
Abstract
Surface soil moisture is a key hydrologic state variable that greatly influences the global environment and human society. Its significant decrease in the Mediterranean region, registered since the 1950s, and expected to continue in the next century, threatens soil health and crops. Microwave remote sensing techniques are becoming a key tool for the implementation of climate-smart agriculture, as a means for surface soil moisture retrieval that exploits the correlation between liquid water and the dielectric properties of soil. In this study, a workflow in Google Earth Engine was developed to estimate surface soil moisture in the agricultural fields of the Marche region (Italy) through Synthetic Aperture Radar data. Firstly, agricultural areas were extracted with both Sentinel-2 optical and Sentinel-1 radar satellites, investigating the use of Dual-Polarimetric Entropy-Alpha decomposition's bands to improve the accuracy of radar data classification. The results show that Entropy and Alpha bands improve the kappa index obtained from the radar data only by 4% (K = 0.818), exceeding optical accuracy in urban and water areas. However, they still did not allow to reach the overall optical accuracy (K = 0.927). The best classification results are reached with the total dataset (K = 0.949). Subsequently, Water Cloud and Tu Wien models were implemented on the crop areas using calibration parameters derived from literature, to test if an acceptable accuracy is reached without in situ observation. While the first model’s accuracy was inadequate (RMSD = 12.3), the extraction of surface soil moisture using Tu Wien change detection method was found to have acceptable accuracy (RMSD = 9.4).
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Surface soil moisture (SSM) describes the water content of the top few centimeters of soil and is a fundamental boundary condition that influences land surface-atmosphere heat and water exchanges, essential for drought monitoring (Long et al., 2019), heat waves prediction (Fischer et al., 2007) and soil loss by water erosion estimation (Todisco et al., 2015).
Climate change is modifying SSM variability and its feedbacks with precipitation and temperature; a significant decrease in soil moisture has been registered since the 1950s in the Mediterranean region, particularly in south-eastern and south-western Europe (EEA, 2017; Kurnik et al., 2015). By the end of this century, a decrease of 20% in land surface water availability is predicted (Mariotti et al., 2008), due to the fast-warming trend and changes in the distribution and intensity of precipitations (EEA, 2017). In agricultural lands, SSM exerts relevant effects on yields, providing the transpirable water for plants, controlling rainfall-runoff response, and the diversity in ecosystems (Robinson et al., 2008). In a climate-smart agriculture (FAO, 2022) perspective, monitoring SSM in agricultural fields at high temporal and spatial resolution is essential to safeguard soil and water resources, developing sustainable cropping systems, and thus positively determine the adaptability to new climate scenarios (Lewis, 2019). SSM estimate can find applicability in irrigation scheduling, to facilitate a rational use of water, reduce plant stress and improving crop yield (Pradhan et al., 2018). It could also encourage diversification of production orientations at the expense, in areas where it is environmentally sustainable, of low-income crops (Zucaro et al., 2009).
In situ measurements of SSM provide distributed point measurements which, due to the large dynamism of the soil moisture parameter, are not sufficient to characterize its spatial and temporal variability at larger scale (Panciera & Monerris, 2013). Instead, microwave remote sensing techniques provide an exceedingly powerful means for SSM retrieval, both with passive (Mohanty et al., 2017), and active sensor (Bauer-Marschallinger et al., 2019; Hornacek et al., 2012). These measurements exploit the correlation between liquid water and the dielectric properties of soil, which influence, along with several other physical characteristics and sensor parameters, the interaction between the electromagnetic power and the target material (Woodhouse, 2017).
However, many passive microwaves satellites, which are providing SSM estimation at low resolution from the decades (Fang et al., 2019), are not suitable for agricultural monitoring.
Instead, Synthetic Aperture Radar (SAR) can provide higher-resolution data measuring the backscattering coefficient,\({\sigma }^{0}\), defined as the ratio of the incident to received signal intensity, normalized to the actual scattering area (Meyer, 2019; Pulvirenti et al., 2018). Nevertheless, ground roughness and the presence of vegetation complicate the SSM retrieval (Bindlish & Barros, 2002).
The models which have been developed to address the soil moisture retrieval problem can be divided into two main approaches: snap-shot algorithms and multi-temporal algorithms. Snap-shot model are usually grouped into theoretical (Fung et al., 1992; Hajnsek et al., 2003), empirical (Oh et al., 1992; Zribi & Dechambre, 2003)—among which the use of Artificial Neural Network techniques (Ge et al., 2018) has recently been introduced—and semiempirical algorithms (Panciera & Monerris, 2013). For vegetated areas, the popular semiempirical algorithm Water Cloud Model (WCM) uses calibration parameters to isolate the soil contribution and, subsequently, employs the linear correlation between SAR backscatter measurement and volumetric soil moisture (Baghdadi et al., 2006) to retrieve SSM. On the other side, multi-temporal approaches are popular techniques to generate global high-resolution soil moisture products (Bauer-Marschallinger et al., 2019; Bhogapurapu et al., 2022), using more acquisition to minimize the effect of vegetation and roughness.
Radar SSM retrieval over the Italian peninsula has been an object of interest in the last years, especially for the southern part of Italy, more vulnerable to drought and desertification (Filion et al., 2016; Montaldo et al., 2021).
Sentinel-1 mission provides dense time-series of SAR data, making possible to relate short term changes in the backscattering coefficient to SSM variations (Balenzano et al., 2010; Pulvirenti et al., 2018). To take advantage of the great availability of Sentinel-1 high-resolution acquisition, the Tu Wien multi-temporal change detection method, originally developed for ASCAT data, has been modified according to Sentinel-1 SAR data characteristics by Bauer-Marschallinger et al. (2019).
Nowadays, besides these case studies, the Copernicus Global Land Service estimates are available for SSM with a low spatial resolution (\(1\mathrm{km}\)) and the MULESME software, which makes use of multi-temporal Sentinel-1 acquisition to obtain a systematic mapping of surface soil, is tested.
In this study, the Marche region has been considered. Located in central east of Italy and characterized by an agrarian landscape of sharecropping origin, it is evaluated as highly vulnerable to climate variations, especially regarding agricultural productivity (Shukla et al., 2019). In 2007, 9% of the Marche territory was considered sensitive or vulnerable to desertification, while only 5 years before, in 2002, the region had not been included in the National Atlas of the areas at desertification risk (Costantini et al., 2007). The main regional soil degradation systems, that can lead to functional sterility, include denudation by water erosion and drought (Costantini et al., 2007).
In order to estimate the SSM in agricultural areas, a workflow has been developed in the cloud computing platform Google Earth Engine (GEE). Firstly, agricultural areas are derived from a land use/land cover (LULC) Random Forest classification, using both optical (Sentinel-2) and radar (Sentinel-1) data, and the Entropy-Alpha dual pol decomposition parameters. Subsequently, SSM is estimated using the semiempirical model WCM and the change detection Tu Wien model.
This study has two objectives:
-
the first goal is to investigate the use of polarimetric decomposition’s bands \(H\text{/}\alpha\) to improve the accuracy of classification (Banque et al., 2015)
-
the second goal is to implement in GEE Tu Wien and Water Cloud Model (WCM) using calibration parameters derived from literature, to test if an acceptable accuracy is reached without any in situ observation.
2 Materials and method
2.1 Study area
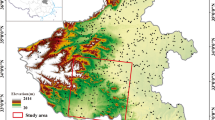
The study area is the Marche region, located in central-northern Italy and overlooking the Adriatic Sea (Fig. 1a). The Foglia River and the Tronto River indicatively delimit the northern and southern boundaries of the region, while the Apennines and the Adriatic Sea mark its western and eastern limits (Fig. 1b). The region covers a total area of \(\mathrm{9,694,51k}{\mathrm{m}}^{2}\).

