
Abstract
A novel AGV (Automated Guided Vehicle) control architecture has recently been proposed where the AGV is controlled remotely by a virtual Programmable Logic Controller (PLC), which is deployed on a Multi-access Edge Computing (MEC) platform and connected to the AGV via a radio link in a 5G network. In this scenario, we leverage advanced deep learning techniques based on ensembles of N-BEATS (state-of-the-art in time-series forecasting) to build predictive models that can anticipate the deviation of the AGV’s trajectory even when network perturbations appear. Therefore, corrective maneuvers, such as stopping the AGV, can be performed in advance to avoid potentially harmful situations. The main contribution of this work is an innovative application of the N-BEATS architecture for AGV deviation prediction using sequence-to-sequence modeling. This novel approach allows for a flexible adaptation of the forecast horizon to the AGV operator’s current needs, without the need for model retraining or sacrificing performance. As a second contribution, we extend the N-BEATS architecture to incorporate relevant information from exogenous variables alongside endogenous variables. This joint consideration enables more accurate predictions and enhances the model’s overall performance. The proposed solution was thoroughly evaluated through realistic scenarios in a real factory environment with 5G connectivity and compared against main representatives of deep learning architectures (LSTM), machine learning techniques (Random Forest), and statistical methods (ARIMA) for time-series forecasting. We demonstrate that the deviation of AGVs can be effectively detected by using ensembles of our extended N-BEATS architecture that clearly outperform the other methods. Finally, a careful analysis of a real-time deployment of our solution was conducted, including retraining scenarios that could be triggered by the appearance of data drift problems.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
An Automated Guided Vehicle (AGVs) is a transport vehicle that operates under the direction of a computer system. AGVs are widely used in material transport applications, such as industrial manufacturing and automotive assembly plants, as well as commercial settings such as warehouses and hospitals [1, 2]. A key factor of AGVs is that they can be remotely controlled, allowing greater flexibility and efficiency on the job site [3]. 5G is the key enabler for remote control of AGVs because it provides the high-speed, low-latency and reliable connectivity that these vehicles need to operate safely and efficiently in real-time.
Taking advantage of 5G capabilities, in [4] we proposed a novel control scheme for 5G-enabled AGVs that involves deploying their remote control as a virtualized Programmable Logic Controller (PLC) running in a 5G MEC (Mobile Edge Computing) infrastructure. By migrating the controller to the MEC, the AGV can reduce its hardware requirements, as the controller can share the resources of the MEC, which can result in significant cost savings for the AGV manufacturer. Furthermore, using this scheme, the AGV can take advantage of the flexibility, scalability, and fault tolerance of the virtualized infrastructure, allowing the AGV to adapt more quickly to changing needs and requirements and ensuring that it remains available to perform its tasks. Furthermore, since the controller is no longer inside the AGV, this scheme also results in a reduction in the weight of the AGV, which also allows for reduced power consumption.
In the scheme described above, the controller uses the information from the sensors placed on the AGV to make decisions about its trajectory. In particular, the controller can use information from the guiding sensors to measure the current deviation from the trajectory. This information is stored in AGV variables that are periodically transmitted from the AGV to the PLC. The controller processes this information to generate a corrective action that is sent back to the AGV to bring it back to the desired trajectory or to raise an alarm if the deviation is too large. For the logic implemented in the PLC to guide the AGV it is important to consider that the AGV, due to the inertia of its mass, may not be able to respond immediately to the controller’s commands. To solve this problem, predictive models can be used to compensate for AGV response time. Based on the current deviation from the track path, AGV malfunction can be detected ahead of time, allowing appropriate corrective actions to be applied to ensure that the AGV remains on the track or to bring it to a complete stop in order to prevent an accident from occurring, thus ensuring work safety and reducing operational downtime. This problem can be modeled as a time series forecasting problem, where the objective is to predict the future state of the AGV location based on its past state and the current deviation from the desired trajectory. In AGV applications, trajectory deviation is often referred to as "Guide Error" or "Guiding Error", so we will use the term "Guide Error" to refer to trajectory deviation in the remainder of this paper. Note that this term should not be confused with a malfunction of the AGV, as the Guide Error is the natural deviation from the trajectory that appears when the AGV is in motion.
In this work, we propose innovative sequence-to-sequence approaches based on an enhanced N-BEATS architecture to improve the accuracy of predicting ahead of time the deviation of an AGV from the desired trajectory. The research questions this work addresses are:
-
RQ-1: Is it worth deploying a state-of-the-art neural network architecture (N-BEATS) that consumes more resources than traditional machine learning (Random Forest), statistical (ARIMA) and deep learning (LSTM) models for this AGV scenario? (In this context, our aim is to maximize the forecasting performance/accuracy when limited CPU/GPU resources are available).
-
RQ-2: What are the most appropriate forecasting variables to predict AGV malfunction?
-
RQ-3: Is there an optimal combination of DL/ML models, time windows, and input features that maximizes the forecast performance for this AGV scenario?
-
RQ-4: How does each of these factors affect the forecast accuracy?
-
RQ-5: How can the occurrence of data drift problems in real-time deployment scenarios be effectively resolved?
To address the research question RQ-1, in sharp contrast to a previous work [4], this research aims to adapt modern sequence-to-sequence time-series forecasting models, including recent state-of-the-art techniques such as N-BEATS and other advanced methods such as ensemble learning, to assess whether it is possible (i) to further improve the accuracy of AGV deviation prediction generating a sequence of future predictions instead of a single point in the future, and (ii) to achieve better forecast stability with a longer forecast horizon to more reliably anticipate AGV malfunction.
In this context, we propose a novel application of sequence-to-sequence prediction in the AGV scenario that differs fundamentally from the classical approach of predicting a single value representing the expected AGV deviation over a specific time horizon, as it offers the advantage of allowing greater flexibility in the selection of the maximum prediction horizon. This improvement provides the operator with the ability to evaluate a range of prediction horizons and dynamically choose the optimal one that maximizes accuracy for the specific operational context in which the AGV is deployed.
Furthermore, N-BEATS was selected in this work because it is considered the state-of-the-art method for univariate time-series forecasting. As a novelty, we modified the original N-BEATS architecture to add exogenous variables in its input. We compare the forecasting performance of the modified N-BEATS architecture to a variety of representative DL, ML and statistical methods for time-series forecasting. In addition, we apply the model ensemble technique to further increase the final prediction accuracy of individual models. Although N-BEATS as the state-of-the-art model in time-series forecasting is expected to outperform the rest of the models in the proposed AGV scenario, it should be noted that there is a trade-off between the increase in performance and the extra resources that are consumed by this model.
To tackle the second research question (RQ-2), several forecasting variables, were proposed. Regarding the fact that due to the inertia of a moving AGV, it takes approximately 10 s in the worst case to stop it, we establish the period from 10 to 20 s as the useful range to predict in advance the AGV deviation. To infer trajectory problems in an AGV, two variables, the Guide Error and Guide Oscillations, were considered to be predicted in advance. The former stores the deviation of the AGV’s guiding sensor from the tape on the floor, and the latter stores the number of times that the guiding sensor has crossed the tape from left to right or vice versa. Intuitively, high values for these two variables would suggest that the AGV is having difficulties maintaining its trajectory.
To address research question RQ-3, several experiments were conducted to evaluate the optimal combinations of models, time windows and input feature set to achieve the best forecasting performance. To train the models, we used real data collected by conducting extensive experiments with an industrial grade AGV provided by ASTI Mobile Robotics and a virtualized PLC that were connected in a 5G network deployed at 5TONIC, an open laboratory for 5G experimentation. Realistic network errors (e.g. delay and jitter) were reproduced in the experiments with different degrees of intensity. Therefore, the proposed forecast models were trained to predict the AGV malfunction even when different degrees of network disturbances appeared.
Once trained, we compared the performance of the different models in order to understand the importance of each of the selected feature sets, the importance of time window segmentation, and ultimately the capabilities of each of the proposed architectures. Our experimental results showed that the proposed ensembles of N-BEATS provide consistently robust predictions throughout the forecast horizon, producing highly accurate long-term predictions even in the presence of significant degradation of network conditions.
Finally, to address the research question RQ-4, a careful analysis of a real-time deployment of our solution was conducted, including retraining scenarios that might be triggered by the appearance of data drift problems. We apply the Transfer Learning technique to perform a realistic experimental analysis of the retraining of the proposed models in an online fashion using data previously collected in the 5TONIC lab. The results show a significant decrease in the time required to retrain the model with respect to training the models from scratch.
1.1 Contributions
The main contributions of this work can be highlighted as follows.
-
An innovative approach to predict AGV deviations in a sequence-to-sequence fashion is presented for the first time in the AGV literature. Unlike existing approaches, which rely on predicting a single time step at a time and applying a rolling mechanism to obtain a sequence of future values, the proposed approach relies on advanced sequence-to-sequence models applied to N-BEATS and LSTM architectures to learn to forecast a sequence of future AGV deviations based on the temporal correlation between future time steps and a window of past deviations. Importantly, our approach does not incur the accumulation of errors that rolling strategies generate, as it does not rely on an iteration-based algorithm to generate the desired sequence of predictions, which can lead to a dramatic increase in prediction error. Instead, using a single-learned model and a window of historical data, our approach is able to provide the complete time series of future predictions in which all time steps to be predicted are contained in the same output vector. In this way, multiple horizons are constrained in the same model structure, providing the AGV operator with a flexible way to select the most suitable horizon for predicting the future deviation sequence based on the current needs of the application without requiring model retraining and without losing performance.
-
As a novelty, we extend the architecture of N-BEATS to consider exogenous variables as input. The inclusion of exogenous features was motivated by the need to provide the model with additional context that could explain, at least partially, the outcome of the predictions. We focus specifically on the AGV-PLC connection statistics, as they are directly affected by degradation of network conditions. A degradation in the quality of the AGV-PLC connection will result in poor control of the AGV trajectory, which will eventually generate difficulties for the AGV that will be reflected in an increase in the deviation of the AGV from its trajectory. To the best of our knowledge, this is the first time that exogenous features that are not directly related to the domain of the target series under study are considered as input to the multivariate time-series prediction task in N-BEATS. By incorporating the AGV-PLC connection parameters as exogenous variables into an N-BEATS model, we achieve the best overall results in forecasting the deviation of the AGV trajectory, demonstrating that feeding salient features into an N-BEATS model can significantly improve the overall predictive performance achievable with this architecture.
-
We propose a new approach to AGV malfunction prediction based on the analysis of AGV’s Guide Oscillations, a derived variable we calculate using some of the AGV variables present in the packets of the PLC-AGV connection. This derived variable presents great potential to improve prediction performance and opens a new line of research in the AGV motion modeling literature. To our knowledge, the proposed approach is the first in the literature to perform a multivariate analysis of the measured AGV’s Guide Oscillations, allowing for the combination of this new variable with other conventional measures, such as the Guide Error and network-related statistics. Our empirical results confirm that the use of AGV oscillations as an additional exogenous input can be exploited as a useful indicator of AGV malfunction, as confirmed by the significantly better performance achieved by the LSTM and Random Forest models when trained with this variable. This result allows us to highlight the potential of using the Guide Oscillations variable in AGV control systems.
-
We observed that on some occasions the training of N-BEATS and Random Forest can generate models that obtain a good score in the forecasting metric (e.g., MAE or MSE) but tend to predict values close to the mean of the target variable. In other words, the distribution of the predictions is highly centered around the mean of the Guide Error variable, which causes highly inaccurate predictions in extreme values and regions of high fluctuations of the target variable. We refer to this specific phenomenon as "lazy behavior", as the models attempt to be on the safe side in almost every prediction, avoiding extreme values to minimize the likelihood of making highly erroneous predictions. To the best of our knowledge, this is the first time this bad effect has been reported in the literature. This anomalous behavior prevents the deployment of such lazy models in realistic scenarios, as these models will not be able to predict in advance that an AGV is having difficulties because these difficulties are directly correlated with the sudden appearance of large Guide Error values that tend not to be predicted by the lazy models. It is worth noting that we found that this problem was not present in the LSTM, indicating that this architecture seems to be robust against this anomaly. In addition, we suggest a manual heuristic to detect and discard lazy models, but specific research should be conducted as future work to avoid or mitigate this harmful behavior. Furthermore, another important task is to explore which ML/DL algorithms are shown to be vulnerable and which appear to be robust against this type of phenomenon.
-
We performed a simulation of a real-time deployment of the models, conducting extensive analyses of (a) the deployment feasibility of N-BEATS and LSTM models in a production environment for real-time control of a fleet of AGVs; and (b) the model retraining times in a data drift scenario when Transfer Learning techniques are applied.
1.2 Paper structure
The rest of the manuscript is organized as follows: Sect. 2 discusses related work. In Sect. 3 we describe the use case architecture and the setup procedure that we use to simulate different network conditions and explain the data collection and processing steps. Section 4.1 identifies the ML and DL models we selected to carry out the experiments and provides a justification for why they were selected among the rest of similar techniques. In Sect. 4 we define the experimental framework used for data processing, model training, and performance evaluation. Section 5 presents the results obtained in the experiments. This section details the training and testing of a variety of deep learning models (N-BEATS and LSTM), machine learning algorithms (Random Forest) and statistical methods (ARIMA) using different combinations of endogenous and exogenous features and ensembles. Furthermore, a realistic deployment and the re-training issues that can appear when data drift occurs are detailed in this section. In Sect. 6 we conclude by summarizing the main findings derived from the results obtained and present interesting future work to explore. Finally, Appendix A contains the preliminary analysis of the Guide Oscillations variable Sect. 6, details of the experimental results Sect. 1, additional plots reflecting the lazy behaviour we observed in some models Sect. 3, and details of the ensemble experiments Sect. 4.
2 Related work
Modern AGVs can operate to follow a dynamic trajectory, allowing greater flexibility and efficiency in many applications [1, 5]. In real smart factories, AGVs must coexist and interact with other automated systems and human [2]. These interactions must be properly managed to avoid disruptions, maintain efficiency, and ensure safe operation [6]. In real situations, AGVs cannot move freely in the environment because otherwise the factory floor must be mapped in advance, which is impractical and expensive. Instead, many studies have proposed the use of guide lines to establish a predefined circuit to address this issue. This guide line can be physical (e.g., a tape physically embedded on the floor [7]) or virtual (e.g., a memorized path [8]). The guide line restricts the movement of the AGV and provides a mean for the AGV to locate itself on the factory floor. There is a lack of published research that takes advantage of advanced DL techniques for time-series forecasting to predict ahead of time the AGV trajectory deviation from the guideline in order to avoid unexpected vehicle collisions and to identify system malfunctioning in advance.
Industrial sectors are benefiting from the adoption of time-series analysis to improve the efficiency of their operations [9,10,11]. Although several statistical and Machine Learning (ML) techniques have been applied to time-series forecasting, such as Autoregressive Integrated Moving Average (ARIMA) models or linear regression, in recent years there has been a growing interest in the application of Deep Learning (DL) models to perform this task because of their ability to automatically learn complex patterns in data [12, 13]. In particular, DL architectures have shown to be successful in forecasting time-series data with long-term dependencies [14, 15], which is highly relevant for many Industry 4.0 applications such as predictive maintenance and fault detection. Recently, Oreshkin et al. introduced "Neural Basis Expansion Analysis for Interpretable Time Series Forecasting" (N-BEATS) [16], a DL-based architecture that uses a sequence of deeply stacked blocks consisting of several fully connected layers connected through residual links. The proposed architecture exhibits several desirable properties: It is applicable without modification to a wide range of target domains, is fast to train, and can produce interpretable results. Furthermore, this architecture has been widely applied to prediction problems, and among the application fields are energy [17], healthcare [18, 19], and telecommunications [20].
Several studies have investigated path tracking control algorithms for remotely controlled AGVs. One such study [21] presents a wireless AGV path tracking control algorithm that accounts for varying network delays caused by the wireless network. The proposed method includes an optimal delay estimator that adjusts the received AGV position to account for the wireless network delay. This delay estimator utilizes a Kalman filter and a simple stochastic model of wireless delay dynamics to produce an optimal delay estimate. The estimated delay is then used to infer the actual AGV position, which is utilized to compute the appropriate control commands. The efficacy of the proposed approach is evaluated through simulation by measuring the vehicle’s path deviation and total travel time for different paths and network traffic conditions.
Another study [22] proposes a goal-oriented wireless communication solution for remotely controlled AGVs in time-varying wireless channel dynamic factory environments. The authors highlight the inherent dependence between data rate and control accuracy for such a system. To address this issue, they propose a model that can dynamically adapt the transmission data rate to optimize the AGV trajectory. The problem is formulated as a semi-Markov Decision Process, where the channel correlation is evaluated over time to address the fading issue. The Cross Track Error (XTE) is utilized as a metric to measure the distance deviation from the planned path. The proposed approach outperforms fixed-data rate policies as well as state-of-the-art solutions that are solely based on Age-of-Information (AoI), achieving the objective of higher system trajectory accuracy.
However, few articles consider a 5G network for AGV control. The 5G network offers improved data rates, low latency and reliability, which are crucial for the reliable and deterministic operation of an AGV in an industrial environment. To our knowledge, only two studies in the literature address the scenario where an AGV is remotely controlled using a 5G network.
In [23], the authors present an AGV that is remotely operated using 5G equipment deployed on customer premises equipment. In this scenario, the authors proposed an AGV control scheme based on an MEC platform to provide an end-to-end solution for predicting the movement of AGVs. In this case, the AGV is automatically controlled from the 5G base station based on visual information collected by a camera attached to the AGV and transmitted to the remote MEC platform via the 5G RAN link. However, as the authors argue, the control algorithms are based on a simplistic kinematic approach without using any ML or DL technique for predicting ahead of time the AGV trajectory. In sharp contrast, we propose a use case in which predicting AGV trajectory deviations ahead of time is crucial to avoid harmful situations that could arise when the AGV deviates from the trajectory due to errors in the guidance control. Another limitation of the work presented in [23] compared to ours is that its approach was not tested under a variety of realistic conditions in a real factory environment (e.g., no evaluation was performed under network disturbance effects, different traffic loads, etc.) that can significantly affect the performance and effectiveness of the proposed solution in a real environment. In contrast, our work explores the performance of deep learning models in a realistic setup where a wide range of network disturbances (e.g. delay, jitter) were introduced programatically during the AGV operation. Furthermore, their work does not propose a realistic Industry 4.0 setup as ours in which industrial grade components (PLC and AGV) are used in the experiments. Finally, their work does not present any analysis of the response time of the control algorithm under different traffic loads and network conditions as we do in our work.
Previous research has focused primarily on improving the navigation of remotely controlled AGVs using wireless networks. However, anticipating and planning corrective maneuvers in response to deviations caused by network disturbances is an under-explored area of research. To fill this gap and ensure the safe operation of AGVs, prevent collisions, and minimize disruptions in the factory workflow, our study builds on the initial work presented by [4]. In that preliminary work, the proposed solution was mainly focused on demonstrating in an industrial-grade environment that the AGV malfunctioning can be forecast with anticipation by exclusively analysing the AGV-PLC connection and without needing to deploy any meter in the end-user equipment (AGV and PLC). However, several important differences appear when comparing our work with [4]:
-
(i)
First, the approach of [4] relied on the prediction of a single instantaneous value (mean value between 10 and 15 s ahead of time) using a typical regression strategy. In sharp contrast, our proposed solution addresses this problem using an approach based on predicting a sequence of 200 future values (from 1 to 20 s ahead of the instant time with 100 milliseconds steps) using powerful sequence-to-sequence DL models. With this new approach, multiple horizons are contained in the same model structure, providing the AGV operator with a flexible way to select the most appropriate horizon to predict the future deviation sequence based on current application needs without requiring model retraining and without losing performance.
-
(ii)
Furthermore, the forecast horizon of the previous work (15 s) was considerably extended to 20 s in our work, allowing a greater safety margin to apply appropriate maneuvers to prevent the AGV from colliding with surrounding obstacles and thus improving the safety of the work area.
-
(iii)
An important limitation of [4] is that only traditional DL algorithms (LSTM and 1D-CNN) were used and a very modest number of model combinations were trained and tested. In sharp contrast, our work provides an in-depth comparison of an extended version of N-BEATS, the state-of-the-art architecture for time-series forecasting, with traditional ML/DL and statistical models. In this comparison a rich set of hyperparameters was selected and a significant number of model combinations were evaluated. Indeed, our results demonstrate that N-BEATS models allow achieving significantly better forecasting performance than traditional approaches while being able to meet the stringent demands of real-time operation. In addition, we analyze the resultant performance when ensembles of models are used, demonstrating that ensembles of N-BEATS outperform individual models.
-
(iv)
Another significant limitation of the previous work is the use of a fixed temporal window size (60 s). On the contrary, our study explores a broader range of temporal windows, specifically 4, 7.5, 15, and 30 s, and demonstrates that the optimal window size is a hyperparameter that must be tuned individually for each model. Our findings indicate that increasing the time window mostly lead to improved performance.
-
(v)
A very simple study of real-time deployment was conducted in [4]. In contrast, our work thoroughly analyzes the feasibility of a real-time deployment considering CPU or GPU availability, the management a single AGV or groups of them by a single model, and the retraining times by applying or not applying Transfer Learning when models become obsolete.
-
(vi)
Finally, the previous work only used the Guide Error variable as the representative of the AGV status. In contrast, our work also considers a new variable based on AGV guide oscillations. Our results show that the use of AGV oscillations as an additional exogenous input can be successfully exploited as a useful indicator of AGV malfunction, as confirmed by the significantly better performance achieved by some models.
Table 1 provides a comprehensive comparative analysis of the main findings and contributions of our study and other articles that are closely related. This comparison aims to offer a comprehensive overview of the research conducted on the topic addressed in this article, highlighting the distinctive contributions of our study to the existing literature.
3 Use case
In this section, we describe the use case that we intend to solve in this work. Our intention in this study is to exploit the capabilities of sophisticated DL techniques to build predictive models that forecast the deviations of an AGV controlled through a remote PLC.
All AGVs are equipped with a sensor that measures the distance between a point of the AGV and the trajectory to be followed. To this aim, different sensors can be used depending on the nature of the physical reference: magnetic (a magnetic tape on the floor and a magnetic antenna in the AGV), electromagnetic (a wired buried in the ground and an antenna in the AGV), optical (a line painted on the floor and a camera in the AGV). Later AGVs are equipped with SLAM navigation systems that use natural landmarks to create a map and locate the robot in the map. Normally these devices store a virtual trajectory to be followed, and provide the distance to this virtual line, but in essence it is the same concept.
In our case the AGV is equipped with a magnetic antenna in the traction unit which provides the distance between the center of the unit and the circuit described by a magnetic tape. In the AGV field it is common to call this distance "Guide Error", thus hereafter we have followed this convention. The Guide Error is not a strict euclidean distance but it has a sign to indicate if the AGV is located at the left or the right of the circuit. This way, the AGV adjusts the angular speed considering the sign of the Guide Error to move closer to the desired trajectory.
Figure 1 shows a schematic representation of the AGV and the Guide Error. As is possible to observe, this AGV is similar to a tricycle robot, but the front-direction wheel is replaced by a differential traction unit. This way the behavior of the traction unit is similar to a differential robot, but the whole AGV movement is limited by the kinematic constraints of a tricycle. The magnetic sensor is mounted on the traction unit and provides the Guide Error information to correctly follow the path drawn on the floor by the magnetic tape. This AGV configuration is very common in the automotive industry.
Assuming that there is no slippage on the wheels, the movement of this AGV can be described by (1), (2), (3) and (4).
Where the position and orientation of the coordinate system located in the center of the rear axle is denoted by \((x_b, y_b,\theta _b)\) [m, m, rad]; the position and orientation of the coordinate system located on the center of the traction unit is denoted by \((x_h, y_h, \theta _h)\) [m, m, rad]; \(L_b\) is the distance between the rear axle and the centre of the traction unit [m]; \(L_h\) is the distance between the wheels of the traction unit [m]; and \((v_l, v_r)\) [m/s, m/s] are the longitudinal speed of the left wheel and right traction wheels, respectively.

