
Abstract
We present a novel method for learning from demonstration 6-D tasks that can be modeled as a sequence of linear motions and compliances. The focus of this paper is the learning of a single linear primitive, many of which can be sequenced to perform more complex tasks. The presented method learns from demonstrations how to take advantage of mechanical gradients in in-contact tasks, such as assembly, both for translations and rotations, without any prior information. The method assumes there exists a desired linear direction in 6-D which, if followed by the manipulator, leads the robot’s end-effector to the goal area shown in the demonstration, either in free space or by leveraging contact through compliance. First, demonstrations are gathered where the teacher explicitly shows the robot how the mechanical gradients can be used as guidance towards the goal. From the demonstrations, a set of directions is computed which would result in the observed motion at each timestep during a demonstration of a single primitive. By observing which direction is included in all these sets, we find a single desired direction which can reproduce the demonstrated motion. Finding the number of compliant axes and their directions in both rotation and translation is based on the assumption that in the presence of a desired direction of motion, all other observed motion is caused by the contact force of the environment, signalling the need for compliance. We evaluate the method on a KUKA LWR4+ robot with test setups imitating typical tasks where a human would use compliance to cope with positional uncertainty. Results show that the method can successfully learn and reproduce compliant motions by taking advantage of the geometry of the task, therefore reducing the need for localization accuracy.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Currently industrial robots are often confined inside mass production factories, where the environment can be precisely modelled and controlled and the production batch sizes are high. However, the use of robots is steadily rising and they are expected to take over households, construction yards and factories within the near future. There is tremendous potential for fast and efficiently automatization of tasks that are recurring frequently but in smaller batches than in car factories.
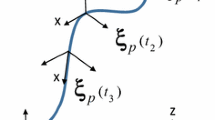
Motions that include contact with the environment can be difficult for robots since pose (position and orientation) errors in tasks with small clearance often lead to high contact forces. Two examples of such motions with initial errors are shown in Fig. 1 (position error in Fig. 1a and orientation error in Fig. 1b). It is essential that the contact wrenches (force and torque) are managed when interacting with the environment; without suitable compliant interaction, the linear motions depicted by the arrows in Fig. 1 would not result in the alignments shown, but instead would cause jamming, wedging, or breakage of equipment or workpieces. Humans, on the other hand, can effectively take advantage of contact forces and utilize the arising compliant motions to mitigate localization uncertainty. Impedance control is a convenient control approach for compliant motions that does not require switching between different control strategies (Hogan 1987). It features a virtual spring with adjustable stiffness between the current and the desired pose. Impedance control allows small deviations from the desired trajectory, while still applying a stiffness-dependent wrench along the desired trajectory. This ability makes impedance controller a natural choice for performing compliant motions. Even though there has been a recent success in developing a feasible trajectory planner for 3-D compliant motions (Guan et al. 2018), there is need for end-user friendly learning methods for impedance-controlled compliant motions. Interested readers can consult a recent survey (Abu-Dakka and Saveriano 2020) for different impedance controllers based on variability, control and learning perspectives.

Compliant motions can be used for aligning both position and orientation of a workpiece
Learning from Demonstration (LfD) (Argall et al. 2009; Osa et al. 2018) is an established paradigm in robotics for skill transfer and encoding. The key idea is that a human expert gives a demonstration of a task, which the robot then learns to reproduce. There are multiple methods for encoding the learned skill, such as Stable Estimator of Dynamical Systems (SEDS) (Khansari-Zadeh and Billard 2011), Gaussian Mixture Models (GMM) with Gaussian Mixture Regression (GMR) (Calinon et al. 2007), Riemannian Motion Policies (Mukadam et al. 2020), and several popular movement primitives, such as Dynamic Movement Primitives (DMP) (Schaal 2006), Kernelized Movement Primitives (KMP) (Huang et al. 2019) and Probabilistic Movement Primitives (ProMP) (Paraschos et al. 2013). Whereas these methods are perfectly capable of representing free space motions and contact tasks without position uncertainties, they have a tight coupling between force and position trajectories, which makes them susceptible to errors in initial position especially when dealing with multiple demonstrations. Even though recent publications have shown that with certain modifications DMPs can be used to realize unseen trajectories (Abu-Dakka et al. 2015), a primitive without the force-position coupling would be more flexible for easy generalization to tasks similar to demonstration.
This paper extends and generalizes the method presented in Suomalainen and Kyrki (2017). In Suomalainen and Kyrki (2017) the goal was to learn a single primitive consisting of a desired direction in translation, and then learn the axes along which compliance was required. However, in this paper, we learn the desired direction, essentially a linear direction in Cartesian space, both for translation and rotation, and the required compliant axes in both translation and rotation as well. The latter means learning the stiffness matrices for impedance controllers in translation and rotation with certain pre-defined restrictions. The desired direction is defined as a linear 6-D direction which, either through free space or with the help of a mechanical gradient such as a chamfer, leads the end-effector to the goal pose of the motion. Kinesthetic teaching is used to show the robot an example of a motion. The key difference to existing LfD methods for in-contact tasks is that the position trajectory is not coupled with the force or impedance profile. This renders the presented primitive more robust against localization errors.
The novelty in this paper includes:
-
(i)
extension of Suomalainen and Kyrki (2017) to cover also rotational motions and combinations of rotations and translations,
-
(ii)
detecting if either translations or rotations are fully compliant, i.e. no desired direction exists, due to work done by the environment,
-
(iii)
evaluating if the desired direction is reliable and finding the compliant axes even when the desired direction is unreliable, and
-
(iv)
showing that, when properly learned with the presented method, the primitive can successfully complete a wide range of linear 6-D motions while taking advantage of the environment as guidance to mitigate localization errors between the tool and the goal.
Learning the segmenting and sequencing of the primitives to complete a full task is outside of the scope of this paper, but has been shown to be possible in Hagos et al. (2018).
2 Related work
It is a well established idea to use force control for taking advantage of geometry in an assembly task. The classical work of Mason (1981) performed force-controlled peg-in-hole with task frames to avoid the need for the end-user to define low-level commands. Schimmels and Peshkin (1991) later defined the concept of geometric force-assemblability in 2-D using screw-theoretical concepts. Even earlier, Ohwovoriole and Roth (1981) used the concept of virtual work (defined as the dot product between the motion twist and the contact wrench) to divide twists into repelling, reciprocal or contrary. Their research inspired us to look into whether work is done by the human teacher or the environment, which is a key point when discovering whether all translational or rotational degrees of freedom must be compliant. For more complicated tasks, it is possible to try detecting the contact formations of the tool (Lefebvre et al. 2005), which allows learning or crafting more elaborate sequences. However, this requires also more information on the tools; thus, the method presented here does not attempt to cover all the problems that can be solved with contact formations, but rather a subset without requiring as much prior information as the use of contact formations.
In other approaches, Stolt (2015) studied robotic assembly using high-level task specification and alternating position and force control. However, we believe that LfD provides an easier interface for the end-user to teach a task. One well established idea is to apply reinforcement learning after learning an initial skill with LfD, such as Kalakrishnan et al. (2011) where exact forces are learned with RL. However, in this paper, we aim to learn the skill without the need for RL; the presented method attempts to learn skills that do not require explicit control of contact forces, such as compliant assembly skills, where the method presented in Kalakrishnan et al. (2011) would be unnecessarily complicated and possibly prone to errors.
Most LfD tasks are encoded as motion primitives, such as the earlier mentioned DMP and SEDS, a general way for presenting a trajectory and possibly an additional force profile. A complex task then consists of a set of primitives, which are triggered in sequence (Kroemer et al. 2014; Hagos et al. 2018). The term motion primitive refers then to a model of a phase (a motion segment) of a task, typically modeled by a continuous function approximator aimed towards learning the task from a human demonstration. In contrast, this paper proposes a primitive that is specifically targeted to encode phases where contact can assist the task, instead of being a general function approximator. This allows the proposed primitive to be more robust to localization errors.
Learning workpiece alignment from demonstrations using DMP’s has been presented by Peternel et al. (2015), Deniša et al. (2016), Abu-Dakka and Kyrki (2020); Abu-Dakka et al. (2015, 2018) and Kramberger et al. (2016, 2017). Peternel et al. used an external interface for the teacher to manually modulate the required stiffness. Compliant Motion Primitives (CMP) by Deniša et al. (2016) and Abu-Dakka et al. (2015) added a force feedback controller in the DMP’s and lately an impedance profile to GMM’s Abu-Dakka et al. (2018). Recently, Abu-Dakka and Kyrki provided geometry-aware DMP’s formulation which capable of direct encoding of compliance parameters (Abu-Dakka and Kyrki 2020). Kramberger et al. performed a peg-in-hole task with varying hole depths, and also performed rotational motions. The aforementioned approaches choose different positions regarding a trade-off between accuracy and error tolerance, and have different expectations with regards to localization capabilities of the robot. The DMP-based methods with an impedance profile can achieve an exact level of compliance at a certain point in the trajectory, and perform nonlinear free-space motions; however, the requirement is that the robot’s end-effector can be properly localized w.r.t. the environment. If this localization fails due to e.g. camera issues or the goal moving without knowledge of the robot, the impedance profile will be applied at a wrong time. In contrast, our approach does not attempt an exact control of the impedance profile and relies only on linear motions; whereas this limits the applications, it allows the localization error of the end-effector to match the mechanical convergence region seen in Fig. 2.
There have been a few other recent publications about new LfD primitives to replace the aforementioned DMP and GMM/GMR strategies. Reiner et al. (2014) and Rozo Castañeda et al. (2013) took advantage of the variations in the recorded trajectory to define where pose accuracy is important and therefore high stiffness required. However, their work was aimed towards free space motion and included the whole variance of demonstrations, whereas we look at the variance of motion outside a specified desired direction in an in-contact task. Ahmadzadeh et al. (2017) proposed an LfD encoding method which can generate unseen trajectories within the cylinder of the given demonstrations. However, both of these methods are presented as tools for free space motion and not for in-contact tasks. Racca et al. (2016) used Hidden Semi-Markov Models (HSMM) with GMR to allow the teaching of in-contact tasks. However, even their work cannot take advantage of the task’s geometry. The goal of this paper is to present a primitive, and a method for learning the primitive, that can maximize the guidance of a physical gradiennt in the environment.
3 Methods
The method presented here is meant for tasks where localization errors between the tooltip and the goal can grow large; indeed, a main difference to many other LfD methods is that even though other methods can converge to a goal from a wide region, the method presented in this paper does not need to know how far it is from the target, or how far it is from the intended starting pose. For example, in Fig. 2, the robot does not need to know where within the shown convergence region the end-effector is. The method does not require any feedback, neither force nor pose, during reproduction of a single segment; the motion and impedance parameters remain the same during a single segment. Whereas this greatly simplifies the requirements for the method, there are also disadvantages, such that there is no proper built-in stopping condition for the primitive, raising the need for e.g. force thresholds to be built into a fully working system and the physical system to have a natural stopping condition. Moreover, the presented primitive can only generate motions that are linear in Cartesian coordinates in free space but might have a different shape if guided by contact.

