
Abstract
Co-benefits are seen as a key factor for overcoming the problems of collective action and extended time horizons holding back mitigation of global warming. The mechanism behind this hypothesis is that public acceptance of mitigation policies constitutes a crucial limiting factor, necessitating ancillary gains such as clean air for mitigation policy to be politically robust. However, the public’s preference for local pollution mitigation and concomitant failure to appreciate the benefits of global warming mitigation is assumed rather than demonstrated. In this paper, we show, first, that people distinguish between the physical manifestations of air pollution and global warming, and second, that they see both phenomena as arising from the same causes as well as having negative impacts on humans. Specifically, using a survey experimental design with open-ended questions in an urban Chinese setting, we demonstrate that citizens relate glacier melt and sea-level rise to global warming, while linking the local phenomenon of smog almost exclusively to air pollution. At the same time, respondents link impacts on humans and vehicle/industrial pollution topics with both air pollution and global warming. These findings are relevant to decision-makers as they suggest that the public values mitigation of global warming in its own right. Our novel method may shed new light on a range of issues relating to energy, the economy, and environmental issues.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Action on short-lived climate pollutants, such as black carbon (also known as soot), has the potential to save millions of lives globally while also significantly slowing global warming, sea-level rise, and Arctic and glacier melt (Victor et al. 2015). Reducing the use of coal for electricity generation and use of personal automobiles in urban settings are examples of measures that have both climate and health benefits (Haines et al. 2009). However, while measures to address air pollution tend to lower greenhouse gas (GHG) emissions as well (Nemet et al. 2010; Woodcock et al. 2009), they do not always have beneficial effects on both dimensions. Scrubbers removing sulfur dioxide from power plant emissions may increase carbon dioxide (CO2) emissions due to higher energy use (Randolph and Dolsak 1996). Conversely, burning of biomass has no net CO2 emissions if sustainably sourced, but produces local emissions of particulate matter (PM) with adverse health effects (Barregard et al. 2006).
Despite the differences between these two types of environmental issues, co-benefits such as clean air are generally seen as a key avenue towards overcoming problems of collective action and extended time horizons related to climate change mitigation (Ürge-Vorsatz et al. 2014; Markandya and Rübbelke 2004). Notably, public acceptance of action on climate change is seen as a crucial limiting factor, necessitating ancillary gains such as clean air for mitigation policy to be politically robust (Dolšak 2009; Pearce 2000; Tvinnereim 2013).
While the existence of a link between local benefits and public acceptance of climate change mitigation is supported by the policy literature, there is little public opinion research to substantiate this connection. For example, while Yu (2014) finds that urban residents express greater urgency in connection with both air pollution and global warming than rural residents, such correlations may be due to generally stronger environmental concerns in cities rather than respondents drawing explicit links between the causes of the two phenomena.
The paucity of public opinion research on the relationship between climate change and air pollution may in part be due to the fact that this combined issue is scientifically complex and linked to numerous different mechanisms in the economy and society at large. Standard, fixed-response questionnaires may thus not contrast the public’s views on these challenges in an accurate way. To solve this problem of measuring complex attitudes and potentially amorphous perceptions, open-ended survey questions have been used to explore the public’s views on climate change/global warming (Leiserowitz 2005; Lorenzoni et al. 2006; Smith and Leiserowitz 2014; Tvinnereim and Fløttum 2015; Shwom et al. 2010; Whitmarsh 2008) and ocean acidification (Capstick et al. 2016). However, these studies limit themselves to one issue at a time and are thus unable to speak to the relationship between two separate but linked issues such as air pollution and climate change.
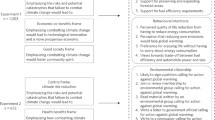
To fill these two gaps in the literature, we design a split-sample survey experimental study using open-ended questions to assess the extent to which air pollution and global warming generate similar or different associations among respondents. This approach builds on the setup used by Whitmarsh (2008) to explore differences in associations with the words “climate change” and “global warming.” First, the open-ended design, combined with quantitative text analysis, addresses the problem of measuring public opinion on complex and multidimensional issues in a way that permits replication of results. Second, the survey experimental design, whereby respondents are asked to offer their associations with either air pollution or global warming, but not both, overcomes the problem of establishing a link between the two phenomena. To the extent that different respondents associate similar words with air pollution and global warming in the aggregate, for example as regards their causes, the two environmental problems are likely to be connected in the minds of citizens on this dimension. Conversely, if different associations are given overall—say, as regards the impacts of the two—we may conclude that the two environmental challenges are seen as separate.