AGV and Guide Error representation
Our main objective is to exploit this information to anticipate the AGV’s movements, allowing it to be stopped before potentially dangerous situations occur, such as a collision with an imminent obstacle or a sudden departure from the circuit, even in situations of degraded network performance between the AGV and the PLC connection.
3.1 Use case architecture
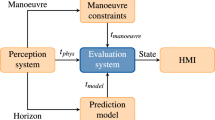
As mentioned previously, AGVs are controlled by a Programmable Logic Controller (PLC). This PLC is a device specifically designed and programmed to control the sequence of operations that the AGV will perform. The PLC is connected to the AGV through a communication network that can be either wired or wireless. The AGV has several sensors that allow it to detect its environment and its location at the factory. The PLC uses this information to control the movement of the AGV. To do this, the AGV is also equipped with actuators that allow it to move in the desired direction. In our case, the PLC is virtualized and deployed at the edge of the 5G network in a MEC infrastructure. Virtualization of the PLC allows a large number of AGVs to be controlled concurrently from a reduced number of PLCs, thus allowing for cost savings while providing greater scalability and flexibility to the system. In addition, virtualization of the PLC in a remote location allows one to save space and reduce the weight and power consumption of the AGVs. Furthermore, placing the PLC close to the AGV greatly reduces communication latency, which is a crucial factor in meeting the stringent real-time requirements of the AGV operation. In this context, URLLC (ultra-reliable low-latency communication) is a key enabler for remote AGV operation. URLLC is a feature of 5G that is designed to provide low-latency and reliable communications that are required in the industrial setting. In the above scenario, the communication between the AGV and the PLC occurs as follows:
-
1.
The AGV sends the location data to the PLC (i.e., the deviation from the current path).
-
2.
The PLC uses the location data to correct the AGV’s trajectory and sends updated commands to the AGV.
-
3.
The AGV executes the commands and sends status updates to the PLC.

Use Case Architecture representing the AGV, 5G RAN, 5G MEC, 5G CORE and ML module
The 5G network architecture of the proposed use case is depicted in Fig. 2. As can be seen, the architecture includes a 5G Radio Access Network (5G RAN) to provide wireless communication capabilities to an AGV. The signaling to authenticate and deliver IP connectivity is managed by the signaling traffic within the 5G Core. The introduction of a 5G link that connects the AGV with the PLC allows replacing the internal PLC module that is traditionally mounted over an AGV with a more lightweight and energy efficient 5G modem chipset. In order to meet the low-latency requirements that enable the effective operation of the AGV through a remote PLC, the use of a MEC platform that hosts a Virtual Machine (VM), on which the remote PLC is deployed, is required. The MEC platform also contains several computing resources, including a component that provides access to the user data plane for different demands of services. These computing resources are deployed using virtualization technology with a hypervisor and several VMs. One of these VMs is a Master PLC that is responsible for controlling multiple AGVs. The ML engine represents the DL-based predictive models running on the MEC platform. The ML engine uses the information captured in real-time from the connection between the AGV and the PLC to predict the occurrence of AGV malfunction in advance.
The input variables to be fed to the ML Engine are obtained from the network packets sent from the AGV to the PLC through the network connection. From these network packets, two different sets of variables are extracted and processed to be used as input to the predictive models: (i) NET variables: connection statistics that can be extracted and aggregated from the packet headers that allow determining and quantifying network degradation problems. Connection statistics can be used as input to ML/DL models to predict the target variable accordingly to the network degradation problems identified by the model. In addition, the use of these features allows us to train more reliable models that remain robust against the occurrence of these situations in the real world scenario. (ii) AGV variables: the current values of the Guide Error that can be further processed to extract the variable Guide Oscillations that measures the number of times the AGV crossed the magnetic tape that traces the circuit on the factory’s floor.
In the experiments conducted, these two sets of variables (AGV and NET) were first tested separately and then combined to determine which combination worked best for predicting AGV malfunction. Demonstrating that using only connection statistics (NET variables) the AGV malfunctioning can be predicted would be extremely beneficial as it would allow operating the AGV without the need for the network operator to intervene in the factory’s non-public network (NPN) and thus enabling the AGV to be controlled from a public network where the transmitted payloads can be encrypted and only network statistics are available. On the contrary, using only the set of AGV variables to predict the AGV malfunctioning will demonstrate that the PLC-AGV operator could eliminate the need to measure and collect the network parameters, which can require the installation of special equipment in the factory to access to the private network to collect the network packets of the PLC-AGV connection. However, this installation may be infeasible in some contexts.
Furthermore, as also shown in Fig. 2, our architecture includes a Network Degradation Emulator (NDE), which is a component that is placed as a man in the middle in the connection between the radio access network and the MEC platform. The NDE is designed to simulate various effects of network degradation on communication between these two entities, such as packet loss, delay, and jitter. By introducing these network degradation effects, the NDE allows evaluating the impact of different network conditions on the performance of the MEC application, such as weak signal, presence of noise, network congestion, and high latency. These conditions are often absent or intermittent in the real environment, making it difficult to capture a sufficient amount of data to adequately train ML/DL models. Simulation of these anomalous network conditions is essential to generate enough data to develop robust models that can accurately predict the behavior of AGVs even under difficult and unpredictable network conditions, which is a critical requirement in the industrial setting.
This use case proposed to use two software connectors deployed on the MEC platform and based on the European Industrial Data Space (IDS) Trusted Connector (IDSTC) technology. These connectors were added to the MEC application with the ultimate goal of consolidating the MEC infrastructure as a valid resource for Industry 4.0 verticals in 5G networks. The IDSTC is an open IoT edge gateway platform that provides a standardized way to communicate with external components. The IDSTC is an implementation of the Trusted Connector in the Industrial Data Space reference architecture, following the open standards DIN Spec 27070 and ISO 62443–3. IDSTC can be used to connect sensors, cloud services and other connectors using a wide range of protocol adapters. In our use case, the left IDS connector allows exporting ML predictions of the Guide Error variable to an external Operation Support System where either human operators or a fully automated Logistic Process Control will process the predictions to apply some corrective manoeuvre to the AGV through the right IDS connector whenever required.
The predictive model proposed in this architecture tries to detect in advance AGV’s trajectory deviations to compensate for AGV response time as due to the inertia of its mass, it may not be able to respond immediately to the PLC’s commands. By forecasting significant deviations from the track path, it is possible to anticipate AGV malfunctions and take appropriate corrective actions to keep the AGV on track or bring it to a complete stop.
In normal situations, AGV deviations can be corrected by the PLC using the instantaneous guide error that is detected by the magnetic antenna and informs the AGV if it is situated at the right or at the left of the trajectory. If the error is positive then the AGV is instructed by the PLC to increase the steering angle to approximate the path. Conversely, if it is negative the PLC indicates the AGV to decrease its steering angle. Finally, if the error is zero means that the AGV is correctly situated in the middle of the path and the direction is maintained. This control strategy allows the AGV to follow the desired path in real time.
Complementarily, forecasting these errors can provide valuable information about the quality of the navigation in the future. If this quality is bad the AGV will have problems following the trajectory, as it will oscillate too much or even it may leave the path. To avoid these situations in advance, the Logistic Process Control can enforce specific actions such as adjusting the longitudinal speed reference using the predicted error. In this way, when the predicted error grows, the longitudinal speed reference is reduced to maintain the navigation level. This severe action may momentarily reduce productivity but avoids the production line shutdown. In an extreme case, the Logistic Process Control can decide to completely stop the AGV to prevent causing damage to material objects or people.
3.2 Use case setup
The use case described in Subsection 3.1 was set up and performed at 5TONIC, an open laboratory founded by Telefónica and IMDEA Networks that provides a controlled but realistic environment to deploy experiments that make use of 5G network capabilities as a core technology. At 5TONIC, we prepared different AGV experimentation scenarios that involve simulation of various network degradation effects to recreate realistic scenarios of network impairments. First, we established a reference circuit indicated by a magnetic tape on the floor in a \(300\,m^{2}\) room that included a battery recharging point for the AGV. Next, a MEC platform was created to host the virtualized PLC and the rest of the services that are required to provide the intended functionality (data collector, packet aggregator, ML engine, and IDS connectors). The virtualized PLC, the Machine Learning engine and the rest of services were deployed in several virtual machines. To acquire data for training and testing the ML/DL models, network packets transmitted from the AGV to the virtual PLC were captured in the Machine Learning virtual machine using the Unix command line tool "tcpdump" and stored in standard "pcap" file format. During this experimentation procedure, several degradation effects on the connection between the AGV and the virtual PLC were applied to ensure robust behavior of the predictive models during operation in the real environment. To generate these network perturbations (delay, jitter, packet drop, and corruption) in the link between the AGV and the PLC, the Unix “Traffic Control” command line tool was run on the MEC platform. The following subsections detail the process that was followed to generate the data, which was later pre-processed, in order to convert them to a suitable format for the training and testing of the ML/DL models. A summary of the workflow of this process can be appreciated in Fig. 3.

Summary of the data collection, preprocessing and DL/ML models training workflow
3.3 Network data generation scenarios
As we plan to train our ML/DL predictive models in a supervised manner, we need to collect labeled data that is representative of real AGV operating scenarios. To this end, we have also performed multiple network data captures in which we emulate network degradation effects on the communication between the AGV and the PLC. Network data captures contain the packets transmitted in the AGV-PLC connection. We refer one data capture to one run of the AGV with the same network configuration. In each data capture, the AGV is initially placed at a fixed position in a figure-eight circuit and then the PLC is commanded to move the AGV across the circuit at least five times. We introduce delay and jitter as network degradation effects. Delay refers to the addition of a fixed delay to the network packets. Jitter refers to the addition of a random delay to network packets. The delay values were randomly sampled from a normal Pareto distribution with a mean of between 50 and 300 microseconds and a standard deviation of between 10 and 50 microseconds. These values were chosen by carefully analyzing the network traffic of a real AGV production line for a considerable time. We should note that for the same experiment, delay and jitter were not introduced simultaneously. The reason is that we wanted to evaluate the effects of each network degradation effect independently. After a thorough inspection of the network traffic, we concluded that a scenario in which both effects are present at the same time is not representative of the real AGV operation scenario and would have made ML/DL training more difficult. Three different types of data capture were differentiated:
-
1.
Clean: No delay or jitter has been introduced in this type of data capture. These data captures are used as a formal verification of the performance of the AGV control system in the absence of network degradation effects (i.e., normal situation).
-
2.
Static: In this type of data capture, delay and jitter are introduced as a constant network degradation effect and the AGV is made to operate under these conditions. The objective of this data capture is to evaluate the effects of network degradation on AGV performance. We should note that during the first and last 30 s, as well as during the 30 s of the middle part of the data capture, no degradation effects were introduced. In this way, the transition from a clean network to a degraded network, and vice versa, is also captured. This is to evaluate the effects of network degradation on AGV performance when these effects are only temporarily introduced. This can help train models that behave as expected, even in situations where network degradation effects appear and disappear abruptly during AGV operation.
-
3.
Ramp: In this type of data capture, delay and jitter are introduced as a network degradation effect that increase gradually over time. This type of data capture allows the effects of network degradation on AGV performance to be evaluated while the AGV is initially under control, but the effects of network degradation become more severe over time, leading to a departure of the AGV from the circuit.
All data captures were collected at least three times to ensure data reliability for each scenario. During each capture, we collected all packets transmitted via the UDP protocol between the AGV and the PLC. Any other packets on the 5G network that were not related to the communication between the AGV and PLC were discarded. Once the data was captured, it was stored as raw PCAP files, totaling almost 100GB. The data captures contained around 434,000 snapshots of the AGV-PLC connection that generated roughly the same number of examples in the dataset used for training and testing.
3.4 Data feature extraction
The network data captured between the connection of the AGV and its virtual PLC underwent a feature extraction process before been input to the ML components. Two types of features were selected: (i) AGV variables that were contained within the payload of the AGV-PLC connection packets, and (ii) statistics of the AGV-PLC connection. An AGV’s proprietary tool was used to decode the control payload of the AGV-PLC connection, and the Tstat tool, a widely-used network analysis tool (http://tstat.polito.it/), was used to extract network statistics from the connection. It is worth noting that because the ML models presented in this work try to predict the future deviation of an AGV controlled by a virtual PLC under a degraded network connection, it was considered important to add network features as exogenous variables to the models in order to detect network degradation and complement the AGV variable that is being forecast.
From over one hundred variables extracted from the AGV-PLC connection payload, only two of them were selected for this study: the instantaneous Guide Error and the Stop Flag. The other variables containing AGV status data such as wheel speed and battery status, were discarded. A limited set of AGV features was used to minimize the dependence on the AGV system provider and to enable easy adaptation of the trained model to other AGVs of different providers in the future. The Stop Flag variable was used only during the preprocessing phase to exclude instances when the AGV was stopped (e.g., when recharging the batteries), as predictions were not relevant during these periods. The Guide Error variable was detected by a magnetic antenna that informed the AGV about its location to the right (with a positive value) or left (with a negative value) of the magnetic strip in centimeters.
Guide Oscillation, another AGV feature that was considered in this study, was derived from the Guide Error variable during the preprocessing phase as it was not present in the connection payload. The Guide Oscillation feature represents the number of times the value of the Guide Error variable changed sign in a predefined interval. We conjecture that an increment of AGV oscillation values with respect to the trajectory could alert us of an AGV malfunctioning. Both AGV variables were considered endogenous when they were the object of the prediction, or exogenous when they helped in the prediction of the other.
Three AGV-PLC connection statistics (packet timestamp, number of packets sent, and number of packets received since the start of the connection) were chosen from a set of eight variables generated by the Tstat tool. The other variables provided by Tstat were discarded as they were constant throughout the connection, which does not provide information to the ML models. Among these discarded variables was the packet size, which, due to the characteristics of the communication protocol between the AGV and the PLC, had a constant length of 80 bytes. It should be noted that Tstat can calculate these statistics from network connections without the need to use payload information, which means that it can do so even if the connection is encrypted.
The three selected features were processed to generate a set of seven exogenous variables, as presented in Table 2 (NET feature set). The reason for this expansion was because these new variables had already been used successfully in previous research works such as [24] and [25]. Specifically, the two features Inter-arrival Time of Client and Inter-arrival Time of Server were proposed in [24], and the five features Total Packets of Client, Total Packets of Server, Total Packets per Second of Client, Total Packets per Second of Server, and the ratio between Total Client Packets and Total Server Packets were presented in [25]. In a preliminary phase, the set of connection statistics used in [4] was also considered, but after observing that the suggested variables, apart from the seven previously mentioned, did not add any significant information to the models, it was decided to exclude them and use only the previous seven.
Finally, all processed data was compiled into a single dataset file that included the first nine columns representing the features in Table 2, along with two additional columns for the timestamp and experiment identifier. The dataset has as many rows as the number of times Tstat calculates statistics for the AGV-PLC connection during its lifetime. Generally, and unless there is a burst of packets, Tstat recalculates the statistics every time a packet arrives. When a burst arrives, the statistics are recalculated only once considering the entire burst of packets. The timestamp was necessary to maintain the packet sequence in the file, as the models proposed in this paper solve the forecasting problem with time series. Similarly, the experiment identifier ensured that data from different experiments were not mixed during the construction of time windows for time-series analysis. The resultant file was saved in Apache Parquet format, which compressed the information and reduced its size to approximately 20 MB. It is worth noting that the initial captures in PCAP format occupied approximately 100 GB of storage space.
3.5 Advantages and disadvantages of the proposed solution
The solution proposed in this section offers a range of benefits and limitations that must be carefully considered. The primary advantage of this solution is that it enables real-time scenarios with a realistic deployment of 5G MEC and industrial-grade AGV. This facilitates the evaluation of the proposed system in a more practical industry setting, enabling accurate assessment of its performance. Related to the above, the proposed system’s ability to realistically simulate and collect data of a wide range of disturbance patterns that may naturally arise in the 5G network is a significant advantage. This allows for the system to be accurately and reliably tested and evaluated under various realistic conditions, making it more robust and reliable when deployed in the real-world scenario. Furthermore, the use of a virtualized PLC system offers cost savings, redundancy, scalability benefits, and easier upgradeability. These features make the system more flexible and adaptable to varying requirements, increasing its overall efficiency.
In addition, as will be discussed in Sect. 5.4, the use of robust and powerful deep learning techniques, capable of running on commonly available hardware, has facilitated the execution of up to 64 AGVs in parallel in real time. This approach drastically reduces the total execution time compared to conventional forecasting methods, such as ARIMA. In addition, the use of deep learning algorithms allows the system to scale effortlessly to accommodate a larger number of AGVs, making it an ideal solution for companies with growing demands. Furthermore, our solution is based on multi-horizon forecasting models that provide the system operator or technician with the ability to dynamically select the most appropriate forecasting step based on factors such as AGV workload, network stability, and desired accuracy. Unlike conventional approaches that necessitate the training and validation of numerous models for different forecasting horizons, this method eliminates the need for such tedious procedures. Moreover, this approach represents a robust solution in the face of unexpected disruptions in the AGV network, which may cause the AGV and PLC to lose connectivity. This characteristic is particularly significant in industrial settings where operational reliability is critical, as it ensures that the system continues to operate even in the presence of disruptions or failures, thereby enhancing its overall reliability.
On the downside, the system reliance on powerful DL algorithms is a potential drawback that must be considered Although we have shown that DL models can be successfully used in real time to control a fleet of up to 64 AGVs working in parallel, the system can become computationally intensive if the number of AGVs increases significantly. Another limitation is that the disturbances used in the system are generated synthetically, and, although great efforts have been made to simulate a realistic environment, it is not possible to completely replicate the real-world conditions. Therefore, it is possible that the system’s performance may differ slightly in real-world situations. Additionally, the circuit chosen in a factory may be different, and the model would have to be retrained for different factories. Finally, the models used in the system are trained for a specific type of AGV, which means that if different AGVs are used, with different guidance mechanisms, it is necessary to train new models.
One additional limitation of the solution to consider is that the proposed forecasting models are trained, validated and evaluated on specific conditions and may not possess the capacity to generalize to different scenarios. In particular, the models are designed to be optimized for a particular circuit layout and AGV type. Consequently, if varying AGV types are utilized, or if there are significant alterations to the circuit layout or factory environment, then the models would require a fine-tuning process with data collected in this new environment to ensure optimal performance.
4 Experiments
The research described in this work has been conducted in the form of a series of experiments. Two AGV variables, Guide Error and Guide Oscillations, were initially considered interesting variables to be predicted in advance, as large values of them suggested a direct correlation with AGV difficulties (Subsection 4.2). Finally, the Guide Oscillations variable was discarded as no direct correlation was found with AGV difficulties (Appendix Subsection A.1). Therefore, only the Guide Error variable was used in our experiments to predict it in advance.
The experiments consist in turn of three different variations:
-
First, we trained two different DL models (N-BEATS and LSTM), Random Forest and ARIMA using only the guide error as input feature to the models.
-
Second, we added a fixed set of network variables consisting of seven different statistics of the UDP connection established between the AGV and the PLC as they can provide timely information of network degradation situations.
-
Third, we tried combining all the previous features with the Guide Oscillations variable that represents the oscillations made by the AGV along the line on the floor that marks the path the AGV must follow. These oscillations are not directly generated by an AGV sensor, but are a handcrafted feature that we computed from the Guide Error measurement. More precisely, we calculated the oscillations as changes in the Guide Error sign, which can be interpreted as the AGV crossing the line. Note that the occurrence of large values for this feature might indicate that the AGV is struggling to maintain its trajectory, and therefore it could be particularly useful for detecting when the AGV is about to leave the track.
Using these three sets of input features, the objective of the experiments is to predict in advance the Guide Error of the AGV. We aim to predict 200 time steps (20 s) in the future for all the time series that we use to feed the models. Table 3 shows the three variations of experiments that we have proposed and their associated coding, which we will use to refer to them throughout the article.
Note that ARIMA was used only in the first variation, as only univariate ARIMA has been reported in the literature to achieve decent performance when compared to more complex models such as DL.
4.1 Time-series forecasting techniques selection
In this work, our aim is to evaluate whether N-BEATS models, as representatives of state-of-the-art sequence to sequence models for time-series forecasting, are able to outperform traditional DL architectures, ML models and statistical methods in the proposed problem.
Our choice of N-BEATS as the DL architecture was motivated by its state-of-the-art performance in several well-known forecasting competitions [16]. N-BEATS is a DL model that was specifically designed for time-series forecasting and has shown excellent results with univariate time-series data, while providing model interpretability capabilities that are absent in other DL architectures [16].
The N-BEATS architecture exhibits a number of highly desirable properties, such as being directly applicable to a wide range of problem types without the need for extensive feature engineering, being faster to train and more scalable than other DL architectures, such as LSTM, with the added benefit of being interpretable, which is extremely valuable in some practical scenarios. In addition, the N-BEATS architecture has shown better generalization capabilities than other DL models when trained on a specific source time-series dataset and applied to a different target dataset [16, 18,19,20, 26].
To carry out our study, we propose a modification of the original N-BEATS architecture [16] to enhance the architecture’s ability to model our multivariate series forecasting problem. In Sect. 4.1.1 a more detailed explanation of this novel architecture is provided highlighting its key components and mechanisms.
Furthermore, Sect. 4.1.2 presents the rationale behind the selection of other techniques for time-series forecasting that will be used as benchmarks to compare with the N-BEATS model. We outline the criteria used to choose these alternative approaches, which encompass a range of traditional deep learning architectures, machine learning models, and statistical methods. By including these diverse techniques, we can perform a comprehensive comparative analysis, examining the strengths and weaknesses of each approach in relation to the proposed problem.
4.1.1 N-BEATS architecture and proposed modification
The development of N-BEATS is based on the motivation to create a method for the prediction of univariate time series using only pure DL architectures, while maintaining the ability of statistical models to interpret the predictions made [16].
N-BEATS is an ensemble of deeply stacked feed-forward networks organized in blocks and interconnected via residual connections. N-BEATS takes advantage of a novel residual network topology that facilitates model interpretability and enables smoother gradient flow. The residual connections of the N-BEATS architecture allow each subsequent block to directly learn the residuals of the previous block, which alleviates the training difficulty and speeds up convergence. The target prediction is then obtained by linearly combining the predictions of all blocks in the network, allowing for better interpretability. Furthermore, in the N-BEATS architecture, specific constraints can be imposed to force the model to decompose the predicted time series into its seasonal and trend components, providing additional information about the data.
The architecture of N-BEATS is constructed using a basic building block, which is depicted on the left side of Fig. 4. Each of these blocks has four fully connected layers with 512 neurons and the ReLU activation function. The output of this last layer is divided into two branches, one used for future prediction, named forecast, and one for prediction of past data, named backast. The forecast is the block’s contribution to predict the sequence of future values following the window of past values it has received as input, while the backast is the result of partially approximating the input it has received. Both predictions are carried out by obtaining an expansion coefficient, which is a numerical vector that allows reconstructing a sequence of the time series from a linear transformation using a basis vector, this basis vector is defined by the set of weights of the next layer to which each branch of the block is connected. More precisely, this other layer, which also has no activation function, will calculate the pointwise product between the expansion coefficient of the branch and the base vector, obtaining as output the forecast or the backast, depending on the branch. As for the weights of this layer, these can be learned together with the rest of the weights of the network or, on the contrary, they can be manually specified to consider certain aspects of the problem to be solved, shaping the structure of the outputs to enable later analysis of the predictions based on its decomposition in trend and seasonality components.

