
Abstract
Purpose
First trimester miscarriage is a major concern in IVF-ET treatments, accounting for one out of nine clinical pregnancies and for up to one out of three recognized pregnancies. To develop a machine learning classifier for predicting the risk of cleavage-stage embryos to undergo first trimester miscarriage based on time-lapse images of preimplantation development.
Methods
Retrospective study of a 4-year multi-center cohort of 391 women undergoing intra-cytoplasmatic sperm injection (ICSI) and fresh single or double embryo transfers. The study included embryos with positive indication of clinical implantation based on gestational sac visualization either with first trimester miscarriage or live-birth outcome. Miscarriage was determined based on negative fetal heartbeat indication during the first trimester. Data were recorded and obtained in hospital setting and research was performed in university setting.
Results
A minimal subset of six non-redundant morphodynamic features were screened that maintained high prediction capacity. Features that account for the distribution of the nucleolus precursor bodies within the small pronucleus and pronuclei dynamics were highly predictive of miscarriage outcome as evaluated using the SHapley Additive exPlanations (SHAP) methodology. Using this feature subset, XGBoost and random forest models were trained following a 100-fold Monte-Carlo cross validation scheme. Miscarriage was predicted with AUC 0.68 to 0.69.
Conclusion
We report the development of a decision-support tool for identifying the embryos with high risk of miscarriage. Prioritizing embryos for transfer based on their predicted risk of miscarriage in combination with their predicted implantation potential is expected to improve live-birth rates and shorten time-to-pregnancy.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Most miscarriages occur during the first trimester of pregnancy (first 13 weeks), accounting for one out of nine clinical pregnancies and for up to one out of three recognized pregnancies (positive pregnancy test) [1, 2]. Unlike second trimester miscarriages and third trimester fetal loses that occur due to multiple reasons (congenital defects, placental problems, cervical insufficiency, and infections) [3, 4], aneuploidy is the main cause of first trimester miscarriages [5]. Early identification of chromosomal abnormalities that permit normal preimplantation development is performed today via preimplantation genetic testing for aneuploidy (PGT-A). PGT-A is an invasive procedure that involves piercing of the zona pellucida and removal of several trophectoderm cells. Since PGT-A typically requires over 24 h in clinical settings, blastocysts are often cryopreserved, thus eliminating fresh transfers. In addition, failure of amplification and mosaicism in PGT-A contribute to false negative prediction [6, 7]. Since euploid embryos have a higher potential to implant, the implementation of non-invasive methods for early identification of embryos with high risk of miscarriage has the potential to improve clinical performance [8].
Machine learning-based decision support tools are increasingly incorporated into the healthcare system [9,10,11] and specifically in the assessment of the developmental potential of preimplantation embryos [12]. Supervised machine learning is the most widely used approach in which retrospective datasets with known outcome (aka labels) are employed for training a classification model. Prediction of non-labeled embryos is then performed by identifying patterns that are associated with positive or negative outcome using the trained model. The incorporation of time-lapse incubation systems in IVF clinics provided high quality video files that record the course of preimplantation embryo development. These data facilitated the prediction of the potential of embryos to reach blastulation [13, 14] and to implant within the uterus [15,16,17]. Retrospectively labeled datasets of significant size can support the training of convolutional neural networks (CNN) that test the relationships between multiple features by convoluting image pixels. CNN’s were used for performing automated morphokinetric annotation [18, 19] and for predicting implantation [20,21,22]. Indeed, we found that CNN classifiers of embryo blastulation and implantation identify dynamic features beyond the discrete morphological elements and morphokinetic events that are broadly used by non-convolutional algorithms [20].
In IVF treatments, embryos that are selected for transfer according to their predicted implantation potential may possess high risk of miscarriage despite exhibiting normal morphological and morphokinetic profiles. The unmet need that arises is to generate technologies that will allow the assessment of embryo miscarriage potential in parallel to existing technologies that assess the implantation potential. Hence, our overall goal was to develop a decision-support tool that will perform accurate and robust evaluation of miscarriage potential non-invasively and within a reasonable time frame to alleviate the requirement for cryopreservation. In line with existing decision support tools, here we employed machine learning models to evaluate miscarriage potential based on time-lapse recordings of embryos from IVF clinics during preimplantation stages. Due to the inherent limitations that are associated with prospective studies, including ethical challenges and study size, we performed a multicenter retrospective study. Specifically, a dataset of 464 transferred and successfully implanted embryos that were obtained from four medical centers and labeled according to miscarriage (MC) or live-birth (LB) outcomes was assembled. The fact all the embryos in the dataset that were available for training the classification models had been carefully selected for transfer in the clinics based on their time-lapse visualization and were further successfully implanted introduces a significant computational challenge for predicting miscarriage outcome. Akin to the prediction of embryo implantation outcome, accuracy of MC prediction is expected to be limited by the fact that no information is provided on the uterine factors nor on the related variation between recipients [23]. Despite these challenges, here we present a machine learning classification model of MC prediction within 3 days from ICSI fertilization and demonstrate AUC ~ 0.7. In this manner, our decision support tool can support both cleavage-stage and blastocyst transfer strategies. The implementation of our decision support tool in the clinic is expected to improve live-birth rates and shorten time-to-pregnancy by deselecting for transfer the embryos with high risk of MC.
Materials and methods
Data acquisition
Patients and embryos
Data from 391 women who underwent fresh single or double embryo transfers were collected from IVF clinics of four medical centers as recently reported (Fig. 1a) [20]. All embryos in the dataset were fertilized via intracytoplasmic sperm injection (ICSI). PGT-A–tested embryos were discarded. A total of 464 positively implanted embryos were included in this study as determined on week 5 by ultrasound imaging of gestational sacs. MC labeling of 96 embryos was determined based on negative ultrasound indication of fetal heartbeat on week 13 or earlier. The remaining 368 embryos were labeled LB in accordance with a confirmed live-birth pregnancy outcome. Importantly, MC or LB labeling was based on known outcome of each individual embryo. For example, in the case of a twin implantation that proceeds to become a vanishing twin pregnancy due to anembryonic implantation or early clinical loss, the embryos remained unlabeled since the identity of the miscarried embryo and the singleton pregnancy embryo cannot be separated.

