
Abstract
In this paper a class of combinatorial optimization problems is discussed. It is assumed that a feasible solution can be constructed in two stages. In the first stage the objective function costs are known while in the second stage they are uncertain and belong to an interval uncertainty set. In order to choose a solution, the minmax regret criterion is used. Some general properties of the problem are established and results for two particular problems, namely the shortest path and the selection problem, are shown.
Similar content being viewed by others

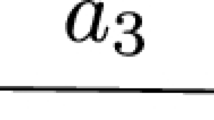

Avoid common mistakes on your manuscript.
1 Introduction
Consider the following deterministic single-stage combinatorial optimization problem:

where \({\mathcal {X}}\subseteq \{0,1\}^n\) is a set of feasible solutions and \(\pmb {c}\in \mathbb {R}_+^n\) is a vector of nonnegative objective function costs. Typically, \({\mathcal {X}}\) is described by a system of linear constraints involving binary variables \(x_i\), \(i\in [n]\) (we will use the notation \([n]=\{1,\dots ,n\}\)), which leads to a 0-1 programming problem. Solution \(\pmb {x}\in {\mathcal {X}}\) can be interpreted as a characteristic vector of some finite element set E. For example, E can be a set of edges of a graph \(G=(V,E)\) and \(\pmb {x}\) describes some objects in G such as paths, trees, matchings etc.
In many practical applications the vector of objective function costs \(\pmb {c}\) is uncertain and it is only known to belong to an uncertainty set \({\mathcal {U}}\). There are various methods of defining \({\mathcal {U}}\) which depend on the application and the information available. Among the easiest and most common is the interval uncertainty representation (see, e.g., Kouvelis and Yu 1997), in which \(c_i\in [{\underline{c}}_i, {\overline{c}}_i]\) for each \(i\in [n]\) and \({\mathcal {U}}=\prod _{i\in [n]} [{\underline{c}}_i,{\overline{c}}_i]\subseteq \mathbb {R}_+^n\). In order to choose a solution, for a specified \({\mathcal {U}}\), one can apply a robust decision criterion, which takes into account the worst cost realizations. Under the interval uncertainty representation, the minmax regret criterion (also called Savage criterion (Savage 1951)) has attracted a considerable attention in the literature. The regret of a given solution \(\pmb {x}\in {\mathcal {X}}\) under a cost scenario \(\pmb {c}\in {\mathcal {U}}\) is the quantity \(\pmb {c}^T\pmb {x}-\mathrm{opt}^{{\mathcal {P}}}(\pmb {c})\). It expresses a deviation of solution \(\pmb {x}\) from the optimum and can be interpreted as the maximal opportunity loss after \(\pmb {x}\) is implemented. In the single-stage minmax regret version of \({\mathcal {P}}\) we seek a solution minimizing the maximum regret, i.e. we study the following problem:

The SStR \({\mathcal {P}}\) problem has been discussed in a number of papers, for example when \({\mathcal {P}}\) is the minimum spanning tree (Montemanni 2006; Montemanni and Gambardella 2005; Yaman et al. 2001), the shortest path (Karaşan et al. 2001; Montemanni and Gambardella 2004; Montemanni et al. 2004), the minimum s-t cut (Aissi et al. 2008; Kasperski and Zieliński 2007), the minimum assignment (Aissi et al. 2005; Pereira and Averbakh 2011), or the selection (Averbakh 2001; Conde 2004) problem (in this case \({\mathcal {X}}=\{\pmb {x}\in \{0,1\}^n: x_1+\dots +x_n=p\}\) for some fixed \(p\in [n]\)). Surveys of known results in this area can be found in Aissi et al. (2009) and Kasperski and Zieliński (2016). Unfortunately, SStR \({\mathcal {P}}\) turned out to be NP-hard for all previously mentioned problems (Aron and van Hentenryck 2004; Averbakh and Lebedev 2004; Zieliński 2004; Kasperski and Zieliński 2006b), with a notable exception when \({\mathcal {P}}\) is the selection problem, for which polynomial algorithms were established in Averbakh (2001) and Conde (2004). The SStR \({\mathcal {P}}\) problem has some well known general properties. There is a nice characterization of scenario \(\pmb {c}\in {\mathcal {U}}\) maximizing the regret of a given solution \(\pmb {x}\) (called a worst-case scenario for \(\pmb {x}\)), namely, \(c_i={\overline{c}}_i\) if \(x_i=1\) and \(c_i={\underline{c}}_i\) if \(x_i=0\) for each \(i\in [n]\). Notice that this scenario depends only on \(\pmb {x}\) and the problem of computing the maximum regret of a given solution has the same complexity as \({\mathcal {P}}\). Also, there is a general 2-approximation algorithm known for SStR \({\mathcal {P}}\), under the assumption that \({\mathcal {P}}\) is polynomially solvable (Kasperski and Zieliński 2006a; Conde 2010; Chassein and Goerigk 2015). We get a 2-approximate solution by solving \({\mathcal {P}}\) under the so-called midpoint scenario \(\pmb {c}^m\in {\mathcal {U}}\) such that \(c_i^m=({\underline{c}}_i+{\overline{c}}_i)/2\) for each \(i\in [n]\). Exact algorithms for solving SStR \({\mathcal {P}}\) are based on compact mixed-integer programming (MIP) formulations (see, e.g., Yaman et al. 2001), when \({\mathcal {P}}\) has a special structure, or constraint generation technique in general (see, e.g., Montemanni 2006; Pereira and Averbakh 2013).
