
Abstract
System-wide optimization of distributed manufacturing operations enables process improvement beyond the standalone and individual optimality norms. This study addresses the production planning of a distributed manufacturing system consisting of three stages: production of parts (subcomponents), assembly of components in Original Equipment Manufacturer (OEM) factories, and final assembly of products at the product manufacturer’s factory. Distributed Three Stage Assembly Permutation Flowshop Scheduling Problems (DTrSAPFSP) models this operational situation; it is the most recent development in the literature of distributed scheduling problems, which has seen very limited development for possible industrial applications. This research introduces a highly efficient constructive heuristic to contribute to the literature on DTrSAPFSP. Numerical experiments considering a comprehensive set of operational parameters are undertaken to evaluate the performance of the benchmark algorithms. It is shown that the N-list-enhanced Constructive Heuristic algorithm performs significantly better than the current best-performing algorithm and three new metaheuristics in terms of both solution quality and computational time. It can, therefore, be considered a competitive benchmark for future studies on distributed production scheduling and computing.
Similar content being viewed by others

Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
1 Introduction
Process integration is a prerequisite for successful supply chain digitalization (Pourhejazy, 2022). System-wide optimization tools should be employed for the planning and control of decentralized production activities. Distributed scheduling problems are developed to address this practical need where production operations across different supply chain facilities are planned simultaneously. The integrated optimization view towards production planning underlines coordination between different units to meet global demands while ensuring optimal overall performance.
The Distributed Two-Stage Assembly Flowshop Scheduling Problem (DTSAFSP; (Xiong & Xing, 2014)) and the Distributed Assembly Permutation Flowshop Scheduling Problem (DAPFSP; (Hatami et al., 2013)) are the mainstream variants of distributed production scheduling under flowshop setting, i.e. when all jobs follow the same processing route and the shop floors are designed considering the flow of jobs. The former variant, DTSAFSP, models a distributed manufacturing system with production and assembly operations at every plant. The latter, DAPFSP, represents a more practical, supply chain-like setting in which an assembly plant is dedicated to the assembly of components arriving from different manufacturing facilities. Given the widespread use of DAPFSP in modern manufacturing, new extensions, and solution algorithms are developed to accommodate this practical scheduling extension and extend its industrial reach.
Among the existing studies, (Hatami et al., 2013) developed three heuristics for solving DAPFSPs, of which the variable neighborhood descent method yielded better outcomes. (Lin & Zhang, 2016) introduced the hybrid biogeography-based optimization algorithm; (S.-Y. Wang & Wang, 2016) developed the estimation of the distribution algorithm-based memetic algorithm; the backtracking search hyper-heuristic was developed by (Lin et al., 2017), and (Sang et al., 2019) put forward the invasive weed optimization algorithm. More recently, (Ferone et al., 2020) solved the DAPFSP using a biased-randomized iterated local search. Solution algorithms based on NEH (Nawaz, Enscore, and Ham; (Nawaz et al., 1983)) with new coding structures and job sorting rules have also been developed for solving DAPFSP variants (Ying et al., 2020). For a detailed and exhaustive review of the published works, we refer interested readers to the literature review in a recent study by (Pourhejazy et al., 2022).
The literature on DAPFSP assumes that the components used in the assembly of the final product have no subcomponents. In practice, however, the components are often complex and require processing. Taking automotive and heavy equipment as an example, main components, such as the engine, are made of many subcomponents that are manufactured and assembled by the component suppliers, the Original Equipment Manufacturers (OEMs). After procurement, the main components should be assembled into the final product at the product manufacturer’s plants. This practical supply chain situation can be modeled by the Distributed Three Stage Assembly Permutation Flowshop Scheduling Problem (DTrSAPFSP), which is a combination of DTSAFSP and DAPFSP.
As a new variant of distributed scheduling problems, DTrSAPFSP can be used for the integrated scheduling of the production of sub-components, the assembly of the sub-components to complete the main parts/components, and the assembly of the components that form the final product; this integration makes the scheduling model highly intractable and calls for tailored solution methods to contribute to the advances in distributed manufacturing and supply chain digitalization. There are very limited published and pre-published papers related to DTrSAPFSP. (J. Wang, Lei, and Cai 2022; J. Wang, Lei, & Li, 2022) extended the distributed three-stage assembly scheduling, which is the most relevant variant to the DTrSAPFSP, which considers the constraints of maintenance and setup time. In a preprint, (Hao et al., 2022) developed three Social Spider Optimization (SSO) metaheuristics for solving the DTrSAPFSP. They showed that their solution methods outperform the earlier algorithms developed for solving DAPFSPs; this is the only study on solving the DTrSAPFSP. To address this gap, the present research paper extends to develop a novel constructive heuristic algorithm, hereafter called the N-list-enhanced Constructive Heuristic (NCH). The NCH method is compared with state-of-the-art algorithms to evaluate its strength. The statistical test follows to confirm the superiority of NCH over the existing methods. The developed algorithm is scalable for parallel computing and is expected to be considered a strong benchmark in the field.
The rest of this paper begins with a review of the relevant literature in Sect. 2. A detailed explanation of the computational elements of the developed solution method follows in Sect. 3. Numerical experiments and statistical analysis of the results are then presented in Sect. 4 to report the performance of the new algorithm. Section 5 concludes this research by summarizing the major findings and providing insights for further developments in the topic of three-stage production scheduling.
2 Relevant literature
Multistage production processes have been extensively studied in the forms of flexible flowshop (Luo et al., 2019) and two-stage assembly flowshop (Lee et al., 1993). Distributed flowshop scheduling has seen considerable development in recent years considering both modeling and solution algorithms.
2.1 Distributed assembly permutation flowshop and distributed two-stage assembly scheduling problems
(Hatami et al., 2013) introduced the Distributed Assembly Permutation Flowshop Scheduling Problem (DAPFSP). This work inspired other scheduling extensions; in one of the seminal works, (Yang & Xu, 2020) suggested that more than one machine should be considered in the assembly stage (i.e., flexible assembly). The DAPFSP with flexible assembly assumes that the assembly stage is executed in a different plant and that no subassemblies are required for producing the components. (Xiong & Xing, 2014) put forward the Distributed Two-Stage Assembly Scheduling Problem (DTSASP), in which the production and assembly operations of a product are performed in the same factory. DTSASP schedules production operations at OEMs, based on which, separate scheduling must be done for the final product manufacturing. To model an integrated production plan, DTSASP should be merged with flexible assembly in a separate factory to enable an integrated production plan of parts and components at OEMs and final products at the mother company. For this reason, (Hao et al., 2022) proposed the DTrSAPFSP and presented three SSO-based metaheuristics to solve it.
2.2 Distributed three-stage assembly permutation flowshop scheduling problems
DTrSAPFSP assumes that there are several OEMs, each of which is responsible for producing parts and assembling them into a certain component. The components from the OEMs then arrive at the main company’s plant, where they are assembled and processed into final products.
The solution algorithms developed for solving DTSAFSPs, as the most relevant variant of DTrSAPFSP, are relatively limited. From the seminal works, (Xiong et al., 2014) developed a Variable Neighborhood Search-based approach for minimizing the total completion time in DTSAFSP with setup times. (Zhang & Xing, 2018) developed the SSO optimization for minimizing the total completion time in DTSAFSP. (Deng et al., 2016) introduced the Competitive Memetic Algorithm (CMA) for minimizing the makespan in DTSAFSPs, which outperformed the earlier algorithms. Most recently, (Pourhejazy et al., 2022) developed the Meta-Lamarckian-based Iterated Greedy algorithm for optimizing DTSAFSP with mixed setups, which outperformed the earlier best-performing algorithms in minimizing the makespan.
From the published studies, (Zheng & Wang, 2021) developed a new variant of the Bat Optimization Algorithm for Solving the Three-Stage Distributed Assembly Permutation Flowshop Scheduling Problem. (J. Wang, Lei, & Li, 2022) developed a Q-Learning-Based Artificial Bee Colony (ABC) algorithm for solving the Distributed Three-Stage Assembly Scheduling Problem with Factory Eligibility and Setup Times. (J. Wang, Lei, and Cai 2022) developed the adaptive ABC for solving the distributed three-stage assembly scheduling problem with maintenance. These metaheuristics used basic constructive algorithms, such as NEH (Nawaz et al., 1983), in the initialization stage of the algorithm. Despite its merits, NEH cannot obtain good initial solutions for complex problems and needs to be adjusted for different scheduling problems. Given the stochastic nature of the above metaheuristics, the quality of the final solution depends heavily on that of the initial solution, especially when dealing with highly intractable problems. In the next section, a new constructive heuristic is developed to contribute to the advances in distributed and multi-stage scheduling.
3 Optimization method
3.1 Problem definition
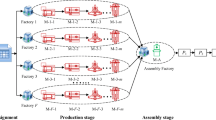
We investigate a distributed manufacturing system where geographically dispersed factories produce the parts/sub-components (Stage I), assemble the component (Stage II), and send the components to a main factory for the assembly of the final product (Stage III); this process is illustrated in Fig. 1. The problem assumes that all jobs follow the same routine and that each job can only be processed on one machine/assembly stage at a time. The processing times are deterministic and independent of the jobs/products sequence. Once a production/assembly job is assigned to a factory, it cannot be re-assigned. The model is symbolized by \({(}DF_{m} \to {1)} \to {1}||C_{max}\) with the first part indicating that the distributed system has \(m\) parallel machines in the production stage of every factory; one assembly machine completes the sub-component, and one assembly stage forms the final product. The objective is to find the production schedule with (near-) minimum maximum completion time (makespan; \(C_{max}\)).

Visual illustration of the three-stage scheduling problem
3.2 Solution algorithm
This study introduces the NCH algorithm as an alternative to the NEH-based algorithms with various initial sorting and tie-breaking rules. Inspired by the N-list technique (Puka et al., 2021), the NCH algorithm adjusts every step of the algorithm considering the problem characteristics. The N-list technique uses a list of N jobs that are candidates for establishing the job sequence. At each stage of the algorithm, each job candidate in the current N-list is individually inserted into all possible positions in the partial sequence, and the one with the best performance index is assigned. The procedure continues until all jobs are assigned and a complete solution is obtained. Employing the N-list technique enables the NEH-based algorithm to run the search procedure in parallel computing environments, which is complicated, if not impossible, to accomplish with traditional methods.
The Fig. 2 shows the pseudocode of the developed NCH algorithm. The computational procedure consists of four steps: (1) sorting the initial sequence of parts within each component; (2) sorting the initial sequence of components within each product; (3) sorting the initial sequence of products; and (4) sorting sequence of parts within each factory and the assembly sequence of the products. These procedures are explained in two phases, one at the component level and the other at the product level.

Pseudocode of the N-list-enhanced Constructive Heuristic
We now elaborate on the computational steps.
3.2.1 Phase I. Component-level sequencing

An illustrative example is now provided to clarify the above steps. Assume a small example with ten parts, two machines, four components, two products, and two factories. In the first assembly phase, the first and second components each contain three parts, while the third and fourth components each contain two parts. In the second assembly phase, each product is made from two components. Table 1 summarizes the processing times in the illustrative example.
In Step 1, the total processing time of each part is calculated as follows: \(SUM_{1} = 5,\) \(SUM_{2} = 6,\) \(SUM_{3} = 6,\) \(SUM_{4} = 6,\) \(SUM_{5} = 5,\) \(SUM_{6} = 4,\) \(SUM_{7} = 5,\) \(SUM_{8} = 3,\) \(SUM_{9} = 5,\) \(SUM_{10} = 7.\) In Step 2, the initial order of the parts of each component considering the total processing time is: \(\pi_{1}^{PL} = \{ j_{2} \, j_{3} \, j_{1} \} ,\) \(\pi_{2}^{PL} = \{ j_{4} \, j_{5} \, j_{6} \} ,\) \(\pi_{3}^{PL} = \{ j_{7} \, j_{8} \} ,\) and \(\pi_{4}^{PL} = \{ j_{10} \, j_{9} \} .\) Taking the component \(c_{1}\) as an example, after setting \(\pi_{1}^{part} = \{ j_{2} \}\) and \(\pi_{1}^{RPL} = \{ j_{3} \, j_{1} \}\), Step 3 consists of extracting the first two parts, i.e., \(j_{3}\) and \( \, j_{1}\), making permutations of two parts,\(\{ j_{3} \, j_{2} \} ,\) \(\{ j_{2} \, j_{3} \} ,\) \(\{ j_{1} \, j_{2} \} ,\) and \(\{ j_{2} \, j_{1} \} ,\) as shown in Fig. 3a–d. At this stage, the sequence with minimum completion time are \(\{ j_{1} \, j_{2} \}\) and \(\{ j_{2} \, j_{1} \}\), in which \(\{ j_{1} \, j_{2} \}\) is randomly selected and set as \(\pi_{1}^{part} .\) Then, the part \(j_{3}\) is inserted into all possible positions of \(\pi_{1}^{part}\), as shown in Fig. 3e–g, in which \(\{ j_{3} \, j_{1} \, j_{2} \}\) is the best part sequence of the component \(c_{1}\). The above procedure is repeated for the rest components to obtain the best part sequences at the component level, as shown in Fig. 4.

An illustrative example for ordering parts of a component

Best part sequences at the component level
3.2.2 Phase II. Product-level sequencing
Based on the best part sequences from Phase I, the following steps determine the order of parts at the product level.

The procedure of phase II is illustrative by applying it to the previous example (Table 1). In Step 1, given the completion time of each component, as shown in Fig. 4, the resulting component lists of the product \(p_{1}\) and \(p_{2}\) are: \(\pi_{1}^{CL} = \left\{ {c_{2} ,\; \, c_{1} } \right\}\) and \(\pi_{2}^{CL} = \left\{ {c_{3} , \, \;c_{4} } \right\}\), respectively. Given that \(CT{(}\pi_{1} {) = 13 + 16 = 29}\) and \(CT{(}\pi_{2} {) = 11 + 15 = 26}\), the resulting product list after applying Step 2 is \(\pi^{PdL} = \left\{ {p_{2} ,\;p_{1} } \right\}\). In Step 3, the first product in \(\pi^{PdL}\), i.e., \(p_{2}\), is extracted and its associated components \(c_{3}\) and \(c_{4}\) are sequentially inserted into factory 1 and factory 2, respectively; the result is shown in Fig. 5.

The output of Step 3 in the illustrative example
Steps 4 – 5 begin with inserting the first component of the first unassigned product, i.e., \(c_{2}\) of product 1, into the last position of every factory to find the alternative with the smallest completion time (round 1). As shown in Fig. 6, the resulting sequence in alternative Fig. 6a is preferred, hence, factory 1 is selected for assigning \(c_{2}\). The next component from \(\pi_{1}^{CL}\), i.e., \(c_{1}\) of product 1, should then be extracted and inserted into the last position of every factory to find the best alternative (round 2). As shown in Fig. 7, the resulting sequence shown in Fig. 7b is better with a smaller completion time, hence, factory 2 should be selected for the permanent insertion. With assigning the last component of product 1, the final order of parts at the product level has been resulted; the result is shown in Fig. 7b.

Round 1 of applying Steps 4 – 5 on the illustrative example

Round 2 of applying Steps 4–5 on the illustrative example
With more components involved in the instance, the chances of perceiving the advantages of the developed method are expected to be greater. In the next section, the performance of NCH in various operational situations is evaluated and compared with the state-of-the-art.
4 Numerical experiments
The performance of the NCH algorithm is now evaluated by comparing it with the best-performing constructive heuristic in the literature of DTSAPFSP and DAPFSP. For this purpose, an adjusted version of the NEH+-based constructive heuristic, hereafter called ANEH+, is considered as a baseline. Besides, three variants of the most recent and state-of-the-art metaheuristic, which were also developed to solve DAPFSP, are included as benchmarks to increase the strength of our numerical analysis.
