
Abstract
Difference sets and their generalisations to difference families arise from the study of designs and many other applications. Here we give a brief survey of some of these applications, noting in particular the diverse definitions of difference families and the variations in priorities in constructions. We propose a definition of disjoint difference families that encompasses these variations and allows a comparison of the similarities and disparities. We then focus on two constructions of disjoint difference families arising from frequency hopping sequences and show that they are in fact the same. We conclude with a discussion of the notion of equivalence for frequency hopping sequences and for disjoint difference families.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Difference sets and their generalisations to difference families arise from the study of designs and many other applications. In particular, the generalisation of difference sets to internal and external difference families arises from many applications in communications and information security. Roughly speaking, a difference family consists of a collection of subsets of an abelian group, and internal differences are the differences between elements of the same subsets, while external differences are the differences between elements of distinct subsets. Most of the definitions do not coincide exactly with each other, understandably since they arise from diverse applications, and the priorities of maximising or minimising various parameters are also understandably divergent. However, there is enough overlap in these definitions to warrant a study of how they relate to each other, and how the construction of one family may inform the construction of another. One of the aims of this paper is to perform a brief survey of these difference families, noting the variations in definitions and priorities, and to propose a definition that encompasses these definitions and allows a more unified study of these objects.
One particular class of internal difference family arises from frequency hopping (FH) sequences. FH sequences allow many transmitters to send messages simultaneously using a limited number of channels and it transpires that the question of how efficiently one can send messages has to do with the number of internal differences in a collection of subsets of frequency channels. The seminal paper of Lempel and Greenberger [50] gave optimal FH sequences using transformations of linear feedback shift register (LFSR) sequences. In another paper by Fuji-Hara et al. [28] various families of FH sequences were constructed using designs with particular automorphisms, and the question was raised there as to whether these constructions are the same as the LFSR constructions in [50]. Here we show a correspondence between one particular family of constructions in [28] and that of [50].
The relationship between the equivalence of difference families and the equivalence of the designs and codes that arise from them has been much studied. Here we will focus on the notion of equivalence for frequency hopping sequences and for disjoint difference families.
1.1 Definitions
Let \({\mathcal {G}}\) be an abelian groupFootnote 1 of size v, and let \(Q_0, \ldots , Q_{q-1}\) be disjoint subsets of \({\mathcal {G}},\,|Q_i|=k_i,\,i=0, \ldots , q-1\). We will call \(({\mathcal {G}}; Q_0, \ldots , Q_{q-1})\) a disjoint difference family \(\mathrm {DDF}(v; k_0, \ldots , k_{q-1})\) over \({\mathcal {G}}\) with the following external \({\mathcal {E}}(\cdot )\) and internal \({\mathcal {I}}(\cdot )\) differences:
We will call the \(\mathrm {DDF}\) uniform if all the \(Q_i\) are of the same size, and we will say it is a perfect Footnote 2 internal (or external) \(\mathrm {DDF}\) if \(|{\mathcal {I}}(d)|\) (or \(|{\mathcal {E}}(d)|\)) is a constant for all \(d \in {\mathcal {G}}\setminus \{0\}\). We will call the \(\mathrm {DDF}\) a partition type \(\mathrm {DDF}\) if \(\{Q_0, \ldots , Q_{q-1}\}\) is a partition of \({\mathcal {G}}\).
Remark 1
As mentioned before and as will be pointed out in Sect. 2, there is by no means a consensus on the terms used to describe a \(\mathrm {DDF}\). Here we point out the disparity between our terms and those of [14], and in Sect. 2 we will point out the differences as they arise. In particular, the definition of difference family in [14] stipulates that the subsets \(Q_i\) are all of the same size, but does not insist that they are disjoint. We have defined a \(\mathrm {DDF}\) to consist of disjoint subsets (of varying sizes) because we want to be able to define external differences. Using the term uniform to describe the subsets \(Q_i\) being of the same size is consistent with terminology used in design theory.
Example 1
A \((v,k, \lambda )\)-difference set \(Q_0\) over \({\mathbb {Z}}_v\) is a perfect internal \(\mathrm {DDF}(v;k)\) with \(|{\mathcal {I}}(d)| = \lambda = k(k-1)/(v-1)\). If we let \(Q_1={\mathbb {Z}}_v \setminus Q_0\) then \(({\mathbb {Z}}_v; Q_0, Q_1)\) is an internal \(\mathrm {DDF}(v; k, v-k)\) with \(|{\mathcal {I}}_0(d)| = \lambda \) and \(|{\mathcal {I}}_1(d)|=v-2k+\lambda \) for all \(d \in {\mathbb {Z}}_v^*\). In fact, \(({\mathbb {Z}}_v; Q_0, Q_1)\) has \(|{\mathcal {I}}(d)|=v-2k+2\lambda \) and \(|{\mathcal {E}}(d)| = v(v-1) - (v-2k+2\lambda )\) and is a perfect internal and external \(\mathrm {DDF}\).
For example, the (7, 3, 1) difference set \(Q_0=\{0,1,3\} \subseteq {\mathbb {Z}}_7\). We have \(|{\mathcal {I}}(d)| = 1\). Let \(Q_1={\mathbb {Z}}_7 \setminus Q_0 =\{2,4,5,6 \}\). Then \(({\mathbb {Z}}_7;Q_0, Q_1)\) has \(|{\mathcal {I}}_0(d)|=1,\,|{\mathcal {I}}_1(d)|=2,\,|{\mathcal {I}}(d)|=3,\,|{\mathcal {E}}_0(d)| = |{\mathcal {E}}_1(d)|=2\) and \(|{\mathcal {E}}(d)|=4\) for all \(d \in {\mathbb {Z}}_7^*\).
It is not hard to see that a perfect partition type internal \(\mathrm {DDF}\) is also a perfect partition type external \(\mathrm {DDF}\) and vice versa. However, this is not generally true for \(\mathrm {DDF}\)s that are not partition type:
Example 2
Let \({\mathcal {G}}= {\mathbb {Z}}_{25},\,Q_0 = \{1,2,3,4,6,15\},\,Q_1=\{5,9,10,14,17,24\}\). This is a perfect external \(\mathrm {DDF}(25; 6,6)\) with \(|{\mathcal {E}}(d)|=3\) for all \(d \in {\mathbb {Z}}_{25}^*\) given in [30]. However, it is not a perfect internal \(\mathrm {DDF}\):
For many codes and sequences [12, 17, 28, 30, 64], desirable properties can be expressed in terms of (some) external or internal differences of \(\mathrm {DDF}\)s. We give a brief survey of these applications and the properties required of the \(\mathrm {DDF}\)s in the next section.
2 Disjoint difference families in applications
This is not intended to be a comprehensive survey of where disjoint difference families arise in applications, nor of each application. We want to show that these objects arise in many areas of communications and information security research and that a study of their various properties may be useful in making advances in these fields.
2.1 Frequency hopping (FH) sequences
Let \(F=\{f_0, \ldots , f_{q-1}\}\) be a set of frequencies used in a frequency hopping multiple access communication system [24]. A frequency hopping (FH) sequence X of length v over F is simply \(X=(x_0, x_1, \ldots , x_{v-1}),\,x_i \in F\), specifying that frequency \(x_i\) should be used at time i. If two FH sequences use the same frequency at the same time (a collision), the messages sent at that time may be corrupted. Collisions are given by Hamming correlations: if a single sequence together with all its cyclic shifts are used then we are interested in its auto-correlation values (the number of positions in which each cyclic shift agrees with the original sequence). If two or more sequences are used then it is also necessary to consider the cross-correlation between pairs of sequences (the number of positions in which cyclic shifts of one sequence agree with the other sequence in the pair).
A single FH sequence X may be viewed in a combinatorial way: Define \(Q_i,\,i =0, \ldots , q-1\), as subsets of \({\mathbb {Z}}_v\), with \(j \in Q_i\) if \(x_j = i\). Hence each \(Q_i\) corresponds to a frequency \(f_i\), and the elements of \(Q_i\) are the positions in X where \(f_i\) is used. (For example, the frequency hopping sequence \(X=(0,0,1,0,1,1,1)\) over \(F=\{0, 1\}\) gives the \(\mathrm {DDF}\) of Example 1.) In [28] it was shown that an FH sequence \((x_0, x_1, \ldots , x_{v-1})\) with out-of-phase auto-correlation value of at most \(\lambda \) exists if and only if \(({\mathbb {Z}}_v; Q_0, \ldots , Q_{q-1})\) is a partition type \(\mathrm {DDF}(v; k_0, \ldots , k_{q-1})\) with \({\mathcal {I}}(d)\) satisfying
In [28] \(({\mathbb {Z}}_v; Q_0, \ldots , Q_{q-1})\) is called a partition type difference packing.
The aim in FH sequence design is to minimise collisions: we would like \(\lambda \) to be small. Lempel and Greenberger [50] proved a lower bound for \(\lambda \), and in [68] bounds relating the size of sets of frequency hopping sequences with their Hamming auto- and cross-correlation values were given. Lempel and Greenberger [50] constructed optimal sequences using transformations of m-sequences (more details in Sect. 4.1). In [28] Fuji-Hara et al. also provided many examples of optimal sequences using designs with certain types of automorphisms. Other constructions of FHS include using cyclotomy [11, 55], random walks on expander graphs [26], and error-correcting codes [20, 23]. A survey of sequence design from the viewpoint of codes can also be found in [70]. Later in this paper we will show that one of the constructions in [28] by Fuji-Hara et al. gave the same sequences as those constructed by Lempel and Greenberger in [50]. It would be interesting to see how the other constructions relate to each other.
Note that in this correspondence to a difference family, the set of frequency hopping sequence is the rotational closure (Definition 1, Sect. 5) of one single frequency hopping sequence. Collections of \(\mathrm {DDF}\)s were used to model more general sets of sequences in [4, 32, 79], referred to as balanced nested difference packings.
It is also to be noted that most of the published work considered either pairwise interference between two sequences (described above as Hamming correlation) or adversarial interference (jamming) [26, 58, 81], which may not reflect the reality of the application where more than two sequences may be in use. To this end Nyirenda et al. [59] modelled frequency hopping sequences as cover-free codes and considered additional properties required to resist jamming.
2.2 Self-synchronising codes
Self-synchronising codes are also called comma-free codes and have the property that no codeword appears as a substring of two concatenated codewords. This allows for synchronisation without external help. Codes achieving self-synchronisation in the presence of up to \(\lfloor \frac{\lambda -1}{2} \rfloor \) errors can be constructed from a \(\mathrm {DDF}(v; k_0, \ldots , k_{q-1})\) \(({\mathbb {Z}}_v; Q_0, \ldots , Q_{q-1})\) with \(|{\mathcal {E}}(d)| \ge \lambda \). In [30], this \(\mathrm {DDF}\) was called a difference system of sets of index \(\lambda \) over \({\mathbb {Z}}_v\). The sets \(Q_0, \ldots , Q_{q-1}\) give the markers for self-synchronisation and are a redundancy, hence we would like \(k=\sum _{i=0}^{q-1} k_i\) to be small. Other optimisation problems include reducing the rate k / v, reducing \(\lambda \), and reducing the number q of subsets.
