
Abstract
Consumer rebates provided by third-party rebate platforms (3RPs) are prevalent in retailing. In this study, we consider the retailer’s decision to introduce a 3RP and whether to share information with the manufacturer by considering the consumers’ sensitivity to rebates, the cost of redeeming rebates, and the proportion of redeeming rebates. We developed a game-theoretic model consisting of a manufacturer, a retailer, and a 3RP. Our main results are summarized as follows: (1) The 3RP should generate reasonable unit sale commission and rebates that can stimulate the retailer to introduce the 3RP and thus maintain the 3RP’s profitability, (2) The entry of the 3RP decreases the wholesale price and retail price but increases the consumers’ demand, (3) The 3RP causes a “win-lose” situation for the retailer and the manufacturer in the non-information sharing case. However, in the information sharing case, the 3RP benefits the manufacturer but harms the retailer, (4) The information sharing benefits the manufacturer but harms the retailer in the supply chain with and without the 3RP. Moreover, information sharing benefits the 3RP. Our analysis provides insights for firms on whether to introduce the 3RP and conditions when the retailer and the 3RP are willing to share information with the manufacturer.



Similar content being viewed by others
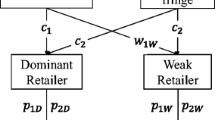

Notes
In Appendix B, to verify the robustness of our findings, we extend the model to the scenario that consider consumers’ rebate redemption uncertainty. And we find the impacts of the 3RP entry and the information sharing on the supply chian members are same with the main model.
In Appendix B, to verify the robustness of our findings, we extend the model to a different gema sequence that the 3RP is the Stackelberg leader, who determines the consumer rebate rate first, and then the manufacturer and the retailer determine the wholesale price and retail price, respectively. And we find the impacts of the 3RP entry and the information sharing on the supply chain menbers are same with the main model.
References
Ando, T. (2015). Merchant selection and pricing strategy for a platform firm in the online group buying market. Annals of Operation Research, 263(1–2), 209–230.
Arcelus, F. J., Kumar, S., & Srinivasan, G. (2012). The effectiveness of manufacturer versus retailer rebates within a newsvendor framework. European Journal Operation Reearch, 219(2), 252–263.
Arya, A., & Mittendorf, B. (2013). Managing strategic inventories via manufacturer-to-consumer rebates. Management SciEnce, 59(4), 813–818.
Cachon, G. P., Daniels, K. M., & Lobel, R. (2017). The role of surge pricing on a service platform with self-scheduling capacity. Manufacturer Service Operation Management, 19(3), 368–384.
Chen, X., Li, C., Rhee, B., & Levi, D. S. (2010). The impact manufacturer rebates on supply chain profits. Naval Research Logistics, 54(6), 667–680.
Chen, P., Liu, X., & Wang, Q. (2022). The implications of competition on strategic inventories considering manufacturer-to-consumer rebates. Omega, 107, 102541.
Chiu, C. H., & Choi, T. M. (2016). Supply chain risk analysis with mean-variance models: A technical review. Annals of Operation Research, 40(2), 489–507.
Choi, S., & Fredj, K. (2013). Pricing competition and store competition: Store brands versus national brand. European Journal of Opration Research, 225(1), 166–178.
Choi, T. M., & He, Y. Y. (2019). Peer-to-peer collaborative consumption for fashion products in the sharing economy: Platform operations. Transportation Research Part E: Logistics and Transportation Review, 126, 49–65.
Choi, H. C. P., Blocher, J. D., & Gavirneni, S. (2008). Value of sharing production yield information in a serial supply chain. Production and Operation Management, 17(6), 614–625.
Dong, C. W., Liu, Q. Y., & Shen, B. (2019). To be or not to be green? Strategic investment for green product development in a supply chain. Transportation Research Part E: Logistics and Transportation Review, 131, 193–227.
Fan, X., Zhao, W., Zhang, T., & Yan, E. (2020). Mobile payment, third-party payment platform entry and information sharing in supply chains. Annals of Operations Research. https://doi.org/10.1007/s10479-020-03749-8
Gerstner, E., & Hess, J. D. (1991). A theory of channel price promotions. American Economic Review, 81(4), 872–886.