Study area. (a) Marche region and its provinces. (b) Elevation and rivers (Reference system: WGS84/Pseudo-Mercator, EPSG: 3857)
The regional territory is characterized by a hillside morphology that slopes towards the sea; the coast extends north to south for \(173\mathrm{km}\) and represents the only flat area of the region. Marche rivers cross the region from west to east, producing valley furrows that gradually expand near the mouth, forming a characteristic comb-like structure. Despite the rapid expansion of urbanized or infrastructure-occupied areas, especially in coastal area (Appiotti et al., 2014), Marche region remains largely rural (Istat, 2013), since the Total Farmland Area (TFA) and the Utilized Agricultural Area (UAA) cover 76.5% of the territory, and the agricultural lands are widely distributed throughout the region (Istat, 2013). Instead, forests and unused land, are found predominantly in the southwest, on the Appennino Umbro-Marchigiano mountains (Arzeni, 2003). The average surface area per farm has increased since 1980s, reaching 10.52 hectares in 2010, higher than the national average of 7.93 hectares (Istat, 2013).
Almost 80% of the UAA is planted with arable crops, just below \(375\) thousand hectares (Istat, 2013), and the most widely grown cereal is durum wheat. The presence of clay-rich soils and the rotation of durum wheat with spring–summer crops, among which sunflower, sugar beet and sorghum, implies the use of frequent tillage, which exposes the soil to erosion by surface runoff, organic matter mineralization and nitrate leaching for long periods (Zucaro et al., 2009).
Water erosion is particularly critical in the hilly terrain of the Marche region, where the relationships between cropping systems and the environment are strongly affected by crop water balance and water flows (Borrelli et al., 2016). Instead, the vulnerability to droughts is increased by the fact that the prevalence of durum wheat crops, a dry soil cultivation, has discouraged public investments on the creation of irrigation facilities. Consequently, it is more difficult for the farmers to diversify production in reaction to the decrease which interested the agricultural incomes of large-scale consumer products during the last decades.
2.2 Dataset
The dataset was created using Sentinel-1 (S1) and Sentinel-2 (S2) data (Table 1). All data were georeferenced in the default cartographic reference system of GEE WGS84/Pseudo-Mercator (EPSG: 3857). The Sentinel-1 mission comprises a constellation of two polar-orbiting satellites, both carrying a C-band SAR dual-polarized instrument with a frequency of \(5.405\mathrm{GHz}\) and a revisit period of 12 days (Torres et al., 2012). For this study, S1A and S1B data at interferometric wide swath (IW) mode and Level-1 of processing were used. IW acquires data with a \(250\mathrm{km}\) swath at \(5\mathrm{m}\) × \(20\mathrm{m}\) spatial resolution, and an incidence angle, \({\theta }_{i}\) which ranges between \(29.1^\circ\) and \(46.0^\circ ,\) i.e., the angle between the incoming EM wave and the normal to the reference surface.
Ground Range Detected (GRD, below called S1-GRD) images are already ingested in Google Earth Engine (GEE), while Single Look Complex (SLC, below called S1-SLC) were downloaded from the Alaska Satellite Facility (https://asf.alaska.edu/). S1-SLC images are used to calculate Entropy, Alpha and Anisotropy parameters through Dual-Polarimetric Entropy-Alpha dual polarimetric decomposition. Marche region is acquired by path 44 and 177 for ascending orbits, and 22 and 95 for descending orbits.
Sentinel-2 is a multi-spectral imaging mission with two polar-orbiting satellites carrying a Multispectral Instrument (MSI) which acquires passively in 13 spectral bands with a spatial resolution of \(60\mathrm{m}\) for the aerosol band, \(10\mathrm{m}\) for visible and \(20\mathrm{m}\) for infrared bands.
From 2015 to 2020, the land cover classification was carried out twice a year, for a total of 48 S1-GRD scenes, 48 S1-SLC scenes and 12 S2 intervals. The whole product names can be found in the Online Resource 1.
2.3 Procedure
Figure 2 shows the whole applied procedure (see GitHub repository). Each S1 and S2 scene has been preprocessed and used to extract the agricultural areas of the Marche region through a supervised Random Forest classification. Subsequently, Tu Wien and Water Cloud Model were implemented in the GEE cloud computing platform and validated using in situ measurements made by two International Soil Moisture Network (ISMN) stations in Umbria, in August 2015. Finally, the estimates were applied to an agricultural area of \(125\mathrm{ha}\), where the relationship between different agricultural land covers, soil moisture and precipitation was analyzed.

The workflow to retrieve surface soil moisture in agricultural fields in Marche region (Italy). The procedure was applied to each S1 and S2 data
2.3.1 Preprocessing
Preprocessing of S2 and S1-GRD was realized in GEE, and the obtained data were then exported as Asset in the Code Editor. Instead, S1-SLC dataset was preprocessed in the Sentinel Application Platform (SNAP), because GEE does not support images with complex values, such as phase and amplitude, due to the inability to average them during pyramiding ingestion (“Google Earth Engine Guides”, n.d.).
Sentinel-2 data with level 1C processing provided by GEE were used. These data have been orthorectified and radiometrically corrected by GEE, providing top-of-atmosphere reflectance values; images bands have maintained their original spatial resolution. The masking of the cloud areas has been realized through the probability band in the dataset Sentinel-2 Cloud Probability, which was created with the sentinel2-cloud-detector library, and the Cloud Displacement Index (CDI), using the near-infrared parallax (AleksMat, 2022; Skakun et al., 2022). To obtain a cloud-free composite, images acquired in 30–45 days were temporally aggregated using the mean method.
Each S1-GRD scene provided by Google Earth Engine has been preprocessed using the SNAP Toolbox, applying the following steps: thermal noise removal, radiometric calibration and terrain correction using Shuttle Radar Topography Mission (SRTM) elevation digital model to \(30\mathrm{m}\) (Farr & Kobrick, 2000). The scenes for the land cover classification were filtered for the speckle. This is a physical phenomenon caused by the interference of coherent waves reflected from many elementary scatterers, corrigible through the Refined Lee Filter implemented in GEE by Guido Lemoine (Thorp & Drajat, 2021). Considering the hilly topography of the study area (Fig. 1b and Fig. 3a), an angular-based radiometric slope correction was applied to the images (Fig. 3b). The model, implemented by Vollrath et al. (2020), is based on the angular relationships between the SAR image and the terrain geometry, and it is optimized for surface scattering and, therefore, for soil characteristic analysis. In addition, a mask is applied for active layover and shadow (Fig. 4).

Comparison between an original image: (a), and a radiometric slope corrected image (b). Acquisition date: 10-09-2019. Descending orbit. RGB bands: VH, VV, VH

Active layover (yellow) and shadow mask (red). Acquisition date: 12-09-2019. Ascending orbit. Local \({\theta }_{i}\) is the background image
S1-SLC data were processed applying the following operators through SNAP: S-1 TOPS Split, Apply Orbit File, Calibrate, S-1 TOPS Deburst, S-1 TOPS Merge, C2 Polarimetric Matrix Generation, Polarimetric Decomposition, Multilooking. Both S1-GRD and S1-SLC images were finally mosaicked in GEE. Previous investigations into radiometric consistency reveal no significant radiometric biases between SLC and GRD products (Small, 2016). However, considering all applied preprocessings and that S1 assets in GEE have been processed at different times with several Toolbox versions and settings, GRD and SLC datasets were compared to ensure that their mean radiometric difference was below S1 radiometric accuracy (\(1\mathrm{dB}\)). The comparison was carried out on GEE using the preprocessed datasets (bold in Table 1), except for C2 Polarimetric Matrix Generation and Dual-Polarimetric Entropy-Alpha dual pol decomposition. The comparison shows mean difference values below \(1\mathrm{dB}\) in each scene, with maximum difference of \(0.40\mathrm{dB}\) (Std Dev \(1.54\)) for band VH and \(0.27\mathrm{dB}\) (Std Dev \(1.68\)) for band VV. Therefore, Entropy, Alpha and Anisotropy values derived from SLC can be considered representative of GRD images.
