
Abstract
Financial news items are unstructured sources of information that can be mined to extract knowledge for market screening applications. They are typically written by market experts who describe stock market events within the context of social, economic and political change. Manual extraction of relevant information from the continuous stream of finance-related news is cumbersome and beyond the skills of many investors, who, at most, can follow a few sources and authors. Accordingly, we focus on the analysis of financial news to identify relevant text and, within that text, forecasts and predictions. We propose a novel Natural Language Processing (nlp) system to assist investors in the detection of relevant financial events in unstructured textual sources by considering both relevance and temporality at the discursive level. Firstly, we segment the text to group together closely related text. Secondly, we apply co-reference resolution to discover internal dependencies within segments. Finally, we perform relevant topic modelling with Latent Dirichlet Allocation (lda) to separate relevant from less relevant text and then analyse the relevant text using a Machine Learning-oriented temporal approach to identify predictions and speculative statements. Our solution outperformed a rule-based baseline system. We created an experimental data set composed of 2,158 financial news items that were manually labelled by nlp researchers to evaluate our solution. Inter-agreement Alpha-reliability and accuracy values, and rouge-l results endorse its potential as a valuable tool for busy investors. The rouge-l values for the identification of relevant text and predictions/forecasts were 0.662 and 0.982, respectively. To our knowledge, this is the first work to jointly consider relevance and temporality at the discursive level. It contributes to the transfer of human associative discourse capabilities to expert systems through the combination of multi-paragraph topic segmentation and co-reference resolution to separate author expression patterns, topic modelling with lda to detect relevant text, and discursive temporality analysis to identify forecasts and predictions within this text. Our solution may have compelling applications in the financial field, including the possibility of extracting relevant statements on investment strategies to analyse authors’ reputations.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
1.1 Motivation
New efficient algorithms [1,2,3,4] and the prolific sources of online information have boosted applied data analysis research. In this scenario, Natural Language Processing (nlp) techniques are being successfully applied to unstructured textual data [5,6,7,8], from the simplest approaches that use morphological information as input [9] to more complex methodologies that take advantage of syntactic patterns and semantic relations [10].
Financial Knowledge Extraction (ke) is of particular interest. nlp techniques have been used to apply a wealth of market forecasting research to financial news, economic reports and financial expert comments [11]. Financial news describes relevant market events, their causes and their possible effects. Transferring human associative discourse capabilities [12] from this type of content is challenging.
1.2 Financial knowledge extraction
Some representative examples of financial ke include information extraction from financial news for firm-based monitoring [13]; analysis of financial risk such as volatility [14] and Personal Finance Management applications [15], among other interesting use cases [7]. Most of these ke systems engineer specific features of the content with their target in mind [16].
It is well known that there is a strong relation between mass media news and stock market state [17, 18]. Previous research has shown that information published in media outlets or shared financial data in printed media, radio, television, and web sites is correlated with future stock market events [19]. Apart from providing valuable objective information in financial news, authors speculate about market events within political, social and cultural contexts. In these unstructured texts the discourse flows around certain key statements and predictions, and an automatic financial news analysis system should distinguish between less relevant data and predictions to gather knowledge to assist investors in decision making [20].
1.3 Temporality at the discursive level
Temporal representation in texts and speculative statements in particular is based on semantic combinations of certain linguistic structures and elements [21]. However, the vast majority of works on temporality research at the discursive level have simply focused on verb tenses [22], ignoring their semantic context.
1.4 Research goal and main contribution
Our research is a case of financial News Analysis (na) [13,14,15] within the field of Intelligence Amplification, which has lately gained attention [23,24,25] as a means of enhancing the understanding and reasoning capabilities of automatic ke solutions and transferring human associative discourse capabilities to expert systems. Our case contributes to solving the problem of extracting relevant text from financial news and, within that relevant text, identifying forecasts and predictions. Our solution may be valuable in helping inexpert stockholders to process more financial news more efficiently.
To the best of our knowledge, this is the first study to propose an approach for the automatic detection of relevant events in financial na based on the joint consideration of relevance and temporality analysis at the discourse level.
1.5 Approach
Our approach comprises:
-
Multi-paragraph topic segmentation and co-reference resolution to separate author expression patterns.
-
Detection of relevant text through topic modelling with Latent Dirichlet Allocation (lda), outperforming a rule-based system.
-
Identification of forecasts and predictions within relevant text using discursive temporality analysis and Machine Learning (ml).
We demonstrate the performance of these features using an experimental data set composed of news items from widely used financial sources. The final data set had 2,158 financial news items similar in size to or even larger than other studies in the literature [26,27,28,29,30,31] that were manually labelled by nlp researchers.
1.6 Structure of the paper
The rest of this article is organised as follows. Section 2 reviews related work on ke and na solutions. Section 3 describes our automatic system for detecting relevant financial events based on nlp and ml techniques. Section 4 presents the text corpus and numerical evaluation of our solution. Finally, Section 5 concludes the article.
2 Related work
Stock market research is based on fundamental and technical approaches [32]. Fundamental approaches involve performing stock market forecasts using numerical data such as price variation. Technical approaches, in turn, focus on the temporal dimension of financial events. They apply trend modelling techniques to historical asset data forecasts.
Previous research on Data Mining and ke for stock market screening on textual data has considered financial news [14, 33], stockholder comments in blogs [18] and social networks [34]. These systems apply nlp techniques [11] or ml models [2, 14], which may be supervised [35], relying on automatic or manually annotated data sets, or unsupervised [36], taking into account the peculiarities of input data and descriptive patterns. The simplest approach consists of using a vector representation of the content and weighting the terms once meaningless elements, such as prepositions [37], are removed. More complex approaches, like the one presented by De Arriba-Pérez et al. (2020) [38], seek to identify syntactic and semantic patterns as key descriptors of financial news through lexica, grammar and name entity recognition techniques.
Traditional extraction methods for filtering relevant text in this context comprise manualFootnote 1 and automaticFootnote 2 pattern discovery approaches [40]. The former require large knowledge bases, such as dictionaries and lexica, and rule sets. They tend to be constrained by specific application domains. Automatic approaches include simple statistical and more demanding, complex linguistic approaches, in addition to the previously mentioned ml solutions [39]. tf-idf [41] is remarkably simple, but it has been reported to under-perform on professional texts, as in our case. Alternative solutions combine the previous techniques with knowledge heuristics such as position, length and text format information. A more competitive solution is fuzzy logic for sentence scoring. However, this lacks adaptability and requires manual rule generation, which directly affects performance [42].
