
Abstract
Reflective practice holds critical importance, for example, in higher education and teacher education, yet promoting students’ reflective skills has been a persistent challenge. The emergence of revolutionary artificial intelligence technologies, notably in machine learning and large language models, heralds potential breakthroughs in this domain. The current research on analyzing reflective writing hinges on sentence-level classification. Such an approach, however, may fall short of providing a holistic grasp of written reflection. Therefore, this study employs shallow machine learning algorithms and pre-trained language models, namely BERT, RoBERTa, BigBird, and Longformer, with the intention of enhancing the document-level classification accuracy of reflective writings. A dataset of 1,043 reflective writings was collected in a teacher education program at a German university (M = 251.38 words, SD = 143.08 words). Our findings indicated that BigBird and Longformer models significantly outperformed BERT and RoBERTa, achieving classification accuracies of 76.26% and 77.22%, respectively, with less than 60% accuracy observed in shallow machine learning models. The outcomes of this study contribute to refining document-level classification of reflective writings and have implications for augmenting automated feedback mechanisms in teacher education.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
1 Introduction
The dawn of the Artificial Intelligence (AI) era has brought about transformative educational changes. From profiling and prediction to automated assessment and personalized learning, the increasing use of AI applications is evidence of its burgeoning influence (Zawacki-Richter et al., 2019; Zhai et al., 2021). One particularly impactful instance of AI’s utility is the deployment of Large Language Models (LLMs) like ChatGPT. This powerful tool can support students in problem-solving, personalized guidance, feedback provision, and other areas. Interestingly, the benefits of AI feedback have been empirically quantified. For instance, a meta-analysis by Cai et al. (2023) revealed a moderate positive impact of feedback on academic achievement in technology-rich learning environments compared to traditional feedback-absent environments. These findings hint at AI’s potential to address long-standing educational challenges, especially those related to providing timely, personalized feedback (Russell & Korthagen, 2013). In light of these developments, the fusion of machine learning (ML) and natural language processing (NLP) technologies may present an efficient way to meet students’ diverse learning needs.
In the rapidly evolving educational technology landscape, a significant breakthrough has occurred in using AI for assessment, particularly concerning reflective writing. Reflection forms an essential bridge between theoretical knowledge and practical application (Korthagen & Vasalos, 2005). Despite the deployment of various approaches aiming to bolster reflective practice, the endeavor has encountered constraints, primarily due to the multifaceted nature of reflective writing, which poses a challenge for evaluation (Körkkö et al., 2016; Poldner et al., 2014; Ullmann, 2019). Recent researches indicate that shallow ML and pre-trained language models are particularly effective in assessing reflective writing, marking a significant advancement in this field (Nehyba & Štefánik, 2023; Solopova et al., 2023; Wulff et al., 2023). Moreover, AI’s role in assessing student reflections is expanding, serving both as an instrument for summative assessment (Barthakur et al., 2022) and as a means for generating formative assessment metrics (Jung et al., 2022).
However, two significant challenges remain in leveraging AI to provide feedback on reflective writings. The first issue concerns the quality of the reflective writing data utilized for training in existing studies. The dataset was often collected in a non-standardized way in many studies, resulting in the data not being high quality. This compromise in data quality can adversely affect the performance metrics of ML-based classifiers, as noted by Gupta et al. (2021), resulting in reduced reliability and a higher risk of fallacious conclusions. The second challenge is that most current research segments the reflective writings into sentences, classifying them on the sentence level. This is particularly problematic in reflective writing, where there is an intrinsic and cohesive link across the narrative (Moon, 2013). An overemphasis on individual sentences risks missing vital information embedded in the larger context of the text. Therefore, a pivot towards a document-level evaluation paradigm is beneficial and necessary for capturing the full scope of reflective thought. Addressing these challenges requires an emphasis on collecting high-quality datasets and classifying them on a document level to improve the effectiveness of AI in giving feedback on reflective writing.
This research aims to classify reflective writing by leveraging shallow ML and pre-trained language models. In contrast to preceding studies, this research employed a document-level classification approach to annotate reflective writings. The methodology employed a range of ML models as well as pre-trained language models like BERT (Devlin et al., 2018) and RoBERTa (Liu et al., 2019a, 2019b), supplemented by advanced models such as BigBird (Zaheer et al., 2020) and Longformer (Beltagy et al., 2020). These advanced language models were employed in the classification technique to address the challenges of processing long text sequences.
2 Literature review
2.1 Theoretical framework for assessing reflective writing
In reflection, John Dewey’s “How We Think” (1933) stands out as a landmark work, which has significantly been complemented by Donald Schön’s influential “The Reflective Practitioner” (1983) and “Educating the Reflective Practitioner” (1987). Schön (1983, 1987) has categorized reflection into two types: reflection-in-action, which occurs during the act, and reflection-on-action, which takes place after the event. The notion of reflection-on-action was used in this study. In subsequent developments, the definition of reflection remains ambiguous. Some argued that reflection should include affective aspects (Boud et al., 2013), while others contended that it is a problem-solving process (Kember, 1999). Additionally, proposals suggested that reflection is a form of metacognition (Flavell, 1979) and an element of self-regulated learning (Zimmerman, 2002).
Given the reflection’s inherent complexity and multidimensional nature, scholars have recognized the necessity to develop various models (Boyd & Fales, 1983; Gibbs, 1988; Hatton & Smith, 1995; Kember, 1999; Kolb, 1984; Mezirow, 1991). These theoretical models were developed around two core dimensions: depth and breadth. Depth pertains to the level of reflection achieved, while breadth refers to various elements involved in reflective writing (e.g., Ullmann, 2019). More specifically, the depth model assesses reflection holistically, considering it an integral whole. For instance, Jung et al. (2022) evaluated reflectivity among 369 dental students through 1500 reflective writings, categorizing reflections as non-reflective, shallow, or deep levels. Similarly, Liu et al., (2019a, 2019b) implemented a binary classification system to examine 301 reflective statements from pharmacy students, effectively differentiating between reflective and non-reflective responses. Providing feedback on different reflection levels facilitates a clear understanding of student’s current situation and the objectives they need to meet. For educators, identifying students at varying levels of reflection enables tailoring specific improvement strategies. In contrast, breadth models embrace a multi-faceted, process-oriented approach, offering a granular analysis of reflection by dissecting its components and examining their interactions. For example, Cui et al. (2019) conducted an extensive review of existing literature and analyzed the reflective writings of 27 dental medicine students over four years. Their study was anchored in a framework comprising six reflective categories: description, analysis, feelings, perspective, evaluation, and outcome. Moreover, Ullmann (2019) centered his research on eight categories commonly found in models for assessing reflective writing: reflection, experience, feeling, belief, difficulty, perspective, learning, and intention. His analysis encompassed 76 student essays, totaling 5080 sentences, primarily from health, business, and engineering students in their second and third years. These studies revealed the richness of reflective practice and provided insights into how educators can better organize reflective practice and assessment to capture the full range of student reflections.
Current research on reflective writing typically employs one of these two basic models or a hybrid. Depth models classify reflections into levels, which assist students in determining and benchmarking the quality of their reflective practice. They also provide educators and institutions with a streamlined metric for evaluating the caliber of teaching and learning. Nevertheless, their singular focus can shorten a comprehensive understanding and development of reflective capabilities. In contrast, breadth models offer multifaceted feedback, encompassing various elements and processes of reflection, thereby offering a more expansive understanding of its dynamics. This model reveals the nuanced interplay within reflective thought and its broader implications. However, the potential for information overload is a drawback of the breadth approach, as the profusion of data points might lead to conflicts or overlaps, possibly obscuring areas needing improvement.
