
Abstract
Whether the vascular effects of inorganic nitrate, observed in clinical trials, translate to a reduction in cardiovascular disease (CVD) with habitual dietary nitrate intake in prospective studies warrants investigation. We aimed to determine if vegetable nitrate, the major dietary nitrate source, is associated with lower blood pressure (BP) and lower risk of incident CVD. Among 53,150 participants of the Danish Diet, Cancer, and Health Study, without CVD at baseline, vegetable nitrate intake was assessed using a comprehensive vegetable nitrate database. Hazard ratios (HRs) were calculated using restricted cubic splines based on multivariable-adjusted Cox proportional hazards models. During 23 years of follow-up, 14,088 cases of incident CVD were recorded. Participants in the highest vegetable nitrate intake quintile (median, 141 mg/day) had 2.58 mmHg lower baseline systolic BP (95%CI − 3.12, − 2.05) and 1.38 mmHg lower diastolic BP (95%CI − 1.66, − 1.10), compared with participants in the lowest quintile. Vegetable nitrate intake was inversely associated with CVD plateauing at moderate intakes (~ 60 mg/day); this appeared to be mediated by systolic BP (21.9%). Compared to participants in the lowest intake quintile (median, 23 mg/day), a moderate vegetable nitrate intake (median, 59 mg/day) was associated with 15% lower risk of CVD [HR (95% CI) 0.85 (0.82, 0.89)]. Moderate vegetable nitrate intake was associated with 12%, 15%, 17% and 26% lower risk of ischemic heart disease, heart failure, ischemic stroke and peripheral artery disease hospitalizations respectively. Consumption of at least ~ 60 mg/day of vegetable nitrate (~ 1 cup of green leafy vegetables) may mitigate risk of CVD.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Identifying evidence-based strategies to prevent cardiovascular disease (CVD) is a global research priority. An important strategy to reduce CVD risk is to identify optimal diets and their cardioprotective components. One such potentially cardioprotective component is dietary inorganic nitrate, an exogenous source of nitric oxide (NO). NO plays a key role in cardiovascular health [1]. Produced primarily through the endogenous L-arginine-NO synthase pathway, there are few options to enhance NO. The discovery that end-products of NO metabolism, nitrate and nitrite, are recycled back into NO through an enterosalivary nitrate-nitrite-NO pathway raised the possibility that dietary nitrate could be an important exogenous source of NO benefitting cardiovascular health [2]. The major dietary sources of nitrate are vegetables, particularly green leafy vegetables and beetroot [3].
Intervention studies have investigated whether inorganic nitrate, through effects on NO, improves validated markers of CVD risk [4]. This was first shown in healthy volunteers in whom significant reductions in BP (− 3.5 mmHg) were observed after ~ 400 mg nitrate intake for 3 days [5]. To date, more than 50 clinical trials (2 h to 42 day duration) have examined the effect of nitrate (sources: beetroot juice, green leafy vegetables, and nitrate salts) on BP and vascular function [4]. Meta-analyses of these studies have shown a significant inverse association between nitrate consumption and BP [6, 7] as well as beetroot juice consumption and BP [8]. However, evidence from observational studies of a reduction in CVD risk with habitual dietary nitrate intake is incomplete. Three Australian prospective studies (< 5500 participants and < 2000 incident cases each) have reported a lower risk of CVD [9,10,11,12], with higher dietary nitrate intakes while a large American prospective study (~ 60,000 participants; ~ 2300 incident cases) observed no benefit [13]. The established pathway via which dietary nitrate augments NO and accumulating evidence from clinical trials provides a strong rationale to further investigate the relationship between habitual dietary nitrate intake and risk of CVD in a large prospective study with a long follow-up, a large number of incident cases, and a comprehensive measure of nitrate intake. Furthermore, yet to be determined is the association between dietary nitrate and the individual CVD subtypes, whether a reduction in CVD risk with habitual dietary nitrate intake is mediated by effects on BP, and whether the association is different in subgroups at higher risk for CVD.
The primary aim of this study was to investigate the association between vegetable nitrate intake and incident CVD in the Danish Diet, Cancer, and Health Study cohort. Vegetable nitrate was the focus as approximately 80% of total dietary nitrate intake comes from consumption of vegetables [10, 14]. Secondary aims were to (1) investigate the association of vegetable nitrate intake with baseline systolic BP (SBP) and diastolic BP (DBP); (2) investigate whether associations with CVD are mediated by BP; and (3) investigate whether associations differ in the presence of risk factors for CVD, including sex, body mass index (BMI), smoking status, and alcohol intake.
Methods
Study population
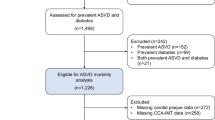
Between 1993 and 1997, the Danish Diet, Cancer, and Health Study recruited 57,053 participants of the greater areas of Copenhagen and Aarhus. Of these, 56,468 completed a food-frequency questionnaire (FFQ) at baseline and were without a cancer diagnosis prior to enrolment. The following databases were cross-linked to the cohort: The Civil Registration System [15], The Integrated Database for Labor Market Research [16], The Danish National Patient Register (DNPR)[17] and The Danish National Prescription Registry [18].