2.3.2 Polarimetric decomposition
Incoherent polarimetric decomposition was originally designed for full-polarimetric data to separate the 3 × 3 Hermitian average covariance \(\langle T\rangle\) and \(\langle C\rangle\) matrices as the combination of simpler or canonical objects, presenting an easier physical interpretation (Haldar et al., 2019; Harfenmeister et al., 2021). In this study, the Entropy-Alpha decomposition modified by Cloude and Pottier (1996) for dual-polarized data is used. Considering the scattering matrix \(\left[{S}_{VV-VH}\right]\)(Eq. 1):
Each of the elements \({S}_{pq}\) is a complex number, describing phase and amplitude of transmitted, \(p\), and received, \(q\), polarization (Woodhouse, 2017). Sentinel-1 is a linear dual-polarized instrument, and, in IW acquisition mode, it mainly transmits a vertical polarized signal, \(V\), and measures the echo in both vertical, \(V\), and horizontal, \(H\), polarization. \({S}_{VV}\) is the co-polarized signal, while \({S}_{VH}\) is the cross-polarized signal. The corresponding scattering vector based on the Pauli matrices, \(k\), is composed by the co-polarized term and twice the cross-polarized term (Eq. 2):
\(k\) is needed as the scattering matrix \(\left[{S}_{VV-VH}\right]\) is only able to characterize the so-called coherent or pure scatterers; to describe distributed target scattering \(\langle {C}_{VV-VH}\rangle\) is calculated from (Eq. 3):
where \(\langle \rangle\) denotes ensemble averaging (Woodhouse, 2017). \(\langle {C}_{VV-VH}\rangle\) is decomposed (Eq. 4) as follows (Ji & Wu, 2015):
where \(\left[V\right]\) is the eigenvector matrix which contains the eigenvectors \(\overrightarrow{{v}_{i}}\) (Eq. 5):
and \(\left[\Lambda \right]\) is the diagonal eigenvalues matrix, i.e., a diagonal representation of the covariance matrix in a Cartesian coordinate system, whose axes are the related eigenvectors.
Once \(\langle {\mathrm{C}}_{\mathrm{VV}-\mathrm{VH}}\rangle\) is decomposed, the three simpler canonical scattering mechanism matrices \(\left[{T}_{i}\right]\) are derived from the Eq. 6:
Each eigenvector \(\overrightarrow{{v}_{i}}\), multiplied by its complex conjugate \(\overrightarrow{{v}_{i}}\)*, corresponds to a scattering mechanism\(\left[{T}_{i}\right]\), while the related eigenvalue \({\lambda }_{i}\) expresses the importance of each mechanism on the total backscattered power, called SPAN. The analysis of the physical information provided by this eigen decomposition is usually carried out through three parameters, derived from the eigenvalues and the eigenvectors of\(\langle {C}_{VV-VH}\rangle\):
-
the Entropy \(H\) (Eq. 7), which expresses the degree of randomness of the scattering mechanism
$$H = \sum\limits_{{i = 1}}^{3} {p_{i} } \cdot \log _{3} \left( {p_{i} } \right)$$(7)where \({p}_{i}\) (Eq. 8) expresses the relative importance of this eigenvalue \({\lambda }_{i}\) with respect to the SPAN:
$${p}_{i}=\frac{{\lambda }_{i}}{{\sum }_{k=1}^{3}{\lambda }_{k}}$$(8) -
the Anisotropy \(A\)(Eq. 9), which quantifies the relationship between the second and the third eigenvalue and is complementary to the Entropy:
$$A=\frac{{\lambda }_{2}-{\lambda }_{3}}{{\lambda }_{2}+{\lambda }_{3}}$$(9) -
the Alpha angle \(\alpha\) (Eq. 10), which describes the averaged scattering mechanisms:
$$\alpha = \sum\limits_{{i = 1}}^{3} {p_{1} \cdot \alpha _{i} }$$(10)For fully polarized data \(\alpha \to 0\) indicates surface scattering;\(\alpha \to \pi /4\) indicates volume scattering and \(\alpha \to \pi /2\) indicates double bounce scattering.
Equations 7, 8, 9 and 10 are derived from Ouarzeddine et al. (2006). H, A and α has been calculated in each SLC scene. The results were uploaded in GEE in geoTIFF format, where they were filtered applying the Refined Lee Filter and radiometric slope corrected with Vollrath et al. (2020) model.
2.3.3 Agricultural areas extraction
Land use/land cover classifications were carried out through one the most frequently used supervised algorithm in GEE, the Random Forest (Kumar & Mutanga, 2019), with 500 trees testing several band datasets. Normalized Difference Vegetation Index (NDVI), Normalized Difference Built-up Index (NDBI), sum and ratio radar bands were considered also. Seven classes were selected: forest, bare soil, water, agricultural fields, urban areas, mixed vegetation, and snow. Training areas are manually added as polygons based on the official Land Cover Map created by Marche region (2007) and derived from visual interpretation of S2 natural color images (Fig. 5).

(a) Example of training and validations polygons (Background’s source: Google Earth), (b) forest example, (c) bare soil example, (d) agricultural fields and (e) vegetation example
Training data are 6.48% of total pixels, while validation data, randomly extracted by the selected polygons, are 1.62%. Ascending and descending images are classified separately and, to speed the classification process, each province was classified individually. Table 2 shows the four datasets considered: optical dataset (OP, optical bands and their combinations), radar dataset (RD, radar bands), polarimetric dataset (PD, polarimetric parameter H and α, and radar band combinations) and total dataset (TD, optical dataset, radar dataset, and polarimetric dataset).
\({M}_{try}\) hyper-parameter, which controls the split-variable randomization feature of Random Forests, was set to \(3\). Consequently, each time a split is to be performed, the search for the split variable is limited to a subset of three bands. The sample size parameter, which determines how many observations are drawn for the training of each tree, is set to \(0.3\), to lower the correlation between trees and decrease the weight of outliers. The producer and user accuracy estimations were used to compare the classification accuracy between datasets; the producer accuracy quantifies how well reference pixels of the ground cover type are classified, and the user accuracy represents the probability that a pixel classified into a given category actually represents that category on the ground. The coefficient of agreement, kappa index, is also used to evaluate how well the classification performed, considering the effect of random agreement (Carrasco et al., 2019; Tang et al., 2015).
2.3.4 Surface soil moisture estimation
SSM estimations by Tu Wien and Water Cloud models were implemented and subsequently applied over agricultural areas extracted through the land cover classification.
The multi-temporal change detection Tu Wien Model was originally developed at Vienna University of Technology (TU Wien) to estimate soil moisture using ASCAT (Advanced SCATterometer) data, and subsequently adapted to S1. It relies on two assumptions: i) the relationship between the backscattering coefficient \({\sigma }^{0}\) and the surface soil moisture content is linear; ii) considering that soil roughness and vegetation exhibit a gradual change over time, any sudden change observed, within an appropriate time interval, is assumed to originate from a change in soil moisture (Panciera & Monerris, 2013).