In some applications a solution from \({\mathcal {X}}\) can be constructed in two stages. Namely, a partial solution is chosen now (in the first stage) and is completed in the future (in the second stage). The current, first-stage costs are known while the future second-stage costs are uncertain and belong to an uncertainty set \({\mathcal {U}}\). However, the partial solution can be completed after a second-stage cost scenario is revealed. The problem consists in computing a best first-stage solution, which corresponds to the decision which must be made now. The two-stage approach has a long tradition in stochastic optimization (see, e.g., Kall and Mayer 2005). When a probability distribution in \({\mathcal {U}}\) is unknown, then a robust two-stage version of \({\mathcal {P}}\) can be considered. First such a model was discussed in Katriel et al. (2008) for the assignment problem. This approach was also applied to the minimum spanning tree (Kasperski and Zieliński 2011) and the selection problems (Chassein et al. 2018). In these papers the robust minmax criterion has been applied, i.e. a first-stage solution is determined minimizing the largest total first and second-stage cost. Two-stage problems with the maximum regret criterion have recently been considered in Poursoltani and Delage (2019) with a focus on continuous problems, and in Crema (2020) under the min-max-min setting.
In this paper we wish to investigate the two-stage version of problem \({\mathcal {P}}\) under the interval uncertainty representation. Namely, for each second-stage cost an interval of its possible values is provided. We use the minmax regret criterion to choose a solution. The interpretation of this problem is the same as in the case of SStR \({\mathcal {P}}\). We seek a first-stage solution, which minimizes the maximum regret, i.e. the maximum distance to a best first-stage solution. We will show that this problem has different properties than its single-stage counterpart. In particular, there is no easy characterization of a worst-case scenario of a given first-stage solution, although there is still a worst-case scenario which is extreme (the second-stage costs take their upper or lower bounds under this scenario). In fact, the problem of computing the maximum regret can be NP-hard, even if \({\mathcal {P}}\) is solvable in polynomial time. Also, the midpoint heuristic does not guarantee any approximation ratio in general. We will show a general method of solving the problem, which is based on a MIP formulation. We then study two special cases, when \({\mathcal {P}}\) is the shortest path and the selection problem.
This paper is organized as follows. In Sect. 2 we state the problem. We also consider three inner problems, in particular the problem of computing the maximum regret of a given first-stage solution. In Sect. 3, we construct MIP formulations, which can be used to compute exact or approximate solutions. Section 4 is devoted to the two-stage version of the shortest path problem. We proceed with the study of two variants of this problem, which have different computational properties. We show that both computing an optimal first-stage solution and the maximum regret of a given first-stage solution are NP-hard. In Sect. 5 we discuss the selection problem. We show that for this problem the maximum regret of a given first-stage solution can be computed in polynomial time and the optimal first-stage solution can by determined by using a compact MIP formulation. We also propose a greedy heuristic for this problem. Numerical results are presented in Sect. 6. Finally, the paper is concluded and further research questions are pointed out in Sect. 7.
