
Abstract
Machine learning (ML) algorithms steer agent decisions in agent-based models (ABMs), serving as a vehicle for implementing behaviour changes during simulation runs. However, when training an ML algorithm, obtaining large sets of micro-level human behaviour data is often problematic. Information on human behaviour is often collected via surveys of relatively small sample sizes. This paper presents a methodology for training a learning algorithm to guide agent behaviour in a spatial ABM using a limited survey data sample. We apply different implementation strategies using survey data and Bayesian networks (BNs). By being grounded in probabilistic directed graphical models, BNs stand out among other learning algorithms in that they can be based on expert knowledge and/or known datasets. This paper presents four alternative implementations of data-driven BNs to support agent decisions in a spatial ABM. We differentiate between training BNs prior to, or during the simulation runs, using only survey data or a combination of survey data and expert knowledge. The four different implementations are then illustrated using a spatial ABM of cholera diffusion for Kumasi, Ghana. The results indicate that a balance between expert knowledge and survey data provides the best control over the learning process of the agents and produces the most realistic agent behaviour.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Learning can be defined as a process in which prior knowledge gained from experience is employed to optimise future decisions [1]. The proliferation of agent-based models (ABMs) as a research method calls for advancements in how agents learn and adapt. In ABMs, agents can possess their own cognitive model that can be trained using real data. Machine learning (ML) algorithms are used increasingly to enhance agent learning abilities and implement autonomous smart behaviour. Notably, ABMs with intelligent agents are argued to capture complex real-world phenomena more realistically [2]. Therefore, the behavioural rules guiding an individual agent’s decisions, and the interactions between agents and environments, significantly affects the macro-patterns emerging from a model [3].
In ABMs, ML algorithms are applied in one of the following phases: (1) prior to running the ABM, (2) during the run of the ABM, or (3) after running the ABM to analyse model output. Before running an ABM, ML algorithms can be used to derive parameter values based on empirical data or to prepare input data [4]. During the simulation, they are used to capture ABM outputs to train a learning algorithm during the simulation [5]. After running the simulation, ML algorithms are applied for calibrating and validating ABM output [6]. The algorithms used for these three types of application vary from neural networks, to Bayesian networks, to genetic algorithms, and other ML algorithms.
ML algorithms, used during the run of the ABM, are often implemented to steer agent behaviour. Complex emerging behaviour can be the result of combinations of previous experiences of an agent (feedback), of social interactions with other agents, but also of changes in the agent’s environment. ML algorithms can play an important role in combining a large number of different variables (spatial and non-spatial variables) and obtaining the social- and spatial intelligence level required. Learning is achieved when agents can use their observations to solve complex problems or derive smart solutions. Examples of ML implemented in spatial ABMs are the implementation of ML for spatial optimization of land-use allocation [7], searching for the best location and pricing strategies in a competitive business environment [8], and optimizing migration patterns [6]. Other researchers use spatial learning to spread spatial externalities and use spatial neighbourhood to diffuse information or strategies [9, 10], in other words for the explicit modelling of spatially-correlated phenomena. Spatial learning can be achieved using rule-based modelling, but via ML it is easier to include spatial factors in an agent’s decision-making [11]. In addition, ML is used to obtain spatial knowledge of a resource and a quality of the environment [5]; or a threat/obstacle [12] in a specific location.
One limitation in the use of intelligence in ABMs in general, and spatial ABMs specifically, is that most learning algorithms require extensive training data [13]. Although massive geo-data is becoming increasingly available, data on human choices and rules that guide behaviour remain scarce. Moreover, the reduced availability of large sets of micro-level data on human behaviour influences the use of learning algorithms [14]. The performance of learning algorithms improves with the increasing quantity and quality of training data [15]. However, in many domains, the problem of obtaining such qualitative large sets of empirical data remains [16].
It is important to note that ML and big data are not synonymous. The amount of data necessary to train and test the algorithm relates to the complexity of the problem at hand and the nature of the learning algorithm. A good addition to any dataset is domain expertise. Bayesian networks (BNs) are not data intensive and represent a viable alternative for small training datasets; also, they tend to exhibit good prediction accuracy – even with small sample sizes [13, 14]. BNs are particularly useful for the simulation of processes such as decisions under risk, which are characterized by multiple related (and uncertain) variables [16, 17]. This is primarily due to BNs being suitable for the reduction of complex domains into computationally manageable models [18, 19]. Another advantageous feature of BNs for such applications includes their capability in managing incomplete data and uncertain information.
Learning in BNs consists of two different tasks: design of a network structure with network probability values (1) and defining the conditional probability tables (CPTs)(2) [20]. The design of the BN determines the variables (nodes) used and the way these variables are combined (linked) to derive a decision. A design can be based on expert knowledge or derived from data. The role of the expert is to resort to subjective assessment of the network design and probabilities and make use of their experience and literature published in the field [21]. The next step is the construction and adjustment of conditional probability distributions. Quantitative information for the BN must be obtained in the form of conditional probabilities (i.e. CPTs). In case of data availability, the CPT values are driven directly from the dataset during the process of constructing the network structure. When no data is available, the expert defines the CPT using marginal likelihood for parameter learning to cover the uncertainty in the values of the parameters. This training will be done during the simulation.
The challenge in constructing BNs from data relates to finding a network that best fits the available data [22]. Expert-driven BNs are entirely reliant on experts with full knowledge about the domain [23]. However, it remains unclear how the outcomes of a model are impacted by variations in constructed BNs or the way in which they are implemented in the ABM (e.g., [11, 24]).
