
Abstract
Statistically sound pattern discovery harnesses the rigour of statistical hypothesis testing to overcome many of the issues that have hampered standard data mining approaches to pattern discovery. Most importantly, application of appropriate statistical tests allows precise control over the risk of false discoveries—patterns that are found in the sample data but do not hold in the wider population from which the sample was drawn. Statistical tests can also be applied to filter out patterns that are unlikely to be useful, removing uninformative variations of the key patterns in the data. This tutorial introduces the key statistical and data mining theory and techniques that underpin this fast developing field. We concentrate on two general classes of patterns: dependency rules that express statistical dependencies between condition and consequent parts and dependency sets that express mutual dependence between set elements. We clarify alternative interpretations of statistical dependence and introduce appropriate tests for evaluating statistical significance of patterns in different situations. We also introduce special techniques for controlling the likelihood of spurious discoveries when multitudes of patterns are evaluated. The paper is aimed at a wide variety of audiences. It provides the necessary statistical background and summary of the state-of-the-art for any data mining researcher or practitioner wishing to enter or understand statistically sound pattern discovery research or practice. It can serve as a general introduction to the field of statistically sound pattern discovery for any reader with a general background in data sciences.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Pattern discovery is a core technique of data mining that aims at finding all patterns of a specific type that satisfy certain constraints in the data (Agrawal et al. 1993; Cooley et al. 1997; Rigoutsos and Floratos 1998; Kim et al. 2010). Common pattern types include frequent or correlated sets of variables, association and correlation rules, frequent subgraphs, subsequencies, and temporal patterns. Traditional pattern discovery has emphasized efficient search algorithms and computationally well-behaving constraints and pattern types, like frequent pattern mining (Aggarwal and Han 2014), and less attention has been paid to the statistical validity of patterns. This has also restricted the use of pattern discovery in many applied fields, like bioinformatics, where one would like to find certain types of patterns without risking costly false or suboptimal discoveries. As a result, there has emerged a new trend towards statistically sound pattern discovery with strong emphasis on statistical validity. In statistically sound pattern discovery, the first priority is to find genuine patterns that are likely to reflect properties of the underlying population and hold also in future data. Often the pattern types are also different, because they have been dictated by the needs of application fields rather than computational properties.

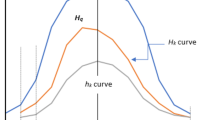
An illustration of the problem of finding true patterns from sample data
The problem of statistically sound pattern discovery is illustrated in Fig. 1. Usually, the analyst has a sample of data drawn from some population of interest. This sample is typically only a very small proportion of the total population of interest and may contain noise. The pattern discovery tool is applied to this sample, finding some set of patterns. It is unrealistic to expect this set of discovered patterns to directly match the ideal patterns that would be found by direct analysis of the real population rather than a sample thereof. Indeed, it is clear that in at least some cases, the application of naive techniques results in the majority of patterns found being only spurious artifacts. An extreme example of this problem arises with the popular minimum support and minimum confidence technique (Agrawal et al. 1993) when applied to the well-known Covtype benchmark dataset from the UCI repository (Lichman 2013). The minimum support and minimum confidence technique seeks to find the frequent positive dependencies in data using thresholds for minimum frequency (‘support’) and precision (‘confidence’). For the Covtype dataset, the top 197,183,686 rules found by minimum support and minimum confidence are in fact negative dependencies (Webb 2006). This gives rise to the suggestion that the oft cited problem of pattern discovery finding unmanageably large numbers of patterns is largely due to standard techniques returning results that are dominated by spurious patterns (Webb 2011).
There is a rapidly growing body of pattern discovery techniques being developed in the data science community that utilize statistics to control the risk of such spurious discoveries. This tutorial paper grew out of tutorials presented at ECML PKDD 2013 (Hämäläinen and Webb 2013) and KDD-14 (Hämäläinen and Webb 2014). It introduces the relevant statistical theory and key techniques for statistically sound pattern discovery. We concentrate on pattern types that express statistical dependencies between categorical attributes, such as dependency rules (dependencies between condition and consequent parts) and dependency sets (mutual dependencies between set elements). The same techniques of testing statistical significance of dependence also apply to situations where one would like to test dependencies in other types of patterns, like dependencies between subgraphs and classes or between frequent episodes.
To keep the scope manageable, we do not describe actual search algorithms but merely the statistical techniques that are employed during the search. We aim at a generic presentation that is not bound to any specific search method, pattern type or school of statistics. Instead, we try to clarify alternative interpretations of statistical dependence and the underlying assumptions on the origins of data, because they often lead to different statistical methods and also different patterns to be selected. We describe the preconditions, limitations, strengths, and shortcomings of different approaches to help the reader to select a suitable method for the problem at hand. However, we do not make any absolute recommendations, as there is no one correct way to test statistical significance or reliability of patterns. Rather, the appropriate choice is always problem-dependent.
The paper is aimed at a wide variety of audiences. The main goal is to offer a general introduction to the field of statistically sound pattern discovery for any reader with a general background in data sciences. Knowledge on the main principles, important concerns, and alternative techniques is especially useful for practical data miners (how to improve the quality or test the reliability of discovered patterns) and algorithm designers (how to target the search into the most reliable patterns). Another goal is to introduce possibilities of pattern discovery to researchers in other fields, like bioscientists, for whom statistical significance of findings is the main concern and who would like to find new useful information from large data masses. As a prerequisite, we assume knowledge of the basic concepts of probability theory. The paper provides the necessary statistical background and summary of the state of the art, but a knowledgeable reader may well skip preliminaries (Sects. 2.2–2.3) and the overview of multiple hypothesis testing (Sect. 6.1).
In the paper we have tried to use terminology that is consistent with statistics for two reasons. First, knowing statistical terms makes it easier to consult external sources, like textbooks in statistics, for further knowledge. Second, common terminology should make the paper more readable to wider audience, like reseachers from applied science who would like to extend their repertoire of statistical analysis with pattern discovery techniques. To achieve this goal, we have avoided some special terms originated in pattern discovery that have another meaning in statistics or may become easily confused in this context (see Appendix).
The rest of the paper is organized as follows. In Sect. 2 we give definitions of various types of statistical dependence and introduce the main principles and approaches of statistical significance testing. In Sect. 3 we investigate how statistical significance of dependency rules is evaluated under different assumptions. Especially, we contrast two alternative interpretations of dependency rules that are called variable-based and value-based interpretations and introduce appropriate tests for different situations. In Sect. 4 we discuss how to evaluate statistical significance of the improvement of one rule over another one. In Sect. 5 we survey the key techniques that have been developed for finding different types of statistically significant dependency sets. In Sect. 6 we discuss the problem of multiple hypothesis testing. We describe the main principles and popular correction methods and then introduce some special techniques for increasing power in the pattern discovery context. Finally, in Sect. 7 we summarize the main points and present conclusions.
2 Preliminaries
In this paper, we consider patterns that express statistical dependence. Dependence is usually defined in the negative, as absence of independence. Therefore, we begin by defining different types of statistical independence that are needed in defining dependence patterns and their relationships, like improvement of one pattern over another one. After that, we give an overview of the main principles and approaches of statistical significance testing. These approaches are applicable to virtually any pattern type, but we focus on how they are used in independence testing. In the subsequent sections, we will describe in detail how to evaluate statistical significance of dependency patterns or their improvement under different sets of assumptions.
2.1 Notations
The mathematical notations used in this paper are given in Table 1. We note that the sample space spun by variables \(A_1,\ldots ,A_k\) is \({\mathcal {S}}= Dom (A_1) \times \ldots \times Dom (A_k)\). When \(A_i\)s are binary variables \({\mathcal {S}}=\{0,1\}^k\). Sample points \({\mathbf {r}}\in {\mathcal {S}}\) correspond to atomic events and all other events can be presented as their disjunctions. Often these can be presented in a reduced form, for example, event \((A_1{=}1,A_2{=}1)\vee (A_1{=}1,A_2{=}0)\) reduces to \((A_1{=}1)\). In this paper, we focus on events that can be presented as conjunctions \(\mathbf {X\,{=}\,x}\), where \({\mathbf {X}}\,{\subseteq }\, \{A_1,\ldots ,A_k\}\). When it is clear from the context, we notate elements of \({\mathbf {X}}\), \(|{\mathbf {X}}|=m\), by \(A_1,\ldots ,A_m\) instead of more complicated \(A_{i_1},\ldots ,A_{i_m}\), \(\{i_1,\ldots ,i_m\}\subseteq \{1,\ldots ,k\}\). We also note that data set \({\mathcal {D}}\) is defined as a vector of data points so that duplicate rows (i.e., rows \({\mathbf {r}}_i\), \({\mathbf {r}}_j\) where \({\mathbf {r}}_i={\mathbf {r}}_j\) but \(i\ne j\)) can be distinguished by their index numbers.
2.2 Statistical dependence
The notion of statistical dependence is equivocal and even the simplest case, dependence between two events, is subject to alternative interpretations. Interpretations of statistical dependence between more than two events or variables are even more various. In the following, we introduce the main types of statistical independence that are needed for defining dependency patterns and evaluating their statistical significance and mutual relationships.
2.2.1 Dependence between two events
Definitions of statistical dependence are usually based on the classical notion of statistical independence between two events. We begin from a simple case where the events are variable-value combinations, \(A\,{=}\,a\) and \(B\,{=}\,b\).
Definition 1
(Statistical independence between two events) Let \(A\,{=}\,a\) and \(B\,{=}\,b\) be two events, \(P(A\,{=}\,a)\) and \(P(B\,{=}\,b)\) their marginal probabilities, and \(P(A\,{=}\,a,B\,{=}\,b)\) their joint probability. Events \((A\,{=}\,a)\) and \((B\,{=}\,b)\) are statistically independent, if
Statistical dependence is seldom defined formally, but in practice, there are two approaches. If dependence is considered as a Boolean property, then any departure from complete independence (Eq. 1) is defined as dependence. Another approach, prevalent in statistical data analysis, is to consider dependence as a continuous property ranging from complete independence to complete dependence. Complete dependence itself is an ambiguous term, but usually it refers to equivalence of events: \(P(A\,{=}\,a,B\,{=}\,b)=P(A\,{=}\,a)=P(B\,{=}\,b)\) (perfect positive dependence) or mutual exclusion of events: \(P(A\,{=}\,a,B{\ne }b)=P(A\,{=}\,a)=P(B{\ne }b)\) (perfect negative dependence).
The strength of dependence between two events can be evaluated with several alternative measures. In pattern discovery, two of the most popular measures are leverage and lift.
Leverage is equivalent to Yule’s \(\delta \) (Yule 1912), Piatetsky-Shapiro’s unnamed measure (Piatetsky-Shapiro 1991), and Meo’s ‘dependence value’ (Meo 2000). It measures the absolute deviation of the joint probability from its expectation under independence:
We note that this is the same as covariance between binary variables A and B.
Lift has also been called ‘interest’ (Brin et al. 1997), ‘dependence’ (Wu et al. 2004), and ‘degree of independence’ (Yao and Zhong 1999). It measures the ratio of the joint probability and its expectation under independence:
For perfectly independent events, leverage is \(\delta =0\) and lift is \(\gamma =1\), for positive dependencies \(\delta >0\) and \(\gamma >1\), and for negative dependencies, \(\delta <0\) and \(\gamma <1\).
If the real probabilities of events were known, the strength of dependence could be determined accurately. However, in practice, the probabilities are estimated from the data. The most common method is to approximate the real probabilities with relative frequencies (maximum likelihood estimates) but other estimation methods are also possible. The accuracy of these estimates depends on how representative and error-free the data is. The size of the data affects also precision, because continuous probabilities are approximated with discrete frequencies. Therefore, it is quite possible that two independent events express some degree of dependence in the data (i.e., \({\hat{P}}(A\,{=}\,a,B\,{=}\,b)\ne {\hat{P}}(A\,{=}\,a){\hat{P}}(B\,{=}\,b)\), where \({\hat{P}}\) is the estimated probability, even if \(P(A\,{=}\,a,B\,{=}\,b)=P(A\,{=}\,a)P(B\,{=}\,b)\) in the population). In the worst case, two events always co-occur in the data, indicating maximal dependence, even if they are actually independent. To some extent the probability of such false discoveries can be controlled by statistical significance testing, which is discussed in Sect. 2.3. In the other extreme, two dependent events may appear independent in the data (i.e., \({\hat{P}}(A\,{=}\,a,B\,{=}\,b)={\hat{P}}(A\,{=}\,a){\hat{P}}(B\,{=}\,b)\)). However, this is not possible if the actual dependence is sufficiently strong (i.e., \(P(A\,{=}\,a,B\,{=}\,b)=P(A\,{=}\,a)\) or \(P(A\,{=}\,a,B\,{=}\,b)=P(B\,{=}\,b)\)), assuming that the data is error-free. Such missed discoveries are harder to detect, but to some extent the problem can be alleviated by using powerful methods in significance testing (Sect. 2.3).
2.2.2 Dependence between two variables
For each variable, we can define several events which describe its values. If the variable is categorical, it is natural to consider each variable-value combination as a possible event. Then, the independence between two categorical variables can be defined as follows:
Definition 2
(Statistical independence between two variables) Let A and B be two categorical variables, whose domains are \( Dom (A)\) and \( Dom (B)\). A and B are statistically independent, if for all \(a \in Dom(A)\) and \(b\in Dom(B)\)\(P(A\,{=}\,a,B\,{=}\,b)=P(A\,{=}\,a)P(B\,{=}\,b)\).
Once again, dependence can be defined either as a Boolean property (lack of independence) or a continuous property. However, there is no standard way to measure the strength of dependence between variables. In practice, the measure is selected according to data and modelling purposes. Two commonly used measures are the \(\chi ^2\)-measure
and mutual information
If the variables are binary, the notions of independence between variables and the corresponding events coincide. Now independence between any of the four value combinations AB, \(A\lnot B\),\(\lnot AB\), \(\lnot A\lnot B\) means independence between variables A and B and vice versa. In addition, the absolute value of leverage is the same for all value combinations and can be used to measure the strength of dependence between binary variables. This is shown in the corresponding contingency table (Fig. 2). Unfortunately, this handy property does not hold for multivalued variables. Figure 3 shows an example contingency table for two three-valued variables where some value combinations are independent and others dependent.

A contingency table for two binary variables A and B expressing absolute frequencies of events AB, \(A\lnot B\), \(\lnot AB\) and \(\lnot A\lnot B\) using leverage, \(\delta =\delta (A,B)\)

An example contingency table where some value combinations of A and B express independence and others dependence. The frequencies are expressed using leverage, \(\delta =\delta (A\,{=}\,a_1,B\,{=}\,b_2)\)
2.2.3 Dependence between many events or variables
The notion of statistical independence can be generalized to three or more events or variables in several ways. The most common types of independence are mutual independence, bipartition independence, and conditional independence (see e.g., Agresti 2002, p. 318). In the following, we give general definitions for these three types of independence.
In statistics and probability theory, mutual independence of a set of events is classically defined as follows (see e.g., Feller 1968, p. 128):
Definition 3
(Mutual independence) Let \({\mathbf {X}}=\{A_1,\ldots ,A_m\}\) be a set of variables, whose domains are \( Dom (A_i)\), \(i=1,\ldots ,m\). Let \(a_i\in Dom (A_i)\) notate a value of \(A_i\). A set of events \((A_1\,{=}\,a_1,\ldots ,A_m\,{=}\,a_m)\) is called mutually independent if for all \(\{i_1,\ldots ,i_{m'}\}\subseteq \{1,\ldots ,m\}\) holds
If variables \(A_i{\in }{\mathbf {X}}\) are binary, the conjunction of true-valued variables \((A_1{=}1,\ldots ,\)\(A_m{=}1)\) can be expressed as \(A_1,\ldots ,A_m\) and the condition for mutual independence reduces to \(\forall {\mathbf {Y}}\,{\subseteq }\, {\mathbf {X}}\)\(P({\mathbf {Y}})=\prod _{A_i\in {\mathbf {Y}}}P(A_i)\). An equivalent condition is to require that for all truth value combinations \((a_1,\ldots ,a_m)\in \{0,1\}^m\) holds \(P(A_1{=}a_1,\ldots ,A_m{=}a_m)=\prod _{i=1}^m P(A_i{=}a_i)\) (Feller 1968, p. 128). We note that in data mining this property has sometimes been called independence of binary variables and independence of events has referred to a weaker condition (e.g., Silverstein et al. 1998)
The difference is that in the latter it is not required that all \({\mathbf {Y}}\,{\subsetneq }\,{\mathbf {X}}\) should express independence. Both definitions have been used as a starting point to define interesting set-formed dependency patterns (e.g., Webb 2010; Silverstein et al. 1998). In this paper we will call this type of patterns dependency sets (Sect. 5).
In addition to mutual independence, a set of events or variables can express independence between different partitions of the set. The only difference to the basic definition of statistical independence is that now single events or variables have been replaced by sets of events or variables. In this paper we call this type of independence bipartition independence.
Definition 4
(Bipartition independence) Let \({\mathbf {X}}\) be a set of variables. For any partition \({\mathbf {X}}={\mathbf {Y}}\cup {\mathbf {Z}}\), where \({\mathbf {Y}}\cap {\mathbf {Z}}=\emptyset \), possible value combinations are notated by \({\mathbf {y}}\in Dom ({\mathbf {Y}})\) and \({\mathbf {z}}\in Dom ({\mathbf {Z}})\).
-
(i)
Event \(\mathbf {Y\,{=}\,y}\) is independent of event \(\mathbf {Z\,{=}\,z}\), if \(P(\mathbf {Y\,{=}\,y},\mathbf {Z\,{=}\,z})=P(\mathbf {Y\,{=}\,y})P(\mathbf {Z\,{=}\,z})\).
-
(ii)
Set of variables \({\mathbf {Y}}\) is independent of \({\mathbf {Z}}\), if \(P(\mathbf {Y\,{=}\,y},\mathbf {Z\,{=}\,z})=P(\mathbf {Y\,{=}\,y})P(\mathbf {Z\,{=}\,z})\) for all \({\mathbf {y}}\in Dom ({\mathbf {Y}})\) and \({\mathbf {z}}\in Dom ({\mathbf {Z}})\).
Now one can derive a large number of different dependence patterns from a single set \({\mathbf {X}}\) or event \(\mathbf {X\,{=}\,x}\). There are \(2^{m-1}-1\) ways to partition set \({\mathbf {X}}\), \(|{\mathbf {X}}|=m\), into two subsets \({\mathbf {Y}}\) and \({\mathbf {Z}}={\mathbf {X}}{\setminus } {\mathbf {Y}}\) (\(|{\mathbf {Y}}|=1,\ldots ,\lceil \frac{m-1}{2}\rceil \)). In data mining, patterns expressing bipartition dependence between sets of events are often expressed as dependency rules\(\mathbf {Y\,{=}\,y}\rightarrow \mathbf {Z\,{=}\,z}\). Because both the rule antecedent and consequent are binary conditions, the rule can be interpreted as dependence between two new binary (indicator) variables \(I_\mathbf {Y\,{=}\,y}\) and \(I_\mathbf {Z\,{=}\,z}\) (\(I_\mathbf {Y\,{=}\,y}\,{=}\,1\) if \(\mathbf {Y\,{=}\,y}\) and \(I_\mathbf {Y\,{=}\,y}\,{=}\,0\) otherwise). In statistical terms, this is the same as collapsing a multidimensional contingency table into a simple \(2\times 2\) table. In addition to statistical dependence, dependency rules are often required to fulfil other criteria like sufficient frequency, strength of dependency or statistical significance. Corresponding patterns between sets of variables are less often studied, because the search is computationally much more demanding. In addition, collapsed contingency tables can reveal interesting and statistically significant dependencies between composed events, when no significant dependencies could be found between variables.
