
Abstract
Visual tracking is a crucial task in computer vision that concentrates on assessing the state of the target in each frame. Siamese based trackers possess an excellent tracking mechanism and balance the accuracy and efficiency well through continuous optimization of network structure. However, the rapid appearance variation and occlusion are still huge challenges to the accuracy and success rate of tracking task. Most Siamese based trackers rely on a fixed object template to match the target in search area and also neglect the importance of feature representation to tracking tasks. Based on the core idea of how to promote the recognition ability of trackers for the dynamic object and keep stable tracking during occlusion process, we present Siamese block attention network for online update object tracking referred to as SBAN. The proposed Siamese block attention module adopts a Siamese network structure to integrate two complementary global descriptors and establish the interdependence among channels to generate channel weights which can enhance the crucial features and restrain inessential ones. We also design an online update target module that can effectively utilize the history tracking information. The final updated target module is the integration of the given template, the process template, and the last tracking results. Experiments on four benchmarks, OTB2015, VOT2018, UAV123, LaSOT, illustrate that our tracker obtains outstanding tracking performance in accuracy and robustness while running at over 53 FPS.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Object tracking is a basic and crucial problem to locate and size the object in each frame of the video,[1] which is widely employed in many fields including automatic driving, activity recognition.[2, 3] Different from the general computer vision task, the tracking target is determined in the initial frame of the video. The tracker aims to generate a bounding box to fit the object as much as possible under various interferences [4]. Therefore, the basic idea of visual tracking is to connect the information provided by the initial frame with the search regions in the rest frames. In the process of tracking, deformation, occlusion, fast motion, background clutter can increase the discrepancy between the current target and the original template to a certain extent which may result in the deviation of the bounding box or even tracking failure [5, 6].
Recently, the Siamese based trackers have made great progress and achieved outstanding performance on multiple datasets. They employ a parallel approach to extracting features from object template and search region through the same backbone. After the convolution calculation of sliding window, the score map which shows the similarity between different areas in the search region and the template can indicate the general location of the target. SiamFC[7] first used the Siamese network in visual tracking. Since then, lots of Siamese based trackers have appeared and are dedicated to improving the accuracy and robustness of the tracker, such as SiamRPN [8], SiamRPN++.[9]
Although these works powerfully promote the development of visual tracking in many aspects, there are still some limitations. One issue is that they ignore the unique property of visual tracking tasks as each video owns specific target. The tracker should focus on distinguishing the object from background rather than its category. It means the deep semantic features extracted from backbone contain redundant parts which will affect the discrimination of the object in the subsequent calculation. Another issue is that most trackers employ the offline training method and only integrate the initial information of the object. They abandon the interaction with the external information to maintain independence in the tracking process. They believe the various training data and a huge number of network parameters can offer generalization ability to capture the unknown object and its morphological variety. But it is still not enough considering the unpredictability of the object and it will lead to the tracking drift while the tracker cannot adapt well to the object with appearance change, deformation, or occlusion.
The mentioned two points reveal that the core issue of tracking tasks is to promote the recognition ability of the tracker for the dynamic object. Based on this point, we propose SBAN to more precisely recognize the target with varying appearance. First, to make the tracker aware of the variation of object, we proposed an online template update strategy to provide the tracker with dynamic state of the object, which can make tracker adapt to object efficiently without extra computation consumption. The final updated template consists of the initial template, the process template, the last tracking results. Then the Siamese block attention module is embedded in both example branch and search branch of the backbone to reinforce features that are meaningful to the current object while suppressing other ones. Two global variables are calculated through different strategies for each channel and then sent into a Siamese structure attention network to obtain the channel weight which indicates the significance of the feature for object in current frame. The integration of the online update strategy and Siamese Block Attention Network makes the tracker gain the state of object in real-time and emphasize the distinction of object, which successfully solves the mentioned problem of promoting the recognition ability of the tracker for the dynamic object. Outstanding results have been achieved on four benchmarks using this proposed tracker, including OTB2015,[10] VOT2018 [11], UAV123,[12] LaSOT[13] while operating at over 53FPS. Figure 1 shows that the results of our tracker are more accurate, robust to appearance change, conclusion, and distractors compared with SiamRPN++ and ECO.