Several studies have combined BNs with ABMs; for example, Kocabase and Dragicevic (2013) derived BN structures for different agent types and obtained their CPT values from census data before using the BN in a land-use change model [5]. In another example, both Ren and Anumba [25] and Ma et al. [26] used a simple BN structure, utilised experts to derive their CPT values, and trained during the simulation [19, 27]. While Matsumoto et al. (2017) constructed a data-driven BN using a survey, they simultaneously trained their network to estimate internal parameters [28]. Furthermore, Pope & Gimblett (2015) used stakeholders to design their BN and CPT values [29].
The present study contributes to this literature by exploring: (1) the possibility of implementing learning in spatial ABMs with a small behavioural dataset, (2) the extent to which supervised learning of ML algorithms should depend exclusively on data, and (3) the level of intelligence necessary for agents to simulate realistic risk perception. To address this aim, we test alternative methods of designing a BN from a small sample of micro-level behavioural data.
The next section (2) describes the three methodological steps designed to address the research aims: it briefly introduces the spatial ABM used as a test case, provides details on how we collected data for BN training, and describes how alternative, empirically-driven BNs are integrated in the spatial ABM. Section 3 discusses the results of the simulation experiments, and Section 4 concludes by discussing the main findings, advantages, and limitations of our approach, as well as possible directions for future work.
2 Methodology
We use a spatial ABM designed to explore cholera diffusion in Kumasi, Ghana in 2005 in combination with survey data [30]. Two online surveys were run to gather data on people’s risk perception for cholera: MOOC survey (Geohealth online course) and Google survey (an online survey). While most of the questions were identical in the two surveys (Appendices 1 and 2), there was one difference. In the MOOC survey participants chose to use or not to use river water for drinking through judging about its quality by the visual appearance (pictures shown). The Google survey collected information on the influence of individual risk factors on the willingness to use the river water without visuals using only textual description of the water quality situation. The risk perception of participants is questioned based on one factor and a combination of factors.
2.1 Spatial agent-based model
To quantitatively assess the impacts of different workflows, we implemented different BNs within an existing spatial model that studies cholera diffusion in Ghana. The Cholera ABM (CABM) was originally developed by Augustijn et al. (2016) using NetLogo [30] for a 2005 epidemic in Kumasi, Ghana. CABM simulates two different cholera infection pathways, via the environment (lower infectiousness) and human-environment-human infection (hyper-infectious). When passing through the digestive system, cholera bacteria transition to a hyper-infectious state. When faecal materials from cholera patients are deposited at open dumpsites, runoff during heavy rains can carry the infection to nearby rivers, and as people use the river water for domestic use, this runoff can contribute to the diffusion of the disease. The original model does not contain any risk awareness of agents. Even when the number of disease cases increase, agents keep on using river water.
A total of four agent types are present in the CABM: households, individuals, media, and rain particles. The model consists of three sub-models: a hydrological model, an activity model (including learning), and a disease model. The study area equals to 19 km2 and consists of 21 communities (Fig. 1 left), eleven of them are completely included. There are no administrative boundaries for these communities. However, for this model the developers determined the boundaries using Thiessen polygons. The spatial environments of CABM consists of: (1) elevation surface data (DEM) to construct hydrological environment to determine the flow direction and flow accumulation of the rain drops; (2) the dumpsites with actual locations gathered using global positioning system (GPS); the (3) house layer with different income levels: high, medium, and low; (4) the river; (5) the centre and ID of communities (Fig. 1).

CABM study area that is located in North-East part of Kumasi
A two-stage ML algorithm was implemented in the model to simulate the intelligent processes of risk perception and agent decision making outlined by Abdulkareem et al. [31]. Protection Motivation Theory is one of the dominant approaches in behavioural science and was used as the theoretical framework in CABM. This theory suggests that risky decisions consist of two stages: threat appraisal (risk perception) and coping appraisal. Additionally, two BNs were implemented to represent these two appraisals using R software (connect to Netlogo via R extension) [31]. All agents except media in CABM – i.e. households, individuals, rain particles, − are associated with a particular location at each moment. Households agents that use BNs also have spatial intelligence, which refers to the fact that agents sense and have an understanding of their spatial environment and make intelligent decisions based on changes in these spatial environments. Here, household agents using BNs perceive the environment where they go to fetch the water, evaluate its visual pollution and combine the information with other factors to evaluate their risk perception using BNs.
High-income agents for our case-study always buy bottled water, therefore, they have been excluded and assumed they are protected from getting cholera. Low- and middle-income household agents, who have no access to tap water, use the BNs to decide whether to fetch water from the river. They perceive and evaluate risk using the first BN (BN1), and, when risk is perceived, they cope by deciding on what type of water to use by employing a second BN (BN2). The structure of the network and its priors are the same for all agents at initialization, but as agents learn, the conditional probabilities depend on the evidences for each agent and will change differently. Risk assessment is based on four criteria: visual pollution of water collection points, media attention, communication with neighbours, and individual memory. During the coping process, they can choose between buying water, boiling river water, or fetching water from another water collection point. Both BN1 and BN2 were designed on the basis of expert knowledge.
In the present study, we alter the ability of BN1 to guide individual risk perception by using new BNs to run our experiments. In particular, our original BN1 that used expert opinions to define both BN structure and parameters is re-implemented in this work to serve as a benchmark. The coping appraisal decision determining which water source agents use remained unchanged (BN2 in [31]).
2.2 Data collection
To derive a BN from data, micro-level behavioural datasets describing the relation between risk perception and the model variables are needed, including visual pollution, media, neighbour, and memory.
This data was collected during two surveys: a survey among international participants of the Massive Open Online Course (MOOC) Geohealth and an online survey (Google survey). The MOOC Geohealth was organised by the Faculty of Geo-Information Science and Earth Observation (ITC) of the University of Twente, in the Netherlands during 2016 and 2017 with 194 and 235 participants from 92 countries (54% were from Africa, including Ghana) completing the survey. MOOC participants were split randomly into four equal subgroups, which were shown pictures of rivers with different levels of visual pollution (Fig. 2). All subgroups answered the same set of survey questions testing their willingness to use the river water for drinking and cooking purposes (Appendix 1). In every subsequent question, additional information on other factors such as memory, media attention, and communication with neighbours was provided.