The third main type of independence is conditional independence between events or variables:
Definition 5
(Conditional independence) Let \({\mathbf {X}}\) be a set of variables. For any partition \({\mathbf {X}}={\mathbf {Y}}\cup {\mathbf {Z}}\cup {\mathbf {Q}}\), where \({\mathbf {Y}}\cap {\mathbf {Z}}=\emptyset \), \({\mathbf {Y}}\cap {\mathbf {Q}}=\emptyset \), \({\mathbf {Z}}\cap {\mathbf {Q}}=\emptyset \), possible value combinations are notated by \({\mathbf {y}}\in Dom ({\mathbf {Y}})\), \({\mathbf {z}}\in Dom ({\mathbf {Z}})\), and \({\mathbf {q}}\in Dom ({\mathbf {Q}})\).
-
(i)
Events \(\mathbf {Y\,{=}\,y}\) and \(\mathbf {Z\,{=}\,z}\) are conditionally independent given \(\mathbf {Q\,{=}\,q}\), if
\(P(\mathbf {Y\,{=}\,y},\mathbf {Z\,{=}\,z}\mid \mathbf {Q\,{=}\,q})=P(\mathbf {Y\,{=}\,y}\mid \mathbf {Q\,{=}\,q})P(\mathbf {Z\,{=}\,z}\mid \mathbf {Q\,{=}\,q})\).
-
(ii)
Sets of variables \({\mathbf {Y}}\) and \({\mathbf {Z}}\) are conditionally independent given \({\mathbf {Q}}\), if
\(P(\mathbf {Y\,{=}\,y},\mathbf {Z\,{=}\,z}\mid \mathbf {Q\,{=}\,q})=P(\mathbf {Y\,{=}\,y}\mid \mathbf {Q\,{=}\,q})P(\mathbf {Z\,{=}\,z}\mid \mathbf {Q\,{=}\,q})\) for all
\({\mathbf {y}}\in Dom ({\mathbf {Y}})\), \({\mathbf {z}}\in Dom ({\mathbf {Z}})\), and \({\mathbf {q}}\in Dom ({\mathbf {Q}})\).
Conditional independence can be defined also for more than two sets of events or variables, given a third one. For example, in set \(\{A,B,C,D\}\) we can find four conditional independencies given D: \(A \perp BC\), \(B\perp AC\), \(C\perp AB\), and \(A\perp B \perp C\). However, these types of independence are seldom needed in practice. In pattern discovery notions of conditional independence and dependence between events are used for inspecting improvement of a dependency rule \({\mathbf {Y}}{\mathbf {Q}}\rightarrow C\) over its generalization \({\mathbf {Y}}\rightarrow C\) (Sect. 4). In machine learning conditional independence between variables or sets of variables is an important property for constructing full probability models, like Bayesian networks or log-linear models.
2.3 Statistical significance testing
Often when searching dependency rules and sets the aim is to find dependencies that hold in the population from which the sample is drawn (cf. Fig. 1). Statistical significance tests are the tools that have been created to control the risk that such inferences drawn from sample data do not hold in the population. This section introduces the key concepts that underlie significance testing and gives an overview of the main approaches that can be applied in testing dependency rules and sets. The same principles can be applied in testing other types of patterns, but a reader would be well advised to consult a statistician with regard to which tests to apply and how to apply them.
The main idea of statistical significance testing is to estimate the probability that the observed discovery would have occurred by chance. If the probability is very small, we can assume that the discovery is genuine. Otherwise, it is considered spurious and discarded. The probability can be estimated either analytically or empirically. The analytical approach is used in the traditional significance testing, while randomization tests estimate the probability empirically. Traditional significance testing can be further divided into two main classes: the frequentist and Bayesian approaches. These main approaches to statistical significance testing are shown in Fig. 4.

Different approaches to statistical significance testing
2.3.1 Frequentist approach
The frequentist approach of significance testing is the most commonly used and best studied (see e.g. Freedman et al. 2007, Ch. 26, or Lindgren 1993, Ch. 10.1). The approach is actually divided into two opposing schools, Fisherian and Neyman–Pearsonian, but most textbooks present a kind of synthesis (see e.g., Hubbard and Bayarri 2003). The main idea is to estimate the probability of the observed or a more extreme phenomenon O under some null hypothesis, \(H_0\). In general, the null hypothesis is a statement on the value of some statistic or statistics S in the population. For example, when the objective is to test the significance of dependency rule \({\mathbf {X}}\rightarrow A\), the null hypothesis \(H_0\) is the independence assumption: \(N_{XA}=nP({\mathbf {X}})P(A)\), where \(N_{XA}\) is a random variable for the absolute frequency of \({\mathbf {X}}A\). (Equivalently, \(H_0\) could be \({\varDelta }=0\) or \({\varGamma }=1\), where \({\varDelta }\) and \({\varGamma }\) are random variables for the leverage and lift.) In independence testing the null hypothesis is usually an equivalence statement, \(S\,{=}\,s_0\) (nondirectional hypothesis), but in other contexts it can also be of the form \(S\le s_0\) or \(S\ge s_0\) (directional hypothesis). Often, one also defines an explicit alternative hypothesis, \(H_A\), which can be either directional or nondirectional. For example, in pattern discovery dependency rules \({\mathbf {X}}\rightarrow A\) are assumed to express positive dependence, and therefore it is natural to form a directional hypothesis \(H_A\): \(N_{XA}>nP({\mathbf {X}})P(A)\) (or \({\varDelta }>0\) or \({\varGamma }>1\)).
When the null hypothesis has been defined, one should select a test statistic \( T \) (possibly S itself) and define its distribution (null distribution) under \(H_0\). The p-value is defined from this distribution as the probability of the observed or a more extreme \( T \)-value, \(P( T \ge t \mid H_0)\), \(P( T \le t \mid H_0)\), or \(P( T \le - t \text { or } T \ge t \mid H_0)\) (Fig. 5). In the case of independence testing, possible test statistics are, for example, leverage, lift, and the \(\chi ^2\)-measure (Eq. 4). The distribution under independence is defined according to the selected sampling model, which we will introduce in Sect. 3. The probability of observing positive dependence whose strength is at least \(\delta ({\mathbf {X}},A)\) is \(P_{{\mathcal {M}}}({\varDelta }\ge \delta ({\mathbf {X}},A)\mid H_0)\), where \(P_{{\mathcal {M}}}\) is the complementary cumulative distribution function for the assumed sampling model \({\mathcal {M}}\).

An example distribution of test statistic T under the null hypothesis. If the observed value of T is t, the p-value is probability \(P(T\ge t)\) (directional hypothesis) or \(P(T\le -t \vee T\ge t)\) (non-directional hypothesis)
Up to this point, all frequentist approaches are more or less in agreement. The differences appear only when the p-values are interpreted. In the classical (Neyman–Pearsonian) hypothesis testing, the p-value is compared to some predefined threshold \(\alpha \). If \(p\le \alpha \), the null hypothesis is rejected and the discovery is called significant at level \(\alpha \). Parameter \(\alpha \) (also known as the test size) defines the probability of committing a type I error, i.e., accepting a spurious pattern (and rejecting a correct null hypothesis). Another parameter, \(\beta \), is used to define the probability of committing a type II error, i.e., rejecting a genuine pattern as non-significant (and keeping a false null hypothesis). The complement \(1-\beta \) defines the power of the test, i.e., the probability that a genuine pattern passes the test. Ideally, one would like to minimize the test size and maximize its power. Unfortunately, this is not possible, because \(\beta \) increases when \(\alpha \) decreases and vice versa. As a solution it has been recommended (e.g., Lehmann and Romano 2005, p. 57) to select appropriate \(\alpha \) and then to check that the power is acceptable given the sample size. However, the power analysis can be difficult and all too often it is skipped altogether.
The most controversial problem in hypothesis testing is how to select an appropriate significance level. A convention is to use always the same standard levels, like \(\alpha =0.05\) or \(\alpha =0.01\). However, these values are quite arbitrary and widely criticized (see e.g., Lehmann and Romano 2005, p. 57; Lecoutre et al. 2001; Johnson 1999). Especially in large data sets, the p-values tend to be very small and hypotheses get too easily rejected with conventional thresholds. A simple alternative is to report only p-values, as advocated by Fisher and also many recent statisticians (e.g., Lehmann and Romano 2005, pp. 63-65; Hubbard and Bayarri 2003). Sometimes, this is called ‘significance testing’ in distinction from ‘hypothesis testing’ (with fixed \(\alpha \)s), but the terms are not used systematically. Reporting only p-values may often be sufficient, but there are still situations where one should make concrete decisions and a binary judgement is needed.
Deciding threshold \(\alpha \) is even harder in data mining where numerous patterns are tested. For example, if we use threshold \(\alpha =0.05\), then there is up to 5% chance that a spurious pattern passes the significance test. If we test 10 000 spurious patterns, we can expect up to 500 of them to pass the test erroneously. This so called multiple testing problem is inherent in knowledge discovery, where one often performs an exhaustive search over all possible patterns. We will return to this problem in Sect. 6.
2.3.2 Bayesian approach
Bayesian approaches are becoming increasingly popular in both statistics and data mining (see e.g., Corani et al. 2016). However, to date there has been little uptake of them in statistically sound pattern discovery. We include here a brief summary of the Bayesian approach for completeness and in the hope that it will stimulate further investigation of this promising approach.
The idea of Bayesian significance testing (see e.g., Lee 2012, Ch. 4; Albert 1997; Jamil et al. 2017) is quite similar to the frequentist approach, but now we assign some prior probabilities \(P(H_0)\) and \(P(H_A)\) to the null hypothesis \(H_0\) and the alternative research hypothesis \(H_A\). Next, the conditional probabilities, \(P(O{\mid }H_0)\) and \(P(O{\mid }H_A)\), of the observed or a more extreme phenomenon O under \(H_0\) and \(H_A\) are estimated from the data. Finally, the probabilities of both hypotheses are updated by the Bayes’ rule and the acceptance or rejection of \(H_0\) is decided by comparing posterior probabilities \(P(H_0{\mid }O)\) and \(P(H_A{\mid }O)\). The resulting conditional probabilities \(P(H_0{\mid }O)\) are asymptotically similar (under some assumptions even identical) to the traditional p-values, but Bayesian testing is sensitive to the selected prior probabilities (Agresti and Min 2005). One attractive feature of the Bayesian approach is that it allows to quantify the evidence for and against the null hypothesis. However, the procedure tends to be more complicated than the frequentist one; specifying prior distributions may require a plethora of parameters and the posterior probabilities cannot always be evaluated analytically (Agresti and Hitchcock 2005; Jamil et al. 2017).
2.3.3 Randomization testing
Randomization testing (see e.g., Edgington 1995) offers a relatively assumption-free approach for testing statistical dependencies. Unlike traditional significance testing, there is no need to assume that the data would be a random sample from the population or to define what type of distribution the test statistic has under the null hypothesis. Instead, the significance is estimated empirically, by generating random data sets under the null hypothesis and checking how often the observed or a more extreme phenomenon occurs in them.
When independence between A and B is tested, the null hypothesis is exchangeability of the A-values on rows when B-values are kept fixed, or vice versa. This is the same as stating that all permutations of A-values in the data are equally likely. A similar null hypothesis can be formed for mutual independence in a set of variables. If only a single dependency set \({\mathbf {X}}\) is tested, it is enough to generate random data sets \({\mathcal {D}}_1,\ldots ,{\mathcal {D}}_b\) by permuting values of each \(A_i\), \(A_i\in {\mathbf {X}}\). Usually, it is required that all marginal probabilities \(P(A_i)\) remain the same as in the original data, but there may be additional constraints, defined by the permutation scheme. Test statistic \( T \) that evaluates goodness of the pattern is calculated in each random data set. For simplicity, we assume that the test statistic \( T \) is increasing by goodness (a higher value indicates a better pattern). If the original data set produced \( T \)-value \( t _0\) and b random data sets produced \( T \)-values \( t _1,\ldots , t _b\), the empirical p-value of the observed pattern is
If the data set is relatively small and \({\mathbf {X}}\) is simple, it is possible to enumerate all possible permutations where the marginal probabilities hold. This leads to an exact permutation test, which gives an exact p-value. On the other hand, if the data set is large and/or \({\mathbf {X}}\) is more complex, all possibilities cannot be checked, and the empirical p-value is less accurate. In this case, the test is called a random permutation test or an approximate permutation test. There are also some special cases, like testing a single dependency rule, where it is possible to express the permutation test in a closed form that is easy to evaluate exactly (see Fisher’s exact test in Sect. 3.2).
An advantage of randomization testing is that the test statistic can have any kind of distribution, which is especially handy when the statistic is new or poorly known. With randomization one can test also such null hypotheses for which no closed form test exists. Randomization tests are technically valid even if the data are not a random sample because strictly speaking the population to which the null hypotheses relate is the set of all permutations of the sample defined by the permutation scheme. However, the results can be generalized to the reference population only to the extent of how representative the sample was for that population (Legendre and Legendre 1998, p. 24). One critical problem with randomization testing is that it is not always clear how the data should be permuted, and different permutation schemes can produce quite different results in their assessment of patterns (see e.g., Hanhijärvi 2011). The number of random permutations plays also an important role in testing. The more random permutations are performed, the more accurate the empirical p-values are, but in practice, extensive permuting can be too time consuming. Computational costs restrict also the use of randomization testing in search algorithms especially in large data sets.
The idea of randomization tests can be extended for estimating the overall significance of all mining results or even for tackling the multiple testing problem. For example, one may test the significance of the number of all frequent sets (given a minimum frequency threshold) or the number of all sufficiently strong pair-wise correlations (given a minimum correlation threshold) using randomization tests (Gionis et al. 2007). In this case, it is necessary to generate complete data sets randomly for testing. The difficulty is to decide what properties of the original data set should be maintained. One common solution in pattern mining is to keep both the column margins (\( fr (A_i)\)s) and the row margins (numbers of 1s on each row) fixed and generate new data sets by swap randomization (Cobb and Chen 2003). A prerequisite for this method is that the attributes are semantically similar (e.g. occurrence or absence of species) and it is sensible to swap their values. In addition, there are some pathological cases, where no or only a few permutations exist with the given row and column margins, resulting in a large p-value, even if the original data set contains a significant pattern (Gionis et al. 2007).
3 Statistical significance of dependency rules
Dependency rules are a famous pattern type that expresses bipartition dependence between the rule antecedent and the consequent. In this section, we discuss how statistical significance of dependency rules is evaluated under different assumptions. Especially, we contrast two alternative interpretations of dependency rules that are called variable-based and value-based interpretations and introduce appropriate tests in different sampling models.
3.1 Dependency rules
Dependency rules are maybe the simplest type of statistical dependency patterns. As a result, it has been possible to develop efficient exhaustive search algorithms. With these, dependency rules can reveal arbitrarily complex bipartite dependencies from categorical or discretized numerical data without any additional assumptions. This makes dependency rule analysis an attractive starting point for any data mining task. In medical science, for example, an important task is to search for statistical dependencies between gene alleles, environmental factors, and diseases. We recall that statistical dependencies are not necessarily causal relationships, but still they can help to form causal hypotheses and reveal which factors predispose or prevent diseases (see e.g., Jin et al. 2012; Li et al. 2016). Interesting dependencies do not necessarily have to be strong or frequent, but instead, they should be statistically valid, i.e., genuine dependencies that are likely to hold also in future data. In addition, it is often required that the patterns should not contain any superfluous variables which would only obscure the real dependencies. Based on these considerations, we will first give a general definition of dependency rules and then discuss important aspects of genuine dependencies.
Definition 6
(Dependency rule) Let \({\mathbf {R}}\) be a set of categorical variables, \({\mathbf {X}}{\subseteq } {\mathbf {R}}\), and \({\mathbf {Y}}{\subseteq } {\mathbf {R}}{\setminus } {\mathbf {X}}\). Let us denote value vectors of \({\mathbf {X}}\) and \({\mathbf {Y}}\) by \({\mathbf {x}}\in Dom ({\mathbf {X}})\) and \({\mathbf {y}}\in Dom ({\mathbf {Y}})\). Rule \(\mathbf {X\,{=}\,x}\rightarrow \mathbf {Y\,{=}\,y}\) is a dependency rule, if \(P(\mathbf {X\,{=}\,x},\mathbf {Y\,{=}\,y})\ne P(\mathbf {X\,{=}\,x})P(\mathbf {Y\,{=}\,y})\).
The dependency is (i) positive, if \(P(\mathbf {X\,{=}\,x},\mathbf {Y\,{=}\,y})> P(\mathbf {X\,{=}\,x})P(\mathbf {Y\,{=}\,y})\), and (ii) negative, if \(P(\mathbf {X\,{=}\,x},\mathbf {Y\,{=}\,y})< P(\mathbf {X\,{=}\,x})P(\mathbf {Y\,{=}\,y})\). Otherwise, the rule expresses independence.
It is important to recognize that while the convention is to specify the antecedent and consequent and use a directed arrow to distinguish them, statistical dependence is a symmetric relation and strictly speaking the direction is arbitrary. Often, the rule is expressed with the antecedent and consequent selected so that the precision (‘confidence’) of the rule (\(\phi (\mathbf {X\,{=}\,x}\rightarrow \mathbf {Y\,{=}\,y})=P(\mathbf {Y\,{=}\,y}\mid \mathbf {X\,{=}\,x})\) or \(\phi (\mathbf {Y\,{=}\,y}\rightarrow \mathbf {X\,{=}\,x})=P(\mathbf {X\,{=}\,x}\mid \mathbf {Y\,{=}\,y})\)) is maximal. An exception is supervised descriptive rule discovery (including class association rules (Li et al. 2001), subgroup discovery (Herrera et al. 2011), emerging pattern mining (Dong and Li 1999) and contrast set mining (Bay and Pazzani 2001)), where the consequent is fixed (Novak et al. 2009).