(Hao et al., 2022) improved the SSO algorithm to solve the DTrSAPFSP. Then they employed three local search methods to develop the Social Spider Optimization hybridized with Local Search Strategies (HSSO). Finally, they introduced the ‘Restart’ and ‘Self-adaptive Selection Probability’ to better regulate the local search and restart strategies in HSSO With Restart Procedures (HSSOR), and HSSOR with Self-adaptive Selection Probability (HSSOPR). Their experiments showed that these algorithms outperform the state-of-the-art in solving distributed assembly flow shops, i.e., the Competitive Memetic Algorithm (CMA; (Deng et al., 2016)) and the Estimation of Distribution Algorithm (EDA; (S.-Y. Wang & Wang, 2016)).
All compared algorithms are coded and compiled using C + + programming language on a personal computer with the Intel® Core™ i5-10210U CPU (1.60CHz) and 8 GB RAM. The same testbed configurations considered in the earlier study for testing the base algorithms are used for the numerical experiments. On this basis, the instances can be grouped by 100, 200, and 500 parts; 4, 6, and 8 factories for producing the components; 5, 10, and 20 machines for the production stage in these factories; 30, 40, and 50 components; and, finally, 10, 15, and 20 products. The identity format 100_5_4_30_10_1 represents the first (out of ten) instance characterized by 100 parts, 5 machines, 4 factories, 30 components, and 10 products. Considering these configurations, and 10 distinct instances under each configuration, a total of 810 instances are considered for conducting the experiments. The processing time parameters are generated as follows. The production time of parts (subcomponents at the first stage) is generated randomly using uniform distribution \(U\;{[}1,\;99]\); the assembly time at the second and third stages are also generated randomly, and separately considering \(U\;{[}1 \times n,\;99 \times n]\).
The maximum computation time is considered as a stopping criterion for the metaheuristic algorithms, as suggested by (Hao et al., 2022); \({20} \times \chi \times M\), \({40} \times \chi \times M\), and \({60} \times \chi \times M\) milliseconds are applied for the largest instance under the small-, medium-, and large-scale problems, respectively. The developed heuristics in the present study stop operating as soon as having a complete solution, i.e., the production schedule for all products.
Each of the compared constructive heuristics is executed in one run for each test instance. Then, the best solution after 20 runs for solving each of the test instances using every metaheuristic is considered for further analysis. Given the best-found solution (BFS; see the Appendix), the Average Relative Percentage Deviation (ARPD) measure is considered to compare the quality of solutions between algorithms; the measure can be calculated using \(RPD = \frac{{C_{max} (X) - C_{max} (X_{best} )}}{{C_{max} (X_{best} )}} \times {\text{100\% }}\), where \(X_{best}\) and \(X\) represent the best solution and the solution under consideration, respectively; smaller RPD values represent better outcomes. The computational results are summarized in Table 2. As shown in Table 2, the proposed NCH algorithm outperforms the best-performing constructive heuristics and state-of-the-art metaheuristics concerning different operational categories.
Next, different numbers of parts (subcomponents), components, products, machines, and factories are considered to analyze the impact of these operational parameters on the performance of the benchmark algorithms. The analytical results are visualized in Fig. 8. The first notable observation is that with an increase in the number of components, products, machines, and factories, the outperformance of NCH becomes larger. However, an increase in the number of parts (subcomponents) closes the performance gap between the algorithms. This may be due to the random ordering of items at the part level. Having many components and products in the instances enabled the NCH algorithm to generate better solutions even when the number of parts increased. That is, with more components involved in scheduling, the average number of parts per component is smaller, hence, the impact of the parts order on the quality of the final solution becomes smaller.


Category-based analysis of the results
Statistical tests are now performed to verify the significance of the difference between the quality of the results obtained by NCH and those obtained by the benchmark algorithms. For this purpose, 0.05 is considered as the p value’s threshold to check whether the differences are statistically significant. The analytical results of the analysis of variance (ANOVA) and the t test are summarized in Tables 3 and 4, respectively.
As the statistical results of ANOVA shown in Table 3, the difference amongst the sets of BFSs obtained by different algorithms can be regarded as statistically significant because the F-statistic is greater than the critical value with 95 percent of confidence. According to Table 4, since all the p values are less than 0.05, the null hypothesis, which implies that the NCH and each of the benchmark algorithms have equivalent effectiveness, can be confidently rejected. In other words, it can be concluded that the performance of NCH is significantly better than that of each benchmark algorithm. Considering that ANEH is a constructive heuristic, its weak performance compared to the three metaheuristics may not be surprising. However, we found the effectiveness of NCH, as a constructive heuristic, in outperforming the state-of-the-art metaheuristics quite remarkable.
As a final step of the numerical analysis, the algorithms’ computational time (CPU time in seconds) is compared considering different problem sizes, i.e., workload and number of machines. The results in Table 5 show that the efficiency of the NCH algorithm is meaningfully better than that of the benchmarks. A computationally efficient constructive heuristic for solving DTrSAPFSP will not only contribute to the development of its literature but also facilitate the industrial reach of this new scheduling extension.
5 Conclusions
Optimization of distributed three-stage production operations was explored in this research article. Under this production setting, the parts (subcomponents) are manufactured and assembled by OEMs to form the product components. The produced components from multiple OEMs then arrive at the main manufacturer for the assembly and preparation of the final products. Many supply chains, like those in the automotive, heavy equipment, and home appliance industries, operate under similar conditions. Coordinated production scheduling benefits the supply chain through cost reduction and improved responsiveness. A new constructive heuristic algorithm is put forward for solving DTrSAPFSP, which forms the basis for further developments in the field of distributed production planning and control. The developed method is particularly beneficial for running the search procedure in parallel computing environments.
Extensive numerical analyzes were conducted to compare the performance of NCH with the state-of-the-art; NEH+ constructive heuristic and three of the state-of-the-art metaheuristics, i.e., HSSO, HSSOR, and HSSORP, were adapted for solving DTrSAPFSP. The major findings are summarized as follows. First, the performance of the proposed constructive heuristic is significantly better than the constructive heuristic that is being widely used in the distributed flowshop scheduling literature. Second, the CPU time of the NCH algorithm showed to be meaningfully less than those of the metaheuristic benchmarks. Third, the analysis of the results considering RPD shows that NCH performs better than the metaheuristics, from an overall perspective, which is quite remarkable. Considering instances with various operational characteristics, we observed that NCH yields the best solution in the majority of test instances except for instances characterized by many parts and only a small number of components and products. The statistical test confirmed the significance of the superior performance. Overall, the N-List technique appeared to be very effective and should be considered in other optimization contexts.
Future studies may extend our research in one of the following directions. First, the mathematical model of DTrSAPFSP can be extended to allow for a more realistic representation of the real-world situation. For example, including the transportation cost of components between facilities and considering the operational efficiencies of the component producers may result in more reliable outcomes. Second, the scheduling approach can be improved to work with the dynamic arrival of new orders, considering different order priorities, emergency changes of those priorities, partial acceptance/rejection of the orders, and the assignment of components to new OEMs. Third, considering the significant improvement compared to the best-performing constructive heuristic in the literature of distributed flowshop scheduling, NCH should be incorporated as a constructive heuristic in metaheuristic algorithms for more effectively solving the problems. As a fourth direction for future research, formulating mathematical models for DTrSAPFSP and the possible new extensions, as well as developing effective metaheuristics are worthwhile topics to pursue. Finally, we feel that the results obtained by NCH can be further improved using machine learning-based approaches; a direction that should be considered for future development of the DTrSAPFSP literature.
Data availability
The raw/processed data required to reproduce these findings can be provided upon reasonable request.
Change history
24 July 2023
A Correction to this paper has been published: https://doi.org/10.1007/s10479-023-05516-x
References
Deng, J., Wang, L., Wang, S., & Zheng, X. (2016). A competitive memetic algorithm for the distributed two-stage assembly flow-shop scheduling problem. International Journal of Production Research, 54(12), 3561–3577. https://doi.org/10.1080/00207543.2015.1084063
Ferone, D., Hatami, S., González-Neira, E. M., Juan, A. A., & Festa, P. (2020). A biased-randomized iterated local search for the distributed assembly permutation flow-shop problem. International Transactions in Operational Research, 27(3), 1368–1391.
Hao J, Liu F, Zhuang X, & Zhang W (2023). Effective social spider optimization algorithms for distributed assembly permutation flowshop scheduling problem in automobile manufacturing supply chain. working paper, School of Information Science and Engineering, Shandong Normal University.
Hatami, S., Ruiz, R., & Andrés-Romano, C. (2013). The distributed assembly permutation flowshop scheduling problem. International Journal of Production Research, 51(17), 5292–5308. https://doi.org/10.1080/00207543.2013.807955
Lee, C.-Y., Cheng, T. C. E., & Lin, B. M. T. (1993). Minimizing the makespan in the 3-machine assembly-type flowshop scheduling problem. Management Science, 39(5), 616–625. https://doi.org/10.1287/mnsc.39.5.616
Lin, J., Wang, Z.-J., & Li, X. (2017). A backtracking search hyper-heuristic for the distributed assembly flow-shop scheduling problem. Swarm and Evolutionary Computation, 36, 124–135.
Lin, J., & Zhang, S. (2016). An effective hybrid biogeography-based optimization algorithm for the distributed assembly permutation flow-shop scheduling problem. Computers & Industrial Engineering, 97, 128–136.
Luo, J., Fujimura, S., El Baz, D., & Plazolles, B. (2019). GPU based parallel genetic algorithm for solving an energy efficient dynamic flexible flow shop scheduling problem. Journal of Parallel and Distributed Computing, 133, 244–257. https://doi.org/10.1016/j.jpdc.2018.07.022
Nawaz, M., Enscore, E. E., Jr., & Ham, I. (1983). A heuristic algorithm for the m-machine, n-job flow-shop sequencing problem. Omega, 11(1), 91–95.
Pourhejazy, P. (2022). Production management and supply chain integration. In J. Sarkis (Ed.), The Palgrave Handbook of Supply Chain Management (pp. 1–26). Cham: Springer International Publishing. https://doi.org/10.1007/978-3-030-89822-9_86-1
Pourhejazy, P., Cheng, C.-Y., Ying, K.-C., & Nam, N. H. (2022). Meta-Lamarckian-based iterated greedy for optimizing distributed two-stage assembly flowshops with mixed setups. Annals of Operations Research. https://doi.org/10.1007/s10479-022-04537-2
Puka, R., Duda, J., Stawowy, A., & Skalna, I. (2021). N-NEH+ algorithm for solving permutation flow shop problems. Computers & Operations Research, 132, 105296. https://doi.org/10.1016/j.cor.2021.105296
Sang, H.-Y., Pan, Q.-K., Li, J.-Q., Wang, P., Han, Y.-Y., Gao, K.-Z., & Duan, P. (2019). Effective invasive weed optimization algorithms for distributed assembly permutation flowshop problem with total flowtime criterion. Swarm and Evolutionary Computation, 44, 64–73.
Wang, J., Lei, D., & Cai, J. (2022). An adaptive artificial bee colony with reinforcement learning for distributed three-stage assembly scheduling with maintenance. Applied Soft Computing, 117, 108371. https://doi.org/10.1016/j.asoc.2021.108371
Wang, J., Lei, D., & Li, M. (2022). A Q-learning-based artificial bee colony algorithm for distributed three-stage assembly scheduling with factory eligibility and setup times. Machines, 10(8), 661. https://doi.org/10.3390/machines10080661
Wang, S.-Y., & Wang, L. (2016). An estimation of distribution algorithm-based memetic algorithm for the distributed assembly permutation flow-shop scheduling problem. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 46(1), 139–149. https://doi.org/10.1109/TSMC.2015.2416127
Xiong, F., & Xing, K. (2014). Meta-heuristics for the distributed two-stage assembly scheduling problem with bi-criteria of makespan and mean completion time. International Journal of Production Research, 52(9), 2743–2766. https://doi.org/10.1080/00207543.2014.884290
Xiong, F., Xing, K., Wang, F., Lei, H., & Han, L. (2014). Minimizing the total completion time in a distributed two stage assembly system with setup times. Computers & Operations Research, 47, 92–105. https://doi.org/10.1016/j.cor.2014.02.005
Yang, S., & Xu, Z. (2020). The distributed assembly permutation flowshop scheduling problem with flexible assembly and batch delivery. International Journal of Production Research, 1–19, 1757174. https://doi.org/10.1080/00207543.2020.1757174
Ying, K.-C., Pourhejazy, P., Cheng, C.-Y., & Syu, R.-S. (2020). Supply chain-oriented permutation flowshop scheduling considering flexible assembly and setup times. International Journal of Production Research, 58(20), 1–24. https://doi.org/10.1080/00207543.2020.1842938
Zhang, G., & Xing, K. (2018). Memetic social spider optimization algorithm for scheduling two-stage assembly flowshop in a distributed environment. Computers & Industrial Engineering, 125, 423–433. https://doi.org/10.1016/j.cie.2018.09.007
Zheng, J., & Wang, Y. (2021). A hybrid bat algorithm for solving the three-stage distributed assembly permutation flowshop scheduling problem. Applied Sciences, 11(21), 10102. https://doi.org/10.3390/app112110102
Funding
Open access funding provided by UiT The Arctic University of Norway (incl University Hospital of North Norway).