Four different pictures of rivers with pollution of various intensity. These pictures differ in colour of river water and level of floating debris (only on banks – in banks and in water). Photos source: https://www.shutterstock.com/
Information on the influence of individual risk factors on water use was collected during a separate survey implemented using a Google form (Appendix 2). The importance of factors including ‘Visual pollution’, ‘Media’, and ‘Contact with neighbours’ was surveyed both individually and in combination with other factors. This survey was distributed to students enrolled in Master of Science courses in Geoinformatics and urban planning and management at the Faculty of ITC, University of Twente. In total, this led to 125 survey participants from 33 countries (35% of them were from Africa including Ghana).
We combine the data gathered from these two surveys into one dataset to ensure that BNs are constructed and trained with all possible combinations of factors states and risk perception responses
2.3 Integration of empirically – Driven BNs in the spatial ABM
All BNs consist of a number of nodes connected by links in the form of a directed acyclic graph (DAG) [32]. When integrated into a spatial ABM to enhance agent intelligence, each node represents a variable in the agent decision-making process simulated in that model. In the present study, these variables include: the observation of visual pollution at water collection points (VP), the reporting of media on cholera cases (Media), communication with neighbours that may or may not have cholera in their household (Neighbours), and updating and retrieving memory representing a household’s previous use of the current water source (Memory). The BN supports agent decisions on assessing water infection level (i.e. Risk node) based on VP, Media, Neighbours, and Memory. The latter nodes (except VP) have a Boolean value (true or false) indicating the presence or absence of their relationship to risk. The VP node has three states: no, low, and high. These states indicate the level of visual pollution at water collection points. In the survey there were four different states, which were mapped as follows: clean water (no risk), brown water or a small amount of garbage around water collection points (low risk), and garbage on the river banks and in the river (high risk). In this paper, we explore four combinations for the specification of either BNs network structure or CPT. Namely, we run our spatial ABM with BNs designed (i): based on data only (both structure design and CPT is derived from data); (ii) based on data complemented with expert knowledge (structure is data-driven but CPT is expert-driven; (iii) on structure that is expert-driven but CPT is data-driven; (iv) based on expert knowledge only (structure and CPT is derived by the expert knowledge).
Any node can be updated upon new evidence, even when they are related to multiple variables. The evidence acquired about a state variable should propagate to update states in the rest of the network, and this process requires network training (learning). The training of BNs can be either by using data or by eliciting expert knowledge [23]. BN training is performed via a flow of information through the network, and it can take place prior to using the network (i.e., before implementation within the ABM) with the availability of data or continue during the simulation runs (when it is an expert-driven network). In the first example, the training process of BNs ends with final probabilities (posterior probabilities) that the network will continue to produce every time it is consulted by the ABM. In the second case, the BN model needs improvement since it is not fully trained at the start of the simulation, though will be trained using data (agent decisions) generated during the simulation. This process is called sequential learning. Usually when no data are available to construct BNs, the adjustment of parameters (nodes) takes place when the network performs identification based on new evidences.
We compare four different BNs (DDBN, DEBN, EDBN, and EEBN). The first letter in the BN acronyms refers to the information source – data-driven (D) or expert-driven (E) – for their derived structure, while the second letter refers to the estimation of probabilistic parameters. When a BN is expert-driven, we either designed the structure and/or retrieved parameters based on census data of the case study area or literature dealing with risk perception of waterborne diseases such (e.g., [33,34,35]). An overview of the networks is provided below.
-
DDBN
In DDBN, both the BN structure and its parameter values were driven by survey data. The scored-based algorithm “Tabu search” is used to construct the BN [36]. This algorithm makes use of a goodness-of-fit score function for evaluating graphical structures with regard to a dataset. Tabu search is a metaheuristic algorithm using short-term memory to ensure that the search explores new areas without remaining in a local optimum. In this algorithm, the fitting function is used to score a network/DAG with respect to the training data, and a search method is used to determine the highest-scoring network structure. This algorithm continually improves scores until converging at optimal results. DDBN was trained prior to the simulation.
-
EDBN
The structure of this BN follows the same approach as in the MOOC surveys. In the survey, we first showed participants a picture of water with a specific level of visual pollution, followed by questions related to the other factor(s). In this approach, VP is assumed to be the parent of the other factors. Then, we derive the probabilities of nodes states and CPT from the survey data and train it prior to simulation.
-
DEBN
The structure of DEBN is identical to that of DDBN. However, an expert assigned probabilities to node states and the related CPTs to formulate logical scenarios. These values were driven from the literature and used in the BNs.
-
EEBN
This is a fully expert-driven network adopted from Abdulkareem et al. (2018) [31]. The probability values of these network variables were derived from the available literature and census data for Kumasi, Ghana. Here, EEBN settings reproduce the original setup and serve as a benchmark to compare the three alternative combinations between survey and expert data for BNs.
2.3.1 Goodness of fit of BNs and model output
BN validation was conducted using two steps: validation of the network structure using scored functions and validation of the learning parameters (CPT) (Fig. 3). We also compared the outcome of integrating the four BNs into the CABM with the survey data to validate the realism of agent risk perception.