For simplicity, we will concentrate on a common special case of dependency rules where 1) all variables are binary, 2) the consequent \(\mathbf {Y{=}y}\) consists of a single variable-value combination, \(A{=}i\), \(i\in \{0,1\}\), and 3) the antecedent \(\mathbf {X{=}x}\) is a conjunction of true-valued attributes, i.e., \(\mathbf {X\,{=}\,x}\equiv (A_1{=}1,\ldots ,A_l{=}1)\), where \({\mathbf {X}}=\{A_1,\ldots ,A_l\}\). With these restrictions the resulting rules can be expressed in a simpler form \({\mathbf {X}}\rightarrow A\,{=}\,i\), where \(i\in \{0,1\}\), or \({\mathbf {X}}\rightarrow A\) and \({\mathbf {X}}\rightarrow \lnot A\). Allowing negated consequents means that it is sufficient to represent only positive dependencies (a positive dependency between \({\mathbf {X}}\) and \(\lnot A\) is the same as a negative dependency between \({\mathbf {X}}\) and A). We note that this restriction is purely representational and the following theory is easily extended to general dependency rules as well. Furthermore, we recall that this simpler form of rules can still represent all dependency rules after suitable data transformations (i.e., creating new binary variables for all values of the original variables).
Finally, we note that dependency rules deviate from traditional association rules (Agrawal et al. 1993) in their requirement of statistical dependence. Traditional association rules do not necessarily express any statistical dependence but relations between frequently occurring attribute sets. However, there has been research on association rules where the requirement of minimum frequency (‘minimum support’) has been replaced by requirements of statistical dependence (see e.g., Webb and Zhang 2005; Webb 2008, 2007; Hämäläinen 2012, 2010b; Li 2006; Morishita and Sese 2000; Nijssen and Kok 2006; Nijssen et al. 2009). For clarity, we will use here the term ‘dependency rule’ for all rule type patterns expressing statistical dependencies, even if they had been called association rules, classification rules, or other similar patterns in the original publications.
Statistical dependence is a necessary requirement of a dependency rule, but in addition, it is frequently useful to impose further constraints like that of statistical significance and absence of superfluous variables. The following example illustrates some of these properties of dependency rules.
Example 1
Let us consider an imaginary database consisting of 1000 patients (50% female, 50% male), 30% of them with heart disease. The database contains information on patients and their life style like smoking status, drinking coffee, having stress, going for sports, and using natural products. Table 2 lists some candidate dependency rules related to heart disease together with their frequency, precision, leverage, and lift.
The first two rules are examples of simple positive and negative dependencies (predisposing and protecting factors for heart disease). Rules 3 and 4 are included as examples of so called independence rules that express statistical independence between the antecedent and consequent. Normally, such rules would be pruned out by dependency rule mining algorithms.
Rule 5 is an example of a spurious rule, which is statistically insignificant and likely due to chance. The database contains only one person who uses pine bark extract regularly and who does not have heart disease. Note that the lift is still quite large, the maximal possible for that consequent. Rule 6 is also statistically insignificant, but for a different reason. The rule is very common, but the difference in the prevalence of heart disease among female and male patients is so small (148 vs. 152) that it can be explained by chance.
Rule 7 demonstrates non-monotonicity of statistical dependence. The combination of stress and female gender correlates positively with heart disease, even though stress alone was independent of heart disease and the female gender was negatively correlated with it.
The last four rules illustrate the problem of superfluous variables. In rule 8, neither of the condition attributes is superfluous, because the dependency is stronger and more significant than simpler dependencies involving only stress or only smoking. However, rules 9–11 demonstrate three types of superfluous rules where extra factors (i) have no effect on the dependency, (ii) weaken it, or (iii) apparently improve it but not significantly. Rule 9 is superfluous, because coffee has no effect on the dependency between smoking and heart disease (coffee consumption and heart disease are conditionally independent given smoking). Rule 10 is superfluous, because going for sports weakens the dependency between smoking and heart disease. This kind of modifying effect might be interesting in some contexts, if it were statistically significant. However, dependency rule mining algorithms do not usually perform such analysis. Rule 11 is the most difficult to judge, because the dependence is itself significant and the rule has larger precision and lift than either of simpler dependencies involving only the female gender or only sports. However, the improvement with respect to rule 2 is so small (\(\phi =0.808\) vs. \(\phi =0.800\)) that it is likely due to chance.
In the previous example we did not state which measure should be preferred for measuring the strength of dependence or how the statistical significance should be evaluated. The reason is that the selection of these measures as well as evaluation of statistical significance and superfluousness depend on the interpretation of dependency rules. In principle there are two alternative interpretations for rule \({\mathbf {X}}\rightarrow A\,{=}\,i\), \(i\in \{0,1\}\): either it can represent a dependency between events \({\mathbf {X}}\) (or \(I_{\mathbf {X}}{=}1\)) and \(A\,{=}\,i\) or between variables \(I_{\mathbf {X}}\) and A, where \(I_{\mathbf {X}}\) is an indicator variable for event \({\mathbf {X}}\). These two interpretations have sometimes been called value-based and variable-based semantics (Blanchard et al. 2005) of the rule. Unfortunately, researchers have often forgotten to mention explicitly which interpretation they follow. This has caused much confusion and, in the worst case, led to missed or inappropriate discoveries. The following example demonstrates how variable- and value-based interpretations can lead to different results.
Example 2
Let us consider a database of 100 apples describing their colour (green or red), size (big or small), and taste (sweet or bitter). Let us notate A=sweet, \(\lnot A\)=bitter (not sweet), \({\mathbf {Y}}\)={red}, \(\lnot {\mathbf {Y}}{=}\{green\}\) (not red), \({\mathbf {X}}{=}\{red,big\}\) and \(\lnot {\mathbf {Y}}{=}\lnot \{red,big\}\) (i.e., green or small).

Apple baskets corresponding to rules red\(\rightarrow \)sweet (top) and red and big\(\rightarrow \)sweet (bottom) (Color figure online)
We would like to find strong dependencies related to either variable ‘taste’ (variable-based interpretation) or value ‘sweet’ (value-based interpretation). Figure 6 represents two such rules: \({\mathbf {Y}}\rightarrow A\) (red\(\rightarrow \)sweet) and \({\mathbf {X}}\rightarrow A\) (red and big\(\rightarrow \)sweet).
The first rule expresses a strong dependency between binary variables \(I_{{\mathbf {Y}}}\) and A (i.e., colour and taste) with \(P(A|{\mathbf {Y}})=0.92\), \(P(\lnot A|\lnot {\mathbf {Y}})=1.0\), \(\delta ({\mathbf {Y}},A)=0.22\), and \(\gamma ({\mathbf {Y}},A)=1.67\). So, with this rule we can divide the apples into two baskets according to colour. The first basket contains 60 red apples, 55 of which are sweet, and the second basket contains 40 green apples, which are all bitter. This is quite a good rule if the goal is to classify well both sweet apples (for eating) and bitter apples (for juice and cider).
The second rule expresses a strong dependency between the value combination \({\mathbf {X}}\) (red and big) and value \(A\,{=}\,1\) (sweet) with \(P(A|{\mathbf {X}})=1.0\), \(P(\lnot A|\lnot {\mathbf {X}})=0.75\), \(\delta ({\mathbf {X}},A)=0.18\), \(\gamma ({\mathbf {X}},A)=1.82\). This rule produces a basket of 40 big, red apples, all of them sweet, and another basket of 60 green or small apples, 45 of them bitter. This is an excellent rule if we would like to predict sweetness better (e.g., get a basket of sweet apples for our guests) without caring how well bitterness is predicted.
So, the choice between variable-based and value-based interpretation results in a preference for a different rule. Either one can be desirable for different modelling purposes. This decision affects also which goodness measure should be used. Leverage suits the variable-based interpretation, because its absolute value is the same for all truth value combinations (\({\mathbf {X}}A\), \({\mathbf {X}}\lnot A\), \(\lnot {\mathbf {X}}A\), \(\lnot {\mathbf {X}}\lnot A\)), but it may miss interesting dependencies related to particular values. Lift, on the other hand, suits the value-based interpretation, because it favours rules where the given values are strongly dependent. However, it is not a reliable measure alone, because it ranks well also coincidental ‘noise rules’ (e.g., apple maggot\(\rightarrow \)bitter). Therefore, it has to be accompanied with statistical significance tests.
In general, the variable-based interpretation tends to produce more reliable patterns, in the sense that the discovered dependencies hold well in future data (see e.g., Hämäläinen 2010a, Ch.5). However, there are applications where the value-based interpretation may better identify interesting dependency rules. One example could be analysis of predisposing factors (like gene alleles) for a serious disease. Some factors \({\mathbf {X}}\) may be rare, but still their occurrence could strongly predict the onset of some disease D. Medical scientists would certainly want to find such dependencies \({\mathbf {X}}\rightarrow D\), even if the overall dependency between variables \(I_{{\mathbf {X}}}\) and D would be weak or insignificant.
In the following sections, we will examine how statistical significance is tested in the variable-based and value-based interpretations.
3.2 Sampling models for the variable-based interpretation
In the variable-based interpretation, the significance of dependency rule \({\mathbf {X}}\rightarrow A\) is determined by classical independence tests. The task is to estimate the probability of the observed or a more ‘extreme’ contingency table, assuming that variables \(I_{\mathbf {X}}\) and A were actually independent. There is no consensus how the extremeness relation should be defined, but intuitively, contingency table \(\tau _i\) is more extreme than table \(\tau _j\), if the dependence between \({\mathbf {X}}\) and A is stronger in \(\tau _i\) than in \(\tau _j\). So, any measure for the strength of dependence between variables can be used as a discrepancy measure, to order contingency tables. The simplest such measure is leverage, but also odds ratio
is commonly used. We note that odds ratio is not defined when \(N_{X\lnot A}N_{\lnot X A}=0\) and some special policy is needed for these cases. In the following, we will notate the relation “table \(\tau _i\) is equally or more extreme to table \(\tau _j\)” by \(\tau _i \succeq \tau _j\).
The probability of each contingency table \(\tau _i\) depends on the assumed statistical model \({\mathcal {M}}\). Model \({\mathcal {M}}\) defines the space of all possible contingency tables \({\mathcal {T}}_{\mathcal {M}}\) (under the model assumptions) and the probability \(P(\tau _i\mid {\mathcal {M}})\) of each table \(\tau _i\in {\mathcal {T_M}}\). Because the task is to test independence, the assumed model should satisfy the independence assumption \(P({\mathbf {X}}A)=P({\mathbf {X}})P(A)\) in some form. For the probabilities \(P(\tau _i\mid {\mathcal {M}})\) holds
Now the probability of the observed contingency table \(\tau _ o \) or any \(\tau _i\), \(\tau _i\succeq \tau _ o \), is the desired p-value
Classically, statistical models for independence testing have been divided into three main categories (sampling schemes) (Barnard 1947; Pearson 1947), which we call multinomial, double binomial, and hypergeometric models. In the statistics literature (e.g. Barnard 1947; Upton 1982), the corresponding sampling schemes are called double dichotomy, 2\(\times \)2 comparative trial, and 2\(\times \)2 independence trial.
In the following we describe the three models using the classical urn metaphor. However, because there are two binary variables of interest, \(I_{\mathbf {X}}\) and A, we cannot use the basic urn model with white and black balls. Instead, we will use an apple basket model, with red and green, sweet and bitter apples, like in Example 2.
3.2.1 Multinomial model
In the multinomial model, it is assumed that the real probabilities of sweet red apples, bitter red apples, sweet green apples, and bitter green apples are defined by parameters \(p_{X A}\), \(p_{X\lnot A}\), \(p_{\lnot X A}\), and \(p_{\lnot X \lnot A}\). The probability of red apples is \(p_X\) and of green apples \(1-p_X\). Similarly, the probability of sweet apples is \(p_A\) and of bitter apples \(1-p_A\). According to the independence assumption, \(p_{X A}=p_X p_A\), \(p_{X\lnot A}=p_X(1-p_A)\), \(p_{\lnot X A}=(1-p_X)p_A\), and \(p_{\lnot X\lnot A}=(1-p_X)(1-p_A)\). A sample of n apples is taken randomly from an infinite basket (or from a finite basket with replacement). Now the probability of obtaining \(N_{X A}\) sweet red apples, \(N_{X\lnot A}\) bitter red apples, \(N_{\lnot X A}\) sweet green apples, and \(N_{\lnot X\lnot A}\) bitter green apples is defined by multinomial probability
Since data size n is given, the contingency tables can be defined by triplets \(\langle N_{X A},\)\(N_{X\lnot A},N_{\lnot X A}\rangle \) or, equivalently, triplets \(\langle N_X, N_A, N_{X A}\rangle \). Therefore, the space of all possible contingency tables is
For estimating the p-value with Eq. (10), we should still solve two problems. First, the parameters \(p_X\) and \(p_A\) are unknown. The most common solution is to estimate them by the observed relative frequencies (maximum likelihood estimates). Second, we should decide when a contingency table \(\tau _i\) is equally or more extreme than the observed contingency table \(\tau _ o \). For this purpose, we have to select the discrepancy measure, which evaluates the overall dependence in a contingency table, when only the data size n is fixed. Examples of such measures are leverage and the odds ratio.
In practice, the multinomial test is seldom used, but the multinomial model is an important theoretical model, from which other models can be derived as special cases.
3.2.2 Double binomial model
In the double binomial model, it is assumed that we have two infinite baskets, one for red and one for green apples. Let us call these the red and the green basket. In the red basket the probability of sweet apples is \(p_{A|X}\) and of bitter apples \(1-p_{A|X}\), and in the green basket the probabilities are \(p_{A|\lnot X}\) and \(1-p_{A|\lnot X}\). According to the independence assumption, the probability of sweet apples is the same in both baskets: \(p_A=p_{A|X}=p_{A|\lnot X}\). A sample of \( fr ({\mathbf {X}})\) apples is taken randomly from the red basket and another random sample of \( fr (\lnot {\mathbf {X}})\) apples is taken from the green basket. The probability of obtaining \(N_{X A}\) sweet apples among the selected \( fr ({\mathbf {X}})\) red apples is defined by the binomial probability
Similarly, the probability of obtaining \(N_{\lnot X A}\) sweet apples among the selected green apples is
Because the two samples are independent from each other, the probability of obtaining \(N_{X A}\) sweet apples from \( fr ({\mathbf {X}})\) red apples and \(N_{\lnot X A}\) sweet apples from \( fr (\lnot {\mathbf {X}})\) green apples is the product of the two binomials
where \(N_A=N_{X A}+N_{\lnot X A}\) is the total number of the obtained sweet apples. (Here \( fr (\lnot {\mathbf {X}})\) was dropped from the condition, because n is given.) We note that the double binomial probability is not exchangeable with respect to the roles of \({\mathbf {X}}\) and A, i.e., generally \(P(N_{X A},N_{\lnot X A}\mid n, fr ({\mathbf {X}}),p_A)\ne P(N_{X A},N_{X\lnot A}\mid n, fr (A),p_X).\) In practice, this means that the probability of obtaining \( fr ({\mathbf {X}}A)\) sweet red apples, \( fr ({\mathbf {X}}\lnot A)\) bitter red apples, \( fr (\lnot {\mathbf {X}}A)\) sweet green apples, and \( fr (\lnot {\mathbf {X}}\lnot A)\) bitter green apples is (nearly always) different in the model of the red and green baskets from the model of the sweet and bitter baskets.
Since \( fr ({\mathbf {X}})\) and \( fr (\lnot {\mathbf {X}})\) are given, each contingency table is defined as a pair \(\langle N_{X A},N_{\lnot X A}\rangle \) or, equivalently, \(\langle N_{A},N_{X A}\rangle \). The space of all possible contingency tables is
We note that \(N_A\) is not fixed, and therefore \(N_A\) is generally not equal to the observed \( fr (A)\).
For estimating the significance with Eq. (10), we should estimate the unknown parameter \(p_A\) and select a discrepancy measure, like leverage or odds ratio. Then the exact p-value is obtained by summing over all possible values of \(N_{XA}\) and \(N_{\lnot XA}\) where the dependence is sufficiently strong. However, often this is considered impractical and the p-value is approximated with asymptotic tests, which are discussed later.
3.2.3 Hypergeometric model
In the hypergeometric model, there is no sampling from an infinite basket. Instead, we can assume that we are given a finite basket of n apples, containing exactly \( fr ({\mathbf {X}})\) red apples and \( fr (\lnot {\mathbf {X}})\) green apples. We test all n apples and find that \( fr ({\mathbf {X}}A)\) of red apples and \( fr (\lnot {\mathbf {X}}A)\) of green apples are sweet. The question is how probable is our basket, or the set of all at least equally extreme baskets, among all possible apple baskets with \( fr ({\mathbf {X}})\) red apples, \( fr (\lnot {\mathbf {X}})\) green apples, \( fr (A)\) sweet apples, and \( fr (\lnot A)\) bitter apples.
Now the baskets correspond to contingency tables. The number of all possible baskets with the fixed totals \( fr ({\mathbf {X}})\), \( fr (\lnot {\mathbf {X}})\), \( fr (A)\), and \( fr (\lnot A)\) is
(We recall that customarily \({m \atopwithdelims ()l }=0\), when \(l>m\).) Assuming that all baskets with these fixed totals are equally likely, the probability of a basket with \(N_{X A}\) sweet red apples is
Because all totals are fixed, the extremeness relation is also easy to define. Positive dependence is stronger than observed, when \(N_{X A}> fr ({\mathbf {X}}A)\). For the p-value it is enough to sum the probabilities of baskets containing at least \( fr ({\mathbf {X}}A)\) sweet red apples. The resulting p-value is
where \(J_1=\min \{ fr ({\mathbf {X}}\lnot A), fr (\lnot {\mathbf {X}}A)\}\). (Instead of \(J_1\) we could give an upper range \( fr (A)\), because the zero terms disappear.) This p-value is known as Fisher’s p, because it is used in Fisher’s exact test, an exact permutation test. We give it a special symbol \(p_F\), because it will be used later. For negative dependence between red and sweet apples (or positive dependence between green and sweet apples) the p-value is
where \(J_2=\min \{ fr ({\mathbf {X}}A), fr (\lnot {\mathbf {X}}\lnot A)\}\).
3.2.4 Asymptotic measures
We have seen that the p-values in the multinomial and double binomial models are quite difficult to calculate. However, the p-value can often be approximated easily using asymptotic measures. With certain assumptions, the resulting p-values converge to the correct p-values, when the data size n (or \( fr ({\mathbf {X}})\) and \( fr (\lnot {\mathbf {X}})\)) tend to infinity. In the following, we introduce two commonly used asymptotic measures for independence testing: the \(\chi ^2\)-measure and mutual information. In statistics, the latter corresponds to the log likelihood ratio (Neyman and Pearson 1928).
The main idea of asymptotic tests is that instead of estimating the probability of the contingency table as such, we calculate some better behaving test statistic \( T \). If \( T \) gets value \( t \), we estimate the probability of \(P( T \ge t )\) (assuming that large \( T \)-values indicate a strong dependency).