Diagram of N-BEATS architecture
A fixed number of the blocks described above is inserted into an arbitrary number of stacks, as illustrated in Fig. 4. Each of these stacks is connected using a novel topology based on the residual blocks of other well-known architectures such as DenseNet [27]. This topology is based on the introduction of connections that allow each stack to receive as input the output of the previous stack, which corresponds to the backast branch of its internal blocks, subtracted from the input of the previous stack. In this way, the input of the next stack will not contain the part of the input of the model that has already been predicted by the previous stack, allowing it to focus on what it has not yet learned to predict. The only exception to the above rule is the first stack, which only receives as input the data that are used to feed the model (i.e. the sequence of values observed in the past). On the other hand, the output of each stack will be the one corresponding to the forecasts of its internal blocks. These outputs are added together to obtain the final future prediction of the model, as can also be seen in Fig. 4. Another clever detail of the proposed architecture is that it allows one to observe the values of the partial forecasts and backcasts, allowing one to clearly identify the contribution of each stack, a fundamental need to achieve a model that produces interpretable results.
Although N-BEATS was originally conceived as a univariate model, we have proposed as a novelty a redesign to provide the architecture with the ability to model multivariate series as well, even allowing to consider variables according to the nature of their relationship with the independent variables (endogenous or exogenous). To achieve this purpose, we have included a concatenation layer that combines multiple inputs into a one-dimensional input layer. With this approach, exogenous features can be incorporated into model learning without interfering with model optimization. That is, the model is optimized only to model the dynamics of the endogenous variables, since the exogenous variables are only used as support for model learning and are not the target of forecasting. Our approach allows the model capability to be fully dedicated to modeling the endogenous dynamics and not the entire multivariate context.
4.1.2 Selected forecasting techniques for comparison
To compare N-BEATS performance with other well-established machine and deep learning models, we reviewed recent literature on time-series forecasting to identify the most relevant models for comparison. Based on this review, we selected the LSTM neural network architecture as the main representative of DL architectures for time-series forecasting, as it has shown superior performance in learning temporal dependencies in multivariate time-series forecasting [28,29,30] and has been used extensively in the literature. As representative of traditional ML regressors, we selected Random Forest, which has demonstrated high robustness and performance in several time-series forecasting applications [31], thus providing a fair comparison with DL models. For statistical methods, we chose ARIMA, which is a widely used and well-established method for general-purpose time-series forecasting and because it is considered a standard benchmark for evaluating forecasting models performance [32]. Additionally, to establish a baseline for comparison, we used a naive baseline based on the prediction of the last known value of each time series, which is a common method in time-series forecasting [32]. Finally, we also used the model ensembling technique to boost the overall prediction performance of individual models using them as the base regressors. Further details of the advantages of the selected models compared to other well-known techniques is given in Subsection 6. In addition, a detailed overview of the selected techniques is presented later in Subsections 1 and 2.
4.2 Forecast target variables
To solve the proposed use case one of our objectives is to predict the future deviations of an AGV with respect to the magnetic tape running along the circuit established on the floor in order to safely plan for corrective manoeuvres. We refer to the variable that quantifies the amount of deviation of this magnetic tape detected by the AGV sensors in both directions as Guide Error. In addition, since the main objective of this work is to detect when the AGV is likely to deviate from the circuit, we have also proposed a second predictor variable called "Guide Oscillations". This variable is quantified as the number of times the AGV has crossed the centre line of the magnetic tape. We have determined that this variable is closely related to the AGV deflection. Specifically, a high number of oscillations is a clear indicator that the AGV is operating erratically and therefore it is highly likely to start deviating from the circuit.
Due to the inertia presented by an AGV moving at high speed, correcting its trajectory once it starts to deviate from the magnetic tape requires a considerable amount of time. In real deployments, it has been observed that it takes 10 s to stop a fully loaded AGV in motion. By conducting several experiments, we have concluded that dedicating a margin of 10 to 15 s has proven to be sufficient in order to provide the AGV operator with the time needed to make the necessary corrections to keep the AGV on track. In our case, we have placed the forecast horizon even further in time (20 s) in order to provide a greater margin of safety for the AGV operator.
Furthermore, when communication between the AGV and the PLC starts to degrade, it causes high fluctuations of the Guide Error variable from positive to negative values. In fact, in preliminary experiments we observed that the models tended to predict the mean value (zero). To solve this problem, we decided to ignore the sign of the values and predict instead the absolute value of the Guide Oscillations variable. We found no evidence that the sign provides relevant information about AGV deviation, i.e., there does not appear to be any correlation between AGV malfunction and a deviation toward one of the two particular sides. Therefore, by omitting this information, we avoided this problem, resulting in more accurate predictions.
Following the same reasoning for the Guide Error variable, by predicting the absolute values of the variable, we put greater emphasis on the intensity of deviations occurring on short periods of time on both sides of the magnetic tape (positive and negative), which is clearly a key indicator of anomalous behaviour of the AGV.
We also decided to predict the mean of the absolute values of the Guide Error and Oscillations variables for the next 20 s instead of predicting the actual values. The reason for this decision is that small deviations of the AGV may occur naturally when it travels through certain curves of the circuit. Fluctuations in the mean value regarding specific locations in the circuit are a strong indicator that the AGV is not performing as expected and therefore corrective action should be taken.
In a preliminary analysis of the Guide Oscillation variable before training any model, we did not observe any significant correlation between this variable and the AGV deviation of the circuit, which led us to discard the Guide Oscillations variable as a predictor of AGV malfunction. Details of this analysis can be found in Appendix Subsection A.1. However, it is worth noting that although we discarded the Guide Oscillations variable as the predicted variable in our experiments, this variable was used as input variable to give the models an opportunity to extract some useful information from it.
4.3 Data processing
To learn the temporal relationship of the Guide Error and Guide Oscillations variables in a supervised learning task, the data is first converted into a set of lagged observations. In this way, the models can be trained to predict the 200 subsequent time steps of the Guide Error and Guide Oscillations from the window of past values of both variables. In the following subsections, we detail the process we followed for the processing of the collected data, including the splitting of the dataset in train and test set, the granularization, aggregation and standardization of the forecast variables and finally, the time-series windowing procedure.
4.3.1 Data granularization, aggregation, and standardization
All the collected data have been processed to obtain granularized time series at a fixed time interval. We decided to forecast time-aggregated values instead of instantaneous values because we observed that this variable presents too much noise for the forecast to be feasible with this approach. In fact, we have been confronted by a considerable difficulty to obtain better results than a model based on random guess. The aggregation of these values can be interpreted as an additional feature engineering step that greatly facilitates the identification of statistical patterns for the DL models, greatly speeding up training times and smoothing the convergence process.
Based on a trial-and-error procedure and evaluating the quality of the predictions using various quantitative metrics (MAE and MSE) over the validation data, we concluded that 100 ms is the best and most logical trade-off that reduces the presence of noise in the measurements while minimizing data loss. For this purpose, we combined the values in 100 ms intervals using the mean absolute value as the aggregation method for the Guide Error variable. We used the absolute value in this aggregation to prevent the model from overfitting to zero.
To accomplish this aggregation process, we decided to perform a moving average using a sliding window of size 100 ms. We have chosen the moving average instead of other aggregation methods to obtain a linear aggregation of the data that does not affect its distribution and only allows a reduction of the noise without introducing bias on the temporal correlations of the measured values. A moving average consists of dividing the time series into contiguous windows of a given size and calculating the mean of the values in each window. The result is a new time series in which each value is the average of the values of the original time series over a given time period. For example, suppose that we have a time series with 10 values and we want to calculate the mean over a sliding window of size 5 with an interval of 1. This would result in a new time series with 10 values, where the values are the result of calculating the mean over 5 contiguous values in the original time series, stepping one value at a time. When there are not enough values available to fill a window, the mean is calculated over the available values. This aggregation process was not performed for the AGV flags (obstacle detection, battery warning, etc.) because these values do not present any kind of temporal behavior related to the target variable forecasting and, therefore, aggregation is not necessary as they are not used as input for the ML/DL models. For this reason, only the last value of every 100 ms interval of the AGV flags was kept. In addition, missing values were filled with the last observed (i.e., non-missing value) of the same variable.
Finally, we applied standardization to the processed data. Standardization is a common pre-processing step in DL used to transform in order to have zero mean and unit variance. This normalization process is crucial to ensure that all the input features are represented on the same scale, which results in easier model trainings. There are several ways to standardize data, but the most simple and effective method is the Z-score method, which transforms each characteristic by individually subtracting the mean of each feature and dividing by its standard deviation.
4.3.2 Time-series windowing
To construct the samples, we used to train our models, we applied a sliding window with a unit window size to each experiment to create a time-series data set of lagged observations of window size K (\(t_{-1},\ t_{-2},...,t_{-K}\)) of each value. It should be noted that this moving window was applied separately to each experiment to ensure that the inter-dependencies captured by the lagged values in the window are between values from a single experiment and are not diluted by the inclusion of values from other experiments that are associated with a different network scenario and thus with dissimilar initial conditions. As the optimal choice of the window size K is very much problem dependant, we defined four different temporal window sizes: 40 time steps (4 s), 75 time steps (7.5 s), 150 time steps (15 s) and 300 time steps (30 s). For this procedure, we decided not to apply padding because we decided not to include any information about future values regarding different experimental conditions. Similarly, the use of a null value to serve as padding was also discarded, as this would have introduced artificial correlations in the data that could potentially bias the neural network learning process.
Finally, samples in which the AGV was completely stationary were removed. As this information was not explicitly collected during the data collection process, we used the AGV flags to identify those samples. In particular, we found that the activation of at least one AGV flag was strongly correlated with an AGV stall. In addition, the first and last 10 s of each data capture were also removed, as they exhibited large fluctuations caused by the transition from a fully stopped state to an operational mode or vice versa.
4.3.3 Dataset creation
In ML and DL, it is common to divide the data into a training dataset and a test dataset. The training dataset is used to train the model, while the test set is used to evaluate the performance of the model. Based on our experience in previous works [33], instead of using the common method of randomly spliting all available data in training and testing datasets, we applied a different separation method to obtain more conservative and robust results after testing: in our data recollection process, the first experiment was used for building the test dataset while the other two experiments were reserved as training data.
Once data separation in training and testing was completed, the training dataset was randomly divided into two separated sets: a training set (\(80\%\)) and a validation set (\(20\%\)). Subsequently, the validation set was also randomly divided into two sets, one for hyperparameter validation (\(10\%\)) and the other to monitor the training procedure in order to prevent overfitting (\(10\%\)).
4.4 Model training procedure
For each combination of input features and time window size, we trained 30 different LSTM and N-BEATS models with hyperparameters sampled using the Tree-structured Parzen Estimator (TPE) algorithm [34], a well-established DL optimization technique that utilizes a tree structure to model the probability density function of hyperparameters and is capable of simultaneously optimizing multiple hyperparameters in an efficient manner. Of those 30 variations, we selected the ones that maximized the average of the Mean Absolute Errors obtained for each one of the 200 predicted time steps during its validation. For this calculation, since our samples were composed using an aggregation method, we omitted the first 10 time steps to avoid leaking information of the present in the prediction. All models were trained using early stopping with a fixed patience of 100 epochs for both experiments. By using the early stopping technique, instead of setting a fixed number of epochs beforehand, the training duration is left undefined, running until the error rate stops improving, which helps to find better local minima. In addition, early stopping helps to avoid overfitting because it terminates the training procedure once the error computed using the validation data does not decrease over the pre-specified number of epochs (100 in our case). We set a high patience in order to compensate for the lower number of weight updates performed when using larger batch sizes. As optimization algorithm, we used Adam with a learning rate of \(10^{-4}\) to mitigate the overfitting issues that appeared in our preliminary experiments. On the other hand, from the data analysis point of view, since we intend to predict continuous values (the Guide Error variable of the AGV), the problem we intend to solve can be classified as a regression type. For this reason, we used the Mean Squared Error (MSE) as loss function over Mean Absolute Error (MAE) to the non-differentiable nature of the latter. In addition, MSE is a monotonically increasing function when the prediction is far from the actual value, providing more informative value over MAE. Furthermore, the Guide Error variable is greatly affected by outliers and the values for his variable are theoretically not bounded (Guide Error is limited by the sensor range and physical visibility of the magnetic tape). For the above reasons, we consider MSE to be a more suitable choice as a loss function than MAE for solving the problem at hand.
On this occasion, we will focus on the generic variant of N-BEATS, for this reason, the interpretable version will not be considered in any of the experiments. Additionally, for a more faithful comparison, we choose to rely on the behaviour of N-BEATS as a Multi-input Multi-output method for multi-step-ahead forecasting (a detailed review of this type of forecasting and the Multi-input Multi-output method can be found in section 7.2). Therefore, we trained the LSTM models as sequence-to-sequence models rather than in an auto-regressive manner, i.e., we force the decoder to return the full sequence of the 200 future time steps instead of obtaining the predictions one at a time by recursively feeding past predictions into future inputs. This approach is described in more detail in the following sub-section.
The search ranges for every hyperparameter of the LSTM and N-BEATS models for both experiments are specified in Table 4, with optimal values for each set of input features evaluated in the Experiment GE, shown in Tables 9, 10, and 11. The above table shows the search type, the hyperparameters to be tuned, and their search ranges for four different models: LSTM, N-BEATS, Random Forest, and ARIMA. Hyperparameters are adjustable parameters that determine the behavior of a ML model during training and can have a significant impact on the model’s performance.
For LSTM, the hyperparameters included in the search are the number of LSTM layers, the number of LSTM units, the use of batch normalization, L2 regularization for the LSTM layers, the number of fully connected (FC) layers, the number of units per FC layer, the use of batch normalization for the FC layers, L2 regularization for the FC layers, and the dropout rate. For N-BEATS, the hyperparameters included in the search are the number of stacks, the number of blocks per stack, the theta dimension, the number of units of each non-linear FC layer per block, the number of non-linear FC layers per block, whether to share weights in each stack, and the same hyperparameters as the number of stacks, blocks per stack, and theta dimension.
For Random Forest, the hyperparameters included in the search are the number of trees and the maximum depth of the trees. For ARIMA, the hyperparameters included in the search are the autoregressive term (p), the moving average term (q), and the integration term (d). The search range for each hyperparameter is defined by the minimum and maximum values. For a more detailed description of the function and effect of each hyperparameter listed in Table 4, we recommend referring to Sect. 4.1. This section provides a detailed explanation of the model architectures presented in the table, as well as the various hyperparameters involved in shaping the behavior of the models.
In addition, we also used Random Forest models as ML regressors, each composed of 100 estimators (decision trees) and unlimited tree depth, and ARIMA as representative of statistical methods. The reason we chose these hyperparameters for the Random Forest model is that it has been demonstrated that 100 estimators are enough to provide good performance in terms of generalization and computational efficiency when using unlimited tree depth. In addition, in some preliminary experiments, we confirmed that these hyperparameters provided the best model performance in all situations. During the testing phase, we used as the baseline a naive model based on predicting in time t the last known value of each time series (i.e., the value in \(t-1\)).
To compare the effectiveness of ARIMA with respect to the other models, a method similar to that proposed in [35] was used to predict the Guide Error variable. We describe this method in Algorithm 1. Initially, the method identifies the ARIMA hyperparameters with the training data set using the Auto ARIMA heuristic from the pmdarima library [36] with default parameters. The best hyperparameters are then used to train the ARIMA model again, but using the statmodels library [37] to store the optimized weights. This step is summarized as getting weights from arima_initial_model (line 6 of Algorithm 1). From this point on, the following steps are iteratively executed in the proposed algorithm: (1) a new element of the test data set is added to the training data set (in a time-ordered manner); (2) a new ARIMA model is trained with the weights of the initially trained model (arima_initial_weights), the initial hyperparameters (arima_hyperparamters) and using the augmented training data set(l_history_val); (3) the prediction is performed 200 steps ahead (20 s) using the last trained ARIMA model (arima_model). Unlike the method used in [35], model retraining is always performed in each step starting from the initial weights (resulting from training with the training data), which speeds up the model training (with respect to the use of the default initial weights) and generalizes the weights obtained with the training data to the test data. At each iteration, the prediction result is accumulated and stored for later comparison with the results of the other ML models.