China is an ideal case for such a test, as the country is the world’s largest GHG emitter while suffering from severe air pollution (Yang et al. 2013). Although no other country suffers air pollution in the same degree as China, urban air pollution is a common challenge for many world mega-cities (World Health Organization 2016: Fig. 4). Many mega-cities in developing countries have been experiencing deteriorating air quality in the last decade; the situation is particularly worrisome in the populous cities in East Asia, South Asia, and Africa. Outdoor air pollution, mostly by PM2.5, imposed severe health threats, leading to 3.3 million premature deaths per year worldwide, predominantly in Asia (Lelieveld et al. 2015).
Urban Chinese has been found to care more about environmental problems immediately affecting them—notably air pollution and waste—than about less accessible problems such as climate change or biodiversity loss (Liu and Leiserowitz 2009). Air pollution has the mobilizing feature that it is inescapable and well known. After air quality measurements taken by the US Embassy in Beijing were circulated widely in the late 2011, knowledge about local air pollution has led to popular mobilization and government response in many Chinese cities (Huang 2015).
The enactment of the Action Plan on Prevention and Control of Air Pollution in September 2013 is a milestone in Chinese government’s battle against pollution (Huang 2015). The action plan specifies the air quality improvement targets for 74 major cities including Xi’an, Chengdu, and three key regions in the capital area, the Yangtze river delta and the Pearl River delta by 2017. Public discussion has also seen a change in the vocabulary describing local air pollution from the rather nebulous “foggy weather” to the more specific term “particulate matter” or more precisely “PM2.5,” which stands for particles smaller than 2.5 μm in diameter. The 2015 documentary film “Under the Dome” was seen by hundreds of millions upon release and used the term “smog” (雾霾) extensively (Hatton 2015). Two years after the implementation of the Action Plan, mid-term evaluation reports show that air quality in China has improved as a whole, but the number of non-attainment days remains high (Clean Air Alliance of China 2016).
Data from a 2012 national telephone survey indicate that 93% of Chinese think that climate change is happening and that 55% think it has mostly human causes, against 38% who think it is mostly natural (China Climate Change Communication Center 2013). The same study finds that 78% of respondents are either very or somewhat worried about climate change. As regards policy, a substantial majority of Chinese respondents in a 2015 study supports limiting GHG emissions (Stokes et al. 2015). Similarly, data from a 2013 non-random sample survey in Chengdu, Guangzhou, and Xian indicate that 90% of Chinese think that climate change is happening and that 53% think it has mostly human causes (Jamelske et al. 2017, forthcoming).
A clear urban-rural divide is found in public perceptions of and knowledge about environmental problems in China. Rural respondents have less pro-environmental attitudes and may view pollution as “distant and latent” “city problems” (Yu 2014: 40). By contrast, one may conjecture that experience with periods of severe air pollution enhances overall environmental concerns among urban Chinese, including concerns over climate change. Smog forecasts have been provided in Chinese cities since 2012 (Wang et al. 2015). A review of the literature finds stronger environmental attitudes among people with more education, the young, and those who are the most affected by pollution. Age and education correlate negatively with rural residency and thus explain some of the urban-rural divide in environmental attitudes (Yu 2014). Dissatisfaction with local air quality constitutes an important predictor of climate change risk perception in China (Lee et al. 2015).
The remainder of this paper proceeds as follows. Section 2 presents our data and methods and notably the split-sample survey instrument. The subsequent section presents the results of the quantitative text analysis, comparing what citizens write about the two environmental issues in an experimental setting. We also examine the effects of demographic variables on topic choice and offer conjectures about the role of education and social media use for popular conceptions of air pollution and global warming. Section 4 concludes with policy implications and directions for future research.
