
Abstract
A numerical integrator is presented that computes a symmetric or skew-symmetric low-rank approximation to large symmetric or skew-symmetric time-dependent matrices that are either given explicitly or are the unknown solution to a matrix differential equation. A related algorithm is given for the approximation of symmetric or anti-symmetric time-dependent tensors by symmetric or anti-symmetric Tucker tensors of low multilinear rank. The proposed symmetric or anti-symmetric low-rank integrator is different from recently proposed projector-splitting integrators for dynamical low-rank approximation, which do not preserve symmetry or anti-symmetry. However, it is shown that the (anti-)symmetric low-rank integrators retain favourable properties of the projector-splitting integrators: given low-rank time-dependent matrices and tensors are reproduced exactly, and the error behaviour is robust to the presence of small singular values, in contrast to standard integration methods applied to the differential equations of dynamical low-rank approximation. Numerical experiments illustrate the behaviour of the proposed integrators.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In this paper we propose and analyse an algorithm that computes a symmetric or skew-symmetric low-rank approximation to large symmetric or skew-symmetric time-dependent matrices that are either given explicitly or are the unknown solution to a matrix differential equation. A related algorithm is given for the approximation of symmetric or anti-symmetric time-dependent tensors by symmetric or anti-symmetric Tucker tensors of low multilinear rank.
In the matrix case, motivation for this work comes from Lyapunov and Riccati differential equations, which have large symmetric matrices as solutions, which can often be well approximated by low-rank matrices [19]. For tensors, our main motivation comes from the quantum dynamics of bosonic or fermionic systems, where the symmetric or anti-symmetric wave function is approximated by low-rank symmetric or anti-symmetric Tucker tensors in the MCTDHB and MCTDHF methods for bosons and fermions, respectively [1, 4]. An efficient integrator that preserves symmetry and anti-symmetry and uses them to reduce the computational complexity, is needed in these and other applications, such as using a step of the integrator as a computationally efficient retraction in optimization algorithms for (anti-)symmetric low-rank matrices and tensors.
The algorithms proposed in this paper are non-trivial modifications of the projector-splitting integrators for the dynamical low-rank approximation of matrices and Tucker tensors that were proposed in [16,17,18], respectively. The projector-splitting integrators have been shown to possess remarkable robustness to the typical presence of small singular values [10, 18], as opposed to applying standard integrators to the differential equations of dynamical low-rank approximation that are given in [12, 13]. However, the projector-splitting integrators do not preserve symmetry or anti-symmetry.
We will show that the (anti-)symmetry-preserving integrators proposed here retain the robustness with respect to small singular values of the projector-splitting algorithms. This relies on an exactness property, namely that explicitly given time-dependent matrices and tensors of the approximation rank are reproduced exactly by the integrator. This exactness property will also be shown to be retained from the projector-splitting integrators. We note, however, that the integrators proposed here can no longer be interpreted as splitting integrators.
The new (anti-)symmetry-preserving integrators are favourable also from the computational viewpoint: compared with the projector-splitting integrator, the computational cost is halved in the (skew-)symmetric matrix case; in the case of d-dimensional (anti-)symmetric tensors, the computational cost for the core tensor is reduced by the factor 1/d!, and that for the basis matrices by 1/d.
A first attempt to modify the projector-splitting integrator and preserve the symmetry in the matrix setting, can be found in [19]: numerical examples show the correct behaviour of the approximate solution but no convergence analysis or extension to multi-dimensional arrays is provided, and no use of the symmetry is made to reduce the computational effort.
The outline of the paper is the following: in Sect. 2, we briefly restate the idea of dynamical low-rank approximation for matrices and we present the matrix projector-splitting integrator with some of its properties. In Sect. 3, we consider the case of (skew-)symmetric matrices; we present the (skew-)symmetry-preserving low-rank integrator and study its properties. In Sect. 4, we recapitulate the projector-splitting integrator for low-rank Tucker tensors. In Sect. 5, we present the integrator for (anti)-symmetric tensors of low multilinear rank and study its properties. In the final section, we present numerical experiments that illustrate the approximation properties and the robustness to small singular values.
Throughout the paper, we use the convention to denote matrices by boldface capital letters and tensors by italic capital letters.
2 General matrices: recap of the projector-splitting integrator for dynamical low-rank approximation
The objective is to approximate large time-dependent matrices \({{\mathbf {A}}}(t)\in {{\mathbb {R}}}^{m\times n}\) for \(0\le t \le T\) by rank-r matrices \({{\mathbf {Y}}}(t)\) with comparatively low rank \(r\ll m,n\), which require much less storage than \({{\mathbf {A}}}(t)\) when they are available in a factorized, SVD-like form. The large, or often too large matrices \({{\mathbf {A}}}(t)\) may be given explicitly or they are the unknown solution to a matrix differential equation (with right-hand side function \({{\mathbf {F}}}:{{\mathbb {R}}}\times {{\mathbb {R}}}^{m\times n} \rightarrow {{\mathbb {R}}}^{m\times n}\))
Dynamical low-rank approximation as presented in [12] determines \({{\mathbf {Y}}}(t)\) as the solution of a projected matrix differential equation, with a projection \(\mathrm {P}({{\mathbf {Y}}})\) onto the tangent space \(T_{{\mathbf {Y}}}{\mathcal {M}}_r\) of the manifold of rank-r matrices at \({{\mathbf {Y}}}\in {\mathcal {M}}_r\),
where \({{\mathbf {Y}}}_0\) is a rank-r approximation to \({{\mathbf {A}}}_0\), typically obtained by a truncated singular value decomposition. (Here, \({{\mathbf {F}}}(t,{{\mathbf {Y}}}) = \dot{{{\mathbf {A}}}}(t)\) if \({{\mathbf {A}}}(t)\) is given explicitly.) The solution \({{\mathbf {Y}}}(t)\) to this projected matrix differential equation then stays in the rank-r manifold \({\mathcal {M}}_r\).