Author information
Authors and Affiliations
Contributions
K-C.Y. conceptualized the study and supervised it. Material preparation and numerical analysis were performed by P-J.F. Investigations and writing the submitted manuscript were done by P.P. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
No | Identity | HSSO | HSSOR | HSSORP | ANEH + | NCH | BFS | No | Identity | HSSO | HSSOR | HSSORP | ANEH + | NCH | BFS |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
1 | [100_5_4_30_10_1] | 2693 | 2691 | 2692 | 2691 | 2617 | 2617 | 406 | [200_10_6_40_15_6] | 4010 | 4009 | 4034 | 4134 | 4078 | 4009 |
2 | [100_5_4_30_10_2] | 2611 | 2612 | 2611 | 2978 | 2808 | 2611 | 407 | [200_10_6_40_15_7] | 3992 | 3992 | 3986 | 4149 | 3852 | 3852 |
3 | [100_5_4_30_10_3] | 2504 | 2495 | 2499 | 2606 | 2521 | 2495 | 408 | [200_10_6_40_15_8] | 3785 | 3789 | 3787 | 4067 | 3735 | 3735 |
4 | [100_5_4_30_10_4] | 2359 | 2352 | 2352 | 2706 | 2360 | 2352 | 409 | [200_10_6_40_15_9] | 3819 | 3819 | 3817 | 3783 | 3812 | 3783 |
5 | [100_5_4_30_10_5] | 2691 | 2691 | 2691 | 2820 | 2869 | 2691 | 410 | [200_10_6_40_15_10] | 3819 | 3805 | 3818 | 3885 | 3885 | 3805 |
6 | [100_5_4_30_10_6] | 2867 | 2864 | 2858 | 2858 | 2858 | 2858 | 411 | [200_10_6_50_20_1] | 5623 | 5623 | 5582 | 5582 | 5373 | 5373 |
7 | [100_5_4_30_10_7] | 2405 | 2399 | 2406 | 2399 | 2205 | 2205 | 412 | [200_10_6_50_20_2] | 4744 | 4727 | 4727 | 4727 | 4638 | 4638 |
8 | [100_5_4_30_10_8] | 2780 | 2772 | 2780 | 2880 | 2743 | 2743 | 413 | [200_10_6_50_20_3] | 4240 | 4240 | 4240 | 4218 | 3925 | 3925 |
9 | [100_5_4_30_10_9] | 2380 | 2379 | 2379 | 2524 | 2363 | 2363 | 414 | [200_10_6_50_20_4] | 5474 | 5443 | 5473 | 5443 | 5184 | 5184 |
10 | [100_5_4_30_10_10] | 2249 | 2249 | 2249 | 2426 | 2208 | 2208 | 415 | [200_10_6_50_20_5] | 4744 | 4720 | 4722 | 4782 | 4556 | 4556 |
11 | [100_5_4_40_15_1] | 3275 | 3277 | 3275 | 3274 | 3274 | 3274 | 416 | [200_10_6_50_20_6] | 4434 | 4426 | 4418 | 4396 | 4441 | 4396 |
12 | [100_5_4_40_15_2] | 3490 | 3490 | 3520 | 3490 | 3709 | 3490 | 417 | [200_10_6_50_20_7] | 4618 | 4610 | 4614 | 4762 | 4593 | 4593 |
13 | [100_5_4_40_15_3] | 3324 | 3323 | 3332 | 3323 | 3407 | 3323 | 418 | [200_10_6_50_20_8] | 4410 | 4410 | 4421 | 4427 | 4430 | 4410 |
14 | [100_5_4_40_15_4] | 3351 | 3351 | 3336 | 3458 | 3502 | 3336 | 419 | [200_10_6_50_20_9] | 4918 | 4930 | 4918 | 4925 | 4925 | 4918 |
15 | [100_5_4_40_15_5] | 3205 | 3204 | 3204 | 3169 | 2934 | 2934 | 420 | [200_10_6_50_20_10] | 4663 | 4663 | 4652 | 4649 | 4649 | 4649 |
16 | [100_5_4_40_15_6] | 3385 | 3382 | 3383 | 3535 | 3548 | 3382 | 421 | [200_10_8_30_10_1] | 3429 | 3381 | 3381 | 3331 | 3329 | 3329 |
17 | [100_5_4_40_15_7] | 3140 | 3140 | 3136 | 3136 | 3136 | 3136 | 422 | [200_10_8_30_10_2] | 3399 | 3396 | 3399 | 3398 | 3399 | 3396 |
18 | [100_5_4_40_15_8] | 2938 | 2938 | 2953 | 2940 | 2938 | 2938 | 423 | [200_10_8_30_10_3] | 3337 | 3305 | 3337 | 3520 | 3442 | 3305 |
19 | [100_5_4_40_15_9] | 3603 | 3600 | 3603 | 3636 | 3586 | 3586 | 424 | [200_10_8_30_10_4] | 3126 | 3126 | 3126 | 3378 | 3283 | 3126 |
20 | [100_5_4_40_15_10] | 3366 | 3382 | 3382 | 3366 | 3366 | 3366 | 425 | [200_10_8_30_10_5] | 3396 | 3396 | 3390 | 3675 | 3718 | 3390 |
21 | [100_5_4_50_20_1] | 4117 | 4117 | 4117 | 4108 | 4132 | 4108 | 426 | [200_10_8_30_10_6] | 3109 | 3109 | 3098 | 3235 | 3121 | 3098 |
22 | [100_5_4_50_20_2] | 4588 | 4567 | 4588 | 4567 | 4567 | 4567 | 427 | [200_10_8_30_10_7] | 3289 | 3264 | 3289 | 3536 | 3116 | 3116 |
23 | [100_5_4_50_20_3] | 4437 | 4437 | 4437 | 4438 | 4247 | 4247 | 428 | [200_10_8_30_10_8] | 3291 | 3312 | 3304 | 3331 | 3513 | 3291 |
24 | [100_5_4_50_20_4] | 4407 | 4407 | 4407 | 4469 | 4164 | 4164 | 429 | [200_10_8_30_10_9] | 3077 | 3077 | 3066 | 3336 | 3041 | 3041 |
25 | [100_5_4_50_20_5] | 4705 | 4714 | 4705 | 4705 | 4772 | 4705 | 430 | [200_10_8_30_10_10] | 3333 | 3333 | 3330 | 3564 | 3191 | 3191 |
26 | [100_5_4_50_20_6] | 4207 | 4191 | 4191 | 4244 | 3957 | 3957 | 431 | [200_10_8_40_15_1] | 3793 | 3793 | 3835 | 3864 | 3819 | 3793 |
27 | [100_5_4_50_20_7] | 4190 | 4178 | 4178 | 4194 | 4175 | 4175 | 432 | [200_10_8_40_15_2] | 3719 | 3719 | 3722 | 3773 | 3773 | 3719 |
28 | [100_5_4_50_20_8] | 3580 | 3631 | 3590 | 3611 | 3540 | 3540 | 433 | [200_10_8_40_15_3] | 4181 | 4181 | 4176 | 4161 | 4161 | 4161 |
29 | [100_5_4_50_20_9] | 4918 | 4894 | 4918 | 4894 | 4894 | 4894 | 434 | [200_10_8_40_15_4] | 3847 | 3857 | 3835 | 3946 | 3835 | 3835 |
30 | [100_5_4_50_20_10] | 4102 | 4091 | 4091 | 4115 | 3979 | 3979 | 435 | [200_10_8_40_15_5] | 3823 | 3817 | 3823 | 3808 | 3808 | 3808 |
31 | [100_5_6_30_10_1] | 1979 | 1971 | 1975 | 2116 | 1927 | 1927 | 436 | [200_10_8_40_15_6] | 3450 | 3444 | 3450 | 3413 | 3099 | 3099 |
32 | [100_5_6_30_10_2] | 2489 | 2487 | 2489 | 2487 | 2562 | 2487 | 437 | [200_10_8_40_15_7] | 3806 | 3775 | 3775 | 3783 | 3819 | 3775 |
33 | [100_5_6_30_10_3] | 2396 | 2390 | 2396 | 2390 | 2239 | 2239 | 438 | [200_10_8_40_15_8] | 3368 | 3388 | 3366 | 3447 | 3239 | 3239 |
34 | [100_5_6_30_10_4] | 2494 | 2477 | 2487 | 2550 | 2563 | 2477 | 439 | [200_10_8_40_15_9] | 3744 | 3744 | 3748 | 3742 | 3550 | 3550 |
35 | [100_5_6_30_10_5] | 2538 | 2521 | 2521 | 2652 | 2658 | 2521 | 440 | [200_10_8_40_15_10] | 3259 | 3253 | 3253 | 3375 | 3034 | 3034 |
36 | [100_5_6_30_10_6] | 2244 | 2252 | 2252 | 2317 | 2284 | 2244 | 441 | [200_10_8_50_20_1] | 4853 | 4863 | 4859 | 4853 | 4787 | 4787 |
37 | [100_5_6_30_10_7] | 2689 | 2680 | 2680 | 2676 | 2676 | 2676 | 442 | [200_10_8_50_20_2] | 4515 | 4509 | 4515 | 4509 | 4509 | 4509 |
38 | [100_5_6_30_10_8] | 2520 | 2520 | 2514 | 2514 | 2514 | 2514 | 443 | [200_10_8_50_20_3] | 4500 | 4497 | 4500 | 4512 | 4367 | 4367 |
39 | [100_5_6_30_10_9] | 2229 | 2221 | 2229 | 2383 | 2221 | 2221 | 444 | [200_10_8_50_20_4] | 5058 | 5089 | 5089 | 5101 | 5049 | 5049 |
40 | [100_5_6_30_10_10] | 2212 | 2212 | 2212 | 2209 | 2162 | 2162 | 445 | [200_10_8_50_20_5] | 4132 | 4132 | 4132 | 4243 | 4276 | 4132 |
41 | [100_5_6_40_15_1] | 3109 | 3115 | 3109 | 3109 | 3109 | 3109 | 446 | [200_10_8_50_20_6] | 4835 | 4826 | 4826 | 4948 | 4905 | 4826 |
42 | [100_5_6_40_15_2] | 3552 | 3552 | 3567 | 3552 | 3423 | 3423 | 447 | [200_10_8_50_20_7] | 4641 | 4641 | 4639 | 4638 | 4333 | 4333 |
43 | [100_5_6_40_15_3] | 3197 | 3197 | 3197 | 3175 | 2914 | 2914 | 448 | [200_10_8_50_20_8] | 4302 | 4277 | 4298 | 4262 | 4114 | 4114 |
44 | [100_5_6_40_15_4] | 4174 | 4158 | 4174 | 4158 | 4165 | 4158 | 449 | [200_10_8_50_20_9] | 5351 | 5351 | 5346 | 5383 | 5244 | 5244 |
45 | [100_5_6_40_15_5] | 3429 | 3429 | 3429 | 3401 | 3242 | 3242 | 450 | [200_10_8_50_20_10] | 4856 | 4823 | 4823 | 4823 | 4823 | 4823 |
46 | [100_5_6_40_15_6] | 3613 | 3613 | 3579 | 3560 | 3560 | 3560 | 451 | [200_20_4_30_10_1] | 5216 | 5215 | 5215 | 5727 | 5219 | 5215 |
47 | [100_5_6_40_15_7] | 3265 | 3265 | 3265 | 3319 | 3428 | 3265 | 452 | [200_20_4_30_10_2] | 5208 | 5181 | 5192 | 5706 | 5014 | 5014 |
48 | [100_5_6_40_15_8] | 3661 | 3632 | 3632 | 3632 | 3568 | 3568 | 453 | [200_20_4_30_10_3] | 5147 | 5120 | 5147 | 5762 | 5195 | 5120 |
49 | [100_5_6_40_15_9] | 3706 | 3677 | 3697 | 3677 | 3438 | 3438 | 454 | [200_20_4_30_10_4] | 5053 | 5053 | 5043 | 5849 | 4807 | 4807 |
50 | [100_5_6_40_15_10] | 3347 | 3330 | 3330 | 3330 | 3069 | 3069 | 455 | [200_20_4_30_10_5] | 5401 | 5420 | 5420 | 5953 | 5511 | 5401 |
51 | [100_5_6_50_20_1] | 4174 | 4141 | 4148 | 4141 | 3940 | 3940 | 456 | [200_20_4_30_10_6] | 5250 | 5250 | 5250 | 5631 | 5118 | 5118 |
52 | [100_5_6_50_20_2] | 4702 | 4665 | 4673 | 4677 | 4545 | 4545 | 457 | [200_20_4_30_10_7] | 5003 | 4976 | 4976 | 5711 | 4795 | 4795 |
53 | [100_5_6_50_20_3] | 4986 | 4916 | 4933 | 4966 | 4677 | 4677 | 458 | [200_20_4_30_10_8] | 5048 | 5048 | 5048 | 5619 | 4476 | 4476 |
54 | [100_5_6_50_20_4] | 3939 | 3929 | 3929 | 3932 | 3932 | 3929 | 459 | [200_20_4_30_10_9] | 5237 | 5247 | 5237 | 5829 | 4947 | 4947 |
55 | [100_5_6_50_20_5] | 4789 | 4817 | 4795 | 4789 | 4581 | 4581 | 460 | [200_20_4_30_10_10] | 5287 | 5315 | 5272 | 5812 | 4575 | 4575 |
56 | [100_5_6_50_20_6] | 3976 | 3976 | 3972 | 3972 | 3757 | 3757 | 461 | [200_20_4_40_15_1] | 5137 | 5135 | 5135 | 5569 | 4680 | 4680 |
57 | [100_5_6_50_20_7] | 4330 | 4311 | 4326 | 4354 | 4302 | 4302 | 462 | [200_20_4_40_15_2] | 4834 | 4838 | 4831 | 5235 | 4486 | 4486 |
58 | [100_5_6_50_20_8] | 4281 | 4281 | 4281 | 4275 | 4313 | 4275 | 463 | [200_20_4_40_15_3] | 5264 | 5264 | 5278 | 5940 | 5265 | 5264 |
59 | [100_5_6_50_20_9] | 4163 | 4178 | 4178 | 4156 | 4078 | 4078 | 464 | [200_20_4_40_15_4] | 5263 | 5263 | 5263 | 5645 | 5006 | 5006 |
60 | [100_5_6_50_20_10] | 4805 | 4800 | 4805 | 4800 | 4542 | 4542 | 465 | [200_20_4_40_15_5] | 5195 | 5200 | 5195 | 5630 | 4828 | 4828 |
61 | [100_5_8_30_10_1] | 2243 | 2239 | 2239 | 2231 | 2239 | 2231 | 466 | [200_20_4_40_15_6] | 4931 | 4931 | 4918 | 5113 | 4199 | 4199 |
62 | [100_5_8_30_10_2] | 2208 | 2181 | 2192 | 2109 | 2109 | 2109 | 467 | [200_20_4_40_15_7] | 5239 | 5239 | 5239 | 5580 | 4807 | 4807 |
63 | [100_5_8_30_10_3] | 2942 | 2916 | 2916 | 2916 | 2916 | 2916 | 468 | [200_20_4_40_15_8] | 4992 | 4992 | 4992 | 5467 | 4450 | 4450 |
64 | [100_5_8_30_10_4] | 2210 | 2210 | 2210 | 2210 | 2027 | 2027 | 469 | [200_20_4_40_15_9] | 5309 | 5285 | 5285 | 5748 | 5045 | 5045 |
65 | [100_5_8_30_10_5] | 2481 | 2471 | 2472 | 2471 | 2471 | 2471 | 470 | [200_20_4_40_15_10] | 5144 | 5124 | 5138 | 5585 | 4480 | 4480 |
66 | [100_5_8_30_10_6] | 2340 | 2355 | 2355 | 2340 | 2216 | 2216 | 471 | [200_20_4_50_20_1] | 5177 | 5166 | 5177 | 5509 | 4960 | 4960 |
