
Abstract
In this paper we propose a product space reformulation to transform monotone inclusions described by finitely many operators on a Hilbert space into equivalent two-operator problems. Our approach relies on Pierra’s classical reformulation with a different decomposition, which results in a reduction of the dimension of the outcoming product Hilbert space. We discuss the case of not necessarily convex feasibility and best approximation problems. By applying existing splitting methods to the proposed reformulation we obtain new parallel variants of them with a reduction in the number of variables. The convergence of the new algorithms is straightforwardly derived with no further assumptions. The computational advantage is illustrated through some numerical experiments.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
A problem of great interest in optimization and variational analysis is the monotone inclusion consisting in finding a zero of a monotone operator. In many practical applications, such operator can be decomposed as a sum of finitely many maximally monotone operators. The problem takes then the form
where \(\mathcal {H}\) is a Hilbert space and \(A_1,A_2,\ldots ,A_r:\mathcal {H}\rightrightarrows \mathcal {H}\) are maximally monotone. When the sum is itself maximally monotone, in theory, inclusion (1.1) could be numerically solved by the well-known proximal point algorithm [38]. However, this method requires the computation of the resolvent of the operator \(A_1+\cdots +A_r\) at each iteration, which is not usually available. In fact, computing the resolvent of a sum at a given point \(q\in \mathcal {H}\), i.e.,
where \(J_{A}\) denotes the resolvent of an operator A, is a problem of interest itself which arises in some optimization subroutines as well as in direct applications such as best approximation, image denoising and partial differential equations (see, e.g., [7]).
Splitting algorithms take advantage of the decomposition and activate each operator separately, either by direct evaluation (forward steps) or via its resolvent (backward steps), to construct a sequence that converges to a solution of the problem. Splitting algorithms include, in particular, the so-called projection methods, which permit to find a point (or the closest point) in the intersection of a collection of sets by computing individual projections onto them. Classical splitting algorithms for monotone inclusions include the Forward-Backward algorithm and its variants, see, e.g., [9, 15, 30, 40], and the Douglas–Rachford algorithm [22, 29], among others (see, e.g., [9, Chapter 23]). On the other hand, different splitting algorithms for computing the resolvent of a sum can be found in, e.g, [1, 5, 16, 19]. See also the recent unifying framework [7].
Most splitting algorithms in the literature are devised for a sum of two operators, whereas there exist just a few three-operator extensions, see, e.g., [8, 20, 37, 39]. In general, problems (1.1) and (1.2) are tackled by splitting algorithms after applying Pierra’s product space reformulation [34, 35]. This technique constructs an equivalent two-operator problem, embedded in a product Hilbert space, that preserves computational tractability in the sense that the resolvents of the new operators can be readily computed. However, since each operator in the original problem requires one dimension in the product space, this technique may result numerically inefficient when the number of operators is too large.
In this work we propose an alternative reformulation, based on Pierra’s classical one, which reduces the dimension of the resulting product Hilbert space. Our approach consists in merging one of the operators with the normal cone to the diagonal set, what allows to remove one dimension in the product space. In fact, in contrast to Pierra’s reformulation, the one proposed in this work reproduces exactly the original problem when this is initially defined by two operators (see Remark 3.4). We would like to note that this reformulation has already been used in other frameworks. For instance, it was employed in [27] for deriving necessary conditions for extreme points of a collection of closed sets. Our main contribution is showing that the computability of the resolvents of the new defined operators is kept with no further assumptions. This result allows us to implement known splitting algorithms under this reformulation, which entails the elimination of one variable defining the iterative scheme in comparison to Pierra’s approach.
After the publication of the first preprint version of this manuscript we became aware of [17], where the authors suggest an analogous dimension reduction technique for structured optimization problems. Although that reformulation is different, the derived parallel Douglas–Rachford (DR) algorithm seems to lead to a scheme equivalent to the one obtained from Theorem 5.1 in this context. Notwithstanding, our analysis is developed in the more general framework of monotone inclusions. Furthermore, we provide detailed proofs of the equivalency and resolvents formulas, as well as numerical comparison to the classical Pierra’s reformulation. On the other hand, Malitsky and Tam independently proposed in [31] another r-operator DR-type algorithm embedded in a reduced-dimensional space. This algorithm, which can be seen as an attempt to extend Ryu’s splitting algorithm [39] (see Remark 5.2), differs from the one proposed in this work and it will also be tested in our experiments.
It is worth mentioning that a similar idea for feasibility problems was previously developed in [18]. In there, the dimensionality reduction was obtained by replacing a pair of constraint sets in the original problem by their intersection before applying Pierra’s reformulation. However, the convergence of some projection algorithms may require a particular intersection structure of these sets. Our approach has the advantage of being directly applicable to any splitting algorithm with no additional requirements.
The remainder of the paper is organized as follows. In Sect. 2 we recall some preliminary notions and auxiliary results. Then Sect.3 is divided into Sect. 3.1, where we first recall Pierra’s standard product space reformulation, and Sect. 3.2, in which we propose an alternative reformulation with reduced dimension. We discuss and illustrate the particular case of feasibility and best approximation problems in Sect. 4. In Sect. 5, we apply our reformulation to construct new parallel variants of some splitting algorithms. Finally, in Sect. 6 we perform some numerical experiments that exhibit the advantage of the proposed reformulation.
2 Preliminaries
Throughout this paper, \(\mathcal {H}\) is a Hilbert space endowed with inner product \(\langle \cdot ,\cdot \rangle\) and induced norm \(\Vert \cdot \Vert\). We abbreviate norm convergence of sequences in \(\mathcal {H}\) with \(\rightarrow\) and we use \(\rightharpoonup\) for weak convergence.
2.1 Operators
Given a nonempty set \(D\subseteq \mathcal {H}\), we denote by \(A:D\rightrightarrows \mathcal {H}\) a set-valued operator that maps any point \(x\in D\) to a set \(A(x)\subseteq \mathcal {H}\). In the case where A is single-valued we write \(A:D\rightarrow \mathcal {H}\). The graph, the domain, the range and the set of zeros of A, are denoted, respectively, by \({\text {gra}}A\), \({\text {dom}}A\), \({\text {ran}}A\) and \({\text {zer}}A\); i.e.,
The inverse of A, denoted by \(A^{-1}\), is the operator defined via its graph by \({\text {gra}}A^{-1}:=\{(u,x)\in \mathbb {R}^n \times \mathbb {R}^n: u\in A(x)\}\). We denote the identity mapping by \({\text {Id}}\).
Definition 2.1
(Monotonicity) An operator \(A:\mathcal {H}\rightrightarrows \mathcal {H}\) is said to be
-
(i)
Monotone if
$$\begin{aligned} \langle x-y,u-v\rangle \ge 0,\quad \forall (x,u),(y,v)\in {\text {gra}}A; \end{aligned}$$Furthermore, A is said to be maximally monotone if it is monotone and there exists no monotone operator \(B:\mathcal {H}\rightrightarrows \mathcal {H}\) such that \({\text {gra}}B\) properly contains \({\text {gra}}A\).
-
(ii)
Uniformly monotone with modulus \(\phi :\mathbb {R}_{+}\rightarrow [0,+\infty ]\) if \(\phi\) is increasing, vanishes only at 0, and
$$\begin{aligned} \langle x-y,u-v\rangle \ge \phi \left( \Vert x-y\Vert \right) ,\quad \forall (x,u),(y,v)\in {\text {gra}}A. \end{aligned}$$ -
(iii)
\(\mu\)-strongly monotone for \(\mu >0\), if \(A-\mu {\text {Id}}\) is monotone; i.e.,
$$\begin{aligned} \langle x-y,u-v\rangle \ge \mu \Vert x-y\Vert ^2,\quad \forall (x,u),(y,v)\in {\text {gra}}A. \end{aligned}$$
Clearly, strong monotonicity implies uniform monotonicity, which itself implies monotonicity. The reverse implications are not true.
Remark 2.2
The notions in Definition 2.1 can be localized to a subset of the domain. For instance, \(A:\mathcal {H}\rightrightarrows \mathcal {H}\) is \(\mu\)-strongly monotone on \(C\subseteq {\text {dom}}A\) if
Lemma 2.3
Let \(A,B:\mathcal {H}\rightrightarrows \mathcal {H}\) be monotone operators. The following hold.
-
(i)
If A is uniformly monotone on \({\text {dom}}(A+B)\), then \(A+B\) is uniformly monotone with the same modulus than A.
-
(ii)
If A is \(\mu\)-strongly monotone on \({\text {dom}}(A+B)\), then \(A+B\) is \(\mu\)-strongly monotone.
Proof
Let \((x,u),(y,v)\in {\text {gra}}(A+B)\), i.e., \(u=u_1+u_2\) and \(v=v_1+v_1\) with \((x,u_1),(y,v_1)\in {\text {gra}}A\) and \((x,u_2),(y,v_2)\in {\text {gra}}B\). (i): Suppose that A is uniformly monotone on \({\text {dom}}(A+B)\) with modulus \(\phi\). Since \(x,y\in {\text {dom}}(A+B)\), we get that
which proves that \(A+B\) is uniformly monotone with the same modulus. The proof of (ii) is analogous and, thus, omitted. \(\square\)
Definition 2.4
(Resolvent) The resolvent of an operator \(A:\mathcal {H}\rightrightarrows \mathcal {H}\) with parameter \(\gamma >0\) is the operator \(J_{\gamma A}:\mathcal {H}\rightrightarrows \mathcal {H}\) defined by
The following result collects some properties of the resolvents of monotone operators. The second assertion corresponds to the well-known Minty’s theorem.
