
Abstract
General elliptic equations with spatially discontinuous diffusion coefficients may be used as a simplified model for subsurface flow in heterogeneous or fractured porous media. In such a model, data sparsity and measurement errors are often taken into account by a randomization of the diffusion coefficient of the elliptic equation which reveals the necessity of the construction of flexible, spatially discontinuous random fields. Subordinated Gaussian random fields are random functions on higher dimensional parameter domains with discontinuous sample paths and great distributional flexibility. In the present work, we consider a random elliptic partial differential equation (PDE) where the discontinuous subordinated Gaussian random fields occur in the diffusion coefficient. Problem specific multilevel Monte Carlo (MLMC) Finite Element methods are constructed to approximate the mean of the solution to the random elliptic PDE. We prove a-priori convergence of a standard MLMC estimator and a modified MLMC—control variate estimator and validate our results in various numerical examples.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Partial differential equations with random operators / data / domain are widely studied. For problems with sparse data or where measurement errors are unavoidable, uncertainties may be quantified using stochastic models. Methods to quantify uncertainty could be divided into two different branches: intrusive and non-intrusive. The former requires solving a high dimensional partial differential equation, where part of the dimensionality stems from the smoothness of the random field or process (see among others [6, 19, 30] and the references therein). The latter are (essentially) sampling methods and require repeated solutions of lower dimensional problems (see, among others [1, 9, 11, 12, 29, 35]). Among the sampling method the multilevel Monte Carlo approach has been successfully established to lower the computational complexity for various uncertain problems, to the point where (depending on the dimension) it is asymptotically as costly as a single solve of the deterministic partial differential equation on a fine discretization level (see [9, 11, 13, 21]). In the cited papers mostly Gaussian random fields were used as diffusivity coefficients in the elliptic equation. Gaussian random fields are stochastically very well understood objects and they may be used in both approaches. The distributions underlying the field are, however, Gaussian and therefore the model lacks flexibility, in the sense that fields cannot have pointwise marginal distributions having heavy-tails. Furthermore, Gaussian random fields with Matérn-type covariance operators have \({\mathbb {P}}\)-almost surely spatial continuous paths. There are some extensions in the literature (see, for example [11, 17, 29]).
In this paper we investigate multilevel Monte Carlo methods for an elliptic PDE where the coefficient is given by a subordinated Gaussian random field. The subordinated Gaussian random field is a type of a (discontinuous) Lévy field. Different subordinators display unique patterns in the discontinuities and have varied marginal distributions (see [7]). Existence and uniqueness of pathwise solutions to the problem was demonstrated in [8]. Spatial regularity of the solution depends on the subordinated Gaussian random field which itself depends on the subordinator. The discontinuities in the spatial domain pose additional difficulty in the pathwise discretization. A sample-adapted approach was considered in [8], but is limited to certain subordinators. Here we investigate not only the limitations of a sample-adapted approach in multilevel sampling, but also a Control Variates ansatz as presented first in [31].
We structured the rest of the paper as follows: In Sect. 2 we introduce a general stochastic elliptic equation and its weak solution under mild assumptions on the coefficient. These assumptions accommodate the subordinated Gaussian random fields we introduce in Sect. 3. In Sect. 4 we approximate the diffusion coefficient and state a convergence result of the elliptic equation with the approximated coefficient to the unapproximated solution. In Sect. 5 we discuss spatial approximation methods, which are needed for the multilevel Monte Carlo methods introduced in Sect. 6 and its Control Variates variant in Sect. 7. Numerical examples are presented in the last section.
2 The stochastic elliptic problem
In this section, we briefly introduce the general stochastic elliptic boundary value problem with random diffusion coefficient and define the corresponding weak solution. This provide the theoretical framework for Sect. 4, where stochastic elliptic PDEs with a specific discontinuous random coefficient are considered. For more details on the existence, uniqueness and measurability of the solution to the considered PDE, we refer the reader to Barth and Merkle [8] and Barth and Stein [11]. For the rest of this paper we assume that a complete probability space \((\varOmega ,{\mathscr {F}},{\mathbb {P}})\) is given. Let \((H,( \cdot ,\cdot )_H)\) be a Hilbert space. A H-valued random variable is a measurable function \(Z:\varOmega \rightarrow H\). The space \(L^p(\varOmega ;H)\) contains all strongly measurable functions \(Z:\varOmega \rightarrow H\) with \(\Vert Z\Vert _{L^p(\varOmega ;H)}<\infty \), for \(p\in [1,+\infty ]\), where the norm is defined by
For a H-valued random variable \(Z\in L^1(\varOmega ;H)\) we define the expectation by the Bochner integral \({\mathbb {E}}(Z):=\int _\varOmega Z\,d{\mathbb {P}}\). Further, for a square-integrable, H-valued random variable \(Z\in L^2(\varOmega ;H)\), the variance is defined by \(Var(Z):=\Vert Z-{\mathbb {E}}(Z)\Vert _{L^2(\varOmega ;H)}^2\). We refer to Da Prato and Zabczyk [15], Kallenberg [27], Klenke [28] or Peszat and Zabczyk [32] for more details on general probability theory and Hilbert space-valued random variables.
2.1 Problem formulation
Let \({\mathscr {D}}\subset {\mathbb {R}}^d\), for \(d\in {\mathbb {N}}\), be a bounded, connected Lipschitz domain. We set \(H:=L^2({\mathscr {D}})\) and consider the elliptic PDE
where we impose the following boundary conditions
Here, we split the domain boundary in two \((d-1)\)-dimensional manifolds \(\varGamma _1,~\varGamma _2\), i.e. \(\partial {\mathscr {D}}=\varGamma _1\overset{.}{\cup }\varGamma _2\), where we assume that \(\varGamma _1 \) is of positive measure and that the exterior normal derivative \(\overrightarrow{n}\cdot \nabla v\) on \(\varGamma _2\) is well-defined for every \(v\in C^1(\overline{{\mathscr {D}}})\). The mapping \(a:\varOmega \times {\mathscr {D}}\rightarrow {\mathbb {R}}\) is a measurable, positive and stochastic (jump diffusion) coefficient and \(f:\varOmega \times {\mathscr {D}}\rightarrow {\mathbb {R}}\) is a measurable random source function. Further, \(\overrightarrow{n}\) is the outward unit normal vector to \(\varGamma _2\) and \(g:\varOmega \times \varGamma _2\rightarrow {\mathbb {R}}\) a measurable function. Note that we just reduce the theoretical analysis to the case of homogeneous Dirichlet boundary conditions on \(\varGamma _1\) to simplify notation. One could also consider non-homogeneous Dirichlet boundary conditions, since such a problem can always be considered as a version of (2.1)–(2.3) with modified source term and Neumann data (see also [11, Remark 2.1]).
2.2 Weak solution
In this subsection, we introduce the pathwise weak solution of problem (2.1)–(2.3) following Barth and Merkle [8]. We denote by \(H^1({\mathscr {D}})\) the Sobolev space on \({\mathscr {D}}\) equipped with the norm
with the Euclidean norm \(\Vert {\underline{x}}\Vert _2:=(\sum _{i=1}^d {\underline{x}}_i^2)^\frac{1}{2}\), for \({\underline{x}}\in {\mathbb {R}}^d\) (see for example [18, Section 5.2] for an introduction to Sobolev spaces). We denote by T the trace operator \(T:H^1({\mathscr {D}})\rightarrow H^{\frac{1}{2}}(\partial {\mathscr {D}})\) where \(Tv=v|_{\partial {\mathscr {D}}}\) for \(v\in C^\infty (\overline{{\mathscr {D}}})\) (see [16]) and we introduce the solution space \(V\subset H^1({\mathscr {D}})\) by
where we take over the standard Sobolev norm, i.e. \(\Vert \cdot \Vert _V:=\Vert \cdot \Vert _{H^1({\mathscr {D}})}\). We identify H with its dual space \(H'\) and work on the Gelfand triplet \(V\subset H\simeq H'\subset V'\).
We multiply Eq. (2.1) by a test function \(v\in V\) and integrate by parts (see e.g. [36, Section 6.3]) to obtain the following pathwise weak formulation of the problem: For \({\mathbb {P}}\)-almost all \(\omega \in \varOmega \), given \(f(\omega ,\cdot )\in V'\) and \(g(\omega ,\cdot )\in H^{-\frac{1}{2}}(\varGamma _2)\), find \(u(\omega ,\cdot )\in V\) such that
for all \(v\in V\). The function \(u(\omega ,\cdot )\) is then called pathwise weak solution to problem (2.1)–(2.3). The bilinear form \(B_{a(\omega )}\) and the operator \(F_\omega \) are defined by
for \(u,v\in V\) and fixed \(\omega \in \varOmega \), where the integrals in \(F_\omega \) are understood as the duality pairings:
3 Subordinated Gaussian random fields
In [7], the authors proposed a new subordination approach to construct discontinuous Lévy-type random fields: the subordinated Gaussian random field. Motivated by the subordinated Brownian motion, the subordinated Gaussian Random field is constructed by replacing the spatial variables of a Gaussian random field (GRF) W on a general d-dimensional domain \({\mathscr {D}}\subset {\mathbb {R}}^d\) by d independent Lévy subordinators (see [3, 7, 34]). For \(d=2\), the detailed construction is as follows: For two positive horizons \(T_1,T_2<+\infty \), we define the domain \({\mathscr {D}}=[0,T_1]\times [0,T_2]\). We consider a GRF \(W = (W(x,y),~(x,y)\in {\mathbb {R}}_+^2)\) with \({\mathbb {P}}\)-a.s. continuous paths and assume two independent Lévy subordinators \(l_1=(l_1(x),~x\in [0,T_1])\) and \(l_2=(l_2(y),~y\in [0,T_2])\) are given (see [3, 7]). The subordinated GRF is then defined by
The corresponding random field \(L=(L(x,y),~(x,y)\in [0,T_1],\times [0,T_2])\) is in general discontinuous on the spatial domain \({\mathscr {D}}\).

Sample of a Matérn-1.5-GRF (left) and a corresponding Poisson-subordinated GRF (middle) and Gamma-subordinated GRF (right)
Figure 1 demonstrates how the subordinators \(l_1\) and \(l_2\) create discontinuities in the subordinated GRF. In the presented samples, the underlying GRF is a Matérn-1.5 GRF. We recall that, for a given smoothness parameter \(\nu _M > 1/2\), correlation parameter \(r_M>0\) and variance \(\sigma _M^2>0\), the Matérn-\(\nu _M\) covariance function on \({\mathbb {R}}_+^d\times {\mathbb {R}}_+^d\) is given by \(q_M({\underline{x}},{\underline{y}})=\rho _M(\Vert {\underline{x}}-{\underline{y}}\Vert _2)\), for \(({\underline{x}},{\underline{y}})\in {\mathbb {R}}_+^d\times {\mathbb {R}}_+^d\), with
where \(\varGamma (\cdot )\) is the Gamma function and \(K_\nu (\cdot )\) is the modified Bessel function of the second kind (see [23, Section 2.2 and Proposition 1]). A Matérn-\(\nu _M\) GRF is a centered GRF with covariance function \(q_M\). It has been shown in [7] that the subordinated GRF constructed in (3.1) is separately measurable. Further, the corresponding random fields display great distributional flexibility, allow for a Lévy–Khinchin-type formula and formulas for their covariance functions can be derived which makes them attractive for applications. We refer the interested reader to [7] for a theoretical investigation of the constructed random fields.
