
Abstract
In this paper we analyze the effects of using nonlinear least squares for parameter identification of symbolic regression models and integrate it as local search mechanism in tree-based genetic programming. We employ the Levenberg–Marquardt algorithm for parameter optimization and calculate gradients via automatic differentiation. We provide examples where the parameter identification succeeds and fails and highlight its computational overhead. Using an extensive suite of symbolic regression benchmark problems we demonstrate the increased performance when incorporating nonlinear least squares within genetic programming. Our results are compared with recently published results obtained by several genetic programming variants and state of the art machine learning algorithms. Genetic programming with nonlinear least squares performs among the best on the defined benchmark suite and the local search can be easily integrated in different genetic programming algorithms as long as only differentiable functions are used within the models.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Symbolic regression is the task of finding a mathematical model that best explains the relationship between one or more independent variables and one dependent variable. The ability to simultaneously search the space of possible model structures and their parameters (in terms of appropriate numerical coefficients) makes genetic programming (GP) [21, 34] a popular approach for symbolic regression.
However, as a biologically-inspired approach guided by fitness-based selection, the GP search process for symbolic regression is characterized by a loose coupling between fitness, expressed as an error measure with respect to the target variable, and variation operators | subordinate search heuristics in solution space that generate new models in each generation.
Consequently, it is difficult to foresee the effects on model output when variation operators perform changes on the model structure, often leading to situations where promising model structures are ignored by the algorithm due to low fitness caused by ill-fitting parameters [44]. In some cases, this can lead to necessary building blocks becoming extinct in the population before they are combined in a solution and thus recognized by the algorithm.
Generally speaking, achieving high-quality solutions in GP-based symbolic regression requires solving three interrelated subtasks:
-
1.
Selection of the appropriate subset of variables (feature selection)
-
2.
Discovery of the best suited model structure containing these variables
-
3.
Determination of optimal parameter values of the model
Each of these subtasks depends on the results of the previous subtask to generate optimal solutions, therefore improvements of one task can lead to improvements to the whole algorithm. Although these three subtasks have to be solved in any case, most algorithms create solutions without explicitly addressing the necessary steps.
Symbolic regression problems can be solved by tree-based GP that evolves individuals which capture all characteristics of a solution such as the appropriate subset of variables, model structure, and parameters. Individuals are in general manipulated as a whole (by crossover and/or mutation), which results in difficulties for generating good solutions. The reason is that such evolutionary variations partially change the model structure and occurring variables which necessitates a re-fitting of all parameters of the model.
In this context, hybridization with local search methods improves algorithm effectiveness by shifting the burden of finding appropriate numerical coefficients to subordinate algorithms or heuristics that become part of the evolutionary process at the same level with crossover and mutation operators. This division of tasks is particularly appropriate since genetic programming is already well suited for variable selection [6, 41].
Memetic algorithms combine such refinement methods with global optimization methods, often population-based, evolutionary algorithms [7]. In its initial definition, a memetic algorithm [30] is a genetic algorithm [11] hybridized with hill climbing, but hybridization generally works with many other algorithms:
-
Metaheuristics such as genetic algorithms [13], differential evolution [52], evolution strategies [2, 49], or simulated annealing [40].
-
Machine learning algorithms such as linear regression [14, 25, 35]
-
Numerical optimization algorithms such as multipoint approximation [43] or gradient descent [5, 42, 50, 51].
In this contribution we study the hybridization of tree-based GP with nonlinear least squares optimization of numeric parameters and discuss aspects ranging from implementation to runtime performance and solution quality. Our methodology for parameter identification in symbolic regression combines linear scaling, automatic differentiation and gradient-based optimization through the Levenberg–Marquardt (LM) algorithm. A novel contribution is the comparison of results produced by our proposed approach to results of a number of similar approaches that integrate local search mechanisms as well and other non-evolutionary regression techniques as reported in [33].
1.1 Numerical parameters in symbolic regression
When performing symbolic regression, numerical parameters are of prime importance. Numerical parameters, also referred to as constants, form together with variables the terminal set \({\mathscr{T}}\). Every new leaf node in a symbolic expression tree is initialized with elements from the terminal set \({\mathscr{T}}\). Internal nodes are initialized with elements from the function set \(\mathscr {F}\). Together, the two sets define the primitive set \({\mathscr{P}}\) used by the GP system to generate new symbolic expressions.
Constants in \({\mathscr{T}}\) can be either explicitly stated (as predefined and immutable numerical constants), or they can be defined as ephemeral random constants (ERC) [21]. In the first case, the terminal set may contain different numerical values alongside variables, such as \({\mathscr{T}} = \{X, 1.0, 2.0, \pi \}\) containing the variable X and three predefined numerical constants. Consequently, random uniform initialization would result in a \(75\%\) probability for a constant to be selected during tree creation when a leaf node is initialized. This disparate ratio between constants and variables could be altered by introducing a selection bias for terminal symbols.