In the case of the \(\chi ^2\)-test, the test statistic is the \(\chi ^2\)-measure. Now the variables are binary and Eq. (4) reduces into a simpler form:
So, in principle, each term measures how much the observed frequency \( fr (I_{\mathbf {X}}{=}i,A{=}j)\) deviates from its expectation \(nP(I_{\mathbf {X}}{=}i)P(A{=}j)\) under the independence assumption. If the data size n is sufficiently large and none of the expected frequencies is too small, the \(\chi ^2\)-measure follows approximately the \(\chi ^2\)-distribution with one degree of freedom. As a classical rule of thumb (Fisher 1925), the \(\chi ^2\)-measure can be used only, if all expected frequencies \(nP(I_{\mathbf {X}}{=}i)P(A{=}j)\), \(i, j\in \{0,1\}\), are at least 5. However, the approximations can still be poor in some situations, when the underlying binomial distributions are skewed, e.g., if P(A) is near 0 or 1, or if \( fr ({\mathbf {X}})\) and \( fr (\lnot {\mathbf {X}})\) are far from each other (Yates 1984; Agresti 1992). According to Carriere (2001), this is quite typical for data in medical science.
One reason for the inaccuracy of the \(\chi ^2\)-measure is that the original binomial distributions are discrete while the \(\chi ^2\)-distribution is continuous. A common solution is to make a continuity correction and subtract 0.5 from the expected frequency \(nP({\mathbf {X}})P(A)\). According to Yates (1984) the resulting continuity corrected \(\chi ^2\)-measure can give a good approximation to Fisher’s \(p_F\), if the underlying hypergeometric distribution is not markedly skewed. However, according to Haber (1980) the resulting \(\chi ^2\)-value can underestimate the significance, while the uncorrected \(\chi ^2\)-value overestimates it.
Mutual information is another popular asymptotic measure, which has been used to test independence. For binary variables Eq. (5) becomes
Mutual information is actually an information theoretic measure, but in statistics \(2n\cdot \textit{MI}\) is known as log likelihood ratio or the G-test of independence. It follows asymptotically the \(\chi ^2\)-distribution (Wilks 1935) and often it gives similar results to the \(\chi ^2\)-measure (Vilalta and Oblinger 2000). However, sometimes the two tests can give totally different results (Agresti 1992).
3.2.5 Selecting the right model
Selecting the right sampling model and defining the extremeness relation is a controversial problem, which statisticians have argued for the last century (see e.g., Yates 1984; Agresti 1992; Lehmann 1993; Upton 1982; Howard 1998). Therefore, we cannot give any definite recommendations which model to select but each situation should be judged in its own context.
The main decision is whether the analysis should be done conditionally or unconditionally and which variables N, \(N_X\), or \(N_A\) should be considered fixed. In the multinomial model all variables except \(N{=}n\) are randomized. However, if the model is conditioned with \(N_X= fr ({\mathbf {X}})\), it leads to the double binomial model. If the double binomial model is conditioned with \(N_A= fr (A)\), it leads to the hypergeometric model. For completeness, we could also consider the Poisson model where all variables, including N, are unfixed Poisson variables. If the Poisson model is conditioned with the given data size, \(N{=}n\), it leads to the multinomial model (Lehmann and Romano 2005, ch. 4.6–4.7).
In principle, the sampling scheme should be decided before the data is gathered. However, in pattern discovery the data may not be sampled according to a particular scheme. In this situation the main choices are to perform an unconditional analysis where none of the margins are considered fixed or a conditional analysis where all margins are considered fixed. The main argument of the unconditional approach is that the results are better generalizable outside the data set, if some variables are kept unfixed. However, both multinomial and double binomial models are computationally demanding, and in practice the corresponding asymptotic tests have been used instead. The opponents have argued that the unconditional approach is also conditional on the data, since the unknown parameters (\(p_X\) and/or \(p_A\)) are anyway estimated from the observed counts (\( fr ({\mathbf {X}})\) and/or \( fr (A)\)). Therefore, Fisher and his followers have suggested that we should always assume both \(N_X\) and \(N_A\) fixed and use Fisher’s exact test or—when it is heavy to compute—a suitable asymptotic test.
In pattern discovery the most popular choices for evaluating dependency rules and other similar bipartition dependence patterns in the variable-based interpretation have been Fisher’s exact test (e.g., Hämäläinen 2012; Terada et al. 2013b, 2015; Llinares López et al. 2015; Jabbar et al. 2016) and the \(\chi ^2\)-test (e.g., Morishita and Sese 2000; Morishita and Nakaya 2000; Nijssen and Kok 2006; Hämäläinen 2011; Jin et al. 2012; Terada et al. 2015). Both of these tests have also been used for evaluating significance of improvement (see Sect. 4). According to our cross-validation experiments (Hämäläinen 2012), the \(\chi ^2\)-measure can be quite unreliable, in the sense that the discovered dependency rules may not hold in the test data at all or their lift and leverage values differ significantly between the training and test sets. The problem is alleviated to some extent when the continuity correction is used, but still the errors can be considerable. On the contrary, Fisher’s p has turned out to be a very robust and reliable measure in the dependency rule search and we recommend it as a first choice whenever applicable. There is also an accurate approximation of Fisher’s p when faster evaluation is needed (Hämäläinen 2016). Mutual information is also a good alternative and it often produces the same rules as \(p_F\).
3.3 Sampling models for the value-based interpretation
In the value-based interpretation the idea is that we would like to find events \({\mathbf {X}}A\) or \({\mathbf {X}}\lnot A\), which express a strong positive dependency, even if the dependency between variables \(I_{\mathbf {X}}\) and A were relatively weak. In this case the strength of the dependency is usually measured by lift, because leverage has the same absolute value for all events \({\mathbf {X}}A\), \({\mathbf {X}}\lnot A\), \(\lnot {\mathbf {X}}A\), \(\lnot {\mathbf {X}}\lnot A\). However, lift alone is not a reliable measure, because it obtains its maximum value also when \( fr ({\mathbf {X}}A\,{=}\,i)= fr ({\mathbf {X}})= fr (A\,{=}\,i)=1\) (\(i\in \{0,1\}\))—i.e., when the rule occurs on just one row (Hahsler et al. 2006). Such a rule is quite likely due to chance and hardly interesting (see Example 1). Therefore, we should evaluate the probability of observing such a large lift value, if \({\mathbf {X}}\) and A were actually independent (independence testing, \(H_0\): \({\varGamma }=1\) (Benjamini and Leshno 2005)) or, alternatively, that the lift is at most some threshold \(\gamma _0>1\) (\(H_0\): \({\varGamma }\le \gamma _0\) (Lallich et al. 2007)).
The p-value is defined like in the variable-based testing by Eq. (10). The only difference is how to define the extremeness relation \(\tau _i \succeq \tau _j\). A necessary condition for the extremeness of table \(\tau _i\) over \(\tau _j\) is that in \(\tau _i\) the lift is larger than in \(\tau _j\). However, since the lift is largest, when \(N_X\) and/or \(N_A\) are smallest (and \(N_{X A}=N_X\) or \(N_{X A}=N_A\)), it is sensible to require that also \(N_{X A}\) is larger in \(\tau _i\) than in \(\tau _j\). If both \(N_X\) and \(N_A\) are fixed, then the lift is larger than observed if and only if the leverage is larger than observed, and it is enough to consider tables where \(N_{X A}\ge fr ({\mathbf {X}}A)\). However, if either \(N_X\), \(N_A\), or both are unfixed, then we should always check the lift \({\varGamma }=\frac{nN_{X A}}{N_X N_A}\) and compare it to the observed lift \(\gamma ({\mathbf {X}},A)\).
In the following, we will describe different approaches for evaluating statistical significance of dependency rules in the value-based interpretation. The approaches fall into two categories depending on whether the dependence is tested only in the part of data where the rule antecedent holds or in the whole data. We will call these main strategies partial and complete evaluation of significance according to corresponding measures that are called partial and complete evaluators (Vilalta and Oblinger 2000). We introduce three approaches: partial evaluation with a single binomial test, complete evaluation under the classical sampling models, and complete evaluation with a single binomial test. Finally, we discuss the problem of selecting the right model.
3.3.1 Partial evaluation with a single binomial test
In the previous research on association rules, some authors (Dehaspe and Toivonen 2001; Lallich et al. 2007, 2005; Bruzzese and Davino 2003; Megiddo and Srikant 1998) have speculated how to test the null hypothesis \({\varGamma }=1\). For some reason, it has often been taken for granted that one should perform partial evaluation and evaluate significance of rule \({\mathbf {X}}\rightarrow A\)in the part of the data where\({\mathbf {X}}\)is true. As a solution, it has been suggested to use only a single binomial from the double binomial model. This is equivalent to assuming two infinite baskets of apples, the red and green one, but taking only a sample of \( fr ({\mathbf {X}})\) apples from the red basket and trying to decide whether there is a dependency between the red colour and sweetness. It is assumed that \(N_{X A}\sim Bin( fr ({\mathbf {X}}),p_A)\) and the unknown parameter \(p_A\) is estimated from the data, as usual. For positive dependence the p-value is defined as (Dehaspe and Toivonen 2001)
and for negative dependence as (Dehaspe and Toivonen 2001)
We see that \(N_X= fr ({\mathbf {X}})\) is the only variable that has to be fixed—even N can be unfixed. We note that since \(N_A\) is unfixed, i goes from \( fr ({\mathbf {X}}A)\) to \( fr ({\mathbf {X}})\) (and not to \(\min \{ fr ({\mathbf {X}}), fr (A)\}\)) in the case of positive dependence (Lallich et al. 2005). The idea is that when \(N_{X A}\ge fr ({\mathbf {X}}A)\), then \(\frac{N_{X A}}{ fr ({\mathbf {X}})}\ge P(A|{\mathbf {X}})\), and since \(p_A=P(A)\) was fixed, then also \({\varGamma }\ge \gamma ({\mathbf {X}},A)\). Similarly, in the negative case \({\varGamma }\le \gamma ({\mathbf {X}},A)\). So, the test checks correctly all cases where the lift is at least as large (or as small) as observed.
Since the cumulative binomial probability is quite difficult to calculate, it is common to estimate it asymptotically by the z-score. The z-score measures how many standard deviations the observed frequency deviates from its expectation. In the case of positive dependence, the binomial variable \(N_{X A}\) has expected value \({\hat{\mu }}= fr ({\mathbf {X}})P(A)\) and standard deviation \({\hat{\sigma }}=\sqrt{ fr ({\mathbf {X}})P(A)P(\lnot A)}\). The corresponding z-score is (Lallich et al. 2005; Bruzzese and Davino 2003)
If \( fr ({\mathbf {X}})\) is sufficiently large and P(A) is not too near to 1 or 0, the z-score follows the standard normal distribution. However, when the expected frequency \( fr ({\mathbf {X}})P(A)\) is low (as a rule of thumb \(<5\)), the binomial distribution is positively skewed. This means that the z-score overestimates the significance.
It is also possible to construct a partial evaluator from the mutual information (Eq. 16) by ignoring terms related to \(\lnot {\mathbf {X}}\). The result is known as J-measure (Smyth and Goodman 1992):
However, it is an open problem how the corresponding p-value could be evaluated and whether the J-measure could be used for estimating statistical significance.
The problem of all partial evaluators is that two rules with different antecedents \({\mathbf {X}}\) are not comparable. So, all rules (with different \({\mathbf {X}}\)) are thought to be from different populations and are tested in different parts of the data. We also note that the single binomial probability (like the double binomial probability) is not an exchangeable measure in the sense that generally \(p({\mathbf {X}}\rightarrow A)\ne p(A\rightarrow {\mathbf {X}})\). The same holds for the corresponding z-score and J-measure. This can be counter-intuitive when the task is to search for statistical dependencies, and these measures should be used with care. In addition, with this binomial model the significance of the positive dependence between \({\mathbf {X}}\) and A is generally not the same as the significance of the negative dependence between \({\mathbf {X}}\) and \(\lnot A\). With the corresponding z-score the significance values are related, and
where \( z_{pos} \) denotes the z-score of positive dependence and \( z_{neg} \) the z-score of negative dependence. With the J-measure the significance of positive dependence between \({\mathbf {X}}\) and A and the significance of negative dependence between \({\mathbf {X}}\) and \(\lnot A\) are equal.
3.3.2 Complete evaluation under the classical sampling models
Let us now analyze the value-based significance of dependency rules using the classical statistical models. For simplicity we consider only positive dependence. We assume that the extremeness relation is defined by lift \({\varGamma }\) and frequency \(N_{X A}\), i.e., a contingency table is more extreme than the observed contingency table, if it has \({\varGamma }\ge \gamma ({\mathbf {X}},A)\) and \(N_{X A}\ge fr ({\mathbf {X}}A)\).
In the multinomial model only the data size \(N=n\) is fixed. Each contingency table, described by triplet \(\langle N_X, N_A, N_{X A}\rangle \), has probability \(P(N_{X A},N_{X}-N_{X A},N_A-N_{X A},n-N_X-N_A+N_{X A}\mid n,p_X,p_A)\), defined by Eq. (11). The p-value is obtained when we sum over all possible triplets where \({\varGamma }\ge \gamma ({\mathbf {X}},A)\):
where \(Q_1=\frac{nN_{X A}}{\gamma ({\mathbf {X}},A) N_X}\). (We note that the terms are zero, if \(N_X<N_{X A}\).)
In the double binomial model \(N_X= fr ({\mathbf {X}})\) is also fixed. Each contingency table, described by pair \(\langle N_A,N_{X A}\rangle \), has probability \(P(N_{X A},N_A-N_{X A}\mid n, fr ({\mathbf {X}}),p_A)\) by Eq. (12). Now we should sum over all possible pairs, where \({\varGamma }\ge \gamma ({\mathbf {X}},A)\):
where \(Q_2=\frac{nN_{X A}}{\gamma ({\mathbf {X}},A) fr ({\mathbf {X}})}\).
In the hypergeometric model also \(N_A= fr (A)\) is fixed. As noted before, the extremeness relation is now the same as in the variable-based case and the p-value is defined by Eq. (13). This is an important observation, because it means that Fisher’s exact test tests significance also in the value-based interpretation. The same is not true for the first two models, where rule \({\mathbf {X}}\rightarrow A\) can get a different p-value in variable-based and value-based interpretations.
3.3.3 Complete evaluation with a single binomial test
When \(N_X\) and/or \(N_A\) are unfixed the p-values are quite heavy to compute. Therefore, we will now introduce a simple binomial model (suggested by Hämäläinen (2010b) and as model 2 by Lallich et al. (2005)), where it is enough to sum over just one variable. The binomial probability can be further estimated by an equivalent z-score or the z-score can be used as an asymptotic test measure as such. Contrary to the previously described binomial test, this test performs a complete evaluation in the whole data set, which means that the p-values of different rules are comparable.
Let us suppose that we have an infinite basket of apples where the probability of red and sweet apples is \(p_{XA}\). According to the independence assumption \(p_{XA}=p_Xp_A\). A sample of n apples is taken randomly from the basket. The probability of obtaining \(N_{XA}\) sweet red apples among all n apples is defined by binomial probability
Since \(N_{X A}\) is the only variable which occurs in the probability, the extremeness relation is defined simply by \(\tau _i \succeq \tau _ o \Leftrightarrow N_{X A}\ge fr ({\mathbf {X}}A)\). When the unknown parameters \(p_X\) and \(p_A\) are estimated from the data, the p-value of rule \({\mathbf {X}}\rightarrow A\) becomes
Since \(N_{X A}\) is a binomial variable with expected value \({\hat{\mu }}=nP({\mathbf {X}})P(A)\) and standard deviation \({\hat{\sigma }}=\sqrt{nP({\mathbf {X}})P(A)(1-P({\mathbf {X}})P(A))}\), the corresponding z-score is
Because the discrete binomial distribution is approximated by the continuous normal distribution, the continuity correction can be useful, like with the \(\chi ^2\)-measure.
We note that this binomial probability and the corresponding z-score are exchangeable, which is intuitively a desired property. However, the statistical significance of positive dependence between \({\mathbf {X}}\) and A is generally not the same as the significance of negative dependence between \({\mathbf {X}}\) and \(\lnot A\). For example, the z-score for negative (or, equally, positive) dependence between \({\mathbf {X}}\) and \(\lnot A\) is
3.3.4 Selecting the right model
The main decision in the value-based interpretation is whether the significance of dependency rule \({\mathbf {X}}\rightarrow A\) is evaluated in the whole data or only in the part of data where \({\mathbf {X}}\) holds. This decision is critical, because partial and complete evaluators can disagree significantly in their ranking and selection of rules. This is demonstrated in the following example.
Example 3
Let us compare two rules, \({\mathbf {X}}\rightarrow A\) and \({\mathbf {Y}}\rightarrow A\), in the value-based interpretation. The frequencies are \(n=100\), \( fr (A)=50\), \( fr ({\mathbf {X}})= fr ({\mathbf {X}}A)=30\), \( fr ({\mathbf {Y}})=60\), and \( fr ({\mathbf {Y}}A)=50\), i.e., \(P(A|{\mathbf {X}})=1\) and \(P({\mathbf {Y}}|A)=1\). The p-values, z-scores, and J-values are given in Table 3.
All of the traditional association rule measures (binomial \( p_{bin2} \), Eq. (17), its z-score \(z_2\), and J-measure) favour rule \({\mathbf {X}}\rightarrow A\), while all the other measures (binomial \( p_{bin1} \), Eq. (21), its z-score \(z_1\), multinomial \( p_{mul} \), double binomial \( p_{double} \), and Fisher’s \(p_F\)) rank rule \({\mathbf {Y}}\rightarrow A\) better. In the three classical models, the difference between the rules is quite remarkable.
In general, we do not recommend partial evaluation for dependency rule mining. The main problem is that the p-values of discovered rules are not comparable, because each of them has been tested in a different part of data. In addition, the measures are not exchangeable, which means that \({\mathbf {X}}\rightarrow A\) can get a totally different ranking than \(A\rightarrow {\mathbf {X}}\), even if they express the same dependency between events.
When the classical statistical models are used, the only difference to the variable-based interpretation is that now the discrepancy measure is lift. Computationally, the only practical choices are the hypergeometric model and asymptotic measures. The hypergeometric model produces reliable results, but it tends to favour large leverage instead of lift, which might be more interesting in the value-based interpretation. In addition, one should check for each rule \({\mathbf {X}}\rightarrow A\) that the dependency is due to strong \(\gamma ({\mathbf {X}},A)\) and not due to \(\gamma (\lnot {\mathbf {X}},\lnot A)\). With this checking the \(\chi ^2\)-measure can also be used. According to our experiment (Hämäläinen 2010a, Ch.5), the \(\chi ^2\)-measure and the z-score (Eq. 22) tend to find rules with the strongest lift (among all compared measures), but at the same time the results are also the most unreliable. Robustness of the \(\chi ^2\)-measure can be improved with the continuity correction, but with the z-score it has only a marginal effect. One solution is to use the z-score only for preliminary pruning and select the rules with the corresponding binomial probability (Hämäläinen 2010b). Based on these considerations, we cannot give a universal recommendation, but Fisher’s exact test is always a safe choice, if there is no specific need to maximize lift. If large lift values are desired, one could consider either the \(\chi ^2\)-measure or the z-score accompanied by an exact binomial test.
4 Redundancy and significance of improvement
An important task in dependency rule discovery is to identify redundant rules, which add little or no additional information on statistical dependencies to other rules. In this section we consider an important type of redundancy called superfluousness, where a more specific dependency rule does not improve its generalization significantly. We present statistical significance tests for evaluating superfluousness in the value-based and variable-based interpretations. Finally, we will briefly discuss the relationship to a more general approach of speciousness testing.