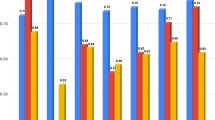
Characteristics of the dataset of 1st trimester miscarriage (MC) and live-birth (LB) embryos. a Top to bottom: distributions of MC/LB labeled embryos, day of transfer, number of transferred embryos, and maternal age obtained from five data providing clinics (H1 to H5). b The embryo dataset was divided into a train/validation set and an MC/LB-balanced test set
Labeled video database
Anonymized time-lapse video files were recorded by time-lapse incubators (Embryoscope, VitroLife) and imported together with the associated clinical metadata. Data curation was performed using a PostgreSQL database that we assembled and formulated as reported recently [20]. In short, the database consisted of a front-end website that supported display, query, and data annotation (Hebrew University IT) and maintained by CHELEM LTD. Morphokinetic annotations and quality assurance were performed by qualified and experienced embryologists [20].
Feature extraction
Extraction of morphological features
Static morphological features are routinely used for evaluating the potential of embryos to implant [24,25,26,27]. The embryos were characterized by their two-cell and four-cell fragmentation percentage and blastomere size symmetry, as annotated in adherence to established criteria [28]. Additional morphological and geometrical features of the zona pellucida, ooplasm, pronuclei (PN’i), and nucleolus precursor bodies (NPB’s) were semi-automatically extracted per the third frame prior to tPNf (~ 1 h) using a custom designed code (Python). The orientation angle of the first cleavage plane was evaluated using the seven z-stack images [29]. The annotation of all morphological features is summarized in Table 1.
Extraction of morphokinetic features
Time-lapse incubators facilitate the annotation of the time points of discrete events. Morphokinetic annotations and quality assurance were performed by qualified and experienced embryologists as we recently reported [20]. In short, morphokinetic profiles were obtained via majority voting according to established protocols [30, 31] and further validated blindly by an expert embryologist. Morphokinetic annotations included the time of PN appearance (tPNa) and fading (tPNf), and cleavage of N blastomeres (tN, N = 2 to 8) [32, 33]. We also introduced all 36 pairwise intervals and pairwise ratios between the events.
DLR
We calculated the distances from the linear regression (DLR) as follows. Pairs of the morphokinetic features of LB embryos appear to be linearly correlated as demonstrated for t2-t3 events (Fig. 2). These morphokinetic relationships are defined by the linear regression of the morphokinetic scatter plot (R2 = 0.87). To estimate the association with the averaged morphokinetic profiles of high quality positively-implanted embryos, we calculated the shortest Euclidean distance of each embryo from these linear Regression (Fig. 2).

Distance from linear regression (DLR). Time of 3-cell cleavage (t3) is plotted versus time of 2-cell cleavage (t2) for a total of 353 LB embryos (gray symbols). The dependence between t3 and t2 is evaluated via linear regression (black line). t2–t3 DLR (DLR2,3) is the shortest distance of an embryo from the regression line as illustrated here for a short DLR2,3 embryo (marked in orange; 2.8 h) and a high DLR2,3 embryo (marked in green; 6.4 h)
PN dynamics
Male and female PN’i were visible for 17 ± 2.5 h (average ± STD) between tPNa and tPNf. The trajectories of the PN’I were extracted using optical flow as follows. Fifteen non-adjacent pixels were selected within each PN using the starting points frame. The time-lapse consecutive coordinates of each episode relative to the embryo frame of reference were obtained via the Lucas-Kanade model and a 15 × 15 pixels surroundings [34]. Both forward (tPNa to tPNf) and reverse (tPNf to tPNa) optical flow tracking episodes were performed, consisting of all the time-lapse images in between. The trajectory of each PN was calculated by averaging the coordinates of all 15 tracks.
Prediction algorithms and data analysis
Prediction models
Due to the limited size of the dataset, we employed XGBoost (XG) and random forest (RF) models that minimize the risk of overfitting by integrating ensembles of multiple classification processes [35, 36]. In addition, XG and RF are based on clusters of decision trees that are suitable for identifying complex patterns which are derived by nonlinear relationships between the features. The XG model was implemented using XGBoost Python library and the RF model was implemented using the Scikit-learn Python package [37]. We set the number of trees and depth 6 and 1 for the XG model, and 65 and 3 for the RF model, and used the default feature importance scores for both models. We set 0.25 learning rate for the XG model and the RF splitting criterion was defined based on Gini impurity. Parameter search optimization over the above models was performed using the Hyperopt Python framework package [38]. Hyperparameter optimization was performed using the following specifications. RF model: Max_depth (sampled from range [1, 3]); Max_features (sampled from range [0.1, 0.5]); Min_samples_leaf (sampled from range [25, 50]); Min_samples_split (sampled from range [25, 50]); N_estimators (sampled from range [1, 100]). XG model: Learning rate (sampled from range [0.01, 0.3]); Min_child_weight (sampled from range [25, 40]); Max_depth (sampled from range [1, 3]); subsample (sampled from range [0.1, 1]); Colsample_bytree (sampled from range [0.1, 0.4]); N_estimators (sampled from range [1, 50]); N_estimators (sampled from range [1, 50]).
Validation and testing methodologies
The embryos were divided into a train/validation set and an uncontaminated test set with balanced numbers of MC and LB labels (Fig. 1b). To effectively increase the variation between train set embryos, we performed a 100-fold Monte-Carlo cross validation scheme. Specifically, the classifier was trained on randomly selected 90% of the relevant train-validation set embryos and validated on the remaining 10%. In this scheme, each embryo was selected for validation multiple times, thus allowing the classifier to “learn” a given embryo as it is contrasted by different combinations of train-set embryos. The fact that the validation set AUC is in high agreement with the test set AUC for both models increases confidence that the Monte-Carlo cross-validation scheme did not generate overfitting (Fig. 8). MC prediction was performed by averaging the cross-validated model’s weights.
Statistical analyses and graphical design
Statistical analyses were performed using NumPy, Scikit-learn, pandas, and SciPy Python packages. Figures were generated using Matplotlib and Seaborn Python packages. Manual features were extracted using the Pillow Python package.
Python packages version stamping
See Supplementary Table S1.
