
Abstract
We consider the sparse subspace learning problem where the intrinsic subspace is assumed to be low-dimensional and formed by sparse basis vectors. Confined to a few sparse bases, projecting data to the learned subspace essentially has an effect of feature selection by taking a small number of the most salient features while suppressing the rest as noise. Unlike existing sparse dimensionality reduction methods, however, we exploit the class labels to impose maximal margin data separation in the subspace, which was previously shown to yield improved prediction accuracy often times in non-sparse models. We first formulate an optimization problem with constraints on the matrix rank and the sparseness of the basis vectors. Instead of computationally demanding gradient-based learning strategies used in previous large-margin embedding, we propose an efficient greedy functional optimization algorithm over the infinite set of the sparse dyadic products. Each iteration in the proposed algorithm, after some shifting operations, effectively reduces to the famous sparse eigenvalue problem, and can be solved quickly by the recent truncated power method. We demonstrate the improved prediction performance of the proposed approach on several image/text classification datasets, especially characterized by high-dimensional noisy data samples with small training sets.




Similar content being viewed by others


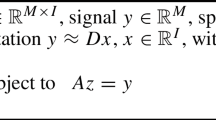
Notes
Whereas semi-supervised learning can be incorporated to utilize relatively larger number of unlabeled data, we do not consider it in this paper. Although it remains as our future work, the proposed approach can be easily extended for semi-supervised setups using manifold regularization [3, 42] or related approaches, and can potentially benefit from it.
In LMNN [37], the rank constraint was ignored since their main goal was learning the metric rather than finding a low-dimensional embedding like ours.
When it happens, there may be three possibilities: i) we found a right embedding solution and it is good to stop, ii) the sparseness constraint was too harsh (i.e., r is so small that there is no decent direction in the feasible space), iii) the maximal allowable rank was chosen too small (i.e., the rank penalty constant μ is so large to overwhelm the maximum \(\textbf {u}^{\top } {\Sigma }_{\textbf {A}} \textbf {u}\) yielding a positive derivative). Possibly, both of the latter two situations may occur, in which cases one needs to tune the constant values appropriately.
Although we didn’t do this in our implementation, one can reduce the overhead by a mini-batch type approximation under the stochastic gradient framework. That is, when computing a sum/expectation, we approximate it by the expectation over a small subset/batch of the data.
Our greedy approach usually takes a small number of stages since each stage tends to increase the rank of A by one.
References
Anguita D, Ghio A, Oneto L, Parra X, Reyes-Ortiz JL Human activity recognition on smartphones using a multiclass hardware-friendly support vector machine (2012). International Workshop of Ambient Assisted Living (IWAAL 2012), Vitoria-Gasteiz, Spain
Bache K, Lichma M (2013) UCI machine learning repository. http://archive.ics.uci.edu/ml
Belkin M, Niyogi P, Sindhwani V (2005) On manifold regularization. Artificial Intelligence and Statistics
Blei D, McAuliffe J (2007) Supervised topic models. Neural Information Processing Systems
Blei D, Ng A, Jordan M (2003) Latent dirichlet allocation. J Mach Learn Res 3:993–1022
Clemmensen L, Hastie T, Witten D, Ersbøll B (2011) Sparse discriminant analysis. Technometrics 53(4):406–413
Crammer K, Singer Y (2002) On the algorithmic implementation of multiclass kernel-based vector machines. J Mach Learn Res 2:265–292
d’Aspremont A, Bach F, Ghaoui LE (2008) Optimal solutions for sparse principal component analysis. J Mach Learn Res 9:1269–1294
d’Aspremont A, Ghaoui LE, Jordan M, Lanckriet G (2007) A direct formulation of sparse PCA using semidefinite programming. SIAM Rev 49(3):434–448
d’Aspremont A, Ghaoui LE, Jordan M, Lanckriet GRG (2007) A direct formulation for sparse PCA using semidefinite programming. SIAM Rev 49:434–448
Friedman J (1999) Greedy function approximation: a gradient boosting machine. Technical Report, Department of Statistics, Stanford University
Fukumizu K, Bach F, Jordan M (2004) Dimensionality reduction for supervised learning with reproducing kernel Hilbert spaces. Journal of Machine Learning Research
Gang P, Zhen W, Zeng W, Gordienko Y, Kochura Y, Alienin O, Rokovyi O, Stirenko S (2018) Dimensionality reduction in deep learning for chest x-ray analysis of lung cancer. International Conference on Advanced Computational Intelligence (ICACI)