4.1 Redundant and superfluous rules
According to a classical definition (Bastide et al. 2000) “An association rule is redundant if it conveys the same information or less general information than the information conveyed by another rule of the same usefulness and the same relevance.” However, what is considered useful or relevant depends on the modelling purpose, and numerous definitions of redundant or uninformative rules have been proposed.
In traditional association rule research, the goal has been to find all sufficiently frequent and ‘confident’ (high precision) rules. Thus, if the sufficient frequency or precision of a rule can be derived from other rules, the rule can be considered redundant (e.g., Aggarwal and Yu 2001; Goethals et al. 2005; Cheng et al. 2008; Li and Hamilton 2004; see also a good overview by Balcazar (2010)). On the other hand, when the goal is to find statistical dependency rules, then rules that are merely side-products of other dependencies can be considered uninformative. An important type of such dependencies are superfluous specializations (\({\mathbf {X}}\rightarrow A\)) of more general dependency rules (\({\mathbf {Y}}\rightarrow A\), \({\mathbf {Y}}{\subsetneq } {\mathbf {X}}\)). This concept of superfluous rules covers earlier notions of non-optimal or superfluous classification rules (Li 2006), (statistically) redundant rules (Hu and Rao 2007; Hämäläinen 2012) and unproductive rules (Webb 2007).
Superfluous rules are a common problem, because rules ‘inherit’ dependencies from their ancestor rules unless their extra factors reverse the dependency. This is regrettable, because undetected superfluous rules may lead to quite serious misconceptions. For example, if disease D is caused by gene group \({\mathbf {Y}}\) (i.e., \({\mathbf {Y}}\rightarrow D\)), we are likely to find a large number of other dependency rules \({\mathbf {Y}}{\mathbf {Q}}\rightarrow D\) where \({\mathbf {Q}}\) contains coincidental genes. Now one could make a conclusion that the combination \({\mathbf {Y}}{\mathbf {Q}}_1\) (with some arbitrary \({\mathbf {Q}}_1\)) predisposes to disease D and begin preventive care only with these patients.
Intuitively, the idea of superfluousness is clear. A superfluous rule \({\mathbf {X}}\rightarrow A\) contains extraneous variables \({\mathbf {Q}}{\subsetneq } {\mathbf {X}}\) which have no effect or only weaken the original dependency \({\mathbf {X}}{\setminus }{\mathbf {Q}}\rightarrow A\). It is also possible that \({\mathbf {Q}}\) apparently improves the dependency but the improvement is spurious (due to chance). In this case the apparent improvement occurs only in the sample, and it may be detected with appropriate statistical significance tests. We recall that significance tests do not necessarily detect all superfluous rules but we can always adjust the significance level to prune more or less potentially superfluous rules. Formalizing the idea of superfluousness is more difficult, because it depends on the used measure, assumed statistical model, required significance level, and—most of all—whether we are using the value-based or variable-based interpretation. Therefore, we give here only a tentative, generic definition of superfluousness.
Definition 7
(Superfluous dependency rules) Let \( T \) be a goodness measure which is used to evaluate dependency rules. Let us assume that \( T \) is increasing by goodness and rule \({\mathbf {X}}\rightarrow A\,{=}\,i\) improves \({\mathbf {Y}}\rightarrow A\,{=}\,i\), \(i\in \{0,1\}\), when \( T ({\mathbf {X}}\rightarrow A\,{=}\,i)> T ({\mathbf {Y}}\rightarrow A\,{=}\,i)\) (for decreasing measures, \( T ({\mathbf {X}}\rightarrow A\,{=}\,i)< T ({\mathbf {Y}}\rightarrow A\,{=}\,i)\)). Let \({\mathcal {M}}\) be a statistical model which is used for determining the statistical significance and \(\alpha \) the selected significance level.
Rule \({\mathbf {X}}\rightarrow A\,{=}\,i\) is superfluous (given \( T \), \({\mathcal {M}}\), and \(\alpha \)) if there exists rule \({\mathbf {Y}}\rightarrow A\,{=}\,i\), \({\mathbf {Y}}{\subsetneq }{\mathbf {X}}\), such that
-
(i)
\( T ({\mathbf {X}}\rightarrow A\,{=}\,i)\le T ({\mathbf {Y}}\rightarrow A\,{=}\,i)\) (vs. \( T ({\mathbf {X}}\rightarrow A\,{=}\,i)\ge T ({\mathbf {Y}}\rightarrow A\,{=}\,i)\)) or
-
(ii)
Improvement of rule \({\mathbf {X}}\rightarrow A\,{=}\,i\) over rule \({\mathbf {Y}}\rightarrow A\,{=}\,i\) is not significant at level \(\alpha \) (value-based interpretation) or
-
(iii)
Improvement of rule \({\mathbf {X}}\rightarrow A\,{=}\,i\) over rule \({\mathbf {Y}}\rightarrow A\,{=}\,i\) is less significant than the improvement of rule \(\lnot {\mathbf {X}}\rightarrow A{\ne }i\) over rule \(\lnot Y\rightarrow A{\ne }i\) (variable-based interpretation).
We note that in a special case where \(P({\mathbf {X}})=P({\mathbf {Y}})\), rules \({\mathbf {X}}\rightarrow A{=}i\) and \({\mathbf {Y}}\rightarrow A{=}i\), \({\mathbf {Y}}{\subsetneq }{\mathbf {X}}\), have equivalent contingency tables and they obtain the same measure value with all commonly used goodness measures (that are functions of \(N_X\), \(N_A\), \(N_{XA}\) and n). Otherwise, if \(P({\mathbf {X}})<P({\mathbf {Y}})\), the contingency tables are different and rule \({\mathbf {X}}\rightarrow A{=}i\) may or may not improve \({\mathbf {Y}}\rightarrow A{=}i\) depending on the observed counts and the selected goodness measure. The special case \({\mathbf {Y}}{\subsetneq } {\mathbf {X}}\), \(P({\mathbf {X}})=P({\mathbf {Y}})\), is closely connected to the notions of closed itemsets (\({\mathbf {X}}\) such that \(\forall {\mathbf {Z}}\supsetneq {\mathbf {X}}\): \(P({\mathbf {X}})>P({\mathbf {Z}})\)) and their minimal generators (\({\mathbf {Y}}{\subseteq } {\mathbf {X}}\) such that \(P({\mathbf {Y}})=P({\mathbf {X}})\) and \(\not \exists \mathbf {Y'}{\subsetneq } {\mathbf {Y}}\): \(P(\mathbf {Y'})=P({\mathbf {Y}})\)) (Pasquier et al. 1999; Bastide et al. 2000). If the rule antecedents \({\mathbf {X}}\) are selected only among closed sets, some of them may have distinct minimal generators \({\mathbf {Y}}{\subsetneq } {\mathbf {X}}\) and are necessarily superfluous. This is avoided, if the rule antecedents are selected only among minimal generators (also called free sets (Boulicaut et al. 2000)), but the rules may still be superfluous when tested against more general rules.
4.2 Testing superfluousness in the value-based interpretation
Let us first consider the problem of superfluousness in the value-based interpretation, where the significance tests are somewhat simpler. To simplify notations, we will consider only rule \({\mathbf {X}}\rightarrow A\) with a positive-valued consequent. For \({\mathbf {X}}\rightarrow \lnot A\) the tests are analogous, except A is replaced by \(\lnot A\).
In traditional association rule research, the goodness measure \( T \) is precision (or, equivalently, lift, because the antecedent is fixed). Rule \({\mathbf {X}}\rightarrow A\) is called productive, if \(P(A|{\mathbf {X}})>P(A|{\mathbf {Y}})\) for all \({\mathbf {Y}}{\subsetneq }{\mathbf {X}}\) (e.g., Bayardo et al. 2000; Webb 2007). The significance of productivity is tested separately for all \({\mathbf {Y}}\rightarrow A\), \({\mathbf {Y}}{\subsetneq }{\mathbf {X}}\), and all p-values should be below some fixed threshold \(\alpha \).
Let us now notate \({\mathbf {X}}{=}{\mathbf {Y}}{\mathbf {Q}}\) (i.e., \({\mathbf {Q}}={\mathbf {X}}{\setminus } {\mathbf {Y}}\), \({\mathbf {Q}}\ne \emptyset \)) so that we can compare rule \({\mathbf {Y}}{\mathbf {Q}}\rightarrow A\) to a simpler rule \({\mathbf {Y}}\rightarrow A\). In each test, the null hypothesis is that there is no improvement in the precision: \(P(A|{\mathbf {Y}}{\mathbf {Q}})=P(A|{\mathbf {Y}})\). The condition means that \({\mathbf {Q}}\) and A are conditionally independent given \({\mathbf {Y}}\). The significance is estimated by calculating \(p({\mathbf {Q}}\rightarrow A|{\mathbf {Y}})\), i.e., the p-value of rule \({\mathbf {Q}}\rightarrow A\) in the set where \({\mathbf {Y}}\) holds. Now it is quite natural to assume \( fr ({\mathbf {Y}})\), \( fr ({\mathbf {Y}}{\mathbf {Q}})\), and \( fr ({\mathbf {Y}}A)\) fixed, which leads to the hypergeometric model. The corresponding test is Fisher’s exact test for conditional independence, and the significance of productivity of \({\mathbf {Y}}{\mathbf {Q}}\rightarrow A\) over \({\mathbf {Y}}\rightarrow A\) is (Webb 2007)
where \(J_1=\min \{ fr ({\mathbf {Y}}{\mathbf {Q}}\lnot A), fr ({\mathbf {Y}}\lnot {\mathbf {Q}}A)\}\). When the \(\chi ^2\)-measure is used to estimate the significance of productivity, the equation is (Liu et al. 1999)
In principle, measure \( T \) can be any goodness measure for statistical dependence between values, including the previously introduced binomial probabilities and corresponding z-scores. However, different measures can disagree on their ranking of rules and which rules are considered superfluous. For example, leverage has a strong bias in favour of general rules, when compared to lift or precision. This is clearly seen from expression \(\delta ({\mathbf {Y}},A)=P({\mathbf {Y}})(P(A|{\mathbf {Y}})-P(A))=P({\mathbf {Y}})(\gamma ({\mathbf {Y}},A)-1)\). On the other hand, asymptotic measures like the z-score and the \(\chi ^2\)-measure tend to overestimate the significance, when the frequencies are small. Therefore, it is possible that a rule is not superfluous, when evaluated with an asymptotic measure, but superfluous, when the exact p-values are calculated.
4.3 Testing superfluousness in the variable-based interpretation
In the variable-based interpretation, superfluousness of dependency rules is more difficult to judge, because there may be two kinds of improvement into opposite directions in the same time. Improvement of rule \({\mathbf {Y}}{\mathbf {Q}}\rightarrow A\) over rule \({\mathbf {Y}}\rightarrow A\) is tested as in the value-based interpretation. However, in the same time rule \(\lnot {\mathbf {Y}}\rightarrow \lnot A\) may improve a more general rule \(\lnot ({\mathbf {Y}}{\mathbf {Q}})\rightarrow \lnot A\), and one should weigh which improvement is more significant.
The significance of improvement of rule \(\lnot {\mathbf {Y}}\rightarrow \lnot A\) over \(\lnot ({\mathbf {Y}}{\mathbf {Q}})\rightarrow \lnot A\) is tested in the same way as productivity of \({\mathbf {Y}}{\mathbf {Q}}\rightarrow A\) over \({\mathbf {Y}}\rightarrow A\). However, now the null hypothesis is conditional independence between \(\lnot {\mathbf {Y}}\) and \(\lnot A\) given \(\lnot ({\mathbf {Y}}{\mathbf {Q}})=\lnot {\mathbf {Y}}\vee {\mathbf {Y}}\lnot {\mathbf {Q}}\). It is natural to assume \( fr (\lnot ({\mathbf {Y}}{\mathbf {Q}}))\), \( fr (\lnot {\mathbf {Y}})\), and \( fr (\lnot ({\mathbf {Y}}{\mathbf {Q}})\lnot A)\) fixed, which leads to an exact test
where \(J_2=\min \{ fr (\lnot {\mathbf {Y}}A), fr ({\mathbf {Y}}\lnot {\mathbf {Q}}\lnot A)\}\). The corresponding \(\chi ^2\)-test is
An important property of variable-based superfluousness testing is that sometimes significance tests can be avoided altogether. This is possible with such goodness measures, for which any improvement is significant improvement. One such measure is \(p_0\), the first and largest term of \(p_F\). It can be shown (Hämäläinen and Webb 2017) that for dependency rules \({\mathbf {Y}}\rightarrow A\) and \({\mathbf {Y}}{\mathbf {Q}}\rightarrow A\) holds
It is an open problem whether the equality holds exactly for the cumulative probability, \(p_F\), but at least it holds approximately. This is also the justification for the simpler superfluousness testing in Kingfisher (Hämäläinen 2012), where a dependency rule is considered superfluous if it has a larger (poorer) \(p_F\)-value than some of its ancestor rules.
Previously, we have already shown that goodness measures for the variable-based and value-based interpretations can diverge quite much in their ranking of rules. The same holds for superfluousness testing. The following example demonstrates that the same rule may or may not be superfluous depending on the interpretation.
Example 4
Let us reconsider the rules \({\mathbf {X}}\rightarrow A\, (={\mathbf {Y}}{\mathbf {Q}}\rightarrow A\)) and \({\mathbf {Y}}\rightarrow A\) in Example 3. Rule \({\mathbf {X}}\rightarrow A\) is clearly productive with respect to \({\mathbf {Y}}\rightarrow A\) (\(P(A|{\mathbf {Y}})=1.00\) vs. \(P(A|{\mathbf {X}})=0.83\)). Similarly, rule \(\lnot {\mathbf {Y}}\rightarrow \lnot A\) is productive with respect to \(\lnot {\mathbf {X}}\rightarrow \lnot A\) (\(P(\lnot A|\lnot {\mathbf {Y}})=1.00\) vs. \(P(\lnot A|\lnot {\mathbf {X}})=0.71\)).
Let us now calculate the significance of productivity using Fisher’s exact test. In the value-based interpretation, we evaluate only the first improvement:
The value is so small that we can assume that the productivity is significant and \({\mathbf {X}}\rightarrow A\) is not superfluous.
In the variable-based interpretation, we evaluate also the second improvement:
This value is much smaller than the previous one, which means that the improvement of \(\lnot {\mathbf {Y}}\rightarrow \lnot A\) over \(\lnot {\mathbf {X}}\rightarrow \lnot A\) is more significant than the improvement of \({\mathbf {X}}\rightarrow A\) over \({\mathbf {Y}}\rightarrow A\). Thus, we would consider rule \({\mathbf {X}}\rightarrow A\) superfluous. We would have ended up into the same conclusion, if we had simply compared the \(p_F\)-values of both rules: \(p_F({\mathbf {Y}}\rightarrow A)=7.47\cdot 10^{-19}<1.60\cdot 10^{-12}=p_F({\mathbf {X}}\rightarrow A)\).
4.4 Relationship to speciousness
The concept of superfluousness is closely related to speciousness (Yule 1903; Hämäläinen and Webb 2017), where an observed unconditional dependency vanishes or changes its sign when conditioned on other variables, called confounding factors. The latter phenomenon, reversal of the direction of the dependency, is also known as Yule-Simpson’s paradox. In the context of dependency rules, rule \({\mathbf {X}}\rightarrow A\) is considered specious if there is another rule \({\mathbf {Y}}\rightarrow A\) or \({\mathbf {Y}}\rightarrow \lnot A\) such that \({\mathbf {X}}\) and A are either independent or negatively dependent in the population when conditioned on \({\mathbf {Y}}\) and \(\lnot {\mathbf {Y}}\). In the sample either of the conditional dependencies may also appear as weakly positive, and one has to test their significance with a suitable test, like Birch’s exact test (Birch 1964), conditional mutual information (Hämäläinen and Webb 2017) or various \(\chi ^2\)-based tests.
It is noteworthy that the confounding factor \({\mathbf {Y}}\) does not necessarily share any attributes with \({\mathbf {X}}\). However, in a special case when \({\mathbf {Y}}\,{\subsetneq }\,{\mathbf {X}}\), Birch’s exact test for speciousness of \({\mathbf {X}}\rightarrow A\) with respect to \({\mathbf {Y}}\rightarrow A\) reduces to Eq. (23) (significance of productivity). On the other hand, Birch’s exact test for speciousness of \({\mathbf {Y}}\rightarrow A\) with respect to \({\mathbf {X}}\rightarrow A\) is equivalent to Eq. (25). So, testing superfluousness of \({\mathbf {X}}\rightarrow A\) with respect to \({\mathbf {Y}}\rightarrow A\) in a variable-based interpretation can be considered as a special case of testing if \({\mathbf {X}}\rightarrow A\) is specious by \({\mathbf {Y}}\rightarrow A\) or vice versa.
5 Dependency sets
Dependency rules capture the most common conception of dependence as a relationship between two elements. Often, however, multiple elements will all interact with each other, and the mutual dependency structure is better represented by set-type of patterns. Dependency sets are a general name for set-type patterns that express interdependence between the elements of the set. In this section we will first give a short overview of set dependency patterns and then describe key approaches for evaluating their statistical significance.
5.1 Overview
Approaches to finding dependency sets differ in terms of the forms of interdependence that they seek to capture. A common starting point is to assume mutual dependence among the elements of the set, i.e., absence of mutual independence (Definition 3). However, this notion is very inclusive because it suffices that \({\mathbf {X}}\) contains at least one subset \({\mathbf {Y}}{\subseteq }{\mathbf {X}}\) where \(P({\mathbf {Y}})\ne \prod _{A_i\in {\mathbf {Y}}}P(A_i)\). This means that the property of mutual dependence is monotonic, i.e., all supersets of a mutually dependent set are also mutually dependent. To avoid an excessive number of patterns, dependency sets usually represent only some of all mutually dependent sets, like minimal mutually dependent sets (Brin et al. 1997), sets that present new dependencies in comparison to their subsets (for some \(A\in {\mathbf {X}}\), \(\delta ({\mathbf {X}}{\setminus } \{A\},A)\ne 0\)) (Meo 2000), or sets for which all bipartitions express statistical dependence (for all \({\mathbf {Y}}{\subsetneq }{\mathbf {X}}\)\(\delta ({\mathbf {Y}},{\mathbf {X}}{\setminus } {\mathbf {Y}})\ne 0\)) (Webb 2010). We note that the latter two approaches assume bipartition dependence (absence of bipartition independence, Definition 4), which is a stronger condition than mutual dependence.
Compared to dependency rules, dependency sets offer a more compact presentation of dependencies, and in some contexts the reduction in the number of patterns can be quite drastic. This is evident when we recall that any set \({\mathbf {X}}\) can give rise up to \(|{\mathbf {X}}|\) rules of the form \({\mathbf {X}}{\setminus }\{A_i\}\rightarrow A_i\) and up to \(2^{|{\mathbf {X}}|}-2\) rules of the form \({\mathbf {X}}{\setminus } {\mathbf {Y}}\rightarrow {\mathbf {Y}}\). In many cases these permutation rules reflect the same statistical dependency. This is always true when \(|{\mathbf {X}}|=2\) (\(A\rightarrow B\) and \(B\rightarrow A\) present the same dependency), but the same phenomenon can occur also with more complex sets as the following observation demonstrates.
