
Abstract
The vocal structure of gibbons has long been believed to be under strong genetic control and consistent with phylogeny. Gibbon vocalizations show hierarchical structures and song coordination behaviors, which may have different functions and convey distinct information compared to basic notes. However, previous studies have not compared vocalizations at multiple levels across species. We compared the vocal structures of three Nomascus species in the wild in South China, namely the western black gibbon (Nomascus concolor), Cao vit gibbon (N. nasutus), and Hainan gibbon (N. hainanus) at the levels of note (six features of four types of notes), male sequence (eight features), and song coordination (four features of the overlap pattern between male and female songs). We selected 15 recordings for each species: N. concolor (six groups, 2006 to 2021), N. nasutus (seven groups, 2008 to 2021), and N. hainanus (six groups, 2020 to 2021). We used permuted random forest analysis to test for species differences in vocal structure and the contribution of acoustic features to species differences at each level. We used acoustic features to construct a hierarchical clustering tree, and compared it with phylogenetic relationships. We found significant differences at all levels except the boom note. Acoustic similarity did not match genetic similarity in boom and pre-modulated notes, suggesting that genetic differences are not the only factor leading to species differences in vocal structures. We also found different contributions of acoustic features to differentiation in vocal structure at different levels. Our study suggests that we need to compare gibbon vocalizations at different levels to understand their differentiation and evolution.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Vocal signals, which are usually produced by the vibration of vocal tracts in vertebrates, are essential for various biological functions including species recognition (de Oliveira et al., 2020; Fan et al., 2022a, 2022b, 2022c; Kwong-Brown et al., 2019), territorial defense (de Kort et al., 2009; Ma et al., 2020; Naguib & Wiley, 2001), anti-predation (Nielsen et al., 2019), reproduction (Fan et al., 2009) and inter-group spacing (Levrero et al., 2019; Ma et al., 2022). Vocal signals may have been shaped by selection pressures such as habitat structure (Arasco et al., 2022; Chen et al., 2022; Sementili-Cardoso et al., 2022), social system (Bouchet et al., 2013; Pougnault et al., 2022), predation (Coye et al., 2022; Jiang et al., 2022; Tuttle & Ryan, 1981), and sexual selection (Seddon, 2005). Many species with a close phylogenetic relationship show similar vocal structures due to their similar morphological and anatomical features, although this is not always the case (Thomassen & Povel, 2006). For example, closely related rodents have more similar laryngeal cartilage structures than those that are less closely related (Borgard et al., 2020), leading to similar acoustic features such as fundamental frequency, amplitude, and bandwidth (Miller & Engstrom, 2012). This phenomenon is also found in birds (McCracken & Sheldon, 1997; Seneviratne et al., 2012), anurans (Manzano & Sawaya, 2022), and primates (Hasiniaina et al., 2020).
Animal vocalizations show species differences at multiple levels, including notes, sequences, and coordination (Nardone et al., 2017). At the note level, clear differences occur in frequency (Friis et al., 2022), duration (Beckers & Ten Cate, 2001; Sementili-Cardoso et al., 2022), amplitude (Beckers & Ten Cate, 2001), and formant dispersion (Bergman et al., 2016). For instance, four source-related acoustic features, three filter-related acoustic features, and feature duration differ significantly among the three Spheniscus species (Favaro et al., 2016). Differences at the note level are driven by sexual selection (Favaro et al., 2016), climatic conditions and geographic isolation (), physiological differences (Friis et al., 2022), predation (Coye et al., 2022), and vegetation cover (Arasco et al., 2022). At the sequence level, animals utter hierarchical structures like sequences of notes, or phrases. This higher-level structure has been found in avians (Suzuki et al., 2018), anurans (de Carvalho et al., 2015), cetaceans (Pace et al., 2022), and primates (Girard-Buttoz, Bortolato, et al., 2022a; Girard-Buttoz, Zaccarella, et al., 2022b; Leroux et al., 2021; Leroux et al., 2023). Sequences also show species differences, especially in birds, in many features such as repertoires, syntax, and intervals between notes (Ivanitskii et al., 2017; Vokurková et al., 2013). For example, Luscinia cyane shows a flexible order, while L. luscinia uses linear syntax in which song types are executed in a strict sequence (Ivanitskii et al., 2017). At the coordination level, patterns of overlap (Mendez & Sandoval, 2021), the initiation of sex (Tobias et al., 1998), and sex specificity (Muller & Anzenberger, 2002) of song coordination (e.g., duetting, a coordinated acoustic display where mated pairs combine their vocalizations) also differ across species. For instance, based on the dominant frequency, duration, call rate, and sex difference, the family Callicebinae shows four distinct duetting patterns (Adret et al., 2018). Unlike at the note level, inter-species differences in the sequence and song coordination levels are mainly driven by group size and structure (Valderrama et al., 2013) and social learning (Vokurková et al., 2013).
The divergence of vocal signals, particularly loud calls, has been studied extensively in primates. For example, temporal-related and frequency-related acoustic features of loud calls show striking differences, influenced by genetic drift in Microcebus spp. (Hasiniaina et al., 2020) and by sexual selection in Alouatta spp. (Bergman et al., 2016). Therefore, vocal signal divergence serves as a valuable tool for species delimitation in many species, including Microcebus spp. (Zimmermann et al., 2000), Nomascus spp. (Ruppell, 2009), and Leontopithecus spp. (Snowdon et al., 1986). Further supporting this idea, playback experiments show that Eulemur spp. (Rakotonirina et al., 2016), Tarsius spp. (Nietsch & Kopp, 1998), and Macaca spp. (Muroyama & Thierry, 1998) can distinguish between species based on vocal signals. Given that hierarchical structures and song coordination have evolved in multiple primate species, with diverse units serving different functions and conveying varying information (Berthet et al., 2019; Ma et al., 2024; Seiler et al., 2015), we need to investigate whether and to what extent differences exist at each level (Bouchet et al., 2010). However, previous studies have compared species at a single level, such as the call note (Propithecus diadema and Indri indri; Valente et al., 2022), sequence (Presbytis spp.; Meyer et al., 2012), or duet (Pitheciidae; Adret et al., 2018), or combine all parameters into one discriminant analysis (Van Ngoc et al., 2011).
Gibbons (Hylobatidae) are arboreal and highly territorial small apes that are distributed throughout Southeast Asia (Yang et al., 2023; Bartlett et al., 2016). Although they live mainly in pairs of one adult male and one adult female (Brockelman et al., 1998), multiple gibbon species can also live in stable groups with one male and two breeding females, or one female and two adult males (Guan et al., 2018; Lappan et al., 2017; Savini et al., 2009). All gibbon species emit a variety of notes that are organized as sequences. Except for Java gibbons (Hylobates moloch) and Kloss’ gibbons (H. klossii), adult males and females coordinate their sequences to form duet or trio songs (Cowlishaw, 1996; Geissmann, 2000). At the note level, physiological factors may strongly influence some features. For instance, frequency-related features of notes such as pitch are significantly correlated with androgen levels in H. lar (Barelli et al., 2013). The sequence level is more flexible. For example, H. lar can produce and perceive speech-like phrases (Terleph et al., 2018a), while H. muelleri inserts phrases (Inoue et al., 2020) and chunk structures (Inoue et al., 2017). In terms of song coordination, gibbons also show high flexibility and complexity. Species including H. funereus (Lau et al., 2022), H. lar (Terleph et al., 2018b), and Symphalangus syndactylus (Geissmann & Orgeldinger, 2000) show high pair consistency in duets by adjusting their song to temporal and spectral aspects of another’s.
Gibbon vocalizations have been thought to be genetically determined because the rate of notes and spectral characteristics of female hybrid gibbon great call sequences are intermediate between those of their parental species (H. lar and H. pileatus; Brockelman & Schilling, 1984; Tenaza, 1985). Additionally, a significant positive correlation has been found between genetic similarity and gibbon song structure (Ruppell, 2009; Van Ngoc et al., 2011), indicating that gibbon species with closer geographical distance and phylogenetic relationships exhibit more similar vocal structures. However, sub-adult and adult H. agilis and H. moloch show socially mediated vocal flexibility and mother–daughter co-singing interactions may enhance vocal development (Koda et al., 2013; Yi et al., 2022), which suggests that a social learning process may exist in the song development of gibbons.