67 | [100_5_8_30_10_7] | 2480 | 2480 | 2480 | 2484 | 2381 | 2381 | 472 | [200_20_4_50_20_2] | 5193 | 5175 | 5175 | 5442 | 5016 | 5016 |
68 | [100_5_8_30_10_8] | 2430 | 2422 | 2422 | 2397 | 2397 | 2397 | 473 | [200_20_4_50_20_3] | 5324 | 5300 | 5314 | 5680 | 5209 | 5209 |
69 | [100_5_8_30_10_9] | 2811 | 2804 | 2804 | 2821 | 2417 | 2417 | 474 | [200_20_4_50_20_4] | 5432 | 5432 | 5433 | 5883 | 5304 | 5304 |
70 | [100_5_8_30_10_10] | 2345 | 2345 | 2337 | 2323 | 2378 | 2323 | 475 | [200_20_4_50_20_5] | 5114 | 5086 | 5092 | 5328 | 4861 | 4861 |
71 | [100_5_8_40_15_1] | 3046 | 3041 | 3041 | 3047 | 2951 | 2951 | 476 | [200_20_4_50_20_6] | 5671 | 5665 | 5670 | 5563 | 5671 | 5563 |
72 | [100_5_8_40_15_2] | 3187 | 3187 | 3196 | 3181 | 3181 | 3181 | 477 | [200_20_4_50_20_7] | 6190 | 6158 | 6190 | 6306 | 6058 | 6058 |
73 | [100_5_8_40_15_3] | 3272 | 3268 | 3272 | 3268 | 3197 | 3197 | 478 | [200_20_4_50_20_8] | 5341 | 5355 | 5337 | 5540 | 5306 | 5306 |
74 | [100_5_8_40_15_4] | 3318 | 3313 | 3318 | 3313 | 3071 | 3071 | 479 | [200_20_4_50_20_9] | 5508 | 5472 | 5508 | 5657 | 5781 | 5472 |
75 | [100_5_8_40_15_5] | 3867 | 3867 | 3834 | 3829 | 3765 | 3765 | 480 | [200_20_4_50_20_10] | 5194 | 5188 | 5150 | 5533 | 4754 | 4754 |
76 | [100_5_8_40_15_6] | 3473 | 3466 | 3466 | 3458 | 3496 | 3458 | 481 | [200_20_6_30_10_1] | 4505 | 4488 | 4505 | 4608 | 4285 | 4285 |
77 | [100_5_8_40_15_7] | 2914 | 2910 | 2914 | 2881 | 2592 | 2592 | 482 | [200_20_6_30_10_2] | 4477 | 4477 | 4477 | 4840 | 4160 | 4160 |
78 | [100_5_8_40_15_8] | 3909 | 3909 | 3909 | 3878 | 3606 | 3606 | 483 | [200_20_6_30_10_3] | 4539 | 4513 | 4519 | 4776 | 3901 | 3901 |
79 | [100_5_8_40_15_9] | 2386 | 2372 | 2386 | 2372 | 2372 | 2372 | 484 | [200_20_6_30_10_4] | 4411 | 4398 | 4398 | 4785 | 4042 | 4042 |
80 | [100_5_8_40_15_10] | 3723 | 3723 | 3723 | 3689 | 3689 | 3689 | 485 | [200_20_6_30_10_5] | 4453 | 4490 | 4490 | 4907 | 3963 | 3963 |
81 | [100_5_8_50_20_1] | 3880 | 3880 | 3880 | 3880 | 3787 | 3787 | 486 | [200_20_6_30_10_6] | 4323 | 4323 | 4323 | 4405 | 4343 | 4323 |
82 | [100_5_8_50_20_2] | 3915 | 3915 | 3915 | 3947 | 3947 | 3915 | 487 | [200_20_6_30_10_7] | 4417 | 4436 | 4426 | 4810 | 3756 | 3756 |
83 | [100_5_8_50_20_3] | 3972 | 3946 | 3958 | 3946 | 3851 | 3851 | 488 | [200_20_6_30_10_8] | 4154 | 4135 | 4128 | 4401 | 4029 | 4029 |
84 | [100_5_8_50_20_4] | 3739 | 3710 | 3716 | 3716 | 3716 | 3710 | 489 | [200_20_6_30_10_9] | 4443 | 4444 | 4418 | 4739 | 4241 | 4241 |
85 | [100_5_8_50_20_5] | 4129 | 4116 | 4129 | 4116 | 3875 | 3875 | 490 | [200_20_6_30_10_10] | 4179 | 4179 | 4190 | 4482 | 3817 | 3817 |
86 | [100_5_8_50_20_6] | 4231 | 4227 | 4191 | 4191 | 3943 | 3943 | 491 | [200_20_6_40_15_1] | 4330 | 4391 | 4330 | 4384 | 4173 | 4173 |
87 | [100_5_8_50_20_7] | 4462 | 4430 | 4430 | 4430 | 4307 | 4307 | 492 | [200_20_6_40_15_2] | 4458 | 4504 | 4488 | 4856 | 4785 | 4458 |
88 | [100_5_8_50_20_8] | 4507 | 4535 | 4509 | 4507 | 4307 | 4307 | 493 | [200_20_6_40_15_3] | 4600 | 4614 | 4594 | 4734 | 4039 | 4039 |
89 | [100_5_8_50_20_9] | 4357 | 4338 | 4340 | 4338 | 4241 | 4241 | 494 | [200_20_6_40_15_4] | 4851 | 4825 | 4825 | 4842 | 4860 | 4825 |
90 | [100_5_8_50_20_10] | 4044 | 4032 | 4044 | 4027 | 3848 | 3848 | 495 | [200_20_6_40_15_5] | 5059 | 5027 | 5027 | 5071 | 5148 | 5027 |
91 | [100_10_4_30_10_1] | 2611 | 2611 | 2624 | 3027 | 2607 | 2607 | 496 | [200_20_6_40_15_6] | 4928 | 4948 | 4924 | 4891 | 4924 | 4891 |
92 | [100_10_4_30_10_2] | 3153 | 3167 | 3167 | 3153 | 2698 | 2698 | 497 | [200_20_6_40_15_7] | 4735 | 4719 | 4732 | 4719 | 4719 | 4719 |
93 | [100_10_4_30_10_3] | 2643 | 2643 | 2643 | 2902 | 2516 | 2516 | 498 | [200_20_6_40_15_8] | 4369 | 4366 | 4366 | 4627 | 4216 | 4216 |
94 | [100_10_4_30_10_4] | 2789 | 2787 | 2789 | 2883 | 2809 | 2787 | 499 | [200_20_6_40_15_9] | 4457 | 4514 | 4512 | 4457 | 4379 | 4379 |
95 | [100_10_4_30_10_5] | 3204 | 3199 | 3200 | 3370 | 3378 | 3199 | 500 | [200_20_6_40_15_10] | 4421 | 4421 | 4421 | 4532 | 4406 | 4406 |
96 | [100_10_4_30_10_6] | 3100 | 3124 | 3118 | 3312 | 3179 | 3100 | 501 | [200_20_6_50_20_1] | 5057 | 5057 | 5020 | 5070 | 4858 | 4858 |
97 | [100_10_4_30_10_7] | 2440 | 2458 | 2437 | 2708 | 2330 | 2330 | 502 | [200_20_6_50_20_2] | 5841 | 5841 | 5837 | 5836 | 5836 | 5836 |
98 | [100_10_4_30_10_8] | 2787 | 2766 | 2766 | 3048 | 2912 | 2766 | 503 | [200_20_6_50_20_3] | 5729 | 5721 | 5721 | 5718 | 5708 | 5708 |
99 | [100_10_4_30_10_9] | 2689 | 2699 | 2699 | 2756 | 2687 | 2687 | 504 | [200_20_6_50_20_4] | 5730 | 5715 | 5730 | 5793 | 5555 | 5555 |
100 | [100_10_4_30_10_10] | 2928 | 2928 | 2928 | 3130 | 2960 | 2928 | 505 | [200_20_6_50_20_5] | 5338 | 5338 | 5338 | 5480 | 5583 | 5338 |
101 | [100_10_4_40_15_1] | 4167 | 4160 | 4160 | 4187 | 4187 | 4160 | 506 | [200_20_6_50_20_6] | 5912 | 5912 | 5912 | 5917 | 5597 | 5597 |
102 | [100_10_4_40_15_2] | 3649 | 3647 | 3647 | 3675 | 3306 | 3306 | 507 | [200_20_6_50_20_7] | 5203 | 5191 | 5203 | 5203 | 4974 | 4974 |
103 | [100_10_4_40_15_3] | 3898 | 3898 | 3879 | 3983 | 3706 | 3706 | 508 | [200_20_6_50_20_8] | 4980 | 4980 | 4980 | 5196 | 5052 | 4980 |
104 | [100_10_4_40_15_4] | 3263 | 3243 | 3263 | 3410 | 3296 | 3243 | 509 | [200_20_6_50_20_9] | 4738 | 4762 | 4732 | 4693 | 4443 | 4443 |
105 | [100_10_4_40_15_5] | 3625 | 3640 | 3640 | 3739 | 3379 | 3379 | 510 | [200_20_6_50_20_10] | 5153 | 5146 | 5146 | 5146 | 4868 | 4868 |
106 | [100_10_4_40_15_6] | 3032 | 3030 | 3033 | 3234 | 2872 | 2872 | 511 | [200_20_8_30_10_1] | 4174 | 4153 | 4165 | 4262 | 4065 | 4065 |
107 | [100_10_4_40_15_7] | 3786 | 3786 | 3771 | 3771 | 3771 | 3771 | 512 | [200_20_8_30_10_2] | 3900 | 3895 | 3899 | 4071 | 3645 | 3645 |
108 | [100_10_4_40_15_8] | 4174 | 4174 | 4174 | 4208 | 4148 | 4148 | 513 | [200_20_8_30_10_3] | 3745 | 3745 | 3750 | 3788 | 3710 | 3710 |
109 | [100_10_4_40_15_9] | 3445 | 3445 | 3422 | 3512 | 3512 | 3422 | 514 | [200_20_8_30_10_4] | 4245 | 4234 | 4234 | 4290 | 4147 | 4147 |
110 | [100_10_4_40_15_10] | 4125 | 4125 | 4124 | 4175 | 4224 | 4124 | 515 | [200_20_8_30_10_5] | 4167 | 4159 | 4167 | 4213 | 3674 | 3674 |
111 | [100_10_4_50_20_1] | 4689 | 4683 | 4689 | 4683 | 4424 | 4424 | 516 | [200_20_8_30_10_6] | 4036 | 4017 | 4017 | 4424 | 3696 | 3696 |
112 | [100_10_4_50_20_2] | 4496 | 4493 | 4494 | 4493 | 4493 | 4493 | 517 | [200_20_8_30_10_7] | 4645 | 4631 | 4634 | 5146 | 3667 | 3667 |
113 | [100_10_4_50_20_3] | 4853 | 4818 | 4833 | 4928 | 4818 | 4818 | 518 | [200_20_8_30_10_8] | 4074 | 4074 | 4080 | 4192 | 4072 | 4072 |
114 | [100_10_4_50_20_4] | 4666 | 4654 | 4673 | 4701 | 4428 | 4428 | 519 | [200_20_8_30_10_9] | 3877 | 3877 | 3877 | 4318 | 4073 | 3877 |
115 | [100_10_4_50_20_5] | 4840 | 4823 | 4840 | 4895 | 4616 | 4616 | 520 | [200_20_8_30_10_10] | 4378 | 4352 | 4374 | 4338 | 4260 | 4260 |
116 | [100_10_4_50_20_6] | 4431 | 4419 | 4405 | 4466 | 4260 | 4260 | 521 | [200_20_8_40_15_1] | 4129 | 4129 | 4135 | 4061 | 4048 | 4048 |
117 | [100_10_4_50_20_7] | 4273 | 4273 | 4273 | 4374 | 4320 | 4273 | 522 | [200_20_8_40_15_2] | 4462 | 4450 | 4450 | 4472 | 4456 | 4450 |
118 | [100_10_4_50_20_8] | 4978 | 4974 | 4978 | 4974 | 4720 | 4720 | 523 | [200_20_8_40_15_3] | 4365 | 4365 | 4365 | 4349 | 4226 | 4226 |
119 | [100_10_4_50_20_9] | 4798 | 4785 | 4766 | 4854 | 4766 | 4766 | 524 | [200_20_8_40_15_4] | 4524 | 4524 | 4523 | 4479 | 4592 | 4479 |
120 | [100_10_4_50_20_10] | 4368 | 4348 | 4353 | 4446 | 4444 | 4348 | 525 | [200_20_8_40_15_5] | 4192 | 4192 | 4204 | 4192 | 3928 | 3928 |
121 | [100_10_6_30_10_1] | 2698 | 2671 | 2671 | 2692 | 2671 | 2671 | 526 | [200_20_8_40_15_6] | 4722 | 4697 | 4717 | 4610 | 4411 | 4411 |
122 | [100_10_6_30_10_2] | 2864 | 2864 | 2864 | 2997 | 2736 | 2736 | 527 | [200_20_8_40_15_7] | 4605 | 4624 | 4622 | 4702 | 4606 | 4605 |
123 | [100_10_6_30_10_3] | 2791 | 2791 | 2791 | 2816 | 2923 | 2791 | 528 | [200_20_8_40_15_8] | 4251 | 4251 | 4251 | 4230 | 4191 | 4191 |
124 | [100_10_6_30_10_4] | 2949 | 2922 | 2946 | 2946 | 3109 | 2922 | 529 | [200_20_8_40_15_9] | 4666 | 4676 | 4670 | 4670 | 4521 | 4521 |
125 | [100_10_6_30_10_5] | 2613 | 2607 | 2613 | 2652 | 2473 | 2473 | 530 | [200_20_8_40_15_10] | 4366 | 4370 | 4370 | 4291 | 4291 | 4291 |
126 | [100_10_6_30_10_6] | 2965 | 2969 | 2965 | 2965 | 2965 | 2965 | 531 | [200_20_8_50_20_1] | 4902 | 4912 | 4909 | 4912 | 4904 | 4902 |
127 | [100_10_6_30_10_7] | 2726 | 2717 | 2717 | 2711 | 2742 | 2711 | 532 | [200_20_8_50_20_2] | 5219 | 5219 | 5218 | 5163 | 5003 | 5003 |
128 | [100_10_6_30_10_8] | 2783 | 2782 | 2783 | 2901 | 2815 | 2782 | 533 | [200_20_8_50_20_3] | 5694 | 5683 | 5694 | 5683 | 5683 | 5683 |
129 | [100_10_6_30_10_9] | 2959 | 2959 | 2959 | 2956 | 2956 | 2956 | 534 | [200_20_8_50_20_4] | 5662 | 5651 | 5651 | 5640 | 5409 | 5409 |
130 | [100_10_6_30_10_10] | 2629 | 2629 | 2629 | 2769 | 2703 | 2629 | 535 | [200_20_8_50_20_5] | 5160 | 5149 | 5160 | 5171 | 5149 | 5149 |
131 | [100_10_6_40_15_1] | 3884 | 3857 | 3871 | 3857 | 3857 | 3857 | 536 | [200_20_8_50_20_6] | 5393 | 5393 | 5393 | 5347 | 5331 | 5331 |
132 | [100_10_6_40_15_2] | 3586 | 3586 | 3586 | 3526 | 3283 | 3283 | 537 | [200_20_8_50_20_7] | 6136 | 6143 | 6143 | 6126 | 6126 | 6126 |
133 | [100_10_6_40_15_3] | 3500 | 3493 | 3493 | 3490 | 3160 | 3160 | 538 | [200_20_8_50_20_8] | 5912 | 5912 | 5907 | 5903 | 5958 | 5903 |
134 | [100_10_6_40_15_4] | 3490 | 3480 | 3490 | 3480 | 3516 | 3480 | 539 | [200_20_8_50_20_9] | 4751 | 4746 | 4751 | 4738 | 4399 | 4399 |
