
Abstract
We study the use of inverse harmonic Rayleigh quotients with target for the stepsize selection in gradient methods for nonlinear unconstrained optimization problems. This not only provides an elegant and flexible framework to parametrize and reinterpret existing stepsize schemes, but it also gives inspiration for new flexible and tunable families of steplengths. In particular, we analyze and extend the adaptive Barzilai–Borwein method to a new family of stepsizes. While this family exploits negative values for the target, we also consider positive targets. We present a convergence analysis for quadratic problems extending results by Dai and Liao (IMA J Numer Anal 22(1):1–10, 2002), and carry out experiments outlining the potential of the approaches.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
We study the unconstrained optimization problem
for strictly convex quadratic and general nonlinear continuously differentiable functions \(f: {\mathbb {R}}^n \rightarrow {\mathbb {R}}\). We consider the popular gradient method
where \(\textbf{g}_k = \nabla f(\textbf{x}_k)\) and \(\beta _k > 0\) is the steplength. It is convenient to introduce a separate notation \(\alpha _k\) for the inverse of the stepsize \(\beta _k\), since both play important roles; \(\alpha _k\) corresponds to (harmonic) Rayleigh quotients, which are scalars providing second-order information (on the Hessian).
As usual, write \(\textbf{s}_{k-1} = \textbf{x}_k-\textbf{x}_{k-1}\) and \(\textbf{y}_{k-1} = \textbf{g}_k-\textbf{g}_{k-1}\). Two popular stepsizes are the Barzilai–Borwein (BB) steplengths [1]
We denote their inverses by \(\alpha _{k}^\mathrm{{BB1}}\) and \(\alpha _{k}^\mathrm{{BB2}}\), respectively. In case of convex quadratic problems
where A is \(n \times n\) symmetric positive definite (SPD), and \(\textbf{b}\in {\mathbb {R}}^n\), the BB steps are the inverses of the Rayleigh quotient and harmonic Rayleigh quotient,
We refer to [2] for a nice recent review on various steplength options.
In this paper, we will consider a general framework for these and other stepsizes by introducing a harmonic Rayleigh quotient including a target \(\tau\). We recall the harmonic Rayleigh–Ritz extraction for matrix eigenvalue problems in Sect. 2. The general form of this extraction features a target \(\tau \in {\mathbb {R}} \, \cup \, \{ \pm \infty \}\). This target is analyzed and exploited in Sect. 3, to develop a new general framework for all possible stepsizes. We will see that the BB stepsizes correspond to \(\tau = 0\) or \(\tau = \pm \infty\). This may not only add towards a new understanding and interpretation of known strategies, but also suggests new competitive schemes. Section 4 closer studies the Adaptive Barzilai–Borwein method (ABB) [3], and provides a new theoretical justification for it. We also showcase the potential of the framework by introducing new families generalizing the ABB method. As is common (see, e.g., [2]) we first consider the convex quadratic problem. Convergence results for this case, extending those of [4], are presented in Sect. 5. The extension of the harmonic steplength to general nonlinear problems is treated in Sect. 6. Finally, we carry out numerical experiments and summarize some conclusions in Sects. 7 and 8.
2 Harmonic extraction and harmonic Rayleigh quotients
The harmonic Rayleigh–Ritz extraction has been introduced in the context of eigenvalue problems (see, e.g., [5,6,7,8]) to extract promising approximate (interior) eigenpairs from a subspace. Consider the eigenproblem \(A\textbf{x}= \lambda \textbf{x}\) for a given square A. Although A does not necessarily need to be symmetric or real for the harmonic extraction method, in our optimization context we are interested in SPD matrices A.
Suppose that we wish to extract promising approximate eigenpairs from a low-dimensional search space \({\mathcal {U}}\) for which the columns of \(U \in {\mathbb {R}}^{n \times d}\) form an orthogonal basis, where usually \(d \ll n\). We are interested in finding approximate eigenpairs \((\theta , \textbf{u}) \approx (\lambda , \textbf{x})\), where \(\textbf{u}\) is of the form \(\textbf{u}= U\textbf{c}\approx \textbf{x}\), with \(\textbf{c}\in {\mathbb {R}}^d\) of unit 2-norm. The standard Rayleigh–Ritz extraction imposes the Galerkin condition
This leads to d approximate eigenpairs \((\theta _j, U\textbf{c}_j)\), for \(j = 1, \dots , d\), obtained from the eigenpairs \((\theta _j, \textbf{c}_j)\) of \(U^T\!AU\).
Denote the eigenvalues of A by \(0 < \lambda _1 \le \cdots \le \lambda _n\). The standard Rayleigh–Ritz extraction enjoys a good reputation for exterior eigenvalues (see, e.g., [9]), which means the largest or smallest few eigenvalues, in our case of symmetric A. However, for interior eigenvalues near a target \(\tau \in (\lambda _1, \lambda _n)\), the harmonic Rayleigh–Ritz extraction tends to produce approximate eigenvectors of better quality. This approach works as follows (see, e.g., [7, Sec. 4.4] for more details).
Let \(\tau\) be not equal to an eigenvalue; in the context of eigenvalue problems, \(\tau\) is typically chosen close to the eigenvalues of interest. Eigenvalues near \(\tau\) are exterior eigenvalues of \((A-\tau I)^{-1}\), which is a favorable situation to impose a Galerkin condition. Therefore, the idea is to impose such a condition involving this shifted and inverted matrix. To avoid having to work with an inverse of a (potentially large) matrix, a modified Galerkin condition
is considered. We note that this is equivalent to the Galerkin condition \((A-\tau I)^{-1} \,\textbf{u}- (\theta -\tau )^{-1} \, \textbf{u}\perp (A-\tau I)\,{\mathcal {U}}\) for \(\textbf{u}\in (A-\tau I)\,{\mathcal {U}}\), which considers this extraction from a different viewpoint.
This implies that the quantities of interest are \((\widetilde{\theta }_j, \widetilde{\textbf{c}}_j)\), for \(j = 1, \dots , d\), the eigenpairs of the pencil \((U^T(A-\tau I)\,AU, \ U^T(A-\tau I)\,U)\); and the associated vectors \(\widetilde{\textbf{u}}_j = U \widetilde{\textbf{c}}_j\). This means that the relation between a harmonic Ritz vector \(\widetilde{\textbf{u}} = U \widetilde{\textbf{c}}\) and the corresponding harmonic Ritz value is
We will exploit this quantity in the next section to introduce a general harmonic framework for the choice of steplengths.
3 A harmonic framework for stepsize selection
Inspired by (2), we now propose and study the use of harmonic Rayleigh quotients of the form
in the context of gradient methods, where the \(\tau _k\) are targets that may be varied throughout the process. In contrast to the use of the target for eigenvalue problems, where the \(\tau _k\) are typically selected inside or very close to the interval \([\lambda _1, \lambda _n]\) (as discussed in Sect. 2), we investigate strategies with \(\tau\)-values outside this interval, as well as schemes where these targets may sometimes be inside.
The stepsize we consider is given by the inverse harmonic Rayleigh quotient
We will refer to these steps as “TBB steps”: Barzilai–Borwein type of steps using a harmonic Rayleigh quotient with target \(\tau _k\). In the rest of this section we will consider various aspects of gradient methods with TBB steps as in (4). In particular, we will discuss strategies for picking \(\tau _k\) in Sects. 3.7 and 4.3.
3.1 Properties of the TBB stepsize
In this section, we discuss some properties of the TBB stepsize for strictly convex quadratic functions, i.e., when the Hessian matrix A is SPD and thus \(\textbf{s}^T\!A\textbf{s}> 0\) for any \(\textbf{s}\ne 0\). Then \(\alpha ^{\textrm{BB1}}_k \le \alpha ^{\textrm{BB2}}_k\) and therefore \(\beta ^{\textrm{BB2}}_k \le \beta ^{\textrm{BB1}}_k\); in fact (see, e.g., [2])
The following proposition summarizes several basic but essential properties of stepsize (4). To ease the notation, we drop the index k whenever it is clear that we are referring to the same iteration in the gradient method.
Proposition 1
Let \(\textbf{s}\in {\mathbb {R}}^n\) be not equal to a multiple of an eigenvector of A, SPD. The function \(\beta (\tau ) = \frac{\textbf{s}^T (A-\tau I) \, \textbf{s}}{\textbf{s}^T (A-\tau I) \, A \, \textbf{s}}\) enjoys the following properties.
-
(i)
\(\beta (\tau )\) is defined for all \(\tau \in {\mathbb {R}}\) with exception of \(\alpha ^{\textrm{BB2}}= \frac{\textbf{s}^T \! A^2 \, \textbf{s}}{\textbf{s}^T \! A \, \textbf{s}}\), and is a strictly monotonically decreasing function on \((-\infty , \alpha _{}^\mathrm{{BB2}})\) and \((\alpha _{}^\mathrm{{BB2}}, \infty )\).
-
(ii)
Alternative expressions are \(\beta (\tau ) = \beta ^{\textrm{BB1}}\, \frac{\tau -\alpha ^{\textrm{BB1}}}{\tau -\alpha ^{\textrm{BB2}}} = \beta ^{\textrm{BB2}}\, \frac{\beta ^{\textrm{BB1}}\tau -1}{\beta ^{\textrm{BB2}}\tau -1}\).
-
(iii)
\(\beta (0) = \beta ^{\textrm{BB2}}\) and \(\displaystyle \lim _{\tau \rightarrow \pm \infty } \beta (\tau ) = \beta ^{\textrm{BB1}}\).
-
(iv)
For \(-\infty< \tau < 0\), it holds \(\beta ^{\textrm{BB2}}< \beta (\tau ) < \beta ^{\textrm{BB1}}\).
