
Abstract
In various situations, a researcher analyses data stored in a matrix. Often, the information is replicated on different occasions that can be time-varying or refer to different conditions. In these situations, data can be stored in a multi-way array or tensor. In this work, using the Tucker4 model, we apply a tensor-based approach to the mortality by cause of death, hence considering data stored in a four-dimensional array. The dataset here considered is provided by the World Health Organization and refers to causes of death, ages, years, and countries. A deep understanding of changing mortality patterns is fundamental for planning public policies. Knowledge about mortality trends by causes of death and countries can help Governments manage their health care costs and financial planning, including public pensions, and social security schemes. Our analysis reveals that the Tucker4 model allows for extracting meaningful demographic insights, which are useful to understand that the rise in survival during the twentieth century was mostly determined by a reduction of the main causes of death.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Since the nineteenth century, developed countries witnessed improvements in longevity and the consequent decline in mortality rates across ages and years (Oeppen & Vaupel, 2002). The decrease in mortality rates is mainly due to actions in preventing diseases through advances in public health, nutrition, and medicine (Wilmoth, 2000). However, this general decline in mortality rates may overshadow periods with stagnation or deceleration in life expectancy for some groups of countries (Levantesi et al., 2021). In particular, past studies highlighted the increase in life expectancy at birth for a group of Scandinavian countries and stagnations for other ones (Lindahl-Jacobsen et al., 2016), whereas, for example, females in France and Japan, exhibit positive improvements in life expectancy. A similar pattern has been shown in the United States and the Netherlands, which experienced a slowdown in life expectancy at age 65 from 1984 to 2000 (Meslé & Vallin, 2006). Recently, longevity decelerations have been extensively documented (Ho & Hendi, 2018), e.g., improvements in life expectancy have slowed in the United Kingdom (Leon et al., 2019). A profound understanding of changing mortality patterns is important for several reasons. From a policy point of view, it is important to establish the causes of the slowdown and, in particular, what can be done to reverse these trends in order to better implement and target health and financial policies. In this perspective, knowledge about mortality trends by causes of death (CoD) and different populations can help Governments manage their health care costs and financial planning, including public pensions, and social security schemes (Devolder et al., 2021; Nigri et al., 2022). Thus, a comprehensive analysis considering different mortality features, such as ages, periods, CoD, and countries, is crucial. However, this task entails several difficulties. Indeed, mortality data are usually referred to as overall mortality for a single country and gender, displayed as a matrix in order to represent ages and periods [Lee-Carter model (Lee & Carter, 1992)]. More recently, models have been proposed that leverage a multi-population framework, as in the Li-Lee model (Li & Lee, 2005), which extends the Lee-Carter model to allow for a group of populations. In this case, the authors solve the higher dimensional issue, using a common factor to describe the long-term mortality trend shared by all countries within a group and use a country-specific factor to describe the short-term country-specific mortality patterns. This aspect becomes more problematic if we look at the multi-population model in the causes of death structure. The single-population mortality modeling problem can be solved by using matrix decomposition (or matrix factorisation), which consists of approximating the original data matrix using low-rank matrix representations through underlying components. For example,the Lee-Carter model uses Singular Value Decomposition (SVD) to forecast the US mortality data. However, the single-population models cannot be applied to multi-population mortality data with three or more dimensions. A natural extension of matrix decomposition (two dimensions) is tensor decomposition (three or more dimensions), which can be used for multi-population mortality modeling. A tensor is a multidimensional or N-way array, being N the number of dimensions. It is only in more recent times that models for tensor decomposition have been used in the analysis of the mortality data (Russolillo et al., 2011; Bergeron-Boucher et al., 2018; Giordano et al., 2019; Dong et al., 2020), where the first attempts of using these models concern the case with \(N=3\) and the so-called Tucker3 model, originally introduced in Tucker (1966), see also Kroonenberg and De Leeuw (1980), Kiers and Van Mechelen (2001). In Russolillo et al. (2011), a three-way extension of the Lee-Carter model by considering death rates aggregated over time, age-groups and country. Paper Bergeron-Boucher et al. (2018) proposes a compositional data adaptation of the Tucker3 model using three-dimensional arrays indexed by time, age, and population, and providing coherent forecasts of the mortality of Canadian provinces. In Giordano et al. (2019) the three-way Lee-Carter model developed in Russolillo et al. (2011) is applied to a group of countries by extending the Lee-Carter model to a three-way structure. In Dong et al. (2020) the model used in Russolillo et al. (2011) is generalized by using different tensor decomposition models and considering death rates aggregated over age, year, and country/gender and addresses the forecasting problem of multi-population mortality. Papers (Russolillo et al., 2011; Giordano et al., 2019; Dong et al., 2020; Li et al., 2019) refer to cause of death log-mortality rates, an alternative involves the use of cause of death rates, in fact, in Kjærgaard et al. (2019) cause-specific death distributions, rather than log-mortality rates, using compositional data analysis are forecasted.
