
Abstract
The key to improving the performance of graph convolutional networks (GCN) is to fully explore the correlation between neighboring and distant information. Aiming at the over-smoothing problem of GCN, in order to make full use of the relationship among features, graphs and labels, a graph residual generation network based on multi-information aggregation (MIA-GRGN) is proposed. Firstly, aiming at the defects of GCN, we design a deep initial residual graph convolution network (DIRGCN), which connects the initial input through residuals, so that each layer node retains part of the information of the initial features, ensuring the localization of the graph structure and effectively alleviating the problem of over-smoothing. Secondly, we propose a random graph generation method (RGGM) by utilizing graph edge sampling and negative edge sampling, and optimize the supervision loss function of DIRGCN in the form of generation framework. Finally, applying RGGM and DIRGCN as inference modules for modeling hypotheses and obtaining approximate posterior distributions of unknown labels, an optimized loss function is obtained, we construct a multi-information aggregation MIA-GRGN that combines graph structure, node characteristics and label joint distribution. Experiments on benchmark graph classification datasets show that MIA-GRGN achieves better classification results compared with the benchmark models and mainstream models, especially for datasets with less dense edge relationships between nodes.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Many actual scene data in the real world are based on non-Euclidean structures, while most traditional neural networks are only suitable for feature extraction on Euclidean data. The application about this aspect poses a challenge to deep learning. GCN [1] and GAT [2] learn new node representations from node characteristics and graph topology information through different aggregation methods. GraphSAGE [3] obtains an embedding method that can be generalized to unknown data by learning the features of nodes, which can deduce the nodes newly added to the graph network, rather than learning the feature representation for each node individually. GR-GCN [4] randomly samples all kinds of labeled data to construct graphs, the random combination of samples can make the generated graphs more diversified and the network more robust. However, these networks reach their best performance in two-order neighborhood and fail to get rid of the constraints of shallow structure. From another point of view, this shallow structure only considers the nearest neighbor and ignores the global nature, so it is impossible to obtain effective information from the far neighbor. Literature [5] shows that when GCN deepens, multiple propagation will lead node eigenvectors convergence to the same value, and it is difficult to distinguish nodes of different categories, which greatly reduces model performance, and this phenomenon is called over-smoothing.
Scholars have proposed different solutions to the optimization problem of GCN. Chen [5] proposes smoothing regularization terms and adaptive edge optimization to alleviate the over-smoothing problem. LDGCN [6] applies the local analysis algorithm similar to the neighbor hypothesis based on the graph embedding technology to GCN, and processes the input data of GCN through a variety of balancing methods, thus ensuing the optimized input data contains detailed local node information. MSAGCN [7] applies multi-angle aggregation and semantic alignment to align the semantics in extracted features and enhances similar content from different perspectives to solve the over-smoothing problem. DropEdge [8] alleviates the problem of over-smoothing by randomly deleting a certain number of edges from the input image in each training period. DAMASK-GCN [9] dynamically adjusts the perceptual field of nodes through dilated mask convolution and adaptive attention fusion mechanism to capture high-order information, which reduces the impact of visual overlap intensity. D2GCN [10] solves the over-smoothing problem by applying residual connection to the two-channel graph convolution neural network and increasing the depth of the two-channel graph convolution neural network. DeepMCGCN [11] uses cross-channel connection to obtain the interaction between sub-graphs of different relationships, and alleviates the over-smoothing problem of depth model by optimizing convolution function and adding residual connection between channels and within channels. Although the above methods improve the GCN based model in various ways to solve the problem of over-smoothing, they do not fully consider the correlation between nearest neighbor information and distant neighbor information, and the lack of certain key information limits the upper limit of their application. Although increasing the depth of network can improve the performance, the most advanced results are still achieved through shallow models for semi-supervised tasks. Therefore, it is still worth considering whether to increase the depth of network in GCN.
Graph Contrastive Learning applies contrastive learning technology to graph representation learning. By comparing positive sample pairs and negative sample pairs, it seeks to maximize the mutual information between input and its representation to improve performance, which provides a new research idea for solving the problem of over-smoothing. Scholars have launched a series of studies on this problem. Tan [12] proposes a community invariant GCL framework, which maintains graph community structure during learnable graph augmentation to solve the problems that current knowledge-based graph augmentation methods can only focus on either topology or node features. Li [13] proposes a method for joint modality fusion and graph contrastive learning for multi-modal emotion recognition to solve the problems that model easily fall into over-smoothing with the number of graph layers increasing. Li [14] designs a cross-view graph contrastive learning framework to solve over-smoothing issue and easily yield indistinguishable node representations. The above methods improve the performance by mining the mutual information of samples and fusion strategy, which opens up a new idea for solving the problem of over-smoothing.
Traditional machine learning methods usually regard data samples as independent and graph structure as fixed, ignoring the fact that graph structure itself which comes from noise data or modeling assumptions, and ignoring the relationship information between data samples and graph structures. The method based on deep learning combines the advantages of traditional machine learning and makes full use of the correlation between sample data [3, 15]. Ma [16] uses random graphs and the latest scalable variational reasoning technology to approximate Bayesian posterior, and proposes a graph-based semi-supervised learning generation framework. Baradaaji [17] proposes a graph based semi-supervised learning framework that simultaneous label inference and linear transform estimation. Ziraki [18] combines the concepts of data smoothness and label smoothness with the label fitness and projection matrix calculation, constructing a semi-supervised learning method using multiple data views. Zhang [19] proposes a semi-supervised graph learning method based on data distribution for fast and effective label propagation and incremental learning. Chen [20] proposes a multi view graph convolutional network with differentiable node selection, which takes multi-channel graph structure data as input, and uses differentiable neural networks to learn more robust graph fusion. Wang [21] proposes a diffusion residual network to improve the performance of classification between nodes by introducing diffusion mechanism into the network.
In recent years, with the rapid development of reinforcement learning, self-supervised learning and other latest technologies, it has been widely used in graph convolution neural network and proves to have remarkable effects in practical application scenarios [22, 23]. Huang [24] proposes a multi-view graph convolution and multi-agent reinforcement learning method to deal with the disadvantages that the current dialogue state tracking ignores the information across domains. Xing [25] designs a bilevel graph reinforcement learning method for electric vehicle fleet charging guidance, Xu [26] proposes a multi-view graph convolution network reinforcement learning algorithm for the decision-making and control of connected autonomous vehicles in mixed traffic scenarios. Song [27] proposes a self-supervised calorie-aware heterogeneous graph network to model the relations between ingredients. Although the above methods make full use of the multi-view strategy to realize full feature extraction and improve the practical application ability of the model, the latest technology still can't solve the problem of over-smoothing, and it is still necessary to use GCN model to improve the practical application of the model while limiting the problem of over-smoothing.