-
(v)
For \(0< \tau < \lambda _1\), we have \(\frac{1-\beta ^{\textrm{BB1}}\lambda _1}{1-\beta ^{\textrm{BB2}}\lambda _1} \cdot \beta ^{\textrm{BB2}}< \beta (\tau ) < \beta ^{\textrm{BB2}}\).
-
(vi)
For \(\tau > \lambda _n\), it holds that \(\beta ^{\textrm{BB1}}< \beta (\tau ) < \frac{\lambda _n-\alpha ^{\textrm{BB1}}}{\lambda _n-\alpha ^{\textrm{BB2}}} \cdot \beta ^{\textrm{BB1}}\).
-
(vii)
\(\beta\) is a bijection from \({\mathbb {R}} \backslash \{ \alpha ^{\textrm{BB2}}\}\) to \({\mathbb {R}} \backslash \{ \beta ^{\textrm{BB1}}\}\), and from \({\mathbb {R}} \cup \{\pm \infty \}-\{\alpha ^{\textrm{BB2}}\}\) to \({\mathbb {R}}\).
Proof
The derivative of \(\beta\) with respect to \(\tau\) is given by
The numerator is equal to \(\Vert A\textbf{s}\Vert ^2 \, \Vert \textbf{s}\Vert ^2 \cos ^2(A\textbf{s}, \textbf{s}) - \Vert A\textbf{s}\Vert ^2 \, \Vert \textbf{s}\Vert ^2 < 0\), since \(\textbf{s}\) is assumed to be not equal to an eigenvector; part (i) follows from this. Item (ii) is obtained by factoring out \(\textbf{s}^T \textbf{s}\) in the numerator, and \(\textbf{s}^T \! A \textbf{s}\) in the denominator. Part (iii) follows directly from (ii). Since \(\beta\) is defined everywhere and strictly decreasing on the interval \((-\infty , 0)\) we get item (iv). Part (v) is derived from (ii) by the fact that \(\beta\) on the interval \((0, \lambda _1)\) is defined everywhere and strictly decreasing. The factor \(\frac{1-\beta ^{\textrm{BB1}}\lambda _1}{1-\beta ^{\textrm{BB2}}\lambda _1}\) is less than one, since \(\beta ^{\textrm{BB1}},\, \beta ^{\textrm{BB2}}< \lambda _1^{-1}\) (again by the fact that \(\textbf{s}\) is not a multiple of an eigenvector) and \(\beta ^{\textrm{BB2}}< \beta ^{\textrm{BB1}}\). Item (vi) follows from the fact that \(\beta\) is defined everywhere and strictly decreasing on the interval \((\lambda _n, \infty )\). The factor \(\frac{\lambda _n-\alpha ^{\textrm{BB1}}}{\lambda _n-\alpha ^{\textrm{BB2}}}\) is greater than one in view of \(\alpha ^{\textrm{BB1}},\, \alpha ^{\textrm{BB2}}< \lambda _n\) and \(\alpha ^{\textrm{BB1}}< \alpha ^{\textrm{BB2}}\). \(\square\)
It is particularly item (vii) that implies that the harmonic Rayleigh quotient with target forms a framework or parametrization for all possible steplengths: together with target \(\tau = \pm \infty\), we have a one-to-one relation between targets in \({\mathbb {R}} \cup \{ \pm \infty \}\) and any real stepsize (positive or negative). We stress that, because of the pole of \(\beta\) in \(\tau = \alpha ^{\textrm{BB2}}\), the stepsize might be unbounded for \(\tau \in (\lambda _1, \lambda _n)\), which evidently is unwanted. Note that in the (unlikely) case that \(\textbf{s}\) is equal to an eigenvector corresponding to eigenvalue \(\lambda\), \(\beta (\tau )\) is equal to the constant function \(\beta (\tau ) \equiv \lambda ^{-1}\) (with exception of the “hole” at \(\tau = \lambda\)). Figure 1 gives an impression of the properties in Proposition 1 for a typical situation.

Harmonic Rayleigh quotient (left) and its inverse, the stepsize (right), as a function of \(\tau\) for the convex quadratic case \(A = \text {diag}(\frac{1}{100}, \frac{1}{99}, \dots , \frac{1}{2}, 1)\), where \(\textbf{s}= (1,\dots ,1)^T\)
For completeness, we also list some characteristics of the inverse stepsize \(\alpha (\tau )\) (see (3)), the harmonic Rayleigh quotient.
Proposition 2
Let \(\textbf{s}\in {\mathbb {R}}^n\) be not equal to a multiple of an eigenvector of A, SPD.
-
(i)
The function \(\alpha (\tau ) = \frac{\textbf{s}^T (A-\tau I) \, A \, \textbf{s}}{\textbf{s}^T (A-\tau I) \, \textbf{s}}\) is defined for all \(\tau \backslash \{ \alpha ^{\textrm{BB1}}\}\), and is a strictly monotonically increasing function on the intervals \((-\infty , \alpha ^{\textrm{BB1}})\) and \((\alpha ^{\textrm{BB1}}, \infty )\).
-
(ii)
Alternative expression are \(\alpha (\tau ) = \alpha ^{\textrm{BB1}}\, \frac{\tau -\alpha ^{\textrm{BB2}}}{\tau -\alpha ^{\textrm{BB1}}} = \alpha ^{\textrm{BB2}}\, \frac{\beta ^{\textrm{BB2}}\, \tau -1}{\beta ^{\textrm{BB1}}\, \tau -1}\).
-
(iii)
\(\displaystyle \lim _{\tau \rightarrow \pm \infty } \alpha (\tau ) = \alpha ^{\textrm{BB1}}\) and \(\alpha (0) = \alpha ^{\textrm{BB2}}\).
Proof
The derivative of \(\alpha\) with respect to \(\tau\) satisfies
The result now follows from a reasoning similar to Proposition 1. Part (ii) can be derived by factoring out a factor of \(\textbf{s}^T\textbf{s}\), \(\textbf{s}^T\!A\textbf{s}\), or \(\textbf{s}^T\!A^2\textbf{s}\) from the numerator or denominator. Item (iii) is straightforward. \(\square\)
3.2 Sensitivity of the stepsize with respect to the target
We now study the sensitivity of the steplength \(\beta (\tau )\) as function of \(\tau\), in particular around \(\tau = 0\) and \(\tau = -\infty\), which correspond to \(\beta ^{\textrm{BB1}}\) and \(\beta ^{\textrm{BB2}}\), respectively. We first consider the situation of small \(\tau\); recall that \(\beta (0) = \beta ^{\textrm{BB2}}\).
Proposition 3
For \(\tau \rightarrow 0\), we have up to higher-order terms in \(\tau\)
Proof
For \(\tau \rightarrow 0\) it holds that (cf. Proposition 1(ii))
\(\square\)
In agreement with Fig. 1 and Proposition 1, an appreciable interpretation of this result is that for small negative \(\tau\), the stepsize \(\beta (\tau )\) increases from \(\beta ^{\textrm{BB2}}\) (for \(\tau = 0\)) towards the larger stepsize \(\beta ^{\textrm{BB1}}\) (corresponding to \(\tau = -\infty\)). Moreover, the rate of change for \(\tau \rightarrow 0\) is asymptotically proportional to the difference between \(\beta ^{\textrm{BB1}}\) and \(\beta ^{\textrm{BB2}}\). As a side note, from (5) we have that \(\beta ^{\textrm{BB1}}- \beta ^{\textrm{BB2}}= \beta ^{\textrm{BB2}}\tan ^2(\textbf{s},\textbf{y})\).
Next, let us investigate the asymptotic situation \(\tau \rightarrow \pm \infty\). To this end, we exploit the transformed variable \(\zeta = \tau ^{-1}\) and consider the expression \(\widehat{\beta }(\zeta ):= \beta (\zeta ^{-1}) = \beta (\tau ) = \frac{\zeta \ \textbf{s}^T \! A \, \textbf{s}- \textbf{s}^T\textbf{s}}{\zeta \ \textbf{s}^T \! A^2 \, \textbf{s}- \textbf{s}^T \! A \, \textbf{s}}\) for \(\zeta \rightarrow 0\).
Proposition 4
For \(\tau \rightarrow \pm \infty\), we have up to higher-order terms in \(\tau ^{-1}\)
Proof
For \(\zeta \rightarrow 0\) it holds that (cf. Proposition 1(ii))
\(\square\)
Again, this result has a nice meaning: for small negative \(\tau ^{-1}\) (i.e., large negative \(\tau\)), the stepsize \(\beta (\tau ^{-1})\) decreases from \(\beta ^{\textrm{BB1}}\) (for \(\tau ^{-1} = 0\)) towards the smaller stepsize \(\beta ^{\textrm{BB2}}\) (associated with \(\tau =0\)). Moreover, the more \(\beta ^{\textrm{BB1}}\) differs from \(\beta ^{\textrm{BB2}}\), the faster \(\beta _k(\tau ^{-1})\) decreases as function of \(\tau ^{-1}\). For small positive \(\tau ^{-1}\) (which means large positive \(\tau\)), the steplength increases, and thus gets larger than \(\beta ^{\textrm{BB1}}\); cf. Fig. 1. In Sects. 3.7, 4.3 and 7 we will discuss and experiment with strategies involving both negative and positive values of \(\tau\).
3.3 Pseudocode for gradient method with TBB steps
In Algorithm 1 we give a pseudocode for a gradient method based on TBB steps. We exploit a relative stopping criterion in line 4, which may be replaced by any other reasonable stopping rule.