Unsupervised extraction is highly practical because it eliminates the burden of text tagging. Nevertheless, many ke solutions rely on supervised methodologies. Examples those of Gottipati S et al. (2018) [43], who designed an ml course improvement solution based on student feedback and compared its performance to a rule-based method; López-Úbeda et al. (2021) [44], who extracted relevant information from radiological reports; and Verneer et al. (2019) [45], who proposed a relevance detection system from social media messages (although they noted the great potential of lda as an alternative).
Among extraction solutions developed to detect relevant topics from news pieces (setting aside temporality analysis), Jacobs et al. (2018) [46] developed a supervised model for economic event extraction in English news using a sentence-level classification approach, as in our case; Oncharoen et al. (2018) [47] applied the Open Information Extraction system to represent the news data as tuples (actor, action and object); Carta et al. (2021) [48] employed a real-time domain-specific clustering-based approach for event extraction in news; and Harb et al. (2008) [49] presented a linguistic-based opinion extraction system for blogs.
Assuming there is a direct causal relationship between financial news and asset prices [17], some authors have explored both ml and other sophisticated techniques such as deep learning to gather context-dependent information for stock market screening [50]. Worthy of note in this respect is the Naive Bayes model by Atkins et al. (2018) [14] for predicting stock market volatility, which employed as input word-topic correspondence feature vectors obtained with lda. Unlike our proposal, this model considered news content as a whole and did not differentiate non-relevant from relevant parts for their target application. Shilpa & Shambhavi (2021) [50] presented a prediction framework based on sentiment analysis and stock market technical-indicator features. Temporality was not considered.
Prior work has addressed linguistic [51], template-based [52] and statistical news summarisation approaches [53]. State-of-the-art summarisation systems may be extractive [53] or abstractive [54]. Extractive summaries, which are more akin to our goal, extract key sentences directly from the input text. These sentences are ranked by importance and selected if they pass a threshold. Query-focused and update summarisation approaches [55] also deserve consideration as they retrieve information tailored to a specific audience. The summarisation of online financial news in our work focuses on financial investors. The temporal dimension, expressed as discursive temporality, is crucial to us because relevant text in finance-related news may include in addition to factual information, speculations or predictions, whether quantitative or not. In further relation to summarisation, template-based systems on financial na [56] were limited in early research due to their computational load, the laborious task of defining the templates and their lack of flexibility.
ke solutions, and in particular, financial na systems, have not paid sufficient attention to temporal analysis. The vast majority simply use temporal references provided by timestamps or verb tenses. Evers-Vermeul et al. (2017) [22], for example, simply noted that as linguistic markers, verb tense suffixes express temporal order and coherence relations through text. Our work goes a step further by analysing sentence-level temporality through syntax and semantics, and detecting temporal elements, expressions and the patterns in which they are arranged.
Summing up, Table 1 compares the most relevant work related to our proposal. Our main contribution is the detection of relevant statements on financial news including forecasts and predictions. To do this, our system automatically groups related data and filters out background information. In brief, we present a novel technique combining lda analysis of automatically segmented news with temporality analysis at the discourse level. To our knowledge, this is the first na approach that jointly considers relevance and temporality at the discourse level.
3 System architecture
In this section, we describe our system for the automatic detection of relevant financial events using nlp techniques and ke algorithms. Figure 1 shows the scheme of the system. First, we segment the input text to group together closely related information. Then, we apply co-reference resolution to discover internal dependencies in the news content among key references to assets. The next stage is the tag processing stage, which consists of the detection, homogenisation and replacement of financial terms. This is followed by relevant topic modelling and temporal analysis to identify predictions and speculative statements, and ultimately provide investors with a synthesised version of financial news highlighting pertinent information, such as asset performance and forecasts/predictions as a summary.

Proposed system
3.1 Multi-paragraph topic segmentation
The first stage of the multi-paragraph topic segmentation process applies the enhanced version of the TextTiling algorithm [57] to segment news content into subtopic paragraphs.
TextTiling exploits lexical co-occurrence and discourse distribution patterns to identify subtopic paragraphs within a text with reasonable precision from a human’s perspective. The algorithm compares, in sequence, the similarity of adjacent text divisions of similar length. If the vocabulary in the first and second parts of the comparison differ, the division is considered a split point. We set a minimum text length of 500 characters to apply the algorithm. Otherwise, no segmentation is performed.
The rationale behind this first stage is the assumption that text segments must be coherent, self-contained information units. Explicit paragraphs of financial news are less useful in our case because, quite often, they just break up the text layout to facilitate readability. It is the informal, inner structure based on key statements and predictions about certain assets or stock markets that interests us.
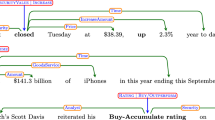
Table 2 shows an example of the original content of a financial news item. Table 3 shows the same item after segmentation with TextTiling (for conciseness, we present just the first two segments). In this example, the first paragraph refers to the current state of the asset and the second describes its past performance. Logically, TextTiling does not always guarantee such a degree of coherence, but in our case, it contributes to the overall efficiency of our system as a building block.
3.2 Co-reference resolution
The purpose of co-reference resolution is to replace references with meaningful words, which improves the performance of the subsequent lda stage. Specifically, after segmenting the text, we use the Neural Network (nn) by Clark et al. (2016) [58] to generate high-dimensional vector representations for co-reference compatibility of cluster pairs. The nn is composed of two task-oriented sub-networks: a mention-pair encoder and a cluster-pair encoder, which create the distributed representations, and the cluster and mention-ranking models to score the pairs of clusters.
Table 4 provides an example of a news entry after this procedure. Note how implicit asset references have been replaced by explicit ones, which is essential for the next stages.
3.3 Tag processing: financial term detection, homogenisation and replacement
After text segmentation and co-reference resolution, the tag processing stage homogenises the input for the subsequent lda stage. First, asset identifiers are detected using our financial lexicaFootnote 3 on stock markets, tickers and currencies. In addition, we search for words such as company, enterprise, manufacturer and shareholder, which may refer to an asset. We then detect dependencies between these key terms. Next, we replace all references to stock markets, assets, asset abbreviations and currencies with the tags stock, ticker, ticker_abr and currency, respectively. Using the same lexica, we also replace financial terms and abbreviations with the tag fin_abr.
