
Abstract
A family of new conjugate gradient methods is proposed based on Perry’s idea, which satisfies the descent property or the sufficient descent property for any line search. In addition, based on the scaling technology and the restarting strategy, a family of scaling symmetric Perry conjugate gradient methods with restarting procedures is presented. The memoryless BFGS method and the SCALCG method are the special forms of the two families of new methods, respectively. Moreover, several concrete new algorithms are suggested. Under Wolfe line searches, the global convergence of the two families of the new methods is proven by the spectral analysis for uniformly convex functions and nonconvex functions. The preliminary numerical comparisons with CG_DESCENT and SCALCG algorithms show that these new algorithms are very effective algorithms for the large-scale unconstrained optimization problems. Finally, a remark for further research is suggested.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The classical conjugate gradient (CG) method with line search is as follows:
where the directions d k is given by
where g k =g(x k )=∇f(x k ). The different choices for the parameter β k correspond to different CG methods, such as HS method [15], FR method [7], PRP method [22, 23], LS method [16], PRP+ method [8], DY method [5] and so on. On the history of the conjugate gradient method, there are several survey articles, such as [11].
In [17], the Perry conjugate gradient algorithm [21] was generalized and the line search directions were formulated as follows:
where s k =x k+1−x k =α k d k , y k =g k+1−g k , α k is the steplength of the line search and σ is a preset parameter,
which is called Perry iteration matrix, and the vector u k is any vector in \(\mathbb{R}^{n}\) such that \(y_{k}^{T}u_{k}\ne0\). In the paper [17], the case u k =y k was discussed. When u k =s k , the CG_DESCENT algorithm [10–12] can be deduced and the D-L method [4] can be derived from the restriction σ>0. Recently, we also studied the case u k =s k in [19] and presented a RSPDCGs algorithm.
In this paper, a family of symmetric Perry conjugate gradient methods is proposed, that is, the line search directions are formulated by
where \(\beta_{k}=\frac{y_{k}^{\mathrm{T}}g_{k+1}}{d_{k}^{\mathrm{T}}y_{k}}- ( \alpha_{k}\sigma+\frac{y_{k}^{\mathrm{T}}y_{k}}{d_{k}^{\mathrm {T}}y_{k}} ) \frac{d_{k}^{\mathrm{T}}g_{k+1}}{d_{k}^{\mathrm{T}}y_{k}}\), \(\gamma _{k}=\frac {d_{k}^{\mathrm{T}}g_{k+1}}{d_{k}^{\mathrm{T}}y_{k}}\) and

which is called the symmetric Perry iteration matrix. When \(\sigma y_{k}^{\mathrm{T}} s_{k}>0\), for any line search, the directions defined by (5) satisfy the descent property [1]
or the sufficient descent property [8]
This paper is organized as follows. In Sect. 2, first, the family of the symmetric Perry conjugate gradient methods is deduced. Then the spectra of the iteration matrix are analyzed, so, its sufficient descent property is proved and several concrete algorithms are proposed. In Sect. 3, the scaling technology and the restarting strategy are applied to the symmetric Perry conjugate gradient methods, thus, a family of scaling Perry conjugate gradient methods with restarting procedures is developed. In Sect. 4, the global convergence of the two families of the new methods with the Wolfe line searches is proven by the spectral analysis of the conjugate gradient iteration matrix. In Sect. 5, the preliminary numerical results are reported. A remark for further research is given in Sect. 6.
2 The symmetric Perry conjugate gradient method
In [21], A. Perry changed the CG update parameter β k of the HS conjugate gradient method [15] into \(\beta_{k}^{P}=\frac{(y_{k}-s_{k})^{\mathrm{T}}g_{k+1}}{y_{k}^{\mathrm{T}} d_{k}}\), and formulated the line search directions
and
where
In [17], (10) and (9) were substituted by
and
respectively, where \(u,v\in\mathbb{R}^{n}\) and σ is a parameter. Thus, it is follows from (11), (12) and d k+1=−Q k+1 g k+1 that \((\sigma s_{k} - vy_{k}^{\mathrm {T}}u)^{\mathrm{T}} g_{k+1}=0\), which yields \(v= \frac{\sigma s_{k}}{y_{k}^{\mathrm{T}}u} \). So,
from which the generalized Perry conjugate gradient method ((1) and (3)) can be obtained [17].
In this paper, we choose a suitable u such that Q k+1 is a symmetric matrix, thus the line search directions d k may satisfy (7) or (8). Let \(Q_{k+1}=Q_{k+1}^{\mathrm{T}}\), then
Therefore, the vector u can be taken as
and u T y k =aσ. We note that the matrix Q k+1 defined by (13) is independent of the nonzero constant a, so, we can choose a=1. Thus, from (13) and (14) we can obtain the matrix Q k+1 defined by (6).
The method formulated by (1) and (5) is called the symmetric Perry conjugate gradient method, denoted by SPCG. And the directions generated by (5) are called the symmetric Perry conjugate gradient directions, which will be proven to be descent directions in Sect. 2.2.
From the above discussions, a family of new nonlinear conjugate gradient algorithms can be obtained as follows:
Algorithm 1
(SPCG)
- Step 1.:
-
Give an initial point x 1 and ε≥0. Set k=1.
- Step 2.:
-
Calculate g 1=g(x 1). If ∥g 1∥≤ε then stop, otherwise let d 1=−g 1.
- Step 3.:
-
Calculate steplength α k with line searches.
- Step 4.:
-
Set x k+1=x k +α k d k .
- Step 5.:
-
Calculate g k+1=g(x k+1). If ∥g k+1∥≤ε then stop.
- Step 6.:
-
Calculate the directions d k+1 via (5) with different σ.
- Step 7.:
-
Set k=k+1, then go to step 3.
Remark 1
In this paper, to ensure the convergence of the algorithm, we adopt the Wolfe line search strategies:
and
where 0<b 1<b 2<1. The stopping criterion, ∥g k ∥≤ε, can be changed into other forms. For the different choices of σ, several concrete forms of the algorithm will be discussed in the Sect. 2.2.
2.1 Spectral analysis
Here, we analyze the spectra of the Perry matrix and the symmetric Perry matrix.
Theorem 1
Let P k+1 be defined by (4). Then when \(\sigma (y_{k}^{\mathrm{T}} s_{k})\ne0\), P k+1 is a nonsingular matrix and the eigenvalues of P k+1 consist of 1 (n−2 multiplicity), \(\lambda_{\,1}^{k+1}\) and \(\lambda_{2}^{k+1}\), where