To make this abstract formulation practically useful, rank-r matrices \({{\mathbf {Y}}}(t)\) are written (non-uniquely) in factored form
where the slim matrices \({{\mathbf {U}}}(t)\in {{\mathbb {R}}}^{m\times r}\) and \({{\mathbf {V}}}(t)\in {{\mathbb {R}}}^{n\times r}\) each have r orthonormal columns, and the small square matrix \({{\mathbf {S}}}(t)\in {{\mathbb {R}}}^{r\times r}\) is invertible. We choose the tangent space projection \(\mathrm {P}({{\mathbf {Y}}})\) as the orthogonal projection onto \(T_{{\mathbf {Y}}}({\mathcal {M}}_r)\) with respect to the Euclidean or Frobenius inner product \(\langle {{\mathbf {A}}},{{\mathbf {B}}}\rangle = \mathbf{vec} ({{\mathbf {A}}})^\top \mathbf{vec} ({{\mathbf {B}}})\), where \(\mathbf{vec} ({{\mathbf {A}}})\in {{\mathbb {R}}}^{mn}\) is a vectorization of \({{\mathbf {A}}}\). Then, \(\mathrm {P}({{\mathbf {Y}}})\) is given as an alternating sum of three subprojections [12],
The projector-splitting integrator of [17] is a Lie–Trotter or Strang splitting method that splits the right-hand side of (2) according to the three terms in (4). It turned out that such a splitting combines very well with the factorization (3). In the first substep of a Lie–Trotter splitting, \(\mathbf{K }:={{\mathbf {U}}}{{\mathbf {S}}}\) is updated, in the second substep \({{\mathbf {S}}}\) is updated, and in the third substep \(\mathbf{L }:={{\mathbf {V}}}{{\mathbf {S}}}^\top \). The algorithm alternates between the numerical solution of matrix differential equations (of dimensions \(m\times r\), \(r\times r\), \(n\times r\)) and orthogonal decompositions of slim matrices (of dimensions \(m\times r\) and \(n\times r\)). One time step of integration from time \(t_0\) to \(t_1=t_0+h\) starting from a factored rank-r matrix \({{\mathbf {Y}}}_0={{\mathbf {U}}}_0{{\mathbf {S}}}_0{{\mathbf {V}}}_0^\top \) proceeds as follows:
-
1.
K-step : Update \( {{\mathbf {U}}}_0 \rightarrow {{\mathbf {U}}}_1, {{\mathbf {S}}}_0 \rightarrow {\hat{{{\mathbf {S}}}}}_1\)
Integrate from \(t=t_0\) to \(t_1\) the \(m \times r\) matrix differential equation
$$\begin{aligned} \dot{\mathbf{K }}(t) = {{\mathbf {F}}}(t, \mathbf{K }(t) {{\mathbf {V}}}_0^\top ) {{\mathbf {V}}}_0, \qquad \mathbf{K }(t_0) = {{\mathbf {U}}}_0 {{\mathbf {S}}}_0. \end{aligned}$$Perform a QR factorization \(\mathbf{K }(t_1) = {{\mathbf {U}}}_1 {\hat{{{\mathbf {S}}}}}_1\).
-
2.
S-step : Update \( {\hat{{{\mathbf {S}}}}}_1 \rightarrow {\tilde{{{\mathbf {S}}}}}_0\)
Integrate from \(t=t_0\) to \(t_1\) the \(r \times r\) matrix differential equation
$$\begin{aligned} {\dot{{{\mathbf {S}}}}}(t) = - {{\mathbf {U}}}_1^\top {{\mathbf {F}}}(t, {{\mathbf {U}}}_1 {{\mathbf {S}}}(t) {{\mathbf {V}}}_0^\top ) {{\mathbf {V}}}_0, \qquad {{\mathbf {S}}}(t_0) = {\hat{{{\mathbf {S}}}}}_1, \end{aligned}$$and set \({\tilde{{{\mathbf {S}}}}}_0 ={{\mathbf {S}}}(t_1)\).
-
3.
L-step : Update \( {{\mathbf {V}}}_0 \rightarrow {{\mathbf {V}}}_1, {\tilde{{{\mathbf {S}}}}}_0 \rightarrow {{\mathbf {S}}}_1\)
Integrate from \(t=t_0\) to \(t_1\) the \(n \times r\) matrix differential equation
$$\begin{aligned} \dot{\mathbf{L }}(t) ={{\mathbf {F}}}(t, {{\mathbf {U}}}_1 \mathbf{L }(t)^\top )^\top {{\mathbf {U}}}_1, \qquad \mathbf{L }(t_0) = {{\mathbf {V}}}_0 {\tilde{{{\mathbf {S}}}}}_0^\top . \end{aligned}$$Perform a QR factorization \(\mathbf{L }(t_1) = {{\mathbf {V}}}_1 {{\mathbf {S}}}_1^\top \).
Then, the approximation after one time step is given by
To proceed, we iterate the procedure taking \({{\mathbf {Y}}}_1\) as starting point for the next step.
The above algorithm describes the first-order Lie–Trotter splitting. The algorithm for the second-order Strang splitting is obtained by concatenating the above algorithm with the same algorithm in reversed order, each for half the step-size; see [17] for the detailed description.
The projector-splitting integrator has remarkable properties. First, it reproduces rank-r matrices without error.
Theorem 1
(Exactness property, [17, Theorem 4.1]) Let \({{\mathbf {A}}}(t) \in {\mathbb {R}}^{m \times n}\) be of rank r for \(t_0 \le t \le t_1\), so that \({{\mathbf {A}}}(t)\) has a factorization (3), \({{\mathbf {A}}}(t)={{\mathbf {U}}}(t){{\mathbf {S}}}(t){{\mathbf {V}}}(t)^\top \). Moreover, assume that the \(r\times r\) matrix \( {{\mathbf {V}}}(t_1)^\top {{\mathbf {V}}}(t_0)\) is invertible. With \({{\mathbf {Y}}}_0 = {{\mathbf {A}}}(t_0)\), the projector-splitting integrator for \(\dot{{{\mathbf {Y}}}}(t)=\mathrm {P}({{\mathbf {Y}}}(t))\dot{{{\mathbf {A}}}}(t)\) is then exact: \( {{\mathbf {Y}}}_1 = {{\mathbf {A}}}(t_1)\).
The second remarkable property is the robustness of the algorithm to the presence of small singular values of the solution or its approximation. This is in contrast to standard integrators applied to (2) or the equivalent differential equations for the factors \({{\mathbf {U}}}(t)\), \({{\mathbf {S}}}(t)\), \({{\mathbf {V}}}(t)\), which contain a factor \({{\mathbf {S}}}(t)^{-1}\) on the right-hand sides [12, Prop. 2.1]. Moreover, the local Lipschitz constant of the tangent space projection \(\mathrm {P}(\cdot )\) is proportional to the inverse of the smallest nonzero singular value [12, Lemma 4.2]. The appearance of small singular values is typical in applications, because the smallest singular value retained in the approximation cannot be expected to be much larger than the largest discarded singular value of the solution, which needs to be small to obtain good accuracy of the low-rank approximation.
