
Abstract
Within seismology, geology, civil and structural engineering, deep learning (DL), especially via generative adversarial networks (GANs), represents an innovative, engaging, and advantageous way to generate reliable synthetic data that represent actual samples’ characteristics, providing a handy data augmentation tool. Indeed, in many practical applications, obtaining a significant number of high-quality information is demanding. Data augmentation is generally based on artificial intelligence (AI) and machine learning data-driven models. The DL GAN-based data augmentation approach for generating synthetic seismic signals revolutionized the current data augmentation paradigm. This study delivers a critical state-of-art review, explaining recent research into AI-based GAN synthetic generation of ground motion signals or seismic events, and also with a comprehensive insight into seismic-related geophysical studies. This study may be relevant, especially for the earth and planetary science, geology and seismology, oil and gas exploration, and on the other hand for assessing the seismic response of buildings and infrastructures, seismic detection tasks, and general structural and civil engineering applications. Furthermore, highlighting the strengths and limitations of the current studies on adversarial learning applied to seismology may help to guide research efforts in the next future toward the most promising directions.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In many practical applications, obtaining a significant number of high-quality data can be challenging for many reasons. However, adopting generative adversarial networks (GANs) in seismology, geology, or civil and structural engineering is a promising way to generate synthetic data reproducing actual samples’ characteristics. Data augmentation based on artificial intelligence (AI) and machine learning (ML) data-driven models is altering current paradigms rooted in e.g. synthetic finite element model-based simulations. Among them, valuable applications are related to the AI-based synthetic generation of ground motion signals and seismic events. To the authors’ knowledge, there are no review studies on using GANs in the seismic field. Therefore, the current work’s primary purpose is to provide a critical overview of the existing literature for the first time. This study hopes to help clarify and classify the existing studies, thus supporting the readers, researchers, and practitioners when approaching this area of research. The present document is organized as follows. Before moving toward the existing literature studies, an introduction to the currently available and current GAN models is provided in Sect. 2. Then, a general overview is provided in Sect. 3 according to the bibliometric records existing in Scopus until July 2022. A more comprehensive insight and discussion into the various literature records is finally provided in Sect. 4.
2 Current GAN models
In 2014, for the first time the study entitled “Generative adversarial nets” (Goodfellow et al. 2014) appeared and echoed a revolution in the deep learning (DL) field. The authors introduced for the first time the novel architecture of GANs, which is based on adversarial learning and adopts two different models in the spirit of a minimax problem, as depicted in Fig. 1. Specifically, a first model called generator (G) produces new samples from random noise (latent space) which appear very similar to the real ones after training. It attempts to reproduce the probability distribution of real data. On the other hand, a second model called discriminator (D) distinguishes between real or fake data. This structure resembles the so-called minimax problem. It can be heuristically explained as a two-people zero-sum game (Wang et al. 2017). In this game, at the end of the training phase, the total gains are zero for both the players, and the loss or gain of the utility of each player stalls to a balanced level. The game, therefore, stops when a Nash trade-off equilibrium has been reached. This means that the generator G learned so well the probability distribution of input data \(p_{\text{data}}(\varvec{x})\) to produce a sample that the discriminator is no more able to distinguish from real ones (Ratliff et al. 2013). Thus, the optimal training of a GAN can be formulated as a minimax problem. In formulae, setting the probability of noise \(p_{\varvec{z}}(\varvec{z})\), the generator performs a mapping \(G(\varvec{z})\) between a differentiable function of learnable parameters. Parallelly, the discriminator provides a mapping \(D(\varvec{x})\), which establishes the probability of \(\varvec{x}\) to come from the real data or the fake generated data. The main goal is, therefore, to solve an optimization problem in which D tries to maximize \(\log [D(\varvec{x})]\), and on the contrary, G attempts to minimize \(\log [1-G(\varvec{z})]\):
where \(E_{x\sim p_{\text{data}}(x)}\) stands for the expected values of all real data occurrence correctly classified from the \(D(\varvec{x})\), which assumes a likelihood meaning, and \( E_{z\sim p_{\varvec{z}}}\) is the expected value on all the fake samples generated by \(G(\varvec{z})\). In this way, they actually not require any use of Markov chains (Goodfellow et al. 2014).
GANs models have been further applied in many scientific and engineering sectors due to their decisive success in the research of generative models field. They have been employed both for supervised or semi-supervised applications (Ratliff et al. 2013), even for data augmentations and synthetic data generation. When convolutional layers are used in the generator and discriminator sub-parts, the network is also acknowledged as deep convolutional (DCGAN) (Radford et al. 2015). Despite the young age, many variants of GANs have already been proposed in the literature. The two most famous architectures are the conditional GAN (cGAN) (Mirza and Osindero 2014), based on conditional supervised learning, and the Wasserstein GAN (WGAN), which is based on the computation of a distance measure between the real and fake generated data distributions (Arjovsky et al. 2017). In cGAN, the discriminator input comes from two domains, x, which is the data, and y, the generator output. The optimal min-max optimization scheme for this network is, as usual, related to the optimal arguments, which minimize the loss function \({\mathcal {L}}_{\text {cGAN}}(G,D)\) for the generator and maximize the loss function \({\mathcal {L}}_{\text {cGAN}}(G,D)\) for the discriminator, and can be expressed as
The optimum \(G^{*}\) for cGAN are obtained by training alternatively the generator and the discriminator for a few iterative cycles (Oliveira et al. 2018a).

Schematic example of a generic GAN model architecture
GANs can be also structured by adopting auto-encoders (AE), see Exterkoetter et al. (2018). The AEs are typically composed of two distinct parts. The foremost is called encoder and consists of a learnable feature extractor to map the input \(\varvec{x}\) to a more compact and compressed representation \(\varvec{y}\), generally expressed as
where \(\varvec{W}\) is the weight matrix, \(\varvec{b}\) is the bias term and \(s(\bullet )=1/(a+e^{-\bullet })\) is the sigmoid function. On the contrary, the decoder part of the AEs non-linearly maps the input compressed representation \(\varvec{y}\) to the reconstruction vector \(\varvec{z}\), which aims to reproduce again the original input \(\varvec{x}\), and generally expressed as
The training is conducted by minimizing the reconstruction error between \(\varvec{x}\) and \(\varvec{z}\), e.g. adopting a squared error or cross-entropy loss function (Exterkoetter et al. 2018). Based on AEs, the variational auto-encoders GAN (VAE-GAN) have been firstly introduced in Larsen et al. (2016). When the training of a GAN becomes hard and unstable due to vanishing gradient or its explosion, Arjovsky et al. (2017) proposed the model acknowledged as Wasserstein GAN (WGAN) by modifying the Jensen–Shannon divergence with the Earth-mover distance to account a sort of distance measure between the real and fake generated data distributions. Moreover, the WGAN should satisfy the 1-Lipschitz conditions, i.e. the output of the discriminator does not change excessively when the input changes. However, these improvements do not mitigate this issue since they introduce additional optimization difficulties. Therefore (Gulrajani et al. 2017) proposed a WGAN with gradient penalty (WGAN-GP), denoting \(\lambda \) as a penalty coefficient and \(\nabla \) indicates the gradient operation, to maintain the stability during the optimization:
The new loss function is based on an additional term accounting for an implicit distribution \(p_{s}\) obtained by uniform sampling between \(p_{\text{data}}\) and \(p_{\text{model}}\), under the assumption of a “straight line” between them.
In later studies, Salimans et al. (2016) proposed in 2016 an innovative improvement of the GAN technique with a semi-supervised learning process, better acknowledged as SGAN. Considering a multi-class classifier with K possible classes, the output after the final softmax layer is a K-dimensional vector in which each element represents the probability of belonging to each class. Therefore, in supervised learning, the model is based on cross-entropy minimization between the ground truth labels and the model predictions, whose distribution is denoted as \(p_M(y|\varvec{x})\). The main innovation of these contributions (Odena 2016; Salimans et al. 2016) is the adaptation of GAN to work also with a great amount of unlabelled data, i.e. in a semi-supervised learning approach. The synthetic generated data represent a new class for the multi-class discriminator classifier, which has, in total \(K+1\) classes. Therefore, three input typologies are possible for the discriminator (Li et al. 2019a): true labelled data \(\varvec{x}_L\) from the real dataset, unlabelled data \(\varvec{x}_U\) still coming from the real dataset, and synthetically generated data \(G(\varvec{z})\). Thus, \(p_M(y=K+1|\varvec{x})\) indicates the probability that the discriminator recognizes fake generated data, which is related to the term \(1-D(\varvec{x})\) in the original GAN loss statement. Therefore, adding the generated data to the initial dataset which contains both labelled and unlabelled data, the loss function to train the discriminator classifier becomes:
In this way, the discriminator loss has been decomposed into two contributions. The model can train and learn directly from unlabeled data, assuming that these data correspond to one of the K possible classes. The unsupervised loss may be rewritten considering \(p_M(y=K+1|\varvec{x})=1-D(\varvec{x})\), eventually obtaining a formally identical min-max problem loss function
Another typical problem is the image-to-image translation which attempts to find a mapping function \(G:X\rightarrow Y\) from a domain X to an output domain Y, exploiting available images in pairs for the training process. However, CycleGAN proposed in Zhu et al. (2017) attempts to find out this mapping without having paired images, exploiting, on the other hand, the inverse mapping \(F:Y\rightarrow X\). This involves a cycle consistency loss, from which the name CycleGAN. This variant approximates a bijective inverse function to obtain the original sample \(F(G(X))\approx X\). Moreover, it exploits transitivity to supervise and regularize the training process (Zhu et al. 2017).
Combining self-attention mechanism and GANs, the authors in Zhang et al. (2019a) developed the SAGAN model which provided long-range dependency modeling for image generation task with an attention-driven way both for the generator and the discriminator.
The illustration presented in Fig. 2 depicts the timeline and relative relationships of the critical breakthrough developed GAN variants analyzed in the current review study. Further comprehensive and deeper insights on GANs from the algorithm, theory, and application perspectives can be found in Gui et al. (2021).

GANs main variants timeline
3 A global literature overview
The authors used the Scopus literature search service with the queries “generative adversarial network” and “seismic” extended to the title, abstract, and keywords bibliographic fields (TITLE-ABS-KEY). The search yielded about 138 documents up to July 2022. See the cumulative curve in Fig. 3. Given the relatively recent arrival of GANs in 2014, Fig. 3 displays how the research topic began to earn considerable engineering interest in 2018. It is still rising and maturing. Indeed, except for this year, 2022, which has not ended, the research lies in this curve’s growing branch, exhibiting a fairly linear growth. This motivates the aim of the current study, i.e. attempting to outline and critically discuss the adoption of the most recent DL techniques, especially the GANs models, in generating synthetic seismic signals in a new AI-based seismic data augmentation perspective. Figure 4a highlights that the majority of the studies belong to the Earth and Planetary Science Scopus category (about 52.9% of the total 138 documents), and the Engineering area represents only about 17%. The Computer Science field appears as third (about 10.7%). These results evidenced the fundamental interconnection among these sectors, with fruitful competencies from geology, geophysics, and structural engineering, all connected by the same AI and ML approaches retrieved from the computer and science field. Figure 4b proves that most of the considered studies are journal articles (about 50.7%) or conference papers (about 44.9%) and only the 2.9% is related to review papers. Therefore, few works have been developed, not enough to exhaustively discuss the most recent developments in the AI-based generation of synthetic seismic signals. Finally, the Pareto chart in Fig. 5 recognizes China as the most prolific country in this field (about 57 published documents), followed by the U.S.A. (about 35 papers). Italy is placed as the 8th country in the current ranking. The first ten main countries represent a percentage of about 80% in the cumulative frequency value of the overall literature on this topic.

Number of documents published from 2018 until July 2022 retrieved from Scopus search service with query “generative adversarial network” and “seismic” for titles, abstracts and keywords query system (TITLE-ABS-KEY)

a Pie chart of the main area of recent years studies. b Pie chart of the main document type of recent years studies. Data retrieved from Scopus search service with query “generative adversarial network” and “seismic” for titles, abstracts and keywords query system (TITLE-ABS-KEY) from year 2018 until July 2022

Pareto chart of the number of documents published on Scopus related to the most active countries, with a limit placed to 80% of the cumulative frequency. Data retrieved from Scopus search service with query “generative adversarial network” and “seismic” for titles, abstracts and keywords query system (TITLE-ABS-KEY) from year 2018 until July 2022
4 Comprehensive literature critical discussion
The current section presents a detailed and critical review of the existing literature studies tied by the fil-rouge of the GANs applied to the seismic field. In Table 1 a synthesis of all the studies analyzed in the current work has been listed, whereas Fig. 6 depicted a literature overview with a pictographic bubble graph. These works have been gathered in two main categories or macro-areas, respectively denoted as earthquake engineering applications, see in detail 4.1, and geophysical studies involving the seismic phenomena, see in detail 4.2.

Bubble graph representing the existing literature classified according to their applications and categorized between the two identified macro-areas, i.e. earthquake engineering and geophysical studies. Each bubble has a size (radius) proportional to the number of existing literature studies

Main research activities in earthquake engineering involving GANs
4.1 Seismology and earthquake engineering studies
4.1.1 Earthquake early warning systems
The GAN architecture represents an innovative model to solve engineering problems in seismology and earthquake engineering, as schematically represented in Fig. 7. The prevention actions against safety threats due to earthquake events start attempting to detect events as early as possible they strike major population centres. However, false alerts of earthquake early warning (EEW) systems may cause a reduction of public confidence in those systems and unnecessary economic loss. These false alarms may be caused by impulsive noise events, both of natural origin, teleseismic signals, instrumentation malfunctions, or anthropogenic activities in the proximity of the EEW system. In Li et al. (2018), the authors successfully exploit the GAN model to automatically analyze the features extracted from broadband, and strong motion primary waves (P-waves) recorded in southern California and Japan. The GAN learned the statistical characteristics of real P-waves examples and offered, in this case, an interesting compact representation of the seismic waves, crucial for the subsequent classification task. Indeed, they combined the trained discriminator with a random forest (RF) classifier to categorize actual seismic P-waves events from noise sources. Because of the statistical learning of the input earthquake P-waves, the GAN generator represented, in this case, a relevant tool for seismic signal synthesis for AI-based data augmentation in seismology applications. Despite the advantage of avoiding complex physical modelling of the P-wave source and wave propagation, the main drawback is the problematic interpretation of the features automatically extracted by the GAN discriminator. In Kim and Torbol (2019), synthetic seismic time histories were produced to perform a dataset augmentation for subsequent practical training of EEW systems. The authors employed WGAN with a gradient penalty. Acceleration waveform data from the Japan Meteorological Agency (JMA) have been used for the model training. The records selected exhibit a magnitude greater or equal than 3, expressed in the Japanese \(M_{\text {JMA}}\) scale (Bormann et al. 2013). Since the various data present different lengths, every input to the network has been standardized and near-zero padded, and its amplitude normalized. The authors attempted to graphically show the effectiveness of the trained WGAN comparing the similarities of the artificial seismic signals with respect to the real ones and also comparing their features, i.e. waveform shapes and amplitude ranges. In Meier et al. (2019) five different DL classifiers have been examined to compare AI-based classifiers with traditional real-time EEW algorithms, denoted as on-site classifiers. The authors analyzed a fully-connected multi-layer perceptron (MLP) with a rectified linear unit (ReLU) activation, a recurrent neural network (RNN) (Elman 1990; Pineda 1987; Werbos 1990), an RNN with attention (RNAi), a CNN and a GAN with RF classifier (GAN+RF), adopting precisely the model exposed in Li et al. (2018). In Meier et al. (2019), the authors adopted the gated recurrent unit (GRU) cell, which adds a sort of “memory” to the RNN (Cho et al. 2014; Chung et al. 2014). On the other hand, the RNAi employs a weighting vector (i.e. the attention) to the input vector at each recursive iteration of the gated RNN structure (Meier et al. 2019; Mnih et al. 2014; Bahdanau et al. 2014). The attention is highly informative for sequence data and is based on novel techniques like the neural transformers (Vaswani et al. 2017). The considered dataset was composed of signals cropped around their peak, and sixteen statistical features were extracted for diagnostic purposes, comparing the uniformity of the information in evaluating the cumulative density functions (CDF) for the magnitude of the seismic events and the hypocentral distance. A comprehensive discussion on precision-recall graphs focused especially on teleseismic signals and how they minimized the false positive alerts, while almost zeroing the false negative rates. The authors demonstrated that the more complex models directly trained on raw seismic signals which also automatically learn the feature extraction, i.e. the CNN and the GAN+RF, remarkably outperform the simpler classifiers in terms of reliability of the real-time EEW system even with high-noise data. In Wu et al. (2021), a GAN model has been combined with an RNN, specifically the long short-term memory (LSTM) unit, to leverage the attention mechanism. The resulting model has been named by the authors EQGAN since it was able to generate realistic seismic signals and the recurrent part captured long-term and short-term features and information provided by the time-history nature of the seismic sequences. In this contribution, the authors adopted popular, low-quality, low-cost micro-electro-mechanical systems (MEMS) sensors. However, they are usually characterized by high SNR because they are polluted by various sources of noise, e.g. by the sensor itself or noise of anthropogenic origin. The EQGAN is composed of an encoder (generator) and a decoder (discriminator) parts, adopting regularization techniques such as the Wasserstein distance and spectral normalization. To prove the reliability of the EQGAN, five different evaluation schemes have been proposed: visual inspection, frequency domain comparisons through the fast Fourier transform (FFT) signal processing, paired scatter plot, autocorrelation, and kernel density estimations of the distributions of actual, noise, or synthetic data points, statistical indexes computation such as mean square error (MSE), mean absolute percentage error (MAPE), and computational complexity comparisons with other DL models. For the sake of improving the quantitative evaluation of the robustness of the generated synthetic seismic signals, the authors proposed to adopt statistical screening and assessments based on the high-throughput screening theory (Malo et al. 2006), which was highly consistent with the distribution of seismic data pattern. In Liu et al. (2022a), the authors adopted a GAN model for discriminating between earthquake events and microtremors within an EEW context. The authors defined microtremors as continuously weak non-earthquake-induced vibrations monitored by the seismic sensors, i.e. referring in short to noises due to natural or anthropogenic sources. The authors adopted an MLP for the generator and a CNN for the discriminator, training their architecture on strong seismic events in Japan. In a later study, the same authors proposed an improvement of their previous contribution in Liu et al. (2022b). Specifically, the authors integrated the GAN with a support vector machine (SVM) classifier (Cortes and Vapnik 1995). The authors leveraged the advantage of a two-step procedure, i.e. firstly, training the GAN to provide an excellent feature extractor and, secondly, conducting the seismic detection task separately. In Li et al. (2021a), the authors adopted a DCGAN combined with an LSTM network to deliver a discriminator model able to distinguish seismic signals from noise ones within complex ambient noises, e.g. in nuclear explosion monitoring which blast events are discriminated from seismic ones. Firstly, the DCGAN model was trained based on seismic data from the international monitoring system array MKAR (Mikhailova and Sokolova 2019). Then, the dataset was preprocessed to extract six real seismic P-wave, and S-wave phases (Storchak et al. 2003). Thereafter, exploiting the feature extraction of the trained discriminator, this network was combined with an LSTM classifier to address the actual discriminative classification task.