Participants were excluded if they had any prevalent CVD (n = 2933), self-reported or recorded diagnosis in the DNPR. Furthermore, participants were excluded if they had missing or implausible values for any covariates (n = 192), or implausible energy intakes [< 2092 kJ/day (< 500 kcal/day) and > 20,920 kJ/day (> 5000 kcal/day), n = 193] Supplemental Figure 1.
This study was approved by the Danish Data Protection Agency (Ref No. 2012-58-0004 I-Suite nr: 6357, VD-2018-117).
Exposures
Prior to their first visit, participants completed a 192-item validated FFQ [19]. Participants reported their average intakes of different food and beverage items over the previous 12 months.
Vegetable nitrate
Vegetable nitrate intake was calculated from vegetables assessed using the FFQ and quantified in grams/day. A recently published comprehensive database, with nitrate data for 178 vegetables from 255 publications, was applied to assess nitrate levels for each vegetable [3]. The nitrate content of vegetables varies according to country of cultivation; therefore, the following strategy was employed. For each vegetable, if 3 or more entries were available in the database for Northern Europe (Denmark, Estonia, Finland, Iceland, Ireland, Latvia, Lithuania, Norway, Sweden and United Kingdom), the median of these values was used. If there were less than 3 entries in the database for Northern Europe, the median of values for all European countries was used. If there were less than 3 entries available for European countries, the median of values for all countries in the database was used. Vegetable nitrate intake (mg/day) was calculated by multiplying the quantity reportedly consumed (g/day) by the median nitrate content (mg/g) of that vegetable. Based on information in the nitrate content of vegetables database [3] and nitrate loss estimates in another cohort [20], for those vegetables not consumed raw, a 50% reduction in the assigned nitrate value was applied to take into account the effect of cooking. The nitrate values from each individual vegetable were added to obtain the sum of daily vegetable nitrate values.
Non-vegetable dietary nitrate
Nitrate intake from non-vegetable items, excluding water, was calculated using values from Inoue-Choi et al. [21]. Nitrate intake was calculated by multiplying the reported quantity of consumption for each food item (g/day) by its assigned mean nitrate value (mg/g). Total non-vegetable nitrate intake (mg/day) was determined by calculating the sum of nitrate values from all items included in the FFQ, excluding vegetables.
Study outcomes
Blood pressure
Baseline SBP and DBP was measured by trained staff members using automated oscillometric sphygmomanometers (model UA 751 or UA-743; Takeda Pharmaceutical Co. Ltd., Osaka, Japan). A measurement was taken on the right arm, with participants lying in a supine position after at least 5 min rest and a minimum of 30 min after tobacco smoking and intake of food, tea, or coffee. Where a participants’ SBP was ≥ 160 mmHg, or DBP was ≥ 95 mmHg, the measurement was repeated after 3 min, with the lower of the two measurements used.
Incident CVD and CVD subtypes
For the time-to-event analysis, the primary outcome was a combined endpoint of first-time incident CVD. Incident CVD was defined as a hospitalization with a primary or secondary diagnosis of ischemic heart disease (IHD), ischemic stroke, hemorrhagic stroke, peripheral artery disease (PAD), heart failure, or inpatient or outpatient diagnosis of atrial fibrillation (AF). Secondary outcomes were: IHD, ischemic stroke, hemorrhagic stroke, PAD, heart failure, and AF discretely. All outcomes were identified by ICD-10 codes using the DNPR. These ICD codes have previously been validated for research purposes in the DNPR with positive predictive values (PPVs) of 92–97% for IHD [22], 81 – 85% for ischemic stroke [23, 24], 88% for hemorrhagic stroke [25], 81% for PAD [26], 76% for heart failure [22] and 95% for AF [22]. We did not include a diagnosis of unstable angina or transient ischemic attack as these in the DNPR lack validity for research purposes.
Validated case analysis
Using only medically reviewed and validated cases of certain CVD diagnoses [myocardial infarction (MI), ischemic stroke, and PAD] during follow-up, we investigated associations to verify our results based on the ICD-10 codes for outcomes. Patients with an ICD-10 discharge code for ischemic stroke, PAD or MI up until 2009, registered as a primary or secondary diagnosis, were considered possible cases to be reviewed (Supplemental Table 1). Due to a prior diagnosis of validated CVD, a further seven participants were excluded in this analysis (n remaining in analysis = 53,143). The methods of case validation have been published previously [24, 26, 27].