An early paper by Golomb et al. [36] took the combinatorial approach to the subject of self-synchronising codes, and [51] gave a survey of results, constructions and open problems of self-synchronising codes. More recent work on self-synchronising codes can be found in [13] which gave some variants on the definitions, and in [6] in the guise of non-overlapping codes, giving constructions and bounds. Further constructions can be found in [30], including constructions from the partitioning of cyclic difference sets and partitioning of hyperplanes in projective geometry, as well as iterative constructions using external and internal \(\mathrm {DDF}\)s.
2.3 Splitting A-codes and secret sharing schemes with cheater detection
In authentication codes (A-codes), a transmitter and a receiver share an encoding rule e, chosen according to some specified probability distribution. To authenticate a source state s, the transmitter encodes s using e and sends the resulting message \(m=e(s)\) to the receiver. The receiver receives a message \(m'\) and accepts it if it is a valid encoding of some source, i.e. when \(m'=e(s^\prime )\) for some source \(s^\prime \). In a splitting A-code, the message is computed with an input of randomness so that a source state is not uniquely mapped to a message. An adversary (who does not know which encoding rule is being used) may send their own message m to the receiver in the hope that it will be accepted as valid. This is known as an impersonation attack, and succeeds if m is a valid encoding of some source s. Also of concern are substitution attacks, in which an adversary who has seen an encoding m of a source s replaces it with a new value \(m^\prime \). This attack succeeds if \(m^{\prime }\) is a valid encoding of some source \(s^\prime \ne s\). We refer to [64] for further background. It was shown in [64] that optimal splitting A-codes can be constructed from a perfect uniform external \(\mathrm {DDF}(v; k_0=k, \ldots , k_{q-1}=k)\) with \(|{\mathcal {E}}(d)| = 1\). This gives an A-code with q source states, v encoding rules, v messages, and each source state can be mapped to k valid messages. This type of \(\mathrm {DDF}\) was called an external difference family (EDF) in [64]. The probability of an adversary successfully impersonating the transmitter is given by kq / v and the probability of successfully substituting a message being transmitted is given by 1 / kq (which also happens to equal \(k(q-1)/(v-1)\) in this particular context). These are parameters to be minimised.
An extensive list of A-code references prior to 1998 is given in [71]. More recent work on splitting authentication codes includes [7, 21, 22, 31, 43–46, 49, 52, 53, 61, 67, 77, 78].
A secret sharing scheme is a means of distributing some information, known as shares, to a set of players so that authorised subsets of players are able to combine their shares to reconstruct a unique secret, whereas the shares belonging to unauthorised subsets reveal no information about the secret. If some of the players are dishonest, however, then they may cheat by submitting false values that are not their true shares and thereby causing an incorrect value to be obtained during secret reconstruction. Such attacks were first discussed by Tompa and Woll in [72]. Various types of difference family have been used in constructing schemes which allow such cheating to be detected with high probability. In [65], difference sets were used to construct schemes that were optimal with respect to certain bounds on the sizes of shares. In [64], EDFs were used in a similar manner to construct optimal schemes. Other schemes that permit detection of cheaters include those proposed in [3, 9, 42, 60, 62, 63]. Many of these constructions can be interpreted as involving particular types of difference family; this observation has led to the definition of the concept of algebraic manipulation detection codes [16] (see Sect. 2.4).
2.4 Weak algebraic manipulation detection (AMD) codes
An AMD code is a tool that can be combined with a cryptographic system that provides some form of secrecy in order to incorporate extra robustness against an adversary who can actively change values in the system. The notion was proposed in [16] as an abstraction of techniques used in the construction of robust secret sharing schemes. In the basic setting for a weak AMD code, a source is chosen uniformly from a finite set S of sources with \(|S|=k\). It is then encoded using a (possibly randomised) encoding map \(E:S \rightarrow {\mathcal {G}}\) where \({\mathcal {G}}\) is an abelian group of order \(v\ge k\). We require the sets of possible encodings of different sources to be disjoint, so that E(s) uniquely determines s. An adversary is able to manipulate this encoded value by adding a group element \(d\in {\mathcal {G}}\) of its choosing. (We suppose the adversary knows the details of the encoding function, but does not know what source has been chosen, nor the specific value of any randomness used in the encoding.) After this manipulation, an attempt is made to decode the resulting value. If the altered value \(E(s)+d\) is a valid encoding \(E(s^\prime )\) of some source \(s^\prime \) then it is decoded to \(s^\prime \). Otherwise, decoding fails and the symbol \(\perp \) is returned; this represents the situation where the adversary’s manipulation has been detected. The adversary is deemed to have succeeded if \(E(s)+d\) is decoded to \(s^\prime \ne s\), that is if they have caused the stored value to be decoded to a source other than the one that was initially stored.
A set of sources S with \(|S|=k\), abelian group \({\mathcal {G}}\) with \(|{\mathcal {G}}|=v\) and encoding rule E constitute a weak \((k, v, \epsilon )\) -AMD (algebraic manipulation detection) code if for any choice of \(d\in {\mathcal {G}}\) the adversary’s success probability is at most \(\epsilon \). (The probability is taken over the uniform choice of source, and over the randomness used in the encoding.)
In [16], it was shown that a weak \((k, v, \epsilon )\)-AMD code with deterministic encoding is equivalent to a \(\mathrm {DDF}(v; k)\) with
In [16] these were called \((v, k, \lambda )\)-bounded difference sets. It is easy to see that these are generalisations of difference sets, allowing general abelian groups and with an upper bound for the number of differences.
Weak AMD codes were introduced in [16], with further detail on constructions, bounds and applications provided in the full version of the paper [15]. Bounds on the adversary’s success probability in a weak AMD code were given in [17] and several families with good asymptotic properties were constructed using vector spaces. Additional bounds were given in [66], and constructions and characterisations were given relating weak AMD codes that are optimal with respect to these bounds to a variety of types of external \(\mathrm {DDF}\). It is desirable to minimise the tag length (\(\log v - \log k\), the number of redundant bits) as well as \(\epsilon \).
2.5 Stronger forms of algebraic manipulation detection (AMD) code
Strong AMD codes were defined in [16]; these are able to limit the success probability of an adversary even when the adversary knows which source has been encoded. Specifically, for every source \(s \in S\) and every element \(d \in {\mathcal {G}}\), the probability that \((E(s)+d)\) is decoded to a value \(s^\prime \not \in \{ s, \perp \}\) is at most \(\epsilon \). (Here the probability is taken over the randomness in the encoding rule E. Unlike the case of a weak AMD code, a strong AMD code cannot use a deterministic encoding rule.)
Write \(Q_i = \{ g \in {\mathcal {G}}\; : \; D(g) = s_i \}\) for each \(s_i \in S,\,i = 0, \ldots , k-1\), and \(|Q_i|=k_i\). In the case where the encoding \(E(s_i)\) is uniformly distributed over \(Q_i\) for every \(s_i\), we have that \(({\mathcal {G}}; Q_0, \ldots , Q_{k-1})\) forms a \(\mathrm {DDF}(v; k_0, \ldots , k_{k-1})\) with \(|{\mathcal {E}}_i(d)| \le \lambda _i =\epsilon k_i\) and \(|{\mathcal {E}}(d)| \le \lambda = \sum _{i=0}^{k-1} \lambda _i\).
Constructions from vector spaces and caps in projective space were given in [17]. Additional bounds and characterisations were given in [66]. A construction based on a polynomial over a finite field was given in [16] and applied to the construction of robust secret sharing schemes, and robust fuzzy extractors. This construction has since been used for a range of applications, including the construction of anonymous message transmission schemes [8], non-malleable codes [25], strongly decodeable stochastic codes [37], secure communication in the presence of a byzantine relay [38, 39], and codes for the adversarial wiretap channel [76]. New constructions, including an asymptotically optimal randomised construction were given in [18].
AMD codes that resist adversaries who learn some limited information about the source were constructed and analysed in [1], and their application to tampering detection over wiretap channels was discussed.
AMD codes secure in a stronger model in which an adversary succeeds even when producing a new encoding of the original source have been used in the design of secure cryptographic devices and related applications [33, 34, 48, 56, 57, 74, 75].
2.6 Optical orthogonal codes (OOCs)
Optical orthogonal codes (OOCs) are sequences arising from applications in code-division multiple access in fibre optic channels. OOC with low auto- and cross-correlation values allow users to transmit information efficiently in an asynchronous environment. A \((v,w,\lambda _a, \lambda _c)\)-OOC of size q is a family \(\{ X_0, \ldots , X_{q-1}\}\) of q (0, 1)-sequences of length v, weight w, such that auto-correlation values are at most \(\lambda _a\) and cross-correlation values are at most \(\lambda _c\). For each sequence \(X_i\), let \(Q_i\) be the set of integers modulo v denoting the positions of the non-zero bits. Then \(({\mathbb {Z}}_v; Q_0, \ldots , Q_{q-1})\) is a uniform \(\mathrm {DDF}(v; k_0=w \ldots , k_{q-1}=w)\) with
Background and motivation to the study of OOC were given in [12], which also included constructions from designs, algebraic codes and projective geometry. In [5] constant weight cyclically permutable codes, which are also uniform \(\mathrm {DDF}\)s, were used to construct OOC, and a recursive construction was given. In [82] OOC were used to construct compressed sensing matrix and a relationship between OOC and modular Golomb rulers ([14]) was given-a (v, k) modular Golomb ruler is a set of k integers \(\{d_0, \ldots , d_{k-1}\}\) such that all the differences are distinct and non-zero modulo v—in fact, a \(\mathrm {DDF}(v; k)\) with \(|I(d)| \le 1\) for all \(d \ne 0\).
A generalisation to two-dimensional OOC with a combinatorial approach can be found in [10, 19]. Combinatorial and recursive constructions as well as bounds can be found in [27], and [47] allowed variable weight OOC and used various types of difference families and designs to construct such OOCs.
2.7 Other applications
The list of applications discussed in this section is by no means exhaustive, and \(\mathrm {DDF}\)s arise in a variety of other areas of combinatorics and coding theory. For example, in [29], complete sets of disjoint difference families (in fact, partition type perfect uniform \(\mathrm {DDF}\)s where the subsets are grouped) were used in constructing 1-factorisations of complete graphs and in constructing cyclically resolvable cyclic Steiner systems. In [80], high-rate quasi-cyclic codes were constructed using perfect internal uniform \(\mathrm {DDF}\), and a generalisation to families of sets of non-negative integers with specific internal differences was given. \({\mathbb {Z}}\) -cyclic whist tournaments correspond to perfect internal \(\mathrm {DDF}\)s over \({\mathbb {Z}}_v\) [2]. In addition, various types of sequences and arrays with specified correlation properties have been proposed for a wide range of applications [35, 40]. Many of these can be studied in terms of a relationship with appropriate forms of \(\mathrm {DDF}\)s [69].
