
Abstract
Cannabis use disorder (CUD) co-occurs with major depressive disorder (MDD) more frequently than would be expected by chance. However, studies to date have not produced a clear understanding of the mechanisms underlying this co-morbidity. Genetically informative studies can add valuable insight to this problem, as they allow the evaluation of competing models of co-morbidity. This study uses data from the Australian Twin Registry to compare 13 co-morbidity twin models initially proposed by Neale and Kendler (Am J Hum Genet 57:935–953, 1995). The analysis sample comprised 2410 male and female monozygotic and dizygotic twins (average age 32) who were assessed on CUD and MDD using the SSAGA-OZ interview. Data were analyzed in OpenMx. Of the 13 different co-morbidity models, two fit equally well: CUD causes MDD and Random Multiformity of CUD. Both fit substantially better than the Correlated Liabilities model. Although the current study cannot differentiate between them statistically, these models, in combination, suggest that CUD risk factors may causally influence the risk to develop MDD, but only when risk for CUD is high.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Major depressive disorder (MDD) and Cannabis use disorder (CUD) are co-morbid (see Degenhardt et al. 2012) and highly relevant from a public health perspective. According to the latest Global Burden of Disease study in 2013, MDD was the 2nd leading cause of disability in the world (Ferrari et al. 2013), and the World Health Organization is now citing it as the leading one (WHO 2016). Heavy cannabis use is linked to several adverse health outcomes (Hall and Degenhardt 2009; Hall 2015), and is the most commonly used illicit drug (Agrawal and Lynskey 2014). The relationship between MDD and CUD is poorly understood, although individuals with co-morbid mental health and substance use disorders are particularly difficult to treat (Kessler 2004). Developing a greater understanding of the relationship between CUD and MDD is therefore important in order to help reduce the prevalence of both conditions through the efficient prevention and treatment of co-morbid cases.
Cross-sectional studies of general and clinical populations consistently show that CUD and MDD co-occur at a rate greater than chance (see Degenhardt et al. 2012 for a review). For instance, an epidemiological study of 43,093 US citizens showed that individuals with mood disorders (MDD, dysthymia, mania, hypomania) had 3.9 (95% CI 2.8–5.3) times higher odds of meeting criteria for lifetime cannabis abuse and dependence (Martins and Gorelick 2011). An epidemiological survey of 25,113 Canadian citizens reported that rates of past-year cannabis dependence among individuals who met 12 month MDD criteria were over 7.25 times higher compared to those who did not (Patten et al. 2015). Rates of past-year abuse were almost 3.6 times higher (Patten et al. 2015). Similar results have been found in clinical samples. For example, a recent study based on the Norwegian patient registry including 2,659,966 individuals, reported that levels of ICD-10 depressive illness were almost 3.9 times higher among individuals with CUD (12.85%), compared to the general population (3.3%, Nesvåg et al. 2015).
There have been several attempts, including longitudinal and genetic studies, to explain this pattern of co-morbidity. Most longitudinal studies have looked at the relationship between MDD and cannabis use, rather than CUD. Studies investigating non-heavy cannabis use have not been able to establish a clear causal link in either direction (e.g. Lev-Ran et al. 2014; Feingold et al. 2014; Cougle et al. 2015; Danielsson et al. 2016). However, heavy cannabis use is more consistently and more strongly associated with MDD. In a meta-analysis Lev-Ran et al. (2014) found a moderate (OR 1.62, 95% CI 1.21–2.16) increase in risk of developing depressive disorders following heavy cannabis use. The strongest statistically significant relationships have been observed between clinical levels of cannabis use and MDD, with cannabis abuse preceding MDD (OR 4.00, 95% CI 1.23–12.99, Bovasso 2001) and CUD preceding MDD (OR 2.54, 95% CI 1.40–4.60, Marmorstein et al. 2012). However, there is also some evidence of a bidirectional relationship, from baseline CUD to incident MDD (OR 1.78, 95% CI 1.17–2.71), as well as baseline MDD to incident CUD (OR 2.28, 95% CI 1.28–4.05; Pacek et al. 2013), while other studies have found no significant relationships (Harder et al. 2008; Feingold et al. 2014).
Overall, causal influences, mainly from CUD to MDD, may be present, but clear conclusions are precluded by the heterogeneity among studies, particularly in terms of the control for confounding factors. Feingold et al. (2014) found that cannabis users and non-users differed significantly on age, gender, household income and marital status. An early study by Fergusson and Horwood (1997) also demonstrated differences on a large number of factors, including childhood adversities, social disadvantage, contact with peers who engaged in substance use or delinquent behaviors, and psychological adjustment problems. Establishing causality in either direction therefore still requires further evidence.