Fact 2.5
Let \(A:\mathcal {H}\rightrightarrows \mathcal {H}\) be monotone and let \(\gamma >0\). Then
-
(i)
\(J_{\gamma A}\) is single-valued,
-
(ii)
\({\text {dom}}J_{\gamma A}=\mathcal {H}\) if and only if A is maximally monotone.
Proof
See, e.g., [9, Proposition 23.8]. \(\square\)
The resolvent of the sum of two monotone operators has no closed expression in terms of the individual resolvents except for some particular situations. The following fact, which is fundamental in our results, contains one of those special cases.
Fact 2.6
Let \(A,B:\mathcal {H}\rightrightarrows \mathcal {H}\) be maximally monotone operators such that \(B(y)\subseteq B(J_{A}(y))\), for all \(y\in {\text {dom}}B.\) Then, \(A+B\) is maximally monotone and
Proof
See, e.g., [9, Proposition 23.32(i)]. \(\square\)
2.2 Functions
Let \(f:\mathcal {H}\rightarrow {]-\infty ,+\infty ]}\) be a proper, lower semicontiuous and convex function. The subdifferential of f is the operator \(\partial f:\mathcal {H}\rightrightarrows \mathcal {H}\) defined by
The proximity operator of f (with parameter \(\gamma\)), \({\text {prox}}_{\gamma f}:\mathcal {H}\rightrightarrows \mathcal {H}\), is defined at \(x\in \mathcal {H}\) by
Fact 2.7
Let \(f:\mathcal {H}\rightarrow {]-\infty ,+\infty ]}\) be proper, lower semicontiuous and convex. Then, the subdifferential of f, \(\partial f\), is a maximally monotone operator whose resolvent becomes the proximity operator of f, i.e.,
Proof
See, e.g., [9, Theorem 20.25 and Example 23.3]. \(\square\)
2.3 Sets
Given a nonempty set \(C\subseteq \mathcal {H}\), we denote by \(d_C\) the distance function to C; that is, \(d_C(x):=\inf _{c\in C}\Vert c-x\Vert\), for all \(x\in \mathcal {H}\). The projection mapping (or projector) onto C is the possibly set-valued operator \(P_C:\mathcal {H}\rightrightarrows C\) defined at each \(x\in \mathcal {H}\) by
Any point \(p\in P_C(x)\) is said to be a best approximation to x from C (or a projection of x onto C). If a best approximation in C exists for every point in \(\mathcal {H}\), then C is said to be proximinal. If every point \(x\in \mathcal {H}\) has exactly one best approximation from C, then C is said to be Chebyshev. Every nonempty, closed and convex set is Chebyshev (see, e.g., [9, Theorem 3.16]).
The next results characterizes the projection onto a closed affine subspace.
Fact 2.8
Let \(D\subseteq \mathcal {H}\) be a closed affine subspace and let \(x\in \mathcal {H}\). Then
Proof
See, e.g., [9, Corollary 3.22]. \(\square\)
The indicator function of a set \(C\subseteq \mathcal {H}\), \(\iota _C:\mathcal {H}\rightarrow {]-\infty ,+\infty ]}\), is defined as
If C is closed and convex, \(\iota _C\) is convex and its differential turns to the normal cone to C, which is the operator \(N_C:\mathcal {H}\rightrightarrows \mathcal {H}\) defined by
Fact 2.9
Let \(C\subseteq \mathcal {H}\) be nonempty, closed and convex. Then, the normal cone to C, \(N_C\), is a maximally monotone operator whose resolvent becomes the projector onto C, i.e.,
Proof
See, e.g., [9, Examples 20.26 and 23.4]. \(\square\)
We conclude this section with the following result that characterizes the projector onto the intersection of a proximinal set (not necessarily convex) and a closed affine subspace under particular assumptions. It is a refinement of [18, Theorem 3.1(c)], whose proof needs to be barely modified.
Lemma 2.10
Let \(C\subseteq \mathcal {H}\) be nonempty and proximinal and let \(D\subseteq \mathcal {H}\) be a closed affine subspace. If \(P_C(d)\cap D\ne \emptyset\) for all \(d\in D\), then
Proof
Fix \(x\in \mathcal {H}\). By assumption we have that \(P_C(P_D(x))\cap D\ne \emptyset\). Pick any \(c\in P_C(P_D(x))\cap D\) and let \(p\in P_{C\cap D}(x)\). Then \(c\in P_C(d)\cap D\), where \(d=P_D(x)\). Since D is an affine subspace and \(d=P_D(x)\), we derive from Fact 2.8 applied to \(c\in D\) and \(p\in D\), respectively, that \(\langle x-d, c-d\rangle =0\) and \(\langle x-d, p-d\rangle =0\). Therefore,
Since \(c\in P_C(d)\) and \(p\in C\) then \(\Vert c-d\Vert \le \Vert p-d\Vert\). This combined with (2.1) yields \(\Vert x-c\Vert \le \Vert x-p\Vert\). Note that \(p\in P_{C\cap D}(x)\) and \(c\in C\cap D\), so it must be
It directly follows from (2.2) that \(c\in P_{C\cap D}(x)\). Furthermore, by combining (2.2) with (2.1) we arrive at \(\Vert c-d\Vert =\Vert p-d\Vert\), which implies that \(p\in P_C(d)\cap D\) and concludes the proof. \(\square\)
3 Product space reformulation for monotone inclusions
In this section we introduce our proposed reformulation to convert problems (1.1)–(1.2) into equivalent problems with only two operators. To this aim, we first recall the standard product space reformulation due to Pierra [34, 35].
3.1 Standard product space reformulation
Consider the product Hilbert space \(\mathcal {H}^r=\mathcal {H}\times {\mathop {\cdots }\limits ^{(r)}}\times \mathcal {H}\), endowed with the inner product
and define
which is a closed subspace of \(\mathcal {H}^r\) commonly known as the diagonal. We denote by \(\varvec{j}_r:\mathcal {H}\rightarrow \varvec{D}_r\) the canonical embedding that maps any \(x\in \mathcal {H}\) to \(\varvec{j}_r(x)=(x,x,\ldots ,x)\in \varvec{D}_r\). The following result collects the fundamentals of Pierra’s standard product space reformulation.
Fact 3.1
(Standard product space reformulation) Let \(A_1,A_2,\ldots ,A_r:\mathcal {H}\rightrightarrows \mathcal {H}\) be maximally monotone and let \(\gamma >0\). Define the operator \(\varvec{A}:\mathcal {H}^r\rightrightarrows \mathcal {H}^r\) as
Then the following hold.
-
(i)
\(\varvec{A}\) is maximally monotone and
$$\begin{aligned} J_{\gamma \varvec{A}}(\varvec{x})=\left( J_{\gamma A_1}(x_1), J_{\gamma A_2}(x_2),\cdots , J_{\gamma A_r}(x_r)\right) , \quad \forall \varvec{x}=(x_1,x_2,\ldots ,x_r)\in \mathcal {H}^r. \end{aligned}$$ -
(ii)
The normal cone to \(\varvec{D}_r\) is given by
$$\begin{aligned} N_{\varvec{D}_r}(\varvec{x}) =\left\{ \begin{array}{ll}\varvec{D}_{r}^\perp =\{\varvec{u}=(u_1,u_2,\ldots ,u_r)\in \mathcal {H}^r : \sum _{i=1}^r u_i=0 \}, &{}\text {if }\varvec{x}\in \varvec{D}_r,\\ \emptyset , &{} \text {otherwise.}\end{array}\right. \end{aligned}$$It is a maximally monotone operator and
$$\begin{aligned} J_{\gamma N_{\varvec{D}_r}}(\varvec{x})=P_{\varvec{D}_r}(\varvec{x})=\varvec{j}_r\left( \frac{1}{r}\sum _{i=1}^r x_i\right) , \quad \forall \varvec{x}=(x_1,x_2,\ldots ,x_r)\in \mathcal {H}^r. \end{aligned}$$ -
(iii)
\({\text {zer}}\left( \varvec{A}+N_{\varvec{D}_r}\right) =\varvec{j}_r\left( {\text {zer}}\left( \sum _{i=1}^r A_i\right) \right)\).
-
(iv)
\(J_{\gamma (\varvec{A}+N_{\varvec{D_r}})}(\varvec{x})=\varvec{j}_r\left( J_{\frac{\gamma }{r}\sum _{i=1}^{r}A_i}\left( x \right) \right) , \quad \forall \varvec{x}=\varvec{j}_r(x)\in \varvec{D}_r.\)
Proof
See, e.g., [9, Proposition 26.4] and [5, Proposition 4.1]. 3, 6, 10, 23,24,25, 28\(\square\)
According to the previous result, the product space reformulation is a convenient trick for reducing problems (1.1) and (1.2) to equivalent problems with two operators that keep maximal monotonicity and computational tractability. However, this approach relies on working in a product Hilbert space in which each operator of the problem requires one product dimension. This may become computationally inefficient when the number of operators increases. In the next section we will analyze an alternative reformulation in a product Hilbert space with lower dimension. Before that, we include the following technical result regarding additional monotonicity properties that are inherited by the product operator defined in the standard reformulation.