2 Data and methods
2.1 Data
The data were collected in intercept surveys in various locations in or around the cities of Chengdu and Xi’an. Both are large metropolitan centers with populations of approximately 14 million and 8.5 million, respectively (2010 China Census). Additionally, both Chengdu (Sichuan) and Xi’an (Shaanxi) are the capital cities of their respective provinces. Respondents were approached in person and selected at random.
Xi’an data collection began on May 26, 2015. As the survey process began in Xi’an, there was some controversy regarding questions in the same survey, but unrelated to the current study, asking about the participation of the Chinese government in international climate negotiations. Due to the perceived sensitivity of these questions, the surveys ended in Xi’an after just 2 days of data collection. The remainder of the data was collected in Chengdu from June 1–17, 2015.
The large majority of surveys in Chengdu (n = 996) and all surveys in Xi’an (n = 82) were undertaken within the city center; some of the Chengdu surveys were done in two areas best described as suburban, approximately 30 km (n = 76) and 50 km (n = 49) outside of the city center (See Supplementary Materials for further details on the data collection.)
Because the surveys were done face-to-face, we do not know the total number of people who were offered the survey and thus cannot calculate an exact response rate. However, our best estimate is that between 30–40% of individuals that were approached to take the survey did so. No incentives were offered.
Respondents were randomly assigned to one group, A or B, and asked one of the following questions at the beginning of the questionnaire:
1A. Please write down the first words that come to mind when you hear or read the words “global warming.” We welcome all answers, from a few sentences to a few words.
[请写出当您听到或者看到气候变暖时,脑海中的第一个词汇。(我们接受任何词句或短语在内的答案)]
1B. Please write down the first words that come to mind when you hear or read the words “air pollution.” We welcome all answers, from a few sentences to a few words.
[请写出当您听到或者看到大气污染时,脑海中的第一个词汇。(我们接受任何词句或短语在内的答案)]
We provide two reasons for presenting only one of the two questions to each respondent and contrasting the textual replies across respondents, rather than asking all respondents to answer both questions. First, asking both questions would likely produce context effects in the responses to the second question (Tourangeau et al. 1989), either in the form of increased similarity or induced contrast among respondents who wish to emphasize the different characteristics of the two. The experimental treatment, where respondents are randomly assigned one out of two related survey questions, also known as split sample design, solves this problem (see, for example, Whitmarsh 2008). Second, open-ended questions are demanding compared to closed questions, and limiting the number of open questions to one thus helps to keep the survey manageable and reduce drop-off during the interview.
We used “气候变暖”—literally, “climatic warming”—as our translation of “global warming” in the survey, as this is the most commonly used term. There are other terms with similar meaning; these include “全球变暖” (literally “global warming”) and “全球气候变暖” (literally “global climate warming”). We believe “气候变暖” is the most appropriate term because it is more used in the media. Based on Baidu.com, the most popular Chinese searching engine, searching for “全球变暖” gave 7.1 million results, while our preferred “气候变暖” resulted in 8.9 million hits. We believe that alternating between these terms would have made only a negligible difference as the Chinese language is highly context-based.
A total of 1204 subjects filled in the survey. Of these, 1126 provided a written answer to the open-ended question they received: 549 on air pollution and 577 on global warming. Respondents were subsequently asked a number of other questions related to the environment. Demographic data such as age, gender, and education were also recorded.
The textual answers ranged in length from one to 47 words. The median answer contained two words; the mean was 2.8 words. The hand-written textual responses were transcribed into computer-readable formats and tokenized with the Stanford Word Segmenter version 3.5.2, using the Chinese Penn Treebank (CTB) standard (Tseng et al. 2005). Frequent and general words such as pronouns, particles, and conjunctions (“stop words”) were removed, and a few key terms were standardized, see Supplementary Table S5. Notably, we treat “smog” (雾霾) as a single word and collapse the Latin “CO2” and the Chinese word for carbon dioxide (二氧化碳) into one unit. Numbers and punctuation were also removed. After stemming, stop word removal, and removal of infrequent terms, the corpus contained 266 unique terms distributed over 1041 responses, see Supplementary Table S6.
