
Abstract
Does loss aversion apply to social image concerns? In a laboratory experiment, we first induce social image in a relevant domain, intelligence, through public ranking. In a second stage, subjects experience a change in rank and are offered scope for lying to improve their final, also publicly reported rank. Subjects who care about social image and experience a decline in rank lie more than those experiencing gains. Moreover, we document a discontinuity in lying behavior when moving from rank losses to gains. Our results are in line with loss aversion in social image concerns.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Humans care how they are perceived by their fellow humans and go a great length to build up a positive image (see, e.g., Bénabou & Tirole, 2006; Bursztyn & Jensen, 2017; Andreoni & Bernheim, 2009; Ariely et al., 2009; Soetevent, 2011; Ewers & Zimmermann, 2015). This carefully crafted social image is at stake in everyday interaction, and reputation can decline rapidly. Casual observations suggest that when social image is at risk, people engage in lies and denial to maintain it. Managers who do not reach expected targets may engage in fraudulent behavior—as happened recently in the manipulation of car emission tests (Aurand et al., 2018). A person losing her job may leave the house everyday pretending to her family that she is still employed. However, the reference point for status loss does not necessarily have to come from own achievements or calamities. It may also be transmitted through generations as a sense of class entitlement (Alsop, 2008). In the 2019 college admission scandal, affluent parents criminally conspired to influence admission decisions of prestigious colleges (Halleck, 2019; Lovett, 2020). While the special role of losses has been extensively documented in the monetary domain (Kahneman & Tversky, 1979; Camerer, 1998; Wakker, 2010; Barberis, 2013), the effect of losses of social image on moral behavior deserves a closer look.
Does trying to shield oneself from a loss in social image generally lead to more morally deviant behavior than striving for a gain in social image? Or is it a particular behavior of those people who are more inclined to immoral decisions that can lead to tragic fall in the first place? Measuring losses of social image is hard to imagine in the field and the extent of lying difficult to observe. Hence, we design a parsimonious laboratory experiment to test for the presence of loss aversion in social image concerns.
To derive testable hypotheses, we develop a simple model combining loss aversion in social image concerns and attitudes towards lying that we present in the Online Appendix. In the experiment, subjects either experience a potential loss or gain in their social image over time, while keeping average social image constant. We then offer subjects scope for improving their social image by lying about their true type. This allows us to test whether—on average—subjects lie more (and are thus willing to incur higher lying costs) when they experience losses than when they experience gains in their social image.
Our results provide evidence for loss aversion in social image concerns. We find that subjects who sufficiently care about their social image—as measured by an independent survey instrument—lie more when experiencing losses as opposed to similar-sized gains in social image over time. Further individual-level analysis documents that the extent of lying decreases discontinuously when moving from small losses to small gains in social image. This pattern in lying behavior is compatible with loss aversion in social image concerns but not a simple concave utility function for social image.
Our findings imply that loss aversion can also play a role in the non-material domain of social image. So far, loss aversion is widely documented for money (e.g., Booij & Van de Kuilen, 2009; Pennings & Smidts, 2003) and material goods (Kahneman et al., 1990), but evidence on whether humans have the same inclination when it comes to social image utility is lacking.Footnote 1
Image concerns expand over various domains:Footnote 2 People care about being perceived smart and skillful (Ewers & Zimmermann, 2015; Burks et al., 2013), prosocial and altruistic (Carpenter & Myers, 2010), pro-environmental (Sexton & Sexton, 2014) and supportive of fair trade (Friedrichsen & Engelmann, 2018), trustworthy (Abeler et al., 2019), promise-keeping (Grubiak, 2019), or wealthy (Leibenstein, 1950).
In our experiment, we use a social image relevant task and identify subjects who care about their social image. We induce social image concerns by letting subjects perform an IQ test and reporting its results publicly, a task that has previously been shown to be relevant for social image in a student population.Footnote 3
To address the heterogeneity in the extent to which people care about social image, we use a survey instrument measuring each subject’s individual intensity of social image concerns. Bursztyn and Jensen (2017) expand the model of Bénabou and Tirole (2006) to explicitly account for heterogeneity in social image concerns.Footnote 4 Friedrichsen and Engelmann (2018) empirically reject the hypothesis of homogeneous image concerns and show that individuals react differently to image-building opportunities.
Our study also contributes to the growing literature on lying behavior, extensively summarized in Abeler et al. (2019).Footnote 5 Based on a comprehensive meta-analysis, Abeler et al. (2019) identify two main channels why people prefer to tell the truth, namely, lying costs and image concerns for being perceived as an honest person. We build on their work. First, our experimental design ensures that lying cannot be detected such that image concerns for being seen as an honest person by others cannot play a role in the context of our experiment. Second, in order to avoid possible interactions between loss aversion in the monetary and social image domain, our design offers subjects a flat payment and uses the extent of lying, i.e., the lying costs subjects are willing to incur, to quantify how much they suffer from losing or gain from improving their social image. Therefore, our finding that subjects who care about their social image report more dishonestly than others speaks to situations in which honest reporting of private information is key but not incentive-compatible. Since lying in the laboratory is a predictor of dishonesty and rule violations in real life (Hanna & Wang, 2017; Dai et al., 2018), our findings suggest that monitoring efforts should be targeted at individuals who strongly care about their reputation.
We also relate to the literature which links the concept of loss aversion to lying behavior. Grolleau et al. (2016) and Schindler and Pfattheicher (2017) compare the extent of lying for individuals who face monetary losses and gains. They find that participants misreport more to avoid a monetary loss than they do to increase their monetary gain. Garbarino et al. (2019) show that the less likely a low monetary payoff is, the more likely individuals lie to avoid it. In a series of experiments involving deception, Pettit et al. (2016) show that subjects threatened by status loss cheat more.
The paper proceeds as follows: Sect. 2 describes the experiment design and procedures, before we outline our hypotheses in Sect. 3. Results are presented in Sect. 4 and Sect. 5 concludes.
2 Experiment design
General setup Our experiment consists of two stages. Stage 1 is designed to establish a personal reference point for social image utility—a publicly reported rank in an intelligence test—against which subjects can fall short of or improve their image in Stage 2. In the second stage, we induce a change of the rank. Subjects are then informed about their true rank and offered scope to manipulate the reporting of their rank to their peers. We test whether subjects whose average rank deteriorates—who experience a loss in social image—misreport their rank more strongly than those who experience an improvement in their rank. We pay special attention towards analyzing misreporting behavior around the reference point in social image in order to identify a possible discontinuity in misreporting as predicted by loss aversion.