Results
Motivated by the prediction of pregnancy using machine learning, we hypothesized that early pregnancy loss can also be predicted based on time-lapse imaging of preimplantation development. Hence, we assembled a dataset of videos of MC- and LB-labeled embryos that were collected from four IVF clinics that accept patients with a diverse ethnic and racial backgrounds (Eastern and Western European Jews, North African and Middle Eastern Jews, Arabs, and others) [39]. This embryo dataset spans a range of maternal age. Clinics H1 and H3 tend to perform double embryo transfers on day-3 of preimplantation development or earlier whereas single embryo transfers are frequently performed in clinics H3 and H4 in which half of the embryos are transferred on day-5 or later (Fig. 1a). We first compared the morphokinetic profiles of MC and LB embryos, and found indistinguishable profiles, suggesting that the risk of MC cannot be assessed using the standard statistical approaches (Fig. 3a). Similarly, there were no differences between MC and LB embryos in terms of their developmental states and day of transfer (Fig. 3b). We conclude that the ethnic diversity, maternal age distributions, and inherent variation in the clinical protocols between the hospitals contribute to the generality of our study. In addition, the overlapping morphokinetic profiles, day of transfer, and the developmental states of the transferred embryos are consistent with communal criteria for selecting both MC and LB embryos for transfer, thus minimizing the effects of confounding parameters and satisfying a natural experiment.

Live-birth and first trimester miscarriage embryos share morphokinetic profiles, embryo state, and time of transfer statistics. a (i) Representative images of selected morphokinetic events from tPNa and tPNf to time of 8-cell cleavage (t8). (ii) Temporal distributions of LB and MC embryos are overlapping (KS p-values > 0.4). b The relationship between time-of-transfer and embryo state at time-of-transfer is overlapping between MC and LB embryos. KS: Kolmogorov–Smirnov
Feature extraction
To identify visual markers of first trimester miscarriage, we assembled an expansive set of 314 features that were derived from measurable static and dynamic properties of preimplantation embryo development and span a range of length scales from the NPB to the zona pellucida (Table-1 and Methods). The feature set included morphological, morphokinetic, and other dynamic features as defined in the “Methods” section and summarized in Table 1. Morphological features account for specific geometrical properties of the embryo as derived from single frames. Morphokinetic features included the time points of morphokinetic events, their pairwise intervals and pairwise ratios, and the DLR features that quantify an effective distance of an embryo from the average profile of positively implanted embryos.
The remaining features are associated with PN dynamics as evaluated using optical flow (the “Methods” section). Optical flow tracking was validated against manual tracking, showing only insignificant disagreement that was upper-bounded by one quarter of PN radius (Fig. 4a). Interestingly, distinctive PN trajectories were observed and classified into one of the following categories based on their end-to-end distance and contour curvature (Fig. 4b): (i) curved trajectories; (ii) linear trajectories; (iii) stationary trajectories. By obtaining the temporal coordinates of the PN’i trajectories with respect to the embryo frame of reference, we defined specific features that were related to PN step size and velocity, the distribution of distances between PN’i, and their distance from embryo center of mass (Table 1).

Trajectories of PN dynamics depicted using optical flow. a Validation of the optical flow algorithm: (i) time-lapse images show a comparison between the dynamic trajectories of a representative PN that was obtained by optical flow (yellow) and via manual tagging of the PN center of mass (orange). (ii) The distance between the locations of the PN as obtained by optical flow versus manual tagging is plotted as a function of time from tPNa to tPNf. The disagreement between automated optical flow and manual tagging is significantly smaller than the relevant length scale set by the PN radius. b Optical flow tracking revealed distinctive types of PN trajectories relative to embryo center of mass: (i) curved trajectories; (ii) linear trajectories; (iii) stationary trajectories. Bottom images show zoom-in of PN trajectories. The temporal appearance of the PN trajectories are color-coded from green (tPNa) to red (tPNf)
Feature screening
The breadth of the feature set allowed us to examine a variety of morphodynamic elements and processes. However, the size of the labeled embryo dataset limited the number of training features in order to avoid overfitting. Hence, we carried out feature screening following a stepwise scheme based on statistical distance criteria between MC and LB embryo distributions followed by MC prediction performance using random forest (RF) and XGBoost (XG) models. Statistical distance between MC and LB embryos were calculated by the Kolmogorov–Smirnov (KS) test and the Kullback–Leibler (KL) divergence (Fig. 5a). Four features were distinguished by high KL-entropy and low KS p-value (green symbols): (1) t2–t3 distance from linear regression (DLR2,3; the “Methods” section); (2) maximal distance between the NPBs of the small PN; (3) the difference between the distances of the two PN’i from the embryo center of mass (at tPNf); (4) the maximal distance between pairs of NPBs in the small PN normalized by small PN radius. These features were thus expected to provide high predictive strength.

Feature screening. a The statistical features distance (n = 314) between their average MC and LB values are quantified using KS test (p-value) and KL divergence (entropy). b RF and XG models were trained on subsets of features with KL entropy above threshold and KS p-value below threshold (dashed black frame in a). Using a series of KL and KS threshold values (black frame in a), 18 subsets of qualified features were selected and are plotted with respect to their AUC coordinates of MC prediction by RF and XG models. The ten most-predictive subsets consisting of 64 features were selected (red frame). c The selected 64 features were ranked with respect to their XG and RF weights as obtained by 100-fold cross validation within each subset experiment. The top eight ranked features are marked in black (red dashed frame). d Pairwise Pearson correlation matrix of the set of eight features highlights redundancy between cf1 and cf3 and between cf2 and cf8. e Blue symbols: starting with a set of eight features, XG AUC values increase with the removal of three features as part of stepwise backward feature selection. Further removal of features decreases both RF and XG prediction. Red symbols: starting with five backward selected features, the addition of one feature via two-step forward feature selection increases both RF and XG AUC values. Addition of subsequent features does not improve prediction. The group of five backward selected features (flue) and one forward selected feature (red) constitute the minimal subset of non-redundant features that retain predictive strength. RF: Random forest. XG: XGBoost. KS: Kolmogorov–Smirnov. KL: Kullback–Leibler
KS-KL statistical distance criteria estimate the predictive potential of each feature individually. Since our goal is to identify the minimal group of features with high predictive strength, we applied a series of KS p-value and KL entropy thresholds, selected the subset of qualified features with lower KS p-value and higher KL entropy, and assessed their predictive potential by training RF and XG models. Six KS p-value thresholds, \({\lambda }_{i}^{KS}\), and three KL entropy thresholds, \({\lambda }_{j}^{KL}\), were chosen (Fig. 5a, black frame), thus defining eighteen feature subsets:
To better assess classification performance by simulating multiple validation sets, we executed a 100-fold Monte-Carlo cross-validation experiment (Methods). The predictive strengths of the selected feature subsets were evaluated by averaging the cross-validated AUC values of the RF and the XG models (Fig. 5b). Next, we selected the ten feature subsets with the highest RF and XG AUC values (Fig. 5b, red frame). In total, these ten subsets included 64 features; a fraction of which were shared by multiple subsets. The features were then ranked by their RF and XG importance scores, as averaged across all relevant Monte-Carlo cross-validation experiments (Fig. 5c). In this manner, we identified the eight top ranked features (Fig. 5c, red frame).