and

Proof
From the fundamental algebra formula
it follows that
Therefore, the Perry matrix (4) is a nonsingular matrix when \(\sigma y_{k}^{\mathrm{T}} s_{k} \ne0\).
Since \(\forall\xi\in\mathrm{span} \{s_{k},y_{k}\}^{\perp}\subset \mathbb{R}^{n}\),

the matrix P k+1 has the eigenvalue 1 (n−2 multiplicity), corresponding to the eigenvectors ξ∈span{s k ,y k }⊥.
By the relationships between the trace and the eigenvalues of matrix and between the determinant and the eigenvalues of matrix, the other two eigenvalues are the roots of the following quadratic polynomial
Thus, the other two eigenvalues are determined by (17) and (18), respectively. □
According to Theorem 1, the following theorem for the symmetric Perry matrix Q k+1 defined by (6) can be deduced.
Theorem 2
Let \(\lambda_{\mathrm{min}}^{(k+1)}\) and \(\lambda_{\mathrm{max}}^{(k+1)}\) be the minimum and maximum eigenvalues of Q k+1, respectively, where Q k+1 is defined by (6). If \(\sigma(y_{k}^{\mathrm{T}} s_{k})> 0\), then



and
where \(\omega_{k}=\frac{y_{k}^{\mathrm{T}}y_{k}s_{k}^{\mathrm {T}}s_{k}}{(s_{k}^{\mathrm{T}}y_{k})^{2}}\). Moreover, Q k+1 is a symmetric positive definite matrix when \(\sigma (y_{k}^{\mathrm{T}} s_{k})>0\).
Proof
When \(\sigma(y_{k}^{\mathrm{T}} s_{k})> 0\), from (14), (17), (18) and the following relations:
it can be proven that \(\lambda_{\mathrm{min}}^{(k+1)}\) and \(\lambda _{\mathrm{max}}^{(k+1)}\) are formulated by (21) and (22), respectively.
Simple calculation claims that

and

So, the inequality (26) implies that

In addition, it follows from (25) that
Therefore, \(\lambda_{\mathrm{max}}^{(k+1)}\ge \max\{\omega_{k},\omega_{k}+\sigma\frac{s_{k}^{\mathrm {T}}s_{k}}{s_{k}^{\mathrm {T}}y_{k}}-1\} \ge\sigma\frac{s_{k}^{\mathrm{T}}s_{k}}{s_{k}^{\mathrm{T}}y_{k}}\).
Similarly,

and

In the end, it follows from (20) that \(\lambda_{\mathrm{min}}^{(k+1)}\lambda_{\mathrm{max}}^{(k+1)}=\sigma\frac {s_{k}^{\mathrm {T}}s_{k}}{y_{k}^{\mathrm{T}} s_{k}}\), which implies that
Hence, (23) and (24) hold, which implies that Q k+1 is a symmetric positive definite matrix when \(\sigma(y_{k}^{\mathrm{T}} s_{k}) > 0\). □
From the above theorem, we can easily obtain the following corollary.
Corollary 1
Let Q k+1 be defined by (6) and \(\sigma (y_{k}^{\mathrm{T}} s_{k}) > 0\). The spectral condition number of Q k+1, κ 2(Q k+1), is formulated by
Especially, κ 2(Q k+1) arrives at the minimum, \((\sqrt {\omega_{k}} + \sqrt{\omega_{k}-1} )^{2}\), when \(\sigma=\frac{y_{k}^{\mathrm {T}}y_{k}}{s_{k}^{\mathrm{T}}y_{k}}\).
Proof
According to Theorem 2, (21) and (22) imply that (27) holds. Let
then, according to (27), κ 2(Q k+1) can be rewritten as follows:
where ψ(⋅) is a strictly increasing function on [1,+∞). Note that
and the above first inequality takes “=” if and only if \(\omega_{k}=\sigma\frac{s_{k}^{\mathrm{T}}s_{k}}{s_{k}^{\mathrm{T}}y_{k}}\), namely, \(\sigma=\frac{y_{k}^{\mathrm{T}}y_{k}}{s_{k}^{\mathrm{T}}y_{k}}\). Hence, the minimum of κ 2(Q k+1) is \((\sqrt{\omega_{k}} + \sqrt{\omega_{k}-1} )^{2}\) when \(\sigma=\frac{y_{k}^{\mathrm{T}}y_{k}}{s_{k}^{\mathrm{T}}y_{k}}\). □
2.2 Descent property
For the SPCG method, Theorem 2 shows that the symmetric Perry conjugate gradient directions defined by (5) satisfy the descent property (7), when \(\sigma y_{k}^{\mathrm{T}} s_{k}>0\). In fact,
When σ=1, Q k+1, defined by (6), becomes

Thus, the method defined by (1) and (5) with σ=1 is the famous memoryless BFGS quasi-Newton method [25], denoted by mBFGS.
According to (30), we let \(\sigma= c \frac{y_{k}^{\mathrm{T}}y_{k}}{s_{k}^{\mathrm{T}}y_{k}}\), c>0 and \(s_{k}^{\mathrm{T}}y_{k}\ne0\), then it follows from (6) and (30) that
and
which shows that the directions defined by (5) with \(\sigma=c \frac{y_{k}^{\mathrm{T}}y_{k}}{s_{k}^{\mathrm{T}}y_{k}}\) satisfy the sufficient descent property (8) for any functions and any line searches. Thus, the method defined by (1) and (5) with \(\sigma=c \frac{y_{k}^{\mathrm{T}}y_{k}}{s_{k}^{\mathrm{T}}y_{k}}\) is called symmetric Perry descent conjugate gradient algorithm, denoted by SPDCG, or by SPDCG(c), to indicate the dependence on the positive constant c. Especially, due to Corollary 1, when c=1, the method is called symmetric Perry descent conjugate gradient algorithm with optimal condition number, denoted by SPDOC. The corresponding iteration matrix is denoted by \(Q_{k+1}^{\mathrm{SPDOC}}\), i.e.
In addition, when σ=0, then it follows from (6) and (30) that
and \(d_{k+1}^{\mathrm{T}}g_{k+1} \le0\). Thus, the method defined by (1) and (5) with σ=0 is the symmetric Hestenes-Stiefel method [18], denoted by SHS, which does not satisfy the descent property (7).
3 Scaling technology and restarting strategy
According to S.S. Oren and E. Spedicato’s idea [20], D.F. Shanno applied the scaling technology to the memoryless BFGS update formula (31) and developed a self-scaling conjugate gradient algorithms [25], i.e., he translated the memoryless BFGS update formula (31) into

