
Abstract
The study of Frank-Wolfe (FW) variants is often complicated by the presence of different kinds of “good” and “bad” steps. In this article, we aim to simplify the convergence analysis of specific variants by getting rid of such a distinction between steps, and to improve existing rates by ensuring a non-trivial bound at each iteration. In order to do this, we define the Short Step Chain (SSC) procedure, which skips gradient computations in consecutive short steps until proper conditions are satisfied. This algorithmic tool allows us to give a unified analysis and converge rates in the general smooth non convex setting, as well as a linear convergence rate under a Kurdyka-Łojasiewicz (KL) property. While the KL setting has been widely studied for proximal gradient type methods, to our knowledge, it has never been analyzed before for the Frank-Wolfe variants considered in the paper. An angle condition, ensuring that the directions selected by the methods have the steepest slope possible up to a constant, is used to carry out our analysis. We prove that such a condition is satisfied, when considering minimization problems over a polytope, by the away step Frank-Wolfe (AFW), the pairwise Frank-Wolfe (PFW), and the Frank-Wolfe method with in face directions (FDFW).


Similar content being viewed by others


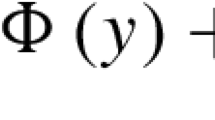
Data availability.
The data analysed during the current study are available in the 2nd DIMACS implementation challenge repository, http://archive.dimacs.rutgers.edu/pub/challenge/graph/benchmarks/clique/
References
Frank, M., Wolfe, P.: An algorithm for quadratic programming. Naval Res. Logist. Q. 3(1–2), 95–110 (1956)
Freund, R.M., Grigas, P., Mazumder, R.: An extended Frank-Wolfe method with in-face directions, and its application to low-rank matrix completion. SIAM J. Opt. 27(1), 319–346 (2017)
Lacoste-Julien, S., Jaggi, M.: On the global linear convergence of frank-wolfe optimization variants. Adv. Neural Inform. Process. Syst. 28, 496–504 (2015)
Berrada, L., Zisserman, A., Kumar, M.P.: Deep Frank-Wolfe for neural network optimization. In: International conference on learning representations (2018)
Jaggi, M.: Revisiting Frank-Wolfe: Projection-free sparse convex optimization. In: Proceedings of the 30th international conference on machine learning, pp. 427–435 (2013)
Joulin, A., Tang, K., Fei-Fei, L.: Efficient image and video co-localization with Frank-Wolfe algorithm. In: European conference on computer vision, pp. 253–268 (2014). Springer
Osokin, A., Alayrac, J.-B., Lukasewitz, I., Dokania, P., Lacoste-Julien, S.: Minding the gaps for block frank-wolfe optimization of structured svms. In: international conference on machine learning, pp. 593–602 (2016). PMLR
Canon, M.D., Cullum, C.D.: A tight upper bound on the rate of convergence of Frank-Wolfe algorithm. SIAM J. Control 6(4), 509–516 (1968)
Wolfe, P.: Convergence theory in nonlinear programming. Integer and nonlinear programming, 1–36 (1970)
Kolmogorov, V.: Practical Frank-Wolfe algorithms. arXiv preprint arXiv:2010.09567 (2020)
Braun, G., Pokutta, S., Tu, D., Wright, S.: Blended conditonal gradients. In: nternational conference on machine learning, pp. 735–743 (2019). PMLR
Braun, G., Pokutta, S., Zink, D.: Lazifying conditional gradient algorithms. In: ICML, pp. 566–575 (2017)
Beck, A., Shtern, S.: Linearly convergent away-step conditional gradient for non-strongly convex functions. Math. Program. 164(1–2), 1–27 (2017)
Kerdreux, T., d’Aspremont, A., Pokutta, S.: Restarting Frank-Wolfe. In: The 22nd international conference on artificial intelligence and statistics, pp. 1275–1283 (2019). PMLR
Hazan, E., Luo, H.: Variance-reduced and projection-free stochastic optimization. In: international conference on machine learning, pp. 1263–1271 (2016)
Lan, G., Zhou, Y.: Conditional gradient sliding for convex optimization. SIAM J. Opt. 26(2), 1379–1409 (2016)
