
Abstract
Programming by demonstration is reaching industrial applications, which allows non-experts to teach new tasks without manual code writing. However, a certain level of complexity, such as online decision making or the definition of recovery behaviors, still requires experts that use conventional programming methods. Even though, experts cannot foresee all possible faults in a robotic application. To encounter this, we present a framework where user and robot collaboratively program a task that involves online decision making and recovery behaviors. Hereby, a task-graph is created that represents a production task and possible alternative behaviors. Nodes represent start, end or decision states and links define actions for execution. This graph can be incrementally extended by autonomous anomaly detection, which requests the user to add knowledge for a specific recovery action. Besides our proposed approach, we introduce two alternative approaches that manage recovery behavior programming and compare all approaches extensively in a user study involving 21 subjects. This study revealed the strength of our framework and analyzed how users act to add knowledge to the robot. Our findings proclaim to use a framework with a task-graph based knowledge representation and autonomous anomaly detection not only for initiating recovery actions but particularly to transfer those to a robot.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
We are heading towards an age where robot programming is no longer subject to experts but requires shop floor workers and people in daily life situations to seamlessly program robots. It has been shown that Learning from Demonstration (LfD) is an intuitive technique to transfer task knowledge to a robot. More specifically, Programming by Demonstration (PbD) avoids manual code writing that is usually done by robotic experts (Calinon and Lee, 2018).
Since we move from purely repetitive robot tasks used in manufacturing and assembly lines towards more adaptive, collaborative and intelligent robotic applications, there is a high demand to increase robustness and adaptability of the robotic behavior. An exemplary scenario is a workspace, which is shared between human and robot and where the human causes uncertainties or intentionally adapts object positions. One way to achieve robustness is a recovery behavior, where the robot has knowledge about how to resolve an erroneous state. Another way is to increase the adaptability to the environment with task decisions that are made based on the environmental state and that enable the robot to act in different ways. With that in mind, we are highly motivated to transfer such knowledge to a robot in an intuitive way, such that end users are capable of creating robot programs that include recovery behaviors and task decisions. To give examples for these scenarios, a robot could react to a failed grasp by a regrasping action or a robot could make a decision based on a specific object property, for instance, sort objects by their weight. Since conditions have to be monitored in an online fashion, these scenarios are also referred to as conditional tasks.
The goal of this work is to propose a new framework for programming conditional tasks, called Collaborative Incremental Programming, which is confronted with two other alternative approaches. To give a broader overview about the methodology of the compared frameworks, we structured it by two means, which are task representation and teaching interaction strategy. In the first part, we introduce two different task structures which represent the main task and its recovery behaviors or alternative actions. In the second part, we compare two different teaching interaction strategies that rely either on manual or automatic detection of erroneous states during execution. The comparison allows the analysis of intuitiveness and teaching efficiency for the end-user. This was achieved by conducting a study involving 21 users, which is evaluated by teaching and execution metrics as well as by user ratings.

Interactive programming by demonstration (PbD) framework for programming of task decisions and recovery behaviors, achieved by inserting decision states (DS) into a task-representing graph. In clock-wise order, a human provides an initial demonstration (left), the robot executes and monitors the current action (top), the robot detects a possible anomaly (right), human and robotic agent interact about how the new information shall be used (bottom) and either the robot executes again or the task structure is extended
The main contribution of this work is twofold: first, we propose a PbD task-graph learning framework that allows intuitive transfer of task knowledge including task decisions and recovery behaviors using a bidirectional communication channel between human and robot (see concept in Fig. 1). Second, we provide valuable insights of how users employ and understand PbD using different task representation structures and different interaction methods within a user study. In comparison to works that focus on the teacher’s efficiency (e.g. Sena and Howard (2020)), we introduce a new programming framework and analyze how end-users collaborate with the robot as an autonomous agent via textual dialogs to achieve their task goals.
In our experimental evaluation, we show the advantage of our newly task-graph based method over an unstructured task representation in terms of robust and semantically consistent action transitioning. Further, we evaluate our anomaly detection method that relies on the robot’s perception capabilities in comparison to a user-triggered anomaly detection. Our findings suggest that end-users have a biased impression about the robot’s sensing capabilities, even though they were informed about them before usage.
This work gives a more detailed overview of our preliminary study on collaborative programming (Willibald et al., 2020) regarding task representations, evaluates the framework in different applications and adds a user study in order to reveal how people interact with different frameworks.
2 Related work
It has been early shown that PbD is a reasonable method for robot programming systems (Muench et al., 1994), which is also employed in our proposed framework. According to the problem to be solved, PbD can allow non-expert users to intuitively set up a new robotic tasks in comparison to manual programming. More recently, it has been shown that PbD can be successfully combined with other task learning methods such as human feedback and transfer learning of similar tasks (Mollard et al., 2015). After PbD has been established in the state of the art, researchers came up with structured representations of tasks, for example in the form of task-graphs (Su et al., 2018; Sauer et al., 2019; Niekum et al., 2013, 2015; Caccavale et al., 2017). In the presence of humans, who might cause uncertainties in the workspace or given a rather complex task, the robot requires some robustness to reach the task goal. In the work of Caccavale et al. Caccavale et al. (2017), this has been achieved by the structured task representation on a visual perception level, where only branches of the task-graph are executed that are feasible for the robot at the given environmental state. A collaborative robot programming framework has been presented in Materna et al. (2018) which uses augmented reality projections and a touch-enabled table to intuitively parameterize an existing robot program. The program itself allows preprogrammed branching or cycling operations. We enable the user to program branching operations by learning such behaviors from scratch without predefined skills, objects and environmental conditions. As the environment is not always fully observable and properties such as forces cannot be observed beforehand, we present a reactive task-graph-based framework that encounters unknown states with recovery behaviors that can be defined by the user.
2.1 Task decisions
Several works have shown a sequential programming paradigm, where the robot executes a sequence of actions or skills in order to achieve the task (Eiband et al., 2019; Pais et al., 2015; Steinmetz et al., 2019). However, a fixed sequence of actions is not able to solve conditional tasks, since it does not include replanning or decision making on the task level. Therefore, we introduced in a prior work (Eiband et al., 2019) how intuitively task decisions can be programmed by demonstration, termed as Sequential Batch Programming (SBP). Compared to this work, we substantially changed the way of task encoding and user interaction to allow a robust execution that is able to cope with unseen task faults. Although replanning of a robotic task during execution is possible, it requires a goal definition and world representation for the planner to work. We instead use the demonstrations itself to transfer the decision making strategy to the robot, which directly learns the required actions from the user. With that strategy, we enable both the definition of task decisions and recovery behaviors within the same framework.
2.2 Fault detection and recovery
In the context of fault detection and recovery, a variety of methods and applications have been presented. First, considering only fault detection, a method based on force data to train a Support Vector Machine has been applied to detect failures during assembly of a shield onto a counterpart (Rodriguez et al., 2010). In Pastor et al. Pastor et al. (2011), task outcome of failure or success is predicted by a statistical model of previous sensor signals. A Hidden Markov model (HMM) approach has been used to classify abnormalities in the force domain of an assembly task (Di Lello et al., 2013). Also based on HMM, a multi-modal abnormality detection has been presented in Park et al. (2016) that monitors forces, vision and sound during execution. Khalastchi et al. presented a data-driven anomaly detection approach based on dimensionality reduction of sensor data, pattern recognition and a threshold on the Mahalanobis distance (Khalastchi et al., 2015) and extensively evaluates this approach later on Khalastchi and Kalech (2018). These approaches have in common that they are able to detect abnormal states or faults but are not designed to recover from them automatically. Donald (1988) proposed the derivation of recovery behaviors from geometric models of the task at hand. We do not require a geometric, predefined task model within our learning framework but extract the recovery actions directly from the user’s demonstrations. Niekum et al. (2015) presented the construction of a finite state machine from a number of human demonstrations. Possible recovery behaviors were only considered, if the human pressed a button during execution. In contrast, our presented system decides autonomously when a demonstration is required via anomaly detection. Further, they provide the pose of all task relevant objects to the robot, which is hard to realize in practical applications. In Maeda et al. (2017), low confidence task regions based on a probabilistic model were exploited to improve the robot’s spatial generalization capabilities for unseen object locations. Although no anomaly detection is performed online, the robot’s knowledge about known motions is analyzed offline in order to request additional user demonstrations that could prevent future execution errors. In both Niekum et al. (2015) and Maeda et al. (2017), the force domain is not considered in the task definition process. Since we put a high emphasis on anomaly detection including the force/torque domain, we enable our framework to react to environmental properties that cannot be observed visually.
2.3 Sequential batch programming (SBP)
SBP is based on the framework presented in Eiband et al. (2019), where the teaching and execution are split up in two distinct phases. First, the teacher successively demonstrates all different task solutions, which are independently stored in a solution pool (see Fig. 2a). Whenever an anomaly is detected during the execution of a task solution, the system switches to the state within an alternative solution that minimizes the error between the current sensor values and all alternative solution states. This error metric is computed by the Mahalanobis distance, that incorporates a confidence bound around each solution. The confidence bound is obtained by encoding multiple demonstrations per solution in a Gaussian Mixture Model (GMM).