4.1.2 Synthetic generation and augmentation
For decades, researchers in the earthquake engineering field have aimed to efficiently detect seismic events to mitigate potential hazards and find earthquake-resistant design solutions. Many algorithms have been proposed to tackle this task, often requiring an extensive high-quality dataset, time-consuming procedures, and seismic data covering extreme events characterized by high return periods. However, the number of seismic time-series data is limited and does not cover more than a half-century. Nowadays, current trends attempt to provide innovative solutions such as the synthetic generation and augmentation of seismic signals. For the very first time, in Wang et al. (2019a), the authors adopted the GAN to generate artificial seismic signals. Despite real seismic signals being affected by many natural factors, they may be considered the summation of low-frequency seismic waveform and high-frequency noise. Moreover, they usually involve three spatial component signals (two planar and one vertical component). Therefore, the authors proposed EarthquakeGen, i.e. a combined model of cGAN and DCGAN whose generator works with three parallel pipelines to create a three-dimensional multi-frequency superimposed time-series resembling the real seismic signals. The author demonstrated the effectiveness of the trained generator in synthetically generating new data which are different from the actual samples but with the same probability distribution. The synthetic data have been combined with the real ones to augment the existing dataset, demonstrating an accuracy improvement of the classifier. In Wang et al. (2021), the same authors extended the previous contribution by providing a new model named SeismoGen to generate synthetic and realistic seismic signals for data augmentation purposed for the detection of earthquake events. The authors pointed out the importance of generalization and robustness of the data augmentation procedure, warning about the risk of jeopardizing the semantic content of the original data if unrealistic synthetic signals are added to the original dataset. Their cGAN adopted three pipelines to generate three-component seismic signals separately, including P-waves and S-waves parts. Given the implemented GAN’s conditional structure, the model can synthesize labelled data with two different labels, i.e. background noise and earthquake signal. In conclusion, the authors warned about some limitations to be aware of. Since they adopted three stations in the Oklahoma region, the synthesized signals would probably reflect only seismic events, which are likely to occur in this specific region. Moreover, since an inner imbalance lives in existing databases due to a limited number of records with low epicentral distance, the GAN model output may also reflect this bias. Furthermore, the authors underlined that their approach was utterly data-driven. To improve the generalization capabilities of the DL model, introducing prior knowledge or emphasizing physical constraints may provide a more reliable and effective physics-informed ML model. In Li et al. (2020b), the authors proposed a GAN-based method to artificially generate time series that resemble realistic seismic signals. The main goal was to produce a high-quality data augmentation procedure in multiple domains to train subsequent ML models to detect earthquake events. Traditional ML data augmentation procedures involve simply shifting, flipping, and scaling training data. However, these trivial procedures are not robust because they may not capture the actual sequence structure of training data or maintain diversity, especially for time series data types. In contrast to Wang et al. (2019a) where three separated pipelines have been employed for each channel of three-dimensional seismic signals, in this contribution, only a single GAN with CNN gated structure was able to produce three-dimensional outputs. Specifically, the generator was composed of a 1D CNN part to capture the overall relationship along the time axis, and a gated CNN part with gated linear unit activations (Dauphin et al. 2017) to address the sequential and hierarchical structure of the time series. The discriminator was instead a 1D CNN structure, denoted as ConvQuakeNet (Perol et al. 2018). The training set was composed of recorded seismic events with a magnitude greater than three, collected from the Korea Meteorological Administration stations. The performance has been evaluated with two approaches: visual and with ConvQuakeNet. Moreover, the authors showed the frequency content through the spectrograms of the generated and real signals. This comparison was missing in previous works (Wang et al. 2019a). The same authors in Li et al. (2020a) adopted a cGAN for synthetic earthquake generation to provide a data augmentation tool. The model consists of 3 parts: a generator with an encoder-decoder U-net structure, a discriminator with a CNN structure, and a pre-trained CNN feature extractor not present in the optimization training process. In addition to the adversarial loss, the authors also considered the content loss, i.e. the MSE between the actual and synthetic feature maps. The goal was to retain the consistency of high-level features, considering a weighted content loss with the adversarial one. The generated artificial signals were evaluated by visual inspection criterion and a time-frequency domain analysis through the Short-Time Fourier Transform (STFT), proving a high degree of similarity with the real data. The authors in Gatti and Clouteau (2020) conceived an innovative and comprehensive study for a more reliable generation of synthetic ground motions for digital twins of the earth–structure systems oriented to seismic risk assessment by leveraging the adversarial framework offered by WGAN. Specifically, the main idea was to integrate and combine physics-based simulations with actual recorded seismic data provided by existing databases. The authors detailed the mathematical framework for this hybrid method, exploiting information obtained from the feature extraction of variational auto-encoders (VAE) and GAN to give a more compact latent space representation with hidden variables. These meaning features have been encoded into a Gaussian manifold known distribution connected with the low-dimensional latent space through a nonlinear stochastic process. The proposed procedure blends with the Bayesian estimation theory since the learning process is based on the adversarial learning of joint probability distributions between generated latent variables conditioned by available seismic data. Therefore, this process is acknowledged as adversarially learned inference with conditional entropy (ALICE) (Li et al. 2017). For the sake of validation of the entire methodology, the visual inspection of generated results was insufficient. Thus, the authors adopted statistical goodness-of-fit metric criterion to measure the level of agreement between original and synthetic reconstructed signals based on both fit in the envelope, phase or arrival time. The resulting artificial seismic signals proved that physics-based simulation results provide enough information to condition the stochastic generator properly.
Many structural collapses during earthquake events occur at the mainshock shaking event and often during the numerous aftershock (AS) events that act on partially damaged structures. To characterize seismic events in traditional seismology, it is necessary to analyze three main variables, i.e. the frequency, the magnitude, and the occurrence time. Three acknowledged relationships among these fundamental variables are at the very foundations of seismology: Omori’s law (Omori 1895), Gutenberg–Richter law (Gutenberg and Richter 1944), and the Bath law (Båth 1965). However, earthquake engineers are interested in the amplitude, spectrum, and duration of a ground motion, which express intensity measures (IMs) associated with that event to evaluate the structural impact of AS events. In Ding et al. (2020), the authors leverage the cGAN predictive capabilities to develop a predictive model of the IMs for some mainshock events and the corresponding AS seismic data recorded by the Pacific Earthquake Engineering Research Center (PEER) and stored in the Next Generation Attenuation-West2 (NGA-West2) database. Specifically, the implemented model was a cGAN which also exploited WGAN to provide stability during training. The authors identified 33 different IM variables in terms of peak displacement, velocity, acceleration, and time duration. Since these IMs act as random variables, there was no well-established mathematical framework to establish a direct relationship to predict the IM’s magnitude starting from mainshock and AS seismic data. On the other hand, the cGAN model offered the possibility to perform such high-dimensional data distribution correlation conditioned by real data availability and even accounting for the stochastic nature of the underneath phenomenon. The same authors in a later study (Ding et al. 2021) adopted the cGAN model to deliver a DL predictive model for assessing the spectral acceleration of aftershock seismic events starting from the information of mainshock events. One of the most adopted traditional methods in seismic hazard analysis is the prediction of ground motion equations. However, this method was designed especially for mainshock events; thus, applying it to aftershock events may not correctly capture their spectral characteristics and any relationship with the related mainshock event. Therefore, the authors leveraged DL models to address this predictive task, focusing on the deterministic model deep MLP architecture with three hidden layers and the stochastic cGAN model. The input data consisted of eight indicators extracted by the mainshock events, e.g. spectral acceleration, hypocenter depth, fault mechanism, average shear-wave velocity in the top 30 m, and others. The predicted outputs for the aftershock events were spectral accelerations. The authors validated the obtained results by checking five statistical indices acting as performance indices, i.e. correlation coefficient, performance parameters, root mean squared error (RMSE), mean absolute percentage error and mean absolute error. In Matinfar et al. (2022) the authors adopted a DCGAN to provide, for the first time, a synthetic ground motion acceleration generation respecting the spectral compatibility with a given target design spectrum. In the nonlinear analysis of structures, artificial ground motions are usually employed. However, the resulting response must respect a target defined by the structural codes to provide a realistic analysis. In structural engineering to respect this task, usually more than one input accelerogram is analyzed for nonlinear time history dynamic analyses, and the codes usually prescribe their number: ASCE 7–16 requires the use of 11 records as the minimum number, whereas Italian national technical code NTC2018 requires the minimum use of 7 accelerograms. Thus, the average response spectra of the different artificial accelerograms adopted must respect spectral compatibility within a certain tolerance. Therefore, the authors adopted a limited number of spectral-compatible ground motions as a training set for their DCGAN model. The authors employed Hancock’s wavelet algorithm Hancock et al. (2006) to adapt their earthquake database to match the desired target response spectrum. In Grijalva et al. (2021), the authors proposed a model denoted as ESeismic-GAN to provide data augmentation for generating synthetic seismic signals for volcano events. Specifically, volcano origin event signals have been studied: long-period earthquakes and volcano-tectonic earthquakes. The authors implemented a modified DCGAN to flatten to 1D convolutional layers both for the generator and discriminator. The time-series training data comes from a publicly available dataset referred to Cotopaxi Volcano in Ecuador, and they have been preprocessed in the frequency domain with the FFT algorithm. The magnitude response was collected and fed to the GAN model to generate new magnitude responses based on features and information from input data. A new synthetic time series was generated by combining the generated responses with actual phases extracted during the FFT preprocessing and adopting the inverse FFT algorithm. To provide a better evaluation of the GAN during training and even for the generated seismic signals, the authors adopted the Fréchet distance metric (Heusel et al. 2017), which established the similarity degree between the two distributions. In Florez et al. (2022) a WGAN was adopted to synthesize realistic three-component ground motion events accelerograms conditioned on a set of continuous physical variables, i.e. magnitude, distance, and shear wave velocity. The quality of generated signals was assessed in a statistical sense using the common engineering ground-motion intensity measures, and inspecting both time (average acceleration envelopes) and frequency (average Fourier amplitudes) domains. In the novel study (Esfahani et al. 2022), the authors simulate non-stationary ground-motion recordings leveraging information contained in the frequency domain and, inspired by Florez et al. (2022), even incorporating physics-based knowledge, i.e. distance, magnitude, and shear wave velocity. Specifically, the authors developed a time-frequency conditional GAN (TF-cGAN), which appears innovative and one of the most promising approaches nowadays. Indeed, the GAN is learning from the Fourier spectrum domain, i.e. inspecting the actual frequency components distribution in real data. Because of a phase retrieval approach, the generated time series are finally returned through the inverse Fourier transform, which seems to effectively capture valid information compared with traditional seismology simulation methods, such as conventional ground-motion prediction equations.
4.1.3 Earthquake engineering applications
Before concluding this section dedicated to earthquake engineering, some studies focused on GAN for specific seismic-related engineering applications are presented in the following. For instance, in Fan et al. (2021), the authors adopted a segment-based cGAN named SegGAN for vibration-based continuous structural health monitoring (SHM). In particular, the model was trained to effectively reconstruct lost structural responses under external, operational, or seismic loading conditions in a data-driven method. Since a limited and finite number of sensors are usually placed on a structure, the monitoring system can collect information from a limited number of degrees of freedom. Therefore, any malfunctioning or technical issue may produce a low-quality vibration response loss, jeopardizing the health monitoring task. Thus, the SegGAN proved its effectiveness in reconstructing dynamic structural responses under operational conditions by analyzing features and intra-channels correlations. Furthermore, conditioned inputs helped the generator to extract features robustly and reliably. The authors demonstrated the ability of SegGAN to deal with numerically simulated responses with high levels of noise under seismic conditions, and finally, they tested the SegGAN on an experimental steel structure and comparing with other DL models, i.e. a DenseNet (Fan et al. 2021) and a CNN. In Yamada et al. (2021), the authors adopted a DCGAN to provide a vision-based algorithm for automatically classifying seismic damages in timber houses in Japan. DL models may help to speed up visual survey operations by automatically detecting and quantifying damage in panoramic images. The authors proposed the integration of classification, detection, and segmentation to correctly identify damage with a rectangular frame, classify the damage typology and define the degree of damage. Since post-earthquake damaged photographs of timber detached houses are limited, the authors adopted GAN for data augmentation. Another compelling application of GAN in earthquake engineering is related to the study (Liao et al. 2021), in which the authors adopted a pix2pix GAN to deliver an automatic conceptual design proposal for shear walls in high-rise residential buildings. The optimal planar arrangement of shear walls represents one feasible solution to provide enough lateral stiffness for high-rise and tall buildings during earthquake conditions. However, the design and planar placement of these reinforced rigid vertical elements are challenging. It is desirable that their stiffness distribution would not move the center of rigidity, also acknowledged as the center of torsion, excessively far from the center of the mass of each floor. Otherwise, detrimental torsional issues arise (Fares 2019). The authors leveraged the GAN capabilities to learn from architectural–structural design documents of existing shear wall buildings. These documents were properly prepared by adopting a semantic process to associate different color patterns with every structural element in the design drawing documents. The authors adopted two different methods to evaluate the design generated by their model, named StructGAN. The first one is a human-based metric based on engineering judgment defined from scores assigned by expert and non-expert engineers. The second evaluation method is referred to more objective computer vision metrics such as pixel accuracy, shear wall ratio, or weighted intersection over union (Rezatofighi et al. 2019). Eventually, the authors provided a finite element model of two StuctGAN designs to prove the overall design performance. The StuctGAN permitted the production of the first synthetic preliminary design framework, reducing the time-consuming traditional design process. It may also be oriented toward structural optimization tasks, e.g., seismic deformation (drift ratio) and material consumption. The same authors in Lu et al. (2022) improved their previous study by integrating the GAN framework for intelligent seismic resistance design of shear walls with a surrogate model which accounts for the physics behavior of the generated design. Notwithstanding these are the first preliminary works in the field of seismic design, the authors’ proposed physics-informed model named StructGAN-PHY appeared to be very promising to guide the generator training more smartly. In Kuurková et al. (2018), Ueda et al. (2018), the authors attempted to use WGAN-GP combined with VAE to learn the mapping of input data to latent space, with the purpose of providing data correction of generator output to the nearest acceptable outcome. The authors employed their implementation for a building frame earthquake resistance retrofitting intervention, converting structural members’ position in voxel data (the three-dimensional equivalent of the pixels in bi-dimensional image data). However, this study appears excessively simplistic from a structural engineering point of view. The main limit of their implementation is related to the missing of more sophisticated nonlinear analysis in dynamic conditions to actually govern the optimal seismic design process and evaluate the final results. An anomaly detection GAN (named ADGAN) was employed to analyze satellite images and unmanned aerial vehicle (UAV) images to detect building damage in post-disaster scenarios, such as earthquakes (Tilon et al. 2020). The advantage of using GAN in this context was to exploit the unsupervised approach coming from the adversarial learning process, even in presence of a scarce amount of available data. Despite this promising application, additional efforts have still to be done to further specialize ADGAN, e.g. recognizing different kinds of damage, and especially to effectively deal with the sometime prohibitive visual complexity of satellite images, e.g. due to vegetation and shadows. For a fairly similar purpose, the authors in Zhang et al. (2022a) trained a GAN model to generate synthetic images of victims partially buried by the debris of earthquakes or building collapses in order to train a further automatic victim detector. Earthquake-induced ground deformations such as liquefaction-induced lateral spreading may cause severe damage to engineered structures. The authors in Woldesellasse and Tesfamariam (2022) used a cGAN with a 10-fold cross-validation procedure to solve the regression problem of lateral spreading from estimated horizontal ground displacement from Japan and U.S.A. databases. Since complex DL model interpretability is still a challenging task, the authors employed the Shapley additive explanations (SHAP) values (Lundberg and Lee 2017) to illustrate the contribution of each input feature to the cGAN model predictions.
4.2 Seismic geophysical studies
Within the seismic studies, a significant amount of the existing studies fall in the earth and planetary sciences, as evidenced in Fig. 4a. Specifically, much research on geophysical techniques involving seismic phenomena, in a broad sense as the propagation of elastic waves in soil, has been carried out. Geophysical seismic surveys are usually carried out to obtain a detailed and reasonably geographically extensive subsurface mapping, as schematically presented in Fig. 8. The goals can be geotechnical characterization, petroleum and mining engineering, e.g. for hydrocarbon exploration, environmental and land engineering, e.g. for reservoir detection and identification, etc.

