
Abstract
The study aimed to develop a Likert-type measurement tool (Digital Literacy Scale, DLS) to determine the digital literacy levels of secondary school students. The validity and reliability of the developed measurement tool were verified using the Rasch model. The Rasch Model can estimate missing data and allow for small study groups (Rasch, Rasch, Probabilistic models for some intelligence and attainment tests, Danish Institute for Educational Research, 1960). Additionally, this model can verify the expected pattern of the measurement tool by calibrating it across participants and items. The content validity of DLS was ensured by expert opinion, and the construct validity was ensured by using the Rach model. In the content validity study, a 25-item pool was created for the draft DLS, and 5 items were removed from the draft DLS at this stage. Construct validity studies were carried out with the remaining 20 items using the classical test theory and item response theory (Rasch model). Exploratory Factor Analysis (EFA) and first-level Confirmatory Factor Analysis (CFA) were used within the scope of classical test theory. Then some Rasch assumptions such as dimensionlessness, local independence, monotonicity, and bias were tested for DLS. In the validity and reliability analysis of DLS, no items were eliminated, and the quantitative theoretical results were statistically confirmed. The analysis results showed that the minimum statistical values required for a good measurement tool were met. Accordingly, 20 valid and reliable compatible items that can be used to determine the digital literacy status of secondary school students were produced.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Digital literacy refers to the ability to access, understand, evaluate, create, and communicate information using digital technologies (Van Laar et al., 2020). In today’s digital age, where technology is everywhere and permeates every aspect of our lives, digital literacy has become an essential skill that everyone should have. Individuals need to gain the ability to use and navigate digital tools and platforms to stay up-to-date and participate fully in society, such as in accessing information, communicating, education, work, and social interactions (Helsper & Eynon, 2010). In society, learning new skills and acquiring knowledge through online resources that can increase employability and career prospects can facilitate lifelong learning and personal and professional development by providing access to a wide range of information and resources (Mishra & Koehler, 2006; Rogers et al., 2014). Knowing how to access information, use their knowledge, and produce new information for these potential benefits is accepted as an indicator that the individual is a member of the information society (Gündüz & Odabaşı, 2004). On the other hand, especially in the digital age, political and social discussions often take place online, and digital literacy is necessary to critically evaluate information, use social media platforms correctly, participate in discussions and make informed decisions, and engage in democratic participation (Mossberger et al., 2007).
In today’s digital society, digital literacy is crucial for economic growth and competitiveness. Individuals who do not have digital literacy skills may face several obstacles to employment and economic opportunities (European Commission, 2017). Additionally, digital technologies are increasingly integrated into various sectors, such as healthcare, education, and finance, and individuals increasingly need digital literacy skills to effectively navigate these areas (Wang & Si, 2023; Yaqoob et al., 2023). Digital literacy is also essential for social inclusion and equality. Inequalities in access to digital technologies and digital literacy skills can lead to a digital divide in which certain individuals or groups are prevented from fully participating in the digital society (Hargittai, 2010). Therefore, it is emphasized that digital literacy should aim to address these inequalities and ensure that everyone has the opportunity to acquire digital skills. According to the Telecommunications Directorate of Communications (2012), in addition to the potential and current benefits of internet use, online theft, fraud, misdirection, cyberbullying, respect for a person’s private rights, sharing of personal information, exploitation of malicious software, etc., it is necessary for individuals to have digital literacy skills to prevent undesirable behavior, ensure the reliability of the source of the news, and ensure communication security (Atif & Chou, 2018; Hamutoğlu et al., 2017).
Considering its multidisciplinary features and the latest progress in the technological field, it seems that digital literacy has become a fundamental component of modern education (Martin & Grudziecki, 2006; Yeşilyurt & Vezne, 2023). The reason for this is that technology is of great importance in determining how education will change in the future and that the learning process in the twenty-first century takes place in a rapidly changing and technology-filled environment (Banaszewski, 2005; Yang & Wu, 2012). Digital literacy, which is defined as the awareness, attitude, and ability of individuals to recognize, access, manage, evaluate, analyze, synthesize digital resources, create new knowledge, create expressions in mass media, and communicate with others, has become an important component of the curriculum in terms of education (Martin, 2005). Many educational institutions, from primary school to higher education, are integrating digital literacy education into their programs in various forms, such as computer science courses, digital citizenship programs, and online safety training. Additionally, integrating technology into education provides students with an engaging learning experience, making them more interested in the subject without distraction (Bilotta et al., 2021; Haleem et al., 2023). However, it is important that digital literacy education not only teaches technical skills but also emphasizes critical thinking, problem-solving, and responsible use of technology (Fraillon et al., 2014). In a study by Voogt et al. (2008) in which the concept of digital literacy was examined in the context of education, it was stated that education should not only focus on technical skills but also emphasize critical thinking, problem-solving, and the ethical use of digital technologies. Similarly, according to Van Laar et al. (2020), digital skills are stated as a tool to achieve concrete results, not an end in themselves. Therefore, digital literacy education should aim to develop critical thinking skills, creativity, problem-solving skills, and the ethical and responsible use of technology. Søby (2013) stated that for the new generation, who are interactive participants in the digitally competent information society, learning environments will move away from the use of traditional tools and the use of more content and motivating digital media will increase. Specifically, to have these skills, it is stated that educational institutions must equip students with the necessary knowledge and skills to function effectively in the digital world. It is also emphasized that digital literacy education for the field of technology, which continues to develop at an unprecedented pace, should be integrated into education and focus on developing lifelong learning skills to prepare students for the rapidly changing digital society, enabling individuals to adapt to new technologies and digital environments (Fraillon et al., 2014). In this context, the digital transformation awareness, digital attitudes and behavioral patterns of secondary school students, who are called digital natives especially in today's technological living conditions, are directly related to their digital literacy status (Jan, 2018).
2 Problem status
In general, the concept of digital literacy has become an indispensable part of society in line with today’s technological conditions and opportunities (Falloon, 2020). Even if we only consider today, it is a fact that digital tools and concepts cannot be avoided in society and that we have access to these tools and concepts either voluntarily or through exposure. It is stated that 94.1% of households in Turkey will have access to the internet from home in 2022, and the regular internet usage rate for children in the 6–15 age group will be 82.7% in 2021 (Turkish Statistical Institute, 2021; Turkish Statistical Institute, 2022). In addition, in a study on the extent to which parents supervised children’s internet use at home, it was found that 56% of them were supervised, and in another study, 52% of them were not at all or almost not at all (Valcke et al., 2007, 2011). The importance of digital literacy for correct, efficient, and safe internet use under current and potential technological conditions is constantly expressed in every medium. According to research, an average of 70% of the user base of internet usage and most gaming industries consists of individuals under the age of 16 (Dean, 2022; Park & Kim, 2022). Digital technology is accessible to everyone, and today digital media has become an important tool for most people, whether children, teenagers, adults, or the elderly. The most commonly used media tools by children are digital media (Üstündağ, 2021).
Due to economic, cultural, and social developments and changes, individuals need achievements in various fields and various skills to reflect these achievements in their lives. To meet these needs, program development studies are constantly carried out in our country (Gömleksiz & Cüro, 2011). In this regard, the curriculum updated in 2018 aims to provide individuals with the skills of each course at a basic level. One of these skills is digital literacy skill (Ministry of National Education, 2020). Especially in the field of education, the dramatic development of the phenomenon of digitalization to provide application, research-based, and more entertaining learning opportunities in the learning processes of students in certain age groups has made distance education a concept we hear frequently (Durak et al., 2020). Especially after the COVID-19 pandemic, which the world has been experiencing for a long time, and the recent severe earthquake centered in Kahramanmaraş, distance education has come to the agenda again, with the education being carried out through digital tools, to continue education (Aksoy et al., 2021; Üstündağ, 2021). It has also been reported that, as a result of the widespread use of digital media tools in recent years, children’s usage rates have increased significantly (Child Trends DataBank, 2015). In addition, with the development of digital technologies, cybercrimes, and threats have increased in parallel with the increasing interest, motivation, and positive attitude toward internet use (Rodríguez-de-Dios et al., 2016). Particularly research conducted after 2020 emphasizes that Generation Z, who was born as a digital native, uses digital technologies more than their teachers and parents, but does not have the same experience with the cyber threats and negativities they may encounter (Bagdi & Bulsara, 2023; Erdoğan, 2021; Evans & Robertson, 2020; Korkmaz, et al., 2024; Talan & Aktürk, 2021; Tran et al., 2020; Turano & Saludadez, 2024).
In addition to all these developments, in studies conducted in the field of education and technology, secondary school students are frequently used as a research group in digital literacy studies for various reasons. Considered a critical period in terms of cognitive, social, and emotional development, secondary school students are at an age where they are increasingly involved in digital technologies and developing their digital literacy skills (Rodríguez-de-Dios et al., 2016). Many middle school students are considered “digital natives” because they grew up in a technology-rich environment (Bennett et al., 2008). They are generally more familiar and comfortable with digital tools and platforms than older generations, making them an important group to study in the context of digital literacy (Toraman & Usta, 2018). Examining digital literacy among secondary school students helps educators and policymakers understand how to best prepare young people for the digital world they will encounter in higher education, the workforce, and society at large. Additionally, by examining this group, researchers can evaluate the effectiveness of various teaching methods, curriculum designs, and interventions (Kilag et al., 2023). Literature in education and digital literacy supports the use of secondary school students as a research group through empirical studies, theoretical frameworks, and educational policies (Reddy et al., 2023a). Research shows that today’s youth have a high level of familiarity and comfort with digital technologies. This familiarity makes them a suitable group to study digital literacy practices and behaviors. Many education systems around the world have recognized the importance of integrating digital literacy into the curriculum (Hays et al., 2023; Morgan et al., 2016). Policies and initiatives aimed at improving digital literacy often target secondary school students, reflecting recognition of their role as future citizens and professionals in the digital society. For these and similar reasons, awareness of the digital skills gap among young people, including secondary school students, is increasing (Walther et al., 2014; Walton et al., 2011). Moreover, the distance education model, which has recently become popular in education independent of time and place, has become an indispensable concept for individuals who cannot participate due to transportation-based access restrictions, keeping up with the times, or various health reasons, to compensate for interrupted education and support existing education (Bozkurt, 2020). What is required for the efficient use of distance education in digitalized classroom environments is the ability of students and teachers to use digital tools such as phones, computers, tablets, and televisions (Søby, 2013). Individuals need to be good digital literates in many aspects such as spending quality time in digital life, obtaining efficient outputs, accessing accurate information, using and sharing information (Özerbaş & Kuralbayeva, 2018). In addition, with technological developments, teaching materials, legal regulations, ethical perceptions, teaching models, society’s demands and accessibility are changing and developing day by day (de Vries, 2022). Since digital literacy skills are dynamic with their constantly developing, changing, and renewing structure, the individual who was digitally literate yesterday needs to develop and change in order not to remain inadequate and incomplete today (Korkmaz & Akçay, 2024).
Considering all its positive effects such as education, social communication, safe internet, and personal development, the importance of digital literacy emerges as an undeniable fact today. In this context, a 4-point Likert-type Digital Literacy Scale (DLS) was developed within the scope of the study to measure the digital literacy levels of secondary school students. Developed for secondary school students, the DLS’s validity and reliability have been confirmed with the Rasch model, which facilitates the interpretation of items of unequal difficulty, eliminates the disadvantage in cases where the differences between categories are not equal, and is described as advantageous in terms of estimating missing data and allowing small study groups (Elhan & Atakurt, 2005). Accordingly, the study aimed to verify the validity and reliability statistics of the DLS for secondary school students using the Rasch model (Rasch, 1960). The problem statement of the research was formed as “What are the digital literacy levels of secondary school students?”.
On the other hand, the sub-problems were determined as follows:
-
1.
Is the scale developed to determine the digital literacy of secondary school students valid and reliable?
-
2.
What are the parameters of the scale developed to determine the digital literacy of secondary school students?
3 Method
3.1 Research model
Although this research is a scale development study in terms of the methods and techniques it includes, it was carried out according to the survey model within the framework of quantitative research. In the research, information about the study group, the development of the scale, the measurement tool, and the techniques used in the analysis of the obtained data are given in the relevant sections, respectively, to determine and explain the current situation and analyze it.
3.2 Data collection tool
In this research covering an academic period, a survey model was used as a data collection tool. The content validity of the draft DLS form was ensured by expert opinion. The structural validity of DLS, whose content validity was established, was examined through Rasch analysis and the Winsteps program. The data obtained from the study group was obtained through a survey form prepared in a 5-point Likert type.Footnote 1 5-point Likert-type rating levels were used for the fear items in the DLS form. After conducting the analysis, it was concluded that the appropriate format for the developed scale is a 4-point Likert scale. The insights gained from the analyses guided the creation of a DLS using a 4-point Likert format to assess the digital literacy levels of secondary school students.
3.3 Study group
Linacre (1993) reported that the results of the analysis of data obtained from a sample in the Rasch measurement method cannot be generalized to the universe. For this reason, the concept of “group study” was used in the study and no population was determined. It is known that children, who have generally spent time at home in the last two years due to the current pandemic process, have been exposed to digital media such as computers, tablets, mobile phones, and television for a long time (Üstündağ, 2021). Additionally, in case of a problem, the sample group was determined with the support of various institutions/organizations or scientific publications. A deliberate sampling technique was used when determining the sample. According to this technique, the sample is selected by the researcher from people who can find answers to the research problems. The criterion in determining the sample is the researcher’s opinion that the sample will meet the need (Altunışık et al., 2005). A digital literacy scale is needed for students to acquire digital literacy skills, improve these skills, and reveal their current situation (Pala & Başıbüyük, 2020). Accordingly, the study group of the research consists of students studying in different classes of various secondary schools in the Çanakkale province located in the southwest of Turkey in the fall semester of the 2022–2023 academic year.
In the research, 251 students (131 female and 120 male students) from various classes (5th, 6th, 7th, and 8th grades) were included in the process. The number of students in the classes was chosen to be similar in terms of gender. The research was conducted with secondary school students who participated in the research within the scope of the voluntary participation principle. Before the scale items developed within the scope of the research were presented to the students, a “Voluntary Consent Text” was prepared and they were asked to fill it out. Since all 251 students who filled out the consent form were willing as individuals, no student refused or offered to do it later (Table 1).
3.4 Data collection process
The survey form developed within the scope of the study was used as a data collection tool in the research. In the study, the steps in Fig. 1 were followed in the development of the DLS for secondary school students. Accordingly, a group of secondary school students were asked to write a composition describing their feelings, thoughts, and skills regarding digital literacy. The compositions were examined and some sentences that were thought to be digital literacy items were edited, and the draft was submitted to DLS. In addition, articles related to digital literacy were scanned in the literature using relevant databases. Care was taken to ensure that the criterion items considered to be included in the measurement tool reflected cognitive, affective, and behavioral dimensions. The 25-item draft DLS was submitted to the expert opinion. DLS was evaluated in terms of language, scope, and psychometrics. In line with expert opinion evaluations and recommendations, 5 items were removed from DLS. Thus, the content validity of the draft DLS was ensured. The draft DLS was then tested for Rasch analysis assumptions. As a result of EFA and reliability analysis, it was determined that all items met sufficient limitations. Thus, the final version of the productive 20-item DLS was obtained (Fig. 1).