Theorem 2
(Robust error bound, [10, Theorem 2.1]) Let \({{\mathbf {A}}}(t)\) denote the solution of the matrix differential equation (1). Assume that the following conditions hold in the Frobenius norm \(\Vert \cdot \Vert =\Vert \cdot \Vert _F\):
-
1.
\({{\mathbf {F}}}\) is Lipschitz-continuous and bounded: for all \({{\mathbf {Y}}}, {\widetilde{{{\mathbf {Y}}}}} \in {\mathbb {R}}^{m \times n}\) and \(0\le t \le T\),
$$\begin{aligned} \Vert {{\mathbf {F}}}(t, {{\mathbf {Y}}}) - {{\mathbf {F}}}(t, {\widetilde{{{\mathbf {Y}}}}}) \Vert \le L \Vert {{\mathbf {Y}}}- {\widetilde{{{\mathbf {Y}}}}} \Vert , \qquad \Vert {{\mathbf {F}}}(t, {{\mathbf {Y}}}) \Vert \le B \ . \end{aligned}$$ -
2.
The non-tangential part of \({{\mathbf {F}}}(t, {{\mathbf {Y}}})\) is \(\varepsilon \)-small:
$$\begin{aligned} \Vert ({{\mathbf {I}}}- \mathrm {P}({{\mathbf {Y}}})) {{\mathbf {F}}}(t, {{\mathbf {Y}}}) \Vert \le \varepsilon \end{aligned}$$for all \({{\mathbf {Y}}}\in {\mathcal {M}}\) in a neighbourhood of \({{\mathbf {A}}}(t)\) and \(0\le t \le T\).
-
3.
The error in the initial value is \(\delta \)-small:
$$\begin{aligned} \Vert {{\mathbf {Y}}}_0 - {{\mathbf {A}}}_0 \Vert \le \delta . \end{aligned}$$
Let \({{\mathbf {Y}}}_n\) denote the rank-r approximation to \({{\mathbf {A}}}(t_n)\) at \(t_n=nh\) obtained after n steps of the projector-splitting integrator with step-size \(h>0\). Then, the error satisfies for all n with \(t_n = nh \le T\)
where the constants \(c_i\) only depend on L, B, and T. In particular, the constants are independent of singular values of the exact or approximate solution.
It is further shown in [10, Section 2.6.3] that an inexact solution of the matrix differential equations in the projector-splitting integrator leads to an additional error that is bounded in terms of the local errors in the inexact substeps, again with constants that do not depend on small singular values.
Numerical experiments with the matrix projector-splitting integrator and comparisons with standard numerical integrators are reported in [10, 17]. These experiments show good behaviour also for spatially discretized partial differential equations where the Lipschitz constant becomes large, a case that as of now is not covered by the theory.
3 Symmetric and skew-symmetric matrices: a structure-preserving integrator for dynamical low-rank approximation
We now assume that the right-hand side function in (1) is such that
This condition ensures that the solutions to the matrix differential equation (1) and the projected differential equation (2) are (skew-)symmetric provided the initial values are (skew-)symmetric. For (2), this is seen from formula (4) for the tangent space projection with equal left and right factors \({{\mathbf {V}}}={{\mathbf {U}}}\) in the decomposition (3) of the (skew-)symmetric rank-r matrix \({{\mathbf {Y}}}={{\mathbf {U}}}{{\mathbf {S}}}{{\mathbf {U}}}^\top \).
While the projector-splitting integrator for dynamical low-rank approximation described in the previous section has favourable properties, it does not preserve symmetry or skew-symmetry of the solution \({{\mathbf {A}}}(t)\) to (1).
3.1 (Skew-)symmetry preserving integrator
We now propose a modified integrator that preserves symmetry and skew-symmetry and still retains the exactness and robustness properties of the projector-splitting integrator. A step with this integrator consists of two substeps. The first substep is identical to the first substep (\(\mathbf{K }\)-step) of the projector-splitting integrator: it updates \(\mathbf{K }={{\mathbf {U}}}{{\mathbf {S}}}\) in the decomposition \({{\mathbf {Y}}}={{\mathbf {U}}}{{\mathbf {S}}}{{\mathbf {U}}}^\top \). The second substep is a substantially modified update of \({{\mathbf {S}}}\), which can be viewed as a Galerkin approximation in the basis provided by the first substep.
Given \({{\mathbf {Y}}}_0 = {{\mathbf {U}}}_0 {{\mathbf {S}}}_0 {{\mathbf {U}}}_0^\top \) with a (skew-)symmetric \(r\times r\)-matrix \({{\mathbf {S}}}_0\) at time \(t_0\), we compute the factorization \({{\mathbf {Y}}}_1 = {{\mathbf {U}}}_1 {{\mathbf {S}}}_1 {{\mathbf {U}}}_1^\top \) with a (skew-)symmetric \(r\times r\)-matrix \({{\mathbf {S}}}_1\) at time \(t_1=t_0+h\) by the following algorithm:

To continue in time, we take \({{\mathbf {Y}}}_1\) as starting value for the next step and perform another step of the integrator.
Note that in this integrator the factor \(\mathbf{R }\) in the QR-decomposition of the first substep is not reused in the second substep, in contrast to the projector-splitting integrator. The computational cost is approximately halved, since the \(\mathbf{L }\)-step is not needed here.
We will now show that the (skew-)symmetric integrator retains the exactness and robustness properties of the projector-splitting integrator, using these known results in the proof.
3.2 Exactness property of the (skew-)symmetric integrator
The exactness result Theorem 1 extends in the following way.
Theorem 3
(Exactness property) Let \({{\mathbf {A}}}(t) \in {\mathbb {R}}^{n \times n}\) be (skew-)symmetric and of rank r for \(t_0 \le t \le t_1\), so that \({{\mathbf {A}}}(t)\) has a factorization (3) with equal left and right factors, \({{\mathbf {A}}}(t)={{\mathbf {U}}}(t){{\mathbf {S}}}(t){{\mathbf {U}}}(t)^\top \). Moreover, assume that the \(r\times r\) matrix \( {{\mathbf {U}}}(t_1)^\top {{\mathbf {U}}}(t_0)\) is invertible. With \({{\mathbf {Y}}}_0 = {{\mathbf {A}}}(t_0)\), the (skew-)symmetric integrator for \(\dot{{{\mathbf {Y}}}}(t)=\mathrm {P}({{\mathbf {Y}}}(t))\dot{{{\mathbf {A}}}}(t)\) is then exact: \( {{\mathbf {Y}}}_1 = {{\mathbf {A}}}(t_1)\).