2.2 ML and NLP for assessing reflective writing
In the realm of analyzing reflective writings, the current research employs a diverse array of methodologies, including dictionary-based (Cui et al., 2019; Springer & Yinger, 2019), rule-based (Chong et al., 2020; Gibson et al., 2016) and increasingly, ML-based techniques (Cutumisu & Guo, 2019; Fan et al., 2017; Ullmann, 2019; Wulff et al., 2023). There has been a notable shift towards adopting ML and NLP strategies, with the field progressively embracing advanced technologies such as deep learning (DL) and pre-trained language models. These sophisticated models offer potent capabilities for accurately identifying complex patterns within extensive datasets of reflective texts, significantly improving the detail and accuracy of analyses.
A review of the literature reveals a predominant focus on deploying shallow ML algorithms for classifying reflective writing. Within this category, algorithms such as Random Forest (Jung & Wise, 2020; Kovanović et al., 2018; Ullmann, 2019), Naïve Bayes (Cheng, 2017; Hu, 2017; Liu et al., 2017), and Support Vector Machine (Carpenter et al., 2020) have been recognized for their exceptional performance. As for language representation techniques, the majority have relied on foundational methods such as Bag-of-Words (BoW) (Hu, 2017; Ullmann, 2019), Linguistic Inquiry and Word Count 2015 (LIWC2015) (Jung & Wise, 2020), and Term Frequency-Inverse Document Frequency (TF-IDF) (Liu et al., 2017). However, the field is gradually advancing towards more sophisticated models, with recent forays into using Global Vectors for Word Representation (GloVe) and Embeddings from Language Models (ELMo) (Carpenter et al., 2020), signaling a shift towards capturing deeper semantic meanings and contextual nuances within the reflective texts. Shallow ML has comparative advantages in terms of simplicity, interpretability, and computational efficiency (Janiesch et al., 2021) when targeting the classification of reflective writing. For example, interpretability in model decision-making refers to the transparency of how a model processes inputs to produce outputs (e.g., Carvalho et al., 2019). Incorporating linguistic metrics, such as those from LIWC2015, into the classification of reflective writing enhances this interpretability (e.g., Cui et al., 2019; Savicki & Price, 2015; Springer & Yinger, 2019). LIWC2015 assigns words to various psycholinguistic categories, encompassing psychological, linguistic, and affective dimensions—such as affect (encompassing both positive and negative emotions), cognitive processes (including insight, causation, negation, and others), and social dynamics (Pennebaker et al., 2015). These categories are grounded in established psychological and linguistic theories, offering a theoretically informed framework that elucidates the model’s methodology in identifying and classifying reflective writing. For instance, the study by Zhang et al. (2023a) demonstrated that words about cognitive and emotional aspects predict reflection levels, showcasing the practical application and relevance of these categories in research. However, the limitations of shallow ML are apparent, notably its heavy reliance on feature engineering. This approach encounters difficulties in capturing deep semantic relationships and subtle contextual nuances within textual data, particularly in instances of reflective writing that encompass complex emotional expressions, metaphors, or advanced cognitive processes (e.g., Dewey, 1933). Moreover, data from reflective writing often exhibits imbalance, with specific categories significantly outnumbering others (Körkkö et al., 2016; Poldner et al., 2014). Shallow ML models may struggle to address this imbalance effectively, leading to biased models toward the majority class.
Although DL and pre-trained language models have not yet achieved widespread adoption in the field, the examples of their application demonstrate a significant performance advantage over shallow ML models. For instance, Nehyba and Štefánik (2023) demonstrated that a neural classifier (XLM-RoBERTa) surpassed the capabilities of a shallow classifier (Random Forest) in categorizing reflective writing within higher education. Additionally, Wulff et al. (2023) reported that the BERT model outperformed both DL Architectures and previously employed shallow ML algorithms (Wulff et al., 2021) in classifying segments of reflective writing by pre-service teachers. Pre-trained language models primarily utilize deep learning neural network architectures, such as the Transformer model, which learns a generalized language representation through pre-training on extensive textual datasets. These models adeptly capture a broad spectrum of linguistic features, encompassing lexical, syntactic, and semantic information. This capability allows them to quickly and efficiently adapt to specific tasks through fine-tuning. Researchers have illustrated that natural language exhibits long-range dependencies (Ebeling & Neiman, 1995; Zanette, 2014), a characteristic that renders Transformer architectures particularly effective for addressing related tasks. Therefore, pre-trained language models can capture language’s deeper semantics and contextual dependencies, providing more affluent and more fine-grained textual representations, which are essential for understanding the nuanced emotions and complex thought processes in reflective writing. However, pre-trained language models provide excellent performance; their “black-box” nature makes the model decision-making process challenging to interpret, which may be a problem in application scenarios requiring high transparency and interpretability (Kraus et al., 2020). Research has demonstrated that implementing non-transparent AI systems in teacher education may provoke AI anxiety among users (Hopcan et al., 2023), and decreasing their acceptance of AI technology (e.g., Zhang et al., 2023b).
In sum, most current research on the classification of reflective writing has predominantly employed shallow ML techniques. However, there has been an emergence of research utilizing pre-trained language models as well. In addition, the classification of reflective writings primarily occurs at the sentence level. In reflective writing, deep reflection involves complex thought processes across many sentences and even whole documents, and it may be difficult to identify true deep reflection based on sentence-level analysis alone. Although sentence-level classification is more accessible, exploring and developing effective document-level analysis methods for assessing reflective writing is essential. Consequently, we advocate for increased research on the document-level classification of reflective writing. Simultaneously, enhancing the model’s explanatoriness and transparency is crucial without compromising its accuracy.
2.3 The current study
In current research on reflective writing classification, the general approach is to subdivide longer writings into individual sentences and to label these sentences one by one. Subsequently, these labeled sentences are used as a training dataset for classification algorithms. While this sentence-based approach simplifies the training process of the algorithm, it may miss contextual connections crucial in reflective writing. To address this shortfall, our study introduces a document-level classification approach. This approach seeks to preserve and analyze the text’s integrity, enabling a more holistic evaluation that considers the narrative arc, thematic coherence, and the interconnectivity of reflective thoughts. By doing so, our research will improve the accuracy of AI feedback.
Regarding the modeling aspect, besides the commonly discussed decision trees (Barthakur et al., 2022), random forests (Kovanović et al., 2018; Liu et al., 2019a, 2019b), and support vector machines (Ullmann, 2019), we incorporated additional algorithms: Ridge Classifier, SGD Classifier, XGB Classifier, and Gradient Boosting Classifier. To the best of our knowledge, these algorithms have yet to be widely applied to the classification task of reflective writing. Therefore, our study aims to fill this research gap and provide a foundation and reference for future related work. Firstly, the Ridge Classifier can effectively deal with the problem of multicollinearity among features and enhance the generalization ability of the model by introducing the L2 regularization term (Hoerl & Kennard, 1970). Secondly, the SGD Classifier is suitable for large-scale and high-dimensional data processing and can effectively improve computational efficiency through iterative optimization (Robbins & Monro, 1951). Next, the XGB Classifier, as an advanced gradient boosting algorithm, especially performs very well when dealing with complex nonlinear data structures (Chen & Guestrin, 2016). Finally, the Gradient Boosting Classifier enhances the prediction accuracy by gradually correcting the errors of the previous model, which is especially effective for unbalanced datasets (Friedman, 2001). These algorithms may have an essential role for the classification of complex reflective writing. As for feature engineering, we employed several methods, including BoW, TF-IDF, and LIWC2015-based approaches.