We create social image concerns through reporting a subject’s ranking in a standardized test of fluid intelligence—Raven’s Progressive Matrices test (1983)—to two randomly selected peers. Fluid intelligence encompasses logical reasoning and abstract thinking and constitutes an image providing trait for university students.Footnote 6 Public reporting of results shall hence create social image utility. In order to strengthen this link, we explicitly mention in the instructions that the matrices (labeled as picture puzzles) are designed to measure fluid intelligence, that fluid IQ is an important part of an individual’s overall IQ, and that such or related tasks are often employed in recruitment processes.
At the beginning of each session, two subjects, one male and one female, are randomly assigned the role of peer observers. This avoids possible gender-specific observer effects. After the observers have been determined, they stand up in front of the other subjects and announce “I am one of the two observers”. The other subjects are randomly assigned to one of two sequences that vary the order of the quizzes over the two stages of the experiment.
In sequence HardEasy subjects work on a Hard quiz in Stage 1 and an Easy quiz in Stage 2 and in EasyHard on an Easy quiz in Stage 1 and a Hard quiz in Stage 2. At the end of the experiment, all subjects in both sequences have worked on the exactly same 48 matrices. All subjects—including the observers—received the same instructions. Then subjects performed two quizzes (consisting of 24 matrices each) and after each quiz reported their relative performance (rank) to the observers. In the second stage, subjects had the possibility to lie in order to improve their rank before reporting it. Figure 1 illustrates the timeline of the experiment that we explain in detail below

Timeline
Matrices task and sequences The original Raven’s Progressive Matrices test (RPM) consists of 60 matrices that are divided into 5 equally sized sets (A to E) which increase in difficulty. Figure 2 provides an example of a Raven’s Progressive Matrix. Subjects have to choose that box below the picture puzzle which is the best logical fit to the empty box within the picture. Progressive means that the matrices are increasing in difficulty. In our design, we do not use the 12 matrices of the easiest set A since we expect our student subjects to solve them all correctly. We split the remaining 48 matrices in two disjoint parts consisting of 24 matrices each that we will use for the quizzes. One quiz is easier (Easy), while the other is harder (Hard). We calibrated the two sets such that Hard has a higher likelihood to contain matrices that have been solved by fewer subjects in a reference sample. The reference sample consists of 413 observations (students) from a previous experiment which took place at the same lab in 2014. Subjects of the reference group solved exactly the same overall 48 matrices as our subjects.Footnote 7 In both quizzes, the difficulty of the tasks is gradually increasing over time. Importantly, both quizzes contain tasks from sets B (easy) to E (difficult) to ensure that subjects do not perceive the difference in difficulty across quizzes as major.
Subjects have 30 s to work on each matrix. The time limit ensures that performance is comparable across subjects: both within our experiment and with respect to the reference sample. On average, it took subjects 11.5 s to answer a matrix. 2.7% of answers were provided in the last five seconds and in only 0.7% of cases subjects ran out of time, which suggests that the time limit was not restrictive. For each correctly solved matrix, subjects get one point. Wrong answers or no answer within the 30 s time limit do not give any points.

Example of a Raven’s progressive matrix
Stage 1 After completing the sequence-specific Raven’s Matrices, subjects received private feedback on their relative performance (i.e., Rank 1) on their screen telling them that “\(X\)% of the participants of the reference group have a higher rank than you in Quiz 1”. A lower \(X\) (lower rank) implies better relative performance. The instructions provide several examples how individual rank is calculated and how to interpret it.Footnote 8
To determine the rank, we compare the share of correctly solved matrices among the first 24 matrices to the distribution of the share of correctly solved matrices among all 48 matrices of the reference sample. Our calibration of the matrix distribution between Easy and Hard ensures that subjects in sequence EasyHard will on average rank better than subjects in sequence HardEasy in Quiz 1 since both groups are compared to the same reference sample but the first 24 matrices are easier for subjects in sequence EasyHard than in HardEasy.
Subjects report their rank in the first stage to the observers. This establishes the individual Rank 1 as a personal reference point for social image concerns. Since subjects are randomized into sequences, their initial reference points before the feedback on Rank 1 are the same on average (given skill, ability, etc.). We give both subjects and observers detailed instructions on the reporting procedure to control the reporting process using the same protocol for all sessions. We instruct subjects to fill in report sheets named “Rank 1” and “Rank 2” in Stages 1 and 2, respectively, and to present these sheets to observers who verify the report. No further verbal communication between subjects and observers is allowed, i.e., the entire reporting procedure happens in silence. Report sheets contain two pieces of information: a 4-digit individual code and a rank. After each Stage, observers see a table on their screen in which each individual code corresponds to a rank, and thus can compare the report sheet to the true information from the table. If the reported rank matches the true rank, observers stamp the report sheet to verify it.Footnote 9 We organized our laboratory setup in a way that subjects cannot see observers’ computer screens while reporting their rank. Additionally, to assure anonymity, we use 4-digit individual codes instead of cubicle numbers.
Stage 2 Subjects work on the remaining 24 matrices. For subjects in sequence EasyHard, Stage 2 is more complicated than Stage 1. In expectation, they rank worse than in Stage 1. For subjects in sequence HardEasy, rank improves in expectation. We construct a Preliminary Rank 2 by comparing the overall individual correctly solved number of matrices to their distribution in the reference group. After completing the task in this stage, both Rank 1 and the Preliminary Rank 2 are displayed privately to each subject, so that subjects can compare their ranking in the two stages. While average Preliminary Rank 2 (that is calculated based on the performance on the same 48 matrices for all subjects) does not differ systematically across sequences, subjects’ average reference point (Rank 1) will be better in sequence EasyHard than HardEasy. The purpose of the two sequences is thus twofold: first, to add an element of variation to subjects’ reference points (Rank 1) in Stage 1 and second, to ensure a roughly balanced data set in which about half of the subjects will experience losses and gains in social image when moving from Stage 1 to 2.
Die reports After learning about their ranks, subjects are asked to throw a die twice and report the rolled numbers. The first reported number is then added to the number of correctly solved matrices in the reference group. The second reported number is added to a subject’s own number of correctly solved matrices, giving the subjects two ways of cheating on the final reported rank that bear exactly the same consequences for their social image.
We use a modified version of the die roll task by Fischbacher and Föllmi-Heusi (2013).Footnote 10 Each subject rolls the die in private in the cubical so that no one, including the experimenters, can observe the actually rolled numbers.Footnote 11 Lying cannot be detected at the individual level in the die roll task. However, the underlying distribution of true die roll outcomes is known such that it can be observed whether and how much subjects lie on average as a group. Hence, we will conduct part of our analysis at the group level, i.e., comparing reported die rolls of subjects who experience gains and losses in social image.