BN models’ validation
There are two approaches that are commonly used to measure the goodness of fit of BN models [37]. The first is to test if the conditional independence assertions involved by the structure of the BN model are satisfied by the training dataset. The second method is to evaluate the degree to which the resulted structure describes the data. To achieve this, we use scoring functions. Many scoring functions exist, and the most popular are AIC (Akaike information criterion), BIC (Bayesian information criterion), and Bayesian Dirichlet with likelihood equivalence (BDe) [38]. The primary issue with scoring functions is the absence of an objective method to determine which function is optimal [38]. AIC provides a relative measure of the information lost when a given BN model is used to represent reality, while BIC is an example of penalised likelihood and it selects the true model that fits the data. Moreover, BDe calculates the joint probability of a BN model for a given dataset. Overall, the optimal model from the set of BN models is the one with the higher absolute AIC, BIC, and BDe values [39].
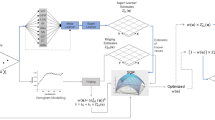
To address the main research questions, we follow a number of steps (Fig. 4). The primary elements of this workflow are explained in the following sections. We conduct a total of four experiments, in which we run the CABM with all four BNs for 100 random seed runs, creating a new synthetic population every 5 runs.Footnote 1 We provide the mean values across 100 sets of runs for all output metrics. In the first set of experiments, we run the CABM with DDBN and EDBN, training them prior to the simulations. Then we run the CABM with DEBN and EEBN, training them during the simulations to adjust the initial values of CPT of both networks proposed by the expert knowledge. Since DDBN and EDBN are trained prior to implementation of the simulation, testing data for the goodness of fit of these two BNs arises from the ABM. Additionally, since DEBN and EEBN are trained while running the simulation, the survey data serves as the goodness of fit data. The sample size of all validation dataset is equal (i.e., the size of the empirical data) to balance the scores.

Methodological workflow used in this article
To compare model outcomes with the survey results, we calculated the average number of agents that perceived risk during the simulation. These percentages were computed for each risk factor and combinations of factors. In addition, mean epidemic curves and risk perception curves were obtained and compared.
2.3.2 BN models and resulting spatial patterns
The implementation of different BN models may impact the behaviour of agents based on their location in space. To evaluate this impact, we present a set of maps that show the spatial distribution of risk perception variables. Risk perception factors: VP alone, VP with media, VP with contact with neighbours, VP combined with media and contact with neighbours, and combination of media and contact with neighbours are displayed per community with the implementation with each BN model. Risk perception based on media or contact with neighbours only does not occur.
3 Results and discussion
3.1 BNs structures and parameters validation
To select the best-fit network among our four BNs, we tested their structure and parameter values. The graphical structures (DAGs) of these BNs are illustrated in Fig. 5.

Graphical structures (DAGs) of Bayesian Networks
We validate DDBN and EDBN using the outcome of CABM, while DEBN and EEBN were validated using the survey data. The validation results are provided in Table 1. The numbers between brackets represent the relative metric of each BN models with (1) corresponding to the best value and (4) to the worst one.
As illustrated in the first half of Table 1 (Entire survey sample), the best-fit network is EDBN, since it exhibits the highest absolute scores for AIC, BIC, and BDe. The AIC score of its absolute value is higher than the other three scores. It also scores best in the BIC and BDe values. EEBN (the original expert network [19]) has the second-best scores, confirming that the involvement of experts leads to a better fit than using data only. This holds true for both the structure of the BN and estimation of probabilistic parameters and CPTs for the network, as indicated by the scores for EEBN.
The second half of Table 1 (subset African Participants) presents fitness scores for the four BNs with respect to responses of African participants. With the change in the sample from the full sample set to African respondents only, measured values of the goodness of fit of BNs change. For the subsample, DDBN exhibits the best fit. African participants seem to be more sensitive to media reporting and less sensitive to visual pollution. EEBN remains the second-best fit BN model. This again supports the usefulness of expert knowledge in implementing ML. in addition, this demonstrates the sensitivity of the metrics (AIC, BIC, and BDe) to the survey sample used.
3.2 Implementation of BNs in CABM
After testing the performance of the four BNs, we integrated them for agent decision making in the ABM. The DDBN and EDBN are trained then linked with the CABM. The DEBN and EEBN are trained during the simulation. We report average results across 100 runs for each BN model for several macro metrics of interest, including: epidemic curve,Footnote 2 risk perception curve,Footnote 3 and percentage of agents that perceived risk.
3.2.1 Epidemic curves and risk perception
It is evident that agents with intelligence are less susceptible to cholera compared to those agents who are not using BN for their coping appraisal [31]. Since BNs steer their interactions during simulations, they learn how to protect themselves. This can be observed in the epidemic curve (Fig. 6 – left) and risk perception over time (Fig. 6 – right).

Results for the four BNs models of running CABM 100 times per BN integration. a Epidemic curves, b Risk perception curves
Epidemic curves resulting from DDBN and EDBN (Fig. 6a) are approximately the same, and both provide lower peaks compared to the two alternatives (average peak value of 200 disease cases). The risk perception curves (Fig. 6b) of both BNs develop in a similar manner Agents are intelligent enough to perceive cholera risk from the start of the simulation, though EDBN exhibits a higher peak in the period between days 25 and 58. The risk perception curves continue to increase until the end of the simulation because this BN is pre-trained and does not change during the simulation. As such, agents do not realise that the epidemic is over and risk is decreasing.
Running the CABM with DEBN and EEBN produces average epidemic curves with higher peaks of 230 disease cases for EEBN and 300 cases for DEBN (Fig. 6a). The risk perception curve for EEBN (Fig. 6b) exhibits a very steep increase in risk perception at approximately day 21, when media begins reporting. The same increase is observed for DEBN, though later in the simulation (day 25), and with a less dramatic increase in the number of individuals perceiving risk. It should be noted that the BN models are trained endogenously during the simulation, and agents learn to perceive risk and cope with cholera diffusion. This implies that they also learn (especially for EEBN) that the epidemic is over and risk levels are declining. This is evident in the decrease in risk perception after day 45.