Previous twin studies investigating this co-morbidity have been scarce, and offered mixed evidence. In a discordant twin study by Lynskey et al. (2004), there was a significant genetic correlation between cannabis dependence and MDD (men, r = 0.44, 95% CI = 0.17–1.00; women, r = 0.69, 95% CI 0.30–1.00), but cannabis dependence was not a unique causal factor for MDD. Among MZ twins discordant for cannabis dependence, the dependent twins did not have greater odds for MDD (OR 1.16, 95% CI 0.64–2.17). Lynskey et al. (2004) also found no evidence of causality in the opposite direction (OR 1.38, 95% CI 0.55–3.42). In contrast, Lin et al. (1996) reported that MZ twins with MDD were more likely to be cannabis dependent (OR 2.3, 95% CI 1.1–4.7), compared to their co-twins without MDD. Differences in results between these studies might be explained by differences in their samples. Lin et al.’s (1996) analysis sample, i.e. twins discordant for lifetime MDD, comprised 234 male veterans twin pairs, while Lynskey et al. (2004) examined a sample of 156 twin pairs from the general population, including both male and female same-sex twins. Additionally, Fu et al. (2002) found that antisocial personality disorder explained 62% of the genetic correlation between CUD and MDD in a multivariate twin study.
This mixed evidence suggests that the exact nature of the relationship between CUD and MDD warrants further study. One possibility to comprehensively investigate competing models of co-morbidity is to fit Neale and Kendler’s (1995) 13 co-morbidity models, which were based on the work of Klein and Riso (1993). Each model and each class of models makes different assumptions about the etiological mechanisms that lead to the co-morbidity. Four broad classes are examined: single liability, independent liability, multiformity and correlated liabilities. No other twin model approach examines such a large variety of model classes. If the co-morbid form arises from a single liability shared by CUD and MDD, the diagnostic boundary between MDD and CUD may have been artificially drawn, and they could be alternate forms of the same disorder. Alternatively, liability to the co-morbid form may be entirely independent: co-morbidity arises due to a third disorder, unrelated to the pure forms of MDD and CUD. Multiformity models suggest that the risk factors for CUD and MDD are unrelated, but once certain thresholds on the liability of one disorder are crossed, the risk of symptoms of the other disorder increases sharply. In other words, MDD and CUD influence each other in a discontinuous way, only once certain levels of risk are reached. In contrast, correlated liabilities models assume that liabilities between two disorders are related continuously, and etiological factors overlap. Any change in risk for one disorder is accompanied by a change in risk for the other disorder, whether this is due to shared risk factors or causality. In addition, the models test whether the co-morbidity observed in the population has occurred by chance.
The NK comorbidity models have been used to examine the relationship between a range of other substance-use phenotypes (Agrawal et al. 2004, 2007, 2010). Twin models of co-morbidity would also be a useful tool to study the relationship between cannabis involvement and depression (Agrawal and Lynskey 2014), as both MDD (e.g. Sullivan et al. 2000; Kendler et al. 2006a) and cannabis dependence (Lynskey et al. 2002; Verweij et al. 2010) are influenced by genetic factors.
To date, no study has examined all 13 models with respect to these phenotypes, although previous longitudinal and twin studies have produced conflicting findings regarding the relationship between MDD and CUD. Therefore, the current study aimed to fit all 13 NK co-morbidity models to examine the relationship between CUD and MDD in a cross-sectional sample of 2410 Australian twins born between 1972 and 1979.
Methods
Participants
From a sample of 4131 twin pairs included in the Australian Twin Registry, 3824 twins and non-twin siblings born between 1972 and 1979 were interviewed on cannabis use, related drug use and other psychopathology (see Lynskey et al. 2012 for further details of the sample). The analyses presented in this paper were conducted on twins only and required complete data from each twin pair for both phenotypes. Consequently, 2410 individual twins were included in the analysis sample: 565 (396 female, 169 male) complete MZ pairs and 640 (298 female–female, 118 male–male and 224 female–male) complete DZ twin pairs. The mean age of the sample was 32 years.
Measures
SSAGA-OZ interview
Computer-assisted telephone interviews based on the Australian version of Semi-Structured Assessment of the Genetics of Alcoholism (SSAGA-OZ; Bucholz et al. 1994) were used to assess twins on several variables. The SSAGA-OZ has been widely used in family studies of alcohol dependence and collects detailed information on patterns of DSM-IV (American Psychiatric Association 2000) symptomatology across a range of mental health and substance use disorders. Assessments of these disorders, including MDD and CUD, have been shown to have good reliability and validity (Bucholz et al. 1994). In order to keep the measures comparable to current literature, items were coded as close to DSM-5 (American Psychiatric Association 2013) as the available information allowed. Although coding the phenotypes as binary variables reduces statistical power, the co-morbidity models were developed for and can currently only be fitted to binary data.