Thus, the symmetric Perry matrix Q k+1 defined by (6) can be scaled as follows:

We substitute σ in Q k+1(ρ) with ρσ, then Q k+1(ρ)=ρQ k+1, where

Thus, the line search directions defined by (5) are rewritten as
from which a family of scaling Perry conjugate gradient methods can be deduced.
Based on Beale-Powell restarting strategy [24] (see also [2, 3, 25, 26]), we define the following scheme to compute the directions. When
at r-th step, we use the directions defined by (38). For k>r, the directions d k+1 are computed by the following double update scheme:
with
and
where \(\widetilde{\sigma}\), \(\widehat{\rho}\) and \(\widehat{\sigma }\) are three preset parameters.
Since
where \(\widetilde{s}_{k}=H_{r+1}^{-1/2}s_{k}\), \(\widetilde{g}_{k+1}=H_{r+1}^{1/2}g_{k+1}\) and \(\widetilde{y}_{k}=H_{r+1}^{1/2}y_{k}\), Corollary 1 asserts that \(\kappa_{2}(H_{r+1}^{-1/2}H_{k+1}H_{r+1}^{-1/2})\) arrives at the minimum if \(\widetilde{\sigma} = \frac{\widetilde{y}_{k}^{\mathrm{T}}\widetilde{y}_{k}}{\widetilde {s}_{k}^{\mathrm{T}}\widetilde{y}_{k}} =\frac{y_{k}^{\mathrm{T}}H_{r+1}y_{k}}{s_{k}^{\mathrm{T}}y_{k}}\). According to (42), Corollary 1 shows that κ 2(H r+1) is minimal when \(\widehat{\sigma}=\frac{y_{r}^{\mathrm{T}}y_{r}}{s_{r}^{\mathrm {T}}y_{r}}\). We also note that the matrix \(H_{r+1}^{-1/2}H_{k+1}H_{r+1}^{-1/2}\) is similar to the matrix \(H_{r+1}^{-1}H_{k+1}\), thus
which implies that the optimal choices for \(\widetilde{\sigma}\) in (41) and \(\widehat{\sigma}\) in (42) are
respectively, such that κ 2(H k+1) is optimal.
Let \(\widehat{g}_{k+1}=H_{r+1}g_{k+1}\) and \(\widehat {y}_{k}=H_{r+1}y_{k}\), namely,
and
then the directions d k+1 defined by (40) can be reformulated by
Hence, we can introduce the following scaling symmetric Perry conjugate gradient method with restarting procedures (SSPCGRP).
Algorithm 2
(SSPCGRP)
- Step 1.:
-
Give an initial point x 1 and ε≥0. Set k=1 and Nrestart=0.
- Step 2.:
-
Calculate g 1=g(x 1). If ∥g 1∥≤ε, then stop, otherwise, let d 1=−g 1.
- Step 3.:
-
Calculate steplength α k using the Wolfe line searches (15) and (16) with initial guess α k,0, where α 1,0=1/∥g 1∥ and α k,0=α k−1∥d k−1∥/∥d k ∥ when k≥2.
- Step 4.:
-
Set x k+1=x k +α k d k .
- Step 5.:
-
Calculate g k+1=g(x k+1). If ∥g k+1∥≤ε then stop.
- Step 6.:
-
If the Powell restarting criterion (39) holds, then calculate the directions d k+1 via (38) with different σ and ρ, let y r =y k and s r =s k (store y r and s r ), set Nrestart=Nrestart+1 and k=k+1, go to step 3. Otherwise, go to step 7.
- Step 7.:
-
If Nrestart=0, then calculate the directions d k+1 via (38) with different σ and ρ, otherwise, calculate d k+1 via (48), where \(\widehat{y}_{k}\) and \(\widehat{g}_{k+1}\) are computed by (46) and (47), respectively, \(\widetilde{\sigma}\), \(\widehat{\sigma}\) and \(\widehat{\rho}\) are preset parameters.
- Step 8.:
-
Set k=k+1, go to step 3.
In Algorithm 2, k and Nrestart record the number of iterations and the number of restarting procedures, respectively.
When ρ=1 and \(\sigma=c_{1}\frac{y_{k}^{\mathrm {T}}y_{k}}{s_{k}^{\mathrm {T}}y_{k}}\) in (38), and \(\widehat{\rho}=1\), \(\widetilde{\sigma} =c_{2}\frac{y_{k}^{\mathrm{T}}H_{r+1}y_{k}}{s_{k}^{\mathrm{T}}y_{k}}\) and \(\widehat{\sigma}=c_{2}\frac{y_{r}^{\mathrm{T}}y_{r}}{s_{r}^{\mathrm {T}}y_{r}}\) in (46)–(48), then the SSPCGRP algorithm is denoted by SPDRP, or SPDRP(c 1,c 2) to indicate the dependence on the positive constants c 1 and c 2. Especially, when they are equal to 1, i.e., \(\sigma=\frac{y_{k}^{\mathrm{T}}y_{k}}{s_{k}^{\mathrm{T}}y_{k}}\) in (38), \(\widetilde{\sigma}\) and \(\widehat{\sigma}\) are computed by (45), the condition numbers κ 2(Q k+1)=κ 2(ρQ k+1), κ 2(H k+1) and κ 2(H r+1) are optimal, where Q k+1 is defined by (6) with \(\sigma=\frac{y_{k}^{\mathrm{T}}y_{k}}{s_{k}^{\mathrm{T}}y_{k}}\). So, the SSPCGRP algorithm is called the symmetric Perry descent conjugate gradient method with optimal condition numbers and restarting procedures, denoted by SPDOCRP.
When ρσ=1, \(\rho=\frac{s_{k}^{\mathrm {T}}s_{k}}{y_{k}^{\mathrm {T}}s_{k}}\), \(\widehat{\rho}\ \widehat{\sigma}=1\), \(\widehat{\rho}=\frac{s_{r}^{\mathrm{T}}s_{r}}{y_{r}^{\mathrm{T}}s_{r}}\) and \(\widetilde{\sigma}=1\), these formulas (38), (46), (47) and (48) were used by N. Andrei in [2], the SSPCGRP algorithm becomes the SCALCG algorithm with the spectral choice for θ k+1 [2], it is also called Andrei-Perry conjugate gradient method with restarting procedures.
4 Convergence
In this section, we analyze the convergence of the symmetric Perry conjugate gradient method (Algorithm 1) and the scaling symmetric Perry conjugate gradient method with restarting procedures (Algorithm 2). For this, we assume that the objective function f(x) satisfies the following assumptions:
- H1.:
-
f is bounded below in \(\mathbb{R}^{n}\) and f is continuously differentiable in a neighborhood \(\mathcal{N}\) of the level set \(\mathcal{L} \stackrel{def}{=}\{x : f(x)\le f(x_{0})\}\), where x 0 is the starting point of the iteration.
- H2.:
-
The gradient of f is Lipschitz continuous in \(\mathcal{N}\), that is, there exists a constant L>0 such that
$$ \bigl\|\nabla f(\bar{x})-\nabla f(x)\bigr\| \leq L\| \bar{x}-x \|, \quad \forall\bar{x},x \in\mathcal{N}. $$(49)
Next, we introduce the spectral condition lemma of the global convergence for an objective function satisfying H1 and H2, which comes from [18], Theorem 4.1.
Lemma 1
Let the objective function f(x) satisfy H1 and H2. Assume that the line search directions of a nonlinear conjugate gradient method satisfy
where M k is the conjugate gradient iteration matrix, which is a symmetric positive semidefinite matrix. For a nonlinear conjugate gradient method (1) and (50) satisfying the sufficient descent condition (8), if its line search satisfies the Wolfe conditions (15) and (16), and
where Λ k is the maximum eigenvalue of M k , then lim inf k→∞∥g k ∥=0. Moreover, if \(\varLambda_{k} \le\widetilde{\varLambda}\) for all k, where \(\widetilde{\varLambda}\) is a positive constant, then lim k→∞∥g k ∥=0.
Remark 2
If M k is a symmetric positive definite matrix, then the spectral condition (51) can be rewritten as
In fact, by (50), it can be derived that
where θ k is the angle between d k and −g k , λ k and Λ k are the minimum eigenvalue and maximum eigenvalue of M k , respectively. The Zoutendijk’s condition (Theorem 2.1 of [8]) asserts that (52) implies that the results of Lemma 1 are true.
In what follows, the convergence of these resulting algorithms is proved by evaluating the spectral boundary of the iteration matrix and Lemma 1. The proof method is called the spectral method. It should be pointed out that the proof method also can be applied to the non-symmetric conjugate gradient methods, if the positive square root of the maximum eigenvalue \(M_{k}^{\mathrm{T}}M_{k}\) substitutes for with the one of M k in Lemma 1, that is, the maximum singular value of M k substitutes for the maximum eigenvalue of M k (see Theorem 3.1 in [17]).
4.1 The convergence for uniformly convex functions
Here, we first prove the global convergence of the symmetric Perry conjugate gradient method (SPCG), the scheme (1) and (5) with Q k+1 defined by (6), for uniformly convex functions. For this, we introduce the following basic assumption, which is an equivalent condition for a uniformly convex differentiable function.
- H3.:
-
There exists a constant m>0 such that
$$ \bigl(\nabla f(\bar{x})-\nabla f(x) \bigr)^{\mathrm{T}}(\bar{x}-x)\ge m \|\bar{x}-x\|^2 \quad \forall\bar{x},\ x \in\mathcal{N}. $$(54)
Theorem 3
Assume that H1, H2 and H3 hold. Let ν 0 and ν 1 be two positive constants. For the symmetric Perry conjugate gradient method (1) and (5) with ν 0≤σ≤ν 1, the Wolfe line searches (15) and (16) are implemented. If g 1≠0 and steplength α k >0 for k≥1, then g k =0 for some k>1, or lim k→∞∥g k ∥=0.
Proof
Assume that g k ≠0, \(\forall k\in\mathbb{N}\). Below, by induction, we first prove that the line search direction d k , defined by (5), satisfies the sufficient descent property (8).
When k=1, \(d_{1}^{\mathrm{T}}g_{1}=-\|g_{1}\|^{2}<0\). From (16), it follows that \(s_{1}^{\mathrm{T}}y_{1}\ge-(1-b_{2})\alpha_{1} d_{1}^{\mathrm{T}}g_{1}>0\).
Now, assume that \(d_{k}^{\mathrm{T}} g_{k} \le-\frac{\nu_{0} m}{L^{2} +\nu_{0} m}\|g_{k}\|^{2}\). Then, it follows from (16) that \(s_{k}^{\mathrm {T}}y_{k}\ge -(1-b_{2})\alpha_{k} d_{k}^{\mathrm{T}}g_{k}>0\). So, (30) and the assumptions H2 and H3 imply that
Hence, by induction, the sufficient descent property (8) holds.
Next, we prove that \(\lambda_{\mathrm{max}}^{(k+1)}\), the maximum eigenvalue of Q k+1 defined by (6), is uniformly bounded above. From the above analysis, it can be derived that \(s_{k}^{\mathrm{T}}y_{k}>0\). So, from (23) in Theorem 2, it can be deduced that