Observation 1
Let \({\mathbf {X}}\) be a set of binary attributes such that for all \({\mathbf {Y}}\,{\subsetneq }\, {\mathbf {X}}\)\(P({\mathbf {Y}})=\prod _{A_i\in {\mathbf {Y}}}P(A_i)\) (i.e., attributes are mutually independent). Then for all \({\mathbf {Z}}{\subsetneq } {\mathbf {X}}\)\(\delta ({\mathbf {X}}{\setminus } {\mathbf {Z}},{\mathbf {Z}})=P({\mathbf {X}})-\prod _{A_i\in {\mathbf {X}}{\setminus } {\mathbf {Z}}}P(A_i)\prod _{A_i\in {\mathbf {Z}}}P(A_i)=P({\mathbf {X}})-\prod _{A_i\in {\mathbf {X}}}P(A_i)\).
This means that when all proper subsets of \({\mathbf {X}}\) express only mutual independence, then all permutation rules of \({\mathbf {X}}{\setminus } {\mathbf {Z}}\rightarrow {\mathbf {Z}}\) have the same leverage, frequency and expected frequency, and many goodness measures would rank them equally good. In real world data, the condition holds seldom precisely, but the same phenomenon tends to occur to some extent also when all subsets express at most weak dependence. In this case, it is intuitive to report only set \({\mathbf {X}}\) instead of listing all of its permutation rules.
In principle, all dependency rules could be represented by dependency sets without losing any other information than the division to an antecedent and a consequent. The reason is that for any dependency rule \({\mathbf {X}}{\setminus } {\mathbf {Y}}\rightarrow {\mathbf {Y}}\), set \({\mathbf {X}}\) is mutually dependent. This follows immediately from the fact that mutual independence of \({\mathbf {X}}\) (Definition 3) implies bipartition independence between \({\mathbf {X}}{\setminus } {\mathbf {Y}}\) and \({\mathbf {Y}}\) (Definition 4) for any \({\mathbf {Y}}{\subsetneq }{\mathbf {X}}\). However, as explained below, some set dependency approaches have more stringent constraints which may exclude interesting dependency rules selected under other schemes. Further, if mutual independence is violated only by a single bipartition, or if the objective is to find dependencies with a specific element of interest, a dependency rule between the relevant partitions will more concisely convey the relevant information. Which dependency rule or set scheme is most appropriate depends entirely on the analytic objective.
The approaches for finding statistically significant dependency sets can be roughly divided into two categories: (i) selecting dependency sets among frequent item sets and testing their statistical significance afterwards and (ii) searching directly all sufficiently strong and significant dependency sets using appropriate goodness measures and significance tests. In the following subsections we describe the main methods for evaluating statistical significance in these approaches.
5.2 Statistically significant dependency sets derived from candidate frequent itemsets
Frequent itemsets (Agrawal et al. 1996) are undoubtedly the most popular type of set patterns in knowledge discovery. A frequent itemset is a set of true-valued binary attributes (called items, according to the original market-basket setting) whose frequency exceeds some user-specified minimum frequency threshold (‘minimum support’). However, being frequent does not ensure that the elements in an itemset express statistical dependence. For example, consider two elements A and B that each occur in all but one example such that the examples in which A and B do not occur differ. In this case itemset \(\{A,B\}\) will occur in all but two examples and thus be frequent, but it will represent negative dependence rather than positive dependence such as association discovery typically seeks.
Frequent itemsets have been employed as an initial step in dependency set discovery in order to constrain the number of patterns that must be considered. The idea is to search first all frequent itemsets and then select statistically significant dependency set patterns among them. A limitation is that this approach will fail to discover statistically significant but infrequent dependency sets, which can be the most significant.
The most common null hypothesis used for significance testing of dependency sets is mutual independence between all attributes of the data (Definition 3). Statistical significance of a set is defined as the probability that its frequency is at least as large as observed, given the mutual independence assumption. In principle, any significance testing approach could be used, but often this is done with randomization testing. In swap randomization (e.g., Gionis et al. 2007; Cobb and Chen 2003), both column margins (attribute frequencies) and row margins (numbers of items on each row) are kept fixed. The latter requirement allows suppression of dependencies that are due to co-occurrence of items only due to their appearing solely in rows that contain many items. A variant is iterative randomization (Hanhijärvi et al. 2009). This approach begins with fixed row and column margins, but on each iteration it adds the most significant frequent itemset as a new constraint. The randomization problem is computationally very hard, and thus it is sufficient that the frequencies of itemsets hold only approximately. The process is repeated until no more significant itemsets can be found.
Vreeken and Tatti (2014) have proposed identifying statistically significant dependency sets \({\mathbf {X}}\) using the binomial test for the null hypothesis of independence of events \(A_i\,{\in }\,{\mathbf {X}}\) (Eq. 7). Under the independence assumption, the probability of \({\mathbf {X}}\) in the population is \(p_X=\prod _{A_i\in {\mathbf {X}}}p_{A_i}\), where \(p_{A_i}\)s can be estimated by observed \(P(A_i)\)s as usual. Then the probability of observing \(N_X\ge fr ({\mathbf {X}})\) in a sample of n rows is
We note that this test assumes a weaker notion of independence than mutual independence (Definition 3). In consequence, it may find fewer dependency patterns than the previously described randomization test for mutual independence.
5.3 Direct search for significant dependency sets
An alternative approach is to search directly for sets that satisfy specific criteria of statistical dependence and significance, using those criteria to prune the search space and support efficient search. Sometimes, these set patterns are still called ‘rules’ or are represented by the best rule that can be derived from the set. Examples are correlation rules (Brin et al. 1997), strictly non-redundant association rules (Hämäläinen 2010b, 2011), and—the most rigorous of all—self-sufficient itemsets (Webb 2010; Webb and Vreeken 2014). All these pattern types have three common requirements: dependency set \({\mathbf {X}}\) expresses mutual dependence, it adds new dependencies to its subsets \({\mathbf {Y}}{\subsetneq } {\mathbf {X}}\), and the dependency is significant with the selected measure.
Correlation rules (Brin et al. 1997) are defined as minimal sets \({\mathbf {X}}\), where \({\mathbf {X}}\) expresses mutual dependence (at least for some \({\mathbf {x}}\in Dom ({\mathbf {X}})\)\(P({\mathbf {X}}{=}{\mathbf {x}})\) is greater than expected under independence) but all \({\mathbf {Y}}{\subsetneq }{\mathbf {X}}\) express mutual independence. The significance is evaluated with the \(\chi ^2\)-measure
with one degree of freedom. Since all supersets of \({\mathbf {X}}\) can only increase the \(\chi ^2\)-value, only minimal sets whose \(\chi ^2\)-value exceeds a specified threshold are presented.
Strictly non-redundant association rules are an intermediate form between set type and rule type patterns, where each set is presented by its best rule, whose significance is evaluated in the desired sampling model. The discovered patterns are mutually dependent sets \({\mathbf {X}}\) that express bipartition dependence between some \(A\in {\mathbf {X}}\) and \({\mathbf {X}}{\setminus } \{A\}\) and the bipartition dependence is more significant than any bipartition dependence in simpler sets \({\mathbf {Y}}{\subsetneq }{\mathbf {X}}\) (between any \(B\in {\mathbf {Y}}\) and \({\mathbf {Y}}{\setminus } \{B\}\)). In the significance testing, one can assume either value- or variable-based interpretation and use any of the sampling models presented in Sect. 3. For search purposes, feasible choices are the binomial model and the corresponding z-score (Hämäläinen 2010b) for the value-based interpretation, the double binomial test and the corresponding \(\chi ^2\)-measure (Hämäläinen 2011) for the variable-based interpretation, and Fisher’s exact test that can be used in both interpretations.
Self-sufficient itemsets are a pattern type that imposes much stronger requirements. The core idea is that an itemset should only be considered interesting if its frequency cannot be explained by assuming independence between any partition of the items. That is, there should be no partition \({\mathbf {Q}}{\subsetneq }{\mathbf {X}}, {\mathbf {X}}{\setminus }{\mathbf {Q}}\) such that \(P({\mathbf {X}})\approx P({\mathbf {Q}})P({\mathbf {X}}\backslash {\mathbf {Q}})\). For example, being male (M) and having prostate cancer (P) are associated and hence should form a dependency set \(\{M,P\}\). Suppose that having a name containing a ‘G’ (G) is independent of both factors. Then \(\{M,P,G\}\) should not be a dependency set. However, it is more frequent than would be expected by assuming independence between \(\{M\}\) and \(\{P,G\}\) or between \(\{M,G\}\) and \(\{P\}\), and hence most interestingness measures would assess both \(\{P,G\}\rightarrow \{M\}\) and \(\{M,G\}\rightarrow \{P\}\) as interesting. Nonetheless, under the self-sufficient itemset approach \(\{M,P,G\}\) can be discarded because it is not more frequent than would be expected by assuming independence between \(\{G\}\) and \(\{M,P\}\).
In self-sufficient itemsets this requirement is formalized as a test for productivity. It is required that there is a significant positive dependency between every partition of the itemset, when evaluated with Fisher’s exact test. In addition, self-sufficient itemsets have two additional criteria: they have to be non-redundant and independently productive.
In the context of self-sufficient itemsets, set \({\mathbf {X}}\) is considered redundant, if
The motivation is that if A is a necessary consequent of another set of items \({\mathbf {Z}}\), then \({\mathbf {Y}}=\{A\} \cup {\mathbf {Z}}\) should be associated with everything with which \({\mathbf {Z}}\) is associated. For example \({\mathbf {Z}}= \{pregnant\}\) entails \(A= female \) (\({\mathbf {Y}}= \{female, pregnant\}\)) and pregnant is associated with oedema. In consequence, \({\mathbf {X}}= \{female, pregnant, oedema\}\) is not likely to be interesting if \(\{ pregnant , oedema \}\) is known.
A final form of test that can be employed is whether the frequency of an itemset \({\mathbf {X}}\) can be explained by the frequency of its productive and nonredundant supersets \({\mathbf {Y}}{\supsetneq }{\mathbf {X}}\). For example, if A, B and C are jointly necessary and sufficient for D then all subsets of \(\{A, B, C,D\}\) that include D should be productive and nonredundant. However, they may be misleading, as they fail to capture the full conditions necessary for D. Webb (2008) proposes that if \({\mathbf {Y}}{\supsetneq }{\mathbf {X}}\) is productive and nonredundant, \({\mathbf {X}}\) should only be considered potentially interesting if it is independently productive, meaning that it passes tests for productivity when data covered by \({\mathbf {Y}}{\setminus }{\mathbf {X}}\) are not considered.
6 Multiple testing problem
The goal of pattern discovery is to find all sufficiently good patterns among exponentially many possible candidates. This leads inexorably to the problem of multiple hypothesis testing. The core of this problem is that as the number of tested patterns increases, it becomes ever more likely that spurious patterns pass their tests, causing type I error.
In this section, we will first describe the main principles and popular correction methods that the statistical community has developed to remedy the problem. Such understanding is critical to addressing this issue in the pattern discovery context. We then introduce some special techniques for increasing the power to detect true patterns while controlling the number of false discoveries in the pattern discovery context.
6.1 Overview
The problem of multiple testing is easiest to demonstrate in the classical Neyman–Pearsonian hypothesis testing. Let us suppose we are testing m true null hypotheses (spurious patterns) and in each test the probability of type I error is exactly the selected significance level \(\alpha \). (In general, the probability is at most \(\alpha \), but with increasing power it approaches \(\alpha \).) In this case the expectation is that in every \(m\cdot \alpha \) tests a type I error is committed and a spurious pattern passes the test. With normal significance levels this can be quite a considerable number. For example if \(\alpha =0.05\) and 100,000 spurious patterns are tested, we can expect 5000 of them to pass the test.
Solutions to the multiple testing problem try to control type I errors among all tests. In practice, there are two main approaches: The traditional approach is to control the familywise error rate which is the probability of accepting at least one false discovery (rejecting a true null hypothesis). Using the notations of Fig. 7 the familywise error rate is \(FWER=P(V\ge 1)\). Another, less stringent approach is to control the false discovery rate, which is the expected proportion of false discoveries, \(FDR=E\left( \frac{V}{\max \{R,1\}}\right) =E\left( \frac{V}{R}\mid R>0\right) P(R>0)\).

A contingency table for m significance tests. Here \(m_0\) is an unknown parameter for the number of true null hypotheses and R is an observable random variable for the number of rejected hypotheses. S, T, U, and V are unobservable random variables
Since \(FDR\le FWER\), control of FWER subsumes control of FDR. In a special case where all null hypotheses are true (\(m{=}m_0\)), \(FWER=FDR\). The latter means that a FDR controlling method controls FWER in a weak sense, when the probability of type I errors is evaluated under the global null hypothesis\(H_0^C=\cap _{i=1}^m H_i\) (all m hypotheses are true). However, usually it is required that FWER should be controlled in a strong sense, under any set of true null hypotheses (for details, see e.g., Ge et al. 2003).
In general, FWER control is preferred when false discoveries are intolerable (e.g., accepting a new medical treatment) or when it is expected that most null hypotheses would be true, while FDR control is often preferred in exploratory research, where the number of potential patterns is large and false discoveries are less serious (e.g., Goeman and Solari 2011).
6.2 Methods for multiple hypothesis testing
The general idea of multiple hypothesis testing methods is to make rejection of individual hypotheses more difficult by adjusting the significance level \(\alpha \) (or the corresponding critical value of some test statistic) or, equivalently, adjusting individual p-values, \(p_1,\ldots , p_m\), corresponding to hypotheses \(H_1,\ldots ,H_m\). When the goal is to control FWER at level \(\alpha \), the procedure determines for each hypothesis \(H_i\) an adjusted significance level \({\hat{\alpha }}_i\) (possibly \({\hat{\alpha }}_1=\ldots ={\hat{\alpha }}_m\)) such that \(H_i\) is rejected if and only if \(p_i\le {\hat{\alpha }}_i\). Alternatively, the p-value of \(H_i\) can be adjusted and the adjusted p-value \({\hat{p}}_i\) is compared to the original significance level \(\alpha \). Now FWER can be expressed as
where K is the set of indices of true null hypotheses and \(P_i\) and \({\hat{P}}_i\) denote random variables for the original and adjusted p-values.
The correction procedures are designed such that \(FWER\le \alpha \) holds at least asymptotically, when the underlying assumptions are met. In addition, it is usually required that the adjusted p-values have the same order as the original p-values, i.e., \(p_i\le p_j \Leftrightarrow {\hat{p}}_i\le {\hat{p}}_j\). This ‘monotonicity of p-values’ is by no means necessary for FWER control, but it is in line with the statistical intuition according to which a pattern should not be declared significant if a more significant pattern (with smaller p) is declared spurious (Westfall and Young 1993, p. 65). Reporting adjusted p-values (together with original unadjusted p-values) is often recommended, since they are more informative than binary rejection decisions. However, individual p-values cannot be interpreted separately because \({\hat{p}}_i\) is the smallest \(\alpha \)-level of the entire test procedure that rejects \(H_i\) given p-values or tests statistics of all hypotheses (Ge et al. 2003).
Famous multiple testing procedures and their assumptions are listed in Table 4. Bonferroni and Šídák corrections as well as the single-step minP method are examples of single-step methods, where the same adjusted significance level is applied to all hypotheses. All the other methods in the table are step-wise methods that determine individual significance levels for each hypothesis, depending on the order of p-values and rejection of other hypotheses. Step-wise methods can be further divided into step-down methods (Holm–Bonferroni method and the step-down minP method by Westfall and Young (1993)) that process hypotheses in the ascending order by their p-values and step-up methods (Hochberg, Benjamini–Hochberg and Benjamini–Hochberg–Yekutieli methods) that proceed in the opposite order. In general, single-step methods are least powerful and step-up methods most powerful, with the exception of the powerful minP methods.
Powerful methods are always preferable since they can detect most true patterns, but the selection of the method depends on also other factors like availability of all p-values during evaluation, the expected proportion of true patterns (false null hypotheses), seriousness of false discoveries, and assumptions on the dependency structure between hypotheses. In the following we will briefly discuss these issues. For more details, we refer the interested reader to e.g., (Goeman and Solari 2014; Ge et al. 2003).
The least powerful method for controlling FWER is the popular Bonferroni correction. The lack of power is due to two pessimistic assumptions: \(m_0\) is estimated by its upperbound m and the probability of type I error by upperbound \(P((P_1\le \frac{\alpha }{m})\vee \ldots \vee (P_m\le \frac{\alpha }{m}))\le \sum _{i=1}^mP(P_i\le \frac{\alpha }{m})\) (Boole’s or Bonferroni’s inequality). Therefore, the Bonferroni correction is least powerful when many null hypotheses are false or the hypotheses are positively associated. The Šídák correction (Šídák 1967) is slightly more powerful, because it assumes independence of true null hypotheses and can thus use a lower upperbound for the probability of type I error. However, the method gives exact control of FWER only under the independence assumption. The control is not guaranteed if the true hypotheses are negatively dependent and the method may be overly conservative if they are positively dependent. The Bonferroni and Šídák corrections are attractive for pattern discovery where the size of the space of alternatives can be predetermined, because they impose minimal computational burden requiring simply that the value of \(\alpha \) be appropriately decreased.
The Holm–Bonferroni method (Holm 1979) is a sequential variant of the Bonferroni method. It proceeds in a step-wise manner, by comparing the smallest p-value to \(\frac{\alpha }{m}\) like the Bonferroni method, but the largest to \(\alpha \). Therefore, it rejects always at least as many null hypotheses as the Bonferroni method and the gain in power is greatest when most null hypotheses are false. The Hochberg method (Hochberg 1988) can be considered as a step-up variant of the Holm–Bonferroni method. It is a more powerful method especially if there are many false null hypotheses or the p-values of false null hypotheses are positively associated. However, it has extra requirements for the dependency structure among hypotheses. Sufficient conditions for the Hochberg method (and the underlying Simes inequality) are independence and certain types of positive dependence (e.g., positive regression dependence on a subset (Benjamini and Yekutieli 2001)) between true hypotheses. Šídák’s method can also be implemented in a similar step-wise manner by using criterion \(p_i>1-(1-\alpha )^{1/(m-i+1)}\) in the Holm–Bonferroni method. However, the resulting Holm-Šídák method assumes also independence of hypotheses.
The Benjamini–Hochberg method (Benjamini and Hochberg 1995) and the Benjamini–Hochberg–Yekutieli method (Benjamini and Yekutieli 2001) are also step-up methods, but they control FDR instead of FWER. The Benjamini–Hochberg method is always at least as powerful as the Hochberg method, and the difference is most pronounced when there are many false null hypotheses. The Benjamini–Hochberg method is also based on the Simes inequality and has the same requirements for the dependency structure between true hypotheses (independence or certain types of positive dependence). The Benjamini–Hochberg–Yekutieli method allows also negative dependencies, but it is less powerful and may sometimes be even more conservative than the Holm–Bonferroni method (Goeman and Solari 2014).