Cannabis Use Disorder: Participants were assessed on DSM-IV Cannabis Abuse/Dependence criteria. Abuse items included “hazardous use”, “social/interpersonal problems related to use”, “neglecting major roles to use” and “legal problems”. Dependence items included “tolerance”, “using larger amounts or using longer”, “repeated attempts to quit or control use”, “much time spent using”, “physical or physiological problems related to use”, and “activities given up to use”. In addition, an assessment of cannabis withdrawal was available (see Verweij et al. 2013). However, no assessment of “craving”, a criterion introduced in DSM-5, was available for this sample. CUD was coded as a binary phenotype. To approximate DSM-5 criteria, individuals were coded as 1 (“affected”) if they reported at least 2 symptoms of DSM-5 CUD, except for “craving”. The remaining participants were coded as 0 (“unaffected”), whether or not they reported a lifetime history of cannabis use. The “legal problems” criterion was removed from DSM-5 and therefore was not included in our definition of CUD.
Major Depressive Disorder: Participants were assessed on the following DSM-IV symptoms of MDD: “depressed or irritable mood”, “loss of pleasure”, “change in appetite or weight”, “change in sleep”, “energy loss or fatigue”, “change in psychomotor activity”, “feelings of guilt or worthlessness”, “difficulty concentrating or making decisions”, and “suicidal ideation”.
MDD was also coded as a binary phenotype. The participant was coded as 1 (“affected”) if they experienced 5 or more of the above symptoms for over 2 weeks, including depressed/irritable mood or loss of pleasure. Participants were not coded as having MDD if they met the following exclusion criteria: (i) their symptoms did not affect functioning in any area of life, or (ii) they occurred within 2 months of bereavement, (iii) within 1 month of using tranquilizers, blood pressure medication or steroids, or (iv) just after having used illegal drugs, alcohol or tobacco. As there have been no major changes in the diagnostic criteria for MDD between DSM-IV and DSM-5, the coding was representative of DSM-5 MDD.
Statistical models
A summary of all models can be found in Table 1. Each model makes different assumptions about the way in which co-morbid cases arise. A detailed discussion of each model can be found in Neale and Kendler (1995) and Rhee et al. (2004).
Because both phenotypes were coded as binary variables, the foundation of each co-morbidity model was a normal liability threshold model, which is based on the multifactorial theory of inheritance (Falconer 1965).
Similar to widely used liability threshold models, all models estimate genetic (A), shared (C) and non-shared environmental (E) factors. D was not estimated in the current sample, because the difference between MZ and DZ correlations indicated an ACE model. However, there are several important differences between models:
-
1.
The models differ in the number of liability distributions they assume. For instance, the Alternate Forms model assumes that both phenotypes arise from one distribution of liability. In contrast, the Three Independent Disorders model assumes that there are three underlying liability distributions. Two of those give rise to the pure forms of the phenotypes, and one gives rise to the co-morbid form.
-
2.
The models differ in the way in which the above-mentioned liabilities produce the phenotype. For example, in the Alternate Forms model, an individual develops co-morbid CUD and MDD by crossing the threshold on the shared liability distribution. However, in the Three Independent Disorders model, an individual can develop CUD and MDD if they cross the threshold on the CUD-specific and MDD-specific distribution at the same time, or if they do so on the liability distribution for the co-morbid form.
-
3.
One model, the Extreme Multiformity Model, also differs from all others in the number of thresholds it assumes. Under the assumptions of this model, each liability distribution has two thresholds. If an individual crosses the first threshold, they only develop the pure form of a disorder. Crossing the second threshold means that the individual develops the co-morbid form. Consequently, co-morbidity arises if an individual crosses the first threshold on both liability distributions, the second threshold on one liability distribution (e.g. CUD), and/or the other distribution (e.g. MDD).
Data analysis
Data analysis was conducted using OpenMx (Neale et al. 2016) for R statistical software (R Core Team 2014). The input to each model was a frequency table, which summarized the number of twin pairs fitting into 10 MDD-CUD co-morbidity categories (see Table 2). Each twin pair member was assigned to one of four disease state categories: MDD but no CUD (i.e. 1 0), no MDD, but CUD (i.e. 0 1), both MDD and CUD (i.e. 1 1), and neither (i.e. 0 0). Thereafter, twin disease states were combined (i.e. 0 0 0 1). Although there are 16 different combinations of co-twin disease states, information about twin order was disregarded to avoid low cell counts. For instance, “0 0 1 0” (see Table 2) is a category that contains cases where twin 1 only (i.e. 1 0 0 0) or twin 2 only (i.e. 0 0 1 0) was affected by MDD. Subsuming all replicating disease states resulted in ten categories.
For every model, the number of twin pairs expected in each of the 10 categories was based on the assumptions of the model. Maximum likelihood estimation was used to minimize the difference between the observed number of cases in each co-morbidity category and the expected number according to the model. A chi-squared goodness-of-fit (χ2) test compared these observed and expected values, and indicated model fit. The p value of the χ2 test was used to reject models whose predicted data was significantly different from the observed data. The best fitting and most parsimonious model was chosen based on the Akaike Information Criterion (AIC; Akaike 1987). According to Burnham and Anderson (2002) an AIC difference of 3 and over indicates that the model with the lower AIC has substantially more support.