Comparison of the tracking results among ours and ECO, SiamRPN++. Our results show better performance in appearance change, occlusion, and distractors
2 Related work
Correlation-filter based trackers is a classical branch of tracking algorithm and have been broadly employed in the past few years due to expansibility and efficiency [14]. MOOSE[15] first applies the correlation filter in the visual tracking task and shows the potential of correlation-filter based trackers. Then the performance is further improved by employing multi-channel features.[16] The progress of deep learning has brought a powerful ability to learn more representative semantic features. The correlation-filter based trackers attempt to embed the deep learning network in the correlation filter structure, including ECO [17,18,19,20] employs the combination of two different kernel filters to improve the robustness to distraction. MDDCF [21] uses a multi-task learning strategy to explore the characteristic of features in different levels and conjunctly optimizes correlation filters and network parameters during the training phase.
Siamese based tracker is another branch and develops to the main trend recently because of the outstanding performance and off-line training pattern. The structure of Siamese based trackers is commonly composed of three sections, two branches of backbone network sharing same parameters for feature extraction from object template and search area, a similarity matching module obtains score map by cross-correlation of both input features, and a head network infers the location and scale of object from the score map. Many researchers focus on applying more sophisticated architecture to enhance the representation of features or using different heads to improve the precision of tracking results.
SiamFC [7] first introduces the Siamese network in visual tracking tasks from the signal processing field and employs five convolution layers in AlexNet as the backbone. The cross-correlation performs to generate a score map at multiple scales and the final result is calculated by interpolation based on the point with the highest score on score map. However, SiamFC uses a multiple scale search method to evaluate the size of object which is rough and time-consuming. Dsiam[22] adds a transformation update model to online learn target variation and suppress the backbone interference from previous frames. Based on SiamFC, Li et al. [8] first apply region proposal network in Siamese based tracking task. SiamRPN generates a batch of anchors which possess multiple scales and ratios in every coordinate on score map. The classification head classifies the object from background and the regression head computes the accurate boundary of the object. SiamRPN enriches the structure of Siamese based tracker and emerges lots of potential. DaSiamRPN [23] proposed a strategy to expand the training data and designs a distractor-aware module that is effective against semantic distractors. Siam R-CNN [24] applies ameliorated Faster R-CNN in Siamese network to enhance robustness to appearance variation of target. SiamRPN++ [9] breaks the restriction of translation invariance through a spatial aware sampling strategy and successfully employs ResNet as the backbone with significant performance gain. It also performs a depth-wise correlation structure to decrease the computation consumption and balance parameters of both branches which make the training process more stable. MeMu [25] proposes a negative sample enhancement method and embeds the correlation filter in Siamese network. PTDK [26] simultaneously uses Siamese network and correlation filter for object tracking and fuses the two tracking results. To solve the restriction of anchor, anchor-free Siamese trackers are proposed including SiamFC++,[27] SiamBan,[28] SiamCar.[29]
The Siamese based trackers have gained popularity because of the good balance between computational speed and tracking performance. But they are still affected by target appearance changes and complex background during the tracking process. Recent work such as SiamET [30], MLT [31], UpdateNet [32], and GradNet [33] attempt to update the template online to adapt the object variation. [34] adopts reinforcement learning to select appropriate template image through multiple heat map scores. But they neglect potential in updated features that can enhance the representation of object. ATOM [35] and DIMP [36] introduce online learning strategy to update parameters of network using target information in the tracking results. However, online optimizing parameters raises computational burden and will reduce the tracking speed. Moreover, it can also tend to overfit the specific target.
Attention mechanism is a method to make the system learn how to select key features. RASNet[37] employs both channel attention and spatial attention in template branch. It only reinforces the initial template which is a sample strategy with limited improvement. Based on RASNet, DSA [38] adds cross attention to calculate the correlation between template and search image. [39] integrates four kinds of feature attention modules in the network. FSNet [40] proposed a feature selection method to improve the computation efficiency. Recent work [41, 42] apply Transformer [43] network in Siamese architecture and gain marked performance promotion. However, the fixed template may cause the attention weight to deviate from the current state of object. Our work combines the online update strategy with the Siamese block attention module, which promotes the recognition ability of tracker for the dynamic object.
