Lemma 49
Let  and \(D\theta = C\). Let \(\sigma \) and \(\rho \) be substitutions such that \(x\sigma \rho = x\theta \) for all variables x in D. Let L be a (strictly) \(\succeq \)-eligible literal in C w.r.t. \(\textit{GHSel}\). Then there exists a (strictly) \(\succsim \)-eligible literal \(L'\) in D w.r.t. \(\sigma \) and \(\textit{HSel}\) such that \(L'\theta = L\).
and \(D\theta = C\). Let \(\sigma \) and \(\rho \) be substitutions such that \(x\sigma \rho = x\theta \) for all variables x in D. Let L be a (strictly) \(\succeq \)-eligible literal in C w.r.t. \(\textit{GHSel}\). Then there exists a (strictly) \(\succsim \)-eligible literal \(L'\) in D w.r.t. \(\sigma \) and \(\textit{HSel}\) such that \(L'\theta = L\).
Proof
If \(L \in \textit{GHSel}(C)\), then there exists \(L'\) such that \(L'\theta = L\) and \(L' \in \textit{HSel}(D)\) by the definition of  . Otherwise, L is \(\succeq \)-maximal in C. Since \(C = D\sigma \rho \), there are literals \(L'\) in \(D\sigma \) such that \(L'\rho = L\). Choose \(L'\) to be a \(\succsim \)-maximal among them. Then \(L'\) is \(\succsim \)-maximal in \(D\sigma \) because for any literal \(L''\in D\) with \(L'' \succsim L'\), we have \(L''\rho \succeq L'\rho = L\) and hence \(L''\rho = L\) by \(\succeq \)-maximality of L.
. Otherwise, L is \(\succeq \)-maximal in C. Since \(C = D\sigma \rho \), there are literals \(L'\) in \(D\sigma \) such that \(L'\rho = L\). Choose \(L'\) to be a \(\succsim \)-maximal among them. Then \(L'\) is \(\succsim \)-maximal in \(D\sigma \) because for any literal \(L''\in D\) with \(L'' \succsim L'\), we have \(L''\rho \succeq L'\rho = L\) and hence \(L''\rho = L\) by \(\succeq \)-maximality of L.
If L is strictly \(\succeq \)-maximal in C, \(L'\) is also strictly \(\succsim \)-maximal in \(D\sigma \) because a duplicate of \(L'\) in \(D\sigma \) would imply a duplicate of L in C. \(\square \)
Lemma 50
(Lifting of ERes, EFact, GArgCong, and GExt) All ERes, EFact, GArgCong, and GExt inferences from  are liftable.
are liftable.
Proof
ERes: Let \(\iota \in \textit{GHInf}^\textit{GHSel}\) be an ERes inference with  . Then \(\iota \) is of the form
. Then \(\iota \) is of the form

where  and the literal \(s\theta \not \approx s'\theta \) is \(\succeq \)-eligible w.r.t. \(\textit{GHSel}\). Since \(s\theta \) and \(s'\theta \) are unifiable and ground, we have \(s\theta = s'\theta \). Thus, there exists an idempotent \(\sigma \in {{\,\mathrm{CSU}\,}}(s,s')\) such that for some substitution \(\rho \) and for all variables x in C, we have \(x\sigma \rho = x\theta \). By Lemma 49, we may assume without loss of generality that \(s \not \approx s'\) is \(\succsim \)-eligible in C w.r.t. \(\sigma \) and \(\textit{HSel}\). Hence, the following inference \(\iota '\in \textit{HInf}\) applies:
and the literal \(s\theta \not \approx s'\theta \) is \(\succeq \)-eligible w.r.t. \(\textit{GHSel}\). Since \(s\theta \) and \(s'\theta \) are unifiable and ground, we have \(s\theta = s'\theta \). Thus, there exists an idempotent \(\sigma \in {{\,\mathrm{CSU}\,}}(s,s')\) such that for some substitution \(\rho \) and for all variables x in C, we have \(x\sigma \rho = x\theta \). By Lemma 49, we may assume without loss of generality that \(s \not \approx s'\) is \(\succsim \)-eligible in C w.r.t. \(\sigma \) and \(\textit{HSel}\). Hence, the following inference \(\iota '\in \textit{HInf}\) applies:

Then \(\iota \) is the \(\sigma \rho \)-ground instance of \(\iota '\) and is therefore liftable.
EFact:Analogously, if \(\iota \in \textit{GHInf}^\textit{GHSel}\) is an EFact inference with  , then \(\iota \) is of the form
, then \(\iota \) is of the form

where  , the literal \(s\theta \approx t\theta \) is \(\succeq \)-eligible in C w.r.t. \(\textit{GHSel}\), and \(s\theta \not \prec t\theta \). Then \(s\not \prec t\). Moreover, \(s\theta \) and \(s'\theta \) are unifiable and ground. Hence, \(s\theta = s'\theta \) and there exists an idempotent \(\sigma \in {{\,\mathrm{CSU}\,}}(s,s')\) such that for some substitution \(\rho \) and for all variables x in C, we have \(x\sigma \rho = x\theta \). By Lemma 49, we may assume without loss of generality that \(s\approx t\) is \(\succsim \)-eligible in C w.r.t. \(\sigma \) and \(\textit{HSel}\). It follows that the following inference \(\iota '\in \textit{HInf}\) is applicable:
, the literal \(s\theta \approx t\theta \) is \(\succeq \)-eligible in C w.r.t. \(\textit{GHSel}\), and \(s\theta \not \prec t\theta \). Then \(s\not \prec t\). Moreover, \(s\theta \) and \(s'\theta \) are unifiable and ground. Hence, \(s\theta = s'\theta \) and there exists an idempotent \(\sigma \in {{\,\mathrm{CSU}\,}}(s,s')\) such that for some substitution \(\rho \) and for all variables x in C, we have \(x\sigma \rho = x\theta \). By Lemma 49, we may assume without loss of generality that \(s\approx t\) is \(\succsim \)-eligible in C w.r.t. \(\sigma \) and \(\textit{HSel}\). It follows that the following inference \(\iota '\in \textit{HInf}\) is applicable:

Then \(\iota \) is the \(\sigma \rho \)-ground instance of \(\iota '\) and is therefore liftable.
GArgCong: Let \(\iota \in \textit{GHInf}^\textit{GHSel}\) be a GArgCong inference with  . Then \(\iota \) is of the form
. Then \(\iota \) is of the form

where  , the literal \(s\theta \approx s'\theta \) is strictly \(\succeq \)-eligible w.r.t. \(\textit{GHSel}\), and \(s\theta \) and \(s'\theta \) are of functional type. It follows that s and \(s'\) have either a functional or a polymorphic type. Let \(\sigma \) be the most general substitution such that \(s\sigma \) and \(s'\sigma \) take n arguments. By Lemma 49, we may assume without loss of generality that \(s \not \approx s'\) is strictly \(\succsim \)-eligible in C w.r.t. \(\sigma \) and \(\textit{HSel}\). Hence the following inference \(\iota '\in \textit{HInf}\) is applicable:
, the literal \(s\theta \approx s'\theta \) is strictly \(\succeq \)-eligible w.r.t. \(\textit{GHSel}\), and \(s\theta \) and \(s'\theta \) are of functional type. It follows that s and \(s'\) have either a functional or a polymorphic type. Let \(\sigma \) be the most general substitution such that \(s\sigma \) and \(s'\sigma \) take n arguments. By Lemma 49, we may assume without loss of generality that \(s \not \approx s'\) is strictly \(\succsim \)-eligible in C w.r.t. \(\sigma \) and \(\textit{HSel}\). Hence the following inference \(\iota '\in \textit{HInf}\) is applicable:

Since \(\sigma \) is the most general substitution that ensures well-typedness of the conclusion, \(\iota \) is a ground instance of \(\iota '\) and is therefore liftable.
GExt: The conclusion of a GExt inference in \(\textit{GHInf}\) is by definition a ground instance of the conclusion of an Ext inference in \(\textit{HInf}\). Hence, the GExt inference is a ground instance of the Ext inference. Therefore it is liftable. \(\square \)
Some of the Sup inferences in \(\textit{GHInf}\) are liftable as well:
Lemma 51
(Instances of green subterms) Let s be a \(\lambda \)-term in \(\eta \)-short \(\beta \)-normal form, let \(\sigma \) be a substitution, and let p be a green position of both s and \(s\sigma {\downarrow }_{\beta \eta }\). Then \((s|_p)\sigma {\downarrow }_{\beta \eta } = (s\sigma {\downarrow }_{\beta \eta })|_p\).
Proof
By induction on p. If \(p=\varepsilon \), then \((s|_p)\sigma {\downarrow }_{\beta \eta } = s\sigma {\downarrow }_{\beta \eta } = (s\sigma {\downarrow }_{\beta \eta })|_p\). If \(p=i.p'\), then \( s = {\textsf {f}}{\langle {\bar{\tau }}\rangle } \> s_1 \dots s_n \) and \( s\sigma = {\textsf {f}}{\langle {\bar{\tau }\sigma }\rangle } \> (s_1\sigma ) \dots (s_n\sigma ) \), where \(1 \le i \le n\) and \(p'\) is a green position of \(s_i\). Clearly, \(\beta \eta \)-normalization steps of \(s\sigma \) can take place only in proper subterms. So \( s\sigma {\downarrow }_{\beta \eta } = {\textsf {f}}{\langle {\bar{\tau }\sigma }\rangle } \> (s_1\sigma {\downarrow }_{\beta \eta }) \dots (s_n\sigma {\downarrow }_{\beta \eta }). \) Since \(p = i.p'\) is a green position of \(s\sigma {\downarrow }_{\beta \eta }\), \(p'\) must be a green position of \((s_i\sigma ){\downarrow }_{\beta \eta }\). By the induction hypothesis, \((s_i|_{p'})\sigma {\downarrow }_{\beta \eta } = (s_i\sigma {\downarrow }_{\beta \eta })|_{p'}\). Therefore \((s|_p)\sigma {\downarrow }_{\beta \eta } = (s|_{i.p'})\sigma {\downarrow }_{\beta \eta } = (s_i|_{p'})\sigma {\downarrow }_{\beta \eta } = (s_i\sigma {\downarrow }_{\beta \eta })|_{p'} = (s\sigma {\downarrow }_{\beta \eta })|_p\). \(\square \)
Lemma 52
(Lifting of Sup) Let \(\iota \in \textit{GHInf}^\textit{GHSel}\) be a Sup inference