A search is also made for capitalised proper names in the news items. Initially, these names are checked in the above and replaced by fin_abr, ticker_abr and ticker tags, as appropriate, when there is a match. In the absence of a match, they are replaced by category tags taken from an entity recognition database.
We homogenise numerical values and dates, and group dates and times under the tag date and quantitative terms under the tag num using a Name Entity Recogniser (ner, see Section 4.1). Table 5 provides a complete example of co-reference resolution and tag processing with detection of financial terms, homogenisation and replacement using the tools specified in Section 4.1.
3.4 Relevant text detection with lda topic modelling
lda [59] is an unsupervised algorithm that identifies different topics in a particular document, but it can be generalised to unknown documents if they belong to the same domain and share similar context and structure [60]. We use it to differentiate between relevant and less relevant information in segments (“documents” in this section) produced from financial news content. Our goal is thus to discover relevant information in financial news by separating it from non-relevant information. Note that this type of news has a rather characteristic structure where relevant information is often presented along with precise contextual data and expression patterns, unlike other conventional news items.
Therefore, we employ a Dirichlet distribution with two topics (1). The training algorithm iterates to minimise the number of topics per word and document.
-
Z is the set of target topics, two in this work.
-
W is the set of words (once stop-wordsFootnote 4 are discarded), with size N.
-
M is the size of the document collection.
-
α and β are the symmetric smoothing hyper-parameters to avoid discarding one of the topics due to zero intra-document or intra-corpus topic occurrences. Both hyper-parameters are initialised randomly. Specifically, α and β are the topic-document and word-topic densities, respectively. Lower values of α and β reduce the variability of topic assignment to specific documents and words.
-
P(𝜃j;α) and P(ϕi;β) are the topic-documents and word-topics Dirichlet distributions, respectively.
-
\(P(Z_{j,t} \rvert \theta _{j})\) and \(P(W_{j,t} \rvert \phi _{Z_{j,t}})\) are the topic-documents and word-topics multinomial distributions, respectively.
During lda model training, by modifying α and β, (i) topics are assigned randomly to the words in each document, then, (ii) the algorithm iterates across the word-topic pairs in different documents generating new assignments and accepting them if they decrease the number of topics per word and document.
The algorithm converges when it finds a solution that minimises the number of intra-document topics and topics per word. Alternatively, an iteration limit can be set. Ultimately, the resulting assignment of words to topics can be used to define a criterion for detecting topics in new text. To this end, when a new sentence is presented to the algorithm, the step (ii) is repeated by also taking into account the words in the new sentence. The score of a sentence for a given topic is the number of words of that topic in the sentence divided by the length of the sentence in words. In principle, the sentence is considered to belong to the topic with the largest score. Note that in this estimation, the algorithm is started using the distribution with the best hyper-parameters α and β when the training algorithm terminates.
The capability of the system to differentiate between relevant and non-relevant information in the resulting topics is related to two combined effects of data conditioning in previous stages. First, TextTiling groups text by the different expression patterns that the authors of financial news tend to use in relevant and non-relevant text. Second, co-reference resolution and tag processing create a higher density of certain tags in relevant text. For this reason, as a practical contribution, we defined a topic score ρ that represents the density of significant tags stock, ticker, currency and fin_abr in financial news content, which is computed as the percentage of significant tags in a topic divided by the total number of tags in the whole data set. The topic with the highest ρ value is considered relevant. Furthermore, to improve the precision of the lda algorithm in detecting relevant text (that is, its ability to avoid false positives) we introduced another practical contribution: an lda score threshold for accepting a sentence as relevant. It is computed as the minimum value of the configurable parameter δ and the mean value of the topic scores of the relevant sentences in the same segment.
Table 6 shows an example of relevant information detection, together with some sentences on the relevant topic from the same segment and the corresponding lda classification scores. The mean value of the scores is 0.878.Footnote 5 Thus, assuming that δ = 0.8, even though the third sentence belongs to the relevant topic, the system would consider it irrelevant.
3.5 Temporal analysis
Table 7 shows the set of temporal features used to train the ml temporal analysis model. The focal point of this analysis is the use of verbs when referring to stock markets, assets and currencies, but, unlike previous works, we consider them to be part of the semantic context.
Within each relevant sentence, we perform a dependency analysis to link verbs to stock markets, assets and currencies and a proximity analysis based on the proximity between the verbs and the key elements identified. The system measures the distance of a term to the nearest verb as the number of intermediate words in both directions. For both analyses (dependency and proximity), we consider whether assets are the subjects or objects of their clauses. For each feature, we estimate the verb tense by majority voting among past, present and future tenses (in case of a tie, the future tense prevails).
Algorithms 1 and 2 describe the generation of the temporal features of a segment based on the dependency (Algorithm 1) and the proximity (Algorithm 2) analysis of the corresponding sentences. Both algorithms have linear time complexity O(n ⋅ d) owing to the d independent loops with a limited number of n elements (subject and object sentences in our case). In the particular scenario in which the number of subject sentences equals the number of object sentences, for each loop and each tense, time complexity is O(2 ⋅ 3 ⋅ n) for 2 analyses (subject and object) and 3 tenses (past, present, future). Table 8 shows an example of the outcome. Note the financial terms and associated verbs. For this segment, for example, features FutDepSubObj and FutProxSubObj in Table 7 are set to 1.

Dependency analysis

Proximity analysis
In addition to the temporal features, we also consider textual and numerical features in the ml temporal analysis model. The textual features are char-grams, word-grams and word tokens (n-grams within word boundaries), whose parameter ranges are selected by combinatorial searching. The two numerical features are the number of numerical values (excluding percentages) and the number of percentages in the news content.
After empirical tests with diverse ml algorithms, we chose a Linear Support Vector Classifier (svc) to estimate the temporality (past, present, future) of a segment (see our previous work [61]). Before training the svc, we pre-processed the clauses in the financial news by converting text to lower case, and removing punctuation marks and non-Unicode characters such as accents and symbols.
Finally, Algorithm 3 shows the logical flow of the proposed solution.

Solution pipeline
4 Experimental results
In this section, we describe the experimental data set and the performance of our system for the detection of relevant financial events. Well-known state-of-the-art metrics were used for the evaluation: Alpha-reliability and accuracy [62], and the Recall-Oriented Understudy for Gisting Evaluation (rouge) metricFootnote 6 [21, 63, 64]. Comparisons of the proposed solution with a rule-based baseline and a supervised extraction approach are also provided.
