
Abstract
Model validation and probabilistic simulations are routinely used for quantifying the uncertainties originating from the numerical models and their inputs, respectively. How the two uncertainty types combine in the context of fire risk analyses is not well understood. In this work, we study the propagation of modeling uncertainty to the predicted distributions of probabilistic fire simulations using model validation data representing an uncertain compartment fire scenario. The wall temperatures are predicted in three different ways: one using a coupled model in which the input is the fire heat release rate, and two models using a standalone conduction solver and either experimentally or numerically (CFD) determined heat flux as a boundary condition. Using the predicted wall temperatures, we calculated demonstrative wall failure probabilities assuming different critical threshold temperatures. We propose a simple method for correcting the simulated distributions and probabilities towards the experimentally observed ones. The simulation results with the Fire Dynamics Simulator show that the obtained uncertainties of this particular validation set are similar to the ones reported in the validation guide. In average, the most accurate model over-predicts wall temperature by \(\sim \) 5.0% and the prediction uncertainty for both gas phase and solid phase temperature is \(\sim \) 10%. The wall temperatures predicted from the measured heat-fluxes show higher modeling uncertainty than the ones predicted by a coupled model of the entire gas-wall system. The proposed correction method is shown to improve the accuracy of the predicted distributions for internal wall temperatures at different times. In practical applications, this would lead to more accurate estimates of the time-dependent failure probabilities.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
With an aim to enable the performance-based design of fire safety, the development and validation of essential computational tools is underway. In about a half-century, in this context, numerous simulation tools emerged. Some of them primarily evolved to solve the fire-related problems, while others are general purpose tools that now include the fire simulation module. Among them, the tools adopting the well-known integration techniques such as the finite difference method (FDM) and finite volume method (FVM) are the fire dynamics simulator (FDS), fireFOAM and ANSYS Fluent. The validity and modeling uncertainty of these tools for fire engineering calculations has been investigated and reported by numerous studies. For example, using FDS, Lee [1] accurately simulated the tunnel fires, Shen [2] and Drean [3] predicted the building fires and Yu [4] simulated the momentum-driven jet flows. Similarly, using fireFOAM, Zadeh [5] predicted the turbulent air plume induced ceiling jet and using ANSYS fluent Jujuly [6] simulated the liquefied natural gas (LNG) pool fire.
All numerical models have a certain modeling uncertainty; i.e. the model cannot capture the actual physical phenomenon perfectly. For a particular output, the modeling uncertainty should be quantified in a meaningful way. In fire safety engineering, the most common practice is to express it as a measure of systematic and random deviation from the experimentally observed value. For example, in the validation guide of FDS, the modeling uncertainty is presented for various output quantities. The data obtained from numerous fire experiments are compared with the corresponding model simulations and the model uncertainty is quantified in terms of systematic bias and the second central moment of random errors. These two parameters represent the trending error property of the model, hence can be used to estimate the prediction uncertainty resulting from using the tool [7, 8].
The fire simulation tools have been reported to be used also in the probabilistic analysis. For example, Matala [9] used FDS to study the performance of cables in the tunnel fires, Hietaniemi [10] used it to study the performance of load-bearing wood beams in the building fires, Ayala [11] used it for the stochastic simulations of atrium fires, and Anderson [12] used the CFAST zone model to estimate the community-averaged extent of fire damage in homes. The main task in such an analysis is to calculate the output uncertainty corresponding to the given input uncertainty. The term “output uncertainty” can be used in the case of non-parametric analysis as well but should not be confused with the one used for the parametric analysis. McGrattan [13] presents a method to estimate the output uncertainty based on the available information of the model uncertainty. In his method, the output uncertainty is the interpretation of normally distributed random errors around a single unbiased output. In other words, it is simply the representation of the possible modeling uncertainty resulting from using the tool. In the parametric analysis, the output uncertainty is rather the desired quantity, and should not be dependent on the modeling uncertainty but only the input parameter uncertainty. The problem not addressed in the above-mentioned and similar other studies is that the stochastically inferred output uncertainty is inevitably a combination of both input and modeling uncertainties, being possibly very different from the true output uncertainty [14, 15].
In this study, we present an uncertainty model that can be used to obtain the true output uncertainty from the stochastically simulated one. We use the model to illustrate how the model uncertainty propagates together with parameter uncertainty. We demonstrate this using the validation data representing the uncertain scenarios of the compartment fire. A set of real fire experiments with three varying parameters represents the stochastic set of simulations. Finally, we present that the model uncertainty metrics can be used to statistically compensate for their effect in a probability calculation. Unlike in the previous works, where the uncertainties are usually presented for the peak values, we present the uncertainty pertaining to each time instance of the output.
2 Uncertainty Modeling
2.1 Parameter Uncertainty
If the inputs of a mathematical model are uncertain then the outputs will be uncertain too. This uncertainty propagation depends upon the characteristics of the model itself. The expression of uncertainty in output, \(T = f({\mathbf {X}})\), f being continuous and one time differentiable function, can be derived by Taylor expanding T about its mean and utilizing the definition of standard deviation in T [16]. The first order approximation is,
where \(\sigma _T^2\) represents variance in T, \(\mathbf {\Sigma ^X}\) is variance-covariance matrix of the input vector, \({\mathbf {X}}\), and \({\mathbf {J}} = (J_1,J_2,J_3\ldots )\), \(J_i=\partial f /\partial X_i\). If the input variables, \({\mathbf {X}}\), are independent of each other then the Eq. 1 would simply reduce to
Figure 1 depicts the uncertainty propagation for a simple model, \(T=\pi X\). A normally distributed output, \(T\sim {\mathcal {N}}\left( \pi 10, \pi ^2\right) \), is obtained for a normally distributed input, \(X\sim {\mathcal {N}}\left( 10,1\right) \). For complex and non-linear problems, such derivation is mathematically challenging, therefore, stochastic methods are adopted. Some examples of stochastic methods are Monte-Carlo (MC), Latin hypercube sampling (LHS) and Fourier amplitude sensitivity test (FAST) [17,18,19].