Development process of DLS
3.5 Data analysis
As part of the comprehensive evaluation of the content validity of the DLS questionnaire, an in-depth analysis of the data collected from expert evaluations was meticulously conducted using Microsoft Excel 2019. Subsequently, the quest for unidimensionality, a fundamental prerequisite for Rasch analysis, and the pursuit of reliability assessments was undertaken through the utilization of the SPSS® Statistics 28.0 software. To further delve into the construct validity and reliability of the DLS questionnaire, an extensive examination was carried out with the aid of the WINSTEPS software package (version 5.1.5.2). In the realm of Rasch analyses, particular emphasis was placed on scrutinizing the dimensionality and assessing the questionnaire’s reliability. Furthermore, a meticulous evaluation of item polarity and item compliance was conducted to enhance the robustness and validity of the DLS questionnaire.
4 Results
This section encompasses a comprehensive exposition of the outcomes derived from the rigorous validity and reliability investigations conducted during the intricate developmental phase of the DLS questionnaire. Within this contextual framework, detailed presentations of the Content Validity Ratio (CVR) and Content Validity Index (CVI) values for each questionnaire item, as assessed through expert evaluations, are provided to offer a robust foundation for understanding the content validity of the DLS. Additionally, we delve into the results of thorough examinations, encompassing normality analysis, dimensionality analysis, and the alignment of data-model fit. These investigations pertain to the structural validity of the DLS questionnaire, elucidating the compatibility of the questionnaire’s structure with the underlying constructs it aims to measure. This multifaceted approach serves to comprehensively document the meticulous process undertaken to ensure the DLS questionnaire’s soundness, integrity, and effectiveness as a measurement tool.
4.1 Content validity of DLS
Content validity is the extent to which the items developed in a measurement tool accurately represent the intended attitude to be assessed, ensuring that each item effectively serves its purpose. This concept is essential for ensuring that the measurement tool includes relevant concepts with strong representational power, rather than irrelevant ones. Evaluating the appropriateness of each item in terms of its capacity to provide meaningful data for the intended purpose is of paramount importance. To address this, the content validity of the DLS questionnaire for secondary school students was assessed by the guidelines put forth by Polit and Beck (2006). The assessment of content validity for DLS was achieved through the collective judgment of experts. An expert panel, comprising specialists from diverse fields, was assembled through appropriate sampling methods, and the initial 30-item draft of the DLS questionnaire was subjected to expert scrutiny. First of all, 5 items were removed at this stage. The 25-item draft DLS was submitted to expert opinion for content validity. Additionally, space for additional comments or suggestions from the experts was provided for each item in the draft questionnaire. The expert panel consisted of one Turkish language expert, one measurement and evaluation expert, five computer teaching experts, two computer engineers, and five science teachers. The research areas and interests of all experts in this group overlap with the subject of the research.
The area of expertise of the Turkish language expert in the expert group is scale development. In this context, a Turkish language expert was asked to examine the suitability of the scale for the sample group. Thus, it was aimed to optimize the sample group in terms of meaning and understandability, taking into account the age group. The expert in the expert group, whose field of expertise is scale development, received ideas regarding the technique and meaning of the scale items. The previous works of the expert in the field of scale development were taken into consideration and the quality of his work was examined. As a result of the necessary examinations, it was decided that he would be in the group as an expert. The expert was asked to examine features such as conformity to the literature, language, and understandability. In addition, their opinions and suggestions about examining the integrity of the entire scale were also received orally. In the selection of computer teaching and computer engineering experts, their characteristics of both studying innovative technologies and working in the field of scale development were taken into consideration. Thanks to computer teaching experts, the harmony of technology and its integration in education and the scale items were examined. Opinions were received for the scale items in terms of digital literacy. Finally, science teachers and experts who worked on 21st-century skills, specifically digital literacy skills were selected. It was aimed to obtain the opinions of selected science experts within the framework of the updated program as of the 2018 Science Curriculum (Ministry of National Education, 2018). Obtaining up-to-date data from science teachers and examining students’ current age range and interests, as well as their digital literacy skills, were in-depth.
A group of 14 experts was separately consulted to gather their insights on various aspects of the test, including the clarity of the test language, the test’s overall structure, the need for specialized knowledge in responding to items, the adequacy of the item count, and identification of inadequacies within the items. The scoring methodology for each item was by the recommendations of Muhamad Saiful Bahri Yusoff (Yusoff, 2019). Content validity plays a pivotal role in ensuring the accurate measurement of the intended phenomenon with a measurement tool. To secure content validity, both quantitative and qualitative indicators obtained from experts’ evaluations of the proposed items are vital. These indicators aid in rectifying any missteps during the development of the measurement tool and refining its content. Key quantitative measures for estimating content validity include the Content Validity Ratio (CVR) and the Content Validity Index (CVI). CVR is critical for deciding whether each item should be retained in the measurement tool, while CVI provides an average content validity rate for all items retained (Ayre & Scally’s, 2014).
In a nutshell, CVR determines the necessity of each item within the measurement tool, while CVI establishes the relationship of each item to the measurement tool. In this study, CVR values were calculated in line with Ayre and Scally’s (2014) recommendations, and CVI values were assessed based on the guidelines of Polit and Beck (2006). A critical CVR value of 0.51 was established for the evaluation by the panel of 14 experts, leading to the identification of five items in the draft questionnaire that did not meet the recommended criteria. In addition, this study expanded the scope of content validity assessment by considering Muhamad Saiful Bahri Yusoff’s (2019) suggestions. The usability of these five items in the measurement tool was also determined through I-CVR and S-CVI values. I-CVI reflects the item-specific scope indices, while S-CVI assesses the overall content validity of the scale. Moreover, S-CVI can be expressed in two ways, either as S-CVI/Ave, which averages I-CVI values across all items, or as S-CVI/UA, which accounts for the number of experts in agreement, referred to as the universal consensus method in content validity assessment.
The concepts mentioned in this context were previously articulated by Polit and Beck (2006). By their recommendations, it is emphasized that in studies involving five or more expert panels, the I-CVI value should attain a minimum threshold of 0.78 or higher. Furthermore, it is underscored that the suggested S-CVI/Ave and S-CVI/AU values should ideally surpass 0.80 to ensure the overall scale’s robust content validity. A value exceeding 0.90 is deemed exemplary for a measurement tool’s quality. In the evaluation of the DLS, it was found that each item achieved an I-CVI value greater than 0.78. Additionally, the S-CVI/Ave ratios were observed at 0.99, and 0.88 for S-CVI/AU. Subsequently, the kappa index (k*) was computed to account for chance factors among participants. k* serves as an inter-expert agreement index that delves into the relevance, clarity, comprehensibility, and overall quality of the items, as outlined by Wynd et al. (2003). In the assessment of kappa, Fleiss’ (1971) recommended criteria were employed. As a result of expert opinions, five items—specifically, those numbered 7, 17, 18, 22, and 25 were excluded from the initial 25-item draft measurement tool. These items were omitted due to their inability to meet the required thresholds for CVRcritical, I-CVR, and kappa values. Subsequently, the revised DLS, now comprising 20 items, each using a 5-Likert scale, was deemed suitable for construct validity assessment. Table 2 is presented to provide a comprehensive overview of expert opinions regarding the content validity of the DLS questionnaire.
4.2 Structure validity of DLS
In the meticulous endeavor to establish the construct validity of the DLS questionnaire, Rasch modeling was employed to ascertain its underlying limitations. This in-depth examination was complemented by EFA and internal consistency analyses, providing a holistic perspective on the questionnaire’s construct validity. Furthermore, the interactions among items within the DLS questionnaire were subject to rigorous scrutiny. This involved an extensive investigation, employing techniques such as Analysis of Variance (ANOVA) with Tukey’s Test for Nonadditivity and Hotelling’s T-Squared analysis. These analytical methods were crucial in uncovering intricate item relationships and patterns within the questionnaire. Additionally, the interclass correlation coefficients were meticulously computed, shedding light on the extent of agreement and consistency among the questionnaire’s items. In parallel with the Rasch analysis, a comprehensive examination of dimensionality, reliability, item polarity, and item cohesion was conducted. This multifaceted approach allowed for a comprehensive understanding of the DLS questionnaire’s underlying structure, internal consistency, and the intricate dynamics between its constituent items. Such rigorous assessments serve to strengthen the construct validity of the DLS questionnaire, reinforcing its effectiveness as a robust measurement tool.
4.3 Normality analysis and one-dimensionality
To commence the assessment of structural validity for the 20-item draft of the DLS questionnaire, which has previously undergone meticulous content validity evaluation, an initial step involved conducting normality analyses. In structural validity studies, the normal distribution of the data was first evaluated in the study. Normal distribution is a basic assumption for statistical analysis and EFA and CFA (Hair et al., 2010). Hair et al. (2010) attributed normality to the way the data were distributed for individual metric variables. In this study, skewness and kurtosis statistical methods, which are analytical methods, were applied to check normality (Hair et al., 2010; Kline, 2011; Tabachnick & Fidell, 2013). Kim (2013) emphasized the importance of skewness and kurtosis test, regardless of sample size, for a valid normality test. However, Tabachnick and Fidell (2013) stated that when sample sizes are over 200, deviations in skewness and kurtosis normalities do not affect statistical analyzes much. There is some debate in the literature regarding the statistical values of skewness and kurtosis. Trochim and Donnelly (2006), George (2011) and Field (2009) accepted the skewness and kurtosis statistical value ranges as ± 2 in their normality analyses, but Hair et al. (2010) stated that the skewness of the data should be between ± 2 and the kurtosis should be between ± 7 at most. This situation was also supported by Byrne (2010). On the other hand, Brown (2006) stated that the data can be considered normally distributed if the skewness value is between ± 3 and the kurtosis value is at most ± 10. Kline (2011) reported that the kurtosis value exceeding ± 20 was a major problem. According to the literature summary stated above, the skewness value should not exceed 3 and the kurtosis value should not exceed 10. Accordingly, it was concluded that the data obtained from 251 people met the normality assumptions, and the research continued by giving the relevant data in Table 3.
Consequently, a dataset derived from the responses of 251 secondary school students to the 20 questionnaire items was scrutinized. The skewness coefficient for this dataset was computed as -1.94 ± 0.154, while the kurtosis coefficient was determined to be 4.28 ± 0.306. In statistics, the kurtosis of a standard normal distribution is accepted as 3 and is defined as mesokurtic. Increased kurtosis can be visualized as a thin “bell” with a high apex. Whereas reduced kurtosis (leptokurtic distribution—kurtosis > 3) corresponds to broadening of the peak and “thickening” of the tails (platykurtic distribution—kurtosis < 3). Leptokurtic distributions have a broader or flatter shape with thicker tails (Algina et al., 1989; d'Acremont et al., 2016; Stühmer et al., 2020). This type of overload greatly affects the greater chance of positive or negative events resulting. This has been interpreted as the main reason for the collapse of category 3 in DLS, as will be reported in the following sections (See “The Diagnostics” and “Discussion”). In the domain of item response theory, the Rasch analysis stands as a pivotal approach (Linacre, 2003). To ensure a correct interpretation of the results yielded by the Rasch analysis, a prerequisite entails verifying that the data adheres to the assumption of unidimensionality. In this vein, EFA was employed as a crucial diagnostic tool to assess the unidimensionality of the dataset. Through EFA, a thorough investigation was conducted to ascertain whether the data manifested the essential characteristic of unidimensionality, a pivotal determinant of the DLS questionnaire’s structural validity. As delineated by Raykov and Marcoulides (2008), EFA serves as a potent analytical approach that offers profound insights into the psychometric properties of a measurement instrument, shedding light on the latent variables within the dataset. EFA plays a pivotal role in elucidating the inherent structural underpinnings of the data, thus providing a comprehensive understanding of its multidimensional facets. In the present study, the factor extraction method employed within the EFA framework was the principal component method. Rotation was carried out using the Varimax method, and missing data were addressed using the Listwise Selection approach. To assess the sample adequacy, the Kaiser–Meyer–Olkin (KMO) statistic yielded a value of 0.965, and the Bartlett test of sphericity exhibited statistical significance (χ2 = 6335.707, df = 190, p < 0.00). These results collectively affirmed the suitability of the sample for factor analysis, as reported by Büyüköztürk (2005). Notably, when the KMO coefficient surpasses 0.9, the adequacy of the sample is considered impeccable, indicating that the dataset is essentially unifactorial, thus confirming the data’s unidimensionality.
