
Abstract
Querying in isolation lacks the potential of reusing intermediate results, which ends up wasting computational resources. Multi-Query Optimization (MQO) addresses this challenge by devising a shared execution strategy across queries, with two generally used strategies: batched or cached. These strategies are shown to improve performance, but hardly any study explores the combination of both. In this work we explore such a hybrid MQO, combining batching (Shared Sub-Expression) and caching (Materialized View Reuse) techniques. Our hybrid-MQO system merges batched query results as well as caches the intermediate results, thereby any new query is given a path within the previous plan as well as reusing the results. Since caching is a key component for improving performance, we measure the impact of common caching techniques such as FIFO, LRU, MRU and LFU. Our results show LRU to be the optimal for our usecase, which we use in our subsequent evaluations. To study the influence of batching, we vary the factor - derivability - which represents the similarity of the results within a query batch. Similarly, we vary the cache sizes to study the influence of caching. Moreover, we also study the role of different database operators in the performance of our hybrid system. The results suggest that, depending on the individual operators, our hybrid method gains a speed-up between 4x to a slowdown of 2x from using MQO techniques in isolation. Furthermore, our results show that workloads with a generously sized cache that contain similar queries benefit from using our hybrid method, with an observed speed-up of 2x over sequential execution in the best case.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In many OLAP instances, users submit multiple queries to a DBMS in a short time (Gurumurthy et al., 2020) These queries are similar, such that processing them together might save processing time (Broneske et al., 2018). To illustrate, Fig. 1 shows the frequency of TPC-H tables fetched in the 22 benchmark queries. As we can see, multiple queries access the same table (e.g., 15 queries access lineitem) such that combing these queries can avoid redundant table scans. Coming up with such a common execution plan is the key goal of multi-query optimization (MQO).
MQO processes a query set commonly in two ways: shared sub-expressions (SSE) (Silva et al., 2012) and materialized view resolution (MVR) (Perez & Jermaine, 2014). The former devises a single execution plan for a batch of queries, while the latter optimizes queries individually on the fly. Though these techniques are beneficial, they also have key disadvantages: SSE does not persist results, and every batch is given a new execution plan. On the contrary, MVR persists the query results but lacks a common execution plan for a query batch. However, a hybrid of these techniques can avoid both their disadvantages.

No. of times TPCH tables accessed in benchmark queries
Hybrid MQO Technique Our hybrid MQO comes with a common query plan for a query batch and stores its intermediate results. Whenever a new query is introduced, we reuse both the existing execution plan and the stored results. Any new result is persisted replacing existing ones using certain caching techniques. Thus, in this work, we successfully combine common query planning of shared sub-expression with results reuse from materialized views. More details about our hybrid MQO technique are discussed in Section 4.
Due to its flexibility, the hybrid MQO can work in both batched and real-time contexts. Accordingly, we examine the performance of our hybrid MQO w.r.t. sequential, batched, and real-time execution of the queries under different evaluation settings. Our performance evaluation shows a consistent performance improvement which in the best case reaches up to 2x over traditional methods. Specifically, we consider the following aspects when designing and evaluating our hybrid method:
-
Workload impact: The effect of various database operators on the hybrid method.
-
Caching impact: The effect of different cache sizes on the hybrid method.
-
Batching impact: The effect of query similarities on the performance of our hybrid method.
-
Baseline comparison: The viability of a hybrid method using performance comparison against SSE, MVR, and sequential isolated execution.
This is an extension of our previous work (Gurumurthy et al., 2023), where we include the concept and evaluation by investigating different caching techniques. Hence, we also contribute the investigation of:
-
Cache replacement impact: The effect of different cache replacement strategies for our hybrid method.
Overall, the paper is structured as follows: In Section 2, we describe related existing MQO techniques. Next, in Section 3, we briefly introduce background concepts for MQO. We explain the hybrid multi-query optimizer in Section 4 and evaluate it against existing approaches in Section 7. Within Section 7, we first describe the dataset used, followed by our performance evaluation. Finally, our findings and conclusion are summarized in Section 8.
2 Existing Work
This section weighs the hybrid MQO with various other existing MQO approaches. A closely related work - OLTPshare by Rehrmann et al. (2018) - proposes result sharing within a batch of OLTP queries. However, in our work, we analyze the sharing potential among OLAP workloads. The main goal of SSE is to identify covering expressions, hence many earlier SSE solutions used dynamic programming to identify them (Michiardi et al., 2019). A cloud-based solution is proposed by Silva et al. (2012). Unlike these, we statically identify SSE from a batch of queries. In the case of MVR, Bachhav et al. (2021) proposes a cloud-based solution to process query batches. Perez and Jermaine (2014) design Hawc (History aware cost-based optimizer), that uses the historical query plans to derive results. However, unlike our approach, these approaches don’t batch upfront a set of queries before execution. In addition to the above-mentioned MQO approaches, many works improve the efficiency of these MQO approaches. Makreshanski et al. (2018) study the effect of joins in hundreds of queries. Jindal et al. (2018) propose BIGSUBS - designed to efficiently identify common sub-expressions. Similarly, Ge et al. (2014) propose a lineage-signature method for common sub-expressions. Jonathan et al. (2018) study the effect of executing queries in a shared computational framework over a wide area network (WAN). All these approaches complement the hybrid MQO by enhancing its performance.