Lemma 3.2
Let \(A_1,A_2,\ldots ,A_r:\mathcal {H}\rightrightarrows \mathcal {H}\) be monotone operators and let \(\varvec{A}:\mathcal {H}^r\rightrightarrows \mathcal {H}^r\) be the product operator defined in (3.1). Then the following hold.
-
(i)
If \(A_{i}\) is uniformly monotone with modulus \(\phi _i\) for all \(i\in I_0\subseteq \{1,\ldots ,r\}\), then \(\varvec{A}\) is uniformly monotone on \({\text {dom}}(\varvec{A})\cap \varvec{D}_r\) with modulus \(\sum _{i\in I_0}\phi _i(\tfrac{\cdot }{\sqrt{r}})\).
-
(ii)
If \(A_i\) is \(\mu _i\)-strongly monotone for all \(i\in I_0\subseteq \{1,\ldots ,r\}\), then \(\varvec{A}\) is \(\mu\)-strongly monotone on \({\text {dom}}(\varvec{A})\cap \varvec{D}_r\) with \(\mu :=\frac{1}{r}\sum _{i\in I_0} \mu _i\).
Proof
-
(i)
Suppose that \(A_{i}\) is uniformly monotone with modulus \(\phi _i\) for all \(i\in I_0\subseteq \{1,\ldots ,r\}\). Let \(\varvec{x}=\varvec{j}_r(x),\varvec{y}=\varvec{j}_r(y)\in \varvec{D}_r\), for some \(x,y\in \mathcal {H}\), and let \(\varvec{u}=({u_1},\ldots ,u_r), \varvec{v}=(v_1,\ldots ,v_r)\in \mathcal {H}^r\) such that \((\varvec{x},\varvec{u}),(\varvec{y},\varvec{v})\in {\text {gra}}\varvec{A}\). Then,
$$\begin{aligned} \langle \varvec{x}-\varvec{y}, \varvec{u}-\varvec{v}\rangle&= \sum _{i=1}^r \langle x-y, u_i-v_i\rangle \ge \sum _{i\in I_0}\langle x-y, u_{i_0}-v_{i_0}\rangle \\&\ge \sum _{i\in I_0} \phi _i(\Vert x-y\Vert ) = \sum _{i\in I_0}\phi _i\left( \frac{1}{\sqrt{r}}\Vert \varvec{x}-\varvec{y}\Vert \right) , \end{aligned}$$which implies that \(\varvec{A}\) is uniformly monotone on \({\text {dom}}(\varvec{A})\cap \varvec{D}_r\) with modulus \(\sum _{i\in I_0}\phi _i\left( \frac{\cdot }{\sqrt{r}}\right)\).
-
(ii)
Follows from (i) by taking \(\phi _i=\mu _i(\cdot )^2\) for all \(i\in I_0\). \(\square\)
3.2 New product space reformulation with reduced dimension
We introduce now our proposed reformulation technique which permits to eliminate one space in the product with respect to Pierra’s classical trick. More specifically, our approach reformulates problems (1.1) and (1.2) in the product Hilbert space
To this aim, consider its diagonal \(\varvec{D}_{r-1}\), with canonical embedding \(\varvec{j}_{r-1}:\mathcal {H}\rightarrow \varvec{D}_{r-1}\).
Theorem 3.3
(Product space reformulation with reduced dimension) Let \({\gamma >0}\) and let \(A_1,A_2,\ldots ,A_r:\mathcal {H}\rightrightarrows \mathcal {H}\) be maximally monotone. Consider the operators \(\varvec{B},\varvec{K}:\mathcal {H}^{r-1}\rightrightarrows \mathcal {H}^{r-1}\) defined, at each \(\varvec{x}=(x_1,\ldots ,x_{r-1})\in \mathcal {H}^{r-1}\), by
Then the following hold.
-
(i)
\(\varvec{B}\) is maximally monotone and
$$\begin{aligned} J_{\gamma \varvec{B}}(\varvec{x})=\left( J_{\gamma A_1}(x_1), \ldots , J_{\gamma A_{r-1}}(x_{r-1})\right) , \quad \forall \varvec{x}=(x_1,\ldots ,x_{r-1})\in \mathcal {H}^{r-1}. \end{aligned}$$ -
(ii)
\(\varvec{K}\) is maximally monotone and
$$\begin{aligned} J_{\gamma \varvec{K}}(\varvec{x})=\varvec{j}_{r-1}\left( J_{\frac{\gamma }{r-1}A_r}\left( \frac{1}{r-1}\sum _{i=1}^{r-1} x_i\right) \right) , \quad \forall \varvec{x}=(x_1,\ldots ,x_{r-1})\in \mathcal {H}^{r-1}. \end{aligned}$$If, in addition, \(A_r\) is uniformly monotone (resp. \(\mu\)-strongly monotone), then \(\varvec{K}\) is uniformly monotone (resp. \(\mu\)-strongly monotone).
-
(iii)
\({\text {zer}}\left( \varvec{B}+\varvec{K}\right) =\varvec{j}_{r-1}\left( {\text {zer}}\left( \sum _{i=1}^r A_i\right) \right)\).
-
(iv)
\(J_{\gamma (\varvec{B}+\varvec{K})}(\varvec{x})=\varvec{j}_{r-1}\left( J_{\frac{\gamma }{r-1}\sum _{i=1}^{r}A_i}\left( x \right) \right) , \quad \forall \varvec{x}=\varvec{j}_{r-1}(x)\in \varvec{D}_{r-1}.\)
Proof
Note that (i) directly follows from Fact 3.1(i). For the remaining assertions, let us define the operator \(\varvec{S}:\mathcal {H}^{r-1}\rightrightarrows \mathcal {H}^{r-1}\) as
so that \(\varvec{K}=\varvec{S}+N_{\varvec{D}_{r-1}}\).
(ii): Fix \(\varvec{x}=(x_1,\ldots ,x_{r-1})\in \mathcal {H}^{r-1}\). On the one hand, from Fact 3.1(i) we get that \(\varvec{S}\) is maximally monotone with
On the other hand, Fact 3.1(ii) asserts that
is maximally monotone with
Now pick any \(\varvec{y}\in {\text {dom}}N_{\varvec{D}_{r-1}}=\varvec{D}_{r-1}\). It must be that \(\varvec{y}=\varvec{j}_{r-1}(y)\) for some \(y\in \mathcal {H}\) and thus
Hence, we have that
Since \(\varvec{y}\) was arbitrary in \({\text {dom}}N_{\varvec{D}_{r-1}}\) we can apply Fact 2.6 to obtain that \(\varvec{S} + N_{\varvec{D}_{r-1}}\) is maximally monotone and
where the last equality follows from combining (3.3) and (3.4).
If, in addition, \(A_r\) is uniformly monotone (resp. \(\mu\)-strongly monotone), then \(\varvec{S}\) is uniformly monotone (resp. \(\mu\)-strongly monotone) on \({\text {dom}}(\varvec{S})\cap \varvec{D}_{r-1}\) according to Lemma 3.2(i) (resp. Lemma 3.2(ii)). Since \(N_{\varvec{D}_{r-1}}\) is a maximally monotone operator with domain \(\varvec{D}_{r-1}\), the result follows from Lemma 2.3(i) (resp. Lemma 2.3(ii)).
(iii): To prove the direct inclusion, take any \(\varvec{x} \in {\text {zer}}\left( \varvec{B}+\varvec{K}\right) = {\text {zer}}\left( \varvec{B}+\varvec{S}+N_{\varvec{D}_{r-1}}\right)\). It necessarily holds that \(\varvec{x}\in {\text {dom}}N_{\varvec{D}_{r-1}}=\varvec{D}_{r-1}\), so \(\varvec{x}=\varvec{j}_{r-1}(x)\) for some \(x\in \mathcal {H}\). There exist \(\varvec{u}\in \varvec{B}(\varvec{x})\), \(\varvec{v}\in \varvec{S}(\varvec{x})\) and \(\varvec{w} \in N_{\varvec{D}_{r-1}}(\varvec{x})\) with \(\varvec{u}+\varvec{v} + \varvec{w}=0\). By definition of these operators \(\varvec{u}=(u_1,\ldots ,u_{r-1})\), with \(u_i\in A_i(x)\) for \(i\in \{1,\ldots ,r-1\}\), \(\varvec{v}= \varvec{j}_{r-1}(\frac{1}{r-1} v)\), with \(v\in A_r(x)\), and \(\varvec{w}=(w_1,\ldots ,w_{r-1})\), with \(\sum _{i=1}^{r-1} w_i=0\). Hence,
Summing up all these equations we arrive at
which yields \(x\in {\text {zer}}(\sum _{i=1}^r A_i)\).
For the reverse inclusion, take any \(x\in {\text {zer}}(\sum _{i=1}^r A_i)\) and let \(\varvec{x}=\varvec{j}_{r-1}(x)\in \varvec{D}_{r-1}\). Then there exists \(u_i\in A_i(x)\), for each \(i\in \{1,2,\ldots ,r\}\), with \(\sum _{i=1}^r u_i = 0\). Define
Since \(\varvec{u}+\varvec{v}+\varvec{w} = \varvec{0}\) it follows that \(\varvec{x}\in {\text {zer}}\left( \varvec{B}+\varvec{S}+N_{\varvec{D}_{r-1}}\right)\).