2.2 Methods
We use structural topic modeling (STM) to analyze the textual responses and organize them into computer-induced topics based on relative word frequencies. STM clusters documents— in this case, open-ended survey responses—according to the co-occurrence of words (Roberts et al. 2014a). Notably, this method permits analysis of response content alongside other variables such as gender, age, and experimental treatment variables (Roberts et al. 2014b). Besides the analysis of open-ended survey questions on climate change (Tvinnereim and Fløttum 2015), STM has so far been applied to the analysis of documents produced by organizations opposed to action on climate change (Farrell 2016), classification of Arab Muslim cleric writings, and reactions to the Edward Snowden case (Lucas et al. 2015). Related topic modeling methods have been employed to classify think tank statements on climate science and policy (Boussalis and Coan 2016) as well as analyze trends in newspaper coverage of nuclear technology over time (Jacobi et al. 2016),
The STM process starts with the researcher providing a corpus of text, such as open-ended survey responses with associated numeric data, and determining the number of topics to be induced from the documents. An automated, iterative process subsequently assigns words and textual responses to topics based on a clustering algorithm. The process runs until it converges or reaches a pre-determined maximum number of iterations. This produces for each word a vector expressing its probability of appearing in each topic. A vector expressing the topic prevalence for each individual text response is also calculated, based on the words contained in the response. The elements of this vector sum up to one for each response. The model thus allows membership in multiple topics.
For example, a response may be estimated by the model to belong .7 to one topic and .1 to each of the remaining topics in a four-topic model, based on the words it contains. These relative shares are called topic prevalence, a statistic that may be summed up for the topic as a whole (e.g., what topic is the most prevalent in the survey?) or according to sub-groups such as demographic variables pertaining to the survey respondents (e.g., do women write about Topic 3 more than men? Do younger people emphasize Topic 2 more?).
The degree to which each response fits each topic is thus a variable, the variation on which can subsequently be explained using standard techniques such as T tests or regression analysis. In our case, the experimental treatment variable, which takes on two values, “air pollution” and “global warming,” constitutes a key explanatory variable for such analysis.
It should be noted here that the topic induction process is fully automatic and that the assignment of words and responses to different topics is probabilistic, based on actual word co-occurrence. This has two implications. First, researchers need to validate model outputs (most representative words and most representative statements by topic) through close reading of such outputs, to ensure that classifications are sensible and useful. The approach chosen in this paper is to run several sets of models and choose the model that provides the best semantic fit. Second, the model will produce a certain number of counterintuitive classifications in some cases, based on word co-occurrence. Again, close reading of representative statements is needed to judge whether the model run remains useful or another run should be chosen. It is also instructive here to support the analysis using simpler methods such as counts of salient words (as shown in Table 1).
Our open-ended design permits respondents to emphasize the most salient aspects of the given environmental issue (either air pollution or global warming) and in their own words, without prompting. Table 1 provides an overview of the most frequent terms used in the responses. Term counts by randomized question wording show that the word “smog” is strongly connected with air pollution, while “hot” is mostly mentioned in the context of climate change. “Pollution,” “tailpipe emissions,” and “car” are more mixed.
3 Results and discussion
3.1 Structural topic modeling of survey responses
To generate a more detailed classification of the roughly one thousand open-ended survey responses, we conducted a large number of automated STM runs. The desired number of topics varied from four to ten, and dozens of model runs were conducted for each number of topics. In the end, one model with 10 topics was selected based on qualitative readings of the model outputs. Notably, this model run comprises automatically generated topics with the greatest semantic cohesion. It is furthermore representative of underlying themes that were frequently encountered in several hundred different model runs, of which about 50 were read in some depth.
From this selected model run, the four most salient may be usefully labeled as the following:
-
Smog
-
Glacier melt and sea-level rise
-
Vehicle and industrial emissions
-
Impact on humans
The topics and the most representative words for each topic are listed in Table 2. The most representative statements of each topic are given in Table 3.