Geophysical seismic surveys and main correlated research activities involving GANs
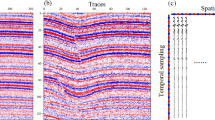
4.2.1 Seismic imaging: interpolation and supersampling
In Siahkoohi et al. (2018), the authors adopted GANs for data reconstruction of seismic imaging (Scales 1997). As schematically depicted in Fig. 8, it is a geophysics technique related to emitting intense elastic waves into the ground and collected back by the geophones (or hydrophones in marine environments) to evaluate subsurface conditions, contaminations of soils, etc. In this context, the authors pointed out the difficulties of acquiring densely sampled data. Moreover, the current sparsity-promoting iterative algorithms for data reconstruction, which mainly rely on linear models and waveforms superpositions, are incapable of capturing the information in seismic data and the physics complexity of the problem. The DL technique based on GANs represents a data-driven nonlinear generalized seismic data reconstruction model, which does not require any strong assumptions on the data. In Lu et al. (2018), the GAN has been adopted for seismic image supersampling to improve the subsequent deep-learning seismic fault detection and interpretation. Because of their abstractness, not physics-based, and generalization abilities, the GAN could reproduce reliable supersampling from blurred images through a Gaussian filter. GAN helped to effectively maintain the spatial resolution of the original data, involving just a slight increase of the magnitude of local extrema in seismic traces. Despite it could represent an ambiguous situation for geophysical resolution and human fault interpretation, increasing the image resolution and sharpness generally improves DL automatic fault detection performances. Similarly, in Halpert (2018), the GAN has been adopted for seismic bi-dimensional and three-dimensional image supersampling for high-frequency resolution. The ultimate goal is to improve reflector sharpness (e.g. reservoir presence, etc.) and thus the image interpretability. Existing limits of standard seismic imaging techniques are related to prohibitive computational costs for high-frequency images associated with the theoretical constraints due to the wave propagation physics mechanisms in subsurface mean. In hydrocarbon production, fault extraction results often face difficulties locating the fault plane characterized by low reflectivity. The authors in Jiang and Norlund (2020) executed a super-resolution generative adversarial network to help improving the resolution of fault prediction results. First, synthetic fault data were used as training data to train a modified GAN system, and then the trained GAN model was applied to two different field data sets. The results demonstrate that the GAN can reconstruct the prediction map and enhance and clarify data where low probability exists. However, the authors do not quantify these approaches’ advantages by comparing them with more standard techniques. The authors in Li and Luo (2019) adopted the GAN to synthesize priors with ultrahigh-resolution samples to accomplish seismic acoustic impedance inversion for thin reservoir characterization. Traditional approaches generally require arbitrary mathematical assumptions on the prior data distribution. However, they are usually chosen only for mathematical convenience, and they are often referred to geological unrealistic hypotheses. In contrast, this study demonstrated how GANs may learn richer and more informative priors essentially guided by a data-driven approach. Seismic image resolution enhancement has also been treated in Zhang et al. (2019b). Traditional methods to deal with 3D post-stack seismic field data require calibrating a deconvolution operator. On the contrary, the authors in Zhang et al. (2019b) simplified the resolution increase procedure by exploiting the GAN generator to extract features, regrouping, and merging them into a downstream subpixel-convolution up-sampling layer. The authors in Zhang et al. (2021) implemented a cycle generative adversarial network (CycleGAN) to improve seismic data resolution. The training set includes synthetic (labeled) and actual seismic data (unlabeled). Artificial experiments demonstrate the advantages of this approach in improving the resolution. According to Zhang et al. (2021), the field data application established the practicality and superiority of CycleGAN. In Han et al. (2022), the authors proposed a GAN-based model to deliver deep and ultra-deep underground prestack seismic wavelets separation, which could be beneficial for prestack seismic migration or full seismic waveform inversion tasks. In Picetti et al. (2018), two examples have been presented adopting the pix2pix GAN (Isola et al. 2017) for seismic image processing. The foremost example involved a data interpolation for image supersampling, i.e. obtaining high-quality images from coarse seismic data. In contrast, the second one involved a deconvolution problem for the subsurface reflectivity of seismic waves. A deconvolution layer, also known as convolution transpose, can map a single input activation to multiple outputs (Exterkoetter et al. 2018). In this latter case of Picetti et al. (2018), a modified three terms loss function has been adopted also involving a regularization factor based on the generator loss, thus improving the overall GAN performances. Furthermore, the authors underline that in adversarial learning the discriminator behaves as a regularizer of the generator. The same authors in Picetti et al. (2019) provided a more comprehensive study on adopting GAN for seismic imaging. Specifically, a mathematical formulation of the seismic imaging problem has been presented, illustrating the relationships, matrices, and operators involved in the image migration process. Despite the theoretical framework, the rendering quality may be further reduced due to noise in the data, spatial aliasing, limited aperture, nonuniform illumination, etc., and even from model uncertainties, e.g. migration artefacts, limited bandwidth, and variable amplitudes. The authors, therefore, proposed to treat the seismic image inverse problem by adopting a compound operator considering a post-processing mapping operator and a back-projection linear operator. A customized loss has been adopted in the current GAN implementation based on pix2pix CNN model for two different tasks: interpolation/dealiasing and deconvolution. An extended simulated campaign has been analyzed to explore the effects of data preprocessing, additional loss terms, patch overlap, discriminator loss weight, and regularization loss weight on the GAN optimization learning process and generalization capabilities. The authors in Avila et al. (2021) compared DL models for seismic imaging migration deconvolution process. Specifically, the authors analyzed the Hessian filter least-squares migration by adopting three different DL techniques to estimate the inverse operator: a fully connected CNN, a U-net structure, and a WGAN. Despite WGAN seeming to visually provide the best resolution for migrated images, it provided slightly worse quantitative results than the others models. On the other hand, U-net appeared the most computationally expensive. In Wei et al. (2021a) the authors adopted a cGAN based on pix2pix GAN to perform interpolation for reconstructing irregular missing seismic data. The main novelty of the present work is that the authors improved the discriminator by adding a Gaussian-noise layer to avoid the vanishing gradient issue. This also enhanced the learning capabilities of the generator. The same authors in Wei et al. (2021b) implemented a cGAN with Wasserstein distance loss (cWGAN) for seismic interpolation to solve spatial de-aliasing. When geophone receivers are relatively mutually far, the seismic collected data result in poor accuracy of subsequent migration process mainly due to spatial aliasing issues. This problem may virtually be solved by reducing the spacing of the receivers. However, this operation is not always economically and physically possible. Thus, the authors suggested that a workaround may consist in interpolating seismic traces among the receivers by interpreting spatial-aliased seismic data as missing data. The model composed of a U-net generator and a PatchGAN discriminator (Isola et al. 2017) provided not only spatial de-aliasing ability but also generated a more dense seismic data reconstruction, beneficial for improving a subsequent migration process. The same authors in Wei et al. (2021c) used the cGAN for interpolating seismic data in the mainstream of data augmentation. In detail, the cGAN, trained on synthetic datasets, successfully removed spatial aliasing from measured signals. Unfortunately, despite the successful attempts, the scholars do not provide any comparison with other approaches’ performances. Analogously, the authors in Ferreira et al. (2019a) attempted to recover the frequency content or the missing traces in seismic data using the cGAN. The authors propose amplitude encoding and histogram equalization to stabilize the performance of GANs on seismic data. The analyses were promising for typical seismic processing and interpretation applications. They generated low-pass-filtered seismic images and then trained the pix2pix network to recover the high frequencies from seismic images based on the low-pass filtered input images. The use of histogram equalization and amplitude encoding makes the training faster and more stable. The study compares two cases: with and without histogram equalization and amplitude encoding. In Chang et al. (2018), the GAN has been adopted to accomplish the seismic data interpolation task. The adopted model has been denoted as SIGAN composed of CNN residual networks (ResNet). The SIGAN demonstrated its capabilities to interpolate and reconstruct seismic data effectively. Nonetheless, the authors warned about the challenging training due to the prone behaviour of gradient vanishing or explosion. The same authors in a later study (Chang et al. 2019) extended the previous work by providing a cGAN, named TF-cGAN, to perform seismic data interpolation in the time and frequency domain. From input data with missing traces, two main pipelines are evidenced. The foremost extracts the features and reconstructs interpolated data in the time domain. The second pipeline carries out the FFT preprocessing of the input images, then extracts features and reconstructs interpolated frequency data. In a later contribution, the same authors implemented in Chang et al. (2020) a dual-domain cGAN (DD-CGAN) for seismic data interpolation. The term dual-domain indicated that authors leveraged information from time-domain seismic data and discrete FFT preprocessed data in the frequency domain. The discriminator was demanded to compute the feature differences between original and interpolated data. In Wei and Li (2021), the authors adopted a cWGAN for seismic data interpolation in prestack seismic reflection data when big missing gaps occur, probably due to significant obstacles. Furthermore, the authors also adopted L\(^1\)-norm regularization inspired by pix2pix GAN model and adopted the gradient penalty strategy to satisfy the 1-Lipschitz constraint, denoting their implementation as cWGAN-GP. In Kaur et al. (2019a), a CycleGAN has been adopted for seismic trace interpolation on artificially decimated images. CycleGAN appeared beneficial due to its flexibility and ability to learn nonlinear mapping and not need any assumptions about the sparsity of the data or the linearity of seismic events. The use of transitivity of CycleGAN and the adoption of additional loss functions helped to regularize the model. In Kaur et al. (2021a), the same authors expanded their previous work for seismic interpolation, experimenting on GAN with synthetic seismic data, marine field data, and three-dimensional seismic data. The same authors in Kaur et al. (2020a) adopted a CycleGAN to propose an alternative method to improve the resolution of seismic migrated images. Nowadays, imaging reverse-time migration is the most widespread method involving an adjoint operator. The seismic migration process towards reflectivity or impedance imaging occurs with a data-driven least square estimate. The solution to this least square problem requires a huge computational effort. It computes the inverse Hessian matrix which acts as a non-stationary deconvolution operator for the amplitude correction of the migrated image. Adopting pairs of seismic and migrated images, the authors proposed to estimate the inverse Hessian matrix by CycleGAN. As a matter of fact, since the consistent learning cycles, CycleGAN permits transformation from source to target distribution and vice-versa. Furthermore, the authors conditioned the model with additional information to better lead the training and the data generation process. Three different synthetic velocity models have been adopted for training purposes, and, finally, the trained model has been employed on actual field data. The final results evidenced the proposed method’s advantages but revealed some shortcomings in real data. Since migration considers a specific frequency bandwidth, the model struggled to reconstruct these unseen frequency components if some frequencies were not considered during training. Moreover, the adopted velocity model is essential to gain a high-quality migrated image. Therefore, it is necessary to train the numerical model with some noise in training data to deal with real data effectively.
4.2.2 Ground-roll attenuation
In Yuan et al. (2020) the pix2pix GAN has been accomplished to deal with the acknowledged ground-roll attenuation task. Seismic sources produce low-frequency surface waves, i.e. Rayleigh waves and Love waves. Specifically, Rayleigh produces elliptical waves in the vertical plane with an exponential decrease in the distance from the source (Al-Husseini et al. 1981). In seismology, the ground-roll issue denotes the signal-to-noise ratios (SNRs) deterioration due to noise caused by Rayleigh-type surface waves, which produce an information masking in collected seismic data. The authors in Yuan et al. (2020) compared GANs which do not require strict model assumptions with traditional ground-roll attenuation techniques. The goal is to evaluate the amplitude spectra quantitatively, the SNR improvement, comparing the f-k spectrum (Foti et al. 2002), and computing two metrics, i.e. the peak signal-to-noise ratio (PSNR) and the structural similarity index measure (SSIM). Although GAN is not a unique method for performing ground-roll attenuation, traditional methods require an optimal definition of various filters. In contrast, GAN can be trained to identify and filter out any random noise in the data. The authors in Kaur et al. (2020b) adopted a similar CycleGAN implementation from their previous paper (Kaur et al. 2020a, 2019a) to perform seismic ground-roll noise attenuation. Two seismic field datasets have been analyzed: the foremost contained nearly radial ground-roll noise contamination, whereas severely aliased hyperbolic ground-roll phenomena characterized the latter. To create labels, the authors adopted two traditional techniques, the local time-frequency transform (Liu and Fomel 2013), and the regularized non-stationary regression (Fomel 2009). The CycleGAN generator was arranged in three parts: an encoder, a subsequent part composed of ResNet residual blocks denoted transformer from the authors (whose name has nothing in common with the neural transformers Vaswani et al. 2017), and a decoder part. To improve the stability during the training phase, the updating rule of the discriminator considers a buffer of images, which has reduced the model oscillations. In Kaur et al. (2019b), the authors used a GAN for ground-roll attenuation. Specifically, they used the framework of the CycleGAN algorithm (Zhu et al. 2017) by adding additional loss functions to regularise the model and preserve the amplitudes. As a result, the algorithm attenuated the ground-roll noise similar to the regularised non-stationary regression. However, the authors do not explicitly quantify the discrepancy between the two methods. Similar findings were obtained by Si (2020). The authors in Oliveira et al. (2020) extended their previous work (Borges Oliveira et al. 2020), proposing for the first time a self-supervised two-step approach for ground-roll noise attenuation in prestack seismic data. In the first step, the authors leveraged a CNN U-net segmentation network to focus on those seismic images portion affected by ground-roll noise. After that, these images underwent a noise attenuation filtering process by a subsequent cGAN model while preserving noise-free signals. The authors provided two datasets with noise-free and noisy data for the two stages of the process, delivering a self-supervised method. The authors effectively combined adversarial learning, detection, and segmentation for a reliable and self-supervised ground-roll attenuation framework. The authors tried an alternative approach to the traditional metrics to evaluate the resulting de-noised images. It compared the similarity between noisy and noise-free regions, delivering quality metrics and scores based on detection accuracy, amplitude changes, differences in noise segmentation, power spectrum and trace correlation coefficient with human expert reference.