Within the assessment of factor loadings for the criteria, it was revealed that the smallest factor loading value amounted to 0.779, while the highest factor loading value reached 0.911. Furthermore, the analysis results unveiled that the common load values spanned a range from 0.830 to 0.607. By Pallant’s (2007) recommendation, common load values, indicative of an item’s alignment with other items in the factor, should ideally exceed 0.3. As a result, no item within the 20-item draft measurement tool, which had undergone rigorous content validity verification, exhibited a common load value below this crucial threshold. The outcomes of the EFA are meticulously detailed in Table 4, providing an insightful overview of the structural characteristics and the extent of item interrelatedness within the dataset.
These findings further underscore the robustness and cohesiveness of the measurement tool, emphasizing the harmonious alignment of its constituent items within the identified factor structure. The criteria incorporated within the assessment tool effectively accounted for a substantial portion of the total variance within the DLS dataset, specifically amounting to 71.54%. In accordance with the guideline proposed by Büyüköztürk (2005), an interpretation of the results suggests that a substantial fraction, 30% or more, of the total variance aligns adequately with a single-factor structure.
Consequently, the EFA not only affirmed the dimensionality of the DLS dataset but also illustrated the strength of this dimensionality. This affirmation is based on the examination of both the DLS coefficient value and the analysis of variance, which collectively provide robust evidence in favor of the dataset’s unifactorial nature. The interplay between these statistics offers valuable insights into the intricate structural characteristics of the DLS, reinforcing the confidence in its underlying dimensionality.
4.4 Internal consistency analysis
The draft version of the DLS questionnaire underwent a rigorous evaluation of its reliability, encompassing an in-depth analysis of item statistics and the implementation of the iso-half method. Reliability stands as a crucial metric, reflecting the degree to which a test or scale effectively captures the intended construct. In concordance with the insights presented by Green and Yang (2009), as Cronbach’s Alpha (α) coefficient approaches unity, the internal consistency of the measurement tool attains a higher level of reliability (Table 5).
In this vein, the computed α coefficient for the DLS questionnaire stood at an impressive 0.982, indicative of a remarkably high level of internal consistency among the constituent items. Furthermore, it is imperative to recognize that the α coefficient serves as a robust indicator of the homogeneity within the draft. In the case of this assessment tool, the α coefficient’s proximity to unity suggests that the criterion draft embodies a unidimensional structure. Thus, based on these compelling findings, it is warranted to assert that the assessment tool exhibits dimensionality, a characteristic that further underscores its structural coherence and reliability (Table 5).
Conversely, an array of reliability assessments was conducted to ascertain the two-half test reliability coefficients of the 20-item draft version of the DLS questionnaire, guided by the insights derived from item statistical analyses. This multifaceted evaluation encompassed the examination of the Spearman-Brown coefficient, the Guttman split-half reliability coefficient, and the traditional Cronbach’s Alpha (α) coefficient. Each of these reliability indices serves as a valuable lens through which the robustness of the measurement tool can be appraised. The Spearman-Brown coefficient offers an estimation of the internal consistency of a test when extended to its full length, providing insights into the questionnaire’s reliability when administered in its entirety.
In a similar vein, the Guttman split-half reliability coefficient assesses the reliability of the measurement tool when divided into two equal halves, thereby yielding an estimate of its stability. Furthermore, the traditional Cronbach’s Alpha (α) coefficient, which has been a cornerstone of reliability assessments, contributes a comprehensive perspective on the internal consistency of the draft questionnaire. These various reliability coefficients, rooted in empirical analysis, collectively contribute to a holistic understanding of the DLS questionnaire’s reliability, offering valuable insights into its robustness and consistency in measuring the intended construct (Table 6). Table 6 presents the Alpha values obtained for the two halves of the 20-item draft DLS. These alpha values were found to be highly similar and exceeded the threshold of 0.70. This finding suggests that the items in the scale exhibit strong internal consistency and reliability. Additionally, the correlation between the two halves was determined to be 0.896, the Guttman split-half correlation coefficient was 0.945 and the Spearman-Brown coefficient for the two halves was 0.945. The alpha values calculated for the first and second halves, comprising 11 and 12 questions respectively, were 0.971 and 0.962 indicating high reliability.
The structure, summability, and homogeneity of the items in the 20-item draft DLS were examined using ANOVA with Tukey’s Test for Nonadditivity and the findings are displayed in Table 7. The results presented in Table 6 indicate that the items comprising the DLS exhibit a consistent and interconnected structure (F = 18,517 p < 0.00). Furthermore, the test demonstrated satisfactory collectability, as evidenced by the result (F = ,026, p > 0.00).
By Özdamar’s guidelines (2013), it becomes imperative to explore the extent to which the parameters, anticipated to be delineated by Hotelling’s T-squared analysis, can be aptly discerned through the utilization of the measurement tool. Consequently, the reliability analysis conducted on the 20-item draft version of the DLS questionnaire sought to ascertain the harmonious alignment of the questionnaire’s items with the intended test design. Remarkably, the results of the reliability analysis provided compelling evidence, demonstrating that the items within the measurement tool exhibited conformity with the overall test structure, as evidenced by an observed F-statistic of 4.267 with statistical significance (p < 0.05). This outcome underscores the reliability and structural integrity of the DLS questionnaire, affirming its capacity to effectively capture the parameters under scrutiny. Detailed insights into the Hotelling’s T-Squared analysis of DLS are thoughtfully presented in Table 8, offering a comprehensive overview of the analytical outcomes and their implications for the assessment tool’s aptitude in encapsulating the key parameters of interest. This thorough exploration further bolsters the questionnaire’s utility and reliability in measuring the targeted construct (Table 8).
In line with the insights shared by Ridout et al. (1998), the interpretation of the intraclass correlation coefficient (ICC) holds valuable implications for the strength of the intra-class relationships. As expounded, an ICC value below 0.40 signifies a relatively weak intra-class relationship, while values ranging from 0.40 to 0.59 denote a moderate level of intra-class association. Moreover, ICC values falling within the range of 0.60 to 0.74 characterize a robust intra-class relationship, and any value surpassing 0.74 underscores a very strong intra-class association. The analytical outcomes have unequivocally demonstrated the commendable consistency of the 20-item draft DLS questionnaire concerning individual questions, yielding an ICC value of 0.70 with statistical significance (p < 0.05). This finding provides substantial evidence of the questionnaire’s reliability and its ability to capture the intricacies of the individual items. Moreover, the examination of the DLS questionnaire’s construct validity in terms of average measures yielded an ICC value of 0.984 with statistical significance (p < 0.05), further underlining the questionnaire’s reliability and validity (Table 9).
These results affirm that the structural and substantive attributes of the questionnaire items align effectively with the intended construct, bolstering the tool’s integrity and aptitude. It is noteworthy that the intraclass correlations emerge as highly favorable, reflecting the questionnaire’s strong performance with respect to individual measurements and average measures alike. The detailed data about the ICC analysis for DLS are comprehensively presented in Table 9, offering a thorough account of the analytical outcomes and their implications for the measurement tool’s reliability and validity.
4.5 Confirmatory factor analysis
Confirmatory Factor Analysis (CFA) serves as a foundational and indispensable tool in the realms of psychological and social science research, offering a robust means to scrutinize the underlying structure and validity of measurement scales. This analytical approach empowers researchers to rigorously assess the correspondence between their theoretical models and the empirical data, facilitating a quantitative evaluation of construct validity (Brown, 2015; Byrne, 2016). An essential facet of CFA resides in its capacity to either affirm or refute the postulated factor structure. As elucidated by Brown (2015), CFA particularly shines when researchers possess well-defined theoretical expectations regarding the configuration of their measurement scales. By explicitly stipulating a priori relationships between latent factors and observed variables, researchers can meticulously probe whether their theoretical model faithfully reflects the observed data. CFA further extends its utility in the evaluation of convergent and discriminant validity. Through the scrutiny of factor loadings, researchers can rigorously appraise the extent to which observed variables accurately reflect their respective latent constructs. Substantial factor loadings signify a robust association between the latent factor and its corresponding indicator, thus offering compelling evidence of convergent validity (Byrne, 2016). Additionally, CFA affords the means to investigate discriminant validity by scrutinizing the correlations between latent factors (Hair et al., 2017). Should observed variables exhibit stronger associations with their designated latent factors compared to other latent factors, it strongly implies the distinctiveness of the constructs (Brown, 2015).
Another vital application of CFA rests in its role in measurement invariance testing. This methodological procedure equips researchers with the ability to ascertain whether measurement scales operate uniformly across various groups or populations (Byrne, 2016; Hair et al., 2017). The establishment of measurement invariance stands as a pivotal prerequisite for enabling meaningful cross-group comparisons and drawing valid conclusions across diverse populations. In addition to its diagnostic capabilities, CFA offers a palette of fit indices for evaluating the goodness of fit between the hypothesized model and the observed data. These indices, including the Comparative Fit Index (CFI) and the Goodness of Fit Index (GFI), yield quantitative metrics of the model-data congruence (Hu & Bentler, 1999). For instance, CFI assesses the comparative fit of the hypothesized model in relation to a null model, with values proximate to or exceeding 0.95 indicative of a strong fit (Schermelleh-Engel et al., 2003). Additionally, the flexibility of CFA extends to the realm of model modification and refinement. Modification indices play a pivotal role in pinpointing areas where the model can be enhanced to achieve a more harmonious fit with the empirical data (Kline, 2016). Researchers can employ these indices to delve into potential sources of misfit and iteratively fine-tune the model to achieve a closer alignment with the observed data.
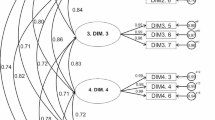
For our specific study, an initial CFA was performed, focusing on the relationships between latent variables within the proposed model. The CFA path diagram, visually portraying the alignment between the empirical data and the model derived from EFA, is meticulously delineated in Figs. 2 and 3. The analysis unveiled that the DLS comprises a total of 20 items. Throughout the course of the CFA analyses, it is noteworthy that all standardized factor loadings emerged as remarkably robust, indicative of a robust relationship between the observed variables (items) and the latent construct. This finding reinforces our confidence in the proposed model, underscoring its strong alignment with the empirical data and its position within the realm of acceptable fit. Shortly, the CFA results provide compelling evidence that the envisaged model offers an excellent fit to the observed data, affirming its utility and validity in the context of our study. Following the CFA, the Cmin/df value was calculated for the 20-item, one-factor scale, resulting in a value of 3.46 (Cmin: 544.49, df: 157, p < 0.05). According to Kline (2016), a Cmin/df value below 2 indicates an excellent fit for the proposed model, while a value below 5 suggests an acceptable level of fit. Hence, the derived Cmin/df metric, which denotes the ratio of the minimum discrepancy to degrees of freedom, serves as an additional pillar fortifying the assertion that the proposed model elegantly and substantively aligns with the empirical data. In essence, the quantitative validation gleaned from the CFA outcomes substantiates the one-dimensional structure of the 20-item DLS questionnaire, signified by the presence of statistically significant path coefficients and notably robust factor loadings. This pivotal metric, the Cmin/df, plays an instrumental role in gauging the appropriateness of the model fit within the data context. Its confirmation within an acceptable range serves as an additional and compelling testament, reiterating the impeccable alignment of the proposed model with the empirical data. Consequently, the established Cmin/df value buttresses the robustness of the proposed model, reinforcing the resounding conclusion drawn from the CFA analysis.