Ha, A., Long, X., & Nasiry, J. (2016). Quality in supply chain encroachment. Manufuring & Service Operations ManagEment, 18(2), 280–298.
Ha, A., Wang, W., & Wang, Y. (2017). Manufacturer rebate competition in a supply chain with a common retailer. Production and Operation Management., 26(11), 2122–2136.
Ha, A. Y., Luo, H., & Shang, W. (2022). Supplier encroachment, information sharing, and channel structure in online retail platforms. Production and Operations Management, 31(3), 1235–1251.
Hu, S., Hu, X., & Ye, Q. (2017). Optimal rebate strategies under dynamic pricing. Operation ResEarch, 65(6), 1546–1561.
Huang, S., Guan, X., & Chen, Y. J. (2018). Retailer information sharing with supplier encroachment. Production and Operation Management, 27(6), 1133–1147.
Jiang, B., Tian, L., Xu, Y., & Zhang, F. (2016). To share or not to share: Demand forecast sharing in a distribution channel. Marking SciEnce, 35(5), 800–809.
Kung, L. C., & Zhong, G. Y. (2017). The optimal pricing strategy for two-sided platform delivery in the sharing economy. Transportation Research Part e: Logistics and Transportation Review, 101, 1–12.
Liang, D., Li, G., Sun, L., & Chen, Y. (2013). The role of rebates in the hybrid competition between a national brand and a private label with present-biased consumers. International Journal of Production Economics, 145(1), 208–219.
Liu, W., Yan, X., Wei, W., & Xie, D. (2019). Pricing decisions for service platform with provider’s threshold participating quantity, value-added service and matching ability. Transportation Research Part E: Logistics and Transportation Review, 122, 410–432.
Shamir, N., & Shin, H. (2016). Public forecast information sharing in a market with competing supply chains. Management Science, 62(10), 2994–3022.
Shang, W., Ha, A. Y., & Tong, S. (2016). Information sharing in a supply chain with a common retailer. Management SciEnce, 62(1), 245–263.
Tsunoda, Y., & Zennyo, Y. (2021). Platform information transparency and effects on third-party suppliers and offline retailers. Production and Operations Management, 30(11), 4219–4235.
Vatankhah, B., Wang, W., Li, Z., & Guerra-Zubiaga, D. A. (2019). Intelligent e-commerce logistics platform using hybrid agent based approach. Transportation Research Part E: Logistics and Transportation Review, 126, 15–31.
Zhang, J. (2016). The benefits of consumer rebates: A strategy for gray market deterrence. European Journal of Opration Research, 251(2), 509–521.
Zhang, T., Zhu, X., & Gou, Q. (2017). Demand forecasting and pricing decision with the entry of store brand under various information sharing scenarios. Asia-Pacific Journal of Operation Research, 34(2), 1–26.
Zhang, T., Choi, T. M., & Zhu, X. (2018). Optimal green product’s pricing and level of sustainability in supply chains: Effects of information and coordination. Annals of Operation Research. https://doi.org/10.1007/s10479-018-3084-8
Zhou, Y., Cao, B., Tang, Q., & Zhou, W. (2017). Pricing and rebate strategies for an e-shop with a cashback website. European Journal of Operational Research, 262(1), 108–122.
Zhu, X. (2017). Outsourcing management under various demand information sharing scenarios. Annals of Operation Research, 257(1–2), 449–467.
Zhu, X., Mukhopadhyay, S. K., & Yue, X. (2011). Role of forecast effort on supply chain profitability under various information sharing scenarios. International Journal of Production Economics, 129, 284–291.
