
Abstract
Standard Data Envelopment Analysis (DEA) models consider continuous-valued and known input and output statuses for measures. This paper proposes an extended Slacks-Based Measure (SBM) DEA model to accommodate flexible (a measure that can play the role of input and output) and integer measures simultaneously. A flexible measure’s most appropriate role (designation) is determined by maximizing the technical efficiency of each unit. The main advantage of the proposed model is that all inputs, outputs, and flexible measures can be expressed in integer values without inflation of efficiency scores since they are directly calculated by modifying input and output inefficiencies. Furthermore, we illustrate and examine the application of the proposed models with 28 university hospitals in Germany. We investigate the differences and common properties of the proposed models with the literature to shed light on both teaching and general inefficiencies. Results of inefficiency decomposition indicate that “Third-party funding income” that university hospitals receive from the research-granting agencies dominates the other inefficiencies sources. The study of the efficiency scores is then followed up with a second-stage regression analysis based on efficiency scores and environmental factors. The result of the regression analysis confirms the conclusion derived from the inefficiency decomposition analysis.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Data Envelopment Analysis (DEA) is a nonparametric approach introduced by Charnes, et al. [1] to estimate the relative efficiency of a set of homogeneous Decision-Making Units (DMUs) where utilize similar inputs to generate similar outputs. This basic model (from now referred to as CCR) has come up with a fruitful area for efficiency evaluation. DEA models can be categorized as radial and non-radial. The CCR represents the radial models where they cope with relative changes of input and/or output factors so that, the efficiency score imitates the proportional maximum output (input) expansion (reduction) rate which is common to all outputs (inputs). However, in many practical applications, not all inputs/outputs operate proportionally. Consider the hospitals as an instance, we utilize beds, physicians, and nurses as inputs where they may not change proportionally. There might be several non-radial slacks left that play an imperative role in reporting managerial efficiency, but they are not taken into account in the radial model. The Slacks-Based Measure (SBM) approach, on the other hand, disregards proportional changes and evaluates efficiency by considering the input excess and output shortfall (slacks) directly [2]. Both non-radial and radial DEA models have been well-documented from the theoretical perspective in the literature [3]. In addition to the theoretical development of DEA models, their application is significantly growing since it is well-known as a reliable methodology, e.g., for healthcare [4,5,6,7,8]. However, to our knowledge, most of the previous studies done in the field of teaching hospital performance assessment use the basic DEA models and pay no attention to two principal challenges that exist in the real-world situation: integer-valued amounts and flexible measures. In the following subsections, these two issues are adequately addressed.
1.1 Integrality-constrained DEA
Conventional DEA models consider that inputs and outputs are continuous values. However, we face many real situations in which one or some of the inputs/outputs are unavoidably integer values, for instance, the number of beds (as input) and outpatients (as output) in the hospital performance assessment. Usually the first step in DEA application, after identifying the list of inputs and outputs, is determining the suitable technology or the Production Possibility Set (PPS). These technologies are grouped as non-convex and convex. The non-convex Free Disposal Hull (FDH) [9] and the convex Constant and Variable Returns to Scale (CRS and VRS respectively) technologies are the most common choices. FDH targets are always feasible when some of the inputs/outputs are integer-valued since they project the units whose efficiency is to be evaluated onto one of the existing DMUs. In contrast, the PPS in both CRS and VRS assumes feasible operating points that are a convex combination of evaluating units without essentially considering any integrality constraint of some inputs/outputs. While imposing the integrality constraints by rounding off the optimum solution of the large integer values may have not a major effect on the optimality, it is not the case with small integer values where a few units less or more can make a significant difference in the optimality [10,11,12]. Assuming the integer-valued inputs/outputs as continuous values and arbitrarily rounding up (or down) of them may easily cause infeasibility (i.e., an operation point out of the PPS) or to a dominated (inferior) operating unit as mentioned by [13]. As illustrated by a single input single output example in Fig. 1, DMUs B and C are inefficient and their reference set includes DMUs A and D. The input excess of DMUs B and C are 1.5 and 2.67. That means 1.5 and 2.67 units reduction in the input of DMU B and C, respectively, project them on the green marks B′ and C′ on the efficient frontier (blue dashed line). However, if they are integer-valued, arbitrarily rounding up the input excess of C to 3.0 causes infeasibility, in other words, the red mark C′′ where is out of the PPS. As it is clear from the graph, an arbitrary rounding down the input excess of B to 1.0 (B′′) does not approach the efficient frontier.

An example of infeasibility in the presence of integer-valued input under the VRS setting
1.2 Flexible measure DEA
The usual setting for a DEA study is to evaluate DMUs, such as hospitals, according to specific input and output factors. The output represents the result of the DMU, while the input is intended to describe what led to the creation of that output. However, there exist some situations where some measures can play the role of either output or input. Consider, for example, the number of graduates or trainee nurses in a university hospital. These measures can constitute either input (two available human resources to the hospital) or output (trained staff, henceforth an advantage resulting from teaching/research funding). These measures are known as flexible or dual-role measures in DEA literature. In cases of ambiguity, it is imperative to adhere to the most equitable treatment possible for a particular DMU in order to decide the status of a variable. This ambiguity is further compounded if one views performance measurement from the perspective of an administrative organization as a manager. As with university hospitals, deciding whether graduates are to be regarded as an input or an output can have a tremendous impact on the funding received by each individual candidate. Therefore, these hospitals have a financial interest in using the least controversial and most fair method possible to assess efficiency.
The use of a factor as both an input and an output is not completely unheard of in the DEA framework. The status of flexible variables in DEA settings can be determined by at least three approaches. The first approach treats flexible measures on both the input and output sides simultaneously. For example, Beasley [14] treats “research funding” on both the input and output sides at the same time in university efficiency measuring. Later, Cook, et al. [15] show that this treatment is not completely appropriate. Second, and perhaps most obvious, is to consider the issue from the standpoint of individual DMUs. A DEA model is run specifically for each DMU to determine the optimal role of each flexible measure. It could then be decided based on the majority choice among the DMUs what the overall input versus output status of any flexible measure is. In this case, it would seem to be the least controversial way to choose to apply a simple majority decision rule [16]. As a third alternative, it is possible to consider the situation from the viewpoint of the manager of a collection of DMUs. Specifically, consider defining each flexible variable as an input or output so that the average or aggregate efficiency of the set of DMUs is maximized. An approach such as this would be useful if ties are encountered on a case-by-case basis [15,16,17].
This study aims to develop an SBM DEA model that includes integer- and continuous-valued inputs, outputs, and flexible measures at the same time. Each flexible measure in the proposed model can be viewed as input, output, or both. The flexible measure’s optimal role for the DMU being evaluated is dedicated to maximizing its technical efficiency. As a result, both the input surplus and output shortfall (slacks) may be present in the optimal solution set for each inefficient DMU. For efficient DMUs, flexible measures can be viewed both as input and output without affecting the degree of efficiency, since they are the ones with no slacks in their optimal solution. The proposed model has another advantage in that all three classes of measures can only take integer-valued slacks.
The rest of this paper is structured as follows. The literature on theoretical and application issues is reviewed in Section 2. In section 3, we review the advances in SBM DEA models in the presence of integer-valued and flexible measures. Then, we propose a new model as well as a new efficiency index. Section 4 presents the case study of the German university hospitals and the results of running the proposed models (efficiencies and slacks) and the developed ones in the literature. We also analyze the obtained results from the models and investigate the inefficiencies sources in this section. Finally, we wrap up our study and findings in Section 5.
2 Literature review
This section provides an overview of the theoretical and application literature. We begin by examining studies related to the measurement of university hospital performance. Afterward, we review the theoretical development of the DEA models for integer-valued and flexible measures.
From a practical perspective, this study focuses on the performance evaluation of university hospitals. As reported in the health economics literature, teaching and university hospitals are more expensive than non-teaching counterparts (e.g., acute and general hospitals) since they engage in not only patient care but also in medical education and research. Therefore, this teaching/researching mission should be appropriately captured by defining proper measurements in the performance assessment process. One of the first studies in this field is conducted by Grosskopf, et al. [18]. They compare the patient service provision of both non-teaching and teaching hospitals by the means of the basic DEA model. They apply the DEA model to a dataset that includes 556 non-teaching and 236 teaching hospitals in the US. Their results specify around 10% of the teaching hospitals can efficiently compare with non-teaching counterparts. Later, Grosskopf, et al. [19] evaluate the relative scale and technical efficiencies of 254 US teaching hospitals. They find that intensified competition results in superior efficiency deprived of cooperating teaching intensity. Ozcan, et al. [20] evaluate the performance of Brazilian teaching hospitals considering both medical care and teaching/research. They conclude their study by indicating the required changes for the inefficient teaching hospitals as some recommendations for public financing and teaching ratios. In another study, Lobo, et al. [21] study the efficiency of 104 teaching hospitals in Brazil. They use a two-stage weighted DEA model followed by logistic regression analysis in the second stage to examine the effect of non-discretionary variables (e.g., ownership type) on the efficiency scores. The result of the regression shows no significant relationship between ownership and efficiency. In the case of the German hospital market, recently, Schneider, et al. [22] conduct a study on efficiency analysis of German hospitals (including both teaching and non-teaching) with a focus on investigating the relation between medical urgency and efficiency. Their results show a lower efficiency for teaching hospitals compared to the non-teaching ones. This is because the same set of input/output with the non-teaching hospitals is only used in their DEA model and the teaching function is not apprehended.