Inspired by the fusion strategy in the latest technology, it is a feasible method to use graph structure, node features and known labels to help the network predict unknown labels on the basis of GCN model. In order to fully leverage the shallow advantages of graph convolutional neural networks, exploring the correlation between neighboring and distant information, and achieving universality in different application scenarios, this study starts from two aspects that alleviating the problem of over-smoothing and fully mining the correlation information between graph structure, node features, and labels to improve the classification performance of GCN. A Graph residual generation network based on multi information aggregation (MIA-GRGN) is proposed. The main innovation points include the following three aspects:
-
(1)
Designing the depth initial residual graph convolution network DIRGCN to solve the problems of over-smoothing and losing diversity and locality of node features when the existing graph convolution network is too deep. DIRGCN uses the relationship between neighboring and distant information, connects the initial residual term with the feature representation output of the current graph convolution unit in a set proportion by establishing the residual structure of the dependency relationship between nodes on the graph, uses the dropout unit to randomly discard neurons to reduce the dimension, obtains the output features through full connection and completes the classification and division of topology nodes to obtain the final prediction label matrix, which fully learns the feature information of nodes, ensures the locality of the graph structure and effectively alleviates the problem of over-smoothing.
-
(2)
Proposing a random graph generation method RGGM to make full use of the relationship information of data samples in the network structure and solve the problems of limiting feature information learned by the model and poor classification effect. RGGM uses two-layer perceptron module to linearly transform and classify the input features, uses graph edge sampling module to sample between node pairs, uses negative edge sampling module to randomly sample edges between nodes that do not exist on the graph according to the established negative edge probability, and combines the edges and nodes sampled by the two modules to construct a noise graph provides modeling assumptions for DIRGCN, which helps to train the model.
-
(3)
Constructing a graph residual generation network based on multi-information aggregation MIA-GRGN to solve the problem of insufficient semantic relations and dependency relations mining among multi-tags in existing models. MIA-GRGN combines the inconsistency between the label predicted by DIRGCN and the real label of the sample with the loss of two-layer perceptron module, graph structure, feature information and joint distribution of labels in RGGM, adds disturbance to the training process of DIRGCN module, corrects the parameters of the depth initial residual graph convolution module, captures the long distance dependence in the graph and obtains the inherent characteristics of the graph structure to improve the generalization ability of the model.
We fully explore the relevant information between graph structure, node features and labels, striving to solve the problem of over-smoothing, playing the advantages of shallow GCN, thus providing new research ideas for challenging problems such as target area edge segmentation, energy industry power prediction, mobile robot path planning, spectral image clustering analysis, etc. The studied method can make full use of the relationship between far and near neighbor information, fully explore significant features, and improve the performance of the algorithm.
We organize the remainder of this study as follows. Section 2 reviews some related works. Section 3 presents the proposed MIA-GRGN in detail. Four experiments are conducted on model structure, semi-supervised and fully-supervised node classification tasks and model complexity to verify the effectiveness of the MIA-GRGN in Sect. 4. Section 5 concludes this study.
2 Related work
The graph is defined as \({\varvec{G}}=({\varvec{V}},{\varvec{E}})\), where G is a simple connected undirected graph, \({\varvec{V}}\) is a node set indexed from 1 to n, E is the edge set formed by nodes in V, \(n=|{\varvec{V}}|\) and \(m=|{\varvec{E}}|\) are the number of nodes and edges respectively. \(j\in \{1,\cdots ,n\}\) represents the node subscript of G, \({d}_{j}\) is the degree of node j in G, and D is the diagonal degree matrix formed by \({d}_{j}\). Let A be the adjacency matrix of G, \(\widetilde{{\varvec{A}}}={\varvec{A}}+{{\varvec{I}}}_{n}\) is the adjacency matrix with \({\varvec{A}}\) self-ring, and \({{\varvec{I}}}_{n}\in {\mathbb{R}}^{n\times n}\) is the identity matrix. \({x}_{j}\in \{{x}_{1},\cdots ,{x}_{n}\}\) is the eigenvector of node j, \({\varvec{X}}\in {\mathbb{R}}^{n\times d}\) is the eigenmatrix of node, where each node j is associated with a d dimensional eigenvector.
2.1 GCN model analysis
Although GCN has brought a new approach to graph learning, the existing GCN models cannot be deepened as convolutional neural network (CNN) in visual tasks. For reasons, Hoang [28] believes that GCN can be regarded as a low-pass filter, which is a special form of Laplacian smoothing. In order to alleviate gradient explosion or gradient disappearance, GCN replaces convolution kernel with symmetric normalized Laplace matrix \(\widetilde{{\varvec{Z}}}={\widetilde{{\varvec{D}}}}^{-1/2}\widetilde{{\varvec{A}}}{\widetilde{{\varvec{D}}}}^{-1/2}=({\varvec{D}}+{{\varvec{I}}}_{n}{)}^{-1/2}({\varvec{A}}+{{\varvec{I}}}_{n})({\varvec{D}}+{{\varvec{I}}}_{n}{)}^{-1/2}\). GCN is defined as follows:
where \({{\varvec{H}}}^{(l+1)}\) and \({{\varvec{H}}}^{(l)}\) are the output and characteristic input of layer l, respectively, \({\mathbf{W}}^{(l)}\) is the weight matrix of layer l. For GCN, the structure that mainly affects network performance after lth convolution is \({\widetilde{{\varvec{Z}}}}^{l}\), when l is \(+\infty \):
where \(\widetilde{{\varvec{Z}}}\) is a symmetric semispositive matrix that can be decomposed into \({\varvec{U}}\widetilde{\boldsymbol{\Lambda }}{{\varvec{U}}}^{\text{T}}\), \(\widetilde{\boldsymbol{\Lambda }}\) is the eigenvalue diagonal matrix of \({\widetilde{{\varvec{Z}}}}^{l}\), and \({\varvec{U}}\in {\mathbb{R}}^{n\times n}\) is the unitary matrix decomposed by \(\widetilde{{\varvec{Z}}}\). Assuming that graph G has m connected components, after repeated smoothing operations, the eigenvectors of \({\widetilde{{\varvec{Z}}}}^{l}\) at \({\widetilde{{\varvec{\lambda}}}}_{i}\) will converge to the linear combinations of \({\lambda }_{i\in \{0,m\}}=1\) and \({\lambda }_{i\in \{m,n\}}=0\). Nodes in the same cluster are often densely connected. Smoothing operation makes their characteristics similar, which makes the classification task easier, but it also leads to the problem of over-smoothing. From the perspective of spatial domain, the essence of GCN is to aggregate neighbor node information using graph structure, which is necessary to generate new node features. When GCN deepens to a certain extent, the aggregation operation will cause each node to be filled with a large amount of redundant information, thus losing the diversity and localization of node features. Therefore, we expect to introduce residual mechanism to suppress the over-smoothing problem and improve the model expression ability with the help of generation framework.
