
Abstract
Recent advances in genomics make it possible to predict individual differences in education from polygenic scores that are person-specific aggregates of inherited DNA differences. Here, we systematically reviewed and meta-analyzed the strength of these DNA-based predictions for educational attainment (e.g., years spent in full-time education) and educational achievement (e.g., school grades). For educational attainment (k = 20, n = 16, Ntotal = 314,757), a multilevel meta-analysis showed an association with polygenic scores of ρ = .27 (95% CI from .22 to .32). For educational achievement (k = 19, n = 10, Ntotal = 83,788), the association was ρ = .24 (95% CI from .18 to .30). Eurocentric biases were evident with only 15% of estimates being reported in samples of non-European ancestry. After accounting for sample ancestry, age at assessment, and education measure, the meta-analytic estimates increased to ρ = .29 (95% CI from .24 to .33) for educational attainment and ρ = .50 (95% CI from .39 to .61) for educational achievement, indicative of large effect sizes. All meta-analytic estimates were associated with significant heterogeneity. Our findings suggest that DNA-based predictions of education are sizeable but vary across samples and studies. We outline three steps to safeguard potential applications of polygenic score predictions in education to maximize their benefits for personalizing learning, while minimizing the bioethical risks of perpetuating social, cultural, and economic inequalities.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Education equips us with the skills and knowledge that we need to navigate through and master our lives. People’s differences in educational opportunities and outcomes have pervasive, long-term influence on their life-course development, including lifetime cognitive functioning (Chen et al., 2019; Lövdén et al., 2020), socioeconomic status attainment (Mackenbach et al., 2008), the likelihood of becoming employed (Oreopoulos & Salvanes, 2011), marriage partner choice (Cave et al., 2022), health and wellbeing (Cutler & Lleras-Muney, 2010, 2012), and life expectancy (Montez & Hayward, 2014). From the first day of kindergarten, vast differences in children’s educational performance can be observed, and these differences magnify as children grow older (Heckman, 2006; Schoon et al., 2002; von Stumm, 2017; von Stumm et al., 2019). Understanding the origin of people’s differences in educational outcomes is key to improving how we teach and learn, which, in turn, will greatly benefit the psychological development of both individuals and society at large.
The search for causes of children’s differences in school performance has traditionally focused on characteristics of students’ learning environments, such as their teachers’ expertise (Bardach et al., 2021; Nye et al., 2004), classroom sizes (Filges et al., 2018; Karvonen et al., 2018), and school quality (Shin & Chung, 2009; von Stumm et al., 2020). Yet in recent years, the role of genetic propensities on children’s learning differences has garnered much attention (e.g., Asbury & Plomin, 2013; Harden, 2021; Malanchini et al., 2020; Plomin, 2018). Twin studies that compare the phenotypic resemblance of identical twins (i.e., monozygotic) to that of fraternal twins (i.e., dizygotic) documented that differences in education are highly heritable (Ayorech et al., 2017; Polderman et al., 2015; Rimfeld et al., 2018a, b; see Glossary in Supplementary Table S1 for terminology explanations). Heritability refers to the proportion of differences in a phenotypic trait that can be observed between people and attributed to their inherited DNA differences (Plomin, 2018; Visscher et al., 2008). For example, 57% of children’s differences in children’s learning over the primary school years were heritable in a Dutch twin sample of 12-year-olds (Bartels et al., 2002). That is, 57% of the differences in pupils’ scores on the national CITO elementary test that children in the Netherlands take at the end of primary school could be attributed to their genetic differences, while 43% of their differences in test scores were due to environmental factors (e.g., teacher expertise or school quality; Bartels et al., 2002). Other studies confirmed that more than half of students’ differences in school performance can be attributed to their genetic differences (Malanchini et al., 2020; Polderman et al., 2015), including analyses of a UK sample of 16-year-olds for whom 58% of their differences in end-of-year exam grades were heritable; these exam grades indexed pupils’ suitability for further, university-level studies (Shakeshaft et al., 2013).
Notwithstanding the many robust and replicable findings from behavior genetic studies (Plomin et al., 2016), genetically informed research on psychological or behavioral traits is often misinterpreted (Asbury & Plomin, 2013; Crosswaite & Asbury, 2019) and met with skepticism and even hostility (e.g., Lewis-Kraus, 2021). A common misconception is that finding genetic influences implies that people’s differences are “fixed” or “destined,” an idea known as genetic determinism. Yet, genetic influences neither determine destinies nor do they mean that people’s differences are immutable. In fact, genetic and environmental influences exist in a concerted balance: If environments vary greatly in a population, for example when the opportunity to go to school is only available to some but not others, genetic influences will only explain a small proportion of that population’s differences in education. In this case, the effects of having access to a school versus not would be the far stronger predictor of school performance. However, if environmental conditions are more equal for people (e.g., when schooling is available to or even compulsory for all children), genetics accounts for a greater proportion of the differences due to less environmental variance (Knigge et al., 2022). Some have argued that this is the reason why heritability could be thought of as an index of equality of opportunity: If heritability is high, environmental variability is low (Ayorech et al., 2017, 2019), meaning that opportunities are, on average, equally available to everybody in the population.
The realization that eradicating environmental inequality will produce greater genetic inequality reads somewhat uncomfortable, yet it is true. Heritability describes the relative contribution of genetic and environmental influences to phenotypic variability in a particular population at a particular moment in time, but it says little about a trait’s susceptibility to environmental influences (Maccoby, 2000). For example, individual differences in height are highly heritable at about 80% (Yengo et al., 2022), and yet, people’s average height has increased across generations on average by ~ 1 cm per decade (Roser et al., 2013). These gains cannot be explained by changes in the population’s gene pool, which evolves over millennia, but are likely due to environmental changes, such as improved nutrition and medical care (Perkins et al., 2016). Akin to height, steep increases in school enrolment and school completion rates have been reported over the past century. People’s mean years of schooling has grown from 4 to 12 years in high-income countries (i.e., a 67% increase) and from half a year to 8 years in low- and middle-income countries (i.e., a 94% increase; Lee & Lee, 2016; Ritchie et al., 2023). These gains in educational attainment stem from the broader availability of education opportunities—an environmental change—rather than from changes in populations’ gene pools.
Recent advances in genomic research make it possible to predict people’s differences in education directly from their inherited DNA variants that we refer to as polygenic scores but that are also known as polygenic risk score (PRS), polygenic index (PGI), genetic risk scores, or genome-wide score in the literature (Allegrini et al., 2020; Cesarini & Visscher, 2017; Lee et al., 2018; Okbay et al., 2016, 2022; Rietveld et al., 2013; Selzam et al., 2017). Just like heritability estimates, DNA-based predictions for phenotypic traits do not imply immutability or fixedness, nor do they allow per se for causal inferences (Plomin & von Stumm, 2022). They reflect a person’s genetic propensity or likeliness to think, feel, and behave in certain ways (Cesarini & Visscher, 2017; Plomin & von Stumm, 2018). For example, children with lower genetic propensities for educational achievement are likely to find concentrating on homework more difficult, be less engaged with lessons, and forgo study sessions in favor of other activities more often than children with higher genetic propensities for eruditeness. It may therefore take more effort, time, and educational support for children with lower genetic propensities for education to achieve the same learning success as others with higher genetic propensities, but they could nonetheless perform just as well or even better. In other words, children’s genetic propensities for education describe learning tendencies or preferences but do not determine educational trajectories, akin to the observation that children’s performance in secondary school predicts but does not determine tertiary education outcomes (e.g., university-level studies; Starr et al., 2024).
Polygenic scores reflect not only direct genetic influences but also capture gene-environment correlations, assortative mating, and population stratification (Plomin & von Stumm, 2022). Gene-environment correlations arise, for example, because children are recipients of both inherited DNA differences and rearing environments from their parents (Wertz et al., 2019). Assortative mating refers to parents’ greater genetic resemblance than can be expected for two randomly chosen individuals (Horwitz et al., 2023). Population stratification occurs when allele frequencies differ systematically across subpopulations, giving rise to heterogenous population structures (Morris et al., 2020a, b). The effects of gene-environment correlations, assortative mating, and population stratification may account for up to 60% of polygenic score predictions of educational outcomes (Selzam et al., 2019), although estimates vary substantially across studies that have been published to date in this area (Howe et al., 2022).
At present, equal opportunity is the epitome of the education system in meritocratic societies that aim to achieve fairness in education by instructing all children in the same curriculum, at the same pace, and with the same pedagogical methods and approaches. Corresponding education policies favor pedagogies that are thought to benefit all students (e.g., Machin & Vignoles, 2006) but because children differ in their abilities, skills, and interests, the “equal” learning opportunities that school affords them do not translate into equity in learning outcomes (Chmielewski, 2019; von Stumm et al., 2022). A more productive way for achieving fairness in education is likely prioritizing equity in outcomes over equality in opportunity (Knigge et al., 2022; Sokolowski & Ansari, 2018), such as assigning more teaching staff to children who are at risk of academic failure, while better performing children are looked after by fewer teachers (Arold et al., 2022).
Acknowledging and understanding the role of genetics may help improve the fairness of education systems in three ways. The first is that finding genetic influences on children’s learning differences advocates for teaching that recognizes children’s inherent heterogeneity in abilities, skills, and interests, rather than for “one-size-fits-all” pedagogical approaches. Effective teaching must be “personalized” to respond to and remediate children’s vastly different, individual learning needs (Asbury & Plomin, 2013; von Stumm & Wertz, 2021). Some differentiated instructional strategies are already employed by teachers, including individual education plans that support students with special educational needs and disabilities (SEND) to monitor their learning progress and improve their learning outcomes (Dalgaard et al., 2022; Department of Education, 2015; Jørgensen et al., 2020). In 2022, 17% of UK pupils received support for SEND, including 4% of pupils who were taught according to personalized education, health, and care plans (EHC; Farquharson et al., 2022). While teachers strongly and unanimously endorse the principles of personalized learning, the practical implementation of corresponding pedagogies within current schools and education settings remains difficult (Dalgaard et al., 2022; Gunawardena et al., 2024; Martschenko, 2019; Williams-Brown & Hodkinson, 2020).
Second, the availability of DNA-based predictors for children’s learning differences opens possibilities for identifying children at risk for poor educational outcomes and intervening early before maladaptive learning behaviors have manifested. This feature distinguishes DNA from other predictors of learning difficulties, such as teachers raising concerns or children agonizing over homework and struggling to read, that only become observable after they have emerged. Education interventions that involve DNA-based predictors would need to be carefully planned to preclude any discrimination against children because of their genetics (Asbury et al., 2021; Martschenko et al., 2024). Yet, such interventions resemble in many ways current approaches to remediating children’s family background inequality in education: For example, in France and in the UK, schools receive extra funding from the state to support pupils from under-resourced family homes in mitigating their learning disadvantages (Flavier & Moussay, 2014; Roberts et al., 2021). Akin to families’ (lack of) resources as predictor of children’s learning support needs, polygenic scores could be used to guide the allocation of educational resources to the children with the genetic indication for developing learning difficulties (cf. Au, 2022).
Third, a deeper understanding among parents, educators, and policymakers of the role of genetics in education could increase tolerance, commiseration, and kindness toward the children who struggle with school—as well as reduce envy of and animosity toward those who breeze through (Asbury & Plomin, 2013; Asbury et al., 2021). Prioritizing equity of outcomes will reduce the extent to which children are held personally responsible for their academic achievements and failures, an attribution that prevails in meritocratic education systems (Renoux et al., 2024). At present, children who do well in school are widely believed to “deserve” better lives than those who do poorly (Anderson, 1999, 2007; Sandel, 2020)—a rather twisted notion of fairness, if we acknowledge that children’s school performance is largely a function of circumstances beyond their control, such as their family background, including their inherited DNA differences (Harden, 2021; von Stumm et al., 2020; von Stumm & d’Apice, 2021).
Notwithstanding the potential benefits that behavioral genetic findings may hold for designing fair educational systems, they also bear risks of social separation, pessimism, and creating perceptions of unmanageable behavior within the classroom (Larsen et al., 2022; Martschenko et al., 2024). Research on how teachers, students, and parents might interpret polygenic score feedback is currently sparse, as are findings on how polygenic score predictions may affect students’ academic motivations (e.g., Larsen et al., 2022; Matthews et al., 2021).
Our article is structured into four sections. First, we define educational attainment and achievement, review their respective assessments in research studies, and discuss what is known about their heritability. Second, we explain what polygenic scores are and how they can be used to predict individual differences in education. In the third part of this paper, we present meta-analytic findings on the prediction of educational attainment and achievement from polygenic scores. Finally, we embed our meta-analytic results in the broader context of the research literature and discuss how the benefits of DNA-based predictions of education may be leveraged while effectively mitigating their risks.
The Heritability of Educational Achievement and Attainment
Educational achievement refers to students’ relative performance within an educational setting or level, for example the end-of-year exam grades in school. Educational attainment pertains to the level of education that a person acquires, ranging typically from school leaving certificates to vocational training to tertiary qualifications, such as university degrees. In putatively meritocratic societies, educational achievement and attainment are intertwined because the former regulates the access to the latter: Children who achieved relative to others at one educational level (e.g., secondary school) will be offered opportunities for further studies (e.g., at university), while those who performed poorly at an education level typically fail to qualify for progressing to the next (Schoon et al., 2012; von Stumm et al., 2019).