The integer DEA models have not attracted too much attention even though this situation can happen frequently in real-case applications. One reason for this may be the commitment of the DEA researchers to Linear Programming (LP) models since most LP DEA models can be proficiently solved even for big datasets using non-commercial solvers. To our knowledge, Lozanoand Villa [23] introduce the first DEA model whose inputs and outputs are intuitively constrained to take integer values only. They model their problem as a Mixed-Integer Linear Programming (MILP) for assessing efficiency of DMUs. Kuosmanenand Matin [11] develop a new axiomatic foundation (namely, “natural disposability” and “natural divisibility”) for DEA subject to the integrality constraints. They derive a new DEA PPS that fulfills the minimum extrapolation principle under their advanced axioms. They also present an MILP formula for assessing efficiency scores of Iranian university departments under the CRS assumption. Later, Kazemi Matinand Kuosmanen [24] extend their axiomatic foundation for the integer DEA under VRS, non-increasing, and non-decreasing returns to scale. Khezrimotlagh, et al. [25] critique these two models and show that the input targets obtained from the model proposed by Kuosmanenand Matin [11] and Kazemi Matinand Kuosmanen [24] may not be less than those computed by the model developed by Lozanoand Villa [23]. Jie, et al. [26] provide a technical note on the model proposed by Kuosmanenand Matin [11] and improve their model into a rectified model. They show that the new model can effectively answer the problem of a counter case studied by Khezrimotlagh, et al. [25]. Since additive models target slacks directly in reporting the efficiency, they reveal higher discrimination power especially in the presence of integer values. Du, et al. [12] propose new models based on Andersen and Petersen’s technique [27] in which slacks are directly investigated in order to compute efficiency and super-efficiency scores when inputs and outputs are integer-valued.
For the purpose of incorporating flexible measures, Cookand Zhu [16] present a modification of the standard CCR DEA model and illustrate its application in two practical problem settings. They develop their model using the MILP approach to suggest both a specific DMU model and an aggregate model as methods to originate suitable descriptions for flexible measures. However, their technique may report incorrect inefficiency indices attributable to a computational problem as a result of utilizing a large positive number in their model. This situation is addressed by Toloo [28]. He revises Cook and Zhu’s model so that it does not need to introduce a large positive number. The methodology classifies flexible measures either as input or output according to their contribution to technical efficiency optimization (optimum solution) based on MILP housing both possibilities simultaneously. Afterward, several studies try to propose further refinements [17, 29,30,31]. Some of the researchers also try to provide an ensuing and instructive discussion on the infeasibility issues of these models such as Amirteimooriand Emrouznejad [32] and Sedighi Hassan Kiyadeh, et al. [33]. The flexible SBM (FSBM) models have recently been addressed by some studies. Amirteimoori, et al. [34] introduce an FSBM for calculating the efficiency score where flexible measures are present. They show that if a DMU is perceived as efficient the flexible measure can play both input and output roles. Tohidiand Matroud [35] develop an alternative non-oriented model to classify the status of flexible measures and determine returns to scale setting.
There are as well situations in the real world where certain measures can play either input or output roles and can only take integer values, for instance, the number of graduates. Such real situations result in new unified DEA models in which both integer-valued amounts and flexible measures are simultaneously addressed. Kordrostami, et al. [36] contribute to this topic by proposing an additive slacks-based approach which is also treatable under both VRS and CRS environments. However, additive models do not directly calculate the efficiency score of the DMU under evaluation in their objective function. Therefore, the final efficiency score can be (post) calculated using the SBM DEA model’s definition. However, as pointed out by Khezrimotlagh, et al. [37] the score of SBM for the additive model may not result in an appropriate efficiency score. The SBM model measures the maximum possible slacks to minimize the efficiency score, whereas the additive model measures the maximum possible slacks without concerning the minimum efficiency score [2]. Therefore, the proposed model by Kordrostami, et al. [36] which is based on Du, et al. [12] may not report all inefficiencies (efficiency scores) correctly. Another issue that can be recognized is the way the flexible measures have been addressed in the FSBM models such as in Amirteimoori, et al. [34]. They address the flexible measures in a way that deviates from the standard SBM. Since flexible measures can simultaneously be designated as input and output in the objective function, the averages in both the numerator (input excess) and denominator (output shortfall) are respectively computed using the fixed numbers of inputs plus the flexible measures and the fixed numbers of outputs plus the flexible measures regardless of the optimum solution where the status of the flexible measure is determined. Consequently, the efficiency score is overestimated compared to the efficiency score obtained from the standard SBM. Furthermore, the flexible measure may be differently classified for some DMUs. Boďa [38] addresses this issue by proposing a modified model that distinguishes the same efficient and inefficient DMUs as Amirteimoori, et al. [34], however, realizes different projections for inefficient DMUs which means different classifications of flexible measures.
This study proposes an SBM model in which both flexible and integer measures are simultaneously presented. The main advantage of the proposed model is all input, output, and flexible measures can take integer-valued quantities without fluctuating the efficiency level. In addition, the mathematical reformulation of the proposed models considers two main properties of the SBM DEA model: units-invariant and monotone decreasing in slacks. Furthermore, the technical efficiency score is directly calculated in the proposed SBM model and inflation of scores is prevented by modifying the input and output inefficiencies. The proposed model is developed based on the MILP approach then, can be easily solved by most non-commercial and open-source solvers. Furthermore, slack values of inputs, outputs, and flexible measures calculated by the proposed model are reported and compared with those obtained from Kordrostami, et al. [36]. However, the same efficient and inefficient DMUs are detected as Kordrostami, et al. [36], the projections for inefficient DMUs and, consequently, classifications of flexible measures are different from each other. We also propose a new objective function for the model developed by Kordrostami, et al. [36] so that the new additive efficiency index falls between zero and one. The applicability of the introduced models is illustrated and scrutinized via a real-case dataset of German university hospitals. The main practical goal is to indicate the magnitude and source of inefficiencies for the university hospitals. This might support both local and national health authorities in decision-making processes including resource allocation, utilization, and planning.
3 Slacks-based measure data envelopment analysis
We first present progress made in integer-valued and flexible DEA models in literature before moving on to the final proposed model. By doing this, readers should be able to better understand how the models have evolved over the past two decades. Moreover, it allows us to point out how our proposed model advances other models by investigating their differences and commonalities. To begin with, it is worth mentioning the notations used in this paper as follows:
Sets and indices:
-
N: set of DMUs, N = {1, …, n}
-
I: set of real-valued inputs, I = {1, …, m}
-
O: set of real-valued outputs, O = {1, …, s}
-
K: set of real-valued flexible measures, K = {1, …, p}
-
II: set of the integer-valued inputs, II = {1, …, mI}
-
INI: set of the non-integer valued inputs, INI = {1, …, mNI}
-
OI: set of the integer-valued outputs, OI = {1, …, sI}
-
ONI: set of the non-integer-valued outputs, ONI = {1, …, sNI}
-
KI: set of integer-valued flexible measures, KI = {1, …, pI}
-
KNI: set of non-integer-valued flexible measures, KNI = {1, …, pNI}
-
j: index of DMUs, j ∈ N = {1, …, n}
-
i: index of inputs i ∈ I = II ∪ INI
-
r: index of outputs r ∈ O = OI ∪ ONI
-
k: index of flexible measures k ∈ K = KI ∪ KNI
Parameters:
-
xij: real-valued amounts of input i utilized by DMUj
-
yrj: real-valued amounts of output r produced by DMUj
-
zkj: real-valued amounts of flexible measure k utilized/produced by DMUj
Decision variables:
-
λj: coefficients of the convex linear combination
-
\({s}_i^x\): real-valued amounts of input i (excess)
-
\({s}_r^y\): real-valued amounts of output r (shortfall)
-
\({s}_{1k}^z,{s}_{2k}^z\): real-valued amounts of flexible measure k slack designated as input and output, respectively
-
\(\tilde{s}_i^x\): integer-valued amounts of input i (excess)
-
\(\tilde{s}_r^y\): integer-valued amounts of output r (shortfall)
-
\(\tilde{s}_{1k}^z,\tilde{s}_{2k}^z\): integer-valued amounts of flexible measure k slack designated as input and output, respectively
-
\(\tilde{d}_k,{d}_k\): binary variables to indicate the role of integer- and non-integer valued flexible measure k, (respectively)
Auxiliary variables:
-
\(\tilde{x}_{ij}\): integer-valued reference point for input i utilized by DMUj
-
\(\tilde{y}_{rj}\): integer-valued reference point for output r produced by DMUj
-
\(\tilde{z}_{kj}\): integer-valued reference point for flexible measure k utilized/produced by DMUj
-
\({s^{\prime}}_{1k}^z,{s^{\prime}}_{2k}^z\): auxiliary variables for real flexible measure k as input and output, respectively
-
\({\delta}_i^x\): auxiliary variable for the real input i (excess)
-
\({\delta}_r^y\): auxiliary variable for the real output r (shortfall)
-
\({\delta}_{1k}^z,{\delta}_{2k}^z\): auxiliary variables for real flexible measure k as input and output, respectively
-
\({\tilde{s}^{\prime}}{}^{z}_{1k},{\tilde{s}^{\prime}}{}^{z}_{2k}\): auxiliary variables for integer flexible measure k as input and output, respectively
-
\({\overset{\sim }{\delta}}_i^x\): auxiliary variable for the integer input i (excess)
-
\({\overset{\sim }{\delta}}_r^y\): auxiliary variable for the integer output r (shortfall)
-
\({\overset{\sim }{\delta}}_{1k}^z,{\overset{\sim }{\delta}}_{2k}^z\): auxiliary variables for integer flexible measure k as input and output, respectively
-
\({a}_{k^{\prime }},\tilde{a}_{k^{\prime }}\): auxiliary binary decision variables
Now, assume we have n DMUs, DMUj ∀ j = 1, …, n, that utilize m inputs (real-valued inputs), xij, ∀ j, i = 1, …, m to produce s outputs (real-valued outputs) yrj, ∀ j, r = 1, …, s. The inputs and outputs can take only positive valuesFootnote 1 i.e., x, y > 0. Then, the SBM DEA model proposed by Tone [2] can be formulated as:
where \({\uprho}_h^{SBM}\)is the SBM efficiency score of the unit under evaluation DUMh. λ = (λ1, …, λn) is called the intensity vector which identifies the reference sets for DMUh. \({\boldsymbol{s}}^x=\left({s}_1^x,\dots, {s}_m^x\right)\) and \({\boldsymbol{s}}^y=\left({s}_1^y,\dots, {s}_r^y\right)\) are respectively representing the input and output slacks. Note that Model (1) and the following models are formulated under the CRS setting, however, they can be reformulated under the VRS setting by simply adding \({\sum}_{j=1}^n{\lambda}_j=1\) to the set of constraints.