Input and output distribution for T =πX. The mean and variance of X is 10 and 1 respectively
2.2 Combining Model and Parameter Uncertainty
The model uncertainty can be decomposed into two components: systematic bias and random error [7]. The systematic bias is assumed to be a measure of the multiplicative factor by which the observed output is away from the true value. On average, it is the ratio of observed and true output. The random error is assumed to be an additive error that makes the observed output to fluctuate around the true value. We assume that these parameters can be determined for each output parameter, and are constants for a specific type of fire scenario.
The output for a simulation model, \(T=f(X)\), with systematic bias, \(\delta \), and random error, \(\epsilon \), is
where \({\hat{T}}\) is the simulated quantity and T is the true quantity. Here, the T and \(\epsilon \) are independent and the mean of \(\epsilon \) is zero. For such conditions, the mean and variance of the observed quantity can be written as,
Where \( \mu _T \) and \( \sigma _{T}^2 \) are the mean and variance of the true quantity and \(\sigma _\epsilon ^2\) is the variance of the random error. The derivation for these expressions can be found in the Appendix A.
For a normally distributed output, T, Table 1 lists the expressions of distributions in the presence or absence of model uncertainty. Figure 2 shows the histogram plots for specific values of \( \delta \) and \( \sigma _{\epsilon } \). The left figure compares the effect of only the bias, the middle one compares the effect of only the random error, and the right one compares the effect of both. Figures show that the bias simply shifts the distribution, while the random error widens it.

The simulated and true output distribution for, Left: δ=1.1, \(\boldsymbol{\sigma} _{\bf \epsilon} =\boldsymbol {\rm 0}\), Middle: δ=1, \( \boldsymbol{\sigma} _{\bf \epsilon} =\boldsymbol{\pi }\) and Right: δ=1.1, \(\boldsymbol{\sigma} _{\bf \epsilon} =\boldsymbol{\pi} \)
2.3 Correction of Output Distribution
If the prior information of \( \delta \) and \( \sigma _\epsilon \) is available, one can correct the simulated output towards the true one. The corrected moments, \( \mu _{T} \) and \( \sigma _{T} \), can be derived from Eq. 4. The corrected distribution is then the distribution generated using the corrected moments. The cumulative distribution function (CDF) of the corrected values can be obtained by substituting \( \mu _{T} \) and \( \sigma _{T} \) into the general expression of CDF. For Gaussian distribution, the CDF is
This method works well for the output distributions that can be represented by the first two moments, e.g., Gaussian and uniform. When the shape of the output distribution cannot be well represented by the first two moments, the output distribution can be corrected using
where T is the corrected realization corresponding to the observed realization, \({\hat{T}}\). The derivation for this expression can be found in Appendix A.

Upper: The true, T, simulated, \( \boldsymbol{{\hat{T}}} \), and corrected distributions. Lower: Corresponding cumulative density functions
We illustrate the correction method using two arbitrarily chosen examples [20]. In one of the examples, both the simulated and the true distribution are Gaussian, while in the remaining one, the distribution shape is irregular. First, we calculate the correction parameters, \(\delta \) and \(\sigma _\epsilon \), by comparing the simulated and true values,
where \( {\hat{T}}_i \) and \( T_i \) are the ith realization of the simulated and the true quantity respectively and N is the sample size. Then, using the correction parameters we estimate the true shape from the simulated one.
Figure 3 shows the true, simulated and corrected distributions along with CDF. In the upper plots, the dotted line represents the distribution generated using Eq. 5 and the continuous line represents the distribution generated using Eq. 6. Plots indicate that both methods work well with the normally distributed output. For irregularly distributed outputs, as expected, the estimation is better with Eq. 6. The maximum difference between the CDF of true and the corrected distribution is \( \sim \) 0.05 and \(\sim \) 0.01 respectively for Eqs. 5 and 6. Even with Eq. 6, complete trace-backing is not possible because the random error that occurred per realization cannot be known.
2.4 Sampling Uncertainty
In the stochastic analysis, the inferred moments and the probabilities depend upon the sample size and sampling method. This is known as sampling uncertainty. Figure 4 illustrates such uncertainty using one of the examples presented in the previous section. The simulated distribution \( {\hat{T}} \), corrected distribution, T, and the 95% fractiles values, \( z_{95} \), are presented for sample sizes N=100, 1000 and 10,000. Higher sample size well represents the distribution and \( z_{95} \) values increases with the increase in the sample size.