Types of derivability
3 Background and Related Work
MQO leverages the similarities across queries to avoid re-computation. Specifically, MQO approaches derive the result for a given query from the results of its predecessor. Depending on the similarity across queries, we have varying types of derivability. Likewise, we have varying MQO approaches depending on their characteristics. In this section, we give an overview of derivability as well as the MQO approaches used in our hybrid system. The information gathered when processing a query – such as the statistics, and the table and column information – is usually cached temporarily to easily and quickly execute any subsequent queries of a similar nature. Unfortunately, these measures are not directed toward inter-query processing but instead toward faster plan generation for future queries; the difference is that queries are still executed singly. A relatively simple approach to introducing an element of MQO to conventional query processing without much alteration of the query planning part can be achieved by using materialized views.
3.1 Derivability
Derivability quantifies the amount of results that can be derived from an existing result set (Dursun et al., 2017; Roy et al., 2000). As illustrated in Fig. 2, there are four general types of derivability: exact - where the result is the exact copy (Fig. 2-a), Figure partial - only a subset of results is present (Fig. 2-b), subsuming - the current result is part of the previously computed ones (Fig. 2-c) and none - where no results can be derived (Fig. 2-d). These types are illustrated in Fig. 2. If we consider a query Q and a pre-existing materialized view MV containing rows 10-100, then we can say that the type of derivability is
-
Exact, if Q requires rows \((10-100)\) since these are precisely the ones present in the view MV, as shown in Fig. 2.
-
Partial, if only a subset of results that Q requires are present in the view MV. As depicted in Fig. 2Q requiring rows \((0-30)\) is an example of this case.
-
Subsuming, if Q requires rows \((40-70)\) as shown in Fig. 2, since MV contains a superset of required results.
-
Subsuming, if a superset of results that Q requires are present in the view MV.
-
None, if no results for the query Q are present in the view MV, as shown in Fig. 2.
Please note that although the given example seems to be only applicable to selection clauses, the same applies to more complex queries such as aggregations or joins. In the next section, we will take a broader look at MQO, examining the two important types of techniques that are used in executing queries mutually.
3.2 MQO Approaches
As we have mentioned, the goal of MQO is to produce an efficient execution plan for multiple queries, irrespective of the performance of individual ones (Sellis, 1988). In In this section, we briefly explain the working of the two MQO approaches considered.
3.2.1 Batching - Shared Sub-Expression
An advantage of batched processing of queries is that the information required by the optimizer – the types of queries and their operators and predicates – to make informed decisions is available upfront, making the optimization more sound (Giannikis et al., 2014; Michiardi et al., 2019; Silva et al., 2012). An obvious problem with this approach is that the time taken to create batches is inversely related to the optimization performance. Unfortunately, there is no ubiquitous solution to what the batching time should be, primarily because this is context-dependent. Alternatively, a single query can be split into many sub-queries, each of which can be considered as a part of a batch. This is advantageous in situations where there is a lot of inherent complexity in every query or if the queries contain several shared sub-expressions (SSE).
In SSE, possible common expressions are initially identified among a set of queries. The identified sub-expressions are executed in parallel, with their results being provided to the queries that require them. Specifically, a shared execution plan is created that includes covering expressions derived from combining the sub-expressions. Naturally, as the number of queries in a set increases, the possibility of finding suitable common sub-expressions also increases.
3.2.2 Real-time - Materialized View Reuse
In real-time processing, the queries are submitted to the database system as they occur (Perez & Jermaine, 2014). Here, the optimized query execution plan can be viewed as a growing window. Hence, the advantage of such an approach over batching is its promptness in delivering results. Materialized View Reuse (MVR) does this by caching previous results.
Even though real-time processing solves the problem of delayed responses posed by batched processing, it has a few problems of its own. Firstly, when processing queries in real-time, i.e., separately, we have fewer avenues for optimization – as complete information about upcoming queries is not available at the outset. Secondly, the determination of whether and to what extent a query is optimizable, and the process of optimization, should be quick to offset the gains against sequential execution.
Materialized View Reuse (MVR) As we have seen in the previous section, in MVR we need to generate and cache suitable materialized views, which will then be matched against successive queries for their potential re-usability.
There are some inherent challenges in such a system, such as the selection of materialized views for caching and substitution (Gosain & Sachdeva, 2017; Perez & Jermaine, 2014). Furthermore, there is also the issue of the physical and logical storage of the materialized views. The time taken to access the stored materialized views must be low, and so must the selection algorithm for determining whether a materialized view is suitable for reuse. Inefficient implementation of these issues can be harmful to the performance of the system.