Covariates
Information on age, sex, education, smoking habits, alcohol consumption, and daily activity was obtained from self-administered lifestyle questionnaires completed by participants. Dietary data were obtained from the semi-quantitative FFQ described above. Anthropometric measurements were taken, and SBP, DBP, and cholesterol levels were measured at the study centers. Household annual income after taxation and interest for the value of the Danish currency was averaged over the 5-years immediately prior to study enrolment in 2015. ICD-8 and ICD-10 codes were used for diagnosis of chronic kidney disease, chronic obstructive pulmonary disease, and cancers. For diabetes mellitus, only self-reported data were used due to the low validity of ICD-codes in DNPR [28]. For treatment of diabetes mellitus, both self-reported data and data on filled prescription for insulin and non-insulin medication were used. Use of antihypertensive medication was obtained from self-reported use or the use of two or more antihypertensive medications within 180 days prior to study enrolment. Presence of hypertension was defined by a combination of the use of two or more antihypertensive medications within 180 days prior to study enrolment or self-reported hypertension, which has a PPV of 80.0% and a specificity of 94.7% to predict hypertension [28, 29]. Statin use at study enrolment was obtained from a combination of self-reported use and filled prescriptions. Hypercholesterolaemia was defined by self-reported hypercholesterolaemia or self-reported statin-use. Prescriptions were identified by ATC codes in the Danish National Prescription Registry if they were claimed within 180 days prior to enrolment in the study (from 1994 onwards). All ATC codes used are presented in Supplemental Table 2.
Statistical analysis
Baseline characteristics of the cohort are presented overall, and across quintiles of vegetable nitrate intake. First, a cross-sectional linear regression analysis was performed to investigate the association between vegetable and non-vegetable nitrate intake in quintiles and baseline SBP and DBP, both in the whole population and stratified by use of antihypertensive medication. Second, participants’ time-to-events were based on a maximum of 23 years of follow-up from the date of enrollment until the date of death, emigration, event of interest, or end of follow-up (August 2017), whichever came first. Nonlinear relationships were examined using restricted cubic splines, with hazard ratios (HRs) based on Cox proportional hazards models. All HRs and 95% confidence intervals (CIs) were obtained from the model with the exposure fitted as a continuous variable through a restricted cubic spline; HR estimates are reported for the median intake in each quintile with the first quintile median as the reference point and are graphed over a fine grid of x values. Cox proportional hazards assumptions were tested using log–log plots of the survival function versus time and assessed for parallel appearance, with no violation found. Our main models of adjustment were: Model 1a adjusting for age and sex; Model 1b adjusting for all covariates in Model 1a plus BMI, smoking status (current/former/never), physical activity (total daily metabolic equivalent), social economic status (income), marital status, education, pure alcohol intake (g/day), hypercholesterolemia (yes/no), and prevalent disease (diabetes, chronic obstructive pulmonary disease, chronic kidney disease, and cancer); entered into the model separately); Model 2 adjusting for all covariates in Model 1b plus energy; and Model 3: adjusting for all covariates in Model 2 plus intakes (g/day) of fish, red meat, polyunsaturated fatty acids, monounsaturated fatty acids, saturated fatty acids, and all fruit. Covariates were chosen a priori using expert and prior knowledge of potential confounders of nitrate intake and CVD. Additionally, standard logistic regression models were used to obtain the 20-year absolute risk estimates of incident CVD and CVD subtypes.
Analyses were further stratified by sex, BMI (above/below 30 kg/m2), alcohol intake (above/below 20 g/day), smoking status (ever/never), and by tertiles of total vegetable intake. When stratifying by alcohol intake and BMI, all participants with an alcohol intake of zero (n = 1180) and a BMI < 18.5 (n = 426) were excluded due to potential underlying pathologies or habits that may increase CVD risk. Stratification cut-off points of 20 g alcohol/day and a BMI of 30 kg/m2 were chosen as risk of disease is higher beyond these levels [30, 31]. We tested for interactions using chi-squared tests comparing nested standard cox proportional hazards models, using quintiles of vegetable nitrate intake.
The extent to which the association between vegetable nitrate intake and CVD was mediated by baseline SBP was quantified through natural direct and indirect effects [32], using a Cox proportional hazards model in the medflex package for R [33].
Analyses were undertaken using STATA/IC 14.2 (StataCorp LLC) and R statistics (R Core Team, 2019)[34].
Results
The 53,150 Danish participants included in the present study had a median [IQR] age of 56 [52–60] years at entry and a median [IQR] follow-up of 21 [15–22] years. Total median [IQR] vegetable nitrate intake was 59 mg/day [35–98] and non-vegetable nitrate intake was 15 mg/day [12–18]. Major individual vegetables that contributed to vegetable nitrate intake were lettuce (41%), potato (22%), celery (10%), carrot (5%), and spinach (3%). During follow-up, 14,088 participants were hospitalized for any CVD, 5327 for IHD, 2,885 for ischemic stroke, 709 for haemorrhagic stroke, 3081 for heart failure, 1867 for PAD, and 6748 for AF, with 4699 (8.84%) participants receiving a diagnosis of two or more types of CVD.
Baseline characteristics
Compared to participants in the lowest quintile of vegetable nitrate intake, those in the highest quintile were more likely to be female, have a slightly lower BMI, be more physically active, have never smoked, have a higher degree of education, have a higher income, and were less likely to hypertensive and more likely to be diabetic. Furthermore, those with a high vegetable nitrate intake tended to consume more fish, vegetables, fruit, fibre, flavonoids, and less processed meat than those with a low vegetable nitrate intake (Table 1).