Combettes, C.W., Pokutta, S.: Boosting Frank-Wolfe by chasing gradients. arXiv preprint arXiv:2003.06369 (2020)
Mortagy, H., Gupta, S., Pokutta, S.: Walking in the shadow: A new perspective on descent directions for constrained minimization. Advances in neural information processing systems 33 (2020)
Lacoste-Julien, S.: Convergence rate of Frank-Wolfe for non-convex objectives. arXiv preprint arXiv:1607.00345 (2016). Accessed 2020-08-03
Bomze, I.M., Rinaldi, F., Zeffiro, D.: Active set complexity of the away-step Frank-Wolfe algorithm. SIAM J. Opt. 30(3), 2470–2500 (2020)
Qu, C., Li, Y., Xu, H.: Non-convex conditional gradient sliding. In: international conference on machine learning, pp. 4208–4217 (2018). PMLR
Attouch, H., Bolte, J., Redont, P., Soubeyran, A.: Proximal alternating minimization and projection methods for nonconvex problems: An approach based on the Kurdyka-Łojasiewicz inequality. Math. Operat. Res. 35(2), 438–457 (2010)
Bolte, J., Daniilidis, A., Lewis, A., Shiota, M.: Clarke subgradients of stratifiable functions. SIAM J. Opt. 18(2), 556–572 (2007)
Bolte, J., Daniilidis, A., Ley, O., Mazet, L.: Characterizations of Łojasiewicz inequalities: subgradient flows, talweg, convexity. Transact. Am. Math. Soc. 362(6), 3319–3363 (2010)
Attouch, H., Bolte, J., Svaiter, B.F.: Convergence of descent methods for semi-algebraic and tame problems: proximal algorithms, forward-backward splitting, and regularized Gauss-Seidel methods. Math. Program. 137(1–2), 91–129 (2013)
Bolte, J., Nguyen, T.P., Peypouquet, J., Suter, B.W.: From error bounds to the complexity of first-order descent methods for convex functions. Math. Program. 165(2), 471–507 (2017)
Wang, Y., Yin, W., Zeng, J.: Global convergence of admm in nonconvex nonsmooth optimization. J. Sci. Comput. 78(1), 29–63 (2019)
Xu, Y., Yin, W.: A block coordinate descent method for regularized multiconvex optimization with applications to nonnegative tensor factorization and completion. SIAM J. Imag. Sci. 6(3), 1758–1789 (2013)
Absil, P.-A., Mahony, R., Andrews, B.: Convergence of the iterates of descent methods for analytic cost functions. SIAM J. Opt. 16(2), 531–547 (2005)
Grippo, L., Lampariello, F., Lucidi, S.: A nonmonotone line search technique for newton’s method. SIAM J. Num. Anal. 23(4), 707–716 (1986)
Zhang, L., Zhou, W., Li, D.-H.: A descent modified Polak-Ribière-Polyak conjugate gradient method and its global convergence. IMA J. Num. Anal. 26(4), 629–640 (2006)
Kolda, T.G., Lewis, R.M., Torczon, V.: Stationarity results for generating set search for linearly constrained optimization. SIAM J. Opt. 17(4), 943–968 (2007)
Lewis, R.M., Shepherd, A., Torczon, V.: Implementing generating set search methods for linearly constrained minimization. SIAM J. Sci. Comput. 29(6), 2507–2530 (2007)
Garber, D., Meshi, O.: Linear-memory and decomposition-invariant linearly convergent conditional gradient algorithm for structured polytopes. Adv. neural Inform. Process. syst. 29 (2016)
Guelat, J., Marcotte, P.: Some comments on Wolfe’s away step. Math. Program. 35(1), 110–119 (1986)
Rinaldi, F., Zeffiro, D.: A unifying framework for the analysis of projection-free first-order methods under a sufficient slope condition. arXiv preprint arXiv:2008.09781 (2020)
Absil, P.-A., Malick, J.: Projection-like retractions on matrix manifolds. SIAM J. Opt. 22(1), 135–158 (2012)
Balashov, M.V., Polyak, B.T., Tremba, A.A.: Gradient projection and conditional gradient methods for constrained nonconvex minimization. Num. Funct. Anal. Opt. 41(7), 822–849 (2020)
Levy, K., Krause, A.: Projection free online learning over smooth sets. In: The 22nd international conference on artificial intelligence and statistics, pp. 1458–1466 (2019)
Johnell, C., Chehreghani, M.H.: Frank-Wolfe optimization for dominant set clustering. arXiv preprint arXiv:2007.11652 (2020)
Cristofari, A., De Santis, M., Lucidi, S., Rinaldi, F.: An active-set algorithmic framework for non-convex optimization problems over the simplex. Comput. Opt. Appl. 77, 57–89 (2020)