3 A geometrical look at a perfect partition type disjoint difference family
In [28] a perfect partition type \(\mathrm {DDF}(q^{n}-1; k_0=q-1,k_1=q, \ldots , k_{q^{n-1}-1}=q)\) over \({\mathbb {Z}}_{q^n-1}\) was constructed from line orbits of a cyclic perspectivity \(\tau \) in the n-dimensional projective space PG(n, q) over \(\mathrm {GF}(q)\). In [50] another construction with the same parameters was given. In the next section we will show a correspondence between the two constructions. Before that we will describe in greater detail the the construction of [28, Section III].
An n-dimensional projective space PG(n, q) over the finite field of order q admits a cyclic group of perspectivities \(\langle \tau \rangle \) of order \(q^n-1\) that fixes a hyperplane \({\mathcal {H}}_{\infty }\) and a point \(\infty \notin {\mathcal {H}}_{\infty }\). (We refer the reader to [41] for properties of projective spaces and their automorphism groups.) This group \(\langle \tau \rangle \) acts transitively on the points of \({\mathcal {H}}_{\infty }\) and regularly on the points of \(PG(n,q) \setminus ({\mathcal {H}}_{\infty } \cup \{\infty \})\). We will call the points (and spaces) not contained in \({\mathcal {H}}_{\infty }\) the affine points (and spaces).
The point orbits of \(\langle \tau \rangle \) are \(\{ \infty \},\,{\mathcal {H}}_{\infty }\), and \(PG(n,q) \setminus ({\mathcal {H}}_{\infty } \cup \{\infty \})\). Dually, the hyperplane orbits are \({\mathcal {H}}_{\infty }\), the set of all hyperplanes through \(\infty \), and the set of all hyperplanes of \(PG(n,q) \setminus {\mathcal {H}}_{\infty }\) not containing \(\infty \). Line orbits under \(\langle \tau \rangle \) are:
-
(A)
One orbit of affine lines through \(\infty \)— this orbit has length \(\frac{q^n - 1}{q-1}\); and
-
(B)
\(\frac{q^{n-1} - 1}{q-1}\) orbits of affine lines not through \(\infty \)—each orbit has length \(q^n-1\), and \(\langle \tau \rangle \) acts regularly on each orbit; and
-
(C)
One orbit of lines contained in \({\mathcal {H}}_{\infty }\).
A set of parallel (affine) lines through a point \(P_{\infty } \in {\mathcal {H}}_{\infty }\) consists of one line \(L_0\) from the orbit of type (A) and \(q-1\) lines from each of the \((q^{n-1}-1)/(q-1)\) orbits of type (B). We will write this set of \(q^{n-1}\) lines \({\mathcal {P}} = \{L_0, L_1, \ldots , L_{q^{n-1}-1}\}\) as follows (See Fig. 1):
-
\(L_0\), a line through \(\infty \) and \(P_{\infty } \in {\mathcal {H}}_{\infty }\);
Fig. 1 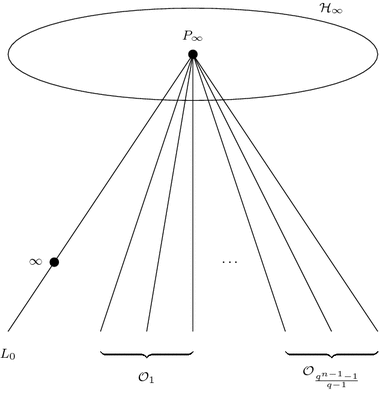
The parallel class \({\mathcal {P}}\)
-
\({\mathcal {O}}_i = \{ L_{(i-1)(q-1)+1}, L_{(i-1)(q-1)+2}, \ldots , L_{(i-1)(q-1)+(q-1)} \},\,i = 1, \ldots , \frac{q^{n-1}-1}{q-1},\) each \({\mathcal {O}}_i\) belonging to a different orbit under \(\langle \tau \rangle \).

We consider the two types of \(d \in {\mathbb {Z}}_{q^n-1}^*\) depending on the action of \(\tau ^d\) on \(L_0\):
-
(I)
There are \(q-2\) values of \(\tau ^d,\,d \in {\mathbb {Z}}_{q^n-1}^*\), fixing the line \(L_0\) (and the points \(P_{\infty }\) and \(\infty \)) and permuting the points of \(L_0\). These \(\tau ^d\) permute but do not fix the lines within each \({\mathcal {O}}_i\). Hence we have, for these \(d \in {\mathbb {Z}}_{q^n-1}^*\),
$$\begin{aligned} L_0^{\tau ^d} \cap L_0 = L_0 \text{ and } L_i^{\tau ^d} \cap L_i = \{P_\infty \}. \end{aligned}$$(1) -
(II)
The remaining \((q^n-1) - (q-2)\) values of \(\tau ^d\) map lines in \({\mathcal {P}}\) to affine lines not in \({\mathcal {P}}\). Hence we have
$$\begin{aligned} L_0^{\tau ^d} \cap L_0 = \{\infty \} \text{ and } |L_i^{\tau ^d} \cap L_i| = 0 \text{ or } 1. \end{aligned}$$(2)Without loss of generality consider \(L_1 \in {\mathcal {O}}_1\). Suppose \(|L_1^{\tau ^d} \cap L_1| = 1\), say \(L_1^{\tau ^d} \cap L_1 = \{P\}\). Let \(L_k \in {\mathcal {O}}_1\) be another line in the same orbit as \(L_1\), so there is a \(d_k\) such that \(L_1^{\tau ^{d_k}} = L_k\). It is not hard to see that \(\{P^{\tau ^{d_k}}\} = L_k^{\tau ^d} \cap L_k\), since
$$\begin{aligned} P \in L_1\Rightarrow & {} P^{\tau ^{d_k}} \in L_1^{\tau ^{d_k}} = L_k, \\ P \in L_1^{\tau ^d}\Rightarrow & {} P^{\tau ^{d_k}} \in (L_1^{\tau ^d})^{\tau ^{d_k}} = (L_1^{\tau ^{d_k}})^{\tau ^{d}} = L_k^{\tau ^{d}}. \end{aligned}$$Hence for any orbit \({\mathcal {O}}_i\), if \(|L_j^{\tau ^d} \cap L_j| = 1\) for some \(L_j \in {\mathcal {O}}_i\) then \(|L_k^{\tau ^d} \cap L_k|=1\) for all \(L_k \in {\mathcal {O}}_i\).
Now, suppose again that \(|L_1^{\tau ^d} \cap L_1| = 1\). Let \(P_1\) be the point on \(L_1\) such that \(P_1^{\tau ^d} \in L_1^{\tau ^d} \cap L_1\). Consider \(L_j \in {\mathcal {O}}_k,\,k\ne 1\). Suppose \(|L_j^{\tau ^d} \cap L_j| = 1\). Let \(P_2\) be the point on \(L_j\) such that \(P_2^{\tau ^d} \in L_j^{\tau ^d} \cap L_j\). (See Fig. 2.) Since \(\langle \tau \rangle \) is transitive on affine points (excluding \(\infty \)), there is a \(d_j\) such that \(P_1^{\tau ^{d_j}} = P_2\). Then
$$\begin{aligned} (P_1^{\tau ^d})^{\tau ^{d_j}} = (P_1^{\tau ^{d_j}})^{\tau ^{d}} = P_2^{\tau ^d}. \end{aligned}$$This means that \(\tau ^{d_j}\) maps \(P_1\) to \(P_2\) and \(P_1^{\tau ^d}\) to \(P_2^{\tau ^d}\) and hence maps the line \(L_1\) to \(L_j\). But this is a contradiction since \(L_1\) and \(L_j\) belong to different orbits under \(\langle \tau \rangle \). Hence if \(|L_j^{\tau ^d} \cap L_j| = 1\) for any \(L_j\) in some orbit \({\mathcal {O}}_i\) then \(|L_k^{\tau ^d} \cap L_k| = 0\) for all \(L_k\) in all other orbits.
It is also clear that for any \(L_i\) in any orbit, there is a d such that \(|L_i^{\tau ^d} \cap L_i| = 1\), because \(\langle \tau \rangle \) is transitive on affine points (excluding \(\infty \)). Indeed, \(\langle \tau \rangle \) acts regularly on these points, so that for any pair of points (P, Q) on \(L_i\) there is a unique d such that \(P^{\tau ^d} = Q\). There are \(q(q-1)\) pairs of points and so there are \(q(q-1)\) such values of d. These \(q(q-1)\) values of d for each \({\mathcal {O}}_i\) in \({\mathcal {P}}\), together with the \(q-2\) values of d where \(\tau ^d\) that fixes \(L_0\), account for all of \({\mathbb {Z}}_{q^n-1}^*\).

\(L_1,\,L_j\) in different orbits
Now, the points of \(PG(n,q) \setminus ({\mathcal {H}}_{\infty } \cup \{\infty \})\) can be represented as \({\mathbb {Z}}_{q^n-1}\) as follows: pick an arbitrary point \(P_0\) to be designated 0. The point \(P_0^{\tau ^i}\) corresponds to \(i \in {\mathbb {Z}}_{q^n-1}\). The action of \(\tau ^d\) on any point P is thus represented as \(P+d\). Affine lines are therefore q-subsets of \({\mathbb {Z}}_{q^n-1}\). Let \(Q_0 \subseteq {\mathbb {Z}}_{q^n-1}\) contain the points of \(L_0 \setminus \{\infty \}\), and let \(Q_i\) contain the points of \(L_i\). It follows from the intersection properties of the lines [Properties (1), (2)] that \(\{Q_0, \ldots , Q_{q^{n-1} -1} \}\) forms a perfect partition type \(\mathrm {DDF}(q^{n}-1; q-1,q, \ldots , q)\) over \({\mathbb {Z}}_{q^n-1}\), with \(|{\mathcal {I}}(d)| = q-1\) for all \(d \in {\mathbb {Z}}_{q^n-1}^*\).
3.1 A perfect external \(\mathrm {DDF}\)
Given that a partition type perfect internal \(\mathrm {DDF}\) over \({\mathbb {Z}}_v\) with \(|{\mathcal {I}}(d)| = \lambda \) must be a perfect external \(\mathrm {DDF}\) with \(|{\mathcal {E}}(d)| = v-\lambda \), the intersection properties \(|L_i^{\tau ^d} \cap L_j|,\,i \ne j\) can be deduced as follows for the two different types (I), (II) of d:
-
(I)
For the \(q-2\) values of \(\tau ^d\) of type (I) fixing \(L_0\), we have:
-
(a)
\(L_0\) is fixed, so \(|L_0^{\tau ^d} \cap L_i| = 0\) for all \(L_i \ne L_0\).
-
(b)
If \(L_i\) and \(L_j\) are in different orbits then \(|L_i^{\tau ^d} \cap L_j| = 0\) (since \(\tau ^d\) fixes \({\mathcal {O}}_i\)).