135 | [100_10_6_40_15_5] | 3408 | 3408 | 3408 | 3350 | 3132 | 3132 | 540 | [200_20_8_50_20_10] | 5832 | 5823 | 5829 | 5823 | 5823 | 5823 |
136 | [100_10_6_40_15_6] | 3281 | 3276 | 3271 | 3271 | 3271 | 3271 | 541 | [500_5_4_30_10_1] | 8988 | 8988 | 8979 | 10,753 | 10,743 | 8979 |
137 | [100_10_6_40_15_7] | 3657 | 3653 | 3657 | 3653 | 3478 | 3478 | 542 | [500_5_4_30_10_2] | 8209 | 8204 | 8204 | 9075 | 8898 | 8204 |
138 | [100_10_6_40_15_8] | 3498 | 3498 | 3498 | 3606 | 3606 | 3498 | 543 | [500_5_4_30_10_3] | 8262 | 8260 | 8260 | 10,989 | 9160 | 8260 |
139 | [100_10_6_40_15_9] | 3926 | 3923 | 3926 | 3913 | 3935 | 3913 | 544 | [500_5_4_30_10_4] | 8413 | 8358 | 8388 | 11,204 | 9260 | 8358 |
140 | [100_10_6_40_15_10] | 3352 | 3352 | 3352 | 3421 | 3432 | 3352 | 545 | [500_5_4_30_10_5] | 8777 | 8777 | 8757 | 10,190 | 9521 | 8757 |
141 | [100_10_6_50_20_1] | 4453 | 4453 | 4453 | 4446 | 4135 | 4135 | 546 | [500_5_4_30_10_6] | 8651 | 8563 | 8563 | 10,737 | 9327 | 8563 |
142 | [100_10_6_50_20_2] | 4851 | 4845 | 4845 | 4853 | 4571 | 4571 | 547 | [500_5_4_30_10_7] | 8457 | 8467 | 8451 | 9796 | 8876 | 8451 |
143 | [100_10_6_50_20_3] | 4390 | 4390 | 4387 | 4373 | 4076 | 4076 | 548 | [500_5_4_30_10_8] | 8369 | 8319 | 8358 | 9113 | 8413 | 8319 |
144 | [100_10_6_50_20_4] | 4142 | 4131 | 4134 | 4134 | 4162 | 4131 | 549 | [500_5_4_30_10_9] | 7927 | 7895 | 7918 | 10,447 | 6858 | 6858 |
145 | [100_10_6_50_20_5] | 4145 | 4145 | 4148 | 4194 | 4194 | 4145 | 550 | [500_5_4_30_10_10] | 8895 | 8881 | 8884 | 10,737 | 10,330 | 8881 |
146 | [100_10_6_50_20_6] | 4967 | 5017 | 5002 | 4967 | 4748 | 4748 | 551 | [500_5_4_40_15_1] | 7830 | 7767 | 7783 | 10,036 | 8557 | 7767 |
147 | [100_10_6_50_20_7] | 4888 | 4888 | 4888 | 4888 | 4627 | 4627 | 552 | [500_5_4_40_15_2] | 8592 | 8530 | 8592 | 11,956 | 8233 | 8233 |
148 | [100_10_6_50_20_8] | 4414 | 4408 | 4408 | 4425 | 4285 | 4285 | 553 | [500_5_4_40_15_3] | 7991 | 7927 | 7988 | 10,624 | 9048 | 7927 |
149 | [100_10_6_50_20_9] | 5291 | 5284 | 5284 | 5237 | 5066 | 5066 | 554 | [500_5_4_40_15_4] | 8316 | 8295 | 8316 | 10,304 | 9449 | 8295 |
150 | [100_10_6_50_20_10] | 4433 | 4423 | 4426 | 4423 | 4237 | 4237 | 555 | [500_5_4_40_15_5] | 8100 | 8100 | 8079 | 8888 | 8278 | 8079 |
151 | [100_10_8_30_10_1] | 3084 | 3054 | 3068 | 3054 | 3054 | 3054 | 556 | [500_5_4_40_15_6] | 8611 | 8602 | 8602 | 10,308 | 9578 | 8602 |
152 | [100_10_8_30_10_2] | 3133 | 3123 | 3126 | 3140 | 3188 | 3123 | 557 | [500_5_4_40_15_7] | 8528 | 8528 | 8505 | 9739 | 9689 | 8505 |
153 | [100_10_8_30_10_3] | 2612 | 2612 | 2612 | 2612 | 2375 | 2375 | 558 | [500_5_4_40_15_8] | 8044 | 8044 | 7984 | 9568 | 8166 | 7984 |
154 | [100_10_8_30_10_4] | 2839 | 2839 | 2838 | 2836 | 2726 | 2726 | 559 | [500_5_4_40_15_9] | 8057 | 8035 | 8052 | 9901 | 11,562 | 8035 |
155 | [100_10_8_30_10_5] | 2843 | 2842 | 2842 | 2837 | 2837 | 2837 | 560 | [500_5_4_40_15_10] | 8119 | 8111 | 8119 | 9430 | 8277 | 8111 |
156 | [100_10_8_30_10_6] | 3039 | 3030 | 3039 | 3076 | 3149 | 3030 | 561 | [500_5_4_50_20_1] | 8213 | 8213 | 8160 | 9020 | 8819 | 8160 |
157 | [100_10_8_30_10_7] | 3024 | 3025 | 3023 | 3023 | 3023 | 3023 | 562 | [500_5_4_50_20_2] | 8206 | 8246 | 8242 | 9408 | 7966 | 7966 |
158 | [100_10_8_30_10_8] | 3032 | 3014 | 3032 | 3069 | 2977 | 2977 | 563 | [500_5_4_50_20_3] | 7554 | 7524 | 7528 | 8479 | 6460 | 6460 |
159 | [100_10_8_30_10_9] | 2850 | 2841 | 2843 | 2964 | 2964 | 2841 | 564 | [500_5_4_50_20_4] | 8175 | 8175 | 8221 | 8977 | 8900 | 8175 |
160 | [100_10_8_30_10_10] | 2620 | 2620 | 2620 | 2708 | 2702 | 2620 | 565 | [500_5_4_50_20_5] | 7998 | 8023 | 8023 | 9895 | 8418 | 7998 |
161 | [100_10_8_40_15_1] | 3198 | 3194 | 3194 | 3198 | 3048 | 3048 | 566 | [500_5_4_50_20_6] | 7842 | 7842 | 7853 | 9341 | 7878 | 7842 |
162 | [100_10_8_40_15_2] | 4043 | 4043 | 4032 | 4025 | 3888 | 3888 | 567 | [500_5_4_50_20_7] | 7838 | 7838 | 7800 | 9266 | 7054 | 7054 |
163 | [100_10_8_40_15_3] | 3881 | 3859 | 3862 | 3859 | 3619 | 3619 | 568 | [500_5_4_50_20_8] | 7881 | 7891 | 7881 | 8878 | 8725 | 7881 |
164 | [100_10_8_40_15_4] | 3917 | 3901 | 3917 | 3901 | 3660 | 3660 | 569 | [500_5_4_50_20_9] | 7758 | 7758 | 7858 | 9035 | 7724 | 7724 |
165 | [100_10_8_40_15_5] | 3852 | 3844 | 3844 | 3853 | 3853 | 3844 | 570 | [500_5_4_50_20_10] | 8071 | 8022 | 8071 | 10,241 | 7800 | 7800 |
166 | [100_10_8_40_15_6] | 3652 | 3645 | 3645 | 3645 | 3550 | 3550 | 571 | [500_5_6_30_10_1] | 6013 | 5999 | 5999 | 7288 | 7744 | 5999 |
167 | [100_10_8_40_15_7] | 3740 | 3740 | 3740 | 3740 | 3740 | 3740 | 572 | [500_5_6_30_10_2] | 6518 | 6518 | 6518 | 8269 | 7136 | 6518 |
168 | [100_10_8_40_15_8] | 3698 | 3745 | 3741 | 3698 | 3698 | 3698 | 573 | [500_5_6_30_10_3] | 6974 | 6974 | 6974 | 8095 | 7914 | 6974 |
169 | [100_10_8_40_15_9] | 4224 | 4222 | 4222 | 4222 | 4286 | 4222 | 574 | [500_5_6_30_10_4] | 6573 | 6547 | 6573 | 8095 | 7233 | 6547 |
170 | [100_10_8_40_15_10] | 3416 | 3416 | 3423 | 3416 | 3502 | 3416 | 575 | [500_5_6_30_10_5] | 6599 | 6599 | 6563 | 7706 | 7112 | 6563 |
171 | [100_10_8_50_20_1] | 4483 | 4483 | 4481 | 4480 | 4378 | 4378 | 576 | [500_5_6_30_10_6] | 6480 | 6509 | 6509 | 7828 | 7053 | 6480 |
172 | [100_10_8_50_20_2] | 4618 | 4595 | 4595 | 4649 | 4426 | 4426 | 577 | [500_5_6_30_10_7] | 6077 | 6077 | 6122 | 6642 | 6585 | 6077 |
173 | [100_10_8_50_20_3] | 4993 | 4993 | 4993 | 4993 | 4701 | 4701 | 578 | [500_5_6_30_10_8] | 5807 | 5741 | 5792 | 7585 | 5631 | 5631 |
174 | [100_10_8_50_20_4] | 4219 | 4219 | 4219 | 4230 | 4159 | 4159 | 579 | [500_5_6_30_10_9] | 6329 | 6273 | 6329 | 6984 | 6836 | 6273 |
175 | [100_10_8_50_20_5] | 4930 | 4869 | 4899 | 4869 | 4635 | 4635 | 580 | [500_5_6_30_10_10] | 6690 | 6690 | 6686 | 8010 | 7299 | 6686 |
176 | [100_10_8_50_20_6] | 5019 | 5019 | 5019 | 4987 | 4646 | 4646 | 581 | [500_5_6_40_15_1] | 5750 | 5750 | 5775 | 6238 | 6076 | 5750 |
177 | [100_10_8_50_20_7] | 4889 | 4864 | 4870 | 4864 | 4699 | 4699 | 582 | [500_5_6_40_15_2] | 5842 | 5842 | 5842 | 8180 | 6085 | 5842 |
178 | [100_10_8_50_20_8] | 4506 | 4521 | 4518 | 4506 | 4415 | 4415 | 583 | [500_5_6_40_15_3] | 5863 | 5863 | 5820 | 6850 | 6714 | 5820 |
179 | [100_10_8_50_20_9] | 5153 | 5106 | 5106 | 5106 | 4908 | 4908 | 584 | [500_5_6_40_15_4] | 6098 | 6098 | 6098 | 7222 | 6218 | 6098 |
180 | [100_10_8_50_20_10] | 4127 | 4121 | 4121 | 4121 | 4121 | 4121 | 585 | [500_5_6_40_15_5] | 6239 | 6206 | 6239 | 7194 | 6521 | 6206 |
181 | [100_20_4_30_10_1] | 3625 | 3625 | 3619 | 3735 | 3434 | 3434 | 586 | [500_5_6_40_15_6] | 5969 | 5969 | 5969 | 7089 | 5975 | 5969 |
182 | [100_20_4_30_10_2] | 3685 | 3671 | 3671 | 3870 | 3573 | 3573 | 587 | [500_5_6_40_15_7] | 6247 | 6247 | 6268 | 7394 | 6673 | 6247 |
183 | [100_20_4_30_10_3] | 3501 | 3515 | 3501 | 3834 | 3494 | 3494 | 588 | [500_5_6_40_15_8] | 5676 | 5637 | 5651 | 6622 | 5799 | 5637 |
184 | [100_20_4_30_10_4] | 3763 | 3773 | 3763 | 4011 | 3748 | 3748 | 589 | [500_5_6_40_15_9] | 5801 | 5795 | 5795 | 6438 | 5680 | 5680 |
185 | [100_20_4_30_10_5] | 3534 | 3534 | 3548 | 3832 | 3453 | 3453 | 590 | [500_5_6_40_15_10] | 6213 | 6219 | 6213 | 7222 | 6328 | 6213 |
186 | [100_20_4_30_10_6] | 3361 | 3352 | 3342 | 3570 | 3330 | 3330 | 591 | [500_5_6_50_20_1] | 6049 | 6065 | 6049 | 7574 | 5903 | 5903 |
187 | [100_20_4_30_10_7] | 3526 | 3493 | 3493 | 3736 | 3389 | 3389 | 592 | [500_5_6_50_20_2] | 5992 | 5991 | 5991 | 6474 | 6396 | 5991 |
188 | [100_20_4_30_10_8] | 3228 | 3228 | 3228 | 3802 | 3105 | 3105 | 593 | [500_5_6_50_20_3] | 5861 | 5915 | 5915 | 6788 | 5285 | 5285 |
189 | [100_20_4_30_10_9] | 3552 | 3562 | 3552 | 3947 | 3441 | 3441 | 594 | [500_5_6_50_20_4] | 5974 | 6018 | 6018 | 6857 | 5185 | 5185 |
190 | [100_20_4_30_10_10] | 3554 | 3548 | 3548 | 3950 | 3662 | 3548 | 595 | [500_5_6_50_20_5] | 6379 | 6399 | 6387 | 7186 | 5544 | 5544 |
191 | [100_20_4_40_15_1] | 3684 | 3684 | 3686 | 3795 | 3725 | 3684 | 596 | [500_5_6_50_20_6] | 5872 | 5834 | 5872 | 7593 | 5986 | 5834 |
192 | [100_20_4_40_15_2] | 4059 | 4065 | 4065 | 4236 | 4059 | 4059 | 597 | [500_5_6_50_20_7] | 6077 | 6097 | 6077 | 6528 | 6196 | 6077 |
193 | [100_20_4_40_15_3] | 4054 | 4051 | 4051 | 4099 | 4063 | 4051 | 598 | [500_5_6_50_20_8] | 6349 | 6331 | 6349 | 7488 | 6122 | 6122 |
194 | [100_20_4_40_15_4] | 4595 | 4580 | 4585 | 4580 | 4673 | 4580 | 599 | [500_5_6_50_20_9] | 6450 | 6460 | 6442 | 7657 | 7347 | 6442 |
195 | [100_20_4_40_15_5] | 3961 | 3952 | 3967 | 4088 | 3961 | 3952 | 600 | [500_5_6_50_20_10] | 6026 | 6026 | 6064 | 7269 | 6448 | 6026 |
196 | [100_20_4_40_15_6] | 3794 | 3794 | 3803 | 4230 | 4019 | 3794 | 601 | [500_5_8_30_10_1] | 5442 | 5421 | 5442 | 6469 | 5790 | 5421 |
197 | [100_20_4_40_15_7] | 4178 | 4185 | 4185 | 4234 | 3572 | 3572 | 602 | [500_5_8_30_10_2] | 5759 | 5772 | 5772 | 6356 | 6604 | 5759 |
198 | [100_20_4_40_15_8] | 4336 | 4357 | 4336 | 4428 | 4395 | 4336 | 603 | [500_5_8_30_10_3] | 5859 | 5872 | 5872 | 7455 | 7228 | 5859 |
199 | [100_20_4_40_15_9] | 3986 | 3993 | 3986 | 3986 | 3986 | 3986 | 604 | [500_5_8_30_10_4] | 5514 | 5514 | 5500 | 6913 | 5586 | 5500 |
200 | [100_20_4_40_15_10] | 4375 | 4399 | 4399 | 4589 | 4421 | 4375 | 605 | [500_5_8_30_10_5] | 5549 | 5462 | 5462 | 6450 | 6520 | 5462 |
201 | [100_20_4_50_20_1] | 5103 | 5103 | 5103 | 5102 | 5089 | 5089 | 606 | [500_5_8_30_10_6] | 5097 | 5097 | 5104 | 6436 | 5830 | 5097 |
202 | [100_20_4_50_20_2] | 4686 | 4673 | 4686 | 4797 | 4633 | 4633 | 607 | [500_5_8_30_10_7] | 5605 | 5599 | 5605 | 6222 | 6236 | 5599 |
203 | [100_20_4_50_20_3] | 5482 | 5444 | 5444 | 5435 | 5304 | 5304 | 608 | [500_5_8_30_10_8] | 5647 | 5634 | 5647 | 6081 | 6031 | 5634 |