(iv): Fix any \(x\in \mathcal {H}\) and let \(\varvec{x}=\varvec{j}_{r-1}(x)\in \varvec{D}_{r-1}\) and \(\varvec{p}\in J_{\gamma (\varvec{B}+{\varvec{S}}+N_{\varvec{D}_{r-1}})}(\varvec{x})\). Then
It must be that \(\varvec{p}=\varvec{j}_{r-1}(p)\in \varvec{D}_{r-1}\) for some \(p\in \mathcal {H}\). Hence, we can rewrite the previous inclusion as
with \(\sum _{i=1}^{r-1}u_i=0\). Summing up all the inclusions in (3.5) and dividing by a factor of \(r-1\) we arrive at
which implies that \(p \in J_{\frac{\gamma }{r-1}\sum _{i=1}^{r}A_i}\left( x \right)\).
For the reverse inclusion, take any \(p\in J_{\frac{\gamma }{r-1}\sum _{i=1}^{r}A_i}\left( x \right)\) so that there exist \(a_i\in A_i(p)\), for \(i\in \{1,2,\ldots ,r\}\), such that
Define the vectors \(\varvec{v}:=(a_1,\ldots ,a_{r-1})\), \(\varvec{w}:=\varvec{j}_{r-1}\left( \tfrac{1}{r-1}a_r\right)\) and \(\varvec{u}:=\varvec{x} - \varvec{p} - \gamma \varvec{v} - \gamma \varvec{w}\). Hence, \(\varvec{x}=\varvec{p} + \gamma \varvec{v} + \gamma \varvec{w} + \varvec{u}\), with \(\varvec{v}\in \varvec{B}(\varvec{p})\), \(\varvec{w}\in \varvec{S}(\varvec{p})\) and, in view of (3.6), \(\varvec{u}\in N_{\varvec{D}_{r-1}}\). This implies that \(\varvec{p}\in J_{\gamma ({\varvec{B}}+\varvec{S}+N_{\varvec{D}_{r-1}})}(\varvec{x})\) and concludes the proof. \(\square\)
Remark 3.4
Consider problem (1.1) with only two operators, i.e.,
where \(A_1,A_2:\mathcal {H}\rightrightarrows \mathcal {H}\) are maximally monotone. Although splitting algorithms can directly tackle (3.7), the product space reformulations are still applicable. Indeed, the standard reformulation in Fact 3.1 produces the problem
with \(\varvec{A}=A_1\times A_2\). Then (3.8) is equivalent to (3.7) in the sense that their solution sets can be identified to each other. However, they are embedded in different ambient Hilbert spaces. In contrast, the problem generated by applying Theorem 3.3 becomes
where \(\varvec{B}=A_1\) and \(\varvec{K}=A_2+N_{\varvec{D}_1}\). Since \(\varvec{D}_1=\mathcal {H}\), then \(N_{\varvec{D}_1}=\{0\}\) and (3.9) recovers the original problem (3.7).
4 The case of feasibility and best approximation problems
Given a family of sets \(C_1,C_2,\ldots ,C_r\subseteq \mathcal {H}\), the feasibility problem aims to find a point in the intersection of the sets, i.e.,
A related problem, known as the best approximation problem, consists in finding, not only a point in the intersection, but the closest one to a given point \(q\in \mathcal {H}\), i.e.,
The feasibility problem (4.1) can be seen as a particular instance of the monotone inclusion (1.1) when specialized to the normal cones to the sets. Indeed, one can easily check that
Similarly, under a constraint qualification, problem (4.2) turns out to be (1.2) applied to the normal cones, that is,
According to Fact 2.9, if the involved sets \(C_1,C_2,\ldots ,C_r\) are closed and convex then \(N_{C_i}\) is maximally monotone with \(J_{N_{C_i}}=P_{C_i}\), for all \(i=1,\ldots ,r\). Therefore, Fact 3.1 and Theorem 3.3 can be applied in order to reformulate problems (4.1) and (4.2) as equivalent problems involving only two sets. This is illustrated in the following example.
Example 4.1
(Convex feasibility problem) Consider a feasibility problem consisting of finding a point in the intersection of three closed intervals
where \(C_1:=[0.5,2]\), \(C_2:=[1.5,2]\) and \(C_3:=[1,3]\). By applying Fact 3.1 to the normal cones \(N_{C_1}\), \(N_{C_2}\) and \(N_{C_3}\), the latter is equivalent to
In contrast, if we apply Theorem 3.3 to the normal cones, it can be easily shown that problem (4.3) is also equivalent to
Both reformulations are illustrated in Fig. 1. Furthermore, the usefulness of the reformulations is that the projectors onto the new sets can be easily computed. Indeed, the projections onto \(C_1\times C_2\times C_3\) or \(C_1\times C_2\) are computed componentwise in view of Fact 3.1(i), while the projectors onto \(\varvec{D}_3\) and \(\varvec{K}\) are derived from Fact 3.1(ii) and Theorem 3.3(ii), respectively, as
Observe that, under a constraint qualification guaranteeing the so-called strong CHIP holds (i.e. \(N_{C_1}+N_{C_3}+N_{C_3}=N_{C_1\cap C_2\cap C_3}\)), the reformulations in (4.4) and (4.5) can also be applied for best approximation problems in view of Fact 3.1(iv) and Theorem 3.3(iv), respectively.

Product space reformulations of the convex feasibility problem in Example 4.1
Although the theory of projection algorithms is developed under convexity assumptions of the constraint sets, some of them has been shown to be very efficient solvers in a wide variety of nonconvex applications. In special, the Douglas–Rachford algorithm has attracted particular attention due to its well behavior on nonconvex scenarios including some of combinatorial nature; see, e.g., [3, 6, 10, 23,24,25, 28]. In most of these applications, feasibility problems are described by more than two sets and need to be tackled by Pierra’s product space reformulation. Indeed, as we recall in the next result, the reformulation is still valid under the more general assumption that the sets are proximinal but not necessarily convex.
Proposition 4.2
(Standard product space reformulation for not necessarily convex feasibility and best approximation problems) Let \(C_1,C_2,\ldots ,C_r\subseteq \mathcal {H}\) be nonempty and proximinal sets and define the product set
Then the following hold.
-
(i)
\(\varvec{C}\) is proximinal and
$$\begin{aligned} P_{\varvec{C}}(\varvec{x})=P_{C_1}(x_1)\times P_{C_2}(x_2)\times \cdots \times P_{C_r}(x_r),\quad \forall \varvec{x}=(x_1,x_2,\ldots ,x_r)\in \mathcal {H}^r.\end{aligned}$$If, in addition, \(C_1,C_2,\ldots ,C_r\) are closed and convex then so is \(\varvec{C}\).
-
(ii)
\(\varvec{D}_r\) is a closed subspace with
$$\begin{aligned}P_{\varvec{D}_r}(\varvec{x})=\varvec{j}_{r}\left( \frac{1}{r} \sum _{i=1}^r x_i\right) ,\quad \forall \varvec{x}=(x_1,x_2,\ldots ,x_r)\in \mathcal {H}^r.\end{aligned}$$ -
(iii)
\(\varvec{C}\cap \varvec{D}_r=\varvec{j}_{r}\left( \cap _{i=1}^r C_i\right)\).
-
(iv)
\(P_{\varvec{C}\cap \varvec{D}_r}(\varvec{x})=\varvec{j}_{r}\left( P_{\cap _{i=1}^r C_i}(x)\right) , \quad \forall \varvec{x}=\varvec{j}_r(x)\in \varvec{D}_{r}\).
Proof
-
(i)
Let \(\varvec{x}=(x_1,x_2,\ldots ,x_r)\in \mathcal {H}^r\). By direct computations on the definition of projector we obtain that
$$\begin{aligned} P_{\varvec{C}}(\varvec{x})&= {\text {argmin}}_{\varvec{c}\in \varvec{C}} \Vert \varvec{x}-\varvec{c}\Vert ^2 = {\text {argmin}}_{(c_1,c_2,\ldots ,c_r)\in \varvec{C}} \sum _{i=1}^r\Vert x_i-c_i\Vert ^2\\&={\prod _{i=1}^{r}} {\text {argmin}}_{c_i\in C_i}\Vert x_i-c_i\Vert ^2\\&=P_{C_1}(x_1)\times P_{C_2}(x_2)\times \cdots \times P_{C_r}(x_r). \end{aligned}$$The remaining assertion easily follows from the definition of (topological) product space.
-
(ii)
Follows from Fact 3.1(ii).
-
(iii)
Let \(\varvec{x}\in \varvec{C}\cap \varvec{D}_r\). Then \(\varvec{x}=\varvec{j}_r(x)\in \varvec{D}_r\) with \(x\in C_i\) for all \(i=1,2,\ldots ,r\). The reverse inclusion is also straightforward.
-
(iv)
Let \(\varvec{x}=\varvec{j}_r(x)\in \varvec{D}_r\). Reasoning as in (i) and taking into account (iii) we get that
$$\begin{aligned} P_{\varvec{C}\cap \varvec{D}_r}(\varvec{x})&= {\text {argmin}}_{\varvec{c}\in \varvec{C}\cap \varvec{D}_r}\Vert \varvec{x}-\varvec{c}\Vert \\&=\varvec{j}_r\left( {\text {argmin}}_{c\in \cap _{i=1}^rC_i}\Vert x-c\Vert \right) =\varvec{j}_r\left( P_{\cap _{i=1}^rC_i}(x)\right) , \end{aligned}$$as claimed. \(\square\)
Analogously, we show the validity of the product space reformulation with reduced dimension for feasibility and best approximation problems with arbitrary proximinal sets.