Nutini, J., Schmidt, M., Hare, W.: “Active-set complexity” of proximal gradient: How long does it take to find the sparsity pattern? Opt. Lett. 13(4), 645–655 (2019)
Bomze, I.M., Rinaldi, F., Bulo, S.R.: First-order methods for the impatient: support identification in finite time with convergent Frank-Wolfe variants. SIAM J. Opt. 29(3), 2211–2226 (2019)
Garber, D.: Revisiting Frank-Wolfe for polytopes: Strict complementary and sparsity. arXiv preprint arXiv:2006.00558 (2020)
Rockafellar, R.T., Wets, R.J.-B.: Variational Analysis, vol. 317. Springer, Berlin (2009)
Karimi, H., Nutini, J., Schmidt, M.: Linear convergence of gradient and proximal-gradient methods under the Polyak-Łojasiewicz condition. In: Joint European conference on machine learning and knowledge discovery in databases, pp. 795–811 (2016). Springer
Lojasiewicz, S.: Une propriété topologique des sous-ensembles analytiques réels. Les équations aux dérivées partielles 117, 87–89 (1963)
Polyak, B.T.: Gradient methods for the minimisation of functionals. USSR Comput. Math. Math. Phys. 3(4), 864–878 (1963)
Luo, Z.-Q., Tseng, P.: Error bounds and convergence analysis of feasible descent methods: a general approach. Annal. Operat. Res. 46(1), 157–178 (1993)
Li, G., Pong, T.K.: Calculus of the exponent of Kurdyka-Łojasiewicz inequality and its applications to linear convergence of first-order methods. Found. Comput. Math. 18(5), 1199–1232 (2018)
Bashiri, M.A., Zhang, X.: Decomposition-invariant conditional gradient for general polytopes with line search. In: Advances in neural information processing systems, pp. 2690–2700 (2017)
Rademacher, L., Shu, C.: The smoothed complexity of Frank-Wolfe methods via conditioning of random matrices and polytopes. arXiv preprint arXiv:2009.12685 (2020)
Peña, J., Rodriguez, D.: Polytope conditioning and linear convergence of the Frank-Wolfe algorithm. Math. Oper. Res. 44(1), 1–18 (2018)
Pedregosa, F., Negiar, G., Askari, A., Jaggi, M.: Linearly convergent Frank-Wolfe with backtracking line-search. In: International conference on artificial intelligence and statistics, pp. 1–10 (2020). PMLR
Bolte, J., Sabach, S., Teboulle, M.: Proximal alternating linearized minimization for nonconvex and nonsmooth problems. Math. Program. 146(1), 459–494 (2014)
Alexander, R.: The width and diameter of a simplex. Geometriae Dedicata 6(1), 87–94 (1977)
Gritzmann, P., Lassak, M.: Estimates for the minimal width of polytopes inscribed in convex bodies. Discret. Comput. Geometry 4(6), 627–635 (1989)
Jiang, R., Li, X.: Hölderian error bounds and kurdyka-łojasiewicz inequality for the trust region subproblem. Math. Operat. Res. (2022)
Truemper, K.: Unimodular matrices of flow problems with additional constraints. Networks 7(4), 343–358 (1977)
Bomze, I.M., Rinaldi, F., Zeffiro, D.: Frank–wolfe and friends: a journey into projection-free first-order optimization methods. 4OR 19(3), 313–345 (2021)
Tamir, A.: A strongly polynomial algorithm for minimum convex separable quadratic cost flow problems on two-terminal series-parallel networks. Math. Program. 59, 117–132 (1993)
Bomze, I.M.: Evolution towards the maximum clique. J. Global Opt. 10(2), 143–164 (1997)
Johnson, D.S.: Cliques, coloring, and satisfiability: second dimacs implementation challenge. DIMACS Series Discrete Math. Theoretical Comput. Sci. 26, 11–13 (1993)
Bertsekas, D.P., Scientific, A.: Convex Optimization Algorithms. Athena Scientific Belmont, Nashua (2015)
Burke, J.V., Moré, J.J.: On the identification of active constraints. SIAM J. Num. Anal. 25(5), 1197–1211 (1988)
Kadelburg, Z., Dukic, D., Lukic, M., Matic, I.: Inequalities of Karamata, Schur and Muirhead, and some applications. Teach. Math. 8(1), 31–45 (2005)
Karamata, J.: Sur une inégalité relative aux fonctions convexes. Publications de l’Institut Mathématique 1(1), 145–147 (1932)
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest.
