
Abstract
We propose Text2Motion, a language-based planning framework enabling robots to solve sequential manipulation tasks that require long-horizon reasoning. Given a natural language instruction, our framework constructs both a task- and motion-level plan that is verified to reach inferred symbolic goals. Text2Motion uses feasibility heuristics encoded in Q-functions of a library of skills to guide task planning with Large Language Models. Whereas previous language-based planners only consider the feasibility of individual skills, Text2Motion actively resolves geometric dependencies spanning skill sequences by performing geometric feasibility planning during its search. We evaluate our method on a suite of problems that require long-horizon reasoning, interpretation of abstract goals, and handling of partial affordance perception. Our experiments show that Text2Motion can solve these challenging problems with a success rate of 82%, while prior state-of-the-art language-based planning methods only achieve 13%. Text2Motion thus provides promising generalization characteristics to semantically diverse sequential manipulation tasks with geometric dependencies between skills. Qualitative results are made available at https://sites.google.com/stanford.edu/text2motion.







Similar content being viewed by others


Data availability
Authors are prepared to send relevant documentation or data in order to verify the validity of the results presented.
Code Availability
Authors plan to open source their code.
References
Aeronautiques, C., Howe, A., Knoblock, C., McDermott, I. D., Ram, A., Veloso, M., Weld, D., SRI, D. W., Barrett, A., Christianson, D., et al. (1998). PDDL| the planning domain definition language. Technical Report.
Agia, C., Migimatsu, T., Wu, J., & Bohg, J. (2022). STAP: Sequencing task-agnostic policies. arXiv preprint arXiv:2210.12250
Ahn, M., Brohan, A., Brown, N., Chebotar, Y., Cortes, O., David, B., Finn, C., Gopalakrishnan, K., Hausman, K., Herzog, A., et al. (2022). Do as i can, not as I say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691
Ames, B., Thackston, A., & Konidaris, G. (2018). Learning symbolic representations for planning with parameterized skills. In 2018 IEEE/RSJ international conference on intelligent robots and systems (IROS) (pp. 526–533). IEEE.
Bidot, J., Karlsson, L., Lagriffoul, F., & Saffiotti, A. (2017). Geometric backtracking for combined task and motion planning in robotic systems. Artificial Intelligence, 247, 229–265.
Bommasani, R., Hudson, D.A., Adeli, E., Altman, R., Arora, S., Arx, S., Bernstein, M.S., Bohg, J., Bosselut, A., Brunskill, E., et al. (2021). On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258
Bonet, B., & Geffner, H. (2001). Planning as heuristic search. Artificial Intelligence, 129(1–2), 5–33.
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Dabis, J., Finn, C., Gopalakrishnan, K., Hausman, K., Herzog, A., Hsu, J., Ibarz, J., Ichter, B., Irpan, A., Jackson, T., Jesmonth, S., Joshi, N., Julian, R., Kalashnikov, D., Kuang, Y., Leal, I., Lee, K.-H., Levine, S., Lu, Y., Malla, U., Manjunath, D., Mordatch, I., Nachum, O., Parada, C., Peralta, J., Perez, E., Pertsch, K., Quiambao, J., Rao, K., Ryoo, M., Salazar, G., Sanketi, P., Sayed, K., Singh, J., Sontakke, S., Stone, A., Tan, C., Tran, H., Vanhoucke, V., Vega, S., Vuong, Q., Xia, F., Xiao, T., Xu, P., Xu, S., Yu, T., & Zitkovich, B. (2022). Rt-1: Robotics transformer for real-world control at scale. In: arXiv Preprint arXiv:2212.06817
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877–1901.
Chen, B., Xia, F., Ichter, B., Rao, K., Gopalakrishnan, K., Ryoo, M.S., Stone, A., & Kappler, D. (2022a). Open-vocabulary queryable scene representations for real world planning. arXiv preprint arXiv:2209.09874
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H.P.d.O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., et al. (2021). Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374
Chen, Y., Yuan, L., Cui, G., Liu, Z., & Ji, H. (2022b). A close look into the calibration of pre-trained language models. arXiv preprint arXiv:2211.00151
Chitnis, R., Silver, T., Kim, B., Kaelbling, L., & Lozano-Perez, T. (2021). Camps: Learning context-specific abstractions for efficient planning in factored MDPS. In Conference on robot learning (pp. 64–79). PMLR.
Chitnis, R., Silver, T., Tenenbaum, J. B., Lozano-Perez, T., & Kaelbling, L. P. (2022). Learning neuro-symbolic relational transition models for bilevel planning. In 2022 IEEE/RSJ international conference on intelligent robots and systems (IROS) (pp. 4166–4173). IEEE.
Curtis, A., Fang, X., Kaelbling, L. P., Lozano-Pérez, T., & Garrett, C. R. (2022). Long-horizon manipulation of unknown objects via task and motion planning with estimated affordances. In 2022 International Conference on Robotics and Automation (ICRA) (pp. 1940–1946). IEEE.