Proposition 4.3
(Product space reformulation with reduced dimension for non necessarily convex feasibility and best approximation problems) Let \(C_1,C_2,\ldots ,\) \(C_r\subseteq \mathcal {H}\) be nonempty and proximinal sets and define
Then the following hold.
-
(i)
\(\varvec{B}\) is proximinal and
$$\begin{aligned}P_{\varvec{B}}(\varvec{x})=P_{C_1}(x_1)\times \cdots \times P_{C_{r-1}}(x_{r-1}),\quad \forall \varvec{x}=(x_1,\ldots ,x_{r-1})\in \mathcal {H}^{r-1}.\end{aligned}$$If, in addition, \(C_1,\ldots ,C_{r-1}\) are closed and convex then so is \(\varvec{B}\).
-
(ii)
\(\varvec{K}\) is proximinal and
$$\begin{aligned}P_{\varvec{K}}(\varvec{x})=\varvec{j}_{r-1}\left( P_{C_r}\left( \frac{1}{r-1} \sum _{i=1}^{r-1} x_i\right) \right) ,\quad \forall \varvec{x}=(x_1,\ldots ,x_{r-1})\in \mathcal {H}^{r-1}.\end{aligned}$$If, in addition, \(C_{r}\) is closed and convex then so is \(\varvec{K}\).
-
(iii)
\(\varvec{B}\cap \varvec{K}=\varvec{j}_{r-1}\left( \cap _{i=1}^{r} C_i\right)\).
-
(iv)
\(P_{\varvec{B}\cap \varvec{K}}(\varvec{x})=\varvec{j}_{r-1}\left( P_{\cap _{i=1}^r C_i}(x)\right) , \quad \forall \varvec{x}=\varvec{j}_{r-1}(x)\in \varvec{D}_{r-1}\).
Proof
-
(i)
Follows from Proposition 4.2(i).
-
(ii)
First, let us rewrite
$$\begin{aligned}\varvec{K}=\varvec{j}_{r-1}(C_r)= C_r^{\,r-1} \cap \varvec{D}_{r-1} = (C_r\times {\mathop {\cdots }\limits ^{(r-1)}}\times C_r) \cap \varvec{D}_{r-1}\subseteq \mathcal {H}^{r-1}.\end{aligned}$$Fix \(\varvec{x}=(x_1,\ldots ,x_{r-1})\in \mathcal {H}^{r-1}.\) By Propositions 4.2(i)-(ii), \(C_r^{r-1}\) is a proximinal set and \(\varvec{D}_{r-1}\) is a closed subspace with
$$\begin{aligned} P_{C_r^{r-1}}(\varvec{x})=P_{C_r}(x_1)\times \cdots \times P_{C_r}(x_{r-1})\quad \text {and}\quad P_{\varvec{D}_{r-1}}(\varvec{x})=\varvec{j}_{r-1}\left( \frac{1}{r-1} \sum _{i=1}^{r-1} x_i\right) . \end{aligned}$$Observe that, for any arbitrary point \(\varvec{y}=\varvec{j}_{r-1}(y)\in \varvec{D}_{r-1}\), it holds that
$$\begin{aligned}\varvec{j}_{r-1}(p)\in P_{C_r^{r-1}}(\varvec{y})\cap \varvec{D}_{r-1},\quad \forall p\in P_{C_r}(y).\end{aligned}$$In particular, \(P_{C_r^{r-1}}(\varvec{y})\cap \varvec{D}_{r-1}\ne \emptyset\) for all \(\varvec{y} \in \varvec{D}_{r-1}\). Hence, by applying Lemma 2.10 we derive that
$$\begin{aligned} P_{\varvec{K}}(\varvec{x})&=P_{C_r^{r-1}\cap \varvec{D}_{r-1}}(\varvec{x})=P_{C_r^{r-1}}\left( P_{\varvec{D}_{r-1}}(\varvec{x})\right) \cap \varvec{D}_{r-1}\\&=P_{C_r^{r-1}}\left( \varvec{j}_{r-1}\left( \frac{1}{r-1} \sum _{i=1}^{r-1} x_i\right) \right) \cap \varvec{D}_{r-1}=\varvec{j}_{r-1}\left( P_{C_r}\left( \frac{1}{r-1} \sum _{i=1}^{r-1} x_i\right) \right) . \end{aligned}$$In addition, if \(C_r\) is closed and convex then so is \(C_r^{r-1}\) according to Proposition 4.2(i). Since \(\varvec{D}_{r-1}\) is a closed subspace, the convexity and closedness of \(\varvec{K}\) follows.
-
(iii)-(iv)
Their proofs are straightforward and analogous to the proofs of Proposition 4.2(iii)-(iv), respectively, so they are omitted. \(\square\)
Example 4.4
(Nonconvex feasibility problem) Consider the feasibility problem
where \(C_1:=[0.5,2]\), \(C_2:=[1.5,2]\) and \(\widehat{C}_3:=\{1,2,3\}\); that is, the problem considered in Example 4.1 but replacing \(C_3\) by the nonconvex set \(\widehat{C}_3\). According to Propositions 4.2 and 4.3, the product space reformulations in (4.4) and (4.5), with \(C_3\) replaced by \(\widehat{C}_3\), are still valid to reconvert (4.9) into an equivalent problem described by two sets. Both formulations are illustrated in Fig. 2, where now we denote
Due to the nonconvexity, the projector onto \(\widehat{C}_3\) may be set-valued. In view of Proposition 4.3(ii), the projector onto \(\widehat{\varvec{K}}\) is described by
We emphasize that, in contrast to (4.6b), in the nonconvex case \(P_{\widehat{\varvec{K}}}\ne P_{\widehat{C}_3\times \widehat{C}_3}\circ P_{\varvec{D}_2}\). Indeed, consider for instance the point \(\varvec{x}:=(2,1)\in \mathbb {R}^2\). Then,
Therefore, \(P_{\widehat{C}_3\times \widehat{C}_3}(P_{\varvec{D}_2}(\varvec{x}))\ne P_{\widehat{\varvec{K}}}(\varvec{x})=P_{\widehat{C}_3\times \widehat{C}_3}(P_{\varvec{D}_2}(\varvec{x}))\cap \varvec{D}_2\).

Product space reformulations of the nonconvex feasibility problem in Example 4.4
5 Application to splitting algorithms
In this section, we apply our proposed reformulation in Theorem 3.3 in order to derive two new parallel splitting algorithms, one for solving problem (1.1), and another one for (1.2). In the first case, we consider the Douglas–Rachford (DR) algorithm [22, 29] (see also [11, 12] for recent results in the inconsistent case). The DR algorithm permits to find a zero of the sum of two maximally monotone operators. When it is applied to Pierra’s standard reformulation the resulting method takes the form in [9, Proposition 26.12]. In contrast, if the problem is reformulated via Theorem 3.3 we obtain the following iterative scheme, which requires one variable less.
Theorem 5.1
(Parallel Douglas/Peaceman–Rachford splitting algorithm) Let \(A_1, A_2, \ldots , A_r:\mathcal {H}\rightrightarrows \mathcal {H}\) be maximally monotone operators such that \({\text {zer}}(\sum _{i=1}^r A_i)\ne \emptyset\). Let \(\gamma >0\) and let \(\lambda \in {]}0,2]\). Given \(x_{1,0},\ldots ,x_{r-1,0}\in \mathcal {H}\), set
Then the following hold.
-
(i)
If \(\lambda \in {]0,2[}\), then \(p_k\rightharpoonup p^\star\) and \(z_{i,k}\rightharpoonup p^\star\), for \(i=1,\ldots ,r-1\), with \(p^\star \in {\text {zer}}(\sum _{i=1}^r A_i)\).
-
(ii)
If \(A_r\) is uniformly monotone, then \(p_k\rightarrow p^\star\) and \(z_{i,k}\rightarrow p^\star\), for \(i=1,\ldots ,r-1\), where \(p^\star\) is the unique point in \({\text {zer}}(\sum _{i=1}^r A_i)\).
Proof
Consider the product Hilbert space \(\mathcal {H}^{r-1}\) and let \(\varvec{B},\varvec{K}:\mathcal {H}^{r-1}\rightrightarrows \mathcal {H}^{r-1}\) be the operators defined in (3.2). By Theorem 3.3(i), (ii) and (iii), we get that \(\varvec{B}\) and \(\varvec{K}\) are maximally monotone with \({\text {zer}}(\varvec{B}+\varvec{K})=\varvec{j}_{r-1}({\text {zer}}(\sum _{i=1}^r A_i))\ne \emptyset\). For each \(k=0,1,2,\ldots\), set \(\varvec{x}_{k}:=(x_{1,k},\ldots ,x_{r-1,k}),\varvec{z}_{k}:=(z_{1,k},\ldots ,z_{r-1,k})\in \mathcal {H}^{r-1}\) and \(\varvec{p}_k=\varvec{j}_{r-1}(p_k)\in \varvec{D}_{r-1}\). Hence, according to Theorem 3.3(i) and (ii), we can rewrite (5.1) as
Note that (5.2) is the Douglas–Rachford (or Peaceman–Rachford) iteration applied to the operators \(\varvec{B}\) and \(\varvec{K}\). If \(\lambda \in {]0,2[}\), we apply [9, Theorem 26.11(iii)] to obtain that \(\varvec{p}_k\rightharpoonup \varvec{p}^\star\) and \(\varvec{z}_k\rightharpoonup \varvec{p}^\star\), with \(\varvec{p}^\star \in {\text {zer}}(\varvec{B}+\varvec{K})\). Hence, \(\varvec{p}^\star =\varvec{j}_{r-1}(p^\star )\) with \(p^\star \in {\text {zer}}\left( \sum _{i=1}^r A_i\right)\), which implies (i).