Following this line of research, considering cause of death rates, we analyze the causes of death mortality by taking into consideration an additional dimension. In fact, the dataset here considered is provided by the World Health Organization and refers to \(N=4\) dimensions: causes of death, age groups, years, and countries. Such a four-way dataset is investigated by the Tucker4 model, the four-way extension of Tucker3 [see Kapteyn et al. (1986) for a deeper insight into the generic N-way extension of the Tucker’s model]. We carry out the analysis by distinguishing the results by sex, first considering the males and then the females. The steps we follow are: description of the methodology, identification and description of the database, construction of the four-dimensional array (causes of death, ages, times, and countries), use of the Tucker4 model. Such a four-way analysis is useful for the exploratory analysis of four-way mortality data and it reveals some peculiar aspects of the mortality phenomenon. More in general, by the current applications, our aim is to stimulate the use of tensor decomposition models whenever four-way data are available. Regardless of the specific domain of research, any four-way analysis is composed of different steps involving crucial choices to be made. These will be carefully described and motivated providing a guidance for the practical use of N-way models.
2 Methodology
The primary aim of four-way tensor decomposition models is the exploratory analysis of four-way data that can emerge in different contexts; our context is mortality, with particular reference to the causes of death. Four-way data can be arranged in a four-dimensional array, in our example ‘Causes of death \(\times \) Ages \(\times \) Times \(\times \) Countries”. The four sets of entities associated with this four-way data set are the dimensions (or “modes” ) of the array. By applying the Tucker4 model, the information in the four-way array is efficiently summarized. In particular, the model summarizes the entities of each mode through a few mode-specific components and the relations between these components (stored in the four-way core array \(\underline{{\textbf {G}}}\)). The Tucker4 model is the four-way extension of the Tucker3 one for three-way data. It is also a generalization of Principal Component Analysis (PCA), which is a well-known data reduction technique for two-way data. For convenience, PCA and Tucker3 are briefly presented, before introducing the Tucker4 model.
2.1 Principal component analysis
PCA is a statistical method that can be applied when the available information is collected in a matrix, say X. The generic element of this matrix, \(x_{ij}\), expresses the score of the i-th observation unit (\(i=1,\ldots ,I\)) with respect to the j-th variable (\(j=1,\ldots ,J\)). We can consider X as a two-way tensor in \(\Re ^{I \times J}\) where the two modes are the observation units (from now on simply called “units”) and the variables. In our example the units are the causes of death and the variables are the age classes. PCA with S (\(\le \min (I,J))\) components can be formulated as
where \(a_{is}\) and \(b_{js}\) are the component score of unit i for component s (\(i=1,\ldots ,I\) and \(s=1,\ldots ,S\)) and the component loading of variable j for component s (\(j=1,\ldots ,J\) and \(s=1,\ldots ,S\)), respectively, being S the number of components, and \(e_{ij}\) is the error term, the generic element of the matrix E. In matrix form, PCA can be rewritten as
where A (\(I \times S\)) with generic element \(a_{is}\) and B (\(J \times S\)) with generic element \(b_{js}\) denote the component score and component loading matrices, respectively. PCA finds estimates for A and B by minimizing
with respect to A and B, where the symbol \(||\cdot ||\) denotes the Frobenius norm of matrices. The estimates of A and B are found by computing the SVD of X, thus highlighting a strong connection between PCA and the Lee-Carter model.
2.2 Tucker3
When the available information is replicated in different (time) occasions, there is an additional mode (labelled occasions), and the data is stored in a three-way array or tensor \(\underline{{\textbf {X}}}\) in \(\Re ^{I \times J\times K}\) with generic element \(x_{ijk}\) expressing the score of observation unit i for variable j at occasion k (\(k=1,\ldots ,K\)). In our example, time occasions are years, as it can be better understood in Fig. 1. The Tucker3 model summarizes a three-way tensor as:
Differently from PCA, different sets of components are determined for every dimension. In particular, P (\(\le I\)) components for the units, Q (\(\le J\)) components for the variables and R (\(\le K\)) components for the occasions are sought. In (2), \(a_{ip}\) and \(b_{jq}\) express the relations between the units and the components for the units and the variables and the components for the variables. With respect to PCA, the Tucker3 model adds new loadings, denoted by \(c_{kr}\) (\(k=1,\ldots ,K\) and \(r=1,\ldots ,R\)), linking occasions and components for the occasions. The triple interactions between the components of all the dimensions are provided by \(g_{pqr}\), the generic element of the core tensor \(\underline{{\textbf {G}}}\) of order \((P \times Q \times R)\). A high value of \(g_{pqr}\) in absolute sense suggests a strong relation among these components. Finally, \(e_{ijk}\) is the generic error term belonging to the error tensor \(\underline{{\textbf {E}}}\).