Clearly, the choice of targets \(\tau _k\) in Line 5 is a crucial aspect of the method. We discuss some options for this particularly in Sects. 3.7 and 4.3. In Sect. 6 we also consider practically important details such as the choice of \(\beta _0\).

3.4 Secant conditions
In this subsection we consider an equivalent formulation of the TBB stepsize
where \(\textbf{y}_{k-1} = A\textbf{s}_{k-1}\); this will be useful in Sect. 6 for generic problems where the Hessian changes over the iterations.
We recall from [1] that a justification of the BB steps is the fact that they approximate the Hessian matrix by a scalar multiple of the identity, as follows. It is reasonable that an approximation \(B_k\) to the Hessian approximately satisfies the secant equation \(\textbf{y}_{k-1} = B_k \textbf{s}_{k-1}\). The BB steps solve the secant equation in a least-squares sense [1]:
which results in an approximation of the form \(B_k = \alpha I\) to the Hessian, where \(\alpha\) is \(\alpha _{k}^\mathrm{{BB1}}\) or \(\alpha _{k}^\mathrm{{BB2}}\), respectively.
As the TBB step (4) involves the shifted matrix \(A - \tau I\) (where \(\tau\) may vary over the iterations), this suggests us to consider a shifted secant equation
By replacing \(\textbf{y}_{k-1}\) by \(\textbf{y}_{k-1} - \tau \, \textbf{s}_{k-1}\) and \(\alpha\) by \(\alpha -\tau\) in the second secant condition in (7), we obtain that the TBB step satisfies a modified secant condition, which is equivalent to the second equation of (7) for \(\tau = 0\), but not equivalent to the first or second one for any other target value.
Proposition 5
Let \(\tau \ne \alpha _{k}^\mathrm{{BB1}} = \frac{\textbf{y}_{k-1}^T\textbf{s}_{k-1}}{\textbf{s}_{k-1}^T\textbf{s}_{k-1}}\). Then the inverse TBB step \(\alpha _k = \beta _k^{-1}\) satisfies
Proof
The result follows by setting to zero the derivative of the square of the objective function in (9) with respect to \(\alpha\), which gives
\(\square\)
In addition to this interpretation as modified secant condition, when the target is located outside \([\lambda _1, \lambda _n]\), we can also think of the TBB step as the scalar least squares solution to the following problem involving a certain weighted norm, as follows. Define the standard weighted norm associated with a given SPD matrix W by \(\Vert \textbf{x}\Vert _W^2:= \textbf{x}^TW\textbf{x}\).
Proposition 6
The least squares solution to the weighted secant equation satisfies
Proof
The result follows by setting \(-\textbf{y}_{k-1}^TW\textbf{s}_{k-1} + \alpha \, \textbf{s}_{k-1}^TW\textbf{s}_{k-1}\), the derivative of \(\frac{1}{2} \, \Vert \textbf{y}_{k-1} - \alpha \, \textbf{s}_{k-1}\Vert _W^2\) with respect to \(\alpha\), to zero. \(\square\)
The BB1 and BB2 steps can be obtained from this proposition by taking \(W=I\) and \(W=A\), respectively; cf. (7). The TBB step can be derived by choosing \(W = A-\tau I\) for \(\tau < \lambda _1\) or \(W = \tau I-A\) for \(\tau > \lambda _n\), which gives an SPD weight matrix in both cases.
In conclusion, the BB1, BB2, and TBB steps approximate the Hessian by a positive scalar multiple of the identity of the form \(B_k = \alpha _k I \approx A\). The scalars satisfy one or both (weighted) secant conditions.
3.5 Regularization
Another viewpoint on harmonic steps (4) with a target \(\tau\) outside \([\lambda _1, \lambda _n]\) is as regularization of the Hessian. First consider taking a shift \(\tau < 0\). As we replace A by \(A-\tau I\) for \(\tau < 0\) this yields a “more positive definite” shifted Hessian. As one indicator, the condition number
of A is modified to \(\frac{\lambda _n-\tau }{\lambda _1-\tau }\) by this shift. Consider the function \(\varphi : (-\infty , 0] \rightarrow [1, \infty )\) given by \(\varphi (t) = \frac{\lambda _n-t}{\lambda _1-t}\). Since this function is strictly monotonically decreasing on the domain \((-\infty , 0]\), we conclude that \(\kappa (A-\tau I) < \kappa (A)\). More precisely, we have the following first-order estimate.
Proposition 7
For \(\tau \rightarrow 0\) we have
Proof
Straightforward using the linear approximation \(\varphi (t) \approx \varphi (0) + \varphi '(0)\, t\). \(\square\)
In fact, for \(\tau < 0\), the shifted condition number \(\kappa (A-\tau I)\) may be considerably smaller than \(\kappa (A)\), especially if the Hessian is nearly singular. In conclusion, also in view of (8) and Proposition 5, harmonic stepsizes with \(\tau < 0\) may be viewed as satisfying a secant condition on a regularized Hessian. Note that \(\displaystyle \lim _{\tau \rightarrow -\infty } \kappa (A-\tau I) = 1\).
Moreover, for \(\tau > \lambda _n\), we have a similar situation. It is not difficult to show that \(\kappa (A-\tau I) = \kappa (A)\) when \(\tau = \lambda _n+\lambda _1\) (which is usually close to \(\lambda _n\)). For \(\tau > \lambda _n+\lambda _1\), the condition number of the shifted matrix \(A-\tau I\) decreases monotonically, with the analogous property \(\displaystyle \lim _{\tau \rightarrow \infty } \kappa (A-\tau I) = 1\).
3.6 Connections with other stepsizes
We would like to point out that quotients of the form
for certain polynomials p, have also been considered in different contexts in [10, (2.6)], [8], and [11]. The harmonic Rayleigh quotient (3) is a special case of (12), but a very practical instance for several reasons. First, it gives a clear connection with the harmonic Rayleigh–Ritz extraction for eigenvalue problems, as seen in Sect. 2. Second, as we have seen in Sect. 3.1, by taking first-order polynomials p in \(\tau\), we have a one-to-one correspondence between the target \(\tau\) and the stepsize \(\beta\).
The introduction of an adjustable parameter in the stepsize has been first proposed in [12], where the authors present a convex combination of BB1 and BB2 steps,
where \(\zeta _k \in [0,1]\). Note that \(\beta _{k}^\mathrm{{CON}}(0) = \beta _{k}^\mathrm{{BB2}}\) and \(\beta _{k}^\mathrm{{CON}}(1) = \beta _{k}^\mathrm{{BB1}}\). Its inverse minimizes a linear combination of secant conditions, i.e.,
In [12], several strategies are considered to choose \(\zeta _k\): fixed, randomly from the uniform distribution over [0, 1], or imitating the behavior of the cyclic gradient methods (cf. [12, pp. 56–57] and references therein). In the next section, we show a link between this convex combination steplength and the TBB step. This not only suggests relevant strategies to select \(\zeta _k\), or rather \(\tau _k\) for our TBB methods, but also gives a far wider range of options.
3.7 Strategies to select targets
There is a one-to-one correspondence between the parameter \(\zeta _k\) in Sect. 3.6 and the target \(\tau _k\) in the TBB stepsize: with the choice
the corresponding TBB step coincides with the stepsize in [12]: \(\beta _{k}(\tau _k) = \beta _{k}^\mathrm{{CON}}(\zeta _k)\). In addition, since \(\zeta _k \in [0,1]\), the corresponding target values lie in \(\tau _k \in [-\infty , 0]\). From Proposition 1 we conclude that \(\beta _{k}^\mathrm{{BB2}} \le \beta _{k}^\mathrm{{CON}}(\zeta _k) \le \beta _{k}^\mathrm{{BB1}}\).
Given the relation between \(\zeta _k\) and \(\tau _k\), all strategies mentioned in [12] correspond to negative targets \(\tau _k\) for the TBB steplengths (4). In the next section, we analyze new schemes for the choice of negative targets; here we focus on positive targets \(\tau _k\). As this yields steplengths \(\beta _k(\tau _k) > \beta _{k}^\mathrm{{BB1}}\), this is not equivalent to any of the stepsizes determined by \(\zeta _k\) in [12]. Inspired by the expression in (13), where the target is a negative factor times the inverse BB2 stepsize \(\alpha ^{\textrm{BB2}}_k\), we consider positive targets of the form
This gives us an affine (rather than convex) combination of BB1 and BB2:
This new stepsize is located in the right branch of the hyperbola (right plot of Fig. 1). We will make use of the following bounds for the inverse stepsize:
As in (13), we may let \(\rho\) vary through the iterations. In the numerical experiments, we will consider the strategy \(\tau _1 = 0\) and
Since \(\tau _k \ge k\,\lambda _1\) for all k, the sequence \(\{\tau _k\}\) converges to infinity; therefore, the corresponding inverse stepsizes \(\beta _k(\tau _k)\) behave asymptotically as \(\alpha _{k}^\mathrm{{BB1}}\). In the long run, there exists a \(\rho > 1\) such that \(\alpha _{k}(\tau _k) \in [\frac{\rho -1}{\rho }\lambda _1, \, \lambda _n]\) for all \(k > \rho -1\).
The inverse stepsizes obtained from (14) and (15) are bounded from below by a multiple of \(\alpha _{k}^\mathrm{{BB1}}\), which will play a key role in the global convergence of the resulting gradient method in Sect. 5.
4 An analysis and extension of the ABB scheme
We now present an analysis and “continuous extension” of the ABB method [3]. We propose a new harmonic family of stepsizes, using various options for the target \(\tau _k\) throughout the process. These strategies aim to retain the advantages of the ABB method, while being more flexible and tunable than the original approach.