Selection of a non-redundant feature subset
So far, features were screened based on their individual MC-LB statistical distances and their weighted contributions to RF and XG prediction models. However, redundancy among the eight selected features cannot be excluded. To obtain further insight, we calculated the pairwise Pearson Correlation Matrix between the distributions of their feature values (Fig. 5d). Indeed, feature pairs [cf1, cf3] and [cf2, cf8] were highly correlated. Specifically, the difference between the smallest steps of the two PN’i (cf1) and the difference between the slowest velocities of the two PN’i (cf3) were highly correlated. Likewise, the correlation between the non-normalized (cf2) and the normalized (cf8) maximal distance between NPBs was also high (Table-1).
To identify the minimal subset of non-redundant features that maintain high predictive strength, we first performed feature selection via backward elimination. Starting with the selected group of eight, each feature was removed in its turn and RF and XG 100-fold Monte-Carlo cross-validation was performed on the remaining subsets of seven features (the “Methods” section). The single feature that had the smallest negative effect on RF and XG AUC’s was removed. Backward feature elimination was performed in a stepwise manner, thus identifying a series of subsets with a decreasing number of features from eight-to-one (Fig. 5e, blue symbols). We found that the removal of the first three features did not decrease both RF and XG prediction strengths. However, subsequent removal of the remaining features decreased both XG and RF prediction performance, indicating that the subset of five features represents the minimal collection of non-redundant features with high MC prediction. Consistent with the pairwise Pearson correlation analysis discussed above, cf8, cf2, and cf3 features were indeed discarded in this order (Fig. 5d).
Backward feature selection did not exclude the possibility that reintroducing additional features from the original pool of features that had been screened out would not improve MC prediction. The goal was to assess the integrated contributions of multiple features rather than testing features one by one. Since testing all combinatorial subsets is computationally not feasible, we employed a two-step forward feature selection scheme. Starting with the subset of five-features, the addition of all feature pair combinations was tested by training RF and XG models as described above. The feature pair that improved prediction the most was identified and the feature with the lower index was arbitrarily selected. In this manner, we performed a five + two, six + two, and seven + two forward feature selection cycles thus increasing subset size from five to eight features (Fig. 5e, red symbols). We found that introducing the sixth feature indeed improved the predictive strength of both RF and XG models. However, subsequent addition of the seventh and eighth features failed to increase AUC values. We thus conclude that minimal redundancy and high predictive strength of MC outcome is provided by the final subset of five backward selected features plus one forward selected feature as summarized in Table-1 (right column).
The minimal subset of non-redundant and highly predictive features is described below.
-
\({{\varvec{f}}}_{1}\): the maximal distance between NPB pairs within the small PN normalized to PN radius (Fig. 6a):
Fig. 6 
Illustration of the selected morpho-dynamic features for MC prediction. a, Feature \({f}_{1}\): The distances \({d}_{i,j}\) between all NPB pairs are zoomed-illustrated within the small PN. Feature \({f}_{2}\): the radius of the ooplasm, \({R}_{o}\), and the center of mass of the ooplasm (black ‘\(\times\)’) are depicted. Pink and blue ‘\(\times\)’ marks represent the centers of mass of the small and large PN’i, respectively. b Features \({f}_{5}\): \({tPN}_{a}\) to \({tPN}_{f}\) trajectories consist of (N-1) steps of the small (pink, \({r}_{i}^{s}\)) and large (blue, \({r}_{i}^{l}\)) PN’i. Features \({f}_{6}\): the distances between the PN’i to the center of the zygote, \({l}_{l}\) and \({l}_{s}\), are evaluated at \({tPN}_{f}\)

-
\({{\varvec{f}}}_{2}\): radius of the ooplasm.
[Both \({{\varvec{f}}}_{1}\) and \({{\varvec{f}}}_{2}\) were evaluated using the central focal plane image that was recorded 1 h prior to \({tPN}_{f}\)].
-
\({{\varvec{f}}}_{3}\): \({DLR}_{\mathrm{2,3}}\) (Fig. 2).
-
\({{\varvec{f}}}_{4}\): \({DLR}_{\mathrm{5,6}}.\)
-
\({{\varvec{f}}}_{5}\): the ratio between the maximal step size of the large PN, \({r}_{i}^{l}\), and the small PN, \({r}_{i}^{s}\), (Fig. 6b):
-
$${f}_{5}={\mathrm{max}\left\{{r}_{i}^{l}\right\}}_{i=1}^{N-1}/{\mathrm{max}\left\{{r}_{i}^{s}\right\}}_{i=1}^{N-1}$$
Maximal steps are evaluated across \(N\) steps performed by the PN’i from \({tPN}_{a}\) and \({tPN}_{f}\).
