
Abstract
This paper analyses the impact of highways on the distribution of economic activities between urban agglomerations and peripheral regions in the European Union. In doing so, I use an empirical strategy based on the land use theory employing disaggregated economic and infrastructure data. To address endogeneity, I apply an IV strategy exploiting non-local highway construction as a source of exogenous variation. I find that highways contribute to the diffusion of urban economic activities into surrounding areas, reducing the income gap between European agglomerations and peripheries. Reduced-form estimations suggest that the gap would have been nearly 3% higher in 2020 if the highway networks of European countries had remained at the level of 1990. The study concludes that transportation infrastructure policies can alleviate regional income disparities, increasing economic convergence between urbanised and less urbanised areas.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
One of the European Union’s major priorities is the consolidation of economic cohesion among its regions. In this respect, the EU decision-makers often rely on transportation infrastructure policies, including programmes targeting the member countries’ highway networks. For example, the EU road infrastructure allocations for 2007–2020 through the Cohesion Policy alone reached nearly € 80 billion.Footnote 1 Out of this amount, € 40 billion targeted the Trans-European Road Network (TEN-T), predominantly comprising highways. In many cases, the EU infrastructure funds target regions in lower-income EU states to relieve their economic isolation and increase local productivity. As an illustration, EU funding accounted for nearly 40% of the total national transportation capital expenditure made between 2007 and 2013 by the member countries that joined the EU in 2004 and later (European Commission 2017).Footnote 2 As a result of the EU and member countries’ own transportation infrastructure investments, the total length of highways in the European Union more than doubled in size during 1990–2020, expanding from nearly 30′000 to 73′000 kms.
Highways provide substantial economic advantages by reducing transportation costs, and increasing market accessibility and specialisation.Footnote 3 However, these can also generate significant geographic reallocations of production between agglomerations and peripheral regions. On the one hand, infrastructure can encourage the diffusion of production towards peripheries. For example, highways can substantially decrease the cost of accessing space, causing less localised agglomeration effects, thus motivating firms to relocate to areas with lower land costs. In the context of the present paper, this fact would correspond to the policy intentions of the EU national and supranational decision-makers aiming to increase regional cohesion. On the other hand, highways can also contribute to further geographic concentration of economic activities, favouring territories that already benefit from strong agglomeration effects. Subsequently, infrastructure can deepen the income gap between agglomerations and peripheral regions aggravating the problem of European uneven economic development.
In this paper, I analyse the impact of highways on the distribution of economic activities between urban agglomerations and peripheral regions within the European Union. In doing so, I employ disaggregated economic and infrastructure data covering the period from 1990 to 2020. Following Baum-Snow et al. (2017), I use the land use theory to motivate my empirical strategy.
Highway placement decisions are likely endogenous to income. Transportation policies can target regions with high growth potential or lagging regions, leading to a positive or negative bias in the estimated OLS coefficients, respectively. To address this endogeneity issue, I conditionally exploit non-local highway construction, illustrated through changes in travel speed between regions that are not in the same EU member country, as a source of exogenous variation. In the conditional framework, I include country-year dummies to control for country-specific trends in transportation and economic policies. Also, I use NUTS-2 region dummies to account for local time-invariant covariates. Finally, I add several controls reflecting regional employment, infrastructure, mobility, education, and institutional performance. For the robustness checks, I consider different econometric models and different sample and model specifications. The estimations remain similar across these checks.
The results suggest that highways reduce the income disparities between urban agglomerations and peripheral areas in the European Union. Consolidation of highway networks promotes the diffusion of economic activities from major urbanised areas to surrounding regions, benefiting the latter. The preferred reduced-form elasticity implies that a 10% increase in the length of highway networks reduces the income gap between urban agglomerations and peripheries by 0.33%. The finding suggests that the income disparity would have been 2.9% higher in 2020 if the highway networks of European countries had remained at the level of 1990. The study provides supporting evidence for transportation infrastructure initiatives within the EU Cohesion Policy. These programmes can alleviate regional income disparities, increasing economic convergence between agglomerations and peripheries.
This paper makes three contributions to the literature. The first one is made to the research field analysing the impact of infrastructure in an economic geography context. Existing studies consider the US (Baum-Snow 2007, 2010; Michaels 2008), China (Faber 2014; Baum-Snow et al. 2017, 2020; Banerjee et al. 2020), other countries (ex., Ghani et al. (2016) for India and Jedwab et al. (2017) for Kenya) and even particular cities’ perspectives (ex. Ahlfeldt et al. (2015) for Berlin), while evidence for the European Union as a whole is relatively scarce. To this literature, I add empirical evidence for the influence of infrastructure on core-periphery economic outcomes with a specific focus on the European Union. As such, my paper broadens the field’s geographical coverage.