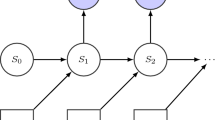
A task representation that incorporates recovery behaviors can be defined as solution pool, where multiple solution actions exist in parallel (a) or as task-graph, which arranges the actions as links and decision states as nodes (b)
2.4 User-triggered incremental programming (UIP)
UIP is inspired by the framework presented in Sauer et al. (2019) that suggests a robot state automaton which is able to observe environmental conditions and to branch into different states during execution. We adapted this approach in a way to only create graph-nodes where a decision state is required in order to obtain a task-graph (see Fig. 2b). Ordinary robot states within a trajectory are not represented as graph nodes, which allows to visually represent the task-graph with only the significant decision states. Similar to the approach we present, a task-representing graph is incrementally constructed in a combined teaching- and execution phase. The difference is, that with UIP, the teacher has to detect anomalies during execution of the task and needs to decide if and when a new demonstration is needed. A decision state can be inserted by manually triggering a button or controlling a GUI. In contrast, we tackle this problem by autonomous anomaly detection to remove this burden from the user.
3 Background: programming of recovery behaviors by demonstration
3.1 Requirements
We argue that a task decision and recovery behavior programming framework requires the following properties:
-
(i)
An anomaly detection mechanism (Sect. 4.2),
-
(ii)
An extendable knowledge representation allowing to learn from the user and environment (Sect. 4.3),
-
(iii)
Adaptability and refinement of robotic actions to increase robustness (Sect. 4.3, and
-
(iv)
An adaptive system to react during task execution (Sect. 4.4).
According to that, we developed the approach of Collaborative Incremental programming (CIP) and compare it with two other approaches we have developed in this domain, namely Sequential Batch Programming (SBP) and User-triggered Incremental Programming (UIP).
3.2 Task representations
We evaluate different task representations in this work that allow reactive behaviors that are required for fault recovery or conditional tasks. We clarify that fault recovery and conditional tasks are closely related, because they require (a) monitoring of the execution, (b) branching from the nominal execution flow, and (c) multiple actions for each decision and recovery behavior. In the following, two fundamental task representations are considered.
3.2.1 Solution pool
This task representation has been introduced in our previous work (Eiband et al., 2019) and represents a storage of multiple actions, so called solutions (Fig. 2a). In the solution pool, no branching states are specified, which enables transitioning between solutions at any time during execution.
3.2.2 Task-graph
In this work, we make use of a structured task-graph (Fig. 2b), that employs specified decision states, which are the graph’s nodes. The links represent the robotic actions that either lead to the next decision state or to a designated termination of the task. Later in this document, we explain how this representation can be generated incrementally in an interactive scheme involving user and robot.
3.3 Fault state detection mechanisms
In the presence of possible task faults, the end user wants the robot to handle such situations autonomously. In reality, it might not be always clear to the robot what is exactly a fault or erroneous state. However, a user might have capabilities that the robot has not in order to identify such states. Therefore, we consider both manual and autonomous detection mechanisms in this work.
3.3.1 Manual fault state detection
It has been shown that users are able to manually identify states where the robot shall make a decision about its next action in a specific environmental state (Niekum et al., 2015; Sauer et al., 2019). This can be achieved by letting the user observe the task execution and by providing manual user feedback, e.g. via a button or GUI.
3.3.2 Autonomous anomaly detection
This detection scheme removes the burden from the user to observe the task execution and react accordingly. It enables detection of abnormal states in absence of the user and of newly occurred situations that could not be foreseen at programming time. In contrast to the identification of low confidence task regions to improve the robot’s spatial generalization capabilities (Maeda et al., 2017), we focus on the identification of anomalies that can occur in the position and force domain. We introduced our anomaly detection scheme in our previous works Eiband et al. (2019) and Willibald et al. (2020), which is based on a probabilistic action encoding and a statistical outlier detection using the Mahalanobis distance. The next section introduces all parts of our methodology in depth.
4 Collaborative incremental programming
Our proposed approach of Collaborative Incremental Programming (CIP) combines the task-graph programming with an autonomous fault detection scheme that requests new user demonstrations in unknown regions of the input space. This enables the robot to decide ad-hoc when new information is required in order to extend the task-graph with decision states and possible recovery behaviors.