Illustration of the potential convergence region (black brace) of the algorithm in a pure translational case (similar as the “valley” experiment in Suomalainen and Kyrki (2017)) with the black arrow presenting the direction of motion (the desired direction in translation \(\pmb {\hat{v}_{d}^*}\) later in the paper). The robot does not need to know where within the black brace the tool is, because the gradients will guide it to the goal
There is no attractor in free space for the primitive. The intuition is to make the robot follow a natural, physical gradient, similarly as a human would intuitively do when faced with localization error. Thus, we assume that even in a demonstration where a human cannot directly align the workpieces but must rely on contact and physical gradients, there is a “correct” direction, called desired direction in this paper; this is the direction where the user would guide the tool if all pose information was correct, that can also be called the working force. This direction is all the information that the robot uses during reproduction—it does not have explicit knowledge about the initial pose or the goal pose. Additionally, there is no in-built upper limit for the forces, which will grow in accordance with the stiffness. For example, if the contact is made near the edge of the convergence region depicted in Fig. 2, the force exerted at the bottom of the valley will be higher than if contact is made closer to the bottom. However, as the goal of this primitive is alignment, this is an acceptable side-effect, and dangerously large forces could be avoided with a simple threshold.
It is assumed that an assembly task can be divided into motion segments which can be completed with combinations of linear motion and compliance; in previous work (Hagos et al. 2018) it was shown that (1) a demonstration for tasks such as hose coupling can be automatically divided into segments which the presented primitive can complete and (2) the contact transitions can be automatically learned for reproducing the motions.
The controller parameters are learned offline after a demonstration. To complete the task, each segment can be executed with an impedance controller defined for the end-effector as
where \(\pmb {F,T}\) are the force and torque used to control the robot, \(\pmb {x}^*\) the desired position, \(\pmb {x}\) the current position, \(B^*,B\in SO(3)\) rotation matrices representing the desired orientation and the current orientation, and \(\log (\cdot )\) denotes the rotation matrix logarithm. \(K_f\) and \(K_o\) are stiffness matrices and \(D_f\pmb {v}\) and \(D_o\pmb {\omega }\) damping terms. Notation summary can be found from Table 1.
As each segment consists of an impedance controller primitive, we calculate the desired trajectory for each segment in a feed-forward manner
where \(\pmb {\hat{v}_{d}^*}\) and \(\pmb {\hat{\omega }_{d}^*}\) are the desired directions in translation and rotation, \([\cdot ]\) denotes the skew symmetric matrix corresponding to a vector, \(\varDelta t\) the sample time of the control loop and \(\nu \) and \(\lambda \) the translational and rotational speeds. Throughout this paper, we will use the circumflex (\(\hat{\,}\)) notation to denote the normalization of a vector (i.e. \(\pmb {\hat{x}}=\frac{\pmb {x}}{|\pmb {x}|}\)) , the subscript \(_d\) when referring to “desired” direction and \(_a\) to “actual”, the latter meaning the observed direction of motion, either translation of rotation.
In this paper, we propose a method to learn \(K_f\), \(K_o\), \(\pmb {\hat{v}_{d}^*}\) and \(\pmb {\hat{\omega }_{d}^*}\) separately for each primitive from one or more human demonstrations, assuming that the damping is sufficient for stabilizing the dynamics, for example by manually tuning the damping parameters \(D_f\) and \(D_o\) to avoid instabilities. \(K_f\) and \(K_o\) will be learned with the restrictions that stiffness of an axis is either “stiff” with an application-dependent stiffness value k, or 0, rendering this axis compliant. Thus, these parameters will lead the tool into a certain direction, accompanied with suitable stiffness parameters, that can take advantage of physical guides to lead the tool into a final pose. We note that the algorithm does not explicitly know this final pose, but there needs to be a physical limitation that eventually stops the end-effector, or a separate thresholding method to detect success.
In cases such as depicted in Fig. 1a, b, giving at least one demonstration from each shown starting position allows the algorithm to learn a set of parameters which can reproduce all motions from within the workpiece’s zone of convergence. The zone of convergence can be considered as the set of workpiece poses from which a mechanical gradient can lead the workpiece to the goal position; a simple case is visualized in Fig. 2. Without correct compliance, the tool will get stuck or misaligned upon reaching contact. Thus, the use of interaction forces as guidance requires task-specific compliance.