where  ,
,  , and
, and  . We assume that s, t, \(s\theta \), and \(t\theta \) are represented by \(\lambda \)-terms in \(\eta \)-short \(\beta \)-normal form. Let \(p'\) be the longest prefix of p that is a green position of s. Since \(\varepsilon \) is a green position of s, the longest prefix always exists. Let \(u = s|_{p'}\). Suppose one of the following conditions applies: (i) u is a deeply occurring variable in C; (ii) \(p = p'\) and the variable condition holds for D and C; or (iii) \(p \ne p'\) and u is not a variable. Then \(\iota \) is liftable.
. We assume that s, t, \(s\theta \), and \(t\theta \) are represented by \(\lambda \)-terms in \(\eta \)-short \(\beta \)-normal form. Let \(p'\) be the longest prefix of p that is a green position of s. Since \(\varepsilon \) is a green position of s, the longest prefix always exists. Let \(u = s|_{p'}\). Suppose one of the following conditions applies: (i) u is a deeply occurring variable in C; (ii) \(p = p'\) and the variable condition holds for D and C; or (iii) \(p \ne p'\) and u is not a variable. Then \(\iota \) is liftable.
Proof
The Sup inference conditions for \(\iota \) are that \(t\theta \approx t'\theta \) is strictly \(\succeq \)-eligible, \(s\theta \mathrel {\dot{\approx }}s'\theta \) is strictly \(\succeq \)-eligible if positive and \(\succeq \)-eligible if negative, \(D\theta \not \succsim C\theta \), \(t\theta \not \precsim t'\theta \), and \(s\theta \not \precsim s'\theta \). We assume that s, t, \(s\theta \), and \(t\theta \) are represented by \(\lambda \)-terms in \(\eta \)-short \(\beta \)-normal form. By Lemma 51, \(u\theta \) agrees with \(s\theta |_{p'}\) (considering both as terms rather than as \(\lambda \)-terms).
Case 1:We have (a) \(p = p'\), (b) u is not fluid, and (c) u is not a variable deeply occurring in C. Then \(u\theta = s\theta |_{p'} = s\theta |_p = t\theta \). Since \(\theta \) is a unifier of u and t, there exists an idempotent \(\sigma \in {{\,\mathrm{CSU}\,}}(t,u)\) such that for some substitution \(\rho \) and for all variables x occurring in D and C, we have \(x\sigma \rho = x\theta \). The inference conditions can be lifted: (Strict) eligibility of \(t\theta \approx t'\theta \) and \(s\theta \mathrel {\dot{\approx }}s'\theta \) w.r.t. \(\textit{GHSel}\) implies (strict) eligibility of \(t \approx t'\) and \(s \mathrel {\dot{\approx }}s'\) w.r.t. \(\sigma \) and \(\textit{HSel}\); \(D\theta \not \succsim C\theta \) implies \(D \not \succsim C\); \(t\theta \not \precsim t'\theta \) implies \(t \not \precsim t'\); and \(s\theta \not \precsim s'\theta \) implies \(s \not \precsim s'\). Moreover, by (a) and (c), condition (ii) must hold and thus the variable condition holds for D and C. Hence there is the following Sup inference \(\iota '\in \textit{HInf}\):

Then \(\iota \) is the \(\sigma \rho \)-ground instance of \(\iota '\) and therefore liftable.
Case 2:We have (a) \(p \ne p'\), or (b) u is fluid, or (c) u is a variable deeply occurring in C. We will first show that (a) implies (b) or (c). Suppose (a) holds, but neither (b) nor (c) holds. Then condition (iii) must hold—i.e., u is not a variable. Moreover, since (b) does not hold, u cannot have the form \(y\>\bar{u}_n\) for a variable y and \(n \ge 1\). If u were of the form \({\textsf {f}}{\langle {\bar{\tau }}\rangle } \> s_1 \dots {s_n}\) with \(n \ge 0\), \(u\theta \) would have the form \({\textsf {f}}{\langle {\bar{\tau }\theta }\rangle } \> (s_1\theta )\dots (s_n\theta )\), but then there is some \(1 \le i \le n\) such that \(p'.i\) is a prefix of p and \(s|_{p'.i}\) is a green subterm of s, contradicting the maximality of \(p'\).
So u must be a \(\lambda \)-expression, but since \(t\theta \) is a proper green subterm of \(u\theta \), \(u\theta \) cannot be a \(\lambda \)-expression, yielding a contradiction. We may thus assume that (b) or (c) holds.
Let \(p = p'.p''\). Let z be a fresh variable. Define a substitution \(\theta '\) that maps this variable z to  and any other variable w to \(w\theta \). Clearly,
and any other variable w to \(w\theta \). Clearly,  . Since \(\theta '\) is a unifier of u and \(z \> t\), there exists an idempotent \(\sigma \in {{\,\mathrm{CSU}\,}}(z \> t, u)\) such that for some substitution \(\rho \), for \(x=z\), and for all variables x in C and D, we have \(x\sigma \rho = x\theta '\). As in case 1, (strict) eligibility of the ground literals implies (strict) eligibility of the nonground literals. Moreover, by construction of \(\theta '\), \(t\theta ' = t\theta \not = t'\theta = t'\theta '\) implies \((z \> t)\theta ' \not = (z \> t')\theta '\), and thus \((z \> t)\sigma \not = (z \> t')\sigma \). Since we also have (b) or (c), there is the following inference \(\iota '\):
. Since \(\theta '\) is a unifier of u and \(z \> t\), there exists an idempotent \(\sigma \in {{\,\mathrm{CSU}\,}}(z \> t, u)\) such that for some substitution \(\rho \), for \(x=z\), and for all variables x in C and D, we have \(x\sigma \rho = x\theta '\). As in case 1, (strict) eligibility of the ground literals implies (strict) eligibility of the nonground literals. Moreover, by construction of \(\theta '\), \(t\theta ' = t\theta \not = t'\theta = t'\theta '\) implies \((z \> t)\theta ' \not = (z \> t')\theta '\), and thus \((z \> t)\sigma \not = (z \> t')\sigma \). Since we also have (b) or (c), there is the following inference \(\iota '\):

Then \(\iota \) is the \(\sigma \rho \)-ground instance of \(\iota '\) and therefore liftable. \(\square \)
The other Sup inferences might not be liftable, but they are redundant:
Lemma 53
Let \(\iota \in \textit{GHInf}^\textit{GHSel}\) be a Sup inference from  not covered by Lemma 52. Then
not covered by Lemma 52. Then  .
.
Proof
Let \(C\theta = C'\theta \vee s\theta \mathrel {\dot{\approx }}s'\theta \) and \(D\theta = D'\theta \vee t\theta \approx t'\theta \) be the premises of \(\iota \), where \(s\theta \mathrel {\dot{\approx }}s'\theta \) and \(t\theta \approx t'\theta \) are the literals involved in the inference, \(s\theta \succ s'\theta \), \(t\theta \succ t'\theta \), and \(C'\), \(D'\), s, \(s'\), t, \(t'\) are the respective subclauses and terms in  and
and  Then the inference \(\iota \) has the form
Then the inference \(\iota \) has the form

To show that  , it suffices to show
, it suffices to show  . To this end, let \(\mathscr {I}\) be an interpretation in \({\mathrm{GF}}\) such that
. To this end, let \(\mathscr {I}\) be an interpretation in \({\mathrm{GF}}\) such that  . We need to show that
. We need to show that  . If
. If  is true in \(\mathscr {I}\), then obviously
is true in \(\mathscr {I}\), then obviously  . So we assume that
. So we assume that  is false in \(\mathscr {I}\). Since \(C\theta \succ D\theta \) by the Sup order conditions, it follows that
is false in \(\mathscr {I}\). Since \(C\theta \succ D\theta \) by the Sup order conditions, it follows that  . Therefore, it suffices to show
. Therefore, it suffices to show  .
.
Let p be the green position in \(s\theta \) where \(\iota \) takes place and \(p'\) be the longest prefix of p that is a green subterm of s. Let \(u = s|_{p'}\). Since Lemma 52 does not apply to \(\iota \), u is not a deeply occurring variable; if \(p=p'\), the variable condition does not hold for D and C; and if \(p\ne p'\), u is a variable. This means either the green position p does not exist in s, because it is below an unapplied variable that does not occur deeply in C, or \(s|_p\) is an unapplied variable that does not occur deeply in C and for which the variable condition does not hold.
Case 1:The green position p does not exist in s because it is below a variable x that does not occur deeply in C. Then \(t\theta \) is a green subterm of \(x\theta \) and hence a green subterm of \(x\theta \> \bar{w}\) for any arguments \(\bar{w}\). Let v be the term that we obtain by replacing \(t\theta \) by \(t'\theta \) in \(x\theta \) at the relevant position. Since  , by congruence,
, by congruence,  for any arguments \(\bar{w}\). Hence,
for any arguments \(\bar{w}\). Hence,  if and only if
if and only if  by congruence. Here, it is crucial that the variable does not occur deeply in C because congruence does not hold in
by congruence. Here, it is crucial that the variable does not occur deeply in C because congruence does not hold in  -encoded terms below \(\lambda \)-binders. By the inference conditions, we have \(t\theta \succ t'\theta \), which implies
-encoded terms below \(\lambda \)-binders. By the inference conditions, we have \(t\theta \succ t'\theta \), which implies  by compatibility with green contexts. Therefore, by the assumption about \(\mathscr {I}\), we have
by compatibility with green contexts. Therefore, by the assumption about \(\mathscr {I}\), we have  and hence
and hence  .
.
Case 2:The term \(s|_p\) is a variable x that does not occur deeply in C and for which the variable condition does not hold.
From this, we know that \(C\theta \succeq C''\theta \), where \(C'' = C\{x\mapsto t'\}\).
We cannot have \(C\theta = C''\theta \) because \(x\theta = t\theta \ne t'\theta \) and x occurs in C. Hence, we have \(C\theta \succ C''\theta \). By the definition of \(\mathscr {I}\), \(C\theta \succ C''\theta \) implies  . We will use equalities that are true in \(\mathscr {I}\) to rewrite
. We will use equalities that are true in \(\mathscr {I}\) to rewrite  into
into  , which implies
, which implies  by congruence.
by congruence.
By saturation, every ArgCong inference \(\iota '\) from D is in \(\textit{HRed}_{\mathrm{I}}(N)\) —i.e.,  . Hence, \(D'\theta \vee t\theta \> \bar{u} \approx t'\theta \> \bar{u}\) is in
. Hence, \(D'\theta \vee t\theta \> \bar{u} \approx t'\theta \> \bar{u}\) is in  for any ground arguments \(\bar{u}\).
for any ground arguments \(\bar{u}\).
We observe that whenever \(t\theta \> \bar{u}\) and \(t'\theta \> \bar{u}\) are smaller than the \(\succeq \)-maximal term of \(C\theta \) for some arguments \(\bar{u}\), we have