Harchaoui Z, Douze M, Paulin M, Dudik M, Malick J (2012) Large-scale classification with trace-norm regularization. IEEE Conference on Computer Vision and Pattern Recognition
He X, Niyogi P (2003) Locality preserving projections. In Advances in Neural Information Processing Systems
Higgins I, Matthey L, Pal A, Burgess C, Glorot X, Botvinick M, Mohamed S, Lerchner A (2017) beta-VAE: Learning basic visual concepts with a constrained variational framework. In: International conference on learning representations
Hofmann T (1999) Probabilistic latent semantic analysis. Uncertainty in Artificial Intelligence
Hollander M, Wolfe DA (1973) Nonparametric statistical methods. Wiley, New York
Journée M, Nesterov Y, Richtárik P, Sepulchre R (2010) Generalized power method for sparse principal component analysis. J Mach Learn Res 11:517–553
Kim H, Mnih A (2018) Disentangling by factorising. International Conference on Machine Learning
Kim M, Pavlovic V (2007) A recursive method for discriminative mixture learning. International Conference on Machine Learning
Kim M, Pavlovic V (2008) Dimensionality reduction using covariance operator inverse regression. IEEE Conference on Computer Vision and Pattern Recognition
Kingma DP, Welling M (2014) Auto-encoding variational Bayes. In: Proceedings of the Second International Conference on Learning Representations, ICLR
Krizhevsky A, Sutskever I, Hinton GE (2012) ImageNet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems
Lecun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11): 2278–2324
LeCun Y, Jackel L, Bottou L, Brunot A, Cortes C, Denker J, Drucker H, Guyon I, Muller U, Sackinger E, Simard P, Vapnik V (1995) Comparison of learning algorithms for handwritten digit recognition. International Conference on Artificial Neural Networks
Li KC (1991) Sliced inverse regression for dimension reduction. Journal of the American Statistical Association
Linderman GC, Rachh M, Hoskins JG, Steinerberger S, Kluger Y (2017) Efficient algorithms for t-distributed stochastic neighborhood embedding. arXiv:1712.09005
van der Maaten L (2014) Accelerating t-sne using tree-based algorithms. J Mach Learn Res 15:3221–3245
Moghaddam B, Weiss Y, Avidan S (2006) Generalized spectral bounds for sparse LDA. International Conference on Machine Learning
Nilsson J, Sha F, Jordan M (2007) Regression on manifolds using kernel dimension reduction. International Conference on Machine Learning
Pavlovic V (2004) Model-based motion clustering using boosted mixture modeling. Computer Vision and Pattern Recognition
Roweis S, Saul L (2000) Nonlinear dimensionality reduction by locally linear embedding. Science 290(5500):2323–2326
Seung HS, Lee DD (2000) The manifold ways of perception. Science 290(5500):2268–2269
Tenenbaum JB, de Silva V, Langford JC (2000) A global geometric framework for nonlinear dimensionality reduction. Science 290(5500):2319–2323
Wang C, Blei DM, Fei-Fei L (2009) Simultaneous image classification and annotation. IEEE International Conference on Computer Vision and Pattern Recognition
Weinberger K, Saul L (2009) Distance metric learning for large margin nearest neighbor classification. J Mach Learn Res 10:207–244
Yuan XT, Zhang T (2013) Truncated power method for sparse eigenvalue problems. J Mach Learn Res 14:899–925
Zhang C, Bi J, Xu S, Ramentol E, Fan G, Qiao B, Fujita H (2019) Multi-Imbalance: An open-source software for multi-class imbalance learning. Knowledge-Based Systems (Available online: https://doi.org/10.1016/j.knosys.2019.03.001)
Zhang C, Liu C, Zhang X, Almpanidis G (2017) An up-to-date comparison of state-of-the-art classification algorithms. Expert Syst Appl 82(1):128–150
Zhu J, Rosset S, Hastie T, Tibshirani R (2003) 1-norm support vector machines. In Advances in Neural Information Processing Systems
Zhu X, Ghahramani Z, Lafferty J (2003) Semi-supervised learning using Gaussian fields and harmonic functions. International Conference on Machine Learning
Zou H, Hastie T (2005) Regularization and variable selection via the elastic net. J R Stat Soc, Ser B 67:301–320
Zou H, Hastie T, Tibshirani R (2006) Sparse principal component analysis. J Comput Graph Stat 15 (2):265–286
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
This study was supported by the Research Program funded by the SeoulTech (Seoul National University of Science & Technology).
Conflict of interests
The authors have no conflict of interest. This research does not involve human participants nor animals. Consent to submit this manuscript has been received tacitly from the authors’ institution, Seoul National University of Science & Technology.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Kim, M. Sparse large-margin nearest neighbor embedding via greedy dyad functional optimization. Appl Intell 49, 3628–3640 (2019). https://doi.org/10.1007/s10489-019-01472-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-019-01472-x