The second contribution of this paper is made to the literature analysing the economic impact of the EU Cohesion Policy (Gagliardi and Percoco 2017; Dicharry et al. 2019; Fidrmuc et al. 2019; Berkowitz et al. 2019; Crescenzi and Giua 2020; Rodríguez-Pose and Dijkstra 2021). To this literature, I add empirical evidence supporting the transportation infrastructure initiatives of the EU Cohesion Policy, concluding that these initiatives represent suitable means to narrow the income discrepancies among EU regions. The third contribution is made to the literature that analyses the economic effects of infrastructure in a broader European context using different methods and approaches (Crescenzi and Rodríguez‐Pose 2012; Crescenzi et al. 2016; Fajgelbaum and Schaal 2020). I extend this field’s research scope in the direction of economic geography by adding empirical evidence for the effect of transportation infrastructure on income disparities between EU agglomerations and peripheral regions. In this respect, my paper relates to Percoco (2016), Melo et al. (2022), Garcia-López et al. (2015), and Holl (2016), who provide country-level evidence for Italy, Portugal, and Spain. In contrast to these studies, my research goes beyond a single-country perspective, providing empirical evidence for the European Union.
In a broader sense, my paper also relates by its scope to the studies that analyse the economic effects of transportation infrastructure employing different methods (Donaldson 2018; Donaldson and Hornbeck 2016; Jaworski and Kitchens 2019; Jaworski et al. 2023; Herzog 2021).
The remainder of this paper is organised as follows: Sect. 2 discusses the data. Section 3 describes the theoretical background and empirical strategy. Section 4 presents the results, Sect. 5 the robustness checks, and Sect. 6 the counterfactuals. Section 7 concludes.
2 Data
I collect European data at NUTS-3 and NUT-2 levels.Footnote 4 NUTS-3 regions are European territorial units having a population between 150′000 and 800′000 people, for example, the Districts of Germany, Departments of France, and Provinces of Italy. NUTS-2 regions reflect European territorial units having a population between 800′000 and 3′000′000 people, usually comprising several NUTS-3 regions. The current NUTS 2021 classification lists 1166 regions at NUTS 3 and 242 regions at NUTS 2 level. According to Eurostat, NUTS-3 territorial units are metropolitan if they belong to an urban agglomeration of at least 250′000 inhabitants and non-metropolitan otherwise.Footnote 5 I use the metropolitan and non-metropolitan split of NUTS-3 regions to analyse the impact of highways on income distribution between urban agglomerations and peripheral areas.
The disaggregated data on NUTS-3 regions’ gross domestic product, sectoral employment, population, and NUTS-2 regions’ gross fixed capital formation are from the Annual Regional Database of the Directorate General for Regional and Urban Policy of the European Commission. The data covers the period from 1990 to 2020. The NUTS-3 region data is then aggregated at the NUTS-2 level by metropolitan and non-metropolitan categories. The final analysis is made at the NUTS-2 level. The study does not include the NUTS-2 regions comprising only urban or peripheral NUTS-3 areas. For these NUTS-2 regions, no peripheral or agglomeration data are available for comparative evaluation.
The regional data on railways, roads other than highways, road safety, the number of cars, lorries, in-region commuters, education, and institutional performances are from Eurostat. Since reporting to Eurostat is not mandatory, many regional authorities hesitate to provide information on many statistics, causing data constraints and, therefore, smaller data samples. The data on the highway network expansions of European Union countries are from the Victoria and Albert Museum in London.Footnote 6 These geocoded data contain detailed information on highways, including the year of construction. I use these data together with data on the spatial representation of NUTS-2 regions from the Geographic Information System of the European Commission to determine the evolution of highways' length in the European Union by regions from 1990 to 2020. For this purpose, I use the QGIS geographic information processing software.
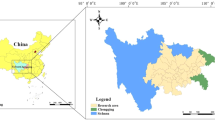
Table 5 in the Appendix provides descriptive statistics of the data employed in the analysis and additional definitions. Figure 1 depicts the geographical distribution of European urban agglomerations. As one can notice, most NUTS-2 regions in the EU have a metropolitan and non-metropolitan subcomponent formed of one or several NUTS-3 regions, respectively.