The motivations for this adaptation are the following. First, it is a popular method. Second, the method contains a threshold parameter \(\eta\), the choice of which may be seen as a bit arbitrary. Third, it is a good showcase of the possibilities that the harmonic framework offers.
We first briefly recall the ABB approach. The stepsize is selected as
Here, \(\eta\) is a user-selected parameter with a common choice \(\eta = 0.8\); see, e.g., [2]. As in the previous section, we study the strictly convex quadratic case, so that \(\beta _{k}^\mathrm{{BB2}} \le \beta _{k}^\mathrm{{BB1}}\). The ABB scheme adaptively picks BB1 and BB2 steps based on the value of \(\beta _{k}^\mathrm{{BB2}} \, / \, \beta _{k}^\mathrm{{BB1}} = \cos ^2(\textbf{s}_{k-1}, \textbf{y}_{k-1})\).
The idea of the ABB stepsize is to take a larger step when \(\cos ^2(\textbf{s}_{k-1}, \textbf{y}_{k-1}) \approx 1\), and a smaller step when this is not the case. If \(\cos ^2(\textbf{s}_{k-1}, \textbf{y}_{k-1})\) is close to 1, this means that \(\textbf{g}_{k-1}\) (or, equivalently, \(\textbf{s}_{k-1}\)) is close to an eigenvector of A corresponding to an eigenvalue \(\lambda > 0\). Thus, as we will see in Sect. 5, by the step \(\beta _{k}^\mathrm{{BB1}}\) we are particularly reducing the gradient component corresponding to \(\lambda\) significantly. When we are far from an eigenvalue, we prefer to take shorter steps, such as \(\beta _{k}^\mathrm{{BB2}}\), since we aim to reduce several gradient components; this fosters the gradient method to take a new longer step in the next iterations. There exist several variants of the ABB method; the interested reader may refer to [3, 13, 14] for such ideas.
4.1 A theoretical foundation for the ABB method
As discussed, a key statement for the ABB method is: “if \(\cos (\textbf{s}_{k-1},\textbf{y}_{k-1}) \approx 1\), then \(\textbf{s}_{k-1}\) is close to an eigenvector” (see, e.g., [2, pp. 179–180]). The following new result quantifies this statement for the quadratic case. We need the assumption that \(\lambda\) is a simple eigenvalue, since otherwise an eigenvector is not uniquely defined. We consider the situation \(\cos ^2(\textbf{s}, A\textbf{s}) \approx 1\), so that \(\sin (\textbf{s}, A\textbf{s})\) is small.
Proposition 8
Let \((\lambda , \textbf{x})\) be an eigenpair of A, where \(\lambda\) is a simple eigenvalue. Let \(\textbf{s}\approx \textbf{x}\) be an approximate eigenvector. Then, up to higher-order terms in \(\angle (\textbf{s},\textbf{x})\),
Proof
Without loss of generality we may assume that \(A = \text {diag}(\lambda , \Lambda )\), where \(\Lambda\) is an \((n-1) \times (n-1)\) diagonal matrix containing all eigenvalues different from \(\lambda\), and that \(\textbf{s}\) is of the form \([1, \ \textbf{z}]^T\), a perturbation of \(\textbf{x}\), the first canonical basis vector. This means \(\tan (\textbf{s},\textbf{x}) = \Vert \textbf{z}\Vert\); our goal is to connect this quantity to \(\angle (\textbf{s}, A\textbf{s})\) via \(\sin (\textbf{s}, A\textbf{s})\). We have \(As = [\lambda , \ \Lambda \,\textbf{z}]^T\), and
We now twice use the Taylor expansion \((1-t)^{-1} = 1+t + {\mathcal {O}}(t^2)\) for small t, so that
This yields that
Multiplication by \(\lambda > 0\) and omitting \({\mathcal {O}}(\Vert \textbf{z}\Vert ^4)\)-terms gives \(\Vert \Lambda \,\textbf{z}-\lambda \textbf{z}\Vert = \lambda \, \sin (\textbf{s}, A\textbf{s})\). The result now follows from
\(\square\)
Next, we investigate the sensitivity of the BB steps for quadratic problems where the direction is close to an eigenvector.
Proposition 9
Let \(\textbf{s}\) be an approximation of an eigenvector \(\textbf{x}\) corresponding to a simple eigenvalue \(\lambda\). Up to higher-order terms in \(\angle (\textbf{s},\textbf{x})\), we have
Proof
With the same notation as in the proof of Proposition 8, we have for the BB1 step
and for the BB2 step
\(\square\)
Comparing these two upper bounds, we conclude that the one for the BB2 steps may be larger by a factor \(\lambda _n / \lambda\), which is close to \(\kappa (A)\) for small \(\lambda\) and may therefore be very large. As a result, one interpretation of this proposition is that, indeed, it may be a good idea to take BB1 steps rather than BB2 steps if \(\textbf{s}\) is close to an eigenvector, since BB2 steps are more sensitive with respect to perturbations in that direction, in view of the extra factor in the upper bound. This seems especially relevant for small \(\lambda\), corresponding to large stepsizes. Therefore, this result forms a clear mathematical motivation for the ABB scheme.
4.2 Sensitivity of \(\beta (\tau )\) with respect to \(\textbf{s}\)
The following result is an extension of Proposition 9 to the harmonic step with target (4). We will see that it reduces to Proposition 9 in the case of \(\tau = 0\) or \(\tau \rightarrow \pm \infty\).
Proposition 10
Let \(\textbf{s}\) be an approximation of an eigenvector \(\textbf{x}\) corresponding to a simple eigenvalue \(\lambda\). Up to higher-order terms in \(\angle (\textbf{s},\textbf{x})\), we have
Proof
With the notation as in Proposition 9, and using similar techniques we get
\(\square\)
Interestingly, the factor \(\vert \lambda _i-\tau \vert \, / \, \vert \lambda -\tau \vert\) converges to 1 for \(\tau \rightarrow \pm \infty\), which reduces to the first inequality in Proposition 9; this corresponds to the BB1 step, the inverse Rayleigh quotient. When \(\tau \rightarrow 0\), this factor converges to that in the second inequality in Proposition 9; this corresponds to the BB2 step, the inverse harmonic Rayleigh quotient for zero target.
4.3 A new family of stepsizes
The ABB strategy may be viewed as “discrete”, in the sense that just two types of stepsizes are possible: the BB1 or the BB2 step. We will now propose a new “continuous” variant of ABB parameterized by choosing appropriate \(\tau _k\). We design this strategy to have a similar behavior as ABB: when \(\cos ^2(\textbf{s}_{k-1}, \textbf{y}_{k-1}) \approx 1\), the steps are close to the BB1 step, while the steps should be close to the BB2 step when \(\cos ^2(\textbf{s}_{k-1}, \, \textbf{y}_{k-1}) \approx 0\). Therefore, we are interested in a function of \(\cos (\textbf{s}_{k-1}, \, \textbf{y}_{k-1})\) such that when \(\tau _k \rightarrow -\infty\) we recover BB1, while \(\tau _k = 0\) yields the BB2 step. One choice to attain this is to use a cotangent function:
Indeed, this choice has the two types of desired asymptotic behavior. To further tune the speed by which we approach the two BB steps when \(\cos (\textbf{s}_{k-1}, \textbf{y}_{k-1})\) approaches 0 or 1, we will also introduce two extra parameters, and consider
for \(q,r > 0\). For example, if we want our gradient method to have shorter steps more often than long ones, we may keep \(r = 1\) but select a higher value of q, e.g., \(q = 2\). This mimics the effect of setting \(\eta\) relatively close to 1, as it is done in [2]. The following result ensures that this “cotangent step” (16) indeed may be regarded as a continuous extension of the ABB step, having similar properties for \(\angle (\textbf{s}, \textbf{y})\) close to 0 or \(\pi /2\).
Proposition 11
For \(q, r > 0\), consider \(\beta (\tau )\) as in (4), where \(\tau\) is defined by (16). We have that \(\beta (\tau ) \rightarrow \beta ^{\textrm{BB1}}\) when \(\angle (\textbf{s}, \textbf{y}) \rightarrow 0\) and \(\beta (\tau ) \rightarrow \beta ^{\textrm{BB2}}\) when \(\angle (\textbf{s}, \textbf{y}) \rightarrow \pi /2\). Moreover, \(\beta (\tau )\) is a decreasing function of \(\angle (\textbf{s}, \textbf{y})\).
Proof
Since \(\sin\) is strictly increasing and \(\cos\) is strictly decreasing on \((0,\frac{\pi }{2})\), the function \(\tau\) defined by (16) is a strictly increasing function of \(\angle (\textbf{s}, \textbf{y})\), ranging from \(-\infty\) for \(\angle (\textbf{s}, \textbf{y}) \rightarrow 0\) to 0 for \(\angle (\textbf{s}, \textbf{y}) = \frac{\pi }{2}\). Therefore, in combination with Sect. 3.1, we conclude that \(\beta\) decreases from \(\beta ^{\textrm{BB1}}\) to \(\beta ^{\textrm{BB2}}\). \(\square\)
We point out that in the quadratic case the targets (16) are negative, which implies that the corresponding stepsize has the same bounds as \(\beta _{k}^\mathrm{{CON}}\) in Sect. 3.7: \(\beta _{k}^\mathrm{{BB1}} \le \beta _{k}(\tau _k) \le \beta _{k}^\mathrm{{BB2}}\). We will test various choices for \(q, r > 0\) in the experiments in Sect. 7.
5 Convergence analysis
In this section, we extend a few results on BB steps for strictly convex quadratics to the TBB step with the choices for the target \(\tau _k\) described in Sects. 3.7 and 4.3. Global convergence of the gradient method with BB steps has been proven by Raydan [15] for strictly convex quadratic functions. Dai and Liao [4] and Dai [16] show R-linear convergence of the method for a class of BB stepsizes. We follow [16, Thm. 4.1] and [4, Thm. 2.5] to extend the results to the TBB steps.