Twin studies from across the world have reported educational achievement as highly heritable: On average, 60% of students’ differences in educational achievement can be attributed to their inherited DNA differences (Bartels et al., 2002; Polderman et al., 2015; Shakeshaft et al., 2013). The heritability of educational achievement increases with age due to gene-environment correlations (rGE; Haworth et al., 2010; Morris et al., 2018) that result from individuals selecting, adapting to, and shaping the environments that correspond to their genotype (Avinun, 2020). Children increasingly seek out environments that align with their genetic propensities as they grow older, for example when avid readers spend weekends at the library, which in turn improves their reading skills; as a result, estimates of genetic influences on phenotypic development increase (Avinun & Knafo, 2014; Haworth et al., 2011; Plomin et al., 1977; Scarr & McCartney, 1983).
Twin study heritability estimates for educational attainment tend to be lower than those for educational achievement (Branigan et al., 2013; Silventoinen et al., 2020). A meta-analysis across 15 populations from seven European countries and Australia (Ntotal = 51,545) reported 40% heritability for attainment, which was assessed as the number of years that people spent in full-time education or the highest educational qualification they obtained (Branigan et al., 2013). Similarly, an analysis of 28 twin cohorts from 16 countries in Europe, North American, Australia, and East Asia reported that differences in educational attainment were on average 43% heritable (Silventoinen et al., 2020). The discrepancy in heritability estimates between educational achievement and attainment likely reflects the constructs’ discrepancy in environmental variance. Educational achievement occurs within defined educational settings (i.e., a class in school) where students experience broadly comparable environments, and thus, their genetic differences gain greater weight (Kovas et al., 2013). By comparison, education attainment measures subsume different environments: students who obtain university degrees have experienced different learning environments than apprentices, who attended vocational training colleges. It follows that differences in educational attainment are on average less heritable than differences in educational achievement, notwithstanding their high covariance at the phenotypic and genetic levels (Kovas et al., 2005; Plomin et al., 2016).
Polygenic Scores as Predictors of Educational Outcomes
The decoding of the human genome (International Human Genome Sequencing Consortium, 2001) and the mapping of the genomic variation in human populations (Gibbs et al., 2003) in the early 2000s made it possible to identify the DNA variants that cause the heritability of phenotypic trait differences. These DNA variants, known as single-nucleotide polymorphisms (SNPs), mark the smallest unit of genetic differences between people (see Supplementary Table S1 for Glossary). These SNPs that drive the heritability of a phenotypic trait can be identified in genome-wide association studies (GWAS). GWAS test associations between people’s differences in a target phenotypic trait and their SNPs across the entire genome and produce summary statistics that reflect the strength (i.e., effect size) and direction with which SNPs are associated with the target phenotype (Choi et al., 2020). These GWAS summary statistics enable computing polygenic scores in independent samples, for whom genotype data are available, by aggregating the SNPs identified in the GWAS, weighed by their effect size (Choi et al., 2020; Pasaniuc & Price, 2016). Polygenic scores therefore index person-specific estimates of genetic propensities for a given target phenotype (Plomin & von Stumm, 2018), while also capturing environmental variances due to gene-environment correlations, assortative mating, and population stratification (Morris et al., 2020a, b). Polygenic scores are unique predictors of psychological traits, in the way they are stable across the lifespan (i.e., they are as predictive of adult outcomes during childhood as they are in adulthood), unaffected by self-report biases (i.e., one cannot inflate or fake their polygenic scores), and preclude backward causation (i.e., inherited DNA differences are unchangeable by behavioral or environmental factors; Plomin & von Stumm, 2018). Polygenic scores are normally distributed and can be modeled as continuous variables in statistical analyses, just like sum scale scores from psychometric tests or other psychological measures. While polygenic scores may be powerful predictors of people’s phenotypic differences, they do not necessarily cause these differences. They are probabilistic rather than deterministic or causal predictors of phenotypic outcomes (Asbury et al., 2021; Harden, 2021; Plomin & von Stumm, 2022), and they also capture environmental influences (Okbay et al., 2022; Selzam et al., 2019).
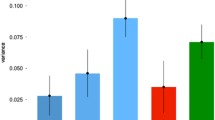
To date, four large-scale GWAS have sought to identify the DNA variants that are associated with people’s differences in educational attainment (Fig. 1), which is inferred from the number of years that people have spent in full-time education, a coarse yet cost-effective and widely used way of assessing educational attainment (Lee et al., 2018; Marioni et al., 2016; Okbay et al., 2022). The first GWAS for years spent in education included a discovery sample of N ~ 130,000, and corresponding polygenic scores predicted about ~ 2% of the educational attainment variance in independent samples (N ~ 3500 and ~ 6800; Domingue et al., 2015; Rietveld et al., 2013), a rather modest effect size relative to the twin study estimates of 40% heritability (Matthews & Turkheimer, 2022). The difference between polygenic score predictions and twin study heritability estimates is known as the “missing heritability” gap (Manolio et al., 2009), which is likely to due to rare variants that will require GWAS discovery sample sizes of tens of millions to be identified (Watanabe et al., 2019). The “missing heritability” gap will likely narrow as research progresses, especially as larger GWAS samples (Yengo et al., 2022), whole-genome sequencing (Wainschtein et al., 2022), and alternative statistical modeling approaches become available (Grotzinger et al., 2019).

Polygenic score prediction of years spent in education across four published GWAS. Note: For each GWAS for educational attainment (EA), the year of publication (in parentheses) is shown along the x-axis, and the discovery sample sizes are given above their respective bar. Bars indicate the weighted mean proportion of variance (R2) of polygenic score predictions of educational attainment in the independent samples that were reported in the original GWAS articles. Error bars reflect 95% confidence intervals (CIs) Some 95% CIs were not reported in the original article and were estimated via https://www.danielsoper.com/statcalc/calculator.aspx?id=28 for the weighted mean R2. Gray circles reflect the polygenic score prediction from each independent sample, whose N is indexed by circle size (for details on the independent samples, see Supplementary Materials section 2)
The second GWAS on years spent in education, published 3 years after the first, included a discovery sample of N ~ 290,000 adults (Okbay et al., 2016). Corresponding polygenic scores predicted ~ 3% of the variance in educational attainment in two independent samples (N ~ 10,000 and ~ 9000 Okbay et al., 2016), as well as ~ 9% of the variance in educational achievement in ~ 3000 British 16-year-olds (Selzam et al., 2017). Quadrupling the prediction effect size for educational achievement from the previous GWAS (Krapohl & Plomin, 2016; Selzam et al., 2017) suggested that even larger samples were needed to achieve sufficient statistical power for identifying the SNPs that drive the heritability of education outcomes.
Two years later, a third GWAS on years spent in education surpassed one million participants (Lee et al., 2018). Its polygenic scores accounted for ~ 11% of the variance in educational attainment across two independent samples (N ~ 5000 and ~ 9000; Lee et al., 2018) and ~ 16% in educational achievement in ~ 7000 British 16-year-olds (Allegrini et al., 2019). These prediction effect sizes are big enough to translate into real-life differences: Students with polygenic scores in the 10th percentile and below achieve on average a C + in their end-of-compulsory school grades, while students with polygenic scores in the 90th percentile and above achieve an A − (von Stumm et al., 2020). The strength of polygenic score predictions for students’ educational achievement greatly exceeds that of other predictors, such as school quality ratings that explain less than 1% variance in end-of-compulsory school grades after accounting for prior school performance and family background (von Stumm et al., 2020).
In 2022, a fourth GWAS on years spent in education with a discovery sample of N ~ 3 million individuals was published (Okbay et al., 2022). The polygenic scores from this GWAS explained on average ~ 14.3% of the variance in educational attainment across two independent samples (N ~ 10,000 and ~ 9000; Okbay et al., 2022), as well as ~ 13% of variance in grade point average at age 16 years (N ~ 4000), and ~ 8% variance in high school grade rank at age 14 years (N ~ 5000; Okbay et al., 2022). These findings consolidated that polygenic score predictions for education strengthen as GWAS samples sizes increase, potentially to the point that polygenic score predictions will approximate the heritability estimates from twin studies (Yengo et al., 2022).
To summarize, four GWAS for years spent in education were published between 2013 and 2022, with their participant numbers growing from N ~ 130,000 to ~ 3 million, a 23-fold increase in less than 10 years. These GWAS’ polygenic scores predicted from ~ 2 to ~ 14% of the variance in educational attainment, a sevenfold increase (Fig. 1). It is important to note that each consecutive GWAS builds upon the discovery sample of the previous, that is to say their samples are not independent but overlap. In this sense, an earlier GWAS can be considered outdated when the next GWAS on the same target phenotype is published, akin to revised psychometric test with improved items rendering its earlier versions obsolete. When we preregistered the current meta-analysis, the fourth GWAS on years spent in education was yet to be published (Okbay et al., 2022). During the writing of this article, the summary statistics of the fourth GWAS on years spent in education became available to some researchers but not all. Thus, we focus here on studies that reported polygenic score predictions of education using the third GWAS (Lee et al., 2018), which was the largest GWAS for which full summary statistics were broadly available when this meta-analysis was completed.
The Current Study
Our meta-analysis aimed to appraise the status quo of the empirical findings on polygenic score predictions of educational outcomes, to evaluate corresponding prediction effect sizes, and to inform future research and applications of polygenic score predictions in education. To this end, we reviewed empirical studies that reported associations between polygenic scores based on Lee et al. (2018) GWAS for years spent in education and phenotypic measures of educational attainment and achievement. We identified a priori three factors that may moderate this association. The first is the genetic ancestry or ethnic origin of the study population. GWAS samples are typically drawn from populations of European ancestry (Mills & Rahal, 2019, 2020), and corresponding polygenic scores tend to be more predictive in European than in samples from other ancestral populations (Duncan et al., 2019; Okbay et al., 2022; Wang et al., 2020). For example, polygenic scores predicted ~ 10.6% of the variance in educational attainment in participants who identified as white American but only ~ 1.6% in participants who reported to be African American (Lee et al., 2018). The second factor that likely influences polygenic score predictions of education is the sample’s age at phenotypic assessment, because genetic influences on education increase with age as a result of gene-environment correlations (Avinun, 2020; Haworth et al., 2010; Plomin et al., 1977). For example, in ~ 3000 British school pupils, the polygenic score predictions of educational achievement increased from 5% at age 7 years to 14% of the variance at age 16 years (von Stumm et al., 2020). Polygenic score predictions are therefore likely stronger for educational achievement during adolescence than in childhood. The third factor that may affect associations between polygenic scores and educational outcomes are cohort effects or generational trends. Contemporaneously with the global increase in the access and availability of education (Lee & Lee, 2016), polygenic score predictions are likely to account for increasing proportions of variance in education attainment in later as compared to earlier generations (Herd et al., 2019; Rimfeld et al., 2018a, b). One study showed that in US women who were born in the 1930s, polygenic scores explained ~ 9.5% of the variance in educational attainment, but in women born two decades later in the 1950s, polygenic scores predicted even ~ 13.6% of the variance (HRS samples; Herd et al., 2019). This and similar gains in polygenic score predictions of education likely result from greater proportions of women enrolling in and completing tertiary education in the 1970s and thereafter, when traditional gender roles became less prescribed.
Methods
Search Strategy
This meta-analysis was performed in line with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) statement (Page et al., 2021) and preregistered on the Open Science Framework (OSF; https://osf.io/xcm43/). We included articles that had been published by August 2022 and reported empirical associations between phenotypic measures of educational attainment or achievement and polygenic scores based on the summary statistics from the third GWAS for years spent in education (Lee et al., 2018), whose summary statistics became available in July 2018, resulting in a publication period of 49 months (i.e., 4.1 years) for this meta-analysis. We identified the publications through the citation record of the GWAS (Lee et al., 2018) on Google Scholar and Web of Science, which yielded a total of 1329 non-duplicate hits (1257 citations in Google Scholar, 776 citations in the Web of Science; flow diagram Fig. 2). We also included the polygenic score prediction estimates that were reported in the original GWAS article (Lee et al., 2018) in our review (k = 4).

PRISMA flow diagram of the identification of eligible studies. Note: n refers to the number of publications; k is the number of estimates
Study Eligibility Criteria, Screening, and Exclusions
Publications that reported the following were included in our meta-analysis: (1) a phenotypic measure of educational attainment (e.g., self-reported years spent in education or highest qualification obtained) OR educational achievement (e.g., school grades or academic test scores reported by children or teachers), (2) polygenic scores based on the summary statistics from Lee et al.’s (2018) GWAS for years spent in education, (3) a statistical estimate of association between a phenotypic measure of education and the polygenic score, (4) an original empirical study (i.e., no meta-analyses or review papers) that was (5) published in a peer-reviewed journal.
Two authors independently screened 20% of the 1329 records; because their interrater agreement was perfect (100%, κ = 1; McHugh, 2012), the first author proceeded to screen all remaining hits. Overall, 77 articles met our eligibility criteria for retention, and full texts were downloaded. Further reasons for exclusions were recorded (flow diagram Fig. 2; Table S2) before extracting, coding, and recording our target variables. Interrater agreement was for coding high (93.75%, κ = 0.64). Overall, 60 articles did not meet our eligibility criteria and were excluded (Fig. 2), while 17 publications as well as the estimates reported in the original Lee et al. (2018) GWAS article were retained for the meta-analysis.