States while creating a task-graph by monitoring the execution and by reacting to anomalies
4.1 Probabilistic action encoding
We request the user to only demonstrate a new behavior once, in order to add a new action. Since the dynamics of the kinesthetic demonstration differ slightly from the robot execution, we record also a robotic repetition of the given demo. Variations between user and robot performance are introduced by small uncertainties in the environment that are possibly introduced by the user, who sets the objects back to their original positions. This shall enable the anomaly detection to handle task-specific uncertainties that are possibly caused by uncertain object locations. Additionally, the anomaly detection shall be robust to system-specific uncertainties as they are caused by the robot controller due to limited tracking performance and variations in dynamics, depending on the stiffness parameters of the impedance controller. The obtained trajectory samples of the task are used to encode this action and determine the regions of variance around the nominal trajectory. An example of these variance regions can be seen in Fig. 3a. Hereby, low variance regions lead to a more sensitive anomaly detection. In parts with more variability, higher deviations are accepted during the execution, which increases the overall robustness. We make use of the robot’s own proprioceptive sensing capabilities, where we use a force-torque sensor at the end-effector, the Cartesian pose and the signals from the gripper, which are the distance between the gripper fingers and the status informing if an object is grasped or not, evaluated by the grasping force. An external vision system is not required in our approach, which performs well in partially structured production environments and hence is independent from object visibility or lighting conditions.
A data sample at time t is given as
consisting of the end-effector’s Cartesian position \({\varvec{p}} \!\!= [x, y, z]\) and orientation in unit quaternions \({\varvec{o}} = [q_w, q_x,\) \(q_y, q_z]\), force \({\varvec{f}} = [f_x, f_y, f_z]\) and torque \({\varvec{\tau }} = [\tau _x, \tau _y, \tau _z]\), as well as the gripper finger distance g and grasp status \(h \in \{-1, 0, 1\}\). The grasp status is defined as follows: \(h=-1\) for no object in gripper, \(h=0\) for gripper closing or opening, and \(h=1\) for object in gripper. We choose these state variables since they were offered from the gripper hardware interface. The data is recorded at a frequency of \(1\,\)kH and is downsampled to \(50\,\)Hz to reduce the computational effort in learning. The recorded data from user demonstration \({\varvec{X}}_\text{ Udem } = [{\varvec{x}}_{\text{ U },1},\ldots , {\varvec{x}}_{\text{ U },{N_\text{ U }}}] \in \mathbb {R}^{15 \times N_\text{ U }}\) and robot repetition \({\varvec{X}}_\text{ Rrep } = [{\varvec{x}}_{\text{ R },1},\ldots , {\varvec{x}}_{\text{ R },{N_\text{ R }}}] \in \mathbb {R}^{15 \times N_\text{ R } }\) with respective sample length \(N_\text{ U }\) and \(N_\text{ R }\) is collected for each new demonstration.
Similar to Eiband et al. (2019), we first apply dynamic time warping (DTW) to align the two sensor sequences on a common time axis and equalize their length N. In a preceding step, the data is standardized dimension-wise with the z-transformation by subtracting the mean and dividing by the standard deviation. This assures that each dimension contributes equally to the dynamic time warping error. After warping the data, the standardization is undone by applying the inverse z-transformation dimension-wise.
In the next step, Expectation Maximization (EM) is used to learn a multivariate, time-based Gaussian Mixture model (GMM) for the input matrix
for an action s and a time vector \({\varvec{n}} = [1,\ldots , N]\). The variables \({\varvec{X_\text{ U }}}\) and \({\varvec{X_\text{ R }}}\) refer to demonstrated and repeated trajectories respectively, where possible scenarios are explained in detail in Sect. 4.3. The model complexity is chosen such that the number of model components k is proportional to the temporal length N of the demonstrated time series data. In the experiments, we chose to add one model component per second of the time series, which has shown to be a reasonable trade off between model accuracy and smoothing of demonstrated motions. The EM algorithm is then initialized using k-means clustering with a number of k clusters. From here, we obtain a model \({\mathcal {M}} = GMM({\varvec{G}}_s)\) that can be used to reproduce a trajectory. Gaussian Mixture Regression (GMR) is applied to reproduce a generalized trajectory
with an associated sequence of covariance matrices
These results allow the execution of the mean trajectory with a controller and to monitor the execution within a confidence area that is derived from the covariance matrices.
4.2 On-line anomaly detection