Therefore, Lemma 1 claims that lim k→∞∥g k ∥=0. □
Remark 3
Theorem 3 shows that the memoryless BFGS quasi-Newton method and the method SPDCG are convergent for uniformly convex functions under the Wolfe line searches. In fact, the global convergence of the method SPDCG and the method mBFGS results from the following inequalities
Next, we prove the global convergence of the SSPCGRP method for uniformly convex functions.
Theorem 4
Assume that H1, H2 and H3 hold, and that ν 0 and ν 1 are two positive constants. Let the sequence {x k } be generated by the SSPCGRP algorithm (Algorithm 2), where the five different parameters σ, ρ, \(\widetilde{\sigma}\), \(\widehat{\sigma}\) and \(\widehat{\rho}\) satisfy \(\nu_{0}\le\sigma, \rho, \widetilde{\sigma},\widehat{\sigma },\widehat {\rho}\le \nu_{1}\). If g 1≠0, and steplength α k >0 for k≥1, then g k =0 for some k>1, or lim k→∞∥g k ∥=0.
Proof
First, we note that \(\widetilde{y}_{k}^{\mathrm{T}}\widetilde {s}_{k}=y_{k}^{\mathrm{T}}s_{k}\) for all k≥1. If \(\widetilde{y}_{k}^{\mathrm{T}}\widetilde{s}_{k}>0\), we can denote the minimum and the maximum eigenvalues of the matrix \(H_{r+1}^{-1/2}H_{k+1}H_{r+1}^{-1/2}\) by \(\widetilde{\lambda}_{\mathrm{min}}^{(k+1)}\) and \(\widetilde{\lambda}_{\mathrm{max}}^{(k+1)}\), respectively. We also denote the minimum and the maximum eigenvalues of the matrix H r+1 by \(\widehat{\lambda}_{\mathrm{min}}^{(r+1)}\) and \(\widehat{\lambda}_{\mathrm{max}}^{(r+1)}\), respectively. Thus, (42), (43), Theorem 2 and the assumptions H2 and H3 imply that
and
where \(\widetilde{\omega}_{k}=\frac{\widetilde{y}_{k}^{\mathrm{T}} \widetilde{y}_{k}\widetilde{s}_{k}^{\mathrm{T}}\widetilde{s}_{k}}{ (\widetilde{s}_{k}^{\mathrm{T}}\widetilde{y}_{k})^{2}}\) and \(\omega_{r}= \frac{y_{r}^{\mathrm{T}}y_{r} s_{r}^{\mathrm{T}}s_{r}}{(s_{r}^{\mathrm{T}}y_{r})^{2}}\).
In what follows, by induction, we prove that \(\widetilde{y}_{k}^{\mathrm{T}}\widetilde{s}_{k}>0\) and the sufficient descent property (8) is true for all k.
If the Powell restarting criterion (39) never holds for all k≥1, the iteration matrix is ρQ k+1. Thus, similar to Theorem 3, it can be easily shown that the results of Theorem 4 are true.
Suppose that k 0 is the first natural number such that the Powell restarting criterion (39) is true, then Nrestart≥1. Similar to Theorem 3, it can be obtained that for k=1,2,…,k 0, \(\widetilde{y}_{k}^{\mathrm{T}}\widetilde{s}_{k}=y_{k}^{\mathrm {T}}s_{k}>0\) and