As Table 3 shows, the responses most strongly associated with Topic 1 are largely concerned with smog, which is brought up in eight of the top 10 answers. The automatic classification routine also produces two instances each of “sandstorm,” “acid rain,” and “global warming” among the ten most representative responses. Of these, the two former relate to the local environment, whereas the latter does not. Thus, the topic’s most representative responses show a relatively coherent picture as an expression of mostly human-made and negative effects on air quality. At the same time, as Table 2 shows, the automatic topic induction process has identified some words among the most representative for Topic 1 (“global,” “El Nino”) that clusters with “smog” in the responses but that semantically relates more to global warming and thus renders Topic 1 less than perfectly coherent. We note that these words are relatively infrequent (12 and 10 occurrences, respectively), and their salience is thus overwhelmed by the word “smog,” which occurs 138 times (see also Supplementary Figure S1).
Topic 2 sees six mentions of glacier melt and sea-level rise each; the poles and snow are also mentioned. The two responses that do not fit this overall theme, numbers 6 and 8, bring up gas masks and would thus likely have been classified by humans as belonging to Topic 1. Nevertheless, we consider the automatically induced topic to be sufficiently coherent for our statistical analysis below.
The third topic emphasizes vehicle and industrial emissions, with six responses mentioning “car” or related words (“tailpipe”) and the same number bringing up “industry.” Beyond the focus on emission sources, three responses use evaluative language such as “inept” (5), “worrying,” “scary” (8), and “severe” (10).
Finally, topic 4 centers on negative effects, notably for humans, including human health. This topic is also different in that it emphasizes the future more than the others. Specifically, four make statements about future events (“people will…”); another two contain rhetorical questions about what will happen in the future (4 and 7), and, finally, one mentions “future generations” explicitly (6). It thus partly mirrors the “future/impact” topic identified by Tvinnereim and Fløttum (2015), but with a stronger health element.
Furthermore, beyond the ten most representative statements shown in Table 3, a number of responses mention “the end of the world” (“世界 末日”) as a key association. Specifically, responses no. 11, 13, 16, 19, and 20 bring up this construct, which are also represented in Table 2 among the most characteristic words of the Impact topic. The specific impacts on humans thus frequently relate to health and more comprehensive, future threats to society, but also to threats facing ecosystems.
Figure 1 shows the distribution of these four topics according to the survey experimental treatment. A placement to the left of the scale indicates that the topic was chosen predominantly by individuals who drew a question about air pollution; a placement on the right indicates that more of those asked about global warming brought up the topic. Thus, the Smog frame was used overwhelmingly by respondents in the air pollution half of the split sample, whereas the Glacier melt and sea-level rise topic was strongly associated with global warming. Both findings are significant at the five percent level. We furthermore find that the experimental effect is somewhat stronger among young respondents and the more educated (Table S2). It may be conjectured that this variation in effect strength is due to younger and more educated respondents having more knowledge about the variety of environmental pollution.

Topic prevalence over experimental treatment. Topics on the left of the central zero line are more likely to have been chosen by the half of the sample receiving the open-ended question about air pollution; those on the right are more likely to have been chosen by the half asked about global warming. Whiskers indicate 95% confidence intervals and include both statistical uncertainty and estimation uncertainty. Effect sizes and uncertainty estimates for the underlying regression models are given in Table S1. N = 1041
By contrast, the experimental treatment does not have a significant effect on respondents’ likelihood of bringing up the topic of Vehicle and industrial emissions. The most representative response for this topic, given the model, is “automobile exhaust, industrial gaseous waste, consumer waste” (ID 159; topic prevalence = .77), which emerges from the global warming experimental group; the second most representative is “Heavy metals, cancer, automobile exhaust, industrial waste gas” (ID 3010; topic prevalence = .68) which was drawn from the air pollution sub-sample. Among the 100 most representative responses from this group, 61 belong to the “air pollution” experimental group and the remaining 39 belong to the “global warming” group. Thus, respondents see vehicle and industrial emissions as causing both local air pollution and global warming and in more or less equal measure.
Perhaps more surprisingly, the Impact on humans topic also straddles the air pollution and global warming treatment groups. This indicates that respondents do not only worry about the impacts of local air pollution, but also about the effects of global warming. Among participants from the global warming treatment group with the highest prevalence of the Impact on humans topic, we see statements such as “If the temperature goes up all the time, what will happen in the future?” (ID 2016, topic prevalence = .49); “What will happen to polar bears, and will penguins lose their home? When too hot, will humans be able to adapt to the changes in climate” (ID 38, topic prevalence = .37); and “the end of the world” (ID 3018, topic prevalence = .35).