Curtis, A., Silver, T., Tenenbaum, J. B., Lozano-Pérez, T., & Kaelbling, L. (2022). Discovering state and action abstractions for generalized task and motion planning. In Proceedings of the AAAI conference on artificial intelligence (Vol. 36, pp. 5377–5384).
Dalal, M., Mandlekar, A., Garrett, C., Handa, A., Salakhutdinov, R., & Fox, D. (2023). Imitating task and motion planning with visuomotor transformers. arXiv preprint arXiv:2305.16309
Dantam, N. T., Kingston, Z. K., Chaudhuri, S., & Kavraki, L. E. (2016). Incremental task and motion planning: A constraint-based approach. In Robotics: Science and systems, Ann Arbor, Michigan. https://doi.org/10.15607/RSS.2016.XII.002
Driess, D., Ha, J.-S., & Toussaint, M. (2020a). Deep visual reasoning: Learning to predict action sequences for task and motion planning from an initial scene image. arXiv preprint arXiv:2006.05398
Driess, D., Ha, J.-S., & Toussaint, M. (2021). Learning to solve sequential physical reasoning problems from a scene image. The International Journal of Robotics Research, 40(12–14), 1435–1466.
Driess, D., Ha, J.-S., Tedrake, R., & Toussaint, M. (2021b). Learning geometric reasoning and control for long-horizon tasks from visual input. In 2021 IEEE international conference on robotics and automation (ICRA) (pp. 14298–14305). IEEE.
Driess, D., Huang, Z., Li, Y., Tedrake, R., & Toussaint, M. (2023). Learning multi-object dynamics with compositional neural radiance fields. In Proceedings of the 6th conference on robot learning. Proceedings of machine learning research (Vol. 205, pp. 1755–1768). PMLR.
Driess, D., Oguz, O., Ha, J.-S., Toussaint, M. (2020b). Deep visual heuristics: Learning feasibility of mixed-integer programs for manipulation planning. In 2020 IEEE international conference on robotics and automation (ICRA) (pp. 9563–9569). IEEE.
Driess, D., Oguz, O., Toussaint, M. (2019). Hierarchical task and motion planning using logic-geometric programming (HLGP). In RSS workshop on robust task and motion planning.
Driess, D., Xia, F., Sajjadi, M.S., Lynch, C., Chowdhery, A., Ichter, B., Wahid, A., Tompson, J., Vuong, Q., Yu, T., et al. (2023). Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378
Felip, J., Laaksonen, J., Morales, A., & Kyrki, V. (2013). Manipulation primitives: A paradigm for abstraction and execution of grasping and manipulation tasks. Robotics and Autonomous Systems, 61(3), 283–296.
Garrett, C. R., Chitnis, R., Holladay, R., Kim, B., Silver, T., Kaelbling, L. P., & Lozano-Pérez, T. (2021). Integrated task and motion planning. Annual Review of Control, Robotics, and Autonomous Systems, 4, 265–293.
Garrett, C. R., Lozano-Pérez, T., & Kaelbling, L. P. (2020). Pddlstream: Integrating symbolic planners and blackbox samplers via optimistic adaptive planning. In Proceedings of the international conference on automated planning and scheduling (Vol. 30, pp. 440–448).
Haarnoja, T., Zhou, A., Abbeel, P., & Levine, S. (2018). Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In J. Dy, & A. Krause (Eds.), Proceedings of the 35th international conference on machine learning. Proceedings of machine learning research (Vol. 80, pp. 1861–1870). PMLR. https://proceedings.mlr.press/v80/haarnoja18b.html
Helmert, M. (2006). The fast downward planning system. Journal of Artificial Intelligence Research, 26, 191–246.
Huang, W., Abbeel, P., Pathak, D., & Mordatch, I. (2022). Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. arXiv preprint arXiv:2201.07207
Huang, W., Xia, F., Xiao, T., Chan, H., Liang, J., Florence, P., Zeng, A., Tompson, J., Mordatch, I., Chebotar, Y., et al. (2022). Inner monologue: Embodied reasoning through planning with language models. arXiv preprint arXiv:2207.05608
Jang, E., Irpan, A., Khansari, M., Kappler, D., Ebert, F., Lynch, C., Levine, S., & Finn, C. (2021). BC-z: Zero-shot task generalization with robotic imitation learning. In 5th annual conference on robot learning. https://openreview.net/forum?id=8kbp23tSGYv
Jiang, Y., Gupta, A., Zhang, Z., Wang, G., Dou, Y., Chen, Y., Fei-Fei, L., Anandkumar, A., Zhu, Y., & Fan, L. (2022). Vima: General robot manipulation with multimodal prompts. arXiv preprint arXiv:2210.03094
Kaelbling, L. P., & Lozano-Pérez, T. (2011). Hierarchical task and motion planning in the now. In 2011 IEEE international conference on robotics and automation (pp. 1470–1477). https://doi.org/10.1109/ICRA.2011.5980391
Kaelbling, L. P., & Lozano-Pérez, T. (2012). Integrated robot task and motion planning in the now. Technical report: Massachusetts Inst of Tech Cambridge Computer Science and Artificial.