Furthermore, we leveraged pre-trained language models such as BERT, RoBERTa, Longformer, and BigBird. These state-of-the-art models, pre-trained on extensive corpora, offer valuable contextual embeddings and enhance the understanding of text semantics. It is worth noting that BERT, a widely adopted pre-trained language model, has gained recognition for its excellent performance (Devlin et al., 2018). However, to address the processing of long-distance dependencies in text, there are improved versions known as Longformer and BigBird. Longformer utilizes a sparse-attention model (Beltagy et al., 2020), while BigBird combines global and local attention mechanisms to handle long sequences efficiently (Zaheer et al., 2020). Utilizing these two models enables more efficient analysis of lengthy text sequences. Based on that, the study has the following research questions:
-
RQ 1: To what extent do shallow machine learning models employing diverse language representations demonstrate effectiveness in classification reflective writing of pre-service teachers?
-
RQ 2: What is the performance of pre-trained language models when employed to classify reflective writing of pre-service teachers?
-
RQ 3: How do shallow machine learning models compare to pre-trained language models in terms of their effectiveness in classifying reflective writing of pre-service teachers?
3 Methods
3.1 Research design and data collection
This study was conducted within a German university teacher education program, focusing on two modules in a lecture: pedagogical diagnostics and classroom management. Both modules were taught through self-study, with the instructor providing study materials such as recorded lectures, slides, recommended readings, case study assignments, and tasks for reflective writing. The student’s reflective writings were collected in a digital portfolio format (Gläser-Zikuda, 2015) throughout these two modules. The module dedicated to pedagogical diagnostics extended over a period of three weeks, whereas the module focusing on classroom management was concluded within a single week. Following the completion of their respective modules, students were obliged to submit reflective writingss within a fortnight. To support pre-service teachers in their reflection, structured prompts based on Narciss’s (2006) framework were developed for this study. Four structured prompts were incorporated, namely knowledge on task constraints (KTC), knowledge about concepts (KC), knowledge on how to proceed I (KH I), and knowledge on how to proceed II (KH II). Pre-service teachers were allowed to choose the prompt that best suited their individual needs. The data for this study were collected from pre-service teachers’ reflective writing during the winter semester 2021/22, summer semester 2022, and winter semester 2022/23. Data was gathered in an anonymous manner consistent with the university’s policy on data protection. A total of N = 1043 reflective writings were obtained, with an average word count of 251.38 (SD = 143.08) for the pre-service teachers reflective writing (see Fig. 1).

Distribution of reflective writing words among pre-service teachers
3.2 Data annotation with qualitative content analysis
First and foremost, before training with ML algorithms, the reflective writing in this study underwent annotation. To accomplish this, a qualitative content analysis (Gläser-Zikuda et al., 2020) was employed, based on Hatton and Smiths’ theory (1995) and Fütterer’s (2019) adapted coding scheme for classification (see Table 1). The coding framework consisted of four levels: descriptive writing, descriptive reflection, dialogic reflection, and critical reflection. Firstly, the entire reflective writing was read to form an initial impression, aligning with a theoretically predefined category system ranging from level 0 to 3; this preliminary rating was recorded. After this, meaning segments within the text were analyzed using the category system following a structured analytical procedure. These segments could comprise single or multiple sentences linked by a common theme. Rather than evaluating individual sentences within a meaning segment, they were counted and employed as a multiplier for the segment’s level. For instance, if a meaning segment included three sentences and was assessed at level two, then level two was counted three times (3 × 2). The level assigned to each meaning segment and the count of sentences it contained was documented post-coding. The text was ultimately rated based on the most frequently occurring level, which had to constitute at least 60% of the text. In cases where no single level met the 60% threshold, the next lower level was selected (e.g., Text 1: 10 sentences: 3 × 0, 2 × 1, 5 × 2 results in level 1; Text 2: 10 sentences: 5 × 0, 5 × 2 results in level 0, as only 50% of the sentences are above level 0 and no elements of level 1 were detected). This rating was then cross-referenced with the initial impression and subsequently reviewed by a second coder to test the intercoder reliability. Three experts independently coded these reflective writings to test for intercoder reliability. Due to the time-consuming nature of coding reflective writing, to ensure coding reliability, 300 pieces of reflective writing (28.76% of the total) were randomly selected for a second round of coding by three different experts, with Cohen’s kappa coefficients of 0.67, 0.66, and 0.73, respectively. These outcomes were received which were considered acceptable (McHugh, 2012).
According to the findings, the number of reflective writings per reflection level was as follows: 261 for the level of descriptive writing, 545 for the level of descriptive reflection, 209 for the level of dialogic reflection, and 28 for the highest level for critical reflection. The critical reflection category (n = 28) sample size in the dataset was tiny compared to the other categories. This resulted in a weaker generalization of the model to this category, affecting the accuracy and reliability of the overall model. While SMOTE oversampling has demonstrated its effectiveness in addressing sample imbalance in numerous studies (Chawla et al., 2002; Jung & Wise, 2020; Kovanović et al., 2018), we found it unsuitable for our long text data upon manual evaluation. Due to the complexity and depth of reflective writing, SMOTE-generated samples did not accurately reflect the characteristics of an authentic critical reflection sample. Consequently, we decided to omit the final category (namely, critical reflection) from the classification process.
3.3 Text pre-processing and feature engineering
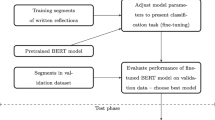
In ML, text pre-processing and feature engineering roles are indispensable. Text pre-processing encompasses a variety of techniques and stages designed to cleanse, transform, and standardize raw text data. The primary aim of this process is to augment the accuracy of subsequent classification tasks. Meanwhile, feature engineering is a critical process involving transforming, extracting, and generating meaningful features from the pre-processed data. It aids in mitigating the risk of overfitting and bolsters the model’s explanatory power. The flow chart for the classification of reflective writing is shown in Fig. 2.

Flowchart for classifying reflective writings (modified to Tan et al., 2021, p. 548)
3.3.1 Text pre-processing
In this study, we employed a standard pipeline for reflective writing. The pipeline consisted of the following procedures: tokenization, stop word removal, and lemmatization. Tokenization involved segmenting the text into individual tokens. Stop word removal was performed to eliminate joint and non-discriminatory words that do not contribute significantly to the meaning of the text. This included typical German stop words (e.g., “die” (the), “sind” (are), and “wo” (where)), as well as specific non-discriminatory words identified in Atzeni et al.’s (2022) work such as “Aufgabe” (task), “pädagogische” (educational), “Bearbeitung” (processing), and others. Additionally, this section removed unnecessary numerical digits, punctuation marks, special characters, or any other symbols from the text. Lemmatization was applied to transform words to their root form, reducing inflectional variations and allowing for better analysis and understanding of the text.