A flowchart describing the whole process of finding the 6-D compliant primitive to reproduce a demonstrated motion. The numbers on the left hand side present different stages of the algorithm for clarification
A flowchart describing the whole process of learning \(K_f\), \(K_o\), \(\pmb {\hat{v}_{d}^*}\) and \(\pmb {\hat{\omega }_{d}^*}\) from a demonstrated motion is shown in Fig. 3 with numbers presenting stages of the algorithm. In Sect. 3.1, matching stage 3 of the flowchart, we validate whether the teacher performed only translation, i.e. \(\pmb {\hat{\omega }_{d}^*}\) is zero (does not exist) even though rotation was observed. This results in all rotational degrees of freedom to be compliant, or vice versa if the teacher performs rotation only (called 3-DOF compliance in this paper). If this is not observed, in Sect. 3.2 which corresponds to stage 4 of the flowchart, the algorithm computes \(\pmb {\hat{v}_{d}^*}\) and \(\pmb {\hat{\omega }_{d}^*}\), or validates if either of them is not required. Finally, in Sect. 3.3 matching stage 5 of the flowchart, it is evaluated if individual degrees of freedom are required to be compliant, yielding \(K_f\) and \(K_o\). As an end result, there can be a desired direction in both translation and rotation, or in only one of them. In addition, compliance is found for both rotation and translation, if required.

The KUKA LWR4+ robot used for the experiments, with equipment for the hose-coupler setup attached
The method requires that during the demonstration, a force/torque (F/T) sensor is placed between the tool and the place where the teacher grabs the robot, such as in Fig. 4. Wrench and pose data at the F/T sensor are recorded, and the force measured by the F/T sensor during contact (neglecting Coriolis and centrifugal force) can be written as
where \(\pmb {F_m}\) is the force measured by the F/T sensor, \(\pmb {F_N}\) the normal force, \(\pmb {F_{\mu }}=\vert \mu \pmb {F_N}|\left( -{\pmb {\hat{v}_a}}\right) \) the force caused by Coulomb friction with \(\mu \) being the friction coefficient and \(\pmb {\hat{v}_a}\) the actual direction of motion, m the mass of the tool and \(\pmb {a}\) it’s acceleration. Similarly, the measured torque \(\pmb {T_m}\) can be written as
where \(\pmb {l}\) and \(\pmb {\rho }\) are the lever arm position vectors perpendicular to corresponding applied forces, I the inertia matrix and \(\pmb {\alpha }\) the angular acceleration. Although this model is for a single-point contact, we show that the method is robust enough that we can teach multi-point contact tasks as well; considering a thorough contact formation treatment is outside the scope of this paper. We assume that the speed of the end-effector is close to constant and therefore the acceleration terms can be ignored from both equations.
3.1 Checking for 3-DOF compliance
In 6-D motion it is possible that, due to contact forces, translational force applied by the teacher causes rotation, or vice versa. In such a case, either the observed translation or rotation is caused completely by the environment and the corresponding degrees of freedom need to be set compliant (i.e. 3-DOF compliance). More insight into the kind of motion falling into this category can be found from Fig. 7 and Sect. 4.2.
The intuition to detect this phenomenon stems from the definition of work in physics, which is defined for translational and rotational motions as
where W is the work, \(\varDelta \pmb {x}\) the change in translation and \(\varDelta \pmb {\beta }\) the change in angle. If the majority of work is done by the environment, we assume that those degrees of freedom (all rotational or translational degrees of freedom) should be compliant since the demonstrator was not explicitly performing those motions but they were caused by the environment. Formally, either rotation or translation is 3-DOF compliant if
where \(W_{tot}\) is the total work during a demonstration and \(W_{env}\) the work done by the environment. We can compute \(W_{tot}\) by
where W is either \(W_{x}\) or \(W_{\beta }\) and taking the absolute value means that we consider work to be path-dependent. As the wrench measured by the F/T sensor is the contact wrench, i.e. caused by the environment, work performed by the environment is observed as positive values for W. Therefore we can compute \(W_{env}\) as
The choice of \(\sigma \) in (6) depends on the task and the accuracy of demonstration; with perfect demonstrations \(\sigma \) could be set to 1, but in practice it has to be reduced to allow human inconsistencies during a demonstration. If the ratio is below \(\sigma \), Algorithm 1 is run as described in Fig. 3 and in the next section. Otherwise rotation or translation is set to 3-DOF compliant.
3.2 Learning desired direction
In this section we describe the method to learn \(\pmb {\hat{v}_{d}^*}\) and \(\pmb {\hat{\omega }_{d}^*}\). To slide the robot’s tool in contact, the robot can be pushed from any direction from the sector s defined as the 2-D sector between the actual direction of motion \(\pmb {v_a}\) and the force measured by the F/T sensor \(\pmb {F_m}\), as seen in (3) and Fig. 5. Thus, different directions and magnitudes of force may result in the same observed trajectory, which is sliding along the surface: this means that when contact is leveraged properly, different actual motions can be realized even when the robot is applying the same force. The key idea is to use this insight to narrow down the possibility of where the teacher’s working force is applied, such that the same working force can cause different motion directions if required. This idea is extended into rotations and 3-D such that at each measurement point of a demonstration, we find a set of force and torque directions which would result in the observed direction of motion. Issues such as curved surfaces and possible surface artifacts, however, often cause the set to vary even along a single motion. By taking an intersection over many such sets, we can find a direction that could have created the direction at any point during the demonstration and thus reproduce motions which can be represented with linear impedance controller parameters. The same algorithm, presented in Algorithm 1 and explained in the upcoming paragraphs, is used to find both \(\pmb {\hat{v}_{d}^*}\) and \(\pmb {\hat{\omega }_{d}^*}\).

Force/torque sensor configuration, the position where the working force by the human teacher \(\pmb {F_{ext}}\) is applied and the forces which sum up to the reading of the force measurement \(\pmb {F_{m}}\) of the F/T sensor
To find an intersection of sectors over a real demonstration in 3-D, sector s must be expanded since a human cannot perform a perfect demonstration (for example, sliding along a straight line on a surface). We expand the sector both perpendicular to s and along the direction of s, as seen in Fig. 6.