Funding
The Funding was provided by National Natural Science Foundation of China (Grant number: 72272097).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A
1.1 Proof of the main models
1.1.1 Derivation of the equilibrium in the case with the 3RP under non-information sharing (Model NP)
We find the sub-game perfect equilibrium by backward induction. In stage 4, the wholesale price is \(w\), the retail price is \(p\), and the unit sale commission is \(T\). The retailer decides on whether to introduce the 3RP or not. When the 3RP does not exist, \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NR} = \left( {p - w} \right)\left( {1 - p + \hat{\varepsilon }} \right)\); when the 3RP exists, \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NP} = \left( {p - w} \right)q_{n} + \left( {p - w - T} \right)q_{p}\). Thus, the retailer will introduce the 3RP if and only if \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NP} \ge E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NR}\) i.e., \(T \le \frac{{\left( {p - w} \right)\left( {\theta r - c} \right)}}{{1 - p + \hat{\varepsilon } + \theta r - c}}\); and the retailer will not introduce the 3RP if and only if \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NP} < E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NR}\), i.e., \(T > \frac{{\left( {p - w} \right)\left( {\theta r - c} \right)}}{{1 - p + \hat{\varepsilon } + \theta r - c}}\).
In stage 3, given the wholesale price \(w\) and retail price \(p\), the 3RP decides on the unit sale commission \(T\) to maximize its profit given by:
Setting \(T > \frac{{\left( {p - w} \right)\left( {\theta r - c} \right)}}{{1 - p + \hat{\varepsilon } + \theta r - c}} \) leads to zero profit and is a dominated strategy for the 3RP. Thus, the 3RP’s optimal decision should satisfy \(T \le \frac{{\left( {p - w} \right)\left( {\theta r - c} \right)}}{{1 - p + \hat{\varepsilon } + \theta r - c}}\), when we have \({ }\frac{{\partial E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NP} }}{\partial T} = q_{p} \ge 0\), i.e., the 3RP’s profit is non-decreasing in \(T\). The optimal decision of the 3RP is,
In addition, the 3RP should set the unit sale rebate to the consumer. The 3RP’s expected profit is \(E\left[ {\pi_{p} |\varepsilon = \hat{\varepsilon }} \right]^{NP} = \left( {T - \delta r} \right)\lambda \left( {1 - p + \hat{\varepsilon } + \theta r - c} \right)\). The 3RP sets the unit sale rebate \(r\) to maximize profit. And substituting \(T^{NP*} = \frac{{\left( {p - w} \right)\left( {\theta r - c} \right)}}{{1 - p + \hat{\varepsilon } + \delta \theta r - c}}\) into \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NP}\), we have,
Since \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NP}\) is concave in \(r\) \(\left( {\frac{{\partial^{2} \pi_{p} }}{{\partial r^{2} }} = - 2\lambda {\updelta }^{2} \theta < 0} \right)\), we can obtain the optimal unit sale rebate by solving the first order condition, \(\frac{{\partial E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NP} }}{\partial r} = 0\), i.e.,
In stage 2, given\(w\), the retailer determines the retailer price \(p\) to maximize its expected profit. Substituting Eq. (A.4) into \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NP}\), i.e.,
Since \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NP}\) is concave in \(p\) \(\left( {\frac{{\partial^{2} E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NP} }}{{\partial p^{2} }} = - 2 < 0} \right)\), we can obtain the best response \(p\) by solving the first order condition, \(\frac{{\partial E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NP} }}{\partial p} = 0\), i.e.,
In stage 1, anticipating the best response of the retailer and the 3RP. The manufacturer decides on the optimal \(w\) to maximize its expected profit given by:
subject to \(w < p\). Because \(E\left[ {\pi_{m} } \right]\) is a concave function in \(w\), we can derive the optimal decision by solving \(\frac{{\partial { }E\left[ {\pi_{m} } \right]}}{\partial w} = 0\), i.e.,
which satisfies \(w < p\).
By substituting Eqs. (A.8)–(A.6), we have the equilibrium retail price:
By substituting Eqs. (A.8–A.9) into Eqs. (A.2–A.4), we have:
We set \(A = 1 - \xi + 2\hat{\varepsilon }\), \(B = \lambda \theta - \lambda \delta + 2\delta\).
By substituting Eqs. (A.8–A.11) to \(E\left[ {\pi_{m} } \right]\), \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]\), and \(E[\pi_{p} |\varepsilon = \hat{\varepsilon }]\), we have:
We set \(a = \frac{AB + 4\lambda \delta c}{{8B}}\). The unconditional expected profits of the retailer and the 3RP are:
We set \(E\left[ a \right] = \frac{{B\left( {1 - \xi } \right) + 4\lambda \delta c)}}{8B}\), \(E\left[ {a^{2} } \right] = \frac{{B\left( {1 - \xi } \right) + 4\lambda \delta c)}}{8B}\left( {\frac{{B\left( {9 - \xi } \right) + 4\lambda \delta c)}}{8B}} \right) + \frac{{\xi^{2} }}{16}\).
