
Abstract
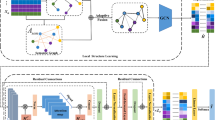
Although Graph Convolutional Networks (GCNs) have achieved excellent results in various graph-related tasks, their performance at low label rates is still unsatisfactory. Previous studies in Semi-Supervised Learning (SSL) for graph primarily focused on utilizing network predictions to generate pseudo-labels or instruct message propagation, often resulting in incorrect predictions owing to over-confidence. To address this issue, we propose a novel approach called Dual-Channel Consistency based Graph Convolutional Networks (DCC-GCN) for semi-supervised node classification. The key idea behind DCC-GCN is to leverage the extraction of embeddings from both node features and topological structures by employing GCN encoders in two separate channels. We consider samples with consistent predictions from these two channels as high-confidence samples, while those with differing predictions are labeled as low-confidence samples. DCC-GCN calibrate the feature embeddings of low-confidence samples by aggregating high-confidence samples from their respective neighborhoods. DCC-GCN can significantly improve the classification accuracy of low-confidence samples, thus improving the overall accuracy. Experiments on seven graph datasets demonstrate that DCC-GCN outperforms prior SSL methods, improving node classification accuracy by a considerable margin.






Similar content being viewed by others


Availability of data and materials
The data used in this paper are all from public datasets.
References
Lee D-H (2013) Pseudo-label : The simple and efficient semi-supervised learning method for deep neural networks. In: Workshop on challenges in representation learning ICML
van den Berg R, Kipf T, Welling M (2017) Graph convolutional matrix completion. arXiv:1706.02263
Shi S, Qiao K, Chen J, Yang S, Yang J, Song B, Wang L, Yan B (2023) Mgtab: A multi-relational graph-based twitter account detection benchmark. arXiv:2301.01123
Shi S, Qiao K, Yang J, Song B, Chen J, Yan B (2023) Over-sampling strategy in feature space for graphs based class-imbalanced bot detection. arXiv:2302.06900
Cao ND, Kipf T (2018) Molgan: An implicit generative model for small molecular graphs. arXiv:1805.11973
You J, Liu B, Ying R, Pande VS, Leskovec J (2018) Graph convolutional policy network for goal-directed molecular graph generation. In: NeurIPS
Sun K, Zhu Z, Lin Z (2020) Multi-stage self-supervised learning for graph convolutional networks. In: 34th AAAI conference on artificial intelligence
Dai E, Aggarwal CC, Wang S (2021) Nrgnn: Learning a label noise resistant graph neural network on sparsely and noisily labeled graphs. Proceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining
Qin J, Zeng X, Wu S, Tang E (2021) E-gcn: graph convolution with estimated labels. Appl Intell 51:5007–5015
Li C, Peng X, Peng H, Wu J, Wang L, Yu PS, Li J, Sun L (2021) Graph-based semi-supervised learning by strengthening local label consistency. Proceedings of the 30th ACM international conference on information & knowledge management
Xu B, Huang J, Hou L, Shen H, Gao J, Cheng X (2020) Label-consistency based graph neural networks for semi-supervised node classification. Proceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval
Vashishth S, Yadav P, Bhandari M, Talukdar PP (2019) Confidence-based graph convolutional networks for semi-supervised learning. arXiv:1901.08255
Guo C, Pleiss G, Sun Y, Weinberger KQ (2017) On calibration of modern neural networks. 14:(2017)
Kumar A, Sarawagi S, Jain U (2018) Trainable calibration measures for neural networks from kernel mean embeddings. In: ICML
Zhang J, Kailkhura B, Han TY-J (2020) Mix-n-match: Ensemble and compositional methods for uncertainty calibration in deep learning. In: ICML
Rizve MN, Duarte K, Rawat YS, Shah M (2021) In defense of pseudo-labeling: An uncertainty-aware pseudo-label selection framework for semi-supervised learning. In: ICLR
Wang X, Zhu M, Bo D, Cui P, Shi C, Pei J (2020) Am-gcn: Adaptive multi-channel graph convolutional networks. In: Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining
Liu C, Wen L, Kang Z, Luo G, Tian L (2021) Self-supervised consensus representation learning for attributed graph. Proceedings of the 29th ACM international conference on multimedia
Yuan J, Yao Y, Xu M, Yu H, Xie J, Wang C-J (2022) Graph structure learning based on feature and label consistency. Intell Data Anal 26:1539–1555
Kipf T, Welling M (2016) Semi-supervised classification with graph convolutional networks. In: ICLR
Wu F, Zhang T, de Souza AH, Fifty C, Yu T, Weinberger KQ (2019) Simplifying graph convolutional networks. In: International conference on machine learning. https://api.semanticscholar.org/CorpusID:67752026
Velickovic P, Cucurull G, Casanova A, Romero A, Lio’ P, Bengio Y (2018) Graph attention networks. In: ICLR
van der Maaten L, Hinton GE (2008) Visualizing data using t-sne. J Mach Learning Res 9:2579–2605
Li Q, Han Z, Wu X-M (2018) Deeper insights into graph convolutional networks for semi-supervised learning. arXiv:1801.07606
Hu ZH, Kou G, Zhang H, Li N, Yang K, Liu L (2021) Rectifying pseudo labels: Iterative feature clustering for graph representation learning. Proceedings of the 30th ACM international conference on information & knowledge management
Zhuang C, Ma Q (2018) Dual graph convolutional networks for graph-based semi-supervised classification. Proceedings of the 2018 World Wide Web Conference
Wang X, Liu H, Shi C, Yang C (2021) Be confident! towards trustworthy graph neural networks via confidence calibration. In: NeurIPS
Chen P, Liao B, Chen G, Zhang S (2019) Understanding and utilizing deep neural networks trained with noisy labels. In: ICML
Yang H, Yan X, DAI X, Chen Y, Cheng J () Self-enhanced gnn: Improving graph neural networks using model outputs. 2021 International Joint Conference on Neural Networks (IJCNN), 1–8
Orbach M, Crammer K (2012) Graph-based transduction with confidence. In: ECML/PKDD
Bojchevski A, Günnemann S (2017) Deep gaussian embedding of graphs: Unsupervised inductive learning via ranking. In: ICLR
Wang X, Ji H, Shi C, Wang B, Cui P, Yu P, Ye Y (2019) Heterogeneous graph attention network. The World Wide Web Conference
Wang W, Liu X, Jiao P, Chen X, Jin D (2018) A unified weakly supervised framework for community detection and semantic matching. In: PAKDD
Zhu X, Ghahramani Z, Lafferty JD (2003) Semi-supervised learning using gaussian fields and harmonic functions. In: ICML
Thekumparampil KK, Wang C, Oh S, Li L-J (2018) Attention-based graph neural network for semi-supervised learning. arXiv:1803.03735
Sun K, Zhu Z, Lin Z () Multi-stage self-supervised learning for graph convolutional networks. arXiv:1902.11038
Tarvainen A, Valpola H (2017) Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In: NIPS
Chien E, Peng J, Li P, Milenkovic O (2021) Adaptive universal generalized pagerank graph neural network. In: ICLR
Acknowledgements
This work was supported by the National Key Research and Development Project of China (Grant No. 2020YFC1522002).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there are no conflicts of interest regarding the publication of this paper.
Consent to participate
The article was submitted with the consent of all the authors to participate.
Consent for publication
The article was submitted with the consent of all the authors and institutions for publication.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A: A.1 Theorem 1 in section III
Appendix A: A.1 Theorem 1 in section III
Proof
The inputs for the two GCN models are graphs \(\mathcal {G}\) and \(\mathcal {G}^{\prime }\), respectively, and the average accuracy of classification is \(p_{1}\) and \(p_{2}\), respectively. There are N nodes in graph \(\mathcal {G}\) and \(\mathcal {G}^{\prime }\). The number of samples with the same classification result for both GCN models \(N_{a}\) is the number of samples \(N_{r}\) correctly classified by both GCN models added to the number of samples \(N_{w}\) incorrectly classified as the same class by the two models.