3.2 Demographic drivers of topic prevalence
To what extent is topic choice predictable in terms of demographic variables? We ran regression analyses within each of the two experimental groups with topic prevalence as the dependent variable and gender, age, education, and respondent’s level of concern with global warming as explanatory variables. For the air pollution treatment group, the Smog topic is significantly more prevalent among women, the young, and the educated (Table 4). By contrast, men are significantly more likely to bring up the frame containing causes—that is, emissions from cars and industry. While this finding is consistent with earlier research from Norway (Tvinnereim and Fløttum 2015), it remains an open question whether the mechanism linking gender to emphasis on causes is the same. Specifically, the Chinese result may be due to a relatively higher level of environmental knowledge in China among men (Xiao and Hong 2010) whereas the Norwegian result is linked to higher levels of climate skepticism in male respondents. Future research should examine this link further, e.g., by using open-ended questions about the causes of air pollution and global warming.
Within the global warming experimental group, older respondents are significantly more likely to volunteer responses where the Impact on humans and Vehicle and industrial emissions topics prevail. Conversely, the Glacier melt and sea-level rise topic is brought up more by younger respondents and also by men. This result differs fundamentally from a similar study in Norway, where women and older respondents brought up weather and ice melt more in an open-ended question about climate change, while men and the younger mentioned the future and impacts more (Tvinnereim and Fløttum 2015).
We suggest three explanations for this discrepancy. First, the topics may not fully correspond, given, for instance, a stronger emphasis on health in the Chinese impact topic than was found in the corresponding topic in Norway. Second, while knowledge about the effects on society of climate change may be taken as a sign of advanced climate knowledge in Europe, we maintain that the ability to associate sea-level rise and glacier melt correctly with global warming (and not with air pollution) is a sign of specific knowledge in China. Thus, while weather and ice melt may be the default association in Northern Europe, the Impact on humans topic may in the context of our study appear as a more likely default association to respondents with significant exposure to urban air pollution. Third, and finally, the discrepancy related to gender may in part be explained by the fact that Chinese women express less concern about the environment (Xiao and Hong 2010); the opposite is the case in OECD countries (McCright 2010; Tvinnereim and Fløttum 2015).
4 Conclusions
This study indicates that Chinese respondents distinguish between climate change and air pollution as regards the manifestations of these phenomena, but associate similar causes as well as significant, negative impacts on humans with the two environmental challenges. Specifically, our results show that most Chinese citizens are aware of the difference between the physical manifestations of air pollution and global warming, in the sense that smog is clearly connected with the former and ice melt and sea-level rise with the other.
Earlier studies have suggested that “many Chinese may be incorrectly applying a mental model of local pollution to the issue of climate change” (Lee et al. 2015: 4); by contrast, our results indicate that such conflation may be less widespread than previously thought. Our findings also differ from what has been found in other countries in earlier studies regarding the public’s ability to distinguish between air pollution and global warming (Dunlap 1998). Furthermore, by tracking what aspects of air pollution and global warming respondents choose to bring up, our study extends the current literature by showing that Chinese respondents have a tendency to correctly identify similar causes but different effects of air pollution and global warming.
One implication of this finding is that the proposition of mitigating global warming as an ancillary benefit of clean air policies may not be warranted. Rather, policymakers should feel confident to promote both the air pollution and global warming benefits of reducing the use of fossil fuels in transportation and industry. Specifically, the combination of knowledge about causes and concern about effects suggests that there may be substantial latent support for global warming mitigation in its own right, an implication in line with Stokes et al. (2015). Thus, far from air pollution mitigation constituting a “co-benefit” of global warming mitigation, the two policy objectives may in fact reinforce each other and share a basis in public opinion that buttresses policies with effects in both areas.