3 Proposed method
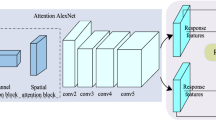
Figure 2 shows the structure of the proposed tracking approach that adopts Siamese network structure to process the input image and template with fixed size. We employ the ResNet50 without fully connected layers as the backbone whose complex convolution stack structure can provide deep semantic features for subsequent calculation. The Siamese block attention module is embedded in the last three layers of both input branches to selectively enhance the features extracted from conv3_x, conv4_x, conv5_x. Three response maps are generated through cross-correlation and added linearly with the weights obtained by offline training. The final score map is sent into the classification head and regression head to locate the position and determine the precise boundary of the object. The tracking results have been collected starting from the first frame by the online update model and continuously integrated into the process state of object. The template is updated by the association of initial template, the process state of object, and the previous tracking result.

The structure of proposed SBAN. A pair of object template and search image is sent into network, and the features extracted from conv3_x, conv4_x, conv5_x are selectively enhanced through Siamese block attention module to calculate the score map. The tracking results are used to update both current template and the process template
3.1 Siamese based trackers
SiamFC first introduces the Siamese structure network in visual tracking tasks which formulated visual tacking as a similarity problem. The backbone consists of two branches of Alexnet sharing the same parameters and is trained completely offline. The example branch extracts feature θ(z) from the template provided by the initial frame and the detection, branch extracts the feature θ(x) from the search area cropped from current frame. Dense response maps are calculated by cross-correlation on multiple scales. The maximum response coordinate represents the most similar patch in the search region, which also determines the location and scales of the object.
SiamRPN retains the two branches of AlexNet as the backbone and adds a region proposal network. A set of anchors are generated on each point of the score map with different ratios and scales to replace the multi-scale search strategy, which can significantly reduce computation consumption and promote tracking speed. The final tracking result is calculated by the RPN subnetwork, of which classification head is to distinguish the object from the background, regression head is used for bounding box regression. This is also the main reason that SiamRPN obtains more accurate performance in most datasets.
SiamRPN++ proposes an effective data enhancement method to solve the position bias existing in the training data so that the complex backbone such as Resnet50 can be applied in Siamese based tracker. The advantage of embedding a deep network is that it can enrich the semantic information in features and also provide different depth features as reference. SiamRPN++ integrates the last three-layer features to make the predicted bounding box more accurate while adopting depthwise cross-correlation containing fewer parameters than up-channel correlation in SiamRPN. Based on SiamPRN++, we illustrate the Siamese Block Attention Network that can selectively enhance features in both template and search region and adopt an online update module that can adapt to the variance of the object. The two models mentioned above can improve tracking performance on both accuracy and robustness.
3.2 Siamese block attention module
We proposed a Siamese block attention module to help the tracker focus on crucial features and suppress inessential features. Distinguishing the target from background and obtaining the accurate bounding box is almost equally crucial for tracking task. Lower-layer features contain detail information which is conducive to accurate localization, and higher-layer features focus on deep semantic information which is helpful to distinguish the object. To make full use of different characteristics in multiple layer features [44, 45] and consider the computation efficiency, we embed Siamese block attention module in con3_x, con4_x, conv5_x in both branches. As shown in Fig. 3, the input of Siamese block attention module is the featureF ∈ RH × W × Cextracted by the convolution block. The proposed Siamese block attention module infers channel attention weights ϕ ∈ R1 × 1 × C. The final attention feature can be calculated by channel-wise multiplication between attention weight and initial feature.
Where⊙is channel-wise multiplication.

The structure of Siamese block attention module. The channel descriptors GAP and GMAP squeezed from features are sent into two branches network sharing the same parameters to get the channel weights
The Siamese block attention module first squeezes global spatial information into two channel descriptors. The global average pooling (GAP) and global max average pooling (GMAP) are adopted to calculate two global properties gc, hc from the channel feature. GAP is the average of the feature value from the same channel and has been commonly used to generate channel-wise statistics. GAP is a comprehensive description of the feature, but it is also affected by weak activations which may reduce the representation of the object area. The original global average pooling (GMP) only cares about the max value in features. It has poor reliability and can not be used as the global characteristics of the channel features. So we proposed GMAP calculated as the average of top N max values in the channel feature. GMAP is determined by the most discriminative parts of the features which can make up for the shortcomings of GAP. To maintain uniformity between two branches of attention features and cover most discriminative features, we use 1/10 amount of channel features, which means the value of N is 23 in template branch and 103 in search branch considering the size of feature map in two branches is 15 × 15 and 32 × 32. We employ both GAP and GMAP to increase the representation ability of the attention module.