Cross sectional analysis of vegetable and non-vegetable nitrate intake and blood pressure
At baseline, vegetable nitrate intake was inversely associated with SBP and DBP in a linear dose–response manner. After multivariable adjustments and compared to participants in quintile 1, participants in quintile 5 had a 2.58 mmHg lower SBP (95% CI − 3.12, − 2.05) and 1.38 mmHg lower DBP (− 1.66, − 1.10) (Table 2). The inverse association between vegetable nitrate intake and BP was present in individuals both on and not on antihypertensive medication at baseline (Supplemental Table 3 and 4). No association was observed between non-vegetable nitrate intake and BP (Supplemental Table 5).
Association between vegetable nitrate intake and incident CVD and CVD subtypes
Vegetable nitrate intake was non-linearly associated with CVD hospitalizations (Model 1b; Fig. 1). On a relative scale, participants with a moderate vegetable nitrate intake (quintile 3) had a 15% lower risk of CVD [HR (95% CI): 0.85 (0.82, 0.89)] after multivariable adjustments (Model 1b; Table 3) and compared to participants in quintile 1. Comparable risk estimates were observed for participants in higher intake quintiles. On an absolute scale, the difference (quintile 3–quintile 1) in the 20-year estimated risk of being hospitalised for CVD was 2.79% for males and 1.88% for females (Supplemental Table 6 and 7).

Cubic spline curves describing the association between vegetable nitrate intake and CVD incidence and the incidence of CVD subtypes; ischemic heart disease, ischemic stroke, hemorrhagic stroke, heart failure, peripheral artery disease and atrial fibrillation. Hazard ratios are based on Cox proportional hazards models adjusted for age, sex, BMI, smoking status, physical activity, alcohol intake, education, social economic status (income), marital status, hypercholesterolemia, diabetes, COPD, chronic kidney disease and cancer and are comparing the specific level of vegetable nitrate intake (horizontal axis) to the median intake for participants in the lowest intake quintile (23 mg/day)
For CVD subtypes, after multivariable adjustments (Model 1b; Table 3) and compared to participants in quintile 1, participants in quintile 3 had a 12% lower risk of IHD [0.88 (0.82, 0.94)], 17% lower risk of ischemic stroke [0.83 (0.76, 0.91)], 15% lower risk of heart failure [0.85 (0.78, 0.93)], and a 26% lower risk of PAD [0.74 (0.67, 0.83)]. The HR remained constant for higher levels of exposure except for PAD for which the lowest risks were observed for those in quintile 5 [Q5; 0.65 (0.57, 0.74)]. There was no clear association between vegetable nitrate intake and haemorrhagic stroke or AF. The association between vegetable nitrate intake and CVD hospitalizations was still observed after adjusting for potential dietary confounders (Model 3; Table 3). The absolute risk differences for the CVD subtypes are presented in Supplemental Table 7 and 8.
Mediation analysis
Mediation analyses showed that baseline SBP explained 21.9% of the total association between vegetable nitrate intake and incident CVD.
Associations between non-vegetable nitrate intake and incident CVD and CVD subtypes
The association between non-vegetable nitrate intake and incident CVD was non-linear (Supplemental Figure 2). After multivariable adjustments (Model 1b) and compared to participants in quintile 1, participants in quintile 3 had a 6% lower risk of a CVD hospitalization [0.94 (0.90, 0.98)]. Of the secondary outcomes, participants in quintile 3 had a 19% lower risk of haemorrhagic stroke [0.81 (0.70, 0.94)], and a 15% lower risk for PAD [0.85 (0.78, 0.94)] (Supplemental Table 8). As observed with vegetable nitrate intake, the HR remained constant for higher levels of exposure except for PAD for which the lowest risks were observed for those in quintile 5 [Q5; 0.79 (0.70, 0.90)].
Validated case analysis
Using only medically reviewed and validated cases, 3,430 participants were admitted to hospital for an MI, ischemic stroke, or PAD. Vegetable nitrate intake was inversely associated with validated cases of MI, ischemic stroke and PAD (Supplemental Figure 3).
Stratified analyses
The association between vegetable nitrate and incident CVD was modified by alcohol intake (p for interaction < 0.001; Fig. 2); the association was stronger in high alcohol consumers [Q5; 0.78 (0.72, 0.84)] than in low alcohol consumers [Q5; 0.92 (0.86, 0.97)]. The association between vegetable nitrate intake and incident CVD did not appear to be modified by sex, baseline BMI, and smoking status (p for interaction > 0.05 for all).