We have so far studied the main techniques that encompass MQO. To summarize, multiple queries can be processed by any system in one of two ways: as a batch or in real-time. Batched processing provides the benefits of providing complete information about queries but at the cost of slower response times. SSE, a batched MQO technique, identifies common sub-expressions from queries and then evaluates these sub-expressions in a common context. On the contrary, real-time processing provides swift responses but suffers from a shortage of information. MVR, a real-time MQO technique, caches, and reuses materialized views to facilitate the optimization of many queries.
So far, we studied the main techniques that encompass MQO. In the next section, we explore a hybrid MQO that places itself in the two approaches. In this way, we can leverage the benefits of both techniques while minimizing the limitations.
4 SSE-MVR Hybrid Multi-Query Optimization
To support a hybrid MQO, certain extensions are needed in a traditional database system. While SSE needs batching as well as generating a shared execution plan, MVR needs access to the stored materialized views while preparing an optimal execution plan. Hence, we form the hybrid of SSE & MVR with: a query batcher, a substituter, and a cache. The overall structure of the hybrid system is shown in Fig. 3.

Components of hybrid MQO system. The blocks colored in gray belong to a conventional database system, whereas the ones in white are exclusive to the hybrid MQO
The execution flow in the system is as follows. First, we start batching queries to develop a common query plan. We perform SSE on the given batch of queries - pruning the redundant operators, identifying the type of derivability possible across queries, etc. Next, such a composite plan is then optimized using an existing traditional optimizer, further simplifying the query plan. The plan is then optimized for MVR based on the cached views from previous runs. If no suitable view is present, we create one from the current run and cache it for future use. In the following sections, we detail the working of the individual components of the hybrid MQO.
4.1 Query Batching
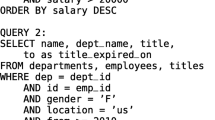
The basic necessity for creating a shared plan across two queries is to have at least a common table scan. For these queries, we then simplify their filter predicates. Similarly, in the next step, we simplify their projection. Let us consider the below queries to be batched. Then, the steps for batching are as follows.
4.1.1 Generating Composite Clauses
Given a batch of queries with common table scans, we start with pruning the ones with common |WHERE| clauses. However, before combining their |WHERE| clauses, we must ensure that the clauses are in their canonical form .i.e in their Conjunctive Normal Form (CNF). Next, we combine these predicates with the |OR| clause. Though such a combined |WHERE| clause might look complex and might even have redundant predicates, the logical optimizer in any traditional DBMS must be able to resolve them easily. Let us consider the queries Q1 & Q2 below as our running example. We already see that both access lineitem table, therefore the combined predicate simplified with the |OR| clause would look as in \(Q_{12}\). A drawback is that the composite clause may be lengthy because it may contain redundant information. These are simplified using predicate covering.



Predicate Covering Even after eliminating irrelevant predicates, we are often left with some predicates that can be simplified according to their access patterns. Our running example after CNF has redundant predicates over the search columns that are to be simplified. For example, l_quantity < 10 OR l_quantity < 15 can be simplified as l_quantity < 15 without any change in the output. Similarly, we can also simplify l_tax < 0.03 OR l_tax > 0.01 fetching all values above 0.01. Once a composite predicate clause is generated, we have to focus on combining operations on projection clauses like aggregations.
4.1.2 Generating Composite Aggregations
Similar to predicates, we can only combine queries that aggregate over a common column. When combining aggregation, the worst case is that two of them might be incompatible. Consider, for example, the two queries \(Q_1\) and \(Q_2\) over the TPC-H schema that we show below.
Our example has \(Q_1\) grouping over the l_quantity column whereas \(Q_2\) groups on the columns l_quantity and l_discount. To combine them, we de-aggregate the queries, so that the columns are fetched, which are then individually aggregated. Applying this, the de-aggregated query would look like \(Q_{12D}\). Finally, from this de-aggregated query, we can channel the results to compute aggregates based on the individual query.



Though the queries seem to do redundant computations at first, we now can use the composite query to cache the results that can be used in the subsequent queries as well. The steps for MVR with such a composite query are given below.
4.2 Materialized View Reuse
At this optimization stage, the shared query plan from the batched queries is taken as input and compared with existing materialized views for result substitution. We essentially pick from the cached materialized views those that are useful in executing a batched query plan and then substitute the relevant parts of the query plan to utilize the materialized view instead of the database.
Of course, finding out whether a query is derivable requires storing materialized views. We will discuss the specifics of how the cache is designed to this end in Section 4.2. The process of reusing materialized views for |JOIN| operator is quite different. For |JOIN|s, we need the materialized views that, in addition to scanning the join of the same tables, scan on any other combination of the tables. This ensures that a subset of relations from the join could be retrieved from the view, whereas the rest are obtained from the database. Finally, since there is only a limited memory available for caching materialized views, we have to regularly evict the materialized views that are not frequently accessed.
4.2.1 Materialized Views Cache
Materialized view cache defines the way to access and maintain the cached views. When the cache reaches a threshold (80% of the total size in our case), a clean routine is called to remove irrelevant views from the cache. Our clean routine supports different caching policies which we detail in Section 6.
