
Abstract
Ensuring the consistent usage of formatting conventions is an important aspect of modern software quality assurance. To do so, the source code of a project should be checked against the formatting conventions (or rules) adopted by its development team, and then the detected violations should be repaired if any. While the former task can be automatically done by format checkers implemented in linters, there is no satisfactory solution for the latter. Manually fixing formatting convention violations is a waste of developer time and code formatters do not take into account the conventions adopted and configured by developers for the used linter. In this paper, we present Styler, a tool dedicated to fixing formatting rule violations raised by format checkers using a machine learning approach. For a given project, Styler first generates training data by injecting violations of the project-specific rules in violation-free source code files. Then, it learns fixes by feeding long short-term memory neural networks with the training data encoded into token sequences. Finally, it predicts fixes for real formatting violations with the trained models. Currently, Styler supports a single checker, Checkstyle, which is a highly configurable and popular format checker for Java. In an empirical evaluation, Styler repaired 41% of 26,791 Checkstyle violations mined from 104 GitHub projects. Moreover, we compared Styler with the IntelliJ plugin CheckStyle-IDEA and the machine-learning-based code formatters Naturalize and CodeBuff. We found out that Styler fixes violations of a diverse set of Checkstyle rules (24/25 rules), generates smaller repairs in comparison to the other systems, and predicts repairs in seconds once trained on a project. Through a manual analysis, we identified cases in which Styler does not succeed to generate correct repairs, which can guide further improvements in Styler. Finally, the results suggest that Styler can be useful to help developers repair Checkstyle formatting violations.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Coding conventions are widely recognized as a means to improve the internal quality of software systems (Prause and Jarke 2015). They are rules that developers agree on for writing code, which encode best coding practices, widely adopted standards, or developers’ preferences. The usage of coding conventions helps to reduce style deviations, which are nothing but distracting noise when reading code (Spinellis 2011; Prause and Jarke 2015).
However, keeping all source code files of a project compliant with the coding conventions agreed by a development team is a challenge. For that, two main activities must be performed: the detection and the repair of coding convention violations. The detection of coding convention violations can be automatically performed using linters. A linter is a tool that statically analyzes code to check its compliance with rules and warns software developers when rule violations are found. The usage of linters also brings challenges because the developers need to create a configuration according to their adopted conventions so that the linter detects the right violations (not more and not less). Nevertheless, in this paper, we focus on the latter task, i.e., the repair of violations, which is a little researched problem.
To repair coding convention violations, developers can either perform fixes manually or use automated solutions that produce fixes. Manually fixing these violations is a waste of valuable developer time. Considering formatting convention violations, which are the focus of this paper, developers could use code formatters as automated solution. However, this alternative is also not satisfactory. With code formatters, the key problem is that they do not take into account the project-specific rules, those that are configured by developers for the used linter.
Inspired by the problem statement of program repair (Monperrus 2018), we state in this paper the problem of automatically repairing formatting violations: given a program, a set of format checker rules, and one rule violation, the goal is to modify the source code formatting so that no violation is raised by the format checker. A format checker is a linter, or a part of a linter, that focuses on formatting checks, since linters cover several classes of coding conventions, e.g., naming and formatting.
In this paper, we explore that problem in the context of CheckstyleFootnote 1, a popular format checker for the Java language. We present Styler, a tool dedicated to fixing formatting violations in Java source code. The uniqueness of Styler is its applicability to any formatting convention because its approach is not based on specific format checker rules. The key idea behind Styler is the usage of machine learning to learn the formatting conventions that are used in a software project. The learning is based on training data generated by Styler through the modification of source code files to trigger violations of the formatting rules configured by developers for a given project. Once trained, Styler predicts changes on formatting characters (e.g., whitespaces) to fix formatting convention violations happening in the wild. Technically, Styler encodes Java source code containing formatting violations into abstract token sequences and uses sequence-to-sequence machine learning models based on long short-term memory neural networks (LSTMs).
To evaluate Styler, we conducted a large scale experiment using 26,791 Checkstyle formatting violations mined from 104 GitHub projects. Based on our research questions, we found out that Styler repairs many violations (41%) from a diverse set of formatting rules (24/25). It generally performs better for fixing violations related to horizontal whitespace between Java tokens than violations related to tabulations and line length. Moreover, Styler produces smaller repairs compared to the state-of-the-art machine learning formatters (Allamanis et al. 2014; Parr and Vinju 2016) and the IntelliJ plugin CheckStyle-IDEA (CheckStyle-IDEA 2021). Finally, Styler repairs violations in seconds, once it is trained for a given project.
To sum up, our contributions are:
-
A novel approach to fix violations of code formatting conventions, based on machine learning. The approach is able to learn project-specific formatting rules with a self-training data generation strategy and repair formatting rule violations with a sequence-to-sequence machine learning model;
-
A tool, called Styler, which implements our approach in the context of Java and Checkstyle, to repair Checkstyle formatting violations. The tool is made publicly availableFootnote 2 for future research and usage;
-
A dataset of real-world Checkstyle violations mined from GitHub repositories. The dataset is publicly availableFootnote 3 for future research;
-
A comparative experiment of the performance of Styler against the state-of-the-art code formatters (CheckStyle-IDEA 2021; Allamanis et al. 2014; Parr and Vinju 2016). The results of the experiment are also publicly availableFootnote 4 for the sake of open science.
The remainder of this paper is organized as follows. Section 2 presents the background of this work. Section 3 presents Styler in detail, including its workflow and technical principles. Section 4 presents the design of our experiment for evaluating Styler and comparing it with three code formatters. The experimental results are then presented in Section 5. Section 6 presents discussions, and Section 7 presents the related works. Finally, Section 8 presents the concluding remarks of this work.
2 Background
Coding conventions play an important role in software development and maintenance. In this section, we present a background on coding conventions and tools that help developers enforce them. In addition, we report on a study of the usage of Checkstyle, a tool that statically checks Java code against a specified set of coding conventions.
2.1 Coding conventions
Coding conventions, also known as coding style and coding standards, are rules that developers agree on for writing code. The usage of coding conventions does not affect the behavior of software systems. Instead, developers use them to improve code readability and maintainability. Although not all coding practices are perceived by developers as enhancing code readability (Santos and Gerosa 2018), they help to reduce style deviations, which are nothing but distracting noise when reading code (Spinellis 2011; Prause and Jarke 2015).
There are several kinds of coding conventions, e.g., conventions related to naming and formatting. In this paper, we focus on the latter, i.e., formatting conventions. Formatting refers to the appearance or the presentation of the source code. One can change the formatting by using, for instance, non-printable characters, such as spaces, tabulations, and line breaks. In free-format languages such as Java and C++, the code formatting does not change the abstract syntax tree of programs. In non-free-format languages, such as Python and Haskell, the formatting is even related to behavior, which means that correcting formatting issues can fix bugs.
To exemplify formatting conventions, consider Fig. 1, which shows two well-known ways that developers may follow when placing left curly braces in code blocks. Note that one way is to place the left curly brace in a new line (Fig. 1a) while another way is to place it at the end of the conditional expression line (Fig. 1b). The way to actually do it in a software project depends on what the project’s development team chooses. Agreeing on coding conventions to be followed in a software project is important to avoid edit wars and endless debates.

Two conventions for placing a left curly brace
2.2 Detection of coding convention violations
A challenge faced by developers is to keep their code compliant with the agreed coding conventions. Basically, every new change in the code must satisfy the adopted coding conventions. Manual analysis of code changes for checking if they do not violate the adopted coding conventions is time-consuming and error-prone. To do so automatically, one can use linters. A linter is a tool that statically analyzes code to check its compliance with rules and warns software developers when rule violations are found. The rules might be related to functional problems, such as resource leakage or incorrect logic, and maintainability problems, such as non-compliance with best practices or violations of style conventions (Beller et al. 2016). As a side note, the literature does not consistently relate linters and automated static analysis tools (abbreviated as ASATs, also known as static analyzers). However, we understand that an automated static analysis tool is any tool that analyzes source code without the need to run it, including, for instance, tools for software analytics. Therefore, in this paper, we consider that any linter belongs to the family of automated static analysis tools, but that automated static analysis tools are not all about analyzing code against a set of rules.
Linters can be usually integrated into IDEs and build tools. On the one hand, when integrated into IDEs, developers may manually run the linter before they commit their changes. If they do not do it, they might face a lot of violations raised by the linter after the end of the building step for a release or for shipping the program. On the other hand, when a linter is integrated into build tools, it might be automatically executed in Continuous Integration (CI) environments. The important coding conventions might be configured to make CI builds break when they are violated. This way, developers are forced to repair coding convention violations early in the software development process.