2.2 DeepGCN network
DeepGCN [29] applies residual connection, dense connection and empty convolution to GCN network respectively with the idea of CNN deepening network. For the residual structural framework in DeepGCN, its mathematical model is defined as follows:
where \({{\varvec{H}}}^{(l)}, {{\varvec{H}}}^{(l+1)}\) and \({{\varvec{W}}}^{(l)}\) have the same meaning as Eq. (1), \({\varvec{H}}\) is the feature representation of \({{\varvec{H}}}^{(l)}\) and \({{\varvec{W}}}^{(l)}\) extracted by mapping function F. Scholars have conducted depth research on residual structures to alleviate gradient disappearance and over-smoothing problems. Hu [30] designs a multi-scale attention residual network to achieve environmental sound classification, which alleviates the problem of gradient explosion and gradient disappearance. Du [31] proposes a noise learning method based on multi-level residual convolutional networks, which solves the problem of gradient disappearance in network learning by designing multi-level residual structures; Chen [32] establishes a residual structure graph neural network RSGNN, which constructs residual links on local subgraphs to alleviate the problem of excessive smoothing. The above methods demonstrate that the feasibility of using residual structures to alleviate gradient disappearance and over-smoothing problem, but the simple residual structure cannot solve the over-smoothing problem well. The performance of the network will inevitably decline when it reaches a certain depth. Therefore, how to maximize the role of residual mechanism and improve the performance of the algorithm has become a problem to be solved. Inspired by the current scholars' research ideas, this paper starts from giving full play to the internal relations of each module in the residual structure and realizing the mining of salient features, so as to improve the performance.
2.3 Semi-supervised generation framework
Ma [16] regards graph structure, node characteristics and labels as random variables to simulate noise graph structure, and forms a semi-supervised generative framework from three aspects: generation process, model reasoning and model learning to learn the low-dimensional representation of data. The generation process is defined as follows:
which means that, in the case of a given graph G, X and L are characteristic matrix and label matrix respectively, \({{\varvec{L}}}_{k}\in {\varvec{L}}\) is known label matrix and \({{\varvec{L}}}_{m}\in {\varvec{L}}\) is unknown label matrix. The generative framework performs well in the case of label missing and semi-supervised learning, but the reasoning ability of the inference model is the key factor to determine the performance of the network. Therefore, optimizing stochastic graph model and inference model can effectively improve network performance.
In conclusion, residual structure can inhibit over-smoothing, and graph-based semi-supervised generation framework can enable GCN to better learn the relationship information among graph structure, node features and labels. It is feasible to improve the performance of GCN model by improving residual mechanism and generation framework.
3 Design of MIA-GRGN
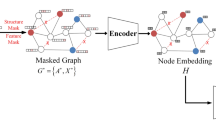
In order to effectively utilize the learning ability of semi-supervised generation framework on graph structure, node features and relationship information among labels, the MIA-GRGN is designed in Fig. 1, which consists of random graph generation process and inference model. The random graph generation method RGGM is proposed by using graph edge sampling and negative edge sampling. The initial input matrix is connected with the residual of each feature extraction layer in the inference model, and the deep initial residual graph convolutional network DIRGCN is proposed. The matrix \({\varvec{X}}\) is the network input, and the prediction label matrix \(\widetilde{Y}\) is the network output. RGGM provides a random graph or modeling hypothesis for the network, and DIRGCN, as a new inference model, is used to learn the approximate posterior distribution of unknown labels. RGGM and the loss function generated by DIRGCN together serve as constraints for the network MIA-GRGN to promote model learning and improve the performance of the generated network.

Schematic diagram of MIA-GRGN
3.1 Initial residual graph convolutional network DIRGCN
Since the repeated application of Laplacian smoothing may mix vertex features from different clusters and make them indistinguishable, how to deal with the over-smoothing problem and make GCN extract more feature information has become a most critical issue at present. In order to imitate the jump connection in residual network [33], Kipf [1] attempted to apply the residual between the input and output of the same layer to GCN. However, this residual structure can only alleviate the over-smoothing problem, and the model performance is still inevitably reduced at a certain depth. Inspired by DeepGCN [29], the same layer residual structure of Eq. (3) is improved by connecting the residual between the initial characteristic matrix and the transformed unit mapping to establish dependency relationships between graph nodes, which fully makes use of the correlation between the nearest neighbor information and distant neighbor information and obtains DIRGCN as shown in Fig. 1. It consists of one Linear input layer, k GC layers and one Linear output layer. DIRGCN is defined as follows:
where \(\text{ReLU}\) is the activation function and \({{\varvec{X}}}^{(0)}\in {\mathbb{R}}^{n\times d}\) is the reduced dimension representation of the initial characteristic matrix \({\varvec{X}}\). \({{\varvec{X}}}^{(k-1)}\) and \({{\varvec{X}}}^{(k)}\in {\mathbb{R}}^{n\times h}\) are the input and output matrices of the kth GC layer respectively, and h is the number of feature vectors of the hidden layer. The prediction label matrix \(\widetilde{{\varvec{Y}}}\) is obtained by the reduction of the kth GC layer output matrix \({{\varvec{X}}}^{(k)}\) and softmax normalization operation. By setting the hyperparameter \(\alpha \) in GC layer, DIRGCN makes the new features of each node containing at least a small part of the original input features, which can ensure that the local structure information can be still retained after the node feature’s multiple aggregation. Thus, the network converges to a normal distribution represented by the input features and graph structure, so that for any node, there will be no over-smoothing problem caused by the large aggregation radius or multiple propagation. At the same time, the existence of multiple feature extraction layers will not lead to inadequate learning of the nodes feature information. Finally, the GC layer of DIRGCN abandons weight matrix to simplify model structure and improve model learning efficiency.