Crested gibbons (Nomascus) are well known for their highly sex-specific and hierarchical vocalizations (Table I; Geissmann, 1995). Among them, cao vit gibbons (N. nasutus), Hainan gibbons (N. hainanus), and western black gibbons (N. concolor) were previously considered as a single species (N. concolor), referred to as the black gibbon, because adult males are all black and display subtle morphological differences (Geissmann, 1995; Mootnick & Fan, 2011). However, adult females differ in the presence or absence of a white face ring, the color of the chin and abdomen, and the shape and size of the black crest (Mootnick & Fan, 2011). Furthermore, the natal color of these species is also different (Zhu et al., 2024). A phylogenetic study analyzed mitochondrial cytochrome b gene sequence data from six Nomascus species, and showed that N. hainanus and N. nasutus are the basal branches of crested gibbons, while N. concolor branched off first in another clade (Thinh et al., 2010). These morphological and anatomical findings suggest they all are distinct species. These species often live in groups consisting of one adult male and two adult breeding females (Fan et al., 2015; Hu et al., 2018; Zhou et al., 2008). They all produce vocalizations at various levels, including note, sequence, and song coordination (Huang et al., 2020).
N. nasutus occurs along the border between Guangxi province, China, and Cao Bang, Vietnam. This area is characterized by a typical karst limestone landscape and is surrounded by degraded scrub and secondary forest (Fan et al., 2013). N. nasutus was thought to be extinct in both China and Vietnam by the 1960s, until a small population was rediscovered in Vietnam in 2002 (Geissmann et al., 2002) and in China in 2006 (Chan et al., 2008). A recent population survey estimated that 11 groups remain, with about 74 individuals (Wearn et al., 2024). N. hainanus is only found in Hainan Tropical Rainforest National Park (18°57’-19°11’ N, 109°03’-17’ E, 350-1560 m), China, which is covered in dense tropical rainforest (Zhang et al., 2010). The current N. hainanus population consists of six groups including about 40 individuals (Zhong et al., 2023). N. concolor is distributed in the mid-montane humid evergreen broadleaved forests and semi-humid evergreen broad-leaved forests in central and southeast Yunnan province, China, north Vietnam, and north Laos (Fan et al., 2022a, 2022b, 2022c; Yang et al., 2021). N. concolor has a larger population size than N. nasutus and N. hainanus. The current global population size is about 1300 (Fan, 2017; Fan et al., 2022a, 2022b, 2022c).
In these Nomascus species, the adult male and females coordinate their sex-specific vocalizations to produce duet or trio singing bouts in the early morning, which serve as territory or resource defense, and mate relationship maintenance (Fan et al., 2009; Ma et al., 2022). Studies have investigated vocal differences in four buff-cheeked Nomascus species: N. leucogenys, N. siki, N. annamensis, and N. gabriellae. Males of N. leucogenys gave loud staccato aa notes, which appeared rarely in N. siki, N. annamensis, and N. gabriellae. N. leucogenys could also be distinguished from the three other species by their female great calls, which had a faster frequency modulation and a longer duration (Van Ngoc et al., 2011). Although studies have described the sonogram structure of N. nasutus (Feng et al., 2013), N. hainanus (Deng et al., 2014), and N. concolor (Fan et al., 2010), no work has explored vocalization differences among these three species. To test whether species differences in vocal structure are present at different levels in gibbons and whether they are influenced by genetic factors, we explored (1) interspecific differences in vocal structure among the three Nomascus species, (2) which features contribute to interspecific differences, and (3) whether the similarity in vocalization at different levels is correlated with genetic similarity.
Methods
Study subjects
We recorded the songs of seven groups of N. nasutus in Bangliang Gibbon National Nature Reserve (22°49’-59’ N, 106°9’-30’ E, 500–1000 m), Guangxi, six groups of N. hainanus in Hainan Tropical Rainforest National Park, Hainan, and six groups of N. concolor from Dazhaizi (24°21’ N, 100°42’ E, 1700–2700 m) on the western slope of Mt. Wuliang National Nature Reserve, Yunnan (Fig. 1).

Distributions of three species of Nomascus in China. We recorded vocalizations in Bangliang Gibbon National Nature Reserve, Guangxi (2008 to 2021), Dazhaizi, Mt. Wuliang National Nature Reserve, Yunnan (2006 to 2021), and Hainan Tropical Rainforest National Park, Hainan (2020 to 2021). We also show the annual temperature, annual precipitation, altitude span, and the number of groups recorded for each species at each site.
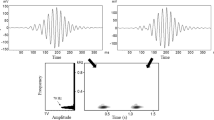
In these species, typical male sequences usually begin with a boom note (bo) or several aa notes (aa), followed by a pre-modulated note (pre), and end with modulated notes (mR) with 0–4 rolls (Table I). Adult females contribute great calls and coordinate their singing with the males (Ma et al., 2024). The great call of females generally consists of 1–2 introductory notes and multiple wa notes (Fig. 2). Following the female great call, the adult male responds with a male coda, collectively forming a successful great call sequence (Fig. 2). If females have failed to produce the wa notes, we define it as a failed great call (Fig. 2c).

Spectrograms of the songs of three Nomascus species with features we measured. Plots on the left show sections of song bouts in N. nasutus (a), N. hainanus (b), and N. concolor (c). d A successful great call sequence of N. nasutus. e A male solo sequence of N. concolor. b A modulated note of N. concolor. MSS: typical male solo sequence; SGCS: successful great call sequence; FGCS: failed great call sequence; OD: overlap duration; CD: male coda sequence duration. Vocalizations in black represent the female great calls. We recorded vocalizations in Bangliang Gibbon National Nature Reserve, Guangxi (2008 to 2021), Dazhaizi, Mt. Wuliang National Nature Reserve, Yunnan (2006 to 2021), and Hainan Tropical Rainforest National Park, Hainan (2020 to 2021). See Table II for descriptions of these features.
We used Sony PCM-D100 recorders with Sony C‐76 directed microphones, Marantz PMD 660 solid-state digital flash recorders, and ZOOM H6 handy recorders with Sennheiser ME 66 directional microphones at a sampling rate of 48 kHz and 24-bit resolution (Huang et al., 2020) to record all loud morning song bouts (Ma et al., 2024). Based on long-term behavioral observations and population monitoring, we knew the home range of each study group. In the center of each groups’ home range, we recorded all song bouts from 6:50 am to 9:00 am at a distance of 20 m to 400 m from the singing individuals.
Data processing
We selected 15 song bouts for each species: six groups for N. concolor (seven song bouts for CG5M4, three song bouts for CG6M2, two song bouts for CG4M1, one song bout for CG4M2, one song bout for CGAM1, and one song bout for CGBM1; Table S1), seven groups for N. nasutus (four song bouts for NG1M3, four song bouts for NGLM1, three song bouts for NGMM1, one song bout for NG2M1, one song bout for NG3M1, one song bout for NG4M1, and one song bout for NG5M1; Table S1), and six groups for N. hainanus (seven song bouts for HGBM1, three song bouts for HGCM1, two song bouts for HGDM1, one song bout for HGAM1, one song bout for HGEM1, and one song bout for HGFM1; Table S1) with the highest quality (a high signal-to-noise ratio) for analysis. We used Annotate (to TextGrid) analysis in Praat (× 64) 6.0.17 to show the spectrograms of each song bout and measured temporal features based on a fast Fourier transform window (1024 points, 50% overlapped Hanning window of 0.005s width, 0–6000 Hz frequency range, 80 dB dynamic range, 0.002 s time step and 20 Hz frequency step, Huang et al., 2020). The first author made all annotations. We used the package librosa 0.9.2 in Python 3.10 to measure frequency features (McFee et al., 2015). We used the function librosa.specshow to load an audio file as a floating-point time series, and then we used the functions librosa.stft and librosa.amplitude_to_db to convert an amplitude spectrogram to a dB-scaled spectrogram. We used the function librosa.display.specshow to generate an interactive spectrogram, with all parameters set to default values. Finally, we manually extracted frequency features from the spectrogram.
We measured 18 features at three levels: six features for each of four types of notes, eight features of the male solo sequence, and four features of song coordination (Fig. 2, Table II). We used a feature called “shape” to evaluate the rise and fall trend and stability of f0 of each note:
Thus, the closer the shape is to 1, the more stable the note's f0 is. We also described the note males were singing when the female(s) began to join the duet or trio and the difference of modulated notes between male solo sequences and coda sequences.