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 KL property
We state here a result showing an implication between the (global) PL property used in [46] and (2.2). We first recall the PL property used in [46]:
with \(f^*\) optimal value of f with non empty solution set \(\mathcal {X}^*\).
Proposition 8.1
If f is convex, the optimal solution set \(\mathcal {X}^*\) of f is contained in \(\Omega \) and (8.1) holds, then (2.2) holds for every \(x \in \Omega \).
Proof
By [46, Theorem 2] the PL property is equivalent, for convex objectives, to the unconstrained quadratic growth condition:
In turn, given that by the assumption \(\mathcal {X}^* \subset \Omega \) the set \(\mathcal {X}^*\) is the solution set for \(f_{\Omega }\) as well, (8.2) implies the global non smooth Holderian error bound condition from [26] with \(\varphi (t) = \sqrt{\frac{2t}{\mu }} \), and by [26, Corollary 6] this is equivalent to the KL property (2.2) holding globally on \(\Omega \). \(\square \)
Remark 4
We remark that without the assumption \(\mathcal {X}^* \subset \Omega \) the implication is no longer true even for convex objectives, a counter example being \(\Omega \) equal to the unitary ball and \(f((x^{(1)},..., x^{(n)})) = (x^{(1)} - 1)^2\). At the same time, the KL property we used does not imply the PL property in general, since the latter only deals with unconstrained minima.
1.2 Proofs
We report here the missing proofs. We start with the proof of Lemma 3.2.
Proof
By the standard descent lemma [64, Proposition 6.1.2],
and in particular
where we used \(\alpha _k \le \bar{\alpha }_k\) in the last inequality. This proves (3.13). \(\square \)
We now state a preliminary result needed to prove Proposition 2.2:
Proposition 8.2
Let C be a closed convex cone. For every \(y \in \mathbb {R}^n\)
As stated in [65] this is an immediate consequence of the Moreau-Yosida decomposition:
Proposition 2.2
First, by continuity of the scalar product we have
Since \(N_{\Omega }(\bar{x}) = T_{\Omega }(\bar{x})^*\) the first equality is exactly the one of Proposition 8.2 if \(g \notin N_{\Omega }(\bar{x})\), and it is trivial since both terms are clearly 0 if \(g \in N_{\Omega }(\bar{x})\).
It remains to prove
which is true by the Moreau - Yosida decomposition. \(\square \)
Proposition 4.1
Let \(B_j = \bar{B}_{\langle g, \hat{d}_j \rangle /L}(x_k)\) and let T be such that \(x_{k + 1} = y_T\).
Inequality (4.3) applied with \(j = T\) gives (4.5). Moreover, by taking \(\tilde{x}_k = y_{\tilde{T}}\) for some \(\tilde{T} \in [0:T]\) the conditions
are satisfied by Lemma 4.1 and (4.3).
Let now \(p_j = \Vert \pi (T_{\Omega }(y_j), -\nabla f(y_j))\Vert \) and \(\tilde{p}_j = \Vert \pi (T_{\Omega }(y_j), g)\Vert = \Vert \pi (T_{\Omega }(y_j), -\nabla f(x_k))\Vert \). We have
reasoning as for (3.17). We now distinguish four cases according to how the SSC terminates.
Case 1 \(T = 0\) or \(d_T = 0\). Since there are no descent directions \(x_{k + 1} = y_T\) must be stationary for the gradient g. Equivalently, \(\tilde{p}_T = \Vert \pi (T_{\Omega }(x_{k + 1}), g)\Vert = 0\). We can now write
where we used (8.7) in the first inequality and \(\tilde{p}_T = 0\) in the equality. Finally, it is clear that if \(T = 0\) then \(d_0 =0\), since \(y_0\) must be stationary for \(-g\).