3.2 Random graph generation method RGGM
Data samples do not exist in isolation in the network structure and the relationship between them is very helpful for semi-supervised learning tasks. In order to effectively utilize this relationship, based on Ma [16]'s semi-supervised generative framework, the feature representation of graph G is obtained from Multi-Layer Perceptron (MLP), then combining with graph edge sampling and negative edge sampling, the random graph generation method RGGM shown in Fig. 1 can be obtained. RGGM consists of MLP, graph edge sampling and negative edge sampling to simulate the noise graph of graph G and provide modeling hypothesis for DIRGCN. MLP consists of one linear input layer and one linear output layer. RGGM is defined as follows:
where \({p}_{\theta }({{\varvec{L}}}_{k}|{\varvec{X}})\) takes the MLP model as the instantiation object to provide the dimension reduction feature representation \({\varvec{Y}}\), then samples \({\varvec{Y}}\) to generate random graph. \({p}_{\theta }({\varvec{G}}|{\varvec{X}},{{\varvec{L}}}_{k})\) is the graph sampling probability. Graph sampling is edge sampling between node pairs of graph structure. If the graph structure is too complex, enumerating all the possible will take a lot of computing cost. Therefore, referring to the negative edge sampling method used in word embedding [34] and graph embedding [35], graph sampling is divided into graph edge sampling and negative edge sampling. Under the circumstances, graph edge sampling is random edge sampling between node pairs with real edge relationship in graph structure, and negative edge sampling is random edge sampling among node pairs without edge relationship. Therefore, \({p}_{\theta }({\varvec{G}}|{\varvec{X}},{{\varvec{L}}}_{k})\) becomes the graph edge sampling probability \({p}_{1\theta }({\varvec{G}}|{\varvec{X}},{{\varvec{L}}}_{k})\) and the negative edge sampling probability \({p}_{2\theta }({\varvec{G}}|{\varvec{X}},{{\varvec{L}}}_{k})\), which are defined as follows:
where \(\text{Concat}\) is the dimensional splicing operation, \(\text{Embed}\) is used to obtain the word embedding representation of nodes, \({\widetilde{{\varvec{Z}}}}_{0}\) and \({\widetilde{{\varvec{Z}}}}_{1}\) are the row index matrix and column index matrix of symmetric normalized Laplacian matrix respectively, \(\text{Random}\) is the random number operation, \(\lambda \) is the negative sample ratio, and \(|\lambda {\widetilde{{\varvec{Z}}}}_{0}|\) is the negative sample total. Equations (11) and (13) obtain \({p}_{1\theta }({\varvec{G}}|{\varvec{X}},{{\varvec{L}}}_{k})\) and \({p}_{2\theta }({\varvec{G}}|{\varvec{X}},{{\varvec{L}}}_{k})\) by dimension splicing the input feature \({\varvec{X}}\), vector \({p}_{\theta }({{\varvec{L}}}_{k}|{\varvec{X}})\) and the embedded representation of the graph structure.
3.3 Optimization of loss function
The loss function of DIRGCN uses logarithmic likelihood cost function. Considering that the constraint conditions of DIRGCN are too single, in order to improve the model generalization ability and enable the network to obtain more intrinsic characteristics of graph structure, it is expected to obtain loss function with gain from other parts of DIRGCN. Therefore, the additional loss function generated in RGGM is added to jointly constrain the model training. The definition of the total loss function is as follows:
where, \({{\varvec{L}}}_{\text{MIA}-\text{GRGN}}\) is the total loss function of the generated network MIA-GRGN, \({\mu }_{1}\) and \({\mu }_{2}\) are the hyperparameters of the loss function of DIRGCN and RGGM respectively. \({{\varvec{L}}}_{\text{DIRGCN}}\) is the loss function of DIRGCN, where C represents the total number of categories,i represents the ith category in C, xi represents the ith element of a real tag and yi represents the probability that the model predicts that x belongs to the ith category. \({{\varvec{L}}}_{\text{MLP}}\) is the loss function of MLP, \(\text{logsigmoid}\) is a nonlinear function. The three following \({{\varvec{L}}}_{\text{MLP}}\) are loss functions composed of graph structure, feature information and label joint distribution. The four terms in brackets multiplied by \({\mu }_{2}\) together constitute the loss function generated by RGGM.
DIRGCN learns empirical errors from labeled data and generates posterior labels for unlabeled data. The unlabeled data in the random graph generated by RGGM sampling will be classified according to the distribution of labeled data. Through the error supervision generated by the posteriori distribution of RGGM and DIRGCN unlabeled data, the DIRGCN learning is promoted by gradient back propagation, thus improving the classification performance of MIA-GRGN model.
3.4 MIA-GRGN implementation process
The flow chart of MIA-GRGN algorithm is shown in Fig. 2. It can be divided into five major steps:

The implementation flow chart of MIA-GRGN
Step 1: The node information on the original topological graph constitutes the original feature input, and the original feature input is input into the DIRGCN block and RGGM block respectively.
Step 2: The original feature input is extracted through the DIRGCN block, the categories of nodes in the original topology map are classified, and the prediction labels of nodes with known categories are output.
Step 3: The original feature input is extracted by RGGM module, and the noise map is constructed, which adds disturbance to the training process of DIRGCN module.
Step 4: The model training is constrained by monitoring module.
Step 5: When the model achieves the best effect, the unknown nodes are reasoned and the prediction labels of the unknown nodes are output, that is, the nodes on the topological graph are classified.
4 Experiments and results
MIA-GRGN has two main improvements compared with GCN. DIRGCN effectively solves the over-smoothing problem by connecting the input feature matrix \({{\varvec{X}}}^{(0)}\) with the residual of the input feature \({{\varvec{X}}}^{(k-1)}\) at the kth layer, so that feature information of nodes can be fully learned. In addition, the design of RGGM provides an additional loss function for DIRGCN. To demonstrate the effectiveness of MIA-GRGN, experiments will be carried out on model structure, semi-supervised and fully-supervised node classification tasks. We carry out experiments on a PC with Intel(R)Core(TM)i7-10700k CPU and 11 GB Nvidia GeForce RTX 2080 Ti GPU under the environment of Pytorch 1.7.1 and Python 3.7. The GPU used the CUDA10.0 and CuDNN7.6.5 to accelerate.
4.1 Experimental settings
4.1.1 Experimental datasets settings
In order to maximize the performance of the model, based on the parameter range of the benchmark model and the current mainstream model, the parameters of the proposed method in semi-supervised node classification and fully-supervised node classification tasks are adjusted to better adapt to different classification tasks. The datasets settings of the two classification tasks are as follows:
For the classification of semi-supervised nodes, three standard citation network datasets, Cora, Citeseer and Pubmed [36], are used to carry out the classification. They are citation networks with literature as nodes and citation as edges. Each node feature corresponds to a word library representation of the document, and the labels represent the research fields which the document belongs to. For fair comparison, the standard used by Kipf [1] and Yang [37] are applied to complete training, verification, and test segmentation on three datasets Cora, Citeseer and PubMed. 20 nodes in each class are used for training, 500 nodes for verification and 1000 nodes for testing.