We use total lying costs which increase in the size of the lie to quantify utility changes due to changes of social image. Importantly, this approach enables us to isolate loss aversion in social image concerns. If subjects could pay to improve their final reported rank, paying money would induce a loss in the monetary domain and a gain in social image at the same time. Using lying costs to quantify utility changes due to changes of social image instead avoids the additional monetary domain of loss aversion and possible interaction effects with loss aversion in the social image domain that would make it impossible to isolate loss aversion in social image concerns.Footnote 12
Including two die rolls instead of only one has the advantage that subjects are not forced to over-report their Rank 2. With just one die roll, any reported rolled number would result in a better Final Rank 2 than Preliminary Rank 2. With two die rolls, however, a subject’s Final Rank 2 can either be better or worse than or equal to the Preliminary Rank 2, depending on whether subjects report a higher, lower, or equal number to be added to the own score compared to the number to be added to the reference group’s score. In order to avoid that subjects’ lying behavior depends on their beliefs on others’ lying and to be able to interpret lying as a reflection of image concerns independent of individual beliefs, it is important to construct a ranking system which compares subjects to a predetermined reference group one by one. In contrast, if we based the ranking system on comparing subjects only within the current experiment (for example, ranking them from best to worst score), there would be an incentive to add a higher number to the own score if subjects expect others to add a high number to their score.
Further remarks Introducing observers instead of allowing subjects to report their rank to each other has two major advantages. First, our subjects do not get feedback on others’ rank which could affect their perception of their own social image. Second, observers only know about the existence of a “further task” on top of the second quiz in Stage 2 and that the score in this task will feed into a subject’s Final Rank 2. Observers are not informed about the exact nature of the die roll task, do not know how and to which extent the further task influences final ranks, and this is common knowledge to all subjects.Footnote 13 Consequently, subjects do not risk losing social image because of possible reputation cost of being seen as a liar. The remaining subjects receive the instructions regarding the die roll task on their computer screen after they have worked on Part 2 of the quiz.
Once the reported die rolls have been added and Final Rank 2 calculated, subjects go to observers again and report their Final Rank 2. After Stage 2, observers’ information tables include, for each subject, the individual code, Final Rank 2, Rank 1 and the difference between Final Rank 2 and Rank 1. This is common knowledge for all subjects. Reporting procedures are the same as in Stage 1.
Procedural details and implementation Our experiment design and hypotheses are preregistered on AEA RCT Registry.Footnote 14 We conducted our experiment using zTree (Fischbacher, 2007). After two pilot sessions as a prerequisite for power calculations, we run 19 main sessions in the DICE Lab, University of Düsseldorf between November 2018 and November 2019. 383 subjects participated, 38 as observers. Our sample mainly consists of a student population and was recruited using ORSEE (Greiner, 2015). 142 subjects were male, 203 were female. Age varied between 18 and 63 years with a median age of 23 years and 95% of subjects being younger than 33 years. No particular exclusion criteria applied. Subjects were randomized to sequences within each session. All participants received a flat payment of 12 Euro, but no additional performance-contingent payment for correctly solving the matrices, which was clearly communicated to the subjects. Subjects’ behavior thus indicates image concerns as a possible motive for exerting effort on solving the matrices correctly, even if this does not increase their monetary reward. On average, subjects earned €12.65, which includes the €12 flat payment plus one lottery outcome (as described below). In total, the experiment lasted about 90 minutes (including payment).
Post-experimental questionnaire The questionnaire provides information on socio-economic and demographic characteristics (age, gender, high school GPA, last math grade at school, student status and field of study, previous participation in experiments). It also assessed subjects’ general willingness to take risks, based on a question from the German Socio-Economic Panel (GSOEP) questionnaire as well as the importance of social image, using the following question (similar to the one used by Ewers and Zimmermann, 2015): “How important is the opinion that others hold about you to you?”. Additionally, following Gächter et al. (2022) and Fehr and Goette (2007), we measure loss aversion in the monetary domain using a set of incentivized lotteries which subjects can choose to accept or decline. Online Appendix F provides the exact wording of the entire questionnaire.
3 Hypotheses
Our modeling framework integrates three key psychological features that—up to now have been treated separately—into individual utility: (1) agents gain positive utility from social image, (2) agents experience loss aversion in the social image domain, i.e., losses of social image loom larger than gains of the same size, and (3) agents dislike lying, i.e., they experience costs of misreporting the true state of the world. We assume that the three components are additively separable. The value function of changes in social image satisfies the standard assumptions of prospect theory (Kahneman & Tversky, 1979): It is concave for gains, convex for losses and has a kink at the reference point. For simplicity, we assume that social image utility and lying costs are linear.Footnote 15 Our predictions do not require linearity but make the model easily tractable. In contrast to common modeling approaches in which the signal value of a particular choice is determined endogenously in equilibrium, we assume for simplicity that image utility is linear in the signal, which can be freely chosen. We derive our hypotheses based on theoretical predictions described in Online Appendix A.
First, we trivially show that individuals with social image concerns will not under-report, leading to Hypothesis 1.
Hypothesis 1
(Social-image relevance of task) On average, subjects will weakly over-report their score.
In our experiment design, over-reporting implies that subjects report higher die rolls for themselves than for the reference group to be able to report a better Final Rank 2 to the observers. Since subjects have already been informed about their own Preliminary Rank 2 before their decision which die rolls to report, it seems plausible to assume that subjects can only misreport their rank to the observers, but not to lie to themselves. Over-reporting then establishes the relevance of social as opposed to self-image concerns for our subjects as a whole.
Hypothesis 2
(Loss aversion in social image concerns)
-
(a)
Losses versus Gains: On average, subjects with sufficiently strong social image concerns over-report more if they experience a loss than a gain in social image.
-
(b)
Discontinuity: There is a discontinuity in the extent of over-reporting at the reference point, i.e., when moving from losses to gains in social image.
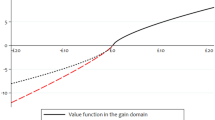
Hypothesis 2 follows directly from Proposition A.1 in the Online Appendix that relies on a standard value function for changes in social image as illustrated in Fig. 3. According to Hypothesis 2(a), we expect subjects who experience a loss in social image (i.e., Rank 2>Rank 1) to over-report more than subjects who experience a gain in social image (Rank 2<Rank 1). Over-reporting is reflected in the difference in die roll reports. If, on average, this difference is higher for subjects experiencing losses than gains, this provides first evidence in line with loss aversion in social image concerns: on average, subjects who risk losing social image are ready to lie more than those with social image gains.
However, a simple concave utility function for social image offers an alternative explanation for Hypothesis 2(a). Holding the level of social image constant, a concave utility function also implies that losses in social image induce stronger changes in utility than equally sized gains. Given the features of our experiment design, subjects who experience a gain in social image (i.e., typically those who worked on the Hard part first) do indeed have, on average, the same level of social image (Preliminary Rank 2) as those in the loss group (i.e., typically those who worked on the Easy part first) at the time of the over-reporting decision since both groups of subjects have worked on the same 48 matrices.