3.3.2 Feature engineering
Three feature extraction methods were employed in this study, namely, BoW, TF-IDF, and LIWC2015 (Pennebaker et al., 2015). To extract features for BoW and TF-IDF, the CountVectorizer and TfidfVectorizer functions from the Scikit-learn in Python were utilized. Furthermore, the LIWC2015 has undergone validation processes and performs satisfactorily classifying reflections in higher education settings (June & Wise, 2020). In this study, 87 out of 93 linguistic features available in the LIWC2015 were utilized. Using the SelectKBest method (top 10) and a correlation coefficient threshold greater than 0.1 or less than -0.1 (considered significant), nineteen noteworthy features were extracted (refer to Table 2). Subsequently, the extracted feature values were preferably normalized using the Z-score method.
3.4 Classification algorithm selection and optimization
The objective of the study was to compare the performance of pre-trained language models with that of other shallow ML approaches. In this study, to ensure the reproducibility of the experimental process and the consistency of the results, we uniformly used 2023 as the seed parameter of the initialized random number generator in all ML and pre-training language model experiments. This section begins by providing an introduction to selected shallow ML, followed by an overview of pre-trained language models.
3.4.1 Shallow machine learning
Prior research has yielded substantial results using Decision Tree, Support Vector Machines, and Random Forest, which are prevalent methods in the classification of reflective writing (Nehyba & Štefánik, 2023; Ullmann, 2019; Wulff et al., 2021). Leveraging this existing knowledge, our study strives to augment these established algorithms and introduce new models to address the complexities inherent in diverse datasets. In our analysis, we implemented seven shallow ML algorithms: Decision Tree, Support Vector Machine, Random Forest, Ridge Classifier, SGD Classifier, XGB Classifier, and Gradient Boosting Classifier. To ensure dependable and consistent outcomes, we trained all algorithms on a training set comprising 80% of the data. We tested them on a separate set that accounted for the remaining 20% of the data. A five-fold cross-validation was further implemented to validate the results. In-depth details regarding the parameters specific to each algorithm are available in Table 3. We evaluated the performance of each algorithm based on its accuracy. True Positives (TP) are the cases where the model correctly predicts the positive class. True Negatives (TN) are the cases where the model correctly predicts the negative class. False Positives (FP) are the cases that are incorrectly predicted as positive when they are actually negative. False Negatives (FN) are the cases that are incorrectly predicted as negative when they are actually positive.
3.4.2 Pre-trained language models
AI has seen a substantial surge in using pre-trained language models in recent years. These models, trained on vast amounts of unlabeled textual data, are adept at understanding semantic word representations and their contextual relationships. A notable category within these models comprises those developed on the Transformer architecture. These Transformer-based pre-trained language models utilize self-attention mechanisms and multi-layered neural networks to encode input text. This process results in the generation of word vector representations that effectively capture the relevance of context. Pre-trained language models present broad application possibilities across diverse NLP tasks. By fine-tuning these models to conform to specific task demands, one can noticeably enhance their performance on the targeted tasks.
In our study, we apply a classification approach to reflective writing using four pre-trained language models. Two of these models, BERT and RoBERTa, are common pre-trained language models. The other two, Longformer and Bigbird, are specifically designed for handling long texts. BERT and its derivatives have proven highly effective in classifying reflective texts. However, the constraint of a 512-token limit on the embedding length in BERT poses challenges when dealing with lengthy text datasets. This limitation often results in subpar performance. Common workarounds for this issue include text truncation, adjustments to the attention mechanism, and sentence-wise processing. Despite their usage, these strategies present certain drawbacks. Truncation can lead to losing vital information, while attention mechanism and sentence-wise processing modifications can significantly increase computational complexity. A “head and tail” strategy was employed for BERT and RoBERTa in experiments. This involved selecting a head length of 255 tokens and a tail length of tokens characters, ensuring the total length of the truncated text remained at 510. While Longformer and BigBird support a maximum length of 4096 tokens, which can cover the entire input of our dataset. The dataset designated for use with the pre-trained language models was partitioned: 70% was allocated for training, 10% for validation, and 20% for testing purposes. We utilized several models available through the Hugging Face platform (https://huggingface.co/). These included: bert-base-german-cased from Deepset (Chan et al., 2020), princetyagi/roberta-base-wechsel-german-finetuned-germanquad as detailed in Minixhofer et al. (2021), allenai/longformer-base-4096 as described in Beltagy et al. (2020), and google/bigbird-roberta-base as presented in Zaheer et al. (2020). The hyperparameters employed for these two categories of pre-trained language models are detailed in Table 4.
3.5 Technical implementation
The study on shallow ML was conducted using Python 3.10 and Scikit-learn version 1.2.1. Our development environment was Jupyter Notebook version 6.4.12. Computations were carried out on a machine featuring an AMD Ryzen 5 4500U processor, Radeon Graphics operating at 2.38 GHz, and equipped with 16.0 GB of RAM. The pre-trained language models were executed on a system with an NVIDIA GeForce GTX 1650 Ti graphics card (6 GByte). The classification tasks were facilitated by Pytorch framework version 2.0.1. Coding activities were conducted within the PyCharm programming environment, version 2022.2.
4 Results
4.1 Results of shallow machine learning
The average accuracy achieved by the shallow ML algorithms is typically under 60%. Among the combinations that performed best, integrating the Gradient Boosting Classifier with LIWC2015 is particularly notable, achieving an accuracy rate of 61.97%. Furthermore, the BoW technique yields the highest performance, recording an accuracy of 60.28% when employed with Support Vector Machines. The TF-IDF method attains optimal results when applied to the XGB classifier, garnering an accuracy of 61.69%. In summary, when it comes to different feature engineering techniques, LIWC2015 generally outperforms both BoW and TF-IDF across various algorithms. A comparative analysis of the accuracy achieved by various feature extraction techniques and algorithms is visually represented in Fig. 3.

Accuracy of shallow machine learning with various feature engineering
4.2 Results of pre-trained language models
The pre-trained language models designed for handling long texts, namely Longformer and BigBird, delivered the most impressive performance with accuracy rates of 77.22% and 76.26% respectively. Furthermore, BERT and RoBERTa, the two other pre-trained language models used in our study, achieved accuracy rates of 73.28% and 74.25% respectively. These accuracy levels mark a considerable improvement, a rise of 12% to 16%, in comparison to the shallow ML models. Table 5 shows all results of pre-trained language models.
5 Disscussion
The primary objective of our research was to classify pre-service teachers’ reflective writings at the document level by employing AI algorithms. For this purpose, we applied a qualitative content analysis for the annotation of the reflective writings to classify reflection levels. Then, we utilized a range of shallow ML algorithms enhanced by pre-trained language models such as BERT, RoBERTa, BigBird, and Longformer. Our empirical analyses led to several significant findings. The results underscore the superiority of pre-trained language models over shallow ML algorithms in classifying reflective writings, with BigBird and Longformer demonstrating notably higher accuracy at the document level. Nonetheless, our research also identified certain biases between AI evaluations and human teachers’ evaluations. These discrepancies are further explored in the subsequent sections.