To further compare PCA and Tucker3, it is convenient to express the Tucker3 model in matrix notation. We get:
where \({\textbf {X}}_A\) is the matrix of order \((I \times JK)\), representing the so-called unit mode matricization of \(\underline{{\textbf {X}}}\), i.e., the matrix obtained by juxtaposing next to each other the matrices corresponding to the K occasions. Note that other matricizations can be used [see, for more details, Kiers (2000)]. The matrices A, B and C of order \((I \times P)\), \((J \times Q)\) and \((K \times R)\), respectively, are the component matrices for the units, variables and occasions, respectively. It can be shown that these matrices can be constrained to be columnwise orthnormal without loss of fit (see Kroonenberg and De Leeuw 1980). Furthermore, \({\textbf {G}}_A\) of order \((P \times QR)\) and \({\textbf {E}}_A\) of order \((I \times JK)\) denote the unit mode matricizations of \(\underline{{\textbf {G}}}\) and \(\underline{{\textbf {E}}}\), respectively. Finally, the symbol \(\otimes \) denotes the Kronecker product of matrices. By comparing (1) and (3) we can understand the motivations underlying the Tucker3 model. The Tucker3 model can be seen as a particular PCA of \({\textbf {X}}_A\) where the component loadings are constrained to \(({\textbf {C}}\otimes {\textbf {B}}){\textbf {G}}_A'\). Such a particular structure allows for properly exploiting the three-way structure of the data. In principle, we might apply standard PCA to \({\textbf {X}}_A\), but in this way the component loadings fully ignore that the same variables are observed in different occasions.
Estimation in Tucker3 is carried out by following the least squares approach. Thus, the parameter estimates are found by minimizing the sum of squared errors:
with respect to A, B, C, and \({\textbf {G}}_A\).
Once the estimates of A, B, C and \(\underline{{\textbf {G}}}\) are determined, the fit percentage of the Tucker3 model can be computed as
The closer to 100, the better the fit of the model, and the fit percentage is used to select the optimal number of components.

Three-way array or tensor and unit mode matricization
2.3 Tucker4
Generalizing the above considerations, with reference to our context in which we consider four-way data, there is an additional dimension (labelled conditions) and the data are stored in a four-way array or tensor \(\underline{{\textbf {X}}}\) in \(\Re ^{I \times J\times K\times L}\) with generic element \(x_{ijkl}\) expressing the score of unit i for variable j at (time) occasion k and at condition l (\(l=1,\ldots ,L\)). In our example these conditions are the different countries, as displayed in Fig. 2.
As we have introduced the four-way tensor \(\underline{{\textbf {X}}}\) generalizing the corresponding three-way one, we can introduce the Tucker4 model by generalizing the Tucker3 model. The Tucker4 model can be formulated as
where there are the new loadings \(d_{ls}\) linking the conditions and components for the conditions and \(e_{ijkl}\) denotes the generic error term pertaining to the four-way array \(\underline{{\textbf {E}}}\). Therefore, the Tucker4 model summarizes every dimension by a limited number of dimension-specific components. In particular, P, Q, R and S (\(\le L\)) denote the number of such components for the units, the variables, the occasions and the conditions, respectively. As a natural extension of Tucker3, the interactions between these components are given by the core \(\underline{{\textbf {G}}}\), which is now a four-way array of order \((P \times Q \times R \times S)\), with generic element \(g_{pqrs}\). Obviously, its elements express the quadruple interaction among component p of the unit mode, component q of the variable mode, component r of the first occasion mode and component s of the second occasion mode and high values of \(g_{pqrs}\) in absolute sense suggest strong relations among the quadruple of components involved.
In matrix notation, the Tucker4 model can be formalized as:
where \({\textbf {X}}_A\) is now a matrix of order \((I \times JKL)\) representing the unit mode matricization of the four-way array \(\underline{{\textbf {X}}}\). In this case, \({\textbf {X}}_A\) is obtained by juxtaposing next to each other the previously-defined matricizations of the three-way arrays pertaining to all the conditions. A, B, C and D are the component matrices for the four modes and \({\textbf {G}}_A\) of order \((P \times QRS)\) is the unit mode matricization of the core tensor \(\underline{{\textbf {G}}}\). Finally, \({\textbf {E}}_A\) is the unit mode matricization of \(\underline{{\textbf {E}}}\). With similar reasoning as for Tucker3, Tucker4 captures the four-way structure of the data by constraining the loadings to take the form \(({\textbf {D}}\otimes {\textbf {C}}\otimes {\textbf {B}}){\textbf {G}}_A'\).
Estimation is done following the least squares approach. In fact, we look for A, B, C, D and \({\textbf {G}}_A\) such that the sum of squared errors
is minimized. To this purpose, an alternating least squares algorithm can be implemented, which in turn minimizes the loss function with respect to one of the parameter matrices upon convergence. More than one (random) start of the algorithm is usually recommended in order to limit the risk of local optima.
The fit of the model can be evaluated according to (4), provided that the unit mode matricizations of the four-way arrays \(\underline{{\textbf {E}}}\) and \(\underline{{\textbf {X}}}\) are used.

Four way array or tensor and unit mode matricization
The Tucker4 solution is not unique. Equally well fitting solutions can be found by postmultiplying the component matrices A, B, C and D by non-singular square rotation matrices and compensating such rotations in the core. For instance, A can be rotated by using the rotation matrix T of order \((P \times P)\) so as to obtain the rotated matrix \(\mathbf{{A}}_R = {\textbf {AT}}\). The rotation must be compensated into the core leading to \(\mathbf{{G}}_{AR} = {\textbf {T}}^{-1}{} \mathbf{{G}}_{A}\). The model fit is not affected because \({\textbf {A}}_R{\textbf {G}}_{AR}({\textbf {D}}\otimes {\textbf {C}}\otimes {\textbf {B}})'={\textbf {ATT}}^{-1}{} {\textbf {G}}_A({\textbf {D}}\otimes {\textbf {C}}\otimes {\textbf {B}})'={\textbf {AG}}_A({\textbf {D}}\otimes {\textbf {C}}\otimes {\textbf {B}})'\). To exploit this rotational freedom, the solution can be rotated to a simple form. In this paper, we achieve simplicity by varimax (Kaiser, 1958) rotating A, B, C and D.
