
Abstract
The study of market power has gained a lot of attention by scholars and policy-makers since De Loecker and Eeckhout (Global market power. Working paper 24768, National Bureau of Economic Research, 2018). In their work, they show the temporal evolution of market power worldwide using detailed data from the financial statements of thousands of firms. In this paper, we propose an alternative way of estimating market power using sectoral-based data. By utilizing the aggregates observable in a series of input–output tables and by applying an estimation procedure based on entropy; indicators of market power can be derived without requiring the use of micro-data. We document a heterogeneous evolution of market power across 28 European countries and 14 manufacturing sectors between 2000 and 2014. Market power is found to be rising for several central- and East-European countries, while decreasing in multiple South- and West-European nations. Globalisation and value chain positioning are both seen to have a significantly decreasing impact on markups.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The study of market power has gained a lot of attention since De Loecker and Eeckhout (2018) and De Loecker et al. (2020). Using firm-based data, their papers have shown that market power has continually increased since the 1980’s (except for a brief decrease during the 2007–2008 Financial Crisis) for the US and the world as a whole, mostly driven by the largest firms within markets. Although a too low market power could indicate a loss of competitiveness, an increase in aggregated market power is often associated, at least in theory, with a range of negative economic developments such as: decreasing total factor productivity and output (Baqaee and Farhi 2017), a decrease in the labour share of income (Autor et al. 2020), decreases in investments (Gutiérrez and Philippon 2017), loss of innovation after reaching a threshold (an inverted U-shape relationship), as seen in, for example, Diez et al. (2018) and Mulkay (2019). Furthermore, rising market power also has societal implications due to its contribution to rising income-inequality, see Ennis et al. (2019).
This development has sparked interest globally among policy-makers, scholars and members of industry who are interested in understanding the cause of these changes, as well as obtaining a deeper understanding to measure market power. Central Banks are amongst the most important of these entities investigating this phenomenon due to the impact it has on pricing (see for example Koujianou Goldberg and Hellerstein (2012)), with examples including the recent speeches made by Praet (2019) at the European Central Bank, and the Economic Policy Symposium of 2018 organized by the Federal Reserve at Jackson Hole. Moreover, the question of competition and market power is gradually seeping into the political arena with calls increasingly being made to make markets fairer for all of those involved and more efficient as evidenced, for example, by the warnings and reform proposals given by the books Eeckhout (2021) and Baker (2019). This can be seen in Europe not only at the EU level (EU commission), but also at the national level with member-states using various tools and policies to reduce monopolistic action.
The topic of market power has always been of crucial importance within the field of industrial organization, ever since Lerner (1934) first proposed an index measuring the markup of price over marginal cost. Subsequent literature adopted the Structural- Conduct-Performance (SCP) approach to study the market structure in detail to understand the causes of market power (Perloff et al. 2007). These papers did not rely on formal models of industry behaviour, rather were often case studies and inter-industry analysis mostly focused on one single year (Schmalensee 1987). The SCP approach was mostly interested in understanding market structures, and therefore limited itself to investigating one or two industries. Hall (1988) outlined a formal model and laid the framework through which markups estimation was generalized. The papers from Olley and Pakes (1996), Levinsohn and Petrin (2003) and Ackerberg et al. (2015) introduced novel ways to estimate production functions using a two- or three stages approach with control functions, solving the usually large problems of endogeneity caused by direct regressions. These papers paved the way to derive estimates for markups directly from production functions, for instance De Loecker et al. (2020). The markup, or the ratio between selling price of a final good and the marginal cost of production, is commonly used in the literature as a proxy for market power. Using De Loecker and Eeckhout (2018) terminology, the markup for firm i at year t is: \(\mu _{it} = {P_{it}}/{\lambda _{it}}\). Assuming that firms are profit maximizers, a markup of 1 is indicative that the firm is setting prices in such a way that they are not able to move beyond the break-even point (\(P_{it} = \lambda _{it}\)), and not making profits. A markup larger than 1 is commonly associated with firms exercising market power (\(P_{it} > \lambda _{it}\)).
We propose using this same methodology of calculating markups based on production functions but using aggregated sector-level data instead of the firm-level data, which it was originally designed for in the paper by Hall (1988).Footnote 1 More specifically, in this paper we propose using a General Maximum Entropy (GME) approach with data from the World Input–Output Database (WIOD) as well as the WIOD Socio Economic Accounts (SEA) in order to estimate sector-level markups. Input–output tables such as the ones from WIOD, divides total global economic activity into sectors or industries (used interchangeably during the remainder of the paper). They provide information on the flows of goods or services encompassed within an industry, originating in one sector and ending up in another.
Even though markup estimation using micro-based data is considered to be the benchmark in terms of precision (being able to provide estimates by percentile of firm-size along the distribution and conduct granular research), it also has a few notable problems, including: potential sample selection bias due to firms entering bankruptcy during the years of observation (sample attrition), difficulty of classifying a firm into a sector if it produces several goods and the problems of extracting volumes of inputs and outputs, which the SEA conveniently does provide, thus avoiding potential estimation bias arising from pricing,Footnote 2 and difficulty of finding data that is accurately representative of total market activity. The largest databases containing firm activity, such as Worldscope, have information for 70000 firms (De Loecker et al. 2020). These firms are often publicly traded thereby potentially skewing results upwards i.e. successful firms with sound balance sheets will be over-proportionately reported as they have better chances of selling stocks. Firm-level data has the further inconvenience of lacking information on certain sectors, thereby any analysis is constrained to a few, predominantly manufacturing sectors. This is a further advantage of using the SEA of the WIOD, as the data contained therein encompasses total market activity within countries, and represents at least 85% of world economic activity (Timmer et al. 2012). Finally, the WIOD and SEA are free and easily accessible to the general public. This runs in contrast to many databases offering firm-level information, as they generally require fees or are private and not accessible to the general public (for example, due to laws requiring confidentiality on handling firm data). Additionally, the use of micro-data is computationally very demanding, with programs having to process thousands (even hundreds of thousands) of firms thereby necessitating considerable amounts of time for estimates to be produced.