Kalashnkov, D., Varley, J., Chebotar, Y., Swanson, B., Jonschkowski, R., Finn, C., Levine, S., & Hausman, K. (2021). Mt-opt: Continuous multi-task robotic reinforcement learning at scale. arXiv
Khatib, O. (1987). A unified approach for motion and force control of robot manipulators: The operational space formulation. IEEE Journal on Robotics and Automation, 3(1), 43–53.
Kim, B., Kaelbling, L. P., & Lozano-Pérez, T. (2019). Adversarial actor-critic method for task and motion planning problems using planning experience. In Proceedings of the AAAI conference on artificial intelligence (Vol. 33, pp. 8017–8024).
Kim, B., Shimanuki, L., Kaelbling, L. P., & Lozano-Pérez, T. (2022). Representation, learning, and planning algorithms for geometric task and motion planning. The International Journal of Robotics Research, 41(2), 210–231.
Konidaris, G., Kaelbling, L. P., & Lozano-Perez, T. (2018). From skills to symbols: Learning symbolic representations for abstract high-level planning. Journal of Artificial Intelligence Research, 61, 215–289.
Kroemer, O., & Sukhatme, G. S. (2016). Learning spatial preconditions of manipulation skills using random forests. In 2016 IEEE-RAS 16th international conference on humanoid robots (Humanoids) (pp. 676–683). IEEE.
Lagriffoul, F., Dimitrov, D., Bidot, J., Saffiotti, A., & Karlsson, L. (2014). Efficiently combining task and motion planning using geometric constraints. The International Journal of Robotics Research, 33(14), 1726–1747.
Lakshminarayanan, B., Pritzel, A., & Blundell, C. (2017). Simple and scalable predictive uncertainty estimation using deep ensembles. In Advances in neural information processing systems (Vol. 30).
Li, X.L., Holtzman, A., Fried, D., Liang, P., Eisner, J., Hashimoto, T., Zettlemoyer, L., & Lewis, M. (2022). Contrastive decoding: Open-ended text generation as optimization. arXiv preprint arXiv:2210.15097
Liang, J., Huang, W., Xia, F., Xu, P., Hausman, K., Ichter, B., Florence, P., & Zeng, A. (2022). Code as policies: Language model programs for embodied control. arXiv preprint arXiv:2209.07753
Liu, B., Jiang, Y., Zhang, X., Liu, Q., Zhang, S., Biswas, J., & Stone, P. (2023). Llm+ p: Empowering large language models with optimal planning proficiency. arXiv preprint arXiv:2304.11477
Loshchilov, I., & Hutter, F. (2017). SGDR: Stochastic gradient descent with warm restarts. In International conference on learning representations. https://openreview.net/forum?id=Skq89Scxx
Mees, O., Hermann, L., Rosete-Beas, E., & Burgard, W. (2022). Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks. IEEE Robotics and Automation Letters (RA-L), 7(3), 7327–7334.
OpenAI: GPT-4 Technical Report (2023)
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. (2022). Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155
Rubinstein, R. (1999). The cross-entropy method for combinatorial and continuous optimization. Methodology and Computing in Applied Probability, 1(2), 127–190.
Shao, L., Migimatsu, T., Zhang, Q., Yang, K., & Bohg, J. (2021). Concept2robot: Learning manipulation concepts from instructions and human demonstrations. The International Journal of Robotics Research, 40(12–14), 1419–1434.
Shridhar, M., Manuelli, L., & Fox, D. (2022a). Cliport: What and where pathways for robotic manipulation. In: Conference on robot learning (pp. 894–906). PMLR.
Shridhar, M., Manuelli, L., & Fox, D. (2022b). Perceiver-actor: A multi-task transformer for robotic manipulation. arXiv preprint arXiv:2209.05451
Silver, T., Athalye, A., Tenenbaum, J. B., Lozano-Pérez, T., & Kaelbling, L. P. (2022). Learning neuro-symbolic skills for bilevel planning. In 6th annual conference on robot learning. https://openreview.net/forum?id=OIaJRUo5UXy.
Silver, T., Chitnis, R., Curtis, A., Tenenbaum, J. B., Lozano-Perez, T., & Kaelbling, L. P. (2021). Planning with learned object importance in large problem instances using graph neural networks. In Proceedings of the AAAI conference on artificial intelligence (Vol. 35, pp. 11962–11971).
Silver, T., Chitnis, R., Tenenbaum, J., Kaelbling, L. P., & Lozano-Pérez, T. (2021). Learning symbolic operators for task and motion planning. In 2021 IEEE/RSJ international conference on intelligent robots and systems (IROS) (pp. 3182–3189). IEEE.