These step-wise approaches are problematic in pattern discovery unless statistical testing is applied as a postprocessing step. This is because they require all null hypotheses to be sorted on p-value which implies that all p-values must be known before the corrections are applied. However, step-wise methods are easily applied in multi-stage procedures (e.g., Webb 2007; Komiyama et al. 2017) that first select constrained sets of candidate patterns which are then subsequently subjected to statistical testing.
The minP methods (Westfall and Young 1993) present a different approach to multiple hypothesis testing. These methods are usually implemented with permutation testing or other resampling methods, and thus they adapt to any dependency structure between null hypotheses. This makes them powerful methods and they have been shown to be asymptotically optimal for a broad class of testing problems (Meinshausen et al. 2011).
The minP methods are based on an alternative expression of FWER (Eq. 30): \(FWER=P(\cup _{i\in K} \{P_i\le {\hat{\alpha }}\}\mid H_K)=P(\min _{i\in K} \{P_i\le {\hat{\alpha }}\}\mid H_K)\), where \(H_K\) is an intersection of all true hypotheses and \({\hat{\alpha }}\) is an adjusted significance level. Therefore, an optimal \({\hat{\alpha }}\) can be determined as an \(\alpha \)-quantile from the distribution of the minimum p-value among the true null hypotheses, i.e.,
In principle, any technique for estimating the \(\alpha \)-quantile can be used, but analytical methods are seldom available. However, the evaluation can be done also empirically, with resampling methods.
For strong control of FWER the probability should be evaluated under \(H_K\), which is unknown. Therefore, the estimation is done under the complete null hypotheses \(H_0^C\). Strong control (at least partial strong control (Rempala and Yang 2013)) can still be obtained under certain extra conditions. One such condition is subset pivotality (Westfall and Young 1993, p. 42) that requires the raw p-values (or other test statistics) of true null hypotheses to have the same joint distribution under \(H_0^C\) and any other set of hypotheses. Since the true null hypotheses are unknown, the minimum p-value is determined among all null hypotheses (the single-step method) or among all unrejected null hypotheses (the step-down method). The resulting single-step adjustment is \({\hat{p}}_i=P(\min \limits _{1\le j\le m}P_j\le p_i\mid H_0^C)\). A similar adjustment can be done with other test statistics \( T \), if subset pivotality or other required conditions hold. Assuming that high \( T \)-values are more significant, the adjusted p-value is \({\hat{p}}_i=P(\max \limits _{1\le j\le m} T _j\le t_i\mid H_0^C)\), where \( T _i\) is a random variable for the test statistic of \(H_i\) and \( t _i\) is its observed value. The probability under \(H_0^C\) can be estimated with permutation testing, by permuting the data under \(H_0^C\) and calculating the proportion of permuted data sets where \(\min P\) or \(\max T \)-value is at least as extreme as the observed \(p_i\) or \(t_i\). In pattern discovery complete permutation testing is often infeasible, but there are more efficient approaches combining the minP correction with approximate permutation testing (e.g., Hanhijärvi 2011; Minato et al. 2014; Llinares López et al. 2015). However, the time and space requirements may still be too large for many practical pattern mining purposes.
6.3 Increasing power in pattern discovery
In pattern discovery the main problem of multiple hypothesis testing is the huge number of possible hypotheses. This number is the same as the number of all possible patterns or the size of the search space that is usually exponential. If correction is done with respect to all possible patterns, the adjusted critical values may become so small that few patterns can be declared as significant. This means that one should always use as powerful correction methods as possible or control FDR instead of FWER when applicable, but this may still be insufficient. A complementary strategy is to reduce the number of hypotheses or otherwise target more power to those hypotheses that are likely to be interesting or significant. In the following we describe three general techniques designed for this purpose: hold-out evaluation, filtering hypotheses and weighted hypothesis testing.
The idea of hold-out evaluation (Webb 2007) (also known as two-stage testing, e.g., (Miller et al. 2001)) is to use only a part of the data for pattern discovery and save the rest for testing significance of patterns. The method consists of three steps:
-
(i)
Divide the data into an exploratory set \({\mathcal {D}}_E\) and a hold-out set \({\mathcal {D}}_H\).
-
(ii)
Search for patterns in \({\mathcal {D}}_E\) and select K patterns for testing. Note that the selection process at this step can use any principle suited to the application and need not involve hypothesis testing.
-
(iii)
Test the significance of the K patterns in \({\mathcal {D}}_H\) using any multiple hypothesis testing procedure.
Now the number of hypotheses is only K which is typically much less than the size of the search space. This makes the method powerful, even if the p-values in the hold-out set are likely larger than they would have been in the whole data set. The power can be further enhanced by selecting powerful multiple testing methods, including methods that control FDR. A potential problem of hold-out evaluation is that the results may depend on how the data is partitioned. In a pathological case a pattern may occur only in the exploratory set or only in the hold-out set and thus remain undiscovered (Liu et al. 2011).
Another approach is to use filtering methods (see e.g., Bourgon et al. 2010) to select only promising hypotheses for significance testing. Ideally, the filter should prune out only true null hypotheses without compromising control of false discoveries. In practice, the true nulls are unknown and the filter uses some data characteristics to detect low power hypotheses that are unlikely to become rejected. Unfortunately, some filtering methods affect also the distribution of the test statistic and can violate strong control of FWER. As a solution it has been suggested that the filtering statistic and the actual test statistic should be independent given a true null hypothesis (Bourgon et al. 2010).
In pattern discovery one useful filtering method is to prune out so called untestable hypotheses (Terada et al. 2013a; Mantel 1980) that cannot cause type I errors. This approach can be used when hypothesis testing is done conditionally on some data characteristics, like marginal frequencies. The idea is to determine a priori, using only the given conditions, if a hypothesis \(H_i\) can ever achieve sufficiently small p-value to become rejected at the adjusted level \({\hat{\alpha }}_i\). If this is not possible (i.e., if the smallest possible p-value, \(p_i^*\), would be too large, \(p_i^*>{\hat{\alpha }}_i\)), then the hypothesis is called ‘untestable’. Untestable hypotheses cannot contribute to FWER and they can be safely ignored when determining corrections for multiple hypothesis testing.
For example, the lowest possible p-value with Fisher’s exact test for rule \(A\rightarrow B\) with any contingency table having marginal frequencies \( fr (A)=10\), \( fr (B)=4\) and \(n=20\) is \(p^*=0.043\). If we test just one hypothesis with \(\alpha =0.05\), then this pattern can pass the test and the hypothesis is considered testable. However, if we test two hypotheses and use Bonferroni correction, then the corrected \(\alpha \)-level is \({\hat{\alpha }}=0.025\) and the hypothesis is considered untestable (\(p^*=0.043>0.025={\hat{\alpha }}\)).
In practice, selecting testable hypotheses can improve the power of the method considerably. In pattern discovery the idea of testability has been utilized successfully in the search algorithms, including the LAMP procedure (Terada et al. 2013a; Minato et al. 2014) that controls FWER with the Bonferroni correction and Westfall–Young light (Llinares López et al. 2015) that implements a minP method.
A third approach is to use a weighted multiple testing procedure (e.g., Finos and Salmaso 2007; Holm 1979) that gives more power to those hypotheses that are likely to be most interesting. Usually, the weights are given a priori according to assumed importance of hypotheses, but it is also possible to determine optimal weights from the data to maximize power of the test (see e.g., Roeder and Wasserman 2009). The simplest approach is an allocated Bonferroni procedure (Rosenthal and Rubin 1983) that allocates total \(\alpha \) among all m hypotheses according to their importance. Each hypothesis \(H_i\) is determined an individual significance level \({\hat{\alpha }}_i\) such that \(\sum _{i=1}^m {\hat{\alpha }}_i\le \alpha \). This is equivalent to a weighted Bonferroni procedure, where one determines weights \(w_i\) such that \(\sum _{i=1}^m w_i=m\) and reject \(H_i\) if \(p_i\le \frac{w_i\alpha }{m}\). There are also weighted variants of other multiple correction procedures like the weighted Holm–Bonferroni procedure (Holm 1979) and the weighted Benjamini–Hochberg procedure (Benjamini and Hochberg 1997). Usually, these procedures do not respect the monotonicity of p-values, which means that the most significant patterns may be missed if they were deemed uninteresting.
In the pattern discovery context one natural principle is to base the weighting on the complexity of patterns and favour simple patterns. This approach is used in the method of layered critical values (Webb 2008) where simpler patterns are tested with looser thresholds and strictest thresholds are reserved to most complex patterns. The motivation is that simpler patterns tend to have higher proportions of significant patterns and can be expected to be more interesting. In addition, this weighting strategy supports efficient search, because it helps to prune deeper levels of the search space.
When dependency patterns are searched, the complexity can be characterized by the number of attributes in the pattern which is the same as the level of the search space. Webb (2008) has suggested an allocation strategy where all patterns at level L are tested with threshold \({\hat{\alpha }}_L\) such that \(\sum _{L=1}^{L_{\max }}{\hat{\alpha }}_L \cdot S_L \le \alpha \), where \(L_{\max }\) is the maximum level and \( S_L \) is the number of all possible patterns at level L. One such allocation is to set
The method was originally proposed for the breadth-first search of classification rules, but it can be applied to other pattern types and depth-first search as well. The only critical requirement is that the bias towards simple patterns fits the research problem. In a pathological case, the method may miss the most significant patterns if they are too complex. However, the same patterns might remain undetected also with a weaker but more balanced testing procedure.
7 Conclusions
Pattern discovery is a fundamental form of exploratory data analysis. In this tutorial we have covered the key theory and techniques for finding statistically significant dependency patterns that are likely to represent true dependencies in the underlying population. We have concentrated on two general classes of patterns: dependency rules that express statistical dependencies between condition and consequent parts and dependency sets that express mutual dependence between set elements.
Techniques for finding true statistical dependencies are based on statistical tests of different types of independence. The general idea is to evaluate how likely it is that the observed or a stronger dependency pattern would have occurred in the given sample data, if the independence assumption had been true. If this probability is too large, the pattern can be discarded as having a high risk of being spurious. In this tutorial we have presented the core relevant statistical theory and specific statistical tests for different notions of dependence under various assumptions on the underlying sampling model.
However, in many applications it is often desirable to use stronger filters to the discovered patterns than a simple test for independence. Statistically significant dependency rules and sets can be generated by adding unrelated or even negatively associated elements to existing patterns. Unless further tests are also satisfied, such as tests for productivity and significant improvement, the discovered rules and sets are likely to be dominated by many superfluous or redundant patterns. Fortunately, statistical significance testing can also be employed to control the risk of ‘discovering’ these and other forms of superfluous patterns. We have also surveyed the key such techniques.
The final major issue that we have covered is that of multiple testing. Each statistical hypothesis test controls the risk that its null hypothesis would be rejected if that hypothesis were false. However, typical pattern discovery tasks explore exceptionally large numbers of potential hypotheses, and even if the risks for each of the individual hypotheses are extremely small, they can accumulate until the cumulative risk of false discoveries approaches almost certainty. We also survey multiple testing methods that can control this cumulative risk.
The field of statistically sound pattern discovery is in its infancy and there are numerous open problems. Most work in the field has been restricted to attribute-value or transactional data. Patterns over more complex data types like sequences and graphs would benefit also from statistically sound techniques but may require new statistical tests to be feasible. The possibilities of allowing for untestable hypotheses are also opening many possibilities for substantially increasing the power of multiple testing procedures. The field has been dominated by frequentist approaches of significance testing, but there is much scope for application of Bayesian techniques. But perhaps the two biggest challenges are determining the right statistical tests to identify patterns of interest for specific applications and then developing efficient search algorithms that find the most significant patterns under those tests.
It is important to remember that statistical significance testing controls only the risk of false discoveries—type I error. It does not control the risk of type II error—of failing to discover a pattern. When sample sizes are reasonably large, it is reasonable to expect that statistically sound pattern discovery techniques will find all real strong patterns in the data and will not find spurious weak patterns. However, it is important to recognize that in some circumstances it will be more appropriate to explore alternative techniques that trade off the risks of type I and type II error.
Statistically sound pattern discovery has brought the field of pattern mining to a new level of maturity, providing powerful and robust methods for finding useful sets of key patterns from sample data. We hope that this tutorial will help bring the power of these techniques to a wider group of users.
References
Aggarwal C, Han J (2014) Frequent pattern mining. Springer, Cham
Aggarwal C, Yu P (2001) A new approach to online generation of association rules. IEEE Trans Knowl Data Eng 13(4):527–540
Agrawal R, Imielinski T, Swami A (1993) Mining association rules between sets of items in large databases. In: Buneman P, Jajodia S (eds) Proceedings of the 1993 ACM SIGMOD international conference on management of data, ACM Press, New York, pp 207–216
Agrawal R, Mannila H, Srikant R, Toivonen H, Verkamo AI (1996) Fast discovery of association rules. In: Fayyad UM, Piatetsky-Shapiro G, Smyth P, Uthurusamy R (eds) Advances in knowledge discovery and data mining. AAAI Press, Menlo Park, pp 307–328
Agresti A (1992) A survey of exact inference for contingency tables. Stat Sci 7(1):131–153
Agresti A (2002) Categorical data analysis, 2nd edn. Wiley series in probability and statistics. Wiley, Hoboken
Agresti A, Hitchcock D (2005) Bayesian inference for categorical data analysis. Stat Methods Appl 14:297–330
Agresti A, Min Y (2005) Frequentist performance of Bayesian confidence intervals for comparing proportions in \(2\times 2\) contingency tables. Biometrics 61:515–523
Albert J (1997) Bayesian testing and estimation of association in a two-way contingency table. J Am Stat Assoc 92:685–693
Balcazar J (2010) Redundancy, deduction schemes, and minimum-size bases for association rules. Log Methods Comput Sci 6(2). http://arxiv.org/abs/1002.4286
Barnard G (1947) Significance tests for \(2 \times 2\) tables. Biometrika 34(1/2):123–138
Bastide Y, Pasquier N, Taouil R, Stumme G, Lakhal L (2000) Mining minimal non-redundant association rules using frequent closed itemsets. In: Lloyd J, , Dahl V, Furbach U, Kerber M, Lau KK, Palamidessi C, Pereira L, Sagiv Y, Stuckey P (eds) Proceedings of the first international conference on computational logic (CL’00). Lecturer notes in computer science, vol 1861. Springer, Berlin, pp 972–986
Bay SD, Pazzani MJ (2001) Detecting group differences: mining contrast sets. Data Min Knowl Discov 5(3):213–246
Bayardo R, Agrawal R, Gunopulos D (2000) Constraint-based rule mining in large, dense databases. Data Min Knowl Discov 4(2/3):217–240
Benjamini Y, Hochberg Y (1995) Controlling the false discovery rate: a practical and powerful approach to multiple testing. J R Stat Soc, Ser B 57(1):289–300
Benjamini Y, Hochberg Y (1997) Multiple hypotheses testing with weights. Scand J Stat 24(3):407–418
Benjamini Y, Leshno M (2005) Statistical methods for data mining. In: Maimon O, Rokach L (eds) The data mining and knowledge discovery handbook. Springer, New York, pp 565–87
Benjamini Y, Yekutieli D (2001) The control of the false discovery rate in multiple testing under dependency. Ann Stat 29(4):1165–1188
Birch M (1964) The detection of partial association, I: the \(2\times 2\) case. J R Stat Soc Ser B (Methodol) 26(2):313–324
Blanchard J, Guillet F, Gras R, Briand H (2005) Using information-theoretic measures to assess association rule interestingness. In: Han J, Wah B, Raghavan V, Wu X, Rastogi R (eds) Proceedings of the fifth IEEE international conference on data mining (ICDM’05). IEEE Computer Society, Washington, USA, pp 66–73
Boulicaut JF, Bykowski A, Rigotti C (2000) Approximation of frequency queris by means of free-sets. In: Proceedings of the 4th European conference principles of data mining and knowledge discovery (PKDD’00). Lecture notes in computer science, vol 1910. Springer, Berlin, pp 75–85
Bourgon R, Gentleman R, Huber W (2010) Independent filtering increases detection power for high-throughput experiments. Proc Natl Acad Sci 107(21):9546–9551
Brin S, Motwani R, Silverstein C (1997) Beyond market baskets: generalizing association rules to correlations. In: Peckham J (ed) Proceedings ACM SIGMOD international conference on management of data. ACM Press, New York, pp 265–276
Bruzzese D, Davino C (2003) Visual post-analysis of association rules. J Vis Lang Comput 14:621–635
Carriere K (2001) How good is a normal approximation for rates and proportions of low incidence events? Commun Stat Simul Comput 30:327–337
Cheng J, Ke Y, Ng W (2008) Effective elimination of redundant association rules. Data Min Knowl Discov 16(2):221–249
Cobb G, Chen YP (2003) An application of Markov chain Monte Carlo to community ecology. Am Math Mon 110:265–288
Cooley R, Mobasher B, Srivastava J (1997) Web mining: Information and pattern discovery on the world wide web. In: Proceedings of the ninth IEEE international conference on tools with artificial intelligence, IEEE, Los Alamitos, pp 558–567
Corani G, Benavoli A, Demsar J (2016) Comparing competing algorithms: Bayesian versus frequentist hypothesis testing. In: Tutorial in the European conference on machine learning and principles and practice of knowledge discovery in databases (ECML-PKDD 2016). http://ipg.idsia.ch/tutorials/2016/bayesian-tests-ml/