4.2.3 Noise attenuation and removal
The authors in Xie et al. (2018) exploited GAN to perform fast noise removal on onshore land seismic data, attempting to provide a new technology for real-time processing. The advantage of adopting GAN is evidenced again by the general-purpose and entirely data-driven approach, which is geophysical model-free. The philosophy is that the generator is learning a specific task, and the discriminator penalizes the training every time the generator produces undesired behaviours. The author in Alwon (2018) applied DCGAN to accomplish seismic data processing applications. At first, a GAN for seismic noise attenuation was implemented, adopting a U-net for the generator, a CNN initially developed for biomedical image segmentation, and a simple CNN based on DCGAN for the discriminator. To permit the learning phase, noise-free sample pairs have been synthetically produced, adopting a finite-difference modelling engine. The model considers physically explainable noise sources and only leaves the GAN to learn about the random noise between real and synthetic samples. To evidence the potentialities of the GAN, with the same discriminator and a slight adaptation of the generator, the same author provide also seismic trace interpolation, similarly to techniques adopted for image super-resolution procedures. Alwon (2018) highlighted the computational effort required when the previous model may be adopted for 3D field seismic data. Moreover, in this contribution, the author critically argued about the limit of GANs when dealing with ill-posed problems, showing some fallacious cases they experienced. The author overcame these issues by adopting the Wasserstein loss with a gradient penalty term (Gulrajani et al. 2017; Arjovsky et al. 2017). This fact underlines that much more research has to be done to improve the promising path offered by GAN. In subsequent studies, e.g. in Oliveira et al. (2018a), the cGAN has been adopted for the seismic trace interpolation problem. Specifically, the authors employed the pix2pix GAN (Isola et al. 2017) to reconstruct artificially masked seismic traces. Working directly with post-stack seismic datasets, the authors introduced masked vertical strips of the seismic traces in the training and test set with variable pixel widths. The authors led a comparison between a single GAN working with all different pixel widths masks and a set of GANs, each delegated to work with masks of specific pixel width. The results have been discussed accordingly to a quantitative metric based on the Pearson correlation coefficient among reconstructed and ground truth images and even a qualitative criterion based on visual interpretability. The study evidenced that the more the masked strip width is, the less the similarity between interpolated and ground truth images, expressed through the Pearson coefficient. Furthermore, by analyzing each pixel column, the authors evidenced how the variability is higher for the central part of the reconstructed gap and is much lower at the edge of the gap, thanks to the actual image information provided by the neighbourhood of the gap. In Oliveira et al. (2018b), the same authors assess the performance of a cGAN for the interpolation problem in post-stack seismic datasets. Specifically, the authors used the pix2Pix cGAN architecture (Isola et al. 2017), based on a classic encoder-decoder generator network and a PatchGAN (Isola et al. 2017) discriminator network. They artificially generated missing seismic traces and trained the pix2pix network to interpolate the missing traces. Parallelly, the discriminator tries to determine whether the seismic traces were artificially generated. The study showed that higher missing gaps lead to worse performance regarding the Pearson correlation coefficient. The chosen metric estimates the similarity between the original and synthetic seismic traces. The same authors in Oliveira et al. (2019) extended the previous contribution by adopting a cGAN for improving seismic post-stack data resolution. Specifically, they adopted the pix2pix cGAN in which the generator is an encoder-decoder model, whereas the discriminator is denoted as PatchGAN. For each pixel, this latter embeds local information encoded in the likelihood of patches belonging to real data distribution into the loss function. The authors in Bugge et al. (2021) used the cGANs to de-noise pre-stack seismic data. They proved that a cGAN trained on synthetic gathers (with and without multiples) successfully removes multiples from authentic gathers even when the multiples interfere with the primary signals. In detail, the generator was a U-net-based network. In Min et al. (2021) the authors proposed an innovative method to provide noise removal from seismic data by adopting a deep denoising auto-encoder (DDAE), which is a convolutional auto-encoder (CAE) integrated with a GAN framework (DDAE-GAN) in a three-step procedure. At first, a WGAN was trained to generate high-quality noise samples and not as usual noisy data. This required extracting noise from paired clean-noisy data. Secondly, a DDAE was pre-trained based on the previously generated noise considered additive noise, which was superimposed on clean data. After feeding the DDAE with a noisy signal, the DDAE was supposed to output the predicted clean data by minimizing the residuals in terms of MSE. The final step was to adopt transfer learning of the previously pre-trained DDAE to produce noise removal from real field data effectively. In Wang et al. (2020a) the authors proposed an innovative implementation of GAN, named Att-DCDN, for seismic denoising. Their execution was inspired by AttGAN (He et al. 2019), an encoder-decoder GAN with an attribute classifier for generating human face images permitting the manipulation and conditioning of the model to create samples with the desired facial attributes. Thus, the authors conceived an innovative way to control the change in the target attributes and not directly constrain the output data representation. The target attributes were hence controlling variables, i.e. the desired characteristics of noise-free data, whereas the input is represented by the selves noisy data. Therefore, the authors produced two new seismic training sets extracting their attribute representation (single or dual attribute) and adopted four loss function components cooperating: adversarial loss, attribute classification loss (which constrains the de-noised data), reconstruction loss (to avoid losses or damage to de-noised signals), and residual loss. The authors added this latter part to account especially for the fact that seismic data are often highly contaminated by noise. This extended the capabilities of the proposed model beyond the denoising task, also permitting it to effectively recover signals with very low SNR. The authors in Ma et al. (2021) also delivered an unsupervised relative attributes-based GAN, named RAGAN, to accomplish seismic noise attenuation in desert regions. In Ovcharenko and Hou (2020), the authors critically compared U-net and GAN models for seismic denoising and interpolation. The authors demonstrated that U-net was more useful, especially for noise removal tasks, whereas GAN performed better in seismic interpolation. The authors explored the performance of GAN in interpolation, considering images with one-half, one-eighth, and one-sixteenth of the total traces respectively. However, this study critically revealed two main pitfalls and shortcomings of GAN. Foremost, the use of \(L^1\)-norm or \(L^2\)-norm makes the networks unable to preserve weak events since these metrics are more biased in the case of strong events. The authors pinpoint the cause in the pixel-wise evaluation metrics and the adversarial loss, which mainly aims to satisfy perceptual realism. Still, they do not incorporate any authenticity of the underlying physical process. The same authors in Ovcharenko et al. (2021) presented a modified GAN to extrapolate low-frequency energy components in seismic data, which can be hard to capture but beneficial to mitigate cycle-skipping issues in the full-waveform seismic inversion task. It is worth noting that low-frequency components exist in the synthetic seismic dataset only because it is pretty hard to measure a high content of low-frequency components in a field measurement campaign. In contrast, middle and high-frequency components are present in both synthetic and field data. Therefore, the authors presented a two-step procedure for GAN training denoted as generative dual-band learning. Foremost, the generator is trained only on synthetic data to provide a mapping between high and middle frequency, extracted with a band-pass filter, toward low and middle-frequency components. Secondly, during the training on synthetic data, field data are started to feed the generator, and the discriminator training started as well. The authors highlighted that the generator could reproduce only synthetic data without training the discriminator. However, the final goal is to extrapolate low-frequency components in actual fielddata. In this way, the proposed model acted as a transfer of knowledge from synthetic to field data. In Zhao et al. (2022) the authors conceived an unsupervised approach to accomplish seismic denoising tasks by leveraging CycleGAN capabilities to work with unlabelled data. Their implementation, named DeGAN, adopted a two-way learning method with double generators with a U-net structure and double discriminators, which use the PatchGAN model. The training of this model adopted adversarial and cycle-consistency loss and exploited information both from synthetic signals and real field data. However, despite the advantage of working without labelled data, the authors argued about some limitations of the model, such as the signal amplitude attenuation or distortion when the signal energy varies considerably. The reason was identified by the restriction of the specific training set adopted (since DL models are severely dataset-dependent) and the inability to use L\(^1\)-norm or L\(^2\)-norm due to the unsupervised approach. To mitigate this latter issue, the author proposed to constrain further the loss function aiming to amplitude preservation or increase the proportion of cycle consistency loss. In Li and Wang (2021) the authors also explored the adoption of CycleGAN to solve seismic data denoising. Their model named RCGAN integrated a residual learning approach within the CycleGAN framework by exploiting convolution and residual blocks to improve the training efficiency. A GAN-based residual learning approach was also employed in Sun et al. (2022) for post-stack seismic profiles. In the generator, the authors adopted the residual learning strategy to address the denoising task and an iterated process in a back-projection unit to provide super-resolution seismic data reconstruction. The discriminator was instead a CNN with large receptive fields to better feature capturing, helping to improve the generator optimization process. In WU Xuefeng (2021), the authors also adopted a CycleGAN to deliver a random noise suppression method assuming a ResNet for the generator and a PatchGAN for the discriminator, eventually evaluating the results by comparing the SNR and RMSE of noisy and de-noised data. The authors in Dong et al. (2022) adopted a WGAN to provide data augmentation for seismic shot gather denoising. The GAN application was functional to effectively train a supervised dilated CNN with a weak dependence on real noise data, named CNN-WDRND, working on pre-arrival noise data acquired from the shot gather. In addition, the dilated convolution improved the feature extraction capacity by enlarging the receptive field size without increasing the number of learnable parameters. In Wang et al. (2020b), the authors adopted a GAN model to address seismic denoising tasks, especially oriented to desert regions. As a matter of fact, in desert regions, low-frequency noise is more substantial due to its emptiness. Furthermore, sand is characterized by selective absorption of high-frequency noise, thus becoming the primary medium for background noise propagation. Those characteristics jeopardize seismic data producing spectrum overlapping and strong energy noise pollution, leaving only low-frequency components in the seismic field data. The CNN-based denoising method with minimization of the MSE of reconstruction delivered only slight improvements in the denoising task but quite poor low SNR signal reconstruction. Therefore, the authors adopted a GAN model based on a RED-Net architecture (Mao et al. 2016), i.e. a deep recurrent convolutional encoder-decoder structure, with a WGAN-GP loss function composed of adversarial and reconstruction losses properly weighted. The same authors in Li et al. (2020c) employed a CycleGAN to work with unpaired data of noisy and clean data for desert regions’ seismic denoising data task. Seismic data collected in desert regions requires a proper denoising procedure since those areas present some issues illustrated in Wang et al. (2020b). In a later work (Li et al. 2021b), the same authors provided an interesting improvement to solve the desert seismic data denoising task. Since seismic data in desert regions is tremendously affected by spectral aliasing and low-frequency noise, the authors proposed a semisupervised learning approach with a GAN model with adaptive layer-instance normalization for Image-to-Image translation, denoted as U-GAT-IT. Furthermore, they combined the GAN framework with an attention module which exploited the resulting attention maps to guide the training process.
4.2.4 Seismic data compression
In the last decades, many authors proposed data compression algorithm to reduce the amount of data transmitted among the nodes and recover the information contained in the original non-compressed data at the data centre level where only compressed data are delivered. The authors in Zhang et al. (2019c) proposed a very innovative solution to overcome the limitations of large-scale seismic exploration. Specifically, the traditional seismic data acquisition system is based on a multi-hop system, which requires distributed interconnected nodes in which signals collected from the sensors on the ground surface under study have to be transmitted. These nodes then will transfer data to other nodes until reaching the central elaboration core, i.e. the data centre. However, this method leads to both increasing computational efforts for the nodes close to the master node and increases in energy consumption, leading to a bottleneck behaviour for highly dense sensor arrays. In Zhang et al. (2019c), the GAN model has been successfully adopted in a novel seismic data compression approach (designated by the authors as CSA-GAN). Generator and discriminator have been trained to reduce the data traffic load and learn the recovery map, even preserving spatial-temporal information reaching high compression ratios (i.e. the ratio among uncompressed and compressed data sizes) with moderate induced SNRs. Compressive sensing with GAN has also been explored by Lu et al. (2019). Information from seismic data can be represented more synthetically by exploiting the sparsity and compressibility properties. In this way, data are transformed into a new domain by retaining only the most essential components of the original signals. In dos Santos Ribeiro et al. (2021), the authors integrated a GAN with a CAE model named 3DSC-GAN, based on an encoder-decoder architecture devoted to providing post-stack volumetric seismic data compression. The main goals were to leverage the volumetric redundancy and to maintain sufficiently low latent space dimensions. The 3DSC-GAN was improved by integrating a GAN model to exploit better seismic data redundancy. The results obtained were promising, with a high-quality visual appearance and increased peak SNR. In Lu et al. (2019), the GAN model composed of CNNs has been adopted to overcome optimization limitations for seismic inversion to reconstruct missing traces in 3D data due to its ability to manage intense noise and aliasing issues. The generator training accounts for a loss that comprises two weighted parts: the standard adversarial loss and a pixel-wise content loss between the original and interpolated data. In classical approaches, window size and spatial dimensions are governing factors for the algorithm’s success. However, GAN demonstrates its potential even in dealing with blurry images providing plausible reconstructions with quite fast convergence. GAN dealt with interpolation on multiple dimensions, i.e. spatial and temporal dimensions. The authors discussed the reliability of this model, focusing on preserving original data information (i.e. visualizing f-k spectra). They further highlighted the GAN robustness in providing consistent, sharp images even with high compression ratios. The authors in Li et al. (2019b) proposed the adoption of WGAN for seismic compressing sensing acquisition survey for inpainting purposes. Since the inner property of GANs performs information recovery from sparse arrays, they can model a manifold of seismic images from historical surveys. The authors named their proposal generative inpainting network with contextual attention (GIN) because they adopted a contextual attention layer able to capture information around the pixel under study and even consider patching position inside the entire starting image. They studied compression sensing effects by assuming a uniform sampling of actual seismic trace data with different compression rates. To evaluate the algorithm’s performance, the authors adopted the PSNR, the SSIM, and the MSE metrics. Finally, the authors proposed recommendations for a realistic random nonuniform sampling scheme. They suggest a more dense sampling scheme in the region riches in lithological features to capture the seismic image’s heterogeneity better. This is possible when prior information from historical surveys is available. Otherwise, it is recommended to conduct additional geological investigations. The authors in Bin et al. (2020) proposed a GAN-based innovative compressive data gathering scheme, named GAN-CDG, to improve efficiency and data compression for seismic wireless sensor networks, i.e. geophones. Notwithstanding lossless compression methods permits a perfect reconstruction, these techniques are usually limited to low compression ratios. Thus, a method such as compressive data gathering may be preferred, albeit it is a lossy compression approach based on compression sensing theory and spatial correlation. Furthermore, due to the large data size of the seismic wireless sensor networks, the data transmission is limited to the wireless bandwidth. Therefore, the authors trained the GAN-CDG on a data projection, which ensured sparse representation of seismic signals and, thus, data compression while adversarially permitting a good accuracy in signal reconstruction. Moreover, considering the topographic sensor layout, the authors adopted the shortest path routing tree algorithm to improve the data collection. In Radosavljevic et al. (2021), the authors adopted the GAN model to provide seismic data restoration in case of missing portions. The strategy adopted the acknowledged edge connect technique inspired by human behaviour. Specifically, this is a two-stage procedure in which humans priorly draw only borders and only in a later phase will colour the image. Similarly, in the beginning, the applied GAN provides only edges of missing seismic traces with artificially induced masked patches; after that, the remaining pixels have been coloured. A generator-discriminator pair has been trained for each phase with adversarial loss and regularization parameters. To evaluate the obtained results, the MSE and the coefficient of determination \(R^2\) have been analyzed.
4.2.5 Seismic inversion studies
In the field of geophysical studies, Mosser et al. (2018a) investigated the seismic inversion problem in the different geological stratigraphy of the ground, focusing on the seismic forward and inverse modeling. The process of seismic data inversion is related to transforming seismic reflection data from seismic testing into a deeper investigation leading to a quantitative description of the ground subsurface properties (Exterkoetter et al. 2018). This Physics-based modelling approaches lead to satisfactory results. However, they require remarkable computational efforts without any guarantee of global convergence. In Mosser et al. (2018a), the GANs have been adopted in a fully data-driven approach by employing deep convolutional generative adversarial networks (DCGAN), i.e. using convolutional neural network (CNN) architectures both for generator and discriminator. The abstractness of the neural models allows the authors to perform a transfer function from seismic amplitude data to velocity functions. The authors even demonstrated how the GAN models might also detect and preserve faults in the velocity model and their successful learning process, preserving the velocity model continuity across the fault when necessary. Furthermore, the ability of GAN to deal with probability distributions evidenced the possibility of relaxing the need to adopt two perfectly matching input-output images to perform direct and inverse seismic modelling with traditional approaches. The same authors in Mosser et al. (2018b) adopted GAN for seismic inversion problems within a Bayesian approach to estimate the prior distribution. They applied it to a synthetic two-dimensional river channel reservoir structure test case. In a later work (Mosser et al. 2019), the same authors explored the adoption of a DCGAN combined with adjoint-based optimization techniques to extract synthetic stochastic posterior samples for ill-posed seismic inverse problems. Specifically, they exploited the parametric generative model offered by the DL techniques by using the gradient-descendent method to update the prior distribution of earth models to match the observed experimental results. The experimental data can be acoustic P-waves recorded by seismic testing on channelized reservoirs accounting for the facies properties (permeability and porosity) of subsurface shale layers in existing production-injection wells pairs. This optimization procedure, jointly with DCGAN’s capability to parametrically deal with latent space of the noise input to the generator, allowed to reduce the variance of the posterior realizations, which become closer to the measured ground-truth observed data. The algorithm could also reliably reproduce the oil extracted and water injected rate volumes even when a pressure decrease occurred. The authors in Sun et al. (2021) used the Gaussian mixture model (GMM) (Reynolds 2009) with the cGAN, labelled GMcGAN, to an inverse problem in geophysics. The ultimate goal was to estimate the nonlinear mapping between seismic elastic parameters and oil saturation. Initially, the network has been trained on the synthetic data set generated by a rock physical model. Then, it was applied to actual data inversion. The main advantage of the GMcGAN, compared with the CNN, was the higher accuracy and the uncertainty quantification. In addition, the GMcGAN provided the oil saturation’s joint probability density function (PDF). A Bayesian seismic inversion framework has been extensively illustrated in Fang et al. (2020), in which the authors proposed the adoption of a DCGAN to generate prior distribution resembling the input training data. Seismic data incorporates different sources of uncertainties and noise, and Bayesian inference offers the mathematical framework to deal with uncertainties. However, since a great computational effort is normally required in dealing with seismic data, the starting point, i.e. the prior distribution, is essential to provide an efficient inversion procedure. Moreover, traditional techniques applied to completely different seismic data may provide the same erroneous inverse representation due to the noise in data and modelling errors. Therefore, DCGAN offered the authors a data-driven framework that could be effectively integrated into the seismic Bayesian inversion procedure. In particular, to reduce the computational effort, a DCGAN with a different number of layers has been adopted to provide a prior generation in the latent space, which has a reduced dimension. This helped to avoid the coarse dimensionality problem and extensively sampling the posterior distribution, beneficial for Markov-Chain Monte Carlo (MCMC) methods. Furthermore, the models with a higher number of layers (8 convolutional blocks) could better capture more complex prior distributions in the training data. To evaluate the obtained results, the authors introduced an L\(^2\)-norm to compare model error between generated and target images and a logarithm L\(^2\)-norm associated with the latent vector to evaluate the generalization capabilities of the generator. Finally, the authors tested the proposed methodology for travel time tomography and waveform seismic inversion applications. In Azevedo et al. (2020), the authors adopted a cGAN with a Wasserstein optimization scheme to perform a stochastic model reconstruction assuming sets of geological realizations and experimental observations. In contrast with model generation techniques, the idea is to provide a model reconstruction where there are no sparse measurements of the subsurface properties under study. This can be helpful, especially for early hydrocarbon exploratory stages when little geological information is usually available (data or small seismic regions). It can also be beneficial when a general and global idea of the area of interest has been inferred from large-scale geological maps or expert geologists. This study evidenced the effectiveness of GANs in producing unconditional and conditional subsurface geological models, i.e. without and with measured experimental data, respectively, both in continuous and discrete domains. Another advantage of the current implementation was that the authors could govern the available experimental data reproduction percentage. Since a high noise level could contaminate these data, the authors can discard the most uncertain data and provide a more reliable model reconstruction. A stochastic approach combined with GAN has been applied in Han et al. (2019) for super-resolution seismic simulations and inversion tasks. To overcome the band-limited issue, which typically characterizes the previous-mentioned tasks, the authors proposed a workflow involving stochastic simulations based on Bayesian sequential simulation and combining the simulated data with limited seismic pre-stack data. Prior probability was obtained by the collocated cokriging method, which is a multivariable interpolation technique (Shamsipour et al. 2010). In contrast, the joint likelihood has been defined by adopting a non-parametric kernel density estimation (Rosenblatt 1956). The idea was to arrange a training data set which collects data with different resolutions. The best simulations have been combined with the dynamic time warping method. Initially designed for speech verification, this technique permitted to the matching of the pre-stack inversion results with simulations with better accuracy. Furthermore, these heterogeneous data have been combined with the