To show this, we assume that \(t\theta \> \bar{u}\) and \(t'\theta \> \bar{u}\) are smaller than the \(\succeq \)-maximal term of \(C\theta \) and we distinguish two cases: If \(t\theta \) is smaller than the \(\succeq \)-maximal term of \(C\theta \), all terms in \(D'\theta \) are smaller than the \(\succeq \)-maximal term of \(C\theta \) and hence \(D'\theta \vee t\theta \> \bar{u} \approx t'\theta \> \bar{u} \prec C\theta \). If, on the other hand, \(t\theta \) is equal to the \(\succeq \)-maximal term of \(C\theta \), then \(t\theta \> \bar{u}\) and \(t'\theta \> \bar{u}\) are smaller than \(t\theta \). Hence \(t\theta \> \bar{u} \approx t'\theta \> \bar{u} \prec t\theta \approx t'\theta \) and \(D'\theta \vee t\theta \> \bar{u} \approx t'\theta \> \bar{u} \prec D\theta \prec C\theta \). In both cases, since \(D'\theta \) is false in \(\mathscr {I}\), by the definition of \(\mathscr {I}\), we have (*).
Next, we show the equivalence of \(C\theta \) and \(C''\theta \) via rewriting with equations of form (*) where \(t\theta \> \bar{u}\) and \(t'\theta \> \bar{u}\) are smaller than the \(\succeq \)-maximal term of \(C\theta \). Since x does not occur deeply in C, every occurrence of x in C is not inside a \(\lambda \)-expression and not inside an argument of an applied variable. Therefore, all occurrences of x in C are in a green subterm of the form \(x\>\bar{v}\) for some terms \(\bar{v}\) that do not contain x. Hence, every occurrence of x in C corresponds to a subterm  in
in  and to a subterm
and to a subterm  in
in  . These are the only positions where \(C\theta \) and \(C''\theta \) differ.
. These are the only positions where \(C\theta \) and \(C''\theta \) differ.
To justify the necessary rewrite steps from  into
into  using (*), we must show that
using (*), we must show that  and
and  are smaller than the \(\succeq \)-maximal term in
are smaller than the \(\succeq \)-maximal term in  for the relevant \(\bar{v}\). If \(\bar{v}\) is the empty tuple, we do not need to show this because
for the relevant \(\bar{v}\). If \(\bar{v}\) is the empty tuple, we do not need to show this because  follows from
follows from  ’s being true and
’s being true and  ’s being false. If \(\bar{v}\) is nonempty, it suffices to show that \(x\>\bar{v}\) is not a \(\succeq \)-maximal term in C. Then
’s being false. If \(\bar{v}\) is nonempty, it suffices to show that \(x\>\bar{v}\) is not a \(\succeq \)-maximal term in C. Then  and
and  , which correspond to the term \(x\>\bar{v}\) in C, cannot be \(\succeq \)-maximal in
, which correspond to the term \(x\>\bar{v}\) in C, cannot be \(\succeq \)-maximal in  . Hence they must be smaller than the \(\succeq \)-maximal term in
. Hence they must be smaller than the \(\succeq \)-maximal term in  because they are subterms of
because they are subterms of  and
and  , respectively.
, respectively.
To show that \(x\>\bar{v}\) is not a \(\succeq \)-maximal term in C, we make a case distinction on whether \(s\theta \mathrel {\dot{\approx }}s'\theta \) is selected in \(C\theta \) or \(s\theta \) is the \(\succeq \)-maximal term in \(C\theta \). One of these must hold because \(s\theta \mathrel {\dot{\approx }}s'\theta \) is \(\succeq \)-eligible in \(C\theta \). If it is selected, by the selection restrictions, x cannot be the head of a \(\succeq \)-maximal term of C. If \(s\theta \) is the \(\succeq \)-maximal term in \(C\theta \), we can argue that x is a green subterm of s and, since x does not occur deeply, s cannot be of the form \(x\>\bar{v}\) for a nonempty \(\bar{v}\). This justifies the necessary rewrites between  and
and  and it follows that
and it follows that  . \(\square \)
. \(\square \)
With these properties of our inference systems in place, Theorem 48 guarantees static and dynamic refutational completeness of \(\textit{HInf}\) w.r.t. \(\textit{HRed}_{\mathrm{I}}\). However, this theorem gives us refutational completeness w.r.t. the Herbrand entailment  , defined so that
, defined so that  if
if  , whereas our semantics is Tarski entailment \(\models \), defined so that \(N_1 \models N_2\) if any model of \(N_1\) is a model of \(N_2\). To repair this mismatch, we use the following lemma, which can be proved along the lines of Lemma 4.19 of Bentkamp et al. [10], using Lemmas 18 and 19.
, whereas our semantics is Tarski entailment \(\models \), defined so that \(N_1 \models N_2\) if any model of \(N_1\) is a model of \(N_2\). To repair this mismatch, we use the following lemma, which can be proved along the lines of Lemma 4.19 of Bentkamp et al. [10], using Lemmas 18 and 19.
Lemma 54
For  , we have
, we have  if and only if \(N \models \bot \).
if and only if \(N \models \bot \).
Theorem 55
(Static refutational completeness) The inference system \(\textit{HInf}\) is statically refutationally complete w.r.t. \((\textit{HRed}_{\mathrm{I}}, {\textit{HRed}}_{\mathrm{C}})\). In other words, if  is a clause set saturated w.r.t. \(\textit{HInf}\) and \(\textit{HRed}_{\mathrm{I}}\), then we have \(N \models \bot \) if and only if \(\bot \in N\).
is a clause set saturated w.r.t. \(\textit{HInf}\) and \(\textit{HRed}_{\mathrm{I}}\), then we have \(N \models \bot \) if and only if \(\bot \in N\).
Proof
We apply Theorem 48. By Theorem 44, \(\textit{GHInf}^\textit{GHSel}\) is statically refutationally complete for all  . By Lemmas 50, 52, and 53, for every saturated
. By Lemmas 50, 52, and 53, for every saturated  , there exists a selection function
, there exists a selection function  such that all inferences \(\iota \in \textit{GHInf}^\textit{GHSel}\) with
such that all inferences \(\iota \in \textit{GHInf}^\textit{GHSel}\) with  either are
either are  -ground instances of \(\textit{HInf}\)-inferences from N or belong to
-ground instances of \(\textit{HInf}\)-inferences from N or belong to  .
.
Theorem 48 implies that if  is a clause set saturated w.r.t. \(\textit{HInf}\) and \(\textit{HRed}_{\mathrm{I}}\), then
is a clause set saturated w.r.t. \(\textit{HInf}\) and \(\textit{HRed}_{\mathrm{I}}\), then  if and only if \(\bot \in N\). By Lemma 54, this also holds for the Tarski entailment \(\models \). That is, if
if and only if \(\bot \in N\). By Lemma 54, this also holds for the Tarski entailment \(\models \). That is, if  is a clause set saturated w.r.t. \(\textit{HInf}\) and \(\textit{HRed}_{\mathrm{I}}\), then \(N \models \bot \) if and only if \(\bot \in N\). \(\square \)
is a clause set saturated w.r.t. \(\textit{HInf}\) and \(\textit{HRed}_{\mathrm{I}}\), then \(N \models \bot \) if and only if \(\bot \in N\). \(\square \)
From static completeness, we can easily derive dynamic completeness:
Theorem 56
(Dynamic refutational completeness) The inference system \(\textit{HInf}\) is dynamically refutationally complete w.r.t. \((\textit{HRed}_{\mathrm{I}}, {\textit{HRed}}_{\mathrm{C}})\) as specified in Definition 34.
Proof
By Theorem 17 of the saturation framework, this follows from Theorem 55 and Lemma 54. \(\square \)
5 Extensions
In addition to the simplification rules presented in Sect. 3.5, the core calculus can be extended with various optional rules for higher-order reasoning. Like the previous rules, they are not necessary for refutational completeness but can allow the prover to find more direct proofs. Most of these rules are concerned with the areas covered by the FluidSup rule and the extensionality axiom.
Two of the optional rules below rely on the notion of “orange subterms.”
Definition 57
A \(\lambda \)-term t is an orange subterm of a \(\lambda \)-term s if \(s = t\); or if \(s = {\textsf {f}}{\langle {\bar{\tau }}\rangle }\> \bar{s}\) and t is an orange subterm of \(s_i\) for some i; or if \(s = x\> \bar{s}\) and t is an orange subterm of \(s_i\) for some i; or if \(s = (\lambda x.\> u)\) and t is an orange subterm of u.
For example, in the term \({\textsf {f}}\> ({\textsf {g}}\> {\textsf {a}})\> (y\> {\textsf {b}})\> (\lambda x.\> {\textsf {h}}\> {\textsf {c}}\> ({\textsf {g}}\> x))\), the orange subterms are all the green subterms—\({\textsf {a}}\), \({\textsf {g}}\> {\textsf {a}}\), \(y\> {\textsf {b}}\), \(\lambda x.\> {\textsf {h}}\> {\textsf {c}}\> ({\textsf {g}}\> x)\) and the whole term—and in addition \({\textsf {b}}\), \({\textsf {c}}\), x, \({\textsf {g}}\> x\), and \({\textsf {h}}\> {\textsf {c}}\> ({\textsf {g}}\> x)\). Following Convention 1, this notion is lifted to \(\beta \eta \)-equivalence classes via representatives in \(\eta \)-short \(\beta \)-normal form. We write  to indicate that u is an orange subterm of t, where \(\bar{x}_n\) are the variables bound in the orange context around u, from outermost to innermost. If \(n = 0\), we simply write
to indicate that u is an orange subterm of t, where \(\bar{x}_n\) are the variables bound in the orange context around u, from outermost to innermost. If \(n = 0\), we simply write  .
.
Once a term  has been introduced, we write
has been introduced, we write  to denote the same context with a different subterm \(u'\) at that position. The \(\eta \) subscript is a reminder that \(u'\) is not necessarily an orange subterm of
to denote the same context with a different subterm \(u'\) at that position. The \(\eta \) subscript is a reminder that \(u'\) is not necessarily an orange subterm of  due to potential applications of \(\eta \)-reduction. For example, if
due to potential applications of \(\eta \)-reduction. For example, if  , then
, then  .
.
Demodulation in Orange Contexts Demodulation, which destructively rewrites using an equality \(t \approx t'\), is available at green positions, as described in Sect. 3.5. In addition, a variant of demodulation rewrites in orange contexts:

where the term \(t\sigma \) may refer to the bound variables \(\bar{x}\). The following side conditions apply:
-
1.
 is a \(\lambda \)-expression or a term of the form \(y\>\bar{u}_n\) with \(n>0\);
is a \(\lambda \)-expression or a term of the form \(y\>\bar{u}_n\) with \(n>0\); -
2.
 ;
; -
3.

 is a
is a  ;
;
Condition 3 ensures that the second premise is redundant w.r.t. the conclusions and may be removed. The double bar indicates that the conclusions collectively make the premises redundant and can replace them.
The third conclusion, which is entailed by \(t \approx t'\) and (Ext), could be safely omitted if the corresponding (Ext) instance is smaller than the second premise. But in general, the third conclusion is necessary for the proof, and the variant of \(\lambda \) DemodExt that omits it—let us call it \(\lambda \) Demod—might not preserve refutational completeness.
An instance of \(\lambda \) DemodExt, where \({\textsf {g}}\>z\) is rewritten to \({\textsf {f}}\>z\>z\) under a \(\lambda \)-binder, follows:

Lemma 58
\(\lambda \) DemodExt is sound and preserves refutational completeness of the calculus.
Proof
Soundness of the first conclusion is obvious. Soundness of the second and third conclusions follows from congruence and extensionality using the premises. Preservation of completeness is justified by redundancy. Specifically, we justify the deletion of the second premise by showing that it is redundant w.r.t. the conclusions—i.e., if for every ground instance  , its encoding
, its encoding  is entailed by
is entailed by  , where N are the conclusions of \({\lambda }\textsc {DemodExt}\). The first conclusion cannot help us prove redundancy because
, where N are the conclusions of \({\lambda }\textsc {DemodExt}\). The first conclusion cannot help us prove redundancy because  might be a \(\lambda \)-expression and then
might be a \(\lambda \)-expression and then  is a symbol that is unrelated to
is a symbol that is unrelated to  . Instead, we use the \(\theta \)-instances of the last two conclusions. By Lemma 23,
. Instead, we use the \(\theta \)-instances of the last two conclusions. By Lemma 23,  has
has  as a subterm. If this subterm is replaced by
as a subterm. If this subterm is replaced by  , we obtain
, we obtain  . Hence, the
. Hence, the  -encodings of the \(\theta \)-instances of the last two conclusions entail the
-encodings of the \(\theta \)-instances of the last two conclusions entail the  -encoding of the \(\theta \)-instance of the second premise by congruence. Due to the side condition that the second premise is larger than the second and third conclusion, by stability under grounding substitutions, the \(\theta \)-instances of the last two conclusions must be smaller than the \(\theta \)-instance of the second premise. Thus, the second premise is redundant. \(\square \)
-encoding of the \(\theta \)-instance of the second premise by congruence. Due to the side condition that the second premise is larger than the second and third conclusion, by stability under grounding substitutions, the \(\theta \)-instances of the last two conclusions must be smaller than the \(\theta \)-instance of the second premise. Thus, the second premise is redundant. \(\square \)
Pruning Arguments of Variables The next simplification rule can be used to prune arguments of applied variables if the arguments can be expressed as functions of the remaining arguments. For example, the clause \(C[\, y\>{\textsf {a}}\>{\textsf {b}}\>({\textsf {f}}\>{\textsf {b}}\>{\textsf {a}}){,}\; y\>{\textsf {b}}\>{\textsf {d}}\>({\textsf {f}}\>{\textsf {d}}\>{\textsf {b}})]\), in which y occurs twice, can be simplified to \(C[\, y'\>{\textsf {a}}\>{\textsf {b}}{,}\; y'\>{\textsf {b}}\>{\textsf {d}}]\). Here, for each occurrence of y, the third argument can be computed by applying \({\textsf {f}}\) to the second and first arguments. The rule can also be used to remove the repeated arguments in \(y\>{\textsf {b}}\>{\textsf {b}} \not \approx y\>{\textsf {a}}\>{\textsf {a}}\), the static argument \({\textsf {a}}\) in \(y\>{\textsf {a}}\>{\textsf {c}} \not \approx y\>{\textsf {a}}\>{\textsf {b}}\), and all four arguments in \(y\>{\textsf {a}}\>{\textsf {b}} \not \approx z\>{\textsf {b}}\>{\textsf {d}}\). It is stated as