ARIMA out of sample prediction
The results obtained with the ARIMA model following the proposed algorithm described in Algorithm 1 can be used to evaluate its effectiveness with test data, although this is a problem in which ARIMA would not normally be used. This method has several problems, such as constant retraining and loss of effectiveness of the method at the concatenation points of the experiments.
It should be noted that since Random Forest and ARIMA have their hyperparameters fixed because they were manually fine-tuned in preliminary experiments to achieve an optimal fit, they were not taken into account during the validation procedure. For this reason, a Random Forest model was trained for each combination of feature set and time window, resulting in a total of 12 models. In the case of ARIMA only a single model was trained since, as mentioned previously, only the AGV feature set was considered as input for this model, and, in addition, it was not necessary to segment the temporal window during the input processing of this model.
Finally, we chose to evaluate the performance of our models in the validation and testing phases by calculating the Mean Absolute Error and the Median Absolute Error of the predicted values and the ground truth time step-wise.
4.5 Multi-step-ahead forecasting
One step-ahead forecasting is the most basic type of forecasting. It involves predicting what will happen in the next period based on what has happened in the past. This type of forecasting is used to predict short-term trends and is most effective when there is a strong correlation between past and future data. In contrast, in multi-step-ahead forecasting, the goal is to produce a time series as a forecast instead of predicting a single time step at a time. This approach is often used when the time series being forecast is highly nonlinear and when there are multiple sources of noise in the data. In this setting, a single-step forecast is likely to be highly inaccurate. By instead producing a forecast for the entire time series, the noise in the data is averaged out and a more robust prediction can be made. It should be noted that, while some accuracy is sacrificed due to the averaging, the improved reliability of the predictions is often worth the trade-off. Moreover, the loss of accuracy is not nearly as important in some contexts as the gain in robustness, such as when the objective is to make a prediction for the near future and not for a specific point in time, as in the case of AGV forecast. There are two main multi-step-ahead strategies: Single-output Prediction and Multiple-output Prediction. A complete review of these two approaches is provided by [38]. On this occasion, we will focus on multiple-output prediction, more precisely, in Multi-input Multi-output method (MIMO).
This method is based on predicting all time steps in the same step, taking into consideration the dependence interrelationships that characterize the time series, while avoiding the independence assumption made by the direct forecasting strategy, as well as the accumulation of errors that can occur with a recursive strategy. This strategy has been successfully applied to several multi-step ahead time-series forecasting tasks [17, 38].
Despite the advantages described above, this strategy also has its drawbacks, the most important of which is that it suffers from low flexibility, since having a single model to predict all horizons makes it inevitable to have to retrain the whole model from the ground up if the horizons need to be adjusted at some point. However, in our case, since we want to validate the effectiveness of our approach using very long-term continuous prediction models, this theoretical disadvantage will not be a problem for our proposed objectives.
From a formal point of view, we can define this strategy as follows. Let I be the unique set of samples in a given time series dataset. Each sample i of the set I is associated with a scalar input \(X_{i,t} \in \mathbb {R}\) and target \(Y_{i,t} \in \mathbb {R}\) at each time step \(t \in [0,T_i]\).
In the above expression, \({\hat{y}}_{i,t:t+r}\) is the predicted sequence of the r-step-ahead forecast with respect to the time step t and f is the prediction model. In time-series analysis, there is a fundamental distinction between endogenous and exogenous variables. Endogenous variables are those that are determined by the system under study, while exogenous variables are those that are determined by external factors that can affect the endogenous variables. In the context of time-series forecasting, endogenous variables are the data points that are predicted (y), while exogenous variables are data points that are not predicted but can also be provided as input to the model to improve forecasting accuracy \((X_i)\). We feed to the model all the past values corresponding to the \(t-k\) time steps within a finite look-back window of size k. In our case, we have chosen r to be always 200, while k could be 40, 75, 150 or 300, depending on the window size that was selected for the experiment.
4.6 Experimental setup
In order to ensure the replicability and comparability of our findings, a comprehensive description of the experimental setup used to conduct the experiments defined in this section is provided below. We conducted our experiments on a server running Ubuntu 21.04 operating system, with an Intel Xeon Silver 4210R CPU with 2.40 GHz base frequency, 192 GB of RAM, and NVIDIA GeForce RTX 3090. We used Python 3.8.12 as our programming language and the following libraries:
-
NumPy (version 1.19.5) for numerical computing.
-
Pandas (version 1.3.4) for data manipulation.
-
Scikit-learn (version 0.23.2) for implementing the machine learning algorithms.
-
TensorFlow (version 2.5.0) for implementing the deep learning models.
5 Results of the experiments
We first describe in Sect. 5.2 the results obtained for predicting the Guide Error variable (Experiment GE), considering the different combinations of feature sets (AGV, NET, and OSCI) that were used as input for model training. Furthermore, in section subsection 5.3, we describe the results obtained by applying the model ensemble technique in order to combine the best models predictions obtained in the testing phase to improve accuracy. Next, in Subsection 5.4, we discuss aspects related to the real-time operation and deployment of the proposed solution in industrial environments, focusing on the analysis of the inference time of the best models obtained and the retraining times required to correct data drift problems that may appear during operational activity. Finally, in Subsection 5.5 a critical discussion of the obtained results is conducted, emphasizing the findings that can be directly applicable to similar scenarios as those considered in this study.
5.1 Evaluation procedure
The performance of our models was evaluated in the testing phase by calculating the Mean Absolute Error and the Median Absolute Error between the real and predicted values. These two metrics were chosen to evaluate the models because they are more robust to outliers, which are not uncommon in our data set due to a certain stochasticity factor present in the Guide Error due to measurement errors, slippery road surface, and unexpected and sudden changes in network traffic conditions. A brief explanation of these metrics is provided below. For this reason, Mean Absolute Error and Median Absolute Error are therefore more relevant in our case to reliably measure model performance. Other metrics such as MSE and RMSE would be less appropriate for assessing model performance in our particular situation, as they are more sensitive to outliers. In addition, MAPE was discarded as a metric to assess model performance due to its limitation of not being able to be calculated when the real value is zero, which is a common value in our time-series data. Moreover, the bias that MAPE shows towards low values that is extremely undesirable for our case, since it is of vital importance to predict higher values accurately in order to correctly detect AGV malfunction. Moreover, the non-symmetric behavior of sMAPE with respect to over/underestimation of the true value and its lack of robustness when the true or predicted values are equal to zero were the most important reasons to discard this metric for our purpose. On the other hand, relative error metrics were also not considered, as they are only relevant when model performance is to be compared between different time-series data, which is not the case.
Mean Absolute Error (MeanAE) is a widely used metric for evaluating the accuracy of a model. It measures the average absolute difference between the predicted value and the actual value. The MeanAE is defined as follows:
where n is the total number of observations, \(y_i\) is the actual value, and \(\hat{y_i}\) is the predicted value.
The MeanAE is a simple metric that provides a measure of how far the predicted values deviate from the actual values. It is a measure of the average absolute error and is expressed in the same units as the original data.
On the other hand, Median Absolute Error (MedianAE) is another evaluation metric that measures the median of the absolute errors. The MedianAE is defined as follows:
where n is the total number of observations, \(y_i\) is the actual value, and \(\hat{y_i}\) is the predicted value.
Unlike MeanAE, MedianAE is a robust metric that is not affected by outliers. The median is less sensitive to extreme values than the mean, which makes MedianAE a better metric for datasets with outliers. Moreover, the use of the median makes the metric less susceptible to skewed data.
In addition, although initially considered, the use of distribution-based metrics as complementary measures was eventually replaced by a detailed visual analysis of the frequency histograms of predicted and real values, as well as the frequency histograms of absolute errors. This decision was made because these values did not provide more information about the performance of the models compared to other common metrics, as we found that they are too simplistic and opaque to provide any valuable insight of the results in our case. Instead, the visual analysis of the frequency histograms of predicted and real values, together with the frequency histograms of absolute errors, provides considerably more useful information about the distribution of values and model performance in our case.
Moreover, in order to determine which feature set and time window leads to the greatest overall performance of each of the proposed models, we have chosen to evaluate them using the average of the Median Absolute Error obtained for each of the 200 time steps. We made this decision because the median is a value that we consider to be more robust to outliers while equally weighting all time steps. In contrast, the mean is a metric that we have found to be misleading, as it favors models that tend to predict linearly (i.e., models that adjust to predict the mean value of the target in order to reduce the risk of overpredicting). For this reason, the mean turns out to be a non-informative metric in our case, as it does not consider how well the model is attempting to predict abrupt changes in the forecast variable.
Related to the above, in our case, it can be concluded that the mean can be a misleading metric because, as its well known, it is very sensitive to the presence of outliers in our data, resulting in poor evaluation performance due to the intrinsic of our collected data. For these two reasons, we suggest using the median to rank and select the best models because it is expected to be a more reliable measure in this context. However, we also include the Mean Absolute Error in the results presented for the sake of completeness and for comparative purposes.
During the evaluation process, the analysis of the Mean and Median Absolute Errors throughout the forecast horizon will be focused on primarily to draw meaningful conclusions about the performance of each model in the short-, medium-, and long-term forecasts. However, linear visualizations of model predictions and real values of the target variable will be presented in order to provide a more direct view of the forecast accuracy of each of the models obtained. In addition, frequency histograms of the predicted and real values and frequency histograms of the absolute errors will be presented to gain a better understanding of the effectiveness of each of the proposed methods in modeling the distribution of the target variable, which will be of vital importance in highlighting overestimation and underestimation issues that may not be evident in the linear visualizations of the predictions.
To test the proposed solution, the performance of each model will be evaluated in a diverse set of 5G network traffic scenarios that have been specifically selected to reflect a variety of realistic traffic conditions that can be experienced in the 5G network during AGV operation. In particular, the performance of the proposed methods will be evaluated under optimal network traffic conditions (clean type) and in the presence of different network disturbances in the packet transmission between the AGV and the PLC that may naturally occur during the AGV operation. The following network degradation effects will be evaluated: (i) a periodically and monotonically increasing delay (ramp type), (ii) a delay with an offset of 150 ms (static type), and (iii) a jitter (variable delay) following a paretonormal distribution with parameters of 100 ms as mean value and 100 ms as standard deviation (static type).

5.2 Guide error forecasting
In this section we summarize the results obtained in the Experiment GE (prediction of the Guide Error Variable) using the three different combinations of feature sets described in Table 3 (AGV, AGV+NET, and AGV+NET+ OSCI) as input to the four proposed models (N-BEATS, LSTM, Random Forest, and ARIMA) and considering various window sizes to perform the segmentation of the time series that were used to train each of the proposed models. Recall that we used as the baseline in the testing a naive model based on predicting in time t the last known value of each time series (i.e., the value in \({t-1}\)). First, a summarized analysis of these results is provided in Sect. 5.2.1. Note that a more detailed analysis of each model combination segregated by feature set can be found in Appendix A. Furthermore, we provide in Sect. 5.2.3 a detailed analysis of the frequency distribution of the predictions and absolute errors of the best models.
5.2.1 Analysis of the performance of models
In this section, we analyze the overall performance of the models obtained in Experiment GE. Firstly, in Table 5 we provide a summary of the results segregated by combinations of feature sets. Table 5 compiles the best models segregated by algorithm (N-BEATS, LSTM and RF) and feature set (AGV, AGV+NET, and AGV+NET+OSCI). The details of the experiment results segregated by feature set can be found in Appendix A(1 Experimental results). Then, we provide in Fig. 5 a different comparison, selecting the best model for each algorithm (RF, LSTM and N-BEATS) without applying any segregation and considering for the selection all time windows and feature sets. In this figure the performance of the models in each time step is shown from \(t+1\) to \(t+200\) (in milliseconds). Finally, we conducted in Fig. 6 an in-depth comparison of the forecasting performance of the three best models (RF, LSTM and N-BEATS) to illustrate a bad effect observed in some models that tend to forecast values near to the mean value of the predicted variable. To the best of our knowledge, this bad effect that we call "lazy behaviour" has not been reported in the literature, and therefore, we analyse its implications in a representative set of network scenarios with different degrees of network perturbations.
Note that although we calculated both the Mean and Median Absolute Error in the predictions of the models, we have chosen to evaluate them and select the best models using the average of the Median Absolute Error obtained for each of the 200 time steps. We made this decision because the median is a value that we consider to be more robust to outliers while equally weighting all time steps. In contrast, the mean is a metric that we have found to be misleading, as it favors conservative models that tend to predict linearly, i.e., models that adjust to predict the mean value of the target in order to reduce the risk of overpredicting. For this reason, the mean turns out to be a non-informative metric in our case, as it does not consider how well the model is attempting to predict abrupt changes in the forecast variable.

Linear visualization of the predictions and residuals of the best models of each algorithm (N-BEATS, LSTM and RF) in a representative set of different network scenarios (Clean without network perturbations, ramp-type Delay, fixed Delay and Jitter) for the Experiment GE. In each plot, time is shown on the x-axis (0.1 seconds each step) and the absolute value of the Guide Error is shown on the y-axis. The Label line plots the absolute value of the Guide Error variable. The Prediction line is constructed with the t+150 element of the forecast horizon of each prediction. The residual points represent the absolute difference between the label and the prediction
Table 5 summarizes the average of the Mean and Median Absolute Errors for different horizon ranges considering the best time window of each of the best models segregated by algorithm (N-BEATS, LSTM and RF) and feature set (AGV, AGV+NET, and AGV+NET+OSCI). In particular, we calculate the average of both metrics in the short-term (ST, ranging from t+1 to t+49), medium-term (MT, ranging from t+50 to t+149), long-term (LT, ranging from t+140 to t+200) and all the time steps of the horizon (AT) of the forecasting horizon (which ranges from t+1 to t+200). In light of the results, we can conclude that N-BEATS is the best performing model using the AGV and AGV+NET feature sets in all horizon ranges (AT, MT, LT, and AT). However, when all features were used as input (AGV+NET+OSCI), LSTM was the best model, although it did not outperform the results obtained by N-BEATS using the other two feature sets.
In Fig. 5 we plot the Mean and Median Absolute Errors of the predictions for the best model for each algorithm (RF, LSTM, and N-BEATS) considering for its selection all time windows and feature sets to highlight the differences of performance among the three algorithms, ARIMA and the naïve baseline. As previously commented, in our analysis we use the Median Absolute Error to rank models. It can be observed that the best RF model only uses AGV features, which indicates that this method is not able to extract any useful information from the exogenous features (NET and OSCI). This limitation of RF is reflected in the fact that it was ranked third in the comparison and only outperforms ARIMA and the baseline. In contrast, N-BEATS obtains the best results of the comparison using a combination of AGV and NET features, which highlights the capacity of the proposed modification of the N-BEATS architecture to extract useful information from exogenous variables. Nevertheless, it is worth noting that N-BEATS did not obtain good results when the OSCI feature was used jointly with the AGV and NET feature sets as input. This observation suggests that a previous feature selection process should be required when using N-BEATS. Finally, the best LSTM model obtained the second position among the three algorithms (N-BEATS, LSTM and RF) in the comparison using all available sets of features (AGV, NET and OSCI). In this case, LSTM can extract useful information from all features, but unfortunately the obtained performance is not better than the obtained by N-BEATS using only a subset of features (AGV and AGV+NET).
We experimentally observed in some experiments that in the case of ARIMA and Random Forest models, there is a clear bias in the predictions towards the mean of the target variable, i.e., the distribution of the predictions is highly centered around the mean of the Guide Error variable, which causes highly inaccurate predictions in extreme values and regions of high fluctuations of the target variable. We refer to this specific phenomenon as "lazy behavior", as the models attempt to be on the safe side in almost every prediction, avoiding extreme values to minimize the likelihood of making highly erroneous predictions. This undesirable behavior prevents the deployment of such lazy models in realistic scenarios, as these models will not predict the large Guide Error values that identify an AGV in difficulty in maintaining its trajectory.
To represent this situation more clearly, we plot in Fig. 6 the predictions at time \(t+150\) of the best models obtained in some representative scenarios, in which different degrees of network perturbations were introduced (clean without any perturbation, ramp-type delay, static delay, static jitter). In the figure, we also indicate the residuals (difference in absolute value) of the data with respect to the predicted values. In all scenarios, the lazy behavior of the Random Forest models manifests itself in the residuals of the predictions. More specifically, as lazy predictions are closely distributed along a constant value, the residuals of a lazy model are highly similar to the Guide Error variable. On the other hand, for non-lazy models (N-BEATS or LSTM), these residuals are spread across the possible values of the target variable, showing significantly higher predictive power of these models in predicting extreme events.
It should be noted that it is crucial to identify models with this lazy behaviour to eliminate them from the selection of the best models as the main goal of our models is to be able to predict sudden changes in the trend of the guide error variable and, what is most important, to predict them early enough to anticipate when problems start to appear in the AGV. Using this anticipatory information, the operator can stop the AGV in time and avoid any potentially harmful situation in the event the AGV leaves the path. In other words, the precision of the forecast of the instantaneous value is not as important as the fact of being able to predict in advance the trend of the guide error values in order to be able to raise some alarm and act on the AGV in time (e.g. stop, slow down). Furthermore, when the best models were selected using the Mean Absolute Error, we found that the occurrence of lazy behaviour among them was more likely than when the Median Absolute Error was used as the selection criterion. For that reason, we previously recommended to select the best models using the Median Absolute Error instead of the Mean Absolute Error.
While lazy behavior is not present in the best global N-BEATS model, we have observed that some of the best N-BEATS models obtained for various combinations of feature sets (e.g., AGV+NET+OSCI) were also affected by this phenomenon, as shown in Appendix Figs. 24 and 28. This observation indicates that this phenomenon is not exclusive of the ARIMA and Random Forest models and can potentially affect a wide range of ML and DL models. Analyzing all trained models by visual inspection, we concluded that Random Forest and N-BEATS and especially ARIMA are the most affected by this issue. Furthermore, we observed that both Random Forest and N-BEATS suffered from this deficiency more frequently when lower time windows were used. On the contrary, we note that none of the best LSTM models obtained during validation for different feature sets and time windows presents this problem. Overall, since the main objective of the models is to accurately predict large fluctuations of the Guide Error variable in order to detect AGV malfunction, this problem is a major concern when models are planned to be deployed in real-time scenarios, and therefore it will be carefully studied in future work.
5.2.2 Influence of the time window in model performance
This subsection presents an analysis of the impact of the time window hyperparameter on the predictive performance of three distinct models, namely N-BEATS, LSTM, and Random Forest. This analysis is carried out for each of the three feature sets investigated in the study, namely AGV, AGV+NET, and AGV+NET+OSCI. Specifically, the objective is to examine how changes in the time window hyperparameter influence the accuracy of Guide Error predictions made by the aforementioned models. The evaluation employs the average Median Absolute Error (MedianAE) as the performance metric, considering the entire forecast horizon. The results of this evaluation for each feature set and time window are presented in Figs. 7, 8 and 9.

Guide Error Prediction Performance using the AGV feature set

Guide Error Prediction Performance using the AGV+NET feature set
Firstly, a performance comparison across time windows using the three different feature sets is presented. For the AGV feature set (Fig. 7), the LSTM model consistently decreased the MedianAE as the time window increased from 40 to 150 time steps, achieving the lowest MedianAE of 0.64 at the longest time window of 150 steps. However, the MedianAE increased slightly to 0.678 when the time window was further extended to 300 steps. On the other hand, the N-BEATS model showed a decreasing trend in MedianAE with the increasing time window, achieving its lowest MedianAE of 0.619 at the longest time window of 300 steps. The Random Forest model followed a similar trend with the lowest MedianAE of 0.678 achieved at the longest time window of 300 steps.
For the AGV+NET feature set (Fig. 8), the LSTM model displayed an increase in performance as the time window increased, achieving its lowest MedianAE of 0.669 at the longest time window of 300 steps. The N-BEATS model generally decreased the MedianAE with the increasing time window, except for the 75-time window that led to an increase in MedianAE compared to the 40-time window. The N-BEATS model achieved its best performance at the longest time window of 300 steps with an MedianAE of 0.599. In contrast, the Random Forest model showed a peculiar behavior, as it exhibited a minimal fluctuation in performance across the time windows of 40, 75, and, 150 steps. However, there was a significant improvement in performance when using the longest time window of 300 steps, with a MedianAE of 0.715.

Guide Error Prediction Performance using the AGV+NET+OSCI feature set
When using the AGV+NET+OSCI feature set (Fig. 9), both the LSTM and N-BEATS models showed a U-shaped pattern albeit in an inverse fashion. Specifically, the LSTM model initially showed a decrease in MedianAE as the time window increased from 40 to 75 steps, reaching its minimum value of 0.637 with a window of 75 steps. However, as the time window increased further, there was a steady increase in MedianAE. On the other hand, the N-BEATS model showed a similar pattern, but with the trend reversed. The model started with the minimum MedianAE of 0.717 and showed a minor increase in MedianAE from 40 to 75 steps. Subsequently, there was an increase in MedianAE as the window widened to 150 steps, followed by a decrease with a time window of 300 steps. However, the minimum value achieved with the 40-time window was not reached. On the other hand, the Random Forest model exhibited a consistent improvement in performance as the time window increased, reaching its best performance at the longest time window of 300 steps, with a MedianAE of 0.685.
At the light of these results, several patterns and trends can be identified in model performance across the different time windows. The results indicate that the performance of the ML/DL models was heterogeneous across different time windows and feature sets. Specifically, the LSTM model demonstrated a U-shaped trend for the AGV and AGV+NET+OSCI feature sets, while displaying a clear and positive trend in its performance as the time window increased for the AGV+NET feature set. The N-BEATS model, on the other hand, showed a decreasing trend in the MedianAE as the time window increased for the AGV and AGV+NET feature sets, while exhibiting a U-shaped pattern for the AGV+NET+OSCI feature set. Lastly, the Random Forest model exhibited minimal variations in its performance across the time windows of 40, 75, and 150 steps for the AGV+NET feature set, yet consistently improved in performance as the time window increased for the AGV and AGV+NET+OSCI feature sets.
In general, all models benefit from larger time windows when using the AGV feature set, while the results obtained with the other feature sets demonstrate a more complex relationship of the different models performance with the time window size. This result suggests that feature sets with a limited number of features may benefit from longer time windows, while larger feature sets may require an optimization of the time window size in order to achieve the optimal performance.
Nevertheless, as shown in Table 5, it is evident that the models generally perform better with larger time windows, especially when considering the best models for each feature set. Therefore, it can be inferred that longer time windows can lead to improved performance in general, but the optimal size of the time window may vary depending on the feature set and model used. Hence, to achieve optimal results, the best approach is to use longer time windows and then optimize the feature set for the specific model to be used.