Multivariable-adjusted association between total vegetable nitrate intake and incident CVD stratified by sex, baseline BMI, smoking status, or alcohol intake. Hazard ratios are based on Cox proportional hazards models and are comparing the specific level of vegetable nitrate intake (horizontal axis) to the median intake for participants in the lowest intake quintile (23 mg/day). All analyses were adjusted for age, sex, BMI, smoking status, physical activity (total daily metabolic equivalent), pure alcohol intake (g/day), social economic status (income), marital status, hypercholesterolemia (yes/no), education, and prevalent disease (diabetes, chronic obstructive pulmonary disease, chronic kidney disease, and cancer; entered into the model separately)
To understand whether vegetable nitrate intake is only a marker of higher vegetable intake, we stratified our analysis by tertiles of total vegetable intake. There still appeared to be an association between vegetable nitrate intakes and a lower risk of CVD in all tertiles of total vegetable intake (Supplemental Table 9).
Discussion
In this prospective cohort study of 53,150 Danish people without CVD at baseline, we found that a higher vegetable nitrate intake was associated with a lower SBP and DBP at baseline. Furthermore, we observed that a moderate intake of vegetable nitrate was inversely associated with incident CVD, with no additional benefits observed for higher intakes. This association was partially mediated by SBP and was stronger in individuals with high alcohol consumption than in those with a low to moderate alcohol consumption. For CVD subtypes, individuals with moderate to high vegetable nitrate intakes had a lower risk of atherosclerotic CVD hospitalisations, namely IHD, ischemic stroke, heart failure, and PAD, but not for other CVD hospitalisations, namely haemorrhagic stroke or AF.
We observed that participants in the highest quintile of vegetable nitrate intake had a 2.58 mmHg lower SBP and a 1.38 mmHg lower DBP at baseline, compared to those in the lowest quintile. In the Atherosclerosis Risk in Communities Study, a 2 mmHg lower SBP was associated with 17.9 fewer CHD events, 9.6 fewer stroke events, and 26.6 fewer heart failure events per 100,000 person-years [35]. Framingham Heart Study investigators observed that a 2 mmHg lower DBP was associated with a 6% lower risk of CHD and a 15% lower risk of stroke in men and women aged 35–64 years [36]. Our results support findings from short-term clinical trials, and meta-analyses of these trials, demonstrating a benefit of nitrate intake on BP [37]. However, not all clinical trials have observed a reduction in BP with nitrate intake. The majority of clinical trials observe reductions in BP with nitrate intake in normotensive individuals, however effects in individuals with high-normal BP and hypertension are less clear [37]. The largest clinical trial to date [38], did not observe a reduction in BP in 243 older subjects with elevated BP after 5 weeks nitrate intake. Interestingly, we observed an inverse association between vegetable nitrate intake and BP in individuals both on and not on anti-hypertensive medication.
To our knowledge, the association between vegetable nitrate intake and long-term cardiovascular outcomes has only been investigated in four cohorts. In the Perth Longitudinal Study of Aging in Women, vegetable nitrate intake was associated with a 21% lower risk of atherosclerotic vascular disease mortality (238 incident cases) and 17% lower risk of an ischemic cerebrovascular disease event (186 incident cases) per 1 SD (~ 30 mg/day) higher intake [9, 10]. In participants of the Australian Blue Mountains Eye Study, those in the highest quartile of vegetable nitrate intake had a 27% lower risk of CVD mortality (188 incident cases) compared to those in the lowest intake quartile [12]. In women of Australian Longitudinal Study on Women’s Health, those in the highest quartile of vegetable nitrate intake had a 27% lower risk of developing self-reported CVD-related complications (1951 incident cases), compared to those in the lowest intake quartile [11]. In the American Nurses’ Health Study, women in the highest quintile of vegetable nitrate intake had weak evidence for a lower risk of either fatal or non-fatal CHD (2267 incident cases), compared to those in the lowest quintile [13]. In the present study, we observed that a higher vegetable nitrate intake was associated with 15% lower risk of incident CVD compared to participants in the lowest quintile. Interestingly, no further reduction in risk of incident CVD was observed for intakes above ~ 60 mg/day (~ 1 cup of green leafy vegetables per day). This is in agreement with results from the previously described prospective studies. In the Perth Longitudinal Study of Aging in Women, the inverse relationship with atherosclerotic vascular disease mortality and ischemic cerebrovascular events plateaued at vegetable nitrate intakes of 53–76 mg/day [9, 10]. Similarly, in the Blue Mountains Eye Study no added benefit on risk of CVD mortality was observed above intakes of 70 – 100 mg/day [12]. In the Australian Longitudinal Study on Women’s Health a threshold effect was not observed, however those in the highest quintile of vegetable nitrate intake had a mean intake of 79 mg/day [11]. Clinical trials investigating the vascular effects of nitrate intake report acute effects at doses ranging from 68 to 1488 mg and chronic effects at doses ranging from 155 to 1200 mg [37].