So, it follows from (16) and the above inequality that
If the Powell restarting criterion (39) holds for k+2, d k+2 is calculated by (38). Thus, Theorem 2 and the assumptions H2 and H3 claim that

If the Powell restarting criterion (39) does not hold for k+2, d k+2 is calculated by (48) with (46) and (47) (i.e., (40)–(42)). Since Nrestart≥1, from (40)–(42) and Theorem 2, it can be obtained that

By (57), (58), the assumptions H2 and H3, it is yielded that

Therefore,
which, together with (16), implies that
By induction, it follows that \(s_{k}^{\mathrm{T}}y_{k}>0\) for all k and the directions generated by the SSPCGRP algorithm (Algorithm 2) satisfy the sufficient descent property (8) with
Next, we prove that κ 2(H k+1) is bounded above. Since \(\widetilde{s}_{k}=H_{r+1}^{-1/2}s_{k}\) and \(\widetilde{y}_{k}=H_{r+1}^{1/2}y_{k}\), from (57), (58) and the assumptions H2 and H3, it can be derived that

and

Thus, it follows from (44), (58) and above two inequalities that
If d k+1 is calculated by (38), the iteration matrix is defined by (37). So, Corollary 1, (28), (29) and the assumptions H2 and H3 imply that
and
where ψ(⋅) is defined by (29).
Hence, the spectral condition number of the iteration matrix of Algorithm 2 is uniformly bounded above, which claims that the results of Theorem 4 are true according to Remark 2. □
From (56) and this theorem, it can be shown that the SPDRP algorithm and the SCALCG algorithm with the spectral choice [2] are global convergence for uniformly convex functions under the Wolfe line searches.
4.2 The convergence for general nonlinear functions
For general nonlinear functions, we first have following result for the symmetric Perry conjugate gradient method.
Theorem 5
Assume that H1 and H2 hold. For the symmetric Perry conjugate gradient method (1) and (5) with \(\sigma=c\frac{y_{k}^{\mathrm{T}}y_{k}}{s_{k}^{\mathrm{T}}y_{k}}\), where c is a positive constant, if the line searches satisfy the Wolfe conditions (15) and (16), then lim k→∞∥y k ∥=0 implies that lim inf k→∞∥g k ∥=0.
Proof
Denote the maximum eigenvalue of the iteration matrix Q k+1 by \(\lambda_{\mathrm{max}}^{(k+1)}\). The Wolfe condition (16) leads to \(s_{k}^{\mathrm{T}}y_{k}\ge-(1-b_{2}) s_{k}^{\mathrm{T}}g_{k}\), which, together with (33), implies that
Thus,
where \(c_{5}=\frac{1+c}{(1-b_{2})\sqrt{c}}\). So,
Now assume that lim k→∞∥y k ∥=0, lim inf k→∞∥g k ∥=ε>0. Then there exists a positive integer N 0 such that for j>N 0, \(\frac{\|y_{j}\|}{\|g_{j}\|}\le c_{5}^{-1}\). Let \(C_{N}=\lambda_{\mathrm{max}}^{(1)}\prod_{j=1}^{N_{0}}c_{5}^{2}\frac{\|y_{j}\|^{2}}{\| g_{j}\|^{2}}\), thus,
Therefore, Lemma 1 and (33) claim that lim k→∞∥g k ∥=0, which contradicts the above assumption. So, lim k→∞∥y k ∥=0 implies that lim inf k→∞∥g k ∥=0. □
Next, we prove the global convergence of the SSPCGRP algorithm (Algorithm 2) for general nonlinear functions.
Theorem 6
Assume that H1 and H2 hold. Let the sequence {x k } be generated by the SSPCGRP algorithm with \(\sigma=c\frac{y_{k}^{\mathrm{T}}y_{k}}{s_{k}^{\mathrm{T}}y_{k}}\) and ν 0≤ρ≤ν 1 in (38), where c, ν 0 and ν 1 are positive constants. If the line searches satisfy the Wolfe conditions (15) and (16), then lim k→∞∥y k ∥=0 implies that lim inf k→∞∥g k ∥=0.
Proof
If lim inf k→∞∥g k ∥≠0 as ∥y k ∥→0, then, for some ε>0, there exists a positive integer N 1 such that ∥g k+1∥>ε and ∥y k ∥≤0.8ε as k≥N 1. Thus,