Illustration of a value function for changes in social image. Note: We illustrate a value function v that is compatible with the assumption of loss aversion in social image concerns. The horizontal axis measures changes in social image. We define Rank 1 and Rank 2 as values between 0 and 100, with lower values corresponding to better performance. Negative values on the horizontal axis are hence realized if Rank 2>Rank 1 and stand for losses in social image, positive values on the horizontal axis are realized if Rank 2<Rank 1 such that subjects experience gains in social image
Hypothesis 2(b) serves the purpose to differentiate between these two competing explanations for evidence in line with Hypothesis 2(a). Hypothesiss 2(b) focuses on small changes in social image and is derived from a particularity in the shape of the value function as postulated by prospect theory. Figure 3 illustrates the assumption of a kink in the value function of social image at a rank difference of zero. This kink implies a discontinuity in the first derivative of the value function when subjects move from the loss to the gain domain. We thus expect to observe a discontinuity in the extent of over-reporting as well when subjects move from losses to gains in social image. Since the value function’s first derivative is higher for losses than gains close to the reference point, over-reporting should decrease. Evidence in line with Hypothesis 2(b) is compatible with loss aversion in social image concerns, but not a concave utility function for social image. We use a concave utility function as a commonly used example for a utility function that is smooth at the reference point. Concave utility for social image yields no kink at the reference point, hence, no discontinuity in lying behavior, independent of the its specific shape.
4 Results
We first establish that the matrices task is a source of social image-concerns, before we analyze how subjects react to losses as opposed to gains in social image.
4.1 Social image relevance of the matrices task
Subjects exerted substantial effort on the quizzes. On average, they solved on average 38.8 out of all 48 matrices correctly. No subject solved less than 20 matrices, and more than 90% of subjects gave 34 or more correct answers. Since correct answers are not incentivized monetarily, substantial effort provision suggests image concerns as one of the driving forces behind solving the matrices along with a potential intrinsic motivation for solving this type of tasks.
In the absence of lying, die roll reports for each of the variables should follow a discrete uniform distribution with the support \(\{1,\ldots , 6\}\) and an average of \(3.5\). Figure 4 displays histograms of DieSubject (left) and DieSample (right) as well as the probability density function of the uniform distribution (red line). The average of DieSubject is \(4.03\) and we reject the null hypothesis for the point prediction (t-test, \(H_{0}\): \(DieSubject=3.5\), \(p<0.0001\)).Footnote 16 The distribution of DieSubject is also highly significantly different from the discrete uniform distribution (Pearson’s \(\chi ^{2}\)-test, \(p<0.0001)\) and left-skewed. In contrast, the average of DieSample is 3.43 which is not significantly different from 3.5 (t-test, \(p=0.4614\)). Moreover, the distribution of DieSample does not differ significantly from the discrete uniform distribution (Pearson’s \(\chi ^{2}\)-test, \(p=0.881\)).

Distributions of DieSubject and DieSample. Note: Figures illustrate histograms of DieSubject (left) and DieSample (right). Horizontal axis indicates reported die rolls (from 1 to 6). Vertical axis indicates the fraction of subjects who reported the respective die rolls. Absent misreporting, die rolls should follow uniform distributions (red lines)
Subtracting DieSample from DieSubject results in the die roll difference, DieDiff, which indicates whether subjects improve or worsen their Final Rank 2 through reporting. The higher DieDiff, the better becomes Final Rank 2. In principle, DieDiff can vary between -5 and \(5\), and, in the absence of lying, follows a discrete binomial distribution with mean zero. Our subjects report an average die roll difference of \(0.59\) which is highly significantly different from zero (t-test, \(p<0.0001)\). As illustrated in Fig. 5, the values of \(4\) and \(5\) are significantly over-reported (binomial probability tests, two-sided \(p=0.0253\) and \(p<0.0001\) for the values of \(4\) and \(5\), respectively). Thus, subjects lie both fully (maximal over-reporting) and partially (less than maximal over-reporting) which is in line with our theoretical predictions in Online Appendix B and experimental evidence of Gneezy et al. (2018) and Fischbacher and Föllmi-Heusi (2013). Over-reporting high values of DieDiff provides further evidence that subjects perceive our matrices task as image-relevant and additionally shows that social image concerns matter: as all subjects know their Preliminary Rank 2, over-reporting their own score is unlikely to improve their self-image.Footnote 17

Reported die roll difference. Note: Figure illustrates a histogram of DieDiff. Horizontal axis indicates a reported die roll difference (from -5 to \(5\), higher DieDiff means adding more to one’s own score). Vertical axis indicates the fraction of subjects who reported the respective die roll difference. Absent misreporting, the die roll difference should follow the discrete binomial distribution (red outlines)
Result 1
Subjects report higher die rolls to be added to their own score than expected by rolling a fair die.
This first set of results suggests that, on average, public reporting of own performance in the Raven’s matrices induces social image concerns and that subjects engage in lying in order to report better ranks to the observers. Our findings are in line with Falk and Szech (2020), Ewers and Zimmermann (2015), Zimmermann (2020), and Burks et al. (2013) who also use reporting of the performance in IQ or knowledge tests to induce image concerns. We find no evidence supporting the aversion to “show of” documented in McManus and Rao (2015). In our experiment, the suggested channels of McManus and Rao (2015) could potentially lead to (a) reduced effort provision and (b) misreporting die roll difference downwards—both are not observed in our data. The effort provision our subjects display is similar to the one of the reference sample we rely on to calculate ranks, i.e., the performance of previous subjects who worked on the exact same tasks without an audience. Our subjects report a positive average die roll difference of \(0.59\) which is highly significantly different from zero (t-test, \(p<0.0001)\). Moreover, the values of \(4\) and \(5\) are significantly over-reported (binomial probability tests, two-sided \(p=0.0253\) and \(p<0.0001\) for the values of \(4\) and \(5\), respectively). Thus, on average, subjects lie in order to signal higher than justified ability.
4.2 Gains and losses in social image
We now turn to the role of gains and losses in social image for reporting behavior. Obviously, loss aversion in social image can only be observed for those subjects who indeed care about their social image and do so sufficiently to bear the lying costs involved. While we have shown above that many of our subjects do over-report, it is also well documented that people are heterogeneous in the degree of social image concerns (see Bursztyn & Jensen, 2017; Friedrichsen & Engelmann, 2018) and lying costs (Abeler et al., 2019). This is also true in our sample, as Figure C.3 in Online Appendix C shows.