Formally, we define the vectors extending the sector s at each time step t as
where \(\pmb {\widehat{\varPi }}\) represents either force or torque and \(\pmb {\widehat{\psi }}\) either translational or rotational motions, such that the equation is either only translations or only rotations, i.e. \(\left( \pmb {\widehat{\varPi }}, \pmb {\widehat{\psi }}\right) \in \lbrace \left( \pmb {\widehat{F}_m}, \pmb {\hat{v}} \right) , \left( \pmb {\widehat{T}_m}, \pmb {\hat{\omega }} \right) \rbrace \). Variable \(\eta \) is the angle with which we wish to extend the sector s perpendicularly and \(\xi \) the angle used to widen the sector. Thus the limits of a desired direction of motion, as illustrated in Fig. 6 for translations, at each time step t can be written as a set of vectors
where \(P_t\) represents the set of vectors limiting the desired directions of motion \(\pmb {\widehat{\psi }_{d,t}}\) at a single time step t in 3-D, either translational or rotational. Thus, we can write the range of possible desired directions at time step t as a positive linear combination of the vectors in \(P_t\). In Algorithm 1 the computation of each \(P_t\) is shown on line 3.
To avoid problems due to representation of orientation, the data is rotated on lines 1 and 5 in Algorithm 1. As taking an intersection over 3-D polyhedra is computationally expensive, each 3-D data point is projected into 2-D unit circle using function vec2ang described in Algorithm 2. Essentially, this step projects the 3-D pyramids \(P_t\), shown in Fig. 6, into 2-D rectangles \(\varTheta _t\) (more details can be found in Suomalainen and Kyrki (2017)).
On lines 9–15 in Algorithm 1 outlier rejection is performed: we find, on a chosen scale, the point (i, j) of grid G which is enclosed by the maximum number of rectangles \(\varTheta _t\). Then on lines 16–21 we choose from the set of rectangles \(\varTheta \) the subset \(\varTheta ^*\) which include the point (i, j). Then we compute the intersection \(\varPhi \) of rectangles \(\varTheta ^*\), compute the Chebyshev center (Garkavi 1964) \(\pmb {\phi ^*}\) of \(\varPhi \), convert \(\pmb {\phi ^*}\) back to a 3-D vector with function ang2vec (Algorithm 3) and rotate it back to get \(\pmb {\widehat{\psi }_d^*}\). The process is similar to Suomalainen and Kyrki (2017), where it is explained in more detail.



Since a motion can consist of both translation and rotation, it is possible that for either translation or rotation there does not exist a desired direction, even if 3-DOF compliance is not detected in (6). This can be evaluated from the ratio of outliers i.e. the ratio between the number of rectangles in the set that contributed to the computation of \(\varPhi \), \(\varTheta ^*\), and all the rectangles \(\varTheta \). If this ratio is low, it means that there has been a large number of outliers and therefore the corresponding \(\pmb {\widehat{\psi }_{d}^*}\) is unreliable. Formally, we assume there is no desired direction if
where \(\zeta \) is a threshold for the ratio and \(|\cdot |\) denotes the cardinality of a set, i.e. the number of elements in it. With perfect demonstrations \(\zeta \) can be set to 1. However, due to measurement errors, noise and imperfect demonstration, a choice must be made depending mainly on the number of demonstrations and the environment. The key point in choosing \(\zeta \) is that higher values demand higher precision from the demonstrations and may discard a detected desired directions, whereas lower values may cause false positives. If, for example, two demonstrations are given from opposite sides such as in Fig. 1a, the value of \(\zeta \) should be over 0.5 to ensure that there exists a common desired direction for the two demonstrations. However, in an environment with high friction the threshold may have to be lowered since high friction reduces the width of sector s from Fig. 5. If the ratio for either translations or rotations is below \(\zeta \), then there is no motion in those degrees of freedom. Whether compliance is required along particular axes is tested as described in the next section, and the non-compliant axes will be set stiff; the exact value for this stiffness depends on the application, but in essence this axis is at least close to pure position control.
Finally, if both \(\pmb {\hat{v}_d^*}\) and \(\pmb {\hat{\omega }_d^*}\) exist, the ratio between rotational and translational motion must be calculated from unnormalized data. Borrowing from screw theory, we call this value the pitch, defined as
where \(\pi \) is the pitch, \(d_{x}\) is the translational distance covered during the motion and \(d_{\beta }\) the amount of degrees rotated during a motion used for learning one primitive. \(\nu \) and \(\lambda \) can be used to modify the execution speed of the robot as the user wants, but they must be set such that \(\nu =\pi \lambda \). We want to note the possibility that \(\pmb {\widehat{\psi }_{d}^*}\) is found in a case where the task requires keeping either rotations or translations only stiff. In such a case the pitch \(\pi \) is important: it will make the velocity small enough that the motion in reproduction is minimal, essentially keeping those degrees of freedom stiff.
3.3 Learning axes of compliance
This section presents how to learn \(K_f\) and \(K_o\) such that, together with \(\pmb {\hat{v}_d^*}\) and \(\pmb {\hat{\omega }_d^*}\), the demonstrated motion can be reproduced. Our key assumption for detecting the axes of compliance is that if there is motion in other directions besides \(\pmb {\hat{\psi }_{d}^*}\), that motion must be caused by the environment, signalling a direction where compliance is required. We assume that if compliance is required along an axis, it must be totally compliant (i.e. stiffness equals zero). Hence if \(\pmb {\hat{v}_d^*}\) exists, the axes of compliance defined in \(K_f\) must be perpendicular to \(\pmb {\hat{v}_d^*}\), and similarly for \(\pmb {\hat{\omega }_d^*}\) and \(K_o\); the robot arm would not move towards a direction with zero stiffness, even if commanded to. We find the directions of the compliant axes with the help of Principal Componen Analysis (PCA). We compute likelihoods of how well each PCA vector fits the data and based on that decide which of the PCA vectors need to be compliant. The whole process for defining the compliant axes is presented in Algorithm 4.