System components for realtime execution and monitoring. Solid connections are realtime-capable up to \(1\,\)kHz, dashed connections are slow asynchronous connections
The system design for on-line anomaly detection is shown in Fig. 4. The main goal is to monitor the execution and detect new situations that are not known to the system. Hereby, sensor modalities are introduced to distinguish also the source of error. These modalities are
-
1.
the robot pose (\({\varvec{p}}, {\varvec{o}}\)),
-
2.
the wrench (\({\varvec{f}}, {\varvec{\tau }}\)), and
-
3.
the gripper opening g and grasp status h.
For each of these modalities, the system constantly compares the commanded and measured values to detect abnormal states. Therefore, not only new situations can be detected but also a possible error source can be assigned, e.g. an abnormal state resulting from external forces. In each time step t of the execution, the deviation between the measurement \({\varvec{m}}_{i,t}\) and commanded state \({\varvec{\mu }}_{i,t}\) of a modality i is quantified using the Mahalanobis distance
By defining a custom anomaly threshold \(\epsilon _i\) for each modality of an action s, this metric leads to a higher error sensitivity in time steps where the execution needs to be precise, indicated by small values of the reduced covariance matrix \({\varvec{\Sigma }}_{i,t}\). During the execution, all modalities are monitored in parallel. If any \(D_{\text{ M }(i,t)}\) exceeds its action and modality specific anomaly threshold \(\epsilon _i\) for e consecutive time steps, an anomaly is detected.
Our approach does not rely on manual error threshold tuning but is automatically parameterized from the training data. We compute an anomaly threshold \(\epsilon _i\) for each modality of an action, based on the recorded trials of the user demonstration U and robot repetition R. After encoding a new demonstration in a GMM, we determine the highest occurring Mahalanobis distance for deviations between the samples \({\varvec{x}}_{d,i,t}\) of each demonstration \(d\in \{\text {U, R}\}\) belonging to one action and the associated mean \({\varvec{\mu }}_{i,t}\) by
Then, the maximum distance over all trials is extracted with
and used as modality specific error threshold.
4.3 Collaborative and incremental graph construction
We use a task-graph to structure the available robotic actions and possible decision states on an abstract level (such as shown in Fig. 3h). This graph is incrementally built by gaining task knowledge from user demonstrations. The graph’s nodes represent system states that can be of type start, end, and decision state (DS) that is explained later on.
In order to construct a new task, a user triggers a demonstration phase and provides an initial task demonstration. A robotic action is extracted from this demonstration as explained in Sect. 4.1 (Fig. 3a). Next, a start and end state is added to the beginning and end of this action. The result can be seen in Fig 3b, which allows an execution of that simple task.
If an anomaly is detected during execution, as explained in Sect. 4.2, the robot stops at the unseen state (Fig. 3c and d). The system now queries the user to choose from the following options. The detected situation shall be handled by a new action in future executions (Graph Extension), or must be incorporated as refinement for the current action (Action Refinement). These two options are explained subsequently.
Graph Extension: If the user selects to add a new action that should resolve the current situation, the robot switches to a demonstration phase and waits for the user input. The robot configuration is still at the abnormal state and can now be changed by the user via kinesthetic teaching. We assume that an anomaly has been detected beforehand at timestep \(t_\text{ anomaly }\). In the following, a user demonstration \({\varvec{X}}_\text {Udem}\) is recorded. This data is appended to the time-series \({\varvec{M}}\) that is recorded during the interval \([t_\alpha ; t_\text {anomaly}]\), resulting in \(\tilde{{\varvec{X}}}_\text {Udem} = [{\varvec{M}}, {\varvec{X}}_\text {Udem}]\). After finishing the demonstration, the user is requested by the system to restore the environment to the state before the demonstration, which means that manipulated object locations are set back to the beginning. Now, the robot moves to the configuration at time step \(t_\alpha \) and repeats the extended user demonstration \(\tilde{{\varvec{X}}}_\text {Udem}\). The two time-series from user and robot are then probabilistically encoded and saved as action \(s_2\).
Finally, a new decision state is inserted into the graph, splitting up action \(s_1\) into two actions before and after the anomaly, depicted \(s_\text {1A}\) and \(s_\text {1B}\) respectively (see Fig. 3g and h). The actions \(s_{1\text {B}}\) and \(s_2\) are then appended to the newly inserted decision state. In detail, action \(s_1\) is split at time step
where \(t_\text {thresh}\) is the time step in which the error metric \(D_{\text {M}(i,t)}\) first exceeds the anomaly threshold \(\epsilon _i\). The parameter e is the number of consecutive time steps for which \(D_{\text {M}(i,t)} > \epsilon _i\) until an anomaly is triggered. The scaling factor \(\alpha \) \((0< \alpha < 1)\) places the decision state in between time step \(t_\text {thresh}\) and \(t_\text {anomaly}\).
An early and smooth transition from action \(s_{1\text {A}}\) to its successor without following a possibly erroneous strategy too long, requires a minimal \(\alpha \). This means that the decision state would be placed close to the timestep \(t_{\text {thresh}}\). However, making a robust decision requires a long enough sequence of unambiguous sensor readings that can be assigned to a specific action, pushing the decision state towards \(t_\text {anomaly}\) and thereby \(\alpha \rightarrow 1\). Furthermore, the decision for the subsequent action must be made before \(t_\text {anomaly}\) is reached during execution of action \(s_{1\text {A}}\), otherwise the anomaly detection would wrongly identify a new situation for the scenario handled by \(s_2\) (see Fig. 3h). Preliminary experiments have shown that setting the number of error samples \(e = 30\) (corresponding to \(30/50\,\text{ Hz }=0.6\,\text{ s }\)) and the scaling factor \(\alpha = 1/3\) is a good compromise between robustness and delay in decision-making.
Action refinement: In case the user wants to refine the action s, during which the anomaly was detected, its encoded trajectory \({\varvec{Y}}_s\) with associated sequence of covariance matrices \({\varvec{Z}}_s\) is adjusted by new data. Hereby, an existing action becomes capable of handling more diverse conditions such that the robot learns which features are important to observe and which regions of the state space do not require a tight monitoring and error handling. For instance, a sorting task for geometrically different objects, that ignores the object weight can be achieved by refining the actions that handle the different geometries. In that case, the refinement leads to actions, where the monitoring becomes invariant to the object weights and therefore avoids false-positive force anomaly detection in future task executions. Such an example is later on evaluated in the experiments section. A trial of the new setup is either acquired by a user demonstration in a user-refine mode or by the robot in auto-refine mode.
In user-refine mode, a manual demonstration offers the possibility to adjust the full trajectory of the correction, which directly starts at the anomaly configuration. In comparison, the auto-refine mode lets the robot autonomously continue the execution after the anomaly has been detected until the end of the action. Since we know already that a new situation shall be incorporated into the action encoding, the anomaly detection is disabled for the remainder of the execution. For both possible modes, the recorded time-series \({\varvec{X}}_{\text{ Rref }}\) is appended to the time-series \({\varvec{M}}\) of the action before the anomaly, resulting in a stacked matrix \(\tilde{{\varvec{X}}}_\text {Rref} = [{\varvec{M}}, {\varvec{X}}_\text {Rref}]\). This data is used together with the initial user demonstration \({\varvec{X}}_\text {Udem}\) and robot repetition \({\varvec{X}}_\text {Rrep}\) of that action for a new probabilistic encoding, as described in Sect. 4.1. Finally, the task-graph is updated with the new action model.
4.4 Task execution
Our main goal is the efficient combination of teaching and execution phases, that switch ad-hoc according to changes in environmental conditions. After an initial task demonstration, an execution phase can immediately follow to start the production. It is seamlessly possible to add knowledge at any time to the task-graph. Either, the user can intentionally add knowledge for known situations from the beginning, or the system just comes back to the user at any time, for instance after unforeseen faults occurred during production. The task-graph enables the robot to reproduce any demonstrated task, but furthermore, allows to adapt to environmental states by exploiting known decision states. This allows a fundamental extension to a simple sequential task execution, which is namely the selection of the appropriate action based on the current sensor readings. Conditional tasks allow, for instance, sorting by object properties, or selection of recovery behaviors at erroneous states.
The task-graph structures the available actions on a high level, while the actions themselves are encoded probabilistically on a low level, enabling their realtime monitoring. Decision states are automatically inserted at critical state transitions of the task, which simplifies the decision process for a specific state, but also eliminates perceptual aliasing and thereby the risk of deciding for a wrong action. Since decision states are known after the first anomaly occurred, the system can evaluate the measurements in an early state and avoid unnecessary robot movements.
Our approach identifies the sensor modality that contributed most to the anomaly, where only relevant sensor values are considered to select the subsequent action in a decision state. In the following, an example is used to explain the action selection in a decision state, referred to Fig. 3h. The robot starts with the first action \(s_{\text{1A }}\). If no anomaly is detected during the execution, the robot reaches the first decision state (DS), in which the subsequent action \({\hat{s}}\) is determined by
\({\varvec{m_\text{ DS }}}\) is the measured state of of a modality in the decision state and \({\varvec{\mu }}_{s,0}\) is the sample of the same modality at the first time step of an encoded action. In our example, the action \({\hat{s}}\) that is executed next is selected from \(\{s_\text{1B }, s_2\}\), which are all actions that are attached to the decision state. In contrast to the anomaly detection, we use the Euclidean distance metric here, because the Mahalanobis distance favors actions with high uncertainty, expressed by large values in the covariance matrix that lead to very small errors in the first time step. With our proposed scheme, the robot always chooses an action that minimizes the error to the current environmental state and keeps on monitoring that action to detect possible future anomalies.
5 Experiments
Our experiment shows a scenario where a user transfers a sorting task to a robot by adding knowledge incrementally.Footnote 1 Hereby, the system queries only three demonstrations from the user by interacting via the GUI. If the robot detects an anomaly during task execution, the user can either demonstrate a new action that solves this unique situation or refine the current action by incorporating the new conditions into the expected outcome of that action. With this experiment we want to demonstrate both the action refinement and the task-graph extension capabilities of our approach allowing the robot to ignore irrelevant features and to learn relevant features of a task.
5.1 Experimental setup

Experimental setup where a conveyor belt (blue in the bottom left) delivers new parts to a pick location, from where they can be sorted (Color figure online)
As seen in Fig. 5, a DLR LWR IV is mounted on a linear axis and equipped with a “Robotiq 85” 2-finger gripper as well as a FT-sensor measuring the forces and torques acting on the end-effector. The robot is impedance controlled with a control frequency of 1 kHz and parameterized with constant stiffness- and damping coefficients \(k_\text{ trans }\) = 1200 N/m, \(k_\text{ rot }\) = 100 Nm/rad and \(d_\text{ m }\) = 0.3 Ns/m respectively. Pedals and a tablet displaying a GUI allow the user to interact with the GUI while guiding the robot at the same time. The pedals are used to open or close the gripper and to start or stop the demonstration recording when using kinesthetic teaching in gravity compensation. The GUI guides the user through the teaching process and requests input from the user when the task definition requires it. A conveyor belt standing perpendicular to the table transports boxes with supplies for an assembly task to a determined place in the working space. These boxes have to be placed in a part storage on the table in front of the user.