The use of macro-data circumvents all of these problems, and is potentially able to yield results for the whole world, yet sacrifices precision. Moreover, this approach allows to fully integrate the strengths of input–output analysis into market power research. Input–output tables are excellent in calculating a myriad of measures and indicators pertinent to the fields of international trade and industrial organisation. These measures may not be easily obtainable using pure firm-level data, thus other dimensions may be opened up for research. A simple example of this type of analysis is shown in Sect. 5.3, which estimates the relationship between the positioning of the production process and Global Value Chains (GVC’s) i.e. the international fragmentation of the production process with markups. The results derived in that section corroborates theory and the empirical results of papers focusing on individual countries and industries.
The paper is organized as follows. Section 2 gives a summary of further relevant literature, Sect. 3 presents the basics of the methodology required to estimate market power indicators from IO data. Section 4 provides a general description of the estimation procedure proposed to derive these indicators from aggregate information. Section 5 presents an empirical application for manufacturing industries in the EU basing on data from the World IO database for the period 2000 to 2014. Section 6 closes the paper.
2 Related literature
Numerous recent papers have expanded the knowledge regarding the study of market power; not only fine-tuning methodological aspects of De Loecker et al. (2020), but also applying the existing technique using evermore detailed datasets and focusing on granularity. In the former category, papers such as Morlacco (2017) expand the existing methodology to include measures of buyer market power and apply this to firms in the French manufacturing industry, finding the significance of this as well as finding evidence for carrying distortionary effects throughout the value chain.
Even though Hall et al. (1986) is considered to have kick-started the research of market power at a macro-level, research using aggregate data was slow relative to the micro approach. This was due to macroeconomists’ reliance on Kaldor’s Stylised Facts that assumes a stable evolution of market power and labour share of income. Nevertheless, De Loecker and Eeckhout (2017) spurred renewed research interest using macro-data. Cavalleri et al. (2019) use both micro- and macro-data to estimate market power trends for four countries in the Eurozone, and find a stable (plateaud) evolution. More recently, Colonescu (2021a) and Colonescu (2021b) derived measures of market power using macro-data contained within IOT’s and the methodology proposed by Olley and Pakes (1996). These recent papers make use of the advantages of using IOT’s, namely the ability to conduct Global Value Chain Analysis (GVC) in conjunction with potential markup estimation, thereby opening-up a whole new potential avenue for research, not possible with with using micro-based data. The use of both micro- and macro-based data can therefore complement each other well.Footnote 3
There has also been an increasing surge in interest on finding determinants of markups, and measuring the types of relationships between both of these. Papers investigating this question often fall into one of two complementary groups: those analysing structural changes and those assessing the impact of policy. Of these, the former has had a noteworthy increase in research activity, with papers increasingly focusing on investigating the role of globalisation (with emphasis on trade in intermediates) on markups, generally finding a pro-competitive relationship. Empirical examples include: De Loecker et al. (2016), Gradzewicz and Mućk (2019) and Choi et al. (2021). Nevertheless, these studies often focus almost exclusively on individual countries, therefore, a comprehensive analysis based on numerous countries is of great interest.
3 Methodology
We follow here the same approach as in De Loecker et al. (2020) to derive market power indicators following the cost-based method. One crucial difference is that they use firm-level data to implement their analysis, while we propose using aggregate data at sectoral level. One reason for doing this is that, even when micro-data analysis allows for a richer detail in the results, the appropriate data required to do this are not always at hand and they are not easily accessible.
Let us denote the production in industry i at time t by the Cobb–Douglas technology:
where \(V_{it}\) denotes the variable inputs i.e., intermediate consumptions plus labor, \(K_{it}\) represents the capital stock and \(\Omega _{it}\) is the total factor productivity. Defining the output and the variable inputs prices as \(P_{it}\) and \(P_{it}^V\), De Loecker et al. (2020) estimate the markup of a firm i (industry i in our case) as:Footnote 4
They implement this approach by estimating first the output elasticity \(\alpha _{it}\) in 1 and then, assuming that this estimate is common for all the firms in the same sector and year, is plugged into 2. The approach proposed here is different and is based on aggregate information by industry, which can be easily accessed from the data present in a standard IO table.
Our point of departure is an (\(N\times N\)) industry-by-industry IO table for an open economy at time period t with the following basic structure:Footnote 5

An illustrative example of an input–output table
The elements \(z_{ij}\) indicate how much of the production of industry i is used as intermediate input on industry j. Industry j requires not only intermediate inputs to produce, but primary factors as well (payments to production factors other than intermediate inputs). The compensation paid for these primary factors is split in our example in labour compensation (\(lc_j\)), plus other terms in the value added (capital compensation, for example) labelled as \(w_j\). Summing up across columns equals the total input on industry j (\(x_j = \sum _i z_{ij} + lc_j + w_j + m_j\)) while the sum across rows adds up to the total production of industry i (\(x_i = \sum _j z_{ij} + y_i\)).Footnote 6
All the terms in this IO table are given in monetary units, so it is relatively easy to find a correspondence between the IO table cells and the elements used by De Loecker and Eeckhout (2018) to estimate the markups. Note that the total output in industry i at time period t in an IO table (\(x_{it}\)) corresponds to \(P_{it} Q_{it}\), while the sum \(\sum _i z_{ijt} + lc_{jt}\) is equal to \(P_{jt}^V V_{jt}\) in Eq. 2. This means that part of the terms required to quantify the market power for one industry as \(\mu _{it}\) can be directly recovered from IO tables.Footnote 7
Additionally, we would need to estimate the output elasticity \(\alpha _{it}\) to finally get measures of \(\mu _{it}\). This step is comparatively more problematic, since only aggregated information is available in IO databases. Ideally, we would need to have data on physical output produced \(Q_{it}\), units of the variable inputs employed (\(V_{it}\)) and stock of capital \(K_{it}\). These variables are not normally observable in IO databases, because of two main problems: (i) IO are expressed in monetary and not physical units, and (ii) IO cells are flows and not stocks.