To enforce the orthogonality between \(\pmb {\widehat{\psi }_{d}^*}\) and the axes of compliance when \(\pmb {\widehat{\psi }_{d}^*}\) exists, we remove the component along \(\pmb {\widehat{\psi }_{d}^*}\) from the mean of actual motion \(\pmb {\overline{\psi }_a}\) by the computation on line 3 in Algorithm 4. Now any non-zero values of \(\pmb {\overline{\psi }_a}\) correspond to motion outside the direction of \(\pmb {\widehat{\psi }_{d}^*}\).
Our idea is to validate how many degrees of freedom are required to explain \(\pmb {\overline{\psi }_a}\) by calculating the likelihoods \(L_d\) for each d number of compliant axes. These degrees of freedom can be understood roughly as the number of linear directions of motion caused by the environment. We use PCA to find the eigenvectors i.e. directions of maximum variance of the data such that they form an orthonormal base. If \(\pmb {\overline{\psi }_a} \approx \pmb {0}\), then \(\pmb {\overline{\psi }_a}\) is best explained by the origin only, corresponding to \(U_d=U_0\) (i.e. a rank 0 matrix, meaning zero matrix) and meaning that no compliance is required. If one axis of compliance is required, all motion \(\pmb {\overline{\psi }_a}\) has been along a single line, the first principle component corresponding to rank 1 PCA approximation \(U_1\). For two axes of compliance, the plane described by the first two principal components best explains the motions. Finally, if not even a plane can explain the data, we require all three axes to be compliant, which can only happen if there is no \(\pmb {\widehat{\psi }_{d}^*}\). These computations happen on rows 6–11 on Algorithm 4.
Since we wish to give preference to simpler models, for choosing the final D we take inspiration from Bayesian Information Criterion (BIC) (Schwarz 1978), which is defined
where n is the number of data points, k the number of parameters and L the likelihood of a model. Now we can choose the correct model on rows 12–14 on Algorithm 4.
It should be noted that the proposed approach does not follow the typical use of BIC which is only applicable when \(n\gg k\) and the variance in the likelihood is calculated from the data. Instead, we assume that the uncertainty of demonstrations can be estimated beforehand, making it possible to use the proposed formulation. Also, we note that although here the three axes of compliance outcome is the same as from (6) in Sect. 3.1, the mechanism behind these outcomes is different: without calculating (6) in Sect. 3.1, the method in Sect. 3.2 can detect a desired direction for translations in a case where the cause is actually rotation and the normal force of the environment, or vice versa. Therefore, these two methods are not overlapping.
If more than one demonstrations are given, the demonstrations are concatenated and the method works exactly the same way. The number of required demonstrations depends on the application and the quality of the demonstrations: with good demonstrations, no more than one demonstration from each approach direction is required. However, there is a lower bound: Algorithm 4 cannot detect more degrees of freedom than provided demonstrations. Therefore to take advantage of geometrical properties of the task such as in Fig. 1a and 1b, at least two demonstrations are required. It should also be noted that with only one demonstration, (13) is not applicable since the first term will always go to zero.
4 Experiments and results
We used a KUKA LWR4+ lightweight arm to test our method. The demonstrations were recorded in gravity compensation mode, where the robot’s internal sensors recorded the pose of the robot and an ATI mini45 F/T sensor placed at the wrist of the robot recorded the wrench. We implemented our controller through the Fast Research Interface (FRI) (Schreiber et al. 2010), where the controller can be executed as
where J is the Jacobian, \(\mathrm {diag}(\pmb {k_{FRI}})\) a diagonal matrix constructed of the gain values of \(\pmb {k_{FRI}}\), \(\pmb {x^*}-\pmb {x}\) the difference between commanded and actual position and \(\pmb {\tau }\) the commanded joint torques. We implemented our controller through the superposed Cartesian wrench term \(\pmb {F_{FRI}}\) (including both desired Cartesian force and torque) by setting \(\pmb {k_{FRI}}=\pmb {0}\) and \(\pmb {F_{FRI}}=K(\pmb {x}^*-\pmb {x})\), getting a controller equal to (1) where K is the stiffness matrix and the dynamics \( \pmb {f_{dyn}}\) and damping \(\mathrm {diag}(\pmb {d_{FRI}})\pmb {v}\) are managed by the KUKA’s internal controller.
In practice, due to noise in the demonstration from human and measurement uncertainty, averaging over a chosen number of time steps to compute P in (10) produces more stable results. To filter the noise, we chose to average over 20 time steps of original 100 Hz measuring frequency, which meant sampling P in 5 Hz. We used manually estimated values of 20\(^{\circ }\) for \(\eta \) and 10\(^{\circ }\) for \(\xi \) in (9).Footnote 1 These values provide a good starting point for any experiment; increasing the values causes longer segments to be detected, which can be valuable in certain use cases. Moreover, we set the stiffness values of the non-compliant axes k to 200 N m\(^{-1}\); this value depends on the robot, but it simply needs to make the robot be non-compliant. Damping was managed by the KUKAs interrnal controller, with \({d_{FRI}}=0.7\). further details on the effects of this choice are explained in Sect. 3.2.
To evaluate the method for purely translational motion, we performed workpiece alignment on a similar valley setup as in Suomalainen and Kyrki (2017) consisting of two aluminium plates set on 45\(^{\circ }\) angle with the table. As expected, the generalized version presented in this paper produced similar results as the translation-only version presented in Suomalainen and Kyrki (2017) and thus the results are not included here for brevity. Since the rest of the results presented in this chapter require rotational compliance, they could not be completed with the translation-only algorithm from Suomalainen and Kyrki (2017) and thus there is no comparison between the results.
To evaluate the method for motions including rotation we performed four motions included in common contact tasks in households and industry. For each motion we first carried out one or more demonstrations and then let the robot perform the learned task. The peg-in-hole setup is a common contact problem where compliance is highly advantageous—with the setup shown in Fig. 14, we analyzed whether the algorithm finds the correct parameters to slide the peg completely in when it starts from a wrong orientation but partly inside the hole. In this setup we also performed a comparison against a DMP with hand-tuned compliance. The hose coupler setup shown in Fig. 4 presents another common aligning and interlocking task found in households and industry alike. With this setup we studied both the alignment phase with varying orientations as shown in Fig. 11 and the interlocking phase where the coupler is rotated to fix the parts together. Finally, to study a case where rotations cause translations as explained in Sect. 3.1, we performed a motion where the peg is rotated around the edge of a table as shown in Fig. 7, a motion required whenever using a lever arm to increase the applied force.

Screenshots from a demonstration of rotating the peg around the edge of the table, where the translational motion is caused by the contact forces. The edge of the table is highlighted in red (Color figure online)
We used an end-effector coordinate system defined at the wrist of the robot (the F/T sensor) in the experiments. However, the choice of the most suitable coordinate system is task-dependent. Whereas automatically choosing the coordinate system has been studied (Ureche et al. 2015), applying it in our context is outside the scope of this paper.
4.1 Identification of desired direction of motion
Our goal was to study if 1) the inlier ratio check in (11) can correctly identify whether \(\pmb {\widehat{\omega }_{d}^*}\) and \(\pmb {\hat{v}_{d}^*}\) are required and 2) if required, \(\pmb {\widehat{\omega }_{d}^*}\) and \(\pmb {\hat{v}_{d}^*}\) computed with Algorithm 1 can reproduce the demonstrated motion. For this we used the peg-in-hole experiment setup, from which we recorded the angle between the peg and the plane as shown in 8. From every 5\(^{\circ }\) angle between 5\(^{\circ }\) and 35\(^{\circ }\), we performed 5 demonstrations by grasping the robot and leading the peg to the hole.

Illustration (in red) of the angle measured in Fig. 9. The tool coordinate system used in the experiments is shown in cyan (Color figure online)

The rectangles used for choosing the desired direction (lines 9–21 of Algorithm 1) for rotations in the peg-in-hole task with three demonstrations (each color corresponds to one demonstration) such that each column a–d corresponds to demonstrations from a certain error angle (5\(^{\circ }\)–20\(^{\circ }\)) mentioned at the bottom of each column. The first three figures from the top on each column show the data from a single of the three demonstrations. and the bottom figure of each column shows all the demonstrations in a single figure. The black cross corresponds to the finally chosen desired direction. The axes represent the coordinate system in the projection plane where the computations are made. The inlier ratio \( \frac{|\varTheta ^*|}{|\varTheta |}\) from (11) is shown for each column. The figure is best seen in color (Color figure online)
A desired direction for translation was found for each angle approximately along the z-axis in tool coordinate system (Fig. 8). In this paper we chose to use three demonstrations for learning a desired direction—a more thorough experiment of how the number of demonstrations affects the learning of desired direction was presented in Suomalainen and Kyrki (2017), where we concluded that already one demonstration along each possible trajectory is enough to learn a valid \(\pmb {\hat{v}_{d}^*}\). For finding the desired direction for rotation, Fig. 9 shows 3 demonstrations with each starting angle of 5\(^{\circ }\), 10\(^{\circ }\), 15\(^{\circ }\) and 20\(^{\circ }\). It can be observed that the inlier ratio \( \frac{|\varTheta ^*|}{|\varTheta |}\) steadily increases with the increase of the starting angle: the rectangles over three demonstrations are well aligned in Fig. 9d, but in Fig. 9a less than half of the rectangles contribute to finding the intersection. This corresponds to the fact that if the error angle (i.e. starting angle in this case, Fig. 8) is too large, a specific rotation needs to be introduced to complete the task. If, however, the error angle is low, it is enough to have compliance along the rotation together with a desired direction in translation. Our algorithm correctly captures this behaviour, and if the threshold \(\zeta \) was set to 0.6, as would be natural for three demonstrations, \(\pmb {\widehat{\omega }_{d}^*}\) would exist when error angle is 15\(^{\circ }\) or more. Naturally the demonstrations are not required to be started from strictly the same error angle- combining demonstrations with error angle 10 or less degrees showed similar results, as did combining demonstrations with error angle of 15\(^{\circ }\) or more. When \(\pmb {\widehat{\omega }_{d}^*}\) was required, the direction was correctly identified along the rotation.
To study the identification of the desired direction in the hose-coupler alignment, two demonstration from starting positions shown in Fig. 11 were given. The algorithm identified a desired translation direction \(\pmb {\hat{v}_{d}^*}\), illustrated as the intersection shown as black polygon in 10a. For the rotations, the maximal intersection covers poorly the demonstrations with inlier ratio of 0.41 as shown in Fig. 10b. Thus, the algorithm concluded correctly that there was no desired rotational direction \(\pmb {\widehat{\omega }_{d}^*}\) and rotational compliance was sufficient to perform the rotational alignment which was demonstrated. Also in the hose-coupler interlocking and peg-around-the-edge motions (Fig. 7), the desired directions were correctly identified to replicate the motions. We conclude that our method can correctly identify the desired direction for both rotations and translations, and motion in both can be correctly combined to reproduce tasks such as peg-in-hole with high error angle, which requires both rotational and translational motions.