Experimental results of the box sorting task with action refinement and graph extension
5.2 Geometry-based sorting task
The goal of the task is to program the robot to distinguish the different boxes based only on their geometry in order to place the supplies at a specific spot in the part storage where the user expects them. Specifically, the weight of the boxes should not be considered when deciding for the final position of a box. Analogously, sorting of objects by their weight can be achieved with similar means, as realized in a previous work (Eiband et al., 2019). We assume that boxes of equal dimensions always contain the same kind of pieces but do not always contain the same number of pieces and therefore differ in weight.
First, the user provides an initial demonstration, where the robot picks up a box with supplies from the start position on the conveyor belt and places it in its designated spot in the part storage (Fig. 6d). After the user demonstration, the box is again placed in the start position on the conveyor belt so that the robot can repeat the demonstrated sequence. As seen in Fig. 6a, b, and c, these two demonstrations are used to learn a model of the action, which is then executed by the robot. During manipulation of a box with a different weight, the robot detects an anomaly caused by an unexpected force \(f_z\) exerted in z-direction (Fig. 6e). Since deviating weights of boxes are not considered important features of the task, the user decides to refine the current action in order to incorporate the new condition into the expected trajectory for that action. The refinement is shown in Fig. 6h and carried out completely by the robot, continuing the learned motion and placing the box in its designated spot. However, when the robot detects a different box geometry during gripping (Fig. 6i), the user can demonstrate a new action, placing the box in another spot of the part storage (Fig. 6l). This user demonstration is then again repeated by the robot and encoded into a probabilistic model of the new action, shown in Fig. 6j.
5.3 Results
We have shown that with our approach the robot can learn important features (box geometry), while considering deviations of other features (box weight) irrelevant for specific actions of a task. As seen in Fig. 6g, refining the learned model with an example of a lighter box adjusts the expected value of \(f_z\) and the variance \(\sigma _{f_z}\) as well as the force anomaly threshold \(\epsilon _f\) for this action (acc. to Eqs. (3) and (4)). Following Sect. 4.2, this leads to a less sensitive force anomaly detection in future executions of this action. This allows to manipulate boxes with a wide range of different weights without triggering a false positive anomaly detection. At the same time, the robot can still learn additional actions for new situations. As seen in Fig. 6i and l, a detected gripper finger distance anomaly when grasping a different box gives the user the opportunity to demonstrate a new action that places this box at another goal position. At the time step of grasping a box, a new decision state is inserted into the task-graph (Fig. 6j) in which the robot decides for the subsequently executed action based on the measured gripper finger distance (see Fig. 6k, Sects. 4.3 and 4.4).
6 User study for approach comparison
In order to evaluate the intuitiveness and user friendliness of CIP, a user study is conducted,Footnote 2 in which it is compared with two other frameworks, SBP and UIP that were introduced in the related work (Sect. 2). The task executions, generated with the different programming frameworks are finally compared by their performance in reaching the task goals.
6.1 Materials and study design
6.1.1 Sample
21 participants (19 male and 2 female) were recruited from the German Aerospace Center (Age = 25.24 ± 7.03 years, ranging from 21–56). All participants have a background in different technical fields, but not necessarily in robotics.
6.1.2 Setup
We use the same setup as described in the previous experiments section. For all robotic tasks in the user study, we use the same object, an aluminum block visible in Fig. 7 (6.8 cm x 4 cm x 2 cm) in different setups.

Initial and final setups of task 1 (left) and task 2 (right) with each two different environmental conditions (Cond. 1 and Cond. 2)
6.1.3 Procedure
Participants are informed about the aim of the study and the procedure. In an introduction, the robot’s sensing capabilities are explained, specifically highlighting that no vision-based monitoring of the environment is used. After up to five minutes to familiarize with handling the robot and operating the pedals, the experimental tasks are explained. Each participant watches a short instruction video explaining each method and then teaches both tasks for all three methods. The order of teaching each task with each method was permuted among all subjects using a Latin square design (Grant, 1948). After programming with one method is completed, the NASA-TLX (Hart and Staveland, 1988) and the Questionnaire for Measuring the Subjective Consequences of Intuitive Use (QUESI) (Naumann and Hurtienne, 2010) are filled out by the participants. With the end of the experiment, an overall evaluation of the methods takes place, where the participants rate intuitiveness and efficiency on a 7-point Likert-type scale followed by a semi-structured interview.
6.1.4 Data analysis
Nominal scaled successful completions were analyzed by means of Cochran’s Q test and McNemar post hoc tests in case of significant differences between methods. For questionnaire items, a repeated measures ANOVA was calculated. In case of violation of sphericity (Mauchly’s sphericity test), Huynh-Feldt (> .75) or Greenhouse-Geisser (< .75) corrections were made. Post hoc tests with Bonferroni correction were performed to identify which methods differ significantly.
6.2 Compared methods
Table 1 provides an overview of the PbD approaches that are compared in the user study, which all use the same sensory input but no visual perception to make task decisions. The approaches were initially described in the related work sections (Sects. 2.3 and 2.4) and are briefly explained in the following.
Sequential Batch Programming (SBP) is based on the framework presented in Eiband et al. (2019), where the teaching and execution phases are separated. First, the teacher successively demonstrates all task solutions which the robot shall be able to handle, and stores these independently in a solution pool. If an anomaly occurs during task execution, the system switches to the state within an alternative solution that minimizes the error between current measurement and all alternative solution states.
Collaborative Incremental Programming (CIP) is our proposed PbD approach that combines anomaly detection with collaborative programming to account for new task conditions. Compared to SBP, the decision state is explicitly programmed by collaboration between user and robotic agent. Therefore, arbitrary switching states that do not guarantee a successful transition are avoided.
User-Triggered Incremental Programming (UIP) is inspired by the framework presented in Sauer et al. (2019), where similar to CIP, a task-representing graph is incrementally constructed in a combined teaching and execution phase. The difference between these methods is that the teacher has to detect anomalies with UIP during execution of the task and needs to decide if and when a new skill demonstration is needed.
6.3 Hypothesis
In this study, we want to verify the following hypotheses:
-
\({\varvec{{\mathcal {H}}1}}\) (based on objective metrics): Using CIP with its collaborative programming concept and autonomous anomaly detection results in a significant increase in successful task completions,
-
compared to SBP (hypothesis \({\varvec{{\mathcal {H}}1.1}}\)), and
-
compared to UIP (hypothesis \({\varvec{{\mathcal {H}}1.2}}\)).
-
-
\({\varvec{{\mathcal {H}}2}}\) (based on subjective ratings): A significant increase in programming intuitiveness is achieved by CIP with its collaborative programming scheme,
-
compared to SBP, which uses a training phase to collect all demonstrations in the beginning (hypothesis \({\varvec{{\mathcal {H}}2.1}}\)), and
-
compared to UIP, which requires the user to trigger the insertion of decision states manually (hypothesis \({\varvec{{\mathcal {H}}2.2}}\)).
-
-
\({\varvec{{\mathcal {H}}3}}\) (based on subjective ratings): A significant decrease in workload is achieved by CIP,
-
compared to SBP (hypothesis \({\varvec{{\mathcal {H}}3.1}}\)), and
-
compared to UIP (hypothesis \({\varvec{{\mathcal {H}}3.2}}\)).
-
6.4 Experimental tasks
We designed two different tasks, namely task 1: Reorientation and task 2: Contact-based Sorting. Their initial and final setup is shown in Fig. 7.
In task 1, the robot shall manipulate an object from an initial location to a target. The object’s long edge shall be aligned with a mark on the table at the target. In addition, the object can be rotated by \(90^{\circ }\) in the start location such that the gripper can grasp it over its short edge. This requires a reorientation of the object before placing it in the target location. A step-wise description is shown in Figs. 8 and 9. In task 2, the robot shall fill a part storage starting with target I (Fig. 7 right). If target I is occupied, the object shall be placed on target II (Fig. 7 right). The manipulation steps as well as the generation of the task-graph are shown in Figs. 11 and 12.