2 Problem formulation
In this paper we assume that a solution from \({\mathcal {X}}\) can be built in two-stages. Given a vector \(\pmb {x}\in \{0,1\}^n\), let
be the set of recourse actions for \(\pmb {x}\). Vector \(\pmb {y}\in {\mathcal {R}}(\pmb {x})\) is a completion of the partial solution \(\pmb {x}\) to a feasible one. Let
be the set of feasible first-stage solutions. Define \({\mathcal {Z}}=\{(\pmb {x},\pmb {y})\in \{0,1\}^{2n}: \pmb {x}\in {\mathcal {X}}', \pmb {y}\in {\mathcal {R}}(\pmb {x})\}\) as the set of all possible combinations between partial first-stage solutions and recourse actions. Given a first-stage cost vector \(\pmb {C}\in \mathbb {R}_+^n\) and a second-stage cost vector \(\pmb {c}\in \mathbb {R}_+^n\), we consider the following two-stage problem:

Given \(\pmb {x}\in {\mathcal {X}}'\) and \(\pmb {c}\in \mathbb {R}_+^n\), we will also examine the following incremental problem:

in which we seek a best recourse action for \(\pmb {x}\in {\mathcal {X}}'\) and \(\pmb {c}\). The quantity \(\mathrm{Inc}(\pmb {x},\pmb {c})-\mathrm{Opt}(\pmb {c})\) is called the regret of \(\pmb {x}\) under \(\pmb {c}\). Suppose that the second-stage costs are uncertain and we only know that \(c_i\in [{\underline{c}}_i,{\overline{c}}_i]\) for each \(i\in [n]\). We thus consider the interval uncertainty representation \({\mathcal {U}}=\prod _{i\in [n]} [{\underline{c}}_i,{\overline{c}}_i]\). Each possible second-stage cost vector \(\pmb {c}\in {\mathcal {U}}\) is called a scenario. Let us define the maximum regret of a given first-stage solution \(\pmb {x}\in {\mathcal {X}}'\) as follows:
A scenario which maximizes the right hand side of (2) is called a worst-case scenario for \(\pmb {x}\). In this paper we study the following two-stage minmax regret problem:

Let us illustrate TStR \({\mathcal {P}}\) when \({\mathcal {P}}\) is the Shortest Path problem shown in Fig. 1a. In this case, \({\mathcal {X}}\) is the set of characteristic vectors of the simple \(s-t\) paths in a given network \(G=(V,A)\).

Two instances of TStR Shortest Path. In the instance b) we assume that \(b\gg 2a \gg \varepsilon >0\)
Let \(\pmb {x}=(x_{s1},x_{s2}, x_{12}, x_{1t}, x_{2t})^T\in {\mathcal {X}}'\) denote a first-stage solution to the instance in Fig. 1a. A candidate solution is \(\pmb {x}'=(1,0,0,0,0)^T\), in which the arc (s, 1) is selected in the first stage. Under scenario \(\underline{\pmb {c}}=(0,0,0,0,0)^T\), this partial solution can be completed to a path by choosing arc (1, t) with total costs \(1+0=1\). As \(\text {Opt}(\underline{\pmb {c}}) = 0\), the maximum regret of \(\pmb {x}'\) is at least 1. It can be verified that there is no other scenario that results in a higher regret. As a second example, the first-stage solution \((0,1,0,0,0)^T\) has the maximum regret equal to 10. Indeed in a worst scenario \(\pmb {c}'\) the cost of (2, t) is set to 10 and the costs of the remaining arcs are set to 0. The arcs (2, t) must be selected in the second stage and \(\mathrm{opt}(\pmb {c}')=0\), which results in the regret of 10. Notice also that solution \((0,0,0,0,0)^T\), when no arc is selected in the first stage, has the maximum regret equal to 2, achieved by using scenario \(\overline{\pmb {c}}=(2,1,0,6,10)\). A full enumeration reveals that \(\pmb {x}'\) is in fact optimal.
The instance in Fig. 1b demonstrates that the mid-point heuristic does not guarantee the approximation ratio of 2 for TStR \({\mathcal {P}}\). Indeed, if we solve the TSt Shortest Path problem for the second-stage midpoint scenario \(\pmb {c}^m=(b/2,a)^T\), then we get solution \(\pmb {x}^m=(0,1)^T\) with \(Z(\pmb {x}^m)=a-\epsilon \). But the optimal first-stage solution is \(\pmb {x}=(0,0)^T\) with \(Z(\pmb {x})=\epsilon \). Hence the ratio \(Z(\pmb {x}^m)/Z(\pmb {x})=(a-\epsilon )/\epsilon \) can be arbitrarily large.