Then the global variable maps Mgap ∈ R1 × 1 × C, Mgmap ∈ R1 × 1 × C computed from all channel features are sent into two branches of the rest attention network. Inspired by SEnet [46], this part of the Siamese block attention module consists of two fully connected layers with a Relu in between. We abandon the dimension reduction operation which embeds the channel feature into a lower dimension space and then restores it. The original function of dimension reduction is to reduce the parameters of the network, but it destroys the direct correlation between the channel feature and corresponding weight and it can also decrease the representation of features [47].
The outputs of both branches are elements added with different weights and then pass through a sigmoid function to generate the final channel weightsW.
Where W1 ∈ Rc × c, W2 ∈ Rc × c are the full connection layers, σ is the sigmoid function, δis ReLU function followingW1, a, β are the weights of two descriptors. We use GAP as fundamental descriptor and GMAP as modulation factor. The initial ratio of a, β is set as 2:1 and we finally adopt 0.68 and 0.32 in this work after experimental test.
3.3 Online update module
In the Siamese based tracker, the search region is cropped from the input image based on the last tracking results while the template is cropped from initial frame. The semantic information of the initial object is insufficient to match the current object state when its appearance changes dramatically. This is the main reason for the bounding box drift and tracking failure. A more comprehensive object appearance model has become a crucial requirement of Siamese based tracker to promote accuracy and robustness. The proposed online update strategy redesigned the structure of object appearance model and integrates three parts of key information to update the template.
The initial template T0 is adopted to build the basic object appearance model. Generally speaking, the initial bounding box offers an accurate boundary and the most common shape of the object without occlusion. It means that the initial template contains little background interference and supplies the most reliable information of the object, which can be used as a reference all the time.
The information of object variant process can enrich the details of the object model. The target appearance change is a dynamic and consistent process and the detailed information of the target contains in the tracking result of each frame. Considering that saving all the tracking results is inefficient and memory consuming, we adopt a flexible strategy to collect object state and update the process template of the object, The process template Pi is updated by merging the previous one Pi-1 with the new information provided by the current tracking results Ri. It is an efficient method to collect object history states by only employing one single template. Considering this method prefers to emphasize the recent object state, we reduce the weight of current tracking results to preserve the earlier target information. We set γ to 0.9.
There is a common theory that the object varies smoothly and consecutively during tracking process. Therefore, the similarity of object state in different frames is inversely proportional to the time interval. The last tracking result includes the most similar state information with the current target according to this theory. We add the last tracking result Ri-1 to the object model to catch up with the appearance change of the target.
As shown in Fig. 4, the final update template Ti is obtained by the linear addition of initial template, the process template, and the last tracking result. Initial template keep the maximum proportion to ensure reliability of updated template and the other two have similar weights with different emphasis. The weights α, β, η in this work are 0.67, 0.16, 0.17. The final template is updated after each frame.

The framework of online update module. The updated template is obtained by the linear addition of initial template, the process template, and the last tracking result
The mentioned update method can effectively conquer the target occlusion in some scenes, Target occlusion in video sequences is a continuous motion, target object is gradually covered by distractor and then appears in subsequent frames. When the distractor covers most or even all of object, the actual area of target contains little target information and plenty of distractor information. The distractor should be regarded as one part of tracking target during the process of occlusion to prevent tracking failure or bounding box drift. Process template Pi merging the occlusion process information and last tracking result Ri-1 can integrate the distractor information in new template. It can prevent bounding box drift when complete occlusion occurs. We set a large weight of initial template in update module. The tracker still owns enough discrimination ability to recognize target when the object moves away from distractor.