Several linters have been developed for different programming languages. Some examples include ESLintFootnote 5 for JavaScript, PylintFootnote 6 for Python, StyleCopFootnote 7 for C#, and RuboCopFootnote 8 for Ruby. For Java, which is our target language in this paper, a commonly used linter is CheckstyleFootnote 9. Checkstyle is composed of several checks that encode style-related rules. For instance, Checkstyle contains a check named LeftCurly that checks for the placement of left curly braces for code blocks, which is about the example illustrated in Fig. 1. Developers specify in a configuration file, then, their coding conventions by selecting and configuring Checkstyle checks. We refer to this configuration file as Checkstyle ruleset and, hereafter, we refer to Checkstyle checks as Checkstyle rules. Finally, Checkstyle is a flexible linter that can be integrated into IDEs (e.g., IntelliJ, Eclipse, and NetBeans) and build tools (e.g., Maven and Gradle).
2.3 Usage of Checkstyle in the wild
Linters have been the subject of investigation in recent research (Zampetti et al. 2017; Vassallo et al. 2018; Marcilio et al. 2019). However, the existing studies did not investigate at scale and look into how style checking tools are specifically used. In this section, we present a study focused on the usage of Checkstyle, which is a popular linter for Java that checks source code style.
2.3.1 Checkstyle usage in open-source projects
Method.
To measure the usage of Checkstyle, we queried GitHubFootnote 10 to only retrieve Java projects with at least five stars, because stars have been shown meaningful to sample projects from GitHub (Beller et al. 2017). We found 171,195 Java projects. Then, we searched each of themFootnote 11 for finding a Checkstyle ruleset file. Note that a Checkstyle ruleset file can have any name, but we followed a conservative approach towards identifying true positive files by using a set of commonly used namesFootnote 12. For simplicity, hereafter, we refer to a Checkstyle ruleset file as checkstyle.xml.
Results.
We found 4,334 Java projects containing a checkstyle.xml file, which is 2.53% of all Java projects with at least five stars on GitHub. Table 1 shows the proportion of these projects that use Maven, Gradle, or Ant as their build tools, and the Travis or Circle CI services. We note that build tools are widely used among projects using Checkstyle: 98% of the projects use at least one build tool. Moreover, 44% of the projects use a continuous integration service, which shows the software engineering maturity of the sampled projects.
2.3.2 Popularity of checkstyle rules
Method.
To check the usage of the 182 Checkstyle rulesFootnote 13, we analyzed the previously-found checkstyle.xml files from the 4,334 projects. Our goal is to investigate the most used rules and check if formatting-related rules, which are the target of this work, are widely used.
Results.
We found out that all Checkstyle rules are used. Figure 2 shows the top-10 most used rules. The bars in dark gray represent formatting-related rules, and the bars in light gray represent non-formatting rules. In addition, the bar in gray with a dot pattern represents a rule that can be about formatting, but it depends on how it is configured since it is a regex rule. In the top-10 most used rules, there are three rules related to formatting and one that can be. Notably, the top-3 most used rules are or can be formatting-related ones. Therefore, we conclude that formatting-related rules are important for developers, which validates the relevance of our work.

The top-10 most used Checkstyle rules
3 Styler
Styler is a tool dedicated to helping developers keep their source code compliant with their adopted formatting conventions by automatically fixing formatting violations in Java source code. Styler could be used in different software development workflows. For instance, Styler could be used locally as a pre-hook commit when developers are about to release projects. It could also be used in continuous integration environments, where pull requests could be automatically opened with formatting fixes’ suggestions. In this section, we present the workflow and the technical principles of Styler.
3.1 Targeted violation types
Styler is about learning and repairing violations related to formatting conventions. For instance, consider that a developer specified that left curly braces must always be placed at the end of lines (as shown in Fig. 1b). If this rule is not satisfied (e.g., such as in Fig. 1a), a given linter triggers a formatting-related violation: for instance, Checkstyle would output the violation presented in Fig. 4a, and SonarJavaFootnote 14 would find a violation of the rule “An open curly brace should be located at the end of a line”Footnote 15. In order to fix this violation, the line break before the token “{” must be replaced by a single space.
As mentioned in Section 2.1, there are different classes of conventions, e.g., formatting and naming, and consequently different automated checks in linters. In Styler, we exclusively focus on formatting checks related to non-printable characters, such as indentation and whitespace before and after punctuation. Hereafter, we refer to the linter part related to these formatting checks as format checker.
3.2 Styler workflow
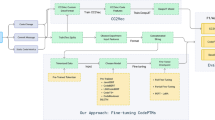
Figure 3 shows the workflow of Styler. It is composed of two main components: ‘Styler training’ for learning how to repair formatting violations and ‘Styler prediction’ for repairing a real formatting violation raised by a format checker. Styler receives as input a software project, including its source code and its format checker ruleset.

Styler workflow
The component ‘Styler training’ is responsible for learning how to repair formatting violations on the given project according to the project-specific format checker ruleset. It creates the training data by injecting formatting violations into violation-free source code files belonging to the project (step A). Then, it encodes the training data into abstract token sequences (step B) in order to train LSTM neural networks (step C). The learned LSTM models are later used to predict repairs.
The component ‘Styler prediction’ is responsible for predicting fixes for real formatting violations. It first detects formatting violations by running the format checker on the project (step D). Then, Styler encodes the violating code into an abstract token sequence (step E), which is given as input to the LSTM models (step F) previously learned. The models predict fixes for the given formatting violation. These fixes are in the format of formatting token sequences, so they are translated back to Java code (step G). Styler then runs the format checker on the new Java code containing the predicted fixes (step H). Finally, among the predicted fixes where no violation is raised by the format checker, Styler selects one formatting fix to give as output (step I). As Styler only impacts the formatting of source code, its repairs do not change the behavior of the program under consideration.
3.3 Styler in action
Consider the formatting violation presented in Fig. 4a. This violation is about the Checkstyle LeftCurly rule, which was configured to enforce that left curly braces are placed at the end of lines. The Java source code that caused such a violation is presented in Fig. 4b.

Styler from a Checkstyle formatting violation to a fix
For that violation, Styler encodes the incorrectly formatted lines (Fig. 4b) into the abstract token sequence shown in Fig. 4c. Then, this abstract token sequence is given as input to LSTM models, which predict alternative formatting token sequences, as the one shown in Fig. 4d, that may fix the current formatting violation. These predicted formatting token sequences are then used to modify the formatting tokens of the original abstract token sequence. It results in predicted abstract token sequences, as the one shown in Fig. 4e. The difference between Fig. 4c and 4e is the replacement of the formatting token 1_NL by 1_SP. This predicted repair means that the line break before the token “{” should be replaced by a single space. Then, the predicted abstract token sequence (Fig. 4e) is translated back to Java code (Fig. 4f). Finally, when running Checkstyle on the new Java code, no Checkstyle violation is raised, meaning that Styler successfully repaired the violation.
3.4 Java source code encoding
Styler encodes Java source code into an abstract token sequence that is required to predict formatting changes. An abstract token sequence is composed of pairs of abstract Java tokens and abstract formatting tokens. Styler represents each Java token as an abstract token by keeping the value of the Java keywords, separators, and operators (e.g., +→ +), and by replacing the other token kinds such as literals, comments, and identifiers by their types (e.g., x → Identifier). For each pair of subsequent Java tokens, Styler creates an abstract formatting token, which depends on the presence of a new line. If there is no new line, Styler counts the number of whitespace characters, and then represents it as n_SP when the characters are spaces and n_TB when the characters are tabulations, where n is the number of whitespaces characters (e.g., ␣→ 1_SP). If there is no whitespace between two Java tokens (e.g., x=), Styler adds 0_None between the two Java tokens.
If there are new lines between two Java tokens, Styler first counts the number of new lines and represents it as n_NL, where n is the number of new lines. Then, Styler calculates the indentation delta (Δ), i.e., the indentation difference, between the line containing the first Java token and the line containing the second Java token. Positive indentation deltas are represented by Δ_ID (indent), negative ones are represented by Δ_DD (dedent), and deltas equal to zero, i.e., no indentation change between the lines, are represented by the absence of an indentation delta representation. The complete representation after the calculation of the number of new lines and the indentation delta is n_NL_Δ_(ID|DD)_(SP|TB). For instance, in Fig. 4b, the new line between lines 7 and 8 is represented by 1_NL_4_ID_SP, i.e., one new line and indentation delta + 4.
3.5 Self-supervised training data generation
Styler does not use predefined templates for repairing formatting violations. Styler uses machine learning for inferring a model to repair formatting violations and, consequently, it needs training data. One option would be to mine past commits from the project under consideration to collect training data. However, there might not exist enough data in the history of the project for training models.