Coding Target Variables
We extracted from the retained publications (1) samples’ ancestry, (2) samples’ birth year, (3) samples’ ages at phenotypic assessment, (4) educational outcome type (i.e., educational attainment or educational achievement) and measure (e.g., school grades or test scores), (5) statistical association estimate (e.g., standardized β coefficient, r coefficient, or R2 coefficient), (6) the polygenic score computation method (i.e., PLINK, PRSice, LDpred, and lassosum), and (7) whether the association estimates were adjusted for age, sex, and the first ten principal components (PC; Table S3). These latter adjustments are typical in polygenic score prediction studies because they help control for population stratification (i.e., systematic differences in genetically heterogenous populations; Allergini et al., 2019; Ni et al., 2021).
Harmonizing Statistical Estimates
Across studies, different statistical estimates were reported to describe the association between polygenic scores and education, including correlation r coefficients (k = 21), standardized β coefficients (k = 8), and R2 values (k = 10). We retained statistical estimates that were reported as r or standardized β coefficients from regression models that included no other covariates except one or more of the following: age, sex, PC (i.e., adjusting for population stratification), and batch and chip (i.e., systematic differences within samples due to genotyping methods) (Peterson & Brown, 2005). Combining r coefficients and β coefficients in a meta-analysis can be problematic and cause bias if predictors and covariates in regression models are intercorrelated (Roth et al., 2018). Because polygenic score covariates (i.e., age, sex, and PCs) are independent from each other (Tables S6 and S16), this issue does not apply here. Where estimates were reported as R2 (k = 10), we transformed them into r coefficients using an effect size converter (https://www.escal.site). We used correlation coefficients as our effect size metric, before transforming them into Fisher’s Ζ coefficients, as is common in meta-analyses (Alexander et al., 1989).
Multilevel Meta-analyses
The R package metafor (R Core Team, 2019; Viechtbauer, 2010) was used to conduct two multilevel meta-analyses using the function rma.mv(). We conducted a three-level model to address the issue of effect size dependency due to “nestedness” (e.g., individual estimates were clustered by study). The multilevel model includes three variance components: at level 1, the sampling error at the level of the participants; at level 2, the variance within-clusters or within-studies (e.g., individual estimates); and at level 3, the variance between-cluster or between-studies. The multilevel approach allows for effect sizes to vary between participants (level 1), estimates (level 2), and studies (level 3), thereby elucidating the sources of variance.
To investigate heterogeneity, we calculated Q, I2 statistics, and σ2. The Q statistic indicates the presence of heterogeneity (Huedo-Medina et al., 2006), and I2 indicates the percentage of variability in estimates that can be attributed to each level within the model (Higgins et al., 2003), using metafor companion package dmetar (Harrer et al., 2019). The σ2 statistic provides a measure of within- and between-study variance (replacing the τ2 statistic of a conventional meta-analysis). σ2 model comparisons indicate if the heterogeneity at the within- and between-level is significant (Assink & Wibbelink, 2016).
Meta-regression
To explore the heterogeneity within polygenic score predictions of educational attainment and achievement, we fitted meta-regression models with the following moderators: (1) sample ancestry (i.e., binary European versus non-European), (2) samples’ mean age and their age range in years at phenotypic assessment; (3) the samples’ mid-birth year and birth year range; (4) the polygenic score computation method (i.e., PRSice, LDpred, PLINK, and lassosum), with LDpred as the reference because it was most frequently used across studies; and (5) whether age, sex, and the first ten principal components were adjusted for (binary yes/no). Continuous moderators (e.g., age and birth year) were centered before adding them to the meta-regression model, to allow for the intercept to be interpretable. We tested each moderator in an individual meta-regression model (not preregistered) and retained those moderators that were individually significant for multiple moderator meta-regression models (Tables S6-S23).
Publication Biases
We tested for publication biases in three ways. First, we generated funnel plots to visually examine the symmetry of data points in the meta-analysis and in the meta-regression after modeling moderator effects. Second, we conducted Egger’s regression tests, using the Standard Errors of the studies’ estimates’ effect sizes as predictors in a meta-regression model. In the absence of biases and heterogeneity, the Standard Errors will be non-significant predictors. Third, we conducted p-curve analyses with histograms of the p-values associated with the studies’ estimates (Simonsohn et al., 2014a, b), generating p-curves for our estimates using an application (http://www.p-curve.com/app4/; see Supplementary Materials section 5 for details). Across all our models, no signs of biases were detected: The funnel plots illustrated no significant degree of asymmetry, the Egger’s regression tests were non-significant (Figs. S1 and S2), and the p-curve analysis indicated that individual studies’ estimates were truly significant (Figs. S3 and S4, Tables S4 and S5).
Results
Studies’ Description
In total, n = 18 publications were identified that reported associations between polygenic scores and educational attainment (n = 11) and/or educational achievement (n = 12). For polygenic predictions of educational attainment, k = 20 estimates from 16 samples were available with Ntotal = 314,757; for polygenic predictions of educational achievement, k = 19 estimates from 10 samples were included with Ntotal = 83,788. Eighteen of the educational attainment estimates (90%) came from European samples across six WEIRD countries (Western, Educated, Industrialized, Rich, and Democratic, Henrich et al., 2010), including Hungary (k = 1), Netherlands (k = 1), New Zealand (k = 1), Norway (k = 1), UK (k = 5), and US (k = 9; Fig. 3). The remaining two estimates (10%) were from samples of African American ancestry from the US. Fifteen of the educational achievement estimates (79%) came from samples of European ancestry across five WEIRD countries, including Australia (k = 1), Netherlands (k = 1), Norway (k = 1), UK (k = 9), and US (k = 3; Fig. 4); the remaining four estimates (21%) were from US samples of African American ancestry.

Polygenic score correlations with educational attainment across countries, ancestries, and birth years. Note: Graph depicts the raw correlation coefficients after harmonizing before Fisher’s z-transformation. Triangles represent samples of African American ancestry; circles represent samples of European ancestry. For samples that ranged in birth year, the birth year mid-point was plotted; birth year ranges were not added to sustain graphical clarity. Symbols' colors reflect samples’ country of origin, and their size reflects the sample size for the correlation estimate. Symbols’ acronyms refer to the respective sample names (full sample names in Table S3). The meta-analytic estimate with 95% confidence intervals (CI) is shown on the right-hand side

Polygenic score correlations with educational achievement across countries, ancestries, and birth years. Note: For legend, see Fig. 3. The size of triangles and circles that reflects sample size are scaled relative to each other; thus, the size of triangles and circles in Fig. 3 refers to samples ranging from N = 406 (FTP) to N = 217,550 (UK Biobank), and in Fig. 4 from N = 402 (MAUES) to N = 26,518 (MoBa)
Multilevel Meta-analysis of Polygenic Score Predications of Educational Attainment
After Fisher’s z-transformation, estimates for the association between polygenic scores and educational attainment ranged from 0.12 to 0.39 with 95% CIs that excluded 0. The meta-analytic association between polygenic scores and educational attainment was ρ = 0.27, p < 0.001 (95% CI from 0.22 to 0.32), reflecting a positive relation of large effect size (Funder & Ozer, 2019; Table 1., Fig. 5). The Q statistic was 881.12 (p < 0.001), with variance being mainly attributed to within-cluster or within-study heterogeneity (i.e., individual estimates) (I2Level 2 = 62.26%). ANOVA model comparisons confirmed that the extent of heterogeneity at level 2 was significant (σ2.1 = 0.005, p < 0.001) (Table 1.).

Forest plots of meta-analyses of polygenic score predictions for (a) educational attainment and (b) educational achievement. Note: “Author and year” show the first authors’ name and year of publication for each estimate of polygenic score predictions. Multiple estimates per study were alphabetized and reported individually. Effect sizes to the right of the solid vertical line indicate positive associations between polygenic scores and educational success. The rectangles represent the individual estimates effect sizes, and the horizontal bars represent 95% CIs for each estimate. The dashed vertical line and the diamond illustrate the meta-analytic effect size, with the dashed horizontal line representing the corresponding 95% CI. No moderator effects were considered in this analysis and plot
Multilevel Meta-analysis of Polygenic Score Predications of Educational Achievement
After Fisher’s z-transformation, estimates for the association between polygenic scores and educational achievement ranged from 0.06 to 0.39. All individual estimates, apart from one (Rabinowitz et al., 2019), were positive and significant (i.e., their 95% CIs excluded 0). The meta-analytic association between polygenic scores and educational attainment was ρ = 0.24, p < 0.001 (95% CI from 0.18 to 0.30), reflecting a positive relation that approximates a large effect size (Funder & Ozer, 2019; Table 1., Fig. 5). The Q statistic was 444.135 (p < 0.001). The variance was mainly attributed to between-study heterogeneity (I2Level 3 = 61%), but ANOVA model comparisons showed significant heterogeneity at both levels 2 and 3 (σ2.1 = 0.004 p < 0.001, σ2.2 = 0.006 p = 0.045) (Table 1.).
Multilevel Meta-regression of Polygenic Score Predications of Educational Attainment
Individual meta-regressions for each moderator were fitted first to identify individually significant moderators (Tables S6-S15). Only sample ancestry emerged as significant moderator of polygenic score predictions of educational attainment (β = − 0.209, p < 0.001, 95% CI from − 0.29 to − 0.13), with European ancestry samples showing stronger polygenic score predictions compared to African American samples. Accounting for sample ancestry increased the association between polygenic score predictions and educational attainment to ρ = 0.287, p < 0.001 (95% CI from 0.242 to 0.332) (Fig. S5). The Q statistic remained significant (Q = 851.832 p < 0.001), suggesting that sample ancestry accounted for only a small proportion of the total heterogeneity (i.e., 3.34%). Ancestry variance was mainly attributed to between-study heterogeneity (I2Level 3 = 84.41%), and ANOVA model comparisons showed the significant remaining heterogeneity at both levels 2 and 3 (σ2.1 = 0.001 p = 0.049, σ2.2 = 0.004 p = 0.006).
Multilevel Meta-regression of Polygenic Score Predications of Educational Achievement
We identified mean age at assessment, measure of educational achievement, and sample ancestry as significant moderators in individual meta-regression models (Tables S16-S23). When added simultaneously to the meta-regression model, the association pooled estimate increased to ρ = 0.50, p < 0.001 (95% CI from 0.39 to 0.61) (Fig. S5). Two moderators were significant in the model: Mean age of assessment (β = 0.014, p < 0.001, 95% CI from 0.007 to 0.021), with polygenic score predictions being stronger in adolescents than in younger children, and the measure of educational achievement (β = − 0.116, p = 0.025, 95% CI from − 0.206 to − 0.026), with predictions being higher for school grades than for standardized test scores. Sample ancestry was no longer significant (β = − 0.008, p = 0.884, 95% CI from − 0.120 to − 0.104). The Q statistic reduced substantially (i.e., by 65.64%) but remained significant (Q = 152.583, p < 0.001), occurring mainly at the within-study level (I2Level 2 = 89.91%). Yet, ANOVA model comparisons showed significant heterogeneity at both levels 2 and 3 (σ2.1 = 0.003 p < 0.001, σ2.2 = 0.001 p < 0.001).
Discussion
A vast body of empirical studies emerged over the past decade on predicting individual differences in psychological and behavioral traits from their inherited DNA differences using polygenic score-based approaches (Cesarini & Visscher, 2017; Malanchini et al., 2020; Plomin & von Stumm, 2018). The potential benefits of DNA-based predictors for healthcare and disease prevention, as well as their risks, are widely discussed, and some areas have started to apply them. For example, polygenic scores for lifetime risk of breast cancer are used to help women make informed decisions about their healthcare (Ho et al., 2022; Jolie, 2013), although they are not (yet) recommended for wider clinical use (Martin et al., 2019; Shah, 2021). The possibility of analogous uses of polygenic scores in educational settings has become the central subject of large-scale empirical research efforts, fierce debates, and some fervent speculations (Abdellaoui & Verweij, 2021; Harden, 2021; Karavani et al., 2019; Martschenko et al., 2024; Okbay et al, 2022; Plomin, 2018; Polyakov et al., 2022; von Stumm & Plomin, 2021). While the current consensus is that polygenic scores are only informative for identifying differences within European ancestries that occur at the population level (i.e., inferences based on aggregated individual-level data; Morris et al., 2020a, b; Okbay et al., 2022), the possibility for individual prediction is on the horizon.
Our meta-analyses appraised the current literature, focusing on the consistency and strength of polygenic score predictions for educational attainment and educational achievement across studies. Our findings show that people’s genetic propensities for years spent in education predict their phenotypic differences in educational attainment and achievement, with large effect size that suggest substantial explanatory power and practical applications (Funder & Ozer, 2019). Indeed, the effect sizes of DNA-based predictions of educational attainment and achievement rival that of other predictors that have been previously extensively reported on, including children’s socioeconomic status (Selvitopu & Kaya, 2021) and their personality traits (Mammadov, 2021), teachers’ characteristics and expertise (Bardach et al., 2021), and school belonging and quality (Allen et al., 2018; von Stumm et al., 2020). Our meta-analytic results suggest that a SD increase in polygenic scores is associated with spending 1.08 more years in full-time education.Footnote 1 In the UK, an additional year of full-time education translates, for example, into obtaining a postgraduate degree (e.g., Masters), which forecasts favorable long-term life outcomes (Oreopoulos & Salvanes, 2011), including a 10% premium in future lifetime earnings compared to those with only an undergraduate degree (OECD, 2001). Our findings also suggested that an SD increase in polygenic scores was associated with obtaining a 0.19 higher school GPA,3 which may seem small in relative terms but can be critical for gaining admission to highly competitive tertiary education programs, such as Ivy League schools. Graduating from an Ivy League or similar school is associated 32% greater earnings compared to obtaining educational qualifications at other 4-year universities (Claybourn, 2023; U.S News & World Report, 2020).