Before stating the assumptions that the TBB stepsize must satisfy, we introduce some expressions that will be useful for the following results. Since the Hessian is fixed through the iterations, it is sensible to decompose the gradient along an orthonormal basis of eigenvectors of A. Let \(\textbf{v}_1, \dots , \textbf{v}_n\) be the (orthonormal) eigenvectors associated with the eigenvalues \(\lambda _1, \dots , \lambda _n\). The gradient can be expressed as linear combination of these eigenvectors (cf., e.g., [4, (2.2)])
Therefore, the TBB step expressed in the eigenvalues of A and the \(\gamma _{i}^{k-1}\) is
provided the denominator is nonzero. In particular, for \(\tau \rightarrow \pm \infty\), this stepsize converges to the BB1 stepsize, which is expressed as (cf., e.g., [4, Eq. (2.18)])
For strictly convex quadratic functions, we have the following recursive formula for the gradients \(\textbf{g}_k\) and, as a consequence, for their coefficients (cf., e.g., [15, Eq. (8)])
Equations (19)–(20) can also be applied to the error \(\textbf{e}_k = \textbf{x}_k - A^{-1}\textbf{b}\) and its components \(e_i^k\) in the directions of the eigenvectors. Using these equations, the following results can be obtained for the error components as well. The only complication is that higher powers of the eigenvalues appear:
since \(\beta _{k}\textbf{s}_k = A\textbf{e}_k\) for all k. This expression extends [15, Eq. (12) and p. 325]. To prove the convergence of the gradient method for strictly convex quadratic functions, it is sufficient to show that \(\Vert \textbf{g}_k\Vert \rightarrow 0\). Since we chose an orthonormal basis, \(\Vert \textbf{g}_k\Vert ^2 = \sum _i (\gamma _{i}^{k})^2\) and thus we aim to show \(\gamma _{i}^{k}\rightarrow 0\) for \(i=1,\dots ,n\). We remark that working with the \(\gamma _{i}^{k}\) is equivalent to assuming that our Hessian matrix A is diagonal.
5.1 Assumptions for the TBB stepsize
We state the assumptions on the TBB stepsize, needed to get R-linear convergence. We adapt [16, Property A] to the TBB steplengths proposed in Sects. 3.7 and 4.3:
Assumption 1
The inverse stepsize \(\alpha _{k}\) satisfies Assumption 1 if there exist positive constants \(\xi _{\textrm{low}}\in (\frac{1}{2}, 1]\), \(\xi ^{\textrm{up}}\ge 1\) and \(M_2\) such that, for any k,
-
(i)
\(\xi _{\textrm{low}}\cdot \lambda _1\le \alpha _{k} \le \xi ^{\textrm{up}}\cdot \lambda _n\);
-
(ii)
for any \(1 \le \ell \le n-1\) and \(\varepsilon > 0\), if \(\sum _{i=1}^\ell (\gamma _{i}^{k-1})^2 \le \varepsilon\) and \((\gamma _{\ell +1}^{k-1})^2\ge M_2 \, \varepsilon\), then \(\alpha _{k} \ge \frac{\xi _{\textrm{low}}}{\xi _{\textrm{low}}+1/2} \, \lambda _{\ell +1}\).
[16, Property A] also includes retards in the BB steps, but, as we are not interested in retards in this paper, we will not include them to ease the notation in what follows. The interested reader is referred to [10] for the definition of BB steps with retards, and to [16] for the proof of R-linear convergence under this property. Secondly, we note that [16, Property A] requires \(\xi _{\textrm{low}}= 1\), while we allow a looser lower bound for the inverse stepsize. In other words, admissible stepsizes are larger than the largest eigenvalue of \(A^{-1}\). Finally, our upper bound in (i) has a more specific shape than the one set in [16, Property A], which is some \(M_1 \ge \lambda _1\). This will enable us to express some bounds as a function of the condition number of A. Given all the differences between Assumption 1 and [16, Property A], it is worthwhile to analyze the new situation.
We show that targets (14), (15), and (16) all lead to a stepsize that satisfies Assumption 1. In addition, we show a useful bound for the \((\ell + 1)\)st gradient component. Analogous proofs can be found in, e.g, [16, Corollary 4.2] or [15, Lemma 2]. First notice that, with these choices for the target, for k sufficiently large:
for certain \(0 < \xi _{\textrm{low}}\le 1\) and \(\xi ^{\textrm{up}}\ge 1\). Consequently,
Lemma 12
Let the inverse stepsize \(\alpha _{k}(\tau _k)\) satisfy (21) with \(\frac{1}{2} < \xi _{\textrm{low}}\le 1\) and \(\xi ^{\textrm{up}}\ge 1\). Then such stepsize satisfies Assumption 1. In addition, given k, there exists a constant \(c\in (0,1)\) such that
Proof
Part (i) of Assumption 1 immediately follows from the bounds on the BB1 step. Given the hypotheses in (ii) of Assumption 1, Equation (18) and \(M_2 = (\xi _{\textrm{low}}-\frac{1}{2})^{-1}\), it follows that
Since \(\alpha _{k}(\tau _{k}) \le \xi ^{\textrm{up}}\, \lambda _n\),
Given (20), this implies \(\vert \gamma _{\ell +1}^{k+1}\vert \le c\, \vert \gamma _{\ell +1}^{k}\vert\) for constant \(c:= \max \{(2\xi _{\textrm{low}})^{-1}, \, 1 - \lambda _{\ell +1} \, (\xi ^{\textrm{up}}\, \lambda _n)^{-1} \} < 1\). \(\square\)
Remark 13
If \(\tau _k = \rho \, \alpha _{k}^\mathrm{{BB2}}\) (cf. (14)), Lemma 12 does not hold for all the values of \(\rho\): we must restrict ourselves to \(\rho > 2\). Nevertheless, in the non-quadratic case, the gradient method is endowed with a line search, where bounds on the stepsize are provided by the user (see, e.g., [17] and Sect. 6). In this context, we may try also \(\rho \le 2\), which corresponds to \(\xi _{\textrm{low}}<\frac{1}{2}\).
5.2 Bounds on gradient components
We establish two bounds on the gradient components. To do so, the bounds in Assumption 1 are used, with an appropriate restriction on \(\xi _{\textrm{low}}\). We then show that the first gradient component converges to 0 under certain conditions. Let us start with the following lemma, which is an extension of [15, Lemma 1]: this holds for \(\xi _{\textrm{low}}= \xi ^{\textrm{up}}= 1\) and it is stated for the components of the error, that enjoy the same recursive formula as the components of the gradient.
Lemma 14
Under Assumption 1, \(\gamma _{1}^{k}\) converges to zero Q-linearly, i.e., there exists a constant \(c_1\in (0,1)\) such that
Proof
From part (i) in Assumption 1, we have
with \(\kappa (A)\) the condition number as in (11). Thus, when applying these bounds to (20), we see that (23) holds with \(c_1= \max \{\xi _{\textrm{low}}^{-1}-1, \ 1 - (\kappa (A) \, \xi ^{\textrm{up}})^{-1}\}\). The conditions on \(\xi _{\textrm{low}}\) and \(\xi ^{\textrm{up}}\) guarantee that \(c_1\) is indeed in the interval (0, 1). \(\square\)
Unfortunately, it is not possible to prove the Q-linear convergence of the other gradient components, but the following inequality will play a role later. This result generalizes [4, Lemma 2.1].
Lemma 15
Under Assumption 1, there exists a constant \(c_2> 0\) such that for \(i = 2, \dots , n\)
Proof
From part (i) in Assumption 1, we have
Application of these bounds to (20) implies that (24) holds with positive constant \(c_2:= \max \{\xi _{\textrm{low}}^{-1} \, \kappa (A)-1, \ 1-(\kappa (A) \, \xi ^{\textrm{up}})^{-1}\}\). \(\square\)
We note that usually \(c_2\) will be \(\xi _{\textrm{low}}^{-1} \, \kappa (A)-1\), and that this quantity may be very large. However, this still provides us with a needed tool for proving the convergence of the gradient method for quadratics. In addition, we remark that Lemma 15 still holds in general for \(\xi _{\textrm{low}}\in (0,1]\) and \(\xi ^{\textrm{up}}\ge 1\).
5.3 Proof of R-linear convergence
Finally, we are able to state the R-linear convergence result under Assumption 1, which closely follows the line of the proof of [16, Thm. 4.1]. The key parts of the proof are the bounds on the gradient components from Lemmas 14 and 15, the result on the \((\ell +1)\)st gradient component of Lemma 12. Our contribution is to adapt all these results that were already in [16] but derived from [16, Property A]. A slightly less general proof of R-linear convergence was previously presented in [4].
Theorem 16
Let f be a strictly convex quadratic function and let \(\textbf{x}^*= A^{-1}\textbf{b}\) be its unique minimizer. Let \(\{\textbf{x}_k\}\) be the sequence generated by the gradient method where the stepsize satisfies Assumption 1. Then, either \(\textbf{g}_k = \textbf{0}\) for some finite k, or the sequence \(\{\Vert \textbf{g}_k\Vert \}\) converges to zero R-linearly.
Proof
Let \(G(k,\ell ):= \sum _{i=1}^{\ell }(\gamma _{i}^{k})^2\), \(\delta _1 = c_1^{\,2}\), \(\delta _2 = c_2^{\,2}\) and \(\delta = c^2\). In particular, notice that \(G(k,n) = \Vert \textbf{g}_k\Vert ^2\). Assume also that \(c_2> 1\), otherwise we would immediately conclude the proof due to Lemma 15.