3.1 Integer-valued SBM DEA model
Suppose that some of the inputs and outputs are only valid in integer form. The input set I = II ∪ INI, where II shows the index of the integer-valued inputs and INI shows the index of the rest of the inputs (non-integers). Similarly, the output set O = OI ∪ ONI. To analyze the efficiency score of DMUs in the presence of integer-valued quantities, Model (1) can be straightforwardly formulated based on the PPS defined by Du, et al. [12]. Accordingly, the Integer-valued SBM (ISBM) DEA model can be written as follows:
where \({\uprho}_h^{ISBM}\) shows the efficiency score of DMUh in the presence of integer measures. Du et al. [11] ‘s model does not offer a zero-to-one integrated efficiency score, as in the standard additive DEA model. Model (2) differs from the Du, et al. [12] model in its definition of the efficiency index (the objective function), which mirrors SBM’s efficiency score [2]. Variables \(\tilde{s}_i^x\) and \(\tilde{s}_r^y\) are respectively non-radial slacks for integer-valued inputs and outputs while variables \(\tilde{x}_{ih}\ \textrm{and}\ \tilde{y}_{rh}\in {\mathbb{Z}}^{+}\)are the integer-valued reference points (targets) for inputs and outputs of DMUh, respectively. The slack variables \(\tilde{s}_i^x\) and \(\tilde{s}_r^y\) signify the absolute difference between the reference points (\(\tilde{x}_{ih}\) and \(\tilde{y}_{rh}\)) and the integer-valued inputs and outputs. As shown in Fig. 1, under the VRS setting, the integer DEA targets may not lie within the feasible area (the convex hull). That is why the modeling of the relationship between the convex linear combination and the integer-valued targets i.e., Eqs. (2.4) and (2.5) for integer-valued inputs, and Eqs. (2.6) and (2.7) for integer-valued outputs are slightly different from real-valued counterparts in Model (1). In other words, by defining the integer-valued reference points (\(\tilde{x}_{ih}\ \textrm{and}\ \tilde{y}_{rh}\)) we guarantee the feasibility of the integer DEA model [12].
3.2 Flexible SBM DEA model
Consider p flexible measures shown by zkj, ∀ j = {1, …, n}, k = {1, …, p} whose statuses (input or output) are unknown. To incorporate these measures, Model (1) can be reformulated based on the SBM model proposed by Amirteimoori, et al. [34] for classifying the flexible measures as follows:
where \({s}_{1k}^z\) and \({s}_{2k}^z\) are the slacks vectors responding to the flexible measures treating as inputs and outputs, respectively. \({s}_{1k}^z>0\) results in designating zko as input and \({s}_{2k}^z>0\) means zko plays the role of output in the PPS. Since zkh must be either designated as input or output, the unique status of it in the PPS is indicated by Eq. (3.5). The nonlinearity of this constraint can be handled by introducing a large positive number \(\mathcal{M}\) and a binary decision variable dk, ∀ k that assures one and only one of the variables \({s}_{1k}^z\) and \({s}_{2k}^z\) takes positive (non-zero) values simultaneously. Then, Eq. (3.5) can be replaced with the following equivalent linear constraints:
This condition should be reflected in the objection function Eq. (3.1) as well. In other words, if \({s}_{1k}^z>0,\forall k\) (dk = 0, ∀ k) then \({s}_{2k}^z=0\) (dk = 1, ∀ k) and the total number of inputs is (m + p) in the numerator consequently, the total number of the outputs in the denominator is (s). However, this issue is skipped by Amirteimoori, et al. [34], and the number of inputs and outputs they utilize are (m + p) and (s + p), respectively. In other words, they consider the number of flexible measures at the same time in both numerator and denominator of the objective function. This results in overestimating the efficiency score since the second term of both numerator and denominator is underestimated. This issue can be solved by redefining the efficiency score as Eq. (3.1). However, the objective function of Model (3) is non-linear. A linear counterpart of Model (3) is proposed by Boďa [38]. He modifies the FSBM model proposed by Amirteimoori, et al. [34] and proposes the following model:
where the optimal solution of the model determines the source of overestimating efficiency scores \({\sum}_{k=1}^K{d}_k\). This issue can be fixed by introducing an auxiliary binary variable \({a}_{k^{\prime }},\forall {k}^{\prime }=\left\{0,\dots, p\right\}\) which controls the optimized number of flexible measures indicated as outputs \({\sum}_{k=1}^p{d}_k\). Constraints (4.6) to (4.13) ensure that the decision variables \({\delta}_i^x={\left(m+\left(p-{\sum}_{k=1}^p{d}_k\right)\right)}^{-1}\cdot {s}_i^x,\forall i\), \({\delta}_r^y={\left(r+{\sum}_{k=1}^p{d}_k\right)}^{-1}\cdot {s}_r^y,\forall r\), \({\delta}_{1k}^z={\left(m+\left(p-{\sum}_{k=1}^p{d}_k\right)\right)}^{-1}\cdot {s}_{1k}^z,\forall k\), and \({\delta}_{2k}^z={\left(s+{\sum}_{k=1}^p{d}_k\right)}^{-1}\cdot {\delta}_{2k}^z,\forall k\). Therefore, the efficiency score is calculated based on the correct total number of inputs and outputs. Eqs. (4.6) and (4.7) ensure the abovementioned equalities are accomplished only and only for \({k}^{\prime }={\sum}_{k=1}^p{d}_k\) (equivalently, \({a}_{\sum_{k=1}^p{d}_k}=1\)) in Constraints (4.8) to (4.11) otherwise, they turn into free limits. The conditions defined for flexible measures in Model (3) are valid in this model as well. Let dk = 1 then \({s}_{1k}^z=0,\forall k\), \({s}_{2k}^z>0,\forall k\), and the flexible measure zko is designated as output. In contrast, if dk = 0 then zko plays the role of input.
3.3 Integer-valued flexible SBM DEA model
In the presence of both integer and flexible measures (K = KI ∪ KNI), Kordrostami, et al. [36] develop the additive model proposed by Du, et al. [12] to assess the relative efficiency. Our first step towards assessing the model’s properties is to write the model as follows:
where \({\uptau}_h^{FISBM}\) is the maximum summation of slacks. Similar to Model (2), a new integer decision variable \(\tilde{z}_{ko},\forall k\) is introduced which represents integer-valued projection points for flexible measure k of DMUo. To calculate the efficiency score, Kordrostami, et al. [36] calculate the optimum value of slacks \({\boldsymbol{s}}^{\ast }=\left({{\boldsymbol{s}}^{\ast}}^x,{{\boldsymbol{s}}^{\ast}}^y,{{\overset{\sim }{\boldsymbol{s}}}^{\ast}}^x,{{\overset{\sim }{\boldsymbol{s}}}^{\ast}}^y,{{\boldsymbol{s}}^{\ast}}_1^z,{{\boldsymbol{s}}^{\ast}}_2^z\right)\) and the determined status of flexible measure d∗ obtained from Model (5). Then, they use the SBM’s scalar measure as a posteriori efficiency index based on a set of optimal solution from Model (5) as follows:
This model (as an additive model) deals directly with both integer- and real-valued input excesses and output shortfalls. However, it has no ratio efficiency term (scalar measure) per se. Model (5) is able to discriminate inefficient from efficient DMUs by looking for slacks, but it is unable to assess the real degree of inefficiency [3, 37]. Mathematically speaking, \(\min \left[\frac{1-{\boldsymbol{s}}^x/m}{1+{\boldsymbol{s}}^y/s}\ \right]\not\equiv \max \left[\frac{{\boldsymbol{s}}^x}{m}+\frac{{\boldsymbol{s}}^y}{s}\right]\). For example, consider sx + sy = 0.2 + 0.4 = 0.8 which is greater than sx + sy = 0.4 + 0.3 = 0.7 but \(\frac{1-{s}^x}{1+{s}^y}=\frac{1-0.2}{1+0.4}=0.5\) is not less than \(\frac{1-{s}^x}{1+{s}^y}=\frac{1-0.4}{1+0.3}=0.46\). Therefore, we introduce a modified SBM DEA model (hereafter mFISBM) in an attempt to define the efficiency index directly based on the slacks and in the presence of integer and flexible measures as Model (7).