We observed substantial heterogeneity in polygenic score predictions across within- and between-study levels. For one, polygenic score predictions for educational attainment and achievement were reduced by 57% and 50%, respectively, in samples that were described as African American compared to those of European ancestry, although this effect was only significant for educational attainment. These results align with prior findings that polygenic scores based on GWAS in European ancestry populations have limited prediction in populations of other ancestries (Duncan et al., 2019; Mills & Rahal, 2020; Popejoy & Fullerton, 2016; Wang et al., 2020). For the other, polygenic predictions of educational achievement varied by type and age of assessment. First stronger predictions emerged for school grades than test scores. This difference in PGS prediction strength may reflect that school grades capture a broader range of educational skills, such as motivation and intellectual curiosity, than test scores. Yet, previous studies reported no differential heritability estimates for alternative measures of educational achievement (Bartels et al., 2002; Shakeshaft et al., 2013). Second, polygenic score predictions were stronger for educational achievement during adolescence than in childhood, in line with previous findings that the heritability of cognitive traits increases with age (Haworth et al., 2010; Morris et al., 2018). Even after considering these moderator effects, significant heterogeneity remained in our meta-analysis, whose origin future research must identify.
Two principal observations emerged about the samples for whom polygenic score predictions of education outcomes have been reported. First, only 15% of the samples were of non-European ancestry; they had been recruited in the US, where 46% of all estimates included in this meta-analysis stemmed from. We could not identify a single study that reported polygenic score predictions in samples drawn from non-WEIRD countries (Western, Educated, Industrialized, Rich, and Democratic, Henrich et al., 2010), in line with other behavioral genetics research findings that emanate predominantly from Iceland and the US and UK (Mills & Rahal, 2019). To disrupt the dominance of eurocentrism in genomic research, funding bodies like the National Institute of Health (NIH) now mandate the inclusion of non-European ancestry samples in data collection projects, although dedicated funding calls to study and foster ancestral diversity remain scarce (Fatumo et al., 2022; Mills & Rahal, 2020). Ethical and practical challenges, as well as substantial time and financial investment demands, oftentimes hinder collecting genetic and phenotypic data from diverse human populations. These challenges are likely to perpetuate eurocentrism in genomics for the foreseeable future, at the cost of excluding 84% of the world’s people in genomic studies (only 16% of the global population are of European ancestry; Martin et al., 2019; Mills & Rahal, 2020).
Our second observation was that samples’ birth years and ages at assessment range varied greatly across studies. As a result, systematic interpretations of generation effects and age trends in polygenic predictions of educational outcomes were difficult. Knowing when genetic propensities are more or less strongly associated with education is likely critical for effectively supporting people in their learning, for example by identifying school students’ ages when additional tutoring or making educational choices achieve optimal learning outcomes (Harden et al., 2020). To better elucidate age and generation trends in polygenic score predictions of education, more data are needed. These could also help identify the socio-political conditions under which societies achieve the balance between equality of opportunity and equity of outcomes in education.
Bioethics of Polygenic Score Predictions in Education
Applications of polygenic score predictions for psychological and behavioral traits at the level of the individual are on the horizon, urging the careful consideration of their ethical, legal, and social implications. The bioethics of polygenic scores have been discussed across a range of contexts elsewhere (Asbury & Plomin, 2013; Chapman, 2023; Chapman et al., 2019; Linnér & Koellinger, 2021; Martschenko et al., 2024). Here, we focus on two concerns that pertain in particular to the implementation of DNA-based predictors in education: the risk of widening achievement gaps in schools, and children’s and families’ psychosocial responses to learning about their genetic propensities for educational outcomes.
The greatest fear associated with the use of DNA-based predictors in educational settings, as well as elsewhere, is that they could foster genetic discrimination, diminish support for educational policies that prioritize fairness and inclusion, and reinforce genetic essentialist narratives that designate some children as “lost causes” or “unmanageable” in the classroom (Lapham et al., 1996; Martschenko, 2019; Tiller et al., 2024). For example, students’ differences in their genetic makeup could be (mis)used to justify limiting the learning opportunities for children with lower genetic propensities for educational achievement, while focusing on enhancing the learning experiences for children with higher genetic propensities for educational achievement (Larsen et al., 2022). In such a scenario, children with lower genetic propensities for educational achievement may be assigned more often to schools of poorer quality that employ less accomplished teachers than children with higher genetic propensities for educational achievement. Without education policies in place that prohibit these and other forms of genetic discrimination, polygenic score predictions could—even inadvertently—contribute to creating educational systems that increase rather than reduce achievement gaps. At present, laws make it illegal to discriminate against individuals based on their genotypes in health insurance or employment contexts (i.e., the 2008 Genetic Information Nondiscrimination Act, GINA), but there is no comparable non-discrimination act that protects students from being subject to genetic discrimination in their education.
In meritocratic societies, where power and socioeconomic resources are distributed according to demonstrated achievement and attainment, differences in the access to and exploitability of educational opportunities become the principal cause of social inequality (e.g., Keohane et al., 2014; Starr et al., 2024). Education systems that offer greater opportunities to students who are predicted to excel deepen social inequalities, regardless if the basis of such performance predictions are polygenic scores or prior school performance or family wealth (Farquharson et al., 2022; Hanushek & W ößmann, 2006; Piketty & Wood, 2024; Wilkinson & Pickett, 2010). Because students’ differences in educational opportunities are already conditioned by their family backgrounds (Chmieleski, 2019; von Stumm et al., 2022), polygenic score predictions may deepen further family background inequalities in education, if no policies are in place that recognize and effectively mitigate their perpetuation.
The second bioethical concern that requires addressing is parents’ and children’s psychosocial reactions to information about their genetic propensities for educational achievement. Parents, who learn of their children’s low genetic propensity for educational achievement, may feel guilty and attribute blame to themselves for their children’s education outcomes, akin to the responses observed in parents who learned about the role of genetics in hereditary diseases and in childhood obesity (James et al., 2006; Persky et al., 2019; Weil, 2002). Conversely, children, who are told that they have low genetic propensities for educational achievement, may take personal responsibility for their struggles or failures in school, resigning from learning opportunities, losing their academic motivation, and lowering their educational efforts (i.e., self-fulfilling prophecy; Filippello et al., 2019; Ghasemi & Karimi, 2021; Matthews et al., 2021).
The two bioethical concerns are not independent but may intersect. For example, parents with greater financial resources can purchase DNA-based predictions of their children’s psychological profiles from various companies that offer direct-to-consumer genetic testing (Au, 2022; Martschenko et al., 2024; von Stumm & Plomin, 2021), which is more difficult to afford for families with fewer financial resources. Furthermore, parents with plenty resources can then supply their children with the learning support that their polygenic scores may have indicated they need to excel in school (Au, 2022). Thus, DNA-based predictions of children’s learning may lead to disproportional advantages for children from wealthier backgrounds and contribute to widening educational achievement gaps. We therefore caution that anonymized population-level data must not be migrated into personalized education until the benefits of DNA-based predictions for the individual, the family, and the school can be guaranteed to outweigh their risks.
Safeguarding Polygenic Score Predictions in Education
Notwithstanding the bioethical concerns outlined above, DNA-based predictions of education have the potential to improve teaching and learning in three ways. First, they can help personalizing education to meet students’ different learning needs, for example recommending additional classes or tutoring, or allocating more teaching staff to students with lower polygenic scores (Arold et al., 2022). Second, polygenic scores could serve as an early “warning system” that signals learning difficulties before they have manifested as maladaptive behaviors, such as “learned helplessness” which occurs when students withdraw from educational opportunities after experiencing academic setbacks (e.g., Ghasemi & Karimi, 2021). Third, recognizing that DNA is a core driver of children’s differences in learning, rather than factors that are under their personal control, may increase society’s compassion for and understanding of people’s differences in academic performance (Asbury & Plomin, 2013; Asbury et al., 2021; Harden, 2021). To ensure that these potential benefits of polygenic score predictions can be realized, while the risks of misapplications, misinterpretations, and misattributions are minimized, safeguarding is imperative. We propose here three preliminary ways for ascertaining adequate safeguarding for polygenic score predictions in education.
First, efforts to teach and inform about genetic predispositions should target the wider public rather than a handful of elite university students, as is currently too often the case. The nature and nurture of genetic predispositions can be effectively taught to and understood people from many walks of life (Asbury & Plomin, 2013; Asbury et al., 2022; Crosswaite & Asbury, 2019; Donovan et al., 2019, 2022; Rutherford, 2020) to help preventing misattributions of genetic risks (Driver et al., 2022). Over 60% of people who learn of their polygenic predictions for mental and physical health disorders report experiencing negative emotions, and 75% misinterpret their genetic risks (Peck et al., 2021). College students, who imagined receiving a low-percentile polygenic score for educational attainment, reported afterwards lower self-esteem, academic efficacy, and educational competence relative to individuals, who imagined having a high-percentile score or who did not “receive” a polygenic score (Matthews et al., 2021). These findings align with the mixed blessing model that submits that biogenetic explanations can soften public stigma but also induce pessimism, avoidance, and helplessness among affected individuals (Haslam & Kvaale, 2015; Larsen et al., 2022). As long as the fear of bad news in your genes remains a prevalent public opinion (Harden, 2023), polygenic score applications in educational contexts risk worsening discrimination, prejudice, and inequality rather than translating into benefits.
Second, changing the narrative of genetic influences is—in part—the responsibility of researchers who apply polygenic score predictions in psychological science. In recent years, this responsibility has been met by a number of excellent popular science books that accessibly communicated the ins and outs of behavioral genetics to broad audiences (e.g., Harden, 2021; Plomin, 2018; Rutherford, 2020). Some of these books are specifically aimed at helping teachers (e.g., Asbury & Plomin, 2013) and parents to nurture children’s nature (e.g., Dick, 2021; Gopnik, 2016). Another way of ensuring that research findings in behavioral genetics are adequately disseminated is accompanying research article publications with explanations of the findings in lay language (e.g., FAQs: Beauchamp et al., 2019; Benjamin et al., 2018, 2022). These FAQs are mainly used by journalists and science communicators, who through their own media contributions influence the consensus of opinions formed in public spheres (Garman, 2019; Habermas, 1989). The majority of public communication efforts by researchers are under- or non-funded, and they often only reach a fraction of the population (Office of Science and Technology & Wellcome Trust, 2000). While some funding agencies have started to mandate public engagement and dissemination strategies (e.g., Asbury et al., 2021, 2022), achieving a fundamental change in the public opinion and interpretation of the role of genetics in education will require substantial, concerted efforts.
Finally, facilitating more research into the heterogeneity of children’s learning abilities is crucial to safeguarding the use of DNA-based predictions for education. A central aim of such research should be conducting GWAS for differentiated learning-related phenotypes, such as reading ability (e.g., Eising et al., 2022) or mathematic skills (Chen et al., 2017; Harden et al., 2020), rather than general “education,” to enable pinpointing and differentiating the educational support that will best meet a child’s specific learning needs (Procopio et al., 2022). Such GWAS could maximize the utility of polygenic scores as diagnostic tools or early warning systems for learning difficulties (Procopio et al., 2022).
Limitations
A principal limitation of current polygenic score predictions for education is that they are somewhat blunt tools that cannot discern children’s specific learning needs (Peters & Ansari, 2019), for example struggling with reading versus having difficulties with algebra. Although this limitation is not specific to our meta-analysis, polygenic scores for years spent in education may predict general learning difficulties but cannot forecast known learning difficulties, such as dyslexia and dyscalculia, for which targeted, effective interventions have been developed and validated (e.g., Cancer et al., 2020; Youman & Mather, 20132015). We view this generality of current polygenic score predictions as analogous to the prediction from being eligible for free school meals or raised in foster care, two common criteria for receiving extra educational support (Flavier & Moussay, 2014; Roberts et al., 2021). Associations between free school meals or foster care and educational achievement have been broadly documented (Education Endowment Foundation, 2017; Office for National Statistics, 2022; Schwartz & Rothbart, 2020), yet they are probabilistic rather than causal (Plomin & von Stumm, 2022), akin to our current meta-analytic findings. Children eligible for free school meals or in foster care are vastly heterogenous in their learning abilities and difficulties, just like children of the same polygenic score percentile rank (Allegrini et al., 2019). This heterogeneity prohibits improving children’s learning outcomes through “one-size-fits-all” intervention approaches that typically follow from broad, general predictors, such as difficult early life experiences and polygenic scores.
Our meta-analysis could not model the interplay between genes and the environment, including differentiating polygenic score variance due to gene-environment correlations (rGE), assortative mating, and population stratification (Nivard et al., 2024; Plomin & von Stumm, 2022; Selzam et al., 2019; Wertz et al., 2019). Comparisons of within- and between-family polygenic score predictions have shown genetic effects on educational attainment that are environmentally mediated (i.e., passive rGE; Selzam et al., 2019; Wang et al., 2021). The most recent GWAS of years spent in education found that only ~ 30% of the prediction of educational attainment was due to direct genetic effects, with environmental confounding playing a major role (Okbay et al., 2022). While no studies to date reported comparable findings for educational achievement, polygenic scores should not be interpreted as reflecting direct genetic effects but as predictors that capture genetic and environmental effects (Plomin & von Stumm, 2022).