4 The subordinated GRF in the elliptic model equation
In this section we incorporate the subordinated GRF in the diffusion coefficient of the elliptic PDE (2.1)–(2.3). Further, we show how to approximate the diffusion coefficient and state the most important results on the approximation of the corresponding PDE solution following Barth and Merkle [8]. For the proofs and a more detailed study of subordinated GRFs in the elliptic model equation we refer the reader to Barth and Merkle [8].
4.1 Subordinated GRFs in the diffusion coefficient
It follows from the Lévy–Itô decomposition that any Lévy process on a one-dimensional (time) domain can be additively decomposed into a deterministic drift part, a continuous noise part and a pure-jump process (see [3, Section 2.4]). Motivated by this, we construct the diffusion coefficient a in the elliptic PDE as follows.
Definition 4.1
(See [8, Definition 3.3]) We consider the domain \({\mathscr {D}}=(0,D)^2\) with \(D<+\infty \).Footnote 1 We define the jump diffusion coefficient a in problem (2.1)–(2.3) with \(d=2\) as
where
-
\({\overline{a}}:{\mathscr {D}}\rightarrow (0,+\infty )\) is deterministic, continuous and there exist constants \({\overline{a}}_+,{\overline{a}}_->0\) with \({\overline{a}}_-\le {\overline{a}}(x,y)\le {\overline{a}}_+\) for \((x,y)\in {\mathscr {D}}\).
-
\(\varPhi _1,~\varPhi _2:{\mathbb {R}}\rightarrow [0,+\infty )\) are continuous .
-
\(W_1\) and \(W_2\) are zero-mean GRFs on \({\mathscr {D}}\) respectively on \([0,+\infty )^2\) with \({\mathbb {P}}-a.s.\) continuous paths.
-
\(l_1\) and \(l_2\) are Lévy subordinators on [0, D].
It follows by a pathwise application of the Lax–Milgram lemma that the elliptic model problem (2.1)–(2.3) with the diffusion coefficient constructed in Definition 4.1 has a unique pathwise weak solution.
Theorem 4.2
(See [8, Theorem 3.6]) Let a be as in Definition 4.1 and let \(f\in L^q(\varOmega ;H),~g\in L^q(\varOmega ;L^2(\varGamma _2))\) for some \(q\in [1,+\infty )\). Then there exists a unique pathwise weak solution \(u(\omega ,\cdot )\in V\) to problem (2.1)–(2.3) for \({\mathbb {P}}\)-almost every \(\omega \in \varOmega \). Furthermore, \(u\in L^r(\varOmega ;V)\) for all \(r\in [1,q)\) and
where \(C({\overline{a}}_-,{\mathscr {D}})>0\) is a constant depending only on the indicated parameters.
4.2 Problem modification
Theorem 4.2 guarantees the existence of a unique solution u to problem (2.1)–(2.3) for the specific diffusion coefficient a constructed in Definition 4.1. However, accessing this pathwise weak solution numerically is a different matter. Here, we face several challenges: the first difficulty is related to the domain on which the GRF \(W_2\) is defined. The Lévy subordinators \(l_1\) and \(l_2\) can in general attain any value in \([0,+\infty )\). Hence, it is necessary to consider the GRF \(W_2\) on the unbounded domain \([0,+\infty )^2\). However, most regularity and approximation results on GRFs are formulated for the case of a parameter space which is at least bounded and cannot easily be extended to unbounded domains (see e.g. [2, Chapter 1]). Therefore, we modify the diffusion coefficient a from Definition 4.1 and cut the Lévy-subordinators at a deterministic threshold \(K>0\) depending on the choice of the subordinator. The resulting problem then coincides with the original problem up to a set of samples, whose probability can be made arbitrary small (see [8, Remark 4.1]). Furthermore, we have to bound the diffusion coefficient itself by a deterministic upper bound A in order to show the convergence of the solution (see [8, Section 5] for details). Therefore, we also cut the diffusion coefficient at a deterministic level \(A>0\). It can be shown that this induces an additional error in the solution approximation which can be controlled and vanishes for growing threshold A (see [8, Section 5.1, esp. Theorem 5.3 and Theorem 5.4]). The two described modifications of the original problem (2.1)–(2.3) are formalized in this subsection.
We define the cut function \(\chi _{K}(z) :=\min (z,K)\), for \(z\in [0,+\infty )\), with a positive number \(K>0\). Further, for fixed numbers \(K,A>0\), we consider the following problem
where we impose the boundary conditions
The diffusion coefficient \(a_{K,A}\) is defined byFootnote 2
where we assume that the functions \({\overline{a}}\), \(\varPhi _1\), \(\varPhi _2\), the GRFs \(W_1\), \(W_2\) and the Lévy subordinators \(l_1\), \(l_2\) are as described in Definition 4.1. Again, Theorem 4.2 applies in this case and yields the existence of a pathwise weak solution \(u_{K,A}\in L^r(\varOmega ;V)\), for \(r\in [1,q)\), if \(f\in L^q(\varOmega ;H)\) and \(g\in L^q(\varOmega ;L^2(\varGamma _2))\). In [8], the authors investigated in detail how this modification affects the solution u of the original problem and how the resulting error can be controlled by the choice of the deterministic thresholds K and A. Therefore, from now on we decide to consider problem (4.2)–(4.5) for a fixed choice of K and A and focus on the approximation of the GRFs \(W_1,W_2\) and the Lévy subordinators \(l_1,l_2\) in the following. We come back on the choice of K and A in specific situations in Sect. 8.
4.3 Approximation of the GRFs and the Lévy subordinators and convergence of the approximated solution
In order to approximate the random solution \(u_{K,A}\) of problem (4.2)–(4.5) we have to generate samples from the GRFs \(W_1,~W_2\) and the Lévy subordinators \(l_1,~l_2\) to obtain samples of the diffusion coefficient \(a_{K,A}\) defined in Eq. (4.5). However, the GRFs \(W_1,~W_2\) and the Lévy subordinators \(l_1,~l_2\) may in general not be simulated exactly and, hence, appropriate approximations have to be used. Therefore, we have to impose some additional assumptions on the GRFs and the Lévy subordinators. We summarize our working assumptions in the following.
Assumption 4.3
(See [8, Assumption 4.2]) Let \(W_1\) be a zero-mean GRF on \([0,D]^2\) and \(W_2\) be a zero-mean GRF on \([0,K]^2\). We denote by \(q_1:[0,D]^2\times [0,D]^2\rightarrow {\mathbb {R}}\) and \(q_2:[0,K]^2\times [0,K]^2\rightarrow {\mathbb {R}}\) the covariance functions of these random fields and by \(Q_1,Q_2\) the associated covariance operators defined by
for \(\phi \in L^2([0,z_j]^2)\) with \(z=(D,K)\) and \(j=1,2\). We denote by \((\lambda _i^{(1)},e_i^{(1)},~i\in {\mathbb {N}})\) resp. \((\lambda _i^{(2)},e_i^{(2)},~i\in {\mathbb {N}})\) the eigenpairs associated to the covariance operators \(Q_1\) and \(Q_2\). In particular, \((e_i^{(1)},~i\in {\mathbb {N}})\) resp. \((e_i^{(2)},~i\in {\mathbb {N}})\) are orthonormal bases of \(L^2([0,D]^2)\) resp. \(L^2([0,K]^2)\).
-
i.
We assume that the eigenfunctions are continuously differentiable and there exist positive constants \(\alpha , ~\beta , ~C_e, ~C_\lambda >0\) such that for any \(i\in {\mathbb {N}}\) it holds
$$\begin{aligned}&\Vert e_i^{(1)}\Vert _{L^\infty ([0,D]^2)},~\Vert e_i^{(2)}\Vert _{L^\infty ([0,K]^2)}\le C_e,\\&\Vert \nabla e_i^{(1)}\Vert _{L^\infty ([0,D]^2)},~\Vert \nabla e_i^{(2)}\Vert _{L^\infty ([0,K]^2)}\le C_e i^\alpha ,~ \\&\sum _{i=1}^ \infty (\lambda _i^{(1)}+ \lambda _i^{(2)})i^\beta \le C_\lambda < + \infty . \end{aligned}$$ -
ii.
There exist constants \(\phi ,~\psi , C_{lip}>0\) such that the continuous functions \(\varPhi _1,~\varPhi _2:{\mathbb {R}}\rightarrow [0,+\infty )\) from Definition 4.1 satisfy
$$\begin{aligned} |\varPhi _1'(x)|\le \phi \, \exp (\psi |x|),~ |\varPhi _2(x)-\varPhi _2(y)|\le C_{lip}\,|x-y| \text { for } x,y\in {\mathbb {R}}. \end{aligned}$$In particular, \(\varPhi _1\in C^1({\mathbb {R}})\).
-
iii.
\(f\in L^q(\varOmega ;H)\) and \(g\in L^q(\varOmega ;L^2(\varGamma _2))\) for some \(q\in (1,+\infty ).\)
-
iv.
\(l_1\) and \(l_2\) are Lévy subordinators on [0, D] which are independent of the GRFs \(W_1\) and \(W_2\). Further, we assume that we have approximations \(l_1^{(\varepsilon _l)},~l_2^{(\varepsilon _l)}\) of these processes and there exist constants \(C_l>0\) and \(\eta >1\) such that for every \(s\in [1,\eta )\) it holds
$$\begin{aligned} {\mathbb {E}}(|l_j(x)-l_j^{(\varepsilon _l)}(x)|^s)\le C_l\varepsilon _l, \end{aligned}$$for \(\varepsilon _l >0\), \(x\in [0,D]\) and \(j=1,2\).
The first assumption on the eigenpairs of the GRFs is natural (see [11, 23]). Assumption 4.3(ii) is necessary to be able to quantify the error of the approximation of the diffusion coefficient and Assumption 4.3(iii) guarantees the existence of a solution. The last assumption ensures that we can approximate the Lévy subordinators with a controllable \(L^s\)-error. Here, the parameter \(\varepsilon _l\) may be interpreted as the maximum stepsize of the grid on [0, D] on which the piecewise constant approximation \(l_j^{(\varepsilon _l)}\) of the Lévy process \(l_j\) is defined (see Sect. 8). The prescribed error bound may then always be achieved under appropriate assumptions on the tails of the distribution of the Lévy subordinators, see [10, Assumptions 3.6, 3.7 and Theorem 3.21].
For technical reasons we have to work under the following assumption on the integrability of the gradient of the solution \(\nabla u_{K,A}\) of problem (4.2)–(4.5). This assumption is necessary to prove convergence of the approximation to the solution \(u_{K,A}\) in Theorem 4.5. Its origin lies in the fact that we cannot approximate the Lévy subordinators in an \(L^s(\varOmega ;L^\infty ([0,D]))\)-sense due to the discontinuities. To showcase this consider a Poisson process with constant jump size 1 (cf. [34, Section 5.3.1]): for almost every path, a piecewise constant approximation of the process on an equidistant grid leads to a pathwise error of at least 1 measured in the \(L^\infty ([0,D])\)-norm. Note that the approximation property given by Assumption 4.3(iv) is weaker than an approximation in the \(L^s(\varOmega ;L^\infty ([0,D]))\)-norm.
Assumption 4.4
(See [8, Assumption 5.5]) We assume that there exist constants \(j_{reg}>0\) and \(k_{reg}\ge 2\) such that
There are several results on higher integrability of the gradient of the solution to an elliptic PDE of the form (4.2)–(4.5) which guarantee the condition of Assumption 4.4. We refer to Barth and Merkle [8, Section 5.2] and especially Remarks 5.6 and 5.7 therein for more details.