Before examining the remaining cases we remark that if the SSC terminates in Phase II then \(\alpha _{T- 1} = \beta _{T-1}\) must be maximal w.r.t. the conditions \(y_T \in B_{T-1}\) or \(y_T \in \bar{B}\). If \(\alpha _{T-1} = 0\) then \(y_{T-1} = y_T\), and in this case we cannot have \(y_{T-1} \in \partial \bar{B}\), otherwise the SSC would terminate in Phase II of the previous cycle. Therefore necessarily \(y_T = y_{T-1} \in \text {int}(B_{T-1})^c\) (Case 2). If \(\beta _{T - 1} = \alpha _{T- 1} > 0\) we must have \(y_{T-1}\in \Omega _{T-1} = B_{T-1} \cap \bar{B}\), and \(y_T \in \partial B_{T - 1}\) (case 3) or \(y_T \in \partial \bar{B}\) (case 4) respectively.
Case 2 \(y_{T-1} = y_T \in \text {int}(B_{T-1})^c\). We can rewrite the condition as
Thus
where in the equality we used \(y_{T} = y_{T-1}\), the first inequality follows from (8.7) and again \(y_T = y_{T-1}\), the second from \(\frac{\langle g, \hat{d}_T \rangle }{\tilde{p}_T} \ge \text {DSB}_{\mathcal {A}}(\Omega , y_{T}, g) \ge \text {SB}_{\mathcal {A}}(\Omega ) = \tau \), and the third from (8.8). Then \(\tilde{x}_k = x_{k + 1} = y_T\) satisfies the desired conditions.
Case 3 \(y_T = y_{T - 1} + \beta _{T - 1} d_{T-1}\) and \(y_T \in \partial B_{T-1}\). Then from \(y_{T-1} \in B_{T-1}\) it follows
and \(y_T \in \partial B_{T-1}\) implies
Combining (8.10) with (8.11) we obtain
Thus
where we used (8.11), (8.12) in the last inequality and the rest follows reasoning as for (8.9). In particular we can take \(\tilde{x}_k = y_{T-1}\), where \(\Vert \tilde{x}_k - x_k\Vert \le \Vert x_{k + 1} - x_k\Vert \) by (8.12).
Case 4 \(y_T = y_{T - 1} + \beta _{T - 1} d_{T-1}\) and \(y_T \in \partial \bar{B}\).
The condition \(x_{k + 1} = y_T \in \bar{B}\) can be rewritten as
For every \(j \in [0:T]\) we have
We now want to prove that for every \(j \in [0:T]\)
Indeed, we have
where we used (8.13) in the first equality, (8.14) in the second, \(\langle g, d_j \rangle \ge 0\) for every j in the first inequality and \(y_j \in \bar{B}\) in the second inequality.
We also have
Thus for \(\tilde{T} \in \text {argmin}\left\{ \frac{\langle g, d_j \rangle }{\Vert d_j\Vert } \ \vert \ 0 \le j \le T-1 \right\} \)
where we used (8.16) in the first inequality and (8.13) in the second.
We finally have
where we used (8.15), (8.17) in the last inequality and the rest follows reasoning as for (8.9). In particular \(\tilde{x}_k = y_{\tilde{T}}\) satisfies the desired properties, where \(\Vert \tilde{x}_k - x_k\Vert \le \Vert x_{k + 1} - x_k\Vert \) by (8.15). \(\square \)
Proof of Proposition 4.3
Let T(k) be the number of iterates generated by the SSC at the step k in Phase II. For the AFW and the PFW, reasoning as in the proof of Proposition 4.2 we obtain that if the SSC does T(k) iterations, the number of active vertices decreases by at least \(T(k) - 2\). Then on the one hand
while on the other hand
Combining (8.18) and (8.19) and rearranging, we obtain:
and the desired result follows by taking the limit for \(k \rightarrow \infty \).