Firstly, the superior efficacy of pre-trained language models over shallow ML models in analyzing reflective writing is consistently corroborated by other research. For example, Nehyba and Štefánik (2023) illustrated that in the classification of reflective writing within higher education contexts, the accuracy of a deep neural model (XLM-RoBERTa) varied from 92.68% to 97.56%, surpassing the performance of a shallow ML algorithm (Random Forest), which ranged from 80.49% to 82.93%. Furthermore, Wulff et al. (2023), in their research of reflective writing classification, discovered that the feedforward neural network (FFNN) exhibited the lowest performance, achieving weighted F1 mean scores of 0.62 and 0.64, respectively. This was closely followed by long short-term memory neural networks (LSTM) with weighted F1 mean values of 0.72. In contrast, the fine-tuned BERT model results significantly surpassed other models, achieving a weighted F1 mean score of 0.82. Despite the variations in research contexts, datasets, and theoretical frameworks across these studies, the consistently high performance of pre-trained language models in analyzing reflective writing is apparent. These results highlight the robustness and versatility of pre-trained language models in capturing the complex nature of reflective content.
Moreover, our study further highlights the outstanding performance of the BigBird and Longformer models in classifying reflective writing at the document level. To our knowledge, there is currently no research specifically focused on the classification of reflective writing using these models (BigBird and Longformer). However, these approaches have been extensively applied in other domains. For instance, in the medical field, Li et al. (2023) demonstrated that Clinical-Longformer and Clinical-BigBird significantly outperform ClinicalBERT and other models designed for short sequences across all evaluated downstream tasks. Compared to shallow ML algorithms and pre-trained language models optimized for short sequences, these pre-trained language models designed to handle long sequences exhibit superior performance across various tasks. For example, shallow ML models often face challenges when dealing with long-sequence inputs due to factors such as high-dimensional feature spaces, retaining contextual relevance over lengthier texts, and the absence of sequential information. BERT and RoBERTa models address some of these challenges; however, their localized self-attention mechanisms can struggle to capture longer dependencies within the text (Devlin et al., 2018; Liu et al., 2019a, 2019b). The self-attention mechanism’s demand for memory grows quadratically as sequence lengths extend, making training times unfeasibly long and rapidly surpassing the memory limits of current Graphics Processing Units (GPUs). Therefore, models depending on full self-attention, like BERT and RoBERTa, usually set a cap on the input sequence length at 512 tokens to manage these constraints. However, BigBird and Longformer models, which incorporate global attention mechanisms and extended local attention spans, more effectively capture textual context (Beltagy et al., 2020; Zaheer et al., 2020). The utilization of pre-trained language models adept at processing long sequences is crucial for the classification of reflective writing. As Rosé et al. (2008) have pointed out, the choice of segmentation method significantly affects classification performance. Numerous scholars argue that reflections often extend across multiple sentences and cannot be adequately captured through sentence-level classification alone (Moon, 2013). This perspective is supported by Wulff et al. (2023), as well as Nehyba and Štefánik (2023), who underscore the limitations of sentence-level segmentation in capturing long-range dependencies and addressing the complexities of classification challenges, respectively. Reflection may span several sentences or be interwoven with various reflective categories within complex sentences. In addition to the technical aspects, it has been proposed that incorporating strong theoretical frameworks such as discourse theory can improve segmentation practices (Stede, 2016).
Lastly, it is essential to acknowledge the bias of the pre-trained language model for the analysis of reflective writing when compared to the teacher’s assessment. The cases of RW1-KM and RW2-KM (translated into English by the authors) exemplify instances where the AI (Longformer) has been underestimated and overestimated, respectively. These two examples showed that teachers can better understand students’ intentions, background knowledge, and implicit meanings in reflective writing. For example, RW1-KM delves into the particulars of a classroom discipline issue, presenting an investigation of the event’s specifics. This includes an analysis of the underlying motivations behind the student’s behavior and the coping strategies employed. Such a reflection exhibits a profound comprehension of the circumstances and a personalized approach, aligning with the characteristics of dialogic reflection. However, the AI’s assessment classified this reflection as descriptive, likely due to the extensive use of descriptive language within the reflection’s narrative. In RW2-KM, the student showcased an ability to objectively recount events and delve into their underlying causes, employing Becker’s theory to elucidate the classroom scenario. This analysis penetrates beyond surface-level observations to provide a theoretical interpretation of the teaching and learning context, an approach that typifies descriptive reflection. Nonetheless, the AI’s evaluation misidentified this reflection as dialogic, likely influenced by the extensive use of language related to third-party actions and the text’s complex linguistic expressions. From the analyses of the two reflections described above, it is possible to observe differences in the classification of types of reflections between manual and AI assessments. The potential limitations of AI in understanding the depth and multidimensionality of reflections remind us of the caution that should be taken in using AI in educational assessment, especially when evaluating complex thinking and reflective processes. Also, this emphasizes the irreplaceability of manual assessment in dealing with the evaluation of complex cognitive processes.
“After reading through the situation, I realized that the class disruption was on the students’ part. However, the situation did not explicitly mention whether the teacher saw who threw the sponge in her face. Therefore, I was unsure whether the teacher should address someone personally or the whole class when dealing with the conflict. Furthermore, it was not easy for me to tell from the situation whether the pupils threw the objects around the classroom out of boredom or whether it was a targeted attack on the teacher. Accordingly, the characteristic of aggressive behavior did not appear in my analysis of the situation. It was also unclear to me how practically orientated I should argue, so my answer contained more of a theoretical aspect. In order to put myself more in the situation, it would be useful to know which year group and which type of school was involved. Measures such as a note for parents in the homework booklet would not have much effect in the ninth or tenth year of secondary school, as many parents are not interested in their children’s school affairs. Unfortunately, many parents do not speak German. I was able to gain such insights during my orientation internship.” (Human Assessment: Dialogic Reflection; AI Assessment: Descriptive Reflection) [RW1-KM]
“The comparison with the feedback variants shows a high degree of agreement with the proposed solutions. The task processing is based centrally on Becker’s analysis, as is the feedback. The processing describes what has happened, classifies the degree of conflict, and then looks for possible causes. Just as Becker describes and proposes the model solution. In the possible response, the processing focuses more on the student's well-being than on the feedback. In both, the teacher's misconduct is looked at. In processing, a conversation is sought with the students, whereas feedback focuses more on disciplinary measures. However, it should be noted that the option of silent and individual work is good for showing students their unacceptable behavior. The treatment also classifies the situation as a central conflict. From a personal point of view, the end of the situation described seems extreme, and such behavior on the part of the students is only conceivable in individual cases. Nevertheless, it is challenging to develop case studies that do justice to real-life situations. However, always starting from an extreme situation can be a good way of preparing the trainee teachers so that the real situation does not take them by surprise. However, more than individual case studies is required as an all-encompassing preparation.” (Human Assessment: Descriptive Writing, AI Assessment: Dialogic Reflection) [RW2-KM]
5.1 Limitations
This study faces several limitations that warrant acknowledgment and consideration. First, regarding data limitations, we encountered challenges in addressing category imbalance. Despite employing rigorous sampling techniques to mitigate this issue, the “critical reflection” category was excluded due to its inconsistent fit within the dataset. Although this decision facilitated a concentrated examination of categories possessing adequate data, it concurrently limited the possibility to comprehensively investigate the role and impact of critical reflection within educational practices. Secondly, regarding the evaluation aspect, our study utilized the reflective level framework proposed by Hatton and Smith in 1995. This framework offers significant benefits, however, it might not fully encompass the breadth of reflective outcomes. Students’ reflections encompass a wide range of subjects and levels of cognitive depth, suggesting that a singular framework may not adequately capture this diversity. Consequently, the assessment criteria used in this study could restrict the thoroughness of our evaluation. Lastly, regarding the transparency and interpretability of the algorithms, our study employed sophisticated ML models, including pre-trained language models. Although pre-trained language models, such as BERT, demonstrate superior performance compared to shallow ML models. They often act as “black boxes,” offering limited insights into their decision-making processes. This opacity can be a significant shortcoming when the goal is to understand the nuanced aspects of reflective writing, a process inherently rich in context and subjectivity.