We now turn to the final approximation of the diffusion coefficient using approximations \(W_1^{(\varepsilon _W)}\approx W_1\), \(W_2^{(\varepsilon _W)}\approx W_2\) of the GRFs and \(l_1^{(\varepsilon _l)}\approx l_1\), \(l_2^{(\varepsilon _l)}\approx l_2\) of the Lévy subordinators (see Assumption 4.3): we consider discrete grids \(G_1^{(\varepsilon _W)}=\{(x_i,x_j)|~i,j=0,\dots ,M_{\varepsilon _W}^{(1)}\}\) on \([0,D]^2\) and \(G_2^{(\varepsilon _W)}=\{(y_i,y_j)|~i,j=0,\dots ,M_{\varepsilon _W}^{(2)}\}\) on \([0,K]^2\) where \((x_i,~i=0,\dots ,M_{\varepsilon _W}^{(1)})\) is an equidistant grid on [0, D] with maximum step size \(\varepsilon _W\) and \((y_i,~i=0,...,M_{\varepsilon _W}^{(2)})\) is an equidistant grid on [0, K] with maximum step size \(\varepsilon _W\). Further, let \(W_1^{(\varepsilon _W)}\) and \(W_2^{(\varepsilon _W)}\) be approximations of the GRFs \(W_1,~W_2\) on the discrete grids \(G_1^{(\varepsilon _W)}\) resp. \(G_2^{(\varepsilon _W)}\) which are constructed by point evaluation of the random fields \(W_1\) and \(W_2\) on the grid points and linear interpolation between the them. Such an approximation may be obtained, for example, by the circulant embedding method (cf. [24, 25]).
We approximate the diffusion coefficient \(a_{K,A}\) from Eq. (4.5) by \(a_{K,A}^{(\varepsilon _W,\varepsilon _l)}:\varOmega \times {\mathscr {D}}\rightarrow (0,+\infty )\) with
for \((x,y)\in {\mathscr {D}}\). Further, we denote by \(u_{K,A}^{(\varepsilon _W,\varepsilon _l)}\in L^r(\varOmega ;V)\), with \(r\in [1, q)\), the weak solution to the corresponding elliptic problem
with boundary conditions
Note that Theorem 4.2 also applies to the elliptic problem with coefficient \(a_{K,A}^{(\varepsilon _W,\varepsilon _l)}\). We are now able to state the most important result on the convergence of the approximated solution \(u_{K,A}^{(\varepsilon _W,\varepsilon _l)}\) to \(u_{K,A}\). For a proof we refer the reader to Barth and Merkle [8].
Theorem 4.5
(See [8, Theorem 5.9]) Assume \(q>2\) in Assumption 4.3. Let \(r\in [2,q)\) and \(b,c\in [1,+\infty ]\) be given such that it holds
with a fixed real number \(\gamma \in (0,min(1,\beta /(2\alpha ))\). Here, the parameters \(\eta , \alpha \) and \(\beta \) are determined by the GRFs \(W_1\), \(W_2\) and the Lévy subordinators \(l_1\), \(l_2\) (see Assumption 4.3).
Let \(m,n\in [1,+\infty ]\) be real numbers such that
and let \(k_{reg}\ge 2\) and \(j_{reg}>0\) be the regularity specifiers given by Assumption 4.4. If it holds that
then the approximated solution \(u_{K,A}^{(\varepsilon _W,\varepsilon _l)}\) converges to the solution \(u_{K,A}\) of the truncated problem for \(\varepsilon _W,\varepsilon _l\rightarrow 0\) and it holds
This result is essential since it guarantees the convergence of the approximated solution \(u_{K,A}^{(\varepsilon _W,\varepsilon _l)}\) to the solution \(u_{K,A}\) with a controllable upper bound on the error. Further, the error estimate given by Theorem 4.5 will be used in the error equilibration for the MLMC estimator in Sect. 6. It allows to balance the errors resulting from the approximation of the diffusion coefficient and the Finite Element (FE) error resulting from the pathwise numerical approximation of the PDE solution.
5 Pathwise finite element approximation
In this section, we describe the numerical method which is used to compute pathwise approximations of the solution to the considered elliptic PDE following Barth and Merkle [8, Section 6]. We use a FE approach with standard triangulations and sample-adapted triangulations of the spatial domain, which is described in the following.
5.1 The standard pathwise finite element approximation
We approximate the solution u to problem (2.1)–(2.3) with diffusion coefficient a given by Eq. (4.1) using a pathwise FE approximation of the solution \(u_{K,A}^{(\varepsilon _W,\varepsilon _l)}\) of problem (4.7)–(4.9) with the approximated diffusion coefficient \(a_{K,A}^{(\varepsilon _W,\varepsilon _l)}\) given by (4.6). Therefore, for almost all \(\omega \in \varOmega \), we aim to approximate the function \(u_{K,A}^{(\varepsilon _W,\varepsilon _l)}(\omega ,\cdot )\in V\) such that it holds
for every \(v\in V\) with fixed approximation parameters \(K,A,\varepsilon _W,\varepsilon _l\). We compute a numerical approximation of the solution to this variational problem using a standard Galerkin approach with linear elements: assume \({\mathscr {V}}=(V_\ell ,~\ell \in {\mathbb {N}}_0)\) is a sequence of finite-dimensional subspaces \(V_\ell \subset V\) with increasing \(\dim (V_\ell )=d_\ell \). Further, we denote by \((h_\ell ,~\ell \in {\mathbb {N}}_0)\) the corresponding refinement sizes which are assumed to converge monotonically to zero for \(\ell \rightarrow \infty \). Let \(\ell \in {\mathbb {N}}_0\) be fixed and denote by \(\{v_1^{(\ell )},\dots ,v_{d_\ell }^{(\ell )}\}\) a basis of \(V_\ell \). The (pathwise) discrete version of (5.1) reads: find \(u_{K,A,\ell }^{(\varepsilon _W,\varepsilon _l)}(\omega ,\cdot )\in V_\ell \) such that
Expanding the function \(u_{K,A,\ell }^{(\varepsilon _W,\varepsilon _l)}(\omega ,\cdot )\) with respect to the basis \(\{v_1^{(\ell )},\dots ,v_{d_\ell }^{(\ell )}\}\) yields the representation
where the coefficient vector \(\mathbf{c }=(c_1,\dots ,c_{d_\ell })^T\in {\mathbb {R}}^{d_\ell }\) is determined by the linear equation system
with a stochastic stiffness matrix \(\mathbf{B }(\omega )_{i,j}=B_{a_{K,A}^{(\varepsilon _W,\varepsilon _l)}(\omega )}(v_i^{(\ell )},v_j^{(\ell )})\) and load vector \({\mathbf {F}}(\omega )_i=F_\omega (v_i^{(\ell )})\) for \(i,j=1,\dots ,d_\ell \).
Let \(({\mathscr {K}}_\ell ,~\ell \in {\mathbb {N}}_0)\) be a sequence of triangulations on \({\mathscr {D}}\) and denote by \(\theta _\ell >0\) the minimum interior angle of all triangles in \({\mathscr {K}}_\ell \). We assume \(\theta _\ell \ge \theta >0\) for a positive constant \(\theta \) and define the maximum diameter of the triangulation \({\mathscr {K}}_\ell \) by \(h_\ell :=\underset{K\in {\mathscr {K}}_\ell }{\max }\, diam(K),\) for \(\ell \in {\mathbb {N}}_0\) as well as the finite dimensional subspaces by \( V_\ell :=\{v\in V~|~v|_K\in {\mathscr {P}}_1,K\in {\mathscr {K}}_\ell \},\) where \({\mathscr {P}}_1\) denotes the space of all polynomials up to degree one. If we assume that for \({\mathbb {P}}-\)almost all \(\omega \in \varOmega \) it holds \(u_{K,A}^{(\varepsilon _W,\varepsilon _l)}(\omega ,\cdot )\in H^{1+\kappa _a}({\mathscr {D}})\) for some positive number \(\kappa _a>0\), and that there exists a finite bound \(\Vert u_{K,A}^{(\varepsilon _W,\varepsilon _l)}\Vert _{L^2(\varOmega ;H^{1+\kappa _a}({\mathscr {D}}))}\le C_u=C_u(K,A)\) for the fixed approximation parameters K, A, we immediately obtain the following estimate using Céa’s lemma (see [11, Section 4], [8, Section 6], [26, Chapter 8])
By construction of the subordinated GRF, we always obtain an interface geometry with fixed angles and bounded jump height in the diffusion coefficient, which have great influence on the solution regularity, see e.g. [33]. Note that, for general deterministic interface problems, one obtains a pathwise discretization error of order \(\kappa _a \in (1/2,1)\) and in general one cannot expect the full order of convergence \(\kappa _a=1\) without special treatment of the discontinuities of the diffusion coefficient (see [5, 11]). The convergence may be improved by the use of sample-adapted triangulations.
5.2 Sample-adapted triangulations
In [11], the authors suggest sample-adapted triangulations to improve the convergence of the FE approximation for elliptic jump diffusion coefficients. This approach is also used in this paper and the convergence of the corresponding FE method is compared to the performance with the use of standard triangulations. The construction of the sample-adapted triangulations is explained in the following. Consider a fixed \(\omega \in \varOmega \) and assume that the discontinuities of the diffusion coefficient are described by the partition \({\mathscr {T}}(\omega )=({\mathscr {T}}_i,~i=1,\dots , \tau (\omega ))\) of the domain \({\mathscr {D}}\) with \(\tau (\omega )\in {\mathbb {N}}\) and \({\mathscr {T}}_i\subset {\mathscr {D}}\). Assume that \({\mathscr {K}}_\ell (\omega )\) is a triangulation of \({\mathscr {D}}\) which is adjusted to the partition \({\mathscr {T}}(\omega )\) in the sense that for every \(i=1,\dots ,\tau (\omega )\) it holds
for all \(\ell \in {\mathbb {N}}_0\), where \(({\overline{h}}_\ell ,~\ell \in {\mathbb {N}}_0)\) is a deterministic, decreasing sequence of refinement thresholds which converges to zero. We denote by \({\hat{V}}_\ell (\omega )\subset V\) the corresponding finite-dimensional subspaces with dimension \({\hat{d}}_\ell (\omega )\in {\mathbb {N}}\). Figure 2 illustrates the adapted triangulation for a sample of the diffusion coefficient where we used a Poisson(5)-subordinated Matérn-1.5-GRF.

Sample of the diffusion coefficient using a Poisson-subordinated Matérn-1.5-GRF (left) with corresponding sample-adapted triangulation (right)
The sample-adapted approach leads to an improved sample-wise convergence rate for the elliptic PDE with discontinuous diffusion coefficient (see e.g. [11, Section 4.1]). This is particularly true in the situation of jump diffusion coefficients with polygonal jump geometry, which is the case for the diffusion coefficients considered in this paper (see Figure 2, [11, 14, 8, Sections 6 and 7]). However, one should also mention that the sample-adapted approach causes additional computational costs since adapted meshes have to be constructed for each single sample of the diffusion coefficient. This might inflate the computational costs especially in situations of jump coefficients with many interfaces or jumps which are closely located to each other (see also Sects. 7 and 8.3).
While mean squared convergence rates cannot be derived theoretically in our general setting due to the stochastic regularity of the PDE solutions, in practice one at least recovers the convergence rates of the deterministic jump diffusion problem in the strong error, which also has been investigated numerically in [8]. This observation, together with the comments in the end of Sect. 5.1, motivate the following assumption for the remaining theoretical analysis (see [8, Assumption 6.2]).