Silver, T., Hariprasad, V., Shuttleworth, R. S., Kumar, N., Lozano-Pérez, T., & Kaelbling, L. P. (2022). PDDL planning with pretrained large language models. In NeurIPS 2022 foundation models for decision making workshop.
Singh, I., Blukis, V., Mousavian, A., Goyal, A., Xu, D., Tremblay, J., Fox, D., Thomason, J., & Garg, A. (2022). Progprompt: Generating situated robot task plans using large language models. arXiv preprint arXiv:2209.11302
Skreta, M., Yoshikawa, N., Arellano-Rubach, S., Ji, Z., Kristensen, L.B., Darvish, K., Aspuru-Guzik, A., Shkurti, F., & Garg, A. (2023). Errors are useful prompts: Instruction guided task programming with verifier-assisted iterative prompting. arXiv preprint arXiv:2303.14100
Stepputtis, S., Campbell, J., Phielipp, M., Lee, S., Baral, C., & Ben Amor, H. (2020). Language-conditioned imitation learning for robot manipulation tasks. Advances in Neural Information Processing Systems, 33, 13139–13150.
Toussaint, M. (2015). Logic-geometric programming: An optimization-based approach to combined task and motion planning. In Twenty-fourth international joint conference on artificial intelligence.
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al. (2023). Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971
Valmeekam, K., Olmo, A., Sreedharan, S., & Kambhampati, S. (2022). Large language models still can’t plan (a benchmark for LLMS on planning and reasoning about change). arXiv preprint arXiv:2206.10498
Vemprala, S., Bonatti, R., Bucker, A., & Kapoor, A. (2023). Chatgpt for robotics: Design principles and model abilities. Technical Report MSR-TR-2023-8, Microsoft
Wang, Z., Cai, S., Liu, A., Ma, X., & Liang, Y. (2023). Describe, explain, plan and select: Interactive planning with large language models enables open-world multi-task agents. arXiv preprint arXiv:2302.01560
Wang, Z., Garrett, C. R., Kaelbling, L. P., & Lozano-Pérez, T. (2018). Active model learning and diverse action sampling for task and motion planning. In 2018 IEEE/RSJ international conference on intelligent robots and systems (IROS) (pp. 4107–4114). IEEE.
Wang, Z., Garrett, C. R., Kaelbling, L. P., & Lozano-Pérez, T. (2021). Learning compositional models of robot skills for task and motion planning. The International Journal of Robotics Research, 40(6–7), 866–894.
Williams, G., Aldrich, A., & Theodorou, E. (2015). Model predictive path integral control using covariance variable importance sampling. arXiv preprint arXiv:1509.01149
Wu, J., Antonova, R., Kan, A., Lepert, M., Zeng, A., Song, S., Bohg, J., Rusinkiewicz, S., & Funkhouser, T. (2023). Tidybot: Personalized robot assistance with large language models. arXiv preprint arXiv:2305.05658
Xu, D., Mandlekar, A., Martín-Martín, R., Zhu, Y., Savarese, S., & Fei-Fei, L. (2021). Deep affordance foresight: Planning through what can be done in the future. In 2021 IEEE international conference on robotics and automation (ICRA) (pp. 6206–6213). IEEE.
Zelikman, E., Huang, Q., Poesia, G., Goodman, N. D., & Haber, N. (2022). Parsel: A unified natural language framework for algorithmic reasoning. arXiv preprint arXiv:2212.10561
Zeng, A., Wong, A., Welker, S., Choromanski, K., Tombari, F., Purohit, A., Ryoo, M., Sindhwani, V., Lee, J., Vanhoucke, V., et al. (2022). Socratic models: Composing zero-shot multimodal reasoning with language. arXiv preprint arXiv:2204.00598
Zhao, Z., Wallace, E., Feng, S., Klein, D., & Singh, S. (2021). Calibrate before use: Improving few-shot performance of language models. In International conference on machine learning (pp. 12697–12706). PMLR.
Zhou, L., Palangi, H., Zhang, L., Hu, H., Corso, J., & Gao, J. (2020). Unified vision-language pre-training for image captioning and VQA. In Proceedings of the AAAI conference on artificial intelligence (Vol. 34, pp. 13041–13049).
Funding
Toyota Research Institute and Toshiba provided funds to support this work. This work was also supported by the National Aeronautics and Space Administration (NASA) under the Innovative Advanced Concepts (NIAC) program.
Author information
Authors and Affiliations
Contributions
KL initiated the Text2Motion project, implemented the LLM planning algorithms, trained the underlying manipulation skill library, ran simulation and real robot experiments, and wrote the paper. CA initiated the Text2Motion project, trained the underlying manipulation skill library, implemented the out-of-distribution detection algorithms, ran simulation experiments, and wrote the paper. TM advised on the project, helped set the research direction and wrote parts of the paper. MP advised on the project, helped set the research direction and wrote parts of the paper. JB advised on the project, helped set the research direction and wrote parts of the paper.