Conclusion
Our meta-analyses showed that polygenic scores predict educational achievement and attainment with large effect sizes. These findings imply that individuals with higher genetic propensities perform on average better in school, remain longer in full-time education, and obtain higher educational qualifications. Our meta-analyses’ samples came from WEIRD countries, and polygenic score predictions were strongest for school grades in adolescents of European ancestry. Polygenic score predictions remained heterogenous after accounting for a number of plausible moderators, suggesting that at present polygenic scores are neither suitable for individual level assessments nor for personalizing education in applied settings.
Our findings underscore the importance of inherited DNA variants for understanding and addressing students’ heterogeneity in learning abilities. Applications of polygenic scores in education are becoming increasingly tangible, even though they are not yet effective tools for improving teaching and learning (Asbury et al., 2021; Au, 2022; Harden, 2021; Morris et al., 2020a, b). With even more powerful polygenic scores for education on the horizon (e.g., Okbay et al., 2022), the interest in and potential for applying polygenic scores in education is growing, and with that the need for safeguarding and further research. In the words of Marie Curie (cited in Curie & Sheean, 1938, p.13): “Nothing in life is to be feared, it is only to be understood. Now is the time to understand more, so that we may fear less.”
Notes
The SD of years spent in education is thought to be 4 years (Visscher, 2022), and our meta-analytic coefficient for educational attainment was ρ = .27 (i.e., 4 years × .27 = 1.08 years). The SD of high school GPA has been reported as 0.80 (Lee et al., 2018), and our meta-analytic estimate was ρ = .24 (i.e., 0.80 GPA × .24 = 0.19).
References
Abdellaoui, A., & Verweij, K. J. H. (2021). Dissecting polygenic signals from genome-wide association studies on human behaviour. Nature Human Behaviour, 5, 686–694. https://doi.org/10.1038/s41562-01110-y
Alexander, R. A., Scozzaro, M. J., & Borodkin, L. J. (1989). Statistical and empirical examination of the chi-square test for homogeneity of correlations in meta-analysis. Psychological Bulletin, 106(2), 329–331. https://doi.org/10.1037/0033-2909.106.2.329
Allegrini, A. G., Selzam, S., Rimfeld, K., von Stumm, S., Pingault, J. B., & Plomin, R. (2019). Genomic prediction of cognitive traits in childhood and adolescence. Molecular Psychiatry, 24(6), 819–827. https://doi.org/10.1038/s41380-019-0394-4
Allegrini, A. G., Karhunen, V., Coleman, J. R. I., Selzam, S., Rimfeld, K., von Stumm, S., Pingault, J.-B., & Plomin, R. (2020). Multivariable G-E interplay in the prediction of educational achievement. PLOS Genetics, 16(11), e1009153. https://doi.org/10.1371/journal.pgen.1009153
Allegrini, A. G., Selzam, S., Rimfeld, K., von Stumm, S., Pingault, J. B., & Plomin, R. (2019). Genomic prediction of cognitive traits in childhood and adolescence. Molecular Psychiatry, 24(6), 819–827. https://doi.org/10.1038/s41380-019-0394-4
Allen, K., Kern, M. L., Vella-Brodrick, D., Hattie, J., & Waters, L. (2018). What schools need to know about fostering school belonging: A meta-analysis. Educational Psychology Review, 30, 1–34. https://doi.org/10.1007/s10648-016-9389-8
Anderson, E. S. (1999). What is the point of equality. JSTOR, 109(2), 287–337. https://doi.org/10.1086/233897
Anderson, E. (2007). Fair opportunity in education: a democratic equality perspective. JSTOR: Symposium on Education and Equality, 117(4), 595–622. https://doi.org/10.1086/518806
Arold, B., Hufe, P., & Stöckli, M. (2022). Genetic endowments, educational outcomes and the mediating influence of school investments. IZA Institute of Labor Economics, 15430. https://www.iza.org/en/publications/dp/15430/genetic-endowments-educational-outcomes-and-the-mediating-influence-of-school-investments. Retrieved 18 Mar 2024.
Asbury, K., & Plomin, R. (2013). G is for genes: the impact of genetics on education and achievement. Wiley-Blackwell.
Asbury, K., McBride, T., & Rimfeld, K. (2021). Genetics and early intervention: exploring ethical and policy questions. Early Intervention Foundation report. https://www.eif.org.uk/report/genetics-and-early-intervention-exploring-ethical-and-policy-questions. Retrieved 18 Mar 2024.
Asbury, K., McBride, T., & Bawn, R. (2022). Can genomic research make a useful contribution to social policy? Royal Society of Open Science, 9(11). https://doi.org/10.1098/rsos.220873
Assink, M., & Wibbelink, C.M. (2016). Fitting three-level meta-analytic models in R: A step-by-step tutorial. The Quantitative Methods for Psychology, 12(3), 154–174. https://doi.org/10.20982/tqmp.12.3.p154
Au, L. (2022). Testing the talented child: Direct-to-consumer genetic talent tests in China. Public Understanding of Science, 31(2), 195–210. https://doi.org/10.1177/09636625211051964
Avinun, R. (2020). The E Is in the G: Gene–environment–trait correlations and findings from genome-wide association studies. Perspectives on Psychological Science, 15(1), 81–89. https://doi.org/10.1177/1745691619867107
Avinun, R., & Knafo, A. (2014). Parenting as a reaction evoked by children’s genotype: A meta-analysis of children-as-twins studies. Personality and Social Psychology Review, 18(1), 87–102. https://doi.org/10.1177/1088868313498308
Ayorech, Z., Krapohl, E., Plomin, R., & von Stumm, S. (2017). Genetic influence on intergenerational educational attainment. Psychological Science, 28(9), 1302–1310. https://doi.org/10.1177/0956797617707270
Ayorech, Z., Plomin, R., & von Stumm, S. (2019). Using DNA to predict educational trajectories in early adulthood. Developmental Psychology, 55(5), 1088–1095. https://doi.org/10.1037/dev0000682
Bardach, L., Klassen, R. M., & Perry, N. E. (2021). Teachers’ psychological characteristics: Do they matter for teacher effectiveness, teachers’ well-being, retention, and interpersonal relations? An integrative review. Educational Psychology Review, 34, 259–300. https://doi.org/10.1007/s10648-021-09614-9
Bartels, M., Rietveld, M. J., Van Baal, G. C., & Boomsma, D. I. (2002). Heritability of educational achievement in 12-year-olds and the overlap with cognitive ability. Twin Research and Human Genetics, 5(6), 544–553. https://doi.org/10.1375/136905202762342017
Beauchamp, J. P., Benjamin, D. J., Linnér, R. K., Koellinger, P. D., & Meyer, M. N. (2019). FAQs about “Genome-wide association analyses of risk tolerance and risky behaviors in over 1 million individuals identify hundreds of loci and shared genetic influences.” Social Science Genetic Association Consortium. https://www.thessgac.org/faqs. Retrieved 18 Mar 2024.
Benjamin, D. J., Cesarini, D., Chabris, C. F., Koellinger, P. D., Laibson, D., Meyer, M. N., Okbay, A., Turley, P., Visscher, P. M., & Zacher, M. (2018). FAQs about “Gene discovery and polygenic prediction from a 1.1-million-person GWAS of educational attainment”. Social Science Genetic Association Consortium. https://www.thessgac.org/faqs. Retrieved 18 Mar 2024.
Benjamin, D., Laibson, D., Meyer, M. N., & Turley, P. (2022). FAQs about “Polygenic prediction within and between families from a 3-million-person GWAS of educational attainment”. Social Science Genetic Association Consortium. https://www.thessgac.org/faqs. Retrieved 18 Mar 2024.
Branigan, A. R., McCallum, K. J., & Freese, J. (2013). Variation in the heritability of educational attainment: An international meta-analysis. Social Forces, 92(1), 109–140. https://doi.org/10.1093/sf/sot076
Cancer, A., Bonacina, S., Antonietti, A., Salandi, A., Molteni, M., & Lorusso, M. L. (2020). The effectiveness of interventions for developmental dyslexia: Rhythmic reading training compared with hemisphere-specific stimulation and action video games. Frontiers in Psychology,11, 1158. https://doi.org/10.3389/fpsyg.2020.01158
Cave, S. N., Wright, M., & von Stumm, S. (2022). Change and stability in the association of parents’ education with children’s intelligence. Intelligence, 90, 101597. https://doi.org/10.1016/j.intell.2021.101597
Cesarini, D., & Visscher, P. M. (2017). Genetics and educational attainment. npj Science of Learning, 2(4). https://doi.org/10.1038/s41539-017-0005-6
Chapman, C. R. (2023). Ethical, legal, and social implications of genetic risk prediction for multifactorial disease: A narrative review identifying concerns about interpretation and use of polygenic scores. Journal of Community Genetics, 14(5), 441–452. https://doi.org/10.1007/s12687-022-00625-9
Chapman, C. R., Mehta, K. S., Parent, B., & Caplan, A. L. (2019). Genetic discrimination: Emerging ethical challenges in the context of advancing technology. Journal of Law and the Biosciences, 7(1), lsz016. https://doi.org/10.1093/jlb/lsz016
Chen, H., Gu, X-H., Zhou, Y., Ge, Z., Wang, B., Siok, W. T., Wang, G., Huen, M., Jiang, Y., Tan, L-H., and Sun, Y. (2017). A genome-wide association study identifies genetic variants associated with mathematics ability. Scientific Reports, 7, 40365. https://doi.org/10.1038/srep40365
Chen, Y., Lv, C., Li, X., Zhang, J., Chen, K., Liu, Z., Li, H., Fan, J., Qin, T., Luo, L., & Zhang, Z. (2019). The positive impacts of early-life education on cognition, leisure activity, and brain structure in health aging. Aging, 11(14), 4923–4942. https://doi.org/10.18632/aging.102088
Chmielewski, A. K. (2019). The global increase in the socioeconomic achievement gap, 1964 to 2015. American Sociological Review, 84(3), 517. https://doi.org/10.1177/0003122419847165
Chmielewski, A. K. (2019). The Global Increase in the Socioeconomic Achievement Gap, 1964 to 2015. American Sociological Review, 84(3). https://doi.org/10.1177/0003122419847165
Choi, S. W., Mak, T.S.-H., & O’Reilly, P. F. (2020). Tutorial: A guide to performing polygenic risk score analyses. Nature Protocols, 15, 2759–2772. https://doi.org/10.1038/s41596-020-0353-1
Claybourn, C. (2023). How much is an Ivy League degree worth? US News & World Report. https://www.usnews.com/education/best-colleges/articles/how-much-is-an-ivy-league-degree-worth. Retrieved 18 Mar 2024.
Crosswaite, M., & Asbury, K. (2019). Teacher beliefs about the aetiology of individual differences in cognitive ability, and the relevance of behavioral genetics to education. British Journal of Educational Psychology, 89, 95–110. https://doi.org/10.1111/bjep.12224
Curie, E., & Sheean, V. (1938). Madame Curie, a biography (V. Sheean, Trans.). Garden City, NY: Doubleday, Doran
Cutler, D. M., & Lleras-Muney, A. (2010). Understanding differences in health behaviors by education. Journal of Health Economics, 29(1), 1–28. https://doi.org/10.1016/j.jhealeco.2009.10.003
Cutler, D. M., & Lleras-Muney, A. (2012). Education and health: insights from international comparisons. National Bureau of Economic Research. http://www.nber.org/papers/w17738. Retrieved 18 Mar 2024.
Dalgaard, N. T., Bondebjerg, A., Viinholt, B. C. A., & Filges, T. (2022). The effects of inclusion on academic achievement, socioemotional development and wellbeing of children with special educational needs. Campbell Systematic Reviews, 18(4), e1291. https://doi.org/10.1002/cl2.1291
Department of Education. (2015). Special educational needs and disability code of practice: 0 to 25. https://assets.publishing.service.gov.uk/media/5a7dcb85ed915d2ac884d995/SEND_Code_of_Practice_January_2015.pdf. Retrieved 18 Mar 2024.
Dick, D. (2021). The child code: Understanding your child’s unique nature for happier, more effective parenting. Penguin Publishing Group.
Domingue, B. W., Belsky, D. W., Conley, D., Harris, K. M., Boardman, J.D. (2015). Polygenic influence on educational attainment: New evidence from the national longitudinal study of adolescent to adult health. American Educational Research Association, 1(3). https://doi.org/10.1177/2332858415599972
Donovan, B. M., Semmens, R., Keck, P., Brimhall, E., Busch, K. C., Weindling, M., Duncan, A., Stuhlsatz, M., Bracey, Z. B., Bloom, M., Kowalski, S., & Salazar, B. (2019). Towards a more humane genetics education: Learning about the social and quantitative complexities of human genetic variation research could reduce racial bias in adolescent and adult populations. Science Education, 103, 529–560. https://doi.org/10.1002/sce.21506
Donovan, B. M., Salazar, B., & Weindling, M. (2022). How can we make genetics education more humane? In M. Haskel-Ittah, & A. Yarden (Eds.), Genetics education. Contributions from biology education research. Springer. https://doi.org/10.1007/978-3-030-86051-6_10
Driver, M. N., Kuo, S. I-C., Petronio, L., Brockman, D., Dron, J. S., Austin, J., & Dick, D. (2022). Evaluating the impact of a new educational tool on understanding of polygenic risk scores for alcohol use disorder. Frontiers in Psychiatry, 13. https://doi.org/10.3389/fpsyt.2022.1025483
Duncan, L., Shen, H., Gelaye, B., Meijsen, J., Ressler, K., Feldman, M., Peterson, R., & Domingue, B. (2019). Analysis of polygenic risk score usage and performance in diverse human populations. Nature Communications, 10, 3328. https://doi.org/10.1038/s41467-019-11112-0
Education Endowment Foundation. (2017). The Attainment Gap. https://d2tic4wvo1iusb.cloudfront.net/production/documents/support-for-schools/bitesizesupport/EEF_Attainment_Gap_Report_2018.pdf?v=1723076423. Retrieved 18 Mar 2024.