Task 1: Reorientation, SBP: In step (1), the user demonstrates a pick and place action \(s_1\). In step (2), the user extends the solution pool with a second action \(s_2\), in which the object gets rotated by \(90^{\circ }\) before placing it in the target location. During execution of the nominal solution \(s_1\), the rotated object in the start location causes an anomaly, that triggers a transition to the alternative solution. The bottom row illustrates an example of a failed execution, where the robot decides for a wrong entry point of the alternative and skips the reorientation part of \(s_2\)

Task 1: Reorientation, CIP and UIP: In step (1), the user demonstrates a pick and place action \(s_1\). Step (2) shows the updated graph after first execution where an anomaly leads to inserting decision state (DS) and splitting \(s_1\) into \(s_{1A}\) and \(s_{1B}\). The DS is created by the anomaly detection algorithm in CIP and by the user manually in UIP. In step (3), the user adds a new action \(s_2\) that accounts for the anomaly and properly rotates the object before placing it

Correct (a) and wrong (b) robot configuration to provide an alternative action for solving a new situation. Due to the user’s influence on the anomaly detection, a configuration in which the robot can’t sense the anomaly is more likely with UIP
6.5 Results
Methods were evaluated using objective performance data and subjective user feedback in post-experimental questionnaires and the interview. Additionally, some exemplary executions from the user study experiments are shown in Fig. 13.
6.5.1 Objective data
Successful Completions: A binary metric was used to determine if a learned task can be successfully executed in order to reach the task goal as described in the experimental task description. This allows to compute the success rate of executions for each method, as shown in Fig. 14. Cochran’s Q test indicated significant differences between the conditions for task 1 (p < .001) as well as for task 2 (p < .001). McNemar post hoc tests revealed significant differences between SBP and CIP (p < .05) and CIP and UIP (p < .001) for task 1. For task 2, significant differences could be found for SBP versus UIP (p < .001) as well as CIP versus UIP (p < .001).
\({\varvec{{\mathcal {H}}1.1}}\) does not hold for task 1 (✘) but holds for task 2 (\(\checkmark \)) such that there are significantly more successful task completions by using the collaborative programming scheme of CIP compared to the collection of demonstrations in a batch, used in SBP. This could be explained by the importance of right timing in task 1 (Reorientation), where it was critical for SBP to find the precise entry point in the alternative solution, which could lead to failed grasps and an unsuccessful task outcome. In task 2, this timing issue was less critical as the recovery behavior did not grasp the object again, but just executed an action with different trajectory while the gripper remained closed. \({\varvec{{\mathcal {H}}1.2}}\) holds for both tasks (\(\checkmark \)) with significantly more successful task completions by using the autonomous anomaly detection of CIP in favor of a manual anomaly detection in UIP. Due to this discrepancy in the success rates, we analyzed where exactly the decision states were inserted in these approaches.

Task 2: Contact-based Sorting, SBP: The user successively demonstrates two pick and place actions in step (1) and (2). In demonstration of action \(s_2\), the object is placed in target location II, if target location I is occupied by another object. The bottom row shows the execution of the nominal solution \(s_1\), where an unexpected contact force triggers a transition to \(s_2\) while approaching target location I. The robot interpolates to the entry state of the alternative solution and places the object in location II
Decision State Insertion: The timestep where the anomaly is detected defines where the decision state is inserted in the task-graph. This is critical for selecting the appropriate action from the task-graph during execution. This timestep reflects a specific position of the end effector. In both tasks, the position of the end effector at the decision state is the main constraint to allow force sensing or grasp status identification of an object. To analyze this further, we derive a ground truth for the position of a decision state for each task. Hereby, we store the end effector position of all decision states from successful task executions of both CIP and UIP. Next, we compute the mean over all stored positions. This serves as ground truth, which can be considered as a near optimal solution to solve the task. Finally, we compute the distance \(d_{EE,C}\) between the end effector position of each decision state and the ground truth and show these values as green marks in Fig. 15. With CIP (left column), the automatically identified decision states lie close to the ground truth while with UIP, these were manually inserted and show larger errors. These errors lead to decision states, that are not physically grounded because the targeted sensor signal is not present in that state. Imagine that a user manually triggers a decision state that should decide about the weight of an object before the robot actually grasped it, which makes it impossible to sense such property.

Task 2: Contact-based Sorting, CIP and UIP: Step (1) shows the initial demonstration of a pick and place action \(s_1\). Step (2) shows the updated graph after first execution where an anomaly leads to decision state (DS) insertion and splitting of \(s_1\) into \(s_{1A}\) and \(s_{1B}\). The DS is created by the anomaly detection algorithm in CIP and by the user manually in UIP. In step (3), the user added a new action \(s_2\) that recovers from the anomaly