We have so far looked at the individual components that constitute the hybrid MQO system: the batcher, the substituter, and the cache. In the following section, we will understand how these three components jointly form our hybrid MQO system. We will also visualize the process of batching and substitution through a relevant example.
4.3 System Integration
In this section, we briefly explain the interaction between all these components. Similar to the example above, let us assume the below batch of queries \(Q_1 - Q_6\).
Consider that our system receives as input the list of queries presented below and let us also assume for this illustration that the cache is currently empty. This example illustrates the versatility of the hybrid MQO method quite well because the queries are of different types: Select-Project, Select-Project-Join, and Select-Project-Join-Aggregate.







Functional example of our hybrid MQO
Firstly, the batcher segregates queries that can be batched together. In our case, \(Q_4\) and \(Q_5\) can be batched as they both access lineitem. For the others, we still have the possibility of achieving performance gains through materialized view substitution.
Next, the optimizer checks for any existing materialized view that can be used to execute \(Q_1\). Since our cache is initially empty, a new view representing \(Q_1\) is generated (\(MV_1\) in Fig. 4). This view can be now reused for \(Q_2\), as s_suppkey column is now present in \(MV_1\). Therefore, we can see that the relation of JOIN in \(Q_2\) – supplier – can be derived from the materialized view. A similar case is also applicable for \(Q_3\), \(Q_4\), and \(Q_5\). Next, the optimizer processes \(Q_4\) and \(Q_5\) in tandem. Since these queries can be batched together, the batcher creates a composite query as explained in Section 4.1. For this composite query, we check if any existing materialized view can be substituted. In our case, the only materialized view present is \(MV_1\), which does not scan on the relation lineitem, so we can directly conclude that \(MV_1\) is not applicable. Having found no possible candidates for substitution, we create a materialized view from the composite query, \(MV_{4+5}\), as shown in the figure. Because we know that our composite query contains all the tuples from both \(Q_4\) and \(Q_5\), we can safely use \(MV_{4+5}\) for substitution.
Finally, to execute \(Q_6\), the optimizer goes through similar steps as for the previous queries. \(Q_6\) is a join of the relations lineitem and partsupp and the information about lineitem can be obtained from the materialized view \(MV_{4+5}\). The tuples for the relation partsupp are fetched from the database, and then the join is performed. Now that we have seen the conceps behind our hybrid MQO, in next section, we detail the way to realize its implementation.
5 Realization of Hybrid MQO
Thus far we have looked, in detail, at the workings of our hybrid MQO approach. We have studied the creation of composite plans, materialized view substitutions, and the design of the cache. In this chapter, we will briefly discuss the specifics of implementing this approach. We initially start with a discussion about Apache Calcite (Begoli et al., 2018), which is the framework used for the core of the optimization. Then we look at how Calcite can be used to facilitate materialized view substitutions. Finally, we look at how this can be combined with batching queries within the context of Apache Calcite to form the complete hybrid MQO system. The complete code for the implementation of our hybrid MQO method is available on GithubFootnote 1.
5.1 Apache Calcite
Apache Calcite (Begoli et al., 2018) is a framework, written in Java, that enables query optimization support to popular database systems. Even though Calcite provides a lot of the functionality of a DBMS, it is not actually a complete database management system. For instance, unlike a DBMS, it does not dictate how the data is precisely stored in a physical sense. Rather, it is only concerned with processing the data. The two main principles it is built on are modularity and extensibility. The complete framework is modular; if some particular functionality is not required, it is possible to fallback to the database defaults. Owing to its modularity, it is possible in Calcite to process data from heterogeneous data sources simultaneously. Extensibility in Calcite allows the addition (or redesign) of its existing components using a simple and intuitive interface.
Although Calcite allows for many possible operations related to databases, such as query validations and heterogeneity in data-sourcing, it is primarily designed for query optimization. The optimizer in Calcite works by applying rules to a logical query plan. There are hundreds of default rules available but custom ones can also be written since Calcite is extensible. Calcite provides two planner engines: Heuristic planner where pre-defined rules are applied regardless of their impact on the cost of the plan, and Volcano planner where cost-based optimization of the query plan is performed.
5.2 Materialized View Substitution
One of the prominent features of Calcite is that it provides an interface for substituting query plans by using materialized views, based on the approaches suggested by Goldstein and Larson (2001); Chaudhuri et al. (1995). Calcite has its own concept of a materialized view, which some databases, such as Cassandra, have incorporated into their architecture (Begoli et al., 2018). Materialized view substitution in Apache Calcite works as follows: the query plan and the materialized view are registered in the planner along with unification rules that determine the extent of substitution possible. The advantage of unification rules is that partial derivability, in addition to exact and subsuming derivabilities, is also feasible.