gradual deformation method, which permits a linear combination of different stochastic models and maintains their spatial distribution (Han et al. 2019). Finally, to reconstruct seismic inversion with super-resolution, the authors proposed a modified cGAN combined with a VAE, denoting this model as GAN with a decoder (DeGAN). This model was structured as a generator, a discriminator, and a decoder working in a three-flows way. The first two flows feed the network with logging data and simulations simultaneously for the training process. The last flow, helpful for the decoder part, was demanded to construct high-frequency components, exploiting VAE to capture the implicit information. These high-frequency components were essential to replace the lost frequencies in the seismic inversion results. The outcomes effectively accomplished super-resolution inversion tasks, revealing the presence of possible thin layers and, thus, improving geophysical interpretation for hydrocarbon exploration. In Araya-Polo et al. (2019), the GAN has been demanded to learn earth and geologic representations from a finite number of model examples. In this case, the GAN carried out a supervised data augmentation task to effectively train a subsequent CNN tomographic operator responsible for reconstructing subsurface seismic velocity models. The idea of the authors was to provide an AI-based workflow to create earth models with sufficient quality, competitive with the traditional methods, and acting as a precursor of further seismic imaging operations. Furthermore, since GANs can learn the intrinsic statistical distribution of earth models, the authors evidenced the GAN’s generalization property to spread to any other possible geologic regime. For the first time in the field under study, an innovative semi-supervised GAN approach has been adopted in Li et al. (2019a) for seismic inversion to perform lithology recognition. To overcome the deficient number of labelled data, the authors proposed to adopt an SGAN to combine the small amount of labelled borehole-side data from well testing and the slightly greater amount of unlabeled seismic data. Since information retrieved from unlabelled data is intrinsically limited, to improve the unsupervised loss of the discriminator, the authors proposed a modified unsupervised loss considering an entropy-regularization term, i.e. the Gini-regularization term. This modification increased the convergence speed and the stabilization of the model. However, this method depends on a arbitrary user-defined and data-dependent regularization factor. Nevertheless, the authors provided mathematical proof of the effectiveness of the Gini-regularization term influencing the gradient and affecting the learning rate, thus improving the generalization capabilities of the model. In Liu et al. (2019), a semi-supervised GAN has been adopted for 3D seismic facies multi-class classification to detect floodplains, channels, and levees from the background. For the sake of comparisons, the authors also trained a CNN model based on the Visual Geometry Group model (VGG-net) (Aggarwal et al. 2018; Simonyan and Zisserman 2014). To address computational issues, three CNN models have been trained separately based on the input representation: a 2D-CNN for two orthogonal seismic slices, a 2D-CNN for seismic slices stacked in time, and a complete 3D-CNN to deal with an entire 3D seismic cube as input. To evidence the effectiveness of the automatic feature extractor, the authors illustrated the input data and the extracted features with a visualization technique acknowledged as t-distributed stochastic neighbour embedding (t-SNE) graphs (Van der Maaten and Hinton 2008). Despite the good results already obtained with CNN, this model presents a bottleneck because it requires a significant amount of labelled data and, thus, the availability of many wells in the area under study. On the contrary, the semi-supervised GAN model provided better results, even with a limited number of seismic wells data. In Meng et al. (2020), the authors adopted a semi-supervised approach to train a WGAN model for seismic impedance inversion to overcome the limitation of limited labelled data often related to well logs availability only. The discriminator was composed of three parts: an encoder, a middle part with atrous spatial pyramid pooling (Chen et al. 2017) to capture features at multiple scales, and a final fully connected part. A semi-supervised strategy is used since the algorithm learns in a supervised way by impedance label from the well logs and the forward model constrains. The same authors in Wu et al. (2021) expanded their previous work by adopting the GAN model for semi-supervised learning for seismic impedance inversion with similar findings. Similarly, in Meng et al. (2021), some of the same previous authors adopted a cGAN instead to address the seismic impedance inversion task. The authors in Cai et al. (2020) proposed a Cycle-GAN for seismic impedance inversion with a semi-supervised learning approach, incorporating unpaired data into its training. This study improved the Cycle-GAN algorithm by integrating the Wasserstein loss with gradient penalty loss as the target loss function, denoted as the Wasserstein cycle-consistent GAN (WCycle-GAN). Likewise, the new algorithm benefits from weaker topology in Wasserstein distance and better data regularizations in cycle-consistent loss, leading to enhanced training robustness and generalization abilities. The algorithm was validated on the impedance inversion on a subset of the 3D Seismic Advanced Modeling (SEAM) data. It proved a good performance compared to the conventional CycleGAN, highlighting the prospect of semi-supervised learning applications. In a later study (Cai et al. 2022), the same authors proposed adopting their WCycle-GAN to address surface wave tomography for the shear wave velocity inversion. The semi-supervised approach accounts for both observed surface wave dispersion data and synthetic model-generated data. The authors successfully tested their proposal on fundamental mode Rayleigh wave velocity dispersion data. The main CycleGAN advantage is to consider also unlabeled data, with interesting and promising predictive results requiring only a small amount of labelled data. The authors in Zhang et al. (2022b) developed a comparative analysis of the effects of hyperparameters of DL techniques on seismic impedance inversion. Specifically, the authors focused on the number of channels and layers and kernel sizes of conventional CNN, multi-scale CNN, and U-net. Eventually, the authors proposed a more realistic seismic impedance inversion enhancing high-frequency details by adopting a GAN model based on the enhanced super-resolution GAN (ESRGAN) architecture (Wang et al. 2018). In Zhang and Lin (2020), the authors proposed a WGAN, denoted as VelocityGAN, to effectively deal with data-driven real-time full-waveform seismic inversion tasks for stratigraphy or site geology recognition and to evaluate rock quality. The authors adopted an end-to-end mapping from seismic data to recover the velocity map of wave propagation in the various subsurface lithology with a transfer learning approach and analyzed different cases to highlight the transfer learning efficiency and robustness. They employed an encoder-decoder structure for the generator and a PatchGAN classifier network for the discriminator. Since DL models generally suffer from ill-posedness, robustness, and generalization issues, the authors presented a data-driven regularization technique directly learned from the training data. To cope with the inverse tasks’ ill-posedness issue, it is usually beneficial to include prior knowledge to constrain the generated solution to be consistent at least with the prior knowledge and penalize the inconsistent ones. A widespread but often ineffective solution is to adopt a generic function like L\(^1\)-norm or L\(^2\)-norm. Instead, in the current implementation, the loss function accounts for both MSE loss, devoted to catching geological faults, and maximum absolute error (MAE) loss, which revealing the lithological interfaces, incorporates data-driven regularization into the GAN framework. The authors also evaluated the test error of the trained model on unseen data, usually composed of the summation of training error and the generalization error. Typical techniques, such as cross-validation, appeared useless in this case; therefore, the authors adopted some special-designed test data to stress the trained model the most. In Saraiva et al. (2021), the authors adopted the pix2pix GAN to provide a surrogate model for the full seismic waveform inversion task, avoiding the traditional iterative computational expensive operation. Seismic velocity estimation is normally arranged with three phases: the first manually normal moveout velocity estimation, then a ray-based or grid tomography which provides a low-frequency (2–3 Hz) velocity model, and finally the full seismic waveform inversion model. This latter attempts to cover the information gap between the low-frequency tomographic model and the seismic reflection image, which concerns the high-frequency part. The authors used three input types, i.e. the average tomographic velocity, post-stack seismic image, and two-way time grid, to provide a reliable surrogate model. This delivered velocity images with a quality and resolution similar to traditional full seismic waveform inversion. The evaluation of the results was performed with percent error, SSIM, and visual inspection. The authors in Kaur et al. (2021b) adopted a CycleGAN to provide an innovative estimation of the elastic wave-mode separation of a seismic wave propagating in a heterogeneous isotropic and anisotropic medium, for specific time steps and given a certain seismic source. The resulting model has great potential for applications such as full seismic waveform inversion or reverse-time migration. Furthermore, this GAN-based approach avoids the numerical resolution of the Christoffel equation for seismic wave propagation in a particular medium at each spatial location for each time instant of interest (Sripanich et al. 2017). Thus, the goal of the implemented CycleGAN was to learn the inverse mapping between the horizontal and vertical displacement components of the propagating wavefield towards the corresponding polarized P-wave and S-wave elastic wave modes. In O’Brien (2020), the author adopted a CycleGAN to investigate the capabilities of this DL model to deal with seismic inversion by conditioning the typical image gathers for improved removal of post-migration artefacts. The author defined the quantitative interpretation of seismic data as transforming seismic data, such as reflectivity maps, into the physical properties of the ground. A typical example of a quantitative interpretation technique is the common image gathers, and its conditioning variant address both pattern recognition and image translation tasks. Specifically, three different GAN models have been trained to accomplish various tasks: noise removal only, multiples removal only, and a combined conditioned task for both noise and multiples removal. The term multiples denotes multiplicative and overlapped reflected waves evidenced in seismic sections due to stratified geological structures with substantial wave impedance. The final results demonstrated the effectiveness and potentialities of GAN to improve the current raw gather to translate and clean the artefact-rich test data into an artefact-free seismic gather. In addition, the model could also translate complex moveouts into flat gathers while maintaining the amplitude response. In Pan et al. (2021), the authors proposed a modified pix2pix GAN version to map high-dimensional, stochastic reservoir models into a low-dimensional latent space based on Gaussian random variables. The GAN was conditioned by numerical simulations produced with the rule-based reservoir modelling technique, a method able to capture the geological structure of oil or water reservoirs and channel systems into sedimentary zones (Jo et al. 2020). In addition, the GAN was also conditioned with actual data collected in strategic wells. Therefore, the authors included a penalty term in the loss function to constrain the various realizations to be consistent with the conditional data. The main limitation of pix2pix GAN is the lack of variability in generated samples. The authors affirmed that this was probably due to the reconstruction loss based on \(L^1\)-norm, which may cause overfitting. Also, conditioning data are given in input to the discriminator reducing the variety of recognizable patterns. Therefore, the authors’ implementation overcomes the previously-mentioned issues and considers additional loss terms to constrain the model to be more consistent with conditioning data, governing the authors’ belief in the conditioning data with a proper weighting term. Since the visual inspection of the results is usually deficient, the authors developed a new metric denoted mean categorical error to check the consistency of the output results compared with conditioning data. The authors in Liu-Rong et al. (2021) developed a GAN named CAE-SAGAN for the separation of seismic surface-related multiples. The authors implemented a CAE as the generator model with a self-attention mechanism, whereas adopted a CNN for the discriminator. The training was performed considering a set with primaries and surface-related multiples and a second dataset with primaries only. In this study, the authors adopted a supervised strategy with a loss function with a regularization coefficient. Moreover, they provided a z-score standardization procedure to preprocess the input data to mitigate overfitting issues. The same authors have obtained similar findings in Tao et al. (2022) in which a GAN with self-attention blocks, denoted as SAGAN, has been employed for seismic surface-related multiples suppression. Within the seismic imaging process, a valid technique may be separating diffraction events, a process acknowledged as diffraction imaging to better emphasize the presence of subsurface discontinuities. In Lowney et al. (2021) the authors proposed a image-to-image GAN-based method for seismic diffraction imaging on pre-migrated data. The authors implemented a pix2pix GAN for pre-migration images, which presents the advantage of being processed independently before the migration process. The generator was a U-net structure, and the discriminator was a PatchGAN network. The training set was composed of both synthetic data and field data. Specifically, seismic field data were properly preprocessed by an analytical method denoted as plane-wave destruction, which unfortunately was not optimal in certain conditions. Thus, the authors have manually removed all those training samples, which could potentially bias the GAN training, i.e. seismic data collected in synclines or complex geology layouts. The study (Durall et al. 2020) proposes using GAN to pick the diffractions from seismic signals, compared to the tedious manually picking. Generally, the scholars create a synthetic labelled training dataset, followed by testing on actual unlabeled data, although synthetic data oversimplifies the real one. Therefore, the authors use GANs to create a semi-synthetic dataset that fills the gap between artificial and actual domains. In hydrocarbon exploration, to overcome the limits of traditional petrophysical facies classification, the authors in Kim and Byun (2020) adopted a CycleGAN to perform a data augmentation procedure. The first issue encountered is typically the absolute rarity problem, which means the missing or limited amount of labelled facies information data, especially the hydrocarbon area of interest. However, the greatest challenge for ML algorithms is the unbalance of training set data which may lead to the mode collapse problem, e.g. a generator model biased towards only one class or a small subset of the training data. Therefore, the authors adopted a CycleGAN adopting 1D CNN with bi-directional learning to mitigate the mode collapse issue. Exploiting the cycle consistency learning, two generators and two discriminators were respectively adopted to map from one domain to another and, vice-versa, to map the inverse backward transformation. The augmented data helped improving the more accurate seismic facing classification. The same authors in Kim and Byun (2021) extended their previous contribution by exposing an objective selection criterion for CycleGAN to accomplish the imbalance problem in facies classification. Based on the difference between the recall and the weighted precision for each class, the authors explain an interesting strategy to choose the number of synthetic data that should be generated and for which category to tackle the seismic facing classification imbalance issue. The prediction of the spatial distribution of facies is an ill-posed problem, but it is of utmost importance for flow simulations and, thus, the prediction of production curves of an oil/gas field. In Talarico et al. (2020), the authors applied the cGANs with a progressive training strategy (Karras et al. 2017; Hamada et al. 2018) to sample geological facies sections from migrated seismic sections. The algorithm yielded detailed and realistic images. They were characterized by a good spatial correlation between negative impedances and reservoir facies. Additionally, they preserved the stratigraphic relations. The authors in Kaur et al. (2021c) adopted a GAN with a combination of adversarial loss and multi-class cross-entropy for seismic facies classification starting from seismic reflection data. The authors trained the network on manually labelled data and tested it on real field data. The novelty of this work is to provide a naive method for a simple uncertainties quantification of the GAN predictions. By leveraging the random dropout layers and recalling the trained model many times for the same input, one may obtain different output predictions for the same input. Thus, the authors affirmed that the mechanism of dropout layers belongs in some way to the Bayesian approximation framework. Therefore, the authors could estimate confidence levels for GAN output predictions in this simple way. To reconstruct the petroleum and oil reservoir connectivity patterns, a DCGAN has been adopted in Exterkoetter et al. (2018) for seismic inversion data. To overcome the limits of the current geostatistics approaches (such as traditional two-point statistics (Bosch et al. 2010) or multi-Point geostatistics Strebelle 2002), the GAN revealed the ability to rapidly post-process the data from seismic testing to reconstruct the internal reservoir connectivity structure, crucial to estimate the optimal location for injection wells and production wells for gas and oil recovery. In this case, for the generator, a fully CAE has been adopted. In contrast, a CNN has been employed for the discriminator with a softmax activation to determine the probability of each pixel belonging to the reservoir or non-reservoir class. CAE implements layers similar to CNN in an encoder-decoder structure, with the ability to consider the spatial correlation among image pixels. The decoder part adopts deconvolutional and unspooling layers for a reliable reconstruction of the shapes present in the original image and captures the features at different hierarchical levels, similarly to what happens in conventional CNNs. In a later study (Xie et al. 2022), the authors adopted a WGAN-GP for reservoir modelling, considering well data, seismic data, and information from geology with promising results. The seismic impedance inversion task handles seismic data with narrower bandwidth to retrieve the wave impedance data with broader frequency bandwidth. Within this context, the labelled data are always limited. Thus in Wang et al. (2019b) a 1D CycleGAN was adopted to mitigate this limitation thanks to the cycle consistent loss. Two sub-networks have been adopted for the generator and discriminator to deal with both seismic forward and inversion tasks. This allows the GAN to extract information even with unlabelled data. The generator comprises a CNN 1D U-net model with an encoder and a decoder part with skip connections to capture multi-scale features. The discriminator is composed of a CNN 1D AlexNet model (Krizhevsky et al. 2011) with a scalar output performing a binary classifier between real or generated data. During training, the discriminator ensured that the generated data distribution approaches the real data distribution. In a later study (Wang et al. 2022a), the same authors extended their previous contribution of adopting a 1D CycleGAN for seismic impedance inversion. Again, the authors delivered extended and comprehensive robustness experiments with promising results. In Zhong et al. (2020) a CycleGAN has also been adopted. In this contribution, the aim was to continuously monitor 3D seismic survey data of the same area over time to characterize the dynamic property changes of a reservoir fluid to track carbon dioxide CO\(_2\) capture and storage. This technique is named 4D seismic inversion for reservoir monitoring, and it is also better acknowledged as time-lapse seismic reservoir monitoring. As often happens in seismic inversion, obtaining high-resolution CO\(_2\) saturation maps from 4D seismic data is an ill-posed and highly nonlinear inverse problem, and traditional gradient-based methods appear meaningless due to the high computational efforts. Therefore, the authors proposed a physics-based CycleGAN to tackle this problem to obtain a bidirectional mapping that solves both forward and inverse problems between these two high-dimensional domains. In this way, it was possible to relate changes in seismic properties (e.g. travel time, seismic wave celerity, seismic noise level and magnitude etc.) to dynamic changes in reservoir properties (e.g. pore pressure, fluid content, saturation, CO\(_2\) plume tracking etc.). The authors defined this cross-domain learning between the seismic acoustic impedance domain and the reservoir fluid property domain. Numerical training and tests have been conducted on a synthetic saline storage aquifer modelled with a commercial reservoir simulator. The authors underline the importance of the “end-to-end” property of their GAN implementation, meaning that input data are directly transformed into output predictions without the feature extraction phase, which is usual in other ML frameworks. This property was beneficial to avoiding adversarial attack phenomenon, i.e. the tendency of a trained model to biased misclassify once only a little noise is added to training data. CycleGAN remained stable in performance for both forward and inverse tasks even when heterogeneity structure changes, suggesting the ability to self-adjust the model parameters to changes. The author in Navarro et al. (2020) presented a pipeline to adopt cGAN for real-time inference of seismic attributes. A seismic attribute can be seen as a mapping of any measure of seismic data which can be used to quantify or characterize any features under study, starting from a 3D input amplitude volume. The generator has been decomposed into two sub-networks devoted to coarse and fine quality capturing, respectively, promoting the aggregation between global and local scale information. The discriminator is composed of three networks to avoid overfitting issues and to perform multi-scale feature analysis with a large receptive field. The results demonstrated how a single network was generally good enough to catch more attributes. Still, for high-quality attribute capturing, the network has to be specialized, i.e. one network dedicated to each feature. In Wei et al. (2019), the authors adopted the cGAN for P-wave separation and reconstruction based on vertical seismic profile (VSP) data collected with geophones placed on the lateral walls of a drilled well. Since the sensors are placed directly in the subsurface, they can capture more detailed information about the stratigraphy. However, it is strictly necessary to proceed with wave separation techniques. Divergence and curl operators are traditionally employed. Nevertheless, they may not be directly applied to VSP data unless a careful calibration of the model parameters is performed. The data-driven method based on a cGAN with a U-net as a generator has been trained with a multi-scale strategy, i.e. starting with the P-wave discrimination in simpler waveform and progressively increasing the complexity of the data. Since the separation task is quite different from standard classification or regression tasks, the authors adopted six metrics to evaluate the results in terms of accuracy, precision, recall, f1-score, \(R^2\) for the envelope and raw data. In Cao et al. (2021), the authors successfully applied the GAN with asymmetric convolution blocks to separate up-going and down-going wave fields from vertical seismic profiles. In Ferreira et al. (2019b), the authors explored the adoption of sketches for seismic imaging data augmentation. Since, in ML the bottleneck is the need to have enough data, the authors adopted a cGAN model to generate seismic profiles starting from simple sketches usually used only for quick representation and transmitting ideas about the subsurface stratigraphy. After that, in Ferreira et al. (2019c), the same authors extended the previous contribution by adopting pix2pix cGAN with a generator with an encoder-decoder structure and a discriminator with the PatchGAN structure (Oliveira et al. 2019). They tested different combinations of artificially generated sketched images to reconstruct realistic seismic ones. The results demonstrated that the sketch type composed of a variety of filled background colours, representing the rock layers, and colourful edges, defined by two geoscientists, produced the best results. The authors in Chuang et al. (2020) adopted a DCGAN to perform the first-arrival pickup tomographic inversion task from seismic data for seismic exploration. For example, the SNR of seismic data is low in a mountainous areas and, in general, in locations with complex near-surface conditions. This determines an appreciable first-arrival wave travel time change. The first-arrival pickup accuracy directly reflects on the propagation velocity model in the mean and directly affects the tomographic inversion. Therefore, the authors adopted a DCGAN for its generality and efficiency with generator and discriminator composed of CNNs. The training and testing of the model involved preprocessed mountain seismic data. However, the authors underlined that more types of seismic data need to be trained in future to improve the generalization capabilities of the model. The authors in Zhang and Sheng (2020) leverage the WGAN for data augmentation to effectively perform first-arrival picking of microseismic signals in a deficient SNR environment. Specifically, they adopted WGAN to generate adversarially synthetic samples to test and improve a subsequent DL model, i.e. a residual link nested U-net structure (RLU-net). This latter model was devoted to retaining spatial information and even accomplishing the first arrival picking task in an end-to-end approach. The simulated microseismic training data for the WGAN were obtained by finite difference forward modelling.