Corresponding authors
Ethics declarations
Conflict of interest
Not applicable.
Consent for publication
All authors agreed with the content and that all gave explicit consent to submit and that they obtained consent from the responsible authorities at the institute/organization where the work has been carried out.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A Implementation details
The Text2Motion planner integrates both shooting and greedy-search to construct skill sequences that are feasible for the robot to execute in the environment. The planning procedure relies on four core components: (1) a library of learned robot skills, (2) a method for detecting when a skill is out-of-distribution (OOD), (3) a large language model (LLM) to perform task-level planning, and (4) a geometric feasibility planner that is compatible with the learned robot skills. All evaluated language-based planners use the above components, while saycan-gs and innermono-gs are myopic agents that do not perform geometric feasibility planning. We provide implementation details of these components in the following subsections.
1.1 A.1 Learning robot skills and dynamics
Skill library overview: All evaluated language planners interface an LLM with a library of robot skills \(\mathcal {L}=\{\psi ^1, \ldots , \psi ^N\}\). Each skill \(\psi \) has a language description (e.g. Pick(a)) and is associated with a parameterized manipulation primitive (Felip et al., 2013) \(\phi (a)\). A primitive \(\phi (a)\) is controllable via its parameter a which determines the motion (Khatib, 1987) of the robot’s end-effector through a series of waypoints. For each skill \(\psi \), we train a policy \(\pi (a|s)\) to output parameters \(a\in \mathcal {A}\) that maximize primitive’s \(\phi (a)\) probability of success in a contextual bandit setting (Eq. 1) with a skill-specific binary reward function \(R(s, a, s')\). We also train an ensemble of Q-functions \(Q_{1:B}^\pi (s, a)\) and a dynamics model \(T^\pi (s' | s, a)\) for each skill, both of which are required for geometric feasibility planning. We discuss the calibration of Q-function ensembles for OOD detection of skills in “Appendix A.2”.
We learn four manipulation skills to solve tasks in simulation and in the real-world: \(\psi ^{\text {Pick}}\), \(\psi ^{\text {Place}}\), \(\psi ^{\text {Pull}}\), \(\psi ^{\text {Push}}\). Only a single policy per skill is trained, and thus, the policy must learn to engage the primitive over objects with differing geometries (e.g. \(\pi ^{\text {Pick}}\) is used for both Pick(box) and Pick(hook)). The state space \(\mathcal {S}\) for each policy is defined as the concatenation of geometric state features (e.g. pose, size) of all objects in the scene, where the first n object states correspond to the n skill arguments and the rest are randomized. For example, the state for the skill Pick(hook) would have be a vector of all objects’ geometric state features with the first component of the state corresponding to the hook.
Parameterized manipulation primitives: We describe the parameters a and reward function \(R(s, a, s')\) of each parameterized manipulation primitive \(\phi (a)\) below. A collision with a non-argument object constitutes an execution failure for all skills, and as a result, the policy receives a reward of 0. For example, \(\pi ^{\text {Pick}}\) would receive a reward of 0 if the robot collided with a box during the execution of Pick(hook).
-
Pick(obj): \(a\sim \pi ^{\text {Pick}}(a \vert s)\) denotes the grasp pose of obj w.r.t the coordinate frame of obj. A reward of 1 is received if the robot successfully grasps obj.
-
Place(obj, rec): \(a\sim \pi ^{\text {Place}}(a \vert s)\) denotes the placement pose of obj w.r.t the coordinate frame of rec. A reward of 1 is received if obj is stably placed on rec.
-
Pull(obj, tool): \(a\sim \pi ^{\text {Pull}}(a \vert s)\) denotes the initial position, direction, and distance of a pull on obj with tool w.r.t the coordinate frame of obj. A reward of 1 is received if obj moves toward the robot by a minimum of \(d_{\text {Pull}}=0.05m\).
-
Push(obj, tool, rec): \(a\sim \pi ^{\text {Push}}(a \vert s)\) denotes the initial position, direction, and distance of a push on obj with tool w.r.t the coordinate frame of obj. A reward of 1 is received if obj moves away from the robot by a minimum of \(d_{\text {Push}}=0.05m\) and if obj ends up underneath rec.
Dataset generation: All planners considered in this work rely on accurate Q-functions \(Q^\pi (s, a)\) to estimate the feasibility of skills proposed by the LLM. This places a higher fidelity requirement on the Q-functions than typically needed to learn a reliable policy, as the Q-functions must characterize both skill success (feasibility) and failure (infeasibility) at a given state. Because the primitives \(\phi (a)\) reduce the horizon of policies \(\pi (a|s)\) to a single timestep, and the reward functions are \(R(s, a, s')\in \{0, 1\}\), the Q-functions can be interpreted as binary classifiers of state-action pairs. Thus, we take a staged approach to learning the Q-functions \(Q^\pi \), followed by the policies \(\pi \), and lastly the dynamics models \(T^\pi \).