where similar to Model (4), the set of decision variables {δx, δy, δz}, and their equivalents for integer-valued measures (i.e., \(\left\{{\overset{\sim }{\boldsymbol{\delta}}}^x,{\overset{\sim }{\boldsymbol{\delta}}}^y,{\overset{\sim }{\boldsymbol{\delta}}}^z\right\}\)) make sure that the efficiency score is calculated based on the correct total number of inputs and outputs in the objective function by setting the boundaries of Constraints (7.4) to (7.7) and Constraints (7.10) to (7.13) via introducing the binary decision variable set \(\left\{{d}_k,{a}_{k^{\prime }},\tilde{d}_k,\tilde{a}_{k^{\prime }}\right\}\). The nonlinear Constraints (5.12) to (5.15) can be equivalently reformulated as the following set of linear constraints:
The modified flexible integer-valued SBM DEA model introduced here has all properties of the SBM DEA model originally developed by Tone [2]. The mFISBM is units-invariant, i.e., the value of \({\uprho^{\ast}}_h^{mFISBM}\) (≤1) is autonomous of the units in which the inputs, outputs, and flexible measures are assessed. It can as well be confirmed that \({\uprho}_h^{mFISBM}\) is monotone decreasing in all input excesses, output shortfalls, and flexible slacks. To such an extent, a larger value results larger performance score in the attainment of the efficient frontier/facet. \({\uprho^{\ast}}_h^{mFISBM}=1\) means \({{\boldsymbol{s}}^{\boldsymbol{x}}}^{\ast }=\textbf{0},{{\boldsymbol{s}}^{\boldsymbol{y}}}^{\ast }=\textbf{0},{{\boldsymbol{s}}_{\textbf{1}}^{\boldsymbol{z}}}^{\ast }=\textbf{0},{{\boldsymbol{s}}_{\textbf{2}}^{\boldsymbol{z}}}^{\ast }=\textbf{0},{{\overset{\sim }{\boldsymbol{s}}}^{\boldsymbol{x}}}^{\ast }=\textbf{0},{{\overset{\sim }{\boldsymbol{s}}}^{\boldsymbol{y}}}^{\ast }=\textbf{0},{{\overset{\sim }{\boldsymbol{s}}}_{\textbf{1}}^{\boldsymbol{z}}}^{\ast }=\textbf{0},\textrm{and}\ {{\overset{\sim }{\boldsymbol{s}}}_{\textbf{2}}^{\boldsymbol{z}}}^{\ast }=\textbf{0}\), i.e., no real and integer input excesses, no real and integer output shortfalls, and no real and integer flexible measure slacks in any optimal solution. DMUh \(\left({\boldsymbol{x}}_h,{\boldsymbol{y}}_h,{\boldsymbol{z}}_h,{\overset{\sim }{\boldsymbol{x}}}_h,{\overset{\sim }{\boldsymbol{y}}}_h,{\overset{\sim }{\boldsymbol{z}}}_h\right)\) is inefficient if \({\uprho^{\ast}}_h^{mFISBM}<1\). This condition means we have the following expression for inefficient DMUh \(\left({\boldsymbol{x}}_h,{\boldsymbol{y}}_h,{\boldsymbol{z}}_h,{\overset{\sim }{\boldsymbol{x}}}_h,{\overset{\sim }{\boldsymbol{y}}}_h,{\overset{\sim }{\boldsymbol{z}}}_h\right)\): xh = Xλ∗ + sx∗, yh = Yλ∗ − sy∗, \({\boldsymbol{z}}_h=\boldsymbol{Y}{\boldsymbol{\lambda}}^{\ast }+{{\boldsymbol{s}}_{\textbf{1}}^{\boldsymbol{z}}}^{\ast}-{{\boldsymbol{s}}_{\textbf{2}}^{\boldsymbol{z}}}^{\ast}\) where \({{\boldsymbol{s}}_{\textbf{1}}^{\boldsymbol{z}}}^{\ast}.{{\boldsymbol{s}}_{\textbf{2}}^{\boldsymbol{z}}}^{\ast}=\textbf{0}\), \({\overset{\sim }{\boldsymbol{x}}}_h=\overset{\sim }{\boldsymbol{X}}{\boldsymbol{\lambda}}^{\ast }+{{\overset{\sim }{\boldsymbol{s}}}^{\boldsymbol{x}}}^{\ast}\), \({\overset{\sim }{\boldsymbol{y}}}_h=\overset{\sim }{\boldsymbol{Y}}{\boldsymbol{\lambda}}^{\ast }-{{\overset{\sim }{\boldsymbol{s}}}^{\boldsymbol{y}}}^{\ast}\), \({\overset{\sim }{\boldsymbol{z}}}_h=\overset{\sim }{\boldsymbol{Y}}{\boldsymbol{\lambda}}^{\ast }+{{\overset{\sim }{\boldsymbol{s}}}_{\textbf{1}}^{\boldsymbol{z}}}^{\ast}-{{\overset{\sim }{\boldsymbol{s}}}_{\textbf{2}}^{\boldsymbol{z}}}^{\ast}\) where \({{\overset{\sim }{\boldsymbol{s}}}_{\textbf{1}}^{\boldsymbol{z}}}^{\ast}.{{\overset{\sim }{\boldsymbol{s}}}_{\textbf{2}}^{\boldsymbol{z}}}^{\ast}=\textbf{0}\). Straightforwardly, DMUh can become efficient by omitting the slacks i.e., xh ← xh − sx∗, yh ← yh + sy∗, \({\boldsymbol{z}}_h\leftarrow {\boldsymbol{z}}_h-{{\boldsymbol{s}}_{\textbf{1}}^{\boldsymbol{z}}}^{\ast}+{{\boldsymbol{s}}_{\textbf{2}}^{\boldsymbol{z}}}^{\ast}:{{\boldsymbol{s}}_{\textbf{1}}^{\boldsymbol{z}}}^{\ast}\cdot {{\boldsymbol{s}}_{\textbf{2}}^{\boldsymbol{z}}}^{\ast}=\textbf{0}\), \({\overset{\sim }{\boldsymbol{x}}}_h\leftarrow {\overset{\sim }{\boldsymbol{x}}}_h-{{\overset{\sim }{\boldsymbol{s}}}^{\boldsymbol{x}}}^{\ast}\), \({\overset{\sim }{\boldsymbol{y}}}_h\leftarrow {\overset{\sim }{\boldsymbol{y}}}_h+{{\overset{\sim }{\boldsymbol{s}}}^{\boldsymbol{y}}}^{\ast}\), \({\overset{\sim }{\boldsymbol{z}}}_h\leftarrow {\overset{\sim }{\boldsymbol{z}}}_h-{{\overset{\sim }{\boldsymbol{s}}}_{\textbf{1}}^{\boldsymbol{z}}}^{\ast}+{{\overset{\sim }{\boldsymbol{s}}}_{\textbf{2}}^{\boldsymbol{z}}}^{\ast}:{{\overset{\sim }{\boldsymbol{s}}}_{\textbf{1}}^{\boldsymbol{z}}}^{\ast}\cdot {{\overset{\sim }{\boldsymbol{s}}}_{\textbf{2}}^{\boldsymbol{z}}}^{\ast}=\textbf{0}\). These operations can be called mFISBM-projections as the SBM-projection in Tone [2].
The set of DMUs with the corresponding λ∗ > 0 is called reference-set to DMUh as the SBM DEA model. Furthermore, a DMU is FISBM-efficient if and only if it is mFISBM-efficient (see Appendix 1). Similar to the SBM model [2], the formulation of \({\uprho}_h^{mFISBM}\) in Model (7) can be interpreted as the product of input and output inefficiencies or the second term of numerator and denominator, correspondingly. Then, the numerator and denominator evaluate, respectively, the mean reduction rate of inputs and mean expansion rate of outputs considering the optimal role of flexible measures as well. It should be noted that when \({\uprho^{\ast}}_h^{mFISBM}=1\), the status of the real- and integre-valued flexible measures cannot be declared for DMUo. As explained by Boďa [38], this is the case of indefinite and it reports technical efficiency score where no matter what L-tuple of {0, 1} is taken for \(\left\{\boldsymbol{d},\overset{\sim }{\boldsymbol{d}}\right\}\).
The non-oriented mFISBM DEA model can be reformulated as input-oriented (IO) by setting the denominator of Eq. (7.1) to one and excluding Constraints (7.4), (7.6), (7.10), and (7.12) from the system. In the same way, the output-oriented (OO) mFISBM DEA model can be written but, in this case, we maximize the denominator and set the numerator to 1, and remove Constraints (7.5), (7.7), (7.11), and (7.13) from the model. The oriented mFISBM technical efficiency scores are optimal values \({\uprho^{\ast}}_h^{mFISBM- IO}\)and \(1/{\uprho^{\ast}}_h^{mFISBM- OO}\) where \({\uprho^{\ast}}_h^{mFISBM- IO} and1/{\uprho^{\ast}}_h^{mFISBM- OO}\ge {\uprho^{\ast}}_h^{mFISBM}\). Then, there is no need for the Charnes–Cooper transformation (explicitly, no need for dealing with multiplying the scalar variable t > 0 in slacks) since both objective functions are linear and the optimum solutions are directly reported by the models.
When dealing with large case studies, there may be a concern about the size (total number of decision variables and constraints) of Model (7) compared to Model (5). This could be problematic from the perspective of computational complexity. To handle this issue, we propose Model (8) with less size than Model (7) as follows (hereafter revised FISBM or rFISBM):
Model (8) is also units-invariant and provides an integrated efficiency index (\({\Omega}_h^{rFISBM}\)) ranging from 0 to 1 (see Appendix 2). \({\Omega}_h^{rFISBM}\)can be also called monotonically decreasing with respect to input, output, and flexible slacks so that a larger value represents a smaller slack ratio then, better performance in reaching the efficient frontier. However, unlike \({\uprho}_h^{mFISBM}\), \({\Omega}_h^{rFISBM}\) cannot be construed as the product of input and output inefficiencies. Therefore, the efficiency index calculated by Model (8) cannot be recommended when the investigation of inefficiency sources is the goal of performance evaluation.