4.2.6 Fiber-optic distributed acoustic sensing systems
In Shiloh et al. (2018), the GAN has been adopted to perform an essential data augmentation procedure, helpful for training an automatic detection and classification of seismic acoustic waves for fibre-optic distributed acoustic sensing (DAS) system. However, a reliable automatic classification based on the DAS system is still computationally and human resources demanding due to all the training database construction, e.g. collecting labeled signals for the different phenomena to classify. Additionally, overly complex approaches may invalidate real-time applications, e.g. due to processing-delay issues. To improve the database creation, the authors in Shiloh et al. (2018) adopted GAN for data generation and augmentation purposes, exploiting limited available real data. Furthermore, a great advantage of GAN is not requiring an accurate definition of the physical parameters involved in the generation and propagation of seismic waves in the soil medium and the sometimes challenging interaction phenomena modelling with the DAS fibres. Thus, they tested experimentally with human-step recognition in the proximity of the buried DAS system, simulating the fibre sensor response to a seismic event. In a later study, the same authors in Shiloh et al. (2019) expanded the results by adopting the GAN for the DAS system and vehicle excitations. The authors evidenced the advantage of the method based on the GAN model, which is virtually adaptable to any medium soil type and fibre length. Moreover, parallel real-time computing for each fibre of DAS has been made possible by exploiting narrow spatial segments and short time windows of the collected DAS signals. In Eaid et al. (2021), the authors analyzed the DAS system to characterize the microseismic source and to determine the source mechanism. Since DAS produces a considerable quantity of data, an effective way to manage them is crucial for moment tensor estimation. Firstly, the authors trained a CAE to extract the most critical features from the data. After that, the authors provided two techniques to estimate moment tensor, adopting at first a density-based clustering technique (DBSCAN) (Ester et al. 1996). The second technique was a GAN model to train the generator to provide moment tensor estimation predictions directly from feature space vectors extracted from the CAE. An attention-aided GAN was applied by Ji et al. (2022) to reduce the noise of vertical seismic profiles obtained from DAS. The feature extractor is the multi-head self-attention mechanism, generating a spatial attention weight matrix to extract the key information of the noises. In the second step, the generator receives the original signal and the spatial attention weight matrix. Lastly, the noise reduction of the original signal is achieved with the adversarial mechanism between the generator and the discriminator. In Zhao et al. (2022), the authors examine deep learning models’ limits in denoising DAS signal data. The performance of data-driven approaches depends on the quantity and quality of the training datasets, and thus they are strongly limited with small datasets. Therefore, the authors proposed combining a GAN with CNN. First, they used a small noise dataset to train a GAN for synthesizing artificial noise, with the final purpose of noise dataset augmentation. Afterward, the expanded noise dataset and the signal dataset from modeling were used together to compile a synthetic training set. Finally, the CNN was specialized to de-noise the experimental data. Seismic data from DAS systems are thus often characterized by a low SNR due to the weak energy of scattered optical signals. Also, in Dong and Li (2020), a GAN-based model, named convolutional adversarial denoising network (CADN), has been implemented to address the DAS denoising process and improve data quality by increasing the SNR. The network architecture utilized a RED-Net model (Mao et al. 2016), i.e. a deep recurrent convolutional encoder-decoder structure.
5 Actual limitations and future challenges
Notwithstanding that the GAN model is a relatively recent technique in DL prospect (Goodfellow et al. 2014), their innovative capabilities have already successfully permitted broadening the earthquake-related engineering actual frontiers. The critical comprehensive review of the previous sections demonstrated how GANs had paved the way for novel methodologies and unprecedented breakthroughs, representing valuable alternatives to current traditional workflows. Many research papers have already been published on the wide range of aspects involved in geophysical studies. On the other hand, slower but progressively increasing developments have been achieved recently, even within the earthquake engineering field. However, in both disciplines, many research opportunities are still possible, also promoted by the latest advances in GANs (Gui et al. 2021) and, in wider terms, into AI, ML, and DL areas.
Through adversarial learning, GANs act as efficient generative models able to synthesize different but plausible artificial representations of any input data, by estimating their probability distribution (Wu et al. 2022; Shiloh et al. 2018, 2019). Their thoroughly data-driven perspective provided an indisputable advantage to accounting for highly nonlinear relationships between data and complex domain mappings, where often traditional analytical modeling approaches have failed (Mosser et al. 2018a). Generally, ML algorithms can map complex interactions even when there is any prior knowledge of the form of relationship between input and output variables (Woldesellasse and Tesfamariam 2022). This should help to understand why the overall most commonly used GAN architectures in the previously analyzed studies are represented by image-to-image translation pix2pix GANs (Ferreira et al. 2019a, c; Liao et al. 2021; Lowney et al. 2021; Oliveira et al. 2018a, b, 2019; Pan et al. 2021; Picetti et al. 2018, 2019; Saraiva et al. 2021; Wei et al. 2021a; Yuan et al. 2020) and CycleGANs (Cai et al. 2020, 2022; Kaur et al. 2019a, 2021b, a, 2020a, b; Kim and Byun 2020, 2021; Li et al. 2020c; Li and Wang 2021; O’Brien 2020; Wang et al. 2019b, 2022a; WU Xuefeng 2021; Zhang et al. 2021; Zhao et al. 2022; Zhong et al. 2020).
Nonetheless, the main pitfalls of many data-driven approaches are basically and intrinsically embedded into the input datasets themselves (Wu et al. 2022). To implement a reliable GAN model, it is desirable to use a high-quality dataset that almost covers the entire input domain range (Kim and Byun 2020). This would ensure non-biased training procedures and provide accurate estimates of the input data probability distribution. Furthermore, the considerable number of learnable parameters commonly involved in complex DL model training, such as GANs, usually require large enough datasets. However, this is often economically and time prohibitive to fulfill seismic-related engineering practical purposes. Therefore, in the previously discussed papers, many authors leveraged GAN generative capabilities for data augmentation goal, in order to increase seismic datasets artificially for EEW systems (Li et al. 2018), for detecting earthquake events (Grijalva et al. 2021; Li et al. 2020b, a; Wang et al. 2021), for earthquake engineering applications and post-disaster analysis (Yamada et al. 2021), for geophysical seismic imaging (Wei et al. 2021c), noise attenuation (Dong et al. 2022), seismic inversion (Araya-Polo et al. 2019; Ferreira et al. 2019b; Kim and Byun 2020; Zhang and Sheng 2020), and for DAS systems (Shiloh et al. 2018). However, the final generalization and robustness of the data augmentation procedure must be carefully evaluated. The actual risk is jeopardizing the original data semantic content if unrealistic synthetic signals are added to the initial dataset (Wang et al. 2021). Furthermore, in the training procedure of the GAN model itself, some scholars have occasionally used only a small amount of synthetic seismic data generated by current traditional procedures, analytical or numerical (Jiang and Norlund 2020; Kaur et al. 2020a; Ovcharenko et al. 2021). However, training GANs only on these data may provide biased models. Analytical or numerical synthetic seismic data generated with traditional methods may be unable to capture all the real-world aspects (Kaur et al. 2020a; Ovcharenko et al. 2021; Wang et al. 2022b). Therefore, many authors trained GAN models by mixing synthetic data with artificially added noise and real field data in the input dataset. A critical future challenge would be providing high-quality, certified, and openly accessible seismic databases to effectively support AI applications and research on both earthquake engineering and geophysical studies. Some efforts in that direction have been already carried on with seismic data curation responsibilities provided by some acknowledged institutions worldwide. It is worth mentioning, e.g. the European Mediterranean Seismological Centre (EMSC) which provides real-time earthquake information for seismic events, or the Italian National Institute of Geophysics and Volcanology (INGV) which provides high-quality and certified seismic databases for open-science and research project. For instance, the ITalian ACcelerometric Archive (ITACA) (Luzi et al. 2017) is concerned with Italian seismic events only and, on the other hand, the Engineering Strong-Motion (ESM) database (Luzi et al. 2020) is related to strong seismic events mainly recorded in the European-Mediterranean regions and the Middle East.
Albeit a well-trained GAN is virtually able to successfully capture the probability distribution of the input data, its limited extrapolation capabilities represent another possible drawback. Some scholars warned about the difficulty of GANs to generate synthetic seismic data which are completely different from the starting training set (Kaur et al. 2020a). Specifically, a dataset referred to a specific and topographically limited restricted area will probably bias the generated samples to reflect only seismic events likely to occur in that specific region, thus reflecting the seismological conditions of that region only (Wang et al. 2021). Another future promising approach may involve conditioning GANs with both topographical and seismological metadata, thus providing spatial correlation information to even generate georeferenced synthetic seismic data.
Another focal point that is worth to dwelling on is the lack of interpretability for which ML models are often blamed (Woldesellasse and Tesfamariam 2022). However, in recent years some innovative interpretability methods have been developed to explain DL models’ learned parameters and weights (Li et al. 2022; Selvaraju et al. 2017; Zhou et al. 2016), e.g. providing interpretative maps such as in Rosso et al. (2023). These methods permit deeper insights and further explanations of the resulting outputs. Moreover, in the previous sections, all the scholars agreed on considering deficient a simple visual inspection to assess the quality of generated synthetic seismic results, since it would be an overly subjective evaluation. Therefore, many studies adopted more objective metrics, i.e. accuracy, precision, recall, f1-score, \(R^2\) (Wei et al. 2019), correlation coefficients, performance parameters, RMSE, mean absolute percentage error and mean absolute error (Ding et al. 2021), MSE (Li et al. 2019b), computer vision metrics (Liao et al. 2021), PSNR and SSIM metrics (Yuan et al. 2020; Saraiva et al. 2021; Ji et al. 2022), statistical goodness-of-fit metric (Gatti and Clouteau 2020) and mean categorical error (Pan et al. 2021).
Although the main advantage of GANs models is their general purpose and data-driven strategy, generally ML models may still suffer ill-posedness, robustness, and generalization issues. Furthermore, the final outputs may not incorporate any authenticity of the underlying seismic physical process (Ovcharenko and Hou 2020). Therefore, in the most recent studies, the physics-informed ML philosophy appeared as a promising solution to overcome those obstacles, mainly enhanced by the conditional GAN perspective. Thus, considering prior knowledge and information about the involved seismic phenomena, the conditioned GAN models were able to generate synthetic samples consistent with the prior knowledge (Zhang and Lin 2020), avoiding any lack of variability (Pan et al. 2021), and even regularizing the training process with additional loss terms (Gatti and Clouteau 2020; Kaur et al. 2020a). Furthermore, since earthquake phenomena are often characterized by significant uncertainty and noise levels, another future aspect to address would be integrating also the aleatory and epistemic uncertainties which affect seismological data and metadata. Some basic attempts to deal with seismic-related uncertainties have been already done by integrating the Bayesian framework into the GAN-based workflows (Fang et al. 2020; Kaur et al. 2021c, c).
Last but not least, the computational effort required to train GAN models needs to be considered. Since GANs involve the adversarial training of two DL networks simultaneously, this procedure may require significant computational costs (Kaur et al. 2020a; Wu et al. 2022). Nevertheless, this strongly depends on the specific kind of implementation adopted for the generator network and the discriminator one. Thus, especially focusing on the DL side, immediate future promising research paths are already offered by the most recent GAN implementations (Gui et al. 2021) or by the latest breakthrough developments in the DL field. For instance, innovative implementation improvements may be achieved by employing the state-of-art neural transformer architecture in the generator and/or the discriminator parts (Dosovitskiy et al. 2020; Vaswani et al. 2017), or even adapting the novel generative transformer architecture (GPT) (Radford et al. 2018), hitherto applied for natural language processing tasks only.
6 Conclusions and remarks
In the current study, the authors critically review the various GAN models and architectures adopted within the seismic field. The existing literature studies can be organized into two macro-areas: earthquake engineering for synthetic signals generations and applications on one side and geophysical studies for the earth and planetary sciences on the other. To the authors’ knowledge, the present document represents the first work within this research field that outlines and categorizes the existing literature for a more comprehensive overview.
Due to the solid multidisciplinary background, it will be necessary for civil engineers, electrical engineers, artificial intelligence experts, computer science engineers, etc., to create more reliable systems for intelligent structures and infrastructures. Within the current panorama, the GAN and the other ML/DL models may play a central role in the upcoming years because it represents a revolution for innovative paradigms and approaches. Data augmentation has become an essential tool to make it possible to adopt ML algorithms where only a few high-quality data are available.