Integrating caching policies into the MQO system
6 Extending Caching Techniques
As detailed in the previous section, our MQO system is modular and can be extended to add other mechanisms. In this section, we explain the way to extend one such module – the cache. Since when reusing data stored in the cache, we avoid re-computations, caching is one of the key contributors to improving the performance of our MQO system. However, retaining data for maximum utilization depends on the right caching policy. Hence, in this section, we show the ways to integrate different caching policies which we later evaluate in this work.
We set up our caching policies as a hashmap of query and cache object. The cache object furthermore holds the following attributes:
-
order: Order of entry of a cached item.
-
size: Data size of the result in bytes.
-
lastAccessed: Time when the item was recently accessed. If the data is inserted, then the insertion time is stored.
-
numAccessed: This attribute is used to store the number of times the cache item has been accessed.
We identify these parameters so that we can support multiple cacahing techniques out-of-the-box. For example, using order attribute, we can realize FIFO technique. Similarly, using numAccessed we can setup a LRU. The currently available caching techniques are detailed in the evaluation section. Since a single data structure is used for all caching techniques, we wrap this hashmap with an abstract caching class - AbstractCache. This class can be extended to support any caching policy and can be enabled during runtime. Furthermore, we also support a configuration builder that links the target caching policy with the execution. A detailed view of our abstract cache class, its attributes, and the currently available caching techniques are depicted in Fig. 5.
In addition to the cache item attributes, there are additional attributes in the abstract class:
-
PRUNE_TO: It is the percentage limit up to which the cache is allowed to be pruned once it is filled beyond the threshold capacity. It is kept constant (70%) for all our experiments.
-
PRUNE_THRESHOLD: It is the percentage limit beyond which the cache cannot be filled and cleared according to the policy. It is kept at 80% for all our experiments.
-
numberOfCacheItems: The number of cache items currently present in the cache.
-
cacheSizeThreshold: It is calculated at the time of creation of the caching policy by multiplying PRUNE_TO with Dimension’s value. This threshold is used to determine how much cache is to be cleared up.
-
dimension: Dimension is a class used to determine the type of caching and the size (in bytes) of the cache or count of the cache items to initialize. Since here we only consider the size of the cache items, therefore, we only use DimensionType SIZE_BYTES here.
Furthermore, the following functions are shared between all the caching policies. They are as follows: add() - to insert a cache entry, get() - retrieves a cache entry, removeUnwantedIndexes() - clean the cache based on the caching policy used. Additionally, onCacheSizeChange() is used whenever a new cache item is added. It checks whether the current cache size is below the threshold limit, i.e., Dimension’s value * PRUNE_THRESHOLD. If the size is above the threshold limit, then it runs the function removeUnwantedIndexes which removes the cache items according to the policy.
6.1 Configuration Builder
The configuration builder is used to set the caching policy and size threshold of the caching systems using the runtime arguments passed to the system. The following arguments are provided to it and they are as follows:
-
Cache type - The caching policy to be used during execution.
-
Mode - Defines the MQP execution mode. It can be sequential, batched, MVR, or hybrid.
-
Cache size - Defines the caching size in bytes. This depends on the memory space available in the hardware.
-
Derivability - Defines derivability percentage of queries in a given experiment.
Using the configuration builder, we can now define various evaluation criteria and experiment with them. In the next section, we experiment with these configurations and study their impact on the performance of various techniques. Furthermore, we evaluate our hybrid mechanism to see its benefit against the batching and MVR techniques.
7 Evaluation
In this section, we study the performance implications of using a hybrid multi-query optimizer. For our measurements, we extend the existing MVR in Apache calcite (using PostgreSQL plugin) with simple static batching as explained in Section 4.1Footnote 2. Details of our realization of the hybrid MQO system will be discussed in the next section. We performed all our tests using PostgreSQL installed on a virtual machine. Using this implementation, we study: 1) the effect of cache size, 2) performance difference from existing strategies, and 3) the impact of query types, whose details are given in Section 7.2.
7.1 Evaluation Setup
Due to missing OLAP benchmarks for batching, we use the TPCH dataset with scale factor 5 and custom-built queries. We have 320 such custom queries generated from 32 templates derived from the existing TPCH query set. We derive these template queries using the different operators in TPCH queries. There are five such query groups for these different operators. We generate these queries based on three criteria: query type, result size, and derivability. The detail of the query split-up is shown in Fig. 6.
We generate a query from these templates by varying their predicate values. These predicates - picked at random - can vary the result size from a very few bytes to hundreds of MB and, in turn, the derivability of the entire query load. In this case, we vary the predicate range with selectivity from 0% to 90% in increments of 10.
Other than result size, derivability type also affects the overall runtime. For instance, if there are many exactly derivable queries in a batch, our system will show a high-performance benefit compared to sequential execution, but in reality, has marginal improvement. For instance, the prevalence of exactly derivable queries in a query load implies that a marginal improvement in the performance of our hybrid method is not particularly noteworthy.