Assumption 5.1
There exist deterministic constants \({\hat{C}}_{u}, C_{u},{\hat{\kappa }}_a,\kappa _a>0\) such that for any \(\varepsilon _W,\varepsilon _l>0\) and any \(\ell \in {\mathbb {N}}_0\), the FE approximation errors of \({\hat{u}}_{K,A,\ell }^{(\varepsilon _W,\varepsilon _l)}\approx u_{K,A}^{(\varepsilon _W,\varepsilon _l)}\) in the (sample-adapted) subspaces \({\hat{V}}_\ell \), respectively \(u_{K,A,\ell }^{(\varepsilon _W,\varepsilon _l)}\approx u_{K,A}^{(\varepsilon _W,\varepsilon _l)}\) in \(V_\ell \), are bounded by
where the constants \({\hat{C}}_{u},C_{u}\) may depend on a, f, g, K, A but are independent of \({\hat{h}}_\ell ,h_\ell ,{\hat{\kappa }}_a\) and \(\kappa _a\).
We remark that we expect \(1\ge {\hat{\kappa }}_a\ge \kappa _a>0\) in Assumption 5.1 due to the observations given in the beginning of Sect. 5.2 (see also [8, 11] and Sect. 8).
Remark 5.2
Assumption 4.4 on the integrability of the solution gradient and Assumption 5.1 on the convergence rate of the FE method are presented independently. We point out that both assumptions highly depend on the Sobolev regularity of the solution which dictates the integrability of the solution gradient (see for example [8, Remark 5.6]) and controls the convergence rate of the FE method (see for example [8, Remark 6.1]). Hence, both assumptions depend on the regularity of the solution, which itself is related to the specific choice of diffusion coefficient and, therefore, depends on Assumption 4.3. To describe the relation of these three assumptions is not possible in an explicit manner in the general stochastic setting considered, but one should keep in mind that they are not independent from each other.
6 MLMC estimation of the solution
In this section we construct a multilevel Monte Carlo (MLMC) estimator for the expectation \({\mathbb {E}}(u_{K,A})\) of the PDE solution and prove an a-priori bound for the approximation error. We start with the introduction of a general singlelevel Monte Carlo (SLMC) estimation since the MLMC estimator is an extension of this approach.
The next lemma follows by the definition of the inner product on the Sobolev space \(H^1({\mathscr {D}})\) and will be useful in our theoretical investigations.
Lemma 6.1
For independent, centered V-valued random variables \(Z_1\) and \(Z_2\) it holds
Proof
We use the definition of the inner product on \(V\subset H^1({\mathscr {D}})\) together with the independence of \(Z_1\) and \(Z_2\) to calculate
\(\square \)
Let \((u^{(i)},~i\in {\mathbb {N}})\subset L^2(\varOmega ;V)\) be a sequence of i.i.d. random variables and \(M\in {\mathbb {N}}\) a fixed sample number. The singlelevel Monte Carlo estimator for the approximation of the mean \({\mathbb {E}}(u^{(1)})\) is defined by
and we have the following standard result (see also [9, 11]).
Lemma 6.2
Let \(M\in {\mathbb {N}}\) and \((u^{(i)},~i\in {\mathbb {N}})\subset L^2(\varOmega ;V)\) be a sequence of i.i.d. random variables. It holds
One major disadvantage of the SLMC estimator described above is the slow convergence of the (statistical) error for increasing sample numbers M (see Lemma 6.2 and [20]). Multilevel Monte Carlo (MLMC) uses multigrid concepts to reduce the computational complexity for the estimation of the mean compared to the singlelevel approach. The idea is to compute samples of FE approximations with different accuracy where one takes many samples of FE approximations with lower accuracy (and lower computationally costs) and less samples of FE approximations with higher accuracy (and higher computational cost), see also [20, 21].
For fixed parameters K, A the goal is to approximate the value \({\mathbb {E}}(u_{K,A})\). For ease of notation, we focus here on the sample-adapted discretization with the corresponding approximation \({\hat{u}}_{K,A,\ell }^{(\varepsilon _W,\varepsilon _l)}\) with average refinement parameter \({\mathbb {E}}({\hat{h}}_\ell ^{2{\hat{\kappa }}_a})^{1/2}\) and convergence rate \({\hat{\kappa }}_a\) in this section (see Assumption 5.1). However, the reader should always keep in mind that all results also hold in the case of standard triangulations where \({\mathbb {E}}({\hat{h}}_\ell ^{2{\hat{\kappa }}_a})^{1/2}\) should be replaced by \(h_\ell ^{\kappa _a}\). We remind that the approximation parameters \(\varepsilon _W>0\) and \(\varepsilon _l>0\) correspond to the stepsize of the discrete grids on which the approximations \(W_j^{(\varepsilon _W)}\approx W_j\) of the GRFs and \(l_j^{(\varepsilon _l)}\approx l_j\) of the Lévy subordinators are defined, for \(j=1,2\) (see Sect. 4.3).
Assume a maximum level \(L\in {\mathbb {N}}\) is given. We consider finite-dimensional subspaces \(({\hat{V}}_\ell ,~\ell =0,\dots ,L)\) of V with refinement sizes \({\hat{h}}_0>\dots>{\hat{h}}_L>0\) and approximation parameters \(\varepsilon _{W,0}>\dots >\varepsilon _{W,L}\) for the GRFs and \(\varepsilon _{l,0}>\dots >\varepsilon _{l,L}\) for the Lévy subordinators. Since we fix the parameters K and A in this analysis, we omit them in the following and use the notation \({\hat{u}}_{\varepsilon _{W,\ell },\varepsilon _{l,\ell },\ell }:={\hat{u}}_{K,A,\ell }^{(\varepsilon _{W,\ell },\varepsilon _{l,\ell })}\) for the FEM approximation of \(u_{K,A}^{(\varepsilon _{W,\ell },\varepsilon _{l,\ell })}\) on \({\hat{V}}_\ell \), for \(\ell =-1,\dots ,L\), where we set \({\hat{u}}_{\varepsilon _{W,-1},\varepsilon _{l,-1},-1}:=0\). If we expand the expectation on the finest level in a telescopic sum we obtain the following representation
This motivates the multilevel Monte Carlo estimator, which estimates the left hand side of Eq. (6.1) by singlelevel Monte Carlo estimations of each summand on the right hand side (see [20]). To be precise, let \(M_\ell \) be a natural number for \(\ell =0,...,L\). The multilevel Monte Carlo estimator of \({\hat{u}}_{\varepsilon _{W,L},\varepsilon _{l,L},L}\) is then defined by
where \(({\hat{u}}_{\varepsilon _{W,\ell },\varepsilon _{l,\ell },\ell }^{(i,\ell )})_{i=1}^{M_\ell }\) (resp. \(({\hat{u}}_{\varepsilon _{W,\ell -1},\varepsilon _{l,\ell -1},\ell -1}^{(i,\ell )})_{i=1}^{M_\ell }\)) are \(M_\ell \) i.i.d. copies of the random variable \({\hat{u}}_{\varepsilon _{W,\ell },\varepsilon _{l,\ell },\ell }\) (resp. \({\hat{u}}_{\varepsilon _{W,\ell -1},\varepsilon _{l,\ell -1},\ell -1}\)) for \(\ell =0,\dots ,L\) (see also [20]). The following result gives an a-priori bound on the MLMC error. Similar formulations can be found, for example, in [1, 9, 11].
Theorem 6.3
We set \(r=2\) and assume \(q>2\) in Assumption 4.3. Further, let \(b,c\ge 1\) be given such that Theorem 4.5 holds. For \(L\in {\mathbb {N}}\), let \({\hat{h}}_\ell >0\), \(M_\ell \), \(\varepsilon _{W,\ell }>0\) and \(\varepsilon _{l,\ell }>0\) be the level-dependent approximation parameters for \(\ell =0,...,L\) such that \({\hat{h}}_{\ell },~ \varepsilon _{W,\ell },\) and \(\varepsilon _{l,\ell }\) are decreasing with respect to \(\ell \). It holds
where \(C>0\) is a constant which is independent of L and the level-dependent approximation parameters. Note that the numbers \(\gamma >0\) and \(c\ge 1\) are determined by the GRFs resp. the subordinators (cf. Theorem 4.5).
Proof
We estimate
We use the triangular inequality, Theorem 4.5 and Assumption 5.1 to obtain
For the second term we use the definition of the MLMC estimator \(E^L\) and Lemma 6.2 to obtain
Similar as for the first summand \(I_1\) we apply Theorem 4.5 and Assumption 5.1 to get
for \(\ell =0,\dots ,L\) and for \(\ell =-1\) it follows from Theorem 4.2 that
since \(q>2\). Finally, we calculate
where we used the monotonicity of \((\varepsilon _{W,\ell })_{\ell =0}^L\), \((\varepsilon _{l,\ell })_{\ell =0}^L\) and \(({\hat{h}}_\ell )_{\ell =0}^L\). \(\square \)
The error estimate of Theorem 6.3 allows for an equilibriation of the error contributions resulting from the approximation of the diffusion coefficient and the approximation of the pathwise solution with the FE method which then leads to a higher computational efficiency compared to the singlelevel approach. This leads in general to the strategy that one takes only few of the accurate, but expensive samples for large \(\ell \in \{0,\dots ,L\}\) and one generates more on the cheap, but less accurate samples on the lower levels, which can be seen in the following corollary (see also [11, Section 5], [20, 21]).
Corollary 6.4
Let the assumptions of Theorem 6.3 hold. For \(L\in {\mathbb {N}}\) and given (stochastic) refinement parameters \({\hat{h}}_0>\dots>{\hat{h}}_L>0\) choose \(\varepsilon _{W,\ell }>0\) and \(\varepsilon _{l,\ell }>0\) such that
and sample numbers \(M_\ell \in {\mathbb {N}}\) according to
for some positive parameter \(\xi >0\). Then, it holds
Proof
We use Theorem 6.3 together with Eqs. (6.2) and (6.3) to obtain
where \(\zeta (\cdot )\) denotes the Riemann zeta function. \(\square \)
7 Multilevel Monte Carlo with control variates
The jump-discontinuities in the coefficient \(a_{K,A}\) of the elliptic problem (4.2)–(4.5) have a negative impact on the FE convergence due to the low regularity of the solution (see Sect. 5 and [8]). In Sect. 5.2 we presented one possible approach to enhance the FE convergence for discontinuous diffusion coefficients: the sample-adapted FE approach with triangulations adjusted to the discontinuities. However, this approach may be computationally not feasible anymore if one has many jump interfaces. For instance, using subordinators with high jump activity (e.g. Gamma subordinators) may result in a very high number of discontinuities making the construction of sample-adapted triangulations extremely expensive. Besides the usage of adapted triangulations, variance reduction techniques can also be used to improve the computational efficiency of the MLMC estimation of the mean of the PDE solution, as we see in this section. We start with an introduction to a specific variance reduction technique, the control variates (CV), and show subsequently how we use a control variate in our setting (cf. [31]).
7.1 Control variates as a variance reduction technique
Assume Y is a real-valued, square integrable random variable and \((Y_i,~i\in {\mathbb {N}})\) is a sequence of i.i.d. random variables which follow the same distribution as Y. For a fixed number of samples \(M\in {\mathbb {N}}\), the SLMC estimator for the estimation of the expectation \({\mathbb {E}}(Y)\) is given by \( E_M(Y)=1/M\sum _{i=1} ^M Y_i\) (see Sect. 6) and we have the following representation for the statistical error (see Lemma 6.2):
The use of control variates aims to reduce the statistical error of a MC estimation by reducing the variance on the right hand side of (7.1). Assume we are given another real valued, square integrable random variable X with known expectation \({\mathbb {E}}(X)\) and a corresponding sequence of i.i.d. random variables \((X_i,~i\in {\mathbb {N}})\) following the same distribution as X. For a given number of samples \(M\in {\mathbb {N}}\), the control variate estimator is then defined by
(see, for example [22, Section 4.1]). The estimator \(E_M^{CV}(Y)\) is unbiased for the estimation of \({\mathbb {E}}(Y)\) and the standard deviation is
where Cov(X, Y) denotes the covariance of the random variables X and Y. Hence, the standard deviation of the estimator \(E_M^{CV}(Y)\), i.e. the statistical error, is smaller than the standard deviation of the SLMC estimator \(E_M(Y)\) if the random variables X and Y are highly correlated (see [22, Section 4.1.1]).