-
\({{\varvec{f}}}_{6}\): the absolute difference between the distances of the large (\({l}_{l}\)) and small (\({l}_{s}\)) PN from zygote center of mass at \({tPN}_{f}\) (Fig. 6b):
We note that half of the features are associated either with NPB pairwise dynamics (\({{\varvec{f}}}_{1}\)) or with PN dynamics (\({{\varvec{f}}}_{5}\) and \({{\varvec{f}}}_{6}\)). The remaining features correspond to ooplasm size (\({{\varvec{f}}}_{2}\)) and to cleavage-stage morphokinetic profiles (\({{\varvec{f}}}_{3}\) and \({{\varvec{f}}}_{4}\)).
Prediction of MC outcome
MC prediction was performed by training an XG model using the selected feature subset \({f}_{1}\) to \({f}_{6}\) (Fig. 7a). The earliest time for MC prediction is set by the time of six blastomere cleavage event as required for feature \({f}_{6}\). To effectively increase the variation between train set embryos, we performed a 100-fold Monte-Carlo cross validation scheme (the “Methods” section). As expected, the area under the receiver operating characteristic (ROC) curve (AUC) of train set embryos was relatively high, indicative of moderate overfitting, which is consistent with the size of the available dataset. Nevertheless, AUC of 68–69% was robustly obtained both on the validation set and the test set embryos. Importantly, comparable prediction performance was also obtained both by an RF model and by an integrated XG-RF classifier, thus increasing confidence in the utility of this feature subset for MC prediction (Fig. 8). To verify that including H1 clinic in both classification model training, for which there were only LB embryos available, did not introduce confounding effects, we removed all H1 embryos, including the three H1 test set embryos, plotted the ROC curve and calculated the AUC values (Supplementary Fig. S1). Satisfyingly, we found agreement with the AUC values as evaluated for the embryos from all clinics (Fig. 8a–b).

Embryo MC prediction at early preimplantation stages. a Train, validation, and test set ROC curves and AUC values of MC prediction using an XG model. Sensitivity confidence intervals, as derived based on a 100-fold Monte Carlo cross-validation scheme, are depicted by grey margins. b A precision-sensitivity curve of test set embryo is plotted. c Confusion matrices of two binary classifiers that favour (i) precision and (ii) sensitivity are evaluated for test set embryos. The binary classifiers were defined by setting the threshold values depicted in b’. ROC: receiver operating characteristic. AUC: area under the ROC curve. RF: random forest. XG: XGBoost

MC prediction by an RF model and an RF-XG integrated model. Train, validation, and test set ROC curves of MC prediction using an RF model (a) and an integrated XG-RF classifier (b). The latter corresponds to averaging the MC scores that were obtained by RF and XG models. RF: random forest. XG: XGBoost. ROC: receiver operating characteristic. AUC: area under the ROC curve
To demonstrate clinical utility and delineate the trade-off between precision (positive predictive value; PPV) and sensitivity (recall) in relation with improving live-birth rates and shortening time-to-pregnancy, we illustrate two extreme scenarios (Fig. 7b). We first consider a women patient having only a small number of high quality embryos with a predicted high potential of LB outcome. Due to their small number, embryos with both moderate and high predicted LB score should not be discarded by setting a high classification threshold for MC prediction (equivalent to setting a low threshold for LB prediction; Fig. 7c–i). The tradeoff of setting a high MC threshold is the inclusion of embryos with moderate predicted risk of MC outcome. In the opposite case, we consider a woman patient with a large number of embryos with of a high predicted LB potential. Here, the clinicians have the benefit of discarding all embryos with a predicted moderate-to-high risk of MC outcome while also discarding embryos with moderate predicted LB potential by setting a relatively low threshold for MC prediction (equivalent to setting a high threshold for LB prediction; Fig. 7c–ii). Precision is favored in first scenario, which supports increasing live-birth rates at the expense of not shortening time-to-pregnancy due to MC. In the second scenario, the clinicians can sustain losing high-quality embryos in order to shorten time-to-pregnancy by lowering the risk of MC.

Statistical and SHAP feature analysis. a Comparison of feature distributions shows small yet statistically significant differences between MC and LB embryos as measured by KS distances and p-value assessments. b SHAP values are plotted versus feature values (color coded), showing a positive relationship between \({f}_{1}, {f}_{2}, {f}_{3}\), and \({f}_{5}\) and MC prediction, and a positive relationship between \({f}_{4}\) and \({f}_{6}\) and LB prediction. c Feature importance is estimated by the aSHAP, which quantifies the impact on accurate prediction. KS: Kolmogorov–Smirnov. SHPA: Shapley Additive exPlantions. aSHAP: Adjusted SHAP
Feature importance
PN and NPB morphologies were previously associated with aneuploidy [40,41,42,43,44,45] Here we find that the morpho-dynamic properties as characterized by the trajectories of the PN’i and the NPB’s differentiate between the potential of MC versus LB outcomes. The maximal distance between NPB pairs within the small PN (\({f}_{1}\)) is greater in MC embryos than in LB embryos (Fig. 9a; p-value 0.001). In addition, MC outcome is associated with a larger ratio between the maximal step sizes of the large versus the small PN’i (\({f}_{5}\)) and a shorter difference between PN’i locations with respect to zygote center of mass (\({f}_{6}\)). Morphokinetically, \({DLR}_{\mathrm{2,3}}\) distances (\({f}_{3}\)) are longer in MC embryos whereas \({DLR}_{\mathrm{5,6}}\) distances (\({f}_{4}\)) are shorter. This indicates that the potential of LB is more closely associated with the averaged profile of positively-implanted embryos with respect to \(t2-t3\) correlations (p-value < 0.01) and that the potential of MC is more closely associated with the averaged profile of positively implanted embryos with respect to \(t5-t6\) correlation (p-value < 0.04). Lastly, we find that ooplasm radius (\({f}_{2}\)) of MC embryos is slightly larger than of LB embryos (Fig. 9a; p-value < 0.01).
To evaluate the impact that features have on MC prediction by the XG classifier, we employed the SHapley Additive exPlanations (SHAP) methodology [46]. Features that obtained high positive SHAP values contribute to MC prediction of the embryos whereas high negative SHAP values contribute to LB prediction. We find that for all six features, the embryos with high feature values are separated from embryos with low features values along the SHAP axis (Fig. 9b). Specifically, high \({f}_{1}\), \({f}_{2}\), \({f}_{3}\), and \({f}_{5}\) values, which are obtained by embryos with positive SHAP, contribute to MC prediction. On the other hand, high \({f}_{4}\) and \({f}_{6}\) contribute to LB prediction (Fig. 9b). Unlike SHAP that measures the relationship between feature values and prediction, feature importance is assessed using the adjusted SHAP (aSHAP), which scores accurate prediction by adjusting a negative sign to false prediction [20]. Indeed, we find that all the features of the final subset, with the exception of \({f}_{5}\), hold comparable importance in directing accurate MC prediction (Fig. 9c).