Therefore, to have enough data for training, our key insight is to generate the training data in a self-supervised manner. The idea is to modify violation-free Java files belonging to the project under analysis to trigger formatting rule violations. A similar idea has been explored by Yasunaga and Liang (2020). Then, one obtains a pair of files (αorig, αerr): αorig is the file without the formatting violation, and αerr is the file with the formatting violation. αorig is a repaired version of αerr, and we can use supervised machine learning to predict αorig given αerr. We explore this idea in two different ways to generate training data, hereafter referred to as formatting violation injection protocols. The protocol names are Stylerrandom and Styler3grams.
The Stylerrandom protocol for injecting formatting violations in a project consists of automated insertion or deletion of a single formatting character (space, tabulation, or new line) in Java source files. These modifications require a careful procedure so that 1) the project still compiles and 2) its behavior is not changed. For this, we specify the locations in the source code files that are suitable to perform the modifications. For insertions, the suitable locations are before or after any token. For deletions, the suitable locations are 1) before or after any punctuation (“.”, “,”, “(”, “)”, “[”, “]”, “{”, “}”, and “;”), 2) before or after any operator (e.g., “+”, “-”, “*”, “=”, “+=”), and 3) in any token sequence longer than one indentation character.
The Styler3grams protocol is meant to produce likely violations. Instead of directly changing the Java source code as Stylerrandom, Styler3grams performs modifications at the abstract token level. The idea is to replace formatting tokens with the ones used by developers in the same context, i.e., between the same surrounding Java tokens. For that, we use 3-grams, where a 3-gram = {Java token, formatting token, Java token}. So given a violation-free Java file, the task of Styler3grams is the following. First, the Java file is tokenized (see Section 3.4), and a random formatting token is picked and used to form a 3-gram, which is 3-gramorig. Then, given a corpus of 3-grams previously created from software projects, Styler3grams finds a 3-grami in the corpus that matches the Java tokens of 3-gramorig. Several matches can be found, but the selection of a 3-grami is random according to its frequency in the corpus. Then, the formatting token of 3-gramorig is replaced by the formatting token of 3-grami. Finally, Styler3grams performs a de-tokenization so that a violating Java version of the original violation-free Java file is created.
Algorithm 1 presents the algorithm that Styler uses to generate one training dataset per formatting violation injection protocol (Stylerrandom and Styler3grams). The input of the algorithm is the format checker ruleset of the project, a corpus of violation-free Java files taken from the project, the number of violating files to be generated, the injection protocol to be used, and the maximum duration of the process. Then, in each batch iteration (line 7), a file is randomly selected from the corpus of violation-free Java files (line 12), and the specified injection protocol is applied to it (line 13). Once a batch is completed, the format checker is executed on the resulting modified files (line 16) so that the algorithm selects the ones that contain a single violation (line 17). The algorithm ends when the desired number of files with violations is reached or when the process reaches the specified maximum duration.
3.6 Violation encoding
In order to repair formatting violations, the Java source code encoded as an abstract token sequence must capture both the violation in the code and the context surrounding the violation. So, for a given violation, Styler considers a token window of k source code lines before and after the violation location provided by the format checker for creating an abstract token sequence (see Section 3.4). Once the violating line and the ones surrounding it are tokenized, Styler places two tags around the tokens related to the origin of the violation so that the violation location and its type can be further identified. The tags consist of the name of the format checker rule that was violated. For instance, the violation presented in Fig. 4a is about the Checkstyle LeftCurly rule, so the tags around the violation are <LeftCurly> and </LeftCurly> as shown in Fig. 4c.

The strategy to place the tags in the abstract token sequence is primarily based on the fact that the tags should surround the tokens related to the origin of the violation. At the same time, the number of tokens between the two tags should be minimal so to keep precise information about the violation location. Thus, Styler places the tags according to the location information given by the format checker. When the format checker provides the line and the column, Styler places <ViolationType> one token before the violation and </ViolationType> one token after. When the format checker provides the line but not the column (e.g., when the violation is about the Checkstyle LineLength rule), Styler places <ViolationType> one token before the line and </ViolationType> one token after the end of the line.
3.7 Machine learning model
Learning (Fig. 3–step C).
Styler aims to translate a token sequence with a formatting violation (input sequence) to a new token sequence with no formatting violation (output sequence). Styler uses a sequence-to-sequence translation based on recurrent neural network LSTMs (Long Short-Term Memory), similar to what is used for natural language translation. Thanks to the token abstraction employed by Styler to encode Java source code (see Section 3.4 and Section 3.6), the input and output vocabularies are small (respectively \(\sim \)150 and \(\sim \)50), hence are well handled by LSTM models. Styler uses LSTMs with bidirectional encoding, which means that the embedding is able to catch information around the formatting violation in the two directions. For instance, a violation triggered by the Checkstyle WhitespaceAround rule, which checks that a token is surrounded by whitespaces, requires the contexts before and after the token.
Repairing (Figure 3–step F).
Once the LSTM models are trained (one per formatting violation injection protocol, see Section 3.5), Styler can be used for predicting fixes for a token sequence I as in Fig. 4c. For an input sequence I, an LSTM model predicts x alternative formatting token sequences using a technique called beam search, which we use off-the-shelf. These alternatives are all potential repairs for the formatting violation (e.g., Fig. 4d).
Note that the LSTM models predict formatting token sequences (e.g., Fig. 4d), but the goal is to have abstract token sequences containing Java and formatting tokens (e.g., Fig. 4e), so they can further be translated back to Java code. For that, Styler generates a new abstract token sequence (Oi) for each formatting token sequence (Fi), based on the original input I, such as in Fig. 5a. Recall that I is composed of pairs of Java tokens and formatting tokens (see Section 3.4), therefore its number of formatting tokens is LI = length(I)/2. However, an LSTM model does not enforce the output size, thus we cannot guarantee that the length of a predicted formatting token sequence (\(L_{F_{i}} = length(F_{i})\)) is equal to LI. If \(L_{F_{i}}>L_{I}\), Styler uses the first LI formatting tokens from Fi and ignores the remaining ones to generate Oi, such as in Fig. 5b. If \(L_{F_{i}}<L_{I}\), Styler uses all formatting tokens from Fi and copies the \(L_{F_{i}}+1, L_{F_{i}}+2, \ldots , L_{I}\) original formatting tokens from I, such as in Fig. 5c. Finally, after creating x abstract token sequences O, Styler continues its workflow (Fig. 3–step G).

Generation of the sequence Oi based on the predicted formatting tokens Fi and the input I
3.8 Repair verification and selection
Styler performs x predictions per LSTM model (i.e., Stylerrandom-based model and Styler3grams-based model), so in the end Styler generates x × 2 predictions to repair a single violation. After the translation of these predictions back to Java source code (Fig. 3–step G), Styler performs a verification (Fig. 3–step H), where the format checker is executed on the resulting Java source code files. Finally, given the files that do not result in formatting violations, Styler selects the one that has the smallest source code diff to give as output (Fig. 3–step I).
3.9 Implementation
The approach employed by Styler is independent of the considered format checker. The current implementation uses Checkstyle, which is a popular format checker for Java. Other format checkers can be integrated in Styler. However, they must output the violation type and the violation location. This is necessary for the violation encoding (see Section 3.6).
Styler is implemented in Python. We use javalangFootnote 16 for parsing and OpenNMT-pyFootnote 17 for the machine learning part. Styler is publicly available at https://github.com/KTH/styler/. The current calibration of Styler is presented in Section 4.4.1.
4 Evaluation design
We conducted an empirical study to evaluate Styler from different perspectives (see Section 4.1), including a comparison against three state-of-the-art code formatting systems (see Section 4.2). We first built a dataset of Checkstyle violations mined from GitHub repositories (see Section 4.3), and then we gave these violations as input to all the four tools (see Section 4.4) to measure their repairability. In this section, we present the design of our study.
4.1 Research questions
Our goal is to answer the following six research questions.RQ #1 [Overall repairability]: To what extent does Styler repair real-world Checkstyle formatting violations, compared to other systems?
Overall repairability is an important metric to measure the value of tools. We investigate the repairability of Styler on real Checkstyle violations, which allows us to understand to what extent Styler repairs formatting violations that have occurred in practice. Moreover, we compare the repairability of Styler to the repairability of three code formatters by using the same dataset of violations to investigate if, and to what extent, Styler outperforms the related systems.RQ #2 [Violation-type-based repairability]: To what extent does Styler repair different violation types, compared to other systems?
Checkstyle has different formatting rules, so it raises different violation types. In this research question, we investigate if, and to what extent, Styler repairs different violation types compared to the other systems. This analysis is also important to investigate if the systems are complementary to each other.RQ #3 [Unsuccessful repair cases]: What are the cases in which Styler fails to generate a correct repair?