In the second case, the special symbol \({\mathscr{R}}\) is added to the terminal set and every time the ERC symbol \({\mathscr{R}}\) is selected during tree creation a new constant value is sampled from a predefined distribution. ERCs provide greater flexibility as it is possible to create a greater variety of real-valued constants, compared to including constants directly in the terminal set. Whether immutable or ephemeral constants are more suitable largely depends on the problem at hand and both approaches might even be combined.
The numerical constants potentially reachable through the variation of solutions depend solely on the initial constant values during tree creation. To allow new constants to be discovered, GP literature recommends adding special manipulation operators to the algorithm that alter the numerical constants of a solution, for example as described in Schoenauer et al. [38], where a random Gaussian variable is added to the constant, which is inspired by mutation in evolution strategies [39]. A similar technique by Gaussian mutation is detailed in Ryan and Keijzer [37]. Another possibility inspired by simulated annealing [18] is to replace all numeric constants with new values, sampled from a uniform distribution and adapted by a temperature factor [10]. Another alternative for adapting numerical values in symbolic regression is the inclusion of local search in GP.
1.2 Literature review
Local search aims to find a local optimum starting from a single solution. The best solution among a neighboring set of solutions is selected by applying a local move and through iterative application of such moves a local optimum is reached. Local search algorithms are often employed as subordinate heuristics for solution refinement within a higher-level metaheuristic framework. In the context of symbolic regression, local search refers to a further improvement of existing solutions towards a local optimum.
Overall, the hybridization of GP with local search methods represents a good fit. The inherent disadvantage of local search methods of converging toward the next attracting local optimum (depending on initial starting conditions) is reduced by GP, because it is likely that multiple, differently parameterized instances of the same model structure are present in the population, thus providing different starting conditions for the local search.
Another helpful technique to escape such local optima is to keep random mutation enabled, although its role and significance are reduced as the identification of appropriate numerical parameters is often performed by local search methods. As a result mutation is mostly responsible for introducing variations during the search for symbolic regression solutions.
Krawiec [22] integrates a hill-climbing algorithm into GP for symbolic classification and applies it to the best solution in each generation. The author reports a statistically significant improvement over standard GP in terms of classification accuracy. This result shows that even a small amount of local optimization can provide substantial benefits.
Topchy and Punch [42] use gradient-descent for parameter adaptation in GP for symbolic regression. They perform 100 gradient-descent iterations for each individual and show that this successfully prevents the loss of good structures by comparing the results with and without gradient-descent. Furthermore, they show that a bias towards model structures that are more readily adaptable is introduced and that their approach outperforms standard GP.
Wang et al. [48] apply a set of representation-specific local search operators to decision trees, for GP-based classification. The algorithm called Memetic GP (MGP) achieves better training quality but is more prone to overfitting due to the high intensity local search.
Lane et al. [26] use a different approach where they change the functions of internal tree nodes until fitness is improved. They test different strategies, according to several tree parsimony measures, when to apply this form of tuning and to which internal nodes. They report significant improvements in test quality over standard GP. These results are verified by Azad and Ryan [3] when integrating the tuning of internal tree nodes in GP.
Z-Flores et al. [50] use an alternative parameterization of GP trees, where a weight coefficient is assigned to each function node. They employ gradient descent [8] and test different strategies for the integration in GP. They find that best results are obtained when local search is applied to all individuals and that optimizing only a subset of the best individuals also represents a viable strategy. The same approach of adding and tuning weight coefficients of internal nodes is also evaluated in GP for binary classification [51], where the classification accuracy improved on all tested problems.
Juarez et al. [15] test the benefits of integrating local search in GP and neat-GP. While the performance in terms of quality does not increase significantly, they were able to produce consistently smaller and easier to interpret solutions. Trujillo et al. [44] also use gradient descent to optimize a percentage of individuals in each generation. They apply local search stochastically based on a probability given by tree size. They report substantial improvements in terms of solution quality, convergence speed and program size.
La Cava et al. [24] add an “epigenetic layer” as a mechanism for local search and test its effectiveness in solving symbolic regression and program synthesis problems. They attach a corresponding epigenome to each individual, which determines which genes are active in its structure. Epigenomes are altered by mutation and only changes that improve fitness or program complexity are accepted. The proposed approach is able to outperform GP in terms of fitness, exact solutions, and program sizes.
Castelli et al. [4] integrate local search in Geometric Semantic GP and test it on a number of real-world symbolic regression problems. They find that the resulting algorithm severely overfits and propose an alternative approach where local search is only applied in the first 50 generations of the evolutionary run.
Table 1 offers a detailed summary of previous approaches of local search in genetic programming. Gradient descent and hill climbing are prevalent local search methods, while Lamarckian evolution is the preferred local learning behavior. In the context of learning behavior, Lamarckian and Baldwinian learning refer to the way GP handles the information obtained via local search, which can be coded back into the genotype (Lamarckian) or not (Baldwinian). In both cases, local search affects the selection process and changes the behavior of the algorithm.