Discussion
Time-lapse incubation systems provide high-quality visualization of preimplantation embryos that facilitate the development of machine learning-based classifiers. Such classifiers are routinely utilized within IVF clinics worldwide for selecting the embryos for transfer with the highest implantation potential. However, these algorithms are sensitive to various morphological elements and morphokinetic features that mark the potential to implant but fail to detect features that are associated with the risk of MC outcome. Using the same video files of preimplantation development, our algorithm predicts MC potential as early as the time of 6-cell cleavage event based on the following six morpho-dynamic features: (1) the normalized maximal distance between NPB within the smaller PN; (2) radius of the ooplasm; (3,4) the DLR’s of morphokinetic event pairs t2–t3 and t5–t6; (5) the ratio between the maximal step sizes of the large and small PN’i; (6) the difference in the distance of the large and small PN’s from zygote center. In this manner, our classifier supports MC prediction within 3 days from fertilization in parallel to prediction of embryo implantation.
Training a machine learning-based classifier for assessing MC potential requires positively-implanted embryos with MC or LB indications. We used a large dataset of 70 K embryos that included 5,500 embryos with known implantation outcome, out of which 96 MC-labeled and 368 LB-labeled embryos were available for training. These proportions demonstrate the challenge in allocating the required clinically-labeled data for our retrospective multi-center study. Owing to the fact that the embryos in our dataset had been selected for transfer according to consensual morpho-dynamic guidelines, their visual diversity was lower than the heterogeneity that is demonstrated among transferred and non-transferred embryos. Importantly, the reduced diversity among the embryos that are available for model training is shared by other classification tasks including the prediction of embryo implantation and pregnancy outcome. Hence, our retrospective study was limited by sample size and by the morpho-dynamic heterogeneity of the embryos.
To overcome the abovementioned challenges, we performed a rigorous multistep feature screening of the embryos that minimizes the KS p-value while maximizing the KL divergence while evaluating their predictive potential using RF and XG models. We identified a subset of six morpho-dynamic features that retain prediction accuracy during early stages of preimplantation development. Interestingly, the selected subset was enriched with features that manifest the differences in the dynamic properties of PN and NPB compartments between MC and LB embryos. Since aneuploidy is tightly associated with first trimester MC [5], the contribution of PN and NPB-based features is consistent with a direct consequential impact that chromosomal abnormalities may have on PN and NPB dynamics. It would be insightful to test the capacity of the MC classifier to predict various forms of embryo aneuploidy; however, this task stems beyond the scope of this report. The fact that DLR2,3 and DLR5,6 features are included within the selected subset highlights potential downstream effects that chromosomal abnormalities may have on cleavage regulation in a manner that decouples early cleavage events (t2–t3) and late cleavage events (t5–t6). Feature screening as reported here is not a deterministic process and the selection of a different feature subset that is both predictive and non-redundant cannot be excluded. While the reported features were extracted using semi-automated algorithms, clinical implementation would be further supported by developing fully automated tools for the extraction of the reported features or of an equivalent subset of predictive and non-redundant features [47].
We demonstrate the prediction of embryo MC outcome with AUC 68%. This AUC value is comparable with the prediction accuracy of other reported algorithms, including CNN-based classification models of embryo implantation outcome [20, 22]. The fact that the accuracy in the prediction of embryo implantation and MC outcome, as assessed via AUC, appears to have a finite upper limit may be indicative of the missing input uterine parameters and/or maternal factors [23]. In terms of clinical application, our work provides a real-time non-invasive decision-support tool that can improve the current policy in IVF treatments. Embryos will first be selected for transfer based on their implantation potential as predicted using existing classifiers. Then, the embryos with a high risk of MC will be de-selected, thus improving live-birth rates while shortening time-to-pregnancy. In conclusion, we hope that by providing a proof-of-concept of assessing the risk of MC, our retrospective study will motivate future work using larger datasets that will eventually lead to prospective clinical studies.
Data availability
The clinical data are owned by Hadassah Medical Center and by Clalit Health Services. Restrictions apply to the availability of these data, which were used anonymously under ethical agreements with each clinic separately for this study, and so are not made publically available. Access requests can be directed to A.B.M. (Hadassah Medical Center), Y.O. (Kaplan Medical Center), I.H.V (Soroka University Medical Center), and Y.S. (Women’s Hospital, Rabin Medical Center).
Code availability
The copyrights of the code are owned by Yissum–the technology transfer company of The Hebrew University of Jerusalem. Requests can be sent to A.B.
References
Wilcox AJ, Weinberg CR, O’Connor JF, Baird DD, Schlatterer JP, Canfield RE, Armstrong EG, Nisula BC. Incidence of early loss of pregnancy. N Engl J Med. 1988;319:189–94.
Nybo Andersen AM, Wohlfahrt J, Christens P, Olsen J, Melbye M. Maternal age and fetal loss: population based register linkage study. BMJ. 2000;320:1708–12.
Michels TC, Tiu AY. Second trimester pregnancy loss. Am Fam Physician. 2007;76:1341–6.
Allanson B, Jennings B, Jacques A, Charles AK, Keil AD, Dickinson JE. Infection and fetal loss in the mid-second trimester of pregnancy. Aust N Z J Obstet Gynaecol. 2010;50:221–5.
Romero ST, Geiersbach KB, Paxton CN, Rose NC, Schisterman EF, Branch DW, Silver RM. Differentiation of genetic abnormalities in early pregnancy loss. Ultrasound Obstet Gynecol. 2015;45:89–94.
Practice Committees of the American Society for Reproductive M, the Society for Assisted Reproductive Technology. Electronic address Aao, Practice Committees of the American Society for Reproductive M, the Society for Assisted Reproductive T: The use of preimplantation genetic testing for aneuploidy (PGT-A): a committee opinion. Fertil Steril 2018;109:429–436.