3.4 Decomposition of inefficiency
Using optimal slacks \({\boldsymbol{s}}^{\ast }=\left({{\boldsymbol{s}}^{\ast}}^x,{{\boldsymbol{s}}^{\ast}}^y,{{\overset{\sim }{\boldsymbol{s}}}^{\ast}}^x,{{\overset{\sim }{\boldsymbol{s}}}^{\ast}}^y,{{\boldsymbol{s}}^{\ast}}_1^z,{{\boldsymbol{s}}^{\ast}}_2^z\right)\) and the optimal role of integer- and non-integer valued flexible measures \(\left({\overset{\sim }{\boldsymbol{d}}}^{\ast },{\boldsymbol{d}}^{\ast}\right)\)obtained from the models, we can decompose the inefficiency scores as input and output inefficiencies. These two terms are informative for identifying the sources of inefficiency and the magnitude of their influence on the efficiency score. In other words, the greater the inefficiency, the lower the efficiency score since the inefficiency value is subtracted from the maximum viable efficiency score (=1).
3.5 Analysis of environmental variables
An environmental factor refers to factors that can influence the efficiency of a teaching hospital but are not traditional variables that can be controlled by the manager. A health care organization’s environment may be affected by a variety of factors, including patient needs, a local economy, the location of its facilities, or institutional constraints related to access to capital. The environment in which hospitals operate may seriously bias conclusions if the environment is not adequately accounted for. There must be appropriate factors identified in advance so as to determine whether or not the conditions of the environment in which a hospital operates affect the relative efficiency scores. Due to the lack of data and difficulty in identifying or delineating catchment areas for university hospitals, we use state-specific values. Five factors identified to model the environment in which the university hospitals operate are:
-
Population Density. This factor can influence inputs and outputs and thus efficiency. This might be, for example, due to the fact that the lower population density surrounding hospitals could lead to less staff availability and limited access to education and medical care.
-
Mortality Rate. This factor indicates the number of deaths per million population. As a result of this factor, we can speculate that a higher mortality rate may be linked to more hospitalizations or a higher previous illness rate.
-
Population over 65 (% of the total population). As a demographic indicator, this figure is suitable for investigation, since a higher proportion of older people might result in a higher probability of illness and lower employment rates.
-
Education Index. This factor shows the extent to which a federal state’s education system contributes to economic growth and prosperity. It can be taken from the Education Monitor report published by the Cologne Institute for Economic Research. Since it is a comprehensive assessment spectrum, from the number of dropouts to new doctoral graduates, this metric seems to be suitable for examining whether different existing educational structures of the various states can influence the teaching performance of the university hospitals under study.
-
Gross Domestic Product per Capita (GDP/Capita). One reason this economic indicator deserves attention is that starting and completing a medical degree program (which usually takes six years in Germany) often depends on the financial circumstances of the aspiring students and their parents. In addition, this indicator is suitable for capturing the financial support provided by the federal state, and thus the teaching resources available across German states.
By applying a two-stage analysis, we first solve DEA by taking into account the inputs, outputs, and flexible variables, then regress the efficiency scores (as the dependent variable) on the environmental variables (Ferrier and Valdmanis 1996). The efficiency scores are often fitted with a censored Tobit regression model since they are bounded on both ends of the distribution (0 ≤ Efficiency Score ≤ 1). The environmental factors for each university hospital can be defined as a (1 × r) vector E. The Tobit regression is then projected as \({\hat{\delta}}_j={\boldsymbol{E}}_j\boldsymbol{\beta} +{\varepsilon}_j\). The independent variable (the efficiency score of DMUj or Effj) can be given by Eq. (11).
where, \({\hat{\updelta}}_{\textrm{j}}\) is the efficiency score obtained from Model (7) and Model (8). β is an (r × 1) vector of coefficients that need to be estimated in the stage associated with each contextual (environmental) variable through the maximum (log-)likelihood estimation approach. εj is a truncated normal random variable. Simarand Wilson [39], however, show that using efficiency scores as the dependent variable violates the classical regression assumption that variables are independent and identically distributed, which invalidates standard approaches to inference. In this case, it is unwise to draw firm conclusions from conventional statistical tests. Instead, it may be considered exploratory, which variables appear to be most influential on performance.
4 Application: The case of German university hospitals
In this section, we use a dataset of 28 public university hospitals in GermanyFootnote 2 in 2017. The data collection was carried out in different research steps including homepages of the hospitals and direct contact (e-mail/telephone inquiries) to the responsible departments and proved to be very cumbersome. For inputs, we consider the number of beds, physicians, and nurses. The number of beds is an integer-valued input measure. However, physicians and nurses are in full-time equivalent (FTE) units, i.e., real values. The number of outpatients and case-mix adjusted discharges for inpatients are designated as integer and real outputs, respectively. However, these two outputs as the major outputs for general hospitals, do not provide teaching function. Therefore, we use the number of medical students as the integer-valued output of the university hospitals. The total number of students enrolled in the university hospital’s medical degree programs is reflected in this factor. Since they are not yet trained to practice medicine alongside physicians at a population level, they cannot work in any specialties. This makes them ineligible to be considered as input (trained staff) for university hospitals. However, the degree to which teaching contributes to the training of highly skilled personnel is also an important component in the academic mission performance of a university hospital. Therefore, the total number of medical students is considered as an output [20]. We also introduce two more flexible measures to represent the teaching function in the efficiency assessment: the number of graduates and third-party funding income. Graduates who have completed their doctorate in medicine (trained) in a university hospital can play the role of either input (an available and qualified resource who can work under the supervision of the faculties or physicians so can affect their productivity) or output (accomplished staff, then a benefit resulting from teaching funding). Third-party funding income can be similarly interpreted in the efficiency evaluation of university hospitals; as input (a form of earnings received) or as output since most research-granting agencies are willing to assign funds to the university hospitals with the supreme impact.
Table 1 represents the data of 28 university hospitals with 3 inputs, 3 outputs, 2 flexible measures as well as 5 environmental factors. In the last four rows of the table, the descriptive statistics are reported. The university hospitals considered in this study have on average 1475 beds which are categorized as the large hospital. They employ more than 25,000 and 34,000 FTE physicians and nurses, respectively. From the output perspective, in total over 2.8 million adjusted inpatient admissions and over 11.4 million outpatient visits occurred. The teaching measures show that about 11 thousand graduates and about 84 thousand medical students in these hospitals where have received over €1.5 billion from the research-granting agencies.
The results of efficiency analysis of the teaching universities obtained from Model (5) [36], and the proposed Models (7) and (8) are respectively reported in Tables 4, 5, and 6 in Appendix 3. All three models are run under the CRS setting and implemented in IBM ILOG CPLEX Optimization Studio. As might be expected, they exhibit differences and share properties in common. University hospitals 2, 6, 8, 15, 21, 23, and 27 are characterized by all three models as efficient DMUs with the optimum slacks of zero. As claimed in Theorem 1, Model (7) will characterize a DMU as efficient if and only if Model (5) characterizes it as efficient. To interpret the integrality, we run the relaxed form of Model (7) in which the integrality is relaxed. Then, we examine the result of an inefficient unit, say university hospital #9. The optimum objective value of the integrality-relaxed Model (7) \({\uprho^{\ast}}_9^{relaxed}=0.7799\) obtained with the intensity optimum weights \(\left\{{\lambda}_2^{\ast }=0.3189,{\lambda}_5^{\ast }=0.1753,\; {\lambda}_{23}^{\ast }=0.0550\right\}\) and other λ∗ are equal to zero. This set of optimum weights results in the reference input (number of beds) \({\sum}_{j=1}^{28}{\lambda}_j^{\ast }{x}_{Beds,j}=\textrm{1,269.0274}\) which dominates the integer-valued input target obtained from Model (7), \(\tilde{x}_{Beds}=1280\). Model (7) implies that \(\tilde{x}_{Beds}=1280\) (or 330 units reduction in beds) is a feasible target where is not outside of the real PPS. However, there exist some situations in which the integer-valued reference input is not feasible. For example, consider university hospital #4. The optimum efficiency score obtained from the integrality-relaxed Model (7), \({\uprho^{\ast}}_4^{relaxed}=0.8201\). This yields with the intensity optimum weights \(\left\{{\lambda}_6^{\ast }=0.7795,{\lambda}_{12}^{\ast }=0.0245,{\lambda}_{23}^{\ast }=0.0516\right\}\) (others are equal to zero). This reports the reference input (“Beds”) \({\sum}_{j=1}^{28}{\lambda}_j^{\ast }{x}_{Beds,j}=\textrm{1,173.5570}\) which does not dominate the integer-valued input target \(\tilde{x}_{Beds}=1049\). The result is due to the designated status of the flexible measures in the final PPS. For the DMU4, the real flexible measure “Third-party funding income” is detected as input in the non-integer PPS while it plays the role of output in the integer PPS. Therefore, the PPS may not be comparable in some situations where flexible measures can play different roles. Slacks of the convex PPS (produced by the non-integer DEA) are usually real-valued amounts and the optimal integer input/output slacks reported by the models are not constantly a rounding up or down of the real-valued slacks. As reported in Table 5 in Appendix, for example, DMU4, the integer slacks of “Beds” \(\tilde{s}_{Beds}^{\ast }=146\) which is not equal to the rounded up or down of its convex (non-integer) slack \({s}_{Beds}^{\ast }=121.44\). Incontestably, for university hospital #19, \(\tilde{s}_{Beds}^{\ast }=39\) differs expressively from its corresponding non-integer slack \({s}_{Beds}^{\ast }=259.58\).