-
(c)
If \(L_i\) and \(L_j\) are in the same orbit, then since \(\tau ^d\) acts regularly on an orbit of type (B), there is a unique d that maps \(L_i\) to \(L_j\), so \(|L_i^{\tau ^d} \cap L_j| = q\), and for all other \(L_k\) in the same orbit, \(|L_i^{\tau ^d} \cap L_k| = 0\). This applies to each orbit, so that for each of the \(q-2\) values of d, there are \(((q^{n-1}-1)/(q-1)) \times (q-1) = q^{n-1}-1\) cases where \(|L_i^{\tau ^d} \cap L_j| = q\).
-
(a)
-
(II)
For the \((q^n-1)-(q-2)\) values of \(\tau ^d\) of type (II) not fixing \(L_0\), we have:
-
(a)
Pick any point \(P \in L_0 \setminus \{\infty \},\,P^{\tau ^d} \in L_i\) for some \(L_i \ne L_0\), so \(|L_0^{\tau ^d} \cap L_i| = 1\) for some \(L_i\). There are \(q-1\) points on \(L_0 \setminus \{\infty \}\), so there are \(q-1\) lines \(L_i\) such that \(|L_0^{\tau ^d} \cap L_i| = 1\).
-
(b)
Consider \(L_i \ne L_0\). Take any point \(P \in L_i\). We have \(P^{\tau ^d} \in L_j\) for some \(L_j\), so \(|L_i^{\tau ^d} \cap L_j| = 1\). This applies for all \(L_i\), so that for any of the \((q^n-1)-(q-2)\) values of d, there are \((q^{n-1}-1)q\) cases of \(|L_i^{\tau ^d} \cap L_j| = 1,\,q-1\) of which are when \(L_j = L_i\).
-
(a)
Defining the sets \(Q_0, \ldots , Q_{q^-1}\) as before, we see that \(\{Q_0, \ldots , Q_{q^-1}\}\) forms a perfect partition type \(\mathrm {DDF}\) with \({\mathcal {E}}(d) = q(q^{n-1}-1)\).
4 A correspondence between two difference families
In [28], Fuji-Hara et al. constructed the perfect partition type \(\mathrm {DDF}(q^{n}-1; q-1,q, \ldots , q)\) over \({\mathbb {Z}}_{q^n-1}\) with \(|{\mathcal {I}}(d)| = q-1\) described in Sect. 3. Using parallel t-dimensional subspaces (we described the case when \(t=1\)), perfect partition type \(\mathrm {DDF}(q^n-1; q^t-1, q^t, \ldots , q^t)\) with \(|{\mathcal {I}}(d)| = q^t-1\) can also be constructed.
This construction gives \(\mathrm {DDF}\) with the same parameters as those constructed using m-sequences in [50], though [50] restricted their constructions to the case when q is a prime. It was asked in [28] whether these are “essentially the same” constructions. In this section we show a correspondence between these two constructions, and in Sect. 5 we discuss what “essentially the same” might mean. This correspondence also shows that the restriction to q prime in [50] is unnecessary. (Indeed it was pointed out in [70] that the assumption that the field must be prime is not necessary.)
4.1 The Lempel–Greenberger m-sequence construction
We refer the reader to [54] for more details on linear recurring sequences. Here we sketch an introduction. Let \((s_t)=s_0s_1s_2\ldots \) be a sequence of elements in \(\mathrm {GF}(q),\,q\) a prime power, satisfying the \(n^\mathrm{th}\) order linear recurrence relation
Then \((s_t)\) is called an (\(n^\mathrm{th}\) order) linearly recurring sequence in \(\mathrm {GF}(q)\). Such a sequence can be generated using a linear feedback shift register (LFSR). An LFSR is a device with n stages, which we denote by \(S_0, \ldots ,S_{n-1}\). Each stage is capable of storing one element of \(\mathrm {GF}(q)\). The contents \(s_{t+i}\) of all the registers \(S_i\) (\(0 \le i \le n-1\)) at a particular time t are known as the state of the LFSR at time t. We will write it either as \(s(t,n)=s_{t}s_{t+1} \ldots s_{t+n-1}\) or as a vector \({\mathbf s}_t = (s_t, s_{t+1}, \ldots , s_{t+n-1})\). The state \({\mathbf s}_0 =(s_0,s_1, \ldots , s_{n-1})\) is the initial state.
At each clock cycle, an output from the LFSR is extracted and the LFSR is updated as described below.
-
The content \(s_t\) of the stage \(S_0\) is output and forms part of the output sequence.
-
For all other stages, the content \(s_{t+i}\) of stage \(S_i\) is moved to stage \(S_{i-1}\) (\(1 \le i \le n-1\)).
-
The new content \(s_{t+n}\) of stage \(S_{n-1}\) is the value of the feedback function
$$\begin{aligned} f(s_t,s_{t+1},\ldots ,s_{t+n-1}) = c_0s_t + c_1s_{t+1} + \cdots c_{n-1}s_{t+n-1},\; c_i \in \mathrm {GF}(q). \end{aligned}$$The new state is thus \({\mathbf s}_{t+1}=(s_{t+1}, s_{t+2}, \ldots , s_{t+n})\). The constants \(c_0, c_1, \ldots , c_{n-1}\) are known as the feedback coefficients or taps.
A diagrammatic representation of an LFSR is given in Fig. 3.

Linear feedback shift register
The characteristic polynomial associated with the LFSR (and the linear recurrence relation) is
The state at time \(t+1\) is also given by \({\mathbf s}_{t+1}= {\mathbf s}_t C\), where C is the state update matrix given by
A sequence \((s_t)\) generated by an n-stage LFSR is periodic and has maximum period \(q^n-1\). A sequence that has maximum period is referred to as an m-sequence. An LFSR generates an m-sequence if and only if its characteristic polynomial is primitive. An m-sequence contains all possible non-zero states of length n, hence we may use, without loss of generality, the impulse response sequence [the sequence generated using initial state \((0\cdots 01)\)].
Let \(S = (s_t) = s_0s_1s_2 \ldots \) be an m-sequence over a prime field \(\mathrm {GF}(p)\) generated by an n-stage LFSR with a primitive characteristic polynomial f(x). Let \(s(t,k) = s_t s_{t+1} \ldots s_{t+k-1}\) be a subsequence of length k starting from \(s_t\).
The \(\sigma _k\)-transformations, \(1 \le k \le n-1\) introduced in [50] are described as follows:
We write the \(\sigma _k\)-transform of S as \(U = (u_t),\,u_t = \sigma _k( s(t,k) )\), which is a sequence over \({\mathbb {Z}}_{p^k}\).
In [50, Theorem 1] it is shown that the sequence U forms a frequency hopping sequence with out-of-phase auto-correlation value of \(p^{n-k}-1\), and hence a partition type perfect \(\mathrm {DDF}\) with \(|{\mathcal {I}}(d)| = p^{n-k}-1\) (Sect. 2.1). We see in the next section that this corresponds to the geometric construction of [28] described in Sect. 3.
4.2 A geometric view of the Lempel–Greenberger m-sequence construction
We refer the reader to [41] for details about coordinates in finite projective spaces over \(\mathrm {GF}(q)\). Here we only sketch what is necessary to describe the m-sequence construction of Sect. 4.1 from the projective geometry point of view.
Let PG(n, q) be an n-dimensional projective space over \(\mathrm {GF}(q)\). Then we may write

with the proviso that \(\rho (x_0, x_1, \ldots , x_n)\) as \(\rho \) ranges over \(\mathrm {GF}(q) \setminus \{0\}\) all refer to the same point. Dually a hyperplane of PG(n, q) is written as \([a_0, a_1, \ldots , a_n],\,a_i \in \mathrm {GF}(q)\) not all zero, and contains the points \((x_0, x_1, \ldots , x_n)\) satisfying the equation
Clearly \(\rho [a_0, a_1, \ldots , a_n]\) as \(\rho \) ranges over \(\mathrm {GF}(q) \setminus \{0\}\) refers to the same hyperplane. A k-dimensional subspace is specified by either the points contained in it, or the equations of the \(n-k\) hyperplanes containing it.
Now, let \(S = (s_t) = s_0s_1s_2 \ldots \) be an m-sequence over \(\mathrm {GF}(p),\,p\) prime, generated by an n-stage LFSR with a primitive characteristic polynomial f(x) and state update matrix C, as described in the previous section. For \(t=0, \ldots , p^n-2\), let \(P_t = (s_t, s_{t+1}, \ldots , s_{t+n-1}, 1)\). Then the set \({\mathcal {O}}=\{P_t \; | \; t=0, \ldots p^n-2 \}\) are the points of \(PG(n,p) \setminus ( {\mathcal {H}}_{\infty } \cup \{ \infty \})\) where \({\mathcal {H}}_{\infty }\) is the hyperplane \(x_{n}=0\) and \(\infty \) is the point \((0, \ldots , 0, 1)\).
Let \(\tau \) be the projectivity defined by
Then \(\tau \) fixes \({\mathcal {H}}_{\infty }\) and \(\infty \), acts regularly on \({\mathcal {O}}=\{P_t \; | \; t=0, \ldots , p^n-2 \}\), and maps \(P_t\) to \(P_{t+1}\). Now we consider what a \(\sigma _k\)-transformation means in PG(n, p).
Firstly we consider \(\sigma _{n-1}\). This takes the first \(n-1\) coordinates of the point \(P_t = (s_t, s_{t+1}, \ldots , s_{t+n-1}, 1)\) and maps them to \(\sum _{i=0}^{n-2} s_{t+i} p^i \in {\mathbb {Z}}_{p^{n-1}}\). There are \(p^{n-1}\) distinct \(z_i \in {\mathbb {Z}}_{p^{n-1}}\) and for each \(z_i \ne 0\), there are p points \(Z_i=\{P_{t_0}, \ldots , P_{t_{p-1}} \} = \{(s_t, s_{t+1}, \ldots , s_{t+n-2}, \alpha , 1) \; | \; \alpha \in \mathrm {GF}(p)\}\) which are mapped to \(z_i\) by \(\sigma _{n-1}\). For \(z_i=0\) there are \(p-1\) corresponding points in \(Z_0\) since the all-zero state does not occur in an m-sequence.
It is not hard to see that the sets \(Z_0 \cup \{\infty \},\,Z_1, \ldots Z_{p^{n-1}-1}\) form the set of parallel (affine) lines through the point \((0,\ldots , 0,1,0) \in {\mathcal {H}}_{\infty }\), since \(Z_i\) is the set \(\{(s_t, \ldots , s_{t+n-2}, \alpha , 1)\;|\; \alpha \in \mathrm {GF}(p) \}\) for some \((n-1)\)-tuple \((s_t, \ldots , s_{t+n-2})\) and this forms a line with \((0,\ldots , 0,1,0) \in {\mathcal {H}}_{\infty }\) (the line defined by the \(n-1\) hyperplanes \(x_0 - s_t x_n=0,\,x_1 - s_{t+1} x_n = 0,\,\ldots ,\,x_{n-2} - s_{t+n-2} x_n = 0\)). This is precisely the construction given by [28] described in Sect. 3. For each \(Z_i =\{P_{t_0}, \ldots , P_{t_{p-1}} \},\,i=1, \ldots , p^{n-1}-1\), let \(D_i = \{t_0, \ldots , t_{p-1} \}\), and for \(Z_0=\{P_{t_0}, \ldots , P_{t_{p-2}}\}\), let \(D_0 = \{t_0, \ldots , t_{p-2} \}\). Then the sets \(D_i\) form a partition type perfect internal \(\mathrm {DDF}(p^n; p-1, p, \ldots , p)\) over \({\mathbb {Z}}_{p^n}\) with \(|{\mathcal {I}}(d)| = p-1\) for all \(d \in {\mathbb {Z}}_{p^n}^*\).