The distributions of simulated values, \(\boldsymbol{{\hat{T}}} \), corrected values, T, and 95% fractiles for three different sample sizes N=100, 1000 and 10,000

Left: The 95% fractiles value, z95, of the simulated, \( \boldsymbol{{\hat{T}}} \), and corrected, T, distributions for different sample size, N. Right: The difference of z95 (N) and the converged value, z95 (N=10,000)
The sampling uncertainty can be presented as \( \pm \) bounds from the corrected value. For example, if the probability inferred from the corrected distribution is p, then the probability is \(p\pm \Delta p\), where \( \Delta p \) is the sampling uncertainty. The sampling uncertainty for simple MC simulation having sample size N is \( z_a\sqrt{p(1-p)/N}\), where \( z_a \) is a multiplier number that determines the level of confidence [21]. For 99% level of confidence \( z_a \) is 2.58. For LHS, such analytical expression is not available, and a separate convergence analysis is needed. Figure 5 shows the result of the convergence analysis carried out for the distributions presented in Fig. 4. The left plot shows \( z_{95}(N) \). The right plot shows their difference with the converged value, \( z_{95}\)(\(N=10,000\)), and the maximum bound represents the sampling uncertainty. With N = 1000, the corrected \( z_{95} \) and the sampling uncertainty are 61 and 2 respectively. This means the 95% fractiles value is 61\(\,\pm \,\)2.
3 FDS Model Validation
3.1 Validation Experiment
In October of 1998, a series of fire test was carried out at VTT Building Technology with an aim to produce a set of data for validation of fire models [22]. The tests were conducted in a compartment, \(10 \times 7\times 5\)\(\hbox {m}^3\), having one door opening to the large fire testing hall. The walls and ceiling were made of lightweight concrete and the floor was made of normal concrete. Figure 6 depicts one of the test setups with a fire plume and measurement devices. Table 2 lists the material properties and the thickness of the obstructions.

Left: Schematic diagram representing the fire experiment. Right: The selected pool locations
Systematic variations of fire size and locations were made to determine their effect on the fire environment. The selected fire locations are indicated in Fig. 6 and the test series are summarized in Table 3. Test 10 and 14 were for calibrations, and hence not included in the table.
The fire source was n-Heptane circular steel pool placed over a load cell measuring mass loss rate. Water was used under n-Heptane to stabilize the fire. The free height from the water surface to pool edge was 0.13 m. The free height from the fuel surface to pool edge was 0.11 m in most of the tests.
Burning rates, gas temperatures, wall temperatures, and heat fluxes were measured during the tests. There were 30 thermocouples to measure hot gas layer(HGL) temperature, 46 thermocouples to measure ceiling jet temperature, 25 thermocouples to measure plume temperature, 5 heat-flux gages to measure the heat flux on the wall and 9 thermocouples to measure the inside wall temperature. Figure 7 shows the three locations where the inside wall temperatures were measured. At each location, a light-weight concrete block with three thermocouples was placed in order to measure the temperatures at varying depths from the inner wall surface.

The locations of the block of thermocouples placed to measure the inside wall temperatures
3.2 FDS Model
The fire experiment was modeled using FDS version 6.5.3. Figure 8 shows the 3D representation of the simulation domain with transparent gas region and the gray structural region. The fire driven flows in the gas region were simulated by numerically solving the weakly compressible form of the Navier–Stokes equations. The governing equations are presented in Technical Reference Guide of FDS [23]. The heat-transfer in the structural region was simulated by numerically solving the one-dimensional heat-conduction equation

3D representation of the computational setup
with boundary conditions
where x is the wall/ceiling depth from the heat-exposed surface. l represents the wall/ceiling thickness such that the hot-side and cold side surface are at \( x=0 \) and \( x=l \) respectively. \( q'' \) is the interface heat-flux, e is the emissivity, \( T_\infty \) is the ambient temperature and the field variable T(x, t) represents the wall temperature. The density, \( \rho \), the specific heat capacity, \(c_{\text {p}} \), and the thermal conductivity, k, are assumed to be constant. The heat transfer coefficient, h, at the front and the back of the wall is calculated based on a combination of natural and forced convection correlations [23].

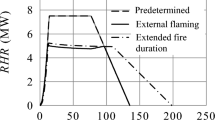
The specified heat release rate for different tests. Four test groups based on the pool diameter
The fire source was modeled as a circular burner with an appropriate heat release rate (HRR), corresponding to a fuel inflow boundary condition. Figure 9 shows the specified HRR for the tests. The text in the figure indicates four different test groups having the same pool diameter. The pool front surface temperature was specified to follow the same trend as HRR, starting from the room temperature at \(t=0\) and increasing to a peak value of 98.4\(^\circ \text {C}\) at the time of the peak HRR, and staying in that value until the end of the simulation. To account for the incomplete combustion, soot yield was set to 2%.