We are particularly interested in testing whether subjects with social image concerns are loss averse in social image. We therefore present two sets of results: evidence from subjects with versus without (substantial) social image concerns and evidence for our sample as a whole. We classify subjects based on a median sample split on social image concerns as measured at the individual level through our survey instrument: “How important is the opinion that others hold about you to you?” In our main analysis, we classify subjects as having social image concerns if their answer is 6 or higher on the 11-point Likert scale.Footnote 18
In the following, we will provide evidence based on whether subjects are in the loss or gain domain of social image, our subject of interest. We push subjects into the gain or loss domain by randomly varying the sequence in which subjects performed the tasks. In 87.8 percent of the cases, we were successful in inducing losses and gains as intended by the respective sequence. The remaining 12.2 percent of subjects have mainly experienced small gains and losses in social image. Since the main contribution of our paper is analyzing loss aversion in social image concerns (i.e., the kink around the reference point in social image), these subjects belong to the sample that is of a particular interest in the subsequent sections. In particular, there are 10 subjects with a rank difference of zero and 3 subjects experience a loss in social image in HardEasy. In EasyHard, 20 subjects have a zero rank difference and 19 subjects experience a gain in social image. By introducing the actually realized categories of Gain and Loss, we reassign those 42 out of 345 individuals to the intended category. Overall, 38.3% of subjects have a negative rank difference, 8.7% have a rank difference of zero, and the remaining 53% have a positive rank difference. Subjects with a rank difference of zero are assigned to the Gain category. Hence, 213 out of 345 subjects are in the Gain category and 132 out of 345 subjects in the Loss category.
The gain-loss border In Fig. 6, we compare reported die roll differences for subjects who experience gains and losses in social image. Positive rank differences are labeled as “Gain” indicating better performance in Part 2 than in Part 1, and negative rank differences as “Loss”. As illustrated in Fig. 6(a), subjects with image concerns who experience a loss in social image misreport more than those who experience a gain (MWU test, \(p=0.0754\)), which is in line with Hypothesis 2(a). We see a similar, however statistically insignificant, pattern for the sample as a whole in Fig. 6(c), i.e., irrespective of whether subjects care about their social image or not (MWU test, \(p=0.3970\)). The pattern is reversed, but not significant for subjects who do not care about social image concerns (MWU test, \(p=0.5571\)).Footnote 19
Varying the threshold at which we perform the social image sample split in Fig. 6(a), the die roll difference remains marginally significant or becomes even more significant for the smaller group of subjects with even stronger image concerns than in the baseline median split. It fades gradually when we include additional subjects with weaker social image concerns in the group of subjects with image concerns. In particular, in MWU tests, \(p=0.086\) for the 82 subjects who reported the importance of social image to be 8 or above, \(p=0.005\) for 146 subjects who reported the importance of social image to be 7 or above, \(p=0.075\) for 173 subjects who reported the importance of social image to be 6 or above, \(p=0.193\) for 209 subjects who reported the importance of social image to be 5 or above, and \(p=0.317\) for 238 subjects who reported the importance of social image to be 4 or above. Finally, we present a further robustness check in Online Appendix Table D.1. In a two-limit tobit model, we regress the die roll difference on a loss dummy, Preliminary Rank 2 that corresponds to subjects’ performance in the IQ test as a proxy for ability, and their interaction. In line with our main results, we document in Panel A that subjects with image concerns who experience a loss in social image misreport significantly more than those who experience a gain. We see a similar, however statistically insignificant, pattern for the sample as a whole.

Reported die roll difference by gains and losses in social image. Note: This Figure illustrates reported die roll differences for subjects who experience gains versus losses in social image. The vertical axis indicates the average die roll difference (from -5 to \(5\), higher DieDiff means adding more to one’s own score). Absent misreporting, average die roll differences should be zero. (a) Shows differences for subjects with above-median social image concerns (6 or above on 11-point scale), (b) for subjects with below-median image concerns, and c (c) for the sample as a whole. Above each figure, we report MWU test results comparing distributions of DieDiff for the respective groups
Result 2
On average, subjects with social image concerns over-report more if they experience a loss than a gain in social image.
Assuming loss aversion in social image concerns and the standard shape of the value function, we do not expect to observe very large, average differences in misreporting when comparing rank losses and gains of all sizes. As the value function depicted in Fig. 3 illustrates, a further implication of the standard assumptions regarding the value function is that small rank losses and gains will induce the largest marginal changes in social image utility. We thus expect to observe larger differences in misreporting when comparing small losses and gains in rank, but only small differences for larger losses and gains in rank.

Die roll difference by rank difference. Note: This Figure illustrates the dynamics of die roll differences in response to rank differences for different samples: a shows subjects with social image concerns, b shows subjects without social image concerns, and c shows the whole sample. All three panels display differences between subjects who experience losses (diamonds) versus gains (circles) in social image. Each diamond and circle represents the average die roll difference at a given rank difference, where rank differences are grouped in 20 equal-sized bins. Dashed and dotted lines represent a linear fit based on all the data from the sample of subjects with losses and gains in social image, respectively. (Color figure online)

Reported die roll differences for small gains and small losses in social image. Note: This Figure illustrates reported die roll differences for subjects who experience small gains versus losses in social image, i.e., with rank differences between -10 and 10. The vertical axis indicates the average die roll difference (from -5 to \(5\), higher DieDiff means adding more to one’s own score). Absent misreporting, average die roll differences should be zero. a Shows differences for subjects with above-median social image concerns (6 or above on 11-point scale), b for subjects with below-median image concerns, and c for the sample as a whole. Above each figure, we report MWU test results comparing distributions of DieDiff for the respective groups
In order to differentiate between the two possible explanations of misreporting behavior—a concave utility function for social image concerns versus loss aversion in social image concerns—, we proceed by taking a look at the behavior of subjects close to the gain-loss border. We start by plotting the die roll differences that subjects with various rank differences report in Fig. 7. Adding a linear fit visualizes a discontinuity in lying behavior for subjects with social image concerns around the gain-loss border. We also observe larger differences in misreporting when comparing small losses and gains in rank, but only small differences for larger losses and gains in rank. Both observations are in line with loss aversion in social image concerns and the standard shape of the value function.
Next, we “zoom in” and compare the die roll differences for subjects with small gains and losses in social image concerns in Fig. 8. We restrict the sample to subjects with rank differences between -10 and 10. As in Fig. 6, we present separate results for subjects with above and below median social image concerns as well as the whole sample. Similar to the results above, we observe that subjects who experience a small loss in social image misreport more than those with a small gain in social image—a result that is highly statistically significant for the whole sample (MWU test, \(p=0.0080\)). This difference in lying behavior gets even larger for subjects with social image concerns (MWU test, \(p=0.0023\)). As one would expect, subjects without social image concerns, on the contrary, do not differ in terms of their lying behavior if they experience gains and losses in social image (MWU test, \(p=0.5376\)). Similarly, Panel B of Table D.1 documents significant differences in misreporting behavior between small gains and losses in social image, both for subjects with social image concerns and for the sample as a whole.