To account for roughness and vegetation, a reference backscatter value \({\sigma }_{dry}^{0}\left({\theta }_{ref}\right)\), representing backscatter from the vegetated land surface under dry soil conditions, is subtracted from the actual backscatter measurement, normalized to a reference angle, \({\sigma }^{0}\left({\theta }_{ref}\right)\).
Therefore, relative soil moisture changes \({m}_{r,t}\) are calculated by dividing the result by the sensitivity, which is the difference between the maximum value, \({\sigma }_{wet}^{0}\left({\theta }_{ref}\right)\), and the minimum, \({\sigma }_{dry}^{0}\left({\theta }_{ref}\right)\) backscattering value measured in each pixel in the chosen time interval. Equation 11 is used:
To retrieve the volumetric soil moisture value in each scene, two parameters should be introduced:
-
the wilting point (WP), which is set to 9%, assuming that it corresponds to the minimum backscatter value registered in the time interval, \({\sigma }_{dry}^{0}\left({\theta }_{ref}\right)\);
-
the saturation point (SAT), assuming that it corresponds to the minimum backscatter value registered in the time interval, \({\sigma }_{wet}^{0}\left({\theta }_{ref}\right)\). SAT is set to 30%, as beyond 30–35% any further increase in SSM does not correspond to an increase in radar backscatter (Gao et al., 2017).
Then, the volumetric soil moisture is calculated by Eq. 12:
Concerning the semiempirical Water Cloud Model, developed by Attema and Ulaby (1978), the total backscattering coefficient is defined in a linear scale by Eq. 13:
where \({\sigma }_{veg}\) (Eq. 14) is the contribution from the vegetation to the total backscatter and \({\sigma }_{soil}\) (Eq. 15) is the contribution from bare soil attenuated by vegetation through \({\tau }^{2}\) (Eq. 16) (Baghdadi et al., 2017).
where \(V\) is a vegetation’s descriptor, \(A\) and \(B\) are parameters of the model depending on the vegetation and radar’s configuration, parameter \(C\) is mainly related to surface roughness, while parameter \(D\) expresses the radar configuration sensitivity to soil moisture (Shamambo et al., 2019). In this study, the NDVI (Eq. 17) is used as vegetation descriptor.
Others calibration parameters are derived from literature (Table 3).
Finally, for SSM validation, three parameters were used (Eqs. 18, 19, 20):
where \({p}_{i}\) is the predicted soil moisture value, \({\alpha }_{i}\) is the actual in situ moisture value and N is the number of agricultural fields pixel
3 Results
3.1 Classification accuracy
In order to evaluate the polarimetric characteristics contribution, a preliminary analysis for each land cover training class was carried out throughout mean and standard deviations statistics of Entropy, α and Anisotropy bands. For Entropy mean values a range of 0.35–0.73 was obtained, for Alpha mean values a range of 12.0–27.5 and for a range of 0.41–0.73 (Fig. 6).

On the right, mean Entropy and Alpha values for each training class. On the left, mean Entropy, and Anisotropy values. Vertical and horizontal lines represent, respectively \(\alpha\), Anisotropy and Entropy standard deviation
Subsequently, the classification accuracy of each dataset scenario was assessed using kappa indices and confusion matrices (see Online Resource 2). Only optical data lead to a mean kappa index of 0.927, while only radar data lead to a mean kappa index of 0.783. Entropy and Alpha bands improve the kappa index to 0.948 for optical data and to 0.818 for radar data. Optical and radar bands result in a mean kappa index of 0.942, which is slightly improved by 0.007 by adding the polarimetric bands, obtaining a 0.949 kappa index for the entire dataset.
For every province, Fig. 7 shows the contribution of radar and decomposition’s bands to the optical classification, and the contribution of optical and decomposition’s bands to the radar classification using mean kappa indices.

Mean kappa indices for each province
The Anisotropy band was not included in the dataset as it would not improve the classification, and it could even worsen it in some cases. The assessment of the variable’s importance was realized in GEE: each optical band contributes on average by 24.8%, NDVI and NDBI by 26.5%, VV and VH by 24.8%, and Entropy, Alpha, sum and ration contribute by 23.7% in the final classification.
Although decomposition’s bands contribute meanly less than any other dataset, Fig. 8 shows that these bands can greatly improve radar classification, especially in urban, snow and water classes. The accuracy was calculated by averaging the user and producer’s accuracy for each land cover class over all the classifications (Carrasco et al., 2019).

Accuracy obtained from the three datasets in each land cover class
Figure 9 displays an example of comparison between the maps obtained from the different datasets.

Comparison between (a) Sentinel-2 image; (b) total dataset classification; (c) optical dataset classification; (d) radar dataset classification; (e) polarimetric dataset. Acquisition date: 21-12-2020. Descending orbit
3.2 Surface soil moisture estimates
The surface soil moisture values were retrieved at a spatial resolution of 10 m. The validation of two models applied was carried out using RMSD, bias and ubRMSD (Eq. 18, Eq. 19, Eq. 20) between predicted SSM and in situ measurements acquired by the International Soil Moisture Network (ISMN) in Umbria region (Italy), in two stations, WEEF 1 and WEEF 2, in August 2015.
Both stations, belonging to the HYDROL-NET-PERUGIA network, were in agricultural dry-lands and measured soil moisture at three depth levels using a TDR- Soil Moisture Equipment Corp. TRASE-BE sensor. Considering that the band-C radar cannot penetrate the soil more in-depth, the data acquired at 5 cm were used.
Table 4 shows the validation results.
3.3 Application
Subsequently, the Tu Wien change detection method, which obtained lower RMDS, was applied to the agricultural area managed by the Università Politecnica delle Marche (UNIVPM, n.d.). The farm extends on a total surface of about \(125\mathrm{ha}\) in Agugliano and Gallignano (Ancona province), cultivated with trees and herbaceous crops to be part of research projects (UNIVPM, n.d.). The farm zone is part of the lower Esino river valley, whose lithologies belong to the Marche and Umbria succession, during which sedimentary rocks were deposited in the marine environment from the Upper Triassic (\(200\mathrm{ma}\)) until the Lower Pliocene (\(\mathrm{3,5ma}\)), on which rest the subsequent Quaternary Continental Deposits (Barchiesi, 2017). The farm’s area is located between two opposite slopes, which form at their feet a flat strip consisting of alluvial deposits. The study areas lie along this strip. The average slope of the area of interest is 4.131%. The ASSAM weather station, located beside the farm, provided precipitation data, used to investigate the relationship between soil moisture and precipitation in different crop types (Fig. 10). The mean soil moisture/precipitation correlation is 0.46 of Pearson correlation index.

Correlation between surface soil moisture and precipitation values for different crop classes
Finally, minimum, maximum, and mean soil moisture values are retrieved from different land cover types in 2020 (Table 5) in order to evaluate them on the basis of the main crop phenological cycles.
4 Discussion
From the reported results, some observations arise. For fully polarimetric data, land cover classes may produce distinct clustering in the H/\(\alpha\) plane plot, in which Entropy and \(\alpha\) values are plotted on the x and y axis and the plane plot space is linearly separated to identify nine zones, each related to a different scattering mechanism. Thus, H/\(\alpha\) plane plot is often used for unsupervised classification.
Instead, as proven by Ji and Wu (2015), in Dual-Polarimetric H/\(\alpha\) dual pol decomposition the loss of information caused by the lack of co-polarized data, as in the case of S1, makes it impossible to distinguish the three canonical scattering mechanisms (surface, dihedral and volumetric) in the dual \(H\text{/}\alpha\) plane plot, where most zones are diffusing and transferring. Therefore, VV-VH polarization cannot distinguish isotropic surface, horizontal dipole, and isotropic dihedral scattering mechanism based on Alpha value, and it can only partially extract low, medium, and high Entropy scattering mechanisms (Ji & Wu, 2015).