However, these two difficulties can be partially solved by using the information publicly available in the World IO database—the Socio-Economic Accounts, which complements the national and international IO tables with additional indicators of physical output and intermediate consumptions, number of hours worked by the employees and stocks of capital. This information is available for 43 different countries along the period 2000–2014 with a sectoral breakdown into 56 industries.Footnote 8
Since the indicators on gross output and intermediate consumptions are given in the form of volume indices (with base at 2010), some modifications are necessary in the estimable forms of the production function. In particular, we will assume that for one specific industry i and a time period t, the output elasticities \(\alpha _{itc}\) and \(\beta _{itc}\) as well as the factor productivity in \(\Omega _{itc}\) are constant for all the countries studied. This transforms Eq. (1), which can be re-written as:
Then, Eq. (3) is linearised and expressed in differences with respect to the 2010 levels as:
Where the subscript 0 refers to the base period 2010. By adding a noise term \(\epsilon _{itc}\), equations like the following can be estimated:
Being \(\Omega _{it}^*= ln\left( \frac{\Omega _{it}}{\Omega _{i0}}\right)\). Equations like (5) will be estimated for each one of the 56 industries present in the WIOD tables. This implies that the estimates of \(\alpha _{it}\) will based on a number of data points that correspond to the number of countries that we want to study (C), and for which we assume that the production technology is the same. This naturally generates a set-up where the sample size C is expected to be small, which prevents the use of traditional econometric techniques that rely on the central limit theorem due to the limited number of degrees of freedom. Note that we want to produce an estimate of the elasticity \(\alpha _{ij}\) for each industry and year, and not imposing parameter homogeneity along time. This prevents the use of more traditional estimators based on a panel-data structure. Our proposal is to use estimators based on entropy econometrics, which have been previously used in contexts of limited information (see, among others, Golan and Vogel (2000); or Fernandez-Vazquez (2015); for applications within the field of IO tables).
4 GME estimation of market power for EU manufactures; 2000–2014
A GME estimator has been applied to equations like 5 for each year from 2000 to 2014 and for a set of 23 manufacturing industries.Footnote 9 The dataset comprises the EU-28 economy (\(C=28\)), and the values of \(Q_{itc}\), \(V_{itc}\) and \(K_{itc}\) have been taken from the WIOD database. The list of countries and industries studied are reported in Tables 3 and 4.
Applying the GME estimator, requires the specification of supporting vectors for the parameters and the error terms. The parameters in Eq. 5 are the output elasticities \(\alpha _{it}\) and \(\beta _{it}\) and the factor productivities \(\Omega _{it}\). For the term \(\Omega _{it}\) we set support vectors with \(M=3\) values \((b_{\Omega m})\) centered at 0 and with bounds at \(\pm 10\). For the output elasticities we define supporting vectors with \(M=3\) points (\(b_{\alpha m}\) and \(b_{\beta m}\) respectively) centered at the corresponding mean value of the shares of \(V_{itc}\) and \(K_{itc}\), and the limits of these vectors set as these means \(\pm 10\) to assure having wide enough supports. Similarly, for the error term, the support vectors are based on the three-sigma rule, which specifies vectors centered at 0 and sets the limits as ± three times the standard deviation of the dependent variable. Note that this approach implies that, in absence of information, the GME estimator produces uniform probabilities and the point estimates of the parameters will be equal to the central value in the vectors. By setting these central values at the mean of \(V_{itc}\), the uninformative GME solution makes the mean mark-up \(\mu _{itc}\) equal to one by construction. In other words, our prior assumption is that there is no market power and only if data contains information that contradicts this initial assumption, the GME estimator will produce a different result.
The GME programs for the estimations on each industry \(i=1, \dots ,23\) and \(t= 2000, \dots ,2014\) can be written as follows:
subject to:
One additional advantage of using the GME estimator in this context is that its flexibility allows us to accommodate additional constraints related to the theoretical characteristics of the phenomenon analyzed. In the case under study, theory tells us that the market power should not be lower than one, and this theoretical restriction is included into the GME program by means of Eq. 10. Note that this equation forces the estimates of \(\mu _{itc}\) to be equal or larger than one, preventing to get solutions that do not fit with the basic assumptions used in the model from which the estimable equations have been derived.
By solving these programs, the GME estimator produces point estimates and estimated variances for the parameters of interest. In particular our estimates of \(\alpha _{it}\) are calculated as \(\sum _{m=1}^{M} b_{\alpha m} p_{\alpha m}\) and the estimates of \(\mu _{itc}\) as \(\sum _{m=1}^{M} b_{\alpha m} p_{\alpha m}\frac{P_{itc} Q_{itc}}{P_{itc}^V V_{itc}}\).Footnote 10 Next section shows the main results found and compares them with other alternative approaches.Footnote 11
5 Results
We have estimated Eq. 5 by using GME based on the available data from WIOD. Furthermore, we got access to sector-level aggregated micro-data obtained from the database CompNet,Footnote 12 on which the original approach presented by De Loecker and Eeckhout (2018) and De Loecker et al. (2020) can be replicated. This comparison allows for testing to what extent the GME estimates are similar to those obtained from more detailed data.