1.3 Scope of this study
Only few other works [15, 42, 50] referenced in our survey use gradient-based local search with GP for symbolic regression. We therefore consider it opportune to revisit the topic and investigate additional aspects such as the effectiveness of local search, its convergent behavior and runtime impact on the evolutionary algorithm.
The main aim of this work is to provide a detailed treatment of gradient-based numerical optimization in the context of GP local search for symbolic regression. We follow the Lamarckian model where numerical coefficients optimized via nonlinear least squares are written back to the genotype. We investigate the benefits of nonlinear least squares optimization for two GP flavors (Standard GP and Offspring Selection GP [1]) and analyze performance in comparison with several other state-of-the-art methods on a large selection of benchmark problems [33].
2 Methodology
Our approach for parameter identification in symbolic regression combines automatic differentiation with gradient-based optimization [19, 20]. This approach is integrated as a local search mechanism in genetic programming and has been implemented in the open source framework for heuristic optimization HeuristicLab [47].
2.1 Mathematical formulation
For simplicity, we assume no implicit feature selection is performed and each GP model uses the entire set of input variables.
-
1.
Let \(X \in {\mathbb{R}}^{n \times m}\) be an \(n \times m\) matrix where each column \(x_i \in {\mathbb{R}}^n, i=1,\ldots ,m\) is an n-dimensional input variable and each row \(s_j \in {\mathbb{R}}^m, j=1,\ldots,n\) is an m-dimensional training sample. In what follows we take X as training data for the algorithm.
-
2.
Let \(y \in {\mathbb{R}}^n\) be the target vector for the regression problem.
-
3.
Let \({\mathscr{P}}\) be the GP primitive set and S the syntactic search space defined by it.
-
4.
Let \(\varPhi\) be the space of possible expressions and their parameters. That is, the set of all tuples \((E,\theta )\), where \(E \in S\) is a symbolic expression and \(\theta \in {\mathbb{R}}^p\) a parameter vector of length p corresponding to the numerical parameters of E. Let us call a tuple \((E,\theta )\) a symbolic expression model\(M_{E,\theta } \in \varPhi\).
-
5.
Let \(G : \varPhi \times {\mathbb{R}}^{n \times m} \rightarrow {\mathbb{R}}^n\) be a function that evaluates a model \(M_{E,\theta } \in \varPhi\) on training data X and returns an n-dimensional output vector \(\hat{y} \in {\mathbb{R}}^n\):
$$\begin{aligned} \hat{y} = G(M_{E,\theta },X) \end{aligned}$$
The overall symbolic regression goal is to find the optimal model \(M_{opt} = (E_{opt}, \theta _{opt}\))
During local search the model structure E remains fixed for a model \(M_{E,\theta }\) while the parameter vector \(\theta \in {\mathbb{R}}^{p}\) is subject to optimization. Thus, for the sake of simplicity we define the local search residual \(H:{\mathbb{R}}^p \rightarrow {\mathbb{R}}^n\) as a function that evaluates parameter vector \(\theta\) and returns the difference between the model output and the actual target:
We formulate the goal of local search as a minimization problem:
To optimize \(\theta\) over n training samples we consider the Jacobian \(J(\theta )\) of \(H(\theta )\):
For nonlinear least squares, at each iteration of the gradient descent algorithm we use the linearization
which leads to the following linear least squares problem:
The problem described by Eq. (5) can be efficiently solved using trust region or line search methods [31].
2.2 Local search algorithm
Our implementation uses a trust region gradient descent approach, namely the Levenberg–Marquardt (LM) algorithm [27, 29] with an iteration limit as stopping criterion. Per default the LM algorithm is stopped after ten iterations.
Derivatives are calculated using automatic differentiation [12, 36], since the structure of the evaluated expressions is known and contains only arithmetic operations and elementary functions that can be derived using the chain rule.
We integrate linear scaling [16, 17] with local search in order to bring each estimate \(\hat{y}\) in range with the target values y. The reason is to eliminate the need to find the correct offset and scale for the estimates, allowing GP to focus on finding the correct model structure.
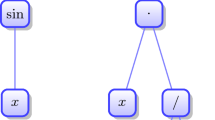
Linear scaling is achieved in practice by introducing a structural extension such that a model \(M_{E,\theta }\) is added as an input to a linear transformation block as illustrated in Fig. 1. The resulting expression will contain four additional nodes and its parameter vector \(\theta\) will include two additional coefficients (the slope and intercept of the linear transformation).

Model \(M_{E,\theta }\) extended with linear scaling nodes
These individual components linear scaling, gradient calculation, and nonlinear least squares optimization are the building blocks for parameter identification of symbolic regression models and the whole method is given as pseudo-code in Algorithm 1.