A lower risk of IHD, ischemic stroke, heart failure, and PAD, but not haemorrhagic stroke or AF, was observed in individuals with moderate to high vegetable nitrate intakes. The primary mechanism through which dietary nitrate may impact cardiovascular health is via augmentation of NO [2]. Endothelium-derived NO maintains vascular tone influencing blood flow and BP [2]. In the present study, baseline SBP explained 21.9% of the total association between vegetable nitrate intake and incident CVD, indicating that the effects of nitrate on BP reported in clinical trials, translate to a lower risk of incident CVD, but also that other mechanisms are in play. Hypertension is associated with ischemic stroke, CHD, heart failure, AF, and PAD [39]. It may be that the decrease in SBP or DBP may not be enough to mitigate the risk of AF and haemorrhagic stroke, however, the impact of BP reduction on the risk of AF is still unclear [40].
We demonstrated that the association between vegetable nitrate intake and incident CVD was stronger in those who consume, on average, more than 20 g (2 standard drinks) of alcohol per day compared to those who consume less than 20 g of alcohol per day. Heavy alcohol consumption increases the risk of CVD [41] and detrimental effects on a number of physiological parameters, including blood pressure [31] and endothelial function [42] have been reported. Our findings suggest the vegetable nitrate intake may partially mitigate these harmful effects.
This study has several strengths. The large number of incident cases and 23-year duration of follow-up, with limited loss to follow-up, afforded us the statistical power to examine associations in subpopulations at higher risk of CVD. Our findings were supported by a validated case analysis. A comprehensive database detailing the nitrate content of vegetables was used to calculate vegetable nitrate intake [3] in combination with a validated FFQ that included average intakes of foods commonly consumed in Denmark over the previous 12 months. The same up to date database was used in three previous smaller prospective studies [9,10,11,12], with results consistent with the current analysis. However, an older less comprehensive nitrate database was used in the Nurses Health Study [13]. This may partially explain the apparent weaker associations observed in this study.
Several limitations should also be considered. As this is an observational study, we are unable to infer causality or rule out residual or unmeasured confounding factors. Although the association between higher nitrate intake and lower risk of a hospital admission for CVD was still present after adjustment for lifestyle factors and other indicators of a healthy diet, as well as amongst participants in the highest vegetable intake tertile, determining the effect of nitrate alone can only be achieved through intervention studies. Furthermore, we were unable to investigate potential interactions with known inhibitors of the nitrate-nitrite-NO pathway, including antibacterial mouthwash and proton pump inhibitors. The measurement of BP was not gold standard, but any measurement error would have reduced our power to detect an association. Finally, participants in this study were most likely Caucasian meaning that caution should be taken when extrapolating these findings to other races and ethnicities.
Conclusion
In this Danish prospective cohort study, we observed an inverse association between vegetable nitrate intakes, up to 60 mg/day, and hospital admissions for CVD. More specifically, moderate to high nitrate intakes were associated with a lower risk of IHD, ischemic stroke, PAD, and HF. A higher vegetable nitrate intake was also associated with a lower baseline SBP and DBP. Our results suggest that ensuring the consumption of nitrate-rich vegetables, corresponding to ~ 1 cup of green leafy vegetables, may lower the risk of CVD.
Data availability
Data described in the manuscript, code book, and analytic code will be made available upon request pending application and approval by the Diet, Cancer and Health Steering Committee at the Danish Cancer Society.
References
Jin RC, Loscalzo J. Vascular nitric oxide: formation and function. J Blood Med. 2010;1(1):147–62.
Lundberg JO, Govoni M. Inorganic nitrate is a possible source for systemic generation of nitric oxide. Free Radic Biol Med. 2004;37(3):395–400.
Blekkenhorst LC, Prince RL, Ward NC, Croft KD, Lewis JR, Devine A, et al. Development of a reference database for assessing dietary nitrate in vegetables. Mol Nutr Food Res. 2017. https://doi.org/10.1002/mnfr.201600982.
Bondonno CP, Blekkenhorst LC, Liu AH, Bondonno NP, Ward NC, Croft KD, et al. Vegetable-derived bioactive nitrate and cardiovascular health. Mol Aspects Med. 2018;61:83–91. https://doi.org/10.1016/j.mam.2017.08.001.
Larsen FJ, Ekblom B, Sahlin K, Lundberg JO, Weitzberg E. Effects of dietary nitrate on blood pressure in healthy volunteers. N Engl J Med. 2006;355(26):2792–3.
Jackson JK, Patterson AJ, MacDonald-Wicks LK, Oldmeadow C, McEvoy MA. The role of inorganic nitrate and nitrite in cardiovascular disease risk factors: a systematic review and meta-analysis of human evidence. Nutr Rev. 2018;76(5):348–71.
Siervo M, Lara J, Ogbonmwan I, Mathers JC. Inorganic nitrate and beetroot juice supplementation reduces blood pressure in adults: a systematic review and meta-analysis. J Nutr. 2013;143(6):818–26.
Bahadoran Z, Mirmiran P, Kabir A, Azizi F, Ghasemi A. The nitrate-independent blood pressure-lowering effect of beetroot juice: a systematic review and meta-analysis. Adv Nutr. 2017;8(6):830–8. https://doi.org/10.3945/an.117.016717.