Understanding the cases in which Styler fails to generate a correct repair is important so that i) Styler can be further improved, ii) hard-to-repair violations are identified and, consequently, researchers might study them and develop tools specialized to repair them, and iii) the limitations of Styler can be taken into account by developers when deciding whether or not to use Styler in their projects. To discover the most frequent cases in which Styler does not succeed to generate a correct repair, we manually analyzed violations of the rules for which Styler does not perform well.RQ #4 [Quality]: What is the size of the repairs generated by Styler, compared to other systems?
What are the cases in which Styler fails to generate a correct repair? There may be several alternative repairs that fix a given Checkstyle violation, including ones that change source code lines other than the ill-formatted line. In this research question, we compare the size of the repairs generated by Styler against the repairs generated by the other systems.RQ #5 [Performance]: How fast is Styler for learning and predicting formatting repairs?
To investigate if Styler could be applicable in practice, we measure its performance for fixing the mined Checkstyle violations. This is valuable information for those who could be interested in using Styler as a pre-commit hook in IDEs or continuous integration services.RQ #6 [Technical analysis]: How do the two training data generation techniques of Styler contribute to its repairability?
Finally, we perform a comparison between the two formatting violation injection protocols used to generate training data (see Section 3.5). This comparison is done through the LSTM models trained with the two different training sets. We investigate if, and to what extent, one of the models contributes more to the repairability of Styler. This is an important investigation from the point of view of users who might want to use Styler with only one model for performance reasons.
4.2 Systems under comparison
We selected three systems to compare Styler with: CheckStyle-IDEA (CheckStyle-IDEA 2021), Naturalize (Allamanis et al. 2014), and CodeBuff (Parr and Vinju 2016). CheckStyle-IDEA, also referred to as CS-IDEA in this paper, is an IDE-based code formatter plugin for the IntelliJ IDE. It provides IDE-integrated feedback against a given Checkstyle ruleset and fixes Checkstyle violations through the IntelliJ formatter by taking into consideration a Checkstyle ruleset. Naturalize is a tool dedicated to assisting developers in fixing coding conventions related to naming and formatting in Java programs. It learns coding conventions from a codebase and suggests fixes to developers, such as formatting modifications, based on the n-gram model. CodeBuff is a code formatter applicable to any programming language with an ANTLR grammar. Instead of formatting the code according to ad-hoc rules for a language, CodeBuff aims to infer the formatting rules given a grammar for the language and a set of files following the same formatting rules. For each token, a KNN model decides to indent it or to align it with another token based on the abstract syntax tree of the source file.
All three systems are code formatters. CheckStyle-IDEA takes a Checkstyle ruleset into consideration, and Naturalize and CodeBuff are the state-of-the-art machine learning formatters that aim to assist developers to fix formatting-related issues without any prior or ad-hoc formatting rules.
4.3 Data collection
To execute Styler and the systems under comparison and, consequently, answer our research questions, we created a dataset of Checkstyle formatting violations by mining open-source projects. The first step was to build a list of projects, which was done based on the data previously collected for the study presented in Section 2.3. We selected all the projects that have exactly one Checkstyle ruleset file and use Maven. This resulted in 2,143 projects.
For each project, we tried to reproduce Checkstyle violations with the following automated lightweight approach. First, the remote repository of the project is cloned from GitHubFootnote 18. Then, a sanity check is performed on the checkstyle.xml file contained in the project. If the file contains variables, the project is discarded. Otherwise, a search in the history of the project is done for the last commit (ci) that contains modifications in the checkstyle.xml file, which is the commit to be used as the starting point for the reproduction of real violations. Then, ci is checked out, and all the files of the project are submitted to a process that aims to check if our automated approach can successfully execute Checkstyle on the project and with which version of Checkstyle. The latter is necessary because new versions of Checkstyle might introduce breaking backward compatibilityFootnote 19 and, then, fail to parse a checkstyle.xml file that was used with previous versions of Checkstyle. Such a process consists of executing multiple Checkstyle versions on the project, from a newer version to an older one, until finding one version that does not fail or until the available options endFootnote 20. If a successful Checkstyle execution is found, the last tested Checkstyle version, x, is chosen to be used on the project. All commits since ci are then gathered, inclusive, so that all commits to be analyzed are based on the same Checkstyle ruleset.
Then, each selected commit is checked out, and a sanity check is performed on the pom.xml file of the commit. If it points to a suppression file, the commit is discarded because we want violations that happened in practice and our lightweight approach does not solve paths. Otherwise, the Checkstyle version x is executed on the files of the project. If the commit under analysis is the first one to be analyzed, Checkstyle is executed on all the files of the project. Otherwise, Checkstyle is executed only on the files changed in the commit under analysis to avoid duplicate violations in the dataset. Moreover, Java files in folders named test or resources are ignored since we want violations that happened in the main source code. Then, after executing Checkstyle, if at least one Checkstyle violation is raised, the violating Java files and information about the violations, e.g., Checkstyle violation types and locations, are saved.
Such a process was executed for all the 2,143 projects in our list. At the end of the process, we removed duplicate Java files according to the file content among all commits if any. Then, we selected the files containing a single Checkstyle violation that is related to formatting. We performed this selection to accurately evaluate repairs produced by Styler and the other tools. Finally, we kept projects where all criteria yield at least 20 Checkstyle formatting violations. By applying this systematic reproduction and selection process, we obtained a dataset containing 27,058 Checkstyle violations spread over 105 projects. We used one project, and the violations found in it (267), to calibrate Styler (see Section 4.4.1), and the other 104 projects with 26,791 violations for the actual evaluation.
The dataset is diverse in terms of projects and violation types. Table 2 shows the subject projects. The projects are very diverse in several aspects, such as in number of Java files (min = 2, med = 532, max = 18,206), commits (min = 13, med = 1,251, max = 71,544), contributors (min = 1, med = 14, max = 249), and stars (min = 5, med = 46, max = 24,888). Additionally, Table 3 shows the stats per Checkstyle formatting rule. We note that the most frequent violations in our dataset are violations of the rules RegexpSingleline, EmptyLineSeparator, and LineLength.
4.4 Setup and execution of the systems
We gave the dataset of violations as input to Styler and the three systems under comparison to evaluate their repairability. In this section, we present the setup of the systems, which includes the calibration of Styler, the adaptations performed in Naturalize and CodeBuff, and how the four systems were executed.
4.4.1 Styler calibration
To calibrate Styler, i.e., the Stylerrandom- and Styler3grams-based models, we performed an exploratory study by training LSTM models with different configurations. The configurations combine values for key parameters, which are the model attention type (general or mlp), the number of layers (one or two) and units (256 or 512) for the model encoder/decoder, and the model word embedding size (256 or 512). For each configuration, the training was performed for a maximum of 20k iterations, with a batch size of 32, and a model was saved in the iterations 5k, 10k, 15k, and 20k. This means that, in the end, we obtained 64 models (2 model attention types × 2 numbers of layers × 2 numbers of units × 2 embedding sizes × 4 training iterations) per training data generation protocol (i.e., Stylerrandom and Styler3grams).
Those models were created for one open-source projectFootnote 21 contained in our dataset (see Section 4.3), which was randomly selected from the top-5 projects with the most diversity of violated formatting rules. The project was given as input to Styler, which produced training data by injecting Checkstyle violations in violation-free files found in the project (see Section 3.5). For each protocol, 10k violations were injected. This data was used to train the LSTM models, where 9k violations were used for training and 1k for validation. Once the 64 models per protocol were created, we executed Styler with each of them on the real violations found in the project so that we could test the models and choose the configuration of the best ones. Then, for each protocol, we picked the configuration of the model that repaired violations in a more balanced way in terms of Checkstyle rules. The best Stylerrandom-based model was with the mlp model attention, one layer, 256 units, embedding size of 512, and 5k training iterations, and the best Styler3grams-based model was with the same values for the numbers of layers, embedding size, and training iterations, but with the general model attention and 512 units. These are the configurations we used for training the models for our experiments presented in Section 5.
For prediction, the beam search creates x = 5 potential repairs per model. As for the violation encoding (see Section 3.6), we set k = 6. Recall that this parameter is about the token window before and after the violation (i.e., the context surrounding the violation). This parameter is made big enough to contain important information and, at the same time, small enough to still allow learning and prediction, and was set based on meta-optimization.
4.4.2 Naturalize and CodeBuff adaptation
To use Naturalize, we had to slightly modify it. Naturalize recommends multiple fixes, so we take the first one for a given violation as being the repair. In addition, we changed Naturalize to only work for indentation, excluding fixes regarding naming conventions (which are out of the scope of this paper). To run CodeBuff, we give it the required configuration, including the number of spaces for indentation. This value depends on the project given as input to CodeBuff. Thus, before running CodeBuff on a project, we count the most frequent indentation size found in the violation-free files of the project and provide it to CodeBuff.