Histogram of the predictions of the best models obtained for the Experiment GE: (a) LSTM with time window 75 and AGV, NET & OSCI; (b) N-BEATS with time window 300 and AGV & NET and (c) Random Forest with time window 300 and AGV feature set. In each plot, the frequency of predictions is shown on the x-axis (5000 at each mark) and the bins of the predictions are shown on the y-axis (0.25 for each bin). Next to each histogram bar, the exact frequency of the predictions in each bin is plotted. In addition, the frequency of the predictions that are greater than 4 is shown at the bottom of the histogram. Next to this bin, the maximum prediction of each model and the maximum value of the label are specified

Histogram of the Absolute Errors of the best models obtained for the Experiment GE: (a) LSTM with time window 75 and AGV, NET & OSCI; (b) N-BEATS with time window 300 and AGV & NET and (c) Random Forest with time window 300 and AGV feature set. In each plot, the frequency of absolute errors is shown on the left y-axis (500 at each mark), and the bins of the absolute errors are shown on the x-axis (0.25 for each bin). In addition, the frequency of absolute errors that are greater than 5 is shown in the bin closest to the right. In the top left corner, the maximum absolute error of the predictions of each model is specified
5.2.3 Guide error distribution analysis
An interesting finding that we discovered by visualizing the histograms of the predictions produced by the best-performing models with their corresponding best time window across all feature sets (Sect. 5.2.1) is depicted in Fig. 10. In particular, we found that among the different proposed models, the N-BEATS model was the best fit to the actual frequency distribution of the Guide Error variable, which resembles a heavy-tailed distribution. On the contrary, the LSTM and Random Forest models show a statistically more accentuated dissimilarity. In particular, the Random Forest model appears to conform to a Gaussian distribution in the frequency of predictions, although the skewness of the distributions is less pronounced than that of the distribution of actual values. In fact, as can also be seen in the histogram depicted, the lowest values are rarely predicted by this model. This histogram provides an indicative visual of the lazy behavior that was represented in Sect. 5.2.1, since it can be clearly seen that this model has a high tendency to predict values centered on the mean of the Guide Error variable.
On the other hand, the N-BEATS and LSTM models show noticeably less discrepancy with the true distribution, in fact, both almost perfectly fit the higher rare values, which are smoothly distributed along the tail of the true distribution ("Labels" distribution in Fig. 10). However, in the case of the LSTM model, the highly pronounced peak of the lower-middle frequency values leads to a high skewness of the distribution that is substantially dissimilar to the one exhibited by the Guide Error variable. This result indicates that the LSTM model is clearly biased towards the most frequent values of the target variable. In the case of the N-BEATS model, the frequency distribution of the predictions perfectly matches the distribution exhibited by the Guide Error variable, with a slight tendency to not predict lower values. This result indicates that the N-BEATS architecture is able to appropriately capture the actual distribution, while the LSTM model suffers from clear biases towards the most frequent observations, and in the case of Random Forest, the model is unable to accurately capture the true underlying distribution, fitting a Gaussian distribution centered around the mean of the target variable, which clearly reflects its lazy nature. Furthermore, as can also be seen in Fig. 10 (Max. Label) the maximum prediction of the Random Forest model is in the middle of the range of values taken by the AGV deviation in all our experimental conditions, while the maximum prediction of the LSTM and N-BEATS models is closer to the actual maximum value, further illustrating the lazy behavior of the Random Forest model.
Overall, we can conclude that the frequency distribution analysis of the predictions is perfectly in line with the analysis of the previous subsection and it reinforces our conclusions about the disparity observed when visually inspecting the model performance and numerically analyzing the Mean and Median Absolute Error obtained by the three models. Recall that the Mean Absolute Error placed Random Forest as the best model and the Median Absolute Error did not correctly reflect the clear disparity in performance of the Random Forest model in relation to the rest of the models. Therefore, we believe that the frequency distribution analysis of the predictions can be a useful tool to complement the performance evaluation using the Mean and the Median Absolute Errors and to assess the distributional properties of the models and to further analyze its actual predictive power. More importantly, it can provide us with the opportunity to detect and discard models that exhibit lazy behavior in their predictions.
Finally, we are also interested in analyzing the histogram of errors of the models plotted in Fig. 11. Consistent with the results presented in Sect. 5.2.1, as can be seen in the first bin of the absolute error frequency distribution, the N-BEATS model has the highest number of absolute errors close to zero (less than or equal to 0.25, which can be considered negligible for the problem at hand) compared to the other two models, the Random Forest model being the worst in this regard. Thus, the results suggest that the N-BEATS model is the most accurate, as it has the highest proportion of predictions that have absolute errors close to zero when compared with the ground truth, followed by the LSTM model and, finally, the Random Forest model.
5.3 Model ensembling
To construct our model ensembles, our first approach was to combine a mixture of the three architectures (N-BEATS, LSTM, and Random Forest) to build what we call heterogeneous model ensembles. Next, we evaluated the results obtained by applying the ensemble technique only to models of the same architecture (homogeneous model ensembles). Finally, we combined both approaches (mixed model ensembles) by joining homogeneous models from different architectures.
To build heterogeneous ensembles, we combined the predictions of the best N-BEATS, LSTM, and Random Forest models with their best corresponding time windows. Homogeneous ensembles were built as sets of DL models that conformed to the same architecture. We took advantage of the different N-BEATS and LSTM models obtained during the validation process and performed a grid search procedure to find the best number of models in terms of prediction performance in homogeneous sets. We combined the two approaches (heterogenous and homogeneous) to construct mixed model ensembles. To do so, we first combined a variable number of N-BEATS models with a variable number of LSTM models. For this purpose, we selected the best N-BEATS models \(K_{\textrm{NB}}\) and the best LSTM models \(K_{\textrm{LSTM}}\) that were generated during validation, with \(K_{\textrm{NB}}, K_{\textrm{LSTM}} \in \{2,3,5,10,20,30\}\). The three types of ensembles use the mean as the aggregation method to combine their predictions since the median gives more weight to the central tendency of the target variable, which may result in more conservative estimates that may lead to increased false negative alarm rates in the detection of AGV malfunction. More details on the three ensemble types can be found in Appendix A.7 (Ensembles).