Proof
We note that the projector-splitting integrator and the (skew-)symmetric integrator have the same first step. Let \({{\mathbf {U}}}_1 \in {\mathbb {R}}^{n \times r}\) be the matrix with orthonormal columns computed in the first substep. Due to the exactness of the matrix projector-splitting integrator as given by Theorem 1 we know that \({{\mathbf {U}}}_1\) and \({{\mathbf {A}}}(t_1)\) have the same range and therefore
Denoting \(\varDelta {{\mathbf {A}}}= {{\mathbf {A}}}(t_1) - {{\mathbf {A}}}(t_0)\), the (skew-)symmetric integrator provides for the second substep the solution
since \({{\mathbf {Y}}}_0={{\mathbf {A}}}(t_0)\). The result after a time step of the (skew-)symmetric integrator is
where the last equality holds because of (6) and the (skew-)symmetry of \({{\mathbf {A}}}(t_1)\). \(\square \)
3.3 Robustness to small singular values
The error bound of Theorem 2 extends in the following way.
Theorem 4
(Robust error bound) Let \({{\mathbf {A}}}(t)\) denote the (skew-)symmetric solution of the matrix differential equation (1) with \({{\mathbf {F}}}\) satisfying (5). Assume that conditions 1.-\(\,3\). of Theorem 2 are fulfilled.
Let \({{\mathbf {Y}}}_n\) denote the rank-r approximation to \({{\mathbf {A}}}(t_n)\) at \(t_n=nh\) obtained after n steps of the (skew-)symmetric integrator of Algorithm 1 with step-size \(h>0\). Then, the error satisfies for all n with \(t_n = nh \le T\)
where the constants \(c_i\) only depend on L, B, and T. In particular, the constants are independent of singular values of the exact or approximate solution.
As in [10, Section 2.6.3], it can be further shown that an inexact solution of the matrix differential equations in the projector-splitting integrator leads to an additional error that is bounded in terms of the local errors in the inexact substeps, again with constants that do not depend on small singular values.
Remark 1
The method of Algorithm 1 is of order 1, and higher order can be obtained simply by composition as, e.g., in [8, Section II.4]. However, like for the projector-splitting integrator of [17], it is not known if an error bound of higher order in the step-size h can be obtained with constants that are independent of small singular values. Numerical experiments with the Strang version of the projector-splitting integrator, which is of order 2, indicate an order reduction in some examples with very small singular values [21].
We now prepare for the proof of Theorem 4, which views the (skew-)symmetric integrator as a perturbed variant of the projector-splitting integrator.
Let us introduce the quantity
which represents the local error bound after one time step of the projector-splitting integrator, as proved in [10, Theorem 2.1].
In the following, we denote by \({{\mathbf {U}}}_1\in {{\mathbb {R}}}^{n\times r}\) the matrix with orthonormal columns obtained in the first substep of the integrator. We recall that the matrix projector-splitting and the (skew-)symmetric integrator have the first substep in common.
We denote by \({{\mathbf {A}}}_1\) the (skew-)symmetric solution at time \(t_1\) of the full problem (1), where we consider the initial data to coincide with the (skew-)symmetric rank-r matrix \({{\mathbf {Y}}}_0\). For the local error analysis, the following lemma is needed.
Lemma 1
Let \({{\mathbf {U}}}_1, {{\mathbf {A}}}_1\) be defined as above. The following estimate holds:
Proof
The local error analysis in [10] shows that the \(r\times n\) matrix \({{\mathbf {Z}}}={{\mathbf {S}}}_1^\mathrm {ps}{{\mathbf {V}}}_1^{\mathrm {ps},\top }\), where \({{\mathbf {S}}}_1^\mathrm {ps}\) and \({{\mathbf {V}}}_1^\mathrm {ps}\) are the matrices computed in the third substep of the projector-splitting algorithm, satisfies
The square of the left-hand side can be split into two terms:
Hence,
From the second term it follows that
By the (skew-)symmetry of \({{\mathbf {A}}}_1\), this implies
which yields the result. \(\square \)
In the following lemma, we show that the approximation given after one time step is \(O(h(h + \varepsilon ))\) close to the solution of system (1) when the starting values coincide.
Lemma 2
(Local error) The following local error bound holds:
where the constants only depend on L and B and a bound of the step size. In particular, the constants are independent of singular values of the exact or approximate solution.
Proof
By the identity \({{\mathbf {Y}}}_1={{\mathbf {U}}}_1{{\mathbf {S}}}_1{{\mathbf {U}}}_1^\top \) and Lemma 1 we have that
The analysis of the local error thus reduces to estimating \(\Vert {{\mathbf {S}}}_1 - {{\mathbf {U}}}_1^\top {{\mathbf {A}}}_1 {{{\mathbf {U}}}}_1 \Vert \). To this end, we introduce the following quantity: for \(t_0\le t \le t_1\),
We observe that
where \(\mathbf{R }(t)\) is defined as the term in big brackets. From Lemma 1 and from the bound B of \({{\mathbf {F}}}\), which yields for \(t_0 \le t \le t_1\)
we conclude that the remainder term is bounded by
This yields that \({{\mathbf {F}}}(t, {{\mathbf {A}}}(t))\) can be written as
where the defect
is bounded via the Lipschitz continuity of \({{\mathbf {F}}}\) as
We now compare the two differential equations
By construction, the solution of the first differential equation at time \(t_1\) is \( {{\widetilde{{{\mathbf {S}}}}}}(t_1) = {{\mathbf {U}}}_1^\top {{\mathbf {A}}}_1 {{{\mathbf {U}}}}_1\). The solution of the second differential equation is \({{\mathbf {S}}}_1\) as given by the second substep of the (skew-)symmetric integrator. We now apply the Gronwall inequality to the previous system and obtain
The result now follows using the definition of \(\vartheta \). \(\square \)
Thanks to the Lipschitz continuity of the function \({{\mathbf {F}}}\), we conclude the proof of Theorem 4 from the local to the global errors by the standard argument of Lady Windermere’s fan [9, Section II.3].
