
Abstract
Gradient method is a simple optimization approach using minus gradient of the objective function as a search direction. Its efficiency highly relies on the choices of the stepsize. In this paper, the convergence behavior of a class of gradient methods, where the stepsize has an important property introduced in (Dai in Optimization 52:395–415, 2003), is analyzed. Our analysis is focused on minimization on strictly convex quadratic functions. We establish the R-linear convergence and derive an estimate for the R-factor. Specifically, if the stepsize can be expressed as a collection of Rayleigh quotient of the inverse Hessian matrix, we are able to show that these methods converge R-linearly and their R-factors are bounded above by \(1-\frac{1}{\varkappa }\), where \(\varkappa\) is the associated condition number. Preliminary numerical results demonstrate the tightness of our estimate of the R-factor.



Similar content being viewed by others

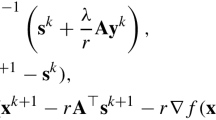
Notes
The definition of \(A^p\): let \(A=U^TDU\) be the eigendecomposition, where \(D=\mathrm{diag}(\lambda _1,\lambda _2,\ldots ,\lambda _n)\) and \(U\in {\mathbb {R}}^{n\times n}\) is an orthonormal matrix, then \(A^{p}=U^TD^{p}U\). Here \(D^{p}=\mathrm{diag}({\lambda _1^p},{\lambda _2^p},\ldots ,{\lambda _n^p})\).
Noticing that the gradient method (2) with the stepsize (4) is invariant under orthogonal transformation of the variables, without loss of generality, we assume that the matrix A is of the form \(A = \mathrm{diag}(0,\ldots ,0,\,\lambda _{\ell },\ldots , \lambda _n),\) where \(0 < \lambda _{\ell } \le \ldots \le \lambda _n\). Let \(b^{(i)}\) and \(g(x)^{(i)}\) denote the i-th component of b and g(x), respectively. It follows from \(Ax^*-b=0\) that \(b^{(i)}=0\) holds for all \(1\le i\le \ell -1\). This shows that, for any \(x\in {\mathbb {R}}^n\) and \(i\in \{1,2,\ldots ,\ell -1\}\), \(g(x)^{(i)}=(Ax-b)^{(i)}=0\). Hence, g(x) belongs to the eigenspace of all positive eigenvalues of A.
References
Akaike, H.: On a successive transformation of probability distribution and its application to the analysis of the optimum gradient method. Ann. Inst. Stat. Math. Tokyo 11, 1–17 (1959)
Barzilai, J., Borwein, J.M.: Two-point step size gradient methods. IMA J. Numer. Anal. 8(1), 141–148 (1988)
Burdakov, O., Dai, Y.-H., Huang, N.: Stabilized Barzilai-Borwein method. J. Comp. Math. 37(6), 916–936 (2019)
Cauchy, A.: Méthode générale pour la résolution des systemes d’équations simultanées. Comp. Rend. Sci. Paris 25, 536–538 (1847)
Curtis, F.E., Guo, W.: \(R\)-linear convergence of limited memory steepest descent. IMA J. Numer. Anal. 38, 720–742 (2018)
Dai, Y.-H.: Alternate step gradient method. Optimization 52, 395–415 (2003)
Dai, Y.-H.: A new analysis on the Barzilai-Borwein gradient method. J. Oper. Res. Soc. China 1(2), 187–198 (2013)
Dai, Y.-H., Al-Baali, M., Yang, X.: A positive Barzilai-Borwein-like stepsize and an extension for symmetric linear systems. In: Numerical Analysis and Optimization, pp. 59–75. Springer, New York p (2015)
Dai, Y.-H., Fletcher, R.: On the asymptotic behaviour of some new gradient methods. Math. Program. 103, 541–559 (2005)
Dai, Y.-H., Fletcher, R.: Projected Barzilai-Borwein methods for large-scale box-constrained quadratic programming. Numer. Math. 100(1), 21–47 (2005)
Dai, Y.-H., Hager, W.W., Schittkowski, K., Zhang, H.: The cyclic Barzilai-Borwein method for unconstrained optimization. IMA J. Numer. Anal. 26(3), 604–627 (2006)