Unstandardized factor loads in path diagram of DLS

Standardized factor loads in path diagram of DLS
In a comprehensive summary, the implications drawn from the CFA findings lay a robust foundation for the validity of the one-dimensional structure encapsulated within the 20-item DLS questionnaire. The statistical significance of the path coefficients and the discernibly high factor loadings offer compelling evidence supporting the model’s fidelity to the empirical data. Additionally, the consistent alignment with the acceptable range within the calculated Cmin/df metric further accentuates the exceptional fit between the proposed model and the observed data. Ultimately, the amalgamation of these quantitative measures and statistical indices unveiled through CFA underscores the profound suitability and robustness of the proposed model in encapsulating the intricacies of the observed data, further strengthening the validity of the one-dimensional structure embodied within the 20-item DLS questionnaire. In addition to the scrutiny of the model’s relationship with the empirical data, a comprehensive array of goodness-of-fit indices was thoughtfully leveraged to meticulously gauge the degree of alignment. These indices encompassed the Normed Fit Index (NFI ≥ 0.90, good; Bentler and Bonett, 1980), Comparative Fit Index (CFI ≥ 0.95, good; Hooper et al. 2008), Goodness of Fit Index (GFI ≥ 0.90, acceptable; Schermelleh and Moosbrugger, 2003), Relative Fit Index (RFI ≥ 0.90, acceptable; Schermelleh and Moosbrugger, 2003), Incremental Fit Index (IFI ≥ 0.90, acceptable; Schermelleh and Moosbrugger, 2003), Tucker-Lewis Index (TLI ≥ 0.90, acceptable; Schermelleh and Moosbrugger, 2003). Upon a meticulous evaluation, the obtained values for the alignment between the model and the empirical data unfolded as follows: GFI: 0.904, NFI: 0.911, RFI: 0.901, CFI: 0.940, IFI: 0.941, and TLI: 0.928. These values collectively offer both theoretical and statistical underpinnings for the viability of the proposed three-factor model, signifying a commendable harmony between the model’s representations and the observed data. This comprehensive assessment of goodness-of-fit indices not only bolsters our confidence in the model’s validity but also underscores its seamless alignment with the empirical data. Consequently, the results emanate with a resounding endorsement of a satisfactory level of fit between the model and the meticulously collected data, further attesting to the model’s robustness and fidelity in capturing the nuances of the observed phenomenon (Table 10).
4.6 Dimensional analysis
In this part of the study, the examination of the construct validity of the 20-item DLS was continued with Rasch analyzes in addition to EFA and reliability analyses. As a result of the analyses, the Rasch model result was obtained from the 20-item DLS form and the results were presented in the next stages. The Rasch model applies principal component analysis as in EFA. In Rasch analyses, one-dimensionality of the data is essential, and when making predictions, it is necessary to know whether errors that do not belong to latent variables occur systematically or by chance (Bond & Fox, 2015). In dimensionless systems, internal consistency must be proven. Accordingly, 45.8% of the 61.3% variance explained here comes from the individual and 15.5% comes from the item parameters (Fig. 4).

Standard waste variance values of DLS
Additionally, while the variance due to randomness is 38.7%, the variance of the first contrast over the entire data set is 6.0%. In this case, it can be said that the variance resulting from the first contrast is not large enough to harm the measurements (Bond & Fox, 2015). In the Rasch model, the literature reports the raw variance value explained as acceptable if greater than 20%, good if greater than 40%, and excellent if greater than 60%. In addition, it was stated that the unexplained variance value should be less than 15%. The results obtained in Fig. 4 support the unidimensionality result obtained in EFA. It also shows that the measurement tool DLS has one-dimensional characteristics and can be mapped.
4.7 Standardized residual correlations
Local independence plays a pivotal role in assessing the interrelationships between residuals and items within a measurement scale. The foundational assumption underlying the concept of local independence in the framework of the Rasch Rating Scale Model (RSM) posits that the items constituting the scale should exhibit minimal to no interrelatedness. Specifically, when local dependence is observed, it implies that the responses to one item are significantly associated with the responses to another. A critical threshold for identifying local dependence is often defined when correlations between items exceed the threshold of 0.7 (Linacre, 2013). In our pursuit to ascertain whether the DLS adheres to the stringent criteria of local independence, we embarked on a meticulous exploration of standardized residual correlation values. Figure 5, a visual representation of these standardized residual correlations, illuminates the most substantial relationships between item pairs within the DLS. Figure 5 notably showcases that a specific pair of items falls within the correlation range of -0.28 to 0.51, signifying a standard residual correlation value. Importantly, it is imperative to highlight that all score measurement correlation values for the items remained below the 0.7 threshold. This pivotal finding decisively reveals that the survey respondents adeptly distinguished between item pairs, encountering no substantial confusion in the interpretation of the items (Azrilah et al., 2017). This empirical exploration into the local independence of the DLS underscores the instrument’s effectiveness in upholding the fundamental prerequisite of minimal interdependence between items. The result reinforces the tool’s robustness in accurately capturing distinct facets of the construct under investigation, thereby enhancing the overall credibility of the measurement instrument.

Largest standardized residual correlations
4.8 Reliability analysis
The Rasch measurement model serves as a robust analytical framework, delving into the intricacies of both inter-rater and item interactions, thereby contributing to a comprehensive assessment of the validity and reliability of measurement tools. As elucidated by Mofreh et al. (2014), reliability, a cornerstone in measurement evaluation, is construed as the degree of consistency manifested in raters’ responses to the administered items. This statistical metric not only gauges the reliability of the measurement tool but also underscores the item’s efficacy in discriminating individuals across varying levels of the targeted concept. Linacre’s (2014) stipulation adds further nuance to the evaluation criteria, positing that for Rasch measurement values to attain acceptability in validating and ensuring the reliability of a measurement tool, both rater and item reliability must surpass the threshold of 0.50. Additionally, the discrimination value, an indicator of the item’s ability to distinguish among individuals at different proficiency levels, should exceed the benchmark of 2. In the context of the DLS, a detailed examination of item and rater analyses is presented in Fig. 6.

Item and rater reliability of DLS
This visual representation encapsulates the nuanced interplay between the measurement values, shedding light on the intricate dynamics of the assessment process. These analytical insights not only contribute to the ongoing discourse on measurement validity and reliability but also provide a substantive foundation for refining and enhancing the precision of measurement tools in educational and organizational contexts. In Fig. 6, the representation of measurements reveals that as criterion items approach zero, their level of difficulty intensifies, and conversely, the farther they extend from zero, the less challenging they become. Moreover, the data depicted in Fig. 6 illustrates that the mean proficiency level of individuals is situated at 2.34 logits. This numerical value signifies that tasks related to digital awareness pose minimal difficulty for students (Linacre, 2014). The estimated value stands at 0.97, meeting the fundamental requisites. Furthermore, the fit indices of the DLS fall within an efficacious range, closely approximating 1. In Fig. 6, the rater reliability registers at 0.82, accompanied by a person separation index of 3.92. This substantiates the assertion that the DLS exhibits commendable reliability, surpassing the benchmark of ≥ 0.8 (Bond & Fox, 2015). Such reliability implies that the raters authentically embody the traits targeted for assessment. Notably, a separation index exceeding 2 indicates the diverse skill sets encapsulated in the responses to the DLS. A pivotal metric gauging the internal consistency of the test is the α value. A value surpassing 0.90 signifies commendable internal consistency (Bond & Fox, 2015).
As illustrated in Fig. 6, the α value is determined as 0.98. Upon scrutinizing individual reliability and discrimination values, it becomes evident that the test comprises an ample number of items and is sufficiently sensitive to discern disparities among individuals with varying proficiency levels (Linacre, 2014). Examination of item reliabilities in Fig. 6 reveals real item reliability values at 0.81, model item reliability values at 0.94, and discrimination values exceeding 2. Simultaneously, Fig. 6 indicates that the average difficulty of items aligns with expectations at 0.00. The internal and external fit values (infit-outfit MnSq values) of average item difficulties hover around 1. The anticipated correlation between item raw scores and difficulty estimates is close to -1, as increasing item difficulty corresponds to a decreased likelihood of success (Linacre, 2014). Among the reliability indicators, the item reliability, rater reliability of 0.96 and 0.97, and an α value of 0.98 collectively affirm the commendable internal consistency of the test items. These outcomes conduce to the inference that the test items operate cohesively and align with their intended purpose. In culmination, the data analysis underscores the robust compatibility of the DLS form with the Rasch model.
4.9 Analysis of ıtem polarity and ıtem fit
In the evaluation of construct validity, the determination of item polarity is imperative to align with Rasch model expectations. This analytical approach bears semblance to EFA, employed for scrutinizing the interrelationships among items in structural validity assessments. Specifically, the Polytomous Total Measure of Expected Agreement (PTMEA) should exceed 0.20 to adhere to established criteria (Bond & Fox, 2015). Notably, the examination of PTMEA-correlation values for all items within the DLS depicted in Fig. 7 reveals values surpassing 0.20, devoid of negative indicators. As asserted by Linacre (2014), congruence between observed and expected correlation values signifies complete compatibility between data and model. Figure 7 further reinforces this alignment, indicating close proximity in correlation values among all items in the DLS. This observation underscores the positive relationships among DLS items, affirming their alignment with the intended structural framework and attesting to the model’s efficacy in discerning the targeted abilities. Furthermore, Fig. 7 portrays PTMA values for all DLS items falling within the range of 0.71 to 0.84, all of which are positive and notably distant from zero. According to Bond and Fox (2015), such positive PTMA values affirm the congruence of DLS items with the anticipated structure. This robust alignment indicates that all items within the DLS harmonize effectively with the underlying construct. Another crucial facet validating the alignment of DLS items with Rasch model expectations lies in the analysis of MnSq (Mean-Square) values. These values are individually assessed for each item within DLS to identify potential maladaptive elements. As per Bond and Fox’s (2015) recommendations, MnSq values falling between 0.4 and 1.5 indicate productive items. An MnSq value exceeding 2.0 suggests an item disrupts the measurement system, while a value below 2.0 implies inefficiency. Notably, Fig. 7 presents the polarity and compatibility analysis of substances within the DLS, encapsulating the comprehensive evaluation of these items against Rasch model expectations.