Mean and Median of the Absolute Error of the predictions for the best individual models and homogeneous and heterogeneous model ensembles obtained for Experiment GE
Table 6 summarizes the best overall models for individual, heterogeneous, and homogeneous ensembles, segregated by the three feature sets (AGV, AGV+NET and AGV+NET+OSCI) and selected based on the lowest average of the Median Absolute Error across all time steps (AT column). Furthermore, in Fig. 12 we plot the mean and median absolute errors of the best individual model along with the best homogeneous and heterogeneous ensembles obtained among all feature sets and time windows. In light of these results some conclusions can be extracted:
-
Overall, as can be seen, for both the Mean and the Median Absolute Error, the best model obtained is the homogeneous ensemble composed of the 20 N-BEATS models that were obtained during validation. It is clear that both types of ensembles are considerably better than individual models. Note that the power of the ensemble technique appears when a decent number of models are combined to improve the diversity of predictions (at least 5 models in homogeneous ensembles in the case of AGV:AGV and AGV:AGV+NET). On the contrary, in the heterogeneous experiment, only three models were combined at most and, therefore, the results did not improve the previously obtained by the individual models
-
An important result is that homogeneous model ensembles are considerably more accurate than heterogeneous models for every time step in the forecast horizon.
-
Another crucial result is that all the ensemble models present an almost constant Mean and Median Absolute Error throughout the forecast horizon, which is not the case for individual models, since their error tends to grow with the number of time steps in the forecasting horizon. That is, the individual models are significantly worse at predicting the evolution of the Guide Error variable in the long-term future than in the near future. We observe that all the ensemble models present an almost constant Mean and Median Absolute Error in the short and medium-term with only a slight increment in the long-term. This behavior is similar to the one observed for individual models, but the ensemble models obtain a better performance. From this result, we can conclude that the ensemble models are significantly better at predicting the evolution of the Guide Error variable in the long-term future than the individual models, which is highly beneficial for effective detection of AGV malfunction. The conclusions derived are important, as it means that the proposed sets of ensemble models are able to provide reliable forecasts in the short, medium, and even long-term, which is essential to anticipate the evolution of the Guide Error variable with high accuracy in the long-term in order to make the necessary corrections in a timely manner, while also being much less sensitive to the selection of the length of the forecasting horizon than the individual models. This is of great importance in the context of an AGV control system, as the selection of the forecast horizon, although it has been shown that at least 15 s are needed to bring the AGV to a complete safe stop, it may depend on the physical evolution of AGVs in the future and other factors. In any case, the results obtained with this approach demonstrate the possibility of further increasing the forecast horizon without a significant loss of accuracy, which is extremely important to further improve the safety of AGV control systems.
-
The results obtained using the Mean Absolute Error are practically identical to those obtained using the Median Absolute Error, since no variation in the relative ranking of the ensembles is observed. This is another important result, as it means that, the proposed ensemble models are not sensitive to outliers and are, therefore, more robust and reliable than the individual models during forecasting of the Guide Error variable.
After visually analysing several scenarios containing different network perturbations, we observed that the homogeneous ensembles conformed by models of the N-BEATS architecture and the heterogeneous models composed of the best N-BEATS and LSTM models obtain extremely accurate predictions in all the representative network situations shown, and significantly better than the individual models. The details of these scenarios can be found in appendix A, Subsubsection 4 (Performance comparison of ensembles with individual models (linear visualization). However, as can be observed in appendix A, Fig. 35 the presence of some lazy models in the ensemble process inevitably contaminates the ensemble resulting in lazy behavior, as the predictions flatten toward the mean when the predictions of these lazy models are considered during the averaging. This observation highlights the importance of studying and correcting this problem in the future, which will enable one to further exploit the advantages of the ensemble learning approach to improve the Guide Error prediction.
In summary, we can conclude that the construction of homogeneous ensembles is the best approach to improve the Guide Error prediction results. More specifically, the homogeneous ensemble composed of the N-BEATS models with AGV and network parameters (AGV:AGV+NET) produces the best results. We would like to point out that the homogeneous ensemble of N-BEATS models that was trained only with the AGV parameters produces the second best results, which are almost on par with the results of the best performing ensemble. This is an important result, as it demonstrates that superior performance can be obtained using only AGV parameters as input to the forecasting models, eliminating the need to measure the network parameters, which is a complex task, as it requires the installation of special equipment in the factory and access to the private network, which may be infeasible in some contexts.
5.4 Aspects of the real-time deployment
In this section, we discuss aspects related to the real-time deployment of the system. First, we analyze the inference time of the best individual models and model ensembles that were obtained for Guide Error forecasting. Next, we focus on retraining times to continuously update the model in an online fashion to correct the data drift problems that may appear over the course of the operational activity. To this end, we leverage the Transfer Learning technique to efficiently retrain our models in a data streaming environment where operational data is collected over time to generate new training examples to retrain the model when triggered to correct data drift problems.
5.4.1 Model predictions
This section elaborates on the results described in the previous section with respect to the problem of real-time control of an AGV. The inference times of the models were compared in terms of their ability to provide control commands to an AGV in real time. All models were run on a machine with a single NVIDIA RTX 3090 (24 GB of VRAM), 200 GB of RAM, and a 2.40 GHz Intel(R) Xeon(R) Silver 4210R CPU with 10 cores.
To maintain the AGV transmission rate, models are required to provide control commands at a rate of 100 ms or less. That is, the models must produce at least 10 predictions per second. This is because the data used to train the models were aggregated at a granularity of 100 ms. Therefore, at each 100 ms interval, a new time window of features is ready to be input to the ML model. Failure to process inputs at this rate will result in an increasing delay in predictions. This delay in generating predictions, also called local drift in the context of job scheduling of a real-time system, will eventually produce predict values for time steps that will have already elapsed. For example, in a scenario where ML/DL preditions are sent to a dashboard that supports an AGV operator, the predictions of the ML/DL models will be displayed on the dashboard increasingly delayed, and eventually, the forecast for a time t will arrive on the dashboard after t when the real value is already monitored. In other words, the forecasting ability will be completely lost. The accumulation of this local drift (global drift) will inevitably make the predictions no longer useful, resulting in the inability to anticipate AGV deviation with the required forecast horizon.
In Table 7, we compare the average prediction time for each sample at 100 ms granularity considering the best models obtained for each combination of feature set and time window for different batch sizes ([1, 64, 128, 256]). To perform this analysis, we estimate the inference time for each model by calculating the average of the inference times of 500 batches of data that were randomly sampled for statistical significance. Different batch sizes were considered to study the effect of the number of AGVs in the system on the performance of the models. A batch size of 1 corresponds to a single AGV in the system, while a batch size of 64 corresponds to a system with 64 AGVs running simultaneously the same prediction model. Speed-up is calculated as \( \frac{\text {InferenceTimeBatch\_1}}{ \mathrm {InferenceTimeBatch\_K} / K} \), where \(\text {InferenceTimeBatch\_K}\) is the average of the inference times obtained when predicting a batch of size K. It is worth noting that in the batch scenario, we are assuming that a set of AGVs behave in the same way and therefore, they are using the same forecast model, which implies that a batch of inputs can be processed by a single ML model. Otherwise, if all AGVs used different ML models, batch aggregation could not be implemented.
LSTM and N-BEATS models run on a dedicated GPU, while Random Forest and ARIMA run on the CPU. Using a unitary batch size (i.e., a single AGV is managed by the forecast model), it can be observed that all models with the exception of ARIMA are capable of providing predictions at the required rate of 100 milliseconds. Note that the margin with the minimum time required for the decisions is significantly high in all cases, leaving more than enough margin to apply other subsequent processes or algorithms on the output of the models. Furthermore, up to 64 AGVs can be managed by the same DL model independently of the set of features that are used without compromising the constraint of 100 milliseconds. Greater batch sizes can be used only if AGV:AGV models are selected, as the increase on the number of input features in the other two sets of features (AGV+NET and AGV+NET+OSCI) imply more complex calculations during the inference process.
As can be seen, the RF models running on the CPU are the fastest, and their inference time seems to be independent of the batch size. We have experimentally observed that the deployment of RF trees implies a fixed amount of 22 milliseconds, and each inference (using 100 trees running on 20 cores) is done in approximately 60 microseconds. Therefore, a batch size greater than 256 is needed to observe significant changes in the total inference time. Regarding the fact that it is not likely to have such a number of AGVs controlled by the same RF model, we can assume that the inference time for RF is going to be nearly constant (roughly 0.03 secs) for all batch sizes in our scenario. Unfortunately, RF prediction performance is not at the same level as that of N-BEATS and LSTM and, worse, RF models often exhibit lazy behavior, which invalidates their use for the detection of AGV malfunction.
The application of ARIMA in a real deployment is completely unfeasible, since the total inference time to perform a single prediction is approximately more than ten times the minimum time required.
As can be observed in the table, the inference times of LSTM and N-BEATS for smaller batch sizes do not take advantage of the massive parallelization capability of GPUs. This is because for GPU inference, the data must first be transferred from the CPU to the GPU, and, for small batch sizes, this data transfer time dominates the total GPU inference time. In contrast, for large batch sizes, the data transfer time is negligible compared to the total inference time, and the GPU models are faster than their CPU counterparts. Another aspect to note is that smaller time windows result in faster predictions because there is less data to process. This is more relevant for smaller batch sizes due to the bottleneck of memory transfer from CPU to GPU. However, since most of the best models obtained were those with the longest time windows, this fact does not have a significant effect on the overall comparison.
Furthermore, as can be seen from the results, N-BEATS is the most favored as the batch size increases. That is, the speed-up gain in the case of N-BEATS is greater than that of LSTM. This is because LSTM is much more computationally complex than N-BEATS, in terms of the number of FLOPs per batch. In addition, N-BEATS is a much simpler architecture than LSTM, as it consists of simpler matrix multiplication, while LSTM involves more complex recurrent operations that have a sequential nature. For this reason, in terms of execution time in a real-time constrained environment, N-BEATS can be considered a more suitable architecture for controlling fleets of AGVs than LSTM.
In light of the results of Table 7 we can summarize that taking advantage of the parallelization capabilities provided by the TensorFlow library, the results obtained using the two DL models indicate that these models are capable of providing control orders to a fleet of up to 64 AGVs in real time with a high safety margin on a single machine.
With regard to model ensembles, in the same way as for the individual models, the combined inference time between the models that compose each ensemble is also crucial for their deployment to be feasible in a real-time operation context. For this analysis we assume a conservative scenario in which the prediction of each component of the ensemble is executed sequentially. More efficient scenarios could be achieved using several GPUs to parallelize the inference of several models. Since we consider each component of the ensemble to run sequentially, the inference times of the ensemble are the sum of the inference times of its component models. Note that the time consumed by the aggregation strategy over a vector of K predictions (e.g., calculate the mean, median, or the maximum or minimum) can be considered negligible in the final calculation as K will be in the range of tens (Table 6).
In the case of heterogeneous ensembles, and considering the inference times of individual models (see Table 7), only in certain scenarios we can guarantee the real-time response (i.e, inference time \(< 0.1\)). For example, the sum of inference times of the heterogeneous ensemble of LSTM, N-BEATS and Random Forest using the AGV:AGV feature set gives 0.074, which indicates that this deployment is feasible. In contrast, the heterogeneous ensemble of LSTM and N-BEATS using the AGV:AGV+NET feature set gives 0.115 and therefore, an upgrade of the current hardware would be needed to deploy this ensemble model in real-time. In the case of homogeneous ensembles, we observe that none of the models satisfy this constraint as the number of models being aggregated is high enough that the sequential execution of the models leads to exceeding the required deadline. In the best case, K has a value of 10, and hence, \(\mathrm {Inference\_time} = 10 * 0.02 > 0.1\)). To overcome this problem, a straightforward alternative to allow these complex models to be deployed in a real-time scenario is to scale the hardware vertically or horizontally: run the models (i) on more powerful hardware (e.g., increase the amount of RAM, upgrade the CPU/GPU, etc.) or (ii) on a larger number of computational resources (e.g., several CPUs and/or GPUS), in order to reduce inference times and meet the required deadline.
5.4.2 Model retraining
To control a fleet of AGVs deployed in a dynamic environment, ML/DL models will need to be retrained on a regular basis to account for changes in the layout of the environment, changes in the AGVs themselves (e.g., if an AGV is replaced by a different model), and data drift problems that arise during model operation in a production environment, possibly caused by changes in network disturbance patterns and in the physical components of the AGV. A real-time deployment of the trained and tested DL/ML models should consider how to detect when a model needs to be retrained due to changes in the statistical behavior of the input data and determine the cost and feasibility of such retraining. In this context, the most important thing is to detect when retraining is necessary. This can be done in several ways, for example, by monitoring the performance of the AGVs over time and triggering a retraining when significant degradation is observed. Furthermore, well-established techniques (e.g., Kolmogorov-Smirnov test and Kullback-Liebler divergence) can allow the identification of data drift problems by helping to automate this detection. That said, and assuming that the physical parts of the AGVs will not suffer a significant degradation (mainly the wheels and the guiding sensors that measure Guide Error) and that the circuit will not be altered, we expect that a retraining will only be necessary at large time intervals.
For retraining, the most interesting solution is to use a technique called Transfer Learning (TL) [39], in which a model is first trained on a large dataset and then this trained model is used as starting point for the training of a new model on the smaller dataset. The idea is to take advantage of the general knowledge learned from the first model to avoid retraining subsequent models from scratch, which can greatly reduce the downtime of the AGV control system during the retraining period and speed up the deployment of new models in production. In this context, data collected from AGVs while in operation can be used to adjust the model and keep it up-to-date with real-world conditions. This process can be performed in the background while the AGVs are in operation. In this way, when a data drift (a slight change in its distribution) occurs, the model can automatically adapt to the new conditions without the need for human intervention. In other words, new models can be quickly deployed to automatically replace older ones without affecting AGV performance at all. However, it should be noted that this technique is exclusive of DL models and is not applicable to traditional ML algorithms, which do not offer the same benefits. For this reason, Random Forest and ARIMA were not considered as possible alternatives to the selected models for retraining.
Regarding the particular implementation for the TL application, two approaches can be distinguished: (i) fixing the pre-trained model weights or (ii) allowing the weights to be updated during the tuning process. The former solution can be used when new layers are added to the pre-trained model to increase its complexity, while the latter is more suitable to account for data drifts that may occur over time. To provide a proof of concept, we considered the second approach to analyze the effect of retraining on a pre-trained model with data deviations to measure the retraining time required for the model to fit the new data. Specifically, we perform retraining by simulating the data collection process during AGV operation to keep models updated in an online fashion. To this end, we removed older data captures that were used for the training process and added new data captures that were reserved for testing to the training dataset. The total number of data captures used for retraining remained the same as for the original training (35 data captures). We then selected the best performing N-BEATS and LSTM models to be retrained using the newly updated data set and evaluated it with the remaining test data. However, note that the results obtained during model testing have not been included because they are not relevant for the purpose of this analysis.
To perform this analysis, the same weights of the original model, adjusted for the original training data, were used for the retraining process. The retraining of each model combination was repeated three times. No architectural changes were introduced in the retrained models. The training hyperparameters (batch size, optimizer, learning rate, and cost function) were the same as in the original training and the same hardware was used as in the original training to obtain a fair comparison. Furthermore, the early stopping technique was used with the same patience as in the original training to stop the training process when the validation loss stopped decreasing. It should also be noted that, to achieve an accurate time calculation, the validation loss was calculated in the same way as in the original training, discarding the first 10 predicted time steps to avoid leakage of past information due to the aggregation that was performed to create the time series during the data processing stage. In addition, for comparison purposes, we also provide the time it took to train the models from scratch. Finally, to illustrate the efficiency gain with this approach, the speed-up was calculated, defined as the ratio between the training time of the TL model and that of the model trained from scratch.
The results obtained are shown in Table 8. In light of them, some reflections can be highlighted.
-
When the number of data captures transferred was small (1 or 5), the three retraining times obtained for each model combination exhibited a great disparity. Only when 10 data captures were transferred, the three retraining times were similar. Considering that 35 new data captures are available, when a small number of captures are transferred, it is likely that the amount of new information contained in each of the three runs will be different. Therefore, the time needed to learn the new data during retraining presents a significant variability. On the contrary, when 10 data captures are transferred, it is highly probable that the total amount of information contained in the new data in the three experiments will be similar and therefore the three retrainings and their durations are similar. The downside of this is that the greater the amount of information, the longer the retraining time, as the model has to learn more information.
-
When only the endogenous Guide Error variable is used (AGV:AGV models), increasing the number of data captures transferred (from 1 to 5 and 10) seems to increase the training time (and consequently decrease the speed up), although no linear pattern is observed. This is due to the fact that both the number of data captures used to update the model and their variability affect the amount of information that is passed to the model and, therefore, the time that the model requires to learn the new information. In particular, the more variability that is passed to the model, the slower it will be possible to update it. This happens because the model has to learn more new patterns that were not present in the original training data. In summary, when using AGV:AGV models, only when 1 data capture is transferred, speed up is significantly greater than 1 and, therefore, retraining is more efficient from a time perspective than a complete training from scratch.
-
When exogenous variables are used (AGV:AGV+NET and AGV:AGV+NET+OSCI models) the speed up is always significantly greater than 1, regardless of the number of data captures that are transferred. We conjecture that the essence and complexity of these models enriched with exogenous variables (NET and OSCI) were learned in the original learning phase, requiring significantly longer learning time than when only the endogenous variable Guide Error was used as input. Then, the retraining process required only a small fraction of the previous time to learn the data variations contained in the transferred captures, since most of the complexity of the guide error variable was already learned during the original training.
It is worth noting that the number of data captures required to update the model also depends on the variability of the data, or, in other words, the dissimilarity between the original training and retraining data sets. In particular, if the data drift is significant, more data captures are required to update the model than if the data variations are small.
Finally, in terms of speedup, we observe that the application of TL is significantly more efficient than training models from scratch. For example, with the transfer of 1 data captures, the speedup is almost 6, indicating that the retraining is approximately six times faster than training from scratch. On the other hand, for the case of transferring five data captures, the speedup is 2.87x, while transferring 10 data captures yields a speedup of 3.8x.
5.5 Discussion of the results
This study demonstrates the potential of modern deep learning techniques to predict the long-term failure of an industrial AGV in real-time scenarios. In the light of the results obtained, the key findings of this study are presented below.
-
Based on the results of our experimental evaluation, N-BEATS appears as the best overall model for predicting the Guide Error in all horizon ranges, showing a substantial gain in the medium and long term over the rest of the models.
-
Although N-BEATS was not originally conceived to use exogenous variables in its input, we extended the original architecture to add such variables. Adding network parameters (i.e., AGV-PLC connection statistics) as exogenous input variables, significantly reduces the prediction error for almost all trained models, which highlights the capacity of the modified N-BEATS architecture to effectively extract relevant information from exogenous variables, ultimately improving predictions of AGV behavior in scenarios where network connectivity is degraded.
-
Despite the fact that the Guide Oscillations variable did not prove to be a valuable endogenous variable for predicting AGV malfunction, its incorporation as an exogenous variable in models can enhance the accuracy of forecasting the Guide Error variable, particularly as demonstrated by the better results obtained with LSTM models. It is worth noting that although the N-BEATS architecture does not exploit the Guide Oscillations as exogenous variable, it can benefit from the integration of other features as exogeneous variables, as evidenced by the improved performance achieved when incorporating network parameters in the input. Consequently, the selection of an appropriate set of features is crucial when using N-BEATS models to ensure optimal results.
-
We conducted our experiments using an innovative approach on N-BEATS architecture based on predicting AGV deviation in a sequence-to-sequence fashion. Using single learned models and a window of past observations, we were able to produce accurate predictions of the entire forecast horizon at once without incurring in any error accumulation. With this approach, the AGV operator can select the most appropriate forecast horizon according to the particular needs of the application without having to retrain the models. In particular, the ensemble models trained for a large forecast horizon (20 seconds in our experiments), present an almost constant Mean and Median Absolute Error in the short and medium-term with only a slight increment in the long-term.
-
We note that the results obtained with the N-BEATS model are not sensitive to different window sizes. This suggests that the model is robust to the choice of temporal window and that it can generalize well independently of this hyperparameter, which can favor rapid real-time deployments by not requiring fine-tuning of this hyperparameter. In contrast, the LSTM model is substantially more sensitive to this choice, being necessary to tune this hyperparameter to obtain satisfactory results.
-
During our evaluation, we found that some models exhibited what we call "lazy" behavior, tending to predict close to the mean of the target variable. To the best of our knowledge, this is the first time this bad effect has been mentioned in the literature. Although lazy models perform well in terms of the used metrics, as we were able to verify visually, the prediction obtained is very poor and completely lacks utility for the detection of AGV malfunction, since the large fluctuations of the target variable (which are the main indication of an AGV operational failure) are not accurately predicted. It should be noted that it is crucial to identify models with lazy behaviour to eliminate them from the selection of the best models as the main goal of our models is to be able to predict abrupt changes in the trend of the guide error variable and, what is most important, to predict them early enough to anticipate when problems start to appear in the AGV. In this way, the operator can stop the AGV in time and avoid any potentially harmful situation in the event the AGV leaves the path. This problem is a major concern when models are planned to be deployed in real-time scenarios, and therefore it will be carefully studied in future work.
-
In our experimental results, we show that homogeneous ensembles can provide more accurate predictions than individual models and heterogeneous and mixed ensembles. The ensemble technique exploits its statistical properties when a sufficient number of models are aggregated, which is the case for the best homogeneous models that aggregate at least 5 models. More importantly, the three types of ensembles produce predictions that exhibit a relatively minimal error that remains constant in the short and medium-term with only a slight increment in the long-term, even in the presence of significant degradation of network conditions, indicating that these models can reliably provide accurate predictions for short-, medium-, and even long-term forecasts.
-
The best overall model obtained in our experiments is a homogeneous ensemble composed of the top 20 N-BEATS models using a combination of Guide Error and network parameters. This model achieves the lowest prediction error compared to all other models. Furthermore, we show that this model produces very reliable and accurate predictions throughout the entire forecast horizon under a wide variety of network perturbations. The second best of these homogeneous ensembles uses only the information collected from the AGV as input, indicating that the proposed solution can provide accurate forecasts without relying on network parameters. This is an interesting result, since AGV traffic is dynamic and highly dependent on external factors, such as the status of the network connection between the AGV and the PLC. This result can open new opportunities for the adoption of ensembles of N-BEATS models to detect AGV malfunction in the industrial environment, as it eliminates the need to have installed the necessary equipment in the factory to collect the network parameters and allows the AGV owner to deploy its own solutions independently of the network operator.
-
After measuring the inference times of the best individual models developed in a commodity PC workstation equipped with a modest GPU and executing single models in individual predictions (a single prediction per AGV at each instant) and in batch predictions (predictions of several AGVs for the same instant of time) less than 64, the results demonstrate that all selected models can be successfully deployed in a production environment to obtain real-time predictions. In the case of ensemble models, we assumed a conservative scenario in which the prediction of each component of the ensemble is executed sequentially. In this scenario, the inference time of the ensemble is the sum of the inference times of its component models, which generates in many ensembles that the total inference time for a single element is greater than the required deadline of 100 ms per prediction, and as a consequence the real-time deployment is not realizable. In this case, feasible real-time deployments can be achieved using more powerful hardware or several CPUs or GPUs to parallelize the inference of the models in an ensemble.
-
Despite the computational and memory cost of training the most accurate models, when Transfer Learning is applied, the retraining times of these models are considerably reduced compared to the initial training times. This experimental evaluation demonstrates that the proposed methodology can be used for the deployment of updated models in production environments to ensure that the models have the ability to adapt to new scenarios without the costly need to retrain the models from scratch.
6 Conclusions
The objective of this research is to leverage modern deep learning techniques to predict the long-term failure of an industrial AGV. To achieve this goal, we have implemented a virtualized PLC that allows for remote control of the AGV. This virtualized PLC is deployed in a MEC infrastructure that is connected through a 5G network to ensure minimum latencies, which enable real-time remote control of the AGV.
The data required to train and validate the forecasting models were collected from a large number of experiments carried out at the 5TONIC laboratory, in which different realistic scenarios of degradation of the network connection between the AGV and the PLC were simulated, inducing different levels of network disturbances such as delay and jitter. We selected the N-BEATS model as the state-of-the-art in time-series forecasting and extended its architecture to incorporate two types of exogenous variables: AGV’s Guide oscillations and a set of AGV-PLC connection statistics. In addition, the architecture was adapted to a sequence-to-sequence model to obtain a flexible prediction horizon of 20 s ahead of time. Furthermore, LSTM, Random Forest and ARIMA as representatives of DL, ML, and statistical methods, respectively, were selected to compare the results of N-BEATS to them. We applied the model ensemble technique to combine the individual performance of the best models and architectures with the aim of obtaining better predictions. A careful analysis of a real-time deployment of our solution was conducted, including retraining scenarios that might be triggered by the appearance of data drift problems. The experimental evaluation of model retraining times was carried out by applying the Transfer Learning technique to analyse the savings obtained when this technique is applied instead of complete retraining.
The main conclusions of this study are the following:
-
N-BEATS is the best overall model for predicting the Guide Error in all horizon ranges, showing a substantial gain in the medium and long term over the rest of the models.
-
We extended the N-BEATS architecture to incorporate exogenous variables, such as AGV-PLC connection statistics, resulting in a notable decrease in prediction error for most of the trained models. This demonstrates the modified N-BEATS architecture’s capability to extract valuable information from exogenous variables, although, a careful selection of them is crucial to ensure optimal results.
-
Our modified N-BEATS architecture involved predicting AGV deviation in a sequence-to-sequence manner. By using a single learned model and a window of past observations, accurate predictions of the entire forecast horizon can be produced without error accumulation. This property enables the AGV operator to choose the suitable forecast horizon without having to retrain the models, while fixed horizon rolling-window models require retraining for each new forecast horizon.
-
The N-BEATS model is found to be insensitive to different window sizes, indicating that it is robust and can generalize well regardless of this hyperparameter. This allows for quick real-time deployment without the need to fine-tune this parameter.
-
Homogeneous ensembles outperform individual models and heterogeneous/mixed ensembles in terms of prediction accuracy. In addition, the three types of ensemble are reliable and can produce accurate predictions for short-, medium-, and long-term forecasts.
-
The inference times of the best individual models running on a commodity PC workstation equipped with a modest GPU show that these models can be successfully deployed in a production environment to obtain real-time forecasts.
-
In real-time scenarios where data drift issues arise, Transfer Learning greatly reduces retraining times compared to the initial training period, effectively avoiding the costly need for retraining from scratch.
As future work, we propose to conduct a comprehensive study to further explore the root cause of the appearance of lazy models during validation and propose methods to mitigate this problem to improve the overall predictive performance of AGV malfunction detection. Furthermore, we propose to examine and evaluate the most suitable methods for detecting data drifts that can occur over time during production activities to automatically trigger model retraining using the data collected while the AGV fleet performs its operational activities.
Availability of data and materials
The data that support the findings of this study are available from Telefonica and ASTI Mobile Robotics but restrictions apply to the availability of these data, which were used under licence for the current study, and so are not publicly available. Data are however available from the authors upon reasonable request and with permission of Telefonica and ASTI Mobile Robotics.
References
Fragapane G, de Koster R, Sgarbossa F, Strandhagen JO (2021) Planning and control of autonomous mobile robots for intralogistics. Lit Rev Res Agenda 294(2):405–426. https://doi.org/10.1016/j.ejor.2021.01.019. Accessed 01-May-2023
Goli A, Tirkolaee EB, Aydın NS (2021) Fuzzy integrated cell formation and production scheduling considering automated guided vehicles and human factors. IEEE Trans Fuzzy Syst 29(12):3686–3695
Espinosa F, Santos C, Sierra-García J (2020) Transporte multi-agv de una carga: estado del arte y propuesta centralizada. Rev Iberoam de Autom e Inform Ind 18(1):82–91
Vakaruk S, Sierra-García JE, Mozo A, Pastor A (2021) Forecasting automated guided vehicle malfunctioning with deep learning in a 5g-based industry 4.0 scenario. IEEE Commun Mag 59(11):102–108. https://doi.org/10.1109/MCOM.221.2001079
Oyekanlu EA, Smith AC, Thomas WP, Mulroy G, Hitesh D, Ramsey M, Kuhn DJ, Mcghinnis JD, Buonavita SC, Looper NA, Ng M, Ng’oma A, Liu W, Mcbride PG, Shultz MG, Cerasi C, Sun D (2020) A review of recent advances in automated guided vehicle technologies: Integration challenges and research areas for 5g-based smart manufacturing applications. IEEE Access: practical innovations, open solutions 8:202312–202353. https://doi.org/10.1109/ACCESS.2020.3035729
Tirkolaee EB, Goli A, Bakhsi M, Mahdavi I (2017) A robust multi-trip vehicle routing problem of perishable products with intermediate depots and time windows. Numer Algebra, Control Optim 7(4):417
Sierra-García JE, Santos M (2020) Mechatronic modelling of industrial AGVs: A complex system architecture 2020:6687816. https://doi.org/10.1155/2020/6687816. Accessed 01-May-2023
Filip I, Pyo J, Lee M, Joe H (2023) LiDAR SLAM with a wheel encoder in a featureless tunnel environment. Electronics 12(4):1002. https://doi.org/10.3390/electronics12041002
Kiangala KS, Wang Z (2020) An effective predictive maintenance framework for conveyor motors using dual time-series imaging and convolutional neural network in an industry 4.0 environment. IEEE Access: practical innovations, open solutions 8:121033–121049. https://doi.org/10.1109/ACCESS.2020.3006788
Paolanti M, Romeo L, Felicetti A, Mancini A, Frontoni E, Loncarski J (2018) Machine learning approach for predictive maintenance in industry 4.0. In: 2018 14th IEEE/ASME International Conference on Mechatronic and Embedded Systems and Applications (MESA), pp. 1–6. IEEE. https://doi.org/10.1109/MESA.2018.8449150
Chen J, Gusikhin O, Finkenstaedt W, Liu Y-N (2019) Maintenance, repair, and operations parts inventory management in the era of industry 4.0. IFAC-PapersOnLine 52(13):171–176. https://doi.org/10.1016/j.ifacol.2019.11.171
Károly AI, Galambos P, Kuti J, Rudas IJ (2020) Deep learning in robotics: Survey on model structures and training strategies. IEEE Transactions on Systems, Man, and Cybernetics: Systems 51(1):266–279
Mozo A, Ordozgoiti B, Gómez-Canaval S (2018) Forecasting short-term data center network traffic load with convolutional neural networks. PLOS ONE 13(2):0191939
Yang Y, Fan C, Xiong H (2022) A novel general-purpose hybrid model for time series forecasting. Appl Intell 52(2):2212–2223
Wang X, Wang Y, Peng J, Zhang Z, Tang X (2022) A hybrid framework for multivariate long-sequence time series forecasting. Applied Intelligence, 1–20
Oreshkin BN, Carpov D, Chapados N, Bengio Y (2020) N-beats: Neural basis expansion analysis for interpretable time series forecasting. In: Eighth International Conference on Learning Representations
Oreshkin BN, Dudek G, Pełka P, Turkina E (2021) N-beats neural network for mid-term electricity load forecasting. Applied Energy 293:116918. https://doi.org/10.1016/j.apenergy.2021.116918
Puszkarski B, Hryniów K, Sarwas G (2022) Comparison of neural basis expansion analysis for interpretable time series (n-BEATS) and recurrent neural networks for heart dysfunction classification 43(6):064006. https://doi.org/10.1088/1361-6579/ac6e55. Publisher: IOP Publishing. Accessed 29-April-2023
Jossou TR, Tahori Z, Houdji G, Medenou D, Lasfar A, Sanya F, Ahouandjinou MH, Pagliara SM, Haleem MS, Et-Tahir A (2022) N-beats as an EHG signal forecasting method for labour prediction in full term pregnancy. Electronics 11(22):3739. https://doi.org/10.3390/electronics11223739
Deng L, Ruan K, Chen X, Huang X, Zhu Y, Yu W (2022) An IP network traffic prediction method based on ARIMA and n-BEATS. In: 2022 IEEE 4th International Conference on Power, Intelligent Computing and Systems (ICPICS), pp. 336–341. https://doi.org/10.1109/ICPICS55264.2022.9873564
Lozoya C, Martí P, Velasco M, Fuertes JM, Martín EX (2011) Simulation study of a remote wireless path tracking control with delay estimation for an autonomous guided vehicle. The International Journal of Advanced Manufacturing Technology 52(5):751–761. https://doi.org/10.1007/s00170-010-2736-x
de Sant Ana PM, Marchenko N, Soret B, Popovski P (2023) Goal-oriented wireless communication for a remotely controlled autonomous guided vehicle. IEEE Wireless Communications Letters 12(4):605–609. https://doi.org/10.1109/LWC.2023.3235759
Yaovaja K, Bamrungthai P, Ketsarapong P (2019) Design of an autonomous tracked mower robot using vision-based remote control. In: 2019 IEEE Eurasia Conference on IOT, Communication and Engineering (ECICE), pp. 324–327. https://doi.org/10.1109/ECICE47484.2019.8942741
Wang P, Chen X, Ye F, Sun Z (2019) A survey of techniques for mobile service encrypted traffic classification using deep learning 7:54024–54033. https://doi.org/10.1109/ACCESS.2019.2912896. Conference Name: IEEE Access
Pastor A, Mozo A, Vakaruk S, Canavese D, López DR, Regano L, Gómez-Canaval S, Lioy A (2020) Detection of encrypted cryptomining malware connections with machine and deep learning 8:158036–158055. https://doi.org/10.1109/ACCESS.2020.3019658. Conference Name: IEEE Access
Benidis K, Rangapuram SS, Flunkert V, Wang Y, Maddix D, Turkmen C, Gasthaus J, Bohlke-Schneider M, Salinas D, Stella L, Aubet F-X, Callot L, Januschowski T (2022) Deep learning for time series forecasting: Tutorial and literature survey. ACM Computing Surveys 55(6):121–112136. https://doi.org/10.1145/3533382
Huang G, Liu Z, Maaten LVD, Weinberger KQ (2017) Densely connected convolutional networks, pp. 2261–2269. IEEE Computer Society. https://doi.org/10.1109/CVPR.2017.243. ISSN: 1063-6919. https://www.computer.org/csdl/proceedings-article/cvpr/2017/0457c261/12OmNBDQbld Accessed 01-May-2023
Dama F, Sinoquet C (2021) Time Series Analysis and Modeling to Forecast: A Survey. arXiv (2021)
Siami-Namini S, Tavakoli N, Siami Namin A (2018) A comparison of arima and lstm in forecasting time series. In: 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), pp. 1394–1401. https://doi.org/10.1109/ICMLA.2018.00227
Hewamalage H, Bergmeir C, Bandara K (2021) Recurrent neural networks for time series forecasting: Current status and future directions. Int J Forecast 37(1):388–427. https://doi.org/10.1016/j.ijforecast.2020.06.008
Masini RP, Medeiros MC, Mendes EF (2021) Machine learning advances for time series forecasting. J Econ Surv 12429. https://doi.org/10.1111/joes.12429
Petropoulos F, Apiletti D, Assimakopoulos V, Babai MZ, Barrow DK, Ben Taieb S, Bergmeir C, Bessa RJ, Bijak J, Boylan JE, Browell J, Carnevale C, Castle JL, Cirillo P, Clements MP, Cordeiro C, Cyrino Oliveira FL, De Baets S, Dokumentov A, Ellison J, Fiszeder P, Franses PH, Frazier DT, Gilliland M, Gönül MS, Goodwin P, Grossi L, Grushka-Cockayne Y, Guidolin M, Guidolin M, Gunter U, Guo X, Guseo R, Harvey N, Hendry DF, Hollyman R, JanuschowskiX T, Jeon J, Jose VRR, Kang Y, Koehler AB, Kolassa S, Kourentzes N, Leva S, Li F, Litsiou K, Makridakis S, Martin GM, Martinez AB, Meeran S, Modis T, Nikolopoulos K, Önkal D, Paccagnini A, Panagiotelis A, Panapakidis I, Pavía JM, Pedio M, Pedregal DJ, Pinson P, Ramos P, Rapach DE, Reade JJ, Rostami-Tabar B, Rubaszek M, Sermpinis G, Shang HL, Spiliotis E, Syntetos AA, Talagala PD, Talagala TS, Tashman L, Thomakos D, Thorarinsdottir T, Todini E, Trapero Arenas JR, Wang X, Winkler RL, Yusupova A, Ziel F (2022) Forecasting: Theory and practice. Int J Forecast 38(3):705–871. https://doi.org/10.1016/j.ijforecast.2021.11.001
Mozo A, Segall I, Margolin U, Gomez-Canaval S (2019) Scalable prediction of service-level events in datacenter infrastructure using deep neural networks. IEEE Access: practical innovations, open solutions 7:179779–179798
Yang L, Shami A (2020) On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing 415:295–316
XSiami-Namini S, Tavakoli N, Namin AS (2018) A comparison of arima and lstm in forecasting time series. In: 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), pp. 1394–1401. IEEE
Smith TG, et al (2017) pmdarima: ARIMA estimators for Python. [Online; accessed on 2022-May-9. http://www.alkaline-ml.com/pmdarima
Seabold S, Perktold J (2010) Statsmodels: Econometric and statistical modeling with python. In: 9th Python in Science Conference
Ben Taieb S, Sorjamaa A, Bontempi G (2010) Multiple-output modeling for multi-step-ahead time series forecasting. Neurocomputing 73(10–12):1950–1957. https://doi.org/10.1016/j.neucom.2009.11.030
Zhuang F, Qi Z, Duan K, Xi D, Zhu Y, Zhu H, Xiong H, He Q (2020) A comprehensive survey on transfer learning. Proceedings of the IEEE 109(1):43–76
Lim B, Zohren S (2021) Time-series forecasting with deep learning: A survey. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 379(2194):20200209. https://doi.org/10.1098/rsta.2020.0209
Torres JF, Hadjout D, Sebaa A, Martínez-Álvarez F, Troncoso A (2021) Deep learning for time series forecasting: A survey. Big Data 9(1):3–21. https://doi.org/10.1089/big.2020.0159
Mozo A, Morón-López J, Vakaruk S, Pompa-Pernía ÁG, González-Prieto Á, Aguilar JAP, Gómez-Canaval S, Ortiz JM (2022) Chlorophyll soft-sensor based on machine learning models for algal bloom predictions. Scientific Reports 12(1):13529. https://doi.org/10.1038/s41598-022-17299-5
Januschowski T, Wang Y, Torkkola K, Erkkilä T, Hasson H, Gasthaus J (2022) Forecasting with trees. Int J Forecast 38(4):1473–1481. https://doi.org/10.1016/j.ijforecast.2021.10.004
Galicia A, Talavera-Llames R, Troncoso A, Koprinska I, Martínez-Álvarez F (2019) Multi-step forecasting for big data time series based on ensemble learning. Knowl-Based Syst 163:830–841. https://doi.org/10.1016/j.knosys.2018.10.009
Kuncheva LI (2014) Combining Pattern Classifiers: Methods and Algorithms. J Wiley
Ganaie MA, Hu M, Malik A, Tanveer M, Suganthan P (2022) Ensemble deep learning: A review. Eng Appl Artif Intell 115:105151
Wickstrøm K, Mikalsen KØ, Kampffmeyer M, Revhaug A, Jenssen R (2021) Uncertainty-aware deep ensembles for reliable and explainable predictions of clinical time series. IEEE J Biomed Health Inform 25(7):2435–2444. https://doi.org/10.1109/JBHI.2020.3042637
Kamath U, Liu J (2021) Explainability in time series forecasting, natural language processing, and computer vision. In: Kamath U, Liu, J. (eds.) Explainable Artificial Intelligence: An Introduction to Interpretable Machine Learning, pp. 261–302. Springer. https://doi.org/10.1007/978-3-030-83356-5_7
Breiman L (2001) Random forests. Machine learning 45(1):5–32
Chen T, Guestrin C (2016) Xgboost: A scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. KDD ’16, pp. 785–794. Association for Computing Machinery. https://doi.org/10.1145/2939672.2939785
Cortes C, Vapnik V (1995) Support vector machine. Machine learning 20(3):273–297
Adhikari R, Agrawal RK (2013) An introductory study on time series modeling and forecasting. arXiv:1302.6613
Box GEP, Jenkins GM, Reinsel GC, Ljung GM (2015) Time Series Analysis: Forecasting and Control. Wiley Series in Probability and Statistics. Wiley
Alsharef A, Aggarwal K, Kumar M, Mishra A (2022) Review of ml and automl solutions to forecast time-series data. Archives of Computational Methods in Engineering 29(7):5297–5311
Kingma DP, Ba J (2015) Adam: A method for stochastic optimization. In: Bengio Y, LeCun Y (eds.) 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings. arXiv:1412.6980
Funding
Open Access funding provided thanks to the CRUE-CSIC agreement with Springer Nature. This work was partially supported by the European Commission, under European Project Big Data Value Spaces for COmpetitiveness of European COnnected Smart FacTories 4.0 (BOOST 4.0), grant number 780732. This work was partially supported by Universidad Politécnica de Madrid under the project MLSEC with reference RP2161220029.
Author information
Authors and Affiliations
Contributions
All authors contributed equally to the manuscript.
Corresponding author
Ethics declarations
Ethics approval
Not applicable.
Competing Interests
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A
Appendix A
1.1 A.1 Preliminary analysis of the guide oscillations variable
In this section, we analyze the reasons that led us to discard the Guide Oscillations variable as a predictor of AGV malfunction. In particular, we show that there is no obvious correlation between the Guide Oscillations variable and the AGV deflection of the circuit and provide the most reasonable explanations for the observed phenomenon. It should be noted that we performed this analysis before training any predictive model, as it was crucial to first evaluate the usefulness of a control system that can take advantage of the predictions of this variable to detect anomalies in the AGV behavior during operation.