Similarly, for \(\sigma _k,\,1 \le k \le n-1\), the set of points
corresponding to each \(z_i \in {\mathbb {Z}}_{p^k}\) form an \((n-k)\)-dimensional subspace and the set of \(Z_i\) forms a parallel class. These are the constructions of [28, Lemmas 3.1, 3.2].
Example 3
Let \(S = (s_t)\) be an m-sequence over \(\mathrm {GF}(3)\) satisfying the linear recurrence relation \(x_{t+3} = 2x_t + x_{t+2}\). The state update matrix is therefore
The impulse response sequence is \(S=(00111021121010022201221202)\), and the \(\sigma _3\)-, \(\sigma _2\)- and \(\sigma _1\)-transformations give
\(P_t\) | s(t, 3) | \(\sigma _3[s(t,3)]\) | s(t, 2) | \(\sigma _2[s(t,2)]\) | \(s(t,1)=\sigma _1[s(t,1)]\) |
|---|---|---|---|---|---|
\(P_0\) | 001 | 9 | 00 | 0 | 0 |
\(P_1\) | 011 | 12 | 01 | 3 | 0 |
\(P_2\) | 111 | 13 | 11 | 4 | 1 |
\(P_3\) | 110 | 4 | 11 | 4 | 1 |
\(P_4\) | 102 | 19 | 10 | 1 | 1 |
\(P_5\) | 021 | 15 | 02 | 6 | 0 |
\(P_6\) | 211 | 14 | 21 | 5 | 2 |
\(P_7\) | 112 | 22 | 11 | 4 | 1 |
\(P_8\) | 121 | 16 | 12 | 7 | 1 |
\(P_9\) | 210 | 5 | 21 | 5 | 2 |
\(P_{10}\) | 101 | 10 | 10 | 1 | 1 |
\(P_{11}\) | 010 | 3 | 01 | 3 | 0 |
\(P_{12}\) | 100 | 1 | 10 | 1 | 1 |
\(P_{13}\) | 002 | 18 | 00 | 0 | 0 |
\(P_{14}\) | 022 | 24 | 02 | 6 | 0 |
\(P_{15}\) | 222 | 26 | 22 | 8 | 2 |
\(P_{16}\) | 220 | 8 | 22 | 8 | 2 |
\(P_{17}\) | 201 | 11 | 20 | 2 | 2 |
\(P_{18}\) | 012 | 21 | 01 | 3 | 0 |
\(P_{19}\) | 122 | 25 | 12 | 7 | 1 |
\(P_{20}\) | 221 | 17 | 22 | 8 | 2 |
\(P_{21}\) | 212 | 23 | 21 | 5 | 2 |
\(P_{22}\) | 120 | 7 | 12 | 7 | 1 |
\(P_{23}\) | 202 | 20 | 20 | 2 | 2 |
\(P_{24}\) | 020 | 6 | 02 | 6 | 0 |
\(P_{25}\) | 200 | 2 | 20 | 2 | 2 |
Writing this in \(PG(3,3),\,P_t = (s_t, s_{t+1}, s_{t+2}, 1)\), and \({\mathcal {H}}_{\infty }\) is the hyperplane \(x_3=0\), and \(\infty \) is the point (0, 0, 0, 1). The projectivity \(\tau \) maps \(P_t\) to \(P_{t+1}\), where \(\tau \) is represented by the matrix A,
The \(\sigma _2\) transformation maps three points to every \(z_i \in {\mathbb {Z}}_9^*\). These form the affine lines of PG(3, 3) through the point (0, 0, 1, 0). For example, the points \(P_{1}, P_{11}, P_{18}\) lie on the line defined by \(x_0=0,\,x_1-x_3=0\). The set \(\{1, 11, 18\}\) would be one of the subsets of the difference family. This gives \(Q_0=\{0,13\},\,Q_1=\{1, 11, 18\},\,Q_2=\{5,14,24\},\,Q_3=\{4,10,12\},\,Q_4=\{2,3,7\},\,Q_5 = \{8, 19, 22\},\,Q_6 = \{17, 23, 25\},\,Q_7=\{6,9,21\},\,Q_8=\{15, 16, 20\}\).
The \(\sigma _1\) transformation maps 9 points to every \(z_i \in {\mathbb {Z}}_3^*\). These form the affine planes of PG(3, 3) through the point (0, 0, 1, 0). For example, the points \(P_2,\,P_3,\,P_4,\,P_7,\,P_8,\,P_{10},P_{12},\,P_{19},\,P_{22}\) lie on the plane \(x_0-x_3=0\). The sets
form a difference family over \({\mathbb {Z}}_3\).
4.3 The other way round?
We see that the m-sequence constructions of [50] gives the projective geometry constructions of [28]. Here we consider how the constructions of [28] relate to m-sequences.
In PG(n, q) we may choose any \(n+2\) points (every set of \(n+1\) of which are independent) as the simplex of reference (there is an automorphism that maps any set of such \(n+2\) points to any other set). Hence we may choose the hyperplane \(x_n=0\) (denoted \({\mathcal {H}}_{\infty }\)) and the point \((0,0,\ldots , 0,1)\) (denoted \(\infty \)).
Now, consider a projectivity \(\tau \) represented by an \((n+1) \times (n+1)\) matrix A that fixes \({\mathcal {H}}_{\infty }\) and \(\infty \). It must take the form
and we see that
So the order of A is given by the order of C. Let the characteristic polynomial of C be f(x). The order of A is hence the order of f(x).
Consider the action of \(\langle \tau \rangle \) on the points of \(PG(n,q) \setminus ({\mathcal {H}}_{\infty } \cup \infty )\). For \(\langle \tau \rangle \) to act transitively on these points A must have order \(q^n-1\), which means that f(x) must be primitive. If we use this f(x) as the characteristic polynomial for an LFSR we generate an m-sequence, as in Sect. 4.1. For prime fields, this is precisely the construction of [50].
Projectivities in the same conjugacy classes have matrices that are similar and therefore have the same characteristic polynomial. There are \(\frac{\phi (q^n-1)}{n}\) primitive polynomials of degree n over \(\mathrm {GF}(q)\) and this gives the number of conjugacy classes of projectivities fixing \({\mathcal {H}}_{\infty }\) and \(\infty \) and acting transitively on the points of \(PG(n,q) \setminus ({\mathcal {H}}_{\infty } \cup \infty )\).
For a particular \(\langle \tau \rangle \) with characteristic polynomial f(x) and difference family \(\{Q_0, \ldots , Q_{q^{n-1}-1} \}\), there are \(q^n-1\) choices for the point \(P_0\) to be designated 0 in the construction described in Sect. 3. Each choice gives \(Q_i + d\) for each \(Q_i,\,i = 1, \ldots , q^{n-1}-1,\,d \in {\mathbb {Z}}_{q^n-1}^*\). This corresponds to the \(q^n-1\) shifts of the m-sequence generated by the LFSR with characteristic polynomial f(x). The choice of parallel class (the point \(P_{\infty } \in {\mathcal {H}}_{\infty }\)) gives the difference family \(\{Q_i + d \; : \; d \in {\mathbb {Z}}_{q^n-1},i = 1, \ldots , q^{n-1}-1 \}\). (There are \(q-1\) values of d such that \(\{Q_i + d\} = \{Q_i\}\).) This corresponds to a permutation of symbols and a shift of the m-sequence. If the set of shifts of an m-sequence is considered as a cyclic code over \(\mathrm {GF}(q)\) then this gives equivalent codes (more on this in Sect. 5). The group \(\langle \tau \rangle \) has \(\phi (q^n-1)\) generators, and each of the generators \(\tau ^i,\,(i, q^n-1)=1\) corresponds to a multiplier w such that \(\{w Q_i \; : \; i = 1, \ldots , q^{n-1}-1 \} = \{Q_i \; : \; i = 1, \ldots , q^{n-1}-1 \}\).
We have described this correspondence in terms of the lines of PG(n, q) but this also applies to the correspondence between higher dimensional subspaces and the \(\sigma _k\)-transformations.
Example 4
In PG(3, 3), the group of perspectivities generated by \(\tau \), represented by the matrix
fixes the plane \(x_3=0\) and fixes the point \(\infty =(0,0,0,1)\). An affine point (x, y, z, 1) is mapped to the point \((y,x+z,y+z,1)\) and a plane [a, b, c, d] is mapped to the plane \([a+b-c,a,-a+c,d]\). Taking the point (1, 0, 0, 1) as 0, we have the affine lines through \(P_{\infty }=(1,0,0,0)\) in \(x_3=0\) as
If we consider the action of \(\tau ^5\), we have
If we choose a different parallel class, say, \(P'_{\infty }=(0,0,1,0)\), we will instead have
and \(\{Q'_0, \ldots , Q'_8\} = \{Q_0+10, \ldots , Q_8+10\}\).
The characteristic polynomial of A is \(f(x) = x^3 - x^2 - 2x - 2\). Using f(x) as the characteristic polynomial of an LFSR we have the update matrix C as
Using the process described in Sect. 4.2, we obtain (with (0, 0, 1, 1) as 0) the difference family \(\{Q_i -1\;: \; i=0, \ldots 8\}\).
It is clear from this correspondence that the m-sequence constructions of [50] also works over a non-prime field. The \(\sigma _k\) transform is essentially assigning a unique symbol to each k-tuple from the initial m-sequence.
5 Equivalence of FH sequences
In [28], Fuji-Hara et al. stated “Often we are interested in properties of FH sequences, such as auto-correlation, randomness and generating method, which remain unchanged when passing from one FH sequence to another that is essentially the same. Providing an exact definition for this concept and enumerating how many non ‘essentially the same’ FH sequences are also interesting problems deserving of attention.” Here we discuss the notion of equivalence of FH sequences.
Firstly we adopt the notation of [59] for frequency hopping schemes: An (n, M, q)-frequency hopping scheme (FHS) \({\mathcal {F}}\) is a set of M words of length n over an alphabet of size q. Each word is an FH sequence.
Elements of the symmetric group \(S_n\) can act on \({\mathcal {F}}\) by permuting the coordinate positions of each word in \({\mathcal {F}}\). Let \(\rho _n\) denote the permutation \(\begin{pmatrix}1&\quad \! 2&\quad \! \cdots&\quad \! n\end{pmatrix}\in S_n\). We say that an element of \(S_n\) is a rotation if it belongs to \(\langle \rho _n \rangle \), the subgroup generated by \(\rho _n\).