The rectangles used for choosing the desired direction (lines 8–21 of Algorithm 1, or the projected bottom of the pyramid in Fig. 6) either for translations or rotations in the hose-coupler task. The red and blue colors indicate the two separate demonstrations of the task and the black rectangle is the intersection \(\varPhi \), i.e. the set of all desired directions in the angle coordinate system. The rotations from the two demonstrations are clearly apart, and thus the desired direction is discarded (Color figure online)

Two starting positions for demonstrations of the hose-coupler alignment task
4.2 Learning axes of compliance
Our goal was to study whether our method can find the number of compliant axes and their directions in \(K_f\) and \(K_o\) which, together with the desired directions \(\pmb {\widehat{\omega }_{d}^*}\) and \(\pmb {\hat{v}_{d}^*}\), can reproduce the demonstrated motion. In the peg-around-the-edge motion (Fig. 7), the demonstration was performed such that the demonstrator was only rotating the tool, and the translation at the wrist occurred due to coupling of the translational and rotational motions. Therefore it was recognized in (6) that the translations need to be 3-DOF compliant. To give an insight about this result, the dot products between speed and force and between angular speed and torque are plotted over time in Fig. 12. It can be observed that with translations there is more work done by the environment than the demonstrator, since the curve stays on the positive semi-axis the whole time. The method correctly concluded that translations must be 3-DOF compliant in this motion.

The dot products between speed and force and between angular speed and torque over time on the peg-around-the-edge motion
In the other case where most of the work is not done by the environment, the number of compliant axes and their directions must be detected individually. The directions of the compliant axes are directly the vectors of the chosen matrix \(U_d\) from Algorithm 4. Vectors from \(U_3\), i.e. the candidate axes of compliance, are visualized in Fig. 13 for the hose-coupler alignment task. In Fig. 13a a desired direction in translation \(\pmb {\hat{v}_{d}^*}\) is detected, which overlaps as expected with one of the eigenvectors. Consequently, the component along \(\pmb {\hat{v}_{d}^*}\) is removed from \(\pmb {\bar{v}_{a}}\) (blue crosses) and they are projected onto the plane of the other eigenvectors (green crosses). The green crosses are far from the origin, meaning that compliance is required, but they fall along a single eigenvector, which leads to conclusion of a single compliant axis. In Fig. 13b there is no desired direction, and thus no projection is required. A line through the blue crosses indicates the direction of the single compliant axis detected by the algorithm.

Illustrations of choosing the directions of compliant axes on the hose-coupler alignment experiment. The black arrows denote the world coordinate system, the red ones the eigenvectors U and the blue crosses the average motions of each demonstration, \(\pmb {\overline{\psi }_{a}}\). In a \(\pmb {\hat{v}_{d}^*}\) is plotted in cyan and the \(\pmb {\bar{v}_{a}}\) with the component along \(\pmb {\hat{v}_{d}^*}\) removed, as on line 3 in Algorithm 4, are plotted as green crosses. In both a and b 1 compliant axis is chosen (Color figure online)
In the peg-in-hole experiments, at least one axis of compliance was detected for each error degree between 5 and 35. This is according to theory- without a desired direction, at least one compliant direction is required, whereas with a desired direction the compliant directions merely assist the motion. The difference is that whereas in 5–10 error degrees the first axis of compliance is found to approximately match the direction of motion, with higher error degrees the rotation motion is handled by \(\pmb {\widehat{\omega }_{d}^*}\). We conclude that the method correctly identified the compliant axes and their directions.
4.3 Reproduction of motion
Finally, to evaluate that the motions can be reproduced with the learned parameters, we performed the motions on all the aforementioned experiments. In Suomalainen and Kyrki (2017) we already showed that the learning of desired direction is robust by randomizing over multiple sets of demonstrations. Now we show the generalization capabilities in the peg-in-hole case- in particular, how much error can be tolerated with compliance alone, and when is actual rotation required.
In the peg-in-hole experiments, we first used parameters learned from all 5 demonstrations with 10\(^{\circ }\) of error. As shown in Fig. 9, no \(\pmb {\widehat{\omega }_{d}^*}\) was found, but only \(\pmb {\hat{v}_{d}^*}\) along z-axis (Fig. 8) moves the peg. Compliance is required and found both in rotations and translations- in translations it is found along y-axis and in rotations around x-axis. With these parameters we performed five reproduction attempts starting from ever 5\(^{\circ }\) angle. The peg is successfully inserted with error angles 5\(^{\circ }\)–15\(^{\circ }\). With an error angle of 20\(^{\circ }\), friction prevents sliding and the motion is unsuccessful. This result is in par with the results of Sect. 4.1: demonstration of 15\(^{\circ }\) error is on the border regarding identification of desired direction for rotation, but this amount of error can still be handled with only desired direction in translation.
For the cases where both \(\pmb {\hat{v}_{d}^*}\) and \(\pmb {\widehat{\omega }_{d}^*}\) were detected, \(\pmb {\hat{v}_{d}^*}\) was again along z-axis but \(\pmb {\widehat{\omega }_{d}^*}\), as expected, varied depending on the starting orientation of the tool. Nevertheless, for demonstrations recorded with 20\(^{\circ }\) and 30\(^{\circ }\) error, reproduction was successful with the learned angle and lower angles but not on higher angles. These results are summarized in Table 2a. Thus we conclude that whenever the worst case scenario of error is demonstrated, the method can successfully interpolate to cases where the orientation error is smaller than in the demonstration.
We also repeated the peg-in-hole experiment through a direct reproduction of a single demonstration for each angle using Cartesian-DMP (Abu-Dakka et al. 2015) with hand-tuned compliance in an impedance controller. The results are shown in Table 2b. Neither of the methods can reliably extrapolate to larger error angles, even though both methods succeed in this on occasions. However, the presented method can always manage lower error angles, whereas DMP with compliance struggles with these. This shows the main difference of the presented method to methods based on attractors; in many tasks simply carrying out a learned linear motion will result in success, whereas learning a certain trajectory is always to the vicinity of the trajectory. Nonetheless, attractor methods are useful in many tasks, and thus the choice of method should be task-dependent.
In Fig. 14 are shown screenshots from a reproduction of the peg-in-hole reproduction with 30\(^{\circ }\) error. Our algorithm also successfully reproduced the demonstrated motion on the hose-coupler alignment, hose-coupler interlocking and peg-around-the-edge experiments. We conclude that the parameters our method learns from human demonstration can be used to perform the motions with an impedance controller primitive.