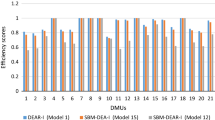
In Tables 4, 5, and 6 in Appendix 3, \({d}_k^{\ast }\) and \(\tilde{d}_k^{\ast }\) indicate the roles of “Third-party funding income” and “Graduates” in the final PPS, respectively. In Model (5), 19 out of the 28 university hospitals treat these two flexible measures as output i.e., the majority treats both as output. The same results are reported by Model (7) where 18 and 20 DMUs determine the status of both “Third-party funding income” and “Graduates” as output, correspondingly. However, Model (8) assigns different optimal designations for these two flexible measures so that only 9 and 7 university hospitals identify the role of “Third-party funding income” and “Graduates” respectively as output, i.e., the majority of 19 and 21 DMUs treat them as input. This can explain the difference between the efficiency scores calculated by Models (5) and (7) with those calculated by Model (8) as illustrated in Fig. 2. The inefficiency scores obtained from all three models are asymmetrically distributed since the medians of inefficiency scores are not in the middle of the boxes, and the whiskers are not about the same on the upper and lower sides. These boxes are also advantageous for offering a visual indicator of the variability of inefficiencies. The minimum of 0.6263, the first quartile at 0.7660, and a standard deviation equal to 0.1095, all signify the limited discriminative power of Model (8)‘s inefficiencies in this case. However, the situation changes with Models (5) and (7) where the longer boxes show more dispersed and scattered inefficiency scores. Since the median lines of Model (5) (=0.6434) and Model (7) (=0.6760) are close to each other, there is likely to be no difference between the efficiency scores of these two models. On the other hand, the median line of Model (5) which sits above 0.8534, represents the possibility of a difference between the inefficiency scores calculated by this model and the others. No inefficiency score is detected as the outlier. In other words, the lowest inefficiency score computed by the models is within one and a half interquartile range of its 25th-percentile, and the maximum efficiency score (1.0) is within one and a half of its 75th percentile.

Efficiency scores calculated by Models (5), (7), and (8)
To analyze the magnitudes and sources of inefficiency regarding the corresponding inputs/outputs for each inefficient university hospital, the inefficiency scores can be decomposed using the optimal solution obtained from the models as exhibited in Table 2. This decomposition provides managers or policy-makers with enlightening information about how to become an efficient DMU by examining the magnitudes and sources of inefficiency. For each inefficient university hospital e.g., DMU3, we can use the optimal slacks obtained from the input-oriented form of Model (7) to calculate input and output inefficiencies via Eqs. (9) and (10), respectively. This indicates the excesses in inputs (Input Ineffieicncy = 0.070) dominate shortages in outputs (Output Ineffieicncy = 0.0122 ). As might be expected, the majority of the inefficiency sources identified by this model are input inefficiency (17 out of 21) since we run an input-oriented model. This also explains why most of the output slacks and correspondingly output inefficiencies are equal to zero. Those four university hospitals (namely, 5, 12, 16, and 24) in which the output inefficiency is identified as the main source of inefficiency share one significant property in common. They all have a considerable amount of slacks of the flexible measure “Third-party funding income” that is designated as output (\({d}_k^{\ast }=1\)) in the optimum solutions obtained from all three models (see Tables 4, 5, and 6 in Appendix 3). This indicates the significant shortage in the third-party funding income dominates other inefficiencies. However, this is different for Model (5) where 18 out of 21 inefficiencies are attributed to output inefficiency. In other words, most university hospitals are input efficient. Part of the clarification for the distinct results is that Model (5) is additive and its objective function maximizes the summation of slacks (see Eq. (5.1)) instead of targeting input/output inefficiencies. Therefore, the real degree of inefficiency of the university hospitals can not be assessed.
Now turning to the teaching function, we can see from the reported slacks in Tables 5 and 6 that “Third-party funding income” as one of the teaching proxies has the maximum ratio of slacks (either input excesses or output shortfalls) in all university hospitals except DMU7 in Model (7) where excesses in inputs (“Beds”, “Physicians”, and “Nurses”) dominate other inefficiencies. This specifies in almost all the evaluating university hospitals in Germany, teaching inefficiency dominates the general inefficiency. As is now apparent the same result is not seen in the optimum solutions calculated by Model (5) in Table 4 in Appendix 3. In this model, the slacks of “Third-party funding income” are as well substantial while shortages in “Outpatients” are identified as the dominator. This disparity can be due to the fact that Model (5) is additive and its objective function cannot be explained as the inefficiency ratio.
We now investigate the influence of the environmental factors on the efficiency scores, by regressing the efficiency scores obtained from Model (7) and Model (8) against environmental factors, as shown in Table 3. The environmental factors appear to be statistically insignificant, and someone would argue for their exclusion from the DEA analysis on this basis. As a result of the bias in standard errors, the statistical significance may be misestimated - the omission would represent the same as committing a Type I error. Both regression models reveal matching results. In general, the education index of each federal state has a positive impact on the efficiency of university hospitals (but not statistically significant). Assuming a higher education index relates to better academic infrastructure, this can be expected to facilitate attainment and access to education in general. Additionally, a greater proportion of the population over 65 years of age negatively impacts the efficiency scores of university hospitals. It can also be expected that the employment rate will be lower as an older population has less available trained staff and expertise.
Despite its small impact, GDP per capita shows a positive impact on the performance of university hospitals. Assumedly, a higher GDP would also allow for more teaching resources to be available. This analysis confirms what we found in the study of inefficiency decomposition, which indicated that third-party funding income can play a principal role in inefficiency sources for German university hospitals.
While German hospitals are credited with reducing hospital and health care expenditure inflation under the Diagnostic Related Group (DRG) based payment system, other significant objectives may be jeopardized by these financial constraints. The university hospital is one type of organization that can be particularly hard hit by budget restrictions. Aside from caring for patients, these hospitals are responsible for training the German medical workforce and conducting medical research. Though both of these endeavors are critical, they are rarely adequately compensated. The results of this study also show how important it is to get more third-party funding incomes (as teaching and research objectives) in order for German university hospitals to become more efficient. In a market where there are few sources of financing, teaching hospitals are in a more competitive position than their non-teaching counterparts. As reported by the German Rectors’ Conference (2016),Footnote 3 to a varying extent, German university hospitals have structural underfunding, which is aggravated by a severe investment lag in building fabric and research infrastructure. Therefore, a substantial and guaranteed increase in their funding allocations is necessary. They aim to establish a well-organized and adequately funded university healthcare system, which does not exist at the moment. Rather, the current framework places hospitals at risk of overshadowing and dominating the research concerns of university medicine due to the economic competition they face. A clear set of regulations should be implemented in order to curtail the cross-subsidization of university hospitals with funds allocated for research and teaching. This means healthcare policymakers need to reconsider the funding structures and strategic plans of German university hospitals and investigate how third-party funding has evolved over time.
It is not easy to evaluate our findings in the light of other studies since there are no recent and comparable studies on the university hospital performance assessment, especially in Germany. However, studies dealing with the efficiency of university hospitals (as discussed in Section 2) have already pointed out differences in efficiency between teaching and non-teaching hospitals. Generally speaking, university hospitals are not able to compete with non-teaching counterparts since they pursue different goals.
5 Conclusions
In this study, we advance the SBM DEA model proposed by Tone [2] to consider the real circumstances of the integer nature of certain measures whose status can be flexibly designated. Besides, we develop a revision to the additive model developed by Kordrostami, et al. [36] to make the model report a non-negative inefficiency index with an upper limit of one. Then, the optimal solutions derived from the proposed and revised models are investigated in comparison with Kordrostami’s solutions. This is illustrated by the performance analysis of 28 university hospitals in Germany. In this case study, in addition to the patient care function, the teaching function of the units is captured in the PPS by introducing two flexible measures containing one real-valued (“Third-party funding income”) and one integer-valued (“Graduates”) as well as one integer-valued output (“Students”). In this application, the inclusion of the integrality constraints leads to more valid slacks, i.e., ensures to lie within the integer PPS and not be dominated by any other feasible units. The proposed model describes more reliable and discriminated inefficiency scores from which a more successful ordering of the university hospitals can be originated.
From a practical viewpoint, the decomposition of inefficiencies provides hospital managers, local and national health authorities some informative insights on the source and magnitude of the inefficiency of German university hospitals. The significant shortage in the third-party funding that university hospitals receive as a form of revenue is identified as the main source of inefficiency. Having this fact in mind that most research-granting organizations (e.g., German Research Foundation) consider the university hospitals with the greatest impact, it can be concluded that targeting research missions might boost the efficiency of German university hospitals. Furthermore, hospitals’ operating environments may seriously bias conclusions if they are not adequately taken into account. Therefore, we define five environmental factors in advance to analyze whether the hospital’s operating environment affects its relative efficiency scores via Tobit regression analysis. The results obtained from the second-stage regression analysis confirm that third-party funding income can have a positive impact on the efficiency of German university hospitals. A reconsideration might therefore be required in the university hospital performance management. The enormous public funds that flow into medical education should be allocated more according to efficiency aspects. Now that health care is under increasing pressure to be more efficient due to the introduction of a more results-oriented reimbursement system, similar instruments should also be used for the reimbursement of the academic mission. The proposed SBM DEA model could be used as an accompanying controlling and monitoring instrument. At the same time, in order to avoid cross-subsidies between academic and patient care missions in university hospitals, more transparency is urgently needed by applying a performance assessment approach that allows both missions to be efficiently combined under one roof. Since high-quality teaching cannot be separated from patient care, this realization can give politicians a clear mandate to find a solution to this dilemma. The proposed model could be a suitable monitoring approach for this path, taking into account further comparative parameters and the necessary modifications in the dataset used in the analysis such as identifying new measures.