Scenes in our simulated environment are instantiated from a symbolic specification of objects and spatial relations, which together form a symbolic state. The goal is to learn a Q-function that sufficiently covers the state-action space of each skill. We generate a dataset that meets this requirement in four steps: a) enumerate all valid symbolic states; b) sample geometric scene instances s per symbolic state; c) uniformly sample actions over the action space \(a\sim \mathcal {U}^{[0,1]^d}\); (d) simulate the states and actions to acquire next states \(s'\) and compute rewards \(R(s, a, s')\). We slightly modify this sampling strategy to maintain a minimum success-failure ratio of 40%, as uniform sampling for more challenging skills such as Pull and Push seldom emits a success (\(\sim \)3%). We collect 1 M \((s, a, s', r)\) tuples per skill of which 800K of them are used for training (\(\mathcal {D}_t\)), while the remaining 200K are used for validation (\(\mathcal {D}_v\)). We use the same datasets to learn the Q-functions \(Q^\pi \), policies \(\pi \), and dynamics models \(T^\pi \) for each skill.
Model training: We train an ensemble of Q-functions with mini-batch gradient descent and logistic regression loss. Once the Q-functions have converged, we distill their returns into stochastic policies \(\pi \) through the maximum-entropy update (Haarnoja et al., 2018):
Instead of evaluating the policies on \(\mathcal {D}_v\), which contains states for which no feasible action exists, the policies are synchronously evaluated in an environment that exhibits only feasible states. This simplifies model selection and standardizes skill capabilities across primitives. All Q-functions achieve precision and recall rates of over 95%. The average success rates of the converged policies over 100 evaluation episodes are: \(\pi _{\text {Pick}}\) with 99%, \(\pi _{\text {Place}}\) with 90%, \(\pi _{\text {Pull}}\) with 86%, \(\pi _{\text {Push}}\) with 97%.
We train a deterministic dynamics model per skill using the forward prediction loss:
The dynamics models converge to within millimeter accuracy on the validation split.
Hyperparameters: The Q-functions, policies, and dynamics models are MLPs with hidden dimensions of size [256, 256] and ReLU activations. We train an ensemble of \(B=8\) Q-functions with a batch size of 128 and a learning rate of 1\(e^{-4}\) with a cosine annealing decay (Loshchilov and Hutter, 2017). The Q-functions for Pick, Pull, and Push converged on \(\mathcal {D}_v\) in 3 M iterations, while the Q-function for Place required 5 M iterations. We hypothesize that this is because classifying successful placements demands carefully attending to the poses and shapes of all objects in the scene so as to avoid collisions. The policies are trained for 250K iterations with a batch size of 128 and a learning rate of 1\(e^{-4}\), leaving all other parameters the same as Haarnoja et al. (2018). The dynamics models are trained for 750K iterations with a batch size of 512 and a learning rate of 5\(e^{-4}\); only on successful transitions to avoid the noise associated with collisions and truncated episodes. The parallelized training of all models takes approximately 12 hours on an Nvidia Quadro P5000 GPU and 2 CPUs per job.
1.2 A.2 Out-of-distribution detection
The training dataset described in Sect. 1 contain both successes and failures for symbolically valid skills like Pick(box). However, when using LLMs for robot task planning, it is often the case that the LLM will propose symbolically invalid skills, such as Pick(table), that neither the skill’s policy, Q-functions, or dynamics model have observed in training. We found that a percentage of out-of-distribution (OOD) queries would result in erroneously high Q-values, causing the invalid skill to be selected. Attempting to execute such a skill leads to control exceptions or other failures.
Whilst there are many existing techniques for OOD detection of deep neural networks, we opt to detect OOD queries on the learned Q-functions via deep ensembles due to their ease of calibration (Lakshminarayanan et al., 2017). A state-action pair is classified as OOD if the empirical variance of the predicted Q-values is above a determined threshold:
where each threshold \(\epsilon ^\psi \) is unique to skill \(\psi \).
To determine the threshold values, we generate a calibration dataset of 100K symbolically invalid states and actions for each skill. The process takes less than an hour on a single CPU as the actions are infeasible and need not be simulated in the environment (i.e. rewards are known to be 0). We compute the mean and variance of the Q-ensemble for each (s, a) sample in both the training dataset (in-distribution inputs) and the calibration dataset (out-of-distribution inputs), and produce two histograms by binning the computed ensemble variances by the ensemble means. We observe that the histogram of variances corresponding to OOD inputs is uniform across all Q-value bins and is an order of magnitude large than the ensemble variances computed over in-distribution inputs. This allows us to select thresholds \(\epsilon ^\psi \) which are low enough to reliably detect OOD inputs, yet will not be triggered for in-distribution inputs: \(\epsilon ^{\text {Pick}} = 0.10\), \(\epsilon ^{\text {Place}} = 0.12\), \(\epsilon ^{\text {Pull}} = 0.10\), and \(\epsilon ^{\text {Push}} = 0.06\).