1.1.2 Derivation of the equilibrium in the case without the 3RP under non-information sharing (Model NR)
When the 3RP does not exist, the game sequence is: in Stage 1, the manufacturer sets the wholesale price w; in Stage 2, the retailer set the retail price p. Using backward induction, we can get the equilibrium
The expected profit of the retailer \(E\left[ {\hat{\pi }_{r} |\varepsilon = \hat{\varepsilon }} \right] \) is concave in p \(\left( {\frac{{\partial^{2} E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NR} }}{{\partial p^{2} }} = - 2 < 0} \right)\), we can get the optimal retail price by calculating \(\frac{{\partial E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NR} }}{\partial p} = 0\), i.e.,
In stage 1, the manufacturer predicts the retailer’s decision, and sets the optimal wholesale price \(w\) to maximize its expected profit:
Subject to \({ }w < p\). Because \(E\left[ {\hat{\pi }_{m} } \right] \) is a concave function of \({ }w\), we can obtain the manufacturer’s optimal decision by calculating \({ }\frac{{\partial E\left[ {\hat{\pi }_{m} } \right]}}{\partial w} = 0\), i.e.,
which self satisfies \(w < p\).
By substituting Eqs. (A.17–A.19), we can get the optimal retail price:
Thus, we can get the expected profit of the manufacturer as follows:
We can get the expected profit and the unconditional expected profit of the retailer as follows:
1.1.3 Derivation of the equilibrium in the information sharing case with the 3RP (Model IP)
In Stage 1, based on predicting the decision of the retailer and the 3RP, the manufacturer sets the wholesale price to maximize its expected profit:
subject to \({ }w < p\). The manufacturer’s expected profit \(E\left[ {\pi_{m} {|}\varepsilon = \hat{\varepsilon }} \right]\) is a concave function of w by calculating \({ }\frac{{\partial E\left[ {\pi_{m} |\varepsilon = \hat{\varepsilon }} \right]^{IP} }}{\partial w} = 0\), i.e.,
which self satisfies \(w < p\).
By substituting Eq. (A.26) into Eq. (A.18), we can get the optimal retail price:
By substituting Eqs. (A.25–A.26) into Eqs. (A.2) and (A.4), we can get:
By substituting Eqs. (25)-(28) into \( E[\pi_{p} |\varepsilon = \hat{\varepsilon }],E[\pi_{r} |\varepsilon = \hat{\varepsilon }]\), \(E[\pi_{m} |\varepsilon = \hat{\varepsilon }]\), we can get:
We set \(A = 1 + \hat{\varepsilon }\), \(B = \lambda \theta - \lambda \delta + 2\delta\) and \(a = \frac{AB + 4\lambda \delta c}{{8B}}\).
The unconditional expected profits of the 3RP, the retailer and the manufacturer are:
We set \( E\left[ a \right] = \frac{B + 4\lambda \delta c}{{8B}}\) and \(E\left[ {a^{2} } \right] = \frac{{\left( {B + 4\lambda \delta c} \right)\left( {2B + \lambda \delta c} \right)}}{{16B^{2} }} + \frac{{\xi^{2} }}{16}\).
1.1.4 Derivation of the equilibrium in the case without the 3RP under information sharing (Model IR)
When the 3RP does not exist, in Stage 1, the manufacturer sets the wholesale price w; in Stage 2, the retailer sets retail price p. we derive the equilibrium by backward induction.
Since \(E\left[ {\hat{\pi }_{r} |\varepsilon = \hat{\varepsilon }} \right] \) is concave in p \(\left( {\frac{{\partial^{2} E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{IR} }}{{\partial p^{2} }} = - 2 < 0} \right)\), we can obtain the best response p by solving the first order condition, \(\frac{{\partial E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{IR} }}{\partial p} = { }0\), i.e.,
In Stage 1, the manufacturer predicts the retailer’s decision, and sets the optimal wholesale price to maximize its expected profits:
subject to \({ }w < p\). Because \(E\left[ {\pi_{m} |\varepsilon = \hat{\varepsilon }} \right]^{IR}\) is a concave function of \({ }w\). By calculating \(\frac{{\partial E\left[ {\pi_{m} |\varepsilon = \hat{\varepsilon }} \right]^{IR} }}{\partial w} = 0\), we can get the manufacturer’s optimal decision, i.e.,
Which self satisfies \(w < p\).