4 General tensors: recap of the projector-splitting integrator for the dynamical low-rank approximation by Tucker tensors
The objective is to approximate time-dependent tensorsFootnote 1\(A(t)\in {{\mathbb {C}}}^{n_1\times \dots \times n_d}\) for \(0\le t \le T\) by tensors Y(t) of multilinear rank \({{\mathbf {r}}}=(r_1,\dots ,r_d)\), with \(r_i \ll n_i\). (We recall that \(r_i\) is the rank of the ith matricization \({{\mathbf {Mat}}}_i(Y)\in {{\mathbb {C}}}^{n_i\times n_i'}\) with \(n_i'=\prod _{j\ne i} n_j\), which aligns all entries of Y with ith index k in the kth row. The retensorization is denoted by Ten\(_i(\cdot )\), such that Ten\(_i({{\mathbf {Mat}}}_i(Y)) = Y\).)
The tensors A(t) may be given explicitly or they are the unknown solution to a tensor differential equation (with right-hand side function \(F:{{\mathbb {R}}}\times {{\mathbb {C}}}^{n_1\times \dots \times n_d} \rightarrow {{\mathbb {C}}}^{n_1\times \dots \times n_d}\))
Dynamical low-rank approximation as presented in [13] determines Y(t) as the solution of the projected matrix differential equation, with a projection \(\mathrm {P}(Y)\) onto the tangent space \(T_Y {\mathcal {M}}_{{\mathbf {r}}}\) of the manifold of tensors of multilinear rank \({{\mathbf {r}}}\) at \(Y\in {\mathcal {M}}_{{\mathbf {r}}}\),
where \(Y_0\) is a rank-\({{\mathbf {r}}}\) approximation to \(A_0\). (Here, \(F(t,Y) = \dot{A}(t)\) if A(t) is given explicitly.) Tensors Y(t) of multilinear rank \({{\mathbf {r}}}\) are represented non-uniquely in the Tucker form [5] (using here the multilinear notation of [14])
where the core tensor \(C(t) \in {\mathbb {C}}^{r_1 \times \dots \times r_d }\) is of full multi-linear rank and the basis matrices \({{\mathbf {U}}}_i \in {\mathbb {C}}^{n \times r_i}\) have orthonormal columns. We choose the tangent space projection \(\mathrm {P}(Y)\) as the orthogonal projection onto \(T_Y({\mathcal {M}}_r)\) with respect to the Euclidean inner product \(\langle A,B \rangle = \mathbf{vec} (A)^* \mathbf{vec} (B)\), where \(\mathbf{vec} (A)\) is a vectorization of A. Then, \(\mathrm {P}({{\mathbf {Y}}})\) is given as an alternating sum of \(2d-1\) subprojections [16], and like in the matrix case, a projector-splitting integrator with favourable properties can be formulated and efficiently implemented. The matrix projector-splitting integrator proposed in Section 2.1 has been successfully extended to the Tucker tensor format in different algorithmic versions in [16, 18]. It is shown in [18, Section 6] that the proposed Tucker integrators are mathematically equivalent. The algorithm runs through the modes \(i=1,\dots ,d\) and solves differential equations for matrices of the dimension of the slim basis matrices and for the core tensor in alternation with orthogonal decompositions of slim matrices. We refer also to [3, 11] for the formulation and implementation of this algorithm in the context of the MCTDH method [20] of molecular quantum dynamics in the chemical physics literature.
Moreover, the Tucker integrator has been proved in [18] to satisfy analogous properties to the matrix projector-splitting integrator: the exactness property and the robust convergence in the presence of small singular values of matricizations of the core tensor. We refer to [18, Theorems 4.1 and 5.1] for the precise formulation, which is very similar to the matrix case.
5 Symmetric and anti-symmetric tensors: a structure-preserving integrator for dynamical low-rank approximation
A tensor \(A=(a_{i_1,\dots ,i_d})\in {{\mathbb {C}}}^{n\times \dots \times n}\) is symmetric if for every permutation \(\sigma \in S(d)\),
and A is anti-symmetric if for every permutation \(\sigma \in S(d)\),
It follows from [5, 7] that a symmetric/anti-symmetric tensor \(Y\in {{\mathbb {C}}}^{n\times \dots \times n}\) of multi-linear rank \( \mathbf{r } = (r, \dots , r)\) admits a Tucker decomposition
where the core tensor \(C\in {{\mathbb {C}}}^{r\times \dots \times r}\) is symmetric/anti-symmetric of full rank \({{\mathbf {r}}}\) and the basis matrix \({{\mathbf {U}}}\in {{\mathbb {C}}}^{n\times r}\) is the same for all indices.
We assume that the right-hand side function in (7) is such that
Like (5) in the matrix case, this ensures that the solutions to the tensor differential equation (7) and the projected differential equation (8) are (anti-)symmetric provided the initial tensors are (anti-)symmetric. As we noted already in the matrix case, the projector-splitting Tucker integrator does not preserve (anti-)symmetry.
5.1 (Anti-)symmetry preserving Tucker integrator
The numerical integrator defined in Sect. 3 for the matrix case extends in a natural way to the Tucker tensor format. The first substep, which updates the basis matrix \({{\mathbf {U}}}\), is identical to the first substep of the general Tucker integrator in [16, 18]. The second substep is a Galerkin method with the updated basis and determines the updated (anti-)symmetric core tensor.
Given the (anti-)symmetric tensor \(Y_0 = C_0 {\textsf {X}}_{i=1}^{d} {{\mathbf {U}}}_0 \), we compute the (anti-)symmetric approximation \(Y_1 = C_1 {\textsf {X}}_{i=1}^{d} {{\mathbf {U}}}_1 \) at time \(t_1 = t_0 + h\) as follows:

To continue, we take \(Y_1\) as the starting value for the next step.
5.2 Exactness property of the (anti-)symmetric Tucker integrator
The following result extends the exactness results of Theorem 3 and [18, Theorem 4.1] to (anti-)symmetric tensors.
Theorem 5
(Exactness property) Let \(A(t) \in {{\mathbb {C}}}^{n \times \dots \times n}\) be (anti-)symmetric and of multilinear rank \((r,\dots ,r)\) for \(t_0 \le t \le t_1\), so that \(A(t)=C(t){\textsf {X}}_{i=1}^d {{\mathbf {U}}}(t)\), where the \(n\times r\) basis matrix \({{\mathbf {U}}}\) has orthonormal columns. Moreover, assume that the \(r\times r\) matrix \( {{\mathbf {U}}}(t_1)^* {{\mathbf {U}}}(t_0)\) is invertible. With \(Y_0=A(t_0)\), the (anti-)symmetric Tucker integrator for \(\dot{Y}(t)=\mathrm {P}(Y(t))\dot{A}(t)\) is then exact: \(Y_1 = A(t_1)\).