Statistical analysis
We used Python (version 3.10) to conduct statistical analysis. We used Kruskal–Wallis tests to test for differences among species for each feature, then used Wilcoxon tests with Bonferroni correction for multiple testing to test for differences between pairs of species. If p < 0.017, we rejected the null hypothesis and considered that feature to differ significantly between pairs of species. To account for pseudoreplication, we used a random forest model with permutations to test for interspecies differences and feature importance (Breiman, 2001) at the note, male solo sequence, and song coordination levels. For each level, we had m individuals, among which the lowest number of observations was n. We extracted \(\frac{\text{n}}{{2}}\) observations from each of m individuals as the training set and took all remaining observations as the testing set. We repeated this process 100 times, training and testing a random forest classifier at each time to calculate the mean testing accuracy M and mean importance of each feature Ni, where i is the number of features. Next, we permuted species labels of each individual and split data (m ×\(\frac{\text{n}}{ \, {2}}\) observations for training, others for testing) to train and test a random forest model. We repeated this 1000 times, resulting in 1000 testing accuracies pMj and 1000 values of importance for each feature pNij, where j is the number of repeats (Mundry & Sommer, 2007).
To test for species differences at each level, we calculated the number of pM with values greater than M and divided by 1000 to obtain a p-value. To determine which feature contributes significantly to species classification, for each feature, we calculated the number of pN values greater than N, divided by 1000, and obtained a p-value. If p < 0.05, we rejected the null hypothesis and considered that level to differ significantly between species or that feature to contribute significantly to species classification (Mundry & Sommer, 2007).
We took the arithmetic mean and standard deviation of all features of each level as the features of hierarchical clustering (Dong et al., 2021) to compare whether the vocal structures are consistent with phylogenetic relationships at different levels, and we used Euclidean distance to calculate similarity between features of vocal structures.
Ethical note
The research activities reported in this article comply with corresponding national and institutional guidelines and were approved by the Bangliang Gibbon National Nature Reserve Administration Bureau, Mt. Wuliang National Nature Reserve Administration Bureau, and Hainan Tropical Rainforest National Park. All research activities reported in this article comply with Chinese legal requirements. The authors have no conflicts of interest to disclose.
Data availability
The codes and datasets from the current study can be found in figshare: https://figshare.com/s/adb9a0bd068bb2491ebb (will be published at acceptance).
Results
Inter-specific differences in vocal structure
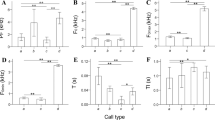
All note features differed significantly among the three species (Kruskal–Wallis tests: p < 0.001; Table S2; Fig. 3). However, some differences between two species were not significant after correction for multiple testing (Wilcoxon tests with Bonferroni correction: p > 0.017; Tables S3; Fig. 3). We found significant interspecific differences at the note level (permuted random forest analysis: p < 0.001; Table III), except for the boom note (permuted random forest analysis: p = 0.294; Table III).

Box plots of four types of notes, male solo sequences, and song coordination levels for Nomascus nasutus in Bangliang Gibbon National Nature Reserve, Guangxi (2008 to 2021), N. concolor Dazhaizi, Mt. Wuliang National Nature Reserve, Yunnan (2006 to 2021), and and N. hainanus in Hainan Tropical Rainforest National Park, Hainan (2020 to 2021). Box colors show different levels of analysis, the midline represents the median, boxes represent the 25th and 75th percentiles, and the whiskers represent the maximum and minimum values of the acoustic features for each species. All features show significant differences among three species (Kruskal–Wallis tests: p < 0.05; Table S2, S4, and S6).
All male solo sequence features differed significantly among the three species (Kruskal–Wallis tests: p < 0.001; Table S4; Fig. 3). Difference in feature duration between N.nasutus and N. hainanus and feature mintd between N.concolor and N. hainanus were not significant after correction for multiple testing (Wilcoxon tests with Bonferroni correction: p > 0.017; Tables S5; Fig. 3). We found significant interspecific differences at the male solo sequence level (permuted random forest analysis: p < 0.001; Table III).
All song coordination features differed significantly among the three species (Kruskal–Wallis tests: p < 0.001; Table S6; Fig. 3). Difference in feature duration and overlap duration between N. nasutus and N. hainanus were not significant after correction for multiple testing (Wilcoxon tests with Bonferroni correction: p > 0.017; Tables S7; Fig. 3). We found significant interspecific differences at the song coordination level (permuted random forest analysis: p < 0.001; Table III). N. nasutus and N. hainanus showed similar coordinated patterns, while N. concolor differed (Fig. 3, Table S6). In N. concolor and N. nasutus, females emitted great calls when males emitted aa notes. In contrast, the timing of the female's great calls was more flexible in N. hainanus (Table S8). In each song bout, females produced a mean of 4.13 ± SD 3.18 great calls in N. concolor, 3.27 ± SD 2.08 great calls in N. hainanus, and 3.00 ± SD 1.41 great calls in N. nasutus. In N. nasutus, male coda sequences often consisted of more deeply modulated notes than those produced during the male solo sequence (Fig. 2a). Coda sequences usually consisted of at least three mR notes, each with at least two rolls. In N. hainanus, no mR notes included rolls in the male solo sequence, but the males sometimes deeply modulated and produced a roll in the first modulated note of the coda sequence (Fig. 2b).
Importance of each feature
For boom notes, no feature contributed significantly to distinguishing species (Fig. 4a). For aa notes, end f0 contributed significantly to distinguishing species (Fig. 4b). For pre notes, shape significantly contributed to distinguishing between species (Fig. 4c). For mR notes, shape and min f0 contributed significantly to distinguishing species (Fig. 4d). At the male solo sequence level, the number of boom notes and rolls of mR notes contributed significantly to distinguishing species (Fig. 4e). At the song coordination level, no feature contributed significantly to distinguishing species (Fig. 4f).

The importance of vocalization features in classifications at four types of notes, male solo sequence, and song coordination levels after 100 iterations of a random forest model for three gibbon species in China. Bars show the importance of the feature in distinguishing species. Black vertical lines show standard errors. Numbers above bars are P-values derived from permuted random forest analysis, see Methods for details. The smaller the p-value, the greater the difference in feature importance before and after the permutation of species labels. We studied Nomascus nasutus in Bangliang Gibbon National Nature Reserve, Guangxi (2008 to 2021), N. concolor Dazhaizi, Mt. Wuliang National Nature Reserve, Yunnan (2006 to 2021), and and N. hainanus in Hainan Tropical Rainforest National Park, Hainan (2020 to 2021).
Hierarchical clustering of vocal structure
For boom and pre notes, the similarity in vocal structure did not align with phylogenetic relationships. Nomascus hainanus and N. concolor clustered together significantly (Fig. 5a, c), indicating that their vocal structures of boom and pre notes were more similar than both are to N nasutus. In contrast, N. hainanus and N. nasutus clustered together significantly for the aa note, mR note, male solo sequence, and song coordination level (Fig. 5b, d, e, f), which aligns with the phylogenetic relationships.

Results of hierarchical cluster analysis showing the similarity in four types of notes, male solo sequence, and song coordination levels in three species of gibbon in China based on the standardized mean values of features. Colors represent clusters, and the length of the branch represents the Euclidean distance between species. We studied Nomascus nasutus in Bangliang Gibbon National Nature Reserve, Guangxi (2008 to 2021), N. concolor Dazhaizi, Mt. Wuliang National Nature Reserve, Yunnan (2006 to 2021), and and N. hainanus in Hainan Tropical Rainforest National Park, Hainan (2020 to 2021).
Discussion
We found interspecific differences at the aa note, pre note, mR note, male solo sequence, and song coordination level among the three Nomascus species. This indicates these species have evolved different note and sequence structures and coordination patterns. Together with morphological (Mootnick & Fan, 2011) and genetic differences (Van Ngoc et al., 2011), our results support regarding N. concolor, N. hainanus, and N. nasutus as distinct species. However, the boom note did not show significant species differences. Boom notes show a lower frequency and amplitude compared to other notes (Fig. 3, Table S2). In other species, species-specific information is also conveyed by calls with high frequency or high amplitude (Czocherová et al., 2022; Zuk et al., 2008). We speculate that the soft short boom may function as within-group communication and that its acoustic characteristics may be subject to fewer selection pressures than other notes.
At the note level, feature shape was most important in identifying species in pre and mR notes, while feature end f0 and min f0 were most important in aa and mR notes. All these features are frequency-related, suggesting that frequency-related features may play a more important role than temporal features at the note level. These findings reflect those in a study of Alouatta palliata and A. pigra, which found that frequency-related features such as formant dispersion and highest frequency are more likely to reflect interspecific differences than temporal traits such as the longest syllable duration (Bergman et al., 2016). In environments with denser vegetation coverage, species with lower f0 may have higher fitness (Luther & Gentry, 2013; Martens & Michelsen, 1981). Furthermore, in an environment with high humidity and high temperature, signals with high f0 decay faster (Haupert et al., 2023). We currently lack data on the habitat differences among the three Nomascus species.