By calculating Eq. (38) into Eq. (7), we can get the optimal retail price:
We can get the expected profits of the manufacturer and the retailer:
The unconditional expected profits of the retailer and the manufacturer are
Thus, the unconditional expected profit of the supply chain is
1.1.5 Proof of Propositions 1–2
The results can be straightforwardly obtained by comparing the equilibrium with and without the 3RP, the details are omitted.
1.1.6 Proof of Propositions 3–5
The results can be straightforwardly obtained by comparing the equilibrium in the non-information sharing case and the information sharing case, the details are omitted.
Appendix B
In this section, we analyze and discuss the robustness of our insights into several alternative modeling assumptions. First, we provide an analysis of a model where consumers are uncertain to whether they will redeem the rebate. Second, we extend the model to consider a different game sequence that the 3RP moves first to determine the consumer rebate and then the manufacturer and retailer determine the wholesale price and retail price, respectively.
2.1 Proof of extension 1: considering consumer’s rebate redemption uncertainty
In the main model, we consider consumers who use the 3RP believe they will redeem rebates. However, some consumers do not fully believe they will redeem the rebate in the reality. Thus, we consider that \(1 - \lambda\) proportion ensures they purchase the product through the retailer, \(\lambda\) proportion purchases the product through the 3RP, in which \(\left( {1 - \alpha } \right)\lambda \) proportion ensures they redeem the rebate, and the remaining purchase the product through the 3RP but uncertain whether they will redeem the rebate. We consider \(\beta\) proportion consumers who do not fully believe they will remember to redeem the rebate, and the remaining fail to redeem the rebate. Consistent with the main model, we also consider \(\delta\) proportion of the 3RP users who will redeem rebates successfully, and the remaining \(1 - \delta\) proportion of 3RP users who will fail to redeem rebates. Based on the above and following Fan et al. (2020), we can find that the demand in this section is the same as the main model. And the profit of the 3RP is as follows,
2.2 Derivation of the equilibrium in the case with the 3RP under non-information sharing (Model NPU)
We find the sub-game perfect equilibriums in the case considering consumer’s rebate redemption uncertainty by backward induction which is the same as the main model. We get the equilibriums in the case with the 3RP under non-information sharing (Model NPU), the details are omitted. Note that we set \(A = 1 - \xi + 2\hat{\varepsilon }\), \(B = 1 - \alpha + \alpha \beta\).
The unconditional expected profits of the retailer and the 3RP are:
2.3 Derivation of the equilibrium in the case without the 3RP under non-information sharing (Model NRU)
The equilibriums in the case without the 3RP under non-information sharing (Model NRU) are the same with that in Model NR.
2.4 Derivation of the equilibrium in the information sharing case with the 3RP (Model IPU)
We find the sub-game perfect equilibriums in the case considering consumer’s rebate redemption uncertainty by backward induction which is the same as the main model. We get the equilibriums in the case with the 3RP under information sharing (Model IPU), the details are omitted. Note that we set \(A = 1 + \hat{\varepsilon }\), \(B = 1 - \alpha + \beta \alpha\), \(C = 1 + \xi\).
The unconditional expected profits of the retailer and the 3RP are:
2.5 Derivation of the equilibrium in the case without the 3RP under non-information sharing (Model IRU)
The equilibriums in the case without the 3RP under information sharing (Model IRU) are the same with that in Model IR.