4 Experimental results
4.1 Training details
We choose COCO,[48] DET,[49] VID, and YouTubeBB[50] to produce the training dataset. All the training data are cropped and resized to 127 × 127, 255 × 255 image pairs as the input of two branches network. The image enhancement is carried out during the data loader to avoid central bias, which makes the target shift around the center point by uniformly distributed sampling on the search patch. Stochastic gradient descent is used to find the appropriate model parameters to minimize the loss function. There are 20 epochs in training process and each epoch contains 20,000 videos. The ResNet50 pretrained on ImageNet is frozen in the first 10 epochs and is finetuned on the last 10 epochs. The learning rate in the first 5 epochs is 0.001 and decays from 0.005 to 0.0005 in the last 15epochs. The momentum is set as 0.9 and the weight decay as 0.0005. The classification and regression heads are used to generate tracking results, the loss function L is as follows:
4.2 Result on several datasets
OTB2015 dataset
OTB2015 is a professional tracking dataset that is commonly used to assess tracker performance. The 100 annotated video sequences in OTB2015 represent 11 categories of difficult situations appearing frequently in tracking tasks which can test the tracker function comprehensively. The precision and success plot of OTB2015 visually display the experimental results of tracker. The center distances between the tracking results and the ground truth of all framed is calculated. The precision plot lines represent the percentage of frames whose distances is lower than certain threshold. And the precision rate is the percentage at the threshold of 20 pixels. The intersection over union (IOU) between tracking results and ground truth is also computed. The illustrates the percentage of frames with IOU larger than certain threshold. Area under the curve (AUC) of success plot is another key parameter to measure the tracker. Figure 5 exhibits comprehensive experiment results among proposed SBAN and several advanced trackers such as SiamBAN, KYS [51], SiamFCpp, SiamCAR, SiamRPN++, ECO, DiMP, DaSiamRPN, ATOM. Our SBAN tracker takes the first place on AUC with a score of 70.0% which suppresses that of SiamRPN++ by 0.4%. The precision score is only 0.1% lower than that of SiamRPN++. Since our tracker focuses on the representation of the dynamic object, experiments on the situation of object appearance change are also crucial. Figure 6 shows the success and precision plots with object deformation. Our SBAN obtains first-class performance in both evaluation methods and gets a gain of 1.2% on AUC compared with the baseline tracker SiamRPN++. Figure 7 illustrates the success and precision plots with object in-plane rotation. Our tracker also achieves outstanding performance in both parts and outperforms SiamRPN++ with a gain of 1.4% on AUC. Tracking results on sequence Bird1 are shown in Fig. 8. Our tracker can keep stable tracking during occlusion and rapid appearance variation process benefit from Siamese attention network and online template update strategy. It is worth noting that SiamBAN scored slightly better than our method in Fig. 7. That is because the anchor free mechanism employed by SiamBAN can provide flexibly bounding box regression under some circumstances. Nonetheless, the method we proposed can promote the recognition ability of the tracker for the dynamic object and keep stable tracking during occlusion process.

Success and precision plots on OTB2015

Success and precision plots with deformation on OTB2015

Success and precision plots with rotation on OTB2015

Comparison tracking results on sequence Bird1 of OTB2015
VOT2018 dataset
VOT2018 is also a widely used tracking dataset including 60 video sequences with 21,356 frames. VOT proposed a special experiment mechanism, the tracker will be reinitialized in 5 frames later if the system judges that the tracking object has been lost, which promotes the utilization efficiency of video sequences. Trackers are evaluated in three aspects, accuracy (A), robustness (R), expected average overlap score (EAO). Accuracy is the average IOU of tracking results and ground truth and robustness represents the percentage of frames with tracking failure. EAO is a combination of both two values and considers the properties of all the video sequences in VOT2018 as well. Figure 9 presents the relation between accuracy and robustness, the tracker close to the upper right corner has better performance. Our SBAN shows first-class overall performance and a good balance between both methods.

Accuracy-Robustness plot on VOT2018
Table 1 exhibits the detailed experiment results of test trackers. Our approach outperforms other trackers in accuracy with a score of 61.4%. Compared with baseline tracker SiamPRN++, our approach obtains a certain promotion in all three aspects with a gain of 1.4% in A, 2.1% in EAO, and 3.3% in robustness. As shown in Fig. 10, our approach can keep the high performance in the video sequence with occlusion situation.

Accuracy-Robustness plot with occlusion on VOT2018
UVA123 dataset
The UAV dataset is comprised of 123 videos, 20 of which are long video sequences named UAV20L. Different from other tracking datasets, the video sequences in UVA123 are taken by unmanned drones at low altitude. Frequent change of view angle and small target size raise the difficulty of tracking. As shown in Table 2, compared with advanced trackers ECO, SiamRPN, DaSiamRPN, ATOM, DiMP SiamRPN++ SiamBan, our tracker obtains a success rate of 62.4%, which outperform SiamRPN++ with a gain of 1.1%.