Part I. First we prove that, for an integer \(1 \le \ell \le n-1\) and given \(k\ge 1\), if there exists some \(\varepsilon _\ell \in (0,M_2^{-1})\) and integer \(m_\ell\) such that
then there exists \(j_0 \in \{m_\ell , \dots , m_\ell + \Delta _\ell + 1\}\), with \(\Delta _\ell = \Delta _\ell (M_2, \varepsilon _\ell , \delta _2, \delta , m_\ell )\), such that
Assume that \((\gamma _{\ell +1}^{k+j})^2 > M_2\, \varepsilon _\ell \, \Vert \textbf{g}_k\Vert ^2\) for all \(j \in \{m_\ell , \dots , m_\ell +\Delta _\ell \}\). We show that the thesis holds for \(j_0 = m_\ell +\Delta _\ell + 1\). First, apply Lemma 12\(\Delta _\ell +1\) times, and Lemma 15\(m_\ell\) times to obtain
Then choose \(\Delta _\ell\) as the smallest integer that solves \(\delta ^{\Delta _\ell +1}\delta _2^{m_\ell } \le M_2\, \varepsilon _\ell\) (such \(\Delta _\ell\) exists due to the choice of \(\varepsilon _\ell\) and the fact that \(\delta < 1\)) and complete the first proof:
Part II. Let \(m_{\ell +1} = m_\ell + \Delta _\ell + 1\) and \(\varepsilon _{\ell +1} = (1+M_2\, \delta _2^2)\, \varepsilon _\ell\). If (25) holds, we show that
Since \(G(k+j, \ell +1) = G(k+j, \ell ) + (\gamma _{\ell +1}^{k+j})^2\) and \(m_{\ell +1} > m_\ell\), it is sufficient to prove that
From the first result, there are infinitely many pairs of indices \(j_1,j_2\) with \(j_2 \ge j_1 + 2 > j_1 \ge j_0 \ge m_\ell\) such that
From Lemma 12 it holds that \((\gamma _{\ell +1}^{k+j})^2 \le \delta \, (\gamma _{\ell +1}^{k+j-1})^2 < (\gamma _{\ell +1}^{k+j-1})^2\) for \(j \in \{j_1+3, \dots , j_2 + 1\}\), since \(\delta < 1\). This results in a chain of inequalities, halting at \(j = j_1 + 2\), which corresponds to the rightmost term; to get any further, we apply Lemma 15:
Note that the last inequality also holds when \(j = j_1,\,j_1+1\) (in place of \(j = j_1 + 2\)), since we assumed \(\delta _2 > 1\). Thus our conclusion is
Since \(j_1\) and \(j_2\) are chosen arbitrarily and \(j_0 \le m_{\ell +1}\), the result automatically holds for any \(j \ge m_{\ell +1}\).
Part III. Finally, we prove by induction that (25) holds for all \(1 \le \ell \le n\) with
For \(\ell = 1\) and from Lemma 14, the first component of the gradient satisfies \(G(k+j, 1) \le \delta _1^j \, \Vert \textbf{g}_k\Vert ^2\). As in the first step, we ask \(\delta _1^j \le \varepsilon _1\) and get \(j \ge m_1\), with \(m_1 = \lceil \frac{\log \varepsilon _1}{\log \delta _1}\rceil\). Once the thesis is true for some \(1 \le \ell \le n-1\), the second step shows that it also holds for \(\ell + 1\), with \(m_{\ell + 1} = m_\ell + \Delta _\ell + 1\) and \(\varepsilon _{\ell +1} = \frac{1}{4}\, (1 + M_2\, \delta _2^2)\, (1+M_2\, \delta _2^2)^{\ell -n}\). We can conclude that the thesis holds for \(\ell = n\), and thus
where \(m_n\) does not depend on k. Renumbering the indices as in [4] enables us to conclude that the \(\textbf{g}_k\) converge to zero R-linearly. \(\square\)
We remark that, when the objective function is quadratic, Theorem 16 shows that no line search is required to guarantee the convergence of the gradient method with TBB stepsizes. For generic unconstrained optimization problems, we add a line search procedure with a condition of sufficient decrease in the next section.
6 Generic nonlinear functions
We now turn our attention to generic (non-quadratic) continuous differentiable functions f. As the expression (4) is not suitable since the Hessian is usually not available, we use the generalization (6). Just as for the quadratic case (see Proposition 1), the well-known BB1 and BB2 stepsizes are retrieved for \(\tau _k \rightarrow \pm \infty\) and \(\tau _k = 0\), respectively. In the quadratic case, the secant equation \(\textbf{y}_{k-1} = B_k \textbf{s}_{k-1}\) holds for \(B_k \equiv A\), and this allows for the interpretation of BB steps and the TBB step as Rayleigh quotients of A. When f is a generic function, the average Hessian \(B_k = \int _0^1\nabla ^2f(\textbf{x}_{k-1} + t \, \textbf{s}_{k-1})\,dt\) satisfies the secant equation (cf., e.g., [18, Eq. (6.11)]), and thus we can still think at BB steps and the TBB step as Rayleigh quotients, which approximate the eigenvalues of this average \(B_k\) instead of the ones of \(\nabla ^2f(\textbf{x}_k)\). We note that, under the condition that \(B_k\) is SPD, all results of Sects. 3 and 4 continue to hold for generic functions when replacing A by \(B_k\).
Algorithm 2 shows a pseudocode for TBB-step methods for general nonlinear unconstrained optimization problems. As usual (cf., e.g., [2, Alg. 1]), unlike the quadratic case of Algorithm 1, safeguards are added for the steplength. We also include the nonmonotone line search strategy from [19] (see Line 2). Line 3 features a well-known condition of sufficient decrease, where we take the common values of the line search parameters \(c_{\mathrm{{ls}}} = 10^{-4}\), \(\sigma _{\mathrm{{ls}}} = \frac{1}{2}\) (cf. [18, p. 33]), and \(M = 10\) in the experiments. One of the key ingredients to prove the global convergence of Algorithm 2 is the existence of uniform bounds on the stepsize, i.e., \(\beta _{k}\in [\beta _{\min }, \beta _{\max }]\) for all k. Since the TBB stepsize (6) with safeguard lies in this interval, the convergence of the algorithm is guaranteed by [17, Thm. 2.1]. It is possible to show R-linear convergence of the algorithm for uniformly convex functions (cf. [20, Thm. 3.1, Eq. (31)]). We remark that the initial starting steplength in the nonmonotone line search is different from the algorithm in [17], and this might lead to a smaller number of backtracking steps.
The last two features that may significantly affect the speed of the algorithm are the initial stepsize, and the treatment of uphill directions, or, equivalently, negative steplengths. Popular choices for the initial stepsize are \(\beta _{0} = 1\) (cf., e.g., [2, 17]) or \(\beta _{0} = \Vert \textbf{g}_0\Vert ^{-1}\) (cf., e.g., [16]), where the norm is the Euclidean norm or the \(\infty\)-norm. Line 8 deals with possible uphill directions: when \(\textbf{s}_{k-1}^T\textbf{y}_{k-1} < 0\), \(B_k\) is not SPD, and thus all the properties studied in Sects. 3–5 do not necessarily hold. The TBB step may still be positive for some target values, but does not have a clear connection to the eigenvalues of \(B_k\). In fact, when \(\textbf{s}_{k-1}^T\textbf{y}_{k-1} < 0\), the TBB steps (including the BB steps) render a negative approximation of the inverse eigenvalues of \(B_k\). Therefore, the tentative \(\beta _{k}\) is replaced by a certain \(\widehat{\beta }_{k} > 0\). A possible choice is \(\widehat{\beta }_{k} \equiv \beta _{\max }\) (see, e.g., [2]), but this stepsize may be huge and might cause overflow problems. Raydan [17] proposes to set \(\widehat{\beta }_{k} = \max (\min (\Vert \textbf{g}_k\Vert _2^{-1}, \, 10^{5}), \ 1)\), which is an attempt to move away from the uphill direction, while keeping \(\Vert \widehat{\beta }_k\, \textbf{g}_k\Vert\) moderate. Others (e.g., [11, 21]) simply use \(\widehat{\beta }_k = \Vert \textbf{g}_k\Vert ^{-1}\), as it is done for the first stepsize. There is also an interesting alternative of [22] that reuses the previous steplength \(\widehat{\beta }_k = \beta _{k-1}\); this strategy resembles the cyclic gradient method, where the same BB stepsize is reused for several iterations [21].

Algorithms 1 and 2 can be combined with preconditioning or scaling. Scaling may be viewed as the simplest case of preconditioning, that is, by a diagonal SPD matrix. Scaling is a powerful and efficient technique; we refer to [23] for scaling techniques for unconstrained optimization problems. The combination of preconditioning and BB steps for quadratic problems has been discussed in [24]. The use of scaling or more general preconditioning is outside the scope of this paper.
7 Numerical experiments
We test various target strategies on strictly convex quadratics (Algorithm 1) and generic differentiable functions (Algorithm 2). The purpose of these experiments is to show numerically that the introduction of an adaptive target in the stepsizes (4) can sometimes lead to better convergence results, in terms of number of iterations and function evaluations. For non-convex problems, we also observe that different targets can sometimes detect different local optima.