where the following conditions apply:
-
1.
\(\sigma = \{y \mapsto \lambda \bar{x}_{\!j}.\> y'\> \bar{x}_{\!j-1}\}\);
-
2.
\(y'\) is a fresh variable;
-
3.
\(C\sqsupset C\sigma \);
-
4.
the minimum number k of arguments passed to any occurrence of y in the clause C is at least j;
-
5.
there exists a term t containing no variables bound in the clause such that for all terms of the form \(y\>\bar{s}_k\) occurring in the clause we have \(s_{\!j} = t\> \bar{s}_{\!j-1}\>s_{\!j+1}\ldots s_k\).
Clauses with a static argument correspond to the case \(t := (\lambda \bar{x}_{\!j-1}\> x_{\!j+1} \ldots x_k.\; u)\), where u is the static argument (containing no variables bound in t) and j is its index in y’s argument list. The repeated argument case corresponds to \(t := (\lambda \bar{x}_{\!j-1} \> x_{\!j+1} \ldots x_k.\; x_i)\), where i is the index of the repeated argument’s mate.
Lemma 59
PruneArg is sound and preserves refutational completeness of the calculus.
Proof
The rule is sound because it simply applies a substitution to C. It preserves completeness because the premise C is redundant w.r.t. the conclusion \(C\sigma \). This is because the sets of ground instances of C and \(C\sigma \) are the same and \(C \sqsupset C\sigma \). Clearly \(C\sigma \) is an instance of C. We will show the inverse: that C is an instance of \(C\sigma \). Let \(\rho = \{y' \mapsto \lambda \bar{x}_{\!j-1}\> x_{\!j+1} \ldots x_k.\;y\>\bar{x}_{\!j-1}\> (t\>\bar{x}_{\!j-1}\> x_{\!j+1} \ldots x_k)\> x_{\!j+1} \ldots x_k\}\). We show \(C\sigma \rho = C\). Consider an occurrence of y in C. By the side conditions, it will have the form \(y\>\bar{s}_k\>\bar{u}\), where \(s_{\!j} = t\> \bar{s}_{\!j-1}\>s_{\!j+1}\ldots s_k\). Hence, \((y\>\bar{s}_k)\sigma \rho = (y'\>\bar{s}_{\!j-1}\>s_{\!j+1} \ldots s_k)\rho = y\>\bar{s}_{\!j-1}\>(t\> \bar{s}_{\!j-1}\>s_{\!j+1}\ldots s_k)\>s_{\!j+1} \ldots s_k = y\>\bar{s}_k\). Thus, \(C\sigma \rho = C\). \(\square \)
We designed an algorithm that efficiently computes the subterm u of the term \(t = (\lambda x_1 \ldots \,x_{\!j-1} \, x_{\!j+1} \ldots \, x_k.\; u)\) occurring in the side conditions of \(\textsc {PruneArg}\). The algorithm is incomplete, but our tests suggest that it discovers most cases of prunable arguments that occur in practice. The algorithm works by maintaining a mapping of pairs (y, i) of functional variables y and indices i of their arguments to a set of candidate terms for u. For an occurrence \(y \> \bar{s}_{n}\) of y and for an argument \(s_{\!j}\), the algorithm approximates this set by computing all possible ways in which subterms of \(s_{\!j}\) that are equal to any other \(s_i\) can be replaced with the variable \(x_i\) corresponding to the ith argument of y. The candidate sets for all occurrences of y are then intersected. An arbitrary element of the final intersection is returned as the term u.
Example 60
Suppose that \(y\>{\textsf {a}}\>({\textsf {f}} \> {\textsf {a}})\>{\textsf {b}}\) and \(y\>z\>({\textsf {f}} \>z)\>{\textsf {b}}\) are the only occurrences of y in a clause. The initial mapping is  . After computing the ways in which each argument can be expressed using the remaining ones for the first occurrence and intersecting the sets, we get \(\{1 \mapsto \{{\textsf {a}}\}{,}\; 2 \mapsto \{{\textsf {f}}\>{\textsf {a}}{,}\; {\textsf {f}}\>x_1\}{,}\; 3 \mapsto \{{\textsf {b}}\}\}\), where \(x_1\) represents y’s first argument. Finally, after computing the corresponding sets for the second occurrence of y and intersecting them with the previous candidate sets, we get \(\{1 \mapsto \emptyset {,}\; 2 \mapsto \{{\textsf {f}}\>x_1\}{,}\; 3 \mapsto \{{\textsf {b}}\}\}.\) The final mapping shows that we can remove the second argument, since it can be expressed as a function of the first argument: \(t = (\lambda x_1 \, x_3.\; {\textsf {f}}\> x_1\> x_3)\). We can also remove the third argument, since its value is fixed: \(t = (\lambda x_1 \, x_3.\; {\textsf {b}})\).
. After computing the ways in which each argument can be expressed using the remaining ones for the first occurrence and intersecting the sets, we get \(\{1 \mapsto \{{\textsf {a}}\}{,}\; 2 \mapsto \{{\textsf {f}}\>{\textsf {a}}{,}\; {\textsf {f}}\>x_1\}{,}\; 3 \mapsto \{{\textsf {b}}\}\}\), where \(x_1\) represents y’s first argument. Finally, after computing the corresponding sets for the second occurrence of y and intersecting them with the previous candidate sets, we get \(\{1 \mapsto \emptyset {,}\; 2 \mapsto \{{\textsf {f}}\>x_1\}{,}\; 3 \mapsto \{{\textsf {b}}\}\}.\) The final mapping shows that we can remove the second argument, since it can be expressed as a function of the first argument: \(t = (\lambda x_1 \, x_3.\; {\textsf {f}}\> x_1\> x_3)\). We can also remove the third argument, since its value is fixed: \(t = (\lambda x_1 \, x_3.\; {\textsf {b}})\).
Example 61
Suppose that \(y\>(\lambda x.\> {\textsf {a}})\>({\textsf {f}}\>{\textsf {a}})\>{\textsf {c}}\) and \(y\>(\lambda x.\> {\textsf {b}})\>({\textsf {f}}\>{\textsf {b}})\>{\textsf {d}}\) are the only occurrences of y in a clause. Here, PruneArg can be used to eliminate the second argument by taking \(t := (\lambda x_1\>x_3.\; {\textsf {f}}\>(x_1\>x_3))\), but our algorithm fails to detect this.
Alternatives to Axiom (Ext) Following the literature [34, 62], we provide a rule for negative extensionality:

The following conditions apply:
-
1.
\({\textsf {sk}}\) is a fresh Skolem symbol;
-
2.
\(s \not \approx s'\) is \(\succsim \)-eligible in the premise;
-
3.
\(\bar{\alpha }\) and \(\bar{y}\) are the type and term variables occurring free in the literal \(s \not \approx s'\).
Negative extensionality can be applied as an inference rule at any time or as a simplification rule during preprocessing of the initial problem. The rule uses Skolem terms \({\textsf {sk}}\>\bar{y}\) rather than \(\mathsf {diff}\> s\> s'\) because they tend to be more compact.
Lemma 62
(NegExt’s satisfiability preservation) Let  , and let E be the conclusion of a NegExt inference from N. If \(N \mathrel \cup \{{(\textsc {Ext})}\}\) is satisfiable, then \(N \mathrel \cup \{{(\textsc {Ext})}, E\}\) is satisfiable.
, and let E be the conclusion of a NegExt inference from N. If \(N \mathrel \cup \{{(\textsc {Ext})}\}\) is satisfiable, then \(N \mathrel \cup \{{(\textsc {Ext})}, E\}\) is satisfiable.
Proof
Let \(\mathscr {I}\) be a model of \(N \mathrel \cup \{{(\textsc {Ext})}\}.\) We need to construct a model of \(N \mathrel \cup \{{(\textsc {Ext})}, E\}.\) Since (Ext) holds in \(\mathscr {I}\), so does its instance \(s\>(\mathsf {diff}\> s\> s')\not \approx s'\>(\mathsf {diff}\> s\> s') \mathrel \vee s \approx s'\). We extend the model \(\mathscr {I}\) to a model \(\mathscr {I}'\), interpreting \({\textsf {sk}}\) such that \(\mathscr {I}' \models {\textsf {sk}}{\langle {\bar{\alpha }}\rangle }\>\bar{y} \approx \mathsf {diff}\> s\> s'\). The Skolem symbol \({\textsf {sk}}\) takes the free type and term variables of \(s \not \approx s'\) as arguments, which include all the free variables of \(\mathsf {diff}\> s\> s'\), allowing us to extend \(\mathscr {I}\) in this way.
By assumption, the premise \(C' \mathrel \vee s \not \approx s'\) is true in \(\mathscr {I}\) and hence in \(\mathscr {I}'\). Since the above instance of (Ext) holds in \(\mathscr {I}\), it also holds in \(\mathscr {I}'\). Hence, the conclusion \(C' \mathrel \vee s\>({\textsf {sk}}{\langle {\bar{\alpha }_m}\rangle }\>\bar{y}_n) \not \approx s'\>({\textsf {sk}}{\langle {\bar{\alpha }_m}\rangle }\>\bar{y}_n)\) also holds, which can be seen by resolving the premise against the (Ext) instance and unfolding the defining equation of \({\textsf {sk}}\). \(\square \)
One reason why the extensionality axiom is so prolific is that both sides of its maximal literal, \(y\>(\mathsf {diff}\> y\> z) \not \approx z\>(\mathsf {diff}\> y\> z)\), are fluid. As a pragmatic alternative to the axiom, we introduce the “abstracting” rules AbsSup, AbsERes, and AbsEFact with the same premises as the core Sup, ERes, and EFact, respectively. We call these rules collectively Abs. Each new rule shares all the side conditions of the corresponding core rule except that of the form \(\sigma \in {{\,\mathrm{CSU}\,}}(s,t)\). Instead, it lets \(\sigma \) be the most general unifier of s and t’s types and adds this condition: Let  and
and  , where
, where  is the largest common green context of \(s\sigma \) and \(t\sigma \). If any \(s_i\) is of functional type and the core rule has conclusion \(E\sigma \), the new rule has conclusion \(E\sigma \mathrel \vee s_1 \not \approx t_1 \mathrel \vee \cdots \mathrel \vee s_n \not \approx t_n\). The NegExt rule can then be applied to those literals \(s_i \not \approx t_i\) whose sides have functional type. Essentially the same idea was proposed by Bhayat and Reger as unification with abstraction in the context of combinatory superposition [19, Sect. 3.1]. The approach regrettably does not fully eliminate the need for axiom (Ext), as Visa Nummelin demonstrated via the following example.
is the largest common green context of \(s\sigma \) and \(t\sigma \). If any \(s_i\) is of functional type and the core rule has conclusion \(E\sigma \), the new rule has conclusion \(E\sigma \mathrel \vee s_1 \not \approx t_1 \mathrel \vee \cdots \mathrel \vee s_n \not \approx t_n\). The NegExt rule can then be applied to those literals \(s_i \not \approx t_i\) whose sides have functional type. Essentially the same idea was proposed by Bhayat and Reger as unification with abstraction in the context of combinatory superposition [19, Sect. 3.1]. The approach regrettably does not fully eliminate the need for axiom (Ext), as Visa Nummelin demonstrated via the following example.
Example 63
Consider the unsatisfiable clause set consisting of \({\textsf {h}}\>x \approx {\textsf {f}}\>x\), \({\textsf {k}}\>{\textsf {h}} \approx {\textsf {k}}\;{\textsf {g}}\), and \({\textsf {k}}\>{\textsf {g}} \not \approx {\textsf {k}}\>{\textsf {f}}\), where \({\textsf {k}}\) takes at most one argument and \({\textsf {h}} \succ {\textsf {g}} \succ {\textsf {f}}\). The only nonredundant Abs inference applicable is AbsERes on the third clause, resulting in \({\textsf {g}} \not \approx {\textsf {f}}\). Applying ExtNeg further produces \({\textsf {g}}\>{\textsf {sk}} \not \approx {\textsf {f}}\>{\textsf {sk}}\). The set consisting of all five clauses is saturated.
A different approach is to instantiate the extensionality axiom with arbitrary terms \(s, s'\) of the same functional type:

We would typically choose \(s, s'\) among the green subterms occurring in the current clause set. Intuitively, if we think in terms of eligibility, ExtInst demands \(s\>(\mathsf {diff}\> s\> s') \approx s'\>(\mathsf {diff}\> s\> s')\) to be proved before \(s \approx s'\) can be used. This can be advantageous because simplifying inferences (based on matching) will often be able to rewrite the applied terms \(s\>(\mathsf {diff}\> s\> s')\) and \(s'\>(\mathsf {diff}\> s\> s')\). In contrast, Abs assume \(s \approx s'\) and delay the proof obligation that \(s\>(\mathsf {diff}\> s\> s') \approx s'\>(\mathsf {diff}\> s\> s')\). This can create many long clauses, which will be subject to expensive generating inferences (based on full unification).
Superposition can be generalized to orange subterms as follows:

where the substitution \(\rho \) is defined as follows: Let \(P_y = \{y\}\) for all type and term variables \(y \not \in \bar{x}\). For each i, let \(P_{x_i}\) be defined recursively as the union of all \(P_y\) such that y occurs free in the \(\lambda \)-expression that binds \(x_i\) in  or that occurs free in the corresponding subterm of
or that occurs free in the corresponding subterm of  .
.
Then \(\rho \) is defined as \(\{x_i \mapsto {\textsf {sk}}_i{\langle {\bar{\alpha }_i}\rangle }\>\bar{y}_i\text { for each } i\}\), where \(\bar{y}_i\) are the term variables in \(P_{x_i}\) and \(\bar{\alpha }_i\) are the type variables in \(P_{x_i}\) and the type variables occurring in the type of the \(\lambda \)-expression binding \(x_i\). In addition, Sup’s side conditions and the following conditions apply: 10. \(\bar{x}\) has length \(n > 0\);
11. \(\bar{x}\sigma = \bar{x}\);
12. the variables \(\bar{x}\) do not occur in \(y\sigma \) for all variables y in u.
The substitution \(\rho \) introduces Skolem terms to represent bound variables that would otherwise escape their binders.
Example 64
We can shorten the derivation of Example 17 by applying \(\lambda \) Sup as follows:

From this conclusion, \(\bot \) can be derived using only Sup and ERes inferences. We thus avoid both FluidSup and (Ext).
The rule can be justified in terms of paramodulation and extensionality, with the Skolem terms standing for \(\mathsf {diff}\) terms:
Lemma 65
(\(\lambda \) Sup’s satisfiability preservation) Let  , and let E be the conclusion of a \(\lambda \) Sup inference from N. If \(N \mathrel \cup \{{(\textsc {Ext})}\}\) is satisfiable, then \(N \mathrel \cup \{{(\textsc {Ext})}, E\}\) is satisfiable.
, and let E be the conclusion of a \(\lambda \) Sup inference from N. If \(N \mathrel \cup \{{(\textsc {Ext})}\}\) is satisfiable, then \(N \mathrel \cup \{{(\textsc {Ext})}, E\}\) is satisfiable.
Proof
Let \(\mathscr {I}\) be a model of \(N \mathrel \cup \{{(\textsc {Ext})}\}.\) We need to construct a model of \(N \mathrel \cup \{{(\textsc {Ext})}, E\}.\) For each i, let \(v_i\) be the \(\lambda \)-expression binding \(x_i\) in the term  in the rule. Let \(v'_i\) be the variant of \(v_i\) in which the relevant occurrence of \(u\sigma \) is replaced by \(t'\sigma \). We define a substitution \(\pi \) recursively by \(x_i\pi = \mathsf {diff}\> (v_i\pi )\> (v'_i\pi )\) for all i. This definition is well-founded because the variables \(x_{\!j}\) with \(j \ge i\) do not occur freely in \(v_i\) and \(v_i'\). We extend the model \(\mathscr {I}\) to a model \(\mathscr {I}'\), interpreting \({\textsf {sk}}_i\) such that \(\mathscr {I}' \models {\textsf {sk}}_i{\langle {\bar{\alpha }_i}\rangle }\>\bar{y}_i \approx \mathsf {diff}\> (v_i\pi )\> (v'_i\pi )\) for each i. Since the free type and term variables of any \(x_i\pi \) are necessarily contained in \(P_{x_i}\), the arguments of \({\textsf {sk}}_i\) include the free variables of \(\mathsf {diff}\> (v_i\pi )\> (v'_i\pi )\), allowing us to extend \(\mathscr {I}\) in this way.
in the rule. Let \(v'_i\) be the variant of \(v_i\) in which the relevant occurrence of \(u\sigma \) is replaced by \(t'\sigma \). We define a substitution \(\pi \) recursively by \(x_i\pi = \mathsf {diff}\> (v_i\pi )\> (v'_i\pi )\) for all i. This definition is well-founded because the variables \(x_{\!j}\) with \(j \ge i\) do not occur freely in \(v_i\) and \(v_i'\). We extend the model \(\mathscr {I}\) to a model \(\mathscr {I}'\), interpreting \({\textsf {sk}}_i\) such that \(\mathscr {I}' \models {\textsf {sk}}_i{\langle {\bar{\alpha }_i}\rangle }\>\bar{y}_i \approx \mathsf {diff}\> (v_i\pi )\> (v'_i\pi )\) for each i. Since the free type and term variables of any \(x_i\pi \) are necessarily contained in \(P_{x_i}\), the arguments of \({\textsf {sk}}_i\) include the free variables of \(\mathsf {diff}\> (v_i\pi )\> (v'_i\pi )\), allowing us to extend \(\mathscr {I}\) in this way.
By assumption, the premises of the \(\lambda \) Sup inference are true in \(\mathscr {I}\) and hence in \(\mathscr {I}'\). We need to show that the conclusion  is also true in \(\mathscr {I}'\). Let \(\xi \) be a valuation. If \(\mathscr {I}',\xi \models (D' \mathrel \vee C')\sigma \rho \), we are done. So we assume that \(D'\sigma \rho \) and \(C'\sigma \rho \) are false in \(\mathscr {I}'\) under \(\xi \). In the following, we omit ‘\(\mathscr {I}',\xi \models \)’, but all equations (\(\approx \)) are meant to be true in \(\mathscr {I}'\) under \(\xi \). Assuming \(D'\sigma \rho \) and \(C'\sigma \rho \) are false, we will show inductively that \(v_i\pi \approx v'_i\pi \) for all \(i = k, \dots , 1\). By this assumption, the premises imply that \(t\sigma \rho \approx t'\sigma \rho \) and
is also true in \(\mathscr {I}'\). Let \(\xi \) be a valuation. If \(\mathscr {I}',\xi \models (D' \mathrel \vee C')\sigma \rho \), we are done. So we assume that \(D'\sigma \rho \) and \(C'\sigma \rho \) are false in \(\mathscr {I}'\) under \(\xi \). In the following, we omit ‘\(\mathscr {I}',\xi \models \)’, but all equations (\(\approx \)) are meant to be true in \(\mathscr {I}'\) under \(\xi \). Assuming \(D'\sigma \rho \) and \(C'\sigma \rho \) are false, we will show inductively that \(v_i\pi \approx v'_i\pi \) for all \(i = k, \dots , 1\). By this assumption, the premises imply that \(t\sigma \rho \approx t'\sigma \rho \) and  . Due to the way we constructed \(\mathscr {I}'\), we have \(w\pi \approx w\rho \) for any term w. Hence, we have \(t\sigma \pi \approx t'\sigma \pi \). The terms \(v_k\pi \>(\mathsf {diff}\> (v_k\pi )\> (v'_k\pi ))\) and \(v_k'\pi \>(\mathsf {diff}\> (v_k\pi )\> (v'_k\pi ))\) are the respective result of applying \(\pi \) to the body of the \(\lambda \)-expressions \(v_k\) and \(v'_k\). Therefore, by congruence, \(t\sigma \pi \approx t'\sigma \pi \) and \(t\sigma = u\sigma \) imply that \(v_k\pi \>(\mathsf {diff}\> (v_k\pi )\> (v'_k\pi )) \approx v'_k\pi \>(\mathsf {diff}\> (v_k\pi )\> (v'_k\pi )).\) The extensionality axiom then implies \(v_k\pi \approx v'_k\pi \).
. Due to the way we constructed \(\mathscr {I}'\), we have \(w\pi \approx w\rho \) for any term w. Hence, we have \(t\sigma \pi \approx t'\sigma \pi \). The terms \(v_k\pi \>(\mathsf {diff}\> (v_k\pi )\> (v'_k\pi ))\) and \(v_k'\pi \>(\mathsf {diff}\> (v_k\pi )\> (v'_k\pi ))\) are the respective result of applying \(\pi \) to the body of the \(\lambda \)-expressions \(v_k\) and \(v'_k\). Therefore, by congruence, \(t\sigma \pi \approx t'\sigma \pi \) and \(t\sigma = u\sigma \) imply that \(v_k\pi \>(\mathsf {diff}\> (v_k\pi )\> (v'_k\pi )) \approx v'_k\pi \>(\mathsf {diff}\> (v_k\pi )\> (v'_k\pi )).\) The extensionality axiom then implies \(v_k\pi \approx v'_k\pi \).
It follows directly from the definition of \(\pi \) that for all i,  and
and  for some context
for some context  . The subterms \(v_{i+1}\pi \) of
. The subterms \(v_{i+1}\pi \) of  and \(v_{i+1}'\pi \) of
and \(v_{i+1}'\pi \) of  may be below applied variables but not below \(\lambda \)s. Since substitutions avoid capture, in \(v_i\) and \(v_i'\), \(\pi \) only substitutes \(x_{\!j}\) with \(j<i\), but in \(v_{i+1}\) and \(v_{i+1}'\), it substitutes all \(x_{\!j}\) with \(j\le i\). By an induction using these equations, congruence, and the extensionality axiom, we can derive from \(v_k\pi \approx v'_k\pi \) that \(v_1\pi \approx v'_1\pi .\) Since \(\mathscr {I}' \models w\pi \approx w\rho \) for any term w, we have \(v_1\rho \approx v'_1\rho .\) By congruence, it follows that
may be below applied variables but not below \(\lambda \)s. Since substitutions avoid capture, in \(v_i\) and \(v_i'\), \(\pi \) only substitutes \(x_{\!j}\) with \(j<i\), but in \(v_{i+1}\) and \(v_{i+1}'\), it substitutes all \(x_{\!j}\) with \(j\le i\). By an induction using these equations, congruence, and the extensionality axiom, we can derive from \(v_k\pi \approx v'_k\pi \) that \(v_1\pi \approx v'_1\pi .\) Since \(\mathscr {I}' \models w\pi \approx w\rho \) for any term w, we have \(v_1\rho \approx v'_1\rho .\) By congruence, it follows that  With
With  it follows that
it follows that  Hence, the conclusion of the \(\lambda \) Sup inference is true in \(\mathscr {I}'\). \(\square \)
Hence, the conclusion of the \(\lambda \) Sup inference is true in \(\mathscr {I}'\). \(\square \)
Alternatives to FluidSup The next rule, duplicating flex subterm superposition, is a lightweight substitute for FluidSup:

where \(n > 0\), \(\rho = \{y \mapsto \lambda \bar{x}_n.\>z\>\bar{x}_n\>(w\>\bar{x}_n)\}\), and \(\sigma \in {{\,\mathrm{CSU}\,}}(t{,}\> w\>(\bar{u}_n\rho ))\) for fresh variables w, z. The order and eligibility restrictions are as for Sup. The rule can be understood as the composition of an inference that applies the substitution \(\rho \) and of a paramodulation inference into the  . DupSup is general enough to replace FluidSup in Examples 13 and 14 but not in Example 15. On the other hand, FluidSup’s unification problem is usually a flex–flex pair, whereas DupSup yields a less explosive flex–rigid pair unless t is variable-headed.
. DupSup is general enough to replace FluidSup in Examples 13 and 14 but not in Example 15. On the other hand, FluidSup’s unification problem is usually a flex–flex pair, whereas DupSup yields a less explosive flex–rigid pair unless t is variable-headed.
The last rule, flex subterm superposition, is an even more lightweight substitute for FluidSup:

where \(n > 0\) and \(\sigma \in {{\,\mathrm{CSU}\,}}(t{,}\> y\>\bar{u}_n)\). The order and eligibility restrictions are as for Sup.
6 Implementation
Zipperposition [27, 28] is an open-source superposition prover written in OCaml.Footnote 1 Its raw performance might not be comparable to highly optimized provers such as E and Vampire, but its code is easier to maintain and modify. Our rough estimate is that it is about three times slower than E. Originally designed for polymorphic first-order logic (TF1 [21]), Zipperposition was later extended by Cruanes with an incomplete higher-order mode based on pattern unification [53]. Bentkamp et al. [12] extended it further with a complete \(\lambda \)-free clausal higher-order mode. We have now implemented a clausal higher-order mode based on our calculus. We use the order \(\succ _{{\lambda }}\) (Sect. 3.6) derived from the Knuth–Bendix order [45] and the lexicographic path order [43]. We currently use the corresponding nonstrict order \(\succeq _{{\lambda }}\) as \(\succsim \).
Except for FluidSup, the core calculus rules already existed in Zipperposition in a similar form. To improve efficiency, we extended the prover to use a higher-order generalization [68] of fingerprint indices [58] to find inference partners for all new binary inference rules. To speed up the computation of the Sup conditions, we omit the condition \(C\sigma \not \precsim D\sigma \) in the implementation, at the cost of performing additional inferences. Among the optional rules, we implemented \(\lambda \) Demod, PruneArg, NegExt, Abs, ExtInst, \(\lambda \) Sup, DupSup, and FlexSup. For \(\lambda \) Demod and \(\lambda \) Sup, demodulation, subsumption, and other standard simplification rules (as implemented in E [59]), we use pattern unification. For generating inference rules that require enumerations of complete sets of unifiers, we use the complete procedure of Vukmirović et al. [68]. It has better termination behavior, produces fewer redundant unifiers, and can be implemented more efficiently than procedures such as Jensen and Pietrzykowski’s [38] and Snyder and Gallier’s [61]. The set of fluid terms is overapproximated in the implementation by the set of terms that are either nonground \(\lambda \)-expressions or terms of the form \(y\>\bar{u}_n\) with \(n>0\). To efficiently retrieve candidates for Abs inferences without slowing down superposition term indexing structures, we implemented dedicated indexing for clauses that are eligible for Abs inferences [70, Sect. 3.3].
Zipperposition implements a DISCOUNT-style given clause procedure [5]. The proof state is represented by a set A of active clauses and a set P of passive clauses. To interleave nonterminating unification with other computation, we added a set T containing possibly infinite sequences of scheduled inferences. These sequences are stored as finite instructions of how to compute the inferences. Initially, all clauses are in P. At each iteration of the main loop, the prover heuristically selects a given clause C from P. If P is empty, sequences from T are evaluated to generate more clauses into P; if no clause can be produced in this way, A is saturated and the prover stops. Assuming a given clause C could be selected, it is first simplified using A. Clauses in A are then simplified w.r.t. C, and any simplified clause is moved to P. Then C is added to A and all sequences representing nonredundant inferences between C and A are added to T. This maintains the invariant that all nonredundant inferences between clauses in A have been scheduled or performed. Then some of the scheduled inferences in T are performed and the conclusions are put into P.
We can view the above loop as an instance of the abstract Zipperposition loop prover ZL of Waldmann et al. [71, Example 34]. Their Theorem 32 allows us to obtain dynamic completeness for this prover architecture from our static completeness result (Theorem 54). This requires that the sequences in T are visited fairly, that clauses in P are chosen fairly, and that simplification terminates, all of which are guaranteed by our implementation.
The unification procedure we use returns a sequence of either singleton sets containing the unifier or an empty set signaling that a unifier is still not found. Empty sets are returned to give back control to the caller of unification procedure and avoid getting stuck on nonterminating problems. These sequences of unifier subsingletons are converted into sequences containing subsingletons of clauses representing inference conclusions.
7 Evaluation
The evaluation consists of two parts: an assessment of the extensions described in Sect. 5 and a comparison of our prototype implementation with Zipperposition’s modes for less expressive logics and with other higher-order provers. The experiments were run on StarExec nodes equipped with Intel Xeon E5-2609 0 CPUs clocked at 2.40 GHz. Following CASC 2019 [65], we set 180 s as the CPU time limit. Our results are publicly available.Footnote 2
Evaluation of Extensions In the first part, we assess the usefulness of the extensions described in Sect. 5. We used both standard TPTP benchmarks [64] and Sledgehammer-generated benchmarks [52]. From the TPTP, version 7.2.0, we used all 499 monomorphic higher-order theorems in TH0 syntax without interpreted Booleans and arithmetic (TH0). The Sledgehammer benchmarks, corresponding to Isabelle’s Judgment Day suite [23], were regenerated to target clausal higher-order logic (SH-\(\lambda \)). They comprise 1253 problems, each generated from 256 Isabelle facts (definitions and lemmas).
We fixed a reasonable base configuration of Zipperposition parameters. For each extension, we then changed the corresponding parameters and observed the effect on the success rate. The base configuration uses the complete variant of the unification procedure of Vukmirović et al. [68]. It also includes the optional rules NegExt and PruneArg, substitutes FlexSup for the highly explosive FluidSup, and excludes axiom (Ext). This configuration is not refutationally complete.

Number of problems proved without rules included in the base configuration

Number of problems proved using rules that perform rewriting under \(\lambda \)-binders

Number of problems proved using rules that perform extensionality reasoning

Number of problems proved with rules that perform superposition into fluid terms
The rules NegExt (NE) and PruneArg (PA) were added to the base configuration because our informal experiments showed that they usually help. Figure 1 confirms this, although the effect is small. In all tables, \(+R\) denotes the inclusion of a rule R not present in the base, and \(-R\) denotes the exclusion of a rule R present in the base. Numbers given in parentheses denote the number of problems that are solved only by the given configuration and by no other configuration in the same table.
The rules \(\lambda \) Demod (\(\lambda \)D) and \(\lambda \) Sup extend the calculus to perform some rewriting under \(\lambda \)-binders. While experimenting with the calculus, we noticed that for some configurations, \(\lambda \) Sup performs better when the number of fresh Skolem symbols it introduces overall is bounded by some parameter n. As Fig. 2 shows, the inclusion of these rules has a different effect on the two benchmark sets. On the other hand, different choices of n for \(\lambda \) Sup (denoted by \(\lambda \)Sn) do not seem to influence the success rate much.
The evaluation of the Abs and ExtInst rules and axiom (Ext), presented in Fig. 3, confirms our intuition that including the extensionality axiom is severely detrimental to performance. The \(+\)(Ext) configuration solves two unique problems on SH-\(\lambda \) benchmarks, but this small success is coincidental, since (Ext) is not even referenced in the generated proofs.
The FlexSup rule included in the base configuration underperformed. Even the FluidSup and DupSup rules outperform FlexSup, as shown in Fig. 4. This effect is especially visible on SH-\(\lambda \) benchmarks. On TPTP, the differences are negligible.
Most of the extensions have a stronger effect on SH-\(\lambda \) than on TH0. A possible explanation is that the Boolean-free TH0 benchmark subset consists mostly of problems that are simple to solve using most prover parameters. On the other hand, SH-\(\lambda \) benchmarks are of varying difficulty and can thus benefit more from changing prover parameters.
Main Evaluation In the second part, we seek to answer the following research questions:
-
1.
What is the overhead of our implementation on first-order problems, compared with first-order superposition?
-
2.
How does our implementation compare with \(\lambda \)-free clausal superposition on \(\lambda \)-free problems?
-
3.
How does the complete implementation of our calculus compare with incomplete variants?
-
4.
How does our implementation compare with other higher-order provers on Boolean-free higher-order benchmarks?
We needed more benchmarks to answer questions 1 and 2. From the TPTP, we used 1000 randomly selected first-order (FO) problems in CNF, FOF, or TFF syntax without arithmetic. We partitioned the TH0 problems used above into those containing no \(\lambda \)-expressions (TH0\(\lambda \)f, 452 problems) and those containing \(\lambda \)-expressions (TH0\(\lambda \), 47 problems). To make the SH-\(\lambda \) problems accessible to \(\lambda \)-free clausal higher-order provers, we regenerated them using \(\lambda \)-lifted supercombinators (SH-ll), as described by Meng and Paulson [52].
To answer questions 1 and 2, we ran Zipperposition in first-order (FOZip) and \(\lambda \)-free (\(\lambda \)freeZip) modes, as well as in a mode that encodes curried applications using a distinguished binary symbol \({\textsf {@}}\) before using first-order Zipperposition (@+FOZip). To answer question 3, we evaluated the implementation of our calculus in Zipperposition in three configurations: \(\lambda \)Zip-base, \(\lambda \)Zip-pragmatic, and \(\lambda \)Zip-full. The configuration \(\lambda \)Zip-base is the base described above. The configuration \(\lambda \)Zip-pragmatic builds on \(\lambda \)Zip-base by disabling FlexSup and replacing complete unification with the pragmatic variant pv\(^2_{1121}\) of the unification procedure [68]. The configuration \(\lambda \)Zip-full is a refutationally complete extension of \(\lambda \)Zip-base that substitutes FluidSup for FlexSup and includes axiom (Ext).
To answer question 4, we selected all contenders in the THF division of CASC 2019 as representatives of the state of the art: CVC4 1.8 prerelease [9], Leo-III 1.4 [62], Satallax 3.4 [24], and Vampire 4.4 [18]. We also included Ehoh [69], the \(\lambda \)-free clausal higher-order mode of E 2.4. Leo-III and Satallax are cooperative higher-order provers that can be set up to regularly invoke first-order provers as terminal proof procedures. To assess the performance of their core calculi, we also evaluated them with first-order backends disabled. We denote these “uncooperative” configurations by Leo-III-uncoop and Satallax-uncoop, as opposed to the standard versions Leo-III-coop and Satallax-coop. To demonstrate the best performance of Zipperposition, we evaluated it in a portfolio mode that runs the prover in various configurations (Zip-uncoop). We also evaluated a cooperative version of the portfolio which, in some configurations, invokes Ehoh as backend on higher-order problems after a predefined time (Zip-coop). In this version, Zipperposition encodes selected clauses from the proof state to \(\lambda \)-free higher-order logic supported by Ehoh [69]. On first-order problems, we ran Ehoh, Vampire, and Zip-uncoop using the provers’ respective first-order modes.