Left: Discretization of the gas domain. Right: Decomposition of the gas domain for parallel computing
Figure 10 depicts the discretization of the gas domain. To accurately resolve the cylindrical shape of the heat source, the computational cells near the heat source is refined to 5 cm. The cell size in the rest of the region is 10 cm. Similarly, the right side in Fig. 11 depicts the discretization of the 1D heat-conduction model. To resolve the spacing (0.5 mm) between the thermocouples measuring the wall temperatures, the compartment wall (0.3 m thick ) is discretized into 1000 grid points with finer spacing close to the surfaces.
The simulation was carried out using a distributed-memory computer. We used two steps to decompose the simulation domain. First, the entire compartment is divided into \(6 \times 5 = 30\) mesh regions. The right side in Fig. 10 shows the bottom six of them, the view from the top. Then, for the bottom layer, one of the mesh regions is further divided into nine regions. This results all together \(29+9 = 38\) individual mesh regions. It applies to all tests except the ones in which the pool is located in the middle of the compartment. For these cases, the gas domain is divided into \(9 \times 5=45\) mesh regions with one of them further divided into nine, resulting all together \(44+9=53\) individual mesh regions. In both cases, there are two additional mesh region covering the outside geometry, see Fig. 8. Each mesh region used one core and 500 MB memory from a CPU. The models representing all 17 tests were computed at the same time and the total computation time was \(\sim \) 6 h.
3.3 Standalone Analysis
Excluding the gas phase computation, we carry out a separate analysis to predict the compartment wall thermal response. In this case, the heat-diffusion in the wall is simulated in response to a pre-defined boundary heat-flux that represent the possible fire scenario.

Left: Boundary heat-fluxes for the standalone analysis. Right: Schematic diagram representing the heat conduction model
Figure 11 shows a schematic diagram of the standalone model. The left figure shows the Gauge heat-flux, \(q''\), measured during the experiment and \(\alpha = k/(\rho c_{\text {p}}) \) indicates the wall material property. \(i=1,2,\ldots N \) and \(j=1,2,\ldots \) represent the spatial and temporal discretization with N nodes and t time steps respectively. The cold-side boundary condition is both convective and radiative heat flux with a heat transfer coefficient h and emissivity e respectively. The wall temperatures, \( T_{i,j}\), were predicted in response to the heat-flux obtained in two different ways; (i) measured during the experiment, \(q''_{\text {Exp}}\), (ii) predicted from the (CFD+FDM) coupled analysis, \(q''_{\text {FDS}}\).
We compare the solutions of the coupled model and the standalone model to find out how the different error types propagate to the wall temperature predictions. If, for instance, \(q''_{\text {Exp}}\) was error-free and there was no error in interpretation of \(q''_{\text {Exp}}\) as a boundary condition, then the standalone model with \(q''_{\text {Exp}}\) boundary conditions should be more accurate than the coupled model. This is due to the fact that, in the coupled model, both input uncertainties (most importantly fuel mass loss rate) and the gas phase model uncertainty propagate to the wall temperature prediction. In general, the measurement uncertainty of \(q''_{\text {Exp}}\) is higher than the measurement uncertainty of the fuel mass loss rate [22], and the relative performance of the different modeling techniques is not obvious. In addition, comparing the coupled model uncertainties against the standalone model with \(q''_{\text {FDS}}\) boundary condition will indicate how much error is generated by the process of interpreting specified (measured or predicted) heat fluxes as a boundary condition for the numerical model.
4 Results
4.1 Measured and Predicted Outputs
Figure 12 compares several predicted and measured quantities. The Gauge Heat-flux corresponds to the one measured on the side wall 1.35 m above the floor and 4.5 m from the back wall. Most of the predicted and measured curves are overlapping with each other. The curves with highest values correspond to the test no 20. For this test, a noticeable discrepancy can be seen in the beginning and around 8 min. The experimental uncertainty in this test may also be higher than average as the temperatures were significantly higher, and as there was only one repetition of this particular scenario.

The predicted and measured, Left: Heat-flux, Middle: Ceiling jet temperature and Right: Plume temperature
Figure 13 show the measured and predicted inside wall temperatures for the three versions of the heat flux boundary condition. Figure 14 show the times at which the inside wall temperature exceeds a given threshold, \( T_\text {\rm cr}\)\(^\circ \text {C} \). The maximum value of the temperature measured during the experiment was 500\(^\circ \text {C}\), and the horizontal axis of the lower plots is normalized by this maximum value, i.e., \(T_\text {\rm cr}/500\). Most of the curves showing the threshold times do not reach the end because the peak temperature value for those test is below 500\(^\circ \text {C}\). The results indicate that the coupled model predictions overlap more to the measured values than the predictions from the standalone model with \(q''_{\text {Exp}}\) boundary condition. Although the discrepancy in temperatures is small, the discrepancy in times to reach a threshold temperature are sometimes very high, especially when the threshold is close to a semi-steady temperature of the particular experiment.