So, \(g_{k+1}^{\mathrm{T}}g_{k}\ge0.2\|g_{k+1}\|^{2}\) for k≥N 1, which means that the directions d k+1 are calculated by (38) for k≥N 1, that is,
where Q k+1 is defined by (6). Since \(\sigma=c\frac{y_{k}^{\mathrm{T}}y_{k}}{s_{k}^{\mathrm{T}}y_{k}}\) and ν 0≤ρ≤ν 1, from Theorem 2, it follows that
For convenience, we also denote the maximum eigenvalue of ρQ k+1 by \(\lambda_{\mathrm{max}}^{(k+1)}\). Analogous to (60), it can be derived that

where \(c_{5}=\frac{1+c}{(1-b_{2})\sqrt{c}}\). We substitute \(\lambda _{\mathrm{max}}^{(N_{1})}\) and N 1 for \(\lambda_{\mathrm{max}}^{(1)}\) and 1 in (60), respectively, then, similar to Theorem 5, it can be obtain from Lemma 1 and (61) that lim k→∞∥y k ∥=0 implies that lim inf k→∞∥g k ∥=0. □
The above two theorems show that the SPDCG(c) algorithm and the SPDRP(c 1,c 2) algorithm are global convergence for the nonconvex functions under the Wolfe line searches, as lim k→∞∥y k ∥=0. The condition for the global convergence, lim k→∞∥y k ∥=0, was used by J.Y. Han, et al. in [14].
5 Numerical experiments
In this section, we demonstrate our algorithms: SPDCG and SPDRP, and compare them with the CG_DESCENT algorithm [12], the SCALCG algorithm with the spectral choice [2], the mBFGS algorithm (a special form of the SPCG algorithm with σ=1) and the RSPDCGs algorithm [19] whose line search directions are formulated by
where
In numerical experiments, we let η=10−5. The RSPDCGs algorithm is fully detailed in [19].
The numerical experiments use two groups test functions, one group (145 test functions) is taken from the CUTEr [9] library, referring to website:
which is only used to test mBFGS, SPDCG, RSPDCGs and CG_DESCENT algorithms. In order to compare with the SCALCG algorithm, the second group consists of the 73 unconstrained problems but the 71-st in SCALCG Fortran software package coded by N. Andrei, referring to website:
http://camo.ici.ro/forum/SCALCG/.
For the second group, each test function is made ten experiments with the number of variable 1000,2000,…,10000, respectively. The starting points used are those given in the code, SCALCG.
The SPDCG, mBFGS and RSPDCGs algorithms are coded according to the package, CG_DESCENT (C language, Version 5.3), with minor revisions and implement the approximate Wolfe line searches with the default parameters in CG_DESCENT [10, 12]. The package, CG_ DESCENT, can be got from Hager’s web page at
http://www.math.ufl.edu/~hager/.
In addition, in order to compare with the SCALCG algorithm, all subroutines of the SPDRP algorithm are written in Fortran 77 with the double precision, and the SPDRP algorithm uses the Wolfe line searches in the SCALCG Fortran code.
The termination criterion of all algorithms is that ∥g∥∞<10−6, where ∥⋅∥∞ is the infinity norm of a vector. The maximum number of iterations is 500n, where n is the number of variables. The tests are performed on PC (Dell Inspiron 530), Intel® Core™ 2 Duo, E4600, 2.40 GHz, 2.39 GHz, RAM 2.00 GB, with the gcc and g77 compilers.
The SPDCG algorithm is a special form of the SPCG algorithm (Algorithm 1) with \(\sigma=c\frac{y_{k}^{\mathrm{T}}y_{k}}{s_{k}^{\mathrm{T}}y_{k}}\) in (5) (see also step 6 in Algorithm 1). Thus the line search directions are formulated by
with \(\beta_{k}=\frac{y_{k}^{\mathrm{T}}g_{k+1}}{d_{k}^{\mathrm{T}}y_{k}}- (1+c)\frac{y_{k}^{\mathrm{T}}y_{k}}{d_{k}^{\mathrm{T}}y_{k}} \frac{d_{k}^{\mathrm{T}}g_{k+1}}{d_{k}^{\mathrm{T}}y_{k}}\), \(\gamma_{k}= \frac{d_{k}^{\mathrm{T}}g_{k+1}}{d_{k}^{\mathrm{T}}y_{k}}\), and the iteration matrix is defined by (32). For the SPDCG algorithm, we test several different values of c in β k of (63) on the first group of test functions and find that the performance [6] is slightly better when c=1 (SPDOC algorithm) than that when c is taken other values.
For the first group of test functions, to compare the algorithms: mBFGS and SPDOC with the RSPDCGs and CG_DESCENT algorithms. we divide the group into two parts: large scale problems, whose numbers of variables are not less than 100 (72 test functions), and small scale problems, whose numbers of variables are less than 100 (73 test functions).
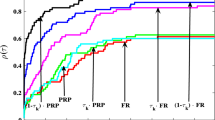
Figures 1 and 2 present that their Dolan-Moré performance profiles for large scale problems based on Nite (the number of iterations) and CPU time, respectively. Figures 3 and 4 present the Dolan and Moré performance profiles of these algorithms for small scale problems with relative to Nite and CPU time, respectively. Figures 1 and 2 show that for large scale problems, the performance of the SPDOC algorithm is similar to that of the CG_DESCENT algorithm and their performances are better than that of the others; the performance of the RSPDCGs algorithm is better than that of the mBFGS algorithm. For small scale problems, Figs. 3 and 4 show that the mBFGS algorithm is best, which means that SPDOC and CG_DESCENT algorithms are more suitable for solving large scale problems. It should be pointed out that although mBFGS algorithm give better results on the small problems, it fails to solve three problems of the CUTEr test set. In the recent paper [13], it is observed that for the small ill-conditioned quadratic PALMER test problems in CUTEr, the gradients generated by the conjugate gradient method quickly lose orthogonality due to numerical errors. See Hager and Zhang’s paper [13] for a strategy for handling these ill-conditioned problems.