Example 5
Consider the (7, 1, 2)-FHS \({{\mathcal {F}}}\) consisting of the single word (0, 0, 0, 1, 0, 1, 1). We have \((0,0,0,1,0,1,1)^{\rho _7}=(1,0,0,0,1,0,1)\).
Definition 1
Let Q be a finite alphabet. Given a set \(S\subseteq Q^n\) we define the rotational closure of S to be the set
If \(\overset{\Leftrightarrow }{S}=S\) then we say that S is rotationally closed.
Example 6
Consider again the binary (7, 1, 2)-FHS \({\mathcal {F}}\) consisting of the single word (0, 0, 0, 1, 0, 1, 1). Its rotational closure is the orbit of the word (0, 0, 0, 1, 0, 1, 1) under the action by the subgroup \(\langle \rho _7\rangle \):
If \({\mathcal {F}}\) is a FHS then \({\overset{\Leftrightarrow }{{\mathcal {F}}}}\) is precisely the set of sequences available to users for selecting frequencies. An important property of a FHS is the Hamming correlation properties of the sequences in \({\mathcal {F}}\).
Let \({\mathcal {F}}\) be an (n, M, q)-FHS and let \(\mathbf {x}=(x_0, \ldots , x_{n-1}),\,\mathbf {y}=(y_0, \ldots , y_{n-1}) \in {\mathcal {F}}\). The Hamming correlation \(H_{\mathbf {x},\mathbf {y}}(t)\) at relative time delay \(t,\,0 \le t < n\), between \(\mathbf {x}\) and \(\mathbf {y}\) is
where
Note that the operations on indices are performed modulo n. If \(\mathbf {x} = \mathbf {y}\) then \(H_{\mathbf {x}}(t) = H_{\mathbf {x},\mathbf {x}}(t)\) is the Hamming auto-correlation. The maximum out-of-phase Hamming auto-correlation of \(\mathbf {x}\) is
and the maximum Hamming cross-correlation between any two distinct FH sequences \(\mathbf {x},\,\mathbf {y}\) is
We define the maximum Hamming correlation of an (n, M, q)-FHS \({\mathcal {F}}\) as
Theorem 1
Let \(\mathbf {w}\in Q^n\). The maximum out-of-phase Hamming auto-correlation \(H({\mathbf w})\) of \(\mathbf {w}\) is equal to \(n-d\), where d is the minimum (Hamming) distance of \(\overset{\Leftrightarrow }{\mathbf {w}}\).
Theorem 2
Let \({\mathcal {F}}\) be an (n, M, q)-FHS. The minimum distance of \(\overset{\Leftrightarrow }{{\mathcal {F}}}\) is equal to \(n-M({\mathcal {F}})\).
The proofs of these theorems are trivial, but the theorems suggest that taking the rotational closure of a frequency hopping sequence allows us to work with the standard notion of Hamming distance in place of the Hamming correlation.
Theorem 3
Let \(\mathbf {w}\in Q^n\). If \(|\overset{\Leftrightarrow }{\mathbf {w}}|<n\) then \(H(\mathbf {w})=n\).
Proof
We observe that \(|\overset{\Leftrightarrow }{\mathbf {w}}|\) is the size of the orbit of \(\mathbf {w}\) under the action of the subgroup \(\langle \rho _n\rangle \), which has order n. By the orbit-stabiliser theorem, if \(|\overset{\Leftrightarrow }{\mathbf {w}}|<n\) then the stabiliser of \(\mathbf {w}\) is nontrivial. That is, there is some (non-identity) rotation that maps \(\mathbf {w}\) onto itself. This implies that its maximum out-of-phase Hamming auto-correlation is n. \(\square \)
In other words, unless a given sequence of length n has worst possible Hamming auto-correlation, its rotational closure always has size n.
The following lemma is also straightforward to prove:
Lemma 1
Let \(\mathbf {w}\in Q^n\). If \(|\overset{\Leftrightarrow }{\mathbf {w}}|<n\) then for \(i=0,1,\cdots ,n-1\) we have \(\overset{\Leftrightarrow }{\mathbf {w}^{\rho _n^i}}=\overset{\Leftrightarrow }{\mathbf {w}}\).
In coding theory, two codes are equivalent if one can be obtained from the other by a combination of applying an arbitrary permutation to the alphabet symbols in a particular coordinate position and/or permuting the coordinate positions of the codewords. These are transformations that preserve the Hamming distance between any two codewords. In the case of frequency hopping sequences, it is the maximum Hamming correlation that we wish to preserve. This is a stronger condition, and hence the set of transformations that are permitted in the definition of equivalence will be smaller. For example, we can no longer apply different permutations to the alphabet in different coordinate positions, as that can alter the out-of-phase Hamming correlations. Because the rotation of coordinate positions is inherent to the definition of Hamming correlation, if we wish to permute the alphabet symbols then we must apply the same permutation to the symbols in each coordinate position. Similarly, not all permutations of coordinates preserve the out-of-phase Hamming auto-correlation of a sequence.
Example 7
Consider the sequence (0, 0, 0, 1, 0, 1, 1). Its maximum out-of-phase Hamming auto-correlation is 3. However, if we swap the first and last column we obtain the sequence (1, 0, 0, 1, 0, 1, 0), which has maximum out-of-phase Hamming auto-correlation 5.
However, we can use the notion of rotational closure to determine an appropriate set of column permutations that will preserve Hamming correlation. Recall that for a given word, its out-of-phase Hamming auto-correlation is uniquely determined by the minimum distance of its rotational closure. Now, any permutation of coordinates preserves Hamming distance, so if we can find a set of permutations that preserve the property of being rotationally closed, then these will in turn preserve the out-of-phase Hamming auto-correlation of individual sequences.
Suppose a word \(\mathbf {w}\) of length n has \(H({\mathbf w})<n\). Then its rotational closure consists of the elements
Applying a permutation \(\gamma \in S_n\) to the coordinates of these words gives the set
We wish to establish conditions on \(\gamma \) that ensure that \(\left( \overset{\Leftrightarrow }{\mathbf {w}}\right) ^\gamma \) is itself rotationally closed.
Theorem 4
Suppose \(\mathbf {w}\in Q^n\) has out-of-phase Hamming auto-correlation less than n. Then \(\left( \overset{\Leftrightarrow }{\mathbf {w}}\right) ^\gamma \) is rotationally closed if and only if \(\gamma \in N_{S_n}(\langle \rho _n\rangle )\), that is \(\gamma \) is an element of the normaliser of \(\langle \rho _n\rangle \) in \(S_n\).
Proof
Suppose \(\gamma \in N_{S_n}(\langle \rho _n\rangle )\) . Then \(\gamma \langle \rho _n\rangle \gamma ^{-1}= \langle \rho _n\rangle \). This implies that
and so
Conversely, if \(\left( \overset{\Leftrightarrow }{\mathbf {w}}\right) ^\gamma \) is rotationally closed, then
where \(\mathbf {w}' = \mathbf {w}^{\rho _n^i\gamma }\) for some i. So we have
This means that \(\mathbf {w}^\gamma = \mathbf {w}^{\rho _n^i\gamma \rho _n^j}\) for some j, and so \(\mathbf {w}^{\gamma \rho _n^{-j} \gamma ^{-1}} = \mathbf {w}^{\rho _n^i}\). Clearly this applies to all \(i,\,j\), and we have \(\gamma \in N_{S_n}(\langle \rho _n\rangle )\). \(\square \)
Example 8
Consider the permutation \(\gamma =\begin{pmatrix}2&\quad \! 5&\quad \! 3\end{pmatrix} \begin{pmatrix}4&\quad \! 6&\quad \! 7\end{pmatrix} \in S_7\). We have \(\gamma ^{-1}=\begin{pmatrix}2&\quad \! 3&\quad \! 5\end{pmatrix} \begin{pmatrix}4&\quad \! 7&\quad \! 6\end{pmatrix}\), and
Since \(\rho _7^2\) generates \(\langle \rho _7\rangle \) this shows that \(\gamma \in N_{S_7}(\langle \rho _7\rangle )\).
Now consider the word (A, B, C, D, E, F, G). The rows of the following matrix give its rotational closure:
If we apply \(\gamma \) to the columns of this matrix, we obtain
which is easily seen to be the rotational closure of any of its rows.
We now look at applying these ideas to the sequence (0, 0, 0, 1, 0, 1, 1). Permuting its coordinates with \(\gamma \) in fact yields (0, 0, 0, 1, 0, 1, 1), which is trivially equivalent to the original sequence. Less trivially, \(\begin{pmatrix}2&\quad \! 4&\quad \! 3&\quad \! 7&\quad \! 5&\quad \! 6\end{pmatrix}\) is another example of an element of the normaliser of \(\langle \rho _7\rangle \), and applying this permutation to the coordinates yields the sequence (0, 1, 1, 0, 1, 0, 0). This is an example of an ‘equivalent’ frequency hopping sequence that is not simply a rotation of the original sequence.
Definition 2
We say that two (n, M, q)-FHSs are equivalent if one can be obtained from the other by a combination of permuting the symbols of the underlying alphabet and/or applying to the coordinates of its sequences any permutation that is an element of \(N_{S_n}(\langle \rho _n\rangle )\).
Equivalent FHSs have the same maximum Hamming correlation.
5.1 Comparison with the notion of equivalence for \(\mathrm {DDF}\)s
Two distinct difference families are said to be equivalent if there is an isomorphism between the underlying groups that maps one \(\mathrm {DDF}\) onto a translation of the other. In Sect. 2.1 we discussed the correspondence between a partition type \(\mathrm {DDF}\) and an FHS. In fact, we will see that two partition type \(\mathrm {DDF}\)s over \({\mathbb {Z}}_n\) are equivalent in this sense if and only if the corresponding FHSs are equivalent in the sense of Definition 2. We begin by noting that the automorphism group of \({\mathbb {Z}}_n\) is isomorphic to \({\mathbb {Z}}_n^*\). As in Sect. 5 let \(\rho _n\in S_n\) be the permutation \(\begin{pmatrix}1&\quad \! 2&\quad \! \cdots&\quad \! n\end{pmatrix}\). Any element \(\gamma \in N_{S_n}(\langle \rho _n\rangle )\) induces a map \(\phi _\gamma :{\mathbb {Z}}_n\rightarrow {\mathbb {Z}}_n\) by sending \(i\in {\mathbb {Z}}_n\) to the unique element \(j\in {\mathbb {Z}}_n\) for which \(\gamma ^{-1} \rho _n^i \gamma =\rho ^j\). The map \(\phi _\gamma \) is a homomorphism, since if \(\phi _\gamma (i_1)=j_1\) and \(\phi _\gamma (i_2)=j_2\) then \(\gamma ^{-1}\rho _n^{i_1+i_2}\gamma =\gamma ^{-1}\rho _n^{i_1}\gamma \gamma ^{-1}\rho _n^{i_2}\gamma =\rho _n^{j_1}\rho _n^{j_2}=\rho _n^{j_1+j_2}\), so \(\phi _\gamma (i_1+i_2)=\phi _{\gamma }(i_1)+\phi _\gamma (i_2)\); in fact it is an automorphism. Every automorphism of \(\langle \rho _n \rangle \) can be obtained in this fashion.