In [31], the authors presented a MLMC-CV combination for the estimation of the mean of the solution to the problem (2.1)–(2.3), where the diffusion coefficient a is modeled as a lognormal GRF. They use a smoothed version of the GRF and the pathwise solution to the corresponding PDE problem to construct a highly-correlated control variate. The considered GRFs have at least continuous paths leading to continuous diffusion coefficients. In the following, we show how we use a similar approach for our discontinuous diffusion coefficients to enhance the efficiency of the MLMC estimator for the case of subordinators with high jump activity.
7.2 Smoothing the diffusion coefficient
In this section we construct the control variate which is used to enhance the MLMC estimation of the mean of the solution to (4.2)–(4.5) for subordinators with high jump activity. Our approach is motivated by Nobile and Tesei [31].
For a positive smoothing parameter \(\nu _s>0\) we consider the Gaussian kernel on \({\mathbb {R}}^2\):
Further, we identify the jump diffusion coefficient \(a_{K,A}\) from Eq. (4.5) with its extended version on the domain \({\mathbb {R}}^2\), where we set \(a_{K,A} (x,y)= 0\) for \((x,y)\in {\mathbb {R}}^2{\setminus } {\mathscr {D}}\), and define the smoothed version \(a_{K,A}^{(\nu _s)}\) by convolution with the Gaussian kernel:
Obviously, Theorem 4.2 applies also to the elliptic PDE (4.2)–(4.4) with smoothed coefficient \(a_{K,A}^{(\nu _s)}\), which guarantees the existence of a solution \(u_{K,A}^{(\nu _s)}\in L^r(\varOmega ;V)\) , for \(r\in [1,q)\), with \(f\in L^q(\varOmega ;H)\) and \(g\in L^q(\varOmega ;L^2(\varGamma _2))\), and yields the bound
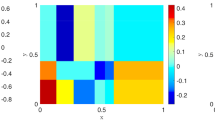
If the smoothing parameter \(\nu _s\) is small, the solution corresponding to the smoothed coefficient \(a_{K,A}^{(\nu _s)}\) is highly correlated with the solution to the PDE with (unsmoothed) diffusion coefficient \(a_{K,A}\). Therefore, the smoothed solution is a reasonable choice as a control variate in the MLMC estimator since it is highly correlated with the solution to the rough problem and easy to approximate using the FE method due to the high regularity compared to the rough problem (see also [31] and [26, Sections 8 and 9]). Figure 3 shows a sample of the diffusion coefficient and smoothed versions using a Gaussian kernel with different smoothness parameters.

Sample of the diffusion coefficient \(a_{K,A}\) using a Gamma-subordinated Matérn GRF (left), smoothed versions of the coefficient using Gaussian kernel smoothing with smoothness parameter \(\nu _s=0.02\) (middle) and \(\nu _s = 0.06\) (right)
7.3 MLMC-CV estimator
Next, we define the MLMC-CV estimator following Nobile and Tesei [31]. We fix a positive smoothing parameter \(\nu _s>0\). We assume \(L\in {\mathbb {N}}\) and consider finite-dimensional subspaces \(({\hat{V}}_\ell ,~\ell =0,\dots ,L)\) of V with refinement sizes \({\hat{h}}_0>\dots>{\hat{h}}_L>0\) and approximation parameters \(\varepsilon _{W,0}>\dots >\varepsilon _{W,L}\) for the GRFs and \(\varepsilon _{l,0}>\dots >\varepsilon _{l,L}\) for the Lévy subordinators (see Sect. 5.2). To unify notation, we focus here again on the sample-adapted discretization with corresponding approximation \({\hat{u}}_{K,A,\ell }^{(\varepsilon _W,\varepsilon _l)}\) with averaged refinement parameter \({\mathbb {E}}({\hat{h}}_\ell ^{2{\hat{\kappa }}_a})^{1/2}\) and convergence rate \({\hat{\kappa }}_a\) for the theoretical analysis of the estimator (see Assumption 5.1 and Sect. 6) and point out again that similar results hold for the non-adapted FE approach. Since we again fix the parameters K and A in this analysis, we omit them in the following and use the notation \({\hat{u}}_{\varepsilon _{W,\ell },\varepsilon _{l,\ell },\ell }:={\hat{u}}_{K,A,\ell }^{(\varepsilon _{W,\ell },\varepsilon _{l,\ell })}\) for the FEM approximation on \({\hat{V}}_\ell \), for \(\ell =0,\dots ,L\). Similar, we denote by \({\hat{u}}_{\varepsilon _{W,\ell },\varepsilon _{l,\ell },\ell }^{(\nu _s)} := {\hat{u}}_{K,A,\ell }^{(\nu _s,\varepsilon _{W,\ell },\varepsilon _{l,\ell })}\), for \(\ell =0,\dots ,L\), the (pathwise) solution to problem (2.1)–(2.3) with diffusion coefficient \(a_{K,A}^{(\nu _s,\varepsilon _{W,\ell },\varepsilon _{l,\ell })}\) as the smoothed version of the coefficient \(a_{K,A}^{(\varepsilon _{W,\ell },\varepsilon _{l,\ell })}\) constructed in (4.6). We define the CV basis experiment by
and we set \({\hat{u}}_{\varepsilon _{W,-1},\varepsilon _{l,-1},-1}^{CV} = 0\). For the moment, we assume that the expectation \({\mathbb {E}}(u_{K,A}^{(\nu _s)})\) of the solution to the smoothed problem is known. Later, we elaborate more on appropriate approximations of this expectation (see Remark 7.7). The MLMC-CV estimator for the estimation of the expectation of the solution is then defined by
with sample sizes \(M_\ell \in {\mathbb {N}}\) for \(\ell = 0,\dots ,L\).
Remark 7.1
The smoothness parameter \(\nu _s\) controls the variance reduction achieved in the MLMC-CV estimator and its optimal choice remains an open question (see [31]). This parameter shifts variance from the rough problem to the smoothed problem within the MLMC-CV estimator. Too large choices of \(\nu _s\) lead to a small correlation between the rough and the smoothed problem which might result in a poor variance reduction in the MLMC-CV estimator. On the other hand, choosing \(\nu _s\) too small might result in high costs for the computation of the CV (see also Remark 7.7). Therefore, the smoothness parameter should be chosen to balance these two viewpoints, which is highly problem dependent (see Sect. 8.3 and [31]).
7.4 Convergence of the MLMC-CV estimator
For the theoretical investigation of the MLMC-CV estimator we extend Assumption 5.1 by the following assumption on the mean-square convergence rate of the pathwise FE method for the smoothed problem.
Assumption 7.2
There exist deterministic constants \({\hat{C}}_{u,s}, C_{u,s}\) such that for any \(\varepsilon _W,\varepsilon _l>0\) and any \(\ell \in {\mathbb {N}}_0\), the FE approximation errors of \({\hat{u}}_{K,A,\ell }^{(\nu _s,\varepsilon _W,\varepsilon _l)}\approx u_{K,A}^{(\nu _s,\varepsilon _W,\varepsilon _l)}\) in the subspaces \({\hat{V}}_\ell \), respectively \(u_{K,A,\ell }^{(\nu _s,\varepsilon _W,\varepsilon _l)}\approx u_{K,A}^{(\nu _s,\varepsilon _W,\varepsilon _l)}\) in \(V_\ell \), are bounded by
where the constants \({\hat{C}}_{u,s},C_{u,s}\) may depend on a, f, g, K, A but are independent of \({\hat{h}}_\ell \) and \(h_\ell \). Further, we assume that Assumption 4.4 also holds for the solution \(u_{K,A}^{(\nu _s)}\) corresponding to the elliptic PDE with the smoothed coefficient \(a_{K,A}^{(\nu _s)}\).
Note that this assumption is natural since we expect (pathwise) full order convergence of the linear FE method for the smoothed elliptic PDE (see also [1, 9, 11, 31] and [26, Section 8.5] together with [18, Section 6.3]). The assumption on the integrability of the gradient of the solution corresponding to the smoothed problem is also natural under Assumption 4.4, since the solution has a higher regularity than the solution \(u_{K,A}\) to the elliptic problem with the jump diffusion coefficient \(a_{K,A}\). The following lemma states that the approximation error of the smoothed coefficient can be bounded by the approximation error of the rough diffusion coefficient.
Lemma 7.3
For \(t> 1\) and fixed parameters \(\nu _s,K,A>0\) and any \(\varepsilon _W,\varepsilon _l>0\) it holds for \({\mathbb {P}}\)-almost every \(\omega \in \varOmega \)
with a constant \(C=C(t,\nu _s,{\mathscr {D}})\) which depends only on the indicated parameters.
Proof
Let \(t'>1\) such that \(1/t+1/t' = 1\). We calculate using Hölder’s inequality and the integrability of the Gaussian kernel \(\phi _{\nu _s}\)
\(\square \)
In order to proof the convergence of the MLMC-CV estimator we need the following error bound on the approximation of the solution of the smoothed problem (cf. Theorem 4.5). As expected, this error bound depends on the approximation parameters \(\varepsilon _W\) of the GRFs and \(\varepsilon _l\) of the Lévy subordinators in the same way as the error bound of the unsmoothed problem in Theorem 4.5.
Theorem 7.4
Assume \(q>2\) in Assumption 4.3. Let \(r\in [2,q)\) and \(b,c\in [1,+\infty ]\) be given such that it holds
with a fixed real number \(\gamma \in (0,min(1,\beta /(2\alpha ))\). Here, the parameters \(\eta , \alpha \) and \(\beta \) are determined by the GRFs \(W_1\), \(W_2\) and the Lévy subordinators \(l_1\), \(l_2\) (see Assumption 4.3).
Let \(m,n\in [1,+\infty ]\) be real numbers such that
and let \(k_{reg}\ge 2\) and \(j_{reg}>0\) be the regularity specifiers given by Assumption 4.4. If it holds that
then the approximated solution \(u_{K,A}^{(\nu _s,\varepsilon _W,\varepsilon _l)}\) of the smoothed problem converges to the solution \(u_{K,A}^{(\nu _s)}\) of the truncated smoothed problem for \(\varepsilon _W,\varepsilon _l\rightarrow 0\) and it holds
Proof
This theorem follows by the same arguments used in [8, Theorem 5.9] together with Lemma 7.3. \(\square \)
We are now able to prove the following a-priori bound on the mean-square error of the MLMC-CV estimator, similar to Theorem 6.3.
Theorem 7.5
We set \(r=2\) and assume \(q>2\). Further, let \(b,c\ge 1\) be given such that Theorem 4.5 (and Theorem 7.4) hold. For \(L\in {\mathbb {N}}\), let \({\hat{h}}_\ell >0\), \(M_\ell \), \(\varepsilon _{W,\ell }>0\) and \(\varepsilon _{l,\ell }>0\) be the level-dependent approximation parameters, for \(\ell =0,...,L\), such that \({\hat{h}}_{\ell },~ \varepsilon _{W,\ell },\) and \(\varepsilon _{l,\ell }\) decrease with respect to \(\ell \). It holds
where \(C>0\) is a constant which is independent of L and the level-dependent approximation parameters. Note that the numbers \(\gamma >0\) and \(c\ge 1\) are determined by the GRFs resp. the subordinators (cf. Theorems 4.5 and 7.4).