Suppose in addition that \(A_r\) is uniformly monotone. Then so is \(\varvec{K}\) according to Theorem 3.3(ii). Hence, (ii) follows from [9, Theorem 26.11(vi)], when \(\lambda \in {]0,2[}\), and [9, Proposition 26.13] when \(\lambda =2\). \(\square\)
Remark 5.2
(Frugal resolvent splitting algorithms with minimal lifting) Consider the problem of finding a zero of the sum of three maximally monotone operators \(A,B,C:\mathcal {H}\rightrightarrows \mathcal {H}\). The classical procedure to solve it has been to employ the standard product space reformulation (Fact 3.1) to construct a DR algorithm on \(\mathcal {H}^3\). The question of whether it is possible to generalize the DR algorithm to three operators without lifting, that is, without enlarging the ambient space, was solved with a negative answer by Ryu in [39]. The generalization is considered in the sense of devising a frugal splitting algorithm which uses the resolvent of each operator exactly once per iteration. In the same work, the author demonstrated that the minimal lifting is 2-fold (in \(\mathcal {H}^2\)) by providing the following splitting algorithm. Given \(\lambda \in {]0,1[}\) and \(x_0,y_0\in \mathcal {H}\), set
Then \(u_k\rightharpoonup w^\star\), \(v_k\rightharpoonup w^\star\) and \(w_k\rightharpoonup w^\star\), with \(w^\star \in {\text {zer}}(A+B+C)\) (see [39, Theorem 4] or [7, Appendix A] for an alternative proof in an infinite-dimensional space).
A few days after the publication of our preprint first version (ArXiv: https://arxiv.org/abs/2107.12355), Malitsky and Tam [31] generalized Ryu’s result by showing that for an arbitrary number of r operators the minimal lifting is \((r-1)\)-fold. In addition, they proposed another frugal splitting algorithm that attains this minimal lifting, whose iteration is described as follows. Given \(\lambda \in {]0,1[}\) and \(\varvec{z}_0=(z_{1,0},\ldots ,z_{r-1,0})\in \mathcal {H}^{r-1}\), set
Then, for each \(i\in \{1,\ldots ,r\}\), \(x_{i,k}\rightharpoonup x^*\in {\text {zer}}(\sum _{j=1}^r A_j)\) (see [31, Theorem 4.5]).
It is worth to notice that the Malitsky–Tam iteration (5.4) does not generalize Ryu’s scheme (5.3), which seems to be difficult to extend to more than three operators as explained in [31, Remark 4.7]. Furthermore, both of these algorithms are different from the one in Theorem 5.1. The main conceptual difference is that (5.4) can be implemented in a distributed decentralized way whereas algorithm (5.1) uses the operator \(A_r\) as a central coordinator (see [31, Sect. 5]). Nevertheless, for the applications considered in this work, the dimensionality reduction obtained through the new product space reformulation seems to be more effective for accelerating the convergence of the algorithm, especially when the number of operators is large as we shall show in Sect. 6.
We now turn our attention into splitting algorithms for problem (1.2). In particular, we concern on the averaged alternating modified reflections (AAMR) algorithm, originally proposed in [4] for best approximation problems, and later extended in [5] for monotone operators (see also [2, 7]). The parallel AAMR splitting iteration obtained from Pierra’s reformulation is given in [5, Theorem 4.1]. As we show in the following result, we can avoid one of the variables defining the iterative scheme if we use the product space reformulation in Theorem 3.3.
Theorem 5.3
(Parallel AAMR splitting algorithm) Let \(A_1, A_2, \ldots , A_r:\mathcal {H}\rightrightarrows \mathcal {H}\) be maximally monotone operators, let \(\gamma >0\) and let \(\lambda \in {]0,2]}\). Let \(\beta \in {]0,1[}\) and suppose that \(q\in {\text {ran}}\left( {\text {Id}}+\frac{\gamma }{2(1-\beta )(r-1)}\sum _{i=1}^rA_i\right)\). Given \(x_{1,0},\ldots ,x_{r-1,0}\in \mathcal {H}\), set
Then \(\left( p_k\right) _{k=0}^\infty\) converges strongly to \(J_{\frac{\gamma }{2(1-\beta )(r-1)}\sum _{i=1}^rA_i}(q)\).
Proof
Consider the product Hilbert space \(\mathcal {H}^{r-1}\) and let \(\varvec{B},\varvec{K}:\mathcal {H}^{r-1}\rightrightarrows \mathcal {H}^{r-1}\) be the operators defined in (3.2). We know that \(\varvec{B}\) and \(\varvec{K}\) are maximally monotone by Theorem 3.3(i) and (ii), respectively. Set \(\varvec{x}_{k}:=(x_{1,k},\ldots ,x_{r-1,k}),\varvec{z}_{k}:=(z_{1,k},\ldots ,z_{r-1,k})\in {\mathcal {H}^{r-1}}\) and \(\varvec{p}_k=\varvec{j}_{r-1}(p_k)\in \varvec{D}_{r-1}\), for each \(k=0,1,2,\ldots\), and set \(\varvec{q}:=\varvec{j}_{r-1}(q)\in \varvec{D}_{r-1}\). On the one hand, according to Theorem 3.3(i) and (ii), we can rewrite (5.5) as
On the other hand, from Theorem 3.3(iv) we obtain that
In particular, the latter implies that \(\varvec{q}\in {\text {ran}}\left( {\text {Id}}+ \frac{\gamma }{2(1-\beta )} (\varvec{B}+\varvec{K})\right)\). Hence, by applying [7, Theorem 6 and Remark 10(i)], we conclude that \(\left( \varvec{p}_k\right) _{k=0}^\infty\) converges strongly to \(J_{\frac{\gamma }{2(1-\beta )} (\varvec{B}+\varvec{K})}(\varvec{q})\) and the result follows. \(\square\)
Remark 5.4
(On Forward-Backward type methods) Forward-Backward type methods permit to find a zero in \(A+B\) when \(A:\mathcal {H}\rightarrow \mathcal {H}\) is cocoercive (see, e.g., [9, Theorem 26.14]) or Lipschitz continuous (see, e.g., [15, 30, 40]) and \(B:\mathcal {H}\rightrightarrows \mathcal {H}\) is maximally monotone. These algorithms make use of direct evaluations of A (forward steps) and resolvent computations of B (backward steps). When dealing with finitely many operators of both nature (single-valued and set-valued), Pierra’s reformulation (Fact 3.1) yields parallel algorithms which need to activate all of them through their resolvents, since all of them are combined into the product operator \(\varvec{A}\) in (3.1). In contrast, the product space reformulation in Theorem 3.3 allows to deal with the case when \(A_1,\ldots ,A_{r-1}:\mathcal {H}\rightarrow \mathcal {H}\) are cocoercive/Lipschitz continuous and \(A_r:\mathcal {H}\rightrightarrows \mathcal {H}\) is maximally monotone. Indeed, it can be easily proved that the product operator \(\varvec{B}\) in (3.2a) keeps the cocoercivity/Lipschitz continuity property. However, the parallel algorithm obtained with this approach will coincide with the original Forward-Backward type algorithm applied to the operators \(\sum _{i=1}^{r-1}A_i\) and \(A_r\). It is worth mentioning that in the opposite case, that is, when one operator is cocoercive and the remaining ones are maximally monotone, a parallel Forward-Backward algorithm was developed in [36].
6 Numerical experiments
In this section, we perform some numerical experiments to assess the advantage of the new proposed reformulation when applied to splitting or projection algorithms. In particular, we compare the performance of the proposed parallel Douglas–Rachford algorithm in Theorem 5.1 with the standard parallel version in [9, Proposition 26.12], first on a convex minimization problem and then in a nonconvex feasibility problem. We will refer to these algorithms as Reduced-DR and Standard-DR, respectively. In some experiments we will also test the algorithms in [39, Theorem 4] and [31, Theorem 4.5], wich will be referred to as Ryu and Malitsky–Tam, respectively. All codes were written in Python 3.7 and the tests were run on an Intel Core i7-10700K CPU 3.80GHz with 64GB RAM, under Ubuntu 20.04.2 LTS (64-bit).