2.3.1 Preprocessing
Multiway models, such as Tucker4, require some preprocessing of the data. In particular, prior to fitting the model to the data, these can be centered and/or normalized. By centering, the aim is to remove offset terms. By normalizing, unwanted differences in scale are removed. Differently from the standard two-way case, where the preprocessing step is performed by centering and/or normalizing every variable, in the multiway context it is not obvious how to proceed. In fact, centering and/or scaling can be done with respect to a dimension or even a combination of dimensions. For instance, one might center the data across, e.g., the occasion mode (single dimension) as
where \( {\bar{x}}_{ij\cdot l}=\frac{\sum _{k=1}^K{{x}_{ijkl}}}{K}\), or across, e.g., the occasion and condition modes (combination of dimensions) as
where \( {\bar{x}}_{ij\cdot \cdot }=\frac{\sum _{k=1}^K{\sum _{l=1}^L{{x}_{ijkl}}}}{KL}\). Similarly, scaling can be done with respect to a single dimension or a combination of dimensions. Suppose to scale the data within, e.g., the unit mode. In this case, we have
where \({\nu }_i\) is the normalizing factor computed within the units. A common choice is based on the square root of the sum of squares:
In the three-way case, refer to (Kiers, 2000; Harshman, 1984) for more details.
2.3.2 Choice of the numbers of components
To choose the numbers of components, the aim is to balance fit and parsimony looking for a solution easy to be interpreted. Therefore, this choice involves subjective decisions (interpretability) based on objective measures (fit and parsimony). To measure the fit of a solution we can use (4). If we based our choice only on fitting, we would choose the most complex model. Therefore, we should consider a compromise between fit and parsimony, expressed as the same total number of components \(\textit{P}+\textit{Q}+\textit{R}+\textit{S}\). To reach a decision, the strategy is to fit different Tucker4 models to the data varying the numbers of components P, Q, R and S. Among the solutions with the same value of \(\textit{P}+\textit{Q}+\textit{R}+\textit{S}\), we select the one with the highest fit. These remaining solutions are then ordered according to the total numbers of components. Finally, we choose the solution corresponding to a noticeable increase of fit with respect to that of the solution with one component less and such that adding one component leads to a relatively unsubstantial increase of fit.
Such a chosen solution is considered as optimal if it offers an interesting interpretation. To this purpose, first, we interpret the components pertaining to each dimension, i.e., the component matrices A, B, C and D; next, the core array \(\underline{{\textbf {G}}}\) summarizing the main interactions in the data. For each component matrix, every component is interpreted by inspecting the values of every column separately. In this sense, interpretation differs from classic PCA where component loadings can be related to correlations between variables and components. To interpret the core, one should bear in mind that its values describe the full four-way data, reduced to the summarizing descriptions given by the components for the four modes. Thus, the core array summarizes the information in the original four-way array and contains main effects and two-, three-, and four-way interactions present in the original array (Kiers & Van Mechelen, 2001). The core elements can be compared with each other. Roughly speaking, high core elements in absolute sense denote strong associations between the components for the four modes.
When the chosen solution is not well interpretable, a new solution with a different total number of components \(\textit{P}+\textit{Q}+\textit{R}+\textit{S}\) is investigated.
2.3.3 Software
Several software tools are available for implementing a multiway analysis. Although most of them are limited to the three-way case (\(N = 3\)), software tools for the general N-way case (\(N > 3\)) exist. A gentle overview can be found in Kroonenberg (2016). In Matlab the N -way toolbox (Andersson & Bro, 2000) is probably the most famous one. We also mention the R package multiway (Helwig, 2019) that is used for obtaining the results reported in this paper. Note that the rotation to simple structure is done by using the R function varimax4 available in the Supplementary Material.
3 Application
We analyse a dataset provided by the World Health Organization (WHO) mortality database, which is an archive of causes of death information for several countries. The longest time series starts in 1950, however, for many countries, the information starts from 1959. The application of the methodology requires the availability of data for all possible combinations of causes of death, ages, times and countries. We thus consider the following \(I=8\) causes of death: Infectious diseases, Smoking-related cancer, Non-smoking-related cancer, Diabetes, Cardiovascular diseases (hereinafter CVD), Respiratory diseases, External causes of death, Other causes of death. It is worth noting that the classification of causes of death has greatly changed since 1959, passing from ICD 7th to ICD 10th revision. Age is organized in classes as follows: age groups 0, 1–4, 5–9, 10–14, 15–19, \(\ldots \), 80–84 (\(J=18\)). Only the countries for which data is available in this time frame are included in the analysis (see the \(L=18\) countries listed in Table 4) and because of this, regarding time, we focus the analysis on the years 1961–2015 (hence, \(K=55\)) to consider the same time window for each country. The analysis is developed distinguishing the results by sex, first considering the males and then the females. Therefore, with respect to the previous papers (Russolillo et al., 2011; Giordano et al., 2019; Dong et al., 2020; Li et al., 2019), we introduce a new dimension, passing from the Tucker3 model to the Tucker4 one that, as far as we saw, was never used for the analysis of mortality data.