Spatial distribution of European NUTS-3 metropolitan areas within NUTS-2 regions. Note that the grey colour depicts EU NUTS-3 metropolitan regions, and the darker shadow of grey denotes those belonging to a capital city. Administrative boundaries: © EuroGeographics, Cartography: Eurostat - GISCO
3 Theoretical background and empirical strategy
Subsection 3.1 discusses the theoretical background, Subsect. 3.2 the derived empirical models and Subsect. 3.3 the IV design.
3.1 Theoretical background
To motivate my empirical analysis, I employ the fundamental principles of the urban land use theory, following Duranton and Puga (2015), as it explains the mechanisms through which the consolidation of highway networks can influence the core-periphery economic outcomes. The theory says that firms face a difficult decision when selecting a production location. On the one hand, if firms choose urbanised areas, they can enjoy agglomeration benefits such as a deeper labour pool, increased specialisation, and a denser network of suppliers and consumers. Altogether, these factors favourably affect the firms’ productivity level. However, the limited availability of commercial real estate in urbanised areas and an increased demand for it from all other businesses make agglomerations an expensive location choice. Thus, moving towards peripheries can significantly decrease the land costs of firms which is particularly relevant when land is intensively used in the production processes.
Labour-intensive firms can also find agglomerations as an expensive location choice due to two reasons. First, these firms would need to compete more intensively with other businesses for the limited number of workers available within cities, which drives up local labour prices. Thus, firms can experience increased wage costs when relying exclusively on the urban labour market. Second, if firms decide to hire workers from surrounding regions to avoid the intense competition, they would have to offset the commuting costs, which also leads to higher wages. Workers reside in peripheral areas, and they would need to commute to the city and back. Opting for a more peripheral location can decrease wage costs for businesses as there is generally less competition outside agglomerations from other firms, and they would also position closer to peripheral workers, implying lower commuting costs.
The theory says that firms can find urbanised areas as more attractive locations to do business if agglomeration effects are territorially concentrated, firms have minimal land requirements, or commuting costs are relatively low. For example, financial service firms would likely prefer urbanised areas as a location, as in their case, the agglomeration effects are highly localised. These firms typically conduct business that involves significant interpersonal contact, which requires proximity to customers. Firms can find peripheral regions as a preferable location for their activities if agglomeration effects spread out over a wider area, firms’ production requires much land or commuting costs are relatively high. For instance, manufacturing firms, primarily involved in production and less in research and development activities, would likely prefer peripheral areas as production spots, as large plants usually require a substantial amount of land. Moreover, a more peripheral location brings these firms closer to workers, reducing labour costs.
The impact of highways on firms’ location choices is not clear. On the one hand, highways decrease transportation costs and increase accessibility, which makes agglomeration effects expand over a wider area. They allow for an easier and faster movement of people, goods, and services among different locations. This rise in interconnectivity can spread out the networks of economic activities, making agglomeration effects less dependent on a particular location choice. On the other hand, highways can reduce commuting costs, making it more cost-effective for firms to hire workers from peripheral areas. Thus, the decrease in commuting costs can result in a concentration of production in urbanised areas, as firms will choose cities to benefit from agglomeration effects while not being cost-constrained in hiring workers from surrounding regions. For example, according to Fujita and Ogawa’s (1982) model, no commuting costs imply a complete concentration of production within agglomerations.
3.2 Empirical models
I organise my empirical strategy around the models discussed in Baum-Snow et al. (2017). Let \({Y}_{itA}\) be the income produced by the agglomeration \(A\) of the NUTS-2 region \(i\) in the year\(t\), and \({Y}_{itP}\) be the income of the periphery \(P\) of the same region, as shown in Eq. (1). In this equation, \(X{\prime}\) depicts a vector of covariates varying at the agglomeration level, Uʹ is a vector of covariates varying at the peripheral level, \({D}{\prime}\) is a set of NUTS-2 region dummies, and Gʹ depicts a set of country-year dummies, subscript \(Q\) denoting country,\(\widehat{\beta }\), \(\widehat{\delta }\), \(\widehat{\gamma }\), \(\widehat{\varphi }\), \(\widehat{\omega }\) and \(\mu\) representing elasticities and \(\varepsilon\) a random error term.