4.1 Experimental setting
The experiments were performed on a computer with the following specifications:
-
Operating system: Ubuntu 18.04.2 lts 64 bits
-
Processor: IntelCore i9-9900K 3.60 GHz
-
RAM: 32 GB DDR4
-
Disk: 500 GB (7200 rpm SATA) + 256 GB SSD
Regarding the implementation, we took the following decisions:
-
Segmentation (Section 3.1): as previously mentioned, we applied the TextTiling algorithm.Footnote 7 For this first stage, we used the default parameters of the classifier (see Listing 1). Stop-words were also removed.
-
Co-reference detection (Section 3.2): we used the nn implementation of the NeuralCoref libraryFootnote 8, which is a pipelined extension of the spaCy libraryFootnote 9 to solve co-reference groups in blocks of text. Specifically, we used the pre-trained word embedding statistical model for English with its default features. Surprisingly, in our analysis, we noticed that NeuralCoref did not always detect the indispensable word stock. To circumvent this problem, following a trial and error process, we replaced stock with index before co-reference resolution.
-
Tag processing (Section 3.3): we employ the Freeling libraryFootnote 10 to detect dependencies between terms. Capitalised proper names are detected with the spaCyFootnote 11 library. If the names are not in our lexica, their categories are selected from spaCy EntityRecognizer tool.Footnote 12 Depending on the category, the names are replaced by the following tags: money, person, norp (nationalities, religions or political groups), org (organisations, companies), product, event, and work of art (titles of artworks). Moreover, all elements recognised as loc, fac (buildings) and gpe (countries, cities, states) are grouped under the tag loc (locations). Numerical values and dates are detected using EntityRecognizer. Terms recognised as date and time are grouped under the tag date, while those recognised as percent, cardinal and quantity are grouped under the tag num.
-
Relevant text detection with lda topic modelling (Section 3.4): we employed the LdaMulticore module from the gensim Python library.Footnote 13 Listing 2 shows the configuration parameters used to train the model. Through repeated trials, we tuned the algorithm to 50 training passes, alpha to symmetric and beta to asymmetric. Finally, we set δ = 0.8.
-
Numtopics is the number of latent topics to be extracted.
-
Passes is the number of passes to be applied during training.
-
Random state is a useful seed for reproducibility.
-
Alpha represents an a-priori belief about document-topic distribution, that is, prior to selection strategies. Its feasible values are: (i) scalar for symmetric document-topic distribution, (ii) symmetric to use a fixed symmetric distribution of 1.0/numtopics, and (iii) asymmetric to use a fixed normalised asymmetric distribution of 1.0/(topicindex + sqrt(numtopics)).
-
Beta is an a-priori belief on topic-word distribution. It has the same feasible values as alpha.
-
-
Temporal analysis (Section 3.5): Freeling is used to tag assets as subjects or objects of their clauses to obtain the corresponding temporal features. We used the svc implementation from the Scikit-Learn Python library.Footnote 14 Regarding the parameterisation of the char-grams, word-grams and word tokens textual features, we applied a GridSearchCVFootnote 15 combinatorial search from Scikit-Learn within the ranges in our prior related work [61]. The final choices were maxdf = 0.30, mindf = 0, ngramrange = (2,4) and maxfeatures = 10000.
-
Mindf and maxdf are used to ignore terms with a lower (cut-off) and higher (corpus-specific stop words) document frequency than the given threshold, respectively.
-
Ngramrange indicates the lower and upper boundary for the extraction of word n-grams.
-
Maxfeatures represents the number of features considered for the best split.
Listing 1 
Configuration parameter ranges of the TextTiling algorithm
Listing 2 
Configuration parameter ranges for the lda model
To select the best features for the temporal analysis across the whole set (temporal, textual and numerical features), we used SelectPercentileFootnote 16 from Scikit-Learn with the χ2 score function and 80th percentile threshold. The hyper-parameters of the svc were tuned using GridSearchCV with 10-fold cross validation within the ranges in Listing 3. The optimal hyper-parameter values used were C = 0.001, classweight = balanced, loss = squared_hinge, maxiter = 1500, multiclass = ovr, penalty = l2, tol = 10− 9. Finally, the svc was evaluated by 10-fold cross validation using 600 sentences from financial news. This auxiliary data set is similar in size to other sets used in the literature [26,27,28,29,30,31] and did not belong to the experimental data set described in Section 4.1 that was used to detect relevant information, and was independently annotated. The svc attained 80.21% precision and 80.40% recall for the auxiliary set.
-
C is the regularisation parameter.
-
Classweight is used to set the parameter C of the classes. If not given, all classes are assumed to have weight one. The balanced mode automatically adjusts weights in a manner that is inversely proportional to class frequencies in the input data.
-
Loss represents the loss function.
-
Maxiter is the hard limit on iterations, or -1 for no limit.
-
Multiclass represents the one-vs-one scheme.
-
Penalty represents the penalty for the model.
-
Tol represents the tolerance for the stopping criterion.
-



Configuration parameter ranges for svc
4.2 Experimental data set
Our experimental data set was composed of 2,158 news pieces (average length of 27.98 sentences and 537.24 words). As previously mentioned, the pieces were automatically extracted with a script from popular and prestigious financial websites between 1st October 2018 and 1st October 2020. We filtered the news pieces to keep those that mentioned at least one of the stocks in our financial lexica.3 For text processing purposes, double spaces, line breaks and tabs were replaced by a single space. Finally, we removed, url s, images and graphics and kept the date and author information.
Each entry in the resulting data set is composed of an identifier, a title, content, author information, source and date of publication. The entries are comparable in size to those described in previous ke [26,27,28,29,30,31] and lda works [65].
A brief descriptive analysis of the data set is given in Table 9.
The texts were annotated by five nlp scientists from the atlanTTic Research Centre for Telecommunication Technologies at the University of Vigo. Manual annotations included relevant texts, asset identifiers and prediction/forecast texts. A number of guidelines were agreed on to enhance consistency (e.g., bold font for relevant text, italics for asset identifiers and underlining for prediction/forecast text). Table 10 shows an example of an annotated news item from the experimental data set. We used the annotated asset identifiers to improve the content of our financial lexica3 which increased by 3.95%.