In order to carry out the four-way analysis, we organize the data in an array of four dimensions (causes of death \(\times \) age classes \(\times \) times \(\times \) countries). The dimension of the array is: 8 \(\times \) 18 \(\times \) 55 \(\times \) 18, for a total of 142,560 entries. In particular, the generic element of the array is the death rate for cause of death i, at age class j in year k, in country l: \(d_{ijkl}\). The death rateFootnote 1 for an individual for cause of death i, at age class j in year k, in country l is \(d_{ijkl}=\frac{D_{ijkl}}{E_{jkl}}\), where \(D_{ijkl}\) is the number of deaths for cause of death i, at age class j during year k, in country l and \(E_{jkl}\) is the risk exposure of the population of age j in year k, in country l. It is noteworthy that it is not possible to obtain causes-specific Exposures, thus the causes-specific mortality rates are computed by using the Number of Deaths specific for each cause, and the Exposures, that are aggregated on the overall mortality.
3.1 Male analysis results
To get more reliable results, before fitting the model to the data, we decide to scale them in such a way that all relevant parts of the data play the same role in the analysis and unwanted differences in scale are eliminated. For these reasons, we decided to scale the data within the countries and the age classes. Such a scaling avoids that the underlying components arbitrarily depend on a particular country and age class. While it is desirable that the mortality patterns of the countries have the same impact on the results and, therefore, the motivation for scaling within the countries should be clear, scaling within the age classes reflects our interest that the underlying components do not strongly depend on the older age classes, characterised by the highest death rates and the largest variability. As we shall see, this allows us to extract relevant components involving patterns not only related to elderly ages but also to children and even infants that, otherwise, would have been overlooked by the model. Moreover, we decide not to center the data because a meaningful zero point already exists. In fact, \(d_{ijkl}=0\) means absence of death due to cause od death i at age j, in year k, in country l.
To choose among the multitude of possible Tucker4 solutions, we run Tucker4 by varying P, Q, R and S from 2 to 8 (\(=\min (I,J,K,L)\)) and compute the associated fit value. In this way, we consider all the Tucker4 solutions with a total number of components \(P+Q+R+S\) ranging from 8 to 32. In Table 1 we listed the best solutions for each total number of components and the corresponding fit expressed as a percentage.
By inspecting Table 6, we conclude that the solution corresponding to the best compromise between fit and parsimony is the one with \(P=3\), \(Q=4\), \(R=2\), \(S=2\) with the fit value equal to 90.5%. This choice is also corroborated by the next interesting interpretation of the underlying components. As already noted, all the component matrices are varimax-rotated, compensating such rotations into the core.
In Table 2, we report the component scores for the causes of death mortality (component matrix \(\textbf{A}\)). Component 1 for the causes of death, labeled ”External”, mainly depends on external causes (0.98), frequently related to young mortality, road accidents, and violence. In other words, it identifies a behavior of mortality characterised by external diseases leading to a higher incidence of mortality with respect to the other causes of death. The meaning will be clearer when we will study the core elements expressing the interactions between the components of the four modes. Component 2, labeled ”CVD+Cancer”, is strongly associated with CVD and Cancer (even if, to a lesser extent, with Non-smoking-related cancer). Component, ”Other”, is strongly related to other diseases (0.97).
Table 3 shows the component scores for the age classes (component matrix \(\textbf{B}\)). Component 1 for the age classes, labeled ”Adults+Old”, reflects the adult and old mortality, showing the typical regularity well described by the linear Gompertz law of mortality. We can relate Component 2, labeled “Teenagers +Early Adults”, to the behavior of mortality of the teenagers and the early adults. In particular, this component captures the excess of mortality for age classes from 15–20 to 40–44. Component 3, ”Infants”, depicts the infant mortality. Finally, Component 4, labeled “Children” reflects the behaviors of mortality of children. It is positively associated with age classes 1–4, 5–9, 10–14 and 15–19.
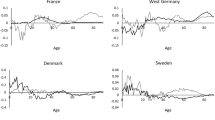
The components for the years (component matrix \(\textbf{C}\)), displayed in Fig. 3, offer an interesting interpretation in the light of longevity literature. We can see two different components: Component 1 (in blue), labeled ”Late”, represents the mortality dynamics after the ”converging period” in the 1980s. Component 2 (in red), labeled ”Early”, shows higher values before 1980. Indeed, the recent historical worldwide longevity dynamics highlight the first decrease of mortality after the 50 s, albeit, with high heterogeneity levels, that flattened in the decades around 75 s-85 s, which might be described as the global convergence (Oeppen & Vaupel, 2002, 2006; Nigri et al., 2021). Subsequently, another improvement emerges quite globally around the world.