Theorem 5
Let \({\mathcal {F}}\) be a length n FHS consisting of a single word, and let \({\mathcal {D}}\) be the corresponding partition type \(\mathrm {DDF}\) over \({\mathbb {Z}}_n\). Then the FHS obtained by applying a permutation \(\gamma \in N_{S_n}(\langle \rho _n\rangle )\) to the coordinate positions of \({\mathcal {F}}\) corresponds to a \(\mathrm {DDF}\) that is a translation of the \(\mathrm {DDF}\) obtained from \({\mathcal {D}}\) by applying the automorphism \(\phi _\gamma \) to the elements of \({\mathbb {Z}}_n\).
Proof
It is straightforward to verify that \(\gamma ^{-1}\rho _n\gamma \) is the cycle \(\begin{pmatrix}1^\gamma&\quad \! 2^\gamma&\quad \! \cdots&\quad \! n^\gamma \end{pmatrix}\). For \(\gamma \in N_{S_n}(\langle \rho _n\rangle )\) this is equal to \(\rho _n^k\) for some k. It follows that for \(i=1,2,\cdots ,n-1\) we have
The correspondence between \({\mathcal {F}}\) and \({\mathcal {D}}\) is obtained by associating positions in the sequence with elements of \({\mathbb {Z}}_n\). For example, the FHS \({\mathcal {F}}= (1,1,2,3,2)\) corresponds to the \(\mathrm {DDF}\) \(({\mathbb {Z}}_{5}; \{0,1\},\{2,4\},\{3\})\):
We observe that in this representation, the \(i+1^\mathrm{th}\) element of the sequence \({\mathcal {F}}\) is in correspondence with the element \(i\in {\mathbb {Z}}_n\). If we apply \(\gamma \) to the positions of \({\mathcal {F}}\), then the entry in the \(j+1^\mathrm{th}\) position is mapped to the \(i+1^\mathrm{th}\) position when \((j+1)^\gamma =i+1\). Repeatedly applying the relation in (3) tells us that in this case we have \(i+1=1^\gamma +jk,\) so \(i=(1^\gamma -1)+jk\).
If we apply \(\phi _\gamma \) to \({\mathbb {Z}}_n\) then element \(j\in {\mathbb {Z}}_n\) is replaced by element i when \(\gamma ^{-1}\rho _n^j\gamma =\rho ^i\). But we have that
so it must be the case that \(i=kj\). It follows that if we then translate this \(\mathrm {DDF}\) by adding \(1^\gamma -1\) to each element of \({\mathbb {Z}}\) we obtain the same overall transformation that was effected by applying \(\gamma \) to \({\mathcal {F}}\). \(\square \)
Example 9
For example, let \(\gamma =\begin{pmatrix}1&\quad \! 5&\quad \! 3&\quad \! 4\end{pmatrix} \in N_{S_5}(\langle \rho _5\rangle )\). Applying \(\gamma \) to \({\mathcal {F}}= (1,1,2,3,2)\) we have
with resulting FHS (3, 1, 2, 2, 1) and corresponding \(\mathrm {DDF}\) \(({\mathbb {Z}}_5; \{0\},\{1,4\},\{2,3\})\). We observe that \(1^\gamma =5\), so that \(1^\gamma -1=4\). Alternatively, we note that \(\gamma ^{-1}\rho _5\gamma =\begin{pmatrix}1&\quad \! 3&\quad \! 5&\quad \! 2&\quad \! 4\end{pmatrix}=\rho _5^2\). Hence \(\phi _\gamma \) gives
which we can rewrite in order as
The resulting FHS is (1, 3, 1, 2, 2), which is simply a cyclic shift of the one obtained previously. The \(\mathrm {DDF}\) is \(({\mathbb {Z}}_5; \{1\},\{0,2\},\{3,4\})\). If we add 4 to each element, we recover the previous \(\mathrm {DDF}\).
6 Conclusion
We have given a general definition of a disjoint difference family, and have seen a range of examples of applications in communications and information security for these difference families, with different applications placing different constraints on the associated properties and parameters. Focusing on the case of FHSs and their connection with partition type disjoint difference families, we have shown that a construction due to Fuji-Hara et al. [28] gives rise to precisely the same disjoint difference families as an earlier construction of Lempel and Greenberger [50], thus answering an open question in [28]. In response to the question of Fuji-Hara et al. as to when two FHSs can be considered to be “essentially the same” we have established a notion of equivalence of frequency hopping schemes. FHSs based on a single sequence correspond to partition type disjoint difference families, and in this case we have shown that our definition of equivalence corresponds to an established notion of equivalence for difference families, although our definition also applies more generally to schemes based on more than one sequence.
Notes
The Handbook of Combinatorial Designs [14] has more material on difference families defined on non-abelian groups, but we will focus on abelian groups here since most of the applications we examine use abelian groups.
References
Ahmadi H., Safavi-Naini R.: Detection of algebraic manipulation in the presence of leakage. In: Padró C. (ed.) Proceedings of the 7th International Conference on Information Theoretic Security (ICITS) 2013. Lecture Notes in Computer Science, vol. 8317, pp. 238–258. Springer, New York (2013).
Anderson I., Finizio N.J.: Whist tournaments. In: Colbourn C.J., Dinitz J.H. (eds.) Handbook of Combinatorial Designs, chap. 64, pp. 663–668. Chapman and Hall/CRC, Boca Raton (2007).
Araki T., Obana S.: Flaws in some secret sharing schemes against cheating. In: Pieprzyk J., Ghodosi H., Dawson E. (eds.) Proceedings of the 12th Australasian Conference on Information Security and Privacy (ACISP 2007), Townsville, 2–4 July 2007. Lecture Notes in Computer Science, vol. 4586, pp. 122–132. Springer, New York (2007).
Bao J., Ji L.: New families of optimal frequency hopping sequence sets. CoRR. arXiv:1506.07372 (2015).
Bitan S., Etzion T.: Constructions for optimal constant weight cyclically permutable codes and difference families. IEEE Trans. Inf. Theory 41(1), 77–87 (1995).
Blackburn S.R.: Non-overlapping codes. IEEE Trans. Inf. Theory 61(9), 4890–4894 (2015).
Blundo C., De Santis A., Kurosawa K., Ogata W.: On a fallacious bound for authentication codes. J. Cryptol. 12(3), 155–159 (1999).
Broadbent A., Tapp A.: Information-theoretic security without an honest majority. In: Kurosawa K. (eds.) Advances in Crypotology—ASIACRYPT 2007. Proceedings of the 13th International Conference on Theory and Application of Cryptology and Information Security. Lecture Notes in Computer Science, vol. 4833, pp. 410–426. Springer, New York (2007).
Cabello S., Padró C., Sáez G.: Secret sharing schemes with detection of cheaters for a general access structure. Des. Codes Cryptogr. 25(2), 175–188 (2002).
Cao H., Wei R.: Combinatorial constructions for optimal two-dimensional optical orthogonal codes. IEEE Trans. Inf. Theory 55(3), 1387–1394 (2009).
Chu W., Colbourn C.J.: Optimal frequency-hopping sequences via cyclotomy. IEEE Trans. Inf. Theory 51(3), 1139–1141 (2005).
Chung F.R.K., Salehi J.A., Wei V.K.: Optical orthogonal codes: design, analysis and applications. IEEE Trans. Inf. Theory 35(3), 595–604 (1989).
Churchill A.L.: Restrictions and generalizations on comma-free codes. Electron. J. Comb. 16(1) (2009). Research Paper R25.
Colbourn C.J., Dinitz J.H.: Handbook of Combinatorial Designs (Discrete Mathematics and Its Applications), 2nd edn. Chapman & Hall/CRC, Boca Raton (2006).
Cramer R., Dodis Y., Fehr S., Padró C., Wichs D.: Detection of algebraic manipulation with applications to robust secret sharing and fuzzy extractors. IACR Cryptol. ePrint Arch. 2008, 30 (2008).
Cramer R., Dodis Y., Fehr S., Padró C., Wichs D.: Detection of algebraic manipulation with applications to robust secret sharing and fuzzy extractors. In: Smart N.P. (eds.) Advances in Cryptology: EUROCRYPT 2008. Proceedings of the 27th International Conference on the Theory and Applications of Cryptographic Techniques. Lecture Notes in Computer Science, vol. 4965, pp. 471–488. Springer, New York (2008).
Cramer R., Fehr S., Padró C.: Algebraic manipulation detection codes. Sci. China Math. 56(7), 1349–1358 (2013).
Cramer R., Padró C., Xing C.: Optimal algebraic manipulation detection codes in the constant-error model. In: Dodis Y., Nielsen J.B. (eds.) Proceedings of the 12th Theory of Cryptography Conference (TCC) 2015. Lecture Notes in Computer Science, vol. 9014, pp. 481–501. Springer, New York (2015).
Dai P., Wang J., Yin J.: Combinatorial constructions for optimal 2-D optical orthogonal codes with AM-OPPTS property. Des. Codes Cryptogr. 71(2), 315–330 (2014).
Ding C., Fuji-Hara R., Fujiwara Y., Jimbo M., Mishima M.: Sets of frequency hopping sequences: bounds and optimal constructions. IEEE Trans. Inf. Theory 55(7), 3297–3304 (2009).
Ding C., Salomaa A., Solé P., Tian X.: Three constructions of authentication/secrecy codes. In: Applied Algebra, Algebraic Algorithms and Error-Correcting Codes, pp. 24–33. Springer, New York (2003).
Ding C., Tian X.: Three constructions of authentication codes with perfect secrecy. Des. Codes Cryptogr. 33(3), 227–239 (2004).
Ding C., Yang Y., Tang X.: Optimal sets of frequency hopping sequences from linear cyclic codes. IEEE Trans. Inf. Theory 56(7), 3605–3612 (2010).
Dixon R.C.: Spread Spectrum Systems, 2nd edn. Wiley, Chichester (1984)
Dziembowski S., Pietrzak K., Wichs D.: Non-malleable codes. In: Yao A.C. (ed.) Proceedings of the Innovations in Computer Science (ICS) 2010, pp. 434–452. Tsinghua University Press, Beijing (2010).
Emek Y., Wattenhofer R.: Frequency hopping against a powerful adversary. In: Afek Y. (eds.) Distributed Computing. Lecture Notes in Computer Science, vol. 8205, pp. 329–343. Springer, Berlin (2013).
Feng T., Chang Y.: Combinatorial constructions for optimal two-dimensional optical orthogonal codes with \(\lambda =2\). IEEE Trans. Inf. Theory 57(10), 6796–6819 (2011).