Results
In the analysis sample, 15.4% (11.9% of females, 22.6% of males) met criteria for lifetime CUD and 26.1% (29.5% of females, 19.2% of males) met criteria for lifetime MDD. Females had a significantly higher prevalence of MDD (OR 1.77, 95% CI 1.44–2.17) and lower prevalence of CUD (OR 0.46, 95% CI 0.37–0.58). CUD was almost twice as frequent in individuals with lifetime MDD (24.3%), compared to those without (12.3%). The odds ratio, adjusted for sex and age, was 2.66 (95% CI 2.10–3.37).
A conditional logistic regression of MZ twin pairs discordant for CUD showed that MZ twins with CUD had significantly elevated rates of MDD (46.0%) relative to their co-twin who did not have CUD (28.12%; OR 2.83, 95% CI 1.12–7.19; N = 63 MZ pairs).
The model-fitting results are summarized in Table 3. In addition to the 13 co-morbidity models, we included a saturated model based on twin correlations for comparison. Five models can be rejected, due to the large, statistically significant differences between the observed cell counts within the co-morbidity categories (see Table 2) and the cell counts expected under the model: the Chance, Alternate Forms, Three Independent Disorders, RM of MDD, and EM of MDD models.
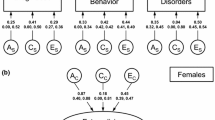
The only models that do not have substantially less support than the saturated model (i.e. an AIC difference larger than 3) are the RM of CUD (model 5) and CUD causes MDD (model 12) models (see Fig. 1a, b), with differences of 2.30 and 2.34 respectively. Both models have substantially more support than the Correlated Liabilities model.

Parameter estimates from best fitting co-morbidity models: a Random Multiformity of CUD, b Causation—CUD causes MDD. r probability of MDD phenotype if above threshold on CUD liability, i CUD regression coefficient, *Significant at the 0.05 level
These two best fitting models are, however, not substantially different from some of the models within their class. The RM of CUD model is not substantially different from the Random Multiformity model. The CUD causes MDD model is not substantially different from the MDD causes CUD and Reciprocal Causation model. Additionally, both models do not substantially differ from the Extreme Multiformity model.
In the best fitting models both CUD and MDD are influenced by genetic and non-shared environmental factors. In the case of CUD, 79–80% of the total variance is estimated to be explained by genetic factors and 20–21% by non-shared environmental factors. For MDD, 43–48% of the total variance is explained by genetic, 52–57% by non-shared environmental factors. Model-fit did not significantly deteriorate when C was dropped from both models. Parameter estimates from all models can be found in Table 4.
Discussion
To our knowledge, this study is the first to fit the 13 co-morbidity models proposed by Neale and Kendler (1995) to cannabis use disorder and major depressive disorder. Both epidemiological and discordant twin analyses confirmed that these models were appropriate for the current sample. In line with other cross-sectional studies (see e.g. Degenhardt et al. 2012) epidemiological analyses showed that CUD and MDD were significantly co-morbid. Discordant twin analyses, which will be discussed further below, showed that causal processes could not be excluded as an explanation for this co-morbidity, because MZ twins with CUD were significantly more likely to display symptoms of MDD than their co-twin without CUD. Therefore, there was sufficient reason to further explore causality in the co-morbidity model analyses.
The two best-fitting models were Random Multiformity of CUD and CUD causes MDD. Both models fit substantially better than the Correlated Liabilities model, and not substantially worse than the Saturated model. In addition, five models could be statistically rejected: the Alternate Forms, Chance, Three Independent Disorders, RM of MDD and EM of MDD models. The heritability estimates in the best fitting models range from 79 to 80% for CUD and 43 to 49% for MDD.
Model-fitting
These model-fitting results suggest that the direction of effect goes from CUD to MDD. Firstly, both RM of MDD and EM of MDD can be statistically rejected. It seems plausible, therefore, that the fit of the bi-directional Random Multiformity and Extreme Multiformity models is driven by the paths they have in common with RM of CUD and EM of CUD, respectively. Secondly, the CUD causes MDD fits better than the MDD causes CUD model. Although this difference is not substantial, the fit of the MDD causes CUD model may reflect that Direction of Causation models are difficult to distinguish when modes of inheritance of the disorders are similar (Heath et al. 1993). In the current study, this may be because both disorders are mainly influenced by A and E, rather than by different etiological factors (e.g. A C E vs. A E). Lastly, the MDD causes CUD model, along with all other models with a direction of effect from MDD to CUD, was a substantially poorer fit than the Saturated Model.
It is unclear, however, which of the two best-fitting models is more likely. The CUD causes MDD model assumes that the liability to develop MDD symptoms increases continuously, as the risk of CUD increases. The threshold in this model does not equal a sudden increase in risk, which means that even sub-threshold increases in liability to CUD have a causal influence on the liability to develop MDD (Rhee et al. 2004). On the other hand, the RM of CUD model assumes that the risk of MDD symptoms increases discontinuously, once the threshold on the CUD liability has been passed (i.e. an individual has reached a liability high enough to develop the disorder). An additional difference between the models is their assumption about etiological processes. The causal model assumes that any causal processes occur at the level of the liability (Rhee et al. 2004), while the RM models remain agnostic about the way in which one disorder leads to symptoms of the other.