4.4.3 Execution of the systems
The four systems were executed to repair the 26,791 violations found in the 104 projects contained in the real violation dataset. The machine-learning-based systems (Styler, Naturalize, and CodeBuff) require a corpus of violation-free files to be trained. Therefore, for each subject project, we selected, as training seeds, all violation-free Java files from the first commit, or any subsequent one, that uses the same Checkstyle ruleset used to collect the real violations. We took special care of consistency in our experiment: all the three machine-learning-based systems were trained to repair a given project using the same corpus of violation-free files from the project.
Styler requires other input for training. Recall that its training process includes a step for creating the actual training data (see Fig. 3–step A), which is based on the corpus of violation-free files. For each protocol, we set Algorithm 1 to create 10,000 files per project, with a maximum duration of three hours. The resulting files with violations were split for learning and validation in a balanced way according to the violation types, considering 90% for learning and 10% for validation.
Finally, to run CheckStyle-IDEA on each subject project, we first loaded the violating Java files and the checkstyle.xml file contained in the project in IntelliJ. Then, we imported the Checkstyle ruleset (Settings > Editor > Code Style > Import Scheme > Checkstyle Configuration) and simply called the function “Reformat Code” from the IDE.
5 Evaluation results
We present and discuss the results for our six research questions in this section.
5.1 Overall repairability (RQ #1)
To investigate the overall repairability of Styler and the other three systems on the 26,791 Checkstyle violations, we categorized the repair attempts per status, as shown in Table 4. There are two groups of status: repaired and not repaired. The repaired violations are either fully repaired, i.e., no violation is raised after the repair attempt, or partially repaired, i.e., the violation no longer exists in the source code but new violations were introduced. For the sake of clarity, it is worth mentioning that only the full repairs are used for the other five research questions. The group of violations that were not repaired includes the cases where a resulting source code file still contains the same violation only or the same + new violations, or is broken, which means that the file cannot be parsed by javalang after the repair attempt.
Styler fully repaired 41% of the violations while CS-IDEA repaired 50%, which is the greatest overall repairability among the four considered tools. Naturalize and CodeBuff repaired fewer violations (15% and 20%, respectively). To check if there is a significant difference between Styler and the other tools regarding the full repairs, we used McNemar test. Table 5 shows the contingency tables given as input to the test. We found p-value< 0.00001 for all the three tests. Considering α = 0.05, this means that Styler and any other tool have a statistically significant different proportion of errors on our dataset of violations. Note that the p-values were not adjusted since they are too small and the adjustment would have no impact.
Considering the numbers presented in Table 4 other than the proportions of fully-repaired violations, we noticed that CS-IDEA and Styler are the most reliable tools in the sense of delivering to an end-user either a repaired source code or, in the worst-case scenario, the code with the same violation. It is not the same case of Naturalize and CodeBuff, which had higher rates of delivering broken source code. They were, however, designed for a different goal and do not take into account the Checkstyle ruleset of the project like Styler and CS-IDEA do. Yet, they are relevant for our experiment since they are the state of the art of machine-learning-based code formatters. Our results show the need for specialized, focused tools to repair Checkstyle violations.
In addition, we observed that some violation types, i.e., violations of different Checkstyle rules, occur in a much higher frequency than others in our dataset (see Table 3). This might cause bias in the results presented in Table 4. Because of that, we performed a normalization of the data by sub-sampling the most frequent violation types. In this way, we obtained a sub-sample of violations that contains the same number of instances for all violation types. We ignored the less frequent ones to avoid using too few instances. For that, we calculated the median of the distribution of the violation types, which is 274, and used it as the minimum number of instances for including Checkstyle rules in the analysis. Then, we randomly selected 274 violations of the included rules. In the end, the analysis comprises half of the rules (13) and 3,562 violations. The normalized results are presented in Table 6. All the tools are impacted positively in terms of fully-repaired violations. However, we note that the normalized results present a different ranking of the tools’ performance, where Styler outperforms CS-IDEA. CS-IDEA is the tool most negatively impacted by the normalization because it increases only 4% fully-repairs, while the other three tools considerably increase their repairability by 7%–20%. This suggests that CS-IDEA performs better than the other tools on violation types that are frequent in our dataset, which is investigated in more detail in the next section, for answering RQ #2. Finally, we also performed McNemar test in the normalized results, as shown in Table 7. Considering α = 0.05, the results show that Styler and any other tool have a statistically significant different proportion of errors on the sub-sample too.

5.2 Violation-type-based repairability (RQ #2)
To answer RQ #2, we investigated the extent to which Styler and the other three systems repair different Checkstyle violation types, i.e., violations of different Checkstyle rules. Figure 6 shows the Checkstyle violations fully repaired by the systems per violation type in a heatmap. The color scale is from black to white, where black represents 0% of fully-repaired violations and white represents 100% (i.e., the lighter, the better).

Types of Checkstyle violation repaired per tool
Styler and Naturalize repaired violations of 24/25 Checkstyle rules, which is the highest coverage of rules considering all the four tools. CS-IDEA and CodeBuff fixed violations of 21 rules. Surprisingly, Naturalize produced fixes for a higher number of violation types than CS-IDEA, even though it does not consider the Checkstyle ruleset of projects because of its different goals. CodeBuff performed relatively well considering that it does not target Checkstyle violations as Naturalize. These facts suggest that our idea of employing a machine learning approach for repairing format checker violations is promising.
The reason for the high overall repairability of CS-IDEA (found in RQ #1) is that it outperformed the other tools in the five most frequent rules in our dataset: RegexpSingleline, EmptyLineSeparator, LineLength, FileTabCharacter, and Indentation. This explains why CS-IDEA is the leading tool in terms of repairability on the entire dataset but not on a sample of it, as shown in RQ #1. Styler, on the other hand, had a perfect success rate in rules that are not that frequent: EmptyForIteratorPad, GenericWhitespace, ParenPad, RegexpMultiline, and SeparatorWrap. Interestingly, CS-IDEA did not repair, at least not fully, any violation of two of these rules. This indicates that the tools are complementary to each other. Moreover, Styler performed very well, with at least 80% of repaired violations, in the rules that are related to horizontal whitespace between two Java tokens, such as MethodParamPad, NoWhitespaceAfter, and WhitespaceAround. For developers, even if fixing these types of violations is easy, they may have dozens of them, which could be overwhelming. To that extent, automation is still valuable. Moreover, Styler is able to repair these violation types for which one would not need to put engineering effort to write the repair code. Finally, we observed that all tools performed poorly on violations of the most frequent type in our dataset, i.e., RegexpSingleline.

5.3 Unsuccessful repair cases (RQ #3)
Styler repaired violations of 24/25 Checkstyle rules, but it did not perform well for some rules as shown in RQ #2. To understand in which cases Styler does not successfully generate repairs, we manually analyzed violations of the Checkstyle rules for which Styler repaired less than 50% violations. The analysis was ad-hoc, where, for each rule, both repaired and non-repaired violations were investigated so that patterns of non-repaired violations or their contexts could be identified. We present the cases of unsuccessful repair we found as follows.
Styler encodes a violation according to the source code position returned by a format checker which is, in this case, Checkstyle. However, in some cases, this position is not where a fix should be applied. For instance, for a violation of the type OneStatementPerLineFootnote 22, a line break should be added in the column 19 or 20 of the line 42, just after the first statement. However, Checkstyle returns column 31, which is the end of the second statement. In such a case, Styler tried to repair the violation in an inappropriate location.
Several non-repaired violations were inside comments. For instance, we found lines of comments exceeding the maximum length of characters, therefore triggering violations of the type LineLengthFootnote 23. We also found tab characters inside comments, triggering FileTabCharacter violationsFootnote 24. These violations also happen with stringsFootnote 25. Styler does not handle cases in which comments or strings should be modified. This is a limitation of Styler due to its tokenization. Comments and strings are tokenized as a single token, i.e., Styler does not take into account the separation of words.
Moreover, we found several occurrences of a case in which Styler repaired a given violation but then another existing one, which was not previously reported by Checkstyle, was triggered. This case of only one violation being reported when multiple ones exist in files is recurrent and happens with FileTabCharacter violations. We were not aware of that at the time we built the real violation dataset, but when a file contains more than one tab character, Checkstyle reports only the first instance of it. In some cases, Styler repaired the first instanceFootnote 26, but the next one was then raised by Checkstyle. Even though Styler repaired the originally reported violation, it was not counted as a repaired violation in our study. Note that one criterion to select files containing violations when building the dataset was the existence of a single violation in them (see Section 4.3). This was a decision we made to guarantee we could automatically check if a given violation was fixed. In such a case with FileTabCharacter violations, however, we could not check that precisely.