Eising, E., Mirza-Schreiber, N., de Zeeuw, E. L., et al. (2022). Genome-wide analyses of individual differences in quantitatively assessed reading- and language-related skills in up to 34,000 people. PNAS, 119(35), e2202764119. https://doi.org/10.1073/pnas.2202764119
Farquharson, C., McNally, S. & Tahir, I. (2022). Education inequalities. Institute for Fiscal Studies Deaton Review of Inequalities.
Fatumo, S., Chikowore, T., Choudhury, A., Ayub, M., Martin, A. R., & Kuchenbaecker, K. (2022). A roadmap to increase diversity in genomic studies. Nature Medicine, 28, 243–250. https://doi.org/10.1038/s41591-021-01672-4
Filges, T., Sonne-Schmidt, C. S., & Nielsen, B. C. V. (2018). Small class sizes for improving student achievement in primary and secondary schools: A systematic review. Campbell Systematic Reviews, 14(1), 1–107. https://doi.org/10.4073/csr.2018.10
Filippello, P., Buzzai, C., Costa, S., Orecchio, S., & Sorrenti, L. (2019). Teaching style and academic achievement: The mediating role of learned helplessness and mastery orientation. Psychology in the Schools, 57(1), 5–16. https://doi.org/10.1002/pits.22315
Flavier, E., & Moussay, S. (2014). Répondre au décrochage scolaire: Expériences de terrain, chapitre 6, Louvain-la-Neuve (pp. 99–112). De Boeck Supérieur.
Funder, D. C., & Ozer, D. J. (2019). Evaluating effect size in psychological research: Sense and nonsense. Advances in Methods and Practices in Psychological Science, 2(2), 156–168. https://doi.org/10.1177/2515245919847202
Garman, A. (2019). The public sphere and journalism. Oxford Encyclopedia of Communication. https://doi.org/10.1093/acrefore/9780190228613.013.880
Genetic Information Nondiscrimination Act. (2008). An act to prohibit discrimination on the basis of genetic information with respect to health insurance and employment. Pubic Law 110–233. https://www.govinfo.gov/app/details/PLAW-110publ233. Retrieved 18 Mar 2024.
Ghasemi, F., & Karimi, M. N. (2021). Learned helplessness in public middle schools: The effects of an intervention program based on motivational strategies. Middle School Journal, 52(4), 23–32. https://doi.org/10.1080/00940771.2021.1948297
Gibbs, R. A., Belmont, J. W., Hardenbol, P., Willis, T. D., Yu, F., Yang, H., Ch’ang, L. Y., Huang, W., Liu, B., Shen, Y., et al. (2003). The international HapMap project. Nature, 426, 789–796.
Gopnik, A. (2016). The gardener and the carpenter. Farrar, Straus and Giroux.
Grotzinger, A. D., Rhemtulla, M., de Vlaming, R., Ritchie, S. J., Mallard, T. T., Hill, W. D., Ip, H. F., Marioni, R. E., McIntosh, A. M., Deary, I. J., Koellinger, P. D., Harden, K. P., Nivard, M. G., & Tucker-Drob, E. M. (2019). Genomic structural equation modelling provides insights into the multivariate genetic architecture of complex traits. Nature Human Behavior, 3, 513–525. https://doi.org/10.1038/s41562-019-0566-x
Gunawardena, M., Bishop, P., & Aviruppola, K. (2024). Personalized learning: The simple, the complicated, the complex and the chaotic. Teaching and Teacher Education, 139, 104429. https://doi.org/10.1016/j.tate.2023.104429
Habermas, J. (1989). The structural transformation of the public sphere: An inquiry into a category of bourgeois society (T. Burger with the Assistance of F. Lawrence, Trans.). Cambridge: Polity Press.
Hanushek, E. A., & Wößmann, L. (2006). Does educational tracking affect performance and inequality? Differences- in-differences evidence across countries. The Economic Journal, 116(510), C63–C76. https://doi.org/10.1111/j.1468-0297.2006.01076.x
Harden, K. P. (2021). The genetic lottery: Why DNA matters for social equality. Princeton University Press. https://press.princeton.edu/books/hardcover/9780691190808/the-genetic-lottery. Retrieved 18 Mar 2024.
Harden, K. P. (2023). Genetic determinism, essentialism and reductionism: Semantic clarity for contested science. Nature Review Genetics, 24, 197–204. https://doi.org/10.1038/s41576-022-00537-x
Harden, K. P., Domingue, B. W., Belsky, D. W., Boardman, J. D., Crosnoe, R., Malanchini, M., Nivard, M., Tucker-Drob, E. M., & Harris, K. M. (2020). Genetic associations with mathematics tracking and persistence in secondary school. npj Science of Learning, 5(1). https://doi.org/10.1038/s41539-020-0060-2
Harrer, M., Cuijpers, P., Furukawa, T., & Ebert, D.D. (2019). dmetar: Companion R package for the guide ‘doing meta-analysis in R’. R package version 0.1.0. http://dmetar.protectlab.org/. Retrieved 18 Mar 2024.
Haslam, N., & Kvaale, E. P. (2015). Biogenetic explanations of mental disorder: The mixed-blessings model. Current Directions in Psychological Science, 24(5), 399–404. https://doi.org/10.1177/0963721415588082
Haworth, C. M. A., Wright, M. J., Luciano, M., Martin, N. G., de Geus, E. J. C., van Beijsterveldt, C. E. M., Bartels, M., Posthuma, D., Boomsma, D. I., Davis, O. S. P., Kovas, Y., Corley, R. P., Defries, J. C., Hewitt, J. K., Olson, R. K., Rhea, S.-A., Wadsworth, S. J., Iacono, W. G., McGue, M., Thompson, L. A., et al. (2010). The heritability of general cognitive ability increases linearly from childhood to young adulthood. Molecular Psychiatry, 15, 1112–1120. https://doi.org/10.1038/mp.2009.55
Haworth, C. M., Asbury, K., Dale, P. S., & Plomin, R. (2011). Added value measures in education show genetic as well as environmental influence. PLoS ONE, 6(2). https://doi.org/10.1371/journal.pone.0016006
Heckman, J. J. (2006). Skill formation and the economics of investing in disadvantaged children. Science, 312(5782), 1900–1902. https://doi.org/10.1126/science.1128898
Henrich, J., Heine, S. J., & Norenzayan, A. (2010). The weirdest people in the world? Behavior Brain Science, 33(2–3), 61–83. https://doi.org/10.1017/S0140525X0999152X. discussion 83–135.
Henrich, J., Heine, S. J., & Norenzayan, A. (2010). The weirdest people in the world? Behavior Brain Science, 33(2–3), 61–83; discussion 83–135. https://doi.org/10.1017/S0140525X0999152X
Herd, P., Freese, J., Sicinski, K., Domingue, B. W., Harris, K. M., Wei, C., & Hauser, R. M. (2019). Genes, gender inequality, and educational attainment. American Sociological Review, 84(6), 1069–1098. https://doi.org/10.1177/0003122419886550
Higgins, J. P., Thompson, S. G., Deeks, J. J., & Altman, D. G. (2003). Measuring inconsistency in meta-analyses. BMJ, 327(7414), 557–560. https://doi.org/10.1136/bmj.327.7414.557
Ho, W.-K., Tai, M.-C., Dennis, J., Shu, X., Li, J., Ho, P. J., Millwood, I. Y., Lin, K., Jee, Y.-H., Lee, S.-H., Mavaddat, N., Bolla, M. K., Wang, Q., Michailidou, K., Long, J., Wijaya, E. A., Hassan, T., Rahmat, K., Tan, V. K. M., et al. (2022). Polygenic risk scores for prediction of breast cancer risk in Asian populations. Genetics in Medicine, 24(3), 586–600. https://doi.org/10.1016/j.gim.2021.11.008
Horwitz, T. B., Balbona, J. V., Paulich, K. N., & Keller, M. C. (2023). Evidence of correlations between human partners based on systematic reviews and meta-analyses of 22 traits and UK Biobank analysis of 133 traits. Nature Human Behaviour, 7, 1568–1583. https://doi.org/10.1038/s41562-023-01672-z
Howe, L. J., Nivard, M. G., Morris, T. T., Hansen, A. F., Rasheed, H., Cho, Y., Chittoor, G., Ahlskog, R., Lind, P. A., Palviainen, T., van der Zee, M. D., Cheesman, R., Mangino, M., Wang, Y., Li, S., Klaric, L., Ratliff, S. M., Bielak, L. F., Naygaard, M., … Willoughby, E. A. (2022). Within-sibship genome-wide association analyses decrease bias in estimates of direct genetic effects. Nature Genetics, 54, 581–592. https://doi.org/10.1038/s41588-022-01062-7
Huedo-Medina, T. B., Sánchez-Meca, J., Marín-Martínez, F., & Botella, J. (2006). Assessing heterogeneity in meta-analysis: Q statistic or I2 index? Psychological Methods, 11(2), 193–206. https://doi.org/10.1037/1082-989X.11.2.193
International Human Genome Sequencing Consortium. (2001). Initial sequencing and analysis of the human genome. Nature, 409(6822), 860–921. https://doi.org/10.1038/35057062
James, C., Hadley, D., Holtzman, N., & Winkelstein, J. A. (2006). How does the mode of inheritance of a genetic condition influence families? A study of guilt, blame, stigma, and understanding of inheritance and reproductive risks in families with X-linked and autosomal recessive diseases. Genetics in Medicine, 8, 234–242. https://doi.org/10.1097/01.gim.0000215177.28010.6e
Jolie, A. (2013). My medical choice. The New York Times. https://www.nytimes.com/2013/05/14/opinion/my-medical-choice.html. Retrieved 18 Mar 2024.
Jørgensen, C. R., Dobson, G., & Perry, T. (2020). Migrant children with special educational needs in European schools – a review of current issues and approaches. European Journal of Special Needs Education, 36(3), 438–453. https://doi.org/10.1080/08856257.2020.1762988
Karavani, E., Zuk, O., Zeevi, D., Barxilai, N., Stefanis, N. C., Hatzimanolis, A., Smyrnis, N., Avrampoulos, D., Kruglyak, L., Atzmon, G., Lam, M., Lenxz, T., & Carmi, S. (2019). Screening human embryos for polygenic traits has limited utility. Cell, 179(6), 1424–1435. https://doi.org/10.1016/j.cell.2019.10.033
Karvonen, S., Tokola, K., & Rimpelä, A. (2018). Wellbeing and academic achievement-differences between schools from 2002 to 2010 in the Helsinki Metropolitan Area. Journal of School Health, 88, 821–829. https://doi.org/10.1111/josh.12691
Keohane, N., Broughton, N., Ezeyi, O., Hupkau, C., & Shorthouse, R. (2014). Open access: An independent evaluation. Social Market Foundation.
Knigge, A., Maas, I., Stienstra, de Zeeuw, E. L., & Boomsma, D. I. (2022). Delayed tracking and inequality of opportunity: Gene-environment interactions in educational attainment. npj Science of Learning, 7(6). https://doi.org/10.1038/s41539-022-00122-1
Kovas, Y., Harlaar, N., Petrill, S. A., & Plomin, R. (2005). ‘Generalist genes’ and mathematics in 7-year-old twins. Intelligence, 33(5), 473–489. https://doi.org/10.1016/j.intell.2005.05.002
Kovas, Y., Voronin, I., Kaydalov, A., Malykh, S. B., Dale, P. S., & Plomin, R. (2013). Literacy and numeracy are more heritable than intelligence in primary school. Psychological Science, 24(10), 2048–2056. https://doi.org/10.1177/0956797613486982
Krapohl, E., & Plomin, R. (2016). Genetic link between family socioeconomic status and children’s educational achievement estimated from genome-wide SNPs. Molecular Psychiatry, 21, 437–443. https://doi.org/10.1038/mp.2015.2
Lapham, E. V., Kozma, C., & Weiss, J. O. (1996). Genetic discrimination: Perspectives of consumers. Science, 274(5287), 621–624. https://doi.org/10.1126/science.274.5287.621
Larsen, S. A., Little, C. W., & Byrne, B. (2022). Teaching the teachers the genetics of learning: An application of the mixed blessings model. Mind, Brain, and Education, 16(4), 328–337. https://doi.org/10.1111/mbe.12315
Lee, J.-W., & Lee, H. (2016). Human capital in the long run. Journal of Development Economics, 122, 147–169. https://doi.org/10.1016/j.jdeveco.2016.05.006
Lee, J. J., Wedow, R., Okbay, A., et al. (2018). Gene discovery and polygenic prediction from a 1.1-million-person GWAS of educational attainment. Nature Genetics, 50(8), 1112. https://doi.org/10.1038/s41588-018-0147-3
Lewis-Kraus, G. (2021). Can progressives be convinced that genetics matter? The New Yorker. https://www.newyorker.com/magazine/2021/09/13/can-progressives-be-convinced-that-genetics-matters. Retrieved 18 Mar 2024.