In addition to Cora, Citeseer and Pubmed, Chameleon [38], Cornell, Texas and Wisconsin from Pei [39] are also included in the fully-supervised node classification datasets. Chameleon is a Wikipedia dataset of chameleon-specific topic pages. Cornell, Texas, and Wisconsin are three subsets of a web dataset collected by Carnegie Mellon University from computer science departments at various universities, where nodes represent web pages and edges are hyperlinks between them, the feature of the node is the word library representation of the web page. For each dataset, the nodes of each class are randomly divided into 60%, 20% and 20% for training, verification and testing. According to the setting of Pei [39], the performance of each model is measured on 10 randomly divided testsets, and take the mean value of 10 measurement results as the final result. The detailed information of semi-supervised and fully-supervised datasets is shown in Table 1.
4.1.2 Experimental hyperparameters settings
In order to determine the hyperparameters of the model, the initial hyperparameters range shown in Table 2 is determined by referring to the hyperparameters setting methods in the classical model and the current mainstream model, and the hyperparameters is optimized through a large number of experiments, and the final parameters are determined.
As for semi-supervised learning, during the experiment, using Adam optimizer [40], the learning rate is set to 0.01, \(\alpha \) is 0.1, \({\mu }_{1}\) and \({\mu }_{2}\) are set 1 and 1.6 respectively, dropout is set to 0.5, the weight attenuation range is 6e−4, the negative sample rate is 5.0. The number of Cora hidden layers and units are all 64, those of Citeseer are 32 and 256, and those of Pubmed are 16 and 256. The number of iterations is set to 1200, and the early stop mechanism of waiting 100 times is adopted to terminate the training of MIA-GRGN in advance. Other parameters are optimized according to the test results and take the average of 100 model classification results as the final result.
As for fully-supervised learning, we fix the learning rate to 0.01, set the hidden layers to 16 except Cora to 64, weight attenuation range as 5e−5, \({\mu }_{1}\) and \({\mu }_{2}\) as 1 and 1.6 respectively, negative sample rate as 5.0, iteration number as 1200, and adjust other hyperparameters according to the test results. We wait for 100 times of negative optimization to terminate the MIA-GRGN training in advance.
In order to better determine the structure and performance of each module and verify the advantages of the method proposed in this paper and the mainstream methods in this field, the accuracy rate is used as an evaluation index to objectively evaluate the classification effect in subsequent experiments. The calculation formula of accuracy rate is:
Among them, TP means that it is actually a positive sample and the predicted value is also a positive sample. FN indicates that it is actually a positive sample but the predicted value is a negative sample. FP indicates that it is actually a negative sample but the predicted value is a positive sample. TN indicates that the actual sample is negative and the predicted value is negative.
4.2 Model structure analysis
4.2.1 The verification of the performance in DIRGCN model
To verify the effectiveness of DIRGCN, semi-supervised classification experiments are carried out with GCN, JKNet [41] and DeepGCN under different layers. The results are shown in Table 3, where, – represents no experiment, and bold represents the optimal results under each depth model. The results show that the classification effect of GCN reaches the best at 2-layer in Cora, Citeseer and PubMed, and then decreases significantly with the deepening of the model. JKNet and DeepGCN also show performance degradation in varying degrees when the number of layers increases. The performance of DIRGCN continues to improve with the increase of layers. The best results are obtained at layers 64, 32 and 32 in the three datasets, respectively. The model performance can be maintained in deeper layers. Based on the comprehensive analysis of the data in the table, the residual connection method introduced by DIRGCN can fully utilize the correlation between nearest neighbor information and distant neighbor information compared to the other three methods, especially in shallow models, it can form complementary information, effectively distinguish the categories of each node, and alleviate the problem of over-smoothing.
4.2.2 The verification of the function of each module in MIA-GRGN
In order to verify the effects of DIRGCN, RGGM and the optimized loss function in MIA-GRGN, MIA-GRGN is compared with GCN after ablation, the results are shown in Table 4. Where, DIRGCN, GCN&RGGM and MIA-GRGN respectively represent that only DIRGCN is included, RGGM is added on the basis of GCN and the complete MIA-GRGN model.
It can be seen from the Table 4 that compared with the benchmark model GCN, the classification accuracy of the model with only DIRGCN on three datasets is improved by 4.29%, 3.27% and 1.27% respectively, and the classification accuracy of the model with RGGM on the basis of GCN is improved by 0.74%, 3.98% and 0.5% respectively. Compared with GCN, the classification accuracy of the complete MIA-GRGN model is improved by 4.54%, 6.83% and 1.77% respectively. Experiments show that DIRGCN, RGGM and the optimized loss function all play a positive role in model learning. For dataset Cora, although the graph structure is small, there are many feature vectors and categories. In this case, GCN can not extract enough feature information to learn the global structure. It needs deep network to extract potential effective information. Therefore, DIRGCN shows excellent classification effect. In addition, GCN&RGGM also obtains more associations between labels and node features from graph edge sampling and negative edge sampling, which can improve GCN performance. For dataset Citeseer, the average number of nodes in the second-order neighborhood of each node is the lowest among the three datasets, and the graph edges are relatively sparse. RGGM can provide greater assistance to the network through noise graph, which is also confirmed by the results of GCN&RGGM and MIA-GRGN. For dataset Pubmed, the graph categories are few and relatively dense. Although DIRGCN has been able to transmit feature information from neighbors well, the performance of MIA-GRGN model is slightly higher than that of DIRGCN under the constraint of optimization loss function. In addition, for the graph structure with few and dense categories like Pubmed, it is easy to encounter over-fitting in the propagation process, which is also one of the reasons for the poor performance of the model.Comprehensive analysis of the data in Table 4, the DIRGCN module ensures the extraction of useful information, the RGGM module ensures the full utilization of inter sample relationship information, the optimized loss function ensures the sufficient supplementation of information, and the combination of the three modules yields good classification results.