Screenshots from a reproduction video of the peg-in-hole motion. The motion starts from the leftmost picture, and the peg is rotated and pushed to the bottom. The peg has radius 16.5 mm, length 80 mm and a rounded tip, and the hole’s radius is 0.25 mm more than the peg’s
4.4 Discussion
In this paper we provided a general geometry-based approach to learn compliant motions from human demonstrations and adapt them to new situation within a region that we call it the convergence region.
The main strengths of our approach are:
-
(a)
The ability to properly leverage contact when completing a task.
-
(b)
The ability to converge to a goal in contact without exact localization of the robot w.r.t. the goal.
-
(c)
No need for any prior information about the robot, the tool or the goal (as needed with e.g., contact formations).
-
(d)
Ability to start from new starting point within the convergence region (unseen in demos).
-
(e)
No need for any numerical information about the change of the goal when extrapolating.
-
(f)
Ability to learn from a small number of demonstrations (application dependent, but typically two are enough).
-
(g)
The ability to extrapolate to trajectories not shown during demonstration by leveraging contact.
while the limitations are:
-
(a)
Inability to perform nonlinear motions unless influenced by the environment.
-
(b)
The stopping condition must be handled separately, either by force signal interpretation or other kind of tracking. Also there must be suitable geometry to facilitate stopping condition detection.
-
(c)
No built-in mechanism for detecting sliding towards a wrong direction, away from the goal.
Experimentally (see Sect. 4), we evaluated the approach extensively using a real setup. The PiH task is used as an example of the practical usability of the proposed approach. However, the method can be applied to different applications, such as the presented hose coupler example, screwing, folding, or other assembly-like tasks that can be performed with linear motions in 6-D.
The stability of a manipulator in contact with the environment has to be handled carefully; the closed loop stability of a robot in contact with the environment depends on the environment’s compliance characteristics, the stiffness and damping. For the closed-loop system to be stable, the damping of the robot’s controller must be sufficient to dampen potential oscillations. We assume that the damping of the robot is above critical damping threshold corresponding to the maximum stiffness set for the proposed method, which depends heavily on the hardware and the application. Noting that the stiffness of the robot-environment system can not be larger than the robot’s own stiffness (only the robot’s compliance remains if the environment is perfectly stiff), the damping will be sufficient to dampen the oscillations of the robot in contact.
Besides the experimental comparison to DMP, some considerations can be made on how the presented method compares to others state-of-the-art LfD methods. Abu-Dakka et al. (2015) integrated iterative learning control (ILC) with DMPs in order to overcome the uncertainties due to the transformation of the acquired skills to the new starting pose. Their approach needs information about robot starting point and the convergence region is smaller than with the method presented in this paper. Moreover, unlike Abu-Dakka’s approach, our method does not need to transfer the demonstration profiles to the new starting pose.
SEDS Khansari-Zadeh and Billard (2011) was proposed to learn the parameters of the dynamic system to ensure that all motions follow closely the demonstrations while ultimately reaching in and stopping at the target. SEDS relies on GMM/GMR, but improves the EM learning strategy by incorporating stability constraints in the likelihood optimization. SEDS represents a global map which specifies instantly the correct direction for reaching the target, considering the current state of the robot, the target, and all the other objects in the robot’s working space. This makes SEDS state-based learning. Although SEDS focused on stabilising movement trajectories, it did not stabilise impedance during interaction. However, SEDS has been extended in Khansari-Zadeh et al. (2014) to learn motion trajectories while regulating the impedance during interaction and ensuring global stability. Saying that, SEDS can learn much more complex attractor landscapes.
To conclude, there are several major differences between the presented method and SEDS, which make them useful in different use cases. Firstly and most importantly, the presented method is not state-based; thus, the presented method does not depend on the accuracy on knowing the coordinate transform between the robot end-effector and the goal. Secondly, related to this, the presented method does not have a specified target, and thus when the target is not geometrically different, SEDS or another method like it should be used. Thirdly, in contrast to our approach, SEDS needs much more data (demonstrations) for learning, particularly in high dimensions.
Defining a “good” demonstration is a difficult task. There are existing attempts to measure “goodness” by coverage in case of free space motions Sena et al. (2018), but for in-contact tasks there exists no current work. In the experiments we simply explained the demonstrators how an informative demonstrations should be performed—the development of a general metric of informativeness for compliant motion demonstrations is outside the scope of this paper and an interesting direction for future research.
The choice of the center of compliance is a prior design choice; the implications of this choice for peg-in-hole were researched in more detail in Suomalainen et al. (2019) and concluded that the tooltip is the most suitable choice. It is, in general, beneficial to choose the center of compliance such that rotations are around it; however, whereas we did not specifically experiment this, there is no reason the presented method could not learn rotations around other points as well, such that rotations comprise of both rotations and translations.
5 Conclusions and future work
We presented a method that can successfully learn and reproduce 6-D compliant motions from human demonstrations. The method finds a desired direction of motion which can be either pure translation, pure rotation or a combination of translation and rotation. Then it finds the compliant axes, both in translation and rotation, necessary to reproduce the motion. We found that compliance along rotation can compensate fairly significant errors in the angle. The exact angle depends heavily on the equipment, but in our setup the tolerance was fairly tight and a simple rounding of the tool’s end created enough of convergence region to take advantage of compliance. Advantages of using compliance only include the ability to use the same controller in free space, as demonstrated with translations in Suomalainen and Kyrki (2017). However, for cases where the angle is not due to error but due to instructions, we show that we can learn an active rotation as well.
The method presented in this paper models an assembly task as a sequence of linear directions and compliances. Taking into account the physics of sliding in contact allows us to use intersection in the desired direction computations. Due to the use of intersection, it is easy to combine as many timesteps as required and thus the number of demonstrations or their ratio of lengths do not cause issues, in contrast to DMP which calculates the average over many demonstrations. Also since our method is programmed to perform the learned linear motion until physical constraints, our primitive generalizes to holes of different depth and chamfers of different length. Finally, not following a pre-specified force trajectory but instead using compliance to adapt to new situations makes our method more robust towards errors in the initial position of the motion. On the other hand, DMP-based methods would perform better in tasks which require non-linear motions in free space or motions where the final position of the motion is not physically constrained.
A whole task would typically consist of a sequence of the primitives presented in this paper. Methods for sequencing primitives with linear dynamics is a common problem, for which various possible solutions have been presented (Kroemer et al. 2014; Hagos et al. 2018). The method presented in this paper is meant mainly for assembly tasks in situations where the coordinate transformations between the robot and the target are not accurately known and the use of vision is complicated. Such a situation arises in, for example, in small-to-medium size enterprises, where a robot must be included in an existing working environment and CAD models of the workpieces are not available.