Component matrix for the years. Male analysis
The components for the countries (component matrix D) are given in Table 4. Component 1 for the countries, labeled ”High Welfare”, is mainly associated with Japan, but also with other European countries characterized by geographical proximity (France, Austria, Switzerland, and Italy) and with two North European countries (Sweden and Finland) that have recently shown relevant improvements in life expectancy leading the global records as the case of Sweden (Oeppen & Vaupel, 2002). In general, the component mainly identifies countries well-known for their longevity and characterized by a high/medium welfare status. This component underlines how, as countries wealth grows, the raising rate of return on human capital causes a demographic transition (Tamura, 1996). This highlights the relation between economic and health status as suggested by Smith (1999). Component 2, labeled “Anglosaxon”, is mainly composed by countries usually considered similar in culture and values: Ireland, UK, USA and Australia, which share the Anglosaxon culture.
The previous component matrices provide a good description of the cause-of-death mortality scenario. Nevertheless, a piece of more detailed information could be achieved by interpreting the core tensor G, which provides the interaction term. Table 5 reports the tabular representation of the core where, once again, we highlight that the higher in absolute value an element of the core, the stronger the interaction among the quadruple of components involved.
The highest core element (\(g_{2111}=6.40\)) refers to the interaction term between CVD and cancer (Component 2 for the causes of death) that occurred at adult and old ages (Component 1 for the age classes) in the late period (Component 1 for the years) for the high welfare countries considered by HMD (Component 1 for the countries). It means that during this period, for adults and elderly, CVD and cancer lead to particularly high mortality in the countries considered. This is explained by the recent trends regarding longevity, we are experiencing, especially in the high welfare countries. The interaction between Component 2 for the causes of death and Component 1 for the age classes is however uniformly high for all country and year components (\(g_{2121}=5.77\), \(g_{2122}=4.98\), \(g_{2112}=4.88\)), thus highlighting its relevance in the analysis of mortality patterns. In the late period, for the high welfare countries, another high core element refers to the interaction linking to external causes of death and young and early adults mortality (\(g_{1211}=5.08\)); it means that during the phase of convergence of longevity, in all the countries considered, young and adult individuals experienced high mortality for external causes. Once again, high interactions are also observed for different countries and/or years, as witnessed by core elements \(g_{1221}=5.02\), \(g_{1212}=4.46\), and, to a lesser extent, \(g_{1222}=2.78\). Moreover, in the early period there is a prevalence of deaths caused by external causes for children in the high welfare countries (\(g_{1421}=5.25\)). Such a finding is also observed for the anglophone countries, even if the corresponding core element is lower (\(g_{1422}=3.66\)), hence the interaction is weaker. Finally, in the high welfare countries, we can note the pretty high interaction between infants and other causes of death in the late period (\(g_{3311}=2.68\)).
3.2 Female analysis results
To get more reliable results, before fitting the model to the data, these are preprocessed. Similarly to the male analysis, we scale the data in such a way that the information pertaining to the countries and the age classes plays the same role and no centering is done.
In Table 6 we listed the best solution for the total number of components \(P+Q+R+S\) with the corresponding goodness of fit index, expressed as a percentage.
We select the solution with \(P=4\), \(Q=4\), \(R=2\), \(S=2\) that provides a fit value equal to 88.85%. Therefore, in comparison with the male analysis, we consider one more component for the causes of death. To motivate this choice, in Table 7, we give the component scores for the causes of death (matrix A). We can see that, to a certain extent, the interpretation of the extracted components resembles the one of the male analysis. Component 1, labeled ”CVD versus Other”, mainly depends on CVD. Similarly to the male analysis, Component 2 is mainly associated with external diseases, while Component 3 is positively related to other causes of death. Finally, Component 4 is associated to non-smoking- and smoking-related cancer (0.84 and 0.52, respectively), portraying the higher incidence of cancer diseases among the populations. Such a component allows us to distinguish cancer diseases from the other causes, therefore legitimating the choice of having one more component for such a dimension compared to the male analysis.
Table 8 reports the component score matrix for the age classes (matrix B). Component 1 reflects the adult mortality (age classes from 35–49 to 60–64). Component 2 is positively associated with all the classes from 1–4 to 30–35, capturing high mortality of children and young individuals. Finally, Component 3 reflects the mortality behavior of old people (age classes from 65–69 to 80–84) and Component 4 depicts the infant mortality (age classes 0 and 1–4).
Figure 4, displaying the component matrix for the years (C), confirms the interesting interpretation previously found in the male analysis with Component 1 (in red), labeled ”Early”, and Component 2 (in blue), labeled ”Late”. Note that, in the two analyses, the interpretation of the components remains the same, but the labels of the components are switched.

Component matrix for the years. Female analysis
Table 9 shows the component matrix for the countries (D). As for the male analysis, Component 1 is associated to high welfare countries (France, Switzerland, and Sweden emerges as in the corresponding component in the male analysis), but some differences are visible. Component 2, labeled ”Other”, includes the two largest countries of Southern Europe, Italy and Spain, but also United Kingdom, Ireland and Hungary. Italy and Spain are usually considered similar in culture, values, and economic patterns; for example, both are Catholic and Latin countries, they are latecomers to European industrialization, and are medium- to large-sized countries with significant regional differences. The paper in Felice et al. (2016) explains the common demographic and economic factors between Italy and Spain. What is more, Ireland is often compared to Spain and Italy for its pattern of mortality, for example in terms of life expectancy (Roser et al., 2013).