For the feature shape, N. hainanus has the most stable mR notes with no rolls (mR0 only). For learned signals, frequency modulation patterns are more complex in larger groups than in smaller groups (Beecher, 1989), and the same rule may apply to larger populations. In small populations, some notes, especially those that are harder to imitate and learn, will disappear (Hudson & Creanza, 2022). The increasing number of individuals that need to be distinguished in large populations also encourages signalers to generate unique personal signatures (Pollard & Blumstein, 2011; Smith-Vidaurre et al., 2021). The population of N. hainanus declined to two groups with only two singing adult males in 2003 (Deng et al., 2014). The reduction of population size and cultural drift might be a potential explanation of the smaller number of note types in N. hainanus and the relatively low complexity of the frequency modulation pattern of mR notes (only mR0 remains). However, the role of social learning in gibbon vocalization is an open question, which deserves more research.
At the male solo sequence level, the number of boom notes and rolls of mR notes contributed the most to the interspecific differences. Compared to specific note features, syntactic features such as the number, type, and order of notes mainly affected the structure of sequences. This reflects the phenomenon observed in the Presbytis species. The loud call sequence of P. tomasi, P. potenziani, P.comata, and P. melalophos contains different types of notes and phrases, and the position of the phrase and the number of notes are also different (Meyer et al., 2012). The diversity and complexity of sequences are also positively correlated with population size (Valderrama et al., 2013). Male solo sequences in N. hainanus contain the fewest boom and aa notes, and the simplest types of notes, the decrease in the note types and number of notes in the sequence may also be related to the decline in population size. Nevertheless, the basic syntactic structure of the male solo sequence in these three Nomascus species is similar, all following the pattern of boom-aa-pre-mR transmission.
The three species showed an obvious difference in coordination pattern. The female great call and the male coda of N. concolor did not overlap. In contrast, female great calls were overlapped by male vocalizations in N. nasutus and N. hainanus. Although the overlap between vocal signals increases the strength of the vocal signal and reflects the cohesion between the overlapping individuals, it may also prevent other individuals from recognizing the identity information of the overlapping individuals (Briseño-Jaramillo et al., 2021). This suggests that female vocalizations in great call sequences in N. nasutus and N. hainanus signal group cohesion better, but at the cost of signaling individual identity and/or caller quality. N. concolor females may advertise individual identity or quality information via great calls that are temporally separated from those of males. In other gibbon species, female great calls convey and advertise information about individual identity (Clink et al., 2017) or quality (Terleph et al., 2016). The maximum f0 of great call climaxes is also lower in older females compared to younger females of Hylobates lar (Terleph et al., 2016). N. concolor lives in a relatively large population (Fan et al., 2022a, 2022b, 2022c; Li et al., 2023) while N. nasutus (Wearn et al., 2024) and N. hainanus (He et al., 2023) each have a tiny population. In small populations, sexual selection is temporarily relaxed due to an increase in mate selection costs or a reduction in territorial competition (Kaneshiro, 1980). Due to the large population, there are also more floating males in the population of N. concolor, which leads to more potential mating choices and extra-group copulations for females (Huang et al., 2022). This might make females of N. concolor display their individual information; this might explain why female and male vocalization do not overlap. However, this hypothesis needs further investigation.
Vocalizations of gibbons have long been considered to be genetically determined (Brockelman & Schilling, 1984; Tenaza, 1985), with interspecific differences among gibbon vocalizations consistent with their phylogenetic relationships (Van Ngoc et al., 2011). Our results are largely consistent with this hypothesis because interspecific differences in aa notes, mR notes, male sequences, and coordination patterns all aligned with phylogeny. However, this pattern is violated in boom notes and pre notes, which indicates that variations in vocal signals do not result solely from phylogenetic factors but can also be influenced by other selective pressures such as group size (Fan et al., 2022a, 2022b, 2022c), vocal learning (Tyack, 2020), and habitat disparities (Morton, 1975). In the future, we need to study the effect of these selection pressures on the differentiation of vocal signals at different levels. We suggest that comparative studies of vocal structure differences between species should distinguish between different levels and compare them one by one. This gives a clearer and more complete picture of the interspecific differences in different aspects of the vocal signal.
Conclusion
We found significant species differences in gibbon vocalizations at the male sequence level, song coordination level, and the note level, except for boom notes. Interspecific differences in aa notes, modulated notes, male sequences, and coordination patterns all align with phylogeny, suggesting that these differences are largely genetically determined. We found obvious differences in male–female coordination among these species. These differences may be driven by factors such as habitat conditions, population size, or vocal learning, and need further research. We suggest that comparative studies of gibbon vocalizations should analyze different levels such as note, sequence, and song coordination, to provide a more comprehensive and accurate representation of their differentiation and evolution.
References
Adret, P., Dingess, K. A., Caselli, C. B., Vermeer, J., Martinez, J., Luna Amancio, J. C., van Kuijk, S. M., Hernani Lineros, L. M., Wallace, R. B., Fernandez-Duque, E., & Di Fiore, A. (2018). Duetting patterns of titi monkeys (Primates, Pitheciidae: Callicebinae) and relationships with phylogeny. Animals, 8(10), 178. https://doi.org/10.3390/ani8100178
Arasco, A. G., Manser, M., Watson, S. K., Kyabulima, S., Radford, A. N., Cant, M. A., & Garcia, M. (2022). Testing the acoustic adaptation hypothesis with vocalizations from three mongoose species. Animal Behaviour, 187, 71–95. https://doi.org/10.1016/j.anbehav.2022.02.016
Barelli, C., Mundry, R., Heistermann, M., & Hammerschmidt, K. (2013). Cues to androgens and quality in male gibbon songs. Plos One, 8(12), 82748. https://doi.org/10.1371/journal.pone.0082748
Bartlett, T. Q., Light, L. E. O., & Brockelman, W. Y. (2016). Long-term home range use in white-handed gibbons (Hylobates lar) in Khao Yai National Park,Thailand. American Journal of Primatology, 78(2), 192–203. https://doi.org/10.1002/ajp.22492
Beckers, G. J. L., & Ten Cate, C. (2001). Perceptual relevance of species-specific differences in acoustic signal structure in Streptopelia doves. Animal Behaviour, 62, 511–518. https://doi.org/10.1006/anbe.2001.1768
Beecher, M. D. (1989). Signalling systems for individual recognition: An information theory approach. Animal Behaviour, 38(2), 248–261. https://doi.org/10.1016/S0003-3472(89)80087-9
Bergman, T. J., Cortes-Ortiz, L., Dias, P. A., Ho, L., Adams, D., Canales-Espinosa, D., & Kitchen, D. M. (2016). Striking differences in the loud calls of howler monkey sister species (Alouatta pigra and A. palliata). American Journal of Primatology, 78(7), 755–766. https://doi.org/10.1002/ajp.22539
Berthet, M., Mesbahi, G., Pajot, A., Cäsar, C., Neumann, C., & Zuberbühler, K. (2019). Titi monkeys combine alarm calls to create probabilistic meaning. Science Advances, 5(5), eaav3991. https://doi.org/10.1126/sciadv.aav3991
Borgard, H. L., Baab, K., Pasch, B., & Riede, T. (2020). The shape of sound: a geometric morphometrics approach to laryngeal functional morphology. Journal of Mammalian Evolution, 27(3), 577–590. https://doi.org/10.1007/s10914-019-09466-9
Bouchet, H., Pellier, A. S., Blois-Heulin, C., & Lemasson, A. (2010). Sex differences in the vocal repertoire of adult red-capped mangabeys (Cercocebus torquatus): a multi-level acoustic analysis. American Journal of Primatology, 72(4), 360–375. https://doi.org/10.1002/ajp.20791
Bouchet, H., Blois-Heulin, C., & Lemasson, A. (2013). Social complexity parallels vocal complexity: a comparison of three non-human primate species. Frontiers in Psychology, 4, 390. https://doi.org/10.3389/fpsyg.2013.00390
Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5–32. https://doi.org/10.1023/a:1010933404324
Briseño-Jaramillo, M., Berthet, M., Estrada, A., Biquand, V., & Lemasson, A. (2021). Socially mediated overlap in vocal interactions between free-ranging black howler monkeys. American Journal of Primatology, 83(8), e23297. https://doi.org/10.1002/ajp.23297
Brockelman, W. Y., & Schilling, D. (1984). Inheritance of stereotyped gibbon calls. Nature, 312(5995), 634–636. https://doi.org/10.1038/312634a0
Brockelman, W., Reichard, U., Treesucon, U., & Raemaekers, J. (1998). Dispersal, pair formation and social structure in gibbons (Hylobates lar). Behavioral Ecology and Sociobiology, 42, 329–339. https://doi.org/10.1007/s002650050445
Chan, B. P. L., Tan, X.-F., & Tan, W.-J. (2008). Rediscovery of the Critically Endangered eastern black-crested gibbon Nomascus nasutus (Hylobatidae) in China, with preliminary notes on population size, ecology and conservation status. Asian Primates Journal, 1(1), 17–25.