2.6 Effects of the 3RP entry
Because the theoretical comparison of the expected profits is difficult to make, a numerical study is used here. We depicted with \(\delta = 0.7\), \(\xi = 0.5\), \(\beta = 0.2\), and \(\alpha = 0.4\). By comparing the cases of 3RP entry and without the 3RP entry in information sharing and non-information sharing scenarios, we examine the value of the 3RP entry when considering consumer’s rebate redemption uncertainty. Let \(V_{m}^{i} = E\left[ {\pi_{m}^{{iPU{*}}} } \right] - E\left[ {\pi_{m}^{{iRU{*}}} } \right]\) (where i = N or I) denote the value of the 3RP for the manufacturer in the non-information sharing and information sharing cases, respectively. Let \(V_{r}^{i} = E\left[ {\pi_{r}^{{iPU{*}}} } \right] - E\left[ {\pi_{r}^{{iRU{*}}} } \right]\) (where i = N or I) denote the value of the 3RP for the retailer in the cases of non-information sharing and information sharing.

Effects of the 3RP entry under non-information sharing and information sharing
We find the effect of the 3RP for the manufacturer and the retailer are the same with that in the main model. The figures show that when \(\lambda\) is higher, the 3RP provides more benefits for the retailer but harms the manufacturer more in the non-information sharing case. However, in the information sharing case, the 3RP provides less benefit for the manufacturer and harms the retailer less with the increase of \(\lambda\).
2.7 Effects of information sharing
We compared the cases of information sharing and non-information sharing when the 3RP was introduced and determined the value of information sharing. Let \(V_{m}^{IN} = E\left[ {\pi_{m}^{{IP{*}}} } \right] - E\left[ {\pi_{m}^{NP*} } \right]\) denote the value of information sharing for the manufacturer. Let \(V_{r}^{IN} = E\left[ {\pi_{r}^{{IP{*}}} } \right] - E\left[ {\pi_{r}^{NP*} } \right]\) denote the value of information sharing for the retailer. We also use \(V_{p}^{IN} = E\left[ {\pi_{p}^{{IP{*}}} } \right] - E\left[ {\pi_{p}^{NP*} } \right]\) to denote the value of information sharing for the 3RP. Consistent with our analytical results, we have \(V_{m}^{IN} > 0\), \(V_{r}^{IN} < 0\) and \(V_{p}^{IN} > 0\). Specifically, the numerical experiments show that, as the increase of \(\lambda\), information sharing harms the retailer more, benefits the manufacturer less, and lastly creates more value for the 3RP. In addition, as the increase of \(\delta\), information sharing benefits the manufacturer and harms both the 3RP and the retailer more (Fig.

Effects of information sharing in the supply chain with the 3RP
5).
2.8 Proof of extension 2: the 3RP as the Stackelberg leader
In the main model, we consider the 3RP sets the commission and rebate after the retailer sets the retail price and the manufacturer sets the wholesale price. However, the 3RP sets the rebate before the manufacturer and the retailer set the wholesale price and retail price, respectively in the reality. Thus, we extend the model to consider a different game sequence that the 3RP moves first to determine the consumer rebate and then the manufacturer and retailer determine the wholesale price and retail price, respectively. Lastly, the 3RP determines the unit sale commission combined with the retail price.
2.9 Derivation of the equilibrium in the case with the 3RP under non-information sharing (Model NPD)
In stage 4, the retailer decides on whether to introduce the 3RP or not. When the 3RP does not exist, \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NPD} = \left( {p - w} \right)\left( {1 - p + \hat{\varepsilon }} \right)\); when the 3RP exists, \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NPD} = \left( {p - w} \right)q_{n} + \left( {p - w - T} \right)q_{p}\). Thus, the retailer will introduce the 3RP if and only if \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NPD} \ge E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NPD}\) i.e., \(T \le \frac{{\left( {p - w} \right)\left( {\theta r - c} \right)}}{{1 - p + \hat{\varepsilon } + \theta r - c}}\); and the retailer will not introduce the 3RP if and only if \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NPD} < E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NPD}\), i.e., \(T > \frac{{\left( {p - w} \right)\left( {\theta r - c} \right)}}{{1 - p + \hat{\varepsilon } + \theta r - c}}\).