Impact of Derivability Furthermore, queries belonging to different derivability types (cf. Section 3) also impact the overall execution. Therefore, it is necessary to ascertain the type of derivability in generated queries. To this end, we plot in Fig. 7 the split-up of different derivability types in a generated query load. As the chart shows, we keep exact derivability at a minimum, with most of the derivability from either partial or subsuming. Now using these queries, in the subsequent sections, we study the performance of hybrid optimization.
Our evaluation uses a Google Cloud - E2-Highmem - instance (with Intel Skylake) with a storage of 100 GB and main memory of 32 GB – all data is stored in main memory.

Composition of query templates

Proportion of different derivabilities in generated query loads
7.2 Impact of Caching Techniques
Before we compare the performance of our hybrid MQO, we investigate the impact of caching on its performance. To this end, in this section, we evaluate different caching policies with our hybrid MQO w.r.t. their impact on the overall execution time as well as their cache hit rate. Our experiments consider derivability of 45%, 75%, and 90% with cache sizes of 32, 64, 128, 256, 512, 1024, 2048 and 4096 MBs.
7.2.1 Effect of Caching Policy Execution Time
As our first evaluation, we measure the time of execution based on various derivabilities. Since an efficient caching techniques has maximum reults reuse, it will result in better execution time. Such execution time for different caching techniques are plotted in Fig. 8.

Relative execution time of caching policies
As expected, the figure shows that increasing the cache size drastically improves execution time. As more and more results are cached, it leads to maximum reuse of results, thereby avoiding unwanted execution.
The results also show that with increasing derivability, we see a clear distinction across the caching policies in terms of performance. For 45% derivability, we see all caching policies have nearly similar performance. However as the derivability increases, the policies FIFO, random, and LFU show poor execution time compared to LRU and MRU. This shows that when more data is being reused FIFO, random and LFU do constant evictions leading to multiple re-inserts of data. Such re-inserts lead to the to poor performance compared to LRU and MRU, where the data is persisted and reused.
In summary, we see that caching policies have similar performance for smaller derivabilities and diverge as derivability % increases. Specifically, based on our results we see that LRU is the optimal caching policy. This is mainly due to the right fit of LRU caching policy and the order of the queries being processed. However, other caching policies would fair better with a different queue order for processing the queries.
7.2.2 Effect of Derivability and Cache Size on Cache Hits
As our second experiment, we measure the amount of cache hits of different caching policies while varying the cache sizes. A complementary metric to execution time, with better cache hits we will have a proportional benefit in execution time. Again, similar to the previous experiment, we test them on three derivability values: 45%, 75%, 90% and their results are plotted in Fig. 9.

Cache hits across different cache sizes
For derivability 45%, we can see that MRU has high hits until 64MB. This can be due to the queries reusing data from their immediate predecessors. Upon further increasing the caching size, LRU quickly catches up. For cache sizes beyond 512MB, all the caching policies have the same cache hit percentage as the cache is saturated.
For derivability 75%, we again see that the MRU caching policy has the highest cache hit rate of every caching policy till 64MB. When increasing the cache size further to 128MB, we can observe that MRU and LFU have a similar cache hit rate. However, despite higher cache hits, MRU does not perform well as it removes all the repeatedly used cached item results. The cache starts to saturate at 256 MB and is completely saturated at 512MB.
Finally for derivatility of 90%, we can observe nearly similar cache hits across all caching policies, except at the size of 128MB. At this size, we see LFU and MRU having better cache hit rate nearly 20% higher than others. However, this benefit can be attributed to the order query that is advantageous to these two policies.
Overall in the above experiments, we showed the impact of different caching policies over our hybrid MQO. In the next section, we expand on these experiments studying the overall performance difference between the hybrid MQO verses simply batched and MVR executions.
7.3 Performance Analysis of the Hybrid MQO
In this section, we present our findings in three parts. In Section 7.2.1 we study how different derivabilities and cache sizes influence the execution times of different approaches. Following this, in Section 7.2.2 we compare the performance gains and losses of different execution strategies over the whole range of tested query loads. Finally, Section 7.2.3 studies the impact of different relational operators on the performance.
7.3.1 The Effect of Derivability and Cache Size
Figure 10 depicts the time to execute different query loads with varying cache sizes. We vary the cache sizes from 4 MB to 2GB to study its performance impact.

Execution times of different execution strategies
Foremost, we can see that caching has no effect on sequential and SSE execution as they are independent of cache sizes. For low derivabilities (less than 25%) MVR & hybrid versions perform worse than sequential and SSE. Such poor performance is due to the time spent on creating, caching, and probing materialized views in addition to the normal execution time. However as the derivability increases there is a drastic reduction in the execution times for MVR and hybrid executions. At this point, an adequate amount of views are stored to aid the subsequent queries. This pattern of results holds for all higher derivabilities. Finally, when derivability increases beyond 50%, we see the performance disparity between MVR and the hybrid method increase – almost a factor of 2.
In this section, we have seen how varying derivabilities and cache sizes influence execution times. Since different query loads contain fundamentally different queries, an absolute comparison of the execution times for different derivabilities is ineffective. So in the next section, we compare the performance of our hybrid system across different derivabilities.