7.1 Sweeping the spectrum of the Hessian matrix
Given the recursive definition of the gradient (19) for quadratic problems, one can see that if a stepsize sweeps the spectrum of the Hessian matrix appropriately, then the convergence of the corresponding gradient method is faster. Before moving to a detailed analysis of the performances of different stepsizes, we illustrate the sweeping capability of each steplength on the three quadratic problems proposed by [2], QP1, QP2 and QP3, in the same setting as [2]. All three problems have a diagonal Hessian with eigenvalues \(0 < \lambda _1 \le \dots \le \lambda _n\). The eigenvalues of QP1 follow the asymptotic distribution of the eigenvalues of a class of covariance matrices; those of QP2 are such that the ratio between two consecutive eigenvalues is constant. In the last problem, eigenvalues are clustered in two groups; see [2] for further details. Table 1 reports all the implemented target strategies, divided into three groups: known schemes from the literature, positive targets, and (negative) targets inspired by the cotangent function. The stepsizes studied throughout this section are summarized in Table 1.
We also consider two effective variants of ABB, which we indicate with \(\text {ABB}_{\text {min}}\) [13] and \(\text {ABB}_{\text {bon}}\) [14]. In the first one, we take the smallest BB2 stepsize over the last \(m+1\) iterations, when \(\cos ^2(\textbf{s}_{k-1},\textbf{y}_{k-1})\) is small:
\(\text {ABB}_{\text {bon}}\) is defined in the same way as \(\text {ABB}_{\text {min}}\) but with an adaptive threshold \(\eta\): starting from \(\eta _0 = 0.5\), this is updated as
With respect to the positive targets, Remark 13 suggests the use of \(\rho > 2\) in (14) to ensure the convergence of the corresponding gradient method for quadratic functions. The aim of setting \(\rho = 2.01\) is to stay close to this lower bound and take the largest possible stepsizes (which are larger than \(\beta ^{\textrm{BB1}}_k\)). An approach with \(\rho = 100\) picks positive targets \(\tau _k\) such that the corresponding stepsize \(\beta _{k}\) is close to, but still larger than \(\beta ^{\textrm{BB1}}_k\).
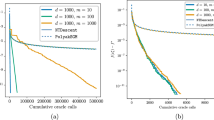
Figure 2 shows the inverse stepsize value \(\alpha _k\) through the iterations for QP1, QP2 and QP3. For each problem, we select the four stepsizes that require the smallest number of iterations for the convergence. All stepsizes seem to explore the whole spectrum in all problems, but in different ways. The two variants of ABB, \(\text {ABB}_{\text {min}}\) and \(\text {ABB}_{\text {bon}}\), perform well in all three problems. As a result of their definition, they both tend to recycle the same stepsize for some consecutive iterations. Interestingly, they gradually cancel the gradient components corresponding to the largest eigenvalues of the Hessian. This feature is particularly clear in QP2: since some gradient components are annihilated at some stage, in the latest iterations the stepsizes are concentrated only in the eigenvalues corresponding to the remaining gradient components. The stepsize COT H1 to some extent shows the same behavior in QP2.
Other stepsize strategies do not explicitly remove some of the gradient components in an early phase, but still show a comparable number of iterations.

Inverse stepsize \(\alpha _k\) per iteration. Gray lines correspond to 21 equally spaced eigenvalues of the Hessian, including the smallest and the largest, for the three quadratic problems QP1–QP3. Stepsizes are ordered based on the (increasing) number of iterations of the corresponding gradient method
7.2 Strictly convex quadratic functions
For the problems of the form (1), we take examples from the SuiteSparse Matrix Collection [25]. The selected matrices A are 65 symmetric positive definite matrices with a number of rows between \(10^2\) and \(10^4\), and an estimated condition number \(\le 10^{8}\) (the condition number is estimated via the routine condest in the Matrix R package). The vector \(\textbf{b}\) is chosen so that the solution of \(A\textbf{x}= \textbf{b}\) is \(\textbf{x}^*= \textbf{e}\), the vector of all ones. For all problems, the starting vector is \(\textbf{x}_0 = -10\,\textbf{e}\), and the initial stepsize is \(\beta _{0} = 1\). The algorithm stops when \(\Vert \textbf{g}_k\Vert \le \textsf{tol}\,\Vert \textbf{g}_0\Vert\) with \(\textsf{tol} = 10^{-6}\), or when \(5\cdot 10^4\) iterations are reached. The problem nos4 is scaled by the Euclidean norm of the first gradient.
We compare the performances of the different stepsizes in Table 1 by means of a performance profile [26]. The cost of solving each problem is normalized based on the minimum cost for that problem, to get the performance ratio [26]. The most efficient method solves the given problem with performance ratio 1, while all other methods solve it with a performance ratio at least 1. We plot the ratio of problems solved by a method within a certain factor of the smallest cost; this results in a cumulative distribution for each method. The algorithms are rated based on the maximum cost that one is willing to pay to get convergence. An infinite cost is assigned whenever a method is not able to solve a problem to the tolerance within the maximum number of iterations.
Given a problem, the cost of each gradient method differs only in the computation of the stepsize. For the computation of (4), we exploit the fact that \(\textbf{s}_k = -\beta _k\textbf{g}_k\) (cf. Algorithm 1) and that the stopping criterion is based on \(\Vert \textbf{g}_k\Vert\). The TBB step requires the additional computation of \(\textbf{g}_k^T\textbf{y}_k\) and \(\Vert \textbf{y}_k\Vert\) and therefore takes two extra inner products. ABB, the ABB variants and BB2 need the same quantities, while BB1 is slightly less expensive, with only one extra inner product. Moreover, computing a gradient is usually (much) more expensive than determining the stepsize. As a consequence, the various methods have approximately the same computational cost per iteration. In addition, in the quadratic case we do not employ a line search procedure, thus we take the number of iterations as the basis of our performance profile.

Performance profile for strictly convex quadratic problems, based on the number of iterations
Figure 3 displays the performance profile of the different stepsizes, based on the number of iterations. The performance ratio is considered in the interval \([1,\, 3]\). It is evident that the ABB variants perform much better than all other stepsizes. The stepsizes proposed in this paper are comparable with BB1, BB2, and ABB. One reason for this behavior may be that the ABB variants are especially favorable to quadratic problems: in fact, when the Hessian matrix is constant, previous BB2 stepsizes still approximate some eigenvalue of the current Hessian. This is no longer true for the generic problems: as a consequence, we will see that, in that case, the ABB variants have similar performances compared to the other stepsizes.
The COT 11 step for a performance ratio \(\le 1.5\) and the IBB2 2.01 step for \([1.5,\,3]\) perform better than the other TBB steplengths; the latter one competes with COT 1H, and COT 12 in different segments of its interval. Nevertheless, while IBB2 2.01 solves slightly more than \(80\,\%\) of the problems with a performance ratio \(\le 3\), \(\text {ABB}_{\text {bon}}\) manages to solve all problems within the same range.
Since we study the performance ratio in a restricted range, we also collect some summary information in Table 2. It is interesting to notice that the minimum performance ratio is 1 for all stepsizes: this means that for each stepsize there is at least one problem where that stepsize performs at least as well as the others. The ABB variants appear to be more robust than the other stepsizes, followed by BB1 and the class of TBB steps with positive target. The steplength \(\text {ABB}_{\text {min}}\) solves the highest proportion of problems at the lowest cost.
7.3 Unconstrained optimization
We take some generic differentiable functions from the collections in [17, 27, 28] and the suggested starting points \(\textbf{x}_0\) therein, as listed in Table 3. For Griewank’s function we choose \(\textbf{x}_0 = \textbf{e}\). For each problem, we also consider the starting points \(5\,\textbf{x}_0\) and \(10\,\textbf{x}_0\), in line with [28].
For all the test functions, we pick \(n = 100\) variables. The generalized Rosenbrock, generalized White and Holst and extended Powell objective functions have been scaled by the Euclidean norm of the first gradient.
The gradient method for unconstrained optimization problems requires the tuning of more parameters than the gradient method for quadratic functions. We maintain the choices made in [2] and set \(\beta _{\min } = 10^{-30}\), \(\beta _{\max } = 10^{30}\), \(c_{\mathrm{{ls}}} = 10^{-4}\), \(\sigma _{\mathrm{{ls}}} = \frac{1}{2}\), \(M = 10\), and \(\beta _{0} = 1\). Although one might argue that the bounds on the stepsize are extremely large, the aim of this choice is to accept the BB stepsize as frequently as possible. Following Raydan [17], we choose \(\widehat{\beta }_k = \max (\min (\Vert \textbf{g}_k\Vert _2^{-1}, \, 10^{5}), \ 1)\) as the replacement for negative stepsizes. Although the alternative of recycling the last positive stepsize also seems plausible, in our experiments we find that this strategy may lead to poor performance for some stepsizes. Raydan’s rule seems to behave well in combination with all stepsizes. Again the algorithm stops when \(\Vert \textbf{g}_k\Vert \le \textsf{tol}\,\Vert \textbf{g}_0\Vert\), or when \(5\cdot 10^4\) iterations are reached. We show the results for three levels of tolerance \(\textsf{tol} \in \{10^{-4},\,10^{-6},\,10^{-8}\}\). All different steps in Table 1 are tested.
Since some test problems are non-convex, we check whether all gradient methods converged to the same stationary point for different stepsizes. For this reason, the following analysis will not include Broyden tridiagonal, extended Freudenstein and Roth, generalized tridiagonal 2, Griewank, trigonometric.
Remark 17
Aside the computational cost of an algorithm, the quality of the reached minimum is also an important aspect. In this context, it is interesting to notice that in the extended Freudenstein and Roth function, for the setting \(\textsf{tol} = 10^{-8}\) and starting point \(\textbf{x}_0\), the choice of IBB2 2.01 leads to the global optimum \(f = 0\), while all the other gradient methods converge to \(f \approx 1225\). The convergence of IBB2 2.01 takes approximately seven times the number of function evaluations of the fastest method, but the gradient method finds a better solution.