The coefficient of interest is \(\widehat{\beta }\) that indicates the extent to which highways, denoted as \(H\), lead to the concentration or, on the contrary, diffusion of metropolitan economic activities holding peripheral area’s income constant. This elasticity shows the proportion of output displaced to or from agglomerations given unit changes in the length of highway networks. The sign and the magnitude of this coefficient represent a combined net impact of all effects of highway network expansions on local economic outcomes, for example, a net impact of the extent to which highways expand agglomeration effects over a wider area and the degree to which they decrease commuting costs.
In Eq. (2), I use a related model that describes the ratio of peripheral income to the income of agglomeration as a function of highways, following Baum-Snow et al. (2017). The coefficient of interest is\(\widehat{\alpha }\), which estimates the effect of infrastructure on a combined peripheral–agglomeration economic outcome. It shows the extent to which the ratio of income produced by peripheral areas relative to cities changes as the networks of highways increase. In Eq. (2),\(X{\prime}\), \(U{\prime}\), \({D}{\prime}\), and Gʹ denote the same vectors of covariates and sets of dummies as those used in Eq. (1), subscript \(Q\) denoting country,\(\widehat{\sigma }\), \(\widehat{\rho }\), \(\widehat{\tau }\), and \(\widehat{\pi }\) representing elasticities and \(\varepsilon\) a random error term.
As Baum-Snow et al. (2017), I am primarily interested in estimating \(\widehat{\beta }\). The coefficient directly depicts the impact of highways on the geographic diffusion of economic activities from agglomerations to surrounding areas, holding peripheral areas’ income fixed. I also present results for \(\widehat{\alpha }\).
The covariates \(X{\prime}\) and \(U{\prime}\) in Eqs. (1) and (2) include several controls reflecting regional employment, infrastructure, mobility, education, and institutional performance that can affect the core-periphery economic outcomes.Footnote 7 The sets of dummies, \({D}{\prime}\) and Gʹ, account for local time-invariant covariates and country-specific trends in transportation and economic policies.
Although the inclusion of covariates and dummy variables helps to reduce the potential bias, it cannot fully solve the problem of endogeneity. Therefore, I further discuss a conditional IV strategy that exploits non-local highway construction, illustrated through changes in travel speed between regions that are not in the same EU member country, as a source of exogenous variation in highways.
3.2.1 IV strategy and controls
Equation (3) computes average travel speed between regions that are not in the same EU member country as provided below:
This equation recalls a similar one applied in Jaworski and Kitchens (2019) to compute average travel times not in the same US state as a source of exogenous variation. As in Jaworski and Kitchens (2019), my IV exploits the exogeneity of non-local highway improvements illustrated through higher travel speeds between regions over a fixed geographical distance.Footnote 8
I do not include the regions within the same EU country in the computation of the instrument because the member states’ governments run infrastructure construction programmes, including the European Union’s initiatives such as the Trans-European Transport Network (TEN-T) policy.Footnote 9 Conditional on controlling for the country-specific trends in transportation and economic policies and regional gross fixed capital formation, the instrument should provide a source of exogenous variation in regional infrastructure. Importantly, higher travel speeds depict the construction of highways in all other countries. In theory, these countries’ highway connections do not stop at one’s border. They represent a strong motivator for an economy to extend the high-speed route internally.Footnote 10
Next, I present the equations reflecting the use of the instrument to address the endogeneity problem in Eq. (1). Equation (3) depicts the first stage regression, and Eq. (4) shows the second stage. In these equations, \(H\) illustrates highways, \(Z\) is the instrumental variable, namely the average travel speed, \({Y}_{itP}\) denotes the income of the region \(i\)’s periphery, and \({Y}_{itA}\) the income of the region \(i\)’s agglomeration. Xʹ and Uʹ are the vectors of time-varying covariates, \({D}_{i}{\prime}\) is the set of NUTS-2 region dummies, and Gʹ depicts the set of country-year dummies, subscript \(Q\) denoting the country, \(t\) the year, and \(\varepsilon\) the error term.
The first stage regression extracts the exogenous information from highways, which is determined by the instrument conditional on the control variables. The second stage regression replaces the endogenous covariate, \(H\), with a predicted variable, \(\widehat{H}\), based on the first stage, providing an unbiased estimate for the impact of highways on local economic outcomes, \({\widehat{\beta }}_{2}\).
Equations (5) and (6) reflect the IV design used to address endogeneity in regression (2), where the dependent variable is a combined peripheral-metropolitan economic outcome, specifically the ratio of income produced by the periphery relative to agglomeration within region \(i\). The first stage estimation in Eq. (5) differs from Eq. (3) by not controlling for the peripheral income, \({Y}_{itP}\), while keeping the remaining variables the same. As further discussed, the results based on these regressions are similar to estimations based on regressions (3) and (4).