Despite some differences, the RM of CUD and CUD causes MDD models are not incompatible. Causality may play a role, and the good fit of the RM of CUD model may indicate that the causal influences on the risk of MDD only occur at higher levels of CUD risk (i.e. post-threshold). Additionally, it is likely that there are shared etiological factors between CUD and MDD. Evidence from twin (Fu et al. 2002; Lynskey et al. 2004) and molecular genetic studies (Bobadilla et al. 2013; Sherva et al. 2016; Hodgson et al. 2016) suggests that there are genetic factors influencing both cannabis involvement and MDD. There is also a plethora of environmental factors that act as risk factors for both (e.g. Fergusson and Horwood 1997; Feingold et al. 2014). Overall, the almost identical fit of both models may indicate that there are threshold-dependent causal links from CUD to MDD, which occur at the level of liability.
This interpretation is compatible with several findings. Risk factors for CUD, such as heavy cannabis use, are likely to exert an environmental and genetic effect on MDD. Heavy cannabis use can alter various domains of cognitive functioning, such as attention and memory (Solowij 2002), and thereby affect daily functioning and potentially create circumstances in which individuals are more likely to develop MDD. For instance, cannabis use impacts negatively on educational attainment (Lynskey and Hall 2000), which in turn may affect emotional wellbeing. Environmental effects may also manifest themselves through changes in brain structure and function. Heavy cannabis users show a decrease in amygdala volumes (Yucel et al. 2008), which is also the case in un-medicated patients with MDD (Hamilton et al. 2008). Furthermore, the endocannabinoid system, primary site of the neurochemical effects of cannabis, is thought to be involved in mood regulation (Ashton and Moore 2011). Genes may modulate these environmental influences. Lastly, the conclusion that causal processes may be at work in individuals at high risk for CUD (e.g. high levels of cannabis use), also fits well with longitudinal studies which show that high levels of cannabis use are more strongly associated with MDD than lower levels.
Heritability estimates
The heritability estimates obtained from the models are similar to other twin studies for MDD (Sullivan et al. 2000; Kendler et al. 2006b), and to studies on cannabis abuse/dependence that included similar samples. Kendler et al. (2006a) report a heritability estimate of 77% (95% CI 46–93%) for DSM-IV cannabis abuse/dependence in a sample of same-sex and opposite-sex twins with a mean age of 28.2. While a meta-analysis on twin studies reporting at least 1 symptom of abuse/dependence, presents lower heritability estimates [males: 54.4% (95% CI 37.9–64.9%), females: 58.5 (95% CI 44.2%–72.9%), Verweij et al. 2010], the higher estimate obtained in the current may be related to differences in sampling or the definition of problematic cannabis use.
Limitations and future research
Difficulties in differentiating between models were a known limitation, based on previous studies. Rhee et al. (2004) provide a detailed discussion of general limitations of the NK model fitting approach. Although Rhee et al. (2004) demonstrated that the NK approach to discriminating between different models of co-morbidity is valid; they did so with a large simulated sample and still noted several challenges. They highlighted that it is particularly difficult to discriminate between the multiformity and the correlated liabilities model classes, which was also the case in the current sample. Additionally, Rhee et al. (2004) pointed out that discrimination within subclasses of models (e.g. RM vs. RM of CUD) is also problematic. In the current analyses, the difference within subclasses was often not more than 3 AIC. It may be beneficial to replicate the study with larger samples or use meta-analysis to examine whether differences between models become more distinct. Replication of our results would be useful to explore whether the results of the current study are cohort-specific or generalize across cohorts, but is outside the scope of the present study.
One limitation of the current study is that sex differences have not been taken into account. The prevalence of MDD and CUD did differ between males and females in the analysis sample, but currently all co-morbidity models can only be fitted on contingency tables, in which it was not possible to specify separate thresholds for males and females. The alternative approach of fitting separate models for males and females was not feasible due to lack of power. However, there are currently no grounds to assume that different co-morbidity models would explain co-morbid cases in males and females. For instance, Agrawal et al. (2010) examined the co-morbidity between cannabis and tobacco use, and fitted separate models for male and female twins. They found that model fits were very similar for both sexes. It may be an interesting avenue for future research to explore sex differences in larger samples or using meta-analysis.
Given that one of the best-fitting models makes assumptions about causality, it is also an important limitation that the data are retrospective and age of onset was not considered in the analyses. Using retrospective data has several disadvantages (see e.g. Coughlin 1990), but for the current analyses the most pertinent drawback is that longitudinal data would be better suited to test direction of causation. Beyond twin models, recent molecular genetic methods also offer an interesting avenue to assess causality (see Pickrell et al. 2016).