Understanding the existing literature represents the very first step toward future developments and studies. Furthermore, understanding the nowadays limits of the various methods will provide a clearer view and track the promising research path for future improvements. The primary present and future accomplishment will be the syncretic interaction between AI, earthquake engineering, and planetary sciences within the complex, intricate, highly uncertain, and nonlinear topics under investigation. To improve the generalization capabilities of the DL model, introducing prior knowledge or emphasizing physical constraints may provide a more reliable and effective physics-informed ML model.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
Abbreviations
- 3DSC-GAN:
-
3-D convolution-based seismic data compression GAN
- ADGAN:
-
Anomaly detection GAN
- AE:
-
Auto-encoders
- ALICE:
-
Adversarially learned inference with conditional entropy
- AS:
-
Aftershocks
- ASCE:
-
American Society of Civil Engineers
- Att-DCDN:
-
Attribute-based double constraint denoising network
- CADN:
-
Convolutional adversarial denoising network
- CAE:
-
Convolutional auto-encoder
- CAE-SAGAN:
-
Convolutional auto-encoder self-attention GAN
- CDF:
-
Cumulative density functions
- cGAN:
-
Conditional GAN
- CNN-WDRND:
-
CNN with a weak dependence on real noise data
- CNN:
-
Convolutional neural network
- CO\(_2\) :
-
Carbon dioxide
- CSA-GAN:
-
Compressed sensing architecture GAN
- cWGAN:
-
Conditional Wasserstein GAN
- Cycle-GAN:
-
Cycle-consistent GAN
- DAS:
-
Distributed acoustic sensing
- DBSCAN:
-
Density-based spatial clustering of applications with noise
- DCGAN:
-
Deep convolutional GAN
- DD-CGAN:
-
Dual-domain cGAN
- DDAE-GAN:
-
Deep denoising auto-encoder GAN
- DeGAN:
-
Denoising GAN
- DL:
-
Deep learning
- GMcGAN:
-
Gaussian mixture conditional GAN
- EEW:
-
Earthquake early warning
- EMSC:
-
European Mediterranean Seismological Centre
- EQGAN:
-
Earthquake GAN
- ESeismic-GAN:
-
Ecuadorian volcano origin seismic GAN
- ESM:
-
Engineering Strong-Motion
- ESRGAN:
-
Enhanced super-resolution GAN
- GAN-CDG:
-
GAN with compressive data gathering
- GAN:
-
Generative adversarial network
- GIN:
-
Generative inpainting network
- GRU:
-
Gated Recurrent Unit
- IM:
-
Intensity measures
- INGV:
-
National Institute of Geophysics and Volcanology
- ITACA:
-
Italian Accelerometric Archive
- JMA:
-
Japan Meteorological Agency
- LSTM:
-
Long Short-Term Memory unit
- MEMS:
-
Micro-electro-mechanical systems
- MKAR:
-
Makanchi Kazakhstan Array
- ML:
-
Machine learning
- MLP:
-
Multi layer perceptron
- MSE:
-
Mean square error
- NGA-West2:
-
Next Generation Attenuation-West2
- NTC:
-
Italian National Techinical Code
- PEER:
-
Pacific Earthquake Engineering Research Center
- pix2pix GAN:
-
Pixels to pixels cGAN
- PSNR:
-
Peak signal-to-noise ratio
- RAGAN:
-
Relative attributes-based GAN
- RCGAN:
-
Residual learning cycle-GAN
- RED-Net:
-
Residual denoising convolutional encoder–decoder network
- ReLU:
-
Rectified Linear Unit
- RF:
-
Random forest
- RLU-net:
-
Residual Link Nested U-net
- RMSE:
-
Root MSE
- RNAi:
-
RNN with attention
- RNN:
-
Recurrent neural network
- SAGAN:
-
Self-attention GAN
- SEAM:
-
3D Seismic Advanced Modeling
- SegGAN:
-
Segment-based cGAN
- SGAN:
-
Semi-supervised GAN
- SHAP:
-
Shapley additive explanations
- SHM:
-
Structural Health Monitoring
- SIGAN:
-
Seismic data interpolation GAN
- SNR:
-
Signal-to-noise ratio
- SSIM:
-
Structural similarity index measure
- STFT:
-
Short-Time Fourier Transform
- StructGAN:
-
GAN-based structural design framework
- StructGAN-PHY:
-
Physics-informed StructGAN
- SVM:
-
Support vector machine
- t-SNE:
-
t-Distributed stochastic neighbour embedding
- TF-cGAN:
-
Time frequency cGAN
- U-GAT-IT:
-
Unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image translation
- UAV:
-
Unmanned aerial vehicl
- U.S.A.:
-
United States of America
- VAE-GAN:
-
Variational auto-encoder GAN
- VGG:
-
Visual Geometry Group
- VSP:
-
Vertical seismic profile
- WCycle-GAN:
-
Wasserstein cycle-consistent GAN
- WGAN-GP:
-
WGAN with gradient penalty
- WGAN:
-
Wasserstein GAN
References
Aggarwal CC et al (2018) Neural networks and deep learning. Springer 10(978):3
Al-Husseini MI, Glover JB, Barley BJ (1981) Dispersion patterns of the ground roll in eastern Saudi Arabia. Geophysics 46(2):121–137
Alwon S (2018) Generative adversarial networks in seismic data processing. In: 2018 SEG international exposition and annual meeting. OnePetro
Araya-Polo M, Farris S, Florez M (2019) Deep learning-driven velocity model building workflow. Lead Edge 38(11):872–18729
Arjovsky M, Chintala S, Bottou L (2017) Wasserstein generative adversarial networks. In: International conference on machine learning, PMLR, pp 214–223
Avila MRV, Osorio LN, de Castro Vargas Fernandes J, Bulcão A, Pereira-Dias B, de Souza Silva B, Barros PM, Landau L, Evsukoff AG, (2021) Migration deconvolution via deep learning. Pure Appl Geophys 178(5):1677–1695
Azevedo L, Paneiro G, Santos A, Soares A (2020) Generative adversarial network as a stochastic subsurface model reconstruction. Comput Geosci 24(4):1673–1692
Bahdanau D, Cho K, Bengio Y (2014) Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473
Båth M (1965) Lateral inhomogeneities of the upper mantle. Tectonophysics 2(6):483–514
Bin K, Luo S, Zhang X, Lin J, Tong X (2020) Compressive data gathering with generative adversarial networks for wireless geophone networks. IEEE Geosci Remote Sens Lett 18(3):558–562
Bormann P, Wendt S, DiGiacomo D (2013) Seismic sources and source parameters. New manual of seismological observatory practice 2 (NMSOP2). Deutsches GeoForschungsZentrum GFZ, Germany, pp 1–259
Bosch M, Mukerji T, Gonzalez EF (2010) Seismic inversion for reservoir properties combining statistical rock physics and geostatistics: a review. Geophysics 75(5):165–176
Bugge A, Lie J, Evensen A, Nilsen E, Slang S (2021) Demonstrating aspects of generative adversarial networks applied to seismic data processing. In: 82nd EAGE annual conference & exhibition, vol. 2021. European Association of Geoscientists & Engineers, pp 1–5
Cai A, Di H, Li Z, Maniar H, Abubakar A (2020) Wasserstein cycle-consistent generative adversarial network for improved seismic impedance inversion: Example on 3d seam model. SEG technical program expanded abstracts 2020. Society of Exploration Geophysicists, USA, pp 1274–1278
Cai A, Qiu H, Niu F (2022) Semi-supervised surface wave tomography with Wasserstein cycle-consistent GAN: method and application to southern California plate boundary region. J Geophys Res Solid Earth 127(3):2021–023598
Cao D, Jia Y, Cuia R (2021) Vsp wavefiled separation using gan base on asymmetric convolution blocks. In: First international meeting for applied geoscience & energy, Society of Exploration Geophysicists, pp 3530–3535
Chang D, Yang W, Yong X, Li H (2018) Generative adversarial networks for seismic data interpolation. In: SEG 2018 workshop: SEG maximizing asset value through artificial intelligence and machine learning, Beijing, China, 17–19 September 2018. Society of Exploration Geophysicists and the Chinese Geophysical Society, pp 40–43
Chang D, Yang W, Yong X, Li H (2019) Seismic data interpolation with conditional generative adversarial network in time and frequency domain. In: SEG international exposition and annual meeting. OnePetro
Chang D, Yang W, Yong X, Zhang G, Wang W, Li H, Wang Y (2020) Seismic data interpolation using dual-domain conditional generative adversarial networks. IEEE Geosci Remote Sens Lett 18(10):1856–1860
Chen L-C, Papandreou G, Kokkinos I, Murphy K, Yuille AL (2017) Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans Pattern Anal Mach Intell 40(4):834–848
Cho K, Van Merriënboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, Bengio Y (2014) Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078
Chuang Z, Xingguo J, Ziang L et al (2020) A deep convolutional generative adversarial network for first-arrival pickup from seismic data. Geophys Prospect Pet 59(5):795–803
Chung J, Gulcehre C, Cho K, Bengio Y (2014) Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20(3):273–297
Dauphin YN, Fan A, Auli M, Grangier D (2017) Language modeling with gated convolutional networks. In: International conference on machine learning, PMLR, pp 933–941
Ding Y, Chen J, Shen J (2020) Conditional generative adversarial network model for simulating intensity measures of aftershocks. Soil Dyn Earthq Eng 139:106281
Ding Y, Chen J, Shen J (2021) Prediction of spectral accelerations of aftershock ground motion with deep learning method. Soil Dyn Earthq Eng 150:106951
Dong X, Li Y (2020) Denoising the optical fiber seismic data by using convolutional adversarial network based on loss balance. IEEE Trans Geosci Remote Sens 59(12):10544–10554
Dong X, Lin J, Lu S, Huang X, Wang H, Li Y (2022) Seismic shot gather denoising by using a supervised-deep-learning method with weak dependence on real noise data: a solution to the lack of real noise data. Surv Geophys 43:1363–1394
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S, et al (2020) An image is worth 16x16 words: transformers for image recognition at scale. arXiv preprint arXiv:2010.11929
dos Santos Ribeiro AP, Schiavon AP, Navarro JP, Vieira MB, Villela SM, e Silva PMC (2021) Poststack seismic data compression using a generative adversarial network. IEEE Geosci Remote Sens Lett 19:1–5
Durall R, Tschannen V, Pfreundt F-J, Keuper J (2020) Synthesizing seismic diffractions using a generative adversarial network. SEG technical program expanded abstracts 2020. Society of Exploration Geophysicists, USA, pp 1491–1495
Eaid M, Hu C, Zhang L, Keating S, Innanen K (2021) Estimation of das microseismic source mechanisms using unsupervised deep learning, vol 2021-September, Society of Exploration Geophysicists, USA, pp 407–411. https://doi.org/10.1190/segam2021-3592849.1
Elman JL (1990) Finding structure in time. Cogn Sci 14(2):179–211
Esfahani RD, Cotton F, Ohrnberger M, Scherbaum F (2022) Tfcgan: nonstationary ground-motion simulation in the time-frequency domain using conditional generative adversarial network (cgan) and phase retrieval methods. Bull Seismol Soc Am 113:453–467
Ester M, Kriegel H-P, Sander J, Xu X et al (1996) A density-based algorithm for discovering clusters in large spatial databases with noise. Kdd 96:226–231
Exterkoetter R, Bordignon F, de Figueiredo LP, Roisenberg M, Rodrigues BB (2018) Petroleum reservoir connectivity patterns reconstruction using deep convolutional generative adversarial networks. In: 2018 7th Brazilian conference on intelligent systems (BRACIS), IEEE, pp 97–102
Fang Z, Fang H, Demanet L (2020) Deep generator priors for Bayesian seismic inversion. Adv Geophys 61:179–216
Fan G, Li J, Hao H, Xin Y (2021) Data driven structural dynamic response reconstruction using segment based generative adversarial networks. Eng Struct 234:111970
Fan G, Li J, Hao H (2021) Dynamic response reconstruction for structural health monitoring using densely connected convolutional networks. Struct Health Monit 20(4):1373–1391
Fares AM (2019) The effect of shear wall positions on the seismic response of frame-wall structures. Int J Civ Environ Eng 13(3):190–194
Ferreira RS, Naeini EZ, Brazil EV (2019a) Stabilized super resolution deep generative networks for seismic data. In: 81st EAGE conference and exhibition 2019 workshop programme, vol. 2019, European Association of Geoscientists & Engineers, pp 1–5
Ferreira R, Oliveira D, Brazil EV (2019b) Synthetic seismic images from simple sketches using deep generative networks. In: 81st EAGE conference and exhibition 2019, vol 2019. European Association of Geoscientists & Engineers, pp 1–5
Ferreira RS, Noce J, Oliveira DA, Brazil EV (2019c) Generating sketch-based synthetic seismic images with generative adversarial networks. IEEE Geosci Remote Sens Lett 17(8):1460–1464
Florez MA, Caporale M, Buabthong P, Ross ZE, Asimaki D, Meier M-A (2022) Data-driven synthesis of broadband earthquake ground motions using artificial intelligence. Bull Seismol Soc Am 112:1979–1996
Fomel S (2009) Adaptive multiple subtraction using regularized nonstationary regression. Geophysics 74(1):25–33
Foti S, Sambuelli L, Socco LV, Strobbia C (2002) Spatial sampling issues in fk analysis of surface waves. In: 15th EEGS symposium on the application of geophysics to engineering and environmental problems, European Association of Geoscientists & Engineers, p 191
Gatti F, Clouteau D (2020) Towards blending physics-based numerical simulations and seismic databases using generative adversarial network. Comput Methods Appl Mech Eng 372:113421
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2014) Generative adversarial nets. In: Advances in neural information processing systems, vol 27
Grijalva F, Ramos W, Perez N, Benitez D, Lara-Cueva R, Ruiz M (2021) Eseismic-GAN: a generative model for seismic events from Cotopaxi Volcano. IEEE J Sel Top Appl Earth Obser Remote Sens 14:7111–7120
Gui J, Sun Z, Wen Y, Tao D, Ye J (2021) A review on generative adversarial networks: algorithms, theory, and applications. IEEE Trans Knowl Data Eng
Gulrajani I, Ahmed F, Arjovsky M, Dumoulin V, Courville AC (2017) Improved training of wasserstein GANs. In: Advances in neural information processing systems, vol 30
Gutenberg B, Richter CF (1944) Frequency of earthquakes in California. Bull Seismol Soc Am 34(4):185–188
Halpert AD (2018) Deep learning-enabled seismic image enhancement. SEG technical program expanded abstracts 2018. Society of Exploration Geophysicists, USA, pp 2081–2085
Hamada K, Tachibana K, Li T, Honda H, Uchida Y (2018) Full-body high-resolution anime generation with progressive structure-conditional generative adversarial networks. In: Proceedings of the European conference on computer vision (ECCV) workshops
Hancock J, Watson-Lamprey J, Abrahamson NA, Bommer JJ, Markatis A, McCoy E, Mendis R (2006) An improved method of matching response spectra of recorded earthquake ground motion using wavelets. J Earthq Eng 10(spec01):67–89
Han F, Zhang H, Chatterjee S, Guo Q, Wan S (2019) A modified generative adversarial nets integrated with stochastic approach for realizing super-resolution reservoir simulation. IEEE Trans Geosci Remote Sens 58(2):1325–1336
Han H, Dai Y, Song J, Wan Y, Sun W, Li H (2022) Deep prestack seismic wavelets extraction in Tarim based on generative adversarial network. Chin J Geophys 65(2):763–772
Heusel M, Ramsauer H, Unterthiner T, Nessler B, Hochreiter S (2017) Gans trained by a two time-scale update rule converge to a local nash equilibrium. In: Advances in neural information processing systems, vol 30
He Z, Zuo W, Kan M, Shan S, Chen X (2019) Attgan: facial attribute editing by only changing what you want. IEEE Trans Image Process 28(11):5464–5478
Isola P, Zhu J-Y, Zhou T, Efros AA (2017) Image-to-image translation with conditional adversarial networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1125–1134
Jiang F, Norlund P (2020) Super resolution of fault plane prediction by a generative adversarial network. In: First EAGE digitalization conference and exhibition, vol. 2020. European Association of Geoscientists & Engineers, pp 1–5
Ji L, Han B, Jing Q, Rao Y, Wu H (2022) Noise suppression for das seismic data with attention-aided generative adversarial network. In: Eighth symposium on novel photoelectronic detection technology and applications, vol 12169. SPIE, pp 1948–1954
Jo H, Santos JE, Pyrcz MJ (2020) Conditioning well data to rule-based lobe model by machine learning with a generative adversarial network. Energy Explor Exploit 38(6):2558–2578
Karras T, Aila T, Laine S, Lehtinen J (2017) Progressive growing of gans for improved quality, stability, and variation. arXiv preprint arXiv:1710.10196
Kaur H, Pham N, Fomel S (2019a) Seismic data interpolation using cyclegan. SEG technical program expanded abstracts 2019. Society of Exploration Geophysicists, USA, pp 2202–2206
Kaur H, Fomel S, Pham N (2019b) Ground roll attenuation using generative adversarial network. In: 81st EAGE conference and exhibition 2019, vol. 2019. European Association of Geoscientists & Engineers, pp 1–5
Kaur H, Pham N, Fomel S (2020a) Improving the resolution of migrated images by approximating the inverse hessian using deep learning. Geophysics 85(4):173–183
Kaur H, Fomel S, Pham N (2020b) Seismic ground-roll noise attenuation using deep learning. Geophys Prospect 68(7):2064–2077
Kaur H, Pham N, Fomel S (2021a) Seismic data interpolation using deep learning with generative adversarial networks. Geophys Prospect 69(2):307–326
Kaur H, Fomel S, Pham N (2021b) A fast algorithm for elastic wave-mode separation using deep learning with generative adversarial networks (GANs). J Geophys Res Solid Earth 126(9):2020–021123
Kaur H, Pham N, Fomel S, Geng Z, Decker L, Gremillion B, Jervis M, Abma R, Gao S (2021c) A deep learning framework for seismic facies classification. In: SEG/AAPG/SEPM first international meeting for applied geoscience & energy. OnePetro
Kim D, Byun J (2020) Data augmentation using cyclegan for overcoming the imbalance problem in petrophysical facies classification. In: SEG international exposition and annual meeting. OnePetro
Kim D, Byun J (2021) Selection of augmented data for overcoming the imbalance problem in facies classification. IEEE Geosci Remote Sens Lett 19:1–5
Kim J, Torbol M (2019) Generative adversarial network for earthquake early warning system. Earthquake geotechnical engineering for protection and development of environment and constructions. CRC Press, Balkema, pp 3318–3322
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. In: Advances in neural information processing systems, vol 25
Kuurková V, Manolopoulos Y, Hammer B, Iliadis L, Maglogiannis I (2018) Artificial neural networks and machine learning–ICANN 2018: 27th international conference on artificial neural networks, Rhodes, Greece, October 4–7, 2018, Proceedings, Part III vol. 11141. Springer, Switzerland
Larsen ABL, Sønderby SK, Larochelle H, Winther O (2016) Autoencoding beyond pixels using a learned similarity metric. In: International conference on machine learning, PMLR, pp 1558–1566
Liao W, Lu X, Huang Y, Zheng Z, Lin Y (2021) Automated structural design of shear wall residential buildings using generative adversarial networks. Autom Constr 132:103931
Li Q, Luo Y (2019) Using GAN priors for ultrahigh resolution seismic inversion. In: SEG international exposition and annual meeting. OnePetro
Liu Y, Fomel S (2013) Seismic data analysis using local time-frequency decomposition. Geophys Prospect 61(3):516–525
Liu-Rong T, Jin-Sheng J, Hao-Ran R, Yue-Ming Y, Bang-Yu W (2021) The separation of seismic surface-related multiples based on CAE-SAGAN. In: SEG/AAPG/SEPM first international meeting for applied geoscience & Energy. OnePetro
Liu M, Li W, Jervis M, Nivlet P (2019) 3d seismic facies classification using convolutional neural network and semi-supervised generative adversarial network. SEG technical program expanded abstracts 2019. Society of Exploration Geophysicists, USA, pp 4995–4999
Liu H, Li S, Song J (2022a) Discrimination between earthquake p waves and microtremors via a generative adversarial network. Bull Seismol Soc Am 112(2):669–679
Liu H, Song J, Li S (2022b) Seismic event identification based on a generative adversarial network and support vector machine. Front Earth Sci 10. https://doi.org/10.3389/feart.2022.814655
Li W, Wang J (2021) Residual learning of cycle-GAN for seismic data denoising. IEEE Access 9:11585–11597
Li C, Liu H, Chen C, Pu Y, Chen L, Henao R, Carin L (2017) Alice: Towards understanding adversarial learning for joint distribution matching. In: Advances in neural information processing systems, vol 30
Li Z, Meier M-A, Hauksson E, Zhan Z, Andrews J (2018) Machine learning seismic wave discrimination: application to earthquake early warning. Geophys Res Lett 45(10):4773–4779