7.3.2 Performance Comparison of Execution Strategies
Figure 11 depicts heatmaps of performance gain/loss of our hybrid MQO method compared to sequential, SSE, and MVR, respectively.

Speed-up or slow-down from our hybrid mechanism in comparison with baselines
From the heatmaps, our hybrid method is approximately 25% slower for lower derivabilities regardless of cache size. However around 50% derivability, we achieve a 25%-30% gain in performance. This gain keeps increasing, such that with a 90% derivable query load, we are twice as fast as sequential execution.
In some cases, we can observe that having a larger cache harms the performance of our hybrid system. Upon closer inspection, this issue seems unique to Apache Calcite and its handling of materialized view substitutions. Specifically, calcite cycles through the entire materialized view even with 0% derivable queries, degrading performance.
Furthermore, we can observe with high derivability, the performance of our hybrid method exceeds the baseline of the basic MVR approach (Fig. 11-c) when the cache is small. This observation suggests that sharing sub-expressions contributes to this increase in performance. Similarly, for larger caches, the hybrid method is much more efficient when compared to SSE, as shown in Fig. 11-b, implying that the efficiency is a result of materialized view reuse.
Overall, we see a 2x speed-up over sequential and SSE when the queries are derivable, and the cache is large, which shows the full benefit of our approach.
7.3.3 Impact of Query Types
Finally in this section, we study the impact of operators with MQO techniques. The overall speed-up / slow-down is given in Fig. 12. In an overview, we see low derivabilities severely diminish the performance of our hybrid method, whereas high derivabilities enhance performance. A detailed description of the results is given below.

Relative performances of individual query types
We observe large fluctuations for filter queries, with speed-ups around 0.5 and 2, respectively. Multiple-column filter queries perform poorly than single-column filter queries, with most multi-column filter query loads being slower to execute with our hybrid method than with sequential ones. The performance deterioration is mainly due to the generation of predicate results from an existing materialized view. However, we observe operators such as joins and aggregates demonstrate improved performance than filters. At best, query loads containing exclusively joins show a speed-up of over 6x. As a whole, mixed query loads with filters, joins, and aggregates show insignificant speed-up. As our hybrid method performs poorly for queries that are not derivable, plotting its performance over the entire range of derivability tends to offset the gains observed for highly derivable queries. Altogether, under high derivable workloads, our hybrid method performs much better compared to sequential (2x) and SSE (2x) executions than MVR (1.4x). This mirrors our already drawn conclusions.
7.4 Discussion
Since the hybrid system has both batching and MVR, it has good performance with large cache and high derivability - which is reflected in our results. As we know from our query load (cf. Figure 7) that exactly derivable queries are not the majority, we can conclude that the observed speedup is due to the optimizations of our hybrid method, as opposed to the relative computational efficiency of deriving exact results from materialized views. Looking at the performance with regard to the various cache sizes, a certain threshold (256MB in our case) must be crossed to see the benefits of the hybrid execution. When the cache size and the derivability is maximum, our hybrid method executes query loads twice as fast as sequential execution and SSE. However, even with smaller caches we still get a considerable benefit from the SSE part of the system.
Finally, with different database operators, we see that filter operations have a large performance variation than joins and aggregates. Additionally, query loads containing joins and aggregates show the least variation but also show lower average performance compared to query loads with only joins or only aggregates.
As a whole, our hybrid method shows a speed-up of 2x when compared to sequential execution for larger caches and higher derivabilities. The size of the cache plays an important role but offers diminishing returns after a certain threshold (256MB in our case), which depends on the query size.
8 Conclusion
In this paper, we have proposed a hybrid MQO technique that merges Shared Sub-Expression (SSE) and Materialized View Reuse (MVR). We have shown that by composing existing MQO techniques, we can achieve a query processing system capable of halving the time taken to execute suitable query loads. Our SSE generates a composite query plan whose results are then persisted using MVR, with various caching policies.
Our caching component is extendable, which includes multiple caching policies (LRU, LFU, MRU, FIFO, and random). We evaluate these caching policies with different derivabilities and cache sizes. Our results show performance differences across these policies w.r.t response time and cache hit rate. Our results show LRU as a better caching policy for the given query order. Next, We also evaluate our hybrid MQO method for different query loads, and cache sizes, and compare the results with different execution strategies. from our evaluations, we see that high cache-size & derivabilities directly correspond to better performance of the hybrid system. Low derivabilities can cause the hybrid system to expend additional resources managing optimization thereby increasing execution time. Additionally, comparing the hybrid MQO to MVR and SSE approaches shows that it can adapt to the workload. It reuses materialized views when the cache is larger, while with smaller caches, the performance gain is from SSE. Further, analyzing the effect of database operators suggests that complex operators such as joins and aggregates benefit more from a hybrid scheme of processing than queries that contain filters. In summary, a hybrid MQO technique combining SSE and MVR demonstrates a clear advantage of up to 2x speed-up over traditional methods.