4 Results
Table 1 provides the first-stage results from running regression (3). Columns (1) to (6) show that the instrumental variable I use is a strong predictor of highways within regions, conditional on the controls, as the cluster-robust first-stage F-statistic is above 10 in all cases. Moreover, the sign of the instrument is as theoretically expected, higher construction of highways in all other countries leading to a larger highway network in a particular region. This provides strong supporting evidence for the IV rationale described in Subsect. 3.3, emphasising its validity. The magnitude of the coefficients is similar across all model specifications. The interpretation of this magnitude is as follows. For example, the coefficient presented in column (1) tells that the length of highways within a region would increase, on average, by 17.2% if the average travel speed in all other countries grows by 1 km per hour due to the expansion of highway networks.
Table 2 shows the results from running regression (4). Column (1) includes peripheral income, country-year dummies, NUTS-2 region dummies, and agglomerations and peripheries’ sectoral employment in agriculture, manufacturing, and sales. Column (1) reports a coefficient of −0.027 on highways, which is significant at the 10% level. Column (2) additionally controls for the regional provision of roads, other than highways, and the number of cars and lorries within regions. The reported coefficient on highways is −0.03, which is significant at the 5% level. In column (3), I add covariates reflecting agglomerations and peripheries’ employment in construction, finance, and public sector. The elasticity marginally increases. In column (4), I control for regional railways, life expectancy, and the share of early leavers from education. The coefficient remains the same as the one in column (3).
My preferred elasticity is given by column (5), which adds covariates depicting traffic safety, namely road fatalities to injured ratio and road fatalities to population ratio, and gross fixed capital formation. The estimated elasticity marginally decreases compared to column (4), remaining statistically significant at the 5% level. The reported coefficient is −0.033. It can be interpreted as follows. A 10% increase in the length of regional highways dislocates 0.33% of urban agglomerations’ economic activity to peripheral areas. In column (6), I include peripheral population, metropolitan population, and tertiary education employment. The reported elasticity is similar to the one in column (5).
Table 6 in the Appendix reports the first stage results from running regression (5), which does not include peripheral income among the independent variables. Table 7 in the Appendix presents the second-stage results from running regression (6), where the dependent variable is a combined periphery-agglomeration economic outcome. With varying statistical significance depending on the specification, the relevant estimations based on these regressions imply similar findings as the results based on Eqs. (3) and (4) for the impact of regional highways on the distribution of economic activities between urban agglomerations and peripheral areas in the European Union.
Columns (1) and (2) in Table 8 in the Appendix report the ordinary least squares (OLS) estimations based on Eqs. (1) and (2). The OLS results are small and statistically insignificant, although the signs on highway coefficients are similar to the IV elasticities. The difference between IV and OLS elasticities highlights that governments could have targeted urban agglomerations with a lower growth potential.
Small or statistically insignificant OLS coefficients on highways and roads are a well-known problem in the literature (Baum-Snow et al. 2017). The OLS regressions can provide unbiased elasticities only if the construction of highways is independent of local economic outcomes and no omitted variables affect both. Since this is likely not the case, one has to be cautious about the OLS results.
5 Additional sensitiveness checks
Baum-Snow et al. (2017) suggest that the effects of infrastructure on local economic outcomes can vary with agglomerations’ characteristics, such as land use planning policy, housing supply elasticity, and availability of alternative transportation to cars. To check whether this is true, I follow the exercise performed by Baum-Snow et al. (2017). The authors excluded from their analysis the cities from Western China, which are generally less economically developed than the cities in the Eastern part of the country. Moreover, the pace of market reforms there is slower, and the role of government is higher.
Following a similar logic, I exclude Romania and Bulgaria from my analysis, countries with low levels of economic development, high levels of corruption at different administrative hierarchies, and pronounced internal income disparities.Footnote 11 These factors can affect agglomerations’ characteristics, such as the efficiency of public transportation. I also exclude Poland, the largest economy in the Eastern European Union.
Table 3 provides the first-stage results from running regression (3). All columns exclude Romania, Bulgaria, and Poland from the analysis. The exclusion of these countries decreases the number of regions used in regressions from 91 to 72 and the number of observations from 1 260 to 1 040. The instrument remains a strong predictor of highways, as the cluster-robust first stage F-statistic is above 10 in all columns. The signs of the coefficients are similar to the results reported in Table 1, while the magnitudes marginally decrease
Table 4 reports the second-stage results from running regression (4). The model specifications used in columns (1) and (2), which employ a limited set of control variables, generate statistically insignificant results. The model specifications used in columns (3) to (6) yield statistically significant results at the 10% level. The magnitudes of these results are similar to the estimations in Table 2.