For the FDFW, notice that at every iteration the SSC performs a sequence of maximal in face steps terminated either by a Frank Wolfe step, after which \(\mathcal {F}(y_j)\) can increase of at most \(\Delta (\Omega )\), or by a non maximal in face step, after which \(\mathcal {F}(y_j)\) stays the same. In both cases, we have
Then,
and
The conclusion follows as for the AFW and the PFW. \(\square \)
Theorem 4.1
The sequence \(\{f(x_k)\}\) is decreasing by (4.5). Thus by compactness \(f(x_k) \rightarrow \tilde{f} \in \mathbb {R}\) and in particular \(f(x_k) - f(x_{k + 1}) \rightarrow 0\). So that by (4.5) also \(\Vert x_{k + 1} - x_k \Vert \rightarrow 0\). Let \(\{x_{k(i)}\} \rightarrow \tilde{x}^*\) be any convergent subsequence of \(\{x_k\}\). For \(\{\tilde{x}_k\}\) chosen as in the proof of Proposition 4.1 we have \(\Vert \tilde{x}_k - x_k\Vert \le \Vert x_{k+1} - x_k\Vert \) because \(\tilde{x}_k = y_T = x_k\) in case 1 and case 2, by (8.12) in case 3, and by (8.15) in case 4. Therefore
Furthermore, \(\Vert \pi (T_{\Omega }(\tilde{x}_{k(i)}), -\nabla f(\tilde{x}_{k(i)})))\Vert ~\le ~\frac{\Vert x_{k(i)+ 1} - x_{k(i) }\Vert }{K} \rightarrow 0 \) again by Proposition 4.1, so that \(\tilde{x}_{k(i)} \rightarrow \tilde{x}^*\) with \(\Vert \pi (T_{\Omega }(\tilde{x}_{k(i)}), -\nabla f(\tilde{x}_{k(i)}))\Vert \rightarrow 0\). Then \(\Vert \pi (T_{\Omega }(\tilde{x}^*), -\nabla f(\tilde{x}^*))\Vert =0 \) and \(\tilde{x}^*\) is stationary.
The first inequality in (4.9) follows directly from (4.6). As for the second, we have
where we used (4.5) in the first inequality, \(\{f(x_i)\}\) decreasing together with \(f(x_i) \rightarrow \tilde{f}\) in the second and the thesis follows by rearranging terms. \(\square \)
We now prove Lemma 4.3. We start by recalling Karamata’s inequality ([66, 67]) for concave functions. Given \(A, B \in \mathbb {R}^N\) it is said that A majorizes B, written \(A \succ B\), if
If h is concave and \(A \succ B\) by Karamata’s inequality
In order to prove Lemma 4.3 we first need the following technical Lemma.
Lemma 8.1
Let \(\{\tilde{f}_i\}_{i \in [0:j]}\) be a sequence of nonnegative numbers such that \(\tilde{f}_{i + 1} \le q \tilde{f}_i\) for some \(q < 1\). Then
Proof
Let \(\bar{j} = \max \{i \ge 0 \ \vert \ \tilde{f}_j \le q^{i} \tilde{f}_0 \}\), so that by (8.32) we have \(\bar{j} \ge j\). Define \(w^*, v \in \mathbb {R}^{\bar{j} + 1}_{\ge 0}\) by
Then for \(0 \le l < \bar{j}\) we have
where we used \(q^{l + 1}\tilde{f}_0 \ge \tilde{f}_{l + 1} \) for \(l \le j - 1\) and \(q^{l + 1}\tilde{f}_0 \ge \tilde{f}_{j}\) for \(j \le l < \bar{j}\) in the inequality. Furthermore, for \(l = \bar{j}\) we have
Now if w is the permutation in descreasing order of \(w^*\), clearly thanks to (8.26), and (8.27) we have \(w \succ v\). Then
where the first inequality follows from Karamata’s inequality. \(\square \)
Proof of Lemma 4.3
If the sequence \(\{x_k\}\) is finite, with \(x_m =\tilde{x}\) stationary for some \(m \ge 0\), we define \(x_k = x_{m}\) for every \(k \ge m\), so that we can always assume \(\{x_k\}\) infinite. Notice that with this convention the sufficient decrease condition (4.5) is still satisfied for every k. Let \(f_k = f(x_k) - f(x^*)\). \(\{f_k\}\) is monotone decreasing by (4.5), and nonnegative since (2.2) holds for every \(x_k\).
We want prove \(f_{k + 1} \le q f_k\). This is clear if \(f_{k + 1} = 0\). Otherwise using the notation of Proposition 4.1 we have
where we used (4.5) in the first inequality, (4.6) in the second. Since \(\tilde{x}_k \in \{y_j\}_{j = 0}^T\) by Proposition 4.1, we can apply (2.2) in \(\tilde{x}_k\) to obtain
Concatenating (8.29), (8.30) and rearranging we obtain
Thus by induction for any \(i \ge 0\)
which implies in particular (4.12).