4.3 Inter-agreement evaluation
We evaluated inter-annotator agreement using two well-known state-of-the-art metrics: Alpha-reliability and accuracy.
Table 11 shows the coincidence matrix of relevance across all annotators. The two components in the diagonal show the number of news sentences on which all the annotators agreed, while the other two components show the cases on which at least one annotator disagreed. Tables 12 and 13 show the Alpha-reliability and accuracy coefficients by pairs of annotators. The mean values were 0.552 and 0.861, respectively. Previous works have considered an Alpha-reliability value above 0.41 to be acceptable [66,67,68,69]. Inter-agreement accuracy was very high, at over 80%.
4.4 Discussion of the results
Before applying our system for the automatic detection of relevant financial events, we first defined a simple rule-based system as a baseline. This system sets a relevance score by counting tickers, numbers and percentages and detecting future tenses using Freeling. As previously mentioned, relevant financial text has characteristic context data and expression patterns, and our goal was to determine whether a sophisticated technique such as lda would perform better than trivial rules.
The rule-based baseline approach is as follows. First, the text is segmented into sentences, and all references to stock markets, assets, asset abbreviations and currencies are replaced by the tags stock, ticker, ticker_abr and currency, respectively. As indicated in Section 3.3, financial terms and abbreviations are also replaced by the tag fin_abr. Freeling is applied to detect percentages and numerical values, which are replaced by the tag num. Sentences containing a future tense as detected by Freeling are considered to refer to the future. In brief, a sentence is considered relevant if it contains at least one financial tag (stock, ticker, ticker_abr, currency or fin_abr) and at least one num tag, and predictive if the main verb is in future tense.
Drawing from related work on more powerful supervised extraction strategies [43,44,45, 49], we also applied a svc modelFootnote 17 as a second comparison reference. The model was trained using manual annotations on relevant text, including predictions. Textual features were generated and hyper-parameter settings optimised as described in Section 4.1.
Next, we evaluated our system by checking it against the annotated segments. To do this, we employed rouge, a widely used set of metrics for evaluating automatic text extraction performance based on overlapping n-grams. We used rouge-l, which measures the longest common sub-sequence between the system output and the annotated news. This rouge variant has been applied as a string matching algorithm to compute the similarity between two texts [70].
Tables 14 and 15 show the results obtained for the baseline systems and the proposed system. Even though the problem case is entirely novel (see Section 1.5), the results show that the application of sophisticated nlp techniques and ke algorithms such as those used in our solution results in improved extraction of relevance and temporality from financial news content.
Table 14 shows the results for the detection of relevant information by the baseline systems and our system for the tags identified by the five annotators. Average values are also provided. In our tests, text was considered relevant when its score for a given topic doubled the score of the other topic.Footnote 18 The remaining text was considered to be less relevant or contextual information. The average rouge-l value across all annotators was 0.662, more than doubling the performance of the rule-based baseline approach. The manually intensive supervised extraction alternative was comparable to our unsupervised approach (in fact the former was often worse, depending on the annotator). This performance can be considered satisfactory in line with other works from the literature [63, 64, 71, 72]. Table 15 shows the results for the detection of relevant predictions/forecasts after the last svc classifier stage. The average rouge-l value in this case, 0.982, was excellent, with a significant improvement over the rule-based baseline reference of 0.713.
Counterintuitively, the performance of the rule-based baseline in Table 14 is worse because this approach gives relevance to text that contains quantitative data even if it corresponds to merely contextual information, such as past states of assets and stock markets. It underperformed our proposed solution by an average of 51%. The level of agreement between our system and the annotators for the detection of predictions/forecasts (Table 15) was near perfect, with rouge values of more than 0.970 for all annotators. As expected, predictions and forecasts within relevant text are easier to detect than relevant text itself, explaining the lower rouge values in this second case, where the highest coefficient observed was 0.727 (for annotator 1).
4.5 Application use case
Figure 2 shows a news piece highlighted by our system. Relevant sentences are highlighted in blue, asset identifiers in pink and predictions/forecasts in green. Note the differences with the manual highlighting in Table 10. For example, human annotators might mark the sentence “In fact, VZ stock is worth at least 55% more than its price today” as a prediction. With our system, however, both forecasts and relevant, informative sentences are marked.

Example of financial event detection
The dashboard at the bottom of Fig. 2 summarises the results, showing the proportion of relevant segments and number of predictions and forecasts. The updated value of the financial asset, taken from Yahoo FinanceFootnote 19, is shown on the right.
5 Conclusions
Many valuable online financial news sources, such as economy journals and web pages (Motley Fool, InvestorDaily, etc.), contain opinions from experts describing relevant market events within sociological, political and/or cultural contexts.
The system proposed in this paper is designed to extract this relevant information, and in particular forecasts and predictions. To do this, it employs nlp techniques. It segments the text and applies lda analysis to filter out less relevant sentences, and then applies discursive temporality analysis to identify predictions and forecasts within the remaining relevant text. The result is a summary of relevant, easy-to-read information. We are not aware of any other ke systems that have applied a similar approach to resolve this problem.
To our knowledge and considering related work, our proposal is the first to jointly consider relevance and temporality at the discursive level. It contributes to transferring human associative discourse capabilities to expert systems by combining (i) multi-paragraph topic segmentation and co-reference resolution to separate author expression patterns, (ii) detection of relevant text through topic modelling with lda, and (iii) identification of forecasts and predictions within relevant text using discursive temporality analysis and ml.
We have created an experimental data set composed of 2,158 financial news items to evaluate our proposal. We have validated its annotation capacity by performing an inter-agreement analysis using Alpha-reliability and accuracy measures and evaluated its performance using the state-of-the-art rouge metric. The system attained rouge-l values of 0.662 and 0.982 for the detection of relevant data and predictions/forecasts, respectively. We also compared the performance of our system with a rule-based baseline system and a fully supervised system (which also performs supervised extraction of relevant text) to evaluate its competitiveness. It outperformed the rule-based system and was comparable to the fully supervised system, which unlike our solution requires manual annotation.
In future work, we plan to extend our research to Spanish and other languages to cover a broader community of investors. We will also evaluate the system in composite (multi-disciplinary) research domains.
Data Availability
The data sets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
Code Availability
The code used in this work is not publicly available.
Notes
E.g., cascaded and non-deterministic finite state automatons, semantic information extraction solutions, etc.
E.g., supervised and unsupervised ml methods, being the first more extended [39].