Difference in the evolution of the Oscillations and Guide Error variables with an aggregation size of 1 s as the error in the connection between the AGV and the PLC increases (Delay 18–29-33/22–12-20)
Initially, we conjectured that when an AGV is in a normal operating state, the Guide Oscillations are expected to have a small value, as they are expected to be less frequent. However, when an AGV is struggling to maintain its trajectory, the Guide Oscillations should have a higher value, which can be exploited to determine whether an AGV is starting to drift or is suffering from some kind of malfunction that prevents it from maintaining a stable trajectory. However, contrary to what was observed for the Guide Error variable, in the case of Guide Oscillations, no obvious pattern has been observed that would allow us to determine with certainty when the AGV has deviated from the circuit by predicting aggregated oscillations. More specifically, we observe that, regardless of the aggregation size, a larger network delay in the connection between the AGV and the PLC does not manifest itself as a larger number of aggregated oscillations, nor vice versa. In other words, there is no positive or negative correlation that explains the AGV deviation in an obvious way by observing this specific feature. The described observation is depicted in Fig. 13 for different aggregation sizes. In addition, Fig. 14 shows a side by side analysis with the Guide Error variable, where it can be seen that Guide Oscillations do not reflect the increasing delay that is being generated in the network, but in contrast, the Guide Error variable is clearly affected by this network disturbance.
One possible explanation for this phenomenon is that, as the network delay increases, communications between the master PLC and the AGV occur more slowly, resulting in fewer corrective actions of the AGV trajectory that can occur in a given time interval. Consequently, the fewer corrections that can occur, the less oscillations the AGV will experience, since the direction change commands issued by the master PLC will be less frequent. Another explanation is that as the AGV deviates from the circuit, the Guide Oscillations occur more slowly as the AGV moves farther away from the magnetic tape. Due to the malfunctioning condition of the AGV, it is reasonable to expect that Guide Oscillations occur more frequently. However, in this situation, the total number of observed oscillations does not increase monotonically, as can be seen in Fig. 13, one reason being that the increase in frequency is being offset by the increase in the amplitude of each oscillation as the AGV deviates from the circuit.
1.2 A. 2 Selection of forecasting techniques
In this study, the selection of forecasting techniques involved a thorough consideration of different factors, such as the performance in general forecasting tasks, ability to learn temporal dependencies, robustness, interpretability, generalization capabilities, and suitability for various problem types. To that end, we conducted a review of recent literature on time-series forecasting to identify the most appropriate models for comparison in this study. The selected models and the reasoning behind their selection are detailed in this section.
Our choice of N-BEATS as the DL architecture was motivated by its state-of-the-art performance in several well-known forecasting competitions [16]. N-BEATS is a DL model that was specifically designed for time-series forecasting and has shown excellent results with univariate time series data, while providing model interpretability capabilities that are absent in other DL architectures [16]. N-BEATS is an ensemble of deeply stacked feed-forward networks organized in blocks and interconnected via residual connections. N-BEATS takes advantage of a novel residual network topology that facilitates model interpretability and enables smoother gradient flow. The residual connections of the N-BEATS architecture allow each subsequent block to directly learn the residuals of the previous block, which alleviates the training difficulty and speeds up convergence. The target prediction is then obtained by linearly combining the predictions of all blocks in the network, allowing for better interpretability. Furthermore, in the N-BEATS architecture, specific constraints can be imposed to force the model to decompose the predicted time series into its seasonal and trend components, providing additional information about the data. The N-BEATS architecture exhibits a number of highly desirable properties, such as being directly applicable to a wide range of problem types without the need for extensive feature engineering, being faster to train and more scalable than other DL architectures, such as LSTM, with the added benefit of being interpretable, which is extremely valuable in some practical scenarios. In addition, the N-BEATS architecture has shown better generalization capabilities than other DL models when trained on a specific source time-series dataset and applied to a different target dataset [16, 18,19,20, 26]. To carry out our study, we propose a modification of the original N-BEATS architecture [16] to adapt it to our multivariate time-series forecasting problem. In subsection 4.1.1 a more detailed explanation of this novel architecture is provided.
The rationale behind the use of LSTM for time-series forecasting is that this approach has shown superior performance in learning temporal dependencies in the multivariate time series forecasting field over the years, as evidenced by prior research [28, 29]. Moreover, empirical evidence supports the suitability of LSTM for forecasting tasks, with performance often surpassing current statistical benchmarks representing the prevailing state-of-the-art within the field, especially in big data scenarios [30]. LSTM is a recurrent neural network architecture that models the time-series data in an auto-regressive scheme, using non-linear input–output mappings. In this way, LSTMs are able to learn the complex dependencies between lagged inputs and lagged targets, making them suitable for handling the non-linearity and seasonality often found in time-series data. The LSTM algorithm has several advantages over conventional Recurrent Neural Networks (RNNs), such as the Gated Recurrent Unit (GRU) network, including the ability to learn long-term dependencies, the ability to handle vanishing gradients, and its robustness against the explosive gradient problem [28, 30, 40, 41].
Random Forest (RF) is a non-parametric ensemble learning algorithm that can be used for both regression [42] and classification tasks [25]. The decision to use RF as the ML regressor was made due to its high robustness and performance in several time-series forecasting applications [31], thus providing a fair comparison with DL models. The main advantage of using RF over other ML algorithms is its statistical robustness, since informative features are given more importance over noisy ones during the tree splitting process, and it can completely eliminate irrelevant ones [43]. Additionally, RF can handle missing values in the data and is not prone to overfitting, which is a common problem in DL models. Tree-based models, such as RF, are also interpretable and provide a clear understanding of the factors that affect the target variable, which is very beneficial for removing irrelevant features and improving training and inference time [43]. Another advantage of RF models over DL architectures is that they can run efficiently on low-end hardware, and therefore, specialized hardware, such as GPUs, is not required.
Ensemble learning is another technique that has started to gain prominence in recent years in time-series forecasting applications, mainly because of its ability to address high-dimensional nonlinear problems with high accuracy and generalizability [41, 44]. Ensemble learning combines the predictions of multiple models to produce a more accurate and robust prediction than could be obtained from an individual model. Ensemble methods have been shown to be highly effective in many different ML tasks, such as classification, regression, and prediction of time series [39, 44,45,46]. In recent years, ensemble learning has attracted increased attention in time-series forecasting applications because of the numerous advantages it offers over traditional single-model methods, such as the reduced risk of incorrect predictions, better approximation of the global minimum, and the ability to approximate any nonlinear function through simple linear predictors [39, 45]. In addition, another attractive capability of using ensembles for time-series forecasting that recent works have begun to exploit is that they can provide a measure of model uncertainty, which is of vital importance for applications that require model explainability to ensure safety and transparency in the decision support process, such as clinical tasks [47].
ARIMA is a well-known statistical approach that has been widely used to forecast time-series data in many different applications due to its simplicity and interpretability [32, 35, 48]. This method follows a parametric approach that models the dependencies of a time series by fitting a linear regression model to the prior values of the time series in the form of an autoregressive model. ARIMA is often used to model the temporal dependencies in univariate time-series data by taking into account the autocorrelations between the values present in the time series. The main advantage of ARIMA over other statistical methods such as Exponential Smoothing is that it can also handle non-stationary data [35]. Another important advantage of using ARIMA models is that they are much easier to interpret its output than ML/DL models [48] and, therefore, they can be used to provide insights into the underlying data if required by the application.
1.3 A.3 Overview of machine learning techniques
ML is a subset of Artificial Intelligence (AI) that provides systems with the ability to automatically learn and improve from experience without being explicitly programmed. Supervised ML algorithms build a mathematical model of sample data, known as "training data", to make predictions or decisions about new data that were not used during the training phase. This process of learning from new data to improve the accuracy of the model predictions is known as model training.
ML models have been widely used in all kinds of problems in the fields of computer vision, natural language processing, and speech recognition, among others. However, different ML models have also been employed in the field of time-series analysis, particularly for long-term forecasts problems. This includes, but is not limited to, Random Forest [49], XGBoost [50], SVM [51], and ARIMA [52]. The work presented in this article uses the Random Forest and ARIMA models as ML regressors for the problem at hand. In the following sections, we present an overview of these models in order to introduce the reader to the main concepts of each technique.
1.3.1 A.3.1 Random forest
Random Forest is a non-parametric model that is composed of multiple decision trees. A decision tree is a model that makes predictions based on a series of if-then-else questions. A Random Forest model is trained using the bagging technique, where each decision tree is trained on a random subset of the data. It is important to note that the bagging technique involves selecting a random subset of data samples and a random subset of features for each decision tree independently. Each decision tree is trained to minimize the impurity of the data samples using a criterion such as the Gini impurity or the entropy. Finally, the predictions are aggregated using a simple average [31]. The main hyperparameters of the Random Forest model are the number of estimators and the maximum tree depth. The first determines the number of decision trees that are used to build the final model. The second is used to control the complexity of each decision tree. Using an unlimited tree depth allows each decision tree to learn the data very accurately while preventing overfitting. This is done by stopping the training process when all the leave nodes are pure (i.e., all the data samples under each node belong to the same label) or when all leaves contain less than the minimum number of samples that decides whether a node must be split.
1.3.2 A.3.2 ARIMA
The AutoRegressive Moving Average (ARMA) model is analogous to Linear Regression (LR) when applied to time series forecasting problems. An ARMA model is a linear regression model that forecasts using lagged past observations and the residual error terms of the model (when it was used to forecast previous observations of the time series). The ARIMA [53, 54] model is an ARMA model that can work with non-stationary time series by including the integration (I) component that differentiates the input time-series data. The hyperparameters of the ARIMA model are: the number of autoregressive terms or lagged past observations (p), the number of times the time series has to be differenced until it becomes stationary (d), and the number of past residual errors (q). Although manual methods exist to select the best ARIMA hyperparameters, it is common to use automatic heuristic methods that search for the best hyperparameter configuration based on a criterion such as the Akaike Information Criterion (AIC) or the Bayesian Information Criterion (BIC).
The ARIMA model cannot predict out-of-sample and therefore is usually trained on all known time series-data to predict one or more future unobserved values. Being able to predict out-of-sample is an indispensable feature to compare with the other models used in this study. Thus, in order to be able to predict with the ARIMA model out-of-sample, an adaptation of the model has been carried out, which is explained in Sect. 4.4.
1.4 A.4 Overview of deep learning architectures
Fully Connected Neural Networks (FCNNs) are a type of Artificial Neural Network (ANN) composed of many interconnected processing nodes, or neurons, that can learn to recognize patterns of input data. The interconnected neurons are organized into layers and the nodes in each layer are connected to the nodes in the adjacent layers. The input layer is the first layer of the network; it serves as an entry point for the data that the network must process to produce the desired output. The input layer is followed by one or more hidden layers. Each of these hidden layers serves as a processing layer that extracts relevant features from the input data and feeds them to the next layer. Multiple hidden layers can be stacked in an FCNN, increasing the complexity of the features that the network can learn to recognize. The output layer is the final layer of the network and produces the desired output based on the features extracted by the hidden layers. The number of hidden layers and the number of nodes in each layer can vary depending on the task the network is trying to perform. Traditionally, FCNNs that have one or two hidden layers are called Shallow Neural Networks (SNNs), whereas deeper FCNNs consisting of three or more hidden layers are instead considered DNNs, although different authors draw the dividing line at different points. Hierarchical learning is a key advantage of FCNNs. With sufficient training data, a large number of hidden layers allow the network to learn complex features by decomposing them into a number of simpler features. This is the fundamental principle driving the DL paradigm. Activation functions are mathematical functions that are applied to the output of each neuron in an FCNN layer. There are a variety of activation functions that can be used, but the most common are non-linear activation functions, which are crucial to allow the network to learn complex patterns in the input data. The most popular activation functions are sigmoid and ReLU.
Gradual descent is the most conventional process used to train FCNNs. More precisely, gradient descent is a technique that allows the network to learn the correct values of the weights that connect the neurons in the network. The weights are adjusted iteratively until the network produces the desired results. Backpropagation is the process used to propagate gradients to minimize prediction errors back through the different layers that comprise the network, allowing one to determine which weights need to be adjusted and by which amount to produce the desired results. The most popular gradient descent implementation is Adam [55], which is a variant of the more traditional stochastic gradient descent algorithm.
Overfitting is a phenomenon that can occur in FCNNs when a model is excessively tailored to the training data such that it fails to generalize the knowledge, leading to poor performance on unseen data. Regularization is a highly effective technique used to avoid overfitting FCNNs. Regularization is applied by adding a penalty term to the cost function used to optimize the network. This penalty term is designed to reduce the chances that the network learns the exact patterns of the training data rather than the general patterns intended. The penalty term can be parameterized to control the amount of regularization that is applied. The higher the value of the regularization parameter, the more the network will be penalized for conforming to the exact patterns of the training data. This will make the network less prone to overfitting the data and result in a more generalized network. Popular regularization techniques include weight decay, L1/L2 regularization, and dropout.
It should also be noted that DNNs suffer from the problem of vanishing gradients. This problem manifests itself when the gradient of the error function with respect to the weights becomes increasingly smaller as the network is traversed. This problem can cause the weights of a DNN to slowly drift toward zero, which can severely degrade its performance. A common approach to deal with the problem of vanishing gradients is to use a technique called batch normalization. Batch normalization is a technique that normalizes the activations of each neuron in a layer before the weights of that layer are updated. This helps ensure that the gradients of the error function remain consistently large across the network. In addition, ReLU activations are also often used in DNNs to avoid this kind of issue during model training.
Feed-forward Neural Networks (FNNs) are a specific case of FCNNs, but are distinguished by their use of a feed-forward topology. This topology restricts the signals that pass through the network to propagate in one single direction, from the input layer to the output layer. On the contrary, in an RNN, signals can propagate in both directions. The feedforward topology is generally more efficient and simpler to train than a recurrent topology. Additionally, since the feedforward topology does not rely on feedback loops, it is less likely to become trapped in a local minimum. In contrast, RNNs can learn more complex patterns and model temporal dependencies better than FNNs. In addition, RNNs are more resistant to noise in the data and other types of artifacts.
1.4.1 A.4.1 LSTM architecture
The LSTM architecture is a type or RNN architecture and consists of hidden layers that feature an arbitrary number of memory cells capable of retaining information for a certain amount of time that can later be used to influence future network outputs. The LSTM employs a gate-based mechanism to control the state of a cell and its output over a period of time. Each memory cell consists of its cell state and three different gates: an input gate, a forget gate, and an output gate [40]. These gates control the flow of information into and out of the cell state. More precisely, the forget gate determines the amount of previous cell state that is retained, and the input gate determines the amount of new input that can modify the cell state. The cell state is a vector that represents the internal state of the LSTM. This vector is a combination of the previous cell and the new input. Each of the gates of the LSTM is defined as a mathematical operation that takes as arguments the current state of the cell and the input to the gate. The expected functionality of each gate is learned during network training by adjusting the weights of the connections between the cells and the gates. In the following, we present the equations that define the gates operations and a high-level diagram that represents the flow of information through the gates of a memory cell Fig. 15.
Where x(t) is the input vector x at time t, and \(W_f\), \(W_i\), \(W_c\) and \(W_o\) are the weight matrices for the forget gate, the input gate, the cell state, and the output gate, respectively, while \(b_f\), \(b_i\), \(b_c\) and \(b_o\) are the bias vectors for the forget gate, input gate, cell state, and output gate, respectively. The interconnection between the gates and their inputs and outputs can be seen in Fig. 15.

Diagram of a LSTM memory cell
LSTMs are often trained using a variant of backpropagation called backpropagation through time (BPTT). BPTT is similar to traditional backpropagation, but takes into account that the LSTM learns to predict a sequence consisting of multiple time steps instead of a single value. To do so, BPTT unwinds the LSTM network over time and computes the gradients of the cell state and gates at each time step. This means that the loss gradient with respect to the cell state at time t is backpropagated through time to the cell state at time \(t_{-1}\). Note that the network parameters are shared among all time steps. Once the gradients are computed, they propagate through the unrolled network [28].

Mean Absolute Error of the predictions of AGV:AGV models for the Experiment GE. In each plot, the time steps are shown on the x-axis, each representing 0.1 s, and the Mean Absolute Error is represented on the y-axis
LSTM solves the gradient vanishing problem by preventing gradients from dissipating as they flow through the network [28, 40]. This is achieved by using the gate-based mechanism described above. These mechanisms allow the cell state to be retained and updated as needed. In this way, past cell states can be conserved to influence future outputs of the network, thus preventing the gradual vanishing of the gradient.
1.5 A.5 Experimental results
In this section, we describe the details of the results obtained in the Experiment GE (prediction of the Guide Error Variable). Specifically, we individually report the results obtained using the three different combinations of feature sets described in Table 9 as input to the models and considering various window sizes to perform the segmentation of the time series that were used to train each of the proposed models. In particular, for each feature set, we provide details of the hyperparameter settings and perform a comprehensive analysis of the results obtained with the four proposed models (N-BEATS, LSTM, Random Forest, and ARIMA), comparing their performance in quantitative and qualitative terms to evaluate the effectiveness of the proposed solution.

Median Absolute Error of the predictions of AGV:AGV models for the Experiment GE. In each plot, the time steps are shown on the x-axis, each representing 0.1 s, and the Median Absolute Error is represented on the y-axis

Mean and Median Absolute Error of the predictions with the best time window of each AGV:AGV model for the Experiment GE. In each plot, the time steps are shown on the x-axis, each representing 0.1 s, and on the y-axis the Mean Absolute Error and Median Absolute Error are represented for 18a and 18b, respectively

Linear visualization of a Delay (ramp type) AGV run: a data capture with increasing network delay in which the best AGV:AGV models were used. Time is shown on the x-axis (0.1 seconds each step) and the absolute value of the Guide Error is shown on the y-axis. The Label line shows the absolute value of the Guide Error variable. The Prediction line is constructed with the t+150 element of the forecast horizon of each prediction
1.5.1 A.5.1 AGV feature set
In Table 9, we describe the number of parameters and the model and training hyperparameters of the best architectures obtained for each of the models with this particular feature set. For each DL architecture (LSTM and N-BEATS), 30 random combinations of hyperparameters were chosen to train 30 models and select the best performing.
Figures 16 and 17 show the average of the Mean and the Median Absolute Error for each time step in the forecast horizon for the different combinations of RF, LSTM and N-BEATS models and time windows that were obtained for this particular feature set. ARIMA and the baseline model were represented in all plots to compare them with each model. As can be seen, the results show low variability between time windows for all three models and a clear outperformance of all models with respect to the baseline model.
In Fig. 18 we represent the Mean and Median Absolute Error obtained in the predictions of the best models, i.e., we only reflect the best window for each type of model (LSTM, N-BEATS and Random Forest). For this purpose, in order to determine the time window that leads to the greatest overall performance for each model, we have chosen to evaluate them and select the best models using the average of the Median Absolute Error obtained for each of the 200 time steps. We made this decision because the median is a value that we consider to be more robust to outliers while equally weighting all time steps. In contrast, the mean is a metric that we have found to be misleading, as it favors models that tend to predict linearly, i.e., models that adjust to predict the mean value of the target in order to reduce the risk of overpredicting. For this reason, the mean turns out to be a non-informative metric in our case, as it does not consider how well the model is attempting to predict abrupt changes in the forecast variable. Related to the above, in our case, we concluded that the mean can be a misleading metric because, as its well known, it is very sensitive to the presence of outliers in our data, resulting in poor evaluation performance due to the intrinsic of our collected data. For these two reasons, we suggest using the median to rank and select the best models because it is expected to be a more reliable measure in this context. However, we also include the mean in the presented results as a comparison to illustrate this reasoning.