5.2 Implications and future work
The implications of this study surpass the boundaries of teacher education, resonating across a wide array of disciplines and professional fields where reflective writing and automated feedback play crucial roles. Enhancing students’ reflective skills presents a significant challenge across all areas of professional education (Jung et al., 2022; Körkkö et al., 2016). By leveraging a broader array of ML models, including the pre-trained language models assessed in this study, students can gain access to more precise and prompt feedback. This enhancement has the potential to significantly improve the quality of their reflective writing, which, in turn, can positively impact pedagogical practices. For educators, the adoption of automated systems offering highly accurate feedback presents benefits. It significantly reduces the workload involved in manually assessing reflective writings, allowing educators to allocate more time and energy to other vital teaching activities, including curriculum development, in-class engagement, and personal support for students.
For future research directions, it is essential to enhance the feedback mechanisms for reflective writing in education adressing several aspects. Firstly, the enhancement of feedback content must include the assessment of students’ self-regulation. As can be seen from the definition of reflection, in addition to including cognitive dimensions, there are also affective, psychological, and other aspects (Boud et al., 2013; Kember, 1999). While existing research has predominantly focused on task-level feedback (e.g., Hattie & Timperley, 2007), there has been a significant oversight in addressing self-regulated learning assessments. These assessments are crucial for evaluating students’ metacognitive and self-directed learning processes during reflective writing activities. By integrating indicators of self-regulation, educators can develop a more comprehensive understanding of students’ capabilities to monitor their learning progress, set objectives, and modify their cognitive approaches. Second, from a technological standpoint, AI-generated technologies, such as Retrieval Augmented Generation (RAG) (Lewis et al., 2020), offer substantial potential for enhancing the quality of feedback. RAG technology, which synergizes information retrieval and text generation capabilities, offers significant advantages in delivering personalized feedback for reflective writing. This method generates targeted and comprehensive feedback by retrieving information pertinent to a student’s specific assignment or query and then integrating it with the generative capabilities of neural networks. Furthermore, training LLMs on literature specific to various didactics (e.g., constructivism, behaviorism, cognitivism) can equip these models with a deeper understanding of these educational theories. This training allows the feedback generated to align more closely with the principles of the relevant didactics, thereby enhancing its educational effectiveness. Lastly, empirical validation of the effectiveness of these proposed assessment and feedback mechanisms is essential. Future research should employ experimental designs that implement these enhanced strategies with actual student populations. Conducting such empirical studies is crucial to determine whether these innovations genuinely support the development of reflective skills among students.
6 Conclusion
Reflective writing is a critical element of teacher education and is crucial for promoting professional development. However, the subjectivity and complexity of reflective writing make providing feedback a substantial challenge, previous research has tackled using ML and NLP techniques. These existing methods frequently encounter two significant obstacles: a reliance on sentence-level classification and the employment of low-quality training data. These approaches fail to capture the nuanced depth and multifaceted complexities of reflective writing. To overcome these challenges, the current study proposes two main innovations. First, we suggest the collection of reflective writings through e-portfolios, enabling a more structured and ongoing assessment of reflective practices. Second, we propose a document-level classification approach for the classification of reflective writing. By considering the entire text as a single unit of analysis, we aim to provide a more holistic and comprehensive understanding of the reflective process. Our study contrasts shallow ML algorithms with pre-trained language models in classifying reflective writing at the document level. Our empirical results demonstrate that pre-trained language models consistently surpass the performance of shallow ML algorithms, particularly highlighting the effectiveness of BigBird and Longformer in processing extended text sequences. This observation not only underscores the technical superiority of advanced language models but also contributes valuable insights into developing efficacious assessment strategies for reflective writing.
Data availability
Due to the presence of personally identifiable information within the dataset, it is not publicly shareable in accordance with privacy protection laws and ethical guidelines of the universities Erlangen-Nürnberg and Berlin involved in this research.
References
Atzeni, D., Bacciu, D., Mazzei, D., & Prencipe, G. (2022). A Systematic Review of Wi-Fi and Machine Learning Integration with Topic Modeling Techniques. Sensors,22(13), 4925. https://doi.org/10.3390/s22134925
Barthakur, A., Joksimovic, S., Kovanovic, V., Mello, R. F., Taylor, M., Richey, M., & Pardo, A. (2022). Understanding Depth of Reflective Writing in Workplace Learning Assessments Using Machine Learning Classification. IEEE Transactions on Learning Technologies,15(5), 567–578. https://doi.org/10.1109/TLT.2022.3162546
Beltagy, I., Peters, M. E., & Cohan, A. (2020). Longformer: The long-document transformer. arXiv:2004.05150. Retrieved June 22, 2023, from https://doi.org/10.48550/arXiv.2004.05150
Boud, D., Keogh, R., & Walker, D. (Eds.). (2013). Reflection: Turning experience into learning. Routledge.
Boyd, E. M., & Fales, A. W. (1983). Reflective learning: Key to learning from experience. Journal of Humanistic Psychology,23(2), 99–117. https://doi.org/10.1177/0022167883232011
Cai, Z., Gui, Y., Mao, P., Wang, Z., Hao, X., Fan, X., & Tai, R. H. (2023). The effect of feedback on academic achievement in technology-rich learning environments (TREs): A meta-analytic review. Educational Research Review, 100521. https://doi.org/10.1016/j.edurev.2023.100521
Carpenter, D., Geden, M., Rowe, J., Azevedo, R., & Lester, J. (2020). Automated analysis of middle school students’ written reflections during game-based learning. In Artificial Intelligence in Education: 21st International Conference, AIED 2020, Ifrane, Morocco, July 6–10, 2020, Proceedings, Part I 21 (pp. 67–78). Springer International Publishing. https://doi.org/10.1007/978-3-030-52237-7_6
Carvalho, D. V., Pereira, E. M., & Cardoso, J. S. (2019). Machine learning interpretability: A survey on methods and metrics. Electronics,8(8), 832. https://doi.org/10.3390/electronics8080832
Chan, B., Schweter, S., & Möller, T. (2020). German’s next language model. arXiv:2010.10906. Retrieved May 22, 2023, from https://doi.org/10.48550/arXiv.2010.10906
Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: Synthetic minority over-sampling technique. Journal of Artificial Intelligence Research,16, 321–357. https://doi.org/10.1613/jair.953
Chen, T., & Guestrin, C. (2016). Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining (pp. 785–794). https://doi.org/10.1145/2939672.2939785
Cheng, G. (2017). Towards an automatic classification system for supporting the development of critical reflective skills in L2 learning. Australasian Journal of Educational Technology, 33(4). https://doi.org/10.14742/ajet.3029
Chong, C., Sheikh, U. U., Samah, N. A., & Shaameri, A. Z. (2020). Analysis on reflective writing using natural language processing and sentiment analysis. In IOP Conference Series: Materials Science and Engineering (Vol. 884, No. 1, p. 012069). IOP Publishing. https://doi.org/10.1088/1757-899X/884/1/012069
Cui, Y., Wise, A. F., & Allen, K. L. (2019). Developing reflection analytics for health professions education: A multi-dimensional framework to align critical concepts with data features. Computers in Human Behavior,100, 305–324. https://doi.org/10.1016/j.chb.2019.02.019
Cutumisu, M., & Guo, Q. (2019). Using topic modeling to extract pre-service teachers understandings of computational thinking from their coding reflections. IEEE Transactions on Education,62(4), 325–332. https://doi.org/10.1109/TE.2019.2925253
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805. Retrieved May 22, 2023, from https://doi.org/10.48550/arXiv.1810.04805
Dewey, J. (1933). How we think: A restatement of the relation of reflective thinking to the educative process. D.C. Heath and Company.