Chen, P., Chen, T., Liu, B., Zhang, M., & Lu, C. (2022). Song variation of a native songbird in a modified habitat by invasive plant. Integrated Zoology, 17(1), 93–104. https://doi.org/10.1111/1749-4877.12573
Clink, D. J., Bernard, H., Crofoot, M. C., & Marshall, A. J. (2017). Investigating individual vocal signatures and small-scale patterns of geographic variation in female Bornean gibbon (Hylobates muelleri) Great calls. International Journal of Primatology, 38(4), 656–671. https://doi.org/10.1007/s10764-017-9972-y
Clink, D. J., Comella, I. A., Tasirin, J. S., & Klinck, H. (2023). Tarsier islands: exploring patterns of variation in tarsier duets from offshore islands of North Sulawesi. American Journal of Primatology, 85(11), e23410. https://doi.org/10.1002/ajp.23410
Cowlishaw, G. (1996). Sexual selection and information content in Gibbon Song Bouts. Ethology, 102(4), 272–284.
Coye, C., Zuberbuhler, K., & Lemasson, A. (2022). The evolution of vocal communication: inertia and divergence in two closely related primates. International Journal of Primatology, 43(4), 712–732. https://doi.org/10.1007/s10764-022-00294-y
Czocherová, I., Rubácová, L., Petrusek, A., & Petrusková, T. (2022). Contrasting patterns of geographical song variation in two closely related passerine species with a simple song. Journal of Ornithology, 163(1), 93–104. https://doi.org/10.1007/s10336-021-01924-7
de Carvalho, T. R., Martins, L. B., & Giaretta, A. A. (2015). The complex vocalization of Scinax cardosoi (Anura: Hylidae), with comments on advertisement calls in the S. ruber Clade. Phyllomedusa, 14(2), 127–137. https://doi.org/10.11606/issn.2316-9079.v14i2p127-137
de Kort, S. R., Eldermire, E. R. B., Cramer, E. R. A., & Vehrencamp, S. L. (2009). The deterrent effect of bird song in territory defense. Behavioral Ecology, 20(1), 200–206. https://doi.org/10.1093/beheco/arn135
de Oliveira, E. A., da Silva, L. A., Silva, E. A. P., Guimaraes, K. L. A., Penhacek, M., Martinez, J. G., Rodrigues, L. R. R., Santana, D. J., & Hernandez-Ruz, E. J. (2020). Four new species of Pristimantis Jimenez de la Espada, 1870 (Anura: Craugastoridae) in the eastern Amazon. Plos One, 15(3), e0229971. https://doi.org/10.1371/journal.pone.0229971
Deng, H., Zhou, J., & Yang, Y. (2014). Sound spectrum characteristics of songs of Hainan gibbon (Nomascus hainanus). International Journal of Primatology, 35(2), 547–556. https://doi.org/10.1007/s10764-014-9767-3
Dong, L. J., Caruso, F., Dong, J. C., Liu, M. M., Lin, M. L., & Li, S. H. (2021). Whistle characteristics of a newly recorded Indo-Pacific humpback dolphin (Sousa chinensis) population in waters southwest of Hainan Island, China, differ from other humpback dolphin populations. Marine Mammal Science, 37(4), 1341–1362. https://doi.org/10.1111/mms.12816
Fan, P. F. (2017). The past, present, and future of gibbons in China. Biological Conservation, 210, 29–39. https://doi.org/10.1016/j.biocon.2016.02.024
Fan, P. F., Xiao, W., Huo, S., & Jiang, X. L. (2009). Singing behavior and singing functions of black-crested gibbons (Nomascus concolor jingdongensis) at Mt. Wuliang, Central Yunnan, China [Article]. American Journal of Primatology, 71(7), 539–547. https://doi.org/10.1002/ajp.20686
Fan, P.-F., Jiang, X.-L., Liu, C.-M., & Luo, W.-S. (2010). Sonogram structure and timing of duets of western black crested gibbon in Wuliang Mountain. Zoological Research, 31(3), 293–302. https://doi.org/10.3724/sp.J.1141.2010.03293
Fan, P. F., Ren, G. P., Wang, W., Scott, M. B., Ma, C. Y., Fei, H. L., Wang, L., Xiao, W., & Zhu, J. G. (2013). Habitat evaluation and population viability analysis of the last population of cao vit gibbon (Nomascus nasutus): implications for conservation. Biological Conservation, 161, 39–47. https://doi.org/10.1016/j.biocon.2013.02.014
Fan, P. F., Bartlett, T. Q., Fei, H. L., Ma, C. Y., & Zhang, W. (2015). Understanding stable bi-female grouping in gibbons: feeding competition and reproductive success. Frontiers in Zoology, 12, 5. https://doi.org/10.1186/s12983-015-0098-9
Fan, P. F., Zhang, L., Yang, L., Huang, X., Shi, K. C., Liu, G. Q., & Wang, C. H. (2022a). Population recovery of the critically endangered western black crested gibbon (Nomascus concolor) in Mt. Wuliang, Yunnan, China. Zoological Research, 43(2), 180–183. https://doi.org/10.24272/j.issn.2095-8137.2021.390
Fan, P. L., Li, J. X., Yang, L. T., Sun, T., Wu, S. J., Grueter, C. C., Huang, C. M., Zhou, Q. H., & Li, M. (2022b). Vocal repertoire of the critically endangered white-headed langur (Trachypithecus leucocephalus): call types, acoustic structures, and related social-ecological contexts. Zoological Research, 43(5), 875–879. https://doi.org/10.24272/j.issn.2095-8137.2022.147
Fan, Y. Z., Fang, K., Sun, R. L., Shen, D., Yang, J., Tang, Y. Z., & Fang, G. Z. (2022c). Hierarchical auditory perception for species discrimination and individual recognition in the music frog. Current Zoology, 68(5), 581–591. https://doi.org/10.1093/cz/zoab085
Favaro, L., Gili, C., Da Rugna, C., Gnone, G., Fissore, C., Sanchez, D., McElligott, A. G., Gamba, M., & Pessani, D. (2016). Vocal individuality and species divergence in the contact calls of banded penguins. Behav Processes, 128, 83–88. https://doi.org/10.1016/j.beproc.2016.04.010
Feng, J., Ma, C., Fei, H., Cui, L., & Fan, P. (2013). Call sonograms of eastern black crested gibbon (Nomascus nasutus) [东黑冠长臂猿鸣叫声谱分析]. Acta Theriologica Sinica, 33(3), 203–214. https://www.mammal.cn/CN/Y2013/V33/I3/203
Friis, J. I., Sabino, J., Santos, P., Dabelsteen, T., & Cardoso, G. C. (2022). Ecological adaptation and birdsong: how body and bill sizes affect passerine sound frequencies. Behavioral Ecology, 33(4), 798–806. https://doi.org/10.1093/beheco/arac042
Geissmann, T. (1995). The yellow-cheeked gibbon (Hylobates gabriellae) in Nam Bai Cat Tien (Southern Vietnam) revisited. Primates, 36(3), 447–455. https://doi.org/10.1007/bf02382867
Geissmann, T. (1999). Duet songs of the siamang, Hylobates syndactylus: II. Testing the pair-bonding hypothesis during a partner exchange. Behaviour, 136, 1005–1039. https://doi.org/10.1163/156853999501694
Geissmann, T. (2000). Duet-splitting in the evolution of gibbon songs. Folia Primatologica, 71(4), 194–194.
Geissmann, T. (2002). Duet-splitting and the evolution of gibbon songs [Review]. Biological Reviews, 77(1), 57–76. https://doi.org/10.1017/s1464793101005826
Geissmann, T., La, Q. T., Trinh Dinh, H., Dang, N. ., Pham, D. T. & Vu, D. T. (2002) Report on an Overall Survey of Cao Vit Gibbon Population Nomascus sp. cf. Nasutus in Trung Khanh District, Cao Bang Province (Second Overall Survey). Technical Report, FFI Asia-Pacific, Hanoi, Viet Nam.