Proof
We split the error by
For the first term we estimate using Theorem 4.5 and Assumption 5.1 together with Theorem 7.4 and Assumption 7.2 to obtain
For the second term we use the definition of the MLMC-CV estimator \(E^{CV,L}\) and Lemma 6.2 to estimate
We estimate each term in this summand with the same strategy as we did for the term \(I_1\) using Theorem 4.5 and Assumption 5.1 together with Theorem 7.4 and Assumption 7.2 to obtain
for \(\ell = 0,\dots ,L\) and for \(\ell = -1\) we get by Theorem 4.2 and Eq. (7.2)
Together, we obtain
where we used monotonicity of \((\varepsilon _{W,\ell })_{\ell =0}^L\), \((\varepsilon _{l,\ell })_{\ell =0}^L\) and \(({\hat{h}}_\ell )_{\ell =0}^L\) in the last step. \(\square \)
As it is the case for the a-priori error bound for the MLMC estimator (see Theorem 6.3), Theorem 7.5 allows for an equilibration of all error contributions resulting from the approximation of the diffusion coefficient and the approximation of the pathwise solution by the FE method, which can be seen by the following corollary.
Corollary 7.6
Let the assumptions of Theorem 7.5 hold. For \(L\in {\mathbb {N}}\) and given (stochastic) refinement parameters \({\hat{h}}_0>\dots>{\hat{h}}_L>0\) choose \(\varepsilon _{W,\ell }>0\) and \(\varepsilon _{l,\ell }>0\) such that
and sample numbers \(M_\ell \in {\mathbb {N}}\) such that for some positive parameter \(\xi >0\) it holds
Then, it holds
Proof
See Corollary 6.4. \(\square \)
We want to emphasize that Theorem 7.5 and Corollary 7.6 imply the same asymptotical convergence of the MLMC-CV estimator as the MLMC estimator which has been considered in Sect. 6. However, it is to be expected that the MLMC-CV estimator is more efficient due to the samplewise correction by the control variate and the resulting variance reduction on the different levels. We close this section with a remark on how to compute the mean of the control variate.
Remark 7.7
Unlike we assumed the CV mean \({\mathbb {E}}(u_{K,A}^{(\nu _s)})\) is in general unknown for fixed parameters K, A, and \(\nu _s>0\). Corollary 7.6 yields that it is sufficient to approximate the CV mean with any estimator which is convergent with order \({\mathbb {E}}(h_L^{2{\hat{\kappa }}_a})^{1/2}\). In fact, we denote by
the realization of the desired estimator and we assume the existence of a constant \(C_{CV}>0\) such that it holds
in the notation of Theorem 7.5. Further, instead of the basis experiment \({\hat{u}}_{\varepsilon _{W,\ell },\varepsilon _{l,\ell },\ell }^{CV}\) from (7.3) we consider
and we set \({\tilde{u}}_{\varepsilon _{W,-1},\varepsilon _{l,-1},-1}^{CV} = 0\) and denote the corresponding MLMC-CV estimator by \(E^{CV,L}({\tilde{u}}_{\varepsilon _{W,\ell },\varepsilon _{l,\ell },\ell }^{CV})\). Then, by Corollary 7.6, it holds
For example, the CV mean could be estimated by another MLMC estimator on the level L where the parameters are chosen according to Corollary 7.6.
8 Numerical examples
In the following section we present numerical examples for the estimation of the mean of the solution to the elliptic PDE (4.2)–(4.5). We perform convergence tests with the proposed multilevel Monte Carlo estimators defined in Sects. 6 and 7. In our numerical examples, we consider different levels \(L\in {\mathbb {N}}\) and choose the sample numbers \((M_\ell ,~\ell =0,\dots ,L)\) and the level dependent approximation parameters for the GRFs \((\varepsilon _{W,\ell },~\ell =0,\dots ,L)\) and the subordinators \((\varepsilon _{l,\ell },~\ell =0,\dots ,L)\) according to Corollary 6.4 resp. Corollary 7.6 if nothing else is explicitly mentioned. Our numerical examples aim to compare the performance of the MLMC estimator with non-adapted triangulations with the MLMC estimator which uses sample-adapted triangulations. Further, we compare the performance of the standard MLMC estimator with the MLMC-CV estimator for high-intensity subordinators whose sample paths possess a comparatively high number of jump discontinuities. This results in a high number of jumps in the diffusion coefficient and, therefore, the sample-adapted triangulations are not feasible anymore. All our numerical experiments are performed in MATLAB R2021a on a workstation with 16 GB memory and Intel quadcore processor with 3.4 GHz.
8.1 PDE parameters
In our numerical examples we consider the domain \({\mathscr {D}}=(0,1)^2\) and choose \({\overline{a}}\equiv 1/10\), \(f\equiv 10\), \(\varPhi _1=1/100\,\exp (\cdot )\) and \(\varPhi _2=5\,|\cdot |\) for the diffusion coefficient in (4.5) if nothing else is explicitly mentioned. Further, we impose the following mixed Dirichlet–Neumann boundary conditions: we split the domain boundary \(\partial {\mathscr {D}}\) by \(\varGamma _1=\{0,1\}\times [0,1]\) and \(\varGamma _2=(0,1)\times \{0,1\}\) and impose the pathwise mixed Dirichlet–Neumann boundary conditions
for \(\omega \in \varOmega \). We use a reference grid with \(401\times 401\) equally spaced points on the domain \({\mathscr {D}}\) for interpolation and prolongation. The GRFs \(W_1\) and \(W_2\) are set to be a Matérn-1.5-GRFs on \({\mathscr {D}}\) (resp. on \([0,K]^2\)) with varying correlation lengths and variance parameters. Note that for Matérn-1.5-GRFs we can expect \(\gamma =1\) in Theorem 4.5 (see [8, Section 7], [12, Chapter 5], [13]). We simulate the GRFs \(W_1\) and \(W_2\) by the circulant embedding method (see [24, 25]) to obtain approximations \(W_1^{(\varepsilon _W)}\approx W_1\) and \(W_2^{(\varepsilon _W)}\approx W_2\) as described in Sect. 4.3. In the experiments, we choose the diffusion cut-off A in (4.5) large enough such that it has no influence on the numerical experiments for our choice of the GRFs, e.g. \(A=100\) and choose the cut-off level K for each experiment individually depending on the specific choice of the subordinator.
8.2 Numerical examples for the MLMC estimator
In this section we conduct experiments with the MLMC estimator introduced in Sect. 6. We consider subordinators with different intensity and GRFs with varying correlation lengths in order to cover problems with different solution regularity. The comparatively low jump activity of the subordinators used in this section (see also Sect. 8.3) allows the application of the pathwise sample-adapted approach introduced in Sect. 5.2 which can then be compared with the performance of the MLMC estimator with standard triangulations. During this section, we refer to these approaches with adapted FEM MLMC and non-adapted FEM MLMC. In our experiments, we use Poisson processes to subordinate the GRF \(W_2\) in the diffusion coefficient in (4.5). We consider both, Poisson processes with high and low intensity parameter leading to a different number of jumps in the diffusion coefficient. For the simulation of the Poisson processes we have two options: the processes may be approximated under Assumption 4.3iv but they may also be simulated exactly (see Sect. 8.2.1). Hence, using Poisson subordinators allows for a detailed investigation of the approximation error caused by the approximation of the Lévy subordinators \(l_1\) and \(l_2\). This will be explained briefly in the following subsection (see also [8, Section 7.3.1]).
8.2.1 The two approximation methods
We simulate the Poisson processes by two conceptional different approaches: the first approach is an exact and grid-independent simulation of a Poisson process using the Uniform Method (see [34, Section 8.1.2]). On the other hand, we may simulate approximations of the Poisson processes satisfying Assumption 4.3iv in the following way (see [8, Section 7.3.1]): We sample values of the Poisson(\(\lambda \))-processes \(l_1\) and \(l_2\) on an equidistant grid \(\{x_i,~i=0,...,N_l\}\) with \(x_0=0\) and \(x_{N_l}=1\) and step size \(|x_{i+1}-x_i|\le \varepsilon _l\le 1\) for all \(i=0,\dots ,N_l-1\) and approximate the stochastic processes by a piecewise constant extension \(l_j^{(\varepsilon _l)}\approx l_j\) of the values on the grid:
for \(j=1,2\). Since the Poisson process has independent, Poisson distributed increments, values of the Poisson process at the discrete points \(\{x_i,~i=0,\dots ,N_l\}\) may be generated by adding independent Poisson distributed random variables with appropriately scaled intensity parameters. For the rest of this paper, we refer to this approach as the approximation approach to simulate a Poisson process. Comparing the results of the MLMC experiments using the two described approaches for the simulation of the Poisson processes allows conclusions to be drawn on the numerical influence of an additional approximation of the subordinator (see Sect. 8.2.2). This is further important especially for situations in which the choice of the subordinators does not allow for an exact simulation of the process.
Note that Poisson processes satisfy Assumption 4.3iv with \(\eta =+\infty \) (see [8, Section 7.3.1]). Since \(\gamma =1\) (see Sect. 8.1), \(\eta =+\infty \) and \(f\in L^q(\varOmega ;H)\) for every \(q\ge 1\) we choose for any positive \(\delta >0\)
to obtain from Theorem 4.5
where we have to assume that \(j_{reg}> 2((1+\delta )/\delta -1)\) and \(k_{reg}> 2(1+\delta )/\delta \) for the regularity constants \(j_{reg},~k_{reg}\) given in Assumption 4.4 since it is not possible to verify this rigorously for our diffusion coefficient (see also [8, Subsection 5.2]). For \(\delta =0.5\) we obtain
Therefore, we get \(\gamma =1\) and \(c=1.5\) in the equilibration formula (6.2) for the numerical examples with the Poisson subordinators.
8.2.2 Poisson(1) subordinators
In our first numerical example we use Poisson(1) - subordinators. With this choice, we get on average one jump in each direction of the diffusion coefficient. The variance and the correlation parameters for the GRF \(W_1\) (resp. \(W_2\)) are set to be \(\sigma _1^2= 1.5^2\) and \(r_1=0.5\) (resp. \(\sigma _2^2=0.1^2\) and \(r_2=0.5\)). Figure 4 shows samples of the diffusion coefficient and the corresponding PDE solution.

Different samples of the diffusion coefficient with Poisson(1)-subordinators and the corresponding PDE solutions with mixed Dirichlet-Neumann boundary conditions
The cut-off threshold K for the subordinators in (4.5) is chosen to be \(K=8\). With this choice we obtain
for \(j=1,2\), such that this cut-off has a negligible influence in the numerical example. We compute the RMSE \( \Vert {\mathbb {E}}(u_{K,A}) - E^L({\hat{u}}_{\varepsilon _{W,L},\varepsilon _{l,L},L})\Vert _{L^2(\varOmega ;V)}\) for the sample-adapted and the non-adapted approach using 10 independent runs of the MLMC estimator on the levels \(L=1,\dots ,5\), where we set \({\overline{h}}_\ell =h_\ell =0.3\cdot 1.7^{-(\ell -1)}\), for \(\ell = 1,\dots ,5\). Further, we use a reference solution computed on level 7 with singlelevel Monte Carlo using the FE method with adapted triangulations. We run this experiment with both approaches for the simulation of the subordinators introduced in Sect. 8.2.1: the approximation approach and the Uniform Method.