4.3 Experiment data analysis
4.3.1 Semi-supervised node classification experiment
After determining the structure of MIA-GRGN, we compare our model with ten methods, GAT [2], Diff-ResNet [21], APPNP [42], CE-GCN [43], AGCN [44], HGAT [45], GSAN [46], PGCN(CE) [47], AIR-GCN [48], GraphCL* [49], optimal model SegCN-GAT [50] of SEGCN, LGGCLSGC [51] and LGAT [52] on three semi-supervised datasets, The hyperparameters of each comparison model are set according to the requirements of the corresponding papers, and three semi-supervised datasets of MIA-GRGN experiment are used to test the performance on a PC with the same software environment. The experiment results are shown in Table 5, where bold is the optimal result, and italic is the suboptimal result.
Compared with 13 models, MIA-GRGN obtains optimal results on Cora and Citeseer dataset, and the classification accuracy reached 85.2% and 75.1% respectively. The classification accuracy of MIA-GRGN on Cora and Citeseer is 0.59% and 0.67% higher than that of suboptimal model SEGCN-GAT and Diff-ResNet respectively. Compared with the two models, the outstanding advantage of MIA-GRGN is that the optimized loss function can promote DIRGCN to make full use of the relationship information between samples and extract features by sending feedback information. Compared with Pubmed dataset, Cora and Citeseer datasets have more categories when there are fewer node features. MIA-GRGN model structure improves the classification accuracy by deeply digging into the relationship between node features and labels, so it has achieved good results. Experiment results demonstrate that MIA-GRGN has fully mined the relevant information between graph structure, node features, and labels in semi-supervised classification tasks, greatly improving the classification ability of the model.
4.3.2 Fully-supervised node classification experiment
The fully-supervised node classification experiment in addition to two baseline models GCN [1] and GAT [2], we also compare our model with GraphSAGE [3], DropEdge [8], three variants of Geom-GCN-I, Geom-GCN-P and Geom-GCN-S of Geom-GCN [39], APPN [42], GRAND [53], NASA [54] and VIGraph [55]. The hyperparameters of each comparison model are set according to the requirements of the corresponding paper, the performance is tested on seven datasets that MIA-GRGN experiment used with PC that have the same software environment.The experimental results are shown in Table 6, where bold and italic correspond to optimal and suboptimal results respectively. It can be seen from table that, MIA-GRGN exceeds 11 comparison models on Cora, Cornell, Texas and Wisconsin datasets, and the classification accuracy is improved by 1.14%, 7.41%, 0.66% and 3.93% respectively compared with the suboptimal model. This is due to the classification superiority of DIRGCN, which ensures the effective transmission of node features at each layer. GCN and GAT are difficult to obtain feature information on small graphs such as Cornell, and even worse than MLP with only linear layer. MIA-GRGN uses DIRGCN module to ensure that the node features are fully learned, which is beneficial to obtain the inherent characteristics of the graph structure and improve the classification accuracy. For dataset Chameleon, the edge relationship between nodes is very dense, the connection between labeled nodes and unlabeled nodes becomes complex in the generation process of random graph with the increase of training sample. There are too many edges for propagating features, and the information from unlabeled nodes is difficult to be effectively transmitted to labeled nodes. Therefore, MIA-GRGN performed poorly on Chameleon.
Based on the Tables 5 and 6, the DIRGCN module in MIA-GRGN emphasizes the correlation between nodes through the use of residual connections, which can fully explore the significant information between nodes and ensure sufficient feature extraction. The RGGM module uses graph edge sampling and negative edge sampling methods to optimize the generation of random graphs. At the same time, the loss functions generated by known labels, graph edge sampling, and negative edge sampling are fed back to the DIRGCN module, which can supervise it to obtain more correlated features from the data. Through a comprehensive analysis of the two tables, it can be seen that MIA-GRGN has a reasonable structure and is capable of semi-supervised node classification and fully-supervised node classification tasks. It performs better in shallow models, especially for datasets with less dense edge relations between nodes.
4.4 Model complexity analysis
The above experiments verify that MIA-GRGN model has a good effect in both semi-supervised node classification and fully-supervised node classification tasks. In order to better measure the advantages and disadvantages of this model, the complexity of this model is measured with GAT, SEGCN, DropEdge, GCN and GRAND models on three standard datasets, the experiment results are shown in Fig. 3. As can be seen from the figure, in the fully-supervised learning, compared with the GRAND model, the accuracy of MIR-GRGN is improved by 9.38% in Cora dataset. In the semi-supervised learning, on the Citeseer dataset, compared with the SEGCN model, although the parameters of MIR-GRGN increased by three times, the accuracy increased by 1.76%. It can be seen that, although the parameters of MIA-GRGN are relatively large, its classification accuracy is much higher than that of the model with small parameters, and it has a good classification effect under the same supervision mode, achieving a compromise between performance and complexity, and can be better applied to actual scenes.

The relationship between parameter quantity and accuracy on three datasets (a: Cora, b: Citeseer, c: Pumbed)
5 Conclusion
Although GCN has achieved amazing results in non-Euclidean structures, most of the GCN structures are shallow, which is easy to encounter smoothing problems in the process of network deepening. DIRGCN designed by initial input residual connection can greatly alleviate the over-smoothing problem. Negative edge sampling and graph edge sampling introduced in RGGM are helpful for the model to obtain the relationship information between samples. By introducing the extra loss function generated by RGGM, the model learning process of DIRGCN can be optimized, the generalization ability of network can be improved, and the high-performance of MIA-GRGN can be obtained. Experimental results show that MIA-GRGN improves the classification accuracy of Citeseer by 1.08% compared with suboptimal model PGCN(CE) in semi-supervised tasks. In the fully-supervised task, MIA-GRGN improves the classification accuracy of Wisconsin by 3.93% compared with the suboptimal model GraphSAGE. MIA-GRGN has advantages over many advanced methods, but there are still deficiencies in the method design. In the future work, it is expected that the model can have the ability of deeply adaptive node aggregation, and improve the random graph generation method to improve the performance of the whole network.
Data availability
The dataset is available at: http://linqs.umiacs.umd.edu/projects//projects/lbc/.
References
Kipf TN, Welling M. Semi-supervised classification with graph convolutional networks. arXiv Preprint. 2016; arXiv: 1609.02907. https://doi.org/10.48550/arXiv.1609.02907
Veličković P, Cucurull G, Casanova A, et al. Graph attention networks. International Conference on Learning Representation. Vancouver: ICLR. 2018; pp 1–12. https://doi.org/10.48550/arXiv.1710.10903
Hamilton WL, Ying R, Leskovec J. Inductive representation learning on large graphs. arXiv Preprint. 2017; arXiv: 1706.02216. https://doi.org/10.48550/arXiv.1706.02216
Zhang C, Wang J, Yao K. Global random graph convolution network for hyperspectral image classification. Remote Sens. 2021;13(12):2285. https://doi.org/10.3390/rs13122285.