Polarity and fit analysis of items of DLS
The model can be deemed as effectively meeting expectations in aptly distinguishing individuals with discernible talents targeted for measurement. Illustrated in Fig. 7, the PTMA values for all items within the DLS range from 0.68 to 0.87, exhibiting positivity and a notable departure from zero. This observation substantiates the assertion that all items in the DLS align seamlessly with the intended construct (Bond & Fox, 2015). Another vital aspect indicating the alignment of DLS items with RSM expectations lies in the examination of MnSq values. The inter-item compatibility within the DLS is meticulously assessed through individual MnSq values for each item. Following Bond and Fox’s (2015) guidance, optimal MnSq values fall within the 0.4 to 1.5 range. If the MnSq value surpasses 2.0, the item disrupts and disperses the measurement system. Conversely, a value below 2.0 may persist in the system but is deemed inefficient.
Additionally, an MnSq value between 0.4 and 1.5 signifies a productive item. However, a value below 0.4 implies lower productivity without causing disruption to the system or measurement integrity. Figure 7 presents a comprehensive analysis of item polarity and fit within the DLS. Furthermore, Fig. 7 delves into the skill-level probability dynamics associated with specific items in the DLS. Individuals possessing a skill level of + 0.60 ± 0.11 logits exhibit a 72.0% probability of correctly answering I15, the most challenging item in the DLS.
Conversely, individuals with a skill level below + 0.60 logits demonstrate a higher likelihood of correctly answering I15 than the 72.0% benchmark. Similarly, individuals with an ability level of I2 at -0.49 ± 0.13 logits, representing the easiest item in the test, have a 79.2% probability of providing correct responses. Contrastingly, individuals with a skill level surpassing -0.49 logits exhibit a probability of correct responses below 79.2%. These nuanced insights contribute to a comprehensive understanding of the skill-difficulty dynamics embedded within the DLS.
4.10 Calibration map
The Rasch model facilitates the amalgamation of individual ability measures and item difficulty measures onto a unified, evenly spaced scale. Illustrated in Fig. 8 is the calibration map delineating the item characteristics within the DLS form. Positioned centrally on this map is the logit scale, serving as the common metric unit for both item difficulty values and individual ability estimates. Derived through the Rasch model, the logit scale transforms ordinal data into a scale with evenly distributed intervals, where each point signifies an equal degree of cognitive development. The logit scale is structured with intervals of 1 logit, ensuring uniformity in measurement. This principle extends to the positioning of individuals on the logit scale, arranged from lowest to highest ability levels, mirroring the bottom-to-top ranking of items from easy to difficult. Examination of Fig. 8 reveals that the average ability level among secondary school students stands at 1.5 logit, with the majority of the cohort distributed between -1 and + 5 logit. Moreover, item difficulty parameters are notably concentrated within the range of -0.8 logit to + 1.5 logit. Notably, Fig. 8 indicates an absence of items corresponding to individuals with ability levels lower than -3 or higher than + 1.5 logit. This observation suggests that the majority of items are aptly designed for measuring individuals at a moderate ability level.

Calibration map for DLS
Figure 8 reveals specific items within the structure, showcasing instances of overlap. Notably, items I14 and I5 exhibit overlapping characteristics. Additionally, there is a convergence of items I4, I9, I11, I13, and I17, as well as another overlap involving items I5, I7, I10, I12, I16, and I20. Further overlapping is observed with items I3, I8, I18, and I19. Lastly, items I1, I2, and I6 share overlapping features. It’s important to note that the presence of overlapping items is not inherently problematic in the context of RSM, as each item is designed to measure a distinct concept. However, while not a flaw, having items that span a range of difficulty levels is ideal for a comprehensive assessment. In light of this, to enhance the test’s effectiveness, future studies could consider adjustments. Given that items appearing side-by-side on the graph tend to segregate individuals with similar ability levels, a potential strategy is to remove these overlapping items. Subsequently, these items can be replaced with alternatives of varying difficulty levels, thereby better distinguishing individuals with lower and higher proficiency levels (Fig. 8). This adjustment aims to optimize the test’s capacity to effectively capture the breadth of skill levels among the test-takers.
4.11 Identification of ıtem bias with the differential ıtem function
Differential Item Function (DIF) shows the inconsistency of item responses between groups of participants with different characteristics. DIF appears when it exists different response possibilities for a particular item from different groups with the same ability level. This is because the test condition is biased by factors other than the ability factor to be measured. Accordingly, test conditions may be affected by various aspects that have nothing to do with ability factors, such as gender, ethnicity, culture, region, and others (Chan et al., 2014). Here DIF analysis was performed to determine the differences in rasch-based item difficulty calibrations between male and female groups on the DLS. The plot results of items identified by DIF or indications of item bias are presented in Figs. 9.

Item bias graph with DIF test
Figure 9 shows gender-based curves such as female (F), male (M), and average values. The higher the point graph, the more difficult the item is for the group (Osterlind, 1983). Here, it can be seen roughly that the distance between the DIF measure values between female and male is the farthest in items 2, 6, 10, 11, 18, 19, and 20. This indicates the size of the difference in difficulty level between male and female in these items. Accordingly, it can be thought that items 2, 6, and 20 are easy for males, and items 10, 11, 18 and 19 for females. Therefore, it should be reviewed whether items 2, 6, 10, 11, 18, 19, and 20 create a bias for a group. Additionally, items 4, 12, 16, and 17 were determined to be appropriate in terms of bias. Figure 10 shows the relative item difficulty level for each group. Accordingly, easy items are located in the negative DIF region relative to each other, while difficult items are located in the positive DIF region. In addition, it is seen from Fig. 10 that the difficulty level of the items is increasing gradually. However, even if there are deviations from the average value according to gender in items 2, 6, 10, 11, 18, 19, and 20 in Fig. 10, the size and statistical significance of the deviations should be checked.

The relative item difficulty level for each group
For this reason, the statistical outputs of the extreme and non-extreme person scores were examined. The study was carried out with 120 females and 131 males. Accordingly, Fig. 11 shows extreme and non-extreme person scores. From here it was shown that there was not much difference overall between DIF measures by gender for DLS. Here, the DIF measurement was determined as 2.48 for females and 1.96 for males. From this, it can be said that there is no bias in general for DLS. However, when the statistical group specifications were examined, it was seen that the average values and DIF measurements for items 2, 6, 10, 11, 18, 19, and 20 were very close to each other and did not deviate much.

Extreme and non-extreme person score
Figure 12 shows that the DIF contrast values, which mean the difference in the difficulty level of the item between the two groups (male and female), for items 2, 6, 10, 11, 18, 19 and 20 are less than 0.6. In addition, it was observed that the probability values of Mantel Hanzel Chi-square statistics (p ≥ 0.05) were above 0.05 for other items except for item 6. According to Swaminathan and Rogers (1990), the DIF contrast value should be greater than 0.60 and the probability value should be less than 0.05 for item bias. Accordingly, the probability values of the other items are not less than 0.05. As a result, statistical outputs showed that there was no DIF in items 2, 6, 10, 11, 18, 19, and 20. Accordingly, any item was not eliminated from the DLS, as there was no limitation that could cause bias.

Group specification values for dispersed items
4.12 The diagnostics
Calibrating the scale in the RSM is a crucial step, serving as a robust method to ascertain the respondents’ comprehension of the survey items and their ability to differentiate between the various scale labels. Linacre (1999) has emphasized the significance of examining certain indicators to diagnose potential issues with a rating scale. Specifically, a structural calibration difference of no less than 1.4 is recommended between categories, ensuring distinctness and preventing overlap. This distinction is vital for respondents to fully grasp the intended meaning of each scale label. According to the principles of RSM, the lowest category is assumed to have the fewest respondents, with an expected increase in respondent numbers as the categories ascend (Bond and Fox, 2007). Any deviation from this expected pattern may lead to a collapse of the rating scale. In such instances, Bond and Fox (2007) propose that adjustments to the scale labels should be made in a logically upward or downward direction.
In the present study, Fig. 13 revealed a consistent increase in the average observed count across categories. However, a notable decrease was observed in category 3 during the structure calibration process, indicating a potential issue with respondents’ ability to distinguish this category. Linacre’s (1999) recommendation for the difference between well-functioning categories falling within the range of 1.4 < × < 5 serves as a benchmark. In the current analysis, the calculated difference between categories 2 and 3 was found to be only 0.99, indicating a deviation from the expected monotonic ordering. The lower peak of category 3, compared to other categories, further suggested its inadequate functioning. Consequently, category 3 was deemed not well-functioning and collapsed. Given that category 3 (I’m undecided) holds a neutral stance in the initial scale labels (1: I strongly disagree, 2: I disagree, 3: I’m undecided, 4: I agree, 5: I totally agree), combining it with either category 4 (I agree) or category 2 (I disagree) was deemed inappropriate. To address this, the pragmatic decision was made to eliminate category 3 from the scale labels, resulting in a conversion to a 4-point Likert type. This adjustment aligns with recommendations found in the relevant literature (Bond & Fox, 2015; Lozano, 2008), aiming to enhance participants’ ability to discern scale labels and achieve a monotonic order with the improved functioning of each category.

The probability of the curve of rating categories
4.13 The test ınformation character
Test information is the amount of information provided by all items regarding any given person parameter. The test information function is the sum of all item information functions (Avinç, 2023). According to the test information function, it can be said that secondary school students with ability levels between -7.0 and 0.5 and between 0.5 and 8.0 provide the most information for DLS. Accordingly, DLS provides the most information from both high- and low-ability secondary school students. Figure 14 shows the level of information that the element in the DLS provides to the form. It was observed that gifted secondary school students gave information between -2.0–0.0 and low-ability secondary school students gave information between 2.0–4.0 regarding the item information function. It was determined that all items provided almost equal information for other students (Fig. 14). Figure 15 shows the distribution of difficulty and ability variables estimated by Rasch analysis for the DLS sample. This graph gives an estimate of the underlying difficulty of an item, calculated from the total number of people who succeeded on that item in a convenience sample. It was observed that item difficulty values did not correspond to secondary school students at some ability levels. Accordingly, it can be said that the DLS form requires items with difficulty levels lower than -1 and greater than + 1.

Test information function

Jury-Item difficulty measurement chart
Thus, more information about secondary school students can be provided by using the DLS form in future studies. It was also observed that secondary school students with some ability levels had more than one item at the corresponding item difficulty level. There are 18 items for secondary school students with an ability level of approximately 0.0 logit. Additionally, there are 2 items for secondary school students whose ability level is approximately + 1.0 logit (Fig. 15). Figure 10 can also be examined to examine the results in detail.
It was determined that the items of the 20-item DLS, developed for secondary school students, were divided into 9 categories. Each category has a significant number of respondents. It was observed that the raters had a logit value range between -6.0 and + 8.0. Raters have a maximum value of + 2.0 logit (Fig. 16). It was observed that the raters concentrated on the + 2.0 logit value, but the items in the category at -1.0 logit were scored more. This showed that individuals with above-average ability responded to above-average questions. Raters with above-average ability levels were also found to answer more difficult questions. The highest test score in logit -1.0 is an indication of this (Fig. 17).