Proof
The projector-splitting Tucker integrator and the (anti-)symmetric integrator have the same first substep. Let \({{\mathbf {U}}}_1 \in {\mathbb {R}}^{n \times r}\) be the basis matrix with orthonormal columns computed in the first substep. Due to the exactness of the projector-splitting Tucker integrator as shown by [18, Theorem 4.1] we have that \(A(t_1)\) has the (anti)-symmetric Tucker representation
for some (anti-)symmetric core tensor \( {{\widehat{C}}}_1 \in {{\mathbb {C}}}^{r\times \dots \times r}\). Using the rule \(A \times _i {{\mathbf {V}}}\times _i \mathbf{W } = A \times _i (\mathbf{WV} )\), this implies that
With \(Y_0 = A(t_0)\) we obtain from the second substep of the algorithm
which proves the exactness. \(\square \)
5.3 Robustness to small singular values
The robust error bounds from Theorem 4 and [18, Theorem 5.1] extend to the (anti)symmetric Tucker integrator as follows. The norm \(\Vert B\Vert \) of a tensor B used here is the Euclidean norm of the entries of B.
Theorem 6
(Robust error bound) Let A(t) denote the (anti-)symmetric solution of the tensor differential equation (7) with F satisfying (10). Assume the following:
-
1.
F is Lipschitz-continuous and bounded.
-
2.
The non-tangential part of F(t, Y) is \(\varepsilon \)-small:
$$\begin{aligned} \Vert (I - \mathrm {P}(Y)) F(t, Y) \Vert \le \varepsilon \end{aligned}$$for all Y of multilinear rank \((r,\dots ,r)\) in a neighbourhood of A(t) and \(0\le t \le T\).
-
3.
The error in the initial value is \(\delta \)-small:
$$\begin{aligned} \Vert Y_0 - A_0 \Vert \le \delta . \end{aligned}$$
Let \(Y_n\) denote the (anti-)symmetric approximation of multinear rank \((r,\dots ,r)\) to \(A(t_n)\) at \(t_n=nh\) obtained after n steps of the (anti-)symmetric Tucker integrator with step-size \(h>0\). Then, the error satisfies for all n with \(t_n = nh \le T\)
where the constants \(c_i\) only depend on the Lipschitz constant L and bound B of F, on T, and on the dimension d. In particular, the constants are independent of singular values of matricizations of the exact or approximate solution.
It can be further shown that an inexact solution of the matrix differential equations in the integrator leads to an additional error that is bounded in terms of the local errors in the inexact substeps, again with constants that do not depend on small singular values.
The proof of Theorem 6 proceeds similar to the proof of Theorem 4 for the (skew)-symmetric matrix case. We begin with a key lemma and then analyze the local error produced after one time step, comparing the numerical solution with the exact solution that starts from the same initial value \(A_0=Y_0\). We denote the value of this solution at \(t_1\) by \(A_1\). The basis matrix computed in the first substep of the integrator is denoted by \({{\mathbf {U}}}_1\).
Lemma 3
The following estimate holds:
where c only depends on d and a bound for hL.
Proof
The error bound of [18, Theorem 5.1] shows that there exists \(Z \in {\mathbb {C}}^{r \times n\times \dots \times n}\) such that
We observe that
As in the matrix case we obtain
Thanks to (anti-)symmetry we have
which yields
To conclude, we observe
and the result follows by an iteration of this argument. \(\square \)
We are now in the position to analyse the local error produced after one time step of the integrator.
Lemma 4
(Local error) The error of the (anti-)symmetric Tucker integrator after one time step satisfies
where \({{\hat{c}}}\) only depends on d and a bound of hL. In particular, the constant is independent of singular values of the exact or approximate solution.
Proof
By construction of the algorithm and by Lemma 3 we have
The problem reduces to estimating \(\Vert C_1 - A_1 {\textsf {X}}_{i=1}^d {{\mathbf {U}}}_1^* \Vert \). We introduce the tensor
which satisfies
In the same way as in the proof of Lemma 2 (replacing \({{\mathbf {S}}}\) by C) this is compared with the differential equation for C(t) in the second substep of the integrator. This yields the stated result. \(\square \)
Using the Lipschitz continuity of the function F, we conclude the proof of Theorem 6 from the local to the global errors by the standard argument of Lady Windermere’s fan [9, Section II.3].
6 Numerical experiments
In this section we show results of various numerical experiments. The computations were done using Matlab R2017a software with Tensor Toolbox package v2.6 [2] and TensorLab package v3.0 [23].
6.1 Addition of symmetric tensors: a computationally inexpensive retraction
Let \(A \in {\mathbb {C}}^{n \times \dots \times n}\) be a symmetric tensor of multi-linear rank \(\mathbf{r }=(r, \dots , r)\) and let \(B \in {\mathbb {C}}^{n \times \dots \times n}\). We consider the addition of two given tensors,
where \(C \in {\mathbb {C}}^{n \times \dots \times n}\) is not necessarily of low rank and we want to compute a symmetric rank-\((r,\dots ,r)\) approximation. Such a retraction is typically required in optimization problems on low-rank manifolds and needs to be computed in each iterative step of a descent algorithm. The approach considered here consists of reformulating the addition problem as the solution of the following differential equation at time \(t=1\):
We will compare the solution obtained by computing the full addition and retracting to the manifold of symmetric tensors of multilinear rank \((r,\dots ,r)\) with the one obtained from the application of the symmetric low-rank tensor integrator. The advantage of the latter method is that the approximation is built inside the manifold, so that no truncation to rank r is needed.
For our numerical example, we initialize A as a symmetric random Tucker tensor of size \(100 \times 100 \times 100\) and multi-linear rank \(\mathbf{r } = (10, 10, 10)\); we take B as an element in the tangent space of the symmetric rank-\(\mathbf{r }\) tensor manifold at A. We compare the dynamical low rank approximation \(Y_1\) generated by the algorithm introduced in Sect. 5 with a low rank symmetric retraction [6, 22] of the full solution denoted by X. For the last part, we use the built-in \(\texttt {tucker\_als}\) and \(\texttt {tucker\_sym}\) functions of the Tensor Toolbox Package.

We observe that the approximation \(Y_1\) shows the correct behavior, at reduced computational cost. Decreasing the norm of the tensor B decreases the approximation error as expected, proportional to \(\Vert B \Vert ^2\).