Finally, the discordant twin results are difficult to interpret due to the small number of MZ twin pairs discordant for CUD. The results are in contrast to study results in Lynskey et al. (2004) and in line with those in Lin et al. (1996), but overall they are not entirely comparable to either: both studies examined cannabis dependence rather than CUD. To conclusively examine whether causal processes can be excluded using the discordant twin method, larger sample sizes would be necessary. However, for the purposes of the current study, the main intention was establishing that causal processes could not be ruled out within the current data set.
A valuable next step would be the inclusion of known confounding factors. As mentioned above, Fu et al. (2002) have found that antisocial personality disorder, while being comparatively rare (Coid et al. 2006) and therefore unlikely to explain most co-morbid cases, is a significant confounder in the genetic relationship between cannabis dependence and MDD. Moreover, longitudinal studies have highlighted that cannabis users and non-users differ on a number of domains (Fergusson and Horwood 1997; Feingold et al. 2014). As such, it would be valuable to examine which models provide the best fit when confounding factors are included.
Conclusion
Overall, the model fitting approach has been a beneficial indicator of the likely relationship between CUD and MDD. While it was not possible to statistically differentiate between the two best fitting models RM of CUD and CUD causes MDD, they both seem to indicate that the direction of influence goes from CUD to MDD. Combined, the models suggest that CUD risk factors may cause MDD symptoms, but only in higher risk individuals. In addition, several models can be statistically excluded: CUD and MDD are not likely to be co-morbid by chance, arise from the same risk factors, or be due to a liability separate from the pure form of the disorders. The fact that a Random Multiformity model is the best fitting model is remarkable, because this model is not widely reported. Replications on larger samples would be beneficial in order to help differentiate between models with subtle differences.
References
Agrawal A, Lynskey MT (2014) Cannabis controversies: how genetics can inform the study of comorbidity. Addiction 109:360–370. doi:10.1111/add.12436
Agrawal A, Neale MC, Prescott CA, Kendler KS (2004) Cannabis and other illicit drugs: comorbid use and abuse/dependence in males and females. Behav Genet 34:217–228. doi:10.1023/B:BEGE.0000017868.07829.45
Agrawal A, Lynskey MT, Bucholz KK et al (2007) Contrasting models of genetic co-morbidity for cannabis and other illicit drugs in adult Australian twins. Psychol Med 37:49–60. doi:10.1017/S0033291706009287
Agrawal A, Silberg JL, Lynskey MT et al (2010) Mechanisms underlying the lifetime co-occurrence of tobacco and cannabis use in adolescent and young adult twins. Drug Alcohol Depend 108:49–55. doi:10.1016/j.drugalcdep.2009.11.016
Akaike H (1987) Factor analysis and AIC. Psychometrika 52:317–332. doi:10.1007/BF02294359
American Psychiatric Association (2000) Diagnostics and statistical manual of mental disorders, 4th edn. American Psychiatric Association, Washington
American Psychiatric Association (2013) Diagnostics and Statistical Manual of Mental Disorders, 5th edn. American Psychiatric Association, Washington
Ashton CH, Moore PB (2011) Endocannabinoid system dysfunction in mood and related disorders. Acta Psychiatr Scand 124:250–261. doi:10.1111/j.1600-0447.2011.01687.x
Bobadilla L, Vaske J, Asberg K (2013) Dopamine receptor (D4) polymorphism is related to comorbidity between marijuana abuse and depression. Addict Behav 38:2555–2562. doi:10.1016/j.addbeh.2013.05.014
Bovasso GB (2001) Cannabis abuse is a risk factor for depressive symptoms. Am J Psychiatry 158:2033–2037. doi:10.1176/appi.ajp.158.12.2033
Bucholz KK, Cadoret R, Cloninger CR et al (1994) A new, semi-structured psychiatric interview for use in genetic linkage studies: a report on the reliability of the SSAGA. J Stud Alcohol 55:149–158. doi:10.15288/jsa.1994.55.149
Burnham KP, Anderson DR (2002) Model selection and multimodel inference: a practical information-theoretic approach, 2nd edn. Springer-Verlag, New York
Coid J, Yang M, Tyrer P et al (2006) Prevalence and correlates of personality disorder in Great Britain. Br J Psychiatry 188:423–431. doi:10.1192/bjp.188.5.423
Coughlin SS (1990) Recall bias in epidemiologic studies. J Clin Epidemiol 43:87–91. doi:10.1016/0895-4356(90)90060-3