204 | [100_20_4_50_20_4] | 4675 | 4675 | 4650 | 4649 | 4430 | 4430 | 609 | [500_5_8_30_10_9] | 5304 | 5314 | 5230 | 6403 | 4950 | 4950 |
205 | [100_20_4_50_20_5] | 5030 | 5023 | 5030 | 5088 | 4621 | 4621 | 610 | [500_5_8_30_10_10] | 5556 | 5544 | 5549 | 7364 | 5806 | 5544 |
206 | [100_20_4_50_20_6] | 5416 | 5396 | 5409 | 5396 | 5237 | 5237 | 611 | [500_5_8_40_15_1] | 5415 | 5415 | 5409 | 6250 | 5404 | 5404 |
207 | [100_20_4_50_20_7] | 5125 | 5125 | 5125 | 5125 | 5125 | 5125 | 612 | [500_5_8_40_15_2] | 5547 | 5488 | 5550 | 6505 | 5912 | 5488 |
208 | [100_20_4_50_20_8] | 4864 | 4861 | 4862 | 5005 | 4797 | 4797 | 613 | [500_5_8_40_15_3] | 5261 | 5261 | 5253 | 5844 | 5772 | 5253 |
209 | [100_20_4_50_20_9] | 4914 | 4904 | 4906 | 5146 | 4705 | 4705 | 614 | [500_5_8_40_15_4] | 5531 | 5555 | 5540 | 6444 | 5603 | 5531 |
210 | [100_20_4_50_20_10] | 5452 | 5424 | 5436 | 5588 | 4807 | 4807 | 615 | [500_5_8_40_15_5] | 4926 | 4926 | 4926 | 6259 | 5654 | 4926 |
211 | [100_20_6_30_10_1] | 3270 | 3260 | 3269 | 3445 | 3181 | 3181 | 616 | [500_5_8_40_15_6] | 5149 | 5203 | 5203 | 6185 | 6466 | 5149 |
212 | [100_20_6_30_10_2] | 3228 | 3228 | 3207 | 3261 | 3204 | 3204 | 617 | [500_5_8_40_15_7] | 4903 | 4895 | 4903 | 5353 | 5277 | 4895 |
213 | [100_20_6_30_10_3] | 3404 | 3404 | 3404 | 3460 | 3357 | 3357 | 618 | [500_5_8_40_15_8] | 5141 | 5134 | 5134 | 6410 | 5166 | 5134 |
214 | [100_20_6_30_10_4] | 3173 | 3161 | 3168 | 3196 | 3086 | 3086 | 619 | [500_5_8_40_15_9] | 5253 | 5253 | 5253 | 5906 | 5992 | 5253 |
215 | [100_20_6_30_10_5] | 3557 | 3556 | 3557 | 3563 | 3588 | 3556 | 620 | [500_5_8_40_15_10] | 5162 | 5160 | 5155 | 6107 | 4988 | 4988 |
216 | [100_20_6_30_10_6] | 3160 | 3166 | 3158 | 3202 | 3268 | 3158 | 621 | [500_5_8_50_20_1] | 5045 | 5034 | 5045 | 5625 | 5439 | 5034 |
217 | [100_20_6_30_10_7] | 3646 | 3616 | 3616 | 3616 | 3616 | 3616 | 622 | [500_5_8_50_20_2] | 5576 | 5620 | 5620 | 6002 | 5695 | 5576 |
218 | [100_20_6_30_10_8] | 3462 | 3475 | 3462 | 3453 | 3197 | 3197 | 623 | [500_5_8_50_20_3] | 5347 | 5347 | 5338 | 5954 | 5623 | 5338 |
219 | [100_20_6_30_10_9] | 3331 | 3331 | 3327 | 3385 | 3327 | 3327 | 624 | [500_5_8_50_20_4] | 4986 | 4986 | 4991 | 5761 | 5401 | 4986 |
220 | [100_20_6_30_10_10] | 3350 | 3356 | 3356 | 3475 | 3475 | 3350 | 625 | [500_5_8_50_20_5] | 5177 | 5170 | 5176 | 5661 | 5465 | 5170 |
221 | [100_20_6_40_15_1] | 4236 | 4236 | 4226 | 4265 | 4010 | 4010 | 626 | [500_5_8_50_20_6] | 5587 | 5566 | 5573 | 5832 | 5761 | 5566 |
222 | [100_20_6_40_15_2] | 3703 | 3700 | 3700 | 3698 | 3698 | 3698 | 627 | [500_5_8_50_20_7] | 5112 | 5078 | 5112 | 5358 | 5662 | 5078 |
223 | [100_20_6_40_15_3] | 4498 | 4494 | 4496 | 4494 | 4518 | 4494 | 628 | [500_5_8_50_20_8] | 5525 | 5525 | 5517 | 5511 | 5456 | 5456 |
224 | [100_20_6_40_15_4] | 4323 | 4323 | 4312 | 4292 | 4415 | 4292 | 629 | [500_5_8_50_20_9] | 5684 | 5671 | 5671 | 6052 | 5472 | 5472 |
225 | [100_20_6_40_15_5] | 4399 | 4399 | 4396 | 4540 | 4407 | 4396 | 630 | [500_5_8_50_20_10] | 5469 | 5425 | 5466 | 5598 | 5635 | 5425 |
226 | [100_20_6_40_15_6] | 4004 | 4004 | 4004 | 4039 | 3989 | 3989 | 631 | [500_10_4_30_10_1] | 8882 | 8882 | 8882 | 10,303 | 10,102 | 8882 |
227 | [100_20_6_40_15_7] | 4279 | 4266 | 4276 | 4279 | 4280 | 4266 | 632 | [500_10_4_30_10_2] | 8460 | 8440 | 8460 | 11,136 | 9575 | 8440 |
228 | [100_20_6_40_15_8] | 3921 | 3917 | 3913 | 3924 | 3924 | 3913 | 633 | [500_10_4_30_10_3] | 8797 | 8818 | 8812 | 10,950 | 8207 | 8207 |
229 | [100_20_6_40_15_9] | 4470 | 4470 | 4448 | 4447 | 4310 | 4310 | 634 | [500_10_4_30_10_4] | 8767 | 8722 | 8745 | 10,420 | 7239 | 7239 |
230 | [100_20_6_40_15_10] | 4078 | 4078 | 4078 | 4078 | 4028 | 4028 | 635 | [500_10_4_30_10_5] | 9279 | 9276 | 9279 | 11,733 | 9813 | 9276 |
231 | [100_20_6_50_20_1] | 4835 | 4835 | 4833 | 4827 | 4695 | 4695 | 636 | [500_10_4_30_10_6] | 9023 | 8997 | 9020 | 11,009 | 8928 | 8928 |
232 | [100_20_6_50_20_2] | 5300 | 5315 | 5300 | 5298 | 4709 | 4709 | 637 | [500_10_4_30_10_7] | 8968 | 8915 | 8915 | 11,759 | 11,074 | 8915 |
233 | [100_20_6_50_20_3] | 5370 | 5325 | 5332 | 5325 | 5385 | 5325 | 638 | [500_10_4_30_10_8] | 9163 | 9187 | 9142 | 10,915 | 8945 | 8945 |
234 | [100_20_6_50_20_4] | 4740 | 4740 | 4743 | 4776 | 4540 | 4540 | 639 | [500_10_4_30_10_9] | 9344 | 9295 | 9326 | 11,231 | 8877 | 8877 |
235 | [100_20_6_50_20_5] | 5647 | 5696 | 5647 | 5647 | 5444 | 5444 | 640 | [500_10_4_30_10_10] | 8734 | 8733 | 8713 | 10,429 | 8757 | 8713 |
236 | [100_20_6_50_20_6] | 4839 | 4839 | 4870 | 4912 | 4642 | 4642 | 641 | [500_10_4_40_15_1] | 8872 | 8858 | 8872 | 10,455 | 8860 | 8858 |
237 | [100_20_6_50_20_7] | 4977 | 4959 | 4959 | 4959 | 4879 | 4879 | 642 | [500_10_4_40_15_2] | 8709 | 8723 | 8723 | 10,054 | 8575 | 8575 |
238 | [100_20_6_50_20_8] | 5015 | 5014 | 5015 | 5065 | 4764 | 4764 | 643 | [500_10_4_40_15_3] | 9260 | 9260 | 9260 | 11,603 | 8573 | 8573 |
239 | [100_20_6_50_20_9] | 5426 | 5426 | 5377 | 5382 | 4954 | 4954 | 644 | [500_10_4_40_15_4] | 8616 | 8616 | 8653 | 9635 | 8492 | 8492 |
240 | [100_20_6_50_20_10] | 5294 | 5294 | 5294 | 5319 | 5159 | 5159 | 645 | [500_10_4_40_15_5] | 8664 | 8678 | 8664 | 9010 | 9071 | 8664 |
241 | [100_20_8_30_10_1] | 3348 | 3354 | 3351 | 3400 | 3381 | 3348 | 646 | [500_10_4_40_15_6] | 8384 | 8384 | 8386 | 9224 | 8234 | 8234 |
242 | [100_20_8_30_10_2] | 3165 | 3165 | 3167 | 3413 | 3279 | 3165 | 647 | [500_10_4_40_15_7] | 8709 | 8709 | 8615 | 9831 | 8634 | 8615 |
243 | [100_20_8_30_10_3] | 3025 | 3025 | 3025 | 3010 | 2654 | 2654 | 648 | [500_10_4_40_15_8] | 8674 | 8674 | 8669 | 10,322 | 7815 | 7815 |
244 | [100_20_8_30_10_4] | 3393 | 3398 | 3392 | 3392 | 3435 | 3392 | 649 | [500_10_4_40_15_9] | 8506 | 8529 | 8506 | 10,657 | 8275 | 8275 |
245 | [100_20_8_30_10_5] | 3519 | 3509 | 3509 | 3509 | 3509 | 3509 | 650 | [500_10_4_40_15_10] | 8708 | 8617 | 8668 | 10,211 | 9089 | 8617 |
246 | [100_20_8_30_10_6] | 3498 | 3500 | 3498 | 3489 | 3579 | 3489 | 651 | [500_10_4_50_20_1] | 8905 | 8909 | 8905 | 10,082 | 9527 | 8905 |
247 | [100_20_8_30_10_7] | 3174 | 3174 | 3166 | 3298 | 3038 | 3038 | 652 | [500_10_4_50_20_2] | 8511 | 8498 | 8498 | 9730 | 6957 | 6957 |
248 | [100_20_8_30_10_8] | 2901 | 2892 | 2892 | 2953 | 3032 | 2892 | 653 | [500_10_4_50_20_3] | 8349 | 8349 | 8349 | 9227 | 7557 | 7557 |
249 | [100_20_8_30_10_9] | 3342 | 3338 | 3342 | 3335 | 3111 | 3111 | 654 | [500_10_4_50_20_4] | 8517 | 8517 | 8487 | 9870 | 7422 | 7422 |
250 | [100_20_8_30_10_10] | 2954 | 2937 | 2954 | 3044 | 3080 | 2937 | 655 | [500_10_4_50_20_5] | 8527 | 8527 | 8527 | 9639 | 8471 | 8471 |
251 | [100_20_8_40_15_1] | 4440 | 4440 | 4462 | 4440 | 4440 | 4440 | 656 | [500_10_4_50_20_6] | 9431 | 9490 | 9478 | 10,598 | 9318 | 9318 |
252 | [100_20_8_40_15_2] | 4067 | 4031 | 4067 | 4100 | 3825 | 3825 | 657 | [500_10_4_50_20_7] | 8686 | 8671 | 8648 | 9868 | 7884 | 7884 |
253 | [100_20_8_40_15_3] | 4828 | 4819 | 4819 | 4819 | 4608 | 4608 | 658 | [500_10_4_50_20_8] | 8829 | 8797 | 8829 | 10,021 | 9217 | 8797 |
254 | [100_20_8_40_15_4] | 4182 | 4159 | 4182 | 4159 | 4328 | 4159 | 659 | [500_10_4_50_20_9] | 8462 | 8462 | 8474 | 10,698 | 8598 | 8462 |
255 | [100_20_8_40_15_5] | 4200 | 4200 | 4207 | 4200 | 3846 | 3846 | 660 | [500_10_4_50_20_10] | 8491 | 8469 | 8485 | 10,043 | 7424 | 7424 |
256 | [100_20_8_40_15_6] | 4289 | 4285 | 4285 | 4289 | 4189 | 4189 | 661 | [500_10_6_30_10_1] | 7087 | 7079 | 7087 | 8448 | 6824 | 6824 |
257 | [100_20_8_40_15_7] | 4213 | 4213 | 4209 | 4282 | 4138 | 4138 | 662 | [500_10_6_30_10_2] | 6794 | 6794 | 6775 | 7821 | 8600 | 6775 |
258 | [100_20_8_40_15_8] | 4855 | 4845 | 4855 | 4855 | 4458 | 4458 | 663 | [500_10_6_30_10_3] | 7250 | 7248 | 7248 | 8046 | 7024 | 7024 |
259 | [100_20_8_40_15_9] | 3603 | 3590 | 3603 | 3646 | 3626 | 3590 | 664 | [500_10_6_30_10_4] | 7139 | 7108 | 7139 | 8884 | 7627 | 7108 |
260 | [100_20_8_40_15_10] | 4728 | 4699 | 4710 | 4699 | 4126 | 4126 | 665 | [500_10_6_30_10_5] | 7240 | 7240 | 7240 | 9262 | 8460 | 7240 |
261 | [100_20_8_50_20_1] | 4857 | 4853 | 4853 | 4848 | 4573 | 4573 | 666 | [500_10_6_30_10_6] | 6665 | 6691 | 6665 | 8739 | 7662 | 6665 |
262 | [100_20_8_50_20_2] | 4451 | 4451 | 4410 | 4410 | 4343 | 4343 | 667 | [500_10_6_30_10_7] | 6541 | 6589 | 6556 | 7974 | 7196 | 6541 |
263 | [100_20_8_50_20_3] | 4930 | 4961 | 4930 | 4906 | 4616 | 4616 | 668 | [500_10_6_30_10_8] | 6711 | 6711 | 6695 | 7256 | 6595 | 6595 |
264 | [100_20_8_50_20_4] | 5382 | 5374 | 5426 | 5382 | 5237 | 5237 | 669 | [500_10_6_30_10_9] | 7219 | 7219 | 7219 | 8702 | 9631 | 7219 |
265 | [100_20_8_50_20_5] | 4928 | 4919 | 4928 | 4919 | 4860 | 4860 | 670 | [500_10_6_30_10_10] | 7211 | 7211 | 7192 | 9368 | 8489 | 7192 |
266 | [100_20_8_50_20_6] | 5374 | 5374 | 5372 | 5372 | 5141 | 5141 | 671 | [500_10_6_40_15_1] | 6769 | 6823 | 6769 | 7972 | 7793 | 6769 |
267 | [100_20_8_50_20_7] | 5109 | 5156 | 5109 | 5105 | 4759 | 4759 | 672 | [500_10_6_40_15_2] | 6362 | 6426 | 6426 | 7589 | 6256 | 6256 |
268 | [100_20_8_50_20_8] | 4986 | 4957 | 4971 | 4989 | 4800 | 4800 | 673 | [500_10_6_40_15_3] | 6790 | 6782 | 6782 | 7858 | 7149 | 6782 |
269 | [100_20_8_50_20_9] | 4542 | 4547 | 4545 | 4635 | 4019 | 4019 | 674 | [500_10_6_40_15_4] | 6814 | 6720 | 6802 | 8283 | 6844 | 6720 |
270 | [100_20_8_50_20_10] | 5072 | 5023 | 5072 | 5023 | 4782 | 4782 | 675 | [500_10_6_40_15_5] | 6718 | 6713 | 6713 | 7755 | 6334 | 6334 |
271 | [200_5_4_30_10_1] | 3707 | 3705 | 3705 | 4036 | 4190 | 3705 | 676 | [500_10_6_40_15_6] | 6574 | 6487 | 6487 | 7316 | 6166 | 6166 |