Chen D, Lin Y, Li W, et al. Measuring and relieving the over-smoothing problem for graph neural networks from the topological view. In Proceedings of the AAAI Conference on Artificial Intelligence. New York: AAAI. 2020;34(04):3438–3445. https://doi.org/10.48550/arXiv.1909.03211
Wang H, Dong L, Fan T, et al. A local density optimization method based on a graph convolutional network. Front Inform Technol Electron Eng. 2020;21(12):1795–803. https://doi.org/10.1631/FITEE.1900663.
Qin J, Zeng X, Wu S, et al. Multi-semantic alignment graph convolutional network. Connect Sci. 2022;34(1):2313–31. https://doi.org/10.1080/09540091.2022.2115010.
Rong Y, Huang W, Xu T, et al. Dropedge: towards deep graph convolutional networks on node classification. Proceedings of Workshop at ICLR. Scottsdale: ICLR. 2020. https://doi.org/10.48550/arXiv.1907.10903
Liao J, Liu F, Zheng J. A dynamic adaptive multi-view fusion graph convolutional network recommendation model with dilated mask convolution mechanism. Inform Sci. 2024; 658. https://doi.org/10.1016/j.ins.2023.120028
Ye Z, Li Z, Li G, et al. Dual-channel deep graph convolutional neural networks. Front Artif Intell. 2024;7:1290491. https://doi.org/10.3389/frai.2024.1290491.
Meng L, Ye Z, Yang Y, et al. DeepMCGCN: Multi-channel deep graph neural networks. Int J Comput Intell Syst. 2024;17(1). https://doi.org/10.1007/s44196-024-00432-9
Tan S, Li D, Jiang R, et al. Community-invariant graph contrastive learning. In Proceedings of the 33rd International conference on Machine learning. Vienna: ICML. 2024. https://doi.org/10.48550/arXiv.2405.01350
Li D, Wang Y, Funakoshi K, et al. Joyful: joint modality fusion and graph contrastive learning for multimodal emotion recognition. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Singapore: EMNLP. 2023. https://doi.org/10.48550/arXiv.2311.11009
Li D, Tan S, Wang Y, et al. Temporal and topological augmentation-based cross-view contrastive learning model for temporal link prediction. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management. Shanghai: CIKM. 2023; 4059–4063. https://doi.org/10.1145/3583780.3615231
Li T, Levina E, Zhu J. Prediction models for network-linked data. Ann Appl Stat. 2019;13(1):132–64. https://doi.org/10.1214/18-AOAS1205.
Ma J, Tang W, Zhu J, et al. A flexible generative framework for graph-based semi-supervised learning. Advances in Neural Information Processing Systems. Vancouver: NIPS. 2019; pp 3276–3285. https://doi.org/10.48550/arXiv.1905.10769
Baradaaji A, Dornaika F. Joint latent space and label inference estimation with adaptive fused data and label graphs. ACM Trans Intell Syst Technol. 2023;14(4). https://doi.org/10.1145/3590172
Ziraki N, Bosaghzadeh A, Dornaika F, et al. Inductive multi-view semi-supervised learning with a consensus graph. Cogn Comput. 2023;15(3):904–13. https://doi.org/10.1007/s12559-023-10123-w.
Zhang Y, Ji S, Zou C, et al. Graph learning on millions of data in seconds: label propagation acceleration on graph using data distribution. IEEE Trans Pattern Anal Mach Intell. 2023;45(2):1835–47. https://doi.org/10.1109/TPAMI.2022.3166894.
Chen Z, Fu L, Xiao S, et al. Multi-view graph convolutional networks with differentiable node selection. ACM Trans Knowl Discov Data. 2024;18(1). https://doi.org/10.1145/3608954
Wang T, Dou Z, Bao C, et al. Diffusion mechanism in residual neural network: theory and applications. IEEE Trans Pattern Anal Mach Intell. 2024;46(2):667–80. https://doi.org/10.1109/TPAMI.2023.3272341.
Nie M, Chen D, Wang D. Reinforcement learning on graphs: a survey. IEEE Trans Emerg Topics Comput Intell. 2023;7(4):1065–82. https://doi.org/10.1109/TETCI.2022.3222545.
Liu Y, Jin M, Pan S, et al. Graph self-supervised learning: a survey. IEEE Trans Knowl Data Eng. 2023;35(6):5879–900. https://doi.org/10.1109/TKDE.2022.3172903.
Huang Z, Li F, Yao J, et al. MGCRL: Multi-view graph convolution and multi-agent reinforcement learning for dialogue state tracking. Neural Comput Appl. 2024. https://doi.org/10.1007/s00521-023-09328-9.
Xing Q, Xu Y, Chen Z. A bilevel graph reinforcement learning method for electric vehicle fleet charging guidance. IEEE Trans Smart Grid. 2023;14(4):3309–12. https://doi.org/10.1109/TSG.2023.3240580.
Xu D, Liu P, Li H, et al. Multi-view graph convolution network reinforcement learning for CAVs cooperative control in highway mixed traffic. IEEE Trans Intell Vehicles. 2024;9(1):2588–99. https://doi.org/10.1109/TIV.2023.3297310.
Song Y, Yang X and Xu C. Self-supervised calorie-aware heterogeneous graph networks for food recommendation. ACM Trans Multimed Comput Commun Appl. 2023;19(1). https://doi.org/10.1145/3524618
Hoang N, Maehara T. Revisiting graph neural networks: all we have is low-pass filters. arXiv Preprint. 2019; arXiv: 1905.19550. https://doi.org/10.48550/arXiv.1905.09550
Li G, Müller M, Thabet A, et al. DeepGCNs: Can GCNs Go As Deep As CNNs? In 2019 IEEE/CVF international conference on computer vision. Seoul: IEEE. 2019; p. 9266–9275. https://doi.org/10.48550/arXiv.1904.03751
Hu F, Song P, He R, et al. MSARN: a multi-scale attention residual network for end-to-end environmental sound classification. Neural Process Lett. 2023;55(8):11449–65. https://doi.org/10.1007/s11063-023-11383-1.
Du W, Yang L, Wang H, et al. LN-MRSCAE: A novel deep learning based denoising method for mechanical vibration signals. J Vib Control. 2024;30(3–4):459–71. https://doi.org/10.1177/10775463231151721.
Chen S, Zhang C, Gu F, et al. RSGNN: residual structure graph neural network. Int J Mach Learn Cybern. 2024. https://doi.org/10.1007/s13042-024-02136-0.