As the performance profile, we may consider two different costs: the number of function evaluations and the number of iterations. The latter corresponds to the number of gradient evaluations, since the line search in Algorithm 2 does not require the computation of the gradient at the new tentative iterate. Our comparison is on the number of function evaluations, since this is the dominant cost for our test cases. The performance profiles are shown in Fig. 4 in the range \([1,\,3]\), for the number of function evaluations, and various tolerances and starting points.

Performance profiles for generic unconstrained optimization problems, based on the number of function evaluations. Each set of performance profiles considers a different \(\textsf{tol}\in \{10^{-4},\,10^{-6},\,10^{-8}\}\) (columns) and starting point \(\{\textbf{x}_0,\,5\,\textbf{x}_0,\,10\,\textbf{x}_0\}\) (rows)
As the tolerance decreases, from left to right, we notice that the performance profiles become more distinct. In contrast with the performance profile for the quadratic case, here the ABB variants are not as prominent as before. We can still distinguish their curves, along with the one of BB2, when \(\textsf{tol} = 10^{-8}\) and the starting points are either \(\textbf{x}_0\) or \(5\,\textbf{x}_0\). The situation changes when the starting point is \(10\,\textbf{x}_0\): especially when \(\textsf{tol} = 10^{-6}\), the ABB variants are mixed with some curves of the cotangent family when the performance ratio is \(\le 1.5\). Then all curves of the cotangent family display more favorable behavior than the rest of the curves.
As in the quadratic case, Table 4 report some statistics on the performance ratios, based on the number of function evaluations, for \(\textsf{tol} = 10^{-6}\). As the performance profiles already suggested, when the starting point is \(\textbf{x}_0\), the \(\text {ABB}_{\text {min}}\) is the best stepsize in terms of proportion of solved problems, and problems solved at minimum cost. The BB2 step is the best method when the starting point is \(5\,\textbf{x}_0\), immediately followed by \(\text {ABB}_{\text {min}}\). Finally, for the problems with \(10\,\textbf{x}_0\), the picture changes: COT 11 and COT H1 are the best stepsizes, followed by BB2, but this time the range of BB2 is larger compared to the previous tables. As a consequence, \(\text {ABB}_{\text {min}}\) and \(\text {ABB}_{\text {bon}}\) solve a smaller proportion of problems at minimum cost.
We have just shown that, as opposed to the quadratic case, there are situations where the TBB steps from the cotangent family show better performance than the ABB variants. In general, we observe that the stepsizes IBB2 100 and ITER are competitive with the BB1 step; IBB2 2.01 performs slightly worse, but this behavior can sometimes lead to better local optima (cf. Remark 17).
8 Conclusions
We have developed a harmonic framework for stepsize selection in gradient methods for unconstrained nonlinear optimization. The harmonic steplength (4) depending on targets \(\tau _k\) is inspired by the harmonic Rayleigh–Ritz extraction for matrix eigenvalue problems.
The one-to-one relation between target and stepsize gives a general framework with new viewpoints and interpretations. Compared to the eigenproblem context, where the target is commonly chosen inside the spectrum, in our situation we have studied both strategies with the target outside the spectrum and schemes that sometimes pick the target inside. Targets on the negative real axis lead to stepsizes between BB2 and BB1. This yields connection with schemes such as [12]. We have analyzed and extended the popular ABB method. While the original ABB approach only allows a choice between two stepsizes based on a single parameter, we have introduced a new competitive family of stepsizes with tunable parameters, that enjoy the same key idea but are more flexible. Additionally, we have considered new families of positives targets, leading to steplengths larger than the BB1 steps. The use of harmonic stepsizes with target requires the same cost as the BB2 step, ABB, and ABB variants, and is only marginally more expensive than BB1. The experiments suggest that both the cotangent family and the approaches with positive targets seem competitive with the well-known BB stepsizes and ABB; they compete also with the ABB variants [13, 14] for generic unconstrained optimization problems.
For an analysis of the new schemes, we have extended convergence results from Dai and Liao [4] in Sect. 5. In view of the TBB steps, instead of \(\lambda _1 \le \alpha _k \le \lambda _n\), we have studied the more general setting \(\xi _{\textrm{low}}\, \lambda _1 \le \alpha _k \le \xi ^{\textrm{up}}\, \lambda _n\), particularly for \(\frac{1}{2} < \xi _{\textrm{low}}\le 1\) and \(\xi ^{\textrm{up}}\ge 1\).
An R implementation of the methods described in this paper can be obtained from github.com/gferrandi/tbbr.
Data Availability
The data used during the current study are available in the SuiteSparse Matrix Collection repository, sparse.tamu.edu.
References
Barzilai, J., Borwein, J.M.: Two-point step size gradient methods. IMA J. Numer. Anal. 8(1), 141–148 (1988)
Di Serafino, D., Ruggiero, V., Toraldo, G., Zanni, L.: On the steplength selection in gradient methods for unconstrained optimization. Appl. Math. Comput. 318, 176–195 (2018)
Zhou, B., Gao, L., Dai, Y.H.: Gradient methods with adaptive step-sizes. Comput. Optim. Appl. 35(1), 69–86 (2006)
Dai, Y.H., Liao, L.Z.: R-linear convergence of the Barzilai and Borwein gradient method. IMA J. Numer. Anal. 22(1), 1–10 (2002)
Morgan, R.B.: Computing interior eigenvalues of large matrices. Linear Algebra Appl. 154, 289–309 (1991)
Paige, C.C., Parlett, B.N., van der Vorst, H.A.: Approximate solutions and eigenvalue bounds from Krylov subspaces. Numer. Linear Algebra Appl. 2(2), 115–133 (1995)
Stewart, G.W.: Matrix Algorithms, vol. II. SIAM, Philadelphia, PA (2001)
Hochstenbach, M.E.: Generalizations of harmonic and refined Rayleigh-Ritz. Electron. Trans. Numer. Anal. 20, 235–252 (2005)
Parlett, B.N.: The Symmetric Eigenvalue Problem. SIAM, Philadelphia, PA (1998)
Friedlander, A., Martínez, J.M., Molina, B., Raydan, M.: Gradient method with retards and generalizations. SIAM J. Numer. Anal. 36(1), 275–289 (1998)
Huang, Y., Dai, Y., Liu, X., Zhang, H.: On the acceleration of the Barzilai–Borwein method. Comput. Optim. Appl. 81(3), 717–740 (2022)
Dai, Y.H., Huang, Y., Liu, X.W.: A family of spectral gradient methods for optimization. Comput. Optim. Appl. 74(1), 43–65 (2019)
Frassoldati, G., Zanni, L., Zanghirati, G.: New adaptive stepsize selections in gradient methods. J. Ind. Manag. 4(2), 299 (2008)
Bonettini, S., Zanella, R., Zanni, L.: A scaled gradient projection method for constrained image deblurring. Inverse Probl. 25(1), 015002 (2009)
Raydan, M.: On the Barzilai and Borwein choice of steplength for the gradient method. IMA J. Numer. Anal. 13(3), 321–326 (1993)
Dai, Y.H.: Alternate step gradient method. Optimization 52(4–5), 395–415 (2003)
Raydan, M.: The Barzilai and Borwein gradient method for the large scale unconstrained minimization problem. SIAM J. Optim. 7(1), 26–33 (1997)
Nocedal, J., Wright, S.J.: Numerical Optimization, 2nd edn. Springer, New York (2006)
Grippo, L., Lampariello, F., Lucidi, S.: A nonmonotone line search technique for Newton’s method. SIAM J. Numer. Anal. 23(4), 707–716 (1986)
Dai, Y.H.: On the nonmonotone line search. J. Optim. Theory Appl. 112(2), 315–330 (2002)
Dai, Y.H., Hager, W.W., Schittkowski, K., Zhang, H.: The cyclic Barzilai–Borwein method for unconstrained optimization. IMA J. Numer. Anal. 26(3), 604–627 (2006)
Park, Y., Dhar, S., Boyd, S., Shah, M.: Variable metric proximal gradient method with diagonal Barzilai–Borwein stepsize. In: ICASSP 2020, pp. 3597–3601 (2020)
Luengo, F., Raydan, M., Glunt, W., Hayden, T.L.: Preconditioned spectral gradient method. Numer. Algorithms 30(3), 241–258 (2002)
Molina, B., Raydan, M.: Preconditioned Barzilai–Borwein method for the numerical solution of partial differential equations. Numer. Algorithms 13(1), 45–60 (1996)
Davis, T.A., Hu, Y.: The University of Florida sparse matrix collection. ACM Trans. Math. Softw. 38(1), 1–25 (2011)
Dolan, E.D., Moré, J.J.: Benchmarking optimization software with performance profiles. Math. Program. 91(2), 201–213 (2002)
Andrei, N.: An unconstrained optimization test functions collection. Adv. Model. Optim 10(1), 147–161 (2008)
Moré, J.J., Garbow, B.S., Hillstrom, K.E.: Testing unconstrained optimization software. ACM Trans. Math. Softw. 7(1), 17–41 (1981)
Griewank, A.O.: Generalized descent for global optimization. J. Optim. Theory Appl. 34(1), 11–39 (1981)
Acknowledgements
The authors thank the referees and editor for their very useful comments. This work has received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No 812912.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ferrandi, G., Hochstenbach, M.E. & Krejić, N. A harmonic framework for stepsize selection in gradient methods. Comput Optim Appl 85, 75–106 (2023). https://doi.org/10.1007/s10589-023-00455-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-023-00455-6
Keywords
- Unconstrained optimization
- Harmonic Rayleigh quotient
- Gradient methods
- Framework for steplength selection
- ABB method
- Hessian spectral properties