6.2 Robustness with respect to small singular values
We present two numerical examples and show robustness of the proposed symmetric integrator in the presence of small singular values. For the sake of presentation we consider the matrix case. Analogous examples can be implemented for Tucker tensors, and similar results are obtained.
In the first example, the time-dependent matrix is given explicitly as
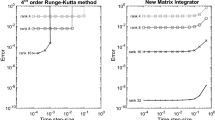
The matrix \(\mathbf{D } \in {{\mathbb {R}}}^{N \times N}\) is diagonal with elements \(d_j = 2^{-j}\) and the matrix \(\mathbf{W } \in {{\mathbb {R}}}^{N \times N}\) is skew-symmetric and randomly generated. We choose \(N=100\) and final time \(T=1\). We compare the symmetric low-rank integrator presented in Sect. 3 with a numerical solution obtained with a 4th order explicit Runge–Kutta method applied to the system of differential equations for dynamical low-rank approximation as derived in [12].

Comparison of the explicit Runge–Kutta method (left) and the proposed symmetry-preserving integrator (right) for different approximation ranks and step sizes in the case of a given time-dependent symmetric matrix
The numerical results for different ranks are shown in Fig. 1. In contrast to the Runge–Kutta method, the proposed symmetric low-rank integrator does not suffer of a step-size restriction in the presence of small singular values.
In the second example, we integrate the Lyapunov matrix differential equation (cf. [19])
Here, we choose \(\mathbf{A } = \texttt {tridiag}(-1,2,-1) \otimes \mathbf{I } + \mathbf{I } \otimes \texttt {tridiag}(-1,2,-1) \in {{\mathbb {R}}}^{N \times N}\) as a discrete Laplacian. The positive definite matrix \(\mathbf{Q } \in {{\mathbb {R}}}^{N \times N}\) has rank 5 and is randomly generated. The orthonormal matrix \(\mathbf{U }_0 \in {{\mathbb {R}}}^{N \times N}\) is randomly generated and \(\mathbf{S }_0 \in {{\mathbb {R}}}^{N \times N}\) is of rank 1 with only one non-zero element, \(s_{11} = 1 \).
The reference solution and the linear subproblems appearing in the definition of the symmetric low-rank integrator have been solved with the Matlab solver ode45 and stringent tolerance parameters {‘RelTol’, 1e–10, ‘AbsTol’, 1e–14}. We choose \(N=100\) and final time \(T=0.1\). The singular values of the reference solution and the absolute errors \(\Vert Y_n -A(t_n) \Vert _F\) at time \(t_n=T\) of the approximate solutions for different ranks calculated with different step-sizes are shown in Fig. 2. In both examples, the error behaviour of the symmetric integrator is similar to the error behaviour of the matrix projector splitting integrator, but the computational cost is approximately halved.

First twelve singular values of the reference solution at time \(T=0.1\) and approximation errors for different ranks at different step-sizes for the Lyapunov matrix differential equation
6.3 Ground state of a fermionic multi-particle system
A natural field of application of the (anti-)symmetric low-rank algorithms is in quantum dynamics of systems of fermions or bosons, which is described by anti-symmetric or symmetric multivariate wave functions, respectively. In the MCTDHF and MCTDHB methods [1, 4], the approximate wave function is sought for in the form of a low-rank Tucker tensor that is anti-symmetric and symmetric, respectively. It approximates the huge tensor of coefficients with respect to some fixed spatial basis, such as a Fourier basis. The (anti-)symmetric low-rank time integrator proposed in this paper appears ideally suited as a numerical integrator for such problems.
As a first illustration of the approach, we apply the method for the calculation of the ground state of a system of d fermions in 1 space dimension. We calculate the ground state as the solution for large time of the imaginary-time Schrödinger equation
We consider the Hamiltonian given by
where \(x_l \in {{\mathbb {R}}}\) represents the position of the lth particle and we choose the torsion potential
Choosing a collocation method with a tensor Fourier basis set (with K basis functions per particle) for approximating the anti-symmetric wave function leads to a huge tensor differential equation (7), where a low-rank approximation to the anti-symmetric d-dimensional tensor \(Y(t)\in {{\mathbb {C}}}^{K\times \dots \times K}\) is to be computed. This is done with a variational splitting method. The stiffness introduced by the Laplacian will be handled with a split-step Fourier method [15] while the two-particle interaction is treated with the anti-symmetric low-rank integrator of Sect. 5.
We introduce the space discretization
Let Y(t) be a time-dependent tensor defined element-wise by
The fermionic property of the system implies that the tensor Y(t) is anti-symmetric. Denoting \({\mathcal {F}}_K\) the Fourier matrix, we define
The Fourier collocation space discretization of (11) is equivalent to the system
Using the trigonometric equality \(\cos (x-y) = \cos (x)\cos (y) + \sin (x)\sin (y)\), the linear operator H can be written in a multi-linear product form as
In order to remove the stiffness introduced by the Laplacian, we split (12) in \((d+2)\) sub-problems. The solution of the first sub-problem at time \(t_1 = t_0 + h\) is obtained updating the core tensor \(C_0\) in the initial data,
Afterwards, we start considering the equation
We matricize in the first mode,
with initial data,
The solution can now be computed with the 1-dimensional split-step Fourier method. Denoting
and tensorizing back in the first mode we have that
Taking this as initial condition and iterating the same process for all the successive modes we obtain the updated anti-symmetric tensor
We now apply the anti-symmetric low-rank integrator to the multi-particle interaction,
where
The core \(C_0\) is renormalized after each step, since the absolute size of the tensor is irrelevant. We emphasize the fact that all along the implementation, it is crucial to use the structure of the Tucker tensor and avoid to build the huge matrix \(\mathbf{V }_0\) appearing in the definition of the integrator. The K and C problems are linear and can be solved with few iterations of the Arnoldi process.
In our numerical experiment we choose \(d=3\) particles in 1 space dimension and fix the number of Fourier basis functions per particle at \(K=128\), the step-size at \(h=0.01\) and we propagate the system until \(T=40\).
We introduce the discrete energy
Although the integrator preserves the anti-symmetry in theory, in a straightforward implementation round-off errors will destroy the anti-symmetry and take the system to the lowest state of energy: the bosonic ground state - the one achieved starting from a symmetric initial value. This behavior can be corrected in the integrator by enforcing the anti-symmetry of the small core tensor (which is violated only by round-off errors) at each step or ever after a few steps. In this way the computation tends to the fermionic ground state. The energy levels generated by the approximation of rank 5 are shown in Fig. 3 for the bosonic system and the fermionic system with and without enforced anti-symmetrization.