Available at https://www.gti.uvigo.es/index.php/en/resources/14-resources-for-finance-knowledge-extraction, October 2022.
Available at bit.ly/3yzvXqJ, October 2022.
Note that this mean value is computed with all relevant sentences in the segment, only some of them are contained in Table 6.
Available at https://github.com/pltrdy/rouge, October 2022.
Available at https://www.nltk.org/_modules/nltk/tokenize/texttiling.html, October 2022.
Available at https://github.com/huggingface/neuralcoref, October 2022.
Available at https://spacy.io, October 2022.
Available at http://nlp.lsi.upc.edu/freeling/node/1, October 2022.
Available at https://spacy.io, October 2022.
Available at https://spacy.io/api/top-level#spacy.explain and https://github.com/explosion/spaCy/blob/master/spacy/glossary.py, October 2022.
Available at https://pypi.org/project/gensim, October 2022.
Available at https://scikit-learn.org/stable/supervised_learning.html#supervised-learning, October 2022.
Available at https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html October 2022.
Available at https://scikit-learn.org/stable/modules/feature_selection.html October 2022.
Note that a supervised approach was also used to estimate the temporality (past, present, future) of text in our proposal.
Note that there are only two topics under analysis in this work.
Available at https://finance.yahoo.com, October 2022.
References
Manogaran G, Varatharajan R, Lopez D et al (2018) A new architecture of internet of things and big data ecosystem for secured smart healthcare monitoring and alerting system. Futur Gener Comput Syst 82:375–387. https://doi.org/10.1016/j.future.2017.10.045
Delić V, Perić Z, Sečujski M et al (2019) Speech technology progress based on new machine learning paradigm. Comput Intell Neurosci 2019:1–19. https://doi.org/10.1155/2019/4368036
Ma X, Fei Q, Qin H et al (2020) A new efficient decision making algorithm based on interval-valued fuzzy soft set. Appl Intell 51(6):3226–3240. https://doi.org/10.1007/s10489-020-01915-w
Zuo Y, Wu Y, Min G et al (2020) An intelligent anomaly detection scheme for micro-services architectures with temporal and spatial data analysis. IEEE Trans Cogn Commun Netw 6(2):548–561. https://doi.org/10.1109/TCCN.2020.2966615
Guetterman TC, Chang T, DeJonckheere M et al (2018) Augmenting qualitative text analysis with natural language processing: methodological study. J Med Int Res 20(6):e231. https://doi.org/10.2196/jmir.9702
Zhang F, Fleyeh H, Wang X, et al. (2019) Construction site accident analysis using text mining and natural language processing techniques. Autom Constr 99:238–248. https://doi.org/10.1016/j.autcon.2018.12.016
Balyan R, McCarthy KS, McNamara DS (2020) Applying natural language processing and hierarchical machine learning approaches to text difficulty classification. Int J Artif Intell Educ 30(3):337–370. https://doi.org/10.1007/s40593-020-00201-7
Lu X, Deng Y, Sun T et al (2022) MKPM: multi keyword-pair matching for natural language sentences. Appl Intell 52(2):1878–1892. https://doi.org/10.1007/s10489-021-02306-5
Kumar S, Kumar MA, Soman K (2019) Deep learning based part-of-speech tagging for Malayalam twitter data (special issue: deep learning techniques for natural language processing). J Intell Syst 28 (3):423–435. https://doi.org/10.1515/jisys-2017-0520
K. V, Gupta D (2018) Unmasking text plagiarism using syntactic-semantic based natural language processing techniques: comparisons, analysis and challenges. Inf Process Manag 54(3):408–432. https://doi.org/10.1016/j.ipm.2018.01.008
Xing FZ, Cambria E, Welsch RE (2018) Natural language based financial forecasting: a survey. Artif Intell Rev 50(1):49–73. https://doi.org/10.1007/s10462-017-9588-9
Lytos A, Lagkas T, Sarigiannidis P et al (2019) The evolution of argumentation mining: from models to social media and emerging tools. Inf Process Manag 56(6):102,055. https://doi.org/10.1016/j.ipm.2019.102055
Kelly S, Ahmad K (2018) Estimating the impact of domain-specific news sentiment on financial assets. Knowl-Based Syst 150:116–126. https://doi.org/10.1016/j.knosys.2018.03.004
Atkins A, Niranjan M, Gerding E (2018) Financial news predicts stock market volatility better than close price. J Financ Data Sci 4(2):120–137. https://doi.org/10.1016/j.jfds.2018.02.002
Isa K, Rahman Ahmad A, Md Yusoff R et al (2018) NEWS analysis towards youth financial competency management. Int J Eng Technol 7(2.29):1151. https://doi.org/10.14419/ijet.v7i2.29.15146
Zhang H, Boons F, Batista-Navarro R (2019) Whose story is it anyway? Automatic extraction of accounts from news articles. Inf Process Manag 56(5):1837–1848. https://doi.org/10.1016/j.ipm.2019.02.012
Cepoi CO (2020) Asymmetric dependence between stock market returns and news during COVID-19 financial turmoil. Financ Res Lett 36:101,658. https://doi.org/10.1016/j.frl.2020.101658
Swathi T, Kasiviswanath N, Rao AA (2022) An optimal deep learning-based LSTM for stock price prediction using twitter sentiment analysis. Appl Intell :1–14
Loughran T, McDonald B (2016) Textual analysis in accounting and finance: a survey. J Account Res 54(4):1187–1230. https://doi.org/10.1111/1475-679X.12123
Lutz B, Pröllochs N, Neumann D (2020) Predicting sentence-level polarity labels of financial news using abnormal stock returns. Exp Syst Appl 148:113,223. https://doi.org/10.1016/j.eswa.2020.113223
Mohamed M, Oussalah M (2019) SRL-ESA-TextSum: a text summarization approach based on semantic role labeling and explicit semantic analysis. Inf Process Manag 56(4):1356–1372. https://doi.org/10.1016/j.ipm.2019.04.003
Evers-Vermeul J, Hoek J, Scholman MC (2017) On temporality in discourse annotation: Theoretical and practical considerations. Dialogue Discourse 8(2):1–20. https://doi.org/10.5087/dad.2017.201
Jang Y, Park CH, Seo YS (2019) Fake news analysis modeling using quote retweet. Electronics 8(12):1377. https://doi.org/10.3390/electronics8121377