Blekkenhorst LC, Bondonno CP, Lewis JR, Devine A, Woodman RJ, Croft KD, et al. Association of dietary nitrate with atherosclerotic vascular disease mortality: a prospective cohort study of older adult women. Am J Clin Nutr. 2017;106(1):207–16. https://doi.org/10.3945/ajcn.116.146761.
Bondonno CP, Blekkenhorst LC, Prince RL, Ivey KL, Lewis JR, Devine A, et al. Association of vegetable nitrate intake with carotid atherosclerosis and ischemic cerebrovascular disease in older women. Stroke. 2017;48(7):1724–9.
Jackson JK, Patterson AJ, MacDonald-Wicks LK, Forder PM, Blekkenhorst LC, Bondonno CP, et al. Vegetable nitrate intakes are associated with reduced self-reported cardiovascular-related complications within a representative sample of middle-aged Australian women, prospectively followed up for 15 years. Nutrients. 2019;11(2):240.
Liu AH, Bondonno CP, Russell J, Flood VM, Lewis JR, Croft KD, et al. Relationship of dietary nitrate intake from vegetables with cardiovascular disease mortality: a prospective study in a cohort of older Australians. Eur J Nutr. 2018. https://doi.org/10.1007/s00394-018-1823-x.
Jackson JK, Zong G, MacDonald-Wicks LK, Patterson AJ, Willett WC, Rimm EB, et al. Dietary nitrate consumption and risk of CHD in women from the Nurses’ Health Study. Br J Nutr. 2019;121(7):831–8.
Hord NG, Tang Y, Bryan NS. Food sources of nitrates and nitrites: the physiologic context for potential health benefits. Am J Clin Nutr. 2009;90:1–10. https://doi.org/10.3945/ajcn.2008.27131.
Pedersen CB. The Danish civil registration system. Scand J Public Health. 2011;39(7_suppl):22–5.
Petersson F, Baadsgaard M, Thygesen LC. Danish registers on personal labour market affiliation. Scand J Public Health. 2011;39(7_suppl):95–8.
Lynge E, Sandegaard JL, Rebolj M. The Danish national patient register. Scand J Public Health. 2011;39(7_suppl):30–3.
Wallach Kildemoes H, Toft Sørensen H, Hallas J. The Danish national prescription registry. Scand J Public Health. 2011;39(7_suppl):38–41.
Tjønneland A, Overvad K, Haraldsdottir J, Bang S, Ewertz M, Jensen OM. Validation of a semiquantitative food frequency questionnaire developed in Denmark. Int J Epidemiol. 1991;20(4):906–12.
Keszei AP, Schouten LJ, Driessen ALC, Huysentruyt CJR, Keulemans YCA, Goldbohm RA, et al. Vegetable, fruit and nitrate intake in relation to the risk of Barrett’s oesophagus in a large Dutch cohort. Br J Nutr. 2014;111(8):1452–62. https://doi.org/10.1017/S0007114513003929.
Inoue-Choi M, Virk-Baker MK, Aschebrook-Kilfoy B, Cross AJ, Subar AF, Thompson FE, et al. Development and calibration of a dietary nitrate and nitrite database in the NIH–AARP Diet and Health Study. Public Health Nutr. 2016;19(11):1934–43.
Sundbøll J, Adelborg K, Munch T, Frøslev T, Sørensen HT, Bøtker HE, et al. Positive predictive value of cardiovascular diagnoses in the Danish National Patient Registry: a validation study. BMJ Open. 2016;6(11):e012832.
Krarup L-H, Boysen G, Janjua H, Prescott E, Truelsen T. Validity of stroke diagnoses in a National Register of Patients. Neuroepidemiology. 2007;28(3):150–4.
Lühdorf P, Overvad K, Schmidt EB, Johnsen SP, Bach FW. Predictive value of stroke discharge diagnoses in the Danish National Patient Register. Scand J Public Health. 2017;45(6):630–6.
Hald SM, Sloth CK, Hey SM, Madsen C, Nguyen N, Rodríguez LAG, et al. Intracerebral hemorrhage: positive predictive value of diagnosis codes in two nationwide Danish registries. Clin Epidemiol. 2018;10:941.
Lasota AN, Overvad K, Eriksen HH, Tjønneland A, Schmidt EB, Grønholdt ML. Validity of peripheral arterial disease diagnoses in the Danish National Patient Registry. Eur J Vasc Endovasc Surg. 2017;53(5):679–85.
Hansen CP, Overvad K, Tetens I, Tjønneland A, Parner ET, Jakobsen MU, et al. Adherence to the Danish food-based dietary guidelines and risk of myocardial infarction: a cohort study. Public Health Nutr. 2018;21(7):1286–96.
Schmidt M, Schmidt SAJ, Sandegaard JL, Ehrenstein V, Pedersen L, Sørensen HT. The Danish National Patient Registry: a review of content, data quality, and research potential. Clin epidemiol. 2015;7:449.
Ekholm O, Hesse U, Davidsen M, Kjøller M. The study design and characteristics of the Danish national health interview surveys. Scand J Public Health. 2009;37(7):758–65.