Taylor TH, Gitlin SA, Patrick JL, Crain JL, Wilson JM, Griffin DK. The origin, mechanisms, incidence and clinical consequences of chromosomal mosaicism in humans. Hum Reprod Update. 2014;20:571–81.
Rubio C, Bellver J, Rodrigo L, Castillon G, Guillen A, Vidal C, Giles J, Ferrando M, Cabanillas S, Remohi J, et al. In vitro fertilization with preimplantation genetic diagnosis for aneuploidies in advanced maternal age: a randomized, controlled study. Fertil Steril. 2017;107:1122–9.
Yu KH, Beam AL, Kohane IS. Artificial intelligence in healthcare. Nat Biomed Eng. 2018;2:719–31.
Topol EJ. High-performance medicine: the convergence of human and artificial intelligence. Nat Med. 2019;25:44–56.
Esteva A, Robicquet A, Ramsundar B, Kuleshov V, DePristo M, Chou K, Cui C, Corrado G, Thrun S, Dean J. A guide to deep learning in healthcare. Nat Med. 2019;25:24–9.
Simopoulou M, Sfakianoudis K, Maziotis E, Antoniou N, Rapani A, Anifandis G, Bakas P, Bolaris S, Pantou A, Pantos K, Koutsilieris M. Are computational applications the "crystal ball" in the IVF laboratory? The evolution from mathematics to artificial intelligence. J Assist Reprod Genet. 2018;35:1545–57.
Motato Y, de los Santos MJ, Escriba MJ, Ruiz BA, Remohi J, Meseguer M. Morphokinetic analysis and embryonic prediction for blastocyst formation through an integrated time-lapse system. Fertil Steril. 2016;105(376–384):e379.
Milewski R, Kuc P, Kuczynska A, Stankiewicz B, Lukaszuk K, Kuczynski W. A predictive model for blastocyst formation based on morphokinetic parameters in time-lapse monitoring of embryo development. J Assist Reprod Genet. 2015;32:571–9.
Meseguer M, Herrero J, Tejera A, Hilligsoe KM, Ramsing NB, Remohi J. The use of morphokinetics as a predictor of embryo implantation. Hum Reprod. 2011;26:2658–71.
Petersen BM, Boel M, Montag M, Gardner DK. Development of a generally applicable morphokinetic algorithm capable of predicting the implantation potential of embryos transferred on Day 3. Hum Reprod. 2016;31:2231–44.
Blank C, Wildeboer RR, DeCroo I, Tilleman K, Weyers B, de Sutter P, Mischi M, Schoot BC. Prediction of implantation after blastocyst transfer in in vitro fertilization: a machine-learning perspective. Fertil Steril. 2019;111:318–26.
Feyeux M, Reignier A, Mocaer M, Lammers J, Meistermann D, Barriere P, Paul-Gilloteaux P, David L, Freour T. Development of automated annotation software for human embryo morphokinetics. Hum Reprod. 2020;35:557–64.
Dirvanauskas D, Maskeliunas R, Raudonis V, Damasevicius R. Embryo development stage prediction algorithm for automated time lapse incubators. Comput Methods Programs Biomed. 2019;177:161–74.
Kan-Tor Y, Zabari N, Amitai T, Erlich I, Or Y, Shoham Z, Horowitz A, Har-Vardi I, Gavish M, Ben-Meir A, Buxboim A: Automated evaluation of human embryo blastulation and implantation potential using deep-learning. Adv. Intell. Syst. 2020:202000080.
Khosravi P, Kazemi E, Zhan Q, Malmsten JE, Toschi M, Zisimopoulos P, Sigaras A, Lavery S, Cooper LAD, Hickman C, et al. Deep learning enables robust assessment and selection of human blastocysts after in vitro fertilization. NPJ Digit Med. 2019;2:21.
VerMilyea M, Hall JMM, Diakiw SM, Johnston A, Nguyen T, Perugini D, Miller A, Picou A, Murphy AP, Perugini M. Development of an artificial intelligence-based assessment model for prediction of embryo viability using static images captured by optical light microscopy during IVF. Hum Reprod. 2020;35:770–84.
Kan-Tor Y, Ben-Meir A, Buxboim A. Can deep learning automatically predict fetal heart pregnancy with almost perfect accuracy? Hum Reprod. 2020;35:1473.
Lazzaroni-Tealdi E, Barad DH, Albertini DF, Yu Y, Kushnir VA, Russell H, Wu YG, Gleicher N. Oocyte scoring enhances embryo-scoring in predicting pregnancy chances with IVF where it counts most. PLoS ONE. 2015;10:e0143632.
Sjoblom P, Menezes J, Cummins L, Mathiyalagan B, Costello MF. Prediction of embryo developmental potential and pregnancy based on early stage morphological characteristics. Fertil Steril. 2006;86:848–61.
Braga DP, Setti AS, Figueira Rde C, Iaconelli A Jr, Borges E Jr. The combination of pronuclear and blastocyst morphology: a strong prognostic tool for implantation potential. J Assist Reprod Genet. 2013;30:1327–32.
Kamran SC, Reichman DE, Missmer SA, Correia KF, Karaca N, Romano A, Racowsky C. Day 3 embryo shape as a morphologic selection parameter in in vitro fertilization. J Assist Reprod Genet. 2012;29:1135–9.
Medicine ASIR, Embryology ESIG. Istanbul consensus workshop on embryo assessment: proceedings of an expert meeting. Reprod Biomed Online. 2011;22:632–46.
Desai N, Gill P. Blastomere cleavage plane orientation and the tetrahedral formation are associated with increased probability of a good-quality blastocyst for cryopreservation or transfer: a time-lapse study. Fertil Steril. 2019;111(1159–1168):e1151.
Ciray HN, Campbell A, Agerholm IE, Aguilar J, Chamayou S, Esbert M, Sayed S, Time-Lapse User G. Proposed guidelines on the nomenclature and annotation of dynamic human embryo monitoring by a time-lapse user group. Hum Reprod. 2014;29:2650–60.