Evolution to the fermionic ground state energy computed with rank 5
6.4 MCTDHF: ultra fast laser dynamics
In the second example we consider the situation where an external pulsing laser field is introduced in the system. We refer to [4] for the physical description of the problem and its MCTDHF formulation. We consider the time-dependent Schrödinger equation
with the Hamiltonian
with the torsion potential V as before and with parameters
As initial value, we choose the ground-state calculated at the previous step. We fix the number of Fourier basis functions per particle at \(K=128\), the step-size at \(h=0.005\) and we propagate the system until \(T=1\) by the same algorithm as in the previous subsection, but this time for the real-time evolution instead of the imaginary-time evolution.
The time evolution of the energy obtained by the approximation of rank 5 is shown in Fig. 4. We are not in the position to provide standard error plots for this high dimensional example.

Energy evolution computed with rank 5
Notes
In view of the applications in quantum dynamics, we here consider tensors with complex entries.
References
Alon, O.E., Streltsov, A.I., Cederbaum, L.S.: Multiconfigurational time-dependent Hartree method for bosons: many-body dynamics of bosonic systems. Phys. Rev. A 77, 033613 (2008)
Bader, B.W., Kolda, T.G. et al.: Matlab tensor toolbox version 2.6. Available online (2015)
Bonfanti, M., Burghardt, I.: Tangent space formulation of the multi-configuration time-dependent Hartree equations of motion: the projector-splitting algorithm revisited. Chem. Phys. 515, 252–261 (2018)
Caillat, J., Zanghellini, J., Kitzler, M., Koch, O., Kreuzer, W., Scrinzi, A.: Correlated multielectron systems in strong laser fields: a multiconfiguration time-dependent Hartree–Fock approach. Phys. Rev. A 71, 012712 (2005)
De Lathauwer, L., De Moor, B., Vandewalle, J.: A multilinear singular value decomposition. SIAM J. Matrix Anal. Appl. 21(4), 1253–1278 (2000)
De Lathauwer, L., De Moor, B., Vandewalle, J.: On the best rank-1 and rank-\((R_1, R_2,\cdots, R_N)\) approximation of higher-order tensors. SIAM J. Matrix Anal. Appl. 21(4), 1324–1342 (2000)
Hackbusch, W.: On the representation of symmetric and antisymmetric tensors. In: Dick, J., Kuo, F.Y., Wozniakowski, H. (eds.) Contemporary Computational Mathematics—A Celebration of the 80th Birthday of Ian Sloan, vol. 1, 2, pp. 483–515. Springer, Cham (2018)
Hairer, E., Lubich, C., Wanner, G.: Geometric Numerical Integration. Structure-Preserving Algorithms for Ordinary Differential Equations, Volume 31 of Springer Series in Computational Mathematics, 2nd edn. Springer, Berlin (2006)
Hairer, E., Nørsett, S.P., Wanner, G.: Solving Ordinary Differential Equations. I. Nonstiff Problems, Volume 8 of Springer Series in Computational Mathematics, 2nd edn. Springer, Berlin (1993)
Kieri, E., Lubich, C., Walach, H.: Discretized dynamical low-rank approximation in the presence of small singular values. SIAM J. Numer. Anal. 54(2), 1020–1038 (2016)
Kloss, B., Burghardt, I., Lubich, C.: Implementation of a novel projector-splitting integrator for the multi-configurational time-dependent Hartree approach. J. Chem. Phys. 146(17), 174107 (2017)
Koch, O., Lubich, C.: Dynamical low-rank approximation. SIAM J. Matrix Anal. Appl. 29(2), 434–454 (2007)
Koch, O., Lubich, C.: Dynamical tensor approximation. SIAM J. Matrix Anal. Appl. 31(5), 2360–2375 (2010)
Kolda, T.G., Bader, B.W.: Tensor decompositions and applications. SIAM Rev. 51(3), 455–500 (2009)
Lubich, C.: From quantum to classical molecular dynamics: reduced models and numerical analysis. Zurich Lectures in Advanced Mathematics. European Mathematical Society (EMS), Zürich (2008)
Lubich, C.: Time integration in the multiconfiguration time-dependent Hartree method of molecular quantum dynamics. Appl. Math. Res. Express AMRX 2, 311–328 (2015)
Lubich, C., Oseledets, I.V.: A projector-splitting integrator for dynamical low-rank approximation. BIT 54(1), 171–188 (2014)
Lubich, C., Vandereycken, B., Walach, H.: Time integration of rank-constrained Tucker tensors. SIAM J. Numer. Anal. 56(3), 1273–1290 (2018)
Mena, H., Ostermann, A., Pfurtscheller, L.M., Piazzola, C.: Numerical low-rank approximation of matrix differential equations. J. Comput. Appl. Math. 340, 602–614 (2018)
Meyer, H.-D., Gatti, F., Worth, G.A.: Multidimensional Quantum Dynamics: MCTDH Theory and Applications. Wiley, London (2009)
Ostermann, A., Piazzola, C., Walach, H.: Convergence of a low-rank Lie-Trotter splitting for stiff matrix differential equations. SIAM J. Numer. Anal. 57(4), 1947–1966 (2019)
Regalia, P.A.: Monotonically convergent algorithms for symmetric tensor approximation. Linear Algebra Appl. 438(2), 875–890 (2013)
Vervliet, N., Debals, O., Sorber, L., Van Barel, M., De Lathauwer, L.: Tensorlab 3.0. (2016). www.tensorlab.net. Accessed Jan 2019
Acknowledgements
Open Access funding provided by Projekt DEAL. We thank Balázs Kovács and Hanna Walach for their constructive comments and suggestions. This work was supported by Deutsche Forschungsgemeinschaft, Graduiertenkolleg 1838 “Spectral Theory and Dynamics of Quantum Systems” and SFB 1173 “Wave Phenomena”.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Marko Huhtanen.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ceruti, G., Lubich, C. Time integration of symmetric and anti-symmetric low-rank matrices and Tucker tensors. Bit Numer Math 60, 591–614 (2020). https://doi.org/10.1007/s10543-019-00799-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10543-019-00799-8
Keywords
- Dynamical low-rank approximation
- (Anti-)symmetric matrices and tensors
- Tucker tensor format
- Projector-splitting integrator
- Matrix and tensor differential equations