1.3 A.3 Task planning with LLMs
Text2Motion, greedy-search , and the myopic planning baselines saycan-gs and innermono-gs usecode-davinci-002 (Chen et al., 2021) to generate and score skills, while shooting queries text-davinci-003 (Ouyang et la., 2022) to directly output full skill sequences. In our experiments, we used a temperature setting of 0 for all LLM queries.
To maintain consistency in the evaluation of various planners, we allow Text2Motion, saycan-gs , and innermono-gs to generate \(K=5\) skills \(\{\psi ^1_t, \ldots , \psi ^K_t\}\) at each timestep t. Thus, every search iteration of greedy-search considers five possible extensions to the current running sequence of skills \(\psi _{1:t-1}\). Similarly, shooting generates \(K=5\) skill sequences.
As described in Sect. 4.3, skills are selected at each timestep t via a combined usefulness and geometric feasibility score:
where Text2Motion, greedy-search , and shooting use geometric feasilibity planning (details below in“Appendix A.4”) to compute \(S_{\text {geo}}(\psi _t)\), while saycan-gs and innermono-gs use the current value function estimate \(V^{\pi _t}(s_t) = {\text {E}}_{a_t\sim \pi _t}[Q^{\pi _t}(s_t, a_t)]\). We find that in both cases, taking \(S_{\text {llm}}(\psi _t)\) to be the SoftMax log-probability score produces a winner-takes-all effect, causing the planner to omit highly feasible skills simply because their associated log-probability was marginally lower than the LLM-likelihood of another skill. Thus, we dampen the SoftMax operation with a \(\beta \)-coefficient to balance the ranking of skills based on both feasibility and usefulness. We found \(\beta =0.3\) to work well.
1.4 A.4 Geometric feasibility planning
Given a sequence of skills \(\psi _{1:H}\), geometric feasibility planning computes parameters \(a_{1:H}\) that maximizes the success probability of the underlying sequence of primitives \(\phi _{1:H}\). For example, given a skill sequence Pick(hook), Pull(box, hook), geometric feasibility planning would compute a 3D grasp position on the hook that enables a successful pull on the box thereafter.
Text2Motion is agnostic to the method that fulfils the role of geometric feasibility planning. In our experiments we leverage Sequencing Task-Agnostic Policies (STAP) (Agia et al., 2022). Specifically, we consider the PolicyCEM variant of STAP, where optimization of the skill sequence’s success probability (Eq. 4) is warm started with parameters sampled from the policies \(a_{1:H}\sim \pi _{1:H}\). We perform ten iterations of the Cross-Entropy Method (Rubinstein, 1999), sampling 10K trajectories at each iteration and selecting 10 elites to update the mean of the sampling distribution for the following iteration. The standard deviation of the sampling distribution is held constant at 0.3 for all iterations.

Shooting-based LLM planner

Search-based LLM planner
1.5 A. 5 Algorithms
In this section, we provide algorithm pseudocode for all language-based planners proposed in this work: shooting in Algorithm 1, greedy-search in Algorithm 2, and Text2Motion in Algorithm 3.

Text2Motion hybrid planner
Appendix B Experiment details
We refer to Table 2 for an overview of the tasks in the TableEnv Manipulation suite.
1.1 B.1 Scene descriptions as symbolic states
For the remainder of this section, we use the following definitions of terms:
-
Predicate: a binary-valued function over objects that evaluates to true or false (e.g. on(a, b))
-
Spatial Relation: a predicate grounded over objects that evaluates to true (e.g. on(rack, table))
-
Predicate Classifier: a function that implements whether a predicate is true or false in the scene. In this work, we use hand-crafted predicate classifiers for each spatial relation we model
-
Symbolic State: the set of all predicates that hold true in the scene
-
Satisfaction Function: a binary-valued function that takes as input a geometric state, uses the predicate classifiers to detect what predicates hold true in the geometric state, and collects those predicates into a set to form a symbolic state. The satisfaction function evaluates to true if the predicted goals (predicates) hold in the symbolic state
To provide scene context to Text2Motion and the baselines, we take a heuristic approach to converting a geometric state s into a basic symbolic state. Symbolic states consist of combinations of one or more of the following predicates that have been grounded: on(a, b), under(a, b), and inhand(a). inhand(a) = True when the height of object a is above a predefined threshold. on(a, b) = True when (i) object a is above b (determined by checking if the centroid of a’s axis-aligned bounding box is greater than b’s axis-aligned bounding box), (ii) a’s bounding box intersects b’s bounding box, and (iii) inhand(a) = False. under(a, b) = True when on(a, b) = False and a’s bounding box intersects b’s bounding box.