Linnér, K. R., & Koellinger, P. D. (2021). Genetic risk scores in life insurance underwriting. Journal of Health Economics, 81, 102556. https://doi.org/10.1016/j.jhealeco.2021.102556
Lövdén, M., Fratiglioni, L., Glymour, M. M., Lindenberger, U., & Tucker-Drob, E. M. (2020). Education and cognitive functioning across the life span. Psychological Science in the Public Interest, 21(1). https://doi.org/10.1177/1529100620920576
Maccoby, E. E. (2000). Parenting and its effects on children: On reading and misreading behavior genetics. Annual Review of Psychology, 51(1), 1–27. https://doi.org/10.1146/annurev.psych.51.1.1
Machin, S., & Vignoles, A. (2006). Education Policy in the UK. Centre for the Economics of Education. https://eprints.lse.ac.uk/19430/1/Education_Policy_in_the_UK.pdf. Retrieved 18 Mar 2024.
Mackenbach, J. P., Stirbu, I., Roskam, A. J., Schaap, M. M., Menvielle, G., Leinsalu, M., Kunst, A. E., & European Union Working Group on Socioeconomic Inequalities in Health. (2008). Socioeconomic inequalities in health in 22 European countries. The New England Journal of Medicine, 358(23), 2468–2481. https://doi.org/10.1056/NEJMsa0707519
Malanchini, M., Rimfeld, K., Allegrini, A. G., Ritchie, S. J., & Plomin, R. (2020). Cognitive ability and education: How behavioral genetic research has advanced our knowledge and understanding of their association. Neuroscience and Biobehavioral Reviews, 111, 229–245. https://doi.org/10.1016/j.neubiorev.2020.01.016
Mammadov, S. (2021). Big Five personality traits and academic performance: A meta-analysis. Journal of Personality, 90(2), 1–34. https://doi.org/10.1111/jopy.12663
Manolio, T. A., Collins, F. S., Cox, N. J., Goldstein, D. B., Hindorff, L. A., Hunter, D. J., McCarthy, M. I., Ramos, E. M., Cardon, L. R., Chakravarti, A., Cho, J. H., Guttmacher, A. E., Kong, A., Kruglyak, L., Mardis, E., Rotimi, C. N., Slatkin, M., Valle, D., Whittemore, A. S., Boehnke, M., et al. (2009). Finding the missing heritability of complex diseases. Nature, 461(7265), 747–753. https://doi.org/10.1038/nature08494
Marioni, R. E., Ritchie, S. J., Joshi, P. K., Hagenaars, S. P., Okbay, A., Fischer, K., Adams, M. J., Hill, W. D., Davies, G., Social Science Genetic Association Consortium, Nagy, R., Amador, C., Läll, K., Metspalu, A., Liewald, D. C., Campbell, A., Wilson, J. F., Hayward, C., Esko, Y., Porteous, D. J., Gale, C. R., & Deary, I. J. (2016). Genetic variants linked to education predict longevity. Proceedings of the National Academy of Sciences, 113(47), 13366–13371. https://doi.org/10.1073/pnas.1605334113
Martin, A. R., Kanai, M., Kamatani, Y., Kamatani, Y., Okada, Y., Neale, B., & Daly, M. J. (2019). Clinical use of current polygenic risk scores may exacerbate health disparities. Nature Genetics, 51, 584–591. https://doi.org/10.1038/s41588-019-0379-x
Martschenko, D. (2019). DNA dreams’: Teacher perspectives on the role and relevance of genetics for education. Research in Education, 107(1). https://doi.org/10.1177/003452371986995
Martschenko, D. O., Matthews, L. J., & Sabatello, M. (2024). Social and behavioral genomics: What does it mean for pediatrics? The Journal of Pediatrics, 264, 113735. https://doi.org/10.1016/j.jpeds.2023.113735
Matthews, L. J., & Turkheimer, E. (2022). Three legs of the missing heritability problem. Studies in History and Philosophy of Science, 93, 183–191. https://doi.org/10.1016/j.shpsa.2022.04.004
Matthews, L. J., Lebowitz, M. S., Ottman, R., & Appelbaum, P. S. (2021). Pygmalion in the genes? On the potentially negative impacts of polygenic scores for educational attainment. Social Psychology of Education, 24, 789–808. https://doi.org/10.1007/s11218-021-09632-z
Matthews, L. J., Lebowitz, M. S., Ottman, R., & Appelbaum, P. S. (2021). Pygmalion in the genes? On the potentially negative impacts of polygenic scores for educational attainment. Social Psychology of Education, 24, 789–808. https://doi.org/10.1007/s11218-021-09632-z
McHugh, M. L. (2012). Interrater reliability: The kappa statistic. Biochemia Medica, 22(3), 276–282.
Mills, M. C., & Rahal, C. (2019). A scientometric review of genome-wide association studies. Nature Communications, 2(9). https://doi.org/10.1038/s42003-018-0261-x
Mills, M. C., & Rahal, C. (2020). The GWAS Diversity Monitor tracks diversity by disease in real time. Nature Genetics, 52, 242–243. https://doi.org/10.1038/s41588-020-0580-y
Montez, J. K., & Hayward, M. D. (2014). Cumulative childhood adversity, educational attainment, and active life expectancy among U. S. adults. Demography, 51(2), 413–435. https://doi.org/10.1007/s13524-013-0261-x
Morris, T., Davies, N. M., Dorling, D., Richmond, R. C., & Smith, G. D. (2018). Testing the validity of value-added measures of educational progress with genetic data. British Educational Research Journal, 44(5), 725–747. https://doi.org/10.1002/berj.3466
Morris, T. T., Davies, N. M., & Smith, G. D. (2020a). Can education be personalised using pupils’ genetic data? eLife, 9, e49962. https://doi.org/10.7554/eLife.49962
Morris, T. T., Davies, N. M., Hemani, G., & Smith, G. D. (2020b). Population phenomena inflate genetic associations of complex social traits. Science Advances, 6(16), eaay0328. https://doi.org/10.1126/sciadv.aay0328
Ni, G., Zeng, J., Revez, J. A., Wang, Y., Zheng, Z., Ge, T., Restuadi, R., Kiewa, J., Nyholt, D. R., Coleman, J. R. I., & Smoller, J. W. (2021). A comparison of ten polygenic score methods for psychiatric disorders applied across multiple cohorts. Biological Psychiatry, 90(9), 611–620. https://doi.org/10.1016/j.biopsych.2021.04.018
Nivard, M. G., Belsky, D. W., Harden, K. P., et al. (2024). More than nature and nurture, indirect genetic effects on children’s academic achievement are consequences of dynastic social processes. Nature Human Behavior, 8, 771–778. https://doi.org/10.1038/s41562-023-01796-2
Nye, B., Konstantopoulos, S., & Hedges, L. V. (2004). How large are teacher effects? Educational Evaluation and Policy Analysis, 26(3), 237–257. https://doi.org/10.3102/01623737026003237
OECD. (2001). The well-being of nations: The role of human and social capital. OECD Publishing. https://doi.org/10.1787/9789264189515-en
Office of Science and Technology, & Wellcome Trust. (2000). Science and the public a review of science communication and public attitudes to science in Britain. https://wellcome.org/sites/default/files/wtd003419_0.pdf. Retrieved 18 March 2024.
Office for National Statistics. (2022). Education, social mobility and outcomes for students receiving free school meals in England: initial findings on earnings outcomes by demographic and regional factors. https://www.ons.gov.uk/peoplepopulationandcommunity/educationandchildcare/articles/educationsocialmobilityandoutcomesforstudentsreceivingfreeschoolmealsin . Retrieved 18 Mar 2024.
Okbay, A., Beauchamp, J., Fontana, M., et al. (2016). Genome-wide association study identifies 74 loci associated with educational attainment. Nature, 533, 539–542. https://doi.org/10.1038/nature17671
Okbay, A., Wu, Y., Wang, N., Jayashankar, H., Bennett, M., Nehzati, S. M., Sidorenko, J., Kweon, H., Goldman, G., Gjorgjieva, T., Jiang, Y., Hicks, B., Tian, C., Hinds, D. A., Ahlskog, R., Magnusson, P. K. E., Oskarsson, S., Hayward, C., Campbell, A., Porteous, D. J., Freese, J., et al. (2022). Polygenic prediction of educational attainment within and between families from genome-wide association analyses in 3 million individuals. Nature Genetics, 54, 437–449. https://doi.org/10.1038/s41588-022-01016-z
Okbay, A., Wu, Y., Wang, N., et al. (2022). Polygenic prediction of educational attainment within and between families from genome-wide association analyses in 3 million individuals. Nature Genetics, 54, 437–449. https://doi.org/10.1038/s41588-022-01016-z
Oreopoulos, P., & Salvanes, K. G. (2011). Priceless: The nonpecuniary benefits of schooling. Journal of Economic Perspectives, 25(1), 159–184. https://doi.org/10.1257/jep.25.1.159
Page, M. J., Moher, D., Bossuyt, P. M., Boutron, I., Hoffmann, T. C., Mulrow, C. D., Shamseer, L., Tatzlaff, J. M., Akl, E. A., Brennan, S. E., Chou, R., Glanville, J., Grimshaw, J. M., Hróbjartsson, A., Lalu, M. M., Li, T., Loder, E. W., Mayo-Wilson, E., McDonald, S., McGuinness, L. A., Stewart, L. A., Thomas, J., et al. (2021). PRISMA 2020 explanation and elaboration: Updated guidance and exemplars for reporting systematic reviews. British Medical Journal, 372. https://doi.org/10.1136/bmj.n160
Pasaniuc, B., & Price, A. L. (2016). Dissecting the genetics of complex traits using summary association statistics. Nature Reviews Genetics, 18, 117–127. https://doi.org/10.1038/nrg.2016.142
Peck, L., Borle, K., Folkersen, L., & Austin, J. (2021). Why do people seek out polygenic risk scores for complex disorders, and how do they understand and reach to results? European Journal of Human Genetics, 30, 81–87. https://doi.org/10.1038/s41431-021-00929-3
Perkins, J. M., Subramanian, S. V., Smith, G. D., & Özaltin, E. (2016). Adult height, nutrition, and population health. Nutrition Review, 74(3), 149–165. https://doi.org/10.1093/nutrit/nuv105
Persky, S., Goldring, M. R., El-Toukhy, S., Ferrer, R. A., & Hollister, B. (2019). Parental defensiveness about multifactorial genomic and environmental causes of children’s obesity risk. Childhood Obesity, 15(5), 289–297. https://doi.org/10.1089/chi.2018.0315
Peters, L., & Ansari, D. (2019). Are specific learning disorders truly specific, and are they disorders? Trends in Neuroscience Education, 17, 100115. https://doi.org/10.1016/j.tine.2019.100115
Peterson, R. A., & Brown, S. P. (2005). On the use of beta coefficients in meta-analysis. Journal of Applied Psychology, 90(1), 175–181. https://doi.org/10.1037/0021-9010.90.1.175
Piketty, T., & Wood, W. (2024). Nature, culture, and inequality. Scribe UK.
Plomin, R. (2018). Blueprint: How DNA makes us who we are. Allen Lane.
Plomin, R., & von Stumm, S. (2018). The new genetics of intelligence. Nature Reviews Genetics, 19(3), 148–159. https://doi.org/10.1038/nrg.2017.104
Plomin, R., & von Stumm, S. (2022). Polygenic scores: Prediction versus explanation. Molecular Psychiatry, 27, 49–52. https://doi.org/10.1038/s41380-021-01348-y
Plomin, R., DeFries, J. C., & Loehlin, J. C. (1977). Genotype-environment interaction and correlation in the analysis of human behavior. Psychological Bulletin, 84(2), 309–322. https://doi.org/10.1037/0033-2909.84.2.309
Plomin, R., DeFries, J. C., Knopik, V. S., & Neiderhiser, J. M. (2016). Top 10 replicated findings from behavioral genetics. Perspectives on Psychological Science, 11(1), 3–23. https://doi.org/10.1177/1745691615617439
Polderman, T., Benyamin, B., de Leeuw, C., Sullivan, P. F., van Bochoven, A., Visscher, P. M., & Posthuma, D. (2015). Meta-analysis of the heritability of human traits based on fifty years of twin studies. Nature Genetics, 47, 702–709. https://doi.org/10.1038/ng.3285
Polyakov, A., Amor, D. J., Savulescu, J., Gyngell, C., Georgiou, E. X., Ross, V., Mizrachi, Y., & Rozen, G. (2022). Polygenic risk score for embryo selection - not ready for prime time. Human Reproduction, 37(10), 2229–2236. https://doi.org/10.1093/humrep/deac159
Popejoy, A., & Fullerton, S. (2016). Genomics is failing on diversity. Nature, 538, 161–164. https://doi.org/10.1038/538161a
Procopio, F., Zhou, Q., Wang, Z., Gidziela, A., Rimfeld, K., Malanchini, M., & Plomin, R. (2022). The genetics of specific cognitive abilities. Intelligence, 95, 101689. https://doi.org/10.1016/j.intell.2022.101689
R Core Team. (2019). R: A language and environment for statistical computing. R Foundation for Statistical Computing. https://www.R-project.org/. Retrieved 18 Mar 2024.