LaSOT dataset
LaSOT is a large-scale tracking dataset that contains 70 categories among 1400 video sequences with accurate manual annotation. The average length of a sequence is 2512 frames which is longer than other benchmarks. The temporary disappearance of the object in a sequence raises the difficulty of tracking. The abundant sequence categories and the long sequence length are challenges for robust and stability of trackers. Table 3 shows the AUC score of our approach and other advanced trackers including SiamFC, ECO, ATOM, ECO, DiMP, SiamRPN, SiamBan, SiamFC++, SiamRPN++. Our tracker exceeds the baseline tracker SiamRPN++ with AUC increased by 2.1%.
4.3 Ablation study
We integrate the proposed SBAN and online update strategy with basic network respectively and test them on OTB and VOT2018 to demonstrate the positive effect of each part following the same criteria mentioned in Section 4.2. The network of SiamRPN++ is considered as the basic model. As shown in Table 4, The baseline tracker achieves the accuracy of 0.600, robustness of 0.234, and ECO of 0.414 on VOT2018, and an accuracy score of 0.696 on OTB100. By adding the proposed SBAN, the EAO improves to 0.431, and the accuracy score in OTB2015 increases from 0.696 to 0.699. It suggests that the proposed Siamese block attention module can effectively increase accuracy of the tracker. By adding the online update strategy, the failure rate(R) in VOT2018 decreased significantly from 0.234 to 0.203, and the other scores also improve compared with the baseline tracker. The online update strategy can promote stability and reduce the possibility of losing targets during tracking. After integrating both two components, the proposed SBAN achieves the best performance among all evaluation methods. The ablation experiment shows that the proposed Siamese block attention module and online update strategy can enhance the tracker in different aspects, and their cooperation brings positive effects.
We also test effects of different feature descriptors to confirm reasonability of SBAN. Table 5 shows the performance of trackers with GAP, GMP, GMAP and combinations among two of them on VOT2018 and OTB2015. Both GAP and GMAP have positive effects on tracking performance and the score of GAP is even higher. However, embedding GMP alone reduces tracking performance, which illustrates that only using the largest value as channel feature descriptor is unreliable and may lead to the deviation of channel weight. The combinations GAP +GMP and GAP+GMAP both obtain better results than the single one and our SBAN(GAP+GMAP) gains the highest score.
Table 6 shows the performance of trackers with different online update modules on VOT2018. Parameter settings are consistent with those mentioned in Section 3.2. Compared to using initial template alone, both the combination with process template or last tracking result can improve tracking performance, and the combination of initial template and process template achieves better scores. Our online update module, the combination of initial template, process template, and last tracking result gains the highest score.
5 Conclusions
We propose Siamese block attention network for online update object tracking in this work. Based on the core idea of promoting the recognition ability of the tracker for the dynamic object, we propose Siamese block attention module and online update strategy. We designed an online update object appearance module and employ a process template to fuse the object information collected in all frames. The final updated template is the intergration of initial template, process template, and the last tracking results. The Siamese block attention module adopts a Siamese network structure to integrate two complementary global descriptors and generate channel weights to enhance the crucial features and restrain inessential ones. We evaluate the proposed SBAN on four commonly used tracking benchmarks: OTB2015, VOT2018, UVA123, LaSOT. Our SBAN obtains outstanding performance compared with several advanced trackers and the experiment results show SBAN can keep stable tracking performance during target appearance variation and occlusion process. The ablation experiment shows the positive effect of the two proposed methods respectively and the cooperation between them can dramatically enhance the tracker performance.