Different teaching hospitals view their three missions (i.e., patient care, teaching, and research) differently. Some might operationalize these three missions equally. In the application of the proposed DEA model, the role of research is absent due to the lack of data. Furthermore, some variables could be reframed to provide a more “apples-to-apples” comparison. For example, one could look at teaching intensity instead of simply using the number of students. Grosskopf, et al. [19] define teaching intensity as the number of FTE residents per hospital bed. If we look at this measure of teaching intensity regarding the data provided in Table 1, we see considerable variation among the 28 hospitals. Look at DMU’s 20 and 21 for example. If we define teaching intensity as the number of students per bed, DMU 20 has a teaching intensity of 1.1, and DMU 21 has a teaching intensity of 2.7. It would appear that these two hospitals place a much different emphasis on their mission of teaching.
However, the choice of variables (inputs, outputs, and flexible measures) and the measurement of those variables need to be carefully examined in DEA applications otherwise they may present a range of procedural issues. In DEA models, generally, the variables are assumed to be isotonic, i.e., an increase in input reduces efficiency while an increase in output increases it [40]. As a result of incorporating ratios into the variable set, a pitfall occurs. It may be acceptable if all variables are of this type, but this can lead to problems when volume measures are mixed in as illustrated by Dyson, et al. [41]. We avoided this pitfall by not including ratios such as teaching intensity into the variable set.
A weakness of the conceptualized model is the lack of quality of patient care in the analysis. However, these datasets are usually classified and are not publicly available. In addition, an attempt should be made to integrate the other university hospitals into the investigation and to conduct an analysis over a longer period of time. A longitudinal study would allow statements on the development of efficiency of individual university hospitals, for instance, in order to assess the efficiency effect of mergers. As a real example, the German Federal Cartel OfficeFootnote 4 has recently explicated plans to merge the cardiological and cardiosurgical services of the Charité and Deutsches Herzzentrum Berlin and establish the heart center Deutsches Herzzentrum der Charité [42]. Furthermore, from a theoretical perspective, one of the limitations of this study that can be addressed in the future may be extending the present model by incorporating the perspective of the radial characteristics of measure in inefficiency sources. This leads to bringing the effects of inputs/outputs that are subject to change proportionally.
Data availability
Not applicable.
Notes
A difficulty arises with zero value measures since the slacks-based ratios are then divided by zero. To handle this problem Tone [2] provides some insights on how to deal with zeros.
There exist 35 German university hospitals together with their medical faculties. However, due to the lack of availability of data for seven units, they have been excluded from the analysis. A complete list of German university hospitals is available at https://www.uniklinika.de/.
In German: Bundeskartellamt
References
Charnes A, Cooper WW, Rhodes E (1978) Measuring the efficiency of decision making units. Eur J Oper Res 2:429–444. https://doi.org/10.1016/0377-2217(78)90138-8
Tone K (2001) A slacks-based measure of efficiency in data envelopment analysis. Eur J Oper Res 130:498–509. https://doi.org/10.1016/S0377-2217(99)00407-5
Tone K (2017) Advances in DEA theory and applications. Wiley, Chichester
Kohl S, Schoenfelder J, Fügener A, Brunner JO (2019) The use of data envelopment analysis (DEA) in healthcare with a focus on hospitals. Health Care Manag Sci 22:245–286. https://doi.org/10.1007/s10729-018-9436-8
Şahin B, İlgün G (2019) Letter to editor: About criticisms regarding manuscript entitled “assessment of the impact of public hospital associations (PHAs) on the efficiency of hospitals under the Ministry of Health in Turkey with data envelopment analysis”. Health Care Manag Sci 22:448–450. https://doi.org/10.1007/s10729-019-09475-3
Santos Arteaga FJ, Di Caprio D, Cucchiari D, Campistol JM, Oppenheimer F, Diekmann F, Revuelta I (2021) Modeling patients as decision making units: Evaluating the efficiency of kidney transplantation through data envelopment analysis. Health Care Manag Sci 24:55–71. https://doi.org/10.1007/s10729-020-09516-2
Sosa-Rubí SG, Bautista-Arredondo S, Chivardi-Moreno C, Contreras-Loya D, La Hera-Fuentes G, Opuni M (2021) Efficiency, quality, and management practices in health facilities providing outpatient HIV services in Kenya, Nigeria, Rwanda, South Africa and Zambia. Health Care Manag Sci 24:41–54. https://doi.org/10.1007/s10729-020-09541-1
Zarrin M, Schoenfelder J, Brunner JO (2022) Homogeneity and best practice analyses in hospital performance management: An analytical framework. Health Care Manag Sci. https://doi.org/10.1007/s10729-022-09590-8
Tulkens H (2006) On FDH efficiency analysis: Some methodological issues and applications to retail banking, courts and urban transit. In: Chander P, Drèze J, Lovell CK et al (eds) Public goods, environmental externalities and fiscal competition. Springer US, Boston, pp 311–342
Lozano S, Villa G (2007) Integer Dea Models. In: Zhu J, Cook WD (eds) Modeling data irregularities and structural complexities in data envelopment analysis. Springer US, Boston, pp 271–289
Kuosmanen T, Matin RK (2009) Theory of integer-valued data envelopment analysis. Eur J Oper Res 192:658–667. https://doi.org/10.1016/j.ejor.2007.09.040
Du J, Chen C-M, Chen Y, Cook WD, Zhu J (2012) Additive super-efficiency in integer-valued data envelopment analysis. Eur J Oper Res 218:186–192. https://doi.org/10.1016/j.ejor.2011.10.023
Kuosmanen T, Keshvari A, Matin RK (2015) Discrete and integer valued inputs and outputs in data envelopment analysis. In: Zhu J (ed) Data envelopment analysis: A handbook of models and methods. Springer US, Boston, pp 67–103
Beasley JE (1990) Comparing university departments. Omega 18:171–183. https://doi.org/10.1016/0305-0483(90)90064-G
Cook WD, Green RH, Zhu J (2006) Dual-role factors in data envelopment analysis. IIE Trans 38:105–115. https://doi.org/10.1080/07408170500245570
Cook WD, Zhu J (2007) Classifying inputs and outputs in data envelopment analysis. Eur J Oper Res 180:692–699. https://doi.org/10.1016/j.ejor.2006.03.048
Ghiyasi M, Cook WD (2021) Classifying dual role variables in DEA: The case of VRS. J Oper Res Soc 72:1183–1190. https://doi.org/10.1080/01605682.2020.1790309
Grosskopf S, Margaritis D, Valdmanis V (2001) Comparing teaching and non-teaching hospitals: A frontier approach (teaching vs. non-teaching hospitals). Health Care Manag Sci 4:83–90. https://doi.org/10.1023/A:1011449425940
Grosskopf S, Margaritis D, Valdmanis V (2004) Competitive effects on teaching hospitals. Eur J Oper Res 154:515–525. https://doi.org/10.1016/S0377-2217(03)00185-1
Ozcan YA, Lins ME, Lobo MSC, da Silva ACM, Fiszman R, Pereira BB (2010) Evaluating the performance of Brazilian university hospitals. Ann Oper Res 178:247–261. https://doi.org/10.1007/s10479-009-0528-1
Lobo MSC, Ozcan YA, Lins MPE, Silva ACM, Fiszman R (2014) Teaching hospitals in Brazil: Findings on determinants for efficiency. Int J Healthc Manag 7:60–68. https://doi.org/10.1179/2047971913Y.0000000055
Schneider AM, Oppel E-M, Schreyögg J (2020) Investigating the link between medical urgency and hospital efficiency - insights from the German hospital market. Health Care Manage Sci 23:649–660. https://doi.org/10.1007/s10729-020-09520-6
Lozano S, Villa G (2006) Data envelopment analysis of integer-valued inputs and outputs. Comput Oper Res 33:3004–3014. https://doi.org/10.1016/j.cor.2005.02.031
Kazemi Matin R, Kuosmanen T (2009) Theory of integer-valued data envelopment analysis under alternative returns to scale axioms. Omega 37:988–995. https://doi.org/10.1016/j.omega.2008.11.002
Khezrimotlagh D, Salleh S, Mohsenpour Z (2013a) A note on integer-valued radial model in DEA. Comput Ind Eng 66:199–200. https://doi.org/10.1016/j.cie.2013.05.007