Rabinowitz, J., Kuo, S.I.-C., Felder, W., Musci, R. J., Bettencourt, A., Benke, K., Sisto, D. Y., Smail, E., Uhl, G., Maher, B. S., Kouzis, A., & Ialongo, N. S. (2019). Associations between an educational attainment polygenic score with educational attainment in an African American sample. Genes, Brain and Behavior, 18(5), e12558. https://doi.org/10.1111/gbb.12558
Renoux, M., Goudeau, S., Alexopoulos, T., Bouquet, C.A., & Cimpian, A. (2024). The inherence bias in preschoolers’ explanations for achievement differences: Replication and extension. npj Science of Learning,9(10). https://doi.org/10.1038/s41539-024-00218-w
Rietveld, C. A., Medland, S. E., Derringer, J., et al. (2013). GWAS of 126,559 individuals identifies genetic variants associated with educational attainment. Science, 340, 1467–1471. https://doi.org/10.1126/science.1235488
Rimfeld, K., Krapohl, E., Trzaskowski, M., Coleman, J., Selzam, S., Dale, P. S., Esko, T., Metspalu, A., & Plomin, R. (2018a). Genetic influence on social outcomes during and after the Soviet era in Estonia. Nature Human Behavior, 2(4), 269–275. https://doi.org/10.1038/s41562-018-0332-5
Rimfeld, K., Malanchini, M., Krapohl, E., Hannigan, H. J., Dale, P. S., & Plomin, R. (2018b). The stability of educational achievement across school years is largely explained by genetic factors. NPJ Science of Learning, 3, 16. https://doi.org/10.1038/s41539-018-0030-0
Roberts, N., Foster, D., & Long, R. (2021). The pupil premium. House of Commons Briefing Paper, Number 6700. House of Commons Library.
Ritchie, H., Samborska, V., Ahuja, N., Ortiz-Ospina, E., & Roser, E. (2023). Global Education. OurWorldInData.org. https://ourworldindata.org/global-education. Retrieved 8 Aug 2024.
Roser, M., Appel, C., & Ritchie, H. (2013). Human height. Our World in Data. https://ourworldindata.org/human-height. Retrieved 18 Mar 2024.
Roth, P. L., Le, H., Oh, I. S., Van Iddekinge, C. H., & Bobko, P. (2018). Using beta coefficients to impute missing correlations in meta-analysis research: Reasons for caution. Journal of Applied Psychology, 103(6), 644–658.
Rutherford, A. (2020). How to argue with a racist. Orion Publishing Co.
Sandel, M. J. (2020). The tyranny of merit: what’s become of the common good? Penguin Books Ltd.
Scarr, S., & McCartney, K. (1983). How people make their own environments: A theory of genotype → environment effects. Child Development, 54, 424–435. https://doi.org/10.2307/1129703
Schoon, I., Bynner, J., Joshi, H., & Parsons, S. (2002). The influence of context, timing, and duration of risk experiences for the passage from childhood to mid-adulthood. Child Development, 73(5), 1486–1504. https://doi.org/10.1111/1467-8624.00485
Schoon, I., Jones, E., Cheng, H., & Maughan, B. (2012). Family hardship, family instability, and cognitive development. Journal of Epidemiology and Community Health., 66(8), 716–722. https://doi.org/10.1136/jech.2010.121228
Schwartz, A. E., & Rothbart, M. W. (2020). Let them eat lunch: The impact of universal free meals on student performance. Journal of Policy Analysis and Management, 39(2), 376–410. https://doi.org/10.1002/pam.22175
Selvitopu, A., & Kaya, M. (2021). A meta-analytic review of the effect of socioeconomic status on academic performance. Journal of Education. https://doi.org/10.1177/00220574211031978
Selzam, S., Krapohl, E., von Stumm, S., O’Reilly, P. F., Rimfeld, K., Kovas, Y., Dale, P. S., Lee, J. J., & Plomin, R. (2017). Predicting educational achievement from DNA. Molecular Psychiatry, 22, 267–272. https://doi.org/10.1038/mp.2016.107
Selzam, S., Ritchie, S. J., Pingault, J.-B., Reyonlds, C. A., O’Reilly, P. F., & Plomin, R. (2019). Comparing within- and between-family polygenic score prediction. American Journal of Human Genetics, 105(2), 351–363. https://doi.org/10.1016/j.ajhg.2019.06.006
Shah, P. D. (2021). Polygenic risk scores for breast cancer—can they deliver on the promise of precision medicine? JAMA Network Open, 4(8), e2119333. https://doi.org/10.1001/jamanetworkopen.2021.19333
Shakeshaft, S. G., Trzaskowski, M., McMillan, A., Rimfeld, K., Krapohl, E., Haworth, C. M. A., Dale, P. S., & Plomin, R. (2013). Strong genetic influence on a UK nationwide test of educational achievement at the end of compulsory education at age 16. PLoS ONE, 8(12), e80341. https://doi.org/10.1371/journal.pone.0080341
Shin, I.-S., & Chung, J. Y. (2009). Class size and student achievement in the United States: A meta-analysis. KEDI Journal of Educational Policy, 6, 3–19.
Silventoinen, K., Jelenkovic, A., Sund, R., et al. (2020). Genetic and environmental variation in educational attainment: An individual-based analysis of 28 twin cohorts. Scientific Reports, 10, 12681. https://doi.org/10.1038/s41598-020-69526-6
Silventoinen, K., Jelenkovic, A., Sund, R., Latvala, A., Honda, C., Inui, F., Tomizawa, R., Watanabe, M., Sakai, N., Rebato, E., Busjahn, A., Tyler, J., Hopper, J. L., Ordoñana, J. R., Sánchez-Romera, J. F., Colodro-Conde, L., Calais-Ferreira, L., Oliveria, V. C., Ferreira, P. H., Medda, E., et al. (2020). Genetic and environmental variation in educational attainment: an individual-based analysis of 28 twin cohorts. Scientific Reports, 10, 12681. https://doi.org/10.1038/s41598-020-69526-6
Simonsohn, U., Nelson, L. D., & Simmons, J. P. (2014a). P-curve: A key to the file-drawer. Journal of Experimental Psychology: General, 143(2), 534–547. https://doi.org/10.1037/a0033242
Simonsohn, U., Nelson, L. D., & Simmons, J. P. (2014b). P-curve and effect size: Correcting for publication bias using only significant results. Perspectives on Psychological Science, 9(6), 666–681. https://doi.org/10.1177/1745691614553988
Sokolowski, H. M., & Ansari, D. (2018). Understanding the effects of education through the lens of biology. npj Science of Learning, 3(17), 26–28. https://doi.org/10.1038/s41539-018-0032-y
Starr, A., Haider, Z. F., & von Stumm, S. (2024). Do school grades matter for growing up? Testing the predictive validity of school performance for outcomes in emerging adulthood. Developmental Psychology. https://doi.org/10.1037/dev0001548
Tiller, J., Bakshi, A., Dowling, G., Keogh, L., McInerney-Leo, A., Barlow-Stewart, K., Boughtwood, T., Gleeson, P., Delatycki, M. B., Winship, I., Otlowski, M., & Lacaze, P. (2024). Community concerns about genetic discrimination in life insurance persist in Australia: A survey of consumers offered genetic testing. European Journal of Human Genetics, 32, 286–294. https://doi.org/10.1038/s41431-023-01373-1
U.S News & World Report. (2020). Best Global University Rankings. https://www.usnews.com/education/best-global-universities/rankings. Retrieved Aug 2023.
Viechtbauer, W. (2010). Conducting meta-analyses in R with the metafor package. Journal of Statistical Software, 36(3), 1–48. https://doi.org/10.18637/jss.v036.i03
Visscher, P. M. (2022). Genetics of cognitive performance, education, and learning: from research to policy? npj Science of Learning, 7(8). https://doi.org/10.1038/s41539-022-00124-z
Visscher, P., Hill, W., & Wray, N. (2008). Heritability in the genomics era — concepts and misconceptions. Nature Review Genetics, 9, 255–266. https://doi.org/10.1038/nrg2322
von Stumm, S. (2017). Socioeconomic status amplifies the achievement gap throughout compulsory education independent of intelligence. Intelligence, 60, 57–62. https://doi.org/10.1016/j.intell.2016.11.006
von Stumm, S., & d’Apice, K. (2021). From genome-wide to environment-wide: Capturing the environme. Perspectives on Psychological Science, 17(1), 30–40. https://doi.org/10.1177/1745691620979803
von Stumm, S., & Plomin, R. (2021). Using DNA to predict intelligence. Intelligence, 86, 101530. https://doi.org/10.1016/j.intell.2021.101530
von Stumm, S., & Wertz, J. (2021). Who’s learning? Using within-family studies to understand personalized learning. npj Science of Learning, 6(3). https://doi.org/10.1038/s41539-020-00082-4
von Stumm, S., Smith-Woolley, E., Ayorech, Z., McMillan, A., Rimfeld, K., Dale, P. S., & Plomin, R. (2019). Predicting educational achievement from genomic measures and socioeconomic status. Developmental Science, 23(3), e12925. https://doi.org/10.1111/desc.12925
von Stumm, S., Smith-Woolley, E., Cheesman, R., Pingault, J.-B., Asbury, K., Dale, P. S., Allen, R., Kovas, Y., & Plomin, R. (2020). School quality ratings are weak predictors of students’ achievement and well-being. The Journal of Child Psychology and Psychiatry, 62(3), 339–348. https://doi.org/10.1111/jcpp.13276
von Stumm, S., Cave, S. N., & Wakeling, P. (2022). Persistent association between family socioeconomic status and primary school performance in Britain over 95 years. NPJ Science of Learning, 7, 4. https://doi.org/10.1038/s41539-022-00120-3
Wainschtein, P., Jain, D., Zheng, Z., et al. (2022). Assessing the contribution of rare variants to complex trait heritability from whole-genome sequence data. Nature Genetics, 54, 263–273. https://doi.org/10.1038/s41588-021-00997-7
Wang, Y., Guo, J., Ni, G., Yang, J., Visscher, P. M., & Yengo, L. (2020). Theoretical and empirical quantification of the accuracy of polygenic scores in ancestry divergent populations. Nature Communications, 11, 3865. https://doi.org/10.1038/s41467-020-17719-y
Wang, B., Baldwin, J. R., Schoeler, T., Cheesman, R., Barkhuizen, W., Dudbridge, F., Bann, D., Morris, T. T., & Pingualt, J.-B. (2021). Robust genetic nurture effects on education: A systematic review and meta-analysis based on 38,654 families across 8 cohorts. American Journal of Human Genetics, 108(9), 1789–1791. https://doi.org/10.1016/j.ajhg.2021.07.010
Watanabe, K., Stringer, S., Frei, O., et al. (2019). A global overview of pleiotropy and genetic architecture in complex traits. Nature Genetics, 51, 1339–1348. https://doi.org/10.1038/s41588-019-0481-0
Weil, J. (2002). Genetic counselling in the era of genomic medicine. As we move towards personalized medicine, it becomes more important to help patients understand genetic tests and make complex decisions about their health. EMBO Reports, 3(7), 590–593. https://doi.org/10.1093/embo-reports/kvf144
Wertz, J., Moffitt, T. E., Agnew-Blais, J., Arseneault, L., Belsky, D. W., Corcoran, D. L., Houts, R., Matthews, T., Prinz, J. A., Richmond-Rakerd, L. S., Sugden, K., Williams, B., & Capsi, A. (2019). Using DNA from mothers and children to study parental investment in children’s educational attainment. Child Development, 91(5), 1745–1761. https://doi.org/10.1111/cdev.13329
Wilkinson, R., & Pickett, K. (2010). The spirit level: Why more equal societies almost always do better. Penguin.
Williams-Brown, Z., & Hodkinson, A. (2020). Development of inclusive education in England: Impact on children with special educational needs and disabilities. In R. Papa (Ed.), Handbook on promoting social justice in education. Springer. https://doi.org/10.1007/978-3-030-14625-2_151
Yengo, L., Vedantam, S., Marouli, E., et al. (2022). A saturated map of common genetic variants associated with human height. Nature, 610, 704–712. https://doi.org/10.1038/s41586-022-05275-y
Youman, M., & Mather, N. (2013). Dyslexia laws in the USA. Annals of Dyslexia 63, 133–153. https://doi.org/10.1007/s11881-012-0076-2.
Funding
This work was supported by a Nuffield Foundation grant awarded to SvS (EDO/44110). SvS supported by fellowships from the Jacobs Foundation (2022–2027) and the Paris Institute of Advanced Study (2023–2024) during the writing of this article. KW held a PhD Scholarship (2021–2024) from the Department of Education at the University of York. MW was supported by a PhD Scholarship (2020–2023) from Hogan Assessment Systems.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Preregistration(s):
PROSPERO; https://www.crd.york.ac.uk/prospero/display_record.php?ID=CRD42021237620
Supplementary Information
Below is the link to the electronic supplementary material.
ESM 1
(DOCX 1.11 MB)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wilding, K., Wright, M. & von Stumm, S. Using DNA to Predict Education: a Meta-analytic Review. Educ Psychol Rev 36, 102 (2024). https://doi.org/10.1007/s10648-024-09928-4
Accepted:
Published:
DOI: https://doi.org/10.1007/s10648-024-09928-4