References
Lu HC, Li PX, Wang D (2018) Visual object tracking: a survey. Pattern Recognit Artif Intell 31(1):61–76
Tang S, Andriluka M, Andres B et al (2017) Multiple people tracking by lifted multicut and person re-identification. Proc IEEE Conf Comput Vis Pattern Recognit:3539–3548
Luo W, Xing J, Milan A, Zhang X, Liu W, Kim TK (2021) Multiple object tracking: a literature review. Artif Intell 293:103448
Marvasti-Zadeh SM, Cheng L, Ghanei-Yakhdan H, Kasaei S (2021) Deep learning for visual tracking: A comprehensive survey. IEEE Transactions on Intelligent Transportation Systems
Ciaparrone G, Sánchez FL, Tabik S et al (2020) Deep learning in video multi-object tracking: a survey. Neurocomputing 381:61–88
Li P, Wang D, Wang L, Lu H (2018) Deep visual tracking: review and experimental comparison. Pattern Recogn 76:323–338
Bertinetto L, Valmadre J, Henriques JF, Vedaldi A, Torr PH (2016). Fully-convolutional siamese networks for object tracking. In Eur Conf Comput Vis. Springer, Cham pp 850–865
Li B, Yan J, Wu W et al (2018) High performance visual tracking with siamese region proposal network. Proc IEEE Conf Comput Vis Pattern Recognit:8971–8980
Li B, Wu W, Wang Q et al (2019) Siamrpn++: evolution of siamese visual tracking with very deep networks. Proceedings of the IEEE/CVF Conf Comput Vis Pattern Recognit:4282–4291
Wu Y, Lim J, Yang MH (2015) Object tracking benchmark. IEEE Trans Pattern Anal Machine Intell 37(9):1834–1848
Kristan M, Leonardis A, Matas J, Felsberg M, Pflugfelder R, ˇCehovin Zajc L, ... Sun Y (2018). The sixth visual object tracking vot2018 challenge results. In Proc Eur Conf Comput Vis (ECCV) Workshops pp 0–0
Mueller M, Smith N, Ghanem B (2016). A benchmark and simulator for uav tracking. In Eur Conf Comput Vis. Springer, Cham pp 445–461
Fan H, Lin L, Yang F et al (2019) Lasot: a high-quality benchmark for large-scale single object tracking. Proceedings of the IEEE/CVF Conference Comput Vis Pattern Recognit 5374–5383
Liu S, Liu D, Srivastava G, Połap D, Woźniak M (2021) Overview and methods of correlation filter algorithms in object tracking. Complex Intell Syst 7:1895–1917
Bolme DS, Beveridge JR, Draper BA, Lui YM (2010). Visual object tracking using adaptive correlation filters. In 2010 IEEE Comput Soc Conf Comput Vis Pattern Recognit. IEEE pp 2544-2550
Henriques JF, Caseiro R, Martins P, Batista J (2015) High-speed tracking with kernelized correlation filters. IEEE Trans Pattern Anal Machine Intell 37(3):583–596
Danelljan M, Bhat G, Shahbaz Khan F et al (2017) Eco: efficient convolution operators for tracking. Proc IEEE Conf Comput Vis Pattern Recognit:6638–6646
Gundogdu E, Alatan AA (2018) Good features to correlate for visual tracking. IEEE Trans Image Process 27(5):2526–2540
Lu X, Ma C, Ni B et al (2019) Adaptive region proposal with channel regularization for robust object tracking. IEEE Trans Circuits Systems vid Technol 31(4):1268–1282
Chen Y, Wang J, Xia R, Zhang Q, Cao Z, Yang K (2019) RETRACTED ARTICLE: the visual object tracking algorithm research based on adaptive combination kernel. J Ambient Intell Humaniz Comput 10(12):4855–4867
Zheng Y, Liu X, Cheng X, Zhang K, Wu Y, Chen S (2020) Multi-task deep dual correlation filters for visual tracking. IEEE Trans Image Process 29:9614–9626
Guo Q, Feng W, Zhou C, Huang R, Wan L, Wang S (2017). Learning dynamic siamese network for visual object tracking. In Proc IEEE Int Conf Comput Vis pp 1763–1771
Zhu Z, Wang Q, Li B, Wu W, Yan J, Hu W (2018). Distractor-aware siamese networks for visual object tracking. In Proc Eur Conf Comput Vis (ECCV) pp 101–117
Voigtlaender P, Luiten J, Torr PH, Leibe B (2020). Siam r-cnn: Visual tracking by re-detection. In Proc IEEE/CVF Conf Comput Vis Pattern Recognit pp 6578–6588
Xiao Y, Li J, Du B et al (2020) MeMu: metric correlation Siamese network and multi-class negative sampling for visual tracking. Pattern Recogn 100:107170
Li T, Wu P, Ding F, Yang W (2020) Parallel dual networks for visual object tracking. Appl Intell 50:4631–4646
Xu Y, Wang Z, Li Z, Yuan Y, Yu G (2020) Siamfc++: towards robust and accurate visual tracking with target estimation guidelines. Proceedings of the AAAI Conference on Artificial Intelligence 34(07):12549–12556