Item category peaks chart

Test measures for scores chart
5 Discussion
Within the framework of this study, a measurement instrument comprising 20 items was meticulously crafted to assess the apprehensions of digital literacy among secondary school students, employing the Rasch measurement model. To commence this process, the introduction of CVR, I-CVR, and kappa values laid the foundation, elucidating a comprehensive roadmap for the iterative development of the measurement tool under scrutiny. The reliability of a measuring instrument is intrinsically tied to its stability, necessitating a rigorous analysis of the tool’s ability to measure the targeted phenomenon through a reliability assessment. It is noteworthy that the reliability and validity outcomes are contingent upon the specific context and objectives of their application (Leech et al., 2013). The measurement tool’s capacity to gauge the intended phenomenon is derived from a content validity analysis, relying on expert opinions to transform qualitative insights into quantitative data (Shuttleworth, 2016). This iterative process not only enhances the quality of the measurement tool’s items but also optimizes processing efficiency (Demiralp & Kazu, 2012). The efficacy of experts in this undertaking is pivotal for ensuring consistent and unbiased outcomes (Shuttleworth, 2016). Consequently, meticulous adherence to recommendations and a systematic roadmap led to the formulation of a measurement tool boasting both content and structural validity. The resultant tool, dubbed the DLS, comprises 20 items utilizing a 4-point Likert scale.
Reid and Shah’s (2007) hierarchical classification was instrumental in shaping the DLS. An item pool of 35 items was prepared. 5 items that were deemed inadequate in terms of meaning and language were removed from this item pool. Thus, a 25-item draft DLS was created. A preliminary 25-item draft was subjected to expert evaluation in line with their insights and suggestions. Subsequently, 5 items were excluded from the DLS due to inadequate CRV, I-CVR, and k* values. The Item-CVI/Ave value for the form reached 0.99, attesting to the high consensus among experts, while the S-CVI/UA value stood at 0.88. Moreover, it was ascertained that none of the items fell below the critical CVR value. Following these validations, the limitations of DLS were explored through EFA and internal consistency analyses. Additionally, item interactions and the test consistency of DLS were scrutinized.
EFA findings indicated the sample’s suitability for factor analysis, revealing a one-dimensional data set as the data could not be factored. Since there were no substances with a common load value less than 0.3, the substance was not removed from the draft DLS. The internal consistency analysis yielded an alpha coefficient of 0.982, underscoring the sequential nature of DLS items, their structural similarity, and their additive and homogeneous characteristics. This comprehensive reliability analysis affirmed that DLS is a proficient measurement tool aligned with its intended purpose. Rasch modeling of DLS encompassed dimensional analysis, item compatibility analysis, item polarities, and an item calibration map. In the dimensional analysis, 38.7% of the unexplained variance and a 6.0% variance in the first contrast over the entire dataset suggested the mappability of DLS. Rater reliability was established at 0.94, with a person separation index of 3.92, indicating genuine raters and diverse skills reflected in DLS responses. Moreover, item reliability and discrimination values were calculated as 0.82 and 2.13, respectively, affirming the compatibility of DLS with the Rasch model. Item compatibility analysis revealed close correlations between observed and expected values, affirming the positive relationship between DLS items and the measured structure. This underscores the efficacy of DLS items in discerning talented individuals.
The calibration map depicted notable overlaps between items at various difficulty levels, signaling limitations in distinguishing individuals with the same ability level. However, it also facilitated the evaluation of item difficulty for secondary school students. The analysis discerned that secondary school students were most successful in deciding on I2, while I15 posed the greatest challenge. In a notable finding, items I14 and I5 share overlapping characteristics. Additionally, items I4, I9, I11, I13, and I17 converge, as do items I5, I7, I10, I12, I16, and I20. Overlapping is also observed with items I3, I8, I18, and I19. Finally, items I1, I2, and I6 share overlapping features. The DIF analysis revealed no inconsistencies in item responses between groups of participants with varying characteristics, indicating the absence of gender bias. Consequently, no item was excluded from the instrument.
A softer approach to data collection used in scale studies is the typical approach, and a significant amount of research has been conducted on the functioning of the rating scale, which is the most popular type of instrument, and the number of categories in the scale, and it is accepted that the categories in the rating scale should be univocal, mutually exclusive, detailed and well-defined (Bond & Fox, 2015; DiStefano & Jiang, 2020; Linacre, 2002; Preston & Colman, 2000). Additionally, the number of categories in a scale should be optimized to ensure that each category is used effectively to collect valid and reliable research data, and the Rasch Model is a reliable method used to diagnose the number of categories in a scale (Smith et al., 2003; Pérez-Sánchez et al., 2023). Additionally, diagnostic studies demonstrated the collapse of Category 3 during scale calibration. The collapse in category 3, which was obtained as a result of the analysis, was observed as a problem in the participants’ ability to distinguish this category and as a confusing option for the participants (Chong et al., 2022). Thus, considering the discrimination situation for Category 3, it was concluded that it was less functional than the other categories. Categories were collapsed to increase qualitative significance, better ensure measurement precision, and enable the scale to collect more comprehensive and precise information (Bond & Fox, 2015). To our knowledge, it is the first study to state that leptokurtic curves cause category collapse. Adhering to the recommendations of pertinent literature, it was suggested to eliminate Category 3 (I’m undecided) from the scale and transform the scale labels into a 4-point Likert format (Linacre, 2002; Wright & Linacre, 1989). This finding further corroborates the conclusion that secondary school students hold either highly positive or highly negative views of digital literacy. As in all analyses, it was aimed to minimize measurement errors by recommending pragmatically narrowing the categories.
6 Conclusion
Over the past decade, digital technologies and media have become integral to people of all ages, with mobile phones being widely used by both teenagers and adults. Platforms like YouTube serve as primary sources for information on various interests, while digital storage allows easy access to TV shows, movies, and music. Communication through email connects individuals globally, and online activities like shopping, banking, and government services have shifted to the Internet. Both online and offline gaming play significant roles in people’s lives. Web 2.0 technologies, including social networking sites, enable collaborative content sharing and editing. Young people, often labeled as “digital natives,” seamlessly navigate the digital landscape from an early age. However, despite their rapid adoption of internet technologies, they tend to lack comprehensive digital literacy due to a lack of proper guidance. This results in a generation deeply engaged in cyberspace but not fully equipped with the necessary knowledge and skills to use technology effectively. Contrary to assumptions, young people need proper support to develop appropriately in the digital culture (Ministry of National Education, 2020). The belief that young people are inherently skilled in digital technologies has led to the characterization of them as “digital natives.” However, this assumption is misleading, as many students struggle with critical digital skills, such as information searching and evaluation. Merely growing up in a technology-centric era does not ensure digital literacy. Teachers play a vital role in supporting students to develop critical thinking skills and integrate technology effectively. Recognizing and incorporating children’s digital experiences in education is essential to bridge the gap between school and daily life, fostering engagement and motivation to learn in the digital age (Buckingham, 2015).
Research worldwide has explored digital literacy’s development, applications, and assessment across various contexts (Chan et al., 2017; Durmaz & Taşçı, 2021; Kuzminska et al., 2018; McDougall et al., 2018; Morgan et al., 2022; Phuapan et al., 2016; Reddy et al., 2023a, 2023b; Rodríguez-de-Dios et al., 2016; Smith et al., 2022; Yaman, 2019; Zhang & Zhu, 2016). Additionally, researchers have devised tools and scales to measure digital competence and identified strategies for enhancement (Acar, 2015; Amin et al., 2021; Arnone et al., 2010; Bayrakçı, 2020; Cao et al., 2024; Chung et al., 2021; Rodríguez-de-Dios et al., 2016; Kıyıcı, 2008; Koc and Barut, 2016; Korkmaz & Akçay, 2024; Lau & Yuen, 2014; Li & Hu, 2022; Lin, 2011; Ng, 2012; Ocak & Karakuş, 2018; Pala, 2019; Pala & Başıbüyük, 2020; Perdana et al., 2019; Santos & Gomes, 2024; Süslü, 2022; Şahin et al., 2022; Üstündağ et al., 2017). According to findings from several studies, a survey of digital literacy scales in the literature has indicated that numerous existing scales, especially those from domestic sources, are outdated in the face of advancing digital technologies. Additionally, there is a noticeable scarcity of current scales. In the examination of research on scale development related to digital literacy in domestic literature, no studies were found that specifically aimed to construct a scale for measuring self-efficacy levels in digital literacy for students in the 6th, 7th, and 8th grades. In some studies, it was noted that only EFA analyses or assessments of validity and reliability using pretest–posttest data were conducted for the developed scales (Acar & Şimşek, 2015; Ng, 2012; Süslü, 2022; Tüfekçi & Ceylan, 2022). Comprehensive analyses like CFA, bias, or Rasch, recommended in the literature for establishing a valid and reliable scale, were often absent. Both EFA and CFA are sophisticated statistical methods that share some assumptions but involve distinct processes. While EFA was prevalent in the majority of studies, the fact that CFA was undertaken in only about half of them suggests that the factor structures obtained in some studies may not necessarily be confirmed (Koyuncu & Kılıç, 2019). Although factor analyses offer evidence for a scale’s construct validity, it is advised that confirming factor structures with CFA strengthens this evidence (Cronbach & Meehl, 1955). Researchers in these studies also recommended conducting the necessary analyses. In this study, all essential analyses outlined in the literature were performed. Consequently, the developed DLS is considered an appropriate, valid, reliable, and useful tool within the parameters set by the literature. This study stands out from others by employing Rasch analysis, a method that considers individuals’ ability estimates. Unlike previous studies that may have overlooked or not thoroughly examined individuals’ ability estimates, this approach adds a unique dimension to the research. Additionally, this study introduces an updated measurement tool aligned with the evolving technology landscape, derived through a thorough literature review.
6.1 Recommendations
This scale has the potential for further enhancement to contribute to the digital literacy development of our generation. It could be expanded to explore the correlation between students’ digital literacy and their academic performance, communication skills, and research abilities, considering various factors. Moreover, the same scale could be applied to diverse sample groups from different educational levels, countries, or with varying variables. It is recognized in the literature that such scales require testing and revisions over time, aligning with the continuous advancements in digital literacy. The scale can also be employed in conjunction with other theoretically related scales serving similar purposes. Testing its validity and reliability across different classes, age groups, or educational levels would be beneficial. Future studies could involve examining global scale development initiatives in education, psychology, and behavioral sciences indexed for comparison with outcomes in Turkey.