6.1 The generalized Heron problem
We first consider the generalized Heron problem, which is described as follows. Given \(\Omega _1,\ldots ,\Omega _r\subseteq \mathbb {R}^n\) nonempty, closed and convex sets, we are interested in finding a point in \(\Omega _r\) that minimizes the sum of the distances to the remaining sets; that is,
This problem was investigated with modern convex analysis tools in [32, 33], where it was solved by subgradient-type algorithms. It was later revisited in [14], where the authors implemented their proposed paralellized Douglas–Rachford-type primal-dual methods for its resolution. Indeed, splitting algorithms such as Douglas–Rachford can be employed to solve problem (6.1) as this is equivalent to the monotone inclusion (1.1) with
According to Facts 2.7 and 2.9, \(J_{\gamma A_r}=P_{\Omega _r}\) and \(J_{\gamma A_i}={\text {prox}}_{\gamma d_{\Omega _i}}\), for \(i=1,\ldots ,r-1\). We recall that the proximity operator of the distance function to a closed and convex set \(C\subseteq \mathcal {H}\) is given by
In our experiments, the constraint sets \(\Omega _1,\ldots ,\Omega _{r-1}\) in (6.1) were randomly generated hypercubes of centers \((c_{i,1},\ldots ,c_{i,n}),\ldots ,(c_{r-1,1},\ldots ,c_{r-1,n})\in \mathbb {R}^n\) with length side \(\sqrt{2}\), while \(\Omega _r\) was chosen to be the closed ball centered at zero with radius 10; that is,
More precisely, the centers of the hypercubes were randomly generated with norm greater or equal than 12, so that the hypercubes did not intersect the ball. Two instances of the problem with \(r=5\), in \(\mathbb {R}^2\) and \(\mathbb {R}^3\), are illustrated in Fig. 3.

The generalized Heron problem consisting in finding a point in a ball in \(\mathbb {R}^2\) (left) or \(\mathbb {R}^3\) (right) that minimizes the sum of the distances to four squares (left) or cubes (right). A solution to the problem is represented by a red point
In our first numerical test, we generated 10 instances of the problem (6.1)–(6.2) in \(\mathbb {R}^{100}\) with \(r=3\). For each \(\gamma \in \{1,10,25,50,75,100\}\) and each \(\lambda \in \{0.1,0.2,\ldots ,1.9\}\), Standard-DR and Reduced-DR were run from 10 random starting points. For those values of \(\lambda \le 1\), Ryu and Malitsky–Tam algorithms were also run from the same initial points. All algorithms were stopped when the monitored sequence \(\{p_k\}_{k=0}^\infty\) verified the Cauchy-type stopping criteria
for the first time. For a fairer comparison, for each algorithm we monitored that sequence which is projected onto the feasible set \(\Omega _r\) so that all of them lay on the same ambient space. The average number of iterations required by each algorithm among all problems and starting points is depicted in Fig. 4. In Table 1 we list the best results obtained by each algorithm and the value of the parameters at which those results were achieved.

Performance of Standard-DR, Reduced-DR, Malitsky–Tam and Ryu algorithms for solving the generalized Heron problem in \(\mathbb {R}^{100}\) with \(r=3\). For each pair of parameters \((\gamma ,\lambda )\), we represent the average number of iterations among 10 problems and 10 random starting points each
Once the parameters had been tuned, we analyzed the effect of the dimension of the space (n), as well as the number of operators (r), on the comparison between all algorithms. For the first purpose, we fixed \(r=3\) and generated 20 problems in \(\mathbb {R}^n\) for each \(n\in \{100,200,\ldots ,1000\}\). Then, for each problem we computed the average time, among 10 random starting points, required by each algorithm to converge. Parameters \(\gamma\) and \(\lambda\) were chosen as in Table 1 according to the previous experiment. The results, shown in Fig. 5a, confirm the consistent advantage of Reduced-DR and Ryu for all sizes. Indeed, these two algorithms were around 4 times faster than Standard-DR, whereas Malitsky–Tam was 2 times faster than Standard-DR.
For the second objective we repeated the experiment where now, for each number of operators \(r\in \{3,4,\ldots ,20\}\), we generated 20 problems in \(\mathbb {R}^{100}\). We did not consider Ryu splitting algorithm since it is only devised for three operators. We show the results in Fig. 5b, from which we deduce that the superiority of Reduced-DR and Malitsky–Tam over Pierra’s standard reformulation is diminished as the number of operators increases. However, this drop is more drastic for the Makitsky–Tam algorithm. In fact, while Reduced-DR is still always preferable to Standard-DR for all the considered values of r, Malitsky–Tam algorithm turns even slower than the classical approach when the number of operators is greater than 6.

Comparison of the performance of Standard-DR, Reduced-DR, Malitsky–Tam and Ryu algorithms for solving 20 instances of generalized Heron problem with r sets in \(\mathbb {R}^{n}\) for different values of n and r. For each problem we represent the ratio between the average time required by each algorithm over Reduced-DR, among 10 random starting points. The colored lines connect the median of the ratios while the dashed grey line represents ratios equal to 1
6.2 Sudoku puzzles
In this section we analyze the potential of the product space reformulation with reduced dimension for nonconvex feasibility problems (Proposition 4.3). To this aim, we concern on Sudoku puzzles, which were first investigated by the Douglas–Rachford algorithm in [24]. Since then, other formulations as feasibility problems have been studied. In this paper we consider the formulation with binary variables described in [3, Sect. 6.2], which we explain next.
Recall that a Sudoku puzzle is defined by a \(9\times 9\) grid, composed by nine \(3\times 3\) subgrids, where some of the cells are prescribed with some given values. The objective is to fill the remaining cells so that each row, each column and each subgrid contains the digits from 1 to 9 exactly once. Possible solutions to a given Sudoku are encoded as a 3-dimensional multiarray \(X\in \mathbb {R}^{9\times 9\times 9}\) with binary entries defined componentwise as
for \((i,j,k)\in I^3\) where \(I:=\{1,2,\ldots ,9\}\). Let \(\mathcal {C}:=\{e_1,e_2,\ldots ,e_9\}\) be the standard basis of \(\mathbb {R}^9\), let \(J\subseteq I^3\) be the set of indices for the prescribed entries of the Sudoku, and denote by \({\text {vec}}M\) the vectorization, by columns, of a matrix M. Under encoding (6.3), a solution to the Sudoku can be found by solving the feasibility problem
where the constraint sets are defined by
Observe that nonconvexity of problem (6.4) arises from the combinatorial structure of \(C_1\), \(C_2\), \(C_3\), \(C_4\subseteq \{0,1\}^{9\times 9\times 9}\). Projections onto these sets can be computed by means of the projector mapping onto \(\mathcal {C}\) (see [3, Remark 5.1]). On the other hand, \(C_5\) is an affine subspace of \(\mathbb {R}^{9\times 9\times 9}\) whose projector can be readily computed component-wise as
In our experiment we considered the 95 hard puzzles from the library top95.Footnote 1 For each puzzle, we run Standard-DR, Reduced-DR and Malitsky–Tam from 10 random initial points. Parameter \(\lambda\) was roughly tuned for good performance and it was fixed to \(\lambda =1\) for Standard-DR and Reduced-DR and \(\lambda =0.5\) for Malitsky–Tam. The algorithms were stopped when either they found a solution or when the CPU running time exceeded 5 minutes. A summary of the results can be found in Table 2. While the success of all three algorithms is very similar, the average CPU time and, specially, the proportion of wins are clearly favorable to Reduced-DR.
In order to better visualize the results we turn to performance profiles (see [21] and the modification proposed in [26]), which are constructed as explained next.
Performance profiles Let \(\mathcal {A}\) denote a set of algorithms to be tested on a set of N problems, denoted by \(\mathcal {P}\), for multiple runs (starting points). Let \(s_{a,p}\) denote the fraction of successful runs of algorithm \(a\in \mathcal {A}\) on problem \(p\in \mathcal {P}\) and let \(t_{a,p}\) be the averaged time required to solve those successful runs. Compute \(t^\star _p:=\min _{a\in \mathcal {A}} t_{a,p}\) for all \(p\in \mathcal {P}\). Then, for any \(\tau \ge 1\), define \(R_a(\tau )\) as the set of problems for which algorithm a was at most \(\tau\) times slower than the best algorithm; that is, \(R_a(\tau ):=\{p\in \mathcal {P}, t_{a,p}\le \tau t^\star _p\}\). The performance profile function of algorithm a is given by
The value \(\rho _a(1)\) indicates the portion of runs for which a was the fastest algorithm. When \(\tau \rightarrow +\infty\), then \(\rho _a(\tau )\) gives the proportion of successful runs for algorithm a.
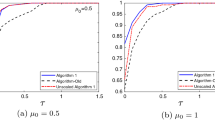
Performance profiles of the results of Sudoku experiment are shown in Fig. 6, which confirm the conclusions drawn from Table 2. Furthermore, we can now asses that Reduced-DR becomes consistently superior since its performance profile is mostly above the one of the remaining two algorithms.

Performance profiles comparing Standard-DR, Reduced-DR and Malitsky–Tam algorithm for solving 95 Sudoku problems (left). For each problem, 10 random starting points were considered. Instances were labeled as unsolved after 5 minutes of CPU running time. For the sake of clarity we focus the view of the performance profiles to the values of \(\tau \in [1,5]\) (right)
We would like to conclude with the following comment regarding the implementation of splitting algorithms on (6.4).
Remark 6.1
(On the order of the sets) Observe that Pierra’s classical reformulation in Proposition 4.2, and thus Standard-DR, is completely symmetric on the order of the sets \(C_1,\ldots ,C_5\). However, this is not the case for the reformulation in Proposition 4.3, where one has to decide which of the sets will be merged to the diagonal to construct the set \(\varvec{K}\) in (4.8b). In our test, we followed the arrangement in Proposition 4.3, that is,
Note that this makes the constrained diagonal set \(\varvec{K}\) to be an affine subspace. Due to the nonconvexity of the problem, the reformulation chosen may be crucial for the success of the algorithm. For example, we tested all the remaining combinations, for which Reduced-DR rarely found a solution on the considered problems within the first 5 minutes of running time.