3.2.2 Agents learning and survey data
After running the experiments, we evaluated the outcomes of the CABM by dividing agents into groups according to their level of risk perception.
Table 2 presents the percentage of agents in the CABM who perceive risk, and compares it to the percentage of survey participants who reported perceived risk in a similar situation. Both DDBN (85%) and EDBN (95%) overestimated the risk perception for VP only, which was 49% in the survey. This disjunction between the actual percentage and simulated percentage is likely due to the BNs being trained prior to the start of the simulation. Based on the training data, agents learned that when visual pollution exists, the RP should be positive. The values of EEBN (46%) and DEBN (53%) for only VP are more in line with the real values (49%).
For Memory, the opposite result was evident. In the survey, 42% of participants perceived risk; however, no risk was observed due to these BNs. In this case, a value of 0 % indicates that when agents have been using river water before the cholera outbreak, they will continue doing so during the cholera outbreak because they trust the source (no perceived risk).
The effect of neighbours communicating experiences of illness in the BNs leads to 100% risk perception in the ABM, while risk perception was only 62% in the survey. For the two BNs – DDBN and EDBN – illness in neighbouring households was a strong indication of possible risk, which explains the high score. The scores for neighbours for EEBN (57%) was much closer to the actual scores of 61%. The scores for VP combined with Memory of DDBN and EDBN are much lower than the survey scores. This is explained in the same way as the score for Memory only. When people have been using the river water, they trust the water and continue using it. Again, EDBN and EEBN score much better.
It is evident that memory (remembering the prior use of a water collection point) has a negative impact on the risk perception. Agents perceive risk during their communication with neighbours and via reporting of media, though they might change their mind via their memory, and continue to use water from a particular location. In addition, during the simulation runs, communication with neighbours had a strong impact on risk perception, although media had a stronger effect in the survey.
For media, the results for DDBN and EDBN are good. Media scores were less robust for DEBN (44% versus 64% in the survey), but were good for EEBN.
Overall, the results obtained from the implementation of EEBN were closer to the data from the surveys than the results of DEBN. This can be explained because the values of CPT in EEBN have been driven by the literature and census data for Kumasi, Ghana. Additionally, the network structure is driven logically from expert knowledge. Again, in both implementations, Memory has a negative impact on the risk perception process. Whenever Memory exists, either alone or in combination with other factor(s), it will lower the RP. Furthermore, VP may also play a negative role in DEBN implementation. This confirms that survey data helps in training BNs, though the agent learning process can be better controlled with the support of expert knowledge.
An implementation using different training datasets per community or water collection point may reveal divergent learning patterns and risk perception throughout the area. Furthermore, in the CABM, each agent calculates their risk level and compares it to a threshold value of 0.5, which determines if risk is perceived or not. In reality, the threshold level will vary by individual, as some are more sensitive to risk than others. Introducing greater heterogeneity among agents by varying the risk threshold value per household may influence the results of the simulation. Such combinations of agents pursuing intelligent decisions in spatial ABMs based on ML algorithms opens opportunities for overlaying spatial, socio-economic, and cognitive heterogeneity in a range of applications.
3.2.3 Spatial patterns
To assess the influence of running CABM with different BN models, the outcome of the spatial patterns of each simulation is presented.
Figure 7 shows the risk perception per community (size of the circles) and the variables the risk perception is based on (colours). The river shows the average VP value scaled from low (green) to high (red). The total risk perception is highest in the EEBN model, however, risk perception in the northern communities in this model is low. This might be due to the fact that most of the household agents that live there are of high-income and can buy bottled-water during the epidemic, or to the fact that the VP level is low.

Spatial distribution of risk perception based on different variables
There is considerable variation in risk perception between the different communities. Risk perception is not always related to the income levels. For example, in the DEBN model, the northern community (18) has a relatively high risk perception but is completely located in a high income and low VP zone. Communities score differently in different models. For community 17, we see low risk perception in DEBN and EDBN but higher risk perception in DDBN and EEBN. In this case, this is not steered by data-driven versus expert-driven models. Community 5 scores a very high risk perception in the EEBN model, has a high score in the DEBN model, but scores lower in risk perception in the DDBN and EDBN. In general, a fully expert based model (EEBN) leads to the highest risk perception followed by the model that is based on expert probabilities for node states. From this we can derive that the design of the model has less impact on the total risk perception compared to the node state probabilities.
The second aspect are the sources the risk perception is based on. This is indicated as colours in the pie-charts of Fig. 7. Household agents in the DDBN model pay more attention to the combination of media and contacts with neighbours (green colour). This also applies to the two communities in the north (16 and 18) and the community in the south-east (13). This can be explained by the fact that in these upstream locations, the VP is low. CABM combined with an EEBN model consider VP (alone or combined) to be more effective as a household agents risk indicator. In addition, risk perception with EEBN represents a more balanced risk perception between all factors (Fig. 7).
Household agents who live in communities 7 and 9 which are located downstream perceive more risk based on VP (red colour of the river represents high VP). This is because more waste accumulates in the river and on the river banks. This also applies to communities 5 and 11 in the EEBN model.