Convergence of the MLMC estimator for Poisson(1)-subordinators (left) and time-to-error plot (right)
The left graph of Fig. 5 shows almost full order convergence of the adapted FEM MLMC method and a slightly slower convergence of the non-adapted FEM MLMC approach. Closer inspection of the figure shows that the choice of the simulation method of the subordinator does not affect the convergence rate of the MLMC estimator: where the Uniform Method yields a slightly smaller RMSE compared to the approximation approach in the sample-adapted case, the behaviour is almost the same for both simulation techniques in the non-adapted FEM MLMC method. The right hand side of Fig. 5 demonstrates a slightly improved efficiency of adapted FEM MLMC compared to non-adapted FEM MLMC. The advantage of the sample-adapted approach can be further emphasized by the use of subordinators with a higher jump intensity and different correlation lengths of the underlying GRF, as we see in the following subsections.
8.2.3 Poisson(5) subordinators: smooth underlying GRF
In the second numerical example we increase the jump-intensity of the subordinators and investigate the effect on the performance of the MLMC estimators. We use Poisson(5)-subordinators leading to an expected number of 5 jumps in each direction in the diffusion coefficient. The variance and the correlation parameter for the GRF \(W_1\) (resp. \(W_2\)) are set to be \(\sigma _1^2= 0.5^2\) and \(r_1=0.5\) (resp. \(\sigma _2^2=0.3^2\) and \(r_2=0.5\)). Figure 6 shows samples of the diffusion coefficient and the corresponding PDE solution.

Different samples of the diffusion coefficient with Poisson(5)-subordinators and the corresponding PDE solutions with mixed Dirichlet-Neumann boundary conditions
The cut-off threshold K for the subordinators in (4.5) is chosen to be \(K=15\). With this choice we obtain
for \(j=1,2\), such that this cut-off has a negligible influence in the numerical example. In order to avoid an expensive simulation of the GRF \(W_2\) on the domain \([0,15]^2\) we set \(K=1\) instead and consider the downscaled processes
for \(t\in [0,1]\) and \(j=1,2\). Note that this has no effect on the expected number of jumps of the processes. We use the Uniform Method to simulate the Poisson subordinators and estimate the RMSE of the MLMC estimators for the sample-adapted and the non-adapted approach using 10 independent MLMC runs on the levels \(L=1,\dots ,5\), where we set \({\overline{h}}_\ell =h_\ell =0.2\cdot 1.7^{-(\ell -1)}\) for \(\ell = 1,\dots ,5\). Further, we use a reference solution computed on level 7 with singlelevel Monte Carlo using the FE method with adapted triangulations.

Convergence of the MLMC estimator for Poisson(5)-subordinators (left) and time-to-error plot (right)
Figure 7 shows almost full order convergence of the adapted FEM MLMC method and a slightly slower convergence for the non-adapted FEM MLMC approach. The right hand side of Fig. 7 demonstrates a higher efficiency of the sample-adapted approach. However, one has to mention that differences in the performance of the estimators are rather small due to the comparatively high convergence rate for the non-adapted MLMC approach of approximately 0.85. This is due to the fact that the jumps in the diffusion coefficient are comparatively small on account of the high correlation length of the underlying GRF \(W_2\). We will see in the following subsection that an increased intensity of the jump heights in the diffusion coefficient has a significant negative influence on the performance of the non-adapted FEM MLMC approach.
8.2.4 Poisson(5) subordinators: rough underlying GRF
In the jump diffusion coefficient (see (4.5)), the jumps are generated by the subordinated GRF in the following way: the number of spatial jumps is determined by the subordinators and the jump heights (measured in the differences in diffusion values across a jump) are essentially determined by the GRF \(W_2\) and its correlation length. Hence, we may control the jump heights in the diffusion coefficient by the correlation parameter of the underlying GRF \(W_2\). In the following experiment we investigate the influence of the jump heights in the diffusion coefficient on the convergence rates of the MLMC estimators.
In Sect. 8.2.3 we subordinated a Matérn-1.5-GRF with correlation length \(r_2=0.5\) by Poisson(5)-processes. In the following experiment we set the correlation length of the GRF \(W_2\) to \(r_2=0.1\) and leave all the other parameters unchanged. Figure 8 presents samples of the resulting GRFs with the different correlation lengths.

Different samples of Matérn-1.5-GRFs with correlation lengths \(r=0.5\) (left) and \(r=0.1\) (right)
By construction of the diffusion coefficient, the subordination of GRFs with small correlation lengths (right plots in Fig. 8) results in higher jump heights in the diffusion coefficient as the subordination of GRFs with higher correlation lengths (left plots in Fig. 8). This relationship is demonstrated in Fig. 9 (cf. Fig. 6).

Different samples of the diffusion coefficient with Poisson(5)-subordinators and small correlation length in the underlying GRF and the corresponding PDE solutions with mixed Dirichlet-Neumann boundary conditions
We use the Uniform Method to compute the RMSE of the MLMC estimators for the sample-adapted and the non-adapted approach using 10 independent MLMC runs on the levels \(L=1,\dots ,5\), where we set \({\overline{h}}_\ell =h_\ell =0.2\cdot 1.7^{-(\ell -1)}\) for \(\ell = 1,\dots ,5\). Further, we use a reference solution computed on level 7 with singlelevel Monte Carlo using the FE method with adapted triangulations. Figure 10 reveals that the increased jump heights in the diffusion coefficient have a negative impact on the convergence rates of both estimators: the adapted and the non-adapted FEM MLMC approach. We obtain a convergence rate of approximately 0.85 for the adapted FEM MLMC estimator and a smaller rate of approximately 0.7 for the MLMC estimator with non-adapted triangulations. Compared to the experiment discussed in Sect. 8.2.3, where we used Poisson(5)-subordinators and a higher correlation length in the underlying GRF, we observe that both convergence rates are smaller in the current example. This matches our expectations since the FEM convergence rate has been shown to be influenced by the regularity of the jump diffusion coefficient (see e.g. [11, 33]). It is also important to mention that the RMSE is significantly smaller for the adapted FEM MLMC estimator due to the increased jump heights in this example. The higher efficiency of the sample-adapted approach is also demonstrated in the time-to-error plot on the right hand side of Fig. 10: In this example we see a significant improvement in the time-to-error plot for the adapted FEM MLMC approach compared to the non-adapted FEM MLMC estimator.

Convergence of the MLMC estimator for Poisson(5)-subordinators and small correlation length in the underlying GRF (left) and time-to-error plot (right)
8.3 Numerical examples for the MLMC-CV-estimator
In the following section, we present numerical examples for the MLMC-CV estimator introduced in Sect. 7. In Sect. 8.2 we considered Poisson subordinators and compared the non-adapted FEM MLMC estimator with the sample-adapted approach and saw that the latter leads to an improved performance of the estimator. However, this approach is computationally not feasible anymore if we consider subordinators with infinite activity, i.e. which have infinitely many jumps on any finite interval. One example of an infinite activity process is the Gamma process (see also [34, Section 5.3]). The aim of this section is to compare the (non-adapted FEM) MLMC estimator with the MLMC-CV estimator for diffusion coefficients with Gamma-subordinated GRFs.
8.3.1 Gamma subordinators
We approximate the Gamma processes in the same way as we approximate the Poisson subordinators in the approximation approach (see Sect. 8.2.1) and obtain a valid approximation in the sense of Assumption 4.3iv for any \(\eta <+ \infty \) (see [8, Section 7.4] and [4]). In our numerical experiments we choose \(l_1 \) and \(l_2\) to be Gamma(4, 10) processes. We set the diffusion cut-off to \(K=2\) to obtain
for \(j=1,2\). Hence, the influence of the subordinator cut-off is again negligible in our numerical experiments. Due to the high jump intensity we have to choose a sufficiently small smoothness parameter \(\nu _s\) since otherwise important detailed information of the diffusion coefficient might be unused. In our two numerical examples, we choose \(\nu _s=0.01\). This leads to a performance improvement in the MLMC-CV estimator for Gamma(4, 10)-subordinators, as we see in our numerical experiments (see also Remark 7.1).
8.3.2 MLMC-CV vs. MLMC for infinite activity subordinators
In our numerical examples, the variance of the \(W_1\) is set to be \(\sigma _1^2=1.5^2\) and the correlation length is defined by \(r_1=0.5\). The parameters of the GRF \(W_2\) are varied in the experiments. Since we aim to compare the performance of the MLMC estimator with the MLMC-CV estimator we use optimal sample numbers in the numerical experiments in this subsection: Assume level dependent FE discretization sizes \(h_\ell \) are given, for \(\ell =1,\dots ,L\) with fixed \(L\in {\mathbb {N}}\). Further, we denote by \(VAR_\ell \) the (estimated) variances of \(u_{\varepsilon _{W,\ell },\varepsilon _{l,\ell },\ell } - u_{\varepsilon _{W,\ell -1},\varepsilon _{l,\ell -1},\ell -1}\) (resp. \(u_{\varepsilon _{W,\ell },\varepsilon _{l,\ell },\ell }^{CV} - u_{\varepsilon _{W,\ell -1},\varepsilon _{l,\ell -1},\ell -1}^{CV}\) for the MLMC-CV estimator). The optimal sample numbers are then given by the formula
since this choice minimizes the variance of the MLMC(-CV) estimator for fixed computational costs (see [21, Section 1.3]). As discussed in Remark 7.7, the expectation of the mean of the control variate \({\mathbb {E}}(u_{K,A}^{(\nu _s)})\) is usually not known explicitly and needs to be approximated separately. We estimate \({\mathbb {E}}(u_{K,A}^{(\nu _s)})\) by a realization of a non-adapted FEM MLMC estimator on level L (see Sect. 6), which is of sufficient accuracy as discussed in Remark 7.7.

Different samples of the diffusion coefficient with Gamma(4, 10)-subordinators with small correlation length in the underlying GRF together with the corresponding PDE solutions with mixed Dirichlet–Neumann boundary conditions
In the following numerical example we choose \(\sigma _2^2=0.3^2\) and \(r_2=0.05\) for the GRF \(W_2\). Figure 11 shows samples of the diffusion coefficient and the corresponding PDE solutions. We define the level dependent FE discretization parameters \(h_\ell = 0.3\cdot 1.7^{-(\ell -1)}\) for \(\ell =1,\dots ,5\) and compare the MLMC estimator with the MLMC-CV estimator. We perform 10 independent MLMC runs on the levels \(L=1,\dots ,5\) to estimate the RMSE where we use a reference solution on level 7 computed by singlelevel Monte Carlo. The results are given in the following figure. Figure 12 shows a similar convergence rate of approximately 0.75 for the MLMC and the MLMC-CV estimator. However, the sample-wise correction by the smooth PDE problem in the MLMC-CV estimator improves the approximation which yields significantly smaller values for the RMSE on the different levels compared to the standard MLMC estimator. The efficiency improvement obtained by the control variate is further demonstrated on the right hand side of Fig. 12: The time-to-error plot demonstrates that the computational effort which is necessary to achieve a certain accuracy is significantly smaller for the MLMC-CV estimator compared to the standard MLMC estimator. Note that the computation of the expectation of the solution to the smoothed problem \({\mathbb {E}}(u_{K,A}^{(\nu _s)})\) is included in the simulation time of the MLMC-CV estimator.

Convergence of the MLMC and the MLMC-CV estimator for Gamma(4, 10)-subordinators with small noise and small correlation length in the underlying GRF (left) and time-to-error plot (right)
In our last numerical example we choose \(\varPhi _1=1/5\,exp(\cdot )\), \(\varPhi _2=3|\cdot |\) and \(\sigma _2^2=0.5^2\), \(r_2=0.2\) for the GRF \(W_2\) and leave all other parameters unchanged. This leads to diffusion coefficient which is more noise accentuated has slightly reduced jump heights (see also Sect. 8.2.4) as can be seen in Fig. 13.