The evolution of market power shows a large variation according to the method of aggregation. Appendix 1 gives detailed descriptive statistics of markups disaggregated by years and industries estimated using WIOD and micro-data. Table 6 illustrates the descriptives for markups disaggregated by industries derived from WIOD, with GME being capped at a minimum of one (due to the constraint depicted in Eq. 10), displaying low levels of variation relative to the evolution obtained from micro-data, as seen in Table 7.
Both the minimum and maximum values are largely heterogeneous across sectors, and have a large standard deviation. The highest maximum values from the GME method is seen to be in the aggregate sector corresponding to coke and petroleum manufacture, the lowest related to textile, rubber and non-metalic mineral products. Table 5 shows individual country—sectors with the five highest markup values for 2000 and 2014. Sectors corresponding to the manufacturing of petroleum and chemical products appear frequently, especially for 2014. Tables 8 and 9 further illustrate these summary statistics disaggregated by years, showing stronger minimum values during 2009 for GME estimates.
5.1 Results using the world input–output database
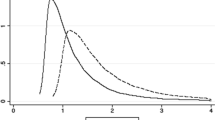
Figure 7 details the evolution of markups in its highest form of aggregation. The markups were found to be highest during 2003 and lowest in 2008. Up until 2008, market power was seen to be having a decreasing trend. Thereafter, market power was increasing nearly continuously for subsequent periods. Estimates for market power were higher at the end of the sample period in 2014 than they were at the start in 2000. Figure 9 further shows how the output elasticity of labour evolved throughout the sample period.
Figure 2 shows the country-aggregate market power for the years 2000 and 2014, for the manufacturing industries illustrated in Table 4. The map indicates persistent variations of market power by levels across geographic regions. Scandinavian and Baltic countries (with the exception of Estonia and Finland in 2014), South-Eastern countries such as Romania, Greece, and finally Ireland consistently reported relatively higher markups compared to other countries. By 2014 many South-European countries had relatively low-levels of market power, especially Italy and Croatia. Additionally, Belgium, Luxembourg and Estonia had low markups relative to the other countries.

Markups during 2000 and 2014
Figure 3 further shows percentage changes for markups between 2000 and 2014. The colouring of the map indicates a remarkable geographic pattern; countries whose markup have increased or decreased tend to be in proximity with each other (with the exception of Ireland and Portugal and Finland). Central European countries such as Germany and Poland saw an increase in market power. Southern Baltic countries, Denmark, Finland, Ireland and the South-eastern region also had increasing markups. In contrast, most South- and West-European countries saw decreasing markups. The manufacturing sectors from a total of 13 countries had increasing markups between 2000 and 2014. A total of 7 of these countries with increasing markups joined the European Union somewhere during the sample period; either in 2004 as in the case of: Hungary, Lithuania, Latvia, Poland and Slovenia, or in 2007 such as Bulgaria and Romania. The remaining countries with increasing markups were: Germany, Denmark, Finland, Greece, Ireland and Portugal.

Percentage change GME markups 2000 to 2014 for each country
Nevertheless, our estimates suggest that the mean value of aggregate market power along these countries have been converging slowly between 2000 and 2014. A country-wise absolute beta-convergence analysis using a fixed effects regression, where market power growth rates between 2000 and 2014 was regressed on its lagged values, produces an estimate of the beta coefficient of \(-0.338\) (significant at 0.1%). The results of which is shown as a scatter-plot in Fig. 4. This result indicates that overall the dispersion of aggregated market power decreased during the sample period.

Beta convergence of markups aggregated by country using a two-way fixed effects model
5.2 Comparisons to firm-level data
A possible concern revolves around the actual precision of these results, given the assumption in an input–output table that each sector is produced by one representative firm. The WIOD Markup sample was compared with the 7th Vintage CompNet database that provides estimates for market power using firm-level micro data. The evolution of these measures of market power were then plotted across time. Even though the WIOD and the SEA contain information for 56 sectors and 43 countries for the years 2000–2014 (except 2010 due to it being the base year), the markup data within CompNet is unbalanced. The is because different European countries have unequal systems for collecting firm data. Some countries report data for every firm, while others require a firm fulfilling certain thresholds, such as a minimum number of workers being employed at a firm. Due to the aggregated nature of WIOD, only CompNet countries with full firm samples were used. In total, 14 sectors were compared for five European countries—each country having data for differing spans of time.Footnote 13 Data from WIOD that did not find a match were removed from the sample, making the comparison as homogeneous as possible. Tables 7 and 9 describe the CompNet variable in more detail.
The markup from the micro data was estimated by using a Cobb–Douglas production function with the firm’s revenue being used as a proxy for output, and the elasticity for intermediates used for the markup computation, see Eq. (2). This form was chosen as it is the most similar to the approach presented here.
Figure 5 shows the evolution of all the markup estimates with confidence intervals at the 95% level. These aggregates are calculated by averaging markups for each country, years and industry using industry volumes of output in the WIOD as weights. A function was fitted through the scatter-plot using the Loess smoothing technique, thereby revealing the evolution. GME markup is seen to generally have overlapping confidence intervals with the estimates derived from micro-data. Nevertheless, disaggregating the data at a sector level shows divergence for some industries; most notably for sectors manufacturing wood, media, pharmaceutical products and other transport equipment not included in the manufacture of cars (notably air-planes, ships, locomotives and spacecraft).
Estimates corresponding to industries C16, C18, C21 and C30, and are seen to deviate significantly from each other. This can highlight how the use of macro-based data for markup estimation has a few unique potential pitfalls that can bias results. These have to do with the uniformity of the distribution within the market being considered. Macro-data assumes that each sector is produced by one representative firm, and considers averages. If the sector is comprised of very few firms, or the distribution is very fat-tailed, bias may ensure. Macro-data cannot disentangle what is happening to top percentile-size within the firm-size distribution, which may be problematic as most market power is seen to be generated by this fragment of the market.