272 | [200_5_4_30_10_2] | 3743 | 3756 | 3737 | 4727 | 3416 | 3416 | 677 | [500_10_6_40_15_7] | 6680 | 6625 | 6656 | 8174 | 7403 | 6625 |
273 | [200_5_4_30_10_3] | 3607 | 3606 | 3606 | 4173 | 4055 | 3606 | 678 | [500_10_6_40_15_8] | 6760 | 6760 | 6779 | 8184 | 7009 | 6760 |
274 | [200_5_4_30_10_4] | 3609 | 3586 | 3586 | 4089 | 3387 | 3387 | 679 | [500_10_6_40_15_9] | 6621 | 6673 | 6654 | 7449 | 6870 | 6621 |
275 | [200_5_4_30_10_5] | 3761 | 3776 | 3776 | 4162 | 3681 | 3681 | 680 | [500_10_6_40_15_10] | 6456 | 6482 | 6480 | 7857 | 5949 | 5949 |
276 | [200_5_4_30_10_6] | 3604 | 3602 | 3604 | 4562 | 3475 | 3475 | 681 | [500_10_6_50_20_1] | 6417 | 6437 | 6410 | 7709 | 6647 | 6410 |
277 | [200_5_4_30_10_7] | 3595 | 3595 | 3614 | 4032 | 3267 | 3267 | 682 | [500_10_6_50_20_2] | 7102 | 7102 | 7102 | 8286 | 7082 | 7082 |
278 | [200_5_4_30_10_8] | 3492 | 3490 | 3469 | 4290 | 3966 | 3469 | 683 | [500_10_6_50_20_3] | 6472 | 6472 | 6472 | 6990 | 6720 | 6472 |
279 | [200_5_4_30_10_9] | 3842 | 3839 | 3824 | 5076 | 3503 | 3503 | 684 | [500_10_6_50_20_4] | 6377 | 6363 | 6363 | 7263 | 6293 | 6293 |
280 | [200_5_4_30_10_10] | 3896 | 3876 | 3891 | 4897 | 4256 | 3876 | 685 | [500_10_6_50_20_5] | 6653 | 6659 | 6653 | 8136 | 7900 | 6653 |
281 | [200_5_4_40_15_1] | 4121 | 4121 | 4121 | 4602 | 4142 | 4121 | 686 | [500_10_6_50_20_6] | 6940 | 6940 | 6861 | 7584 | 6966 | 6861 |
282 | [200_5_4_40_15_2] | 3877 | 3886 | 3886 | 4159 | 3870 | 3870 | 687 | [500_10_6_50_20_7] | 6712 | 6658 | 6702 | 7418 | 6248 | 6248 |
283 | [200_5_4_40_15_3] | 3762 | 3760 | 3760 | 4142 | 3904 | 3760 | 688 | [500_10_6_50_20_8] | 6731 | 6702 | 6702 | 8834 | 6576 | 6576 |
284 | [200_5_4_40_15_4] | 3616 | 3616 | 3608 | 4008 | 3848 | 3608 | 689 | [500_10_6_50_20_9] | 6451 | 6462 | 6451 | 7186 | 6247 | 6247 |
285 | [200_5_4_40_15_5] | 4117 | 4117 | 4090 | 4296 | 4419 | 4090 | 690 | [500_10_6_50_20_10] | 6748 | 6680 | 6748 | 8217 | 6333 | 6333 |
286 | [200_5_4_40_15_6] | 3611 | 3640 | 3632 | 3939 | 3511 | 3511 | 691 | [500_10_8_30_10_1] | 5590 | 5615 | 5615 | 6902 | 5747 | 5590 |
287 | [200_5_4_40_15_7] | 3666 | 3682 | 3666 | 4258 | 3432 | 3432 | 692 | [500_10_8_30_10_2] | 5978 | 5978 | 5986 | 7418 | 5829 | 5829 |
288 | [200_5_4_40_15_8] | 3872 | 3878 | 3876 | 4601 | 3768 | 3768 | 693 | [500_10_8_30_10_3] | 5994 | 5981 | 5988 | 7800 | 7203 | 5981 |
289 | [200_5_4_40_15_9] | 3637 | 3637 | 3670 | 3938 | 3587 | 3587 | 694 | [500_10_8_30_10_4] | 6204 | 6204 | 6228 | 7225 | 7036 | 6204 |
290 | [200_5_4_40_15_10] | 4164 | 4164 | 4170 | 4376 | 4170 | 4164 | 695 | [500_10_8_30_10_5] | 6082 | 6082 | 6067 | 6846 | 5720 | 5720 |
291 | [200_5_4_50_20_1] | 4333 | 4321 | 4321 | 4321 | 4383 | 4321 | 696 | [500_10_8_30_10_6] | 6264 | 6257 | 6262 | 6723 | 6398 | 6257 |
292 | [200_5_4_50_20_2] | 4593 | 4592 | 4593 | 4627 | 4477 | 4477 | 697 | [500_10_8_30_10_7] | 5822 | 5817 | 5822 | 6391 | 5639 | 5639 |
293 | [200_5_4_50_20_3] | 4670 | 4655 | 4655 | 4750 | 4886 | 4655 | 698 | [500_10_8_30_10_8] | 6064 | 6049 | 6056 | 7266 | 6481 | 6049 |
294 | [200_5_4_50_20_4] | 5094 | 5090 | 5091 | 5097 | 5090 | 5090 | 699 | [500_10_8_30_10_9] | 5517 | 5517 | 5487 | 6532 | 6158 | 5487 |
295 | [200_5_4_50_20_5] | 4584 | 4584 | 4584 | 4733 | 4728 | 4584 | 700 | [500_10_8_30_10_10] | 5381 | 5374 | 5400 | 6916 | 6382 | 5374 |
296 | [200_5_4_50_20_6] | 4150 | 4146 | 4148 | 4180 | 4146 | 4146 | 701 | [500_10_8_40_15_1] | 5928 | 5908 | 5908 | 6320 | 5773 | 5773 |
297 | [200_5_4_50_20_7] | 4846 | 4836 | 4836 | 4839 | 4871 | 4836 | 702 | [500_10_8_40_15_2] | 5492 | 5478 | 5484 | 5834 | 5681 | 5478 |
298 | [200_5_4_50_20_8] | 4415 | 4407 | 4415 | 4445 | 4424 | 4407 | 703 | [500_10_8_40_15_3] | 5818 | 5818 | 5805 | 6145 | 5284 | 5284 |
299 | [200_5_4_50_20_9] | 4565 | 4552 | 4565 | 4844 | 4493 | 4493 | 704 | [500_10_8_40_15_4] | 5822 | 5799 | 5799 | 6045 | 5246 | 5246 |
300 | [200_5_4_50_20_10] | 4862 | 4854 | 4860 | 4854 | 4854 | 4854 | 705 | [500_10_8_40_15_5] | 6120 | 6099 | 6120 | 7701 | 6350 | 6099 |
301 | [200_5_6_30_10_1] | 2944 | 2934 | 2934 | 3222 | 2770 | 2770 | 706 | [500_10_8_40_15_6] | 6094 | 6090 | 6094 | 7021 | 6159 | 6090 |
302 | [200_5_6_30_10_2] | 3238 | 3243 | 3243 | 3746 | 3337 | 3238 | 707 | [500_10_8_40_15_7] | 6036 | 6036 | 6035 | 6492 | 5610 | 5610 |
303 | [200_5_6_30_10_3] | 3315 | 3304 | 3315 | 3599 | 3047 | 3047 | 708 | [500_10_8_40_15_8] | 5935 | 5928 | 5935 | 7551 | 6132 | 5928 |
304 | [200_5_6_30_10_4] | 3117 | 3117 | 3108 | 3638 | 3317 | 3108 | 709 | [500_10_8_40_15_9] | 5712 | 5719 | 5740 | 6812 | 6663 | 5712 |
305 | [200_5_6_30_10_5] | 3323 | 3323 | 3321 | 3866 | 3746 | 3321 | 710 | [500_10_8_40_15_10] | 5850 | 5850 | 5850 | 6284 | 5278 | 5278 |
306 | [200_5_6_30_10_6] | 3357 | 3357 | 3359 | 3618 | 3380 | 3357 | 711 | [500_10_8_50_20_1] | 5482 | 5482 | 5499 | 6518 | 5880 | 5482 |
307 | [200_5_6_30_10_7] | 3110 | 3110 | 3110 | 3371 | 3233 | 3110 | 712 | [500_10_8_50_20_2] | 5966 | 5966 | 5944 | 6235 | 6015 | 5944 |
308 | [200_5_6_30_10_8] | 2991 | 2981 | 2981 | 3453 | 3413 | 2981 | 713 | [500_10_8_50_20_3] | 6082 | 6082 | 6082 | 6568 | 5479 | 5479 |
309 | [200_5_6_30_10_9] | 3832 | 3827 | 3832 | 4142 | 3921 | 3827 | 714 | [500_10_8_50_20_4] | 5557 | 5552 | 5556 | 6098 | 5000 | 5000 |
310 | [200_5_6_30_10_10] | 3344 | 3344 | 3344 | 3493 | 3508 | 3344 | 715 | [500_10_8_50_20_5] | 5787 | 5767 | 5787 | 6124 | 5722 | 5722 |
311 | [200_5_6_40_15_1] | 3605 | 3602 | 3605 | 3602 | 3602 | 3602 | 716 | [500_10_8_50_20_6] | 6233 | 6233 | 6233 | 6855 | 6138 | 6138 |
312 | [200_5_6_40_15_2] | 3040 | 3040 | 3040 | 3509 | 3231 | 3040 | 717 | [500_10_8_50_20_7] | 6474 | 6462 | 6474 | 6732 | 5958 | 5958 |
313 | [200_5_6_40_15_3] | 3873 | 3865 | 3873 | 3865 | 3722 | 3722 | 718 | [500_10_8_50_20_8] | 6294 | 6246 | 6246 | 6416 | 5714 | 5714 |
314 | [200_5_6_40_15_4] | 2860 | 2860 | 2865 | 2960 | 2514 | 2514 | 719 | [500_10_8_50_20_9] | 5692 | 5692 | 5692 | 6028 | 6052 | 5692 |
315 | [200_5_6_40_15_5] | 3796 | 3796 | 3794 | 4005 | 3831 | 3794 | 720 | [500_10_8_50_20_10] | 5564 | 5564 | 5574 | 6035 | 4992 | 4992 |
316 | [200_5_6_40_15_6] | 4318 | 4307 | 4309 | 4307 | 4306 | 4306 | 721 | [500_20_4_30_10_1] | 9995 | 9956 | 9995 | 12,400 | 9995 | 9956 |
317 | [200_5_6_40_15_7] | 3669 | 3694 | 3682 | 3700 | 3563 | 3563 | 722 | [500_20_4_30_10_2] | 10,050 | 10,050 | 10,050 | 10,977 | 10,299 | 10,050 |
318 | [200_5_6_40_15_8] | 3733 | 3726 | 3733 | 3735 | 3775 | 3726 | 723 | [500_20_4_30_10_3] | 9934 | 9934 | 9934 | 11,586 | 9434 | 9434 |
319 | [200_5_6_40_15_9] | 3249 | 3248 | 3248 | 3242 | 3242 | 3242 | 724 | [500_20_4_30_10_4] | 10,189 | 10,174 | 10,174 | 11,376 | 10,071 | 10,071 |
320 | [200_5_6_40_15_10] | 3387 | 3387 | 3402 | 3713 | 3259 | 3259 | 725 | [500_20_4_30_10_5] | 9866 | 9858 | 9880 | 11,513 | 9522 | 9522 |
321 | [200_5_6_50_20_1] | 4362 | 4362 | 4360 | 4360 | 4282 | 4282 | 726 | [500_20_4_30_10_6] | 9498 | 9494 | 9468 | 11,866 | 7601 | 7601 |
322 | [200_5_6_50_20_2] | 5184 | 5171 | 5178 | 5209 | 5215 | 5171 | 727 | [500_20_4_30_10_7] | 10,023 | 10,051 | 10,062 | 11,502 | 7922 | 7922 |
323 | [200_5_6_50_20_3] | 5182 | 5182 | 5182 | 5173 | 5184 | 5173 | 728 | [500_20_4_30_10_8] | 10,030 | 10,030 | 10,030 | 11,117 | 9997 | 9997 |
324 | [200_5_6_50_20_4] | 4442 | 4439 | 4436 | 4471 | 4604 | 4436 | 729 | [500_20_4_30_10_9] | 10,117 | 9972 | 10,107 | 11,145 | 8448 | 8448 |
325 | [200_5_6_50_20_5] | 4105 | 4096 | 4105 | 4096 | 4096 | 4096 | 730 | [500_20_4_30_10_10] | 9841 | 9833 | 9841 | 12,059 | 8932 | 8932 |
326 | [200_5_6_50_20_6] | 4710 | 4713 | 4710 | 4707 | 4710 | 4707 | 731 | [500_20_4_40_15_1] | 9774 | 9774 | 9796 | 11,182 | 8869 | 8869 |
327 | [200_5_6_50_20_7] | 4115 | 4110 | 4113 | 4110 | 3925 | 3925 | 732 | [500_20_4_40_15_2] | 9825 | 9825 | 9834 | 11,643 | 8130 | 8130 |
328 | [200_5_6_50_20_8] | 4243 | 4265 | 4243 | 4243 | 4336 | 4243 | 733 | [500_20_4_40_15_3] | 9875 | 9875 | 9875 | 11,064 | 8569 | 8569 |
329 | [200_5_6_50_20_9] | 4068 | 4062 | 4068 | 4118 | 4085 | 4062 | 734 | [500_20_4_40_15_4] | 10,048 | 10,048 | 9987 | 11,413 | 8447 | 8447 |
330 | [200_5_6_50_20_10] | 4388 | 4388 | 4390 | 4386 | 4404 | 4386 | 735 | [500_20_4_40_15_5] | 10,137 | 10,055 | 10,046 | 12,908 | 9789 | 9789 |
331 | [200_5_8_30_10_1] | 2855 | 2839 | 2848 | 2915 | 3351 | 2839 | 736 | [500_20_4_40_15_6] | 10,197 | 10,197 | 10,177 | 11,862 | 10,182 | 10,177 |
332 | [200_5_8_30_10_2] | 2944 | 2944 | 2929 | 3051 | 2862 | 2862 | 737 | [500_20_4_40_15_7] | 9899 | 9852 | 9875 | 11,638 | 9145 | 9145 |
333 | [200_5_8_30_10_3] | 2861 | 2859 | 2859 | 3131 | 2967 | 2859 | 738 | [500_20_4_40_15_8] | 9610 | 9555 | 9610 | 11,039 | 9073 | 9073 |
334 | [200_5_8_30_10_4] | 3481 | 3481 | 3481 | 3494 | 3532 | 3481 | 739 | [500_20_4_40_15_9] | 9924 | 9931 | 9924 | 11,471 | 10,038 | 9924 |
335 | [200_5_8_30_10_5] | 3012 | 3012 | 3014 | 3155 | 2979 | 2979 | 740 | [500_20_4_40_15_10] | 10,235 | 10,235 | 10,232 | 11,811 | 9628 | 9628 |
336 | [200_5_8_30_10_6] | 2790 | 2801 | 2790 | 3101 | 3069 | 2790 | 741 | [500_20_4_50_20_1] | 9684 | 9687 | 9687 | 10,585 | 9987 | 9684 |
337 | [200_5_8_30_10_7] | 2827 | 2827 | 2817 | 3330 | 2655 | 2655 | 742 | [500_20_4_50_20_2] | 9671 | 9592 | 9627 | 10,525 | 8649 | 8649 |
338 | [200_5_8_30_10_8] | 3032 | 3050 | 3048 | 3000 | 3000 | 3000 | 743 | [500_20_4_50_20_3] | 9706 | 9723 | 9694 | 11,599 | 9528 | 9528 |
339 | [200_5_8_30_10_9] | 3151 | 3137 | 3147 | 3142 | 3145 | 3137 | 744 | [500_20_4_50_20_4] | 9808 | 9767 | 9774 | 10,626 | 9466 | 9466 |