Land prices and business competition in large cities can be higher, and thus, the decentralisation effects of highways, in their case, can be more pronounced. As a result, larger urban areas may drive the estimations. Following Baum-Snow et al. (2017), I analyse whether agglomerations’ size matters for the effects of highways. For this purpose, I exclude 10% of data representing the highest metropolitan population in my sample. Tables 9 and 10 in the Appendix show the results. The first-stage results are similar to the estimations in Table 1. The second-stage results are modestly higher, yet the elasticities remain in a similar range as the estimations in Table 2. As in Baum-Snow et al. (2017), the slightly enhanced coefficients suggest that the largest agglomerations do not drive the results.
6 Counterfactuals
Figure 2 presents the counterfactual loss in income convergence between urban agglomerations and peripheral areas in 2020 if the length of highway networks in European countries decreases to the 1990 level. In this extreme case, the preferred estimation suggests that the city-periphery income convergence would have been 2.9% lower. In other words, for the same economic output produced within a NUTS-2 region in 2020, the urban agglomeration would have concentrated 2.9% more production relative to the peripheral area if the highway networks of European countries had not expanded since 1990.

Counterfactual loss in income convergence between urban agglomerations and peripheral areas in the European Union in 2020 for a given length of highway networks. Note: I measure loss in income convergence between metropolitan and non-metropolitan areas by the % increase in the income of urban agglomerations holding peripheral GDP fixed as highways decrease. The years below the line show the length of highways in the European Union in a given year
7 Conclusion
The paper analyses the impact of highways on the distribution of economic activities between agglomerations and peripheral areas in the European Union. In doing so, I employ the basics of the land use theory and newly collected data on infrastructure, transportation, and local economic performance. To tackle endogeneity, I use an instrumental variable design that conditionally exploits non-local highway construction as a source of exogenous information.
I find that highways contribute to the diffusion of urban economic activities into surrounding regions, thus reducing the income gap between urban agglomerations and peripheries. The baseline elasticities imply that the income differences between metropolitan and non-metropolitan areas in 2020 would be nearly 3% higher if the highway networks of European countries had stayed at the level of 1990. The paper supports the transportation infrastructure initiatives within the EU Cohesion Policy, highlighting the capacity of these initiatives to increase income cohesion among European regions.
The results of this paper help to understand the effects of infrastructure policies on the geographical distribution of economic activities. Highways substantially decrease the cost of accessing space, resulting in less localised agglomeration effects. Expanding highway networks can serve as an efficient mechanism to improve economic growth for the less urbanised regions in the European Union. One potentially significant question for future research concerns the analysis of the environmental costs of highways in the European Union.
Data availability
Data will be made available on request.
Notes
The share of European funding in total national transportation capital expenditure is very high for Lithuania, Malta, and Hungary, more than 60%, and Latvia, Poland, and Bulgaria, around 50%.
Specialisation can produce sizeable economic gains through trade (Weder 2017).
NUTS stands for the Nomenclature of Territorial Units for Statistics, a European Union hierarchical system for dividing up the economic territory of the EU to collect statistics for socio-economic analysis and framing of EU policies. More information is available here: https://ec.europa.eu/eurostat/web/nuts/background.
More information is available at: https://ec.europa.eu/eurostat/web/metropolitan-regions/background.
The Victoria and Albert Museum in London. The exhibition "Cars: Accelerating the Modern World". The dataset is available here: https://github.com/StudioFolder/european-motorways/. The historical research on highway networks chronological evolution was done by Brendan Cormier and Esme Hawes from the Victoria and Albert Museum. The initial data source on highways is OpenStreetMap (https://www.geofabrik.de/data/download.html).
I also tried to instrument by using 4-year lagged fatalities per million persons in road accidents as an exogenous source of variation for highways. The idea relied on the fact that more deaths can generate policy demands from the families and friends of the victims and the society for highway construction, as highways are relatively safer. For example, highways minimise the risk of head-on collisions. The lag framework reflects the time-to-spend and time-to-build delays. Although the first stage sign was as expected, with more deaths in the past causing more construction of highways, the first stage F-statistic was below 10 when controlling for time-invariant covariates. As controls, I included, among others, present fatalities per million persons to exploit past variation only and country-year dummies.