Further information can be revealed by the core tensor \(\mathbf{{G}}\) reported in Table 10.
The highest core element (\(g_{2211} = 5.79\)) refers to the interaction term between external causes of death that occur for children and at young ages in the early period for the high welfare countries. It means that during this period, for these age classes, the external causes of death lead to high mortality in such countries. In the early period, for the same group of countries the element linked to CVD versus Other (\(g_{1311} = 4.86\)) reveals that during the early phase, for old people, there is a higher incidence of deaths by CVD compared to Other causes of death. Finally, we can observe, for adults, high levels of mortality caused by CVD compared to Other (\(g_{1111} = 3.43\)), and Cancer (\(g_{4111} = 3.29\)).
In the late period, still focusing our attention on the high welfare countries, high mortality for adults due to cancer emerges (\(g_{4121} = 4.38\)). As for the early period and for the elderly, we can see high mortality due to CVD compared to Other (\(g_{1321} = 3.90\)). The core element \(g_{3421} = 3.03\) allows us to discover the strong level of infant mortality due to Other causes of death. Finally, \(g_{2221} = 4.30\) refers to the interaction between external causes of deaths that occur to children and young individuals in the late period for the high welfare countries.
With respect to the core elements involving Other countries (Component 2 for the countries), in the early period, high mortality due to external causes for children and young people (\(_{g2212} = 3.69\)) is registered. We also observe high mortality for CVD versus Other in adults and elderly (\(g_{1112} = 3.46\), \(g_{1312} = 3.75\)). Note that such results are consistent with the male analysis. Furthermore, in the late period, CVD versus Other is relevant for old people \(g_{1322} = 3.39\)). Finally, we can discover high mortality due to Cancer and External causes for, respectively, adults and children and young individuals (respectively, \(g_{4122} = 3.14\), \(g_{2222} = 3.14\)).
4 Conclusions
Modeling mortality represents a crucial issue in various fields: public health, pension schemes and financial planning are prime examples. In recent years, researchers were prioritizing the investigation of the overall longevity. Nevertheless, more specific mortality data might provide a piece of better information for designing national decision planning. Our approach represents an advance in longevity modeling, showing a more informative view of mortality levels specific for causes of death, in a multi-population framework. Leveraging the Tucker4 model, our contribution to the literature consists of a multi-population and causes of death analysis in a unified framework. Indeed, different populations with similar socio-economic statuses share similar mortality trends to some extent. Such a common information could be extracted and exploited in a multi-population framework to help model mortality of individual populations. The dataset we have considered has been provided by the World Health Organization, arranged into a four-way array structure composed by causes of death, age, years, and countries. For both genders separately, we have shown how the Tucker4 model is able to extract meaningful demographic insights. In fact, the aim of this model is to efficiently summarize all the information in the four-way data, also considering the existing interactions. In particular, it helps us understand how the rises in survival, witnessed in many high-income and developed countries, during the twentieth century, were determined especially by the reduction in a few specific major causes of death groups, which led to the longevity improvements. We also observe that a single five-way analysis by using sex as fifth dimension could have been carried out. Nevertheless, we decided to consider two separate four-way analyses. This is motivated by the fact that different mortality patterns for male and female exist. If we applied the Tucker5 model, the low-dimensional representation of the sex dimension could be achieved by extracting only one component. This implies that the components for the remaining four dimensions would be a sort of compromise of the female and male mortality patterns with weights given by the component scores for sex. Performing two separate four-way analyses allowed us to better investigate and reveal the existing gender-specific peculiarities.
Notes
In Actuarial Science, Demography, Epidemiology, and Biostatistics as well, it is common to deal with the so-called Hazard function (or Force of Mortality), which is, in its continuous formulation, the instantaneous rate of death at age j, conditioned upon surviving to that age, (in a given year k). In practice, researchers work on its discrete counterpart, expressed by the mortality rate as the ratio of the Number of Death/Population (or Exposure to risks). Often, this rate, and thus both Deaths and Exposures, are specific for age and years. Nevertheless, they might also be specified for age classes (j), years (k), and country (l).
References
Andersson, C. A., & Bro, R. (2000). The \(N\)-way toolbox for MATLAB. Chemometrics and Intelligent Laboratory Systems, 52, 1–4.
Bergeron-Boucher, M. P., Simonacci, V., Oeppen, J., & Gallo, M. (2018). Coherent modeling and forecasting of mortality patterns for subpopulations using multiway analysis of compositions: An application to Canadian provinces and territories. North American Actuarial Journal, 22, 92–118.
Devolder, P., Levantesi, S., & Menzietti, M. (2021). Automatic balance mechanisms for notional defined contribution pension systems guaranteeing social adequacy and financial sustainability: an application to the Italian pension system. Annals of Operations Research, 299, 765–795.
Dong, Y., Huang, F., Yu, H., & Haberman, S. (2020). Multi-population mortality forecasting using tensor decomposition. Scandinavian Actuarial Journal, 8, 754–775.
Felice, E., Andreu, J. P., & D’Ippoliti, C. (2016). GDP and life expectancy in Italy and Spain over the long run: A time-series approach. Demographic Research, 35(28), 813–886.