3 Mixed integer programming formulations
In this section we construct mixed integer programming formulations for computing the maximum regret \(Z(\pmb {x})\) of a given first-stage solution \(\pmb {x}\in {\mathcal {X}}'\) and solving the TStR \({\mathcal {P}}\) problem. In particular, we will show that for each \(\pmb {x}\in {\mathcal {X}}'\), there exists a worst-case scenario which is extreme, i.e. which belongs to \(\prod _{i\in [n]}\{{\underline{c}}_i, {\overline{c}}_i\}\). In the following, we will use \(\underline{\pmb {c}}\) to denote the scenario \(({\underline{c}}_1,\dots ,{\underline{c}}_n)^T\). Fix \((\pmb {u},\pmb {v})\in {\mathcal {Z}}\) and define
It is easy to verify that
Proposition 1
It holds that
where scenario \(\pmb {c}_{\pmb {v}}\in {\mathcal {U}}\) is such that \(c_{\pmb {v}i}={\underline{c}}_i\) if \(v_i=1\) and \(c_{\pmb {v}i}={\overline{c}}_i\) if \(v_i=0\).
Proof
Write \(Z_{(\pmb {u},\pmb {v})}(\pmb {x})=\pmb {C}^T\pmb {x}-\pmb {C}^T\pmb {u}+t^*\), where \(t^*\) is computed by solving the following problem:
An optimal solution to (6) and (7) can be determined as follows: for each \(i\in [n]\), if \(v_i=1\), then \(c_i={\underline{c}}_i\) (because \(y_i-v_i\le 0\)) and if \(v_i=0\), then \(c_i={\overline{c}}_i\) (because \(y_i-v_i\ge 0)\). This yields the scenario \(\pmb {c}_{\pmb {v}}\). Observe also that \(\pmb {c}_{\pmb {v}}^T(\pmb {y}-\pmb {v})=-\underline{\pmb {c}}^T\pmb {v}+\min _{\pmb {y}\in {\mathcal {R}}(\pmb {x})} \pmb {c}_{\pmb {v}}^{T}\pmb {y}\), which completes the proof. \(\square \)
Proposition 1 implies the following corollary:
Corollary 1
For each \(\pmb {x}\in {\mathcal {X}}'\), there is a worst-case extreme scenario \(\pmb {c}\in \prod _{i\in [n]} \{{\underline{c}}_i,{\overline{c}}_i\}\).
The result stated in Corollary 1 is analogous to the known result for the single-stage SStR \({\mathcal {P}}\) problem (see, e.g., Aissi et al. 2009). However, in the two-stage model the worst-case scenario for \(\pmb {x}\in {\mathcal {X}}'\) is not completely characterized by \(\pmb {x}\). In order to compute \(Z(\pmb {x})\) one needs to find \((\pmb {u},\pmb {v})\in {\mathcal {Z}}\) maximizing the right-hand side of (3). In Sect. 4 we will show that the problem of computing \(Z(\pmb {x})\) is NP-hard, when \({\mathcal {P}}\) is the Shortest Path problem. Using equality (4) from Proposition 1, we can compute the maximum regret of \(\pmb {x}\) in the following way:
which, by using the definition of \(\pmb {c}_{\pmb {v}}\), can be stated equivalently as
The number of constraints in (8)–(10) can be exponential in n. This problem can be solved by standard row generation techniques. If the problem of optimizing a linear objective function over \({\mathcal {R}}(\pmb {x})\) can be written as a linear program, then it is also possible to find a compact reformulation of constraints (9) using primal–dual relationships (see, e.g., Papadimitriou and Steiglitz 1998). One such case will be demonstrated in Sect. 5. Let us now turn to the TStR \({\mathcal {P}}\) problem. Again, using equality (3) we can express this problem as the following program:
Using Proposition 1, we can convert this model to
Finally, making use of the definition of \(\pmb {c}_{\pmb {v}}\) and \({\mathcal {R}}(\pmb {x})\), we get the following MIP formulation for TStR \({\mathcal {P}}\):
The model (15)–(17) has an exponential number of variables and constraints. One can solve or approximate it by using a row and column generation technique (see, e.g., Zeng and Zhao 2013). The idea is to solve (15)–(17) for some subset \({\mathcal {Z}}'\subseteq {\mathcal {Z}}\) obtaining a solution \(\pmb {x}'\in {\mathcal {X}}'\), together with a lower bound on the optimal objective value. The upper bound and the cut indexed by \((\pmb {u}',\pmb {v}')\in {\mathcal {Z}}\), which can be added to \({\mathcal {Z}}'\), can by computed by solving the formulation (8)–(10) for \(\pmb {x}'\). Adding the cuts iteratively we can compute an exact or approximate solution to TStR \({\mathcal {P}}\). The efficiency of this method can depend on the structure of \({\mathcal {X}}\) and should be verified experimentally for each particular case.