He K, Zhang X, Ren S, et al. Deep residual learning for image recognition. In: 2016 IEEE conference on computer vision and pattern recognition. Las Vegas: IEEE. 2016; p. 770–778. https://doi.org/10.48550/arXiv.1512.03385
Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space. In: Proceedings of Workshop at ICLR. Scottsdale: ICLR. 2013. https://doi.org/10.48550/arXiv.1301.3781
Tang J, Qu M, Wang M, et al. Line: Large-scale information network embedding. In: Proceedings of the 24th international conference on World Wide Web. Florence: WWW. 2015; p. 1067–1077. https://doi.org/10.48550/arXiv.1503.03578
Sen P, Namata G, Bilgic M, et al. Collective classification in network data. AI Mag. 2008;29:93–106. https://doi.org/10.1609/aimag.v29i3.2157.
Yang Z, Cohen W, Salakhutdinov R. Revisiting semi-supervised learning with graph embeddings. In: Proceedings of the 33rd International conference on Machine learning. New York: ICML. 2016; pp 40–48. https://doi.org/10.48550/arXiv.1603.08861
Rozemberczki B, Allen C, Sarkar R. Multi-scale attributed node embedding. J Complex Netw. 2021;9(2). https://doi.org/10.48550/arXiv.1909.13021
Pei H, Wei B, Yu L, et al. Geom-GCN: geometric graph convolutional networks. arXiv Preprint. 2020; arXiv: 2002.05287. https://doi.org/10.48550/arXiv.2002.05287
Kingma D, Ba J. Adam: A method for stochastic optimization. arXiv Preprint. 2014; arXiv: 1412.6980. https://doi.org/10.48550/arXiv.1412.6980
Xu K, Li C, Tian Y, et al. Representation learning on graphs with jumping knowledge networks. In: Proceedings of the 35rd International conference on Machine learning. Stockholm: ICML. 2018; p. 5453–5462. https://doi.org/10.48550/arXiv.1806.03536
Klicpera J; Bojchevski A, Günnemann S. Predict then propagate: Graph neural networks meet personalized pagerank. arXiv Preprint. 2018; arXiv: 1810.05997. https://doi.org/10.48550/arXiv.1810.05997
Liu Y, Wang Q, Wang X, et al. Community enhanced graph convolutional networks. Pattern Recogn Lett. 2020;138:462–8. https://doi.org/10.1016/j.patrec.2020.08.015.
Mahsa M, Abdessamad B. Anisotropic graph convolutional network for semi-supervised learning. IEEE Trans Multimed. 2021;23:3931–3942. https://doi.org/10.48550/arXiv.2010.10284
Feng Y, Li K, Gao Y, et al. Hierarchical graph attention networks for semi-supervised node classification. Appl Intell. 2020;50(10):3441–51. https://doi.org/10.1007/s10489-020-01729-w.
Min Y, Frederik W, Guy W. Geometric scattering attention networks. In: ICASSP 2021–2021 IEEE international conference on acoustics, speech and signal processing (ICASSP). 2021; p. 8518–8522. https://doi.org/10.1109/ICASSP39728.2021.9414557
Negar H, Alexandros I. Progressive graph convolutional networks for semi-supervised node classification. IEEE Access. 2021;9:81957–81968. https://doi.org/10.48550/arXiv.2003.12277
Hu F, Zhu Y, Wu S, et al. Graphair: Graph representation learning with neighborhood aggregation and interaction. Pattern Recogn. 2021;112:107745. https://doi.org/10.48550/arXiv.1911.01731
Hakim H, Mounir G, Philippe C, et al. Negative sampling strategies for contrastive self-supervised learning of graph representations. Signal Process. 2022;190: 108310. https://doi.org/10.1016/j.sigpro.2021.108310.
Luo Y, Ji R, Guan T, et al. Every node counts: Self-ensembling graph convolutional networks for semi-supervised learning. Pattern Recogn. 2020;106: 107451. https://doi.org/10.1016/j.patcog.2020.107451.
Peng M, Juan X and Li Z. Label-guided graph contrastive learning for semi-supervised node classification. Expert Syst Appl. 2023;239. https://doi.org/10.1016/j.eswa.2023.122385
Sun C, Meng F, Li C, et al. LGAT: a light graph attention network focusing on message passing for semi-supervised node classification. Computing. 2024;106(5):1359–93. https://doi.org/10.1007/s00607-024-01261-6.
Feng W, Zhang J, Dong Y, et al. Graph random neural networks for semi-supervised learning on graphs. In: Proceedings of the 34th Conference on Neural Information Processing Systems. Vancouver: NeurIPS. 2020. https://doi.org/10.48550/arXiv.2005.11079
Bo D, Hu B, Wang X, et al. Regularizing graph neural networks via consistency-diversity graph augmentations. In: Proceedings of the 36th AAAI Conference on Artificial Intelligence. Vancouver: AAAI. 2022;36:3913–3921. https://doi.org/10.1609/aaai.v36i4.20307
Hu Y, Ouyang S, Yang Z, et al. VIGraph: Generative self-supervised learning for class-imbalanced node classification. arXiv Preprint. 2024; arXiv: 2311.01191. https://doi.org/10.48550/arXiv.2311.01191
Acknowledgements
We thank the reviewers very much for the insightful and accurate comments and suggestions which helped me improve the final version of the paper.
Funding
The research was supported in part by the National Natural Science Foundation of China (52174141), in part by the Natural Science Foundation of Anhui Province (2108085ME158), and in part by the Suzhou Key Research and Development Project (SGC2021069).
Author information
Authors and Affiliations
Contributions
Zhenhuan Liang: Conceptualization, Formal analysis, Investigation, Methodology, Project administration, Visualization, Writing-original draft, Writing-review & editing. Xiaofen Jia: Conceptualization, Investigation, Data curation, Funding acquisition, Writing-original draft, Writing-review & editing. Xiaolei Han: Data curation, Formal analysis, Investigation, Resources, Validation, Writing-original draft. Baiting Zhao: Data curation, Formal analysis, Writing-original draft. Zhu Feng: Methodology, Writing-original draft.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
This is original article. We confirm that this manuscript has not been published elsewhere and is not under consideration by another journal. All authors have approved the manuscript and agree with submission to Complex & Intelligent Systems.
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liang, Z., Jia, X., Han, X. et al. A graph residual generation network for node classification based on multi-information aggregation. Discov Computing 27, 26 (2024). https://doi.org/10.1007/s10791-024-09461-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10791-024-09461-6