Evolution aggregate and per sector markups using loess smoothing estimated using WIOD and firm-level data from CompNet
Both measures indicate that markups declined until 2008. GME markups reached their lowest point by that year, with a reversal of this declining trend occurring thereafter during the 2009–2014 period. The CompNet markups reportedly remained stable after the 2008 period, not reaching the levels of pre-2007. Both measures show that market power never fully recovered the initial values seen in the 2000 period. Noteworthy is that the estimates derived from CompNet often have a minima under 1, which would seemingly indicate that goods were being sold at a price under its marginal cost of production. This is something which frequently occurs when handling firm-level data. These values contradict theory, since firms will not operate when profits cannot be achieved. This is more relevant with aggregated sector-level values, as this would indicate a substantial number of firms setting prices under marginal costs.
A larger year-to-year variation can be seen in Fig. 6, showing the sector-aggregated development for four selected manufacturing industries (Sect. 1 within the appendix shows the evolution for all the sectors in the combined sample). The sectors corresponding to the manufacture of fabricated metal products and the manufacture of computer and electronics, show a relative larger variation, whereas those sectors related to the manufacture of machinery and motor vehicles were more stable.

Evolution market power for four selected industries
5.3 Markups and global value chains
As can be seen in the descriptive tables in Sect. 1, a large heterogeneity exists across countries and sectors when examining these markups. This section investigates potential causes of this disparity by using two exogenous determinants of markups—making use of WIOT’s capacity to compute measures of inter-industrial linkages. One of these measure indicates how globalised, or internationalised, the factors used to produce an output are within each industry whilst the other indicates the relative positioning with regards to tasks being produced. This section serves as a simple exercise to further give credence to the results derived via the GME approach, but, by no means is this a complete analysis of the full determinants of markups. Other characteristics could theoretically impact markups, such as a country’s institutional quality (including corruption), and ease of access to credit by larger firms, among other things.
In order to understand how these measurements are computed, a few concepts are explained in the following paragraphs. Using the notations in matrix form from Fig. 1 (representing a Leontief Demand Model); X represents a vector with total output for industry i, Y be a vector containing values of final demand, VA be a vector with value added (which includes labour compensation and capital rents) and Z a matrix containing the monetary value of the intermediate inputs coefficients. The technical inputs coefficients A may be obtained by multiplying \(Z{\hat{X}}^{-1}\), with \({\hat{X}}^{-1}\) representing the inverse of the diagonal matrix containing values of total output along the diagonal.
Total output produced can be decomposed into intermediate or final consumption, as seen in: \(X = AX + Y\). This can be re-written as: \(X = (I - A)^{-1}Y\), with I representing an identity matrix. The expression \((I - A)^{-1}\) is known as the Leontief Inverse Matrix and represents the value of output produced across all stages of production required to produce one unit of Y (sometimes called direct and indirect effects by input–output economists). The intuition behind this can be seen more clearly with the following geometric sequence: \(I + A + A^2 + A^3 + \cdots + A^N = (I - A)^{-1}\), with N approaching infinity.
Estimates on the degree of an industry’s degree of globalisation is obtained by calculating the foreign share of value added (factor content) used in producing output in a respective industry. This methodology was first proposed by Johnson and Noguera (2012) and applied with slight modifications by Timmer et al. (2015). The equation of total value added is given by:
\({\widehat{VAS}}\) here represents a diagonal matrix with shares of value added with respect to total output along its diagonal (\({\widehat{VAS}} = VA{\hat{X}}^{-1}\)) and \({\hat{Y}}\) another diagonal matrix with values of final demand along its diagonal. This equation yields another matrix with each element representing direct and indirect value added generated in industry i and used in industry j. Summing along the columns gives the total value added used for production by industry j. This then can be used to calculate the shares of value added of a country’s industry used by origin—being able to separate domestic and foreign value added by doing so. Table 10 summarises these shares of foreign value added for each country in the sample.
The Leontief Demand Model assumes that outputs leave the system at the end of the process (Miller and Blair 2009). An alternative approach proposed by Ghosh measures the unit values entering the system. This is done by transposing the model, giving the following equation: \(X = XB + VA\), with B represent the allocation coefficients, computed by \(B = {\hat{X}}^{-1}Z\). Re-arranging the former equation gives: \(X = VA(I - B)^{-1}\).Footnote 14 The matrix \((I - B)^{-1}\) is known as the Ghosh Inverse Matrix, and counts the monetary value of value added across all stages of production. Summing across each row of this matrix gives a measure of how strong forward linkages are within an industry. Concurrently, Antràs et al. (2012) finds, that summing across each of these rows gives a measure of upstreamness—concretely it gives the average number of times an output is processed before reaching consumers (see also Johnson (2018)). The larger values this measure takes, the more upstream the industry will be positioned.
In order to test the impact of these two variables, a two-way fixed effects model is used:
with \(\beta _0\) representing the constant, \(\beta _1 X_{1it}\) the set of independent variables mentioned previously, \(\alpha _i\) representing entity dummies (in this case for every pair of country-sector), \(\delta _t\) the time dummies and \(\epsilon _{it}\) the error term.
Table 1 shows the regression results of both measures of percentage share of foreign value added and upstreamness. Both variables were also interacted with itself and each other in order to test for possible non-linear relationships. Model 1 clearly shows that foreign value added significantly reduces markups, with upstreamness showing a negative, albeit non-significant, negative coefficient sign. Furthermore, the results in model 2 suggest that both globalisation and upstreamness significantly reduce markups, but at a decreasing rate for higher levels of values. This can be seen more clearly in Table 2, which shows the negative mean marginal effects by countries of both variables on the markups.