Availability of Data and Materials
The data & code of our work are available in the GitHub mentioned in the evaluation section.
Notes
Code is available here: https://github.com/vasudevrb/mqo
References
Bachhav, A., Kharat, V., & Shelar, M. (2021). An efficient query optimizer with materialized intermediate views in distributed and cloud environment. In Tehnički glasnik
Broneske, D., Köppen, V., Saake, G., & Schäler, M. (2018). Efficient evaluation of multi-column selection predicates in main-memory. IEEE Transactions on Knowledge and Data Engineering, 31(7), 1296–1311.
Begoli, E., Rodríguez, J. C., Hyde, J., Mior, M. J., & Lemire, D. (2018). Apache calcite: A foundational framework for optimized query processing over heterogeneous data sources. In Proceedings of ICMD
Chaudhuri, S., Krishnamurthy, R., Potamianos, S., & Shim, K. (1995). Optimizing queries with materialized views. In Proceedings of ICDE
Dursun, K., Binnig, C., Cetintemel, U., & Kraska, T. (2017). Revisiting reuse in main memory database systems. In Proceedings of ACM SIGMOD
Gurumurthy, B., Bidarkar, V. R., Broneske, D., Pionteck, T., & Saake, G. (2023). What happens when two multi-query optimization paradigms combine? In A. Abelló, P. Vassiliadis, O. Romero, & R. Wrembel (Eds.), Advances in Databases and Information Systems (pp. 74–87). Cham. Springer Nature Switzerland.
Gurumurthy, B., Hajjar, I., Broneske, D., Pionteck, T., Saake, G. (2020). When vectorwise meets hyper, pipeline breakers become the moderator. In ADMS@ VLDB, pages 1–10
Goldstein, J., & Larson, P.-Å. (2001). Optimizing queries using materialized views: A practical, scalable solution. In Proceedings of ACM SIGMOD
Giannikis, G., Makreshanski, D., Alonso, G., & Kossmann, D. (2014). Shared workload optimization. In Proceedings of the VLDB Endowment
Gosain, A., & Sachdeva, K. (2017). A systematic review on materialized view selection. In Proceedings of the ICFIC
Ge, X., Yao, B., Guo, M., Xu, C., Zhou, J., Wu, C., & Xue, G. (2014). LSShare: An efficient multiple query optimization system in the cloud. In Distributed and parallel databases
Jonathan, A., Chandra, A., & Weissman, J. (2018). Multi-query optimization in wide-area streaming analytics. In Proceedings of ACM SIGMOD
Jindal, A., Karanasos, K., Rao, S., & Patel, H. (2018). Selecting subexpressions to materialize at datacenter scale. In Proceedings of the VLDB endowment.
Michiardi, P., Carra, D., & Migliorini, S. (2019). In-memory caching for multi-query optimization of data-intensive scalable computing workloads. In Proceedings of DARLI-AP
Makreshanski, D., Giannikis, G., Alonso, G., & Kossmann, D. (2018). Many-query join: Efficient shared execution of relational joins on modern hardware. In Proceedings of the VLDB Endowment
Perez, L., & Jermaine, C. (2014). History-aware query optimization with materialized intermediate views. In Proceedings of the ICDE
Rehrmann, R., Binnig, C., Böhm, A., Kim, K., Lehner, W., & Rizk, A. (2018). Oltpshare: The case for sharing in oltp workloads. In Proceedings of the VLDB endowment
Roy, P., Seshadri, S., Sudarshan, S., & Bhobe, S. (2000). Efficient and extensible algorithms for multi query optimization. In Proceedings of ACM SIGMOD
Sellis, T. (1988). Multiple-query optimization. In Proceedings of ACM SIGMOD
Silva, Y., Larson, P.-A., & Zhou, J. (2012). Exploiting common subexpressions for cloud query processing. In Proceedings of the ICDE
Acknowledgements
Also, we would like to thank Mr. Krishna Kant Sharma for his contributions in evaluating the caching techniques. The work is partially funded by DFG (grant no.: SA 465/51-2 and PI 447/9-2).
Funding
Open Access funding enabled and organized by Projekt DEAL. This work was partially funded by the DFG (grant no.: SA 465/51-2 and PI 447/9-2).
Author information
Authors and Affiliations
Contributions
The work was partially implemented and evaluated by Vasudev Bidarkar. Bala Gurumurthy and David Broneske have supported the implementation, evaluation as well as writing and editing of the work. Gunter Saake and Thilo Pionteck have contributed to developing the concepts and reviewing the draft as well as in writing.
Corresponding author
Ethics declarations
Competing Interest
Not applicable
Ethics Approval and Consent to Participate
not applicable
Consent for Publication
not applicable
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gurumurthy, B., Bidarkar, V.R., Broneske, D. et al. Exploiting Shared Sub-Expression and Materialized View Reuse for Multi-Query Optimization. Inf Syst Front (2024). https://doi.org/10.1007/s10796-024-10506-w
Accepted:
Published:
DOI: https://doi.org/10.1007/s10796-024-10506-w