Mean Absolute Error of the predictions of AGV:AGV+NET models for the Experiment GE. In each plot, the time steps are shown on the x-axis, each representing 0.1 s, and the Mean Absolute Error is represented on the y-axis
As can be seen in Fig. 18a, using the Mean Absolute Error per time step, all models outperform the naive baseline by a wide margin. The Random Forest model with the 300 window is the best model for short- and medium-term prediction. However, in the long term the N-BEATS model with a window of 300 is slightly superior. The LSTM model with a window of 150 is in an intermediate place, showing a worse performance than Random Forest and N-BEATS, but better than ARIMA over the whole forecast horizon.
It is worth noting that the worst of the models in the long-term is the Random Forest model, which tends to predict an almost constant value. This bad behaviour is exemplified in a delay (ramp type) experiment shown in Fig. 19, where \(t+150\) predictions of all algorithms (N-BEATS, LSTM, RF and ARIMA) are plotted. Note that N-BEATS and LSTM are able to decently forecast many of the guide error variations that appear during the experiment. On the contrary, RF and ARIMA generate forecasts close to the mean value of the guide error variable, completely failing the purpose of early detecting the guide error variations that could indicate an AGV malfunction. After observing this behavior in several models, we coined the term "lazy models" to identify those that produce this nearly constant response around the mean of the values to be predicted. To the best of our knowledge, this is the first time that this harmful effect has been identified and reported in the literature. In Subsection 5.2.1 we provide a more detailed discussion of this phenomenon.

Median Absolute Error of the predictions of AGV:AGV+NET models for the Experiment GE. In each plot, the time steps are shown on the x-axis, each representing 0.1 s, and the Median Absolute Error is represented on the y-axis

Mean and Median Absolute Error of the predictions with the best time window of each AGV:AGV+NET model for the Experiment GE. In each plot, the time steps are shown on the x-axis, each representing 0.1 s, and on the y-axis the Mean Absolute Error and Median Absolute Error are represented for Figs. 22a and 22b, respectively
Using the Median Absolute Error per time step (Fig. 24b), the results vary considerably, as N-BEATS is the most performant model across the entire forecast horizon. The LSTM model, on the other hand, comes in second place, showing a performance similar to that of N-BEATS in the medium term but being slightly inferior in the rest of the terms. As for the Random Forest model, it falls to third place, performing worse than N-BEATS and LSTM over the entire forecast horizon. Finally, in the case of ARIMA, although the magnitude of the prediction error is smaller using this metric, it is still comparatively the worst model of the four.

Linear visualization of a Delay (ramp type) AGV run: a data capture with increasing network delay in which the best AGV:AGV+NET models were used. Time is shown on the x-axis (0.1 seconds each step) and the absolute value of the Guide Error is shown on the y-axis. The Label line shows the absolute value of the Guide Error variable. The Prediction line is constructed with the t+150 element of the forecast horizon of each prediction
1.5.2 A.5.2 AGV and NET feature sets
The number of parameters and the model and training hyperparameters of the best architectures obtained for each of the models using AGV and NET as feature set are described in Table 10. For each DL architecture (LSTM and N-BEATS), 30 random combinations of hyperparameters were chosen to train 30 models and select the best performing.
In Figs. 20 and 21 we depict the average of the Mean and the Median Absolute Error for each time step in the forecast horizon for the different combinations of models and time windows that were obtained for this particular set of features. As can be seen, once again, the results show low variability between time windows for all three models. In particular, in the case of N-BEATS, the difference in performance between the different time windows is negligible. This indicates that N-BEATS is not influenced by the choice of this hyperparameter and maintains stable performance in any situation when network parameters are provided as input. This behavior can be very beneficial when deploying N-BEATS models in real-time scenarios, as it would not be necessary to spend time tuning this hyperparameter to obtain a well-performing model.
The Mean and Median Absolute Error produced in the forecasts for each type of model with its corresponding best window size is shown in Fig. 22. Recall that we justified in Subsection 2 why the Median Absolute Error should be used to rank and select models rather than the Mean Absolute Error. As can be seen in this figure, using the average of the Mean Absolute Error per time step, again all models significantly outperform the naive baseline. The N-BEATS model with the 300 window is the best model for short- and medium-term prediction. However, in the long term, the Random Forest model with the 300 window performs very similarly to N-BEATS. Furthermore, the worst of the three models is the LSTM model with the 300 window, showing a worse performance than Random Forest and N-BEATS over the entire forecast horizon. However, using the average of the Median Absolute Error per time step the results again vary substantially. When evaluating the models with this metric, N-BEATS remains the most efficient model throughout the forecast horizon, but the difference in performance is even more remarkable. The LSTM model, on the other hand, is in second place, performing worse than N-BEATS but better than Random Forest over the entire forecast horizon. The Random Forest model, on the other hand, turns out to be the worst of the three models.
As can be seen in the linear visualizations of the predictions represented in Fig. 23 (a delay ramp-type experiment), again the Random Forest model shows a prediction behavior that reflects a strongly linear trend around the mean ("lazy" behavior). Observing the results in Fig. 30, we hypothesize that the Median Absolute Error penalizes the "lazy" behavior of the Random Forest model, placing it in an appropriate third place, in contrast to the Mean Absolute Error which incorrectly places the Random Forest model in the first place. As argued above, we suggest that the Mean Absolute Error might be a misleading metric that tends to favor models that predict values close to the mean of the target variable. For this reason, although the Mean Absolute Error is not informative for our use case, it can help to identify this lazy behavior in a model by presenting both metrics comparatively to detect inconsistencies in the relative performance of the model with respect to each metric.
1.5.3 A.5.3 AGV, NET and OSCI feature sets
In Table 11, the number of parameters and the training hyperparameters of the best architectures obtained using all features (AGV+NET+ OSCI) as input to the models are listed. Recall that for each DL architecture (LSTM and N-BEATS), 30 random combinations of hyperparameters were chosen to train 30 models and select the best performing.
Figures 24 and 25 represent the average of the Mean and the Median Absolute Error for each time step in the forecast horizon for the different combinations of models and time windows that were obtained for this particular set of features. Low variability between time windows is also observed for all three models. However, in the case of N-BEATS, the difference in prediction performance is almost non-existent. Overall, the conclusions drawn for the different set of characteristics suggest that, since more relevant information is provided as input, N-BEATS remains more robust against the choice of time window. Note that in the case of the Median Absolute Error, noisy fluctuation is observed between the different time windows in N-BEATS.

Linear visualization of a Delay (ramp type) AGV run: a data capture with increasing network delay in which the best AGV:AGV+NET+OSCI models were used. Time is shown on the x-axis (0.1 seconds each step) and the absolute value of the Guide Error is shown on the y-axis. The Label line shows the absolute value of the Guide Error variable. The Prediction line is constructed with the t+150 element of the forecast horizon of each prediction

Mean Absolute Error of the predictions of AGV:AGV+NET+OSCI models for the Experiment GE. In each plot, the time steps are shown on the x-axis, each representing 0.1 s, and the Mean Absolute Error is represented on the y-axis

Mean Absolute Error of the predictions of AGV:AGV+NET+OSCI models for the Experiment GE. In each plot, the time steps are shown on the x-axis, each representing 0.1 s, and the Mean Absolute Error is represented on the y-axis

Mean and Median Absolute Error of the predictions with the best time window of each AGV:AGV+NET+OSCI model for the Experiment GE. In each plot, the time steps are shown on the x-axis, each representing 0.1 s, and on the y-axis the Mean Absolute Error and Median Absolute Error are represented for 27a and 27b, respectively
The Mean and Median Absolute Error produced in the forecasts of each type of model with its corresponding best window size is shown in Fig. 27. Once again, using the Mean Absolute Error per time step (Fig. 34a), all models outperform the naive baseline by a wide margin. The Random Forest model with the 300 window shows the best performance for the entire prediction horizon among the three models. The second best model is the LSTM with a window of 7.5 s, it provides strong performance in the short and medium term but not in the long term, being the worst of the three in this regard. Finally, the worst of the three models is the N-BEATS model with a time window of 4 s, whose performance is consistently worse than Random Forest over the entire prediction horizon and only outperforms the LSTM model in the long term. When models are evaluated with the Median Absolute Error per time step (Fig. 27b), LSTM is the most performant model throughout the prediction horizon. The N-BEATS model, on the other hand, is second in class, with a worse performance than LSTM but better than Random Forest over the entire prediction horizon. The Random Forest model is the worst of the three models for the entire prediction horizon.
In sum, the conclusions derived from the analysis of the results of the best models using all features (AGV+NET+ OSCI) as input are similar to those obtained using AGV+NET features. However, as can be seen in Fig. 24 (Delay ramp-type experiment), the N-BEATS model presents an undeniable lazy behavior when using AGV+NET+OSCI features that did not appear when the AGV:AGV+NET features were used. This observation suggests two interesting reflections:
-
N-BEATS performance seems to be affected by the features that are input to the model. In contrast with LSTM that appears to be more robust when difficult-to-learn features are used as input, N-BEATS is significantly affected by such features and therefore, we suggest to conduct a previous feature selection process to avoid generating lazy N-BEATS models.
-
The Median Absolute Error, being more adequate to measure model performance than the Mean Absolute Error, can also be biased towards models that tend to predict lazily, favoring their predictions over models that are able to forecast complex nonlinear patterns and abrupt changes in the target variable. This leads to the conclusion that neither metric (Mean Absolute Error and Median Absolute Error) can avoid the selection of lazy models among the best performers and therefore, visual inspection is necessary to discard lazy models and make an accurate assessment of model performance. Future research should explore this problem and propose automated procedures to detect or avoid these "lazy" behaviors in trained models.
1.6 A.6 N-BEATS lazy model example using AGV+NET+OSCI as input features
To demonstrate that the lazy behavior phenomenon also affects the N-BEATS model, in Fig. 28 we present a linear visualization of the predictions made by some of the best N-BEATS models trained using different feature sets (AGV, AGV+NET, and AGV+NET+OSCI) on a Delay (ramp type) AGV run for the Experiment GE, where data was captured with increasing network delay.

Linear visualization of the predictions of the best N-BEATS models trained with different feature sets (AGV, AGV+NET, and AGV+NET+OSCI) on a Delay (ramp type) AGV run for the Experiment GE: a data capture with increasing network delay. In each plot, the time is shown on the x-axis (0.1 seconds at each step) and the absolute value of the Guide Error is shown on the y-axis. The Label line represents the absolute value of the Guide Error variable. The Prediction line is constructed with the t+150 element of the forecast horizon of each prediction
1.7 A.7 Ensembles
1.7.1 A.7.1 Heterogeneous model ensembles
To build heterogeneous models, we combine the predictions of the best N-BEATS, LSTM, and Random Forest models with their best corresponding time windows. Regarding the evaluation framework, we have used the Mean Absolute Error 3 to evaluate the different combinations of model ensembles. The results obtained for Experiment GE can be seen in Table 12. Considering the Median Absolute Error as a more accurate evaluation metric than the Mean Absolute Error, it can be observed that the best heterogenous ensemble (a combination of LSTM and N-BEATS models using AGV:AGV+NET feature set) did not perform better than the best individual model for the three types of features (Table 6). In general, the power of the ensemble technique appears when a decent number of models are combined to improve the diversity of predictions (at least 5 models in homogeneous ensembles in the case of AGV:AGV and AGV:AGV+NET). In the heterogeneous experiment, only three models were combined at most and, therefore, the results did not improve the previously obtained by the individual models.

Linear visualization of the predictions with residuals of the best individual model (N-BEATS using AGV:AGV+NET) and the best heterogeneous model ensemble (combination of N-BEATS and LSTM using AGV:AGV+NET) obtained in a Delay (ramp type) AGV run for Experiment GE. Different prediction aggregation methods (mean, median, maximum and minimum) are used for the ensemble model
Furthermore, we study the effect of different aggregation methods in heterogeneous ensembles apart from the mean. In Fig. 29 we compare the linear visualizations of the predictions using the minimum, the mean, the median, and the maximum as prediction aggregation methods for the best heterogeneous ensemble obtained for Experiment GE in Table 12 (a combination of LSTM and N-BEATS models with AGV:AGV+NET feature set).
As can be seen in this figure, the minimum is favored in the quantitative evaluation because the real variable presents multiple regions where the values are very low (mostly zeros and ones). Higher values are increasingly rare. Therefore, by combining the values of those models that predict a lower value (closer to zero), the resulting prediction is more accurate due to this imbalance in the target variable, but it always underestimates the variable, which makes it useless for detecting AGV malfunction, as it can produce an intolerable number of false negatives when detecting AGV deviation from the trajectory during actual operation.
On the contrary, we found that the maximum is the least effective aggregation method. The reason is that the values of the target variable must be spread over the range of possible values. If the values are mostly between 0 and 1, the maximum aggregation method will tend to overestimate the value of the target variable. This will result in excessively large errors that may lead to unacceptable false positive alarms and ultimately make it difficult to detect a malfunction of the AGV in the real context.
Excluding lazy models, the mean and median aggregation methods were the most accurate, providing more informative predictions with less noise and thus more reliable detection of AGV malfunction. We were unable to discern a significant difference in accuracy between mean and median as a result of the choice of aggregation methods for the model predictions in different network scenarios. However, we believe that the mean is the most appropriate aggregation method for the problem at hand, since the median gives more weight to the central tendency of the target variable, which may result in more conservative estimates that may lead to increased false negative alarm rates in the detection of AGV malfunction.
1.7.2 A.7.2 Homogeneous model ensembles
In addition to these heterogeneous model ensembles, we also considered a diverse set of DL models that conformed to the same architecture to build our ensembles. We refer to these types of ensembles as homogeneous ensembles. For this particular ensemble type, non-DL models have not been considered. The reason is that a Random Forest ensemble is equivalent to a single Random Forest model with a large number of decision trees. Furthermore, the case of ARIMA models is similar, since these models are composed of a linear combination of auto-regressive and moving average terms and, therefore, ARIMA ensembles can be built with a single model. For this reason, both ML models were excluded from the homogeneous ensembling, as they do not provide any advantage in terms of diversity or prediction accuracy. For this purpose, we took advantage of the different N-BEATS and LSTM models obtained during the validation process. In particular, we performed a grid search procedure to find the best number of models in terms of prediction performance in homogeneous sets, measured by the average of the Mean Absolute Error and the Median Absolute Error, with \(K \in \{1, 5, 10, 20\}\). The results of Experiment GE using the mean as an aggregation method for the predictions are presented in Table 13. The best results in terms of Mean and Median Absolute Error are obtained with an N-BEATS homogeneous ensemble using \(K_{\textrm{NB}}=20\) (i.e., aggregating the top 20 N-BEATS models) and Guide Error and network parameters as input (AGV:AGV+NET). As a side note, we wish to point out that in the case of the homogeneous ensembles, a higher \(K_{\textrm{NB}}\) and \(K_{\textrm{LSTM}}\) values (i.e., greater or equal than 5 N-BEATS or LSTM models) is more beneficial in all cases except for AGV:AGV+NET+OSCI, where a \(K_{\textrm{NB}}\) and \(K_{\textrm{LSTM}}\) equal to 1 clearly indicate that the combination of several N-BEATS or LSTM models does not improve the performance of the individual models when using the OSCI feature.

Linear visualization of the predictions and residuals of the time step 150 of the best individual models and the best homogeneous and mixed model ensembles in a Jitter (Pareto Normal 100 ms - 100ms - 100%) AGV run for Experiment GE. In each plot, time is shown on the x-axis (0.1 s each step) and the absolute value of the GuideError is shown on the y-axis. The Label line plots the absolute value of the Guide Error variable. The Prediction line is constructed with the t+150 element of the forecast horizon of each prediction. The residual points represent the absolute difference between the label and the prediction
1.7.3 A.7.3 Mixed model ensembles
Moreover, we combined the two approaches to construct mixed model ensembles. To do so, we first combined a variable number of N-BEATS models with a variable number of LSTM models. For this purpose, we selected the best N-BEATS models \(K_{\textrm{NB}}\) and the best LSTM models \(K_{\textrm{LSTM}}\) that were generated during validation, with \(K_{\textrm{NB}}, K_{\textrm{LSTM}} \in \{2,3,5,10,20,30\}\). For each of these combinations, we combined their predictions using the mean as the aggregation method. Finally, we evaluate the performance of these ensembles in the test set. The results can be seen in Table 14. As can be observed in this table, building mixed models ensembles using this more complex procedure improves the performance of the individual models in terms of the Mean and Median Absolute Error. However, the resulting models do not improve the results obtained with homogeneous ensembles.

Linear visualization of the predictions and residuals of the best individual model and the best homogeneous and heterogeneous model ensembles in a Clean (without network perturbations) AGV run for Experiment GE. In each plot, time is shown on the x-axis (0.1 seconds each step) and the absolute value of the Guide Error is shown on the y-axis. The Label line plots the absolute value of the Guide Error variable. The Prediction line is constructed with the t+150 element of the forecast horizon of each prediction. The residual points represent the absolute difference between the label and the prediction

Linear visualization of the predictions and residuals of the best individual model and the best homogeneous and heterogeneous model ensembles in a Delay (ramp type) AGV run for Experiment GE. In each plot, time is shown on the x-axis (0.1 seconds each step) and the absolute value of the Guide Error is shown on the y-axis. The Label line plots the absolute value of the Guide Error variable. The Prediction line is constructed with the t+150 element of the forecast horizon of each prediction. The residual points represent the absolute difference between the label and the prediction

Linear visualization of the predictions and residuals of the best individual model and the best homogeneous and heterogeneous model ensembles in a Delay (static type, 150 ms) AGV run for Experiment GE. In each plot, time is shown on the x-axis (0.1 seconds each step) and the absolute value of the Guide Error is shown on the y-axis. The Label line plots the absolute value of the Guide Error variable. The Prediction line is constructed with the t+150 element of the forecast horizon of each prediction. The residual points represent the absolute difference between the label and the prediction

Linear visualization of the predictions and residuals of the best individual model and the best homogeneous and heterogeneous model ensembles in a Jitter (Pareto Normal 100 ms - 100ms - 100%) AGV run for Experiment GE. In each plot, time is shown on the x-axis (0.1 seconds each step) and the absolute value of the Guide Error is shown on the y-axis. The Label line plots the absolute value of the Guide Error variable. The Prediction line is constructed with the t+150 element of the forecast horizon of each prediction. The residual points represent the absolute difference between the label and the prediction

Linear visualization of the predictions and residuals of the time step 150 of the best individual model and the best homogeneous and heterogeneous model ensembles in a Delay (ramp type) AGV run for Experiment GE
In order to evaluate the validity of our results and to check whether the quality of the predictions obtained for the mixed ensembles is in line with the results obtained using the Mean and the Median Absolute Error, in Fig. 30 we represent the linear visualization of the predictions obtained with the best ensemble obtained. As can be seen in the figure, the model presents lazy behavior, as it is clear that it is prone to predicting the mean target value. For this reason, this approach lacks utility and, therefore, mixed ensembles are excluded hereafter. Instead, heterogeneous and homogeneous ensembles will be considered as the final models obtained in the ensemble learning experiments.
1.7.4 A.7.4 Performance comparison of ensembles with individual models (linear visualization)
We selected a set of scenarios containing different network perturbations to visually analyze the performance of the best models when network conditions change. We show in Fig. 31 (Clean scenario with no network perturbations), Figs. 32 (fixed delay), 33 (incremental delay) and 34 (fixed jitter), the predictions at \(t+150\) of the best model of each type (i.e., individual model, homogeneous and heterogeneous ensemble). As can be observed in these figures, the homogeneous ensembles conformed by models of the N-BEATS architecture and the heterogeneous models composed of the best N-BEATS and LSTM models obtain extremely accurate predictions in all the representative network situations shown, and significantly better than the individual models.
Regarding the "lazy behaviour" effect, we present some interesting details in this respect when model ensembling is applied. First, observing in appendix A, Fig. 35, it is clearly noticeable that the heterogeneous model ensemble that includes the Random Forest model provides a linear prediction that increases timidly as the network delay increases. On the other hand, the homogeneous model composed of LSTM models (AGV:AGV+NET+OSCI) also predicts with a linear tendency in the situation shown in this figure, although this linearity was not observed in the best LSTM models obtained for this specific combination of input features and with different time windows. A reasonable hypothesis is that the OSCI variable, given its fluctuating nature, is difficult to learn from. For this reason, some of the models obtained during validation fail to take advantage of it, adopting a lazy behavior during training which results in the depicted situation when their predictions are combined together. As mentioned above, the LSTM model is relatively more robust than N-BEATS and Random Forest against the lazy problem, as we confirmed by visually inspecting the linear predictions of each trained model. However, the presence of some lazy models in the ensemble process inevitably contaminates the ensemble resulting in lazy behavior, as the predictions flatten toward the mean when the predictions of these lazy models are considered during the averaging (recall the case of heterogeneous sets composed by the Random Forest model mentioned earlier). This observation highlights the importance of studying and correcting this problem in the future, which will enable one to further exploit the advantages of the ensemble learning approach to improve the Guide Error prediction.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Karamchandani, A., Mozo, A., Vakaruk, S. et al. Using N-BEATS ensembles to predict automated guided vehicle deviation. Appl Intell 53, 26139–26204 (2023). https://doi.org/10.1007/s10489-023-04820-0
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-023-04820-0