Geissmann, T., & Orgeldinger, M. (2000). The relationship between duet songs and pair bonds in siamangs, Hylobates syndactylus. Animal Behaviour, 60, 805–809. https://doi.org/10.1006/anbe.2000.1540
Girard-Buttoz, C., Bortolato, T., Laporte, M., Grampp, M., Zuberbuhler, K., Wittig, R. M., & Crockford, C. (2022a). Population-specific call order in chimpanzee greeting vocal sequences. iScience, 25(9), 104851. https://doi.org/10.1016/j.isci.2022.104851
Girard-Buttoz, C., Zaccarella, E., Bortolato, T., Friederici, A. D., Wittig, R. M., & Crockford, C. (2022b). Chimpanzees produce diverse vocal sequences with ordered and recombinatorial properties. Communications Biology, 5(1), 410. https://doi.org/10.1038/s42003-022-03350-8
Guan, Z. H., Ma, C. Y., Fei, H. L., Huang, B., Ning, W. H., Ni, Q. Y., Jiang, X. L., & Fan, P. F. (2018). Ecology and social system of northern gibbons living in cold seasonal forests. Zool Res, 39(4), 255 Cao Vit gibbon population 265. https://doi.org/10.24272/j.issn.2095-8137.2018.045
Hasiniaina, A. F., Radespiel, U., Kessler, S. E., Evasoa, M. R., Rasoloharijaona, S., Randrianambinina, B., Zimmermann, E., Schmidt, S., & Scheumann, M. (2020). Evolutionary significance of the variation in acoustic communication of a cryptic nocturnal primate radiation (Microcebus spp.). Ecology and Evolution, 10(8), 3784 Cao Vit gibbon population 3797. https://doi.org/10.1002/ece3.6177
Hedwig, D., Hammerschmidt, K., Mundry, R., Robbins, M. M., & Boesch, C. (2014). Acoustic structure and variation in mountain and western gorilla close calls: a syntactic approach. Behaviour, 151(8), 1091–1120. https://doi.org/10.1163/1568539x-00003175
He, Q. Q., Yan, S. S., Garber, P. A., Ren, B. P., Qi, M., & Zhou, J. (2023). Habitat restoration is the greatest challenge for population recovery of Hainan gibbons (Nomascus hainanus). Integrative Zoology, 18(4), 630–646. https://doi.org/10.1111/1749-4877.12684
Hu, N. Q., Guan, Z. H., Huang, B., Ning, W. H., He, K., Fan, P. F., & Jiang, X. L. (2018). Dispersal and female philopatry in a long-term, stable, polygynous gibbon population: Evidence from 16 years field observation and genetics. American Journal of Primatology, 80(9), e22922. https://doi.org/10.1002/ajp.22922
Huang, M. P., Ma, H. G., Ma, C. Y., Garber, P. A., & Fan, P. F. (2020). Male gibbon loud morning calls conform to Zipf’s law of brevity and Menzerath’s law: insights into the origin of human language. Animal Behaviour, 160, 145–155. https://doi.org/10.1016/j.anbehav.2019.11.017
Huang, X., Hu, N. Q., He, K., Guan, Z. H., Garber, P. A., Chapman, C. A., Jiang, X. L., & Fan, P. F. (2022). Disassociation of social and sexual partner relationships in a gibbon population with stable one-male two-female groups. American Journal of Primatology, 84(7), e23394. https://doi.org/10.1002/ajp.23394
Haupert, S., Sèbe, F., & Sueur, J. (2023). Physics-based model to predict the acoustic detection distance of terrestrial autonomous recording units over the diel cycle and across seasons: Insights from an Alpine and a Neotropical forest. Methods in Ecology and Evolution, 14(2), 614–630. https://doi.org/10.1111/2041-210x.14020
Hudson, E. J., & Creanza, N. (2022). Modeling how population size drives the evolution of birdsong, a functional cultural trait. Evolution, 76(6), 1139–1152. https://doi.org/10.1111/evo.14489
Inoue, Y., Sinun, W., Yosida, S., & Okanoya, K. (2017). Combinatory rules and chunk structure in male Mueller’s gibbon songs. Interaction Studies, 18(1), 1–25. https://doi.org/10.1075/is.18.1.01ino
Inoue, Y., Sinun, W., Yosida, S., & Okanoya, K. (2020). Note orders suggest phrase-inserting structure in male Mueller’s gibbon songs: a case study. Acta Ethologica, 23(2), 89–102. https://doi.org/10.1007/s10211-020-00341-y
Ivanitskii, V., Ivlieva, A., Gashkov, S., & Marova, I. (2017). The song structure of the Siberian Blue Robin Luscinia Larvivora cyane and a comparison with related species. Ornithological Science, 16(1), 71–77. https://doi.org/10.2326/osj.16.71
Jiang, Y. X., Han, J. R., & Yang, C. C. (2022). Anti-predation responses to conspecific versus heterospecific alarm calls by the nestlings of two sympatric birds. Animals, 12(16), 2156. https://doi.org/10.3390/ani12162156
Kaneshiro, K. Y. (1980). Sexual isolation, Speciation and the direction of evolution. Evolution; International Journal of Organic Evolution, 34(3), 437–444. https://doi.org/10.1111/j.1558-5646.1980.tb04833.x
Koda, H., Lemasson, A., Oyakawa, C., Rizaldi, Pamungkas, J., & Masataka, N. (2013). Possible role of mother–daughter vocal interactions on the development of species-specific song in gibbons. Plos One, 8(8), e71432. https://doi.org/10.1371/journal.pone.0071432
Konrad, R., & Geissmann, T. (2006). Vocal Diversity and Taxonomy of Nomascus in Cambodia. International Journal of Primatology, 27(3), 713–745. https://doi.org/10.1007/s10764-006-9042-3
Kwong-Brown, U., Tobias, M. L., Elias, D. O., Hal, I. C., Elemans, C. P. H., & Kelley, D. B. (2019). The return to water in ancestral Xenopus was accompanied by a novel mechanism for producing and shaping vocal signals. Elife, 8, e39946. https://doi.org/10.7554/elife.39946
Lappan, S., Andayani, N., Kinnaird, M. F., Morino, L., Nurcahyo, A., & O’Brien, T. G. (2017). Social polyandry among siamangs: the role of habitat quality. Animal Behaviour, 133, 145–152. https://doi.org/10.1016/j.anbehav.2017.09.017
Lau, A. R., Zafar, M., Ahmad, A. H., & Clink, D. J. (2022). Investigating temporal coordination in the duet contributions of a pair-living small ape. Behavioral Ecology and Sociobiology, 76(7), 91. https://doi.org/10.1007/s00265-022-03193-7
Leroux, M., Bosshard, A. B., Chandia, B., Manser, A., Zuberbuhler, K., & Townsend, S. W. (2021). Chimpanzees combine pant hoots with food calls into larger structures. Animal Behaviour, 179, 41–50. https://doi.org/10.1016/j.anbehav.2021.06.026
Leroux, M., Schel, A. M., Wilke, C., Chandia, B., Zuberbuhler, K., Slocombe, K. E., & Townsend, S. W. (2023). Call combinations and compositional processing in wild chimpanzees. Nature Communications, 14(1), 2225. https://doi.org/10.1038/s41467-023-37816-y
Levrero, F., Touitou, S., Fredet, J., Nairaud, B., Guery, J. P., & Lemasson, A. (2019). Social bonding drives vocal exchanges in Bonobos. Scientific Reports, 9, 711. https://doi.org/10.1038/s41598-018-36024-9
Li, G., Qin, Z., Lu, L., Gao, W., Luo, W., Li, H., Li, Y., Yin, C., Xu, P., Yin, G., Li, F., Niu, X., & Jiang, X. (2023). Population size and distribution of western black crested gibbon(Nomascus concolor)in Ailao Mountain, Chuxiong Prefecture, Yunnan Province [云南楚雄哀牢山地区西黑冠长臂猿种群数量和分布]. Acta Theriologica Sinica, 43(5), 513–522, Article 1000-1050(2023)43:52.0.tx;2-q. https://www.mammal.cn/CN/10.16829/j.slxb.150749
Luther, D., & Gentry, K. (2013). Sources of background noise and their influence on vertebrate acoustic communication. Behaviour, 150(9–10), 1045–1068. https://doi.org/10.1163/1568539x-00003054
Ma, H., Ma, C., Fei, H., Yang, L., & Fan, P. (2020). Cao vit gibbons (Nomascus nasutus) sing at higher elevation but not in peripheral areas of their home range in a karst forest. International Journal of Primatology, 41(5), 701–713. https://doi.org/10.1007/s10764-020-00178-z
Ma, H. G., Ma, C. Y., & Fan, P. F. (2022). Adult male-female social bond advertising: the primary function of coordinated singing intensity in a small ape. American Journal of Primatology, 84(1), e23351. https://doi.org/10.1002/ajp.23351
Ma, H., Wang, Z., Han, P., Fan, P., Chapman, C. A., Garber, P. A., & Fan, P. (2024). Small apes adjust rhythms to facilitate song coordination. Current Biology, 34(5), 935-945.e933. https://doi.org/10.1016/j.cub.2023.12.071
Manzano, M. C. R., & Sawaya, R. J. (2022). Environmental and phylogenetic aspects affect in different ways the acoustic niche of a frog community in southeastern Brazil. Anais Da Academia Brasileira De Ciencias, 94(1), e20200705. https://doi.org/10.1590/0001-3765202220200705
Martens, M. J. M., & Michelsen, A. (1981). Absorption of acoustic energy by plant leaves. Journal of the Acoustical Society of America, 69(1), 303–306. https://doi.org/10.1121/1.385313
McCracken, K. G., & Sheldon, F. H. (1997). Avian vocalizations and phylogenetic signal. Proceedings of the National Academy of Sciences of the United States of America, 94(8), 3833–3836. https://doi.org/10.1073/pnas.94.8.3833
McFee, B., Raffel, C., Liang, D., Ellis, D., Mcvicar, M., Battenberg, E., & Nieto, O. (2015). librosa: Audio and Music Signal Analysis in Python. Python in Science Conference.