Finally, we observed that RegexpSingleline violations are the most frequent ones in our dataset and are poorly handled not only by Styler, but all tools (see the last column of Fig. 6). When analyzing the violations related to this rule and other regex ones, we found out that many violations are not related to formatting. Some examples are violations related to missing, wrong, or duplicated license headerFootnote 27 and the usage of specific patterns, such as a tag in javadoc, that are forbidden in some projectsFootnote 28. Since these violations are not about formatting, they are not in the targeted violation types of Styler and other tools. However, the occurrence of these violations is very frequent in our dataset and, consequently, the repairability of the tools for such regex violations is impacted. For instance, our dataset contains 8,678 RegexpSingleline violations, and 8,102 (93%) of them are non-formatting violations. The overall repairability results about that rule, as presented in Fig. 6, are 3.2% for Styler, 5.8% for CS-IDEA, 1.4% for Naturalize, and 2.6% for CodeBuff. Adjusting the repairability results of the tools by considering only the 576 RegexpSingleline violations that are about formatting, we found out that Styler, CS-IDEA, Naturalize, and CodeBuff repaired 45.1%, 86.8%, 21%, 38.9% of RegexpSingleline violations, respectively.

5.4 Size of the repairs (RQ #4)
One aspect of repair quality is the size of the diff between the source code with a formatting violation and the repaired source code. There might be different repairs for the same violation that pass all Checkstyle rules, but the one with the smaller diff size would be preferable for being the least disrupting for the developers. In the context of a pull request on GitHub, a smaller diff is usually considered as easier to review and merge (Dias 2020).
To answer RQ #4, we calculated the diff size, in number of lines, of the repairs generated by Styler, CS-IDEA, Naturalize, and CodeBuff. Figure 7 shows the distributions of diff size per tool. We observed that the distributions of the repairs generated by Styler and Naturalize have the smallest medians, which are equal to one and three changed lines, respectively. Yet, they suffer from a few bad cases (the right-hand part of the distributions), mainly Naturalize. CS-IDEA and CodeBuff produced larger repairs, with medians equal to nine and 42, respectively. In the worst cases, they produced several repairs with more than 200 changed lines, which can be seen by the fact that their 95th percentiles are not shown in Fig. 7. On the other hand, the 95th percentile of Styler is three. We performed Wilcoxon rank-sum test to verify if the distributions of diff sizes obtained by Styler and the other tools are significantly different from one another. We found p-value< 0.00001 when testing Styler with all the other tools. Considering α = 0.05, we rejected the null hypothesis, which means that the distribution of Styler is significantly different from the other ones.


Size of the repairs per tool. The two boxplot whiskers represent the 5th and the 95th percentiles
5.5 Performance (RQ #5)
To investigate if Styler can be used in practice, we measured the time Styler spent on the real violation dataset. Table 8 shows the minimum, median, average, and maximum time spent on the 104 projects, split over the different steps of the Styler workflow. For training data generation, Styler took at least 15 minutes and up to six hours, which is the maximum execution time allowed by our experimental setup (see Section 4.4.3). The median time for training data generation was 45 minutes. To tokenize the training data, Styler took around two minutes on average, and a maximum of 14 minutes for training the models. The entire training process of Styler (data generation + tokenization + model training) took around one hour and a half on average. This can be considered just fine since the training is meant to happen only when the coding conventions used in a project change (i.e., the Checkstyle ruleset file). After Styler is trained for a given project, it takes on average two seconds to predict a repair, which is fast enough to be used in IDEs or in continuous integration environments.

5.6 Technical analysis on Styler (RQ #6)
At prediction time, Styler used two trained LSTM models, each one based on a different training data generation protocol: Stylerrandom and Styler3grams. In RQ #6, we investigated how the two protocols contribute to the final output of Styler. We found out that Styler fixed 967 violations exclusively with the Stylerrandom-based model and 2,581 violations exclusively with the Styler3grams-based model. 7,460 violations were fixed with both models. This shows that the model based on the Styler3grams protocol is more effective than the model based on the Stylerrandom one. In a real case scenario, one could consider using Styler only with the Styler3grams-based model and still obtain fixes for 91% of what Styler can repair. This would reduce the time for training Styler.

6 Discussion
We discuss, in this section, machine learning versus rule-based approaches, as well as the threats to the validity of our study.
6.1 Machine learning versus rule-based approaches
Styler employs a machine-learning-based approach for repairing formatting convention violations. An alternative approach would be a rule-based one. In such a case, there would be at least one transformation to be applied in the code per format checker rule. However, the engineering of a transformation for every single linter rule is time-consuming. While this is costly, this might be even impractical for highly configurable linters such as Checkstyle, because the rule-based repair system would need to have different transformations for the same linter rule due to the configurable properties. On the contrary, a machine learning approach does not require costly human engineering. It is able to infer transformations for a diverse set of linter rules. Our experiments have validated this property in the context of formatting violations raised by Checkstyle. However, since our approach is far from being perfect and does not work well for certain rules, one avenue for future research is the development of a rule-based system for simple, non-highly configurable rules, to be complementary to Styler.
6.2 Threats to validity
Styler generates training data for learning how to repair violations based on the Checkstyle ruleset file contained in a given project. This means that Styler assumes that all formatting rules contained in such a file are valid. In practice, however, developers might ignore the violations of certain rules. Our experiment does not take this scenario into account, thus we do not claim that all the fixes produced by Styler are necessarily relevant for developers.
The real violation dataset contains Checkstyle violations mined from GitHub repositories. It is to be noted that it does not cover all existing Checkstyle formatting rules. Moreover, the dataset might not be representative of the real distribution of the 25 rules in the real world. Consequently, future research is needed to strengthen the validity of our study.
At the end of the violation collection process for building the dataset, we removed duplicate Java files according to file contents. However, there might still exist duplicate violations in our dataset. A file containing a violation might have changed, but that change might not be related to the line where the violation exists. Therefore, the same violation would exist in both versions of the file, but since the overall file contents are different, they are both kept in our dataset, which might create noise in it.
Another threat related to the creation of the dataset is that, when selecting violating files, we chose only the ones containing a single Checkstyle violation. We performed this selection so that we could accurately check if the violation was correctly repaired by the tools. Files containing more than one violation would make it hard to automatically check the correctness of repairs because once a violation is repaired, the location of the other ones in the file could be different. Therefore, our results are based on single-violation files, and future investigations on multiple-violation files are needed.
Finally, to compare the quality of the repairs produced by Styler with the repairs produced by the other three tools, we measured the size in lines of the diff between the original and repaired program versions. However, the diff size is only one dimension for comparing the tools, which only approximates the developer’s perception of formatting repairs. User studies, such as proposing formatting repairs to developers, are interesting future experiments to further investigate the practical value of this research.
7 Related work
Styler aims to repair formatting violations raised by linters. Linters are a kind of automated static analysis tool. In this section, we first present works on the usage of static analysis tools. Then, we present systems that share similar goals with Styler, which are systems that target linter violation repair and systems that fix source code formatting. Finally, we present works related to Styler in terms of used technique, i.e., machine learning, for repairing compiler errors and behavioral bugs.
7.1 The usage of automated static analysis tools
Static analysis tools have been the subject of investigation in recent research. Zampetti et al. (2017) investigated their usage in 20 popular Java open source projects hosted on GitHub that use Travis CI to support CI activities. They first found out that the projects use seven static analysis tools—Checkstyle, FindBugs (Ayewah et al. 2008), PMDFootnote 29, License Gradle PluginFootnote 30, Apache RatFootnote 31, ClirrFootnote 32, and jDependFootnote 33—being Checkstyle the most used one. About the integration of static analysis tools in CI pipelines, they found out that build breakages due to those tools are mainly related to adherence to coding conventions, while breakages related to likely bugs or vulnerabilities occur less frequently. Zampetti et al. (2017) discuss that some tools are sometimes configured to just produce warnings without breaking the build, possibly because of the high number of false positives.
Vassallo et al. (2018) investigated the usage of static analysis tools from the perspective of the development context in which these tools are used. For that, they surveyed 42 developers and interviewed 11 industrial experts that integrate static analysis tools in their workflow. They found out that static analysis tools are used in three main development contexts, which are local environment, code review, and continuous integration. Moreover, they also found out that developers consider different warning types depending on the context, e.g., when performing code review they mainly look at style conventions and code redundancies.
Marcilio et al. (2019) focused on one specific static analysis tool: SonarQubeFootnote 34. Through an online survey with 18 developers from different organizations, they found out that most respondents agree that the issues reported by static analysis tools are relevant for improving the design and implementation of software.
7.2 Linter violation repair and code formatters
Linter violation repair.