Implementation-wise we prepare a model \(M_{E,\theta }\) from a tree-based symbolic expression by first converting it to a data structure with which automatic differentiation can operate. The initial values for \(\theta\) are extracted from the leaf nodes of the tree. At each iteration the LM algorithm computes the residuals \(H(\theta )\) and the Jacobian \(J(\theta )\) and updates \(\theta\) accordingly.
Then the fitness of the symbolic expression tree is calculated, according to the objective function used by the algorithm solving the symbolic regression problem. This way, although the LM algorithm optimizes the mean squared error, another objective function (for example the coefficient of determination \(R^2\) or the mean relative error) could be used to assess the fitness of the generated model. Finally, the optimized numerical values are written back to the symbolic expression tree according to the Lamarckian learning model.
3 Analysis
We analyze the adaptation of numeric parameter values with respect to achieved improvement, convergence behavior and runtime overhead. We provide a detailed breakdown of measured execution time in relation with the number of training samples and the number of local optimization iterations.
First, we demonstrate the behavior of optimizing the parameters of a predefined model structure that matches the data generating function. The model structure (Eq. 6) contains three variables \(x_i\) and four parameters \(\theta _i\). The training data is generated using Eq. (6) with \(\theta =\{30.0, 1.0, 1.0, 10.0\}\) by randomly sampling 300 data points in the interval [0.05, 2] for \(x_1\) and \(x_3\) and [1, 2] for \(x_2\). This data generating procedure corresponds to the original problem definition given in [45]. We have chosen this particular synthetic problem because the parameters have a nonlinear effect in the model and several iterative steps are required to find the optimal values when using the LM algorithm. The elements of the initial vector \(\theta\) are sampled uniformly from the interval \([-\,100,100]\). Then, \(\theta\) is iteratively optimized until no further improvement can be achieved.
Table 2 illustrates a successful application of the LM algorithm, where the parameters of the model are correctly identified. The first row ’Iteration 0’ states the initial parameter values and each subsequent row the updated parameter vector \(\theta\). It can be observed that all parameters are simultaneously adapted according to the current gradient information. Furthermore, it could happen that the values deviate more from the target values compared to previous iterations (see for example \(\theta _1\) between Iteration 15 and 20), but in this example the correct values are identified after 35 iterations .
Appropriate starting values play a crucial role in the success of the LM algorithm. It requires a starting point within the basin of attraction for the global optimum otherwise it converges to a local optimum. Thus, the algorithm might fail to identify the optimal model parameters even when an optimal model structure is identified by GP. Model structures with multiple optima are particularly vulnerable to this phenomenon.
We illustrate the importance of good starting values by optimizing the model structure \(M_{E,\theta } = sin(\theta x)\). In contrast with the previous example where \(\theta\) was a parameter vector, here \(\theta\) is a scalar value. This corresponds to identification of the frequency of a sinusoidal function. We generate a dataset containing 6000 samples for x ranging from \(-\,3.0\) to 3.0 with a step size of 0.001 and a frequency \(\theta =2.5\).
We test different starting values of \(\theta\) in the interval \([-\,10,10]\) with a step size of 0.05 and plot the mean squared error between the generated data and the model outputs \(sin(\theta x)\) before and after LM optimization. The results illustrated in Fig. 2 show that LM always improves the mean squared error. However, the global optimum is only reached if the starting value for \(\theta\) lies in the interval [0.8, 4] and thus within the basin of attraction of the global optimum. Otherwise, the optimization converges towards a local optimum and a mean squared error of almost zero cannot be reached.

Mean squared errors before and after LM optimization for \(sin(\theta x)\) (Color figure online)
The largest drawback of the methodology is that it is computationally expensive to perform multiple gradient and function evaluations for each model structure. The LM algorithm has an asymptotic runtime complexity of \(O(nd^2)\) with n the number of training samples and d the number of parameters for a fixed number of iterations. We empirically analyze its impact on the execution performance of GP using randomly created expression trees. Figure 3 shows the growth in runtime for the LM algorithm with an increasing number of maximum iterations and training samples. For this experiment we created 1000 symbolic expression trees with the probabilistic tree creator (PTC 2) [28] and report the median execution time of the local search for an individual tree.Footnote 1

Median execution time of parameter identification per tree with varying number of training samples and LM iterations (‘0 iterations’ indicates no parameter identification) (Color figure online)
As expected, the runtime increases linearly with the number of training samples for the different tested LM iterations. The number of training samples has the largest influence, as the training error has to be recalculated after each iteration of the LM algorithm. The number of iterations has a smaller influence on runtime since the LM algorithm may stop early when no more improvement can be achieved.
Compared to tree evaluation without local search (0 iterations), the accumulated overhead exceeds one order of magnitude for training data containing more than 1000 training samples. This effect (observed in numerous other publications) can be alleviated by applying parameter identification to smaller segments of the population, selected either probabilistically or according to fitness, or by using fewer training samples for parameter identification.