Indeed, Fig. 6 shows that each mean \(\alpha\) value is below \(45^\circ\), even for urban areas, which should be characterized by dihedral scattering (\(\alpha \to \pi /4)\) and forested areas, characterized by volume scattering (\(\alpha \to \pi /8\)). High standard deviation values indicate low discriminability especially between vegetated surfaces (agricultural areas, forested areas, and vegetated areas).
Comparable results are obtained from Banque et al. (2015), who define the training sites for each land cover class with Sentinel-1 and get similar Entropy values; instead, in their study the \(\alpha\) band does not reach 20°, confirming that the use of a cross-polarized \(H\text{/}\alpha\) plane plot is not feasible for land cover classification.
Nevertheless, in this study the use of Entropy and Alpha values as supplementary bands in a radar data classification has improved the kappa index by 4.4% and the recognition of each land cover class (Table 4, Fig. 8). In fact, as expected (Carrasco et al., 2019; Steinhausen et al., 2018), radar data classifications obtained lower results than optical data, since some of the classes present similar backscattering power and they cannot be easily differentiated (Banque et al., 2015). It can be noticed that the radar bands obtained the worst classification results in Ascoli-Piceno and Fermo provinces, which are characterized by the predominant presence of Appennine mountains (Fig. 7); in fact, the radar signal is, despite the slope corrections, still strongly dependent on topography characteristics.
The main improvement of H, \(\alpha\), sum and ratio bands can be seen in urban, snow and water classes (Fig. 8). In the case of urban and water, VV, VH, H, \(\alpha\), sum and ratio bands exceed the accuracy of optical data, while for the soil class the accuracy is only 0.04 lower. This result, visible in Fig. 9, was expected for the urban class, where optical data obtained the worst accuracy, confusing artificial structures with bare soil (Fig. 9c); on the other side, for VV and VH bands these two classes are characterized by two different scattering mechanisms, dihedral and surface, thus are easily recognizable.
But only VV and VH bands still obtain low accuracy (Figs. 8, 9d), probably due to the high heterogeneity of these areas, which makes it not easy to distinguish them based on high backscattered power, especially in a hilly terrain, where high backscatter values can be found also in areas characterized by abrupt morphological changes. In fact, VV and VH detect urban areas even in isolated habitations, but often fail to distinguish them from the top of the hills or the vegetation found along drainage ditches between two agricultural fields. Thus, for urban classification, the combined use of optical, radar and decomposition dataset is crucial to achieve a good accuracy.
Concerning the water class, optical data may identify water in shaded bare soil areas while, for radar data, it was expected a good recognition with VV and especially VH band. However, as the sea area has been masked, only tiny mountain lakes and rivers are considered water bodies. Moreover, low VV and VH values can be seen also in other types of surfaces, especially bare soil, which may be confused with water. Entropy and Alpha bands have lower values in bare soil rather than in water, so they can improve their differentiation.
Forest and vegetation classes, instead, present the most limited improvement using H, \(\alpha\), sum and ratio bands, since they present similar Entropy and \(\alpha\) in the dual \(H/\alpha\) plane plot and maybe less discriminable.
Land cover classification is an important preliminary step for many other earth observation applications; regarding SSM retrieval, Sentinel-1 mission showed a strong potential at high/moderate spatial resolutions using multi-temporal acquisitions (Wagner et al., 2009), which are easily manageable in cloud computing platforms like Google Earth Engine (Gorelick et al., 2017; Volpini, 2021). Although the WCM proved to be effective on separation of soil and vegetation contributions using NDVI, it requires real calibration data in situ and sophisticated optimization methods to derive \(C\) and \(D\) parameters. Moreover, the WCM accuracy (RMSD = 12.3) is not adequate. Instead, Tu Wien accuracy (RMSD = 9.4) is still low, also compared to the Copernicus Global Land Service product. This retrieves SSM from Sentinel-1 using the same algorithm with an RMSD of 6% but with a spatial resolution of \(1km\). However, the result obtained is in accordance with that obtained by Bauer-Marschallinger et al. (2019), who investigated the Tu Wien algorithm performance using Sentinel-1 data over Italy. They obtained results that show an overall agreement between S1 SSM and in situ measurements in Umbria of RMSD = 8.8%; due to the interference of vegetation dynamics in summer the retrieval show a lower correlation (RSMD = 9%). Also, the MUSLEM software accuracy ranges between 3 and 12% (Pulvirenti et al., 2018).
Considering that Volpini, 2021 obtained a higher accuracy (6.5%) by applying the same algorithm and validating it using ISMN in Cabrières-d’Avignon (France), where the station is in a flat area, the topography factor may have influenced the results in this study.
While the agreement with ground data acquired at Umbria in situ stations is on average low, the moisture values show adequate correlation to precipitation, with a Pearson correlation index of 0.46 (Fig. 10). This finding can be considered another validation of Tu Wien model, as this value is coherent with the correlation found by Sehler et al., 2019 in Mediterranean region croplands.
The rainfall events always correspond to a peak in SSM values. It must be considered that, due to temporal intervals between the rainfall event and the soil moisture estimate (maximum of three days), the strength of the moisture peak may be reduced and, thus, the correlation between soil moisture and precipitation can be underestimated. SSM estimates in different land cover classes show a different \({R}^{2}\) index in different land cover types. A stronger correlation is visible in bare soil (R2 = 0.655) and cultivated lands (R2 = 0.58). The lower correlation is found in forested areas (R2 = 0.461), where the vegetation structure and dielectric constant may have a greater influence than surface backscattering.
Analyzing more specifically moisture values in different crops type (Tab. 5), corn requires considerable volumes of water during its development cycle: for the total growing season (from April to July) it is around \(580\mathrm{mm}\) (McKenzie & Wood, 2011). Therefore, it needs to be irrigated in the regions of central and southern Italy. During the maturation, it is preferable that the amount of water remains above half of the retention capacity of the soil (Pastrello, 2012). According to the classification made by the United States Department of Agriculture (USDA), the soil texture of the UNIVPM’s farm is clay loam (“Texture USDA class”, n.d.) and water retention capacity, in clay soils, corresponds to 50% of moisture content. The average moisture in which corn is found in the different growth stages, especially during the ripening period, is well below 50% of the water retention capacity. Although this threshold, of course, varies in every single soil, depending on its composition, the moisture of the corn field was in fact not sufficient to meet the water requirements in the final stages of maturation. However, an analysis of the vertical profile of moisture content would still be \(1\mathrm{m}\) depth (Pastrello, 2012).
Concerning the durum wheat, in the emergence and tillering phase water stress is quite rare, while it is higher during the stem elongation and ripening phase. The total growing season water use varies between \(400\) and \(480 \mathrm{mm}\) (McKenzie & Wood, 2011). During the lifting and ripening phases, it is also important that the temperature does not increase excessively, as it often happens in central and southern Italy. In addition to increasing evapotranspiration, the heat squeeze causes a rapid loss of moisture in the grain, causing a stunted harvest (Camerini, 2013). The year 2020 was characterized by high average monthly temperatures compared to the 1981–2010 average, especially in the month of February, where an anomaly of more than 3.7° was recorded (Tognetti & Leonesi, 2020). This aspect, together with the low rainfall winter season, explains the low value of average moisture in the germination-emergence phase. This situation is not unfavorable in wheat, which, on the contrary, fears winter frosts and water stagnation.