Data availability
The author confirms that all data generated or analyzed during this study are included in this published article.
Notes
“I strongly disagree.” (1 point), “I disagree.” (2 points), “I am undecided.” (3 points), “I agree.” (4 points) and “I totally agree.” (5 points).
References
Acar, Ç. Y., & Şimşek, N. T. D. (2015). Parents’ views on the digital literacy of their primary, secondary and high school students and their own. [Doctoral dissertation, Ankara University Institute of Educational Sciences Computer and Instructional Technologies Education Department Educational Technology Programme].
Acar, Ç. (2015). Opinions of Mothers and Fathers Regarding the Digital Literacy of Their Primary School, Secondary and High School Student Children. [Unpublished Master’s Thesis, Ankara University Institute of Educational Sciences].
Aksoy, N. C., Karabay, E., & Aksoy, E. (2021). Examining the digital literacy levels of classroom teachers. Selçuk İletişim, 14(2), 859–894.
Algina, J., Olejnik, S., & Ocanto, R. (1989). Type I error rates and power estimates for selected two-sample tests of scale. Journal of Educational Statistics, 14(4), 373–384.
Altunışık, R., Coşkun, R., Bayraktaroğlu, S., & Yıldırım, E. (2005). Research Methods in Social Sciences SPSS Applied. Sakarya Bookstore.
Amin, H., Malik, M. A., & Akkaya, B. (2021). Development and validation of digital literacy scale (DLS) and its implication for higher education. International Journal of E-Learning and Distance Education, 7, 24–43.
Arnone, M. P., Small, R. V., & Reynolds, R. (2010). Supporting İnquiry by İdentifying Gaps in Student Confidence: Development of a Measure of Perceived Competence. School Libraries Worldwide, 16(1), 47–60.
Atif, Y., & Chou, C. (2018). Digital Citizenship: Innovations in Education, Practice, and Pedagogy. Journal of Educational Technology & Society, 21(1), 152–154.
Avinç, E. (2023). Investigation of the psychometric properties of the metaverse fear scale for secondary school students according to classical test theory and item response theory. [Master’s Thesis, Graduate Education Institute, Department of Mathematics and Science Education, Science Education Program, Çanakkale Onsekiz Mart University, Çanakkale, Turkey].
Ayre, C., & Scally, A. J. (2014). Critical values for Lawshe’s content validity ratio revisiting the original methods of calculation. Measurement and Evaluation in Counseling and Development, 47(1), 79–86.
Bagdi, H., & Bulsara, H. P. (2023). Understanding the role of perceived enjoyment, self-efficacy and system accessibility: digital natives’ online learning intentions. Journal of Applied Research in Higher Education, 15, 1618–1631.
Banaszewski, T. M. (2005). Digital storytelling: supporting digital literacy in grades 4–12 [Master’s Thesis, Institute of Technology, Georgia].
Bayrakçı, S. (2020). Digital literacy as a set of digital competencies: Scale development study. [Unpublished doctoral thesis. Marmara University, Institute of Social Sciences].
Bennett, S., Maton, K., & Kervin, L. (2008). The ‘digital natives’ debate: A critical review of the evidence. British Journal of Educational Technology, 39(5), 775–786.
Bilotta, E., Bertacchini, F., Gabriele, L., Giglio, S., Pantano, P. S., & Romita, T. (2021). Industry 4.0 technologies in tourism education: Nurturing students to think with technology. Journal of Hospitality, Leisure, Sport & Tourism Education, 29, 100275.
Bond, T. G., & Fox, C. M. (2015). Applying the Rasch Model Fundamental Measurement in the Human Sciences (3rd ed.). NJL Erlbaum.
Bozkurt, A. (2020). The coronavirus (Covid-19) pandemic process and evaluations regarding education in the post-pandemic world: New normal and new education paradigm. Journal of Open Education Applications and Research, 112–142.
Brown, T. A. (2006). Confirmatory factor analysis for applied research. Guilford Press.
Buckingham, D. (2015). Defining Digital Literacy: What Young people need to know about digital media? Nordic Journal of Digital Literacy, 2015(4), 21–34.
Büyüköztürk, Ş. (2005). Data Analysis Handbook for Social Sciences. Pegem A Publishing.
Byrne, B. M. (2010). Structural Equation Modeling with Amos: Basic Concepts, Applications, and Programming (2nd ed.). Taylor and Francis Group.
Cao, S., Dong, C., & Li, H. (2024). Emergent digital literacy in Chinese preschoolers: developmental patterns and associated predicators. Early Child Development and Care, 1–15.
Chan, B. S., Churchill, D., & Chiu, T. K. (2017). Digital literacy learning in higher education through digital storytelling approach. Journal of International Education Research (JIER), 13(1), 1–16.
Child Trends DataBank. (2015). Home computer access and internet use: indicators of child and youth well-being. April 06, 2021 Retrieved on from CTDB: https:// www.childtrends.org/wpcontent/uploads/2015/12/69_Computer_Use.pdf
Chong, J., Mokshein, S. E., & Mustapha, R. (2022). Applying the Rasch Rating Scale Model (RSM) to investigate the rating scales function in survey research instrument. Cakrawala Pendidikan: Jurnal Ilmiah Pendidikan, 41(1), 97–111.
Chung, M. H., Kim, J., & Hwang, H. S. (2021). A Study on Development and Validation of Digital Literacy Measurement Tool. Journal of Internet Computing and Services, 22(4), 51–63.
Cronbach, L. J., & Meehl, P. E. (1955). Construct validity in psychological tests. Psychological Bulletin, 52(4), 281.
d’Acremont, M., & Bossaerts, P. (2016). Neural mechanisms behind identification of leptokurtic noise and adaptive behavioral response. Cerebral Cortex, 26(4), 1818–1830.
de Vries, P. (2022). The Ethical Dimension of Emerging Technologies in Engineering Education. Education Sciences, 12(11), 754.
Dean, B. (2022). Roblox User and Growth Stats 2022. April 18, 2023 Retrieved on from backlinko.com: https://backlinko.com/roblox-users#geographic-distribution-of-roblox-users.
Demiralp, D., & Kazu, H. (2012). Teachers’ opinions on the contribution of primary education first stage programs in developing students’ reflective thinking. Pegem Journal of Education and Training, 2(2), 29–38.
DiStefano, C., & Jiang, N. (2020). Applying the Rasch Rating Scale Method to Questionnaire Data. In M. S. Khine (Ed.), Rasch Measurement (pp. 31–46). Springer. https://doi.org/10.1007/978-981-15-1800-3_3.
Durak, G., Çankaya, S., & İzmirli, S. (2020). Investigation of distance education systems of universities in Turkey during the COVID-19 pandemic period. Necatibey Faculty of Education Electronik Journal of Science and Mathematics Education, 14(1), 787–809.
Durmaz, A., & Taşçı, S. A. (2021). Examining secondary school students’ social media use and digital literacy in terms of different variables. Cappadocia Education Journal, 2(2), 26–31.
Elhan, A. H., & Atakurt, Y. (2005). Why should Rasch analysis be used in evaluating scales? Ankara University Faculty of Medicine Journal, 58, 47–50.
Erdoğan, E. (2021). Digital Literacy and Cyberbullying: A Relational Screening Study for Secondary School Students. International Journal of Field Education, 7(2), 61–76.
European Commission. (2017). Digital Skills and Jobs Coalition. Retrieved from https://ec.europa.eu/digital-single-market/en/digital-skills-jobs-coalition.
Evans, C., & Robertson, W. (2020). The four phases of the digital natives debate. Human Behavior and Emerging Technologies, 2(3), 269–277.
Falloon, G. (2020). From digital literacy to digital competence: The teacher digital competence (TDC) framework. Educational Technology Research and Development, 68, 2449–2472.
Field, A. (2009). Discovering statistics using SPSS. SAGE.
Fleiss, J. L. (1971). Measuring nominal scale agreement among many raters. Psychological Bulletin, 76, 378–382.
Fraillon, J., Ainley, J. S., & Schulz, T. W., Friedman, T. & Gebhardt, E.(2014). Preparing for Life in a Digital Age. The IEA International Computer and Information Literacy Study International Report.
George, D. (2011). SPSS for windows step by step: A simple study guide and reference, 17.0 update, 10/e. Pearson Education India.
Gömleksiz, M. N., & Cüro, E. (2011). Teacher opinions on the level of social studies curriculum meeting social needs. National Education Journal, 190, 145–167.
Green, S. B., & Yang, Y. (2009). Commentary on coefficient alpha: a cautionary tale. Psychometrika, 74.
Gündüz, Ş, & Odabaşı, H. F. (2004). The importance of instructional technologies and material development course in the education of teacher candidates in the information age. The Turkish Online Journal of Educational Technology (TOJET), 3, 1.
Hair, J. F., Black, W. C., Babin, B. J., & Anderson, R. E. (2010). Multivariate data analysis (7th ed.). Prentice-Hall.
Haleem, A., Javaid, M., Singh, R. P., Suman, R., & Qadri, M. A. (2023). A pervasive study on Green Manufacturing towards attaining sustainability. Green Technologies and Sustainability, 1, 100018.
Hamutoğlu, N. B., Canan Güngören, Ö., Kaya Uyanık, G., & Gür Erdoğan, D. (2017). Digital Literacy Scale: Adaptation Study to Turkish. Aegean Education Journal, 18(1), 408–429. https://doi.org/10.12984/egeefd.295306
Hargittai, E. (2010). Digital na(t)ives? Variation in internet skills and uses among members of the “net generation.” Sociological Inquiry, 80(1), 92–113.
Hays, L., & Kammer, J. (Eds.). (2023). Integrating digital literacy in the disciplines. Taylor & Francis.
Helsper, E. J., & Eynon, R. (2010). Digital natives: Where is the evidence? British Educational Research Journal, 36(3), 503–520.
Jan, S. (2018). Investigating the Relationship between Students’ Digital Literacy and Their Attitude towards Using ICT. International Journal of Educational Technology, 5(2), 26–34.
Kilag, O. K., Miñoza, J., Comighud, E., Amontos, C., Damos, M., & Abendan, C. F. (2023). Empowering Teachers: Integrating Technology into Livelihood Education for a Digital Future. Excellencia: International Multi-disciplinary Journal of Education (2994–9521), 1(1), 30–41.
Kim, H. Y. (2013). Statistical notes for clinical researchers: Assessing normal distribution (2) using skewness and kurtosis. Restorative Dentistry. Endodontics, 38(1), 4–52.
Kıyıcı, M. (2008). Determination of Numerical Literacy Levels of Teacher Candidates. [Doctoral Thesis, Anadolu University Institute of Educational Sciences].
Kline, R. B. (2011). Principles and practice of structural equation modeling (3rd ed.). Guilford Press.
Koc, M., & Barut, E. (2016). Development and validation of new media literacy scale (NMLS) for university students. Computers in Human Behaviour, 63, 834–843.
Korkmaz, N., Demir, F., Öztürk, İE., & Mutlu, S. U. (2024). Examining the relationship between digital parenting awareness and physical activity in parents of secondary school students. Journal of Physical Education and Sports Sciences, 17(3), 405–418.
Korkmaz, M., & Akçay, A. O. (2024). Determining Digital Literacy Levels of Primary School Teachers. Journal of Learning and Teaching in Digital Age, 9(1), 1–16. https://doi.org/10.53850/joltida.1175453.
Koyuncu, İ., & Kılıç, A. F. (2019). The use of exploratory and confirmatory factor analyses: A document review. Education and Science, 44(198).
Lau, W. W., & Yuen, A. H. (2014). Developing and validating of a perceived ICT literacy scale for junior secondary school students: Pedagogical and educational contributions. Computers & Education, 78, 1–9.
Leech, N., Barrett, K., & Morgan, G. A. (2013). SPSS for intermediate statistics: Use and interpretation. Routledge.
Li, X., & Hu, R. (2022). Developing and validating the digital skills scale for school children (DSS-SC). Information, Communication & Society, 25(10), 1365–1382.
Lin, T. (2011). A computer literacy scale for newly enrolled nursing college students: Development and validation. Journal of Nursing Research, 19(4), 305–317.
Linacre, J. M. (1993). Many of facet Rasch measurement. MESA Press.
Linacre, J. M. (2002). Optimizing Rating Scale Category Effectiveness. Journal of Applied Measurement, 3, 85–106.
Linacre, J. M. (2014). A user’s guide to FACETS: Rasch-model computer programs. Retrieved December, 18, 2018.
Lozano, R. (2008). Envisioning sustainability three-dimensionally. Journal of Cleaner Production, 16(17), 1838–1846.
Martin, A. (2005). DigEuLit–a European framework for digital literacy: A progress report. Journal of e-Literacy, 2(2), 130–136.