4.3 Regression discontinuity
We present results from a regression discontinuity design (RD) in Table 1. The regression discontinuity specification maps the first derivative of the value function v which is commonly assumed to be larger for losses than for gains around zero and discontinuous at zero. Allowing for a discontinuity at a rank difference of zero (i.e., at the origin in Fig. 3), we explore whether subjects report systematically different die roll differences when moving from the loss to the gain domain in social image. If we find such a significant discontinuity in the derivative of the value function at the rank difference of zero, the empirical approximation of the value function has a kink—as is generally assumed in prospect theory. In contrast, such a kink is not compatible with a standard concave utility function \(v'\) for social image.
Table 1 indeed documents a significant discontinuity at the rank difference of zero, both for subjects with social image concerns and for the sample as a whole. Findings are similar in two different specifications: (i) an RD tobit specification focusing on subjects with rank differences between − 10 and 10 in columns (1), (3), and (5) and (ii) the robust procedure of Calonico et al. (2014) (CCT), employing the MSE-optimal bandwidth selection criterion in columns (2), (4), and (6). On average, subjects below the threshold who experience a small loss in social image report \(1.2\)–\(1.5\) higher die roll differences than those above who experience a small gain in social image, see columns (5) and (6) in Panel A. We present robustness checks of (1) and (2) for different thresholds of social image concerns in Figure C.5, showing that our estimates remain stable for a large variety of possible splits along the social image scale. For subjects with social image concerns, this discontinuity is even more pronounced: those below the threshold report on average \(1.9\)–\(2.0\) higher die roll differences than those above, see columns (1) and (2) in Panel A. For subjects without social image concerns, there is no significant discontinuity in misreporting for those who experience small gains and losses in social image concerns, see columns (3) and (4) in Panel A.
The results from the RD design can be interpreted in a causal manner under the assumption that subjects just below and above the threshold (with rank differences of \([-10,0)\) compared to [0, 10]) do not differ systematically in other dimensions than the one that defines the threshold. Using the comprehensive data from our post-experimental questionnaire,Footnote 20 we establish in Table 2 that subjects do not differ significantly with respect to their extent of social image concerns, loss aversion in the monetary domain, risk aversion, field of study, final GPA at school, and fluid IQ (proxied by Preliminary Rank 2).Footnote 21 Differences in age are significant for the sample with social image concerns only. However, according to the results presented in the Online Appendix of the meta-analysis of Abeler et al. (2019), age is not a significant predictor of misreporting behavior when controlling for age and age squared as we do in our specifications. There are less female than male participants with rank differences of \([-10,0]\) compared to (0, 10]. If we only consider those subjects with image concerns, the most relevant group under study, the difference in gender composition is no longer significant. Moreover, we do not find significant differences in misreporting by gender in our data.
Panel B of Table 1 including all control variables confirms the significant discontinuity at the rank difference of zero; estimated coefficients remain rather stable. Subjects who experience a small loss in social image report \(1.2\) to \(1.6\) higher die roll differences than those who experience a small gain in social image. These numbers increase to \(2.1\) for subjects with social image concerns and, as expected, are not significant for subjects without social image concerns.
Result 3
We observe a significant discontinuity in over-reporting at the reference point, indicating a kink in the value function for social image as predicted by loss aversion.
5 Conclusion
Does loss aversion apply to social image concerns? We observe that individuals who care about their reputation lie more if they are threatened by a loss than when facing a gain in social image. Taking a closer look at subjects’ behavior when moving from losses to gains in social image, we find a sharp decrease in lying—providing evidence for loss aversion in social image irrespective of the individual extent of social image concerns.
More generally, our findings underline that loss aversion also plays a role in the non-material domain adding relevance of this phenomenon beyond money and material goods (Kahneman et al., 1991). Our study takes a first step in a new line of research investigating the relevance of loss aversion to non-material sources of utility such as various drivers of reputation or self-image.
Our findings offer several avenues for future research. First and foremost, our experimental design relies on an IQ task that is relevant for individuals’ self- and social image. We build on numerous studies that have previously shown ability to be an important image-relevant domain (e.g., Falk & Szech, 2020; Ewers & Zimmermann, 2015; Zimmermann, 2020; Burks et al., 2013). Switching off the image relevance of the task would be a helpful extension. Despite the clear theoretical prediction that subjects would not misreport their die roll differences if the task did not yield any social image value, it would be beneficial to establish this baseline experimentally. Second, it would be interesting to take a closer look at the emotions involved when experiencing losses and gains in social image, where natural candidates are shame and pride (Butera et al., 2022) that may mediate behavior.
Since our experimental paradigm quantifies utility changes due to changes in social image by the amount of lying that individuals are willing to engage in, our findings also speak to the manifold situations in which honest reporting of private information is of great importance but not necessarily incentive-compatible. Dai et al. (2018) have shown that dishonesty in the lab can predict fraud and rule violation in real life. Our results reveal that individuals who care about their social image tend to report more dishonestly than others when their reputation is at stake. Monitoring efforts should thus be targeted at those individuals. One could also try to make it harder to lie while keeping a good reputation, e.g., via transparency, naming-and-shaming, or reputation systems (see also Abeler et al., 2019).
Finally, we find that the way social image evolves over time affects behavior. While making a decision, this reference-dependence implies that individuals may not only take present or discounted future reputation into consideration, but also account for the history of their social image. Two otherwise identical individuals may thus take opposite actions only due to differences in their social image in the past.
Notes
See Bleichrodt et al. (2001) for an application to health outcomes.
Bursztyn and Jensen (2017) present a detailed overview of the recent literature on social image concerns.
Ewers and Zimmermann (2015) document that, in a student sample similar to the one used in this study, subjects misreport their private information on ability in a laboratory context in order to appear more skillful even when strong monetary incentives are given to tell the truth. Establishing this is important as signaling skillfulness can be a two-sided sword as Austen-Smith and Fryer Jr (2005) show in a two-audience signaling model. For example, high ability students may under-invest in education because such investments lead to rejection by their peer group. This has been documented by Bursztyn et al. (2019) who show that students are less likely to sign up for an SAT preparation course and to take an SAT exam itself, if their choices are observable. They therefore forgo educational investment due to possible social stigma.
Their theoretical framework distinguishes conformists who experience social pressure to act in a socially desirable way, contrarians who feel pressured to act differently from what is socially desirable, and those who are not subject to social image concerns at all.