Performance based on Nite of SPDOC, mBFGS, CG_DESCENT and RSPDCGs for large scale problems

Performance based on CPU time of SPDOC, mBFGS, CG_DESCENT and RSPDCGs for large scale problems

Performance based on Nite of SPDOC, mBFGS, CG_DESCENT and RSPDCGs for small scale problems

Performance based on CPU time of SPDOC, mBFGS, CG_DESCENT and RSPDCGs for small scale problems
The SPDRP algorithm is a special case of the SSPCGRP algorithm (Algorithm 2) with ρ=1 and \(\sigma=c_{1}\frac{y_{k}^{\mathrm {T}}y_{k}}{s_{k}^{\mathrm {T}}y_{k}}\) in (38), and \(\widehat{\rho}=1\), \(\widetilde{\sigma} =c_{2}\frac{y_{k}^{\mathrm{T}}H_{r+1}y_{k}}{s_{k}^{\mathrm{T}}y_{k}}\) and \(\widehat{\sigma}=c_{2}\frac{y_{r}^{\mathrm{T}}y_{r}}{s_{r}^{\mathrm {T}}y_{r}}\) in (46)–(48). For the SPDRP algorithm, we also test several different values of c on the second group of test functions, we find the performance is slightly better when c 1=c 2=1 (i.e., the SPDOCRP algorithm) than that when c 1 and c 2 are taken other values. Next, we compare the SPDOCRP algorithm with the SCALCG algorithms, using the second group of test functions. Figures 5 and 6 present that their Dolan-Moré performance profiles based on Nite and CPU time, respectively. The SPDOCRP algorithm and the SCALCG algorithm use the restarting strategy and the double update scheme, but the SPDOCRP algorithm has the optimal spectral condition number of the iteration matrix, so the SPDOCRP algorithm displays better numerical performance than the SCALCG algorithm.

Performance based on Nite of SPDOCRP and SCALCG algorithms for the second group of test functions

Performance based on CPU time of SPDOCRP and SCALCG algorithms for the second group of test functions
So, the preliminary numerical experiments show that SPDOC and SPDOCRP are very effective algorithms for the large scale unconstrained optimization problems.
In addition, for the SPDCG algorithm, the inequality (33) shows that the descent degree of the line search directions of the algorithm becomes higher and higher as the value of c increases, but the performance of the algorithm is not directly proportional to c. In fact, the line search directions generated by the SPDCG algorithm vary with the value of c. What kind of criterion can be used to evaluate the performance of an algorithm? Does the criterion exist? These are still open problems. Of course, the condition number and the descent property are two important factors.
In the end, it should be pointed out that the version 5.3 of CG_ DESCENT (C code) uses a new formula for β k ,
i.e., η≡0 in (62), instead of
presented in [10]. In [19], we proved that β k formulated by (64) makes the spectral condition number of the iteration matrix defined by (4) with u=s k optimal.
6 Conclusion
In [18], we presented a rank one updating formula for the iteration matrix of the conjugate gradient methods:
where the symmetric Hestenes-Stiefel matrix \(M_{k+1}^{shs}\) is defined by
If we replace D k+1 with \(M_{k+1}^{shs} \) in (11), the symmetric Perry matrix (6) can be rewritten as
that is, if we apply the Powell symmetric technique to D k+1 in (11), we can obtain \(M_{k+1}^{shs}\), then we add a rank one update \(\sigma\frac{s_{k}s_{k}^{\mathrm{T}}}{s_{k}^{\mathrm{T}}y_{k}}\) to \(M_{k+1}^{shs} \), we can also deduce the symmetric Perry matrix (6).
For the parameter σ in SPCG algorithm, besides the cases mentioned above, there also exist other choices, such as \(\sigma =c^{2}\frac{s_{k}^{\mathrm{T}}s_{k}}{s_{k}^{\mathrm{T}} y_{k}}\), \(\sigma =c\frac {s_{k}^{\mathrm{T}} y_{k}}{s_{k}^{\mathrm{T}}s_{k}}\), \(\sigma=c \frac{s_{k}^{\mathrm {T}}y_{k}}{y_{k}^{\mathrm{T}}y_{k}}\), \(\sigma=c \frac{s_{k}^{\mathrm{T}}s_{k}}{y_{k}^{\mathrm{T}}y_{k}}\), \(\sigma=c \frac{y_{k}^{\mathrm{T}}y_{k}}{s_{k}^{\mathrm{T}}s_{k}}\), and so on, where c>0.
For the SSPCGRP algorithm, when ρσ=1, \(\sigma=\frac{y_{k}^{\mathrm{T}}y_{k}}{s_{k}^{\mathrm{T}}y_{k}}\), \(\widehat{\sigma}=\frac{y_{r}^{\mathrm{T}}y_{r}}{s_{r}^{\mathrm{T}}y_{r}}\), \(\widehat{\rho}\ \widehat{\sigma}= \widetilde{\sigma}=1\), these formulas (38), (46), (47) and (48) were suggested by D. F. Shanno in [25] and [26]. When \(\rho=\sigma=\widehat{\rho}=\widetilde{\sigma}=\widehat {\sigma }=1\), the SSPCGRP algorithm becomes the memoryless BFGS conjugate gradient method with restarting procedures. Therefore, it is worthy of studying further how the parameters σ and ρ are chosen to construct more effective nonlinear conjugate gradient algorithms.
The condition number of Q k+1 defined by (6) only depends on the parameter σ and the condition number of ρQ k+1 is the same as the one of Q k+1 (see (37)), so, we let ρ=1 and \(\widehat{\rho}=1\) in SSPCGRP algorithm. That is to say, σ can scale the symmetric Perry iteration matrix Q k+1. Therefore, the symmetric Perry conjugate gradient methods have the self-scaling property, Similarly, σ can also alter the maximum and minimum eigenvalues of the Perry iteration matrix P k+1 defined by (4), and P k+1 is a self-scaling matrix. Thus, the parameter σ in the condition (12) is a self-scaling factor, which can alter the condition number of the iteration matrix of the conjugate gradient method.
From (30) and (23), we find that if we restrict that
then under Lipschitz condition, \(|y_{k}^{\mathrm{T}} s_{k}|>\delta\|s_{k}\| ^{2}\ge\delta/L \|s_{k}\|\|y_{k}\|\), i.e., the angle between y k and s k is less than π/2. Thus,
and
Therefore, according to Lemma 1, if a descent algorithm satisfies the condition (65), then it is globally convergent for nonconvex functions. So, (65) is also an interesting restarting strategy [19]. In fact, (65) is a uniformly convex condition.
Based on (6) and the relationship between the conjugate gradient method and quasi-Newton method, we let