Variation of the upper bound of \(p_{GAIN}\) with \(p_{1}\), \(p_{2}\) (c is 3, 7 and 70 respectively)
If the two GCN models are completely independent:
In fact, due to the correlation between the two GCN models, the number of samples correctly classified by the two models \(N_{r}=p_{1} p_{2} N+\alpha N\), and the number of samples incorrectly classified by the two models as the same category \(N_{w}=\frac{\left( 1-p_{1}\right) \left( 1-p_{2}\right) }{c-1} N+\beta N\). We can get:
The more significant the correlation between the two GCN models, the more excellent \(\alpha \) and \(\beta \) will be,and \(\alpha >0\), \(\beta >0\). For simplicity, let \(\gamma =\alpha +\beta \). The average classification accuracy for low-confidence samples is \(p_{low-conf}\). For the first GCN model, the number of correctly classified samples can be expressed as \(p_{1}N\). The number of correctly classified samples can also be expressed as:
Equation can be obtained as:
An upper bound for \(p_{low-conf}\) can be obtained:
1.1 A. 2 Theorem 2 in section III
Proof
The average classification accuracy of the low- confidence samples is \(p_{low-conf}\), the average classification accuracy after the calibration is \(p_{low-conf}^{\prime }\), and the performance improvement of the model is \(p_{GAIN}\). After the low-confidence samples calibration, the (A5) can be rewritten as:
Substitute \(N_{a}=\left[ p_{1} p_{2}+\frac{\left( 1-p_{1}\right) \left( 1-p_{2}\right) }{c-1}+\gamma \right] N\) into the above expression:
Since \(p_{low-conf}^{\prime }<p_{1}\), we can obtain the inequality:
Simplify inequality,
1.2 A.3 Analysis 2 in section III
\(\gamma \) is related to the correlation between the dual-channel models and is determined by the model and its parameters and data set. According to Assumption 2, \(p_{low-conf}^{\prime }<p_{1}\). Similarly, we can obtain: \(p_{low-conf}^{\prime }<p_{2}\). The upper bound of model improvement accuracy is determined by \(p_{1}\) and \(p_{2}\). For simplicity, let \(\gamma =0\), using \(p_{1}\) and \(p_{2}\) as the X and Y axes respectively, draw the upper bound of the accuracy of the promotion when the category c is 3, 7 and 70 in Fig. 7 respectively.
We can observe that the bigger the difference between \(p_{1}\) and \(p_{2}\), the lower the upper bound of \(p_{GAIN}\). When the value of \(p_{1}\) is fixed and the value of \(p_{2}\) is the same as \(p_{1}\), the upper bound of \(p_{GAIN}\) is the highest.
1.3 A.4 Implementation details
In this paper, all models use a 2-layer GCN with ReLU as the activation function. We train the model for a fixed number of epochs, specifically. 200, 200, 500, 1000 epochs for Cora, Citeseer, Pubmed and CoraFull, respectively, 300 for acm, 200 for Flickr, and 200 for UAI2010. All models along with \(\varvec{\mu }\) are initialized with Xavier initialization, and matrix \(\varvec{\Sigma }\) is initialized with identity. All models were trained using Adam optimizer on all datasets. Our models were implemented in PyTorch version 1.6.0. When constructing feature graph, \(k\in \{2, 3,..., 10\}\) for k-nearest neighbor graph. All dataset-specific hyper-parameters are summarized in Table 7.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Shi, S., Chen, J., Qiao, K. et al. Select and calibrate the low-confidence: dual-channel consistency based graph convolutional networks. Appl Intell 53, 30041–30055 (2023). https://doi.org/10.1007/s10489-023-05110-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-023-05110-5