We can now bound the length of the tails of \(\{x_k\}\):
where we used (4.5) in the first inequality, Lemma 8.1 with \(\{\tilde{f}_i\} = \{f_{k + i}\}\) and for \(j \rightarrow +\infty \) in the second inequality, and (8.32) in the third. In particular \(x_k \rightarrow \tilde{x}^*\) with
by (8.33). \(\square \)
Proof of Theorem 4.2
By continuity, for \(\tilde{\delta } \rightarrow 0\) and \(f_0 = f(x_0) - f(x^*)\) we have that
so we can take \(\tilde{\delta } < \delta /2\) small enough in such a way that
Let now \(x_0 \in B_{{\tilde{\delta }}}(x^*) \cap [f \ge f(x^*)]\), so that
where we use (8.36) in the second inequality. We now want to prove, by induction on k, \(\{x_i\}_{i \in [0:k]} \subset B_{\delta }(x^*)\) with \(f(x_{i + 1}) \le qf(x_i)\) for every \(i \in [0:k]\) and \(k \in \mathbb {N}\). To start with,
where we used (4.5) in the first inequality, and Lemma 8.1 (which we can apply thanks to the inductive assumption) in the second. But then
where we used (8.38) together with (4.5) in the second inequality, the assumption \(x_k \in B_{\delta }(x^*) \Rightarrow f_{k + 1} \ge 0\) in the third inequality, and (8.37) together with \(f_0 \ge f_{k}\) in the last inequality.
We now have
where we use \(\Vert \tilde{x}_k - x_k\Vert \le \Vert x_{k + 1} - x_k\Vert \) in the second inequality and the last inequality follows as in (8.40). Thus \(\tilde{x}_k \in B_{\delta }(x^*)\) as well, which is enough to prove (8.31) and complete the induction. We have thus obtained \(\{\tilde{x}_k\}, \{ x_k \} \subset B_{\delta }(x^*)\), and the conclusion follows exactly as in the proof of Lemma 4.3. \(\square \)
Proof of Corollary 4.2
Let \(x^*\) be a limit point of \(\{x_k\}\), and let \(\tilde{\delta }\) be as in Theorem 4.2. First, for some \(\bar{k} \in \mathbb {N}\) we must have \(x_{\bar{k}} \in B_{\tilde{\delta }}(x^*)\). Furthermore, for every \(k \in \mathbb {N}\) we have \(f(x_k) \ge f(x^*)\) because \(f(x_k)\) is non increasing and converges to \(f(x^*)\). Thus we have all the necessary assumptions to obtain the asymptotic rates by applying Theorem 4.2 to \(\{y_k\}=\{x_{\bar{k} + k}\}\). \(\square \)
Lemma 8.2
Let x be a proper convex combination of atoms in \(A' \subset A\), and \(d \ne 0\) feasible direction in x. Then, for some \(y \in \text {conv}(A')\), we have
Proof
Let \(y\in \text {argmax}_{z \in \text {conv}(A')} \hat{\alpha }^{\max }(z, d)\), and let \(A'' \subset A'\) be such that y is a proper convex combination of elements in \(A''\). Furthermore, let \(\mathcal {F}_y\) be the minimal face containing the maximal feasible step point \(\bar{y}:= y + \hat{\alpha }^{\max }(y, d)\). We claim that \(\mathcal {F}_y \cap A'' = \emptyset \). In fact, for \(p \in A'' \cap \mathcal {F}_y\) we can consider an homothety of center p and factor \(1 + \epsilon \) mapping y in \(y_{\epsilon } \in \text {conv}(A'')\) and \(\bar{y}\) in \(\bar{y}_{\epsilon } \in \mathcal {F}_y\) with
But then we would have \(\hat{\alpha }(\bar{y}_{\epsilon }, d) \ge (1 + \epsilon ) \hat{\alpha }(\bar{y}, d)\), in contradiction with the maximality of \(\hat{\alpha }(\bar{y}, d)\). Therefore
where we used \(A'' \cap \mathcal {F}= \emptyset \) in the second inequality, and [53, Theorem 2] in the equality. \(\square \)
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Rinaldi, F., Zeffiro, D. Avoiding bad steps in Frank-Wolfe variants. Comput Optim Appl 84, 225–264 (2023). https://doi.org/10.1007/s10589-022-00434-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-022-00434-3