Abeler et al. (2019) provide a web interface where they present a detailed overview on recent experiments on lying.
Our approach is similar to Falk and Szech (2020), Ewers and Zimmermann (2015), Zimmermann (2020), and Burks et al. (2013) who also use reporting of the performance in IQ or knowledge tests to induce image concerns. In contrast, McManus and Rao (2015) show experimentally that individuals are more likely to present themselves as low-ability types when observed by a peer audience than when only observing information privately. The authors interpret this finding as an aversion to “showing off”.
The Easy quiz consists of the following matrices: B1, B5, B6, B7, B8, B9, B10, B11, B12, C1, C2, C3, C7, C8, C9, C10, C12, D2, D3, D5, D7, E2, E6, and E11. The Hard quiz contains the following matrices: B2, B3, B4, C4, C5, C6, C11, D1, D4, D6, D8, D9, D10, D11, D12, E1, E3, E4, E5, E7, E8, E9, E10, and E12.
We explicitly explain in instructions:
“For example, the statement “9% of participants of the reference group have a higher rank than you in part 1” implies that “9% performed better than you (i.e., they solved a higher share of the overall 48 matrices from part 1 and 2 correctly than you) and 90% worse (i.e., they solved a lower share of the matrices correctly than you). That means you belong to the 10% of best performers in solving the matrices that were designed to measure fluid IQ.”
Examples of filled in and verified report sheets (in German) as well as their translations to English are shown in Online Appendix Figures C.1 and C.2 for Ranks 1 and 2, respectively.
In Fischbacher and Föllmi-Heusi (2013), subjects roll a die once, report on the rolled number (which does not necessarily need to be the truly rolled number), and are paid according to the reported number (i.e., higher numbers give a higher payoff except for 6, which pays zero). We build on the original die roll task but adjust it for our purposes in two aspects. First, instead of using monetary payoffs, we reward subjects with additional points which add up to the number of correctly solved matrices. Thus, lying enables subjects to improve their rank. Second, our subjects are told to throw the die twice.
According to Gneezy et al. (2018), the fact that the experimenter cannot observe participants’ true outcomes facilitates lying.
We assume that there is no loss aversion in lying costs. Lying costs are zero in the absence of lying and reduce the agent’s utility if she lies. As a consequence, the deviation from the assumed reference point of truth telling can only be negative. The agent cannot improve her utility solely through lying but only if lying carries an instrumental value of social image enhancement. Therefore, there is no gain domain in lying costs and loss aversion does not apply to lying costs.
The role of observers is passive: They are not allowed to communicate with subjects.
Petrishcheva, Vasilisa, Gerhard Riener, and Hannah Schildberg-Hörisch. 2019. “Loss Aversion in Social Image Concerns.” AEA RCT Registry. April 09. https://doi.org/10.1257/rct.3422-5.0.
Throughout the paper, we report two-sided tests and refer to results as (weakly/highly) significant if the two-tailed test’s p-value is smaller than 0.05 (0.10/0.01).
Similarly, Burks et al. (2013) conjecture that individuals’ overstatement of own abilities is more likely induced by social as opposed to self-image concerns.
We deliberately asked this question at the end of the experiment in order to avoid priming subjects on social image. A potential disadvantage of eliciting social image concerns at the end of the experiment is that we cannot exclude a priori that the measure of social image concerns could be affected by subjects’ experiences in the experiment. However, we can show empirically that social image concerns do not differ significantly between HardEasy and EasyHard (MWU test, \(p=0.151\)). Social image concerns are also not significantly correlated with Rank 1 and Preliminary Rank 2 (\(p=0.327\) and \(p=0.997\), respectively).
Figure C.4 in the Online Appendix replicates Fig. 6 based on the sequences HardEasy and EasyHard instead of the gain-loss comparison. While the overall pattern is similar, misreporting differences are smaller and not significant—as one would expect given that the sequences do not translate one-to-one into gains versus losses that are our subject of interest.
Exact variable definitions are provided in Online Appendix F.
The absence of significant differences in Preliminary Rank 2 implies that differences in rank differences are driven by differences in Rank 1. This is exactly what we intended by the design of the two matrix sequences.
References
Abeler, J., Nosenzo, D., & Raymond, C. (2019). Preferences for truth-telling. Econometrica, 87(4), 1115–1153.
Alsop, R. (2008). The trophy kids grow up: How the Millennial generation is shaking up the workplace. Wiley.
Andreoni, J., & Douglas Bernheim, B. (2009). Social image and the 50–50 norm: A theoretical and experimental analysis of audience effects. Econometrica, 77(5), 1607–1636.
Ariely, D., Bracha, A., & Meier, S. (2009). Doing good or doing well? Image motivation and monetary incentives in behaving prosocially. American Economic Review, 99(1), 544–55.
Aurand, T., Finley, W., Krishnan, V., Sullivan, U., Abresch, J., Bowen, J., et al. (2018). The VW Diesel Scandal: A Case of Corporate Commissioned Greenwashing. Journal of Organizational Psychology, 18(1), 23–32.
Austen-Smith, D., & Fryer Jr, R. G. (2005). An economic analysis of “acting white". The Quarterly Journal of Economics, 120(2), 551–583.
Barberis, N. C. (2013). Thirty years of prospect theory in economics: A review and assessment. Journal of Economic Perspectives, 27(1), 173–96.
Bleichrodt, H., Pinto, J. L., & Wakker, P. P. (2001). Making descriptive use of prospect theory to improve the prescriptive use of expected utility. Management Science, 47(11), 1498–1514.
Bénabou, R., & Tirole, J. (2006). Incentives and prosocial behavior. American Economic Review, 96(5), 1652–1678.
Booij, A. S., & Van de Kuilen, G. (2009). A parameter-free analysis of the utility of money for the general population under prospect theory. Journal of Economic Psychology, 30(4), 651–666.
Burks, S. V., Carpenter, J. P., Goette, L., & Rustichini, A. (2013). Overconfidence and social signalling. The Review of Economic Studies, 80(3), 949–983.
Bursztyn, L., Egorov, G., & Jensen, R. (2019). Cool to be smart or smart to be cool? Understanding peer pressure in education. The Review of Economic Studies, 86(4), 1487–1526.
Bursztyn, L., & Jensen, R. (2017). Social image and economic behavior in the field: Identifying, understanding, and shaping social pressure. Annual Review of Economics, 9, 131–153.
Butera, L., Metcalfe, R., Morrison, W., & Taubinsky, D. (2022). Measuring the welfare effects of shame and pride. American Economic Review, 112(1), 122–68.
Calonico, S., Cattaneo, M. D., & Titiunik, R. (2014). Robust nonparametric confidence intervals for regression-discontinuity designs. Econometrica, 82(6), 2295–2326.