Dai, Y.-H., Huang, Y., Liu, X.-W.: A family of spectral gradient methods for optimization. Comput. Optim. Appl. 74, 43–65 (2019)
Dai, Y.-H., Liao, L.-Z.: \(R\)-linear convergence of the Barzilai and Borwein gradient method. IMA J. Numer. Anal. 22(1), 1–10 (2002)
Dai, Y.-H., Yuan, Y.: Analysis of monotone gradient methods. J. Ind. Manag. Optim. 1(2), 181–192 (2005)
De Asmundis, R., di Serafino, D., Hager, W.W., Toraldo, G., Zhang, H.: An efficient gradient method using the Yuan steplength. Comput. Optim. Appl. 59(3), 541–563 (2014)
De Asmundis, R., di Serafino, D., Landi, G.: On the regularizing behavior of the SDA and SDC gradient methods in the solution of linear ill-posed problems. J. Comput. Appl. Math. 302, 81–93 (2016)
Fletcher, R.: On the Barzilai-Borwein method. In: In Optimization and Control with Applications, pp. 235–256. Springer, New York (2005)
Frassoldati, G., Zanni, L., Zanghirati, G.: New adaptive stepsize selections in gradient methods. J. Ind. Manag. Optim. 4(2), 299 (2008)
Friedlander, A., Martínez, J.M., Molina, B., Raydan, M.: Gradient method with retards and generalizations. SIAM J. Numer. Anal. 36(1), 275–289 (1998)
Huang, Y., Dai, Y.-H., Liu, X.-W.: Equipping Barzilai-Borwein method with two-dimensional quadratic termination property, arXiv preprint arXiv:2010.12130, (2020)
Li, D.-W., Sun, R.-Y.: On a faster \(R\)-Linear convergence rate of the Barzilai-Borwein method, arXiv preprint arXiv:2101.00205, (2021)
Luenberge, D.G.: Optimization by Vector Space Methods. Wiley, New York (1968)
Malitsky, Y., Mishchenko, K.: Adaptive gradient descent without descent, arXiv preprint arXiv:1910.09529, (2019)
Nocedal, J., Wright, S.: Numerical Optimization. Springer, New York (1999)
Ortega, J.M., Rheinboldt, W.C.: Iterative Solution of Nonlinear Equations in Several Variables. Academic Press, New York (1970)
Raydan, M.: On the Barzilai and Borwein choice of steplength for the gradient method. IMA J. Numer. Anal. 13(3), 321–326 (1993)
Raydan, M.: The Barzilai and Borwein gradient method for the large scale unconstrained minimization problem. SIAM J. Optim. 7(1), 26–33 (1997)
Raydan, M., Svaiter, B.F.: Relaxed steepest descent and Cauchy-Barzilai-Borwein method. Comput. Optim. Appl. 21(2), 155–167 (2002)
Sun, W.-Y., Yuan, Y.: Optimization Theory and Methods: Nonlinear Programming. Springer, New York (2006)
Yuan, Y.: A short note on the Q-linear convergence of the steepest descent method. Math. Program. 123(2), 339–343 (2010)
Zhigljavsky, A., Pronzato, L., Bukina, E.: An asymptotically optimal gradient algorithm for quadratic optimization with low computational cost. Optim. Lett. 7(6), 1047–1059 (2013)
Zou, Q., Magoulès, F.: Fast gradient methods with alignment for symmetric linear systems without using Cauchy step. J. Comput. Appl. Math. 381, 113033 (2021)
Acknowledgements
The author is very grateful to Professor Oleg Burdakov in Linköping University and Professor Yu-Hong Dai in Chinese Academy of Sciences for their valuable and insightful comments on this manuscript.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This author was supported by the National Natural Science Foundation of China (No. 12001531)
Rights and permissions
About this article

Cite this article
Huang, N. On R-linear convergence analysis for a class of gradient methods. Comput Optim Appl 81, 161–177 (2022). https://doi.org/10.1007/s10589-021-00333-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-021-00333-z