Decision No 1692/96/EC of the European Parliament and of the Council of 23 July 1996 on Community guidelines for the development of the trans-European transport network. Decision No 661/2010/EU of the European Parliament and of the Council of 7 July 2010 on Union guidelines for the development of the trans-European transport network and Regulation (EU) No 1315/2013 of the European Parliament and of the Council of 11 December 2013 on Union guidelines for the development of the trans-European transport network and repealing Decision No 661/2010/EU Text with EEA relevance.
In my analysis, I use the estimates of average travel speed not in the same EU country computed by Ignatov (2024). For this purpose, the author combines time-fixed geocoded data on more than 2.3 million non-highway roads and 1.4 thousand ferry routes as of 2021 with detailed geocoded information on highway networks expansion in Europe from 1990 to 2020.
For example, in 2021, based on Eurostat statistics, the GDP per capita in Bucharest-Ilfov, the most developed region of Romania, was higher than in the North-East, the least-developed part of the country, by a factor of 3.
References
Ahlfeldt GM, Redding SJ, Sturm DM, Wolf N (2015) The economics of density: evidence from the Berlin Wall. Econometrica 83(6):2127–2189
Banerjee A, Duflo E, Qian N (2020) On the road: access to transportation infrastructure and economic growth in China. J Dev Econ 145:102442
Baum-Snow N (2007) Did highways cause suburbanization? Q J Econ 122(2):775–805
Baum-Snow N (2010) Changes in transportation infrastructure and commuting patterns in US metropolitan areas, 1960–2000. Am Econ Rev 100(2):378–382
Baum-Snow N, Brandt L, Henderson JV, Turner MA, Zhang Q (2017) Roads, railroads, and decentralization of Chinese cities. Rev Econ Stat 99(3):435–448
Baum-Snow N, Henderson JV, Turner MA, Zhang Q, Brandt L (2020) Does investment in national highways help or hurt hinterland city growth? J Urban Econ 115:103124
Berkowitz P, Monfort P, Pieńkowski J (2019) Unpacking the growth impacts of European union cohesion policy: Transmission channels from cohesion policy into economic growth. Reg Stud 54(1):60–71
Conference of European Directors of Roads (2019) Trans-European road network, TEN-T (Roads): 2019 performance report. Retrieved on 23 Nov 2021 from https://www.cedr.eu/download/Publications/2020/CEDR-Technical-Report-2020-01-TEN-T-2019-Performance-Report.pdf
Crescenzi R, Di Cataldo M, Rodríguez-Pose A (2016) Government quality and the economic returns of transport infrastructure investment in European regions. J Reg Sci 56(4):555–582
Crescenzi R, Giua M (2020) One or many cohesion policies of the European union? On the differential economic impacts of cohesion policy across member states. Reg Stud 54(1):10–20
Crescenzi R, Rodríguez-Pose A (2012) Infrastructure and regional growth in the European union. Pap Reg Sci 91(3):487–513
Dicharry B, Nguyen-Van P, Pham TKC (2019) “The winner takes it all” or a story of the optimal allocation of the European cohesion fund. Eur J Polit Econ 59:385–399
Donaldson D (2018) Railroads of the Raj: estimating the impact of transportation infrastructure. Am Econ Rev 108(4–5):899–934
Donaldson D, Hornbeck R (2016) Railroads and American economic growth: a “market access” approach. Q J Econ 131(2):799–858
Duranton G, Morrow PM, Turner MA (2014) Roads and trade: evidence from the US. Rev Econ Stud 81(2):681–724
Duranton G, Puga D (2015) Urban land use. In: Duranton G, Vernon Henderson J, Strange WC (eds) Handbook of regional and urban economics, vol 5. Elsevier, Amsterdam, pp 467–560
European Commission (2017) My region, my Europe, our future–7th report on economic, social and territorial cohesion. Retrieved on 18 Jan 2022. Available online at: https://ec.europa.eu/regional_policy/sources/docoffic/official/reports/cohesion7/7cr.pdf
European Court of Auditors (2020) Special report 09–the EU core road network: shorter travel times but network not yet fully functional. Retrieved on 23 Nov 2021 from https://www.eca.europa.eu/Lists/ECADocuments/SR20_09/SR_Road_network_EN.pdf
European Commission (2014) An introduction to EU cohesion policy 20142020. Link: https://ec.europa.eu/regional_policy/sources/docgener/informat/basic/basic_2014_en.pdf. Accessed 23 Nov 2021