In stage 1, anticipating the best response of the retailer and the manufacturer. The 3RP decides on the optimal \(T\) to maximize its expected profit given by:
Setting \(T > \frac{{\left( {p - w} \right)\left( {\theta r - c} \right)}}{{1 - p + \hat{\varepsilon } + \theta r - c}} \) leads to zero profit and is a dominated strategy for the 3RP. Thus, the 3RP’s optimal decision should satisfy \(T \le \frac{{\left( {p - w} \right)\left( {\theta r - c} \right)}}{{1 - p + \hat{\varepsilon } + \theta r - c}}\), when we have \({ }\frac{{\partial E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NPD} }}{\partial T} = q_{p} \ge 0\), i.e., the 3RP’s profit is non-decreasing in \(T\). The optimal decision of the 3RP is,
We find the sub-game perfect equilibrium by backward induction. In stage 3, given \(w\), and \(r\), the retailer determines the retailer price \(p\) to maximize its expected profit. \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NPD}\), i.e.,
Since \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NPD}\) is concave in \(p\) \(\left( {\frac{{\partial^{2} E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NPD} }}{{\partial p^{2} }} = - 2 < 0} \right)\), we can obtain the best response \(p\) by solving the first order condition, \(\frac{{\partial E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NPD} }}{\partial p} = 0\), i.e.,
In stage 2, anticipating the best response of the retailer. The manufacturer decides on the optimal \(w\) to maximize its expected profit given by:
subject to \(w < p\). Because \(E\left[ {\pi_{m} } \right]\) is a concave function in \(w\), we can derive the optimal decision by solving \(\frac{{\partial { }E\left[ {\pi_{m} } \right]}}{\partial w} = 0\), i.e.,
which satisfies \(w < p\).
In addition, the 3RP should set the unit sale rebate to the consumer. The 3RP’s expected profit is \(E\left[ {\pi_{p} |\varepsilon = \hat{\varepsilon }} \right]^{NPD} = \left( {T - \delta r} \right)\lambda \left( {1 - p + \hat{\varepsilon } + \theta r - c} \right)\). The 3RP sets the unit sale rebate \(r\) to maximize profit. And substituting \(T^{NPD*} = \frac{{\left( {p - w} \right)\left( {\theta r - c} \right)}}{{1 - p + \hat{\varepsilon } + \delta \theta r - c}}\) into \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NPD}\), we have,
Since \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NPD}\) is concave in \(r\) \(\left( {\frac{{\partial^{2} \pi_{p} }}{{\partial r^{2} }} = - 2\lambda {\updelta }^{2} \theta < 0} \right)\), we can obtain the optimal unit sale rebate by solving the first order condition, \(\frac{{\partial E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{NPD} }}{\partial r} = 0\), i.e.,
We have the equilibriums:
By substituting Eqs. (B.10–B.13) to \(E\left[ {\pi_{m} } \right]\), \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]\), and \(E[\pi_{p} |\varepsilon = \hat{\varepsilon }]\), we have:
Note that we set \(A = 1 - \xi + 2\hat{\varepsilon }\), \(B = \lambda \theta - \lambda \delta + 2\delta\).
2.10 Derivation of the equilibrium in the case without the 3RP under non-information sharing (Model NRD)
The equilibriums in the case without the 3RP under non-information sharing (Model NRD) are the same with that in Model NR.
2.11 Derivation of the equilibrium in the information sharing case with the 3RP (Model IPD)
In Stage 1, based on predicting the decision of the retailer and the 3RP, the manufacturer sets the wholesale price to maximize its expected profit:
subject to \({ }w < p\). The manufacturer’s expected profit \(E\left[ {\pi_{m} {|}\varepsilon = \hat{\varepsilon }} \right]\) is a concave function of w by calculating \(\frac{{\partial E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{IPD} }}{\partial w} = 0\), i.e.,
which self satisfies \(w < p\).