Cougle JR, Hakes JK, Macatee RJ et al (2015) Quality of life and risk of psychiatric disorders among regular users of alcohol, nicotine, and cannabis: an analysis of the national epidemiological survey on alcohol and related conditions (NESARC). J Psychiatr Res 66:135–141. doi:10.1016/j.jpsychires.2015.05.004
Danielsson A-K, Lundin A, Agardh E et al (2016) Cannabis use, depression and anxiety: A 3-year prospective population-based study. J Affect Disord 193:103–108. doi:10.1016/j.jad.2015.12.045
Degenhardt L, Hall W, Lynskey M, et al (2012) The association between cannabis use and depression: a review of the evidence. In: Castle D, Murray RM (eds) Marijuana and madness: psychiatry and neurobiology, 2nd edn. Cambridge University Press, Cambridge, pp 115–128
Falconer DS (1965) The inheritance of liability to certain diseases, estimated from the incidence among relatives. Ann Hum Genet 29:51–76. doi:10.1111/j.1469-1809.1965.tb00500.x
Feingold D, Weiser M, Rehm J, Lev-Ran S (2014) The association between cannabis use and mood disorders: a longitudinal study. J Affect Disord 172:211–218. doi:10.1016/j.jad.2014.10.006
Fergusson DM, Horwood LJ (1997) Early onset cannabis use and psychosocial adjustment in young adults. Addiction 92:279–296. doi:10.1111/j.1360-0443.1997.tb03198.x
Ferrari AJ, Charlson FJ, Norman RE et al (2013) Burden of depressive disorders by country, sex, age, and year: findings from the global burden of disease study 2010. PLoS Med. doi:10.1371/journal.pmed.1001547
Fu Q, Heath AC, Bucholz KK et al (2002) Shared genetic risk of major depression, alcohol dependence, and marijuana dependence: contribution of antisocial personality disorder in men. Arch Gen Psychiatry 59:1125–1132. doi:10.1001/archpsyc.59.12.1125
Hall W (2015) What has research over the past two decades revealed about the adverse health effects of recreational cannabis use? Addiction 110:19–35. doi:10.1111/add.12703
Hall W, Degenhardt L (2009) Adverse health effects of non-medical cannabis use. The Lancet 374:1383–1391. doi:10.1016/S0140-6736(09)61037-0
Hamilton JP, Siemer M, Gotlib IH (2008) Amygdala volume in major depressive disorder: a meta-analysis of magnetic resonance imaging studies. Mol Psychiatry 13:993–1000. doi:10.1038/mp.2008.57
Harder VS, Stuart EA, Anthony JC (2008) Adolescent cannabis problems and young adult depression: Male-female stratified propensity score analyses. Am J Epidemiol 168:592–601. doi:10.1093/aje/kwn184
Heath AC, Kessler RC, Neale MC et al (1993) Testing hypotheses about direction of causation using cross-sectional family data. Behav Genet 23:29–50. doi:10.1007/BF01067552
Hodgson K, Almasy L, Knowles EEM et al (2016) The genetic basis of the comorbidity between cannabis use and major depression. Addiction. doi:10.1111/add.13558
Kendler KS, Aggen SH, Tambs K, Reichborn-Kjennerud TED (2006a) Illicit psychoactive substance use, abuse and dependence in a population-based sample of Norwegian twins. Psychol Med 36:955–962. doi:10.1017/S0033291706007720
Kendler KS, Gatz M, Gardner CO, Pedersen NL (2006b) A Swedish national twin study of lifetime major depression. Am J Psychiatry 163:109–114. doi:10.1176/appi.ajp.163.1.109
Kessler RC (2004) The epidemiology of dual diagnosis. Biol Psychiatry 56:730–737. doi:10.1016/j.biopsych.2004.06.034
Klein DN, Riso LP (1993) Psychiatric disorders: problems of boundaries and comorbidity. In: Costello CG (ed) Basic issues in psychopathology. Guildford, New York, pp 19–66
Lev-Ran S, Roerecke M, Le Foll B et al (2014) The association between cannabis use and depression: a systematic review and meta-analysis of longitudinal studies. Psychol Med 44:797–810. doi:10.1017/S0033291713001438
Lin N, Eisen SA, Scherrer JF et al (1996) The influence of familial and non-familial factors on the association between major depression and substance abuse/dependence in 1874 monozygotic male twin pairs. Drug Alcohol Depend 43:49–55. doi:10.1016/S0376-8716(96)01287-2
Lynskey M, Hall W (2000) The effects of adolescent cannabis use on educational attainment: a review. Addiction 95:1621–1630. doi:10.1046/j.1360-0443.2000.951116213.x
Lynskey MT, Heath AC, Nelson EC et al (2002) Genetic and environmental contributions to cannabis dependence in a national young adult twin sample. Psychol Med 32:195–207. doi:10.1017/S0033291701005062
Lynskey MT, Glowinski AL, Todorov AA et al (2004) Major depressive disorder, suicidal ideation, and suicide attempt in twins discordant for cannabis dependence and early-onset cannabis use. Arch Gen Psychiatry 61:1026–1032. doi:10.1016/S0084-3970(08)70083-5
Lynskey MT, Agrawal A, Henders A et al (2012) An Australian twin study of cannabis and other illicit drug use and misuse, and other psychopathology. Twin Res Hum Genet 15:631–641. doi:10.1017/thg.2012.41