Chau JY, Reyes-Marcelino G, Burnett AC et al (2019) Hyping health effects: a news analysis of the ‘new smoking’ and the role of sitting. Br J Sports Med 53(16):1039–1040. https://doi.org/10.1136/bjsports-2018-099432
Phi GT (2020) Framing overtourism: a critical news media analysis. Curr Issues Tour 23 (17):2093–2097. https://doi.org/10.1080/13683500.2019.1618249
Li Y, Pan Q, Wang S et al (2018) A Generative model for category text generation. Inf Sci 450:301–315. https://doi.org/10.1016/j.ins.2018.03.050
Long W, Song L, Tian Y (2019) A new graphic kernel method of stock price trend prediction based on financial news semantic and structural similarity. Exp Syst Appl 118:411–424. https://doi.org/10.1016/j.eswa.2018.10.008
Al-Smadi M, Al-Ayyoub M, Jararweh Y et al (2019) Enhancing aspect-based sentiment analysis of Arabic Hotels’ reviews using morphological, syntactic and semantic features. Inf Process Manag 56(2):308–319. https://doi.org/10.1016/j.ipm.2018.01.006
Zhang X, Ghorbani AA (2020) An overview of online fake news: characterization, detection, and discussion. Inf Process Manag 57(2):102,025. https://doi.org/10.1016/j.ipm.2019.03.004
de Oliveira Carosia AE, Coelho GP, da Silva AEA (2021) Investment strategies applied to the Brazilian stock market: a methodology based on sentiment analysis with deep learning. Exp Syst Appl 184:115,470. https://doi.org/10.1016/j.eswa.2021.115470
Xie M, Ye Z, Pan G et al (2021) Incomplete multi-view subspace clustering with adaptive instance-sample mapping and deep feature fusion. Appl Intell 51(8):5584–5597. https://doi.org/10.1007/s10489-020-02138-9
Nti IK, Adekoya AF, Weyori BA (2020) A systematic review of fundamental and technical analysis of stock market predictions. Artif Intell Rev 53(4):3007–3057. https://doi.org/10.1007/s10462-019-09754-z
Carta S, Corriga A, Ferreira A et al (2021) A multi-layer and multi-ensemble stock trader using deep learning and deep reinforcement learning. Appl Intell 51(2):889–905. https://doi.org/10.1007/s10489-020-01839-5
Khan W, Ghazanfar MA, Azam MA et al (2022) Stock market prediction using machine learning classifiers and social media, news. J Ambient Intell Humanized Comput 13(7):3433–3456. https://doi.org/10.1007/s12652-020-01839-w
Rustam F, Reshi AA, Mehmood A et al (2020) COVID-19 future forecasting using supervised machine learning models. IEEE Access 8:101,489–101,499. https://doi.org/10.1109/ACCESS.2020.2997311
Solorio-Fernández S, Carrasco-Ochoa JA, Martínez-Trinidad JF (2020) A review of unsupervised feature selection methods. Artif Intell Rev 53(2):907–948. https://doi.org/10.1007/s10462-019-09682-y
García-Méndez S, Fernández-Gavilanes M, Juncal-Martínez J et al (2020) Identifying banking transaction descriptions via support vector machine short-text classification based on a specialized labelled corpus. IEEE Access 8:61,642–61,655. https://doi.org/10.1109/ACCESS.2020.2983584
De Arriba-Pérez F, García-Méndez S, Regueiro-Janeiro JA et al (2020) Detection of financial opportunities in micro-blogging data with a stacked classification system. IEEE Access 8:215,679–215,690. https://doi.org/10.1109/ACCESS.2020.3041084
Beliga S, Meštrović A, Martinčić-Ipšić S (2015) An overview of graph-based keyword extraction methods and approaches. J Inf Organ Sci 39(1):1–20
Kaiser K, Miksch S (2005) Information extraction. A survey. Tech. rep., Institute of Software Technology & Interactive Systems, Vienna University of Technology
Li C, Guo J, Lu Y et al (2018) LDA Meets Word2Vec. In: Proceedings of the The Web Conference. ACM Press, pp 1699–1706, DOI https://doi.org/10.1145/3184558.3191629
Azhari M, Kumar YJ (2017) Improving text summarization using neuro-fuzzy approach. J Inf Telecommun 1(4):1–14. https://doi.org/10.1080/24751839.2017.1364040
Gottipati S, Shankararaman V, Lin JR (2018) Text analytics approach to extract course improvement suggestions from students’ feedback. Res Pract Technol Enhanc Learn 13(1):6. https://doi.org/10.1186/s41039-018-0073-0
López-Úbeda P, Díaz-Galiano MC, Ureña-López LA et al (2021) Pre-trained language models to extract information from radiological reports. In: CEUR Workshop Proceedings, vol 2936. CEUR
Vermeer SA, Araujo T, Bernritter SF et al (2019) Seeing the wood for the trees: how machine learning can help firms in identifying relevant electronic word-of-mouth in social media. Int J Res Mark 36 (3):492–508. https://doi.org/10.1016/j.ijresmar.2019.01.010
Jacobs G, Lefever E, Hoste V (2018) Economic event detection in company-specific news text. In: Proceedings of the first workshop on economics and natural language processing. association for computational linguistics, pp 1–10, DOI https://doi.org/10.18653/v1/W18-3101
Oncharoen P, Vateekul P (2018) Deep learning for stock market prediction using event embedding and technical indicators. In: Proceedings of the international conference on advanced informatics: concept theory and applications. IEEE, pp 19–24, DOI https://doi.org/10.1109/ICAICTA.2018.8541310
Carta S, Consoli S, Piras L et al (2021) Event detection in finance using hierarchical clustering algorithms on news and tweets. PeerJ Comput Sci 7:e438. https://doi.org/10.7717/peerj-cs.438
Harb A, Plantié M, Dray G et al (2008) Web opinion mining. In: Proceedings of the 5th international conference on Soft computing as transdisciplinary science and technology. ACM Press, p 211, DOI https://doi.org/10.1145/1456223.1456269
Shilpa B, Shambhavi B (2021) Combined deep learning classifiers for stock market prediction: integrating stock price and news sentiments. Kybernetes pp 1–26
Genç S, Akay D, Boran FE et al (2020) Linguistic summarization of fuzzy social and economic networks: an application on the international trade network. Soft Comput 24(2):1511–1527. https://doi.org/10.1007/s00500-019-03982-9
Abu El-Qumsan AY, El-Halees AM (2018) Template based medical reports summarization. Int J Comput Appl 179(17):47–55. https://doi.org/10.5120/ijca2018916301