In addition, the 3RP should set the unit sale rebate to the consumer. The 3RP’s expected profit is \(E\left[ {\pi_{p} |\varepsilon = \hat{\varepsilon }} \right]^{IPD} = \left( {T - \delta r} \right)\lambda \left( {1 - p + \hat{\varepsilon } + \theta r - c} \right)\). The 3RP sets the unit sale rebate \(r\) to maximize profit. And substituting \(T^{IPD*} = \frac{{\left( {p - w} \right)\left( {\theta r - c} \right)}}{{1 - p + \hat{\varepsilon } + \delta \theta r - c}}\) into \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{IPD}\), we have,
Since \(E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{IPD}\) is concave in \(r\) \(\left( {\frac{{\partial^{2} \pi_{p} }}{{\partial r^{2} }} = - 2\lambda {\updelta }^{2} \theta < 0} \right)\), we can obtain the optimal unit sale rebate by solving the first order condition, \(\frac{{\partial E\left[ {\pi_{r} |\varepsilon = \hat{\varepsilon }} \right]^{IPD} }}{\partial r} = 0\), i.e.,
We have the equilibriums:
By substituting Eqs. (B.19–B.22) into \( E[\pi_{p} |\varepsilon = \hat{\varepsilon }],E[\pi_{r} |\varepsilon = \hat{\varepsilon }]\), and \(E[\pi_{m} |\varepsilon = \hat{\varepsilon }]\), we can get:
We set \(A = 1 + \hat{\varepsilon }\), and \(B = \lambda \theta - \lambda \delta + 2\delta\).
2.12 Derivation of the equilibrium in the case without the 3RP under non-information sharing (Model IRD)
The equilibriums in the case without the 3RP under information sharing (Model IRD) are the same with that in Model IR.
2.13 Effects of the 3RP entry
Because the theoretical comparison of the expected profits is difficult to make, a numerical study is used here. We depicted with \(\delta = 0.7\)., \(\xi = 0.5\), \(\beta = 0.2\), and \(\alpha = 0.4\). By comparing the cases of 3RP entry and without the 3RP entry in information sharing and non-information sharing scenarios, we examine the value of the 3RP entry when considering consumer’s rebate redemption uncertainty. Let \(V_{m}^{i} = E\left[ {\pi_{m}^{{iPD{*}}} } \right] - E \left[ {\pi_{m}^{{iRD{*}}} } \right]\) (where i = N or I) denote the value of the 3RP for the manufacturer in the non-informaon sharing and information sharing cases, respectively. Let \(V_{r}^{i} = E\left[ {\pi_{r}^{{iPD{*}}} } \right] - E\left[ {\pi_{r}^{{iRD{*}}} } \right]\) (where i = N or I) denote the value of the 3RP for the retailer in the cases of non-information sharing and information sharing, respectively. We find the effect of the 3RP for the manufacturer and the retailer are the same with that in the main model. The figures show that when \(\lambda\) is higher, the 3RP provides more benefits for the retailer but harms the manufacturer more in the non-information sharing case. However, in the information sharing case, the 3RP provides less benefit for the manufacturer and harms the retailer less with the increase of \(\lambda\) (Fig.

Effects of the 3RP entry under non-information sharing and information sharing
6).
2.14 Effects of information sharing
We compared the cases of information sharing and non-information sharing when the 3RP was introduced and determined the value of information sharing. Let \(V_{m}^{IN} = E\left[ {\pi_{m}^{{IP{*}}} } \right] - E\left[ {\pi_{m}^{NP*} } \right]\) denote the value of information sharing for the manufacturer. Let \(V_{r}^{IN} = E\left[ {\pi_{r}^{{IP{*}}} } \right] - E\left[ {\pi_{r}^{NP*} } \right]\) denote the value of information sharing for the retailer. We also use \(V_{p}^{IN} = E\left[ {\pi_{p}^{{IP{*}}} } \right] - E\left[ {\pi_{p}^{NP*} } \right]\) to denote the value of information sharing for the 3RP. Consistent with our analytical results, we have \(V_{m}^{IN} > 0\), \(V_{r}^{IN} < 0\) and \(V_{p}^{IN} > 0\). Specifically, the numerical experiments show that, as the increase of \(\lambda\), information sharing harms the retailer more, benefits the manufacturer less, and lastly creates more value for the 3RP. In addition, as the increase of \(\delta\), information sharing benefits the manufacturer and harms both the 3RP and the retailer more (Fig.

Effects of information sharing in the supply chain with the 3RP
7).
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Fan, X., Zhao, W. & Zhu, X. Effects of the third-party rebate platform and information sharing on the supply chain. Ann Oper Res 335, 151–183 (2024). https://doi.org/10.1007/s10479-023-05439-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10479-023-05439-7