4 Experiments and results
We use the Penn Machine Learning Benchmarks (PMLB) collection of benchmark regression problems developed by Olson et al. [32] with the same choice of problems as in Orzechowski et al. [33] for evaluating the performance of local search within GP. The authors from [33] only consider problems with fewer than 3000 training samples, leaving a total of 94 problems in their benchmark suite.
We test two GP flavors: Standard GP and Offspring Selection GP [1] in both their standard version using linear scaling and hybridized with nonlinear least squares (NLS) parameter identification. This results in four configurations: GP, GP NLS, OSGP and OSG NLS. For each problem we have tuned the following parameters using grid search and fivefold cross-validation:
-
Maximum tree length: 10, 25, 50, 75 nodes
-
Population size: 100, 500, 1000 individuals
-
Maximum generations: 100, 200, 1000 generations
A fivefold cross-validation is performed on the training data and repeated five times to account for stochastic effects. Hence, we have created 25 symbolic regression models (five times fivefold cross validation) that are trained on 4/5 folds of the training data and evaluated on the remaining fold. Afterwards, we select the best parameter settings for each algorithm and problem based on the average mean squared error on the fold not used for training obtained by these 25 generated models. Using the identified parameter settings we perform 50 repetitions of each algorithm on the whole training partition. The parameter settings for GP and OSGP, which have not been tuned, are detailed in Table 3.
This results are illustrated graphically in Fig. 4 for GP and Fig. 5 for OSGP, where each chart column (ordered ascending by the number of training samples) corresponds to a tested problem. These figures show the difference in the median \(R^2\) between the local search variant and the standard genetic programming variant. The color green represents a positive difference in favor of the NLS hybridization while the color red represents a negative difference. Column hatching indicates statistical significance calculated using a two-sided Wilcoxon rank-sum test (\(\alpha =0.05\)). Overall it can be observed that hybridization with local search drastically improves the modeling accuracy.

Difference in median \(R^2\) on the training and test set between GP NLS and GP on all problems sorted by number of samples. A positive difference indicates that GP NLS performs better and is highlighted in green and vice versa a negative difference is highlighted in red (Color figure online)

Difference in median \(R^2\) on the training and test set between OSGP NLS and OSGP on all problems sorted by number of samples. A positive difference indicates that OSGP NLS performs better and is highlighted in green and vice versa a negative difference is highlighted in red (Color figure online)
A summary of the overall results is given in Table 4, where it can be seen that both GP NLS and OSGP NLS produce statistically-better results for the majority of problems, for both training and test data. For an easier comparison we use symbols \(+,-\) to denote a statistically-significant performance difference between the NLS hybridization and the baseline variant.
The detailed raw data containing the results of each algorithm repetition is available for download at the HeuristicLab homepage.Footnote 2 Aggregated results for each problem are given in Appendix Tables 6 and 7 as median \(R^2\) ± interquartile range on the training and test data. The last column in each table illustrates how GP NLS and OSGP NLS compare against their standard counterparts.
We then perform a large-scale comparison between our GP variants and several symbolic regression methods tested by Orzechowski et al. [33] and summarized in Table 5. We follow the original methodology in [33] and calculate algorithm ranks on the tested problems based on median mean squared error.
The experimental setup has been intentionally chosen as similar as possible to the benchmarking study [33] so that we can compare the results of our methods with already published ones. Therefore, we ranked the performance of all algorithms based on the median mean squared errors. However, we only created new results for GP, GP NLS, OSGP and OSPG NLS and reused the publicly available results and scripts for analysis and visualization provided by the Epistasis Lab at the University of Pennsylvania.Footnote 3 Box plots showing the rank distribution for each algorithm across all problems are shown in Fig. 6 for the training set and in Fig. 7 for the test set.

Algorithm ranking based on the MSE scores on the training set (Color figure online)

Algorithm ranking based on the MSE scores on the test set (Color figure online)
We assess performance on the basis of training and test median ranks, and we compare the significance of the problem rankings obtained by each algorithm using the Kruskal test [23] to ascertain that the calculated rank medians are statistically different and Dunn’s test [9] with Holm–Bonferroni adjustments, to ascertain whether the pairwise rank differences between the tested algorithms are statistically significant. The calculated p values are shown in Appendix Tables 8 and 9.
In terms of training performance, both GP and OSGP algorithms fall behind all other GP variants except AFP. At the same time, neither GP NLS and OSGP NLS distinguish themselves as top performers on this benchmark set as they are outranked by MRGP, XGBoost and GradBoost.
However, in terms of generalization ability (test performance), the results show that GP NLS is tied with OSGP NLS, EPLEX-1M and XGBoost and outperforms all other methods. In turn, OSGP NLS is tied with GP NLS and EPLEX-1M and outperforms all other methods. Overall, the proposed local search hybridization is able to significantly improve the generalization ability of algorithms.