Marmorstein NR, Iacono WG, McGue M (2012) Associations between substance use disorders and major depression in parents and late adolescent-emerging adult offspring: an adoption study. Addiction 107:1965–1973. doi:10.1111/j.1360-0443.2012.03934.x
Martins SS, Gorelick DA (2011) Conditional substance abuse and dependence by diagnosis of mood or anxiety disorder or schizophrenia in the U.S. population. Drug Alcohol Depend 119:28–36. doi:10.1016/j.drugalcdep.2011.05.010
Neale MC, Kendler KS (1995) Models of comorbidity for multifactorial disorders. Am J Hum Genet 57:935–953
Neale MC, Hunter MD, Pritikin JN et al (2016) OpenMx 2.0: Extended structural equation and statistical modeling. Psychometrika 81:535–549. doi:10.1007/s11336-014-9435-8
Nesvåg R, Knudsen GP, Bakken IJ et al (2015) Substance use disorders in schizophrenia, bipolar disorder, and depressive illness: a registry-based study. Soc Psychiatry Psychiatr Epidemiol 50:1267–1276. doi:10.1007/s00127-015-1025-2
Pacek LR, Martins SS, Crum RM (2013) The bidirectional relationships between alcohol, cannabis, co-occurring alcohol and cannabis use disorders with major depressive disorder: results from a national sample. J Affect Disord 148:188–195. doi:10.1016/j.jad.2012.11.059
Patten SB, Williams JVA, Lavorato DH et al (2015) Descriptive epidemiology of major depressive disorder in Canada in 2012. Can J Psychiatry 60:23–30. doi:10.1177/070674371506000106
Pickrell JK, Berisa T, Liu JZ et al (2016) Detection and interpretation of shared genetic influences on 42 human traits. Nat Genet 48:709–717
R Core Team (2014) R: A language and environment for statistical computing, Vienna, Austria
Rhee SH, Hewitt JK, Lessem JM et al (2004) The validity of the neale and kendler model-fitting approach in examining the etiology of comorbidity. Behav Genet 34:251–265. doi:10.1023/B:BEGE.0000017871.87431.2a
Sherva R, Wang Q, Kranzler H et al (2016) Genome-wide association study of cannabis dependence severity, novel risk variants, and shared genetic risks. JAMA Psychiatry 73:472–480. doi:10.1001/jamapsychiatry.2016.0036
Solowij N (2002) cognitive functioning of long-term heavy cannabis users seeking treatment. J Am Med Assoc 287:1123–1131. doi:10.1001/jama.287.9.1123
Sullivan PF, Neale MC, Kendler KS (2000) Reviews and overviews genetic epidemiology of major depression: review and meta-analysis. JAMA 287:1552–1562. doi:10.1176/appi.ajp.157.10.1552
Verweij KJH, Zietsch BP, Lynskey MT et al (2010) Genetic and environmental influences on cannabis use initiation and problematic use: a meta-analysis of twin studies. Addiction 105:417–430. doi:10.1111/j.1360-0443.2009.02831.x
Verweij KJH, Agrawal A, Nat NO et al (2013) A genetic perspective on the proposed inclusion of cannabis withdrawal in DSM-5. Psychol Med 43:1713–1722. doi:10.1017/S0033291712002735
WHO (2016) Depression. In: World Health Organization http://www.who.int/mediacentre/factsheets/fs369/en/. Accessed 30 Aug 2016
Yucel M, Solowij N, Respondek C et al (2008) Regional brain abnormalities associated with long-term heavy cannabis use. Arch Gen Psychiatry 65:694–701. doi:10.1001/archpsyc.65.6.694
Acknowledgements
This research was funded by National Institute on Drug Abuse (NIDA) Grant: DA18267 (ML) and facilitated through access to the Australian Twin Registry. Twins Research Australia receives support from the National Health and Medical Research Council through a Centre of Research Excellence Grant, which is administered by the University of Melbourne. MS is supported by the IoP/MRC Excellence Studentship, and AA acknowledges support from R01DA040411 and K02DA032573. JB was funded by two grants awarded to Michael Neale, R01DA018673 and T32MH65322. We thank Michael Neale for his help, and for work on the OpenMx scripts used in the analyses. We would also like to thank Richard Parker, Soad Hancock, Judith Moir, Sally Rodda, Pieta-Maree Shertock, Heather Park, Jill Wood, Pam Barton, Fran Husband, and Adele Somerville, who worked on this project and the twins and their siblings for participating.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Human and animal rights and Informed consent
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards. Informed consent was obtained from all individual participants included in the study.
Additional information
Edited by Michael Lyons.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Smolkina, M., Morley, K.I., Rijsdijk, F. et al. Cannabis and Depression: A Twin Model Approach to Co-morbidity. Behav Genet 47, 394–404 (2017). https://doi.org/10.1007/s10519-017-9848-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10519-017-9848-0