As regards our analytical approach, we underline the importance of methodological pluralism—combining topic modeling, word counts, and close reading—when analyzing text data. Notably, we argue that the utility of topic modeling varies with the distribution of representative words, that is, across topics. Specifically, when a single word dominates a topic—the way “smog” dominates Topic 1 (see Figure S1)—simple word counts by experimental treatment group, as shown in Table 1, may be as informative as automatically induced topics. By contrast, Topic 2 constitutes an excellent example of how an unsupervised, probabilistic model is able to link “glacier,” “melt,” and “sea-level” into one coherent cluster of survey responses; the third and fourth topics likewise build internally coherent clusters of several words each.
Finally, both in China and elsewhere, future studies would benefit from split-sample designs combined with quantitative text analysis on open-ended questions, as the method elucidates public perceptions of scientifically complex and near-intractable “wicked” problems. In particular, such research would add a crucial dimension to the growing environmental opinion literature by assessing the public’s weighting of local against global environmental problems, as well as introducing additional issues such as the relationship between environmental protection and the economy. Open-ended questions geared more specifically towards the causes and/or effects of various environmental problems could also yield further insights into the mechanisms behind variations in perceptions across demographic groups. For policymakers, studies of this kind would yield more detailed knowledge about how the public perceives various environmental problems and the distinctions between them, providing better knowledge about which abatement options are likely to gain public consent.
References
Barregard L, Sällsten G, Gustafson P et al (2006) Experimental exposure to wood-smoke particles in healthy humans: effects on markers of inflammation, coagulation, and lipid peroxidation. Inhal Toxicol 18:845–853
Boussalis C, Coan TG (2016) Text-mining the signals of climate change doubt. Glob Environ Chang 36:89–100
Capstick SB, Pidgeon NF, Corner AJ, et al. (2016) Public understanding in Great Britain of ocean acidification. Nature Climate Change
China Climate Change Communication Center (2013) Public climate change awareness and climate change communication in China
Clean Air Alliance of China (2016) The evaluation report of China air management (2016). (accessed Oct. 28, 2016.)
Dolšak N (2009) Climate change policy implementation: a cross-sectional analysis. Rev Policy Res 26:551–570
Dunlap RE (1998) Lay perceptions of global risk: public views of global warming in cross-national context. Int Sociol 13:473–498
Farrell J (2016) Corporate funding and ideological polarization about climate change. Proc Natl Acad Sci 113:92–97
Haines A, McMichael AJ, Smith KR et al (2009) Public health benefits of strategies to reduce greenhouse-gas emissions: overview and implications for policy makers. Lancet 374:2104–2114
Hatton C (2015) Under the Dome: The smog film taking China by storm. BBC China Blog. BBC
Huang G (2015) PM 2.5 opened a door to public participation addressing environmental challenges in China. Environ Pollut 197:313–315
Jacobi C, van Atteveldt W, Welbers K (2016) Quantitative analysis of large amounts of journalistic texts using topic modelling. Digit J 4:89–106
Jamelske EM, Boulter J and Jang W. (2017 (forthcoming)) Support for an International Climate Change Treaty among American and Chinese Adults..The International Journal of Climate Change: Impacts and Responses
Lee TM, Markowitz EM, Howe PD et al (2015) Predictors of public climate change awareness and risk perception around the world. Nature Clim Chang 5:1014–1020
Leiserowitz A (2005) American risk perceptions: is climate change dangerous? Risk Anal 25:1433–1442
Lelieveld J, Evans JS, Fnais M et al (2015) The contribution of outdoor air pollution sources to premature mortality on a global scale. Nature 525:367–371
Liu JC, Leiserowitz AA (2009) From Red to Green? Environ: Sci Policy Sustain Dev 51:32–45
Lorenzoni I, Leiserowitz A, de Franca DM et al (2006) Cross‐national comparisons of image associations with “global warming” and “climate change” among laypeople in the United States of America and great Britain. J Risk Res 9:265–281