It should be noted, that WIOTs are capable of computing measures for both forward linkages (value added and intermediate inputs originating from the country-sector being analysed and ending up somewhere in the world) and backward linkages (value added and intermediate inputs originating somewhere in the world and ending up in the country-sector being analysed). The share of Domestic Value Added used here is one that measures backward linkages, whereas the Upstreamness index measures forward linkages. Result might change depending on what kind of linkages are being considered.Footnote 15 These results could therefore still be consistent with papers such as De Loecker and Warzynski (2012), who find a positive effect of trade liberalisation on markups when analysing exporter firms in Slovenia.
6 Concluding remarks
Estimates of market power were given using the methodology of De Loecker et al. (2020) and data provided by the Socio-Economic Accounts of the World Input–Output Database. Using these datasets circumvent several problems when utilizing micro-data. A GME estimator was used to estimate markups, and found that the evolution of market power was heterogeneous when analysing geographic clusters and specific industries. The findings suggest that, all in all, market power for manufacturing sectors in Europe did not increase substantially during the period 2000–2014. In fact, the aggregated markup of several countries saw a decreasing market power. This contradicts the findings from De Loecker and Eeckhout (2018), who found a generalized increase in market power for a substantial number of countries in the world, and are more in line with the results found by Weche and Wambach (2018). These authors also finds a heterogeneous evolution of market power for European manufacturing sectors, with markups decreasing on aggregate until 2009, and seeing a generalised increase after 2013.
Furthermore, two significantly contributing factors were found that impacted markups: a measure of globalisation and an industry’s relative positioning with regards to its production process. It has been found, that both reduce markups as expected by theory, although these effects are progressively smaller at higher levels. These results also confirm the many other papers that have focused on analysing this relationship within specific countries and industries.
The use of aggregate data has notable advantages, as it avoids problems stemming from the use of micro-data. The results derived by this method also ensures that they are economically sound, due to them not being able to take values below 1. Additionally, the method may be applied to any type of dataset containing aggregate information with the relevant variables; the WIOD is not the only possible source of information. In fact, datasets with larger spans of time will make estimations using the entropy method even more robust. Furthermore, IOT’s homogeneous sector classification for total economic activity allows for an efficient inter-sectoral and international analysis. It is therefore possible to extend this analysis to any other country or industry that are of high interest to policy-makers or scholars.
Future research might improve these results and methodology further by estimating each industry’s firm-size distribution. This could be achieved by applying GME to reverse-engineer these distribution by using, for example, measures of concentration ratios and/or the Hirschman-Herfindahl Index. This has been already successfully achieved in Golan et al. (1996), albeit with more narrowly defined industrial classifications.
Notes
A recent paper by Puty (2018) also explores the evolution of markups using aggregate data between 1958 and 1996, finding that market power evolves pro-cyclical relative to the business cycle.
It is not possible to take differences of prices in every firm into account when aggregating firm-level data therefore a bias may arise.
Note: drawbacks for using this methodology is discussed in subsequent chapters.
They derive this equation by solving a cost minimisation problem using Lagrange functions.
The notation is simplified here, and we eliminate the subscript t, although all the figures in the IO table refer to a specific time period.
The terms \(y_j\) and \(m_j\) denote respectively the part of the production in industry j that satisfies its final demand and the part of the cost of this industry devoted to pay its imports and taxes.
Figure 1 represents a national input–output table. In the case of a world input–output table, the imports contained within vector \(m_{ij}\) are included in \(z_{it}\) i.e. elements of column-sector that do not correspond to the rows of the same country.
Timmer et al. (2015) provides a more in-depth explanation for the WIOD project, see http://www.wiod.org/database/seas16 for details.
Technical details of GME methodology can be found in appendix 2.
Details of estimates of \(\alpha _{it}\) can be found on the appendix 4.
A separate file with the dataset containing all the results presented here, is also provided.
see di Mauro and Lopez-Garcia, 2015 for more informarion.
The following countries are represented in the sample: Belgium, Denmark, Spain, Croatia and Italy.
Note: the value added represented in this calculation is the difference between total intermediate inputs and total output. It includes, among other things, taxes, subsidies and transport margins and is therefore different than the value added used in Eq. 11.
Note: A substantial number of papers use VAX or related measures that measure forward linkages. There is still an active debate going on, whether all of these measures using forward linkages are completely accurate and free from double counting and other measurement errors, see, for example, Arto et al. (2019) and other papers from the EU for an overview of these measures with their potential drawbacks.
This rule takes as bounds for the support vector three times the positive and negative values of the sample standard deviation of the dependent variable.