Mendez, C., & Sandoval, L. (2021). Frequency and synchronisation features of a highly overlapped duet changes according to the context [Article]. Bioacoustics—the International Journal of Animal Sound and Its Recording, 30(1), 17–29. https://doi.org/10.1080/09524622.2019.1682672
Meyer, D., Hodges, J. K., Rinaldi, D., Wijaya, A., Roos, C., & Hammerschmidt, K. (2012). Acoustic structure of male loud-calls support molecular phylogeny of Sumatran and Javanese leaf monkeys (genus Presbytis). BMC Evolutionary Biology, 12, 16. https://doi.org/10.1186/1471-2148-12-16
Miller, J. R., & Engstrom, M. D. (2012). Vocal stereotypy in the rodent genera Peromyscu and Onychomys (Neotominae): taxonomic signature and call design. Bioacoustics-the International Journal of Animal Sound and Its Recording, 21(3), 193–213. https://doi.org/10.1080/09524622.2012.675176
Mootnick, A. R., & Fan, P. F. (2011). A comparative study of crested gibbons (Nomascus). American Journal of Primatology, 73(2), 135–154. https://doi.org/10.1002/ajp.20880
Morton, E. S. (1975). Ecological Sources of Selection on Avian Sounds. The American Naturalist, 109(965), 17–34. https://doi.org/10.1086/282971
Muller, A. E., & Anzenberger, G. (2002). Duetting in the titi monkey Callicebus cupreus: structure, pair specificity and development of duets. Folia Primatologica, 73(2–3), 104–115. https://doi.org/10.1159/000064788
Mundry, R., & Sommer, C. (2007). Discriminant function analysis with nonindependent data: consequences and an alternative. Animal Behaviour, 74(4), 965–976. https://doi.org/10.1016/j.anbehav.2006.12.028
Muroyama, Y., & Thierry, B. (1998). Species differences of male loud calls and their perception in Sulawesi macaques. Primates, 39(2), 115–126. https://doi.org/10.1007/bf02557724
Naguib, M., & Wiley, R. H. (2001). Estimating the distance to a source of sound: mechanisms and adaptations for long-range communication. Animal Behaviour, 62, 825–837. https://doi.org/10.1006/anbe.2001.1860
Nardone, V., Ancillotto, L., & Russo, D. (2017). A flexible communicator: Social call repertoire of Savi’s pipistrelle Hypsugo savii. Hystrix — the Italian Journal of Mammalogy, 28(1), 68–72. https://doi.org/10.4404/hystrix-28.1-11825
Nielsen, M. L. K., Bejder, L., Videsen, S. K. A., Christiansen, F., & Madsen, P. T. (2019). Acoustic crypsis in southern right whale mother–calf pairs: infrequent, low-output calls to avoid predation? Journal of Experimental Biology, 222(13), jeb190728. https://doi.org/10.1242/jeb.190728
Nietsch, A., & Kopp, M.-L. (1998). Role of vocalization in species differentiation of sulawesi tarsiers. Folia Primatologica, 69(SUPPL. 1), 371–378. https://doi.org/10.1159/000052725
Pace, D. S., Tumino, C., Silvestri, M., Giacomini, G., Pedrazzi, G., Pavan, G., Papale, E., Ceraulo, M., Buscaino, G., & Ardizzone, G. (2022). Bray-call sequences in the Mediterranean common bottlenose dolphin (Tursiops truncatus) acoustic repertoire. Biology-Basel, 11(3), 367. https://doi.org/10.3390/biology11030367
Pollard, K. A., & Blumstein, D. T. (2011). Social Group Size Predicts the Evolution of Individuality. Current Biology, 21(5), 413–417. https://doi.org/10.1016/j.cub.2011.01.051
Polomova, J., Lukacova, K., Bilcik, B., & Kubikova, L. (2019). Is neurogenesis in two songbird species related to their song sequence variability? Proceedings of the Royal Society B-Biological Sciences, 286(1895), 20182872. https://doi.org/10.1098/rspb.2018.2872
Pougnault, L., Levrero, F., Leroux, M., Paulet, J., Bombani, P., Dentressangle, F., Deruti, L., Mulot, B., & Lemasson, A. (2022). Social pressure drives “conversational rules” in great apes. Biological Reviews, 97(2), 749–765. https://doi.org/10.1111/brv.12821
Rakotonirina, H., Kappeler, P. M., & Fichtel, C. (2016). The role of acoustic signals for species recognition in redfronted lemurs (Eulemur rufifrons). BMC Evolutionary Biology, 16, 100. https://doi.org/10.1186/s12862-016-0677-1
Ruppell, J. C. (2009). Vocal diversity and taxonomy of Nomascus in Central Vietnam and Southern Laos. International Journal of Primatology, 31(1), 73–94. https://doi.org/10.1007/s10764-009-9384-8
Savini, T., Boesch, C., & Reichard, U. H. (2009). Varying ecological quality influences the probability of polyandry in white-handed gibbons (Hylobates lar) in Thailand. Biotropica, 41(4), 503–513. https://doi.org/10.1111/j.1744-7429.2009.00507.x
Schamberg, I., Cheney, D. L., Clay, Z., Hohmann, G., & Seyfarth, R. M. (2017). Bonobos use call combinations to facilitate inter-party travel recruitment. Behavioral Ecology and Sociobiology, 71(4), 75. https://doi.org/10.1007/s00265-017-2301-9
Seddon, N. (2005). Ecological adaptation and species recognition drives vocal evolution in neotropical suboscine birds. Evolution; International Journal of Organic Evolution, 59(1), 200-215. https://doi.org/10.1554/04-300
Seiler, M., Schwitzer, C., & Holderied, M. (2015). Call Repertoire of the Sahamalaza sportive lemur, Lepilemur sahamalazensis. International Journal of Primatology, 36(3), 647–665. https://doi.org/10.1007/s10764-015-9846-0
Sementili-Cardoso, G., Joaquim, L. M., & Donatelli, R. J. (2022). Environmental conditions drive vocal variation in the scaled dove (Columbina squammata). Ornithology Research, 30(1), 3–14. https://doi.org/10.1007/s43388-022-00083-4
Seneviratne, S. S., Jones, I. L., & Carr, S. M. (2012). Patterns of vocal divergence in a group of non-oscine birds (auklets; Alcidae, Charadriiformes). Evolutionary Ecology Research, 14(1), 95–112.