4 Conclusions and future work
Although several studies have combined ABMs and BNs, no comprehensive overview exists on the advantages and disadvantages of different integration approaches and their impact on the output of the models. To explore how learning in spatial ABMs could be realized in the absence of large behavioural datasets, we tested four different ways to design and train BNs to enhance agent cognitive abilities in a spatial ABM. We constructed BN fully data driven, fully expert-knowledge driven and as a mix of data and expert-knowledge, trained prior to running BNs in the ABM or during a simulation run. For models that are data-driven (DDBN and EDBN), the results of both prior trained models show similar percentage of risk perception. Expert-driven models (DEBN and EEBN) outperformed the data-driven ones. It indicates, that supervised learning, which aids training of a BN algorithm with the support of expert knowledge, provides more control over the learning process and offers a logical framework. Expert-knowledge method helps to avoid intense overfitting and enables direct model comparison since it computes a full posterior distribution of the BN. A development of an efficient BN requires a combination of data and expert knowledge [40], as has been also illustrated in other applications in ecology [41], sports [42], robotics [43] and medicine [44]. Hence, instead of deriving BNs directly from data, we advise an expert interpretation and construction of BNs based on expert logic.
We measured the goodness of fit for the four BNs using survey results and the output of CABM as test data. However, goodness of fit scores for these BNs did not differ greatly.
The highest-scoring BN according to goodness of fit is not necessarily the same as the highest-scoring based on e.g. the risk perception curve. We also had two networks with the same structure (DDBN and DEBN), yet leading to different results when combined with our ABM. This confirms that the structure of the BN is the factor that least impacts the final outcomes. Parameterisation and the way the network is trained (prior or during simulation) play a more important role and have more impact on the final model outcomes. We also observe that training prior to a simulation run leads to “overly intelligent agents”, with high risk perception at initialization that does not decline even in the absence of cholera reports. The choice between prior training and training during simulation runs is individual for each application. In our case, although Kumasi citizens had previous experience with cholera before 2005, hence they were not prepared. For other applications, a certain level of risk awareness may be essential at the start of the simulation, demanding prior training of BNs.
As conditions differ per community, it is logical that risk perception differs spatially. This applies to the level of risk perception, but also to the factors contributing to this risk perception. The expert driven model, DEBN and EEBN, provided the most balanced risk perception (based on all risk factors). Risk perception and the process of making a decision are complex processes combining spatial and social factors. However, less implementations are available integrating ML for assessing risky situation engaging agents’ risk perception due to the lack of gather data on people’s risk perception and little is known about spatial risk detection especially in developing countries. Furthermore, risk perception based on spatial learning is not easy to measure. Limited datasets are available about the way the spatial environment influences the human decision making. Most researches that discuss risk perception will evaluate how risk perception varies in space but not which role the environment itself plays in the process of feeling scared.
Our research uses BNs as the ML algorithm because this method can combine expert knowledge and use small behavioural datasets. However, there are other ML methods with the same characteristics. The workflow presented in this paper can also be used for example using, Genetic Algorithms, Decision Trees, linear SVM, and Naive Bayes.
Notably, the survey participants employed in this study were well-educated individuals from a variety of nations. This imposes limitations to make policy-relevant conclusions, though allows us to test the fitness of ML algorithms implemented within a spatial ABM. Still, we recognize, that in communities with low income and marginal education, the response of individuals might be different. In addition, the response of people might also be contingent on whether or not they have an alternative water source to use. Therefore, they could be risk-aware but in the absence of another choice they might still use the water. This highlights the importance of the spatial environment in disease ABMs since agents in different locations have different accessibility to alternative water sources.
Future studies may contribute to the expansion of the present work in a number of directions. Although the CABM is a spatial model, we have not evaluated learning per water collection point or community. In this implementation, learning is based on all agents learning from a common pool of information (training data). It is important to note that this is not congruent with reality, where people have contact with only a small group of other individuals (social network). Our example only used one spatial variable (VP) in the decision making process, in combination with social variables. Little is known about combing a larger number of spatial and social variables in case of risk perception. Do all people observe all components within their spatial environment, do they have the same level of understanding (spatial intelligence) of their spatial environment and do they combine spatial and social observations in the same way. What is also unclear is the role of time. There is a difference between observing a spatial environment and noticing changes in the spatial environment.
Several developments in Health research draw our attention to the implementation of learning in disease models. One is fake news and the impact it has on the behaviour of people. In our model, media only reports the number of disease cases and all information given is correct. However, this model can easily be adjusted to include the spread of fake news. An interesting extension of the current model would be to include vaccination strategies. In this case, a decision about risk has to be taken combining the risk of vaccination and the risk of infection. Such future model extensions will make it a useful tool for testing epidemics management strategies. The implementation of BNs for risk assessment and coping appraisal is independent of the CABM model, and can be implemented for other diseases or even other applications where finding the empirical grounds for agents’ learning is vital.
Notes
The agents in the model are created using a synthetic population in which household agents and individuals are distributed spatially over communities on the basis of the data from Osei (2010). For five runs, we have a fixed synthetic population, in which agents’ initialization attributes such as the number of individuals per household, house location, river fetching water points, and accessibility to tap water remain constant. After five runs new attribute values are created. Stochastic events that influence agents’ behaviour during the simulation include rain time, time to fetch water, spatio-temporal location of VP and cholera bacteria, and selection of dumpsites to be cleaned by the municipality.
Epidemic curves count the number of disease cases in each particular time step.
Risk perception curves plot the number of individuals who perceived cholera disease risk – i.e. the outcome of their risk appraisal, BN1, represented here either as DDBN, EDBN, DEBN, or EEBN becomes 1 – over time.
References
Mitchell TM, (1999) Machine learning and data mining, vol. 42, no. 11.