Lucas C, Nielsen RA, Roberts ME, et al. (2015) Computer-Assisted Text Analysis for Comparative Politics. Political Analysis: mpu019
Markandya A, Rübbelke DT (2004) Ancillary benefits of climate policy. J Econ Stat 224
McCright AM (2010) The effects of gender on climate change knowledge and concern in the American public. Popul Environ 32:66–87
Nemet GF, Holloway T, Meier P (2010) Implications of incorporating air-quality co-benefits into climate change policymaking. Environ Res Lett 5:014007
Pearce D (2000) Policy frameworks for the ancillary benefits of climate change policies: Centre for Social and Economic Research on the Global Environment
Randolph J, Dolsak N (1996) Regional versus global?—Will strategies for reduction of sulfur dioxide emissions from electric utilities increase carbon dioxide emissions? : SUPCON International. IL (United States), Chicago
Roberts ME, Stewart BM and Tingley D (2014) stm: R Package for Structural Topic Models
Roberts ME, Stewart BM, Tingley D, et al. (2014) Structural Topic Models for Open‐Ended Survey Responses. Am J Politic Sci 1064–1082
Shwom R, Bidwell D, Dan A et al (2010) Understanding US public support for domestic climate change policies. Glob Environ Chang 20:472–482
Smith N, Leiserowitz A (2014) The role of emotion in global warming policy support and opposition. Risk Anal 34:937–948
Stokes B, Wike R and Carle J (2015) Global Concern about Climate Change, Broad Support for Limiting Emissions. Pew Research Center
Tourangeau R, Rasinski KA, Bradburn N et al (1989) Belief accessibility and context effects in attitude measurement. J Exp Soc Psychol 25:401–421
Tseng H, Chang P, Andrew G, et al. (2005) A conditional random field word segmenter for sighan bakeoff 2005. Proceedings of the fourth SIGHAN workshop on Chinese language Processing
Tvinnereim E (2013) Paths toward large, unilateral climate policies: policy-seeking, attenuated accountability and second-order government assertiveness. J Energy Nat Res Law 31:379
Tvinnereim E, Fløttum K (2015) Explaining topic prevalence in open-ended survey questions on climate change. Nat Clim Chang 5:744–747
Ürge-Vorsatz D, Herrero ST, Dubash NK et al (2014) Measuring the co-benefits of climate change mitigation. Annu Rev Environ Resour 39:549–582
Victor DG, Zaelke D, Ramanathan V (2015) Soot and short-lived pollutants provide political opportunity. Nature Clim Chang 5:796–798
Wang Y, Sun M, Yang X et al (2015) Public awareness and willingness to pay for tackling smog pollution in China: a case study. J Clean Prod 112:1627–1634
Whitmarsh L (2008) What’s in a name? Commonalities and differences in public understanding of “climate change”and “global warming”. Public Understanding of Science
Woodcock J, Edwards P, Tonne C et al (2009) Public health benefits of strategies to reduce greenhouse-gas emissions: urban land transport. Lancet 374:1930–1943
World Health Organization (2016) Urban ambient air pollution database—update 2016
Xiao C, Hong D (2010) Gender differences in environmental behaviors in China. Popul Environ 32:88–104
Yang G, Wang Y, Zeng Y et al (2013) Rapid health transition in China, 1990–2010: findings from the global burden of disease study 2010. Lancet 381:1987–2015
Yu X (2014) Is environment ‘a city thing’in China? Rural–urban differences in environmental attitudes. J Environ Psychol 38:39–48
Acknowledgements
This research is supported by The University of Wisconsin-Eau Claire (UWEC) Office of Research & Sponsored Programs, the UWEC International Fellows Program, the UWEC Foundation Office and the Research Council of Norway under the Lingclim and European Perceptions of Climate Change projects (grants no. 220654 and 244904). The authors would like to thank James E. Boulter, Hans J. Gaasemyr, Mikko Heino, Wenhan Li, Margaret E. Roberts, Paul M. Sniderman, and Shiying Wang. We also wish to recognize Brittany Flaherty, David Hahn, Emily Koehn, and Gregory Sikowski as well as numerous Chinese students for excellent research assistance.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Tvinnereim, E., Liu, X. & Jamelske, E.M. Public perceptions of air pollution and climate change: different manifestations, similar causes, and concerns. Climatic Change 140, 399–412 (2017). https://doi.org/10.1007/s10584-016-1871-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10584-016-1871-2