5 Conclusion
Hybridization with local search represents a particularly effective approach for improving GP performance on a wide array of symbolic regression and symbolic classification. Many studies in the literature report substantial benefits in terms of solution quality, convergence speed and model size, with the added cost of increased running time caused by additional evaluations required by the local improvement procedure.
In this work we described in detail one such hybridization using GP and Offspring Selection GP for the evolution of model structure and the Levenberg–Marquardt algorithm for optimization of numerical parameters for symbolic regression. Implementation-wise, it is straight-forward to integrate linear scaling by extending the model parameter vector with two additional coefficients for scale and intercept. In general the approach works remarkably well on the suite of benchmark problems that we used for testing regardless of the GP variant employed. However, local search may get trapped in local optima, as we exemplified on the problem of frequency detection for a trigonometric function.
Our testing indicates improved generalization as the main benefit of this approach. In terms of training quality GP NLS and OSGP NLS rank behind MRGP (Multiple Regression Genetic Programming), However, on the test set OSGP NLS produces on average the best predictions among all GP variants.
As future work in this area we plan to investigate in more detail the correspondence between local search effort (in terms of gradient descent iterations) and algorithm performance within the Lamarckian framework. We conjecture that a more efficient search model can be attained by tuning the balance between local and global search effort.
Notes
Actual performance measurements are acquired using BenchmarkDotNet, a benchmarking framework providing an automated environment for performance analysis (https://benchmarkdotnet.org). Each test configuration has been run in an isolated project on an Intel® Core™ i7-8700 processor.
References
M. Affenzeller, S. Wagner, Offspring selection: a new self-adaptive selection scheme for genetic algorithms, in Adaptive and Natural Computing Algorithms, Springer Computer Science, ed. by B. Ribeiro, R.F. Albrecht, A. Dobnikar, D.W. Pearson, N.C. Steele (Springer, Berlin, 2005), pp. 218–221
C.L. Alonso, J.L. Montana, C.E. Borges, Evolution strategies for constants optimization in genetic programming, in 21st International Conference on Tools with Artificial Intelligence. ICTAI ’09 (2009), pp. 703–707
R.M.A. Azad, C. Ryan, A simple approach to lifetime learning in genetic programming-based symbolic regression. Evol. Comput. 22(2), 287–317 (2014)
M. Castelli, L. Trujillo, L. Vanneschi, S. Silva, et al. Geometric semantic genetic programming with local search, in Proceedings of the 2015 Annual Conference on Genetic and Evolutionary Computation (ACM, 2015), pp. 999–1006
Q. Chen, B. Xue, M. Zhang, Generalisation and domain adaptation in GP with gradient descent for symbolic regression, in 2015 IEEE Congress on Evolutionary Computation (CEC) (IEEE, 2015), pp. 1137–1144
Q. Chen, M. Zhang, B. Xue, Feature selection to improve generalisation of genetic programming for high-dimensional symbolic regression. IEEE Trans. Evol. Comput. 21, 792–806 (2017)
X. Chen, Y.S. Ong, M.H. Lim, K.C. Tan, A multi-facet survey on memetic computation. IEEE Trans. Evol. Comput. 15(5), 591–607 (2011)
A. Conn, N. Gould, P. Toint, Trust Region Methods. MPS-SIAM Series on Optimization (Society for Industrial and Applied Mathematics, Philadelphia, 2000)
O.J. Dunn, Multiple comparisons using rank sums. Technometrics 6(3), 241–252 (1964)
T. Fernandez, M. Evett, Numeric mutation as an improvement to symbolic regression in genetic programming, in Evolutionary Programming VII, ed. by V.W. Porto, N. Saravanan, D. Waagen, A.E. Eiben (Springer, Berlin, 1998), pp. 251–260
D.E. Goldberg et al., Genetic Algorithms in Search Optimization and Machine Learning, vol. 412 (Addison-Wesley Reading, Menlo Park, 1989)
A. Griewank, A. Walther, Evaluating Derivatives: Principles and Techniques of Algorithmic Differentiation (SIAM, Philadelphia, 2008)
L.M. Howard, D.J. D’Angelo, The GA-P: a genetic algorithm and genetic programming hybrid. IEEE Expert 10(3), 11–15 (1995)
I. Icke, J.C. Bongard, Improving genetic programming based symbolic regression using deterministic machine learning, in 2013 IEEE Congress on Evolutionary Computation (CEC) (IEEE, 2013), pp. 1763–1770