Asadi R, Mustapha N, Sulaiman N (2009) A framework for intelligent multi agent system based neural network classification model. Int J Comput Sci Inf Secur 5(1):168–174
Alonso E, D’Inverno M, Kudenko D, Luck M, Noble J (2001) Learning in multi-agent systems. Knowl Eng Rev 16(3):277–284
Besaw LE, Pellon MB, Rizzo DM, Grover DK, Eppstein MJ, and Marshall JS, (2010) Up scaling agent based discrete choice transportation models using artificial neural networks, In: Transportation Research Board 89th annual meeting
Kocabas V, Dragicevic S (2013) Bayesian networks and agent-based modeling approach for urban land-use and population density change: a BNAS model. J Geogr Syst 15(4):403–426
Heppenstall AJ, Evans AJ, Birkin MH (2007) Genetic algorithm optimisation of an agent-based model for simulating a retail market. Environ Plann B Plann Des 34(6):1051–1070
Vallejo M, Corne DW, and Rieser V, (2013) Evolving urbanisation policies: Using a statistical model to accelerate optimisation over agent-based simulations, In: ICAART 2013 - Proceedings of the 5th International Conference on Agents and Artificial Intelligence, vol. 2, pp. 171–181
He Z, Cheng TCE, Dong J, Wang S (2014) Evolutionary location and pricing strategies in competitive hierarchical distribution systems: a spatial agent-based model. IEEE Trans Syst Man, Cybern Syst 44(7):822–833
Verstegen JA, Ligtenberg A, and Wachowicz M, (2010) Learning Actors in Spatial Planning: Incorporating Bayesian Networks in an Agent Based Model, in Pwktech.Info, pp. 1–10
Heinonen J, Travis J, Redpath S, and Pinard M, (2012) Combining socio-economic and ecological modelling to inform natural resource management strategies, Iemss.Org
Pooyandeh M, Marceau DJ (2014) Incorporating Bayesian learning in agent-based simulation of stakeholders’ negotiation. Comput Environ Urban Syst 48:73–85
Sharma S, Otunba S, Ogunlana K, Tripathy T (2012) Intelligent agents in a goal finding application for homeland security. In: 2012 Proc. IEEE Southeastcon, pp. 1–5.
Van Der Ploeg T, Austin PC, Steyerberg EW (2014) Modern modelling techniques are data hungry: A simulation study for predicting dichotomous endpoints. BMC Med Res Methodol 14(1):137
Bratko I (1994) Machine learning in artificial intelligence. Artif Intell Eng 8:1993
Walczak S (2001) An empirical analysis of data requirements for financial forecasting with neural networks. J Manag Inf Syst 17(4):203–222
Karr AF (2014) Why data availability is such a hard problem. Stat J IAOS 30(2):101–107
Kontkanen P, Kontkanen P, Myllymäki P, Silander T, and Tirri H, (1997) A Bayesian approach to discretization, Proc Eur Symp Intell Tech, pp. 265-268
Uusitalo L (2007) Advantages and challenges of Bayesian networks in environmental modelling. Ecol Model 203(3–4):312–318
Weber P, Medina-Oliva G, Simon C, Iung B (2012) Overview on Bayesian networks applications for dependability, risk analysis and maintenance areas. Eng Appl Artif Intell 25(4):671–682
Bidyuk PI, Terent’ev AN, Gasanov AS (2005) Construction and methods of learning of Bayesian networks. Cybern Syst Anal 41(4):587–598
Diez FJ, (2003) Parameter adjustement in Bayes networks. The generalized noisy OR-gate, Proc. 9th Conf. Uncertain. Artif. Intell, vol. Abs/1303, pp. 99–105
De Campos LM (2006) A scoring function for learning Bayesian networks based on mutual information and conditional Independence tests. J Mach Learn Res 7:2149–2187
Flores J, Nicholson AE, Brunskill A, Korb KB, Mascaro S (2011) Incorporating expert knowledge when learning Bayesian network structure: a medical case study. Artif Intell Med 53(3):181–204
Shen Y, Liu SF, Fang ZG, and Hu ML, (2011) Modeling and simulation of stranded passengers’ transferring decision-making on the basis of herd behavior, Proc. 2011 IEEE Int. Conf Grey Syst Intell Serv GSIS’11 - Jt with 15th WOSC Int Congr Cybern Syst, no 90924022, pp 795–802
Ren Z, Anumba C (2002) Learning in multi-agent systems: a case study of construction claims negotiation. Adv Eng Inform 16(4):265–275
Ma L, Arentze T, Borgers A, and Timmermans H, (2004) Using Bayesian decision networks for knowledge representation under conditions of uncertainty in multi-agent land use simulation models, Recent Adv. Des. Decis. Support Syst. Archit. Urban Plan.