Predicted and measured inside wall temperature. Left: CFD+FDM coupled model. Middle: Standalone model with boundary, q ″Exp . Right: Standalone model with boundary, q ″FDS

Predicted and measured time at which the wall crosses Tcr °C . Left: CFD+FDM coupled model. Middle: Standalone model with boundary, q ″Exp . Right: Standalone model with boundary, q ″FDS
4.2 Modeling Uncertainty
Table 4 lists the bias, \( \delta \), and the second central moments of random errors, \(\sigma _\epsilon \), calculated following the methods explained in [7]. The \( \delta \) represents the average deviation of model prediction from the measured value. The random errors are presented as a relative term, i.e., \( {\widetilde{\sigma }}_\epsilon = \sigma _\epsilon /\mu _{{\hat{T}}}\). \({\widetilde{\sigma }}_\epsilon \{\text {E}\}\) represent the random experimental errors and \({\widetilde{\sigma }}_\epsilon \{\text {M}\}\) represent the random model errors. For the calculation, we used all the measurement points mentioned in Sect. 3.1. Appendix B shows the scatter plots. The uncertainty values obtained from the current experiment are close to the ones reported in the FDS Validation Guide, except for the Gauge Heat Flux output quantity. The model uncertainty and the systematic bias for the Gauge Heat flux are higher than those reported in the Validation Guide.
In addition to the discretization scheme explained in Sect. 3.2, we studied how the mesh configurations affected the uncertainties (Table 5). The corresponding scatters plots are shown in Appendix C. The first configuration is the one that we explained in Sect. 3.2. In the second configuration, the 10 cm mesh region was made coarse, down to 20 cm. In the remaining two configurations, uniform cell size was used in the entire gas domain and the cylindrically shaped burner was simplified to a rectangle shape. For cylindrical shaped burner and multi-mesh configuration, the bias remains unchanged. For the rectangular burner, the bias increases despite the mesh refinement. This is due to the imperfect modeling of the burner vent area. The vent area is poorly represented when the burner surface is not perfectly aligned with the mesh face. For the coarse mesh, the effective vent area can be lower than the specified value. This results in a lower HRR and ultimately the lower bias.
Figure 15 visualizes the model uncertainty as a function of time. \(\delta \) and \( {\widetilde{\sigma }}_\epsilon \) were calculated, using Eq. 7 at each time, by comparing the measured and predicted temperatures presented in Fig. 12. The plots show that on average, Gauge heat-fluxes are underestimated, while Ceiling Jet and Plume temperatures are overestimated. The Gauge heat-fluxes have higher random components than the Ceiling jet temperatures and Plume temperatures. Most importantly, we see that the model uncertainties at different time instances are not identical to those calculated at the time of the peak output.

Model uncertainty in the prediction of, Left: Gauge heat-flux, Middle: Ceiling jet temperature and Right: Plume temperature
Figures 16 and 17 show the \( \delta \) and \( {\widetilde{\sigma }}_\epsilon \) calculated based on the wall temperatures and threshold times presented in Figs. 13 and 14 respectively. The plot indicates that the wall temperatures on average are overestimated. Due to this, the predicted times are underestimated. In the models based on the FDS gas phase, the early transient temperatures are underestimated, and threshold times hence overestimated. The effect is much less in the right-most plot (standalone model with \( q''_{\text {Exp}} \) boundary condition), indicating that either the HRR boundary condition or CFD solution introduces a temporal delay in the early phase. Comparison of the coupled and standalone analysis predictions over the entire time period, however, indicates that the modeling uncertainty is higher for the latter one. Furthermore, the modeling uncertainty is higher for boundary flux \( q''_{\text {Exp}} \). We therefore conclude that, for the wall temperature prediction, the propagation of gas-phase modeling uncertainty is less harmful than the propagation of heat-flux measurement uncertainty. Better predictions can be achieved with the coupled analysis.

Model uncertainty in the prediction of wall temperature. Left: CFD+FDM coupled model. Middle: Standalone model with boundary, q ″Exp . Right: Standalone model with boundary, q ″FDS

Model uncertainty in the prediction of threshold time. Left: CFD+FDM coupled model. Middle: Standalone model with boundary, q ″Exp . Right: Standalone model with boundary, q ″FDS
4.3 Measured and Predicted Moments
The model uncertainty metrics presented in Figs. 15 and 16 are relative quantities and do not visualize well the quality of parameter uncertainties. Figure 18 compares the measured and the predicted outputs in terms of their first two moments. The line or dot represents the first moment and the half-length of the error bar represent the second moment. Plots show that the measured and the predicted values are close to each other. In average, the first moments of the ceiling jet temperatures and plume temperatures are slightly over-predicted and the first moments of Gauge Heat-fluxes are slightly under-predicted. In most of the plots, the error bar after 8 minutes extends towards the negative axis. This is because after 8 minutes, the mean is close to zero and the standard deviation is high, see Figs. 12 and 13.