7 Concluding remarks
In this work we have introduced a new reformulation in a product space for finding a zero in the sum of finitely many maximally monotone operators with splitting algorithms. The new approach reduces one dimension of the ambient product Hilbert space with respect to Pierra’s standard reformulation.
Having different techniques for reformulating monotone inclusions, which may be of interest itself, lead to different algorithmic implementation. For the considered applications in this work, that reduction of the dimension implied an acceleration of the convergence of the Douglas–Rachford splitting algorithm. Further, our proposed scheme also outperformed Ryu [39] and Malitsky–Tam [31] algorithms on these problems. However, our numerical experiments are far from providing a complete computational study. In fact, numerical comparison of the three algorithms for solving best approximation problems with three subspaces has been recently performed in [13], where the reduced product space reformulation is not as advantageous as in the experiments considered here. This motivate us to further investigate a comprehensive numerical analysis of these algorithms in a future work.
Data Availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
Notes
top95: http://magictour.free.fr/top95.
References
Adly, S., Bourdin, L.: On a decomposition formula for the resolvent operator of the sum of two set-valued maps with monotonicity assumptions. Appl. Math. Opt. 80(3), 715–732 (2019)
Alwadani, S., Bauschke, H.H., Moursi, W.M., Wang, X.: On the asymptotic behaviour of the Aragón Artacho-Campoy algorithm. Oper. Res. Lett. 46(6), 585–587 (2018)
Aragón Artacho, F.J., Borwein, J.M., Tam, M.K.: Recent results on Douglas-Rachford methods for combinatorial optimization problem. J. Optim. Theory. Appl. 163(1), 1–30 (2014)
Aragón Artacho, F.J., Campoy, R.: A new projection method for finding the closest point in the intersection of convex sets. Comput. Optim. Appl. 69(1), 99–132 (2018)
Aragón Artacho, F.J., Campoy, R.: Computing the resolvent of the sum of maximally monotone operators with the averaged alternating modified reflections algorithm. J. Optim. Theory Appl. 181(3), 709–726 (2019)
Aragón Artacho, F.J., Campoy, R., Tam, M.K.: The Douglas-Rachford algorithm for convex and nonconvex feasibility problems. Math. Methods Oper. Res. 91(2), 201–240 (2020)
Aragón Artacho, F.J., Campoy, R., Tam, M.K.: Strengthened splitting methods for computing resolvents. Comput. Optim. Appl. 80(2), 549–585 (2021)
Aragón-Artacho, F.J., Torregrosa-Belén, D.: A direct proof of convergence of Davis-Yin splitting algorithm allowing larger stepsizes. Set-Valued Variat. Anal. (2022). https://doi.org/10.1007/s11228-022-00631-6
Bauschke, H.H., Combettes, P.L.: Convex Analysis and Monotone Operator Theory in Hilbert Spaces, 2nd edn. Springer, Berlin (2017)
Bauschke, H.H., Combettes, P.L., Luke, D.R.: Phase retrieval, error reduction algorithm, and Fienup variants: a view from convex optimization. J. Opt. Soc. Am A 19(7), 1334–1345 (2002)
Bauschke, H.H., Moursi, W.M.: On the Douglas-Rachford algorithm. Math. Program. 164(1–2), 263–284 (2017)
Bauschke, H.H., Moursi, W.M.: On the Douglas-Rachford algorithm for solving possibly inconsistent optimization problems. ArXiv preprint Arxiv: arXiv:2106.11547 (2021)
Bauschke, H.H., Singh, S., Wang, X.: The splitting algorithms by Ryu, by Malitsky–Tam, and by Campoy applied to normal cones of linear subspaces converge strongly to the projection onto the intersection. ArXiv preprint ArXiv: arXiv:2203.03832. (2022)
Bot, R.I., Hendrich, C.: A Douglas-Rachford type primal-dual method for solving inclusions with mixtures of composite and parallel-sum type monotone operators. SIAM J. Optim. 23(4), 2541–2565 (2013)
Cevher, V., Vu, B.C.: A reflected forward-backward splitting method for monotone inclusions involving Lipschitzian operators. Set-Valued Var. Anal. 29(1), 163–174 (2021)
Combettes, P.L.: Iterative construction of the resolvent of a sum of maximal monotone operators. J. Convex Anal. 16(4), 727–748 (2009)
Condat, L., Kitahara, D., Contreras, A., Hirabayashi, A: Proximal splitting algorithms for convex optimization: a tour of recent advances, with new twists. ArXiv preprint Arxiv: arXiv:1912.00137 (2021)
Dao, M., Dizon, N., Hogan, J., Tam, M.K.: Constraint reduction reformulations for projection algorithms with applications to wavelet construction. J. Optim. Theory Appl. 190(1), 201–233 (2021)
Dao, M.N., Phan, H.M.: Computing the resolvent of the sum of operators with application to best approximation problems. Optim. Lett. 14(5), 1193–1205 (2020)
Davis, D., Yin, W.: A three-operator splitting scheme and its optimization applications. Set-Valued Var. Anal. 25(4), 829–858 (2017)
Dolan, E.D., Moré, J.J.: Benchmarking optimization software with performance profiles. Math. Program. 91(2), 201–213 (2002)
Douglas, J., Rachford, H.H.: On the numerical solution of heat conduction problems in two and three space variables. Trans. Am. Math. Soc. 82(2), 421–439 (1956)
Elser, V.: Phase retrieval by iterated projections. J. Opt. Soc. Am. A 20(1), 40–55 (2003)
Elser, V., Rankenburg, I., Thibault, P.: Searching with iterated maps. Proc. Natl. Acad. Sci. 104(2), 418–423 (2007)
Franklin, D.J., Hogan, J.A., Tam, M.K.: Higher-dimensional wavelets and the Douglas–Rachford algorithm. In: 13th International Conference on Sampling Theory and Applications (SampTA), pp. 1–4. IEEE (2019)
Izmailov, A.F., Solodov, M.V., Uskov, E.T.: Globalizing stabilized sequential quadratic programming method by smooth primal-dual exact penalty function. J. Optim. Theor. Appl. 169(1), 1–31 (2016)
Kruger, A.Y.: Generalized differentials of nonsmooth functions, and necessary conditions for an extremum. Sib. Math. J. 26(3), 370–379 (1985)
Lamichhane, B.P., Lindstrom, S.B., Sims, B.: Application of projection algorithms to differential equations: boundary value problems. ANZIAM J. 61(1), 23–46 (2019)
Lions, P.L., Mercier, B.: Splitting algorithms for the sum of two nonlinear operators. SIAM J. Numer. Anal. 16(6), 964–979 (1979)
Malitsky, Y., Tam, M.K.: A forward-backward splitting method for monotone inclusions without cocoercivity. SIAM J. Optim. 30(2), 1451–1472 (2020)
Malitsky, Y., Tam, M.K.: Resolvent splitting for sums of monotone operators with minimal lifting. ArXiv preprint Arxiv: arXiv:2108.02897 (2021)
Mordukhovich, B.S., Nam, N.M., Salinas, J.: Solving a generalized Heron problem by means of convex analysis. Amer. Math. Monthly 119(2), 87–99 (2012)
Mordukhovich, B.S., Nam, N.M., Salinas, J.: Applications of variational analysis to a generalized Heron problem. Appl. Anal. 91(10), 1915–1942 (2012)
Pierra, G.: Méthodes de Décomposition et Croisement D’algorithmes Pour des Problèmes D’optimisation. Doctoral Dissertation. Institut National Polytechnique de Grenoble-INPG, Université Joseph-Fourier-Grenoble I (1976)
Pierra, G.: Decomposition through formalization in a product space. Math. Program. 28(1), 96–115 (1984)
Raguet, H., Fadili, J., Peyré, G.: A generalized forward-backward splitting. SIAM J. Imaging Sci. 6(3), 1199–1226 (2013)
Rieger, J., Tam, M.K.: Backward-forward-reflected-backward splitting for three operator monotone inclusions. Appl. Math. Comput. 381, 125248 (2020)
Rockafellar, R.T.: Monotone operators and the proximal point algorithm. SIAM J. Control Optim. 14(5), 877–898 (1976)
Ryu, E.K.: Uniqueness of DRS as the 2 operator resolvent-splitting and impossibility of 3 operator resolvent-splitting. Math. Program. 182(1), 233–273 (2020)
Tseng, P.: A modified forward-backward splitting method for maximal monotone mappings. SIAM J. Control Optim. 38(2), 431–446 (2000)
Acknowledgements
The author would like to thank two anonymous referees for their careful reading and their constructive comments which helped to improve this manuscript.
Funding
Open Access funding provided thanks to the CRUE-CSIC agreement with Springer Nature. The author was partially supported by the Ministry of Science, Innovation and Universities of Spain and the European Regional Development Fund (ERDF) of the European Commission (PGC2018-097960-B-C22), and by the Generalitat Valenciana (AICO/2021/165).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author has no conflict of interests to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Campoy, R. A product space reformulation with reduced dimension for splitting algorithms. Comput Optim Appl 83, 319–348 (2022). https://doi.org/10.1007/s10589-022-00395-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-022-00395-7
Keywords
- Pierra’s product space reformulation
- Splitting algorithm
- Douglas–Rachford algorithm
- Monotone inclusions
- Feasibility problem
- Projection methods