The proposed goal proposition prediction technique outputs goal propositions consisting of combinations of the three spatial relations above. As an example, for the natural language instruction “Put two of the boxes under the rack" and a symbolic state [on(red box, table), on(green box, rack), on(hook, rack), on(blue box, rack)], the LLM might predict the set of three goals {[under(red box, rack), under(blue box, rack)], [under(red box, rack), under(green box, rack)], [under(green box, rack), under(blue box, rack)]}. We highlight that objects are neither specified as within or beyond the robot workspace, as we leave it to the skill’s Q-functions to determine feasibility (Sect. 1).
Since planning in high-dimensional observation spaces is not the focus of this work, we assume knowledge of objects in the scene and use hand-crafted heuristics to detect spatial relations between objects. There exists several techniques to convert high-dimensional observations into scene descriptions, such as the one used in Zeng et al. (2022). We leave exploration of these options to future work.
1.2 B.2 In-context examples
For all experiments and methods, we use the following in-context examples to construct the prompt passed to the LLMs.











Appendix C Derivations
We provide two derivations to support our approximation of the skill score \(S_{\text {skill}}\) (used to select skills while planning with greedy-search and Text2Motion) defined in Eq. 8. The skill score is expressed as a product of two terms:
1.1 C. 1 Skill usefulness derivation
Equation 9 defines the first term in the skill score product to be the skill usefulness score \(S_{\text {llm}}\). We derive the approximation of \(S_{\text {llm}}\) given in Eq. 10, which corresponds to quantity we use in our experiments.
The final expression is given in Eq. C4. Here, we compute a single sample Monte-Carlo estimate of Eq. C3 under the future state trajectory \(s_{2} \sim T^{\pi _{1}}(\cdot | s_{1}, a^*_{1}), \ldots , s_{t} \sim T^{\pi _{t-1}}(\cdot | s_{t-1}, a^*_{t-1})\), where \(a^*_{1:t-1}\) is computed by STAP (Agia et al., 2022). The key insight is that future state trajectories \(s_{2:t}\) are only ever sampled after STAP has performed geometric feasibility planning to maximize the success probability (Eq. 3) of the running plan \(\psi _{1:t-1}\). By doing so, we ensure that the future states \(s_{2:t}\) correspond to a successful execution of the running plan \(\psi _{1:t-1}\), i.e. achieving positive rewards \(r_{1:t-1}\). This supports the independence assumption on rewards \(r_{1:t-1}\) used to derive Eq. C3 from Eq. C2.
1.2 C. 2 Skill feasibility derivation
Equation 11 defines the second term in the skill score product (Eq. C1) as the skill feasibility score \(S_{\text {geo}}\). We derive the approximation provided in Eq. 12, which is the quantity we use in our experiments.
From Eqs. C5 to C6, the reward \(r_t\) is conditionally independent of the instruction i given the initial state \(s_1\), running plan \(\psi _{1:t}\), and previous rewards \(r_{1:t-1}\). As described in “Appendix C.1”, we can use STAP to make an independence assumption on the previous rewards \(r_{1:t-1}\) between Eq. C7 and Eq. C8. The reward probability in Eq. C8 depends on the parameters \(a^*_{1:t}\) computed by STAP and fed to the underlying primitive sequence \(\phi _{1:t}\), which gives Eq. C9. Equation C10 comes from the Markov assumption, and can be reduced to Eq. C11 by observing that the reward probability \(p(r_t \mid s_t, a^*_t)\) is equal to the Q-value \(Q^{\pi _t}(s_t, a^*_t)\) in the contextual bandit setting we consider. The final expression given in Eq. C12, which represents a single sample Monte-Carlo estimate of Eq. C11 under a sampled future state trajectory \(s_{2} \sim T^{\pi _{1}}(\cdot | s_{1}, a^*_{1}), \ldots , s_{t} \sim T^{\pi _{t-1}}(\cdot | s_{t-1}, a^*_{t-1})\).
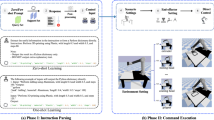
Appendix D Real world demonstration
1.1 D. 1 Hardware setup
We use a Kinect V2 camera for RGB-D image capture and manually adjust the color thresholds to segment objects in the scene. Given the segmentation masks and the depth image, we can estimate object poses to construct the geometric state of the environment. For the skill library, we use the same set of policies, Q-functions, and dynamics models trained in simulation. We run robot experiments on a Franka Panda robot manipulator.
1.2 D.2 Robot demonstration
Please see our project page for demonstrations of Text2Motion operating on a real robot.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Lin, K., Agia, C., Migimatsu, T. et al. Text2Motion: from natural language instructions to feasible plans. Auton Robot 47, 1345–1365 (2023). https://doi.org/10.1007/s10514-023-10131-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10514-023-10131-7