European Commission (2016) 9 ways cohesion policy works for Europe, main results 2007–2013.//ec.europa.eu/regional_policy/en/information/publications/factsheets/2016/9-ways-cohesion-policy-works-for-europe-main-results-2007–2013. Accessed 23 Nov 2021
Faber B (2014) Trade integration, market size, and industrialization: evidence from China’s national trunk highway system. Rev Econ Stud 81(3):1046–1070
Fajgelbaum PD, Schaal E (2020) Optimal transport networks in spatial equilibrium. Econometrica 88(4):1411–1452
Fidrmuc J, Hulényi M, Tunalı ÇB (2019) Can money buy EU love? Eur J Polit Econ 60:101804
Fujita M, Ogawa H (1982) Multiple equilibria and structural transition of non-monocentric urban configurations. Reg Sci Urban Econ 12(2):161–196
Gagliardi L, Percoco M (2017) The impact of European cohesion policy in urban and rural regions. Reg Stud 51(6):857–868
Garcia-López MÀ, Holl A, Viladecans-Marsal E (2015) Suburbanization and highways in Spain when the Romans and the Bourbons still shape its cities. J Urban Econ 85:52–67
Ghani E, Goswami AG, Kerr WR (2016) Highway to success: the impact of the golden quadrilateral project for the location and performance of Indian manufacturing. Econ J 126(591):317–357
Herzog I (2021) National transportation networks, market access, and regional economic growth. J Urban Econ 122:103–316
Holl A (2016) Highways and productivity in manufacturing firms. J Urban Econ 93:131–151
Ignatov A (2024) European highway networks, transportation costs, and regional income. Reg Sci Urban Econ 104:103969. https://doi.org/10.1016/j.regsciurbeco.2023.103969
Jaworski T, Kitchens CT (2019) National policy for regional development: historical evidence from Appalachian highways. Rev Econ Stat 101(5):777–790
Jaworski T, Kitchens C, Nigai S (2023) Highways and globalization. Int Econ Rev. https://doi.org/10.1111/iere.12640
Jedwab R, Kerby E, Moradi A (2017) History, path dependence and development: evidence from colonial railways, settlers and cities in Kenya. Econ J 127(603):1467–1494
Melo PC, Rego C, Anciães PR, Guiomar N, Muñoz-Rojas J (2022) Does road accessibility to cities support rural population growth? Evidence for Portugal between 1991 and 2011. J Reg Sci 62(2):443–470
Michaels G (2008) The effect of trade on the demand for skill: evidence from the interstate highway system. Rev Econ Stat 90(4):683–701
Percoco M (2016) Highways, local economic structure and urban development. J Econ Geogr 16(5):1035–1054
Rodríguez-Pose A, Dijkstra L (2021) Does cohesion policy reduce EU discontent and Euroscepticism? Reg Stud 55(2):354–369
Weder R (2017) The standard ricardian trade model. In: Jones R, Weder R (eds) 200 years of ricardian trade theory. Springer, Cham
Acknowledgements
I gratefully acknowledge financial support from the Swiss Federal Commission for Scholarships for Foreign Students (Swiss Government Excellence Scholarship Grant No. ESKAS:2019.0036), the University of Basel, and the Chair of International Trade and European Integration, Faculty of Business and Economics, University of Basel. I am deeply grateful to the editor, Harald Oberhofer, and the two anonymous referees for the very valuable comments and suggestions. Also, I owe a debt of deep gratitude to my Ph.D. supervisors, Rolf Weder and Conny Wunsch, for their support and guidance. I am also grateful to Dave Donaldson, Andrei Levchenko, Marco Cucculelli, Dragan Filimonović, Matthias Niggli, Thomas Gerber, Beat Spirig, and the participants of the Faculty’s Economics Lunch and the 63rd Annual Conference of the Italian Economic Association, held in Torino, for discussions and comments. All remaining errors are my own.
Funding
Open access funding provided by University of Basel. Swiss Federal Commission for Scholarships for Foreign Students, University of Basel, Chair of International Trade and European Integration, Faculty of Business and Economics, University of Basel.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
No conflict of interest is reported.
Additional information
Responsible Editor: Harald Oberhofer.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ignatov, A. European highways and the geographic diffusion of economic activities from agglomerations to less urbanised areas. Empirica 51, 351–377 (2024). https://doi.org/10.1007/s10663-023-09603-x
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10663-023-09603-x