Giordano, G., Haberman, S., & Russolillo, M. (2019). Coherent modeling of mortality patterns for age-specific subgroups. Decisions in Economics and Finance, 42, 189–204.
Harshman, R. A. (1984). Data preprocessing and the extended PARAFAC model. In: Research methods for multi-mode data analysis (pp. 216–284).
Helwig, N.E. (2019). multiway: Component models for multi-way data. R package version 1.0-6. https://CRAN.R-project.org/package=multiway
Ho, J. Y., & Hendi, A. S. (2018). Recent trends in life expectancy across high income countries: Retrospective observational study. British Medical Journal, 362, k2562.
Kaiser, H. F. (1958). The varimax criterion for analytic rotation in factor analysis. Psychometrika, 23, 187–200.
Kapteyn, A., Neudecker, H., & Wansbeek, T. (1986). An approach ton-mode components analysis. Psychometrika, 51, 269–275.
Kiers, H. A. L. (2000). Towards a standardized notation and terminology in multiway analysis. Journal of Chemometrics, 14, 105–122.
Kiers, H. A. L., & Van Mechelen, I. (2001). Three way component analysis: Principles and illustrative application. Psychological Methods, 6, 84–110.
Kjærgaard, S., Ergemen, Y. E., Kallestrup-Lamb, M., Oeppen, J., & Lindahl-Jacobsen, R. (2019). Forecasting causes of death by using compositional data analysis: The case of cancer deaths. Journal of the Royal Statistical Society Series C, 68, 1351–1370.
Kroonenberg, P. M. (2016). My multiway analysis: from Jan de Leeuw to TWPack and back. Journal of Statistical Software, 73, 1–22.
Kroonenberg, P. M., & De Leeuw, J. (1980). Principal component analysis of three-mode data by means of alternating least squares algorithms. Psychometrika, 45(1), 69–97.
Lee, R. D., & Carter, L. R. (1992). Modeling and forecasting us mortality. Journal of the American Statistical Association, 87, 659–671.
Leon, D. A., Jdanov, D. A., & Shkolnikov, V. M. (2019). Trends in life expectancy and age specific mortality in England and Wales, 1970–2016, in comparison with a set of 22 high income countries: an analysis of vital statistics data. The Lancet Public Health, 4, E575–E582.
Levantesi, S., Nigri, A., & Piscopo, G. (2021). Clustering-based simultaneous forecasting of life expectancy time series through long-short term memory neural networks. International Journal of Approximate Reasoning, 140, 282–297.
Li, H., Li, H., Lu, Y., & Panagiotelis, A. (2019). A forecast reconciliation approach to cause-of-death mortality modeling. Insurance: Mathematics and Economics, 86, 122–133.
Li, N., & Lee, R. (2005). Coherent mortality forecasts for a group of populations: An extension of the Lee-Carter method. Demography, 42, 575–594.
Lindahl-Jacobsen, R., Rau, R., Jeune, B., Canudas Romo, V., Lenart, A., Christensen, K., & Vaupel, J. W. (2016). Rise, stagnation, and rise of Danish women’s life expectancy. Proceedings of the National Academy of Sciences, 113, 4015–4020.
Meslé, F., & Vallin, J. (2006). Diverging trends in female old age mortality: The United States and The Netherlands versus France and Japan. Population and Development Review, 32, 123–145.
Nigri, A., Barbi, E., & Levantesi, S. (2021). The relationship between longevity and lifespan variation. Statistical Methods and Applications. https://doi.org/10.1007/s10260-021-00584-4.
Nigri, A., Levantesi, S., & Piscopo, G. (2022). Causes-of-death specific estimates from synthetic health measure: A methodological framework. Social Indicators Research, 162, 887–908.
Oeppen, J., & Vaupel, J. W. (2002). Broken limits to life expectancy. Science, 296, 1029–1031.
Oeppen, J. & Vaupel, J. W. (2006). The linear rise in the number of our days. Social Insurance. Studies, 3. The Linear Rise in Life Expectancy: History and Prospects.
Roser, M., Ortiz-Ospina, E., & Ritchie, H. (2013). Life expectancy. Our World in Data.
Russolillo, M., Giordano, G., & Haberman, S. (2011). Extending the Lee-Carter model: A three-way decomposition. Scandinavian Actuarial Journal, 2, 96–117.
Smith, J. P. (1999). Healthy bodies and thick wallets: The dual relation between health and economic status. Journal of Economic Perspectives, 13, 145–166.
Tamura, R. (1996). From decay to growth: A demographic transition to economic growth. Journal of Economic Dynamics and Control, 20, 1237–1261.
Tucker, L. R. (1966). Some mathematical notes on three-mode factor analysis. Psychometrika, 31, 279–311.
Wilmoth, J. R. (2000). Demography of longevity: Past, present, and future trends. Experimental Gerontology, 35, 1111–1129.
Funding
Open access funding provided by Università degli Studi di Roma La Sapienza within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cardillo, G., Giordani, P., Levantesi, S. et al. A tensor-based approach to cause-of-death mortality modeling. Ann Oper Res (2022). https://doi.org/10.1007/s10479-022-05042-2
Accepted:
Published:
DOI: https://doi.org/10.1007/s10479-022-05042-2