In Suomalainen and Kyrki (2017) the world coordinate system was used, while in this work we chose the tool coordinate system. Both coordinate systems have their advantages and disadvantages and the choice is task-dependent. A method to automatically choose the most suitable coordinate system would enhance the method’s usability.
Notes
Code available at www.irobotics.aalto.fi.
References
Abu-Dakka, F. J., & Kyrki, V. (2020). Geometry-aware dynamic movement primitives. In IEEE international conference on robotics and automation (ICRA), Paris, France (pp. 4421–4426).
Abu-Dakka, F. J., Nemec, B., Jørgensen, J. A., Savarimuthu, T. R., Krüger, N., & Ude, A. (2015). Adaptation of manipulation skills in physical contact with the environment to reference force profiles. Autonomous Robots, 39(2), 199–217.
Abu-Dakka, F. J., Rozo, L., & Caldwell, D. G. (2018). Force-based variable impedance learning for robotic manipulation. Robotics and Autonomous Systems, 109, 156–167.
Abu-Dakka, F.J., & Saveriano, M. (2020). Variable impedance control and learning: A review. Frontiers in Robotics and AI (pp. 1–27).
Ahmadzadeh, S. R., Rana, M. A., & Chernova, S. (2017). Generalized cylinders for learning, reproduction, generalization, and refinement of robot skills. In: Robotics: science and systems (Vol. 1).
Argall, B. D., Chernova, S., Veloso, M., & Browning, B. (2009). A survey of robot learning from demonstration. Robotics and Autonomous Systems, 57(5), 469–483.
Calinon, S., Guenter, F., & Billard, A. (2007). On learning, representing, and generalizing a task in a humanoid robot. IEEE Transactions on Systems, Man, and Cybernetics Part B (Cybernetics), 37(2), 286–298.
Deniša, M., Gams, A., Ude, A., & Petrič, T. (2016). Learning compliant movement primitives through demonstration and statistical generalization. IEEE/ASME Transactions on Mechatronics, 21(5), 2581–2594.
Garkavi, A. L. (1964). On the Chebyshev center and convex hull of a set. Uspekhi Matematicheskikh Nauk, 19(6), 139–145.
Guan, C., Vega-Brown, W., & Roy, N. (2018). Efficient planning for near-optimal compliant manipulation leveraging environmental contact. In: 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE.
Hagos, T., Suomalainen, M., & Kyrki, V. (2018). Estimation of phases for compliant motions. In IEEE/RSJ international conference on intelligent robots and systems (IROS 2018). IEEE (Accepted for publication. arXiv:1809.00686).
Hogan, N. (1987). Stable execution of contact tasks using impedance control. In Proceedings of 1987 IEEE international conference on robotics and automation (Vol. 4, pp. 1047–1054). IEEE.
Huang, Y., Rozo, L., Silvério, J., & Caldwell, D. G. (2019). Kernelized movement primitives. The International Journal of Robotics Research, 38(7), 833–852.
Kalakrishnan, M., Righetti, L., Pastor, P., & Schaal, S. (2011). Learning force control policies for compliant manipulation. In 2011 IEEE/RSJ international conference on intelligent robots and systems (pp. 4639–4644). IEEE.
Khansari-Zadeh, S. M., & Billard, A. (2011). Learning stable nonlinear dynamical systems with Gaussian mixture models. IEEE Transactions on Robotics, 27(5), 943–957.
Khansari-Zadeh, S. M., Kronander, K., & Billard, A. (2014). Modeling robot discrete movements with state-varying stiffness and damping: A framework for integrated motion generation and impedance control. In Proceedings of robotics: Science and systems X (RSS 2014) (Vol. 10).
Kramberger, A., Gams, A., Nemec, B., Chrysostomou, D., Madsen, O., & Ude, A. (2017). Generalization of orientation trajectories and force-torque profiles for robotic assembly. Robotics and Autonomous Systems, 98, 333–346.
Kramberger, A., Gams, A., Nemec, B., Schou, C., Chrysostomou, D., Madsen, O., et al. (2016). Transfer of contact skills to new environmental conditions. In: IEEE-RAS 16th international conference on humanoid robots (humanoids) (pp. 668–675). IEEE.
Kroemer, O., Van Hoof, H., Neumann, G., & Peters, J. (2014). Learning to predict phases of manipulation tasks as hidden states. In IEEE international conference on robotics and automation (ICRA) (pp. 4009–4014). IEEE.
Lefebvre, T., Bruyninckx, H., & De Schutter, J. (2005). Online statistical model recognition and state estimation for autonomous compliant motion. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 35(1), 16–29.
Mason, M. T. (1981). Compliance and force control for computer controlled manipulators. IEEE Transactions on Systems, Man, and Cybernetics, 11(6), 418–432.
Mukadam, M., Cheng, C. A., Fox, D., Boots, B., & Ratliff, N. (2020). Riemannian motion policy fusion through learnable lyapunov function reshaping. In Conference on robot learning (pp. 204–219).
Ohwovoriole, M., & Roth, B. (1981). An extension of screw theory. Journal of Mechanical Design, 103(4), 725–735.
Osa, T., Pajarinen, J., Neumann, G., Bagnell, J., Abbeel, P., & Peters, J. (2018). An algorithmic perspective on imitation learning. Foundations and Trends in Robotics, 7(1–2), 1–179.
Paraschos, A., Daniel, C., Peters, J. R., & Neumann, G. (2013). Probabilistic movement primitives. In Advances in neural information processing systems (pp. 2616–2624).
Peternel, L., Petrič, T., & Babič, J. (2015). Human-in-the-loop approach for teaching robot assembly tasks using impedance control interface. In IEEE international conference on robotics and automation (ICRA) (pp. 1497–1502). IEEE.
Racca, M., Pajarinen, J., Montebelli, A., & Kyrki, V. (2016). Learning in-contact control strategies from demonstration. In 2016 IEEE/RSJ international conference on intelligent robots and systems (IROS) (pp. 688–695). IEEE.
Reiner, B., Ertel, W., Posenauer, H., & Schneider, M. (2014) Lat: A simple learning from demonstration method. In IEEE/RSJ international conference on intelligent robots and systems (IROS 2014) (pp. 4436–4441). IEEE.
Rozo Castañeda, L., Calinon, S., Caldwell, D., Jimenez Schlegl, P., & Torras, C. (2013). Learning collaborative impedance-based robot behaviors. In Proceedings of the twenty-seventh AAAI conference on artificial intelligence (pp. 1422–1428).
Schaal, S. (2006). Dynamic movement primitives-a framework for motor control in humans and humanoid robotics. In Adaptive motion of animals and machines (pp. 261–280). Berlin: Springer.
Schimmels, J. M., & Peshkin, M. A. (1991). Force-assemblability: Insertion of a workpiece into a fixture guided by contact forces alone. In Proceedings of 1991 IEEE international conference on robotics and automation (pp. 1296–1301). IEEE.
Schreiber, G., Stemmer, A., & Bischoff, R. (2010). The fast research interface for the KUKA lightweight robot. In Proceedings of the IEEE workshop on innovative robot control architectures for demanding (research) applications—How to modify and enhance commercial controllers (ICRA 2010). IEEE.
Schwarz, G., et al. (1978). Estimating the dimension of a model. The Annals of Statistics, 6(2), 461–464.
Sena, A., Zhao, Y., & Howard, M. J. (2018). Teaching human teachers to teach robot learners. In IEEE international conference on robotics and automation (ICRA) (pp. 1–7). IEEE.
Stolt, A. (2015). On robotic assembly using contact force control and estimation. Ph.D. thesis, Lund University.
Suomalainen, M., Calinon, S., Pignat, E., & Kyrki, V. (2019). Improving dual-arm assembly by master-slave compliance. In International conference on robotics and automation (ICRA) (pp. 8676–8682). IEEE.
Suomalainen, M., & Kyrki, V. (2017). A geometric approach for learning compliant motions from demonstration. In IEEE-RAS 17th International conference on humanoid robots (humanoids) (pp. 783–790). IEEE.
Ureche, L., Umezawa, K., Nakamura, Y., & Billard, A. (2015). Task parameterization using continuous constraints extracted from human demonstrations. IEEE Transactions on Robotics, 31, 1458–1471.
Funding
Open access funding provided by University of Oulu including Oulu University Hospital.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was supported by Academy of Finland, decision 286580.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Suomalainen, M., Abu-dakka, F.J. & Kyrki, V. Imitation learning-based framework for learning 6-D linear compliant motions. Auton Robot 45, 389–405 (2021). https://doi.org/10.1007/s10514-021-09971-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10514-021-09971-y