Exemplary executions from the user study experiments
6.5.2 Subjective data
Workload:
NASA-TLX overall score (see Fig. 16) revealed a significant ANOVA main effect (F(2, 40) = 4.30; p < .05). With post-hoc comparisons we found a significant lower workload for SBP (M = 4.48; SD = 2.21) compared to UIP (M = 5.82; SD = 2.79; p < .05). No significant difference was evident comparing CIP (M = 4.81; SD = 2.29) to any other method.
QUESI ratings: As reported in Fig. 17, users rated the intuitive use of SBP best, followed by CIP, except for “perceived achievement of goals”, where CIP reached the highest score. UIP was rated worst for all scales. A repeated measures ANOVA showed that statistically significant differences occurred for the subscales “Subjective Mental Workload” (F(1.37, 27.39) = 5.36; p < .05), “Perceived Effort of Learning” (F(1.38, 27.67) = 5.39; p < .05) and “Familiarity” (F(2, 40) = 4.09; p < .05). Post-hoc comparisons showed that SBP scored higher for those items than UIP (“Subjective Mental Workload”: p < .001; “Perceived Effort of Learning”: p < .05; “Familiarity”: p < .05) (see Fig. 17).
\({\varvec{{\mathcal {H}}3.1}}\) suggests that the programming workload is reduced by CIP in comparison with SBP and \({\varvec{{\mathcal {H}}3.2}}\) suggests the same effect for the comparison of CIP with UIP. Both hypotheses were rejected, instead we only see a significant difference between SBP and UIP. That SBP shows the smallest workload rating could be explained by a minimum of required human-robot interactions, where all knowledge is transferred sequentially in the teaching phase before the robot executes the task.
Overall Evaluation: The user ratings for the following two items are shown in Fig. 18. Intuitiveness of the method (“The method was easy to use and intuitive”). CIP (M = 6.29; SD = 1.35) and SBP (M = 6.00; SD = 1.10) were more intuitive than UIP (M = 4.95; SD = 1.69). This is supported by a significant ANOVA main effect (F(2, 40) = 4.89; p < .05), where CIP and UIP significantly differ (p < .05). Conventional level of significance for the difference between SBP and UIP was not reached (p = .053).
\({\varvec{{\mathcal {H}}2.1}}\) that suggests a higher intuitiveness of CIP compared to SBP in programming a task is supported by the overall QUESI ratings but without statistically significant effect (Fig. 17 very left). In contrast, \({\varvec{{\mathcal {H}}2.1}}\) holds for the comparison of CIP with UIP (\(\checkmark \)) and shows a significantly higher intuitiveness in programming a task.
Efficiency of the method (“I could solve the given tasks efficiently with the method”). Subjects rated CIP (M = 6.43; SD = 0.98) as most efficient, followed by SBP (M = 6.24; SD = 1.09). UIP (M = 5.52; SD = .47) was slightly less efficient. However, this is not supported by a significant ANOVA effect.

Successful completions of the different tasks for all three methods in percent.*, p < .05; **, p < .01; ***, p < .001

Each plot shows the probability density (blue curve) for the computed distances between decision state position and ground truth. These distances are marked by the green samples on the x-axis. The left column displays the automatically detected decision states by CIP, while the right column shows the manually triggered decision states by UIP. Automatically detected states (left column) lie notably closer to the ground truth (Color figure online)

NASA-TLX workload

Scores for QUESI (error bars indicate 95% confidence intervals).*, p < .05; **, p < .01; ***, p < .001

Scores for overall evaluation. p < .05; **, p < .01; ***, p < .001
6.6 Discussion
6.6.1 Objective data
The results from the performance evaluation show, that only programs created with CIP reliably solved both experimental tasks.
Due to the different abilities of the user and the robot to perceive the environment (e.g. vision), UIP cannot guarantee that the robot will be able to measure abnormal values when the user identifies a new situation and demonstrates an alternative behavior. As seen in Fig. 10b, during the experiments, many subjects did not wait with a demonstration until the robot senses the transition condition for the second sub-task. When programming the Reorientation task, 13 participants demonstrated a new action before the robot closed the gripper to grasp the turned object. For the contact-based sorting task, even 16 subjects did not wait until the robot could detect an object in the target location. With CIP, however, a deviation in sensor values is a requirement for detecting new situations. Thereby a measurable difference between the programmed transition conditions for every action of a decision state can be guaranteed. This leads to a successful transition to the appropriate successor action when reproducing the situation, because the measured sensor values reflect a programmed condition for action transitioning.
With SBP, a transition between actions is triggered when an anomaly is detected during the task execution. The time step of an action with the closest sensor values to the anomaly state is chosen as an entry point to continue the task. Since all time steps of all actions are potential candidates for the entry point, the approach is prone to perceptual aliasing, that causes transitions to wrong actions or entry points. Furthermore, the interpolation to the entry point does not guarantee a collision-free trajectory. In CIP, a transition between actions only happens in decision states. This limits the number of possible successor actions to the intended ones for a situation and thereby avoids perceptual aliasing and wrong transitions. This guarantees a successful transition between actions when reproducing known situations.
6.6.2 Subjective data
From analyzing the questionnaires and the responses in the interviews can be concluded, that SBP is an easily usable and intuitive framework for programming a-priori known tasks and conditions. However, compared to SBP, CIP has the advantage that overlapping parts of actions can be reused between different scenarios and complex tasks can be incrementally generated. For tasks with several different decisions and actions, it is difficult to predict all scenarios and to demonstrate the corresponding behavior prior to the execution. We argue, that for more complex tasks, the advantages of CIP can be fully exploited, since the user does not have to anticipate or detect new situations, but can demonstrate new actions when anomalies are detected during the execution. Furthermore, the combined teaching and execution of CIP gives the users the opportunity to instantly verify the result of their demonstrations.
From analysis of the NASA-TLX sub-categories can be seen, that CIP especially reduces the user’s mental workload when programming a task, compared to UIP. CIP reached in this sub-category a score of 6.2, compared to 8.5 for UIP. This is in accordance with the results from the guided interviews, where 19 of 21 participants mentioned as advantages of CIP, that the robot autonomously detects new situations and that the user does not have to pay constant attention. Whereas the negative aspects for UIP, related to an increased need for attention and mental demand, were mentioned 17 times. The increased intuitiveness of CIP over UIP was confirmed by the overall evaluation of the methods. As mentioned 11 times in the interviews, deciding for the right moment to stop the task execution of UIP in order to add a new action is not intuitive for the user. This decision requires a deeper understanding of the principle behind the method. As seen in Fig. 10, by eliminating the user’s influence on that decision, the robot automatically stops the task execution when an anomaly can be sensed by the robot, which significantly improves the task performance.
6.7 Post-experiment user ratings
In a final evaluation, we consulted five subjects again to obtain their ratings for the intuitiveness and efficiency of each of the programming approaches.Footnote 3 Since we have their ratings from before seeing the execution, we are able to compare their scores from before and after they have seen the execution of their own programmed tasks. Fig. 19 shows the results of the comparison. We can see that for both alternative approaches, the intuitiveness and efficiency dropped noticeable, while for our approach the intuitiveness remained the same (no change) and the efficiency increased by 0.2 points on the Likert-type scale. That supports the assumption, that due to the additional feedback loop in CIP, the participants have a better understanding of the robot’s changing task knowledge when teaching a task compared to SBP.
This concludes that our framework is more transparent to the user in terms of what the system has learned and what the robot is expected to do in the task execution. In relation to that, Sena and Howard (2020) proposed an objective metric to evaluate the teacher’s efficiency in robot learning, given a specific feedback channel, e.g. by observing the robot’s execution performance. We concluded from the success rate that our method performed best but the efficiency was still rated by the users, which is a subjective measure. Hence, analyzing the effect of different task representations used as feedback channel in terms of the teaching efficiency could aid developers to create better user interfaces.