P. Juárez-Smith, L. Trujillo, Integrating local search within neat-GP, in Proceedings of the 2016 Genetic and Evolutionary Computation Conference Companion (ACM, 2016), pp. 993–996
M. Keijzer, Improving symbolic regression with interval arithmetic and linear scaling, in Proceedings of the 6th European Conference on Genetic Programming, EuroGP 2003. LNCS, vol. 2610, ed. by C. Ryan, T. Soule, M. Keijzer, E. Tsang, R. Poli, E. Costa (Springer, Berlin, 2003), pp. 70–82
M. Keijzer, Scaled symbolic regression. Genet. Program. Evolvable Mach. 5(3), 259–269 (2004)
S. Kirkpatrick, C.D. Gelatt, M.P. Vecchi et al., Optimization by simulated annealing. Science 220(4598), 671–680 (1983)
M. Kommenda, M. Affenzeller, G. Kronberger, S.M. Winkler, Nonlinear least squares optimization of constants in symbolic regression, in International Conference on Computer Aided Systems Theory (Springer, 2013), pp. 420–427
M. Kommenda, G. Kronberger, S. Winkler, M. Affenzeller, S. Wagner, Effects of constant optimization by nonlinear least squares minimization in symbolic regression, in Proceedings of the 15th Annual Conference Companion on Genetic and Evolutionary Computation (ACM, 2013), pp. 1121–1128
J.R. Koza, Genetic Programming: On the Programming of Computers by Means of Natural Selection (MIT Press, Cambridge, MA, 1992)
K. Krawiec, Genetic programming with local improvement for visual learning from examples, in Computer Analysis of Images and Patterns, ed. by W. Skarbek (Springer, Berlin, 2001), pp. 209–216
W.H. Kruskal, W.A. Wallis, Use of ranks in one-criterion variance analysis. J. Am. Stat. Assoc. 47(260), 583–621 (1952)
W. La Cava, T. Helmuth, L. Spector, K. Danai, Genetic programming with epigenetic local search, in Proceedings of the 2015 Annual Conference on Genetic and Evolutionary Computation (ACM, 2015), pp. 1055–1062
W. La Cava, J.H. Moore, Semantic variation operators for multidimensional genetic programming, in Proceedings of the Genetic and Evolutionary Computation Conference, GECCO ’19 (ACM, New York, NY, 2019), pp. 1056–1064
F. Lane, R.M.A. Azad, C. Ryan, On effective and inexpensive local search techniques in genetic programming regression, in International Conference on Parallel Problem Solving from Nature (Springer, 2014), pp. 444–453
K. Levenberg, A method for the solution of certain non-linear problems in least squares. Q. J. Appl. Math. II(2), 164–168 (1944)
S. Luke, Two fast tree-creation algorithms for genetic programming. IEEE Trans. Evol. Comput. 4(3), 274–283 (2000)
D.W. Marquardt, An algorithm for least-squares estimation of nonlinear parameters. J. Soc. Ind. Appl. Math. 11(2), 431–441 (1963)
P. Moscato et al., On evolution, search, optimization, genetic algorithms and martial arts: towards memetic algorithms. Caltech concurrent computation program. C3P Report 826, 1989 (1989)
J. Nocedal, S.J. Wright, Numerical Optimization, 2nd edn. (Springer, New York, NY, 2006)
R.S. Olson, W. La Cava, P. Orzechowski, R.J. Urbanowicz, J.H. Moore, PMLB: a large benchmark suite for machine learning evaluation and comparison. BioData Min. 10(1), 36 (2017)
P. Orzechowski, W. La Cava, J.H. Moore, Where are we now?: A large benchmark study of recent symbolic regression methods, in GECCO ’18: Proceedings of the Genetic and Evolutionary Computation Conference (ACM, New York, NY, 2018), pp. 1183–1190
R. Poli, W.B. Langdon, N.F. McPhee, A field guide to genetic programming. Published via http://lulu.com and freely available at http://www.gp-field-guide.org.uk (2008). Accessed 2 Dec 2019
J.R. Koza, W. Banzhaf, K. Chellapilla, K. Deb, M. Dorigo, D.B. Fogel, M.H. Garzon, D.E. Goldberg, H. Iba, R.L. Riolo (eds.), in Genetic Programming 1998: Proceedings of the Third Annual Conference, July 22–25, 1998, University of Wisconsin, Madison, Wisconsin (San Francisco, CA, Morgan Kaufmann)
L.B. Rall, Automatic Differentiation: Techniques and Applications. Lecture Notes in Computer Science, vol. 120 (Springer, Berlin, 1981)
C. Ryan, M. Keijzer, An analysis of diversity of constants of genetic programming, in Genetic Programming. Proceedings of EuroGP’2003, LNCS, vol. 2610, ed. by C. Ryan, T. Soule, M. Keijzer, E. Tsang, R. Poli, E. Costa (Springer, Berlin, 2003), pp. 404–413
M. Schoenauer, M. Sebag, F. Jouve, B. Lamy, H. Maitournam, Evolutionary identification of macro-mechanical models, in Advances in Genetic Programming 2, ed. by P.J. Angeline, K.E. Kinnear Jr. (MIT Press, Cambridge, MA, 1996), pp. 467–488
H.P. Schwefel, Numerical Optimization of Computer Models (Wiley, Hoboken, 1981)