References
Ackerberg DA, Caves K, Frazer G (2015) Identification properties of recent production function estimators. Econometrica 83:2411–2451
Antràs P, Chor D, Fally T, Hillberry R (2012) Measuring the upstreamness of production and trade flows. Am Econ Rev 102(3):412–16
Arto I, Dietzenbacher E, Rueda Cantuche J (2019) Measuring bilateral trade in terms of value added (KJ-NA-29751-EN-N (online),KJ-NA-29751-EN-C (print))
Autor D, Dorn D, Katz LF, Patterson C, Reenen JV (2020) The fall of the labor share and the rise of superstar firms. Q J Econ 135(2):645–709
Baker JB (2019) The antitrust paradigm: restoring a competitive economy. Harvard University Press, Harvard
Baqaee DR, Farhi E (2017) Productivity and misallocation in general equilibrium. Working paper 24007, National Bureau of Economic Research
Cavalleri MC, Eliet A, McAdam P, Petroulakis F, Soares A, Vansteenkiste I (2019) Concentration, market power and dynamism in the euro area. Working paper series 2253, European Central Bank
Choi J, Fukase E, Zeufack AG (2021) Global value chain participation, competition, and markups: evidence from Ethiopian manufacturing firms. J Econ Integr 36(3):491–517
Colonescu C (2021a) Compounded markups in complex market structures. Athens J Bus Econ 8:1–14
Colonescu C (2021b) Price markups and upstreamness in world input–output data. Acta Universitatis Sapientiae Econ Bus 9:71–85
De Loecker J, Eeckhout J (2017) The rise of market power and the macroeconomic implications. NBER working papers 23687, National Bureau of Economic Research, Inc
De Loecker J, Eeckhout J (2018) Global market power. Working paper 24768, National Bureau of Economic Research
De Loecker J, Warzynski F (2012) Markups and firm-level export status. Am Econ Rev 102(6):2437–71
De Loecker J, Goldberg PK, Khandelwal AK, Pavcnik N (2016) Prices, markups, and trade reform. Econometrica 84(2):445–510
De Loecker J, Eeckhout J, Unger G (2020) The rise of market power and the macroeconomic implications. Q J Econ 135(2):561–644
di Mauro F, Lopez-Garcia P (2015) Assessing European competitiveness: the new CompNet microbased database. Working paper series 1764, European Central Bank
Diez FJ, Leigh D, Tambunlertchai S (2018) Global market power and its macroeconomic implications. IMF working papers 18/137, International Monetary Fund
Eeckhout J (2021) The profit paradox: how thriving firms threaten the future of work. Princeton University Press, Princeton
Ennis SF, Gonzaga P, Pike C (2019) Inequality: a hidden cost of market power. Oxf Rev Econ Policy 35(3):518–549
Fernandez-Vazquez E (2015) Empirical estimation of non-linear input–output models: an entropy econometrics approach. Econ Syst Res 27(4):508–524
Golan A, Vogel SJ (2000) Estimation of non-stationary social accounting matrix coefficients with supply-side information. Econ Syst Res 12(4):447–471
Golan A, Judge G, Perloff JM (1996) Estimating the size distribution of firms using government summary statistics. J Ind Econ 44(1):69–80
Gradzewicz M, Mućk J (2019) Globalization and the fall of markups. Technical report
Gutiérrez G, Philippon T (2017) Declining competition and investment in the U.S. Working paper 23583, National Bureau of Economic Research
Hall R (1988) The relation between price and marginal cost in U.S. industry. J Polit Econ 96(5):921–47
Hall RE, Blanchard OJ, Hubbard RG (1986) Market structure and macroeconomic fluctuations. Brook Pap Econ Act 1986(2):285–338
Johnson RC (2018) Measuring global value chains. Annu Rev Econ 10(1):207–236
Johnson RC, Noguera G (2012) Accounting for intermediates: production sharing and trade in value added. J Int Econ 86(2):224–236
Koujianou Goldberg P, Hellerstein R (2012) A structural approach to identifying the sources of local currency price stability. Rev Econ Stud 80(1):175–210
Lerner AP (1934) The concept of monopoly and the measurement of monopoly power. Rev Econ Stud 1(3):157–175
Levinsohn J, Petrin A (2003) Estimating production functions using inputs to control for unobservables. Working paper 7819, National Bureau of Economic Research
Miller RE, Blair PD (2009) Input–output analysis: foundations and extensions, 2nd edn. Cambridge University Press, Cambridge
Morlacco M (2017) Market power in input markets: theory and evidence from French manufacturing
Mulkay B (2019) How does competition affect innovation behaviour in French firms? Struct Chang Econ Dyn 51(C):237–251
Olley GS, Pakes A (1996) The dynamics of productivity in the telecommunications equipment industry. Econometrica 64(6):1263–97
Perloff JM, Karp LS, Golan A (2007) Estimating market power and strategies. Number 9780521804400 in Cambridge books. Cambridge University Press, Cambridge
Praet P (2019) Market power: a complex reality. Speech retrieved from https://www.ecb.europa.eu/press/key/date/2019/html/ecb.sp190318_1~8d608350ab.en.html
Pukelsheim F (1994) The three sigma rule. Am Stat 48(2):88–91
Puty CACB (2018) Sectoral mark-ups in U.S. manufacturing. Struct Chang Econ Dyn 46(C):107–125
Schmalensee R (1987) Collusion versus differential efficiency: testing alternative hypotheses. J Ind Econ 35(4):399–425
Shannon CE (1948) A mathematical theory of communication. Bell Syst Tech J 27(3):379–423
Timmer M, Erumban AA, Gouma R, Los B, Temurshoev U, de Vries GJ, Arto I, Genty VAA, Neuwahl F, Rueda-Cantuche JM, Joseph (2012) The world input–output database (WIOD): contents, sources and methods. IIDE discussion papers 20120401, Institute for International and Development Economics
Timmer MP, Dietzenbacher E, Los B, Stehrer R, de Vries GJ (2015) An illustrated user guide to the world input–output database: the case of global automotive production. Rev Int Econ 23(3):575–605
Weche JP, Wambach A (2018) The fall and rise of market power in Europe. Working paper series in economics 379, University of Lüneburg, Institute of Economics
Acknowledgements
We would like to thank Pol Antràs and Davin Chor for help on measuring Upstreamness Index. We also would like to thank Chiara Criscuolo for further support on research papers.
Funding
Open Access funding provided thanks to the CRUE-CSIC agreement with Springer Nature.
Author information
Authors and Affiliations
Corresponding author
Additional information
Responsible Editor: Harald Oberhofer.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Summary statistics
See Tables 3, 4, 5, 6, 7, 8, 9 and 10.
An overview of entropy econometrics
The point of departure is a linear model where the variable of interest y depends on H explanatory variables \(x_h\) with C observations:
where \(\varvec{y}\) is a \((C \times 1)\) vector of observations, \(\varvec{X}\) is a \((C \times H)\) matrix of observations for the \(x_h\) variables, \(\varvec{\beta } = (\beta _1, \dots , \beta _H )\) is the \((H \times 1)\) vector of unknown parameters to be estimated, and \(\varvec{u}\) is a \((C \times 1)\) vector containing the realizations of the random disturbance of the linear model.