Different samples of the diffusion coefficient with Gamma(4, 10)-subordinators with strong noise and higher correlation length in the underlying GRF together with the corresponding PDE solutions with mixed Dirichlet–Neumann boundary conditions
As in the last experiment, we define the level dependent FE discretization parameters \(h_\ell = 0.3\cdot 1.7^{-(\ell -1)}\) for \(\ell =1,\dots ,5\) and compare the MLMC estimator with the MLMC-CV estimator. We use 10 independent MLMC runs on the levels \(L=1,\dots ,5\) to estimate the RMSE and use a singlelevel Monte Carlo estimation on level 7 as reference solution. The results are given in Fig. 14.

Convergence of the MLMC and the MLMC-CV estimator for Gamma(4, 10)-subordinators with strong noise and underlying GRF with higher correlation length (left) and time-to-error plot (right)
The reduced jump heights together with the emphasized (continuous) noise in the diffusion coefficient leads to a slightly improved convergence rate of approximately 0.85 for the estimators in this example (cf. Fig. 12). As in the first experiment, we see that the usage of the control variate yields a significant improvement which is reflected in smaller values for the RMSE on the different levels compared to the standard MLMC approach. As expected, the right hand side of Fig. 14 shows an improved efficiency of the MLMC-CV estimator compared to the standard MLMC estimator without control variates.
8.4 Numerical examples: summary
In our numerical experiments we presented a varied choice of subordinators and parameters of the GRFs. As expected, we see that the convergence rate of the MLMC estimator deteriorates if the jump heights, i.e. the contrast in the diffusion coefficient, increases. We get a convergence rate of approximatively 0.9 (resp. 0.85) for the adapted (resp. non-adapted) FEM MLMC estimator in the examples with Poisson(1)-subordinators (see Subsection 8.2.2). While similar rates have been observed in the first example with Poisson(5)-subordinators (see Sect. 8.2.3), we obtain smaller convergence rates for both approaches with Poisson(5)-subordinators, but a GRF \(W_2\) with smaller correlation parameter \(r_2\), leading to a higher contrast in the samples of the diffusion coefficient. Here, we get a convergence rate of approximatively 0.85 (resp. 0.7) for the adapted (resp. non-adapted) FEM MLMC estimator. Further, the absolute difference between the respective RMSE values (i.e. the advantage of adapted FEM MLMC over non-adapted FEM MLMC) increases significantly in this example (see Sect. 8.2.4). In contrast to the sample adapted MLMC estimator, we cannot expect an improved convergence rate in the MLMC-CV estimator. However, the standard deviation of the MLMC-CV estimator is reduced by the variance reduction effect caused by the control variate which is demonstrated in the numerical examples in Sect. 8.3.
Notes
For simplicity we chose a square domain, rectangular ones may be considered in the same way.
We assume one fixed K for all spatial dimensions to keep notation simple. However, the results presented in the subsequent sections also hold for individual values in each spatial dimension.
References
Abdulle, A., Barth, A., Schwab, C.: Multilevel Monte Carlo methods for stochastic elliptic multiscale PDEs. Multiscale Model. Simul. 11(4), 1033–1070 (2013). https://doi.org/10.1137/120894725
Adler, R.J., Taylor, J.E.: Random fields and geometry. Springer Monographs in Mathematics. Springer, New York (2007)
Applebaum, D.: Lévy processes and stochastic calculus. Cambridge Studies in Advanced Mathematics, vol. 116, second edn. Cambridge University Press, Cambridge (2009). https://doi.org/10.1017/CBO9780511809781
Artin, E.: Einführung in die Theorie der Gamma-Funktion. Hamburger Mathematische Einzelschriften. B.G. Teubner (1931). https://books.google.de/books?id=pMS8xwEACAAJ
Babuška, I.: The finite element method for elliptic equations with discontinuous coefficients. Computing (Arch. Elektron. Rechnen) 5, 207–213 (1970). https://doi.org/10.1007/bf02248021
Babuška, I., Tempone, R., Zouraris, G.E.: Galerkin finite element approximations of stochastic elliptic partial differential equations. SIAM J. Numer. Anal. 42(2), 800–825 (2004). https://doi.org/10.1137/S0036142902418680
Barth, A., Merkle, R.: Subordinated Gaussian random fields. ArXiv e-prints (2020). arXiv:2012.06353 [math.PR]
Barth, A., Merkle, R.: Subordinated Gaussian random fields in elliptic partial differential equations. ArXiv e-prints (2020). arXiv:2011.09311 [math.NA]. To appear in Stochastics and Partial Differential Equations: Analysis and Computations
Barth, A., Schwab, C., Zollinger, N.: Multi-level Monte Carlo finite element method for elliptic PDEs with stochastic coefficients. Numer. Math. 119(1), 123–161 (2011). https://doi.org/10.1007/s00211-011-0377-0
Barth, A., Stein, A.: Approximation and simulation of infinite-dimensional Lévy processes. Stoch. Part. Differ. Equ. Anal. Comput. 6(2), 286–334 (2018). https://doi.org/10.1007/s40072-017-0109-2
Barth, A., Stein, A.: A study of elliptic partial differential equations with jump diffusion coefficients. SIAM/ASA J. Uncertain. Quantif. 6(4), 1707–1743 (2018). https://doi.org/10.1137/17M1148888
Barth, A., Stein, A.: A multilevel Monte Carlo algorithm for parabolic advection-diffusion problems with discontinuous coefficients. In: Springer Proceedings in Mathematics and Statistics, pp. 445–466. Springer (2020). https://doi.org/10.1007/978-3-030-43465-6_22
Charrier, J., Scheichl, R., Teckentrup, A.L.: Finite element error analysis of elliptic PDEs with random coefficients and its application to multilevel Monte Carlo methods. SIAM J. Numer. Anal. 51(1), 322–352 (2013). https://doi.org/10.1137/110853054
Chen, Z., Zou, J.: Finite element methods and their convergence for elliptic and parabolic interface problems. Numer. Math. 79(2), 175–202 (1998). https://doi.org/10.1007/s002110050336
Da Prato, G., Zabczyk, J.: Stochastic equations in infinite dimensions. In: Encyclopedia of Mathematics and its Applications, vol. 152, 2nd edn. Cambridge University Press, Cambridge (2014). https://doi.org/10.1017/CBO9781107295513
Ding, Z.: A proof of the trace theorem of Sobolev spaces on Lipschitz domains. Proc. Am. Math. Soc. 124(2), 591–600 (1996). https://doi.org/10.1090/S0002-9939-96-03132-2
Ernst, O.G., Gottschalk, H., Kalmes, T., Kowalewitz, T., Reese, M.: Integrability and approximability of solutions to the stationary diffusion equation with Lévy coefficient. ArXiv e-prints (2021). arXiv:2010.14912v2 [math.AP]
Evans, L.C.: Partial differential equations. In: Graduate Studies in Mathematics, vol. 19, 2nd edn. American Mathematical Society, Providence (2010). https://doi.org/10.1090/gsm/019
Frauenfelder, P., Schwab, C., Todor, R.A.: Finite elements for elliptic problems with stochastic coefficients. Comput. Methods Appl. Mech. Eng. 194(2–5), 205–228 (2005). https://doi.org/10.1016/j.cma.2004.04.008
Giles, M.B.: Multilevel Monte Carlo path simulation. Oper. Res. 56(3), 607–617 (2008). https://doi.org/10.1287/opre.1070.0496
Giles, M.B.: Multilevel Monte Carlo methods. Acta Numer. 24, 259–328 (2015). https://doi.org/10.1017/S096249291500001X
Glasserman, P.: Monte Carlo methods in financial engineering. In: Applications of Mathematics (New York), vol. 53. Springer, New York (2004). Stochastic Modelling and Applied Probability
Graham, I.G., Kuo, F.Y., Nichols, J.A., Scheichl, R., Schwab, C., Sloan, I.H.: Quasi-Monte Carlo finite element methods for elliptic PDEs with lognormal random coefficients. Numer. Math. 131(2), 329–368 (2015). https://doi.org/10.1007/s00211-014-0689-y
Graham, I.G., Kuo, F.Y., Nuyens, D., Scheichl, R., Sloan, I.H.: Analysis of circulant embedding methods for sampling stationary random fields. SIAM J. Numer. Anal. 56(3), 1871–1895 (2018). https://doi.org/10.1137/17M1149730
Graham, I.G., Kuo, F.Y., Nuyens, D., Scheichl, R., Sloan, I.H.: Circulant embedding with QMC: analysis for elliptic PDE with lognormal coefficients. Numer. Math. 140(2), 479–511 (2018). https://doi.org/10.1007/s00211-018-0968-0
Hackbusch, W.: Elliptic differential equations. In: Springer Series in Computational Mathematics, vol. 18, 2nd edn. Springer, Berlin (2017). https://doi.org/10.1007/978-3-662-54961-2. Theory and numerical treatment
Kallenberg, O.: Foundations of modern probability. In: Probability Theory and Stochastic Modelling, vol. 99, 3rd edn. Springer, Cham (2021). https://doi.org/10.1007/978-3-030-61871-1
Klenke, A.: Wahrscheinlichkeitstheorie. Springer, Berlin (2013). https://doi.org/10.1007/978-3-642-36018-3
Li, J., Wang, X., Zhang, K.: Multi-level Monte Carlo weak Galerkin method for elliptic equations with stochastic jump coefficients. Appl. Math. Comput. 275, 181–194 (2016). https://doi.org/10.1016/j.amc.2015.11.064
Mugler, A., Starkloff, H.J.: On the convergence of the stochastic Galerkin method for random elliptic partial differential equations. ESAIM Math. Model. Numer. Anal. 47(5), 1237–1263 (2013). https://doi.org/10.1051/m2an/2013066
Nobile, F., Tesei, F.: A multi level Monte Carlo method with control variate for elliptic PDEs with log-normal coefficients. Stoch. Part. Differ. Equ. Anal. Comput. 3(3), 398–444 (2015). https://doi.org/10.1007/s40072-015-0055-9
Peszat, S., Zabczyk, J.: Stochastic partial differential equations with Lévy noise. In: Encyclopedia of Mathematics and its Applications, vol. 113. Cambridge University Press, Cambridge (2007). https://doi.org/10.1017/CBO9780511721373. An evolution equation approach
Petzoldt, M.: Regularity results for Laplace interface problems in two dimensions. Z. Anal. ihre Anw. 20(2), 431–455 (2001). https://doi.org/10.4171/zaa/1024
Schoutens, W.: Levy Processes in Finance: Pricing Financial Derivatives. Wiley Series in Probability and Statistics. Wiley (2003). https://books.google.de/books?id=Be4NqIz7h-kC
Teckentrup, A.L., Scheichl, R., Giles, M.B., Ullmann, E.: Further analysis of multilevel Monte Carlo methods for elliptic PDEs with random coefficients. Numer. Math. 125(3), 569–600 (2013). https://doi.org/10.1007/s00211-013-0546-4
Valli, A.: A Compact Course on Linear PDEs, Unitext, vol. 126. Springer, Cham (2020). La Matematica per il 3+2
Acknowledgements
Funded by Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy—EXC 2075—390740016.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Axel Målqvist.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Merkle, R., Barth, A. Multilevel Monte Carlo estimators for elliptic PDEs with Lévy-type diffusion coefficient. Bit Numer Math 62, 1279–1317 (2022). https://doi.org/10.1007/s10543-022-00912-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10543-022-00912-4
Keywords
- Stochastic partial differential equations
- Lévy fields
- Finite element methods
- Circulant embedding
- Subordination
- Discontinuous random fields
- Control variates
- Multilevel Monte Carlo