Finally, sorghum has been studied. This crop has a reduced water requirement, around 300–350 mm, and it is sufficient that it rains between 120 and 150 mm in the summer months. However, this condition was not guaranteed during the summer of 2020. Therefore, sorghum was irrigated twice a month during the reproductive phase between June and July. Usually, a couple of irrigations are sufficient to maintain adequate levels of moisture. Sorghum, in fact, has excellent adaptability to water stress, thanks to a very fit and deep developing root system, and to its leaves, covered by wax. Sorghum can remain in vegetative stasis for a period of drought, until the water becomes available again and the plant resumes its growth. In fact, sorghum shows ideal soil moisture levels for the period analyzed. For these reasons, and because of the possibility of being used as biomass, sorghum is of particular interest in the region (EU, 2017).
Finally, the main limitations of the methods applied are discussed below. It can be noticed that the major limitation of these classifications is the uncertainty of the training data selection, due to the unavailability of updated ground truth data. This uncertainty also affects the final kappa indices, which may be over-estimated, since the data used for validation are a random subset of the polygons drawn for training. The training data have been selected in the most representative areas of each class, anyway, avoiding edges or areas of uncertainty. Precisely within these areas, classification errors can occur that could be over-looked in the validation phase. In urban areas, it is essential to select only pure pixels (without vegetation), which have been classified correctly, as the confusion matrices reported (see Online Resource 2). Urban area mixed pixels (vegetation and urban) are often classified as natural vegetation. Mainly for this reason urban areas are underestimated, even with the radar data addition.
Regarding SSM retrieval, the main sources of error may be due to the fact that a high spatial resolution can generate greater uncertainty with respect to any objects on the surface, and the absence of pronounced wet conditions in the data record period, as at the end of summer mainly dry conditions can be expected. In this study, the short S1 data interval used can lead to underestimating or overestimating the severity of extreme events. Supposing the vegetation and roughness conditions are stable during the month, the other source of error may be the challenging topography and residuals error derived from the imperfect incidence angle normalization.
5 Conclusions
The integration of optical and radar images for land cover classification is of great value because of their complementary and the possibility to improve the temporal resolution of the classification. In this paper it has been shown that the combined use of radar and optical data can improve the classification results. The use of Entropy and Alpha band can be useful to improve radar classification, exceeding optical accuracy in urban and water areas, but still does not allow to reach the overall optical accuracy.
Land cover classification is also an essential precursor to many techniques for extracting geophysical and biophysical information from SAR data. In this study, the land cover results were used to create a mask and isolate the agricultural areas where soil moisture retrieval was carried out. While WCM accuracy was inadequate due to the lack of calibrations data, the extraction of surface soil moisture using Tu Wien change detection method in Google Earth Engine was found to be acceptable. As it showed a low RMDS of 9.4% with in situ measurement, but a correlation with precipitation (0.46) which is in line which the one obtained by Sehler (2019), a further in-depth study is required, to finally develop an easy-accessible and high temporal and spatial resolution method for soil moisture monitoring. In fact, SSM is a valuable information for developing context-specific climate-smart farm practices, such as drought monitoring, irrigation planning and assessment of soil erosion by water estimations, which is a critical Mediterranean region environmental issue. The use of SSM to replace the runoff term in the Modified Universal Soil Loss Equation model has been tested by Todisco et al. (2015) and could be further implemented using S-1 high resolution SSM estimate to calculate soil erosion at the field scale.
Data availability
The Sentinel-1 GRD and Sentinel-2 datasets analyzed during the current study are available in GEE at the following link https://developers.google.com/earth-engine/datasets/. The Sentinel-1 SLC datasets area available through the Alaska Satellite Facility: https://asf.alaska.edu/. Finally, the SSM dataset used for validation is available in the International Soil Moisture Network: https://ismn.geo.tuwien.ac.at/en/. The list of Sentinel-1 data analyzed during the current study is available in the supplementary information (Online resource 1). The datasets generated (confusion matrices) during the current study are available in the supplementary information (Online resource 2). The codes developed during the current study are available in the GitHub repository, https://github.com/benedettabb/agricolture-moisture-Marche.
References
Alaska satellite facility. Retrieved February 1, 2022, from https://asf.alaska.edu/
AleksMat (2022). Sentinel Hub's cloud detector for Sentinel-2 imagery. Retrieved February 1, 2022, from https://github.com/sentinel-hub/sentinel2-cloud-detector
Appiotti, F., Krželj, M., Russo, A., Ferretti, M., Bastianini, M., & Marincioni, F. (2014). A multidisciplinary study on the effects of climate change in the northern Adriatic sea and the Marche region (central Italy). Regional Environmental Change, 14(5), 2007–2024. https://doi.org/10.1007/s10113-013-0451-5
Arzeni, A. (2003). Il territorio rurale e le politiche agricole nelle marche. Osservazioni Analisi. Osservatorio Agroalimentare delle Marche.
Attema, E., & Ulaby, F. T. (1978). Vegetation modeled as a water cloud. Radio Science, 13(2), 357–364. https://doi.org/10.1029/RS013i002p00357
Baghdadi, N., El Hajj, M., Zribi, M., & Bousbih, S. (2017). Calibration of the water cloud model at c-band for winter crop fields and grasslands. Remote Sensing, 9(9), 969. https://doi.org/10.3390/rs9090969
Baghdadi, N., Holah, N., & Zribi, M. (2006). Soil moisture estimation using multi-incidence and multi-polarization ASAR data. International Journal of Remote Sensing. https://doi.org/10.1080/01431160500239032
Balenzano, A., Mattia, F., Satalino, G., & Davidson, M. W. (2010). Dense temporal series of C-and L-band SAR data for soil moisture retrieval over agricultural crops. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 4(2), 439–450. https://doi.org/10.1109/JSTARS.2010.2052916
Banque, X., Lopez-Sanchez, J. M., Monells, D., Ballester, D., Duro, J., & Koudogbo, F. (2015). Polarimetry-based land cover classification with sentinel-1 data. Proc. of POLINSAR, 729, 1–5.
Barchiesi, F. (2017). Analisi morfodinamica di un tratto del fiume Esino (ripa bianca) per la valutazione dell’aggiustamento geomorfologico dell’alveo. Università degli Studi di Urbino "Carlo Bo".
Bauer-Marschallinger, B., Freeman, V., Cao, S., Paulik, C., Schaufler, S., Stachl, T., Modanesi, S., Massari, C., Ciabatta, L., Brocca, L., & Wagner, W. (2019). Toward global soil moisture monitoring with Sentinel-1: Harnessing assets and overcoming obstacles. IEEE Transactions on Geoscience and Remote Sensing, 57(1), 520–539. https://doi.org/10.1109/TGRS.2018.2858004434
Bhogapurapu, N., Dey, S., Homayouni, S., Bhattacharya, A., & Rao, Y. (2022). Field-scale soil moisture estimation using sentinel-1 GRD SAR data. Advances in Space Research. https://doi.org/10.1016/j.asr.2022.03.019
Bindlish, R., & Barros, A. P. (2002). Subpixel variability of remotely sensed soil moisture: An inter-comparison study of SAR and ESTAR. IEEE Transactions on Geoscience and Remote Sensing, 40(2), 326–337. https://doi.org/10.1109/36.992792
Borrelli, P., Paustian, K., Panagos, P., Jones, A., Schütt, B., & Lugato, E. (2016). Effect of good agricultural and environmental conditions on erosion and soil organic carbon balance: A national case study. Land Use Policy, 50, 408–421. https://doi.org/10.1016/j.landusepol.2015.09.033
Camerini, M. (2013). Effetto della tecnica agronomica e dell’ambiente pedo-climatico su accrescimento e resa quali-quantitativa di varietà di frumento duro. Università degli Studi del Molise. Dipartimento Agricoltura, Ambiente e Alimenti. Dottorato di Ricerca in “Difesa e Qualità delle Produzioni Agroalimentari e Forestali”.