Flegal KM, Kit BK, Orpana H, Graubard BI. Association of all-cause mortality with overweight and obesity using standard body mass index categories: a systematic review and meta-analysis. JAMA. 2013;309(1):71–82.
Roerecke M, Kaczorowski J, Tobe SW, Gmel G, Hasan OS, Rehm J. The effect of a reduction in alcohol consumption on blood pressure: a systematic review and meta-analysis. Lancet Public Health. 2017;2(2):e108–20.
Lange T, Rasmussen M, Thygesen LC. Assessing natural direct and indirect effects through multiple pathways. Am J Epidemiol. 2014;179(4):513–8.
Steen J, Loeys T, Moerkerke B, Vansteelandt S. Medflex: an R package for flexible mediation analysis using natural effect models. J Stat Softw. 2017. https://doi.org/10.18637/jss.v076.i11.
R Development Core Team. R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing ISBN 3–900051–07–0. http://www.R-project.org/; 2019.
Shakia TH, Laura RL, Kenneth RB, Sujatro C, Patricia PC, Aaron RF, et al. Reducing the blood pressure-related burden of cardiovascular disease: impact of achievable improvements in blood pressure prevention and control. JAMA. 2015;4(10):e002276. https://doi.org/10.1161/JAHA.115.002276.
Cook NR, Cohen J, Hebert PR, Taylor JO, Hennekens CH. Implications of small reductions in diastolic blood pressure for primary prevention. Arch Intern Med. 1995;155(7):701–9. https://doi.org/10.1001/archinte.1995.00430070053006.
Blekkenhorst LC, Bondonno NP, Liu AH, Ward NC, Prince RL, Lewis JR, et al. Nitrate, the oral microbiome, and cardiovascular health: a systematic literature review of human and animal studies. Am J Clin Nutr. 2018;107(4):504–22.
Sundqvist ML, Larsen FJ, Carlström M, Bottai M, Pernow J, Hellénius M-L, et al. A randomized clinical trial of the effects of leafy green vegetables and inorganic nitrate on blood pressure. Am J Clin Nutr. 2020;111(4):749–56. https://doi.org/10.1093/ajcn/nqaa024.
Fuchs FD, Whelton PK. High blood pressure and cardiovascular disease. Hypertension. 2020;75(2):285–92. https://doi.org/10.1161/HYPERTENSIONAHA.119.14240.
Verdecchia P, Angeli F, Reboldi G. Hypertension and atrial fibrillation. Circ Res. 2018;122(2):352–68. https://doi.org/10.1161/CIRCRESAHA.117.311402.
Bobak M, Malyutina S, Horvat P, Pajak A, Tamosiunas A, Kubinova R, et al. Alcohol, drinking pattern and all-cause, cardiovascular and alcohol-related mortality in Eastern Europe. Eur J Epidemiol. 2016;31(1):21–30.
Tanaka A, Cui R, Kitamura A, Liu K, Imano H, Yamagishi K, et al. Heavy alcohol consumption is associated with impaired endothelial function. J Atheroscler Thromb. 2016;23(9):1047–54.
Funding
This study was supported by the Raine Medical Research Foundation and the Healy Medical Research Foundation (RCA06-20). FD is funded by The Danish Heart Foundation (Grant Number 17-R115-A7443-22062) and Gangstedfonden (Grant Number A35136), Denmark. NPB is funded by a National Health and Medical Research Council Early Career Fellowship (Grant Number APP1159914), Australia. The salary of JMH is supported by a National Health and Medical Research Council of Australia Senior Research Fellowship, Australia (Grant Number APP1116937). The salary of JRL is supported by a National Heart Foundation of Australia Future Leader Fellowship (ID: 102817). The salary of LCB is supported by an NHMRC of Australia Emerging Leadership Investigator Grant (ID: 1172987) and a National Heart Foundation of Australia Post-Doctoral Research Fellowship (ID: 102498).
Author information
Authors and Affiliations
Contributions
CPB, NPB, FD, and JMH designed research (project conception, development of overall research plan, and study oversight); AT conducted the original cohort study; CPB calculated nitrate intake from FFQ data; NPB, KM and FD analysed data; CPB and FD wrote the paper and had primary responsibility for final content; LCB, KM, JRL, KDC, CK, CTP, GG, AT, KO and JMH assisted with interpretation of the results and critically reviewed the manuscript. All authors read and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethics approval
In Denmark, register studies do not require approval from ethics committees. This study was approved by the Danish Data Protection Agency (Ref no 2012-58-0004 I-Suite nr: 6357, VD-2018-117).
Consent to participate
Informed consent was obtained from all participants to search information from medical registers.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bondonno, C.P., Dalgaard, F., Blekkenhorst, L.C. et al. Vegetable nitrate intake, blood pressure and incident cardiovascular disease: Danish Diet, Cancer, and Health Study. Eur J Epidemiol 36, 813–825 (2021). https://doi.org/10.1007/s10654-021-00747-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10654-021-00747-3