Shift of intuitiveness and efficiency scores before and after users have seen the robot’s execution, i.e. a negative sign means that users have downgraded their ratings on average compared to their first ratings
7 Conclusion and future work
We presented a framework that allows non-experts to intuitively program conditional tasks that enables the robot to make decisions ad-hoc during task execution. Hereby, the complete task structure is transferred by demonstration involving sensor readings of motion, force and grasp status and no predefined symbols or objects are required. We have demonstrated that task decisions can be effectively transferred by our interactive programming scheme, where the robot asks for user input in unknown environmental situations. An on-line anomaly detection reduces the user’s workload by just querying necessary information and guarantees a functioning task model, since transitions to specific actions are only allowed within a decision state. This enables the user to scale the complexity of a task over time without cumbersome reprogramming of the whole task.
We compared our framework experimentally with two alternative approaches in a user study, which lets us draw the conclusion that Collaborative Incremental Programming is the approach which users rated as most intuitive to use to transfer knowledge to the system and the one that is reliable in handling decisions during execution according to its success rate.
As a limitation, we state that the anomaly detection halts the robot motion in order to query the user, which could be infeasible for highly dynamic tasks. Further, the reusability of the knowledge represented as task-graph could be improved in the future as only the branching at decision states is considered, but not merging states or the recurrence of actions.
In this work, we stressed on the discrepancies in human and robot perception, since humans use vision but not every robotic system does so. In the future, we would like to consider a vision system as an additional sensor source given the fact that some anomalies can be observed visually before object interaction and some cannot, such as interaction forces.
Change history
06 February 2023
Missing Open Access funding information has been added in the Funding Note.
Notes
The accompanying multimedia material contains a video of this experiment (video 1).
The accompanying multimedia material contains a video of the experiments in the user study (video 2).
The robot’s execution success was evaluated in absence of the 21 users. After that, we were able to contact again five subjects from the original group for this analysis.
References
Caccavale, R., Saveriano, M., Finzi, A., & Lee, D. (2017). Kinesthetic teaching and attentional supervision of structured tasks in human-robot interaction. Autonomous Robots (AURO).
Calinon, S., & Lee, D. (2018). Learning control. In P. Vadakkepat & A. Goswami (Eds.), Humanoid robotics: A reference. Springer.
Di Lello, E., Klotzbucher, M., De Laet, T., & Bruyninckx, H. (2013). Bayesian time-series models for continuous fault detection and recognition in industrial robotic tasks. In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 5827–5833. IEEE
Donald, B. R. (1988). A geometric approach to error detection and recovery for robot motion planning with uncertainty. Artificial Intelligence, 37(1–3), 223–271.
Eiband, T., Saveriano, M., & Lee, D. (2019). Intuitive programming of conditional tasks by demonstration of multiple solutions. IEEE Robotics and Automation Letters, 4(4), 4483–4490. https://doi.org/10.1109/LRA.2019.2935381
Eiband, T., Saveriano, M., & Lee, D. (2019). Learning haptic exploration schemes for adaptive task execution. In: IEEE International Conference on Robotics and Automation (ICRA), pp. 7048–7054. IEEE.
Grant, D. A. (1948). The latin square principle in the design and analysis of psychological experiments. Psychological Bulletin, 45(5), 427.
Hart, S.G., & Staveland, L.E. (1988). Development of nasa-tlx (task load index): Results of empirical and theoretical research. In: Advances in psychology, vol. 52, pp. 139–183. Elsevier.
Khalastchi, E., & Kalech, M. (2018). A sensor-based approach for fault detection and diagnosis for robotic systems. Autonomous Robots, 42(6), 1231–1248.
Khalastchi, E., Kalech, M., Kaminka, G. A., & Lin, R. (2015). Online data-driven anomaly detection in autonomous robots. Knowledge and Information Systems, 43(3), 657–688.
Maeda, G., Ewerton, M., Osa, T., Busch, B., & Peters, J. (2017). Active incremental learning of robot movement primitives. In: Conference on Robot Learning, pp. 37–46.
Materna, Z., Kapinus, M., Beran, V., Smrž, P., & Zemčík, P. (2018). Interactive spatial augmented reality in collaborative robot programming: User experience evaluation. In: 2018 27th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), pp. 80–87. IEEE.
Mollard, Y., Munzer, T., Baisero, A., Toussaint, M., & Lopes, M. (2015). Robot programming from demonstration, feedback and transfer. In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 1825–1831. IEEE.
Muench, S., Kreuziger, J., Kaiser, M., & Dillman, R. (1994). Robot programming by demonstration (rpd)-using machine learning and user interaction methods for the development of easy and comfortable robot programming systems. In: Proceedings of the International Symposium on Industrial Robots, vol. 25, pp. 685. International Federation of Robotics & Robotic Industries.
Naumann, A., & Hurtienne, J. (2010). Benchmarks for intuitive interaction with mobile devices. In: Proceedings of the 12th International Conference on Human Computer Interaction with Mobile Devices and Services, MobileHCI ’10, pp. 401-402. Association for Computing Machinery. https://doi.org/10.1145/1851600.1851685
Niekum, S., Chitta, S., Barto, A.G., Marthi, B., & Osentoski, S. (2013). Incremental semantically grounded learning from demonstration. In: Robotics: Science and Systems, vol. 9.
Niekum, S., Osentoski, S., Konidaris, G., Chitta, S., Marthi, B., & Barto, A. G. (2015). Learning grounded finite-state representations from unstructured demonstrations. The International Journal of Robotics Research, 34(2), 131–157.
Pais, A. L., Umezawa, K., Nakamura, Y., & Billard, A. (2015). Task parameterization using continuous constraints extracted from human demonstrations. IEEE Transactions on Robotics, 31(6), 1458–1471.
Park, D., Erickson, Z., Bhattacharjee, T., & Kemp, C.C. (2016). Multimodal execution monitoring for anomaly detection during robot manipulation. In: IEEE International Conference on Robotics and Automation (ICRA), pp. 407–414. IEEE.
Pastor, P., Kalakrishnan, M., Chitta, S., Theodorou, E., & Schaal, S. (2011). Skill learning and task outcome prediction for manipulation. In: IEEE International Conference on Robotics and Automation (ICRA), pp. 3828–3834. IEEE.
Rodriguez, A., Bourne, D., Mason, M., Rossano, G.F., & Wang, J. (2010). Failure detection in assembly: Force signature analysis. In: Automation Science and Engineering (CASE), IEEE Conference on, pp. 210–215. IEEE
Sauer, L., Henrich, D., & Martens, W. (2019). Towards intuitive robot programming using finite state automata. In: Joint German/Austrian Conference on Artificial Intelligence (Künstliche Intelligenz), pp. 290–298. Springer.
Sena, A., & Howard, M. (2020). Quantifying teaching behavior in robot learning from demonstration. The International Journal of Robotics Research, 39(1), 54–72.
Steinmetz, F., Nitsch, V., & Stulp, F. (2019). Intuitive task-level programming by demonstration through semantic skill recognition. IEEE Robotics and Automation Letters, 4(4), 3742–3749. https://doi.org/10.1109/LRA.2019.2928782
Su, Z., Kroemer, O., Loeb, G.E., Sukhatme, G.S., & Schaal, S. (2018). Learning manipulation graphs from demonstrations using multimodal sensory signals. In: IEEE International Conference on Robotics and Automation (ICRA), pp. 2758–2765. IEEE.
Willibald, C., Eiband, T., & Lee, D. (2020). Collaborative programming of conditional robot tasks. In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).
Acknowledgements
This work has been partially funded by the Helmholtz Association.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Supplementary file 1 (mp4 15467 KB)
Supplementary file 2 (mp4 7437 KB)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Eiband, T., Willibald, C., Tannert, I. et al. Collaborative programming of robotic task decisions and recovery behaviors. Auton Robot 47, 229–247 (2023). https://doi.org/10.1007/s10514-022-10062-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10514-022-10062-9