Meena YK, Gopalani D (2020) Statistical features for extractive automatic text summarization. In: Natural language processing: concepts, methodologies, tools, and applications. IGI Global, pp 619–637, DOI https://doi.org/10.4018/978-1-7998-0951-7.ch030
Gupta S, Gupta SK (2019) Abstractive summarization: an overview of the state of the art. Exp Syst Appl 121:49–65. https://doi.org/10.1016/j.eswa.2018.12.011
Alhoshan M, Altwaijry N (2020) AUSS: an Arabic query-based update-summarization system. J King Saud Univ Comput Inf Sci 1:1319–1578. https://doi.org/10.1016/j.jksuci.2020.11.027
Barros C, Lloret E, Saquete E et al (2019) NATSUM: narrative abstractive summarization through cross-document timeline generation. Inf Process Manag 56(5):1775–1793. https://doi.org/10.1016/j.ipm.2019.02.010
He X, Wang J, Zhang Q et al (2020) Improvement of text segmentation texttiling algorithm. J Phys Conf Ser 1453:12,008–12,015. https://doi.org/10.1088/1742-6596/1453/1/012008
Clark K, Manning CD (2016) Improving coreference resolution by learning entity-level distributed representations. In: Proceedings of the 54th annual meeting of the association for computational linguistics (Volume 1: Long Papers). Association for Computational Linguistics, pp 643–653, DOI https://doi.org/10.18653/v1/P16-1061
Jelodar H, Wang Y, Yuan C et al (2019) Latent Dirichlet allocation (LDA) and topic modeling: models, applications, a survey. Multimed Tools Appl 78(11):15,169–15,211. https://doi.org/10.1007/s11042-018-6894-4
Gupta A, Katarya R (2021) PAN-LDA: a latent Dirichlet allocation based novel feature extraction model for COVID-19 data using machine learning. Comput Biol Med 138:104,920. https://doi.org/10.1016/j.compbiomed.2021.104920
García-Méndez S, de Arriba-Pérez F, Barros-Vila A et al (2022) Detection of temporality at discourse level on financial news by combining natural language processing and machine learning. Exp Syst Appl 197:116,648. https://doi.org/10.1016/j.eswa.2022.116648
Krippendorff K (2018) Content analysis: an introduction to its methodology. SAGE Publications
Sanchez-Gomez JM, Vega-Rodríguez MA, Pérez CJ (2018) Extractive multi-document text summarization using a multi-objective artificial bee colony optimization approach. Knowl-Based Syst 159:1–8. https://doi.org/10.1016/j.knosys.2017.11.029
El-Kassas WS, Salama CR, Rafea AA, et al. (2020) EdgeSumm: graph-based framework for automatic text summarization. Inf Process Manag 57:102,264. https://doi.org/10.1016/j.ipm.2020.102264
Park H, Park T, Lee YS (2019) Partially collapsed Gibbs sampling for latent Dirichlet allocation. Exp Syst Appl 131:208–218. https://doi.org/10.1016/j.eswa.2019.04.028
Rash JA, Prkachin KM, Solomon PE et al (2019) Assessing the efficacy of a manual-based intervention for improving the detection of facial pain expression. Eur J Pain 23(5):1006–1019. https://doi.org/10.1002/ejp.1369
Seité S, Khammari A, Benzaquen M et al (2019) Development and accuracy of an artificial intelligence algorithm for acne grading from smartphone photographs. Exp Dermatol 28(11):1252–1257. https://doi.org/10.1111/exd.14022
Salminen J, Almerekhi H, Kamel AM et al (2019) Online hate ratings vary by extremes. In: Proceedings of the 2019, Conference on human information interaction and retrieval. Association for Computational Linguistics, pp 213–217, DOI https://doi.org/10.1145/3295750.3298954
Kilicoglu H, Rosemblat G, Hoang L et al (2021) Toward assessing clinical trial publications for reporting transparency. J Biomed Inf 116:103,717–103,727. https://doi.org/10.1016/j.jbi.2021.103717
Gulden C, Kirchner M, Schüttler C et al (2019) Extractive summarization of clinical trial descriptions. Int J Med Inf 129:114–121. https://doi.org/10.1016/j.ijmedinf.2019.05.019
Hark C, Karcı A (2020) Karcı summarization: a simple and effective approach for automatic text summarization using Karcı entropy. Inf Process Manag 57(3):102,187. https://doi.org/10.1016/j.ipm.2019.102187
Alqaisi R, Ghanem W, Qaroush A (2020) Extractive multi-document Arabic text summarization using evolutionary multi-objective optimization with K-Medoid clustering. IEEE Access 8:228,206–228,224. https://doi.org/10.1109/ACCESS.2020.3046494
Funding
Open Access funding provided thanks to the CRUE-CSIC agreement with Springer Nature. This work was partially supported by Xunta de Galicia grants ED481B-2021-118 and ED481B-2022-093, Spain. University of Vigo/CISUG covered the open access fee.
Author information
Authors and Affiliations
Contributions
Silvia García-Méndez: Conceptualisation, Methodology, Software, Validation, Formal analysis, Investigation, Data Curation, Writing - original draft. Francisco de Arriba-Pérez: Conceptualisation, Methodology, Software, Validation, Formal analysis, Investigation, Data Curation, Writing - original draft. Ana Barros-Vila: Software, Validation, Investigation, Resources, Data Curation, Writing - review & editing. Francisco J. González-Castaño: Conceptualisation, Methodology, Data Curation, Writing - review & editing, Supervision. Enrique Costa-Montenegro: Methodology, Data Curation, Writing - review & editing.
Corresponding author
Ethics declarations
Competing interests
The authors have no relevant financial or nonfinancial interests to disclose.
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent for Publication
Not applicable.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Silvia García-Méndez, Francisco de Arriba-Pérez, Ana Barros-Vila, Francisco J. González-Castaño and Enrique Costa-Montenegro are contributed equally to this work.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
García-Méndez, S., de Arriba-Pérez, F., Barros-Vila, A. et al. Automatic detection of relevant information, predictions and forecasts in financial news through topic modelling with Latent Dirichlet Allocation. Appl Intell 53, 19610–19628 (2023). https://doi.org/10.1007/s10489-023-04452-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-023-04452-4