The GME estimator re-parametrizes Eq. 13 in terms of probability distributions. First, each element \(\beta _h\) of the vector of parameters \(\varvec{\beta }\) is assumed to be a discrete random variable with \(M \ge 2\) possible realizations. These potential values of the unknown parameter are included in a support vector \(\varvec{b'_h}=\{ b_{h1} , \dots , b_{hM} \}\) with corresponding unknown probabilities \(\varvec{p'_h}=(p_{h1}, \dots ,p_{hM} )\). The values in \(\varvec{b_h}\) are chosen based on priors on the values of \(\beta _h\). Finally, each parameter \(\beta _h\) is specified as follows:
In turn, the vector \(\varvec{\beta }\) can be written as:
where \(\varvec{B}\) and \(\varvec{P}\) are matrices with dimensions \((H \times HM)\) and \((HM \times 1)\) respectively.
A similar approach is followed for the random disturbances. Although, GME does not require specific assumptions about the probability distribution function of \(\varvec{u}\), some assumptions are necessary. First, the uncertainty about the realizations of vector \(\varvec{u}\) is addressed by treating each element \(u_t\) as a discrete random variable with \(J \ge 2\) possible outcomes contained in a convex set \(v'={v_1, \dots , v_J }\) which, for the sake of simplicity, will be common for all the realizations of the random disturbance \(u_t\). Second, we also assume that these possible outcomes of the random disturbance are symmetric and centered on zero \((v_1=v_J)\). As a result, \(\varvec{u}\) has mean \(E[u] = 0\) and a finite covariance matrix \(\sum\). Additionally, it is common practice to establish the upper and lower limits of the vector v applying the three-sigma rule (Pukelsheim 1994).Footnote 16 Under these conditions, the value of the random term for an observation t equals:
Or, in matrix terms:
Therefore, using 15 and 17 Eq. 13 can be rewritten as:
This specification of the original model transforms the estimation of the coefficients of the regression Eq. 13 into the estimation of \(H + C\) probability distributions. At this point, the principle of Maximum Entropy (ME) is used to recover unknown probability distributions of discrete random variables that can take M different values. Specifically, ME estimates \(\varvec{{\hat{p}}}\) by maximizing the Shannon Entropy measure (Shannon 1948) \(E(\varvec{p})\):
\(E(\varvec{p})\) achieves a maximum when all the M values are equally probable i.e., \(\varvec{p}\) is uniform. However, if some additional data are available, this will lead to a Bayesian update of the uniform solution to \(\varvec{p}\). The intuition is that the uniform distribution provides the best estimation when there are no data. In this case, equal probabilities are assigned to all possible outcomes of the discrete random variable. However, the uniform distribution could not be a reasonable estimate if it fails to generate the observed data. Therefore, a reasonable approach is to use as an estimate the probability distribution closer to the uniform able to generate the observed data. In other words, the probability distribution that maximizes the Entropy measure subject to being able to generate the observed data.
The underlying idea of the ME methodology can be applied for recovering the parameters of the re-parametrized Eq. 18, defining the GME estimator. Matrices \(\varvec{P}\) and \(\varvec{W}\) are estimated by maximizing the entropy function \(E(\varvec{P},\varvec{W})\), subject to: (i) being consistent with the sample and (ii) some normalization constraints. The GME estimator can be written as follows:
subject to:
The restrictions in 21 ensure that the estimates can generate the sample data contained on \(\varvec{y}\) and \(\varvec{X}\) while Eqs. 22 and 23 are normalization constraints. By solving this constrained optimization problem, solutions for \(\varvec{P}\) and \(\varvec{W}\) are found and point estimates \(\hat{\beta }_h\) and \({\hat{u}}_c\) are derived.
Additionally, the following basic assumptions guarantee consistency and asymptotically normality :
-
The support for the errors \(v'\) is symmetric around zero.
-
The support space \(b'\) bounds the true value of each one of the unknown parameters and it has a finite lower and upper bounds \(b_1\) and \(b_M\), respectively.
-
The errors are i.i.d.
-
\(\lim \nolimits _{C \rightarrow \infty } C^{-1} \varvec{X'X}\) exists and is non-singular.
Under these assumptions, GME estimates distribute as \(\varvec{\hat{\beta }} \rightarrow N \varvec{[\beta , \hat{\sigma }^2(X'X)}^{-1}\varvec{]}\) and it is possible to obtain their approximate variance matrix as \(\varvec{\hat{\sigma }^2(X'X)}^{-1}\). \(\varvec{\hat{\sigma }}\) is a diagonal matrix, where a typical element \(\hat{\sigma }_h\) is defined as:
Where \(\hat{\sigma }_e^2 = \left[ \frac{1}{C - H} \right] \sum _{c=1}^{C} {\hat{e}}_c^2\); being \({\hat{e}}_c = \sum _{j=1}^{J}v_j {\tilde{w}}_{cj}\) and:
Markup estimates evolution
See Fig. 7.

Evolution GME weighted average markups, using the WIOD full sample. The sector’s volume of output is used as weights
1.1 By sector using WIOD and CompNet
See Fig. 8.


Evolution of GME and Compnet markups aggregated by sector
Evolution output elasticity of variable inputs
This section shows the evolution of the output elasticity of variable inputs (\(\alpha _{it}\)). The full WIOD sample was used for the aggregation (Fig. 9).

Evolution of variable inputs elasticity. Volumes of output were used as weights
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
del Valle, A.R., Fernández-Vázquez, E. Estimating market power for the European manufacturing industry between 2000 and 2014. Empirica 50, 141–172 (2023). https://doi.org/10.1007/s10663-022-09559-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10663-022-09559-4