Ebeling, W., & Neiman, A. (1995). Long-range correlations between letters and sentences in texts. Physica A: Statistical Mechanics and its Applications,215(3), 233–241. https://doi.org/10.1016/0378-4371(95)00025-3
Fan, X., Luo, W., Menekse, M., Litman, D., & Wang, J. (2017). Scaling reflection prompts in large classrooms via mobile interfaces and natural language processing. In Proceedings of the 22nd International Conference on Intelligent User Interfaces (pp. 363–374). https://doi.org/10.1145/3025171.3025204
Flavell, J. H. (1979). Metacognition and cognitive monitoring: A new area of cognitive–developmental inquiry. American Psychologist,34(10), 906. https://doi.org/10.1037/0003-066X.34.10.906
Friedman, J. H. (2001). Greedy function approximation: a gradient boosting machine. Annals of Statistics,29, 1189–1232.
Fütterer, T. (2019). Professional Development Portfolios im Vorbereitungsdienst. Die Wirksamkeit Von Lernumgebungen Auf Die Qualität Der Portfolioarbeit. Wiesbaden: Springer VS. https://doi.org/10.1007/978-3-658-24064-6
Gibbs, G. (1988). Learning by doing: A guide to teaching and learning methods. Oxford University Press.
Gibson, A., Kitto, K., & Bruza, P. (2016). Towards the discovery of learner metacognition from reflective writing. Journal of Learning Analytics,3(2), 22–36. https://doi.org/10.18608/jla.2016.32.3
Gläser-Zikuda, M. (2015). ePortfolios in Higher Education. In M. Spector (Ed.), Encyclopedia of Educational Technology (pp. 275–277). SAGE.
Gläser-Zikuda, M., Hagenauer, G., & Stephan, M. (2020). The potential of qualitative content analysis for empirical educational research. In Forum Qualitative Sozialforschung/Forum: Qualitative Social Research (Vol. 21, No. 1, p. 20). DEU. https://doi.org/10.17169/fqs-21.1.3443.
Gupta, N., Mujumdar, S., Patel, H., Masuda, S., Panwar, N., Bandyopadhyay, S., ... & Munigala, V. (2021). Data quality for machine learning tasks. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining (pp. 4040–4041). https://doi.org/10.1145/3447548.3470817
Hattie, J., & Timperley, H. (2007). The power of feedback. Review of Educational Research,77(1), 81–112. https://doi.org/10.3102/003465430298487
Hatton, N., & Smith, D. (1995). Reflection in teacher education: Towards definition and implementation. Teaching and Teacher Education,11(1), 33–49. https://doi.org/10.1016/0742-051X(94)00012-U
Hoerl, A. E., & Kennard, R. W. (1970). Ridge regression: Biased estimation for nonorthogonal problems. Technometrics, 12(1), 55–67. https://doi.org/10.1080/00401706.1970.10488634
Hopcan, S., Türkmen, G., & Polat, E. (2023). Exploring the artificial intelligence anxiety and machine learning attitudes of teacher candidates. Education and Information Technologies, 1–21. https://doi.org/10.1007/s10639-023-12086-9
Hu, X. (2017). Automated recognition of thinking orders in secondary school student writings. Learning: Research and Practice,3(1), 30–41. https://doi.org/10.1080/23735082.2017.1284253
Janiesch, C., Zschech, P., & Heinrich, K. (2021). Machine learning and deep learning. Electronic Markets,31(3), 685–695. https://doi.org/10.1007/s12525-021-00475-2
Jung, Y., & Wise, A. F. (2020). How and how well do students reflect? Multi-dimensional automated reflection assessment in health professions education. In Proceedings of the Tenth International Conference on Learning Analytics & Knowledge (pp. 595–604). https://doi.org/10.1145/3375462.3375528
Jung, Y., Wise, A. F., & Allen, K. L. (2022). Using theory-informed data science methods to trace the quality of dental student reflections over time. Advances in Health Sciences Education : Theory and Practice,27(1), 23–48. https://doi.org/10.1007/s10459-021-10067-6
Kember, D. (1999). Determining the level of reflective thinking from students’ written journals using a coding scheme based on the work of Mezirow. International Journal of Lifelong Education, 18(1), 18–30. https://doi.org/10.1080/026013799293928
Kolb, D. A. (1984). Experiential learning: Experience as the source of learning and development. Prentice Hall.
Körkkö, M., Kyrö-Ämmälä, O., & Turunen, T. (2016). Professional development through reflection in teacher education. Teaching and Teacher Education,55, 198–206. https://doi.org/10.1016/j.tate.2016.01.014
Korthagen, F., & Vasalos, A. (2005). Levels in reflection: Core reflection as a means to enhance professional growth. Teachers and Teaching,11(1), 47–71. https://doi.org/10.1080/1354060042000337093
Kovanović, V., Joksimović, S., Mirriahi, N., Blaine, E., Gašević, D., Siemens, G., & Dawson, S. (2018). Understand students self-reflections through learning analytics. In Proceedings of the 8th International Conference on Learning Analytics and Knowledge (pp. 389–398). https://doi.org/10.1145/3170358.3170374
Kraus, M., Feuerriegel, S., & Oztekin, A. (2020). Deep learning in business analytics and operations research: Models, applications and managerial implications. European Journal of Operational Research,281(3), 628–641. https://doi.org/10.1016/j.ejor.2019.09.018
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., ... & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33, 9459–9474.
Li, Y., Wehbe, R. M., Ahmad, F. S., Wang, H., & Luo, Y. (2023). A comparative study of pretrained language models for long clinical text. Journal of the American Medical Informatics Association,30(2), 340–347. https://doi.org/10.1093/jamia/ocac225
Liu, M., Shum, S. B., Mantzourani, E., & Lucas, C. (2019a). Evaluating Machine Learning Approaches to Classify Pharmacy Students Reflective Statements. In S. Isotani, E. Millán, A. Ogan, P. Hastings, B. McLaren, & R. Luckin (Eds.), Lecture Notes in Computer Science. Artificial Intelligence in Education (Vol. 11625, pp. 220–230). Springer International Publishing. https://doi.org/10.1007/978-3-030-23204-7_19
Liu, Q., Zhang, S., Wang, Q., & Chen, W. (2017). Mining online discussion data for understanding teachers reflective thinking. IEEE Transactions on Learning Technologies,11(2), 243–254. https://doi.org/10.1109/TLT.2017.2708115
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., ... & Stoyanov, V. (2019b). Roberta: A robustly optimized bert pretraining approach. arXiv:1907.11692. Retrieved May 22, 2023 from https://doi.org/10.48550/arXiv.1907.11692
McHugh, M. L. (2012). Interrater reliability: the kappa statistic. Biochemia medica, 22(3), 276–282. Retrieved May 22, 2023, from https://hrcak.srce.hr/89395
Mezirow, J. (1991). Transformative dimensions of adult learning. Jossey-Bass.