340 | [200_5_8_30_10_10] | 2955 | 2955 | 2934 | 3229 | 3043 | 2934 | 745 | [500_20_4_50_20_5] | 9760 | 9751 | 9751 | 11,260 | 7957 | 7957 |
341 | [200_5_8_40_15_1] | 3427 | 3409 | 3409 | 3514 | 3499 | 3409 | 746 | [500_20_4_50_20_6] | 9650 | 9650 | 9645 | 11,070 | 8905 | 8905 |
342 | [200_5_8_40_15_2] | 3506 | 3505 | 3505 | 3493 | 3429 | 3429 | 747 | [500_20_4_50_20_7] | 9817 | 9817 | 9840 | 11,575 | 8438 | 8438 |
343 | [200_5_8_40_15_3] | 3729 | 3729 | 3730 | 3729 | 3574 | 3574 | 748 | [500_20_4_50_20_8] | 9967 | 9950 | 9848 | 10,964 | 8853 | 8853 |
344 | [200_5_8_40_15_4] | 3424 | 3424 | 3424 | 3424 | 3445 | 3424 | 749 | [500_20_4_50_20_9] | 10,108 | 10,094 | 10,108 | 11,173 | 8066 | 8066 |
345 | [200_5_8_40_15_5] | 3821 | 3821 | 3821 | 3817 | 3611 | 3611 | 750 | [500_20_4_50_20_10] | 9872 | 9872 | 9865 | 10,430 | 8910 | 8910 |
346 | [200_5_8_40_15_6] | 3049 | 3048 | 3048 | 3049 | 3054 | 3048 | 751 | [500_20_6_30_10_1] | 7780 | 7755 | 7777 | 9293 | 6982 | 6982 |
347 | [200_5_8_40_15_7] | 3128 | 3128 | 3128 | 3143 | 3253 | 3128 | 752 | [500_20_6_30_10_2] | 7371 | 7371 | 7377 | 9474 | 7462 | 7371 |
348 | [200_5_8_40_15_8] | 3948 | 3937 | 3943 | 3937 | 3937 | 3937 | 753 | [500_20_6_30_10_3] | 7781 | 7790 | 7781 | 8773 | 8376 | 7781 |
349 | [200_5_8_40_15_9] | 3857 | 3865 | 3858 | 3820 | 3960 | 3820 | 754 | [500_20_6_30_10_4] | 8014 | 7950 | 7950 | 8833 | 8528 | 7950 |
350 | [200_5_8_40_15_10] | 3291 | 3291 | 3291 | 3305 | 3249 | 3249 | 755 | [500_20_6_30_10_5] | 7723 | 7723 | 7670 | 8971 | 8828 | 7670 |
351 | [200_5_8_50_20_1] | 4221 | 4232 | 4221 | 4245 | 4212 | 4212 | 756 | [500_20_6_30_10_6] | 7802 | 7802 | 7802 | 8565 | 7726 | 7726 |
352 | [200_5_8_50_20_2] | 4141 | 4140 | 4141 | 4131 | 4141 | 4131 | 757 | [500_20_6_30_10_7] | 7334 | 7313 | 7334 | 7904 | 7681 | 7313 |
353 | [200_5_8_50_20_3] | 4458 | 4482 | 4458 | 4458 | 4458 | 4458 | 758 | [500_20_6_30_10_8] | 7842 | 7842 | 7823 | 8655 | 7294 | 7294 |
354 | [200_5_8_50_20_4] | 4870 | 4851 | 4851 | 4851 | 4833 | 4833 | 759 | [500_20_6_30_10_9] | 8019 | 8019 | 8013 | 9514 | 9160 | 8013 |
355 | [200_5_8_50_20_5] | 4193 | 4230 | 4230 | 4264 | 4236 | 4193 | 760 | [500_20_6_30_10_10] | 8252 | 8223 | 8223 | 9444 | 9977 | 8223 |
356 | [200_5_8_50_20_6] | 4572 | 4570 | 4572 | 4590 | 4649 | 4570 | 761 | [500_20_6_40_15_1] | 7649 | 7645 | 7645 | 9187 | 7568 | 7568 |
357 | [200_5_8_50_20_7] | 4113 | 4108 | 4108 | 4086 | 4086 | 4086 | 762 | [500_20_6_40_15_2] | 7590 | 7590 | 7595 | 9477 | 6439 | 6439 |
358 | [200_5_8_50_20_8] | 4089 | 4090 | 4088 | 4088 | 3861 | 3861 | 763 | [500_20_6_40_15_3] | 7240 | 7193 | 7231 | 8072 | 6676 | 6676 |
359 | [200_5_8_50_20_9] | 4091 | 4062 | 4083 | 4066 | 3957 | 3957 | 764 | [500_20_6_40_15_4] | 7795 | 7746 | 7765 | 9016 | 8334 | 7746 |
360 | [200_5_8_50_20_10] | 4230 | 4236 | 4230 | 4247 | 4247 | 4230 | 765 | [500_20_6_40_15_5] | 7695 | 7690 | 7692 | 9380 | 7456 | 7456 |
361 | [200_10_4_30_10_1] | 3948 | 3938 | 3948 | 4617 | 3519 | 3519 | 766 | [500_20_6_40_15_6] | 7566 | 7555 | 7558 | 8029 | 6935 | 6935 |
362 | [200_10_4_30_10_2] | 4145 | 4128 | 4128 | 4670 | 3720 | 3720 | 767 | [500_20_6_40_15_7] | 7632 | 7632 | 7702 | 8366 | 6883 | 6883 |
363 | [200_10_4_30_10_3] | 4310 | 4310 | 4335 | 4930 | 3964 | 3964 | 768 | [500_20_6_40_15_8] | 7453 | 7453 | 7452 | 8271 | 6409 | 6409 |
364 | [200_10_4_30_10_4] | 4147 | 4150 | 4139 | 4776 | 4133 | 4133 | 769 | [500_20_6_40_15_9] | 7565 | 7512 | 7549 | 8540 | 7134 | 7134 |
365 | [200_10_4_30_10_5] | 4057 | 4057 | 4057 | 4698 | 3946 | 3946 | 770 | [500_20_6_40_15_10] | 7607 | 7680 | 7667 | 8249 | 6471 | 6471 |
366 | [200_10_4_30_10_6] | 4300 | 4298 | 4298 | 4536 | 3940 | 3940 | 771 | [500_20_6_50_20_1] | 7565 | 7599 | 7565 | 8563 | 6331 | 6331 |
367 | [200_10_4_30_10_7] | 4262 | 4255 | 4262 | 4686 | 3779 | 3779 | 772 | [500_20_6_50_20_2] | 7732 | 7732 | 7732 | 8459 | 7467 | 7467 |
368 | [200_10_4_30_10_8] | 4284 | 4284 | 4283 | 4996 | 3426 | 3426 | 773 | [500_20_6_50_20_3] | 7657 | 7649 | 7649 | 8499 | 6750 | 6750 |
369 | [200_10_4_30_10_9] | 4149 | 4141 | 4145 | 4918 | 3907 | 3907 | 774 | [500_20_6_50_20_4] | 7680 | 7652 | 7663 | 8405 | 7730 | 7652 |
370 | [200_10_4_30_10_10] | 4272 | 4272 | 4261 | 4594 | 4021 | 4021 | 775 | [500_20_6_50_20_5] | 7620 | 7616 | 7620 | 8523 | 7063 | 7063 |
371 | [200_10_4_40_15_1] | 4385 | 4377 | 4377 | 4950 | 4468 | 4377 | 776 | [500_20_6_50_20_6] | 7727 | 7725 | 7725 | 8448 | 8304 | 7725 |
372 | [200_10_4_40_15_2] | 4313 | 4299 | 4308 | 5016 | 4143 | 4143 | 777 | [500_20_6_50_20_7] | 7787 | 7787 | 7810 | 8197 | 7464 | 7464 |
373 | [200_10_4_40_15_3] | 4181 | 4175 | 4181 | 5058 | 4585 | 4175 | 778 | [500_20_6_50_20_8] | 7945 | 7949 | 7957 | 8926 | 7450 | 7450 |
374 | [200_10_4_40_15_4] | 4718 | 4709 | 4717 | 5311 | 4803 | 4709 | 779 | [500_20_6_50_20_9] | 7647 | 7624 | 7647 | 8135 | 7656 | 7624 |
375 | [200_10_4_40_15_5] | 4177 | 4213 | 4187 | 4779 | 3831 | 3831 | 780 | [500_20_6_50_20_10] | 7424 | 7444 | 7417 | 8045 | 6594 | 6594 |
376 | [200_10_4_40_15_6] | 4087 | 4062 | 4083 | 4953 | 4008 | 4008 | 781 | [500_20_8_30_10_1] | 6690 | 6704 | 6704 | 7745 | 6607 | 6607 |
377 | [200_10_4_40_15_7] | 4195 | 4195 | 4195 | 5120 | 4524 | 4195 | 782 | [500_20_8_30_10_2] | 6601 | 6601 | 6601 | 7558 | 5736 | 5736 |
378 | [200_10_4_40_15_8] | 4345 | 4324 | 4324 | 5092 | 4631 | 4324 | 783 | [500_20_8_30_10_3] | 7089 | 7089 | 7089 | 8245 | 6654 | 6654 |
379 | [200_10_4_40_15_9] | 4517 | 4504 | 4517 | 4866 | 4269 | 4269 | 784 | [500_20_8_30_10_4] | 6951 | 6941 | 6951 | 8247 | 7778 | 6941 |
380 | [200_10_4_40_15_10] | 4443 | 4443 | 4443 | 4799 | 4533 | 4443 | 785 | [500_20_8_30_10_5] | 7001 | 6955 | 6955 | 8244 | 6836 | 6836 |
381 | [200_10_4_50_20_1] | 4693 | 4678 | 4693 | 4882 | 4698 | 4678 | 786 | [500_20_8_30_10_6] | 6943 | 6932 | 6939 | 7735 | 7376 | 6932 |
382 | [200_10_4_50_20_2] | 4536 | 4536 | 4536 | 5010 | 4746 | 4536 | 787 | [500_20_8_30_10_7] | 6679 | 6679 | 6679 | 7482 | 6805 | 6679 |
383 | [200_10_4_50_20_3] | 5278 | 5278 | 5278 | 5570 | 5333 | 5278 | 788 | [500_20_8_30_10_8] | 6913 | 6897 | 6897 | 7763 | 6320 | 6320 |
384 | [200_10_4_50_20_4] | 4773 | 4758 | 4766 | 5110 | 5014 | 4758 | 789 | [500_20_8_30_10_9] | 6565 | 6561 | 6561 | 7251 | 6749 | 6561 |
385 | [200_10_4_50_20_5] | 4539 | 4527 | 4530 | 4747 | 4628 | 4527 | 790 | [500_20_8_30_10_10] | 7135 | 7127 | 7127 | 7608 | 6626 | 6626 |
386 | [200_10_4_50_20_6] | 4506 | 4534 | 4506 | 4915 | 4357 | 4357 | 791 | [500_20_8_40_15_1] | 6968 | 6853 | 6938 | 7801 | 6429 | 6429 |
387 | [200_10_4_50_20_7] | 5378 | 5358 | 5358 | 5478 | 5404 | 5358 | 792 | [500_20_8_40_15_2] | 6581 | 6581 | 6572 | 7595 | 5556 | 5556 |
388 | [200_10_4_50_20_8] | 4604 | 4570 | 4570 | 4889 | 4539 | 4539 | 793 | [500_20_8_40_15_3] | 6686 | 6617 | 6684 | 7496 | 6483 | 6483 |
389 | [200_10_4_50_20_9] | 5430 | 5404 | 5404 | 5445 | 5471 | 5404 | 794 | [500_20_8_40_15_4] | 7098 | 7098 | 7065 | 7316 | 7045 | 7045 |
390 | [200_10_4_50_20_10] | 5059 | 5057 | 5057 | 5050 | 4863 | 4863 | 795 | [500_20_8_40_15_5] | 6586 | 6540 | 6540 | 7446 | 5444 | 5444 |
391 | [200_10_6_30_10_1] | 3388 | 3402 | 3388 | 4540 | 3706 | 3388 | 796 | [500_20_8_40_15_6] | 6597 | 6588 | 6597 | 7513 | 6749 | 6588 |
392 | [200_10_6_30_10_2] | 3685 | 3663 | 3672 | 4212 | 3593 | 3593 | 797 | [500_20_8_40_15_7] | 7019 | 7019 | 7060 | 7655 | 6333 | 6333 |
393 | [200_10_6_30_10_3] | 3633 | 3633 | 3633 | 4026 | 3818 | 3633 | 798 | [500_20_8_40_15_8] | 6430 | 6412 | 6423 | 7619 | 7424 | 6412 |
394 | [200_10_6_30_10_4] | 3572 | 3563 | 3563 | 3960 | 3695 | 3563 | 799 | [500_20_8_40_15_9] | 6623 | 6557 | 6557 | 7436 | 6344 | 6344 |
395 | [200_10_6_30_10_5] | 4083 | 4098 | 4080 | 4414 | 3458 | 3458 | 800 | [500_20_8_40_15_10] | 6488 | 6472 | 6488 | 7278 | 6400 | 6400 |
396 | [200_10_6_30_10_6] | 3199 | 3210 | 3210 | 3802 | 3058 | 3058 | 801 | [500_20_8_50_20_] | 6543 | 6575 | 6590 | 7415 | 5912 | 5912 |
397 | [200_10_6_30_10_7] | 3934 | 3920 | 3920 | 4177 | 3432 | 3432 | 802 | [500_20_8_50_20_] | 6882 | 6878 | 6878 | 7216 | 6487 | 6487 |
398 | [200_10_6_30_10_8] | 3787 | 3787 | 3787 | 4117 | 3687 | 3687 | 803 | [500_20_8_50_20_] | 6874 | 6888 | 6874 | 7156 | 7109 | 6874 |
399 | [200_10_6_30_10_9] | 3554 | 3552 | 3554 | 3828 | 3292 | 3292 | 804 | [500_20_8_50_20_] | 6620 | 6620 | 6604 | 7101 | 6109 | 6109 |
400 | [200_10_6_30_10_10] | 3699 | 3699 | 3690 | 3938 | 3495 | 3495 | 805 | [500_20_8_50_20_] | 6836 | 6804 | 6812 | 6988 | 6474 | 6474 |
401 | [200_10_6_40_15_1] | 3484 | 3515 | 3515 | 3859 | 3552 | 3484 | 806 | [500_20_8_50_20_] | 7008 | 7018 | 6998 | 7223 | 5954 | 5954 |
402 | [200_10_6_40_15_2] | 4777 | 4770 | 4769 | 4749 | 4830 | 4749 | 807 | [500_20_8_50_20_] | 6579 | 6578 | 6578 | 6821 | 6176 | 6176 |
403 | [200_10_6_40_15_3] | 4000 | 4000 | 3999 | 4179 | 4122 | 3999 | 808 | [500_20_8_50_20_] | 6881 | 6857 | 6866 | 7489 | 6119 | 6119 |
404 | [200_10_6_40_15_4] | 3770 | 3814 | 3817 | 4208 | 3457 | 3457 | 809 | [500_20_8_50_20_] | 6575 | 6541 | 6548 | 7184 | 5739 | 5739 |
405 | [200_10_6_40_15_5] | 3841 | 3891 | 3891 | 4099 | 3881 | 3841 | 810 | [500_20_8_50_20_] | 6406 | 6406 | 6377 | 7163 | 6132 | 6132 |
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ying, KC., Pourhejazy, P. & Fu, PJ. N-list-enhanced heuristic for distributed three-stage assembly permutation flow shop scheduling. Ann Oper Res (2023). https://doi.org/10.1007/s10479-023-05456-6
Accepted:
Published:
DOI: https://doi.org/10.1007/s10479-023-05456-6