4 The shortest path problem
In this section we deal with the case of \(\textsc {TStR}~{\mathcal {P}}\), in which \({\mathcal {P}}\) is the Shortest Path problem. Let \(G=(V,A)\) be a given network with two distinguished nodes \(s\in V\) and \(t\in V\). We will discuss two variants of the problem. In the first one, \({\mathcal {X}}_{{\mathcal {P}}}\) contains the characteristic vectors of all simple \(s-t\) paths in G. In the second case, \(\overline{{\mathcal {X}}}_{{\mathcal {P}}}\) contains all subsets of the arcs in which s and t are connected. Observe that \({\mathcal {X}}_{{\mathcal {P}}}\subseteq \overline{{\mathcal {X}}}_{{\mathcal {P}}}\) and in the deterministic case the problems with both sets are equivalent. To see that the situation is different in the two-stage model, consider the sample instance shown in Fig. 2.

An instance of TStR Shortest Path, where M is a sufficiently large number
In the problem with set \({\mathcal {X}}_{{\mathcal {P}}}\) the maximum regret of each first-stage solution equals M. On the other hand, for the set \(\overline{{\mathcal {X}}}_{{\mathcal {P}}}\) we can choose \(\pmb {x}=(1,1,0,0)\), i.e. we can select the arcs (s, 1) and (s, 2) in the first stage. Then, depending on the second-stage scenario we can complete this solution by choosing (1, t) or (2, t). The maximum regret of \(\pmb {x}\) is then 0. The example demonstrates that it can be profitable to select more arcs in the first stage, even if some of them are not ultimately used. The next theorem describes the computational complexity of TStR Shortest Path.
Theorem 1
The TStR Shortest Path problem with both \({\mathcal {X}}_{{\mathcal {P}}}\) and \(\overline{{\mathcal {X}}}_{{\mathcal {P}}}\) is NP-hard.
Proof
Consider the NP-hard Partition problem defined as follows (Garey and Johnson 1979). We are given a collection \(a_1,\dots ,a_n\) of positive integers, such that \(\sum _{i\in [n]} a_i=2b\). We ask if there is a subset \(I\subseteq [n]\) such that \(\sum _{i\in I} a_i=b\). Given an instance of Partition we build the graph shown in Fig. 3. For each arc we specify the first-stage cost and the second-stage cost interval, where \(M>2nb+2b\) is a sufficiently large constant (see Fig. 3). We show that the answer to Partition is yes if and only if there is a first-stage solution \(\pmb {x}\) with the maximum regret at most \(\frac{3}{2}b\). We first focus on the set \({\mathcal {X}}_{{\mathcal {P}}}\). To this end, we prove the following three claims:

The instance of TStR Shortest Path from the proof of Theorem 1
-
1.
There is an optimal first-stage solution with the maximum regret at most 2b. Let \(\pmb {x}\) be the first-stage solution in which all arcs \(q_1,\dots ,q_n\) are selected. Under any scenario, the optimal recourse action for \(\pmb {x}\) selects the arcs \(q_1',\dots ,q_n'\). In the worst-case scenario \(\underline{\pmb {c}}\) the second-stage costs of all arcs are set to their lower bounds. We get \(\mathrm{Inc}(\pmb {x},\underline{\pmb {c}})=2nb+2b\), \(\mathrm{Opt}(\underline{\pmb {c}})=2nb\) and \(Z(\pmb {x})=2b\).
-
2.
The first-stage solution \(\pmb {x}\), in which no arc is chosen in the first stage or at least one of the arcs among \(r, p_i', q_i'\), \(i\in [n]\), is chosen in the first stage is not optimal. Define scenario \(\pmb {c}_1\) in which the second-stage cost of arc r is M and the second-stage costs of the arcs \(p_1',\dots ,p_n'\) are 0. Observe that \(\mathrm{Opt}(\pmb {c}_1)=2nb\). It is easy to see that \(\mathrm{Inc}(\pmb {x},\pmb {c}_1)\ge M\). Hence \(Z(\pmb {x})\ge M-2nb>2b\) and \(\pmb {x}\) is not optimal, according to point 1.
-
3.
Any optimal first-stage solution \(\pmb {x}\) selects exactly one of \(p_i\) or \(q_i\) for each \(i\in [n]\). According to point 2. at least one of the arcs among \(p_i, q_i\), \(i\in [n]\), must be selected by \(\pmb {x}\). Assume there is \(k\in [n]\) such that both \(p_k\) and \(q_k\) are not selected in \(\pmb {x}\). Consequently, we must choose \(p_k\) or \(q_k\) in the second stage which implies \(\mathrm{Inc}(\pmb {x},\underline{\pmb {c}})\ge M\). Since \(\mathrm{Opt}(\underline{\pmb {c}})=2nb\), we get \(Z(\pmb {x})\ge M-2nb>2b\) and \(\pmb {x}\) is not optimal, according to point 1.
Let \(I\subseteq [n]\) be the set of indices of the arcs \(p_i\) selected in the first stage. Notice that \([n]{\setminus } I\) is the set of indices of the arcs \(q_i\) selected in the first stage. If arc \(p_i\) is chosen in the first stage, then \(p'_i\) must be chosen in the second state (the same is true for arcs \(q_i\)). In the worst-case scenario \(\pmb {c}\) we fix the cost of r to \(2nb+b\) and the cost of \(p_i'\) to \(\frac{3}{2}a_i\) if \(i\in I\) and to 0, otherwise. We get \(\mathrm{Inc}(\pmb {x}, \pmb {c})=2nb+\sum _{i\in I} \frac{3}{2}a_i+\sum _{i\in [n]{\setminus } I} a_i\) and \(\mathrm{Opt}(\pmb {c})=2nb+\min \{b, \sum _{i\in I} a_i\}\). The maximum regret of the formed path \(\pmb {x}\) is then
We now can see that the maximum regret of the formed path is at most \(\frac{3}{2}b\) if and only if \(\frac{1}{2}\sum _{i\in I} a_i=\frac{1}{2}b\), i.e. the answer to Partition is yes.
Let us now turn to the case of \(\overline{{\mathcal {X}}}_{{\mathcal {P}}}\). Because \({\mathcal {X}}_{{\mathcal {P}}}\subseteq \overline{{\mathcal {X}}}_{{\mathcal {P}}}\), the positive answer to the Partition problem implies that there is a first-stage solution \(\pmb {x}\in \overline{{\mathcal {X}}}_{{\mathcal {P}}}\) such that \(Z(\pmb {x})\le \frac{3}{2}b\). It remains to show the converse implication, i.e. if there is a first-stage solution \(\pmb {x}\in \overline{{\mathcal {X}}}_{{\mathcal {P}}}\) such that \(Z(\pmb {x})\le \frac{3}{2}b\), then the answer to Partition is yes. In the case of \(\overline{{\mathcal {X}}}_{{\mathcal {P}}}\) any subset of arcs in the formed network G is allowed to be selected in the first-stage. Similarly to the previous case, selecting any arc among \(r, p_i', q_i'\), \(i\in [n]\), in the first stage yields a solution \(\pmb {x}\) such that \(Z(\pmb {x})>2b\). Hence, it may only be profitable to choose more than n arcs among \(p_i, q_i\), \(i\in [n]\) in the first stage. Let \(\pmb {x}\) be any such a solution. Under scenario \(\underline{\pmb {c}}\), we get \(\mathrm{Inc}(\pmb {x},\underline{\pmb {c}})\ge 2nb+2b\), while \(\mathrm{Opt}(\underline{\pmb {c}})=2nb\). Hence \(Z(\pmb {x})\ge 2b\), a contradiction with the assumption that \(Z(\pmb {x})\le \frac{3}{2}b\). \(\square \)
Theorem 2
Computing the maximum regret \(Z(\pmb {x})\) for a given \(\pmb {x}\in {\mathcal {X}}'\) is NP-hard for both \({\mathcal {X}}_{{\mathcal {P}}}\) and \(\overline{{\mathcal {X}}}_{{\mathcal {P}}}\).
Proof
Given again an instance of the Partition problem (see the proof of Theorem 1). We construct a network \(G=(V,A)\) consisting of two disjoint paths from s to t, \(P_1\) and \(P_2\), each with n arcs. The network G with the corresponding first-stage costs and the second-stage cost intervals is shown in Fig. 4. Set \(\pmb {x}=\pmb {0}\), so no arc is allowed to be selected in the first stage. We will show that the answer Partition is yes if and only if \(Z(\pmb {x})\ge b\).

The instance of TStR Shortest Path from the proof of Theorem 2
Let \(\pmb {c}\) be a worst-scenario for \(\pmb {x}\). According to Corollary 1, we can assume that \(\pmb {c}\) is an extreme scenario. Let I be the set of indices of the arcs in \(P_1\) whose second-stage costs are set to the upper bounds. The value of \(\mathrm{Inc}(\pmb {x},\pmb {c})\) is the minimum of \(\sum _{i\in [n]} a_i\) (path \(P_2\) is used as the best recourse action) and \(\sum _{i\in I} 2a_i\) (path \(P_1\) is used as the best recourse action). On the other hand \(\mathrm{Opt}(\pmb {c})=\sum _{i\in I} a_i\), because the optimal two-stage path is \(P_1\), where the arcs with indices in I are selected in the first-stage. Hence
Therefore, \(Z(\pmb {x})\ge b\) if and only if the answer to Partition problem is yes. \(\square \)
In the following we analyze the computational complexity of the incremental and two-stage variants of the problem.
Observation 1
The Inc Shortest Path problem with \({\overline{{{\mathcal {X}}}}}_{{\mathcal {P}}}\) can be solved in polynomial time.
Proof
Given network \(G=(V,A)\), a first-stage solution \(\pmb {x}\) and a second-stage cost scenario \(\pmb {c}\), consider a deterministic Shortest Path problem in the same network G, in which the costs of the arcs selected in \(\pmb {x}\) are 0 and the costs of the remaining arcs are determined according to \(\pmb {c}\). We seek a shortest \(s-t\) path in G. The optimal recourse action \(\pmb {y}\in {\mathcal {R}}(\pmb {x})\) selects the arcs on the path computed, which are not selected by \(\pmb {x}\). Notice that \(\pmb {x}+\pmb {y}\) needs not to describe a simple \(s-t\) path in G. \(\square \)
Observation 2
The TSt Shortest Path problem with both \({\overline{{{\mathcal {X}}}}}_{{\mathcal {P}}}\) and \({{\mathcal {X}}}_{{\mathcal {P}}}\) can be solved in polynomial time.
Proof
Given a network \(G=(V,A)\) in which \(C_i\) is the first-stage cost and \(c_i\) is the second-stage cost of the arc \(a_i\in A\), consider a deterministic Shortest Path problem in the same network G, in which the cost of the arc \(a_i\) is \({\hat{c}}_i=\min \{C_i, c_i\}\). Let P be the shortest \(s-t\) path in G with the arc costs \({\hat{c}}_i\). We form solution \((\pmb {x},\pmb {y})\in {\mathcal {Z}}\) as follows: for each \(a_i\in P\), if \({\hat{c}}_i=C_i\), then \(x_i=1\); if \({\hat{c}}_i<C_i\), then \(y_i=1\); for each \(a_i\notin P\), \(x_i=y_i=0\). One can easily verify that \((\pmb {x},\pmb {y})\) is an optimal solution to TSt Shortest Path regardless of which set \({\overline{{{\mathcal {X}}}}}_{{\mathcal {P}}}\) or \({{\mathcal {X}}}_{{\mathcal {P}}}\) is used. \(\square \)
The next result shows a difference between the two problem variants using \({{\mathcal {X}}}_{{\mathcal {P}}}\) and \({\overline{{{\mathcal {X}}}}}_{{\mathcal {P}}}\).
Theorem 3
The Inc Shortest Path problem with \({{\mathcal {X}}}_P\) is strongly NP-hard and not at all approximable if P\(\ne \)NP.
Proof
Consider the following strongly NP-complete Hamiltonian Path problem (Garey and Johnson 1979). We are given a directed graph \(G=(V,A)\) with two distinguished nodes \(v_1,v_n\in V\). We ask if it is possible to find a directed path from \(v_1\) to \(v_n\) that visits each node in V exactly once. We build a graph \(G'=(V',A')\) as follows. For each \(v_i\in V\), the node set \(V'\) contains two nodes \(v_i\) and \(v_i'\). The set of arcs \(A'\) contains the forward arcs \((v_i,v_i')\) for all \(v_i\in V\), and backward arcs \((v_i',v_j)\) for all \((v_i,v_j)\in A\). Finally, there are dummy arcs \((v_i',v_{i+1})\) for all \(i\in [n-1]\). The first stage costs of all arcs in \(A'\) are 0. Under the second-stage scenario \(\pmb {c}\), the costs of all forward and backward arcs are 0 and the costs of all dummy arcs are 1. We set \(s=v_1\) and \(t=v_n\). Figure 5 shows a sample reduction.

A sample reduction in the proof of Theorem 3. Arcs with zero costs are solid. Dashed forward arcs were chosen in the first stage
The presence of dummy arcs ensures that \(\pmb {x}\) is feasible, as we can complete \(\pmb {x}\) to a simple path by using all dummy arcs. Now it is easy to see that there is an optimal recourse action \(\pmb {y}\in {\mathcal {R}}(\pmb {x})\), which selects only the backward arcs if and only if there is a Hamiltonian path in G. In other words, there is \(\pmb {y}\in {\mathcal {R}}(\pmb {x})\) such that \(\mathrm{Inc}(\pmb {x},\pmb {c})=0\) if and only if G has a Hamiltonian path, which proves the theorem. \(\square \)
5 The selection problem
In this section we discuss the TStR Selection problem, in which \({{\mathcal {X}}}_{{\mathcal {S}}}=\{\pmb {x}\in \{0,1\}^n: x_1+\dots +x_n=p\}\) for some fixed \(p\in [n]\). We can interpret \(\pmb {x}\in {{\mathcal {X}}}_{{\mathcal {S}}}\) as a characteristic vector of a selection of exactly p items out of n available. The set of feasible first-stage solutions is then \({{\mathcal {X}}}'_{{\mathcal {S}}}=\{\pmb {x}\in \{0,1\}^n: x_1+\dots +x_n\le p\}\). The deterministic Selection problem can be solved in O(n) time. We first find in O(n) time the pth smallest item cost c (see, e.g., Cormen et al. 1990) and select p items with the costs at most c. It is easy to see that the corresponding TSt Selection and Inc Selection problems are solvable in O(n) time as well. Various robust versions of Selection have been discussed in the literature. In particular, the single-stage minmax and minmax regret models were investigated in Averbakh (2001), Conde (2004), Doerr (2013) and Kasperski et al. (2013) and the robust two-stage models, with the minmax criterion, were discussed in Chassein et al. (2018) and Kasperski and Zieliński (2017).
5.1 Computing the maximum regret
In this section we show that the value of \(Z(\pmb {x})\) for a given \(\pmb {x}\in {\mathcal {X}}'_{{\mathcal {S}}}\) can be computed in polynomial time. Consider the subproblem \(\min _{\pmb {y}\in {\mathcal {R}}(\pmb {x})} \pmb {c}_{\pmb {v}}^T\pmb {y}\) from Proposition 1, which can be represented as the following linear programming problem:
Observe that we have relaxed the constraints \(y_i\in \{0,1\}\), \(i\in [n]\), without changing the optimal objective function value, because the problem (18)–(21) has an integral optimal solution, which is due to total unimodularity of the constraint matrix (19) and (20). Using the definition of \(\pmb {c}_{\pmb {v}}\) (see Proposition 1), we can write the dual to (18)–(21), which is another linear programming problem of the form:
Using Proposition 1 and equality (3), we can build the following compact mixed integer programming formulation for computing the maximum regret of a given first-stage solution \(\pmb {x}\in {\mathcal {X}}'_{{\mathcal {S}}}\):
The constraints (24)–(26) represent a feasible pair \((\pmb {u},\pmb {v})\in {\mathcal {Z}}\). Define \(X=\{i\in [n]: x_i=1\}\