where
So, a new family of quasi-newton method can be obtained from (66), which belongs to Huang’s family, but does not belongs to Broyden’s family. Hence, it is worth probing further to develop new and more effective unconstrained optimization algorithms. For example, we let \(\sigma=c \frac{y_{k}^{\mathrm{T}}H_{k}y_{k}}{s_{k}^{\mathrm{T}}y_{k}}\) in (66).
References
Al-Baali, M.: Descent property and global convergence of the Fletcher-Reeves method with inexact line-search. IMA J. Numer. Anal. 5, 121–124 (1985)
Andrei, N.: Scaled conjugate gradient algorithms for unconstrained optimization. Comput. Optim. Appl. 38, 401–416 (2007)
Andrei, N.: A scaled BFGS preconditioned conjugate gradient algorithm for unconstrained optimization. Appl. Math. Lett. 20, 645–650 (2007)
Dai, Y.H., Liao, L.Z.: New conjugate conditions and related nonlinear conjugate gradient methods. Appl. Math. Optim. 43, 87–101 (2001)
Dai, Y.H., Yuan, Y.X.: A nonlinear conjugate gradient with a strong global convergence properties. SIAM J. Optim. 10, 177–182 (1999)
Dolan, E.D., Moré, J.J.: Benchmarking optimization software with performance profiles. Math. Program., Ser. A 91, 201–213 (2002)
Fletcher, R.M., Reeves, C.M.: Function minimization by conjugate gradients. Comput. J. 7, 149–154 (1964)
Gilbert, J.C., Nocedal, J.: Global convergence properties of conjugate gradient methods for optimization. SIAM J. Optim. 2(1), 21–42 (1992)
Gould, N.I.M., Orban, D., Toint, Ph.L.: CUTEr (and SifDec), a constrained and unconstrained testing environment, revisited. ACM Trans. Math. Softw. 29(4), 373–394 (2003)
Hager, W.W., Zhang, H.: A new conjugate gradient method with guaranteed descent and an efficient line search. SIAM J. Optim. 16, 170–192 (2005)
Hager, W.W., Zhang, H.: A survey of nonlinear conjugate gradient methods. Pac. J. Optim. 2, 35–58 (2006)
Hager, W.W., Zhang, H.: Algorithm 851: CG_DESCENT, a conjugate gradient method with guaranteed descent. ACM Trans. Math. Softw. 32(1), 113–137 (2006)
Hager, W.W., Zhang, H.: The limited memory conjugate gradient method (2012). www.math.ufl.edu/~hager/papers/CG/lcg.pdf
Han, J.Y., Liu, G.H., Yin, H.X.: Convergence of Perry and Shanno’s memoryless quasi-Newton method for nonconvex optimization problems. OR Trans. 1, 22–28 (1997)
Hestenes, M.R., Stiefel, E.: Methods of conjugate gradients for solving linear systems. J. Res. Natl. Bur. Stand. 49(6), 409–439 (1952)
Liu, Y., Storey, C.: Efficient generalized conjugate gradient algorithms, part 1: theory. J. Optim. Theory Appl. 69, 129–137 (1991)
Liu, D.Y., Shang, Y.F.: A new Perry conjugate gradient method with the generalized conjugacy condition. In: Computational Intelligence and Software Engineering (CiSE), 2010 International Conference on Issue Date: 10–12 Dec. 2010. doi:10.1109/CISE.2010.5677114
Liu, D.Y., Xu, G.Q.: Applying Powell’s symmetrical technique to conjugate gradient methods. Comput. Optim. Appl. 49(2), 319–334 (2011). doi:10.1007/s10589-009-9302-1
Liu, D.Y., Xu, G.Q.: A Perry descent conjugate gradient method with restricted spectrum, optimization online, nonlinear optimization (unconstrained optimization), March 2011. http://www.optimization-online.org/DB_HTML/2011/03/2958.html
Oren, S.S., Spedicato, E.: Optimal conditioning of self-scaling variable metric algorithms. Math. Program. 10, 70–90 (1976)
Perry, A.: A modified conjugate gradient algorithm. Oper. Res., Tech. Notes 26(6), 1073–1078 (1978)
Polak, E., Ribière, G.: Note sur la convergence de méthodes de directions conjuguées. Rev. Fr. Inform. Rech. Oper. 3(16), 35–43 (1969)
Polyak, B.T.: The conjugate gradient method in extreme problems. USSR Comput. Math. Math. Phys. 9, 94–112 (1969)
Powell, M.J.D.: Restart procedures for the conjugate gradient method. Math. Program. 12, 241–254 (1977)
Shanno, D.F.: Conjugate gradient methods with inexact searches. Math. Oper. Res. 3, 244–256 (1978)
Shanno, D.F.: On the convergence of a new conjugate gradient algorithm. SIAM J. Numer. Anal. 15, 1247–1257 (1978)
Acknowledgements
The authors are grateful to the anonymous referees and the Editor-in-chief, Prof. W.W. Hager, for their valuable comments and suggestions on the original version of this paper. The authors also thank N. Andrei for the Fortran code, SCALCG, W.W. Hager and H. Zhang for the C code, CG_DESCENT (Version 5.3) and J.J. Moré for Matlab code, perf.m. Finally, the authors thank PhD Kuiting Zhang (Department of Computer Science, Weifang University) for his help of C language and the Linux system.
Author information
Authors and Affiliations
Corresponding author
Additional information
This research is supported by the Natural Science Foundation of China grant NSFC-61174080 and by the Seed Foundation of Tianjin University.
Electronic Supplementary Material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article
Cite this article
Liu, D., Xu, G. Symmetric Perry conjugate gradient method. Comput Optim Appl 56, 317–341 (2013). https://doi.org/10.1007/s10589-013-9558-3
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-013-9558-3