Carrasco, L., O’Neil, A. W., Morton, R. D., & Rowland, C. S. (2019). Evaluating combinations of temporally aggregated Sentinel-1, Sentinel-2 and Landsat 8 for land cover mapping with Google Earth Engine. Remote Sensing, 11(3), 288. https://doi.org/10.3390/rs11030288
Cloude, S. R., & Pottier, E. (1996). A review of target decomposition theorems in radar polarimetry. IEEE Transactions on Geoscience and Remote Sensing, 34(2), 498–518. https://doi.org/10.1109/36.485127
Costantini, E. A., Urbano, F., Bonati, G., & Nino, P. (2007). Atlante nazionale delle aree a rischio di desertificazione. https://doi.org/10.13140/2.1.5124.0645
Developer Guide Google Earth Engine. Retrieved February 1, 2022, from https://developers.google.com/earth-engine. Ultimo accesso: 01.02.2022
EEA. (2017). European Environmental Agency. Climate change, impacts and vulnerability in Europe 2016. An indicator-based report.
Esch, S. (2018). Determination of soil moisture and vegetation parameters from spaceborne c-band sar on agricultural areas. Universität zu Köln.
Fang, B., Lakshmi, V., Jackson, T. J., Bindlish, R., & Colliander, A. (2019). Passive/active microwave soil moisture change disaggregation using SMAPVEX12 data. Journal of Hydrology, 574, 1085–1098. https://doi.org/10.1016/j.jhydrol.2019.04.082
FAO. Climate-Smart Agriculture. Available online: https://www.fao.org/climate-smart-agriculture/on-the-ground/en/. Accessed March 21, 2022.
Farr, T. G., & Kobrick, M. (2000). Shuttle radar topography mission produced a wealth of data. Eos, Transactions American Geophysical Union, 81(48), 583–585. https://doi.org/10.1029/EO081i048p00583
Filion, R., Bernier, M., Paniconi, C., Chokmani, K., Melis, M., Soddu, A., & Lafortune, F. X. (2016). Remote sensing for mapping soil moisture and drainage potential in semi-arid regions: Applications to the Campidano plain of Sardinia, Italy. Science of the Total Environment, 543, 862–876. https://doi.org/10.1016/j.scitotenv.2015.07.068
Fischer, E. M., Seneviratne, S. I., Vidale, P. L., Lüthi, D., & Schär, C. (2007). Soil moisture–atmosphere interactions during the 2003 European summer heat wave. Journal of Climate, 20(20), 5081–5099. https://doi.org/10.1175/JCLI4288.1
Fung, A. K., Li, Z., & Chen, K. S. (1992). Backscattering from a randomly rough dielectric surface. IEEE Transactions on Geoscience and Remote Sensing, 30(2), 356–369. https://doi.org/10.1109/36.134085
Gao, Q., Zribi, M., Escorihuela, M. J., & Baghdadi, N. (2017). Synergetic use of sentinel-1 and sentinel-2 data for soil moisture mapping at 100 m resolution. Sensors, 17(9), 1966. https://doi.org/10.3390/s17091966
Ge, L., Hang, R., Liu, Y., & Liu, Q. (2018). Comparing the performance of neural network and deep convolutional neural network in estimating soil moisture from satellite observations. Remote Sensing, 10(9), 1327. https://doi.org/10.3390/rs10091327
Gorelick, N., Hancher, M., Dixon, M., Ilyushchenko, S., Thau, D., & Moore, R. (2017). Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sensing of Environment, 202, 18–27. https://doi.org/10.1016/j.rse.2017.06.031
Guo, X., Fu, Q., Hang, Y., Lu, H., Gao, F., & Si, J. (2020). Spatial variability of soil moisture in relation to land use types and topographic features on hillslopes in the black soil (mollisols) area of northeast China. Sustainability, 12(9), 3552. https://doi.org/10.3390/su12093552
Hajnsek, I., Pottier, E., & Cloude, S. R. (2003). Inversion of surface parameters from polarimetric SAR. IEEE Transactions on Geoscience and Remote Sensing, 41(4), 727–744. https://doi.org/10.1109/TGRS.2003.810702
Haldar, D., Rana, P., & Hooda, R. S. (2019). Biophysical parameter assessment of winter crops using polarimetric variables—Entropy (H), anisotropy (A), and alpha (α). Arabian Journal of Geosciences, 12(12), 1–14. https://doi.org/10.1007/s12517-019-4516-8
Harfenmeister, K., Itzerott, S., Weltzien, C., & Spengler, D. (2021). Agricultural monitoring using polarimetric decomposition parameters of sentinel-1 data. Remote Sensing, 13(4), 575. https://doi.org/10.3390/rs13040575
Hornacek, M., Wagner, W., Sabel, D., Truong, H. L., Snoeij, P., Hahmann, T., & Doubková, M. (2012). Potential for high resolution systematic global surface soil moisture retrieval via change detection using Sentinel-1. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 5(4), 1303–1311. https://doi.org/10.1109/JSTARS.2012.2190136
Istat. (2013). VI censimento generale dell’agricoltura. Istat
Ji, K., & Wu, Y. (2015). Scattering mechanism extraction by a modified cloude-pottier decomposition for dual polarization sar. Remote Sensing, 7, 7447–7470. https://doi.org/10.3390/rs70607447
Kumar, L., & Mutanga, O. (Eds.). (2019). Remote Sensing of Above Ground Biomass. MDPI.
Kurnik, B., Kajfež-Bogataj, L., & Horion, S. (2015). An assessment of actual evapotranspiration and soil water deficit in agricultural regions in Europe. International Journal of Climatology, 35(9), 2451–2471. https://doi.org/10.1002/joc.4154
Lewis, P. (2019). Climate-Smart Agriculture in action: from concepts to investments. Dedicated Training for Staff of the Islamic Development Bank. Cairo, Egypt. Food and Agriculture Organization of the United Nations (FAO)
Long, D., Bai, L., Yan, L., Zhang, C., Yang, W., Lei, H., & Shi, C. (2019). Generation of spatially complete and daily continuous surface soil moisture of high spatial resolution. Remote Sensing of Environment, 233, 111364. https://doi.org/10.1016/j.rse.2019.111364
Mariotti, A., Zeng, N., Yoon, J. H., Artale, V., Navarra, A., Alpert, P., & Li, L. Z. (2008). Mediterranean water cycle changes: Transition to drier 21st century conditions in observations and CMIP3 simulations. Environmental Research Letters, 3(4), 044001. https://doi.org/10.1098/rsta.2010.0204
McKenzie, R.H., & Wood, S.A. (2011). Crop water use and requirements. Agri-facts. Practical Information for Alberta’s Agriculture Industry. Alberta Agriculture and Rural Development
Meyer, F. (2019). Chapter 2. Spaceborne Synthetic aperture radar: principles, data access, and basic processing techniques. In Flores-Anderson, A. I., Herndon, K. E., Thapa, R. B., & Cherrington, E. (Eds.). The SAR handbook: Comprehensive methodologies for forest monitoring and biomass estimation (No. MSFC-E-DAA-TN67454). https://doi.org/10.25966/nr2c-s697
Mohanty, B. P., Cosh, M. H., Lakshmi, V., & Montzka, C. (2017). Soil moisture remote sensing: State-of-the-science. Vadose Zone Journal, 16(1), 1–9. https://doi.org/10.2136/vzj2016.10.0105
Montaldo, N., Fois, L., & Corona, R. (2021). Soil moisture estimates in a grass field using Sentinel-1 radar data and an assimilation approach. Remote Sensing, 13(16), 3293. https://doi.org/10.3390/rs13163293
Oh, Y., Sarabandi, K., Ulaby, F. T., et al. (1992). An empirical model and an inversion technique for radar scattering from bare soil surfaces. IEEE Transactions on Geoscience and Remote Sensing. https://doi.org/10.1109/36.134086
Ouarzeddine, M., Souissi, B., & Belhadj-Aissa, A. (2006). Target detection and characterization using h/alpha decomposition and polarimetric signatures. In 2006 2nd International Conference on Information & Communication Technologies (Vol. 1, pp. 395–400). IEEE Xplore. https://doi.org/10.1109/ICTTA.2006.1684402
Panciera, R., & Monerris, A. (2013). Basis of an australian radar soil moisture algorithm theoretical baseline document (ATDB) Monash University.