Li XR, Mitsakos N, Lu P, Xiao Y, Zhao X (2019b) Seismic compressive sensing by generative inpainting network: toward an optimized acquisition survey. Lead Edge 38(12):923–933
Li G, Qiao Y, Zheng Y, Li Y, Wu W (2019a) Semi-supervised learning based on generative adversarial network and its applied to lithology recognition. IEEE Access 7:67428–67437
Li Y, Ku B, Zhang S, Ahn J-K, Ko H (2020a) Seismic data augmentation based on conditional generative adversarial networks. Sensors 20(23):6850
Li Y, Ku B, Kim G, Ahn J-K, Ko H (2020b) Seismic signal synthesis by generative adversarial network with gated convolutional neural network structure. In: IGARSS 2020-2020 IEEE international geoscience and remote sensing symposium, IEEE, pp 3857–3860
Li Y, Wang H, Dong X (2020c) The denoising of desert seismic data based on cycle-GAN with unpaired data training. IEEE Geosci Remote Sens Lett 18(11):2016–2020
Li Y, Luo X, Wu N, Dong X (2021b) The application of semisupervised attentional generative adversarial networks in desert seismic data denoising. IEEE Geosci Remote Sens Lett 19:1–5
Li J, Hei D, Cui G, He M, Wang J, Liu Z, Shang J, Wang X, Wang W (2021a) GAN-LSTM joint network applied to seismic array noise signal recognition. Appl Sci 11(21):9987
Li X, Xiong H, Li X, Wu X, Zhang X, Liu J, Bian J, Dou D (2022) Interpretable deep learning: Interpretation, interpretability, trustworthiness, and beyond. Knowl Inf Syst 64:3197–3234
Lowney B, Lokmer I, O’Brien GS, Bean CJ (2021) Pre-migration diffraction separation using generative adversarial networks. Geophys Prospect 69(5):949–967
Lundberg SM, Lee S-I (2017) A unified approach to interpreting model predictions. In: Advances in neural information processing systems, vol 30
Luzi L, Pacor F, Puglia R (2017) Italian accelerometric archive v 2.3. Istituto Nazionale di Geofisica e Vulcanologia, Dipartimento della Protezione Civile Nazionale, vol 10. https://doi.org/10.13127/itaca.3.0
Luzi L, Lanzano G, Felicetta C, D’Amico M, Russo E, Sgobba S, Pacor F, ORFEUS W (2020) Engineering strong motion database (esm)(version 2.0) istituto nazionale di geofisica e vulcanologia (ingv). Rome, Italy. https://doi.org/10.13127/ESM.2
Lu P, Morris M, Brazell S, Comiskey C, Xiao Y (2018) Using generative adversarial networks to improve deep-learning fault interpretation networks. Lead Edge 37(8):578–583
Lu P, Xiao Y, Zhang Y, Mitsakos N (2019) Deep learning for 3d seismic compressive-sensing technique: a novel approach. Lead Edge 38(9):698–705
Lu X, Liao W, Zhang Y, Huang Y (2022) Intelligent structural design of shear wall residence using physics-enhanced generative adversarial networks. Earthq Eng Struct Dyn 51:1657–1676
Malo N, Hanley JA, Cerquozzi S, Pelletier J, Nadon R (2006) Statistical practice in high-throughput screening data analysis. Nat Biotechnol 24(2):167–175
Mao X, Shen C, Yang Y-B (2016) Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. In: Advances in neural information processing systems, vol 29
Matinfar M, Khaji N, Ahmadi G (2022) Deep convolutional generative adversarial networks for the generation of numerous artificial spectrum-compatible earthquake accelerograms using a limited number of ground motion records. Comput Aided Civ Infrastruct Eng 38:225–240
Ma H, Sun Y, Wu N, Li Y (2021) Relative attributes-based generative adversarial network for desert seismic noise suppression. IEEE Geosci Remote Sens Lett 19:1–5
Meier M-A, Ross ZE, Ramachandran A, Balakrishna A, Nair S, Kundzicz P, Li Z, Andrews J, Hauksson E, Yue Y (2019) Reliable real-time seismic signal/noise discrimination with machine learning. J Geophys Res Solid Earth 124(1):788–800
Meng D, Wu B, Liu N, Chen W (2020) Semi-supervised deep learning seismic impedance inversion using generative adversarial networks. In: IGARSS 2020-2020 IEEE international geoscience and remote sensing symposium, IEEE, pp 1393–1396
Meng D, Wu B, Wang Z, Zhu Z (2021) Seismic impedance inversion using conditional generative adversarial network. IEEE Geosci Remote Sens Lett 19:1–5
Mikhailova NN, Sokolova IN (2019) Monitoring system of the institute of geophysical research of the ministry of energy of the republic of Kazakhstan. Summ Bull Int Seismol Centre 53(I):27–38
Min F, Wang L-R, Pan S-L, Song G-J (2021) Ddae-gan: Seismic data denoising by integrating autoencoder and generative adversarial network. In: International joint conference on rough sets, Springer, pp 44–56
Mirza M, Osindero S (2014) Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784
Mnih V, Heess N, Graves A, et al (2014) Recurrent models of visual attention. In: Advances in neural information processing systems, vol 27
Mosser L, Dubrule O, Blunt M (2018b) Stochastic seismic waveform inversion using generative adversarial networks as a geological prior. Mathematical Geosciences. https://doi.org/10.3997/2214-4609.201803018
Mosser L, Kimman W, Dramsch J, Purves S, De la Fuente Briceño A, Ganssle G (2018a). Rapid seismic domain transfer: seismic velocity inversion and modeling using deep generative neural networks. https://doi.org/10.3997/2214-4609.201800734
Mosser L, Dubrule O, Blunt M (2019) Deep stochastic inversion. In: Petroleum geostatistics 2019, vol. 2019. European Association of Geoscientists & Engineers, pp 1–5
Navarro JP, e Silva PMC, Pan D, Hester K (2020) Real-time seismic attributes computation with conditional GANs. In: SEG technical program expanded abstracts 2020. Society of Exploration Geophysicists, USA, pp 1611–1615
O’Brien G (2020) Common image gather conditioning using cycle generative adversarial networks. Geophys Prospect 68(6):1758–1770
Odena A (2016) Semi-supervised learning with generative adversarial networks. arXiv preprint arXiv:1606.01583
Oliveira DA, Ferreira RS, Silva R, Brazil EV (2018a) Interpolating seismic data with conditional generative adversarial networks. IEEE Geosci Remote Sens Lett 15(12):1952–1956
Oliveira D, Ferreira RS, Silva R, Brazil EV (2018b) Seismic data interpolation with conditional generative adversarial networks (cgans). In: First EAGE/PESGB workshop machine learning, vol. 2018. European Association of Geoscientists & Engineers, pp 1–3
Oliveira DA, Ferreira RS, Silva R, Brazil EV (2019) Improving seismic data resolution with deep generative networks. IEEE Geosci Remote Sens Lett 16(12):1929–1933
Oliveira DAB, Semin D, Zaytsev S (2020) Ground roll suppression using convolutional neural networks. arXiv e-prints, 2010
Oliveira DA, Semin DG, Zaytsev S (2020) Self-supervised ground-roll noise attenuation using self-labeling and paired data synthesis. IEEE Trans Geosci Remote Sens 59(8):7147–7159
Omori F (1895) On the after-shocks of earthquakes. PhD thesis, The University of Tokyo
Ovcharenko O, Hou S (2020) Deep learning for seismic data reconstruction: opportunities and challenges. In: First EAGE digitalization conference and exhibition, vol. 2020, European Association of Geoscientists & Engineers, pp 1–5
Ovcharenko O, Kazei V, Peter D, Silvestrov I, Bakulin A, Alkhalifah T (2021) Dual-band generative learning for low-frequency extrapolation in seismic land data. In: First international meeting for applied geoscience & energy, Society of Exploration Geophysicists, pp 1345–1349
Pan W, Torres-Verdín C, Pyrcz MJ (2021) Stochastic pix2pix: a new machine learning method for geophysical and well conditioning of rule-based channel reservoir models. Nat Resour Res 30(2):1319–1345
Perol T, Gharbi M, Denolle M (2018) Convolutional neural network for earthquake detection and location. Sci Adv 4(2):1700578
Picetti F, Lipari V, Bestagini P, Tubaro S (2018) A generative adversarial network for seismic imaging applications. SEG technical program expanded abstracts 2018. Society of Exploration Geophysicists, USA, pp 2231–2235
Picetti F, Lipari V, Bestagini P, Tubaro S (2019) Seismic image processing through the generative adversarial network. Interpretation 7(3):15–26
Pineda F (1987) Generalization of back propagation to recurrent and higher order neural networks. In: Neural information processing systems
Radford A, Metz L, Chintala S (2015) Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434
Radford A, Narasimhan K, Salimans T, Sutskever I, et al (2018) Improving language understanding by generative pre-training
Radosavljevic M, Naugolnov M, Bozic M, Sukhanov R (2021) Restoration of seismic data using inpainting and edgeconnect. In: SPE Russian petroleum technology conference. OnePetro
Ratliff LJ, Burden SA, Sastry SS (2013) Characterization and computation of local Nash equilibria in continuous games. In: 2013 51st Annual Allerton conference on communication, control, and computing (Allerton), IEEE, pp 917–924
Reynolds DA (2009) Gaussian mixture models. Encycl Biom 741:659–663
Rezatofighi H, Tsoi N, Gwak J, Sadeghian A, Reid I, Savarese S (2019) Generalized intersection over union: a metric and a loss for bounding box regression. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 658–666
Rosenblatt M (1956) Remarks on some nonparametric estimates of a density function. Ann Math Stat 27:832–837
Rosso MM, Marasco G, Aiello S, Aloisio A, Chiaia B, Marano GC (2023) Convolutional networks and transformers for intelligent road tunnel investigations. Comput Struct 275:106918
Salimans T, Goodfellow I, Zaremba W, Cheung V, Radford A, Chen X (2016) Improved techniques for training GANs. In: Advances in neural information processing systems, vol 29
Saraiva M, Forechi A, Neto JDO, DelRey A, Rauber T (2021) Data-driven full-waveform inversion surrogate using conditional generative adversarial networks. In: 2021 international joint conference on neural networks (IJCNN), IEEE, pp 1–8
Scales JA (1997) Theory of seismic imaging, vol. 2.2. Samizdat Press, Center for Wave Phenomena Department of Geophysics, Colorado School of Mines, Golden, Colorado 80401
Selvaraju RR, Cogswell M, Das A, Vedantam R, Parikh D, Batra D (2017) Grad-cam: visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE international conference on computer vision, pp 618–626
Shamsipour P, Marcotte D, Chouteau M, Keating P (2010) 3d stochastic inversion of gravity data using cokriging and cosimulation. Geophysics 75(1):1–10
Shiloh L, Eyal A, Giryes R (2018) Deep learning approach for processing fiber-optic das seismic data. In: Optical fiber sensors, Optica Publishing Group, p 22
Shiloh L, Eyal A, Giryes R (2019) Efficient processing of distributed acoustic sensing data using a deep learning approach. J Lightwave Technol 37(18):4755–4762
Si X (2020) Ground roll attenuation with conditional generative adversarial networks. In: SEG international exposition and annual meeting. OnePetro
Siahkoohi A, Kumar R, Herrmann F (2018). Seismic data reconstruction with generative adversarial networks. https://doi.org/10.3997/2214-4609.201801393
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556
Sripanich Y, Fomel S, Sun J, Cheng J (2017) Elastic wave-vector decomposition in heterogeneous anisotropic media. Geophys Prospect 65(5):1231–1245
Storchak DA, Schweitzer J, Bormann P (2003) The IASPEI standard seismic phase list. Seismol Res Lett 74(6):761–772
Strebelle S (2002) Conditional simulation of complex geological structures using multiple-point statistics. Math Geol 34(1):1–21
Sun S, Nie J, Qu Z, Cheng Y, Wang X, Zhu J, Geng J (2021) Oil saturation estimation and uncertainty evaluation by modeling-data-driven Gaussian mixture conditional generative adversarial networks. In: SEG/AAPG/SEPM first international meeting for applied geoscience & energy. OnePetro
Sun Q-F, Xu J-Y, Zhang H-X, Duan Y-X, Sun Y-K (2022) Random noise suppression and super-resolution reconstruction algorithm of seismic profile based on GAN. J Pet Explor Prod Technol, 1–13
Talarico E, De Deus M, Vieira L, Oliveira H (2020) Conditional geology simulation from seismic using progressive gans. In: First EAGE conference on seismic inversion, vol. 2020. European Association of Geoscientists & Engineers, pp 1–5
Tao L, Ren H, Ye Y, Jiang J (2022) Seismic surface-related multiples suppression based on SAGAN. IEEE Geosci Remote Sens Lett 19:1–5
Tilon S, Nex F, Kerle N, Vosselman G (2020) Post-disaster building damage detection from earth observation imagery using unsupervised and transferable anomaly detecting generative adversarial networks. Remote Sens 12(24):4193
Ueda T, Seo M, Nishikawa I (2018) Data correction by a generative model with an encoder and its application to structure design. In: International conference on artificial neural networks, Springer, pp 403–413
Van der Maaten L, Hinton G (2008) Visualizing data using t-sne. J Mach Learn Res 9:2579–2625
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I (2017) Attention is all you need. In: Advances in neural information processing systems, vol 30
Wang K, Gou C, Duan Y, Lin Y, Zheng X, Wang F-Y (2017) Generative adversarial networks: introduction and outlook. IEEE/CAA J Autom Sin 4(4):588–598
Wang X, Yu K, Wu S, Gu J, Liu Y, Dong C, Qiao Y, Change Loy C (2018) Esrgan: Enhanced super-resolution generative adversarial networks. In: Proceedings of the European conference on computer vision (ECCV) workshops
Wang T, Zhang Z, Li Y (2019a) Earthquakegen: earthquake generator using generative adversarial networks. SEG technical program expanded abstracts 2019. Society of Exploration Geophysicists, USA, pp 2674–2678
Wang Y, Ge Q, Lu W, Yan X (2019b) Seismic impedance inversion based on cycle-consistent generative adversarial network. 89th annual international meeting. SEG, Expanded Abstracts, pp 2498–2502
Wang S, Li Y, Wu N, Zhao Y, Yao H (2020a) Attribute-based double constraint denoising network for seismic data. IEEE Trans Geosci Remote Sens 59(6):5304–5316
Wang H, Li Y, Dong X (2020b) Generative adversarial network for desert seismic data denoising. IEEE Trans Geosci Remote Sens 59(8):7062–7075
Wang T, Trugman D, Lin Y (2021) Seismogen: seismic waveform synthesis using GAN with application to seismic data augmentation. J Geophys Res Solid Earth 126(4):2020–020077
Wang Y-Q, Wang Q, Lu W-K, Ge Q, Yan X-F (2022a) Seismic impedance inversion based on cycle-consistent generative adversarial network. Pet Sci 19(1):147–161
Wang J, Zhang J, Cohn AG, Wang Z, Liu H, Kang W, Jiang P, Zhang F, Chen K, Guo W et al (2022b) Arbitrarily-oriented tunnel lining defects detection from ground penetrating radar images using deep convolutional neural networks. Autom Constr 133:104044
Wei Q, Li X (2021) Big gaps seismic data interpolation using conditional Wasserstein generative adversarial networks with gradient penalty. Explor Geophys 53(5):477–486
Wei Q, Li X (2021c) Generative adversarial network for seismic data interpolation. In: 82nd EAGE annual conference & exhibition, vol. 2021, European Association of Geoscientists & Engineers, pp 1–5
Wei Y, Fu H, Li YE, Yang J (2019) A new p-wave reconstruction method for vsp data using conditional generative adversarial network. SEG technical program expanded abstracts 2019. Society of Exploration Geophysicists, USA, pp 2528–2532
Wei Q, Li X, Song M (2021a) Reconstruction of irregular missing seismic data using conditional generative adversarial networks. Geophysics 86(6):471–488
Wei Q, Li X, Song M (2021b) De-aliased seismic data interpolation using conditional Wasserstein generative adversarial networks. Comput Geosci 154:104801
Werbos PJ (1990) Backpropagation through time: what it does and how to do it. Proc IEEE 78(10):1550–1560
Woldesellasse H, Tesfamariam S (2022) Prediction of lateral spreading displacement using conditional generative adversarial network (cGAN). Soil Dyn Earthq Eng 156:107214
Wu A, Shin J, Ahn J-K, Kwon Y-W (2021) Augmenting seismic data using generative adversarial network for low-cost mems sensors. IEEE Access 9:167140–167153
Wu B, Meng D, Zhao H (2021) Semi-supervised learning for seismic impedance inversion using generative adversarial networks. Remote Sens 13(5):909
Wu AN, Stouffs R, Biljecki F (2022) Generative adversarial networks in the built environment: a comprehensive review of the application of gans across data types and scales. Build Environ 233:109477
Xie P, Boelle J-L, Puntous H (2018) Generative adversarial network based fast noise removal on land seismic data. In: 2018 SEG international exposition and annual meeting. OnePetro
Xie P, Hou J, Yin Y, Chen Z, Chen M, Wang L (2022) Seismic inverse modeling method based on generative adversarial networks. J Pet Sci Eng 215:110652
WU Xuefeng ZH (2021) Random noise suppression method of seismic data based on cycle-GAN. Oil Geophys Prospect 56(5):958. https://doi.org/10.13810/j.cnki.issn.1000-7210.2021.05.003
Yamada T, Takahashi N, Chida H (2021) Automation technology of seismic damage investigation for timber houses using deep learning. AIJ J Technol Design 27(67):1578–1583
Yuan Y, Si X, Zheng Y (2020) Ground-roll attenuation using generative adversarial networksground-roll attenuation using GANs. Geophysics 85(4):255–267
Zhang H, Goodfellow I, Metaxas D, Odena A (2019a) Self-attention generative adversarial networks. In: International conference on machine learning, PMLR, pp 7354–7363
Zhang H, Wang W, Wang X, Chen W, Zhou Y, Wang C, Zhao Z (2019b) An implementation of the seismic resolution enhancing network based on GAN. In: SEG International exposition and annual meeting. OnePetro
Zhang X, Zhang S, Lin J, Sun F, Zhu X, Yang Y, Tong X, Yang H (2019c) An efficient seismic data acquisition based on compressed sensing architecture with generative adversarial networks. IEEE Access 7:105948–105961
Zhang Z, Lin Y (2020) Data-driven seismic waveform inversion: a study on the robustness and generalization. IEEE Trans Geosci Remote Sens 58(10):6900–6913
Zhang J, Sheng G (2020) First arrival picking of microseismic signals based on nested U-Net and Wasserstein generative adversarial network. J Petrol Sci Eng 195:107527
Zhang J, Gao Y, Meng Q, Wang D, Zhang Z, Li G, Jiang L (2021) Well-controlled seismic resolution improvement: A machine learning approach. In: 82nd EAGE annual conference & exhibition, vol. 2021. European Association of Geoscientists & Engineers, pp 1–5
Zhang N, Nex F, Vosselman G, Kerle N (2022a) Unsupervised harmonious image composition for disaster victim detection. Int Arch Photogramm Remote Sens Spat Inf Sci 43:1189–1196
Zhang S-B, Si H-J, Wu X-M, Yan S-S (2022b) A comparison of deep learning methods for seismic impedance inversion. Pet Sci 19:1019–1030
Zhao YX, Li Y, Wu N (2022) Unsupervised dual learning for seismic data denoising in the absence of labelled data. Geophys Prospect 70(2):262–279
Zhao Y, Li Y, Wu N (2022) Data augmentation and its application in distributed acoustic sensing data denoising. Geophys J Int 228(1):119–133
Zhong Z, Sun AY, Wu X (2020) Inversion of time-lapse seismic reservoir monitoring data using cyclegan: a deep learning-based approach for estimating dynamic reservoir property changes. J Geophys Res Solid Earth 125(3):2019–018408
Zhou B, Khosla A, Lapedriza A, Oliva A, Torralba A (2016) Learning deep features for discriminative localization. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2921–2929
Zhu J-Y, Park T, Isola P, Efros AA (2017) Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE international conference on computer vision, pp 2223–2232
Funding
Open access funding provided by Politecnico di Torino within the CRUI-CARE Agreement. Giuseppe Carlo Marano and Marco Martino Rosso acknowledge the financial support from PNRR MUR project PE0000013-FAIR.
Author information
Authors and Affiliations
Contributions
MMR contributed to the study conception and design. Material preparation, data collection and analysis were performed by MMR and AA. Supervision and coordination were provided by GCM and GC. The first draft of the manuscript was written by MMR and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Marano, G.C., Rosso, M.M., Aloisio, A. et al. Generative adversarial networks review in earthquake-related engineering fields. Bull Earthquake Eng 22, 3511–3562 (2024). https://doi.org/10.1007/s10518-023-01645-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10518-023-01645-7