Martin, A., & Grudziecki, J. (2006). DigEuLit: Concepts and tools for digital literacy development. Innovation in Teaching and Learning in Information and Computer Sciences, 5(4), 249–267.
McDougall, J., Readman, M., & Wilkinson, P. (2018). The uses of (digital) literacy. Learning, Media and Technology, 43(3), 263–279.
Ministry of National Education. (2018). SCIENCE COURSE TEACHING PROGRAM (Primary and Secondary School 3rd, 4th, 5th, 6th, 7th and 8th Grades). Retrieved from January 31, 2024 https://mufredat.meb.gov.tr/Dosyalar/201812312311937-FEN%20B%C4%B0L%C4%B0MLER%C4%B0%20%C3%96%C4%9ERET%C4%B0M%20PROGRAMI2018.pdf.
Ministry of National Education. (2020). Digital Literacy Teacher Guide. Retrieved from November 11, 2023 https://efeler.meb.gov.tr/meb_iys_dosyalar/2020_12/17092903_dijital_okur_yazar.pdf.
Mishra, P., & Koehler, M. J. (2006). Technological pedagogical content knowledge: A framework for teacher knowledge. Teachers College Record, 108(6), 1017–1054.
Mofreh, S. A. M., Ghafar, M. N. A., Omar, A. H. H., Mosaku, M., & Ma’ruf, A. (2014). Psychometric Properties on Lecturers’ Beliefs on Teaching Function: Rasch Model Analysis. International Education Studies, 7(11), 47–55.
Morgan, A., Sibson, R., & Jackson, D. (2022). Digital demand and digital deficit: Conceptualising digital literacy and gauging proficiency among higher education students. Innovations in Education and Teaching International, 44(3), 1–11. https://doi.org/10.1080/1360080X.2022.2030275
Morgan, R., Bryan, S., Meldrum, K., Mathiesen, B., & Hill, A. (2016). Using an adaptive e-learning curriculum to enhance digital literacy: challenges and opportunities.
Mossberger, K., Tolbert, C. J., & McNeal, R. S. (2007). Digital citizenship: The Internet, society, and participation. MIT Press.
Ng, W. (2012). Can we teach digital natives digital literacy? Computers & Education, 59(3), 1065–1078.
Ocak, G., & Karakuş, G. (2018). Pre-service Teachers’ Digital Literacy Self-Efficacy Scale Development Study. Kastamonu Education Journal, 26(5), 1427–1436. https://doi.org/10.24106/kefdergi.1931
Özdamar, K. (2013). Statistical data analysis with packet programs. Nisan Publication.
Pala, Ş. M., & Başıbüyük, A. (2020). Digital Literacy Scale Development Study for 10–12 Year Old Students. Mediterranean Journal of Educational Research, 14(33).
Pala, Ş. M. (2019). Examination of the academic achievement and skills of 5th grade secondary school students in the field of science, technology and society learning in the social studies course. [Unpublished Doctoral Thesis. Erzincan Binali Yıldırım University].
Park, S., & Kim, S. (2022). Identifying World Types to Deliver Gameful Experiences for Sustainable Learning in the Metaverse. Sustainability, 14(3), 1361. https://doi.org/10.3390/su14031361
Perdana, R., Riwayani, R., Jumadi, J., & Rosana, D. (2019). Development, reliability, and validity of open-ended test to measure student’s digital literacy skill. International Journal of Educational Research Review, 4(4), 504–516.
Pérez-Sánchez, J., Prieto, G., & Delgado, A. R. (2023). Rasch analysis of the scores of the difficulties in emotion regulation scale (DERS) in a traffic context. Quality & Quantity, 57(5), 4681–4692.
Phuapan, P., Viriyavejakul, C., & Pimdee, P. (2016). An analysis of digital literacy skills among Thai university seniors. International Journal of Emerging Technologies in Learning, 11(3), 24.
Polit, D. E., & Beck, C. T. (2006). Essentials of Nursing Research (6th ed.). Lippincott Williams & Wilkins.
Preston, C. C., & Colman, A. M. (2000). Optimal number of response categories in rating scales: Reliability, validity, discriminating power, and respondent preferences. Acta Psychologica, 104(1), 1–15. https://doi.org/10.1016/S0001-6918(99)00050-5
Rasch, G. (1960). Probabilistic models for some intelligence and attainment tests. Danish Institute for Educational Research.
Raykov, T., & Marcoulides, G. A. (2008). An introduction to applied multivariate analysis. Routledge.
Reddy, P., Chaudhary, K., & Hussein, S. (2023). A digital literacy model to narrow the digital literacy skills gap. Heliyon, 9(4), e14878.
Reddy, P., Chaudhary, K., Sharma, B., & Hussein, S. (2023b). Essaying the design, development and validation processes of a new digital literacy scale. Online Information Review, 47(2), 371–397.
Reid, N., & Shah, I. (2007). The role of laboratory work in university chemistry. Chemistry Education Research and Practice, 8(2), 172–185.
Ridout, M., Demétrio, C. G., & Hinde, J. (1998). Models for count data with many zeros. In Proceedings of the XIXth international biometric conference (Vol. 19, pp. 179–192). Cape Town, SA: International Biometric Society Invited Papers.
Rodríguez-de-Dios, I., Igartua, J. J., & González-Vázquez, A. (2016). Development and validation of a digital literacy scale for teenagers. In Proceedings of the fourth international conference on technological ecosystems for enhancing multiculturality (pp. 1067–1072).
Rogers, E. M., Singhal, A., & Quinlan, M. M. (2014). Diffusion of innovations. In An integrated approach to communication theory and research (pp. 432–448). Routledge.
Şahin, A., Özkan, R. A., & Turan, B. N. (2022). Development of a Digital Literacy Scale for Primary School Students: Validity and Reliability Study. Journal of Mother Tongue Education, 10(3).
Santos, M. R., & Gomes, M. M. F. (2024). Lifelong Digital Learning:” Computer Literacy”,“ Digital Literacy”, And” Digital Competence” As Dimensions For Digital Skills. Revista De Gestão Social e Ambiental, 18(1), e04403–e04403.
Shuttleworth, M. (2016). Content validity. Retrieved Apr, 14.
Smith, E. V., Wakely, M. B., De Kruif, R. E. L., & Swartz, C. W. (2003). Optimizing Rating Scales for Self-Efficacy (and Other) Research. Educational and Psychological Measurement, 63(3), 369–391. https://doi.org/10.1177/0013164403251320
Smith, A., Rubio-Rico, L., McClelland, G. T., Monserrate-Gómez, S., Font-Jiménez, I., & de Molina-Fernández, I. (2022). Co-designing and piloting an Integrated Digital Literacy and Language Toolkit for vulnerable migrant students in higher education. Education and Information Technologies, 27(5), 6847–6867.
Søby, M. (2013). Learning to be: Developing and understanding digital competence. Nordic Journal of Digital Literacy, 8(3), 134–138.
Stühmer, J., Turner, R., & Nowozin, S. (2020). Independent subspace analysis for unsupervised learning of disentangled representations. In International Conference on Artificial Intelligence and Statistics (pp. 1200–1210). PMLR.
Süslü, S. İ. (2022). Digital Literacy Self-Efficacy scale: Validity and Reliability Study. [Doctoral dissertation, Necmettin Erbakan University, Turkey].
Swaminathan, H., & Rogers, H. J. (1990). Detecting differential item functioning using logistic regression procedures. Journal of Educational Measurement, 27(4), 361–370.
Tabachnick, B. G., & Fidell, L. S. (2013). Using multivariate statistics (6th ed.). Allyn and Bacon.
Talan, T., & Aktürk, C. (2021). Examining the digital literacy and information security awareness levels of secondary school students. Kahramanmaraş Sütçü İmam University Journal of Social Sciences, 18(1), 158–180.
Toraman, L., & Usta, E. (2018). Ortaokul öğrencilerinin dijital yerli ve siber zorba olma durumlarının çeşitli değişkenler açısından incelenmesi. Ondokuz Mayis University Journal of Education Faculty, 37(2), 57–77.
Tran, T., Ho, M. T., Pham, T. H., Nguyen, M. H., Nguyen, K. L. P., Vuong, T. T., ... & Vuong, Q. H. (2020). How digital natives learn and thrive in the digital age: Evidence from an emerging economy. Sustainability, 12(9), 3819.
Trochim, W. M., & Donnelly, J. P. (2006). The research methods knowledge base (3rd ed.). Atomic Dog.
Tüfekçi, F. N., & Ceylan, M. (2022). A scale development study to determine the digital competency levels of primary school students in order to increase the quality in education. Izmir Democracy University Social Sciences Journal, 5(2), 166–187.
Turano, C. T., & Saludadez, J. A. (2024). Participation and nonparticipation in cyberbullying: a semiotic exploration on a Twitter encounter among young digital natives. In Handbook of Social Media Use Online Relationships, Security, Privacy, and Society Volume 2 (pp. 51–72). Academic Press.
Turkish Statistical Institute. (2021). Information Technology Usage Research in Children, 2021. Retrieved from April 30, 2023 https://data.tuik.gov.tr/Bulten/Index?p=Cocuklarda-Bilisim-Teknolojileri-Kullanim-Arastirmasi-2021-41132.
Turkish Statistical Institute. (2022). Household Information Technologies (IT) Usage Survey, 2022. Retrieved from April 30, 2023 https://data.tuik.gov.tr/Bulten/Index?p=Hanehalki-Bilisim-Teknolojileri-(BT)-Kullanim-Arastirmasi-2022-45587.
Üstündağ, A. (2021). Investigation of digital literacy levels of middle school students during the covid 19 pandemic. Adıyaman University Social Sciences Institute Journal, 39, 1–26.
Üstündağ, M., Güneş, E., & Bahçivan, E. (2017). Turkish adaptation of digital literacy scale and investigating pre-service science teachers’ digital literacy. Journal of Education and Future, 23(12), 19–29.
Valcke, M., Schellens, T., Van Keer, H., & Gerarts, M. (2007). Primary school children’s safe and unsafe use of the Internet at home and at school: An exploratory study. Computers in Human Behavior, 23(6), 2838–2850.
Valcke, M., De Wever, B., Van Keer, H., & Schellens, T. (2011). Long-term study of safe Internet use of young children. Computers & Education, 57(1), 1292–1305.
Van Laar, E., Van Deursen, A. J., Van Dijk, J. A., & de Haan, J. (2020). Determinants of 21st-century skills and 21st-century digital skills for workers: A systematic literature review. SAGE Open, 10(1), 2158244019900176.
Voogt, J., & Knezek, G. (Eds.). (2008). International handbook of information technology in primary and secondary education (Vol. 20). Springer Science & Business Media.
Walther, B., Hanewinkel, R., & Morgenstern, M. (2014). Effects of a brief school-based media literacy intervention on digital media use in adolescents: Cluster randomized controlled trial. Cyberpsychology, Behavior, and Social Networking, 17(9), 616–623.
Walton, G., & Hepworth, M. (2011). A longitudinal study of changes in learners’ cognitive states during and following an information literacy teaching intervention. Journal of Documentation, 67(3), 449–479.
Wang, C., & Si, L. (2023). A Bibliometric Analysis of Digital Literacy Research from 1990 to 2022 and Research on Emerging Themes during the COVID-19 Pandemic. Sustainability, 15(7), 5769.
Wright, B. D., & Linacre, J. M. (1989). Observations are always ordinal; measurements, however, must be interval. Archives of Physical Medicine and Rehabilitation, 70(12), 857–860.
Wynd, C. A., Schmidt, B., & Schaefer, M. A. (2003). Two quantitative approaches for estimating content validity. Western Journal of Nursing Research, 25(5), 508–518.
Yaman, C. (2019). Examining the digital literacy levels of social studies teacher candidates (Niğde Ömer Halisdemir University example) [Master’s Thesis, Niğde Ömer Halisdemir University/Institute of Educational Sciences].
Yang, Y. T. C., & Wu, W. C. I. (2012). Digital storytelling for enhancing student Academic achievement, critical thinking, and learning motivation: A year-long experimental study. Computers & Education, 59(2), 339–352.
Yaqoob, I., Salah, K., Jayaraman, R., & Omar, M. (2023). Metaverse applications in smart cities: Enabling technologies, opportunities, challenges, and future directions. Internet of Things, 100884.
Yeşilyurt, E., & Vezne, R. (2023). Digital literacy, technological literacy, and internet literacy as predictors of attitude toward applying computer-supported education. Education and Information Technologies, 1–27.
Yusoff, M. S. B. (2019). ABC of content validation and content validity index calculation. Education in Medicine Journal, 11(2), 49–54.
Zhang, H., & Zhu, C. (2016). A study of digital media literacy of the 5th and 6th grade. The Asia-Pacific Education Researcher, 25(4), 579–592.
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Funding and/or Conflicts of interests/Competing interests
All authors certify that they have no affiliations with or involvement in any organization or entity with any financial interest or non-financial interest in the subject matter or materials discussed in this manuscript.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Avinç, E., Doğan, F. Digital literacy scale: Validity and reliability study with the rasch model. Educ Inf Technol (2024). https://doi.org/10.1007/s10639-024-12662-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10639-024-12662-7