Minixhofer, B., Paischer, F., & Rekabsaz, N. (2021). WECHSEL: Effective initialization of subword embeddings for cross-lingual transfer of monolingual language models. arXiv:2112.06598. Retrieved May 22, 2023, from https://doi.org/10.48550/arXiv.2112.06598
Moon, J. A. (2013). Reflection in learning and professional development: Theory and practice. Routledge.
Narciss, S. (2006). Informatives tutorielles Feedback: Entwicklungs-und Evaluationsprinzipien auf der Basis instruktionspsychologischer Erkenntnisse. Waxmann.
Nehyba, J., & Štefánik, M. (2023). Applications of deep language models for reflective writings. Education and Information Technologies,28(3), 2961–2999. https://doi.org/10.1007/s10639-022-11254-7
Pennebaker, J. W., Boyd, R. L., Jordan, K., & Blackburn, K. (2015). The development and psychometric properties of LIWC2015. Retrieved June 10,2023, from http://hdl.handle.net/2152/31333
Poldner, E., van der Schaaf, M., Simons, P.R.-J., van Tartwijk, J., & Wijngaards, G. (2014). Assessing student teachers reflective writing through quantitative content analysis. European Journal of Teacher Education,37(3), 348–373. https://doi.org/10.1080/02619768.2014.892479
Robbins, H., & Monro, S. (1951). A stochastic approximation method. The Annals of Mathematical Statistics,22, 400–407.
Rosé, C., Wang, Y. C., Cui, Y., Arguello, J., Stegmann, K., Weinberger, A., & Fischer, F. (2008). Analyzing collaborative learning processes automatically: Exploiting the advances of computational linguistics in computer-supported collaborative learning. International Journal of Computer-Supported Collaborative Learning,3, 237–271. https://doi.org/10.1007/s11412-007-9034-0
Russell, T., & Korthagen, F. (Eds.). (2013). Teachers who teach teachers: Reflections on teacher education. Routledge.
Savicki, V., & Price, M. V. (2015). Student Reflective Writing: Cognition and Affect Before, During, and After Study Abroad. Journal of College Student Development,56(6), 587–601. https://doi.org/10.1353/csd.2015.0063
Schön, D. A. (1983). The reflective practitioner. Jossey-Bass.
Schön, D. A. (1987). Educating the reflective practitioner: Toward a new design for teaching and learning in the professions. Jossey-Bass.
Solopova, V., Rostom, E., Cremer, F., Gruszczynski, A., Witte, S., Zhang, C., ... & Landgraf, T. (2023). PapagAI: Automated Feedback for Reflective Essays. In German Conference on Artificial Intelligence (Künstliche Intelligenz) (pp. 198–206). Cham: Springer Nature Switzerland. https://doi.org/10.1007/978-3-031-42608-7_16
Springer, D. G., & Yinger, O. S. (2019). Linguistic Indicators of Reflective Practice Among Music Education Majors. Journal of Music Teacher Education,28(2), 56–69. https://doi.org/10.1177/1057083718786739
Stede, M. (Ed.). (2016). Handbuch Textannotation: Potsdamer Kommentarkorpus 2.0 (Vol. 8). Universitätsverlag Potsdam.
Tan, L., Lu, J., & Jiang, H. (2021). Tomato Leaf Diseases Classification Based on Leaf Images: A Comparison between Classical Machine Learning and Deep Learning Methods. AgriEngineering,3(3), 542–558. https://doi.org/10.3390/agriengineering3030035
Ullmann, T. D. (2019). Automated Analysis of Reflection in Writing: Validating Machine Learning Approaches. International Journal of Artificial Intelligence in Education,29(2), 217–257. https://doi.org/10.1007/s40593-019-00174-2
Wulff, P., Buschhüter, D., Westphal, A., Nowak, A., Becker, L., Robalino, H., Stede, M., & Borowski, A. (2021). Computer-Based Classification of Preservice Physics Teachers Written Reflections. Journal of Science Education and Technology,30(1), 1–15. https://doi.org/10.1007/s10956-020-09865
Wulff, P., Mientus, L., Nowak, A., & Borowski, A. (2023). Utilizing a pretrained language model (BERT) to classify preservice physics teachers’ written reflections. International Journal of Artificial Intelligence in Education,33(3), 439–466. https://doi.org/10.1007/s40593-023-00330-9
Zaheer, M., Guruganesh, G., Dubey, K. A., Ainslie, J., Alberti, C., Ontanon, S., ... & Ahmed, A. (2020). Big bird: Transformers for longer sequences. Advances in Neural Information Processing Systems, 33, 17283–17297.
Zanette, D. H. (2014). Statistical patterns in written language. arXiv:1412.3336. Retrieved May 2, 2023, from https://doi.org/10.48550/arXiv.1412.3336
Zawacki-Richter, O., Marín, V. I., Bond, M., & Gouverneur, F. (2019). Systematic review of research on artificial intelligence applications in higher education–where are the educators? International Journal of Educational Technology in Higher Education,16(1), 1–27. https://doi.org/10.1186/s41239-019-0171-0
Zhai, X., Chu, X., Chai, C. S., Jong, M. S. Y., Istenic, A., Spector, M., ... & Li, Y. (2021). A Review of Artificial Intelligence (AI) in Education from 2010 to 2020. Complexity, 2021, 1–18. https://doi.org/10.1155/2021/8812542
Zhang, C., Schießl, J., Plößl, L., Hofmann, F., & Gläser-Zikuda, M. (2023a). Evaluating Reflective Writing in Pre-Service Teachers: The Potential of a Mixed-Methods Approach. Education Sciences,13(12), 1213. https://doi.org/10.3390/educsci13121213
Zhang, C., Schießl, J., Plößl, L., Hofmann, F., & Gläser-Zikuda, M. (2023b). Acceptance of artificial intelligence among pre-service teachers: A multigroup analysis. International Journal of Educational Technology in Higher Education,20(1), 49. https://doi.org/10.1186/s41239-023-00420-7
Zimmerman, B. J. (2002). Becoming a self-regulated learner: An overview. Theory into Practice,41(2), 64–70. https://doi.org/10.1207/s15430421tip4102_2
Acknowledgements
We wish to express our appreciation to Jessica Schießl, and Meltem Doganay for their contribution to the secondary coding of sections of the reflective writing.
Funding
Open Access funding enabled and organized by Projekt DEAL. This work was supported by the Federal Ministry of Education and Research (Germany) [obtained by Prof. Dr. Michaela Gläser-Zikuda, grant number 16DHB4019]. The authors express their gratitude.
Author information
Authors and Affiliations
Contributions
MGZ and CZ conceived the study. FH and LP carried out the data collection. CZ conducted data analysis and prepared the manuscript draft. Both MGZ and FH supervised the study and revised the manuscript draft. All authors made significant contributions to the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
None.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, C., Hofmann, F., Plößl, L. et al. Classification of reflective writing: A comparative analysis with shallow machine learning and pre-trained language models. Educ Inf Technol (2024). https://doi.org/10.1007/s10639-024-12720-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10639-024-12720-0