Alpha Scientists in Reproductive M, Embryology ESIGo: The Istanbul consensus workshop on embryo assessment: proceedings of an expert meeting. Hum Reprod. 2011;26:1270–1283.
Armstrong S, Bhide P, Jordan V, Pacey A, Farquhar C: Time-lapse systems for embryo incubation and assessment in assisted reproduction. Cochrane Database Syst Rev. 2018;5:CD011320.
Meseguer M, Rubio I, Cruz M, Basile N, Marcos J, Requena A. Embryo incubation and selection in a time-lapse monitoring system improves pregnancy outcome compared with a standard incubator: a retrospective cohort study. Fertil Steril. 2012;98(1481–1489):e1410.
Lucas BD, Kanade T: An iterative image registration technique with an application to stereo vision. In Proceedings of the 7th international joint conference on Artificial intelligence - Volume 2. pp. 674–679. Vancouver: Morgan Kaufmann Publishers Inc.; 1981:674–679.
Chen T, Guestrin C: XGBoost: a scalable tree boosting system. In KDD '16: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data; 2016. pp. 785–794.
Ho TK: Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition. Montreal, QC Canada; 1995. pp. 278–282.
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, et al. Scikit-learn: machine learning in Python. J Mach Learn Res. 2011;12:2825–30.
Bergstra J, Yamins D, Cox DD: Making a science of model search: hyperparameter optimization in hundreds of dimensions for vision architectures. In Proceedings of the 30th International Conference on International Conference on Machine Learning - Volume 28. Atlanta: JMLR.org; 2013. pp. I-115-I-123
Lewin-Epstein N, Cohen Y. Ethnic origin and identity in the Jewish population of Israel*. J Ethn Migr Stud. 2019;45:2118–37.
Gianaroli L, Magli MC, Ferraretti AP, Fortini D, Grieco N. Pronuclear morphology and chromosomal abnormalities as scoring criteria for embryo selection. Fertil Steril. 2003;80:341–9.
Gamiz P, Rubio C, de los Santos MJ, Mercader A, Simon C, Remohi J, Pellicer A. The effect of pronuclear morphology on early development and chromosomal abnormalities in cleavage-stage embryos. Hum Reprod. 2003;18:2413–9.
Coskun S, Hellani A, Jaroudi K, Al-Mayman H, Al-Kabra M, Qeba M. Nucleolar precursor body distribution in pronuclei is correlated to chromosomal abnormalities in embryos. Reprod Biomed Online. 2003;7:86–90.
Zamora RB, Sanchez RV, Perez JG, Diaz RR, Quintana DB, Bethencourt JC. Human zygote morphological indicators of higher rate of arrest at the first cleavage stage. Zygote. 2011;19:339–44.
Kattera S, Chen C. Developmental potential of human pronuclear zygotes in relation to their pronuclear orientation. Hum Reprod. 2004;19:294–9.
Otsuki J, Iwasaki T, Tsuji Y, Katada Y, Sato H, Tsutsumi Y, Hatano K, Furuhashi K, Matsumoto Y, Kokeguchi S, Shiotani M. Potential of zygotes to produce live births can be identified by the size of the male and female pronuclei just before their membranes break down. Reprod Med Biol. 2017;16:200–5.
Lundberg S, Lee SI: A unified approach to interpreting model predictions. In NIPS; 2017.
Zabari N, Kan-Tor Y, Or Y, Shoham Z, Shofaro Y, Richter D, Har-Vardi I, Ben-Meir A, Srebnik N, Buxboim A: Delineating the heterogeneity of preimplantation development via unsupervised clustering of embryo candidates for transfer using automated, accurate and standardized morphokinetic annotation. medRxiv; 2022.
Acknowledgements
We thank Prof. Tommy Kaplan and Prof. Dafna Shahaf (Hebrew University of Jerusalem) for fruitful discussions.
Funding
A.B. greatly appreciates support from the European Research Council – Proof of Concept Grant (PoC 966830) and the European Research Council Grant (ERC-StG 678977).
Author information
Authors and Affiliations
Contributions
T.A., Y.K.T., N.S., and A.B. performed the study conception and design. Y.O., Z.S., Y.S., D.R., I.H.V., and A.B.M. provided the clinical data. T.A. and Y.K.T. performed data collection and preparation. T.A. conducted the computational and statistical analyses, and generated the figures. T.A. and A.B. wrote the manuscript. A.B. mentored and supervised this work. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval
This research was approved by the Investigation Review Boards of the data-providing medical centers: Hadassah Hebrew University Medical center IRB number HMO 558- 14; Kaplan Medical Center IRB 0040–16-KMC; Soroka Medical Center IRB 0328–17-SOR; Rabin Medical Center IRB 0767–15-RMC.
Competing interests
T.A., N.S., Y.O., Z.S., Y.S., D.R., and A.B. declare no financial or non-financial competing or other conflict of interest. I.H.V. and A.B.M. declare having no conflict of interest during the time of scientific collaboration and data collection that are relevant to this work. Since January 2020 A.B.M. serves as the Chief Medical Officer and since March 2020 I.H.V. serves as the Scientific Director of Fairtility LTD, which is a company that incorporates AI into different stages in fertility treatment. Y.K.T. declares no financial or non-financial competing or other conflict of interest. Since September 2021, Y.K.T. discloses being employed by IBM-Research.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
ESM 1
(XLSX 12.6 KB)

ESM 2
Figure S1: MC prediction by an RF model and an RF-XG integrated model using embryos form H2-to-H4 clinics. Train, validation and test set ROC curves of MC prediction using an RF model (a) and an integrated XG-RF classifier (b). The latter corresponds to averaging the MC scores that were obtained by RF and XG models. RF: Random forest. Here, embryos from H1 clinic were removed. XG: XGBoost. ROC: Receiver operating characteristic. AUC: Area under the ROC curve. (PNG 156 kb)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

{kind=link}
Cite this article
Amitai, T., Kan-Tor, Y., Or, Y. et al. Embryo classification beyond pregnancy: early prediction of first trimester miscarriage using machine learning. J Assist Reprod Genet 40, 309–322 (2023). https://doi.org/10.1007/s10815-022-02619-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10815-022-02619-5