The two moments of the predicted and measured outputs. Left: Gauge heat-flux, Middle: Ceiling jet temperature and Right: Plume temperature

The first two moments of the predicted and measured wall temperatures. Left: CFD+FDM coupled model. Middle: Standalone model with boundary, q ″Exp . Right: Standalone model with boundary, q ″FDS

The first two moments of the predicted and measured times at which the wall crosses Tcr °C . Left: CFD+FDM coupled model. Middle: Standalone model with boundary, q ″Exp . Right: Standalone model with boundary, q ″FDS
Figures 19 and 20 respectively show the first two moments of wall temperatures and the times at which the wall crosses the threshold temperature, \(T_{\text{cr}}\)\(^\circ \text {C}\). In average, the wall temperatures are slightly overpredicted and because of this, the times are underpredicted. Overall, the simulated first two moments are close to the observed one.
4.4 Temperature and Probability Correction
Assuming that the wall fails when it crosses a given temperature threshold, the failure probability would be the fraction of the number of the test cases in which the wall temperature rises above this threshold. We now try to understand how the modeling uncertainty in temperatures propagates to such a probability and how it can be corrected. As the temperature predictions of the previous section were indistinctly close to the measurements, it became very difficult to demonstrate the corrections of probabilities. We, therefore, used the results corresponding to the mesh configuration with the highest modeling uncertainty.

Upper: The predicted, measured and corrected wall temperatures. Lower: Probability that the wall crosses a given threshold in a given time
In Figure 21, the upper plots show the predicted, measured and the corrected wall temperatures at three different times for each of the tests. The corrected temperature were obtained using Eq. 6 and single values of model unceratinty parameters (\( \delta = 1.15 \), \( {\widetilde{\sigma }}_\epsilon \{\text {M}\} = 0.16\), see Table 5). We see that where the prediction and measurement are apart, the corrected value is usually closer to the measurement.
The lower plots of Figure 21 show the failure probabilities at different times for three different threshold temperatures. Initially, the walls are at ambient temperature and probabilities are zero. The probabilities increase as the number of tests exceeding the given threshold increases. The upper middle plot shows the temperatures at 4 min. At this time, the number of temperatures above 100\(^\circ \text {C}\) is 13 for the predicted, corrected as well as the measured quantities. Therefore the probability is, 13/17 \(\sim \) 0.8 (lower left plot). The number of points crossing 300\(^\circ \text {C}\), however, is 7 for the predicted, 3 for the corrected and 2 for the measured quantities, therefore the probabilities are 7/17 \(\sim \) 0.4, 3/17 \(\sim \) 0.15 and 2/17 \(\sim \) 0.1 respectively (lower right plot).
The predicted probabilities are higher than the measured ones. The corrected probability values are closer to the measured ones. Even though the real modeling uncertainty varies with respect to time, the probability correction carried out using the generalized (constant) value was effective at each time instance. This indicates that the model uncertainty values can be generalized for the failure probability correction. Here we used the uncertainty parameters obtained from the same campaign that we used for testing the method. In the validation guide, however, the uncertainty parameters are calculated from the result of numerous fire experiments, hence representing more generalized values.
4.5 Stochastic Analysis
In this study, the variation of fire size, the pool area, pool location and the width of the opening door represent the input parameter uncertainty. For stochastic inputs listed in Table 6, we carry out MC simulation using the model having uniform cell of size of 10 cm. The sampling size, N, is 100 and the sampling method is LHS. The selected fire type is t-square fire. For such fire, HRR is calculated using fire growth time, \(t_g\), and peak HRR as
where t is time in second.

Figure 22 compares the predicted and corrected probability density for wall temperatures. The correction is based on the average value of the model uncertainty, (\( \delta = 1.15 \), and \( {\widetilde{\sigma }}_\epsilon \{\text {M}\} = 0.16\) see Table 5). The plot shows that the correction assuming Gaussian shape is not appropriate for wall temperatures, i.e., the distribution reaches negative axis. The correction using Eq. 6, however, narrows the width of the distribution without deviating significantly from the observed shape.
Figure 23 shows the contour plot for the CDF, \(\Phi \), of wall temperatures. The vertical axis shows the temperature range, the horizontal axis shows the time and the embedded text show the \(\Phi \) values. The left plot shows the predicted values. The middle and right plots show the corrected values calculated according to Eqs. 5 and 6 respectively.

Assuming that the wall fails when it crosses a given temperature threshold, the failure probability would be the fraction of the number of the test cases in which the wall temperature rises above this threshold. From the above CDF plots one can infer the failure probability. For example, the predicted probability that the wall temperature rises above 100\(^\circ \text {C}\) before 6 min is 1–0.1\(\sim \) 0.9, where as the corrected probability is 1–0.2 \(\sim \) 0.8. Similarly the predicted probability for wall to rise above 200\(^\circ \text {C}\) before 6 min is 1–0.6 \(\sim \) 0.4 and the corrected probability is 1–0.7 \(\sim \) 0.3. The predicted probabilities are higher than the measured ones. This is due to bias in the temperature prediction.
5 Discussion
The study propose correction, Eqs. 5 and 6, for the stochastically simulated output, \( {\hat{T}} \), based on the requirement that the corrected quantity, T, and the random error, \(\epsilon \), are independent of each other and the mean of \(\epsilon \) is zero. In general, the output and the total error are dependent and the mean of the total error may not be zero. The significance of the uncertainty model presented in this study is that the total error is decomposed into a dependent constant, i.e., the ratio of simulated and corrected mean, \(\delta =\mu _{{\hat{T}}}/\mu _T\), and a random component, \( \epsilon = {\hat{T}}-\delta \cdot T\), which implies that the mean of \( \epsilon \) must be zero.