Fuji-Hara R., Miao Y., Mishima M.: Optimal frequency hopping sequences: a combinatorial approach. IEEE Trans. Inf. Theory 50(10), 2408–2420 (2004).
Fuji-Hara R., Miao Y., Shinohara S.: Complete sets of disjoint difference families and their applications. J. Stat. Plan. Inference 106(1–2), 87–103 (2002).
Fujiwara Y., Tonchev V.D.: High-rate self-synchronizing codes. IEEE Trans. Inf. Theory 59(4), 2328–2335 (2013).
Ge G., Miao Y., Wang L.: Combinatorial constructions for optimal splitting authentication codes. SIAM J. Discret. Math. 18(4), 663–678 (2005).
Ge G., Miao Y., Yao Z.: Optimal frequency hopping sequences: auto- and cross-correlation properties. IEEE Trans. Inf. Theory 55(2), 867–879 (2009).
Ge S., Wang Z., Karpovsky M., Luo P.: Reliable and secure memories based on algebraic manipulation detection codes and robust error correction. In: Proceedings of the Sixth International Conference on Dependability (DEPEND) (2013).
Ge S., Wang Z., Luo P., Karpovsky M.: Secure memories resistant to both random errors and fault injection attacks using nonlinear error correction codes. In: Proceedings of the 2nd International Workshop on Hardware and Architectural Support for Security and Privacy, p. 5. ACM (2013).
Golomb S.W., Gong G.: Signal Design for Good Correlation: For Wireless Communication, Cryptography, and Radar. Cambridge University Press, Cambridge (2005).
Golomb S.W., Gordon B., Welch L.R.: Comma-free codes. Can. J. Math. 10(2), 202–209 (1958).
Guruswami V., Smith A.: Optimal-rate code constructions for computationally simple channels. CoRR.arXiv:1004.4017 (2010).
He X., Yener A.: Secure communication with a byzantine relay. In: IEEE International Symposium on Information Theory (ISIT) 2009, pp. 2096–2100. IEEE, Piscataway (2009)
He X., Yener A.: Strong secrecy and reliable byzantine detection in the presence of an untrusted relay. IEEE Trans. Inf. Theory 59(1), 177–192 (2013).
Helleseth T.: Sequence correlation. In: Colbourn C.J., Dinitz J.H. (eds.) Handbook of Combinatorial Designs, chap. 7, pp. 313–317. Chapman and Hall/CRC, Boca Raton (2007).
Hirschfeld J.W.P.: Projective Geometries over Finite Fields (Oxford Mathematical Monographs), 2nd edn. Oxford University Press, Oxford (1998).
Hoshino H., Obana S.: Almost optimum secret sharing schemes with cheating detection for random bit strings. In: Tanaka K., Suga Y. (eds.) Advances in Information and Computer Security. Proceedings of the 10th International Workshop on Security, (IWSEC) 2015. Lecture Notes in Computer Science, vol. 9241, pp. 213–222. Springer, New York (2015).
Huber M.: Authentication and secrecy codes for equiprobable source probability distributions. In: IEEE International Symposium on Information Theory (ISIT) 2009, pp. 1105–1109. IEEE, Piscataway (2009).
Huber M.: Combinatorial bounds and characterizations of splitting authentication codes. Cryptogr. Commun. 2(2), 173–185 (2010).
Huber M.: Combinatorial designs for authentication and secrecy codes. Found. Trends Commun. Inf. Theory 5(6), 581–675 (2010).
Huber M.: Information theoretic authentication and secrecy codes in the splitting model. CoRR.arXiv:1112.0038. (2011).
Jiang J., Wu D., Fan P.: General constructions of optimal variable-weight optical orthogonal codes. IEEE Trans. Inf. Theory 57(7), 4488–4496 (2011).
Karpovsky M., Wang Z.: Design of strongly secure communication and computation channels by nonlinear error detecting codes. IEEE Trans. Comput. 63(11), 2716–2728 (2014).
Kurosawa K., Obana S.: Combinatorial bounds on authentication codes with arbitration. Des. Codes Cryptogr. 22(3), 265–281 (2001).
Lempel A., Greenberger H.H.: Families of sequences with optimal Hamming-correlation properties. IEEE Trans. Inf. Theory 20(1), 90–94 (1974).
Levenshtein V.I.: Combinatorial problems motivated by comma-free codes. J. Comb. Des. 12(3), 184–196 (2004).
Liang M., Du B.: A new class of 3-fold perfect splitting authentication codes. Des. Codes Cryptogr. 62(1), 109–119 (2012).
Liang M., Du B.: A new class of splitting 3-designs. Des. Codes Cryptogr. 60(3), 283–290 (2011).
Lidl R., Niederreiter H.: Finite Fields. Encyclopedia of Mathematics and Its Applications, vol. 20, 2nd edn. Cambridge University Press, Cambridge (1997).
Liu F., Peng D., Zhou Z., Tang X.: A new frequency-hopping sequence set based upon generalized cyclotomy. Des. Codes Cryptogr. 69(2), 247–259 (2013).
Luo P., Lin A.Y.-L., Wang Z., Karpovsky M.: Hardware implementation of secure Shamir’s secret sharing scheme. In: Proceedings of the IEEE 15th International Symposium on High-Assurance Systems Engineering (HASE) 2014, pp. 193–200. IEEE, Piscataway (2014).
Luo P., Wang Z., Karpovsky M.: Secure NAND flash architecture resilient to strong fault-injection attacks using algebraic manipulation detection code. In: Proceedings of the International Conference on Security and Management (SAM) 2013. The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp) (2013).
Mpitziopoulos A., Gavalas D., Konstantopoulos C., Pantziou G.: A survey on jamming attacks and countermeasures in WSNs. IEEE Commun. Surv. Tutor. 11(4), 42–56 (2009).
Nyirenda M., Ng S.L., Martin K.M.: A combinatorial model of interference in frequency hopping schemes. CoRR. arXiv:1508.02570. (2015).
Obana S., Araki T.: Almost optimum secret sharing schemes secure against cheating for arbitrary secret distribution. In: Lai X., Chen K. (eds.) Advances in Cryptology: ASIACRYPT 2006. Proceedings of the 12th International Conference on the Theory and Application of Cryptology and Information Security. Lecture Notes in Computer Science, vol. 4284, pp. 364–379. Springer, New York (2006).
Obana S., Kurosawa K.: Bounds and combinatorial structure of \((k, n)\) multi-receiver A-codes. Des. Codes Cryptogr. 22(1), 47–63 (2001).
Obana S., Tsuchida K.: Cheating detectable secret sharing schemes supporting an arbitrary finite field. In: Yoshida M., Mouri K. (eds.) Advances in Information and Computer Security. Proceedings of the 9th International Workshop on Security, IWSEC 2014. Lecture Notes in Computer Science, vol. 8639, pp. 88–97. Springer, New York (2014).
Obana S.: Almost optimum \(t\)-cheater identifiable secret sharing schemes. In: Paterson K.G. (eds.) Advances in Cryptology : EUROCRYPT 2011. Proceedings of the 30th International Conference on the Theory and Applications of Cryptographic Techniques. Lecture Notes in Computer Science, vol. 6632, pp. 284–302. Springer, New York (2011).
Ogata W., Kurosawa K., Stinson D.R., Saido H.: New combinatorial designs and their applications to authentication codes and secret sharing schemes. Discret. Math. 279(13), 383–405 (2004). (In Honour of Zhu Lie)
Ogata W., Kurosawa K., Stinson D.R.: Optimum secret sharing scheme secure against cheating. SIAM J. Discret. Math. 20(1), 79–95 (2006).
Paterson M.B., Stinson D.R.: Combinatorial characterizations of algebraic manipulation detection codes involving generalized difference families. CoRR. arXiv:1506.02711. (2015).
Pei D.: Authentication Codes and Combinatorial Designs (Discrete Mathematics and Its Applications) CRC Press, Boca Raton (2006).
Peng D., Fan P.: Lower bounds on the hamming auto- and cross correlations of frequency-hopping sequences. IEEE Trans. Inf. Theory 50(9), 2149–2154 (2004).
Pott A., Kumaran V., Helleseth T., Jungnickel D.: Difference Sets, Sequences and Their Correlation Properties. Nato ScienceSeries C. Springer, Dordrecht (1999).
Sarwate D.V.: Optimum PN sequences for CDMA systems. In: Glisic S.G., Leppänen P.A. (eds.) Code Division Multiple Access Communications, pp. 53–78. Springer, New York (1995).
Stinson D.R., Wei R.: Bibliography on authentication codes. http://cacr.uwaterloo.ca/~dstinson/acbib.html (1998).
Tompa M., Woll H.: How to share a secret with cheaters. J. Cryptol. 1(2), 133–138 (1988).
Tonchev V.D.: Difference systems of sets and code synchronization. Rendiconti del Seminario Matematico di Messina Series II 9, 217226 (2003).
Wang Z., Karpovsky M.G.: Algebraic manipulation detection codes and their applications for design of secure cryptographic devices. In: Proceedings of the 17th IEEE International On-Line Testing Symposium (IOLTS 2011), pp. 234–239. IEEE, Piscataway (2011)
Wang Z., Karpovsky M.: New error detecting codes for the design of hardware resistant to strong fault injection attacks. In: Proceedings of the International Conference on Security and Management (SAM) 2012. The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp) (2012).
Wang P., Safavi-Naini R.: An efficient code for adversarial wiretap channel. In: IEEE Information Theory Workshop (ITW) 2014, pp. 40–44. IEEE, Piscataway (2014)
Wang J., Su R.: Further results on the existence of splitting BIBDs and application to authentication codes. Acta Appl. Math. 109(3), 791–803 (2010)
Wang J.: A new class of optimal 3-splitting authentication codes. Des. Codes Cryptogr. 38(3), 373–381 (2006).
Wen B.: Construction of optimal sets of frequency hopping sequences. ISRN Combinatorics (Article ID 479408) (2013).
Xia T., Xia B.: Quasi-cyclic codes from extended difference families. In: Proceedings of the IEEE Wireless Communications and Networking Conference, pp. 1036–1040. IEEE (2005).
Xu W., Trappe W., Zhang Y., Wood T.: The feasibility of launching and detecting jamming attacks in wireless networks. In: Proceedings of the 6th ACM International Symposium on Mobile Ad Hoc Networking and Computing (MobiHoc ’05), pp. 46–57. ACM, New York (2005).
Yu N.Y., Zhao N.: Deterministic construction of real-valued ternary sensing matrices using optical orthogonal codes. IEEE Signal Process. Lett. 20(11), 1106–1109 (2013).
Author information
Authors and Affiliations
Corresponding author
Additional information
This is one of several papers published in Designs, Codes and Cryptography comprising the 25th Anniversary Issue.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Ng, SL., Paterson, M.B. Disjoint difference families and their applications. Des. Codes Cryptogr. 78, 103–127 (2016). https://doi.org/10.1007/s10623-015-0149-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10623-015-0149-4