Snowdon, C. T., Hodun, A., Rosenberger, A. L., & Coimbra-Filho, A. F. (1986). Long-call structure and its relation to taxonomy in lion tamarins. American Journal of Primatology, 11(3), 253–261. https://doi.org/10.1002/ajp.1350110307
Smith-Vidaurre, G., Perez-Marrufo, V., & Wright, T. F. (2021). Individual vocal signatures show reduced complexity following invasion. Animal Behaviour, 179, 15–39. https://doi.org/10.1016/j.anbehav.2021.06.020
Suzuki, T. N., Wheatcroft, D., & Griesser, M. (2018). Call combinations in birds and the evolution of compositional syntax. Plos Biology, 16(8), e2006532. https://doi.org/10.1371/journal.pbio.2006532
Tenaza, R. (1985). Songs of hybrid gibbons (Hylobates lar * H. muelleri). American Journal of Primatology, 8(3), 249–253. https://doi.org/10.1002/ajp.1350080307
Terleph, T. A., Malaivijitnond, S., & Reichard, U. H. (2016). Age related decline in female lar gibbon great call performance suggests that call features correlate with physical condition. BMC Evolutionary Biology, 16(13), 4. https://doi.org/10.1186/s12862-015-0578-8
Terleph, T. A., Malaivijitnond, S., & Reichard, U. H. (2018a). An analysis of white-handed gibbon male song reveals speech-like phrases. American Journal of Physical Anthropology, 166(3), 649–660. https://doi.org/10.1002/ajpa.23451
Terleph, T. A., Malaivijitnond, S., & Reichard, U. H. (2018b). Male white-handed gibbons flexibly time duet contributions [Article]. Behavioral Ecology and Sociobiology, 72(1), 13–16. https://doi.org/10.1007/s00265-017-2432-z
Thinh, V. N., Rawson, B., Hallam, C., Kenyon, M., Nadler, T., Walter, L., & Roos, C. (2010). Phylogeny and distribution of crested gibbons (genus Nomascus) based on mitochondrial cytochrome b gene sequence data. American Journal of Primatology, 72(12), 1047–1054. https://doi.org/10.1002/ajp.20861
Thomassen, H. A., & Povel, G. D. E. (2006). Comparative and phylogenetic analysis of the echo clicks and social vocalizations of swiftlets (Aves: Apodidae). Biological Journal of the Linnean Society, 88(4), 631–643. https://doi.org/10.1111/j.1095-8312.2006.00648.x
Tobias, M. L., Viswanathan, S. S., & Kelley, D. B. (1998). Rapping, a female receptive call, initiates male-female duets in the South African clawed frog. Proceedings of the National Academy of Sciences of the United States of America, 95(4), 1870–1875. https://doi.org/10.1073/pnas.95.4.1870
Tuttle, M. D., & Ryan, M. J. (1981). Bat predation and the evolution of frog vocalizations in the neotropics. Science (New York, N.Y.), 214(4521), 677–678. https://doi.org/10.1126/science.214.4521.677
Tyack, P. L. (2020). A taxonomy for vocal learning. Philosophical Transactions of the Royal Society of London Series B, 375(1789), 20180406. https://doi.org/10.1098/rstb.2018.0406
Valderrama, S. V., Molles, L. E., & Waas, J. R. (2013). Effects of population size on singing behavior of a rare duetting songbird. Conservation Biology, 27(1), 210–218. https://doi.org/10.1111/j.1523-1739.2012.01917.x
Valente, D., Miaretsoa, L., Anania, A., Costa, F., Mascaro, A., Raimondi, T., De Gregorio, C., Torti, V., Friard, O., Ratsimbazafy, J., Giacoma, C., & Gamba, M. (2022). Comparative analysis of the vocal repertoires of the indri (Indri indri) and the diademed sifaka (Propithecus diadema). International Journal of Primatology, 43(4), 733–751. https://doi.org/10.1007/s10764-022-00287-x
Van Ngoc, T., Hallam, C., Roos, C., & Hammerschmidt, K. (2011). Concordance between vocal and genetic diversity in crested gibbons. BMC Evolutionary Biology, 11, 36. https://doi.org/10.1186/1471-2148-11-36
Vokurková, J., Petrusková, T., Reifová, R., Kozman, A., Morkovsky, L., Kipper, S., Weiss, M., Reif, J., Dolata, P. T., & Petrusek, A. (2013). The causes and evolutionary consequences of mixed singing in two hybridizing songbird species (Luscinia spp.). Plos One, 8(4), e60172. https://doi.org/10.1371/journal.pone.0060172
Wearn, O. R., Trinh-Dinh, H., Ma, C. Y., Le, Q. K., Nguyen, P., Hoang, T. V., Luong, C. V., Hua, T. V., Hoang, Q. V., Fan, P. F., & Nguyen, T. D. (2024). Vocal fingerprinting reveals a substantially smaller global population of the Critically Endangered cao vit gibbon (Nomascus nasutus) than previously thought. Scientific Reports, 14(1), 416. https://doi.org/10.1038/s41598-023-50838-2
Yang, L., Shi, K. C., Ma, C., Ren, G. P., & Fan, P. F. (2021). Mechanisms underlying altitudinal and horizontal range contraction: the western black crested gibbon. Journal of Biogeography, 48(2), 321–331. https://doi.org/10.1111/jbi.13998
Yang, L., Chen, T., Zhang, L., & Fan, P. F. (2023). Stable habitat supports long-term persistence of critically endangered western black crested gibbon. Global Ecology and Conservation, 47, e02657. https://doi.org/10.1016/j.gecco.2023.e02657
Yi, Y. J., Choi, A., Lee, S., Ham, S., Jang, H., Oktaviani, R., Mardiastuti, A., & Choe, J. C. (2022). Transient co-singing of offspring and mothers in non-duetting Javan gibbons (Hylobates moloch). Frontiers in Ecology and Evolution, 10, 910260. https://doi.org/10.3389/fevo.2022.910260
Zhang, M. X., Fellowes, J. R., Jiang, X. L., Wang, W., Chan, B. P. L., Ren, G. P., & Zhu, J. G. (2010). Degradation of tropical forest in Hainan, China, 1991–2008: Conservation implications for Hainan gibbon (Nomascus hainanus). Biological Conservation, 143(6), 1397–1404. https://doi.org/10.1016/j.biocon.2010.03.014
Zhong, X. K., Zhu, C. Y., Wang, Y. X., Qi, X. M., & Fan, P. F. (2023). Quantified diet provides suggestions for habitat restoration for the world’s rarest primate. Biological Conservation, 284, 110215. https://doi.org/10.1016/j.biocon.2023.110215
Zhou, J., Wei, F., Li, M., Lok, C. B. P., & Wang, D. (2008). Reproductive characters and mating behaviour of wild Nomascus hainanus. International Journal of Primatology, 29(4), 1037–1046. https://doi.org/10.1007/s10764-008-9272-7
Zhu, C., Zhong, X., Wang, Y., Li, W., Qi, X., & Fan, P. (2024). Pelage colour change in Hainan gibbon (Nomascus hainanus) [海南长臂猿的毛色变化]. Acta Theriologica Sinica, 44(1), 1–13.
Zimmermann, E., Vorobieva, E., Wrogemann, D., & Hafen, T. (2000). Use of vocal fingerprinting for specific discrimination of gray (Microcebus murinus) and rufous mouse lemurs (Microcebus rufus). International Journal of Primatology, 21(5), 837–852. https://doi.org/10.1023/A:1005594625841
Zuk, M., Rebar, D., & Scott, S. P. (2008). Courtship song is more variable than calling song in the field cricket Teleogryllus oceanicus. Animal Behaviour, 76(3), 1065–1071. https://doi.org/10.1016/j.anbehav.2008.02.018
Acknowledgements
This study was supported by Key project of Guangxi Natural Science Foundation of China (2022GXNSFDA080004), Key R&D projects of the Ministry of Science and Technology (#2022YFF1301500), National Natural Science Foundation of China (#31822049), Hainan National Park Research Institute (Hainan Gibbon Conservation Research) (#KY-2000105-KT), National Natural Science Foundation of China (32300393) and Sun Yat-Sen University. All research methods adhered to Chinese legal requirements. This study was strongly supported by Bangliang Gibbon National Nature Reserve in Guangxi province, Hainan Tropical Rainforest National Park in southwest Hainan Island, and Jingdong Management Bureau of Wuliangshan National Nature Reserve in Yunnan province in terms of research permission and logistics.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Inclusion and diversity statement
One or more of the authors of this paper self-identifies as an underrepresented ethnic minority in science.
While citing references scientifically relevant for this work, we also actively worked to promote gender balance in our reference list.
Additional information
Handling Editor: Joanna M. Setchell

 Badge earned for open practices: Open Data and Open Code Badges. Experiment materials and data are available in the repository at https://figshare.com/s/adb9a0bd068bb2491ebb.
Badge earned for open practices: Open Data and Open Code Badges. Experiment materials and data are available in the repository at https://figshare.com/s/adb9a0bd068bb2491ebb.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Han, P., Ma, Hg., Wang, Zd. et al. Vocal differences in note, sequence and great call sequence among three closely related Nomascus gibbon species. Int J Primatol (2024). https://doi.org/10.1007/s10764-024-00449-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10764-024-00449-z