Corrected probability density of wall temperature for the data that are shifted in time by Δt. Upper: Δt = 10 s. Lower: Δt = 1 min
In this study, the correction method is illustrated using the true and observed data that are perfectly aligned in time. Figure 24 demonstrate the applicability of the method when data are shifted in time. It is found that the corrected probability density for wall temperatures shifted up to 5 s backward or forward perfectly overlaps with the corrected probability density for wall temperatures that are not shifted in time. Upper and lower plots compare the probability density of the wall temperatures shifted backward by 10 s and 1 min respectively. Plots show that there is an acceptable difference in probability density when the wall temperatures are shifted by 10 s. For 1 min shift, however, the difference is significant. The method, therefore, may not work when the data are significantly shifted in time.
In Sect. 4.2 we conclude that the coupled analysis approach for wall temperatures prediction is more accurate than the standalone approach. This could be confusing as the random model errors, \( {\widetilde{\sigma }}_\epsilon \{\text {M}\} \), presented in Table 4 is lowest for standalone model with boundary \( q_{\text {Exp}}'' \). The basis for this reasoning is the comparatively high bias values for standalone model with boundary \( q_{\text {Exp}}'' \) presented in Table 4 and the first two plots in Figure 16. Similarly, the average model uncertainty values presented in Table 4 may not fully comply with the values presented in Figs. 15 and 16. This is because the values in in Table 4 are based on the peak values of all measurement points, while the ones presented in Figs. 15 and 16 correspond to the measured and predicted outputs presented in Figs. 12 and 13 respectively, i.e., one measurement point located at the side wall 1.3 m from floor and 4.5 m from the back wall.