Chen Z, Zhong B, Li G et al (2020) Siamese box adaptive network for visual tracking. Proceedings of the IEEE/CVF Conf Comput Vis Pattern Recognit:6668–6677
Guo D, Wang J, Cui Y et al (2020) SiamCAR: Siamese fully convolutional classification and regression for visual tracking. Proceedings of the IEEE/CVF Conf Comput Vis Pattern Recognit:6269–6277
Zhou Y, Zhang Y (2022) SiamET: a Siamese based visual tracking network with enhanced templates. Appl Intell
Choi J, Kwon J, Lee KM (2019). Deep meta learning for real-time target-aware visual tracking. In Proc IEEE/CVF Int Conf Comput Vis pp 911–920
Zhang L, Gonzalez-Garcia A, Weijer J et al (2019) Learning the model update for siamese trackers. Proceedings of the IEEE/CVF Int Conf Comput Vis:4010–4019
Li P, Chen B, Ouyang W et al (2019) Gradnet: gradient-guided network for visual object tracking. Proceedings of the IEEE/CVF Int Conf Comput Vis:6162–6171
Gao P, Zhang Q, Wang F, Xiao L, Fujita H, Zhang Y (2020) Learning reinforced attentional representation for end-to-end visual tracking. Inf Sci 517:52–67
Danelljan M, Bhat G, Khan FS, Felsberg M (2019). Atom: Accurate tracking by overlap maximization. In Proc IEEE/CVF Conf Comput Vis Pattern Recognit pp 4660–4669
Bhat G, Danelljan M, Gool LV, Timofte R (2019). Learning discriminative model prediction for tracking. In Proc IEEE/CVF Int Conf Comput Vision pp 6182–6191
Wang Q, Teng Z, Xing J et al (2018) Learning attentions: residual attentional siamese network for high performance online visual tracking. Proc IEEE Conf Comput Vis Pattern Recognit:4854–4863
Yu Y, Xiong Y, Huang W et al (2020) Deformable siamese attention networks for visual object tracking. Proceedings of the IEEE/CVF Conf Comput Vis Pattern Recognit:6728–6737
Chen B, Li P, Sun C, Wang D, Yang G, Lu H (2019) Multi attention module for visual tracking. Pattern Recogn 87:80–93
Cui Z, Lu N (2021) Feature selection accelerated convolutional neural networks for visual tracking. Appl Intell 51:8230–8244
Chen X, Yan B, Zhu J et al (2021) Transformer tracking. Proceedings of the IEEE/CVF Conf Comput Vis Pattern Recognit:8126–8135
Wang N, Zhou W, Wang J et al (2021) Transformer meets tracker: exploiting temporal context for robust visual tracking. Proceedings of the IEEE/CVF Conf Comput Vis Pattern Recognit:1571–1580
Vaswani A, Shazeer N, Parmar N et al (2017) Attention is all you need. Adv Neural Inf Proces Syst 30
Ma C, Huang J, Yang X, Yang M (2019) Robust Visual Tracking via Hierarchical Convolutional Features. IEEE Trans Pattern Anal Machine Intell 41(11):2709–2723
Yu W, Yang K, Yao H, Sun X, Xu P (2017) Exploiting the complementary strengths of multi-layer CNN features for image retrieval. Neurocomputing 237:235–241
Hu J, Shen L, Sun G (2018) Squeeze-and-excitation networks. Proc IEEE Conf Comput Vis Pattern Recognit:7132–7141
Wang Q, Wu B, Zhu P, Li P, Zuo W, Hu Q (2020) Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR):11534–11542
Lin TY, Maire M, Belongie S et al (2014) Microsoft coco: common objects in context. European conference on computer vision. Springer, Cham, pp 740–755
Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, Huang Z, Karpathy A, Khosla A, Bernstein M, Berg AC, Fei-Fei L (2015) Imagenet large scale visual recognition challenge. Int J Comput Vis 115(3):211–252
Real E, Shlens J, Mazzocchi S, Pan X, Vanhoucke V (2017). Youtube-boundingboxes: A large high-precision human-annotated data set for object detection in video. In Proc IEEE Conf Comput Vis Pattern Recognit pp 5296–5305
Bhat G, Danelljan M, Gool LV et al (2020) Know your surroundings: exploiting scene information for object tracking. European Conference on Computer Vision. Springer, Cham, pp 205–221
Acknowledgments
This work was supported by the National Natural Science Foundation of China (NSFC) under Grant 52127809, 51625501.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interests
All authors declare that No conflict of interest exists.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xiao, D., Tan, K., Wei, Z. et al. Siamese block attention network for online update object tracking. Appl Intell 53, 3459–3471 (2023). https://doi.org/10.1007/s10489-022-03619-9
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-022-03619-9