There are some tools to fix violations of rules checked by linters. Considering academic systems, there are Phoenix (Bavishi et al. 2019), which repairs violations of rules checked by FindBugs (Ayewah et al. 2008), and Getafix (Bader et al. 2019), which focuses on rules checked by Infer (Calcagno et al. 2015) and Error Prone (Aftandilian et al. 2012). These tools learn fix patterns by mining past human-written fixes for linter violations. Another tool is SpongeBugs (Marcilio et al. 2020), which repairs violations of rules checked by the two well-known static analyzers SonarJava and SpotBugs with fixed repair templates. Styler shares with these tools the goal of generating patches for linter violations. However, while the mentioned tools focus on rules related to bugs and code smells, Styler focuses on formatting. In addition, there is C-3PR (Carvalho et al. 2020), which does not generate patches itself but proposes fixes through pull request on GitHub generated by linter violation repair tools.
Beyond those academic systems, there are other tools that repair violations found by linters. Related to formatting rules, there is, for instance, ESLint, which is a linter for JavaScript, and it also includes automated solutions to repair violations raised by it.
Code formatters.
A way to enforce formatting conventions lies in code formatters (also known as pretty-printers). In Section 4.2, we described Naturalize (Allamanis et al. 2014) and CodeBuff (Parr and Vinju 2016). Naturalize recommends fixes for coding conventions related to naming and formatting in Java programs, and CodeBuff infers formatting rules to any language given a grammar. Similar to the idea behind CodeBuff, Reiss (2007) had previously experimented with different learning algorithms and feature set variations to learn the style of a given corpus so that it could be applied to arbitrary code. More recently, Markovtsev et al. (2019) presented Style-Analyzer, which helps developers to fix code formatting during code reviews. Style-Analyzer mines the formatting style of the git repository under analysis and expresses the found format patterns with compact human-readable rules. Then, it suggests style inconsistency fixes in the form of code review comments.
Beyond those academic systems, there are code formatters such as google-java-formatFootnote 35, which reformats source code according to the Google Java Style GuideFootnote 36. However, these formatters are usually not configurable or require manual tweaking, which is a tedious process for developers. This is a problem because not all developers are ready to follow a unique convention style. Styler, on the other hand, is generic and automatically captures the conventions used in a project to fix formatting violations.
Finally, there is the CheckStyle-IDEA plugin for IntelliJ (CheckStyle-IDEA 2021), which we used to compare Styler with. CheckStyle-IDEA provides both real-time and on-demand scanning of Java files with Checkstyle from within IDEA. It also uses the Checkstyle ruleset of projects to configure the formatter available in IntelliJ, making it possible to repair Checkstyle formatting violations. However, it is limited in repairing violations of a great number of Checkstyle rules as shown in RQ #2 and creates large repairs as shown in RQ #4.
7.3 Learning for repairing compiler errors and behavioral bugs
Learning for repairing compiler errors.
There are related works in the area of automatic repair of compiler errors. In this case, the compiler syntax rules are the equivalent of the formatting rules. There, recurrent neural networks and token abstraction have been used to fix syntactic errors (Bhatia et al. 2018). In DeepFix, Gupta et al. (2017) use a language model for repairing syntactic compilation errors in C programs. Out of 6,971 erroneous C programs, DeepFix was able to completely repair 27% and partially repair 19% of the programs. Later, Ahmed et al. (2018) proposed TRACER, which outperformed DeepFix, repairing 44% of the programs. Santos et al. (2018) confirmed the efficiency of LSTM over n-grams and of token abstraction for single token compiling errors. These approaches do not target formatting violations, which is the target of Styler.
Learning for repairing behavioral bugs.
As for repairing compiler errors, there are also learning systems for repairing behavioral bugs, those that, for instance, break test cases. Tufano et al. (2018) investigated the feasibility of using Neural Machine Translation techniques for learning bug-fixing patches for real defects. They mined millions of buggy and patched program versions from the history of GitHub repositories and abstracted them to train an Encoder-Decoder model. The model was able to fix hundreds of unique buggy methods in the wild. Chen et al. (2019) proposed SequenceR, a program repair tool based on sequence-to-sequence learning focused on one-line fixes. In an experiment with Defects4J (Just et al. 2014), SequenceR was shown to be able to learn how to repair behavioral bugs by generating patches that pass all tests. Styler and SequenceR share the same idea for formatting violation and bug encoding.
8 Conclusion
In this paper, we presented Styler, which implements a novel approach to repair formatting violations raised by format checkers. Styler creates a corpus of violations, learns from it, and predicts fixes for new violations, using machine learning. Currently, its implementation supports Checkstyle, a popular linter for Java programs. Our experimental results on 26,791 real Checkstyle violations showed that Styler repairs real violations from a diverse set of Checkstyle rules and performs better for fixing violations related to horizontal whitespace between Java tokens than for fixing violations related to tabulations and line length. Moreover, Styler produces smaller repairs than the compared systems, and its prediction time is low, which suggests that it can be used in development environments such as IDEs. Finally, we identified cases in which Styler does not succeed to generate correct repairs, e.g., for Checkstyle violations inside comments or strings. These findings can guide improvements in Styler and help researchers and developers to understand Styler’s limitations.
There are several interesting avenues for future research. First, improvements on the violation injection protocols for creating training data can be done to improve the representativeness of seeded formatting violations. This might increase the repairability of Styler. Second, user studies can be conducted, where repairs predicted by Styler are proposed to developers through, for instance, pull requests on GitHub. This type of study would bring practical insights on the potential of Styler. Third, Styler could be integrated into development environments, such as IDEs and social coding sites, for supporting the mentioned user studies and possibly for developers to use Styler. Fourth, other linters could be plugged in Styler so it could be applicable on projects that use linters other than Checkstyle. Fifth, since Styler does not work well for certain rules, the development of a rule-based system for simple, non-highly configurable rules, could be beneficial to complement Styler. Finally, the overall idea behind Styler could be tried out to repair other linter violations beyond purely formatting ones.
Notes
https://checkstyle.sourceforge.io/, last access: 2020-07-13
https://eslint.org/, last access: 2020-07-13
https://www.pylint.org/, last access: 2020-07-13
https://github.com/StyleCop/StyleCop/, last access: 2020-07-13
https://docs.rubocop.org, last access: 2020-07-13
https://checkstyle.sourceforge.io/, last access: 2020-07-13
On June 23, 2021.
On June 23–24, 2021.
Commonly used names for Checkstyle ruleset files: ‘checkstyle.xml’, ‘.checkstyle.xml’, ‘checkstyle_rules.xml’, ‘checkstyle_config.xml’, ‘checkstyle_configuration.xml’, ‘checkstyle_checker.xml’, ‘checkstyle_checks.xml’, ‘google_checks.xml’, ‘sun_checks.xml’. Variants by replacing ‘_’ by ‘-’ were also used.
The set of Checkstyle rules considered in our study is from the Checkstyle version 8.43 (released on May 30, 2021).
https://github.com/SonarSource/sonar-java, last access: 2020-07-13
https://rules.sonarsource.com/java/RSPEC-1105, last access: 2020-07-13
https://github.com/c2nes/javalang/, last access: 2020-07-13
https://github.com/OpenNMT/OpenNMT-py/, last access: 2020-07-13
All repositories were cloned on June 24–25, 2021.
Checkstyle release notes: https://checkstyle.sourceforge.io/releasenotes.html
Our current implementation supports 48 Checkstyle versions, from 8.0 to 8.43.