Camerer, C. F. (1998). Prospect theory in the wild: Evidence from the field. California Institute of Technology: Tech. rep.
Carpenter, J., & Myers, C. K. (2010). Why volunteer? Evidence on the role of altruism, image, and incentives. Journal of Public Economics, 94(11–12), 911–920.
Dai, Z., Galeotti, F., & Villeval, M. C. (2018). Cheating in the lab predicts fraud in the field: An experiment in public transportation. Management Science, 64(3), 1081–1100.
Ewers, M., & Zimmermann, F. (2015). Image and misreporting. Journal of the European Economic Association, 13(2), 363–380.
Falk, A., & Szech, N. (2020). Competing image concerns: Pleasures of skills and moral values. Working paper, briq.
Fehr, E., & Goette, L. (2007). Do workers work more if wages are high? Evidence from a randomized field experiment. American Economic Review, 97(1), 298–317.
Fischbacher, U. (2007). z-Tree: Zurich toolbox for ready-made economic experiments. Experimental Economics, 10(2), 171–178.
Fischbacher, U., & Föllmi-Heusi, F. (2013). Lies in disguise-an experimental study on cheating. Journal of the European Economic Association, 11(3), 525–547.
Friedrichsen, J., & Engelmann, D. (2018). Who cares about social image? European Economic Review, 110, 61–77.
Garbarino, E., Slonim, R., & Villeval, M. C. (2019). Loss aversion and lying behavior. Journal of Economic Behavior and Organization, 158, 379–393.
Gächter, S., Johnson, E. J., & Herrmann, A. (2022). Individual-level loss aversion in riskless and risky choices. Theory and Decision, 92(3), 599–624.
Gneezy, U., Kajackaite, A., & Sobel, J. (2018). Lying aversion and the size of the lie. American Economic Review, 108(2), 419–53.
Greiner, B. (2015). Subject pool recruitment procedures: Organizing experiments with ORSEE. Journal of the Economic Science Association, 1(1), 114–125.
Grolleau, G., Kocher, M. G., & Sutan, A. (2016). Cheating and loss aversion: Do people cheat more to avoid a loss? Management Science, 62(12), 3428–3438.
Grubiak, K. (2019). Exploring image motivation in promise keeping: An experimental investigation. Tech. rep. School of Economics, University of East Anglia, Norwich, UK.
Halleck, R. (2019). Who’s been charged in the college admissions cheating scandal? Here’s the full list. N.Y. Times, 2019, March 12.
Hanna, R., & Wang, S.-Y. (2017). “Dishonesty and Selection’’ into public service: Evidence from India. American Economic Journal: Economic Policy, 9(3), 262–290.
Kahneman, D., Knetsch, J. L., & Thaler, R. H. (1990). Experimental tests of the endowment effect and the Coase theorem. Journal of Political Economy, 98(6), 1325–1348.
Kahneman, D., Knetsch, J. L., & Thaler, R. H. (1991). Anomalies: The endowment effect, loss aversion, and status quo bias. Journal of Economic Perspectives, 5(1), 193–206.
Kahneman, D., & Tversky, A. (1979). Prospect theory: An analysis of decision under risk. Econometrica, 47(2), 263–292.
Khalmetski, K., & Sliwka, D. (2019). Disguising lies–Image concerns and partial lying in cheating games. American Economic Journal: Microeconomics, 11(4), 79–110.
Leibenstein, H. (1950). Bandwagon, snob, and Veblen effects in the theory of consumers’ demand. The Quarterly Journal of Economics, 64(2), 183–207.
Lovett, B. J. (2020). Disability identification and educational accommodations: Lessons from the 2019 admissions scandal. Educational Researcher, 49(2), 125–129.
McManus, T. C., & Rao, J. M. (2015). Signaling smarts? Revealed preferences for self and social perceptions of intelligence. Journal of Economic Behavior & Organization, 110, 106–118.
Pennings, J. M. E., & Smidts, A. (2003). The shape of utility functions and organizational behavior. Management Science, 49(9), 1251–1263.
Pettit, N. C., Doyle, S. P., Lount, R. B., & To, C. (2016). Cheating to get ahead or to avoid falling behind? The effect of potential negative versus positive status change on unethical behavior. Organizational Behavior and Human Decision Processes, 137, 172–183.
Raven, J. C. (1983). Manual for Raven’s progressive matrices and vocabulary scales. Standard Progressive Matrices.
Riener, G., Petrishcheva, V., & Schildberg-Hörisch, H. (2022). Replication data for: “Loss aversion in social image concerns” by Petrishcheva, Riener, Schildberg-Hörisch, Experimental Economics. https://doi.org/10.25625/IG6ESP.
Schindler, S., & Pfattheicher, S. (2017). The frame of the game: Loss-framing increases dishonest behavior. Journal of Experimental Social Psychology, 69, 172–177.
Sexton, S. E., & Sexton, A. L. (2014). Conspicuous conservation: The Prius halo and willingness to pay for environmental bona fides. Journal of Environmental Economics and Management, 67(3), 303–317.
Soetevent, A. R. (2011). “Payment choice, image motivation and contributions to charity: Evidence from a field experiment’’. American Economic Journal: Economic Policy, 3(1), 180–205.
Wakker, P. P. (2010). Prospect theory: For risk and ambiguity. Cambridge University Press.
Zimmermann, F. (2020). The dynamics of motivated beliefs. American Economic Review, 110(2), 337–61.
Acknowledgements
We are grateful to Johannes Abeler, Loukas Balafoutas, Jonas Fooken, Lorenz Götte, Paul Heidhues, Christian Kellner, Mats Köster, Hans-Theo Normann, Wojtek Przepiorka, Marta Serra-Garcia, Sigrid Suetens, Joël van der Weele, Jana Willrodt, and Florian Zimmermann for helpful comments and suggestions. We also thank Robin Bitter and Vladyslav Zhurakhinskyy for excellent research assistance. Financial support from DFG through the grant for GRK 1974 Competition Economics is gratefully acknowledged. AEA RCT Registry: https://www.socialscienceregistry.org/trials/3422. Our experimental study complies with the code of conduct for experiments at the DICE Lab. According to rules of Heinrich Heine University Düsseldorf, study-specific IRB approval was not required for this study because the experiment did not create any harm or distress beyond participants’ everyday experiences and because we comply with German laws, particular legislation pertaining to physical integrity, privacy rights, and data protection. The replication material for the study is available at https://doi.org/10.25625/IG6ESP (Riener et al., 2022).
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
None.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Petrishcheva, V., Riener, G. & Schildberg-Hörisch, H. Loss aversion in social image concerns. Exp Econ 26, 622–645 (2023). https://doi.org/10.1007/s10683-022-09782-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10683-022-09782-7