Pastrello, A. (2012). Effetti delle lavorazioni del terreno sul contenuto idrico nel suolo nella coltura del mais (Zea mays L.). Università degli studi di Padova. Dipartimento territorio e sistemi agroforestali.
Pradhan, S. N., Anjum, M., & Jena, P. (2018). Estimation of soil moisture content by remote sensing methods: A review. Journal of Pharmacognosy and Phytochemistry, 7, 1786–1792.
Pulvirenti, L., Squicciarino, G., Cenci, L., Boni, G., Pierdicca, N., Chini, M., & Campanella, P. (2018). A surface soil moisture mapping service at national (Italian) scale based on Sentinel-1 data. Environmental Modelling & Software, 102, 13–28. https://doi.org/10.1016/j.envsoft.2017.12.022
Robinson, D. A., Campbell, C. S., Hopmans, J. W., Hornbuckle, B. K., Jones, S. B., Knight, R., Ogden, F., Selker, J., & Wendroth, O. (2008). Soil moisture measurement for ecological and hydrological watershed-scale observatories: A review. Vadose Zone Journal, 7, 358–389. https://doi.org/10.2136/vzj2007.0143
Sehler, R., Li, J., Reager, J., & Ye, H. (2019). Investigating relationship between soil moisture and precipitation globally using remote sensing observations. Journal of Contemporary Water Research & Education, 168(1), 106–118. https://doi.org/10.1111/j.1936-704X.2019.03324.x
Sentinel-1 sar user guide. Retrieved February 1, 2022, from https://sentinels.copernicus.eu/web/sentinel/user-guides/sentinel-1-sar
Shamambo, D. C., Bonan, B., Calvet, J.-C., Albergel, C., & Hahn, S. (2019). Interpretation of ASCAT radar scatterometer observations over land: A case study over Southwestern France. Remote Sensing, 11(23), 2842. https://doi.org/10.3390/rs11232842
Shukla, P., Skea, J., Calvo Buendia, E., Masson-Delmotte, V., Pörtner, H., Roberts, D., Zhai, P., Slade, R., Connors, S., … Van Diemen, R. (2019). IPCC, 2019: Climate Change and Land: an IPCC special report on climate change, desertification, land degradation, sustainable land management, food security, and greenhouse gas fluxes in terrestrial ecosystems
Skakun, S., Wevers, J., Brockmann, C., Doxani, G., Aleksandrov, M., Batič, M., & Žust, L. (2022). Cloud Mask Intercomparison eXercise (CMIX): An evaluation of cloud masking algorithms for Landsat 8 and Sentinel-2. Remote Sensing of Environment, 274, 112990. https://doi.org/10.1016/j.rse.2022.112990
Small, A. S. D. (2016). Sentinel-1a radiometric consistency between tops slc and grd products. Texture USDA class. Retrieved February 1, 2022, from https://esdac.jrc.ec.europa.eu/
Steinhausen, M. J., Wagner, P. D., Narasimhan, B., & Waske, B. (2018). Combining Sentinel-1 and Sentinel-2 data for improved land use and land cover mapping of monsoon regions. International Journal of Applied Earth Observation and Geoinformation, 73, 595–604. https://doi.org/10.1016/j.jag.2018.08.011
Tang, W., Hu, J., Zhang, H., Wu, P., & He, H. (2015). Kappa coefficient: a popular measure of rater agreement. Shanghai Archives of Psychiatry, 27(1), 62–67. https://doi.org/10.11919/j.issn.1002-0829.215010
Thorp, K. R., & Drajat, D. E. N. A. (2021). Deep machine learning with Sentinel satellite data to map paddy rice production stages across West Java. Indonesia. Remote Sensing of Environment, 265, 112679. https://doi.org/10.1016/j.rse.2021.112679
Todisco, F., Brocca, L., Termite, L. F., & Wagner, W. (2015). Use of satellite and modeled soil moisture data for predicting event soil loss at plot scale. Hydrology and Earth System Sciences, 19(9), 3845–3856. https://doi.org/10.5194/hess-19-3845-2015
Tognetti, D. & Leonesi, S. (2020). Regione Marche. Analisi clima.
Torres, R., Snoeij, P., Geudtner, D., Bibby, D., Davidson, M., Attema, E., & Rostan, F. (2012). GMES Sentinel-1 mission. Remote Sensing of Environment, 120, 9–24. https://doi.org/10.1016/j.rse.2011.05.028
UNIVPM. Azienda agraria didattico sperimentale Pasquale Rosati. Università Politecnica delle Marche. Retrieved February 1, 2022, from https://www.azienda.agraria.univpm.it/presentazione
Vollrath, A., Mullissa, A., & Reiche, J. (2020). Angular-based radiometric slope correction for sentinel-1 on google earth engine. Remote Sensing. https://doi.org/10.3390/rs12111867
Volpini, G. (2021). Sentinel-1 data processing in Google Earth Engine for soil moisture estimation and irrigation volume assessment in agricultural areas. Politecnico di Torino.
Wagner, W., Sabel, D., Doubkova, M., Bartsch, A., & Pathe, C. (2009). The potential of sentinel-1 for monitoring soil moisture with a high spatial resolution at global scale. Symposium of Earth Observation and Water Cycle Science, 3, 60.
Woodhouse, I. H. (2017). Introduction to microwave remote sensing. CRC Press.
Zribi, M., & Dechambre, M. (2003). A new empirical model to retrieve soil moisture and roughness from C-band radar data. Remote Sensing of Environment, 84(1), 42–52. https://doi.org/10.1016/S0034-4257(02)00069-X
Zucaro, R., Arzeni, A., Capone, S., Tiberi, M., Boaro, I., Massaccesi, G., Pontrandolfi, A., Tascone, F. L., & Serino, G. (2009). Rapporto sullo stato dell’irrigazione nelle Marche. Rapporto irrigazione.
Acknowledgements
The authors would like to acknowledge FIELDTRONICS S.R.L (Civitanova Marche, Macerata, Italy) for its support in providing crop data needed into the application.
Funding
Open access funding provided by Alma Mater Studiorum - Università di Bologna within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Declarations
All authors, Benedetta Brunelli, Michaela De Giglio, Elisa Magnani and Marco Dubbini, confirm that this work is original and has not been copyrighted or published elsewhere nor is currently under consideration for publication elsewhere.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Brunelli, B., De Giglio, M., Magnani, E. et al. Surface soil moisture estimate from Sentinel-1 and Sentinel-2 data in agricultural fields in areas of high vulnerability to climate variations: the Marche region (Italy) case study. Environ Dev Sustain (2023). https://doi.org/10.1007/s10668-023-03635-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10668-023-03635-w