https://pmd.github.io/, last access: 2020-07-13
https://github.com/hierynomus/license-gradle-plugin, last access: 2020-07-13
https://creadur.apache.org/rat/, last access: 2020-07-13
http://www.mojohaus.org/clirr-maven-plugin/, last access: 2020-07-13
http://www.mojohaus.org/jdepend-maven-plugin/, last access: 2020-07-13
https://www.sonarqube.org/, last access: 2020-07-13
https://github.com/google/google-java-format/, last access: 2020-07-13
http://checkstyle.sourceforge.net/reports/google-java-style-20170228.html, last access: 2020-07-13
References
Aftandilian E, Sauciuc R, Priya S, Krishnan S (2012) Building Useful Program Analysis Tools Using an Extensible Java Compiler. In: Proceedings of the 12th IEEE International Working Conference on Source Code Analysis and Manipulation (SCAM ’12), IEEE Computer Society, USA, pp 14–23 https://doi.org/10.1109/SCAM.2012.28
Ahmed UZ, Kumar P, Karkare A, Kar P, Gulwani S (2018) Compilation Error Repair: For the Student Programs, From the Student Programs. In: Proceedings of the 40th International Conference on Software Engineering: Software Engineering Education and Training (ICSE-SEET ’18), Association for Computing Machinery, New York, NY, USA, pp 78–87, https://doi.org/10.1145/3183377.3183383
Allamanis M, Barr ET, Bird C, Sutton C (2014) Learning Natural Coding Conventions. In: Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering (FSE ’14), Association for Computing Machinery, New York, NY, USA, pp 281–293 https://doi.org/10.1145/2635868.2635883https://doi.org/10.1145/2635868.2635883
Ayewah N, Hovemeyer D, Morgenthaler JD, Penix J, Pugh W (2008) Using Static Analysis to Find Bugs. IEEE Software 25(5):22–29. https://doi.org/10.1109/MS.2008.130
Bader J, Scott A, Pradel M, Chandra S (2019) Getafix: Learning to Fix Bugs Automatically. Proceedings of the ACM on Programming Languages 3(OOPSLA) https://doi.org/10.1145/3360585
Bavishi R, Yoshida H, Prasad MR (2019) Phoenix: Automated Data-Driven Synthesis of Repairs for Static Analysis Violations. In: Proceedings of the 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE ’19), Association for Computing Machinery, New York, NY, USA, pp 613–624, https://doi.org/10.1145/3338906.3338952
Beller M, Bholanath R, McIntosh S, Zaidman A (2016) Analyzing the State of Static Analysis: A Large-Scale Evaluation in Open Source Software. In: Proceedings of the 23rd IEEE International Conference on Software Analysis, Evolution, and Reengineering (SANER ’16), IEEE, pp 470–481 https://doi.org/10.1109/SANER.2016.105
Beller M, Gousios G, Zaidman A (2017) Oops, My Tests Broke the Build: An Explorative Analysis of Travis CI with GitHub. In: Proceedings of the 14th International Conference on Mining Software Repositories (MSR ’17), IEEE Press, pp 356–367 https://doi.org/10.1109/MSR.2017.62
Bhatia S, Kohli P, Singh R (2018) Neuro-Symbolic Program Corrector for Introductory Programming Assignments. In: Proceedings of the 40th International Conference on Software Engineering (ICSE ’18), Association for Computing Machinery, New York, NY, USA, pp 60–70 https://doi.org/10.1145/3180155.3180219https://doi.org/10.1145/3180155.3180219
Calcagno C, Distefano D, Dubreil J, Gabi D, Hooimeijer P, Luca M, O’Hearn P, Papakonstantinou I, Purbrick J, Rodriguez D (2015) Moving fast with software verification. In: Havelund K, Holzmann G, Joshi R (eds) NASA Formal Methods, Springer International Publishing, Cham, pp 3–11
Carvalho A, Luz W, Marcílio D, Bonifácio R, Pinto G, Canedo ED (2020) C-3PR: A Bot for Fixing Static Analysis Violations via Pull Requests. In: Proceedings of the 27th IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER ’20), IEEE, pp 161–171 https://doi.org/10.1109/SANER48275.2020.9054842
CheckStyle-IDEA (2021) CheckStyle-IDEA. https://plugins.jetbrains.com/plugin/1065-checkstyle-idea, last access: 2020-07-13
Chen Z, Kommrusch S, Tufano M, Pouchet LN, Poshyvanyk D, Monperrus M (2019) SequenceR: Sequence-to-Sequence Learning for End-to-End Program Repair. IEEE Transactions on Software Engineering https://doi.org/10.1109/TSE.2019.2940179
Dias H (2020) The anatomy of a perfect pull request: How does a good pull request look like. https://medium.com/@hugooodias/the-anatomy-of-a-perfect-pull-request-567382bb6067, last access: 2020-07-13
Gupta R, Pal S, Kanade A, Shevade S (2017) DeepFix: Fixing Common C Language Errors by Deep Learning. In: Proceedings of the 31st AAAI Conference on Artificial Intelligence (AAAI ’17), AAAI Press, pp 1345–1351
Just R, Jalali D, Ernst MD (2014) Defects4J: A Database of Existing Faults to Enable Controlled Testing Studies for Java Programs. In: Proceedings of the 2014 International Symposium on Software Testing and Analysis (ISSTA ’14), Association for Computing Machinery, New York, NY, USA, pp 437–440 https://doi.org/10.1145/2610384.2628055
Marcilio D, Bonifácio R, Monteiro E, Canedo E, Luz W, Pinto G (2019) Are Static Analysis Violations Really Fixed? A Closer Look at Realistic Usage of SonarQube. In: Proceedings of the 27th International Conference on Program Comprehension (ICPC ’19), IEEE Press, pp 209–219 https://doi.org/10.1109/ICPC.2019.00040
Marcilio D, Furia CA, Bonifácio R, Pinto G (2020) SpongeBugs: Automatically generating fix suggestions in response to static code analysis warnings. Journal of Systems and Software 168:110671. https://doi.org/10.1016/j.jss.2020.110671https://doi.org/10.1016/j.jss.2020.110671. https://www.sciencedirect.com/science/article/pii/S016412122030128X
Markovtsev V, Long W, Mougard H, Slavnov K, Bulychev E (2019) STYLE-ANALYZER: fixing code style inconsistencies with interpretable unsupervised algorithms. In: Proceedings of the 16th International Conference on Mining Software Repositories (MSR ’19), IEEE Press, pp 468–478 https://doi.org/10.1109/MSR.2019.00073
Monperrus M (2018) Automatic Software Repair: A Bibliography. ACM Computing Surveys 51(1) https://doi.org/10.1145/3105906
Parr T, Vinju J (2016) Towards a Universal Code Formatter through Machine Learning. In: Proceedings of the 2016 ACM SIGPLAN International Conference on Software Language Engineering (SLE ’16), Association for Computing Machinery, New York, NY, USA, pp 137–151 https://doi.org/10.1145/2997364.2997383https://doi.org/10.1145/2997364.2997383
Prause CR, Jarke M (2015) Gamification for Enforcing Coding Conventions. In: Proceedings of the 10th Joint Meeting on Foundations of Software Engineering (ESEC/FSE ’15), Association for Computing Machinery, New York, NY, USA, pp 649–660 https://doi.org/10.1145/2786805.2786806
Reiss SP (2007) Automatic Code Stylizing. In: Proceedings of the 22nd IEEE/ACM International Conference on Automated Software Engineering (ASE ’07), Association for Computing Machinery, New York, NY, USA. https://doi.org/10.1145/1321631.1321645, pp 74–83
Santos EA, Campbell JC, Patel D, Hindle A, Amaral JN (2018) Syntax and Sensibility: Using Language Models to Detect and Correct Syntax Errors. In: Proceedings of the 25th IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER ’18), IEEE, pp 311–322 https://doi.org/10.1109/SANER.2018.8330219
Santos RMD, Gerosa MA (2018) Impacts of Coding Practices on Readability. In: Proceedings of the 26th International Conference on Program Comprehension (ICPC ’18), Association for Computing Machinery, New York, NY, USA, pp 277–285 https://doi.org/10.1145/3196321.3196342
Spinellis D (2011) elytS edoC. IEEE Software 28 (2):104. https://doi.org/10.1109/MS.2011.31
Tufano M, Watson C, Bavota G, Di Penta M, White M, Poshyvanyk D (2018) An Empirical Investigation into Learning Bug-Fixing Patches in the Wild via Neural Machine Translation. In: Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering (ASE ’18), Association for Computing Machinery, New York, NY, USA, pp 832–837, https://doi.org/10.1145/3238147.3240732
Vassallo C, Panichella S, Palomba F, Proksch S, Zaidman A, Gall HC (2018) Context Is King: The Developer Perspective on the Usage of Static Analysis Tools. In: Proceedings of the 25th IEEE International Conference on Software Analysis, Evolution, and Reengineering (SANER ’18), IEEE, pp 38–49 https://doi.org/10.1109/SANER.2018.8330195
Yasunaga M, Liang P (2020) Graph-based Self-Supervised Program Repair from Diagnostic Feedback. In: International Conference on Machine Learning (ICML)
Zampetti F, Scalabrino S, Oliveto R, Canfora G, Di Penta M (2017) How Open Source Projects use Static Code Analysis Tools in Continuous Integration Pipelines. In: Proceedings of the 14th International Conference on Mining Software Repositories (MSR ’17), IEEE Press, pp 334–344 https://doi.org/10.1109/MSR.2017.2
Acknowledgments
We thank the anonymous reviewers for their valuable feedback that made us improve this paper. We also thank Terence Parr, Miltos Allamanis, Vadim Markovtsev, Hugo Mougard, Matias Martinez, and the ASSERT members who gave feedback on a draft version of this paper. Fernanda Madeiral would like to thank Thomas Durieux for his support on this work. This work was partially supported by the Swedish Foundation for Strategic Research under the TrustFull project, and by the Knut and Alice Wallenberg Foundation under the Wallenberg AI, Autonomous Systems, and Software Program (WASP). Some experiments were performed on resources provided by the Swedish National Infrastructure for Computing.
Funding
Open access funding provided by Royal Institute of Technology.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by: Andrea De Lucia
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Loriot, B., Madeiral, F. & Monperrus, M. Styler: learning formatting conventions to repair Checkstyle violations. Empir Software Eng 27, 149 (2022). https://doi.org/10.1007/s10664-021-10107-0
Accepted:
Published:
DOI: https://doi.org/10.1007/s10664-021-10107-0