Number of problems proved by the different provers
A summary of these experiments is presented in Fig. 5. Regarding question 1, we observe that \(\lambda \)Zip-pragmatic incurs less than 1% overhead and \(\lambda \)Zip-base incurs less than 3% overhead compared with FOZip, which is very reasonable. Regarding question 2, the numbers show that \(\lambda \)Zip-pragmatic outperforms \(\lambda \)freeZip on TH0\(\lambda \)f problems and but falls behind \(\lambda \)freeZip on SH-ll problems. Regarding question 3, we see that \(\lambda \)Zip-full has substantially more overhead and performs worse than \(\lambda \)Zip-pragmatic and \(\lambda \)Zip-base on almost all benchmark sets, due to the explosive extensionality axiom and FluidSup rule.
Regarding question 4, we learn that, except on TH0\(\lambda \) problems, both \(\lambda \)Zip-base and \(\lambda \)Zip-pragmatic outperform Leo-III-uncoop (which also runs a fixed configuration) by substantial margins. In addition, Zip-uncoop outperforms Satallax-uncoop (which also uses a portfolio). Our most competitive configuration, Zip-coop, emerges as the winner on both problem sets containing \(\lambda \)-expressions. The raw evaluation data show that, on higher-order TPTP benchmarks, Zip-coop does not solve any problems that no other cooperative prover solves. This probably says more about the benchmark set than about the prover. By contrast, on SH-ll benchmarks Zip-coop uniquely solves 21 problems, and on SH-\(\lambda \) benchmarks, it uniquely solves 27 problems, w.r.t. other cooperative provers.
8 Discussion and Related Work
Bentkamp et al. [12] introduced four calculi for \(\lambda \)-free clausal higher-order logic organized along two axes: intensional versus extensional, and nonpurifying versus purifying. The purifying calculi flatten the clauses containing applied variables, thereby eliminating the need for superposition into variables. As we extended their work to support \(\lambda \)-expressions, we found the purification approach problematic and gave it up because it needs x to be smaller than \(x\;t\), which is impossible to achieve with a term order on \(\beta \eta \)-equivalence classes. We also quickly gave up our attempt at supporting intensional higher-order logic. Extensionality is the norm for higher-order unification [30] and is mandated by the TPTP THF format [66] and in proof assistants such as HOL4, HOL Light, Isabelle/HOL, Lean, Nuprl, and PVS.
Bentkamp et al. viewed their approach as “a stepping stone toward full higher-order logic.” It already included a notion analogous to green subterms and an ArgCong rule, which help cope with the complications occasioned by \(\beta \)-reduction.
Our Boolean-free \(\lambda \)-superposition calculus joins the family of proof systems for higher-order logic. It is related to Andrews’s higher-order resolution [1], Huet’s constrained resolution [36], Jensen and Pietrzykowski’s \(\omega \)-resolution [38], Snyder’s higher-order E-resolution [60], Benzmüller and Kohlhase’s extensional higher-order resolution [14], Benzmüller’s higher-order unordered paramodulation and RUE resolution [13], and Bhayat and Reger’s combinatory superposition [19]. A noteworthy variant of higher-order unordered paramodulation is Steen and Benzmüller’s higher-order ordered paramodulation [62], whose order restrictions undermine refutational completeness but yield better empirical results. Other approaches are based on analytic tableaux [8, 46, 47, 55], connections [2], sequents [50], and satisfiability modulo theories (SMT) [9]. Andrews [3] and Benzmüller and Miller [15] provide excellent surveys of higher-order automation.
Combinatory superposition was developed shortly after \(\lambda \)-superposition and is closely related. It is modeled on the intensional nonpurifying calculus by Bentkamp et al. and targets extensional polymorphic clausal higher-order logic. Both combinatory and \(\lambda \)-superposition gracefully generalize the highly successful first-order superposition rules without sacrificing refutational completeness, and both are equipped with a redundancy criterion, which earlier refutationally complete higher-order calculi lack. In particular, PruneArg is a versatile simplification rule that could be useful in other provers. Combinatory superposition’s distinguishing feature is that it uses \({\textsf {SKBCI}}\) combinators to represent \(\lambda \)-expressions. Combinators can be implemented more easily starting from a first-order prover; \(\beta \)-reduction amounts to demodulation. However, according to its developers [19], “Narrowing terms with combinator axioms is still explosive and results in redundant clauses. It is also never likely to be competitive with higher-order unification in finding complex unifiers.” Among the drawbacks of \(\lambda \)-superposition are the need to solve flex–flex pairs eagerly and the explosion caused by the extensionality axiom. We believe that this is a reasonable trade-off, especially for large problems with a substantial first-order component.
Our prototype Zipperposition joins the league of automatic theorem provers for higher-order logic. We list some of its rivals. TPS [4] is based on the connection method and expansion proofs. LEO [14] and Leo-II [17] implement variants of RUE resolution. Leo-III [62] is based on higher-order paramodulation. Satallax [24] implements a higher-order tableau calculus guided by a SAT solver. Leo-II, Leo-III, and Satallax integrate external first-order provers as terminal proof procedures. AgsyHOL [50] is based on a focused sequent calculus guided by narrowing. The SMT solvers CVC4 and veriT have recently been extended to higher-order logic [9]. Vampire now implements both combinatory superposition and a version of standard superposition in which first-order unification is replaced by restricted combinatory unification [18].
Half a century ago, Robinson [56] proposed to reduce higher-order logic to first-order logic via a translation. “Hammer” tools such as Sledgehammer [54], Miz\(\mathbb {AR}\) [67], HOLyHammer [42], and CoqHammer [29] have since popularized this approach in proof assistants. The translation must eliminate the \(\lambda \)-expressions, typically using \({\textsf {SKBCI}}\) combinators or \(\lambda \)-lifting [52], and encode typing information [20].
9 Conclusion
We presented the Boolean-free \(\lambda \)-superposition calculus, which targets a clausal fragment of extensional polymorphic higher-order logic. With the exception of a functional extensionality axiom, it gracefully generalizes standard superposition. Our prototype prover Zipperposition shows promising results on TPTP and Isabelle benchmarks. In future work, we plan to pursue five main avenues of investigation.
We first plan to extend the calculus to support Booleans and Hilbert choice. Booleans are notoriously explosive. We want to experiment with both axiomatizations and native support in the calculus. Native support would likely take the form of a primitive substitution rule that enumerates predicate instantiations [2], delayed clausification rules [32], and rules for reasoning about Hilbert choice.
We want to investigate techniques to curb the explosion caused by functional extensionality. The extensionality axiom reintroduces the search space explosion that the calculus’s order restrictions aim at avoiding. Maybe we can replace it by more restricted inference rules without compromising refutational completeness.
We will also look into approaches to curb the explosion caused by higher-order unification. Our calculus suffers from the need to solve flex–flex pairs. Existing procedures [38, 61, 68] enumerate redundant unifiers. This can probably be avoided to some extent. It could also be useful to investigate unification procedures that would delay imitation/projection choices via special schematic variables, inspired by Libal’s representation of regular unifiers [49].
We clearly need to fine-tune and develop heuristics. We expect heuristics to be a fruitful area for future research in higher-order reasoning. Proof assistants are an inexhaustible source of easy-looking benchmarks that are beyond the power of today’s provers. Whereas “hard higher-order” may remain forever out of reach, we believe that there is a substantial “easy higher-order” fragment that awaits automation.
Finally, we plan to implement the calculus in a state-of-the-art prover. A suitable basis for an optimized implementation of the calculus would be Ehoh, the \(\lambda \)-free clausal higher-order version of E developed by Vukmirović, Blanchette, Cruanes, and Schulz [69].
References
Andrews, P.B.: Resolution in type theory. J. Symb. Log. 36(3), 414–432 (1971)
Andrews, P.B.: On connections and higher-order logic. J. Autom. Reason. 5(3), 257–291 (1989)
Andrews, P.B.: Classical type theory. In: Robinson, J.A., Voronkov, A. (eds.) Handbook of Automated Reasoning, vol. II, pp. 965–1007. Elsevier and MIT Press (2001)
Andrews, P.B., Bishop, M., Issar, S., Nesmith, D., Pfenning, F., Xi, H.: TPS: A theorem-proving system for classical type theory. J. Autom. Reason. 16(3), 321–353 (1996)
Avenhaus, J., Denzinger, J., Fuchs, M.: DISCOUNT: A system for distributed equational deduction. In: Hsiang, J. (ed.) RTA-95, LNCS, vol. 914, pp. 397–402. Springer (1995)
Bachmair, L., Ganzinger, H.: Rewrite-based equational theorem proving with selection and simplification. J. Log. Comput. 4(3), 217–247 (1994)
Bachmair, L., Ganzinger, H.: Resolution theorem proving. In: Robinson, J.A., Voronkov, A. (eds.) Handbook of Automated Reasoning, vol. I, pp. 19–99. Elsevier and MIT Press (2001)
Backes, J., Brown, C.E.: Analytic tableaux for higher-order logic with choice. J. Autom. Reason. 47(4), 451–479 (2011)
Barbosa, H., Reynolds, A., Ouraoui, D.E., Tinelli, C., Barrett, C.W.: Extending SMT solvers to higher-order logic. In: Fontaine, P. (ed.) CADE-27, LNCS, vol. 11716, pp. 35–54. Springer (2019)
Bentkamp, A., Blanchette, J., Cruanes, S., Waldmann, U.: Superposition for lambda-free higher-order logic. Log. Methods Comput. Sci. 17(2), 1:1–1:38 (2021)
Bentkamp, A., Blanchette, J., Tourret, S., Vukmirović, P., Waldmann, U.: Superposition with lambdas. In: Fontaine, P. (ed.) CADE-27, LNCS, vol. 11716, pp. 55–73. Springer (2019)
Bentkamp, A., Blanchette, J.C., Cruanes, S., Waldmann, U.: Superposition for lambda-free higher-order logic. In: Galmiche, D., Schulz, S., Sebastiani, R. (eds.) IJCAR 2018, LNCS, vol. 10900, pp. 28–46. Springer (2018)