K.C. Sharman, A.I. Esparcia Alcazar, Y. Li, Evolving signal processing algorithms by genetic programming, in First International Conference on Genetic Algorithms in Engineering Systems: Innovations and Applications, GALESIA, vol. 414, ed. by A.M.S. Zalzala (IEE, Sheffield, 1995), pp. 473–480
S. Stijven, W. Minnebo, K. Vladislavleva, Separating the wheat from the chaff: on feature selection and feature importance in regression random forests and symbolic regression, in Proceedings of the 13th Annual Conference Companion on Genetic and Evolutionary Computation, ed. by S. Gustafson, E. Vladislavleva (ACM, Dublin, 2011), pp. 623–630
A. Topchy, W.F. Punch, Faster genetic programming based on local gradient search of numeric leaf values, in Proceedings of the Genetic and Evolutionary Computation Conference (GECCO-2001), ed. by L. Spector, E.D. Goodman, A. Wu, W.B. Langdon, H.M. Voigt, M. Gen, S. Sen, M. Dorigo, S. Pezeshk, M.H. Garzon, E. Burke (Morgan Kaufmann, San Francisco, CA, 2001), pp. 155–162
V.V. Toropov, L.F. Alvarez, Application of genetic programming to the choice of a structure of multipoint approximations, in 1st ISSMO/NASA International Conference on Approximations and Fast Reanalysis in Engineering Optimization (1998)
L. Trujillo, Z. Emigdio, P.S. Juárez-Smith, P. Legrand, S. Silva, M. Castelli, L. Vanneschi, O. Schütze, L. Muñoz et al., Local search is underused in genetic programming, in Genetic Programming Theory and Practice XIV, ed. by R. Riolo, B. Worzel, B. Goldman, B. Tozier (Springer, Cham, 2018), pp. 119–137
E.J. Vladislavleva, G.F. Smits, D. Den Hertog, Order of nonlinearity as a complexity measure for models generated by symbolic regression via pareto genetic programming. IEEE Trans. Evolut. Comput. 13(2), 333–349 (2009)
S. Wagner, M. Affenzeller, Sexualga: gender-specific selection for genetic algorithms, in Proceedings of the 9th World Multi-Conference on Systemics, Cybernetics and Informatics (WMSCI), vol. 4 (2005), pp. 76–81
S. Wagner, G. Kronberger, A. Beham, M. Kommenda, A. Scheibenpflug, E. Pitzer, S. Vonolfen, M. Kofler, S. Winkler, V. Dorfer et al., Architecture and design of the HeuristicLab optimization environment, in Advanced Methods and Applications in Computational Intelligence, ed. by R. Klempous, J. Nikodem, W. Jacak, Z. Chaczko (Springer, Heidelberg, 2014), pp. 197–261
P. Wang, K. Tang, E.P. Tsang, X. Yao, A memetic genetic programming with decision tree-based local search for classification problems, in 2011 IEEE Congress on Evolutionary Computation (CEC) (IEEE, 2011), pp. 917–924
S.M. Winkler, Evolutionary system identification—modern concepts and practical applications. Ph.D. thesis, Institute for Formal Models and Verification, Johannes Kepler University, Linz, Austria (2008)
E. Z-Flores, L. Trujillo, O. Schütze, P. Legrand et al., Evaluating the effects of local search in genetic programming, in EVOLVE—A Bridge between Probability, Set Oriented Numerics, and Evolutionary Computation V, ed. by A.A. Tantar, et al. (Springer, Cham, 2014), pp. 213–228
E. Z-Flores, L. Trujillo, O. Schütze, P. Legrand, et al., A local search approach to genetic programming for binary classification, in Proceedings of the 2015 on Genetic and Evolutionary Computation Conference-GECCO’15 (2015)
Q. Zhang, C. Zhou, W. Xiao, P.C. Nelson, Improving gene expression programming performance by using differential evolution, in Sixth International Conference on Machine Learning and Applications, ICMLA 2007 (IEEE, Cincinnati, OH, 2007), pp. 31–37
Acknowledgements
Open access funding provided by University of Applied Sciences Upper Austria. We would especially like to thank the researchers of the Epistasis Lab at the University of Pennsylvania for collecting the benchmark suite and providing their results for comparison as well as the accompanying analysis scripts.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The authors gratefully acknowledge the financial support by the Austrian Federal Ministry for Digital and Economic Affairs and the National Foundation for Research, Technology and Development within the Josef Ressel Center for Symbolic Regression.
Appendix
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kommenda, M., Burlacu, B., Kronberger, G. et al. Parameter identification for symbolic regression using nonlinear least squares. Genet Program Evolvable Mach 21, 471–501 (2020). https://doi.org/10.1007/s10710-019-09371-3
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10710-019-09371-3