Constantinou AC, Fenton N, Marsh W, Radlinski L, Constantinou AC (2016) From complex questionnaire and interviewing data to intelligent Bayesian network models for medical decision support Europe PMC funders group. Artif Intell Med 67:75–93
Matsumoto O, Miyazaki M, Ishino Y, and Takahashi S, (2017) Method for getting parameters of agent-based modeling using Bayesian network: a case of medical insurance market, Agent-Based Approaches Econ Soc Complex Syst, pp. 45–57
Pope AJ, Gimblett R (2015) Linking Bayesian and agent-based models to simulate complex social-ecological systems in semi-arid regions. Front Environ Sci 3:55
Augustijn EW, Doldersum T, Useya J, Augustijn D (2016) Agent-based modelling of cholera. Stoch Env Res Risk A 30(8):2079–2095
Abdulkareem SA, Augustijn EW, Mustafa YT, Filatova T (2018) Intelligent judgements over health risks in a spatial agent-based model. Int J Health Geogr 17(1):1–19
Heckerman D, (1995) A tutorial on learning Bayesian networks
de F. Doria M (2010) Improving effectiveness and efficiency in the water sector: institutions, infrastructure and indicators. Water Policy 12(SUPPL. 1):1–7
Hedman M and Lindberg C, (2009) Women, Water, and Perceptions of Risk -a case study made in Babati, Tanzania
Driedger SM (2007) Risk and the media: a comparison of print and televised news stories of a Canadian drinking water risk event. Risk Anal 27(3):775–786
Beretta S, Castelli M, Gonçalves I, and Ramazzotti D, (2017) A quantitative assessment of the effect of different algorithmic schemes to the task of learning the structure of Bayesian networks
Needham CJ, Bradford JR, Bulpitt AJ, Westhead DR (2007) A primer on learning in Bayesian networks for computational biology. PLoS Comput Biol 3(8. Public Library of Science):1409–1416
Liu Z, Malone B, and Yuan C, Empirical evaluation of scoring functions for Bayesian network model selection, BMC Bioinformatics, vol. 13, no. Suppl 15, p. S14, 2012
Carvalho AM, (2009) Scoring functions for learning Bayesian networks
Fenton N, Neil M (2012) Risk assessment and decision analysis with bayesian networks. Second edition. CRC Press, Boca Raton
De Waal A, Koen H, De Villiers P, Roodt H, Moorosi N, and Pavlin G, (2016) Construction and Evaluation of Bayesian Networks with Expert-Defined Latent Variables, 19th Int. Conf. Inf. Fusion, no. July, p. 2337
Constantinou AC, Fenton NE, Neil M (2012) Pi-football: a Bayesian network model for forecasting association football match outcomes. Knowl-Based Syst 36:322–339
Park H-S and Cho S-B, (2012) A modular design of Bayesian networks using expert knowledge: context-aware home service robot
Yet B, Bastani K, Raharjo H, Lifvergren S, Marsh W, Bergman B (2013) Decision support system for warfarin therapy management using Bayesian networks. Decis Support Syst 55(2):488–498
Acknowledgements
Authors are thankful to the financial support of the split-site PhD program of the Iraqi Kurdistan-region government (KRG) represented by ministry of Higher Education and Scientific Research, and the NWO DID MIRACLE project (640-006-012).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1
1.1 MOOC Survey
Q1: Where do you live? Please select a country.
Please select a group at random below. You will then be presented with a series of questions.
Q2: Case A1: There are no other sources of water except the one in the picture. You are thirsty. Would you drink the water shown in this picture?
Case A2: You know there is another water source, but you need to walk to another location along the river. You are thirsty. Would you drink the water shown in this picture?
Q3: Case B1: You have previously used water from this source for a period of time in your cooking. Would you use this water for cooking food again?
Case B2: You have never used water from this source before for cooking food. Would you use this water for cooking food?
Q4: Case C1: You have heard about Cholera from the media (TV, radio, newspapers). Would you use this water given the fact that you used it for a period of time in your cooking but now there is cholera in your city?
Case C2: You have heard about Cholera from your neighbours but there has not been official confirmation. Would you use this water given the fact that you used it for a period of time in your cooking but now there is cholera in your city?
The survey ran in two rounds of Geohealth course, 2016 and 2017. A total of 429 individuals from 92 countries participated in this survey (54% of them were from Africa). The results illustrate that participants made judgments according to what they observed in the pictures provided (Table 3). Only 39% (world) and 29% (Africa) of respondents perceived cholera risk in clear water, while 84% and 80% perceived risk when water and river banks appeared visually polluted, respectively. However, when other factors entered consideration, we observed a different pattern. For clear water, risk perception increased to 78% with Memory and Neighbours, and 80% when adding Memory and Media (world). A similar increase was observed in the African subsample.
This trend of increasing risk awareness was also observed for water with lower or higher levels of pollution. Additionally, previous experience of safely using a water source (memory) decreases risk perception. When we sketched a situation of previous use of a water source, the percentage of people perceiving risk decreased – even though the picture showed visually polluted water. The communication channels – either media or talking to neighbours – had a positive impact on risk perception. Notably, media had a stronger impact on risk perception than contact with neighbours.
Appendix 2
1.1 Google Survey
The questions were divided in two categories: risk perception based on individual factors and risk perception based on a combination of two factors. Participants were asked to indicate their risk perception for all combinations. The survey proposed as:
Risk perception related to cholera varies from person to person. There are different factors that influence the risk perception.
From literature, we know that three of these factors are: visual appearance of the water (is it visually polluted) (1), the fact that media is reporting on cholera cases in your area (2), and the fact that you hear about cholera in the neighbourhood from neighbours (3).

In this survey, 125 ITC students from 33 countries (35% from Africa) participated (Tables 4 and 5). For single risk factors (Table 4) results indicated that a high level of VP leads to high risk perception (86% world and 83% for Africa). Intensive media reporting particularly influences risk perception for African participants (77%). Contact with Neighbours is less influential to perceiving cholera risk compared to VP and Media (64% world and 66% for Africa). Results for the combination of two risk factors can be found in Table 5.
All responses for the world and Africa were approximately 80%, illustrating that risk perception based on multiple sources leads to a higher perception of risk. In this case, combinations including visual pollution scored higher, though the differences were smaller.
The values observed in this study are comparable to values obtained via the MOOC survey. Therefore, we combined both surveys into one dataset to include all possible combinations of risk factors with their related risk responses.
Appendix 3
1.1 Models’ stability
Figure 8 shows the stability check of the 100 runs per BN model. We measured the how the average number of infected on the epidemic peak day changes as we increase the number of random seeds runs. Each dot is an average across N runs where N changes along the horizontal axis. As one may see, the average value of the epidemic peak stabilizes already at N = 65 for the DDBN model and N = 53 for the EEBN model, confirming that our results averaged across the 100 runs per each BN type are very stable.

Stability check of running CABM 100 times per BN models: DDBN, EDBN, DEBN, and EEBN
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Abdulkareem, S.A., Mustafa, Y.T., Augustijn, EW. et al. Bayesian networks for spatial learning: a workflow on using limited survey data for intelligent learning in spatial agent-based models. Geoinformatica 23, 243–268 (2019). https://doi.org/10.1007/s10707-019-00347-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10707-019-00347-0