Schematic diagram showing the procedure of uncertainty management in the stochastic simulations
Finally, the study presents predicted and corrected CDF of wall temperatures calculated for the input stochastics listed in Table 6. The proposed correction method handles only one type of different uncertainties appearing in a probabilistic simulation with deterministic models. Other uncertainty types, input uncertainty and sampling uncertainty deserve their own studies when aiming at accurate fire risk analyses. Figure 25 presents an overall procedure for uncertainty management in the stochastic simulation. Estimation of input uncertainty distribution is crucially important for the simulation outcome and can require significant effort if the number of uncertain parameters is high. Luckily, in a nonlinear system, such as fire, the number of dominating input parameters is usually small [24]. For sampling uncertainty, the convergence of the distribution moments can be studied, as explained in Sect. 2.4. This would be very expensive if a complex numerical method such as CFD is being used. Means to quantify the sampling convergence in LHS could possibly be developed using surrogate models, such as the response surface method.
6 Conclusion
In this work, we show that the model uncertainties based on the peak outputs and the current experimental data are similar to the ones estimated from the FDS validation database. The coupled analysis (FDS alone) had the smallest model uncertainties in wall temperatures. The higher uncertainties in the standalone analyses were caused by the high uncertainties of the heat flux, i.e. additional uncertainty propagation. The model uncertainties were found to vary over time, however, the probability correction using the generalized uncertainty parameters was effective at each time instance. The model uncertainties reported in the context of a model validation can be, therefore, used for correcting the output distributions resulting from parameter (input) uncertainty. Nevertheless, the proposed method for the model uncertainty compensation may not be effective when the model uncertainty cannot be generalized. Further work is needed to study the effect of Latin hypercube sampling uncertainty in failure probability calculation. Also, validation using larger experimental datasets and a wider range of output quantities would be valuable.
References
Lee SR, Ryou HS (2006) A numerical study on smoke movement in longitudinal ventilation tunnel fires for different aspect ratio. Build Environ 41(6):719–725
Shen TS, Huang YH, Chien SW (2008) Using fire dynamic simulation (fds) to reconstruct an arson fire scene. Build Environ 43(6):1036–1045
Drean V, Schillinger R, Leborgne H, Auguin G, Guillaume E (2018) Numerical simulation of fire exposed facades using LEPIR II testing facility. Fire Technol 54(1):1–24
Yu LX, Beji T, Maragkos G, Liu F, Weng MC, Merci B (2018) Assessment of numerical simulation capabilities of the fire dynamics simulator (fds 6) for planar air curtain flows. Fire Technol 54(3):583–612
Zadeh SE, Maragkos G, Beji T, Merci B (2016) Large eddy simulations of the ceiling jet induced by the impingement of a turbulent air plume. Fire Technol 52(6):2093–2115
Jujuly MM, Rahman A, Ahmed S, Khan F (2015) Lng pool fire simulation for domino effect analysis. Reliab Eng Syst Saf 143(1):19–29
McGrattan K, Toman B (2011) Quantifying the predictive uncertainty of complex numerical models. Metrologia 48(3):173
McGrattan K, Hostikka S, Floyd J, Baum H, Rehm RG, Mell W, McDermott R (2013) Fire dynamics simulator, technical reference guide, volume 3: validation. National Institute of Standards and Technology, Maryland. NIST Special Publication 1018
Matala A, Hostikka S (2011) Probabilistic simulation of cable performance and water-based protection in cable tunnel fires. Nucl Eng Des 241(12):5263–5274
Hietaniemi J (2007) Probabilistic simulation of fire endurance of a wooden beam. Struct Saf 29(4):322–336
Ayala P, Cantizano A, Sánchez-Úbeda E, Gutiérrez-Montes C (2017) The use of fractional factorial design for atrium fires prediction. Fire Technol 53(2):893–916
Anderson A, Ezekoye OA (2018) Quantifying generalized residential fire risk using ensemble fire models with survey and physical data. Fire Technol 54(3):715–747
McGrattan K, Peacock R, Overholt K (2016) Validation of fire models applied to nuclear power plant safety. Fire Technol 52(1):5–24
Liang B, Mahadevan S (2011) Error and uncertainty quantification and sensitivity analysis in mechanics computational models. Int J Uncertain Quantif 1(2):147–161
Olsson K, Anderson J, Lange D (2017) Uncertainty propagation in FE modeling of a fire resistance test using fractional factorial design based model reduction and deterministic sampling. Fire Saf J 91(1):517–523
Hamilton WC (1964) Statistics in physical sciences. Ronald Press Co., New York
Robert C, Casella G (2013) Monte Carlo statistical methods. Springer, Berlin
Iman R, Davenport J, Zeigler D (1980) Latin hypercube sampling (a program users guide): Technical report sand79-1473, Sandia Laboratories, Albuquerque, NM
Suard S, Hostikka S, Baccou J (2013) Sensitivity analysis of fire models using a fractional factorial design. Fire Saf J 62(1):115–124
Paudel D, Hostikka S (2019) Propagation of modeling uncertainty in stochastic heat-transfer simulation using a chain of deterministic models. Int J Uncertain Quantif 9(1):1–14
Crow EL (1956) Confidence intervals for a proportion. Biometrika 43(3/4):423–435
Hostikka S, Kokkala M, Vaari J (2001) Experimental study of the localized room fires: NFSC2 test series. Technical Research Centre of Finland, VTT Research Notes 2104. 49 p
McGrattan K, Hostikka S, McDermott R, Floyd J, Weinschenk C, Overholt K (2013) Fire dynamics simulator, technical reference guide, volume 1: mathematical model. National Institute of Standards and Technology, Maryland. NIST Special Publication 1018
Hostikka S, Keski-Rahkonen O (2003) Probabilistic simulation of fire scenarios. Nucl Eng Des 224(3):301-311
Acknowledgements
Open access funding provided by Aalto University. This work has been funded by the State Nuclear Waste Management Fund of Finland in the scope of the SAFIR-programs, the Finnish Fire Protection Fund (Palosuojelurahasto), Rakennustuotteiden laatu Säätiö SR and Nordic Nuclear Safety Research (NKS).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1: Estimation of True Distribution
In Sect. 2.2 we presented the uncertainty model which includes a constant multiplicative term \( \delta \) and the random additive term \( \epsilon \),
Satisfying Eq. 11 with mean we get,
The mean of the random errors is zero, \(\mu _\epsilon = 0\), hence,
Squaring both side of Eq. 11 and taking average,
T and \(\epsilon \) are independent of each other and \(\mu _\epsilon = 0\)\(\implies \)\(\overline{\delta \cdot T\cdot \epsilon }=0\). This results,
Using \(\mu _{{\hat{T}}} = \delta \mu _T\) from Eq. 12 we get,
Next we estimate the true output T from the simulated output, \( {\hat{T}} \) using the constant coefficients \( \alpha \) and \( \beta \).
To obtain \( \alpha \) and \( \beta \), we use the expression of the mean and variance, Eqs. 12 and 13, respectively. Using the mean,
Similarly, using the expression of variance,
Squaring both side of Eq. 14 and replacing \(T^2\),
Now \(\alpha \) and \(\beta \) can be solved from Eqs. 15 and 16,
Replacing \( \alpha \) and \( \beta \) in Eq. 14,
Appendix 2: Uncertainty Metrics Showing the Measured and Predicted Outputs

Appendix 3: Uncertainty Metrics Showing the Measured and Predicted Wall Temperatures for Different Mesh Configurations

Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Paudel, D., Hostikka, S. Propagation of Model Uncertainty in the Stochastic Simulations of a Compartment Fire. Fire Technol 55, 2027–2054 (2019). https://doi.org/10.1007/s10694-019-00841-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10694-019-00841-9