Jie T, Yan Q, Xu W (2015) A technical note on “a note on integer-valued radial model in DEA”. Comput Ind Eng 87:308–310. https://doi.org/10.1016/j.cie.2015.05.026
Andersen P, Petersen NC (1993) A procedure for ranking efficient units in data envelopment analysis. Manag Sci 39:1261–1264. https://doi.org/10.1287/mnsc.39.10.1261
Toloo M (2009) On classifying inputs and outputs in DEA: A revised model. Eur J Oper Res 198:358–360. https://doi.org/10.1016/j.ejor.2008.08.017
Toloo M (2012) Alternative solutions for classifying inputs and outputs in data envelopment analysis. Comput Math Appl 63:1104–1110. https://doi.org/10.1016/j.camwa.2011.12.016
Toloo M, Ebrahimi B, Amin GR (2021) New data envelopment analysis models for classifying flexible measures: The role of non-Archimedean epsilon. Eur J Oper Res 292:1037–1050. https://doi.org/10.1016/j.ejor.2020.11.029
Arana-Jiménez M, Sánchez-Gil M, Younesi A, Lozano S (2020) Integer interval DEA: An axiomatic derivation of the technology and an additive, slacks-based model. Fuzzy Sets Syst. https://doi.org/10.1016/j.fss.2020.12.011
Amirteimoori A, Emrouznejad A (2012) Notes on “classifying inputs and outputs in data envelopment analysis”. Appl Math Lett 25:1625–1628. https://doi.org/10.1016/j.aml.2012.01.024
Sedighi Hassan Kiyadeh M, Saati S, Kordrostami S (2019) Improvement of models for determination of flexible factor type in data envelopment analysis. Measurement 137:49–57. https://doi.org/10.1016/j.measurement.2019.01.042
Amirteimoori A, Emrouznejad A, Khoshandam L (2013) Classifying flexible measures in data envelopment analysis: A slack-based measure. Measurement 46:4100–4107. https://doi.org/10.1016/j.measurement.2013.08.019
Tohidi G, Matroud F (2017) A new non-oriented model for classifying flexible measures in DEA. J Oper Res Soc 68:1019–1029. https://doi.org/10.1057/s41274-017-0207-6
Kordrostami S, Amirteimoori A, Jahani Sayyad Noveiri M (2019) Inputs and outputs classification in integer-valued data envelopment analysis. Measurement 139:317–325. https://doi.org/10.1016/j.measurement.2019.02.087
Khezrimotlagh D, Salleh S, Mohsenpour Z (2013b) A new robust mixed integer-valued model in DEA. Appl Math Model 37:9885–9897. https://doi.org/10.1016/j.apm.2013.05.031
Boďa M (2020) Classifying flexible measures in data envelopment analysis: A slacks-based measure – A comment. Measurement 150:107045. https://doi.org/10.1016/j.measurement.2019.107045
Simar L, Wilson PW (2007) Estimation and inference in two-stage, semi-parametric models of production processes. J Econ 136:31–64. https://doi.org/10.1016/j.jeconom.2005.07.009
Banker RD, Charnes A, Cooper WW (1984) Some models for estimating technical and scale inefficiencies in data envelopment analysis. Manag Sci 30:1078–1092. https://doi.org/10.1287/mnsc.30.9.1078
Dyson RG, Allen R, Camanho AS, Podinovski VV, Sarrico CS, Shale EA (2001) Pitfalls and protocols in DEA. Eur J Oper Res 132:245–259. https://doi.org/10.1016/S0377-2217(00)00149-1
Bundeskartellamt (2021) Bundeskartellamt clears merger between Charité and Deutsches Herzzentrum Berlin. https://www.bundeskartellamt.de/SharedDocs/Publikation/EN/Pressemitteilungen/2021/07_06_2021_Charite_DHZ.pdf?__blob=publicationFile&v=4. Accessed 12 Aug 2021
Code availability
Not applicable.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Conflicts of interest/competing interests
No conflict of interest to be declared.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Highlights
• An extended SBM DEA model that accommodates flexible and integer measures
• The flexible measure’s designation is determined by maximizing the unit’s efficiency
• Each input, output, and flexible measure can be expressed as an integer
• 28 German university hospitals are considered as the real case application
• The properties of the proposed model are compared to the literature
Appendices
Appendix 1
Theorem 1. A DMU is FISBM-efficient if and only if it is mFISBM-efficient, i.e., \({\uptau^{\ast}}_h^{FISBM}=0\leftrightarrow {\uprho^{\ast}}_h^{mFISBM}=1\).
Proof. \({\uptau^{\ast}}_h^{FISBM}=0\) if and only if the optimum value of all inputs, outputs, and flexible slacks be equal to 0 considering the nonnegativity condition imposed by Constraint (5.16), i.e., \({\boldsymbol{s}}^{\ast }=\left({{\boldsymbol{s}}^{\ast}}^x,{{\boldsymbol{s}}^{\ast}}^y,{{\overset{\sim }{\boldsymbol{s}}}^{\ast}}^x,{{\overset{\sim }{\boldsymbol{s}}}^{\ast}}^y,{{\boldsymbol{s}}^{\ast}}_1^z,{{\boldsymbol{s}}^{\ast}}_2^z\right)=\textbf{0}\). By replacing this solution into Model (7), we have δx ≤ 0 and δx ≥ 0 from Constraint (7.8) which results in δx = 0. The same results about δy, δz and \({\overset{\sim }{\boldsymbol{\delta}}}^x,{\overset{\sim }{\boldsymbol{\delta}}}^y,{\overset{\sim }{\boldsymbol{\delta}}}^z\) would be achieved from Constraints (7.4), (7.5), (7.6), (7.10), (7.11), (7.12), and (7.13), respectively. On the other hand, we know that DMUh in mFISBM model is called efficient if and only if \({\uprho^{\ast}}_h^{mFISBM}=1\). This stipulation is equal to \({\boldsymbol{\delta}}^{\ast}=\left({{\boldsymbol{\delta}}^{\ast}}^x,{{\boldsymbol{\delta}}^{\ast}}^y,{{\boldsymbol{\delta}}^{\ast}}^z,{{\overset{\sim }{\boldsymbol{\delta}}}^{\ast}}^x,{{\overset{\sim }{\boldsymbol{\delta}}}^{\ast}}^y,{{\overset{\sim }{\boldsymbol{\delta}}}^{\ast}}^z\right)=\textbf{0}\). This completes the proof. ■
Appendix 2
Theorem 2. \({\Omega}_o^{rFISBM}\le 1\).
Proof. Assume a solution of DMUh in which all input excesses (including the flexible measures designated as input) are equal to the corresponding utilized inputs (or their maximum values) i.e., \(\left\{{{\boldsymbol{s}}^{\ast}}^x={\boldsymbol{x}}_h,{{\overset{\sim }{\boldsymbol{s}}}^{\ast}}^x={\overset{\sim }{\boldsymbol{x}}}_h,{{\boldsymbol{s}}_1^{\ast}}^z={\boldsymbol{w}}_h,{{{\overset{\sim }{\boldsymbol{s}}}_1}^{\ast}}^z={\overset{\sim }{\boldsymbol{w}}}_h\right\}\). This follows that \(0\le {\left(m+p\right)}^{-1}\left[{\sum}_{\begin{array}{c}i\in {I}^{NI}\end{array}}\frac{{s^{\ast}}_i^x}{x_{ih}}+{\sum}_{\begin{array}{c}i\in {I}^I\end{array}}\frac{{\tilde{s}^{\ast}} {}_i^x}{x_{ih}}+{\sum}_{\begin{array}{c}k\in {K}^{NI}\end{array}}\frac{{s^{\ast}}_{1k}^z}{z_{kh}}+{\sum}_{\begin{array}{c}k\in {K}^I\end{array}}\frac{{\tilde{s}^{\ast}} {}_{1k}^z}{z_{kh}}\right]\le 1\). However, in the case of outputs, the maximum values for output shortfalls cannot be defined since any output slacks can exceed the corresponding produced outputs \(\left\{\textbf{0}\le {{\boldsymbol{s}}^{\ast}}^y,\textbf{0}\le {{\overset{\sim }{\boldsymbol{s}}}^{\ast}}^y,\textbf{0}\le {{\boldsymbol{s}}_2^{\ast}}^z,\textbf{0}\le {{{\overset{\sim }{\boldsymbol{s}}}_2}^{\ast}}^z\right\}\), however, it always holds \(0\le {\left(s+p\right)}^{-1}\left[\begin{array}{c}{\sum}_{\begin{array}{c}r\in {O}^{NI}\end{array}}\frac{{s^{\ast}}_r^y}{y_{rh}}+{\sum}_{\begin{array}{c}r\in {O}^I\end{array}}\frac{{\tilde{s}^{\ast}} {}_r^y}{y_{rh}}+{\sum}_{\begin{array}{c}k\in {K}^{NI}\end{array}}\frac{{s^{\ast}}_{2k}^z}{z_{kh}}+{\sum}_{\begin{array}{c}k\in {K}^I\end{array}}\frac{{\tilde{s}^{\ast}} {}_{2k}^z}{z_{kh}}\end{array}\right]\). Since the inefficiency scores are non-negative (\(0\le {\Omega}_h^{rFISBM}\)), this limits the upper bound of the summation of output mix inefficiencies so that the ratio of average input and output inefficiencies cannot take more than 1. It can reach the upper limit, \({\Omega^{\ast}}_h^{rFISBM}=1\), only if slacks are equal to their minimum values defined by Eq. (5.16), i.e., \(\left\{{{\boldsymbol{s}}^{\ast}}^x=\textbf{0},{{\boldsymbol{s}}^{\ast}}^y=\textbf{0},{{\overset{\sim }{\boldsymbol{s}}}^{\ast}}^x=\textbf{0},{{\overset{\sim }{\boldsymbol{s}}}^{\ast}}^y=\textbf{0},{{\boldsymbol{s}}^{\ast}}^z=\textbf{0},{{\overset{\sim }{\boldsymbol{s}}}^{\ast}}^z=\textbf{0}\right\}\) which is also a feasible solution for Model (8). ■
Appendix 3
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zarrin, M. A mixed-integer slacks-based measure data envelopment analysis for efficiency measuring of German university hospitals. Health Care Manag Sci 26, 138–160 (2023). https://doi.org/10.1007/s10729-022-09620-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10729-022-09620-5