Dehaspe L, Toivonen H (2001) Discovery of relational association rules. In: Džeroski S, Lavrač N (eds) Relational data mining. Springer, Berlin, pp 189–212
Dong G, Li J (1999) Efficient mining of emerging patterns: discovering trends and differences. In: Proceedings of the fifth ACM SIGKDD international conference on knowledge discovery and data mining, ACM, New York pp 43–52
Edgington E (1995) Randomization tests, 3rd edn. Marcel Dekker Inc, New York
Feller W (1968) An introduction to probability theory and its applications, vol I, 3rd edn. Wiley, New York
Finos K, Salmaso L (2007) FDR- and FWE-controlling methods using data-driven weights. J Stat Plan Inference 137:3859–3870
Fisher R (1925) Statistical methods for research workers. Oliver and Boyd, Edinburgh
Freedman D, Pisani R, Purves R (2007) Statistics, 4th edn. Norton & Company, London
Ge Y, Dudoit S, Speed TP (2003) Resampling-based multiple testing for microarray data analysis. TEST: Off J Span Soc Stat Oper Res 12(1):1–44
Gionis A, Mannila H, Mielikäinen T, Tsaparas P (2007) Assessing data mining results via swap randomization. ACM Trans Knowl Discov Data 1(3):14:1–14:32
Goeman JJ, Solari A (2011) Multiple testing for exploratory research. Stat Sci 26(4):584–597
Goeman JJ, Solari A (2014) Multiple hypothesis testing in genomics–tutorial in biostatistics. Stat Med 33(11):1946–1978
Goethals B, Muhonen J, Toivonen H (2005) Mining non-derivable association rules. In: Kargupta H, Srivastava J, Kamath C, Goodman A (eds) Proceedings of the 2005 SIAM international conference on data mining, SIAM, pp 239–249
Haber M (1980) A comparison of some continuity corrections for the chi-squared test on 2 \( \times \) 2 tables. J Am Stat Assoc 75(371):510–515
Hahsler M, Hornik K, Reutterer T (2006) Implications of probabilistic data modeling for mining association rules. In: Spiliopoulou M, Kruse R, Borgelt C, Nürnberger A, Gaul W (eds) From data and information analysis to knowledge engineering. Proceedings of the 29th annual conference of the Gesellschaft für Klassifikation, Studies in classification, data analysis, and knowledge organization, Springer, Berlin, pp 598–605
Hämäläinen W (2010a) Efficient search for statistically significant dependency rules in binary data. Ph.D. thesis, Department of Computer Science, University of Helsinki, Finland, series of Publications A, Report A-2010-2
Hämäläinen W (2010b) Statapriori: an efficient algorithm for searching statistically significant association rules. Knowl Inf Syst: Int J (KAIS) 23(3):373–399
Hämäläinen W (2011) Efficient search methods for statistical dependency rules. Fund Inf 113(2):117–150 (A Special issue on Statistical and Relational Learning in Bioinformatics)
Hämäläinen W (2012) Kingfisher: an efficient algorithm for searching for both positive and negative dependency rules with statistical significance measures. Knowl Inf Syst: Int J (KAIS) 32(2):383–414
Hämäläinen W (2016) New upper bounds for tight and fast approximation of Fisher’s exact test in dependency rule mining. Comput Stat Data Anal 93:469–482
Hämäläinen W, Webb G (2013) Statistically sound pattern discovery. In: Tutorial in the European conference on machine learning and principles and practice of knowledge discovery in databases (ECML-PKDD 2013). http://www.cs.joensuu.fi/~whamalai/ecmlpkdd13/sspdtutorial.html
Hämäläinen W, Webb G (2014) Statistically sound pattern discovery. In: Proceedings of the 20th ACM SIGKDD international conference on knowledge discovery and data mining (KDD14), ACM, New York, p 1976
Hämäläinen W, Webb GI (2017) Specious rules: an efficient and effective unifying method for removing misleading and uninformative patterns in association rule mining. In: Chawla N, Wang W (eds) Proceedings of the 2017 SIAM international conference on data mining, SIAM, pp 309–317
Hanhijärvi S (2011) Multiple hypothesis testing in pattern discovery. In: Elomaa T, Hollmén J, Mannila H (eds) Proceedings on the 14th international conference on discovery science. Lecture notes in artificial intelligence, vol 6926. Springer. Berlin, pp 122–134
Hanhijärvi S, Ojala M, Vuokko N, Puolamäki K, Tatti N, Mannila H (2009) Tell me something I don’t know: randomization strategies for iterative data mining. In: Proceedings of the 15th ACM SIGKDD international conference on knowledge discovery and data mining, ACM, New York, NY, pp 379–388
Herrera F, Carmona CJ, González P, Del Jesus MJ (2011) An overview on subgroup discovery: foundations and applications. Knowl Inf Syst 29(3):495–525
Hochberg Y (1988) A sharper Bonferroni procedure for multiple tests of significance. Biometrika 75:800–802
Holm S (1979) A simple sequentially rejective multiple test procedure. Scand J Stat 6:65–70
Howard JV (1998) The \(2 \times 2\) table: a discussion from a Bayesian viewpoint. Stat Sci 13(4):351–367
Hu S, Rao J (2007) Statistical redundancy testing for improved gene selection in cancer classification using microarray data. Cancer Inf 3:29–41
Hubbard R, Bayarri M (2003) Confusion over measures of evidence (\(p\)’s) versus errors (\(\alpha \)’s) in classical statistical testing. Am Stat 57(3):171–178
Jabbar M, Shazan M, Zaïane O (2016) Learning statistically significant contrast sets. In: Khoury R, Drummond C (eds) Advances in artificial intelligence: Proceedings of the 29th Canadian conference on artificial intelligence. Lecture notes in artificial intelligence, vol 9673. Springer, Cham, 237–242
Jamil T, Ly A, Morey R, Love J, Marsman M, Wagenmakers EJ (2017) Default Gunel and Dickey Bayes factors for contingency tables. Behav Res Methods 49:638–652
Jin Z, Li J, Liu L, Le TD, Sun B, Wang R (2012) Discovery of causal rules using partial association. In: Zaki M, Siebes A, Yu J, Goethals B, Webb G, Wu X (eds) Proceedings of the 12th IEEE international conference on data mining (ICDM 2012), IEEE Computer Society, Los Alamitos, pp 309–318
Johnson D (1999) The insignificance of statistical significance testing. J Wildl Manag 63:763–772
Kim E, Helal S, Cook D (2010) Human activity recognition and pattern discovery. IEEE Pervasive Comput 9(1):48–53
Komiyama J, Ishihata M, Arimura H, Nishibayashi T, Minato S (2017) Statistical emerging pattern mining with multiple testing correction. In: Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining (KDD’17), ACM, New York, pp 897–906
Lallich S, Vaillant B, Lenca P (2005) Parametrised measures for the evaluation of association rule interestingness. In: Janssen J, Lenca P (eds) Proceedings of the 11th symposium on applied stochastic models and data analysis (ASMDA’05), ASMDA International Society, pp 220–229
Lallich S, Teytaud O, Prudhomme E (2007) Association rule interestingness: measure and statistical validation. In: Guillet F, Hamilton H (eds) Quality measures in data mining, studies in computational intelligence, vol 43. Springer, Berlin, pp 251–275
Lecoutre B, Lecoutre MP, Poitevineau J (2001) Uses, abuses and misuses of significance tests in the scientific community: won’t the Bayesian choice be unavoidable? Int Stat Rev/Revue Internationale de Statistique 69(3):399–417
Lee P (2012) Bayesian statistics: an introduction, 4th edn. Wiley, Chichester
Legendre P, Legendre L (1998) Numerical ecology. Elsevier Science, Amsterdam
Lehmann E (1993) The Fisher, Neyman–Pearson theories of testing hypotheses: one theory or two? J Am Stat Assoc 88:1242–1249
Lehmann E, Romano J (2005) Testing statistical hypotheses, 3rd edn. Texts in statistics. Springer, New York
Li G, Hamilton H (2004) Basic association rules. In: Berry M, Dayal U, Kamath C, Skillicorn D (eds) Proceedings of the fourth SIAM international conference on data mining, SIAM, Philadelphia, pp 166–177
Li J (2006) On optimal rule discovery. IEEE Trans Knowl Data Eng 18(4):460–471
Li J, Le T, Liu L, Liu J, Jin Z, Sun B, Ma S (2016) From observational studies to causal rule mining. ACM Trans Intell Syst Technol 7(2):14:1–14:27
Li W, Han J, Pei J (2001) CMAR: Accurate and efficient classification based on multiple class-association rules. In: Cercone N, Lin T, Wu X (eds) Proceedings of the 2001 IEEE international conference on data mining, IEEE, Los Alamitos, pp 369–376
Lichman M (2013) UCI machine learning repository. http://archive.ics.uci.edu/ml
Lindgren B (1993) Statistical theory, 4th edn. Chapman & Hall, Boca Raton
Liu B, Hsu W, Ma Y (1999) Pruning and summarizing the discovered associations. In: Proceedings of the fifth ACM SIGKDD international conference on knowledge discovery and data mining (KDD’99), ACM Press, New York, pp 125–134
Liu G, Zhang H, Wong L (2011) Controlling false positives in association rule mining. Proc VLDB Endow 5(2):145–156
Llinares López F, Sugiyama M, Papaxanthos L, Borgwardt K (2015) Fast and memory-efficient significant pattern mining via permutation testing. In: Proceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining, ACM, New York, pp 725–734
Mantel N (1980) Assessing laboratory evidence for neoplastic activity. Biometrics 36:381–399
Megiddo N, Srikant R (1998) Discovering predictive association rules. In: Agrawal R, Stolorz P (eds) Proceedings of the 4th international conference on knowledge discovery in databases and data mining, AAAI Press, Cambridge, pp 274–278
Meinshausen N, Maathuis MH, Bhlmann P (2011) Asymptotic optimality of the Westfall–Young permutation procedure for multiple testing under dependence. Ann Stat 39(6):3369–3391
Meo R (2000) Theory of dependence values. ACM Trans Database Syst 25(3):380–406
Miller R, Galecki A, Shmookler-Reis R (2001) Interpretation, design, and analysis of gene array expression experiments. J Gerontol Ser A, Biol Sci Med Sci 56:B52–B57
Minato S, Uno T, Tsuda K, Terada A, Sese J (2014) A fast method of statistical assessment for combinatorial hypotheses based on frequent itemset enumeration. In: Calders T, Esposito F, Hüllermeier E, Meo R (eds) Proceedings of the European conference on machine learning and knowledge discovery in databases, Part II. Lecture notes in artificial intelligence, vol 8725. Springer, Berlin, pp 422–436
Morishita S, Nakaya A (2000) Parallel branch-and-bound graph search for correlated association rules. In: Zaki M, Ho CT (eds) Large-scale parallel data mining, revised papers from the workshop on large-scale parallel KDD systems, in the 5th ACM SIGKDD international conference on knowledge discovery and data mining (KDD’00). Lecture notes in computer science, vol 1759. Springer, London, pp 127–144
Morishita S, Sese J (2000) Transversing itemset lattices with statistical metric pruning. In: Proceedings of the nineteenth ACM SIGMOD-SIGACT-SIGART symposium on principles of database systems (PODS’00), ACM Press, New York, pp 226–236
Neyman J, Pearson E (1928) On the use and interpretation of certain test criteria for purposes of statistical inference: Part II. Biometrika 20A(3/4):263–294
Nijssen S, Kok J (2006) Multi-class correlated pattern mining. In: Bonchi F, Boulicaut JF (eds) Proceedings of the 4th international workshop on knowledge discovery in inductive databases. Lecture notes in computer science, vol 3933. Springer, Berlin, pp 165–187
Nijssen S, Guns T, Raedt LD (2009) Correlated itemset mining in ROC space: a constraint programming approach. Proceedings the 15th ACM SIGKDD conference on knowledge discovery and data mining (KDD’09). ACM Press, New York, pp 647–656
Novak P, Lavrac N, Webb G (2009) Supervised descriptive rule discovery: a unifying survey of contrast set, emerging pattern and subgroup mining. J Machine Learn Res 10:377–403
Pasquier N, Bastide Y, Taouil R, Lakhal L (1999) Discovering frequent closed itemsets for association rules. In: Proceedings of the 7th international conference on database theory (ICDT’99). Lecture notes in computer science, vol 1540. Springer, Berlin, pp 398–416
Pearson E (1947) The choice of statistical tests illustrated on the interpretation of data classed in a \(2 \times 2\) table. Biometrika 34(1/2):139–167
Piatetsky-Shapiro G (1991) Discovery, analysis, and presentation of strong rules. In: Frawley W (ed) Knowledge discovery in databases. MIT Press, Cambridge, pp 229–248
Rempala GA, Yang Y (2013) On permutation procedures for strong control in multiple testing with gene expression data. Stat Its Interface 6(1):79–89
Rigoutsos I, Floratos A (1998) Combinatorial pattern discovery in biological sequences: the TEIRESIAS algorithm. Bioinformatics 14(1):55–67
Roeder K, Wasserman L (2009) Genome-wide significance levels and weighted hypothesis testing. Stat Sci 24(4):398–413
Rosenthal R, Rubin D (1983) Ensemble-adjusted p values. Psychol Bull 94(3):540–541
Šídák ZK (1967) Rectangular confidence regions for the means of multivariate normal distributions. J Am Stat Assoc 62:626–633
Silverstein C, Brin S, Motwani R (1998) Beyond market baskets: generalizing association rules to dependence rules. Data Min Knowl Discov 2(1):39–68
Smyth P, Goodman R (1992) An information theoretic approach to rule induction from databases. IEEE Trans Knowl Data Eng 4(4):301–316
Terada A, Okada-Hatakeyama M, Tsuda K, Sese J (2013a) Statistical significance of combinatorial regulations. Proc Natl Acad Sci 110(32):12,996–13,001
Terada A, Tsuda K, Sese J (2013b) Fast Westfall–Young permutation procedure for combinatorial regulation discovery. In: Li GZ, Kim S, Hughes M, McLachlan G, Sun H, Hu X, Ressom H, Liu B, Liebman M (eds) Proceedings of the 2013 IEEE international conference on bioinformatics and biomedicine, IEEE computer society, pp 153–158
Terada A, Kim H, Sese J (2015) High-speed Westfall–Young permutation procedure for genome-wide association studies. In: Proceedings of the 6th ACM conference on bioinformatics, computational biology and health informatics (BCB’15), ACM, New York, pp 17–26
Upton G (1982) A comparison of alternative tests for the \(2 \times 2\) comparative trial. J R Stat Soc Ser A (General) 145(1):86–105
Vilalta R, Oblinger D (2000) A quantification of distance bias between evaluation metrics in classification. In: Langley P (ed) Proceedings of the seventeenth international conference on machine learning (ICML’00), Morgan Kaufmann Publishers Inc., San Francisco, pp 1087–1094
Vreeken J, Tatti N (2014) Interesting patterns. In: Aggarwal C, Han J (eds) Frequent pattern mining. Springer International Publishing, Cham, Switzerland, pp 105–134
Webb G (2006) Discovering significant rules. In: Proceedings of the 12th ACM SIGKDD international conference on knowledge discovery and data mining (KDD’06), ACM Press, New York, pp 434–443
Webb G (2007) Discovering significant patterns. Mach Learn 68(1):1–33
Webb G (2008) Layered critical values: a powerful direct-adjustment approach to discovering significant patterns. Mach Learn 71(2–3):307–323
Webb G (2010) Self-sufficient itemsets: an approach to screening potentially interesting associations between items. Trans Knowl Discov Data 4:3:1–3:20
Webb G (2011) Filtered-top-k association discovery. WIREs Data Min Knowl Discov 1(3):183–192
Webb G, Vreeken J (2014) Efficient discovery of the most interesting associations. Trans Knowl Discov Data 8(3):15:1–15:31
Webb G, Zhang S (2005) K-optimal rule discovery. Data Min Knowl Discov 10(1):39–79
Westfall PH, Young SS (1993) Resampling-based multiple testing: examples and methods for p-value adjustment. Wiley, New York
Wilks S (1935) The likelihood test of independence in contingency tables. Ann Math Stat 6(4):190–196
Wu X, Zhang C, Zhang S (2004) Efficient mining of both positive and negative association rules. ACM Trans Inf Syst 22(3):381–405
Yao Y, Zhong N (1999) An analysis of quantitative measures associated with rules. In: Zhong N, Zhou L (eds) Proceedings of the third Pacific-Asia conference on methodologies for knowledge discovery and data mining (PAKDD’99). Lecture notes in computer science, vol 1574. Springer, London, pp 479–488
Yates F (1984) Test of significance for \(2 \times 2\) contingency tables. J R Stat Soc Ser A (General) 147(3):426–463
Yule G (1903) Notes on the theory of association of attributes in statistics. Biometrika 2:121–134
Yule G (1912) On the methods of measuring the association between two attributes. J R Stat Soc 75:579–652
Author information
Authors and Affiliations
Corresponding author
Additional information
Responsible editor: Johannes Fürnkranz.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This research was supported by the Academy of Finland (Decision Number 307026).
Appendix: Terminology
Appendix: Terminology
The following lists some similar looking terms that have a different meaning in the traditional pattern discovery and statistics.
Association (Statistics)
Generally, statistical dependence between two (or more) random variables. In a narrower sense, it refers to statistical dependence between categorical variables, while the word ‘correlation’ is used for numerical variables.
Association rule (Pattern discovery)
Traditionally, an association rule \({\mathbf {X}}\rightarrow {\mathbf {Y}}\) merely means sufficiently frequent co-occurrence of two attribute sets, \({\mathbf {X}}\) and \({\mathbf {Y}}\). The sufficient frequency is defined by a user-specified threshold \(min_{ fr }\). In the traditional definition (Agrawal et al. 1993), it has also been required that the ‘association’ should be sufficiently strong, measured by precision (‘confidence’). As such, an association rule does not necessarily express any statistical dependence or the dependence may be negative, instead of the assumed positive dependence. Therefore, it has become more common to require that the rule expresses positive statistical dependence, i.e. \(P({\mathbf {X}}{\mathbf {Y}})>P({\mathbf {X}})P({\mathbf {Y}})\), and use statistical dependence measures like lift or leverage instead of precision. In this paper, we call rule-formed statistical dependencies without any necessary minimum frequency requirements as ‘dependency rules’.
Confidence (Pattern discovery)
A traditional measure for the strength of an association rule \({\mathbf {X}}\rightarrow {\mathbf {Y}}\) defined as \(\phi ({\mathbf {X}}\rightarrow {\mathbf {Y}})=P({\mathbf {Y}}|{\mathbf {X}})\). In pattern recognition, information retrieval, and binary classification, this measure is called ‘precision’ or ‘positive predictive value’.
Confidence interval and confidence level (Statistics)
Confidence interval is an interval estimate of some unknown population parameter. Confidence level (e.g., 95%) determines the proportion of confidence intervals that contain the true value of the parameter. The concepts are closely related to statistical hypothesis testing: a confidence interval with confidence level \(1-\alpha \) contains all values \(s_0\) for which the corresponding null hypothesis \(S=s_0\) is not rejected at significance level \(\alpha \).
Support (Pattern discovery)
A term used for frequency in frequent itemset and association rule mining. The support of an attribute set (itemset) \({\mathbf {X}}\) can mean either absolute frequency, \( fr ({\mathbf {X}})\), or relative frequency, \(P({\mathbf {X}})\). The support of association rule \({\mathbf {X}}\rightarrow {\mathbf {Y}}\) usually means \( fr ({\mathbf {X}}{\mathbf {Y}})\) or \(P({\mathbf {X}}{\mathbf {Y}})\) but sometimes it can refer to \( fr ({\mathbf {X}})\) or \(P({\mathbf {X}})\). The latter are also called ‘coverage’ of the rule, although coverage can sometimes refer to \( fr ({\mathbf {X}}{\mathbf {Y}})\) or \(P({\mathbf {X}}{\mathbf {Y}})\).
Support (Mathematics, Statistics)
In general, the support of a function is the set of points where the function is not zero-valued or the closure of that set. In the probability theory and statistics, the support of a distribution whose density function is f, is the smallest closed set S such that \(f(x)=0\) for all \(x \notin S\).
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Hämäläinen, W., Webb, G.I. A tutorial on statistically sound pattern discovery. Data Min Knowl Disc 33, 325–377 (2019). https://doi.org/10.1007/s10618-018-0590-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10618-018-0590-x