Benzmüller, C.: Extensional higher-order paramodulation and RUE-resolution. In: Ganzinger, H. (ed.) CADE-16, LNCS, vol. 1632, pp. 399–413. Springer (1999)
Benzmüller, C., Kohlhase, M.: Extensional higher-order resolution. In: Kirchner, C., Kirchner, H. (eds.) CADE-15, LNCS, vol. 1421, pp. 56–71. Springer (1998)
Benzmüller, C., Miller, D.: Automation of higher-order logic. In: Siekmann, J.H. (ed.) Computational Logic, Handbook of the History of Logic, vol. 9, pp. 215–254. Elsevier (2014)
Benzmüller, C., Paulson, L.C.: Multimodal and intuitionistic logics in simple type theory. Log. J. IGPL 18(6), 881–892 (2010)
Benzmüller, C., Sultana, N., Paulson, L.C., Theiss, F.: The higher-order prover Leo-II. J. Autom. Reason. 55(4), 389–404 (2015)
Bhayat, A., Reger, G.: Restricted combinatory unification. In: Fontaine, P. (ed.) CADE-27, LNCS, vol. 11716, pp. 74–93. Springer (2019)
Bhayat, A., Reger, G.: A combinator-based superposition calculus for higher-order logic. In: Peltier, N., Sofronie-Stokkermans, V. (eds.) IJCAR 2020, Part I, LNCS, vol. 12166, pp. 278–296. Springer (2020)
Blanchette, J.C., Böhme, S., Popescu, A., Smallbone, N.: Encoding monomorphic and polymorphic types. Log. Methods Comput. Sci. (2016)
Blanchette, J.C., Paskevich, A.: TFF1: The TPTP typed first-order form with rank-1 polymorphism. In: Bonacina, M.P. (ed.) CADE-24, LNCS, vol. 7898, pp. 414–420. Springer (2013)
Blanqui, F., Jouannaud, J.P., Rubio, A.: The computability path ordering. Log. Methods Comput. Sci. (2015)
Böhme, S., Nipkow, T.: Sledgehammer: Judgement Day. In: Giesl, J., Hähnle, R. (eds.) IJCAR 2010, LNCS, vol. 6173, pp. 107–121. Springer (2010)
Brown, C.E.: Satallax: An automatic higher-order prover. In: Gramlich, B., Miller, D., Sattler, U. (eds.) IJCAR 2012, LNCS, vol. 7364, pp. 111–117. Springer (2012)
de Bruijn, N.G.: Lambda calculus notation with nameless dummies, a tool for automatic formula manipulation, with application to the Church-Rosser theorem. Indag. Math. 75(5), 381–392 (1972)
Cervesato, I., Pfenning, F.: A linear spine calculus. J. Log. Comput. 13(5), 639–688 (2003)
Cruanes, S.: Extending superposition with integer arithmetic, structural induction, and beyond. Ph.D. thesis, École polytechnique (2015)
Cruanes, S.: Superposition with structural induction. In: Dixon, C., Finger, M. (eds.) FroCoS 2017, LNCS, vol. 10483, pp. 172–188. Springer (2017)
Czajka, Ł., Kaliszyk, C.: Hammer for Coq: automation for dependent type theory. J. Autom. Reason. 61(1–4), 423–453 (2018)
Dowek, G.: Higher-order unification and matching. In: Robinson, J.A. Voronkov, A. (eds.) Handbook of Automated Reasoning, vol. II, pp. 1009–1062. Elsevier and MIT Press (2001)
Fitting, M.: Types, Tableaus, and Gödel’s God. Kluwer (2002)
Ganzinger, H., Stuber, J.: Superposition with equivalence reasoning and delayed clause normal form transformation. Inf. Comput. 199(1–2), 3–23 (2005)
Gordon, M.J.C., Melham, T.F. (eds.): Introduction to HOL: A Theorem Proving Environment for Higher Order Logic. Cambridge University Press, Cambridge (1993)
Gupta, A., Kovács, L., Kragl, B., Voronkov, A.: Extensional crisis and proving identity. In: Cassez, F., Raskin, J. (eds.) ATVA 2014, LNCS, vol. 8837, pp. 185–200. Springer (2014)
Henkin, L.: Completeness in the theory of types. J. Symb. Log. 15(2), 81–91 (1950)
Huet, G.P.: A mechanization of type theory. In: Nilsson, N.J. (ed.) IJCAI-73, pp. 139–146. William Kaufmann (1973)
Huet, G.P.: A unification algorithm for typed lambda-calculus. Theor. Comput. Sci. 1(1), 27–57 (1975)
Jensen, D.C., Pietrzykowski, T.: Mechanizing \(\omega \)-order type theory through unification. Theor. Comput. Sci. 3(2), 123–171 (1976)
Jouannaud, J.P., Rubio, A.: Rewrite orderings for higher-order terms in eta-long beta-normal form and recursive path ordering. Theor. Comput. Sci. 208(1–2), 33–58 (1998)
Jouannaud, J.P., Rubio, A.: Polymorphic higher-order recursive path orderings. J. ACM 54(1), 2:1–2:48 (2007)
Kaliszyk, C., Sutcliffe, G., Rabe, F.: TH1: The TPTP typed higher-order form with rank-1 polymorphism. In: Fontaine, P., Schulz, S., Urban, J. (eds.) PAAR-2016, CEUR Workshop Proceedings, vol. 1635, pp. 41–55. CEUR-WS.org (2016)
Kaliszyk, C., Urban, J.: HOL(y)Hammer: Online ATP service for HOL Light. Math. Comput. Sci. 9(1), 5–22 (2015)
Kamin, S., Lévy, J.J.: Two generalizations of the recursive path ordering. Unpublished manuscript, University of Illinois (1980)
Kőnig, D.: Über eine Schlussweise aus dem Endlichen ins Unendliche. Acta Sci. Math. (Szeged) 3499/2009(3:2–3), 121–130 (1927)
Knuth, D.E., Bendix, P.B.: Simple word problems in universal algebras. In: Leech, J. (ed.) Computational Problems in Abstract Algebra, pp. 263–297. Pergamon Press (1970)
Kohlhase, M.: Higher-order tableaux. In: Baumgartner, P., Hähnle, R., Posegga, J. (eds.) TABLEAUX ’95, LNCS, vol. 918, pp. 294–309. Springer (1995)
Konrad, K.: HOT: A concurrent automated theorem prover based on higher-order tableaux. In: Grundy, J., Newey, M.C. (eds.) TPHOLs ’98, LNCS, vol. 1479, pp. 245–261. Springer (1998)
Kovács, L., Voronkov, A.: First-order theorem proving and Vampire. In: Sharygina, N., Veith, H. (eds.) CAV 2013, LNCS, vol. 8044, pp. 1–35. Springer (2013)
Libal, T.: Regular patterns in second-order unification. In: Felty, A.P., Middeldorp, A. (eds.) CADE-25, LNCS, vol. 9195, pp. 557–571. Springer (2015)
Lindblad, F.: A focused sequent calculus for higher-order logic. In: Demri, S., Kapur, D., Weidenbach, C. (eds.) IJCAR 2014, LNCS, vol. 8562, pp. 61–75. Springer (2014)
Mayr, R., Nipkow, T.: Higher-order rewrite systems and their confluence. Theor. Comput. Sci. 192(1), 3–29 (1998)
Meng, J., Paulson, L.C.: Translating higher-order clauses to first-order clauses. J. Autom. Reason. 40(1), 35–60 (2008)
Miller, D.: A logic programming language with lambda-abstraction, function variables, and simple unification. J. Log. Comput. 1(4), 497–536 (1991)
Paulson, L.C., Blanchette, J.C.: Three years of experience with Sledgehammer, a practical link between automatic and interactive theorem provers. In: Sutcliffe, G., Schulz, S. Ternovska, E. (eds.) IWIL-2010, EPiC, vol. 2, pp. 1–11. EasyChair (2012)
Robinson, J.: Mechanizing higher order logic. In: Meltzer, B., Michie, D. (eds.) Machine Intelligence, vol. 4, pp. 151–170. Edinburgh University Press (1969)
Robinson, J.: A note on mechanizing higher order logic. In: Meltzer, B., Michie, D. (eds.) Machine Intelligence, vol. 5, pp. 121–135. Edinburgh University Press (1970)
Schulz, S.: E–a brainiac theorem prover. AI Commun. 15(2–3), 111–126 (2002)
Schulz, S.: Fingerprint indexing for paramodulation and rewriting. In: Gramlich, B., Miller, D., Sattler, U. (eds.) IJCAR 2012, LNCS, vol. 7364, pp. 477–483. Springer (2012)
Schulz, S., Cruanes, S., Vukmirovic, P.: Faster, higher, stronger: E 2.3. In: Fontaine, P. (ed.) CADE-27, LNCS, vol. 11716, pp. 495–507. Springer (2019)
Snyder, W.: Higher order \(E\)-unification. In: Stickel, M.E. (ed.) CADE-10, LNCS, vol. 449, pp. 573–587. Springer (1990)
Snyder, W., Gallier, J.H.: Higher-order unification revisited: complete sets of transformations. J. Symb. Comput. 8(1/2), 101–140 (1989)
Steen, A., Benzmüller, C.: The higher-order prover Leo-III. In: Galmiche, D., Schulz, S., Sebastiani, R. (eds.) IJCAR 2018, LNCS, vol. 10900, pp. 108–116. Springer (2018)
Sutcliffe, G.: The 10th IJCAR automated theorem proving system competition—CASC-J10 Accepted in AI Commun.
Sutcliffe, G.: The TPTP problem library and associated infrastructure—from CNF to TH0, TPTP v6.4.0. J. Autom. Reason. 59(4), 483–502 (2017)
Sutcliffe, G.: The CADE-27 automated theorem proving system competition–CASC-27. AI Commun. 32(5–6), 373–389 (2019)
Sutcliffe, G., Benzmüller, C., Brown, C.E., Theiss, F.: Progress in the development of automated theorem proving for higher-order logic. In: Schmidt, R.A. (ed.) CADE-22, LNCS, vol. 5663, pp. 116–130. Springer (2009)
Urban, J., Rudnicki, P., Sutcliffe, G.: ATP and presentation service for Mizar formalizations. J. Autom. Reason. 50(2), 229–241 (2013)
Vukmirović, P., Bentkamp, A., Nummelin, V.: Efficient full higher-order unification. In: Ariola, Z.M. (ed.) FSCD 2020, LIPIcs, vol. 167, pp. 5:1–5:17. Schloss Dagstuhl—Leibniz-Zentrum für Informatik (2020)
Vukmirović, P., Blanchette, J.C., Cruanes, S., Schulz, S.: Extending a brainiac prover to lambda-free higher-order logic. In: Vojnar, T., Zhang, L. (eds.) TACAS 2019, LNCS, vol. 11427, pp. 192–210. Springer (2019)
Vukmirović, P., Nummelin, V.: Boolean reasoning in a higher-order superposition prover. In: Practical Aspects of Automated Reasoning (PAAR 2020) (2020)
Waldmann, U., Tourret, S., Robillard, S., Blanchette, J.: A comprehensive framework for saturation theorem proving. In: Peltier, N., Sofronie-Stokkermans, V. (eds.) IJCAR 2020, Part I, LNCS, vol. 12166, pp. 316–334. Springer (2020)
Acknowledgements
Simon Cruanes patiently explained Zipperposition’s internals and allowed us to continue the development of his prover. Christoph Benzmüller and Alexander Steen shared insights and examples with us, guiding us through the literature and clarifying how the Leos work. Maria Paola Bonacina and Nicolas Peltier gave us some ideas on how to treat the extensionality axiom as a theory axiom, ideas we have yet to explore. Mathias Fleury helped us set up regression tests for Zipperposition. Ahmed Bhayat, Tomer Libal, and Enrico Tassi shared their insights on higher-order unification. Andrei Popescu and Dmitriy Traytel explained the terminology surrounding the \(\lambda \)-calculus. Haniel Barbosa, Daniel El Ouraoui, Pascal Fontaine, Visa Nummelin, and Hans-Jörg Schurr were involved in many stimulating discussions. Christoph Weidenbach made this collaboration possible. Ahmed Bhayat, Wan Fokkink, Nicolas Peltier, Mark Summerfield, and the anonymous reviewers suggested several textual improvements. The maintainers of StarExec let us use their service for the evaluation. We thank them all. Bentkamp, Blanchette, and Vukmirović’s research has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation program (grant Agreement No. 713999, Matryoshka). Bentkamp and Blanchette also benefited from the Netherlands Organization for Scientific Research (NWO) Incidental Financial Support scheme. Blanchette has received funding from the NWO under the Vidi program (Project No. 016.Vidi.189.037, Lean Forward).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bentkamp, A., Blanchette, J., Tourret, S. et al. Superposition with Lambdas. J Autom Reasoning 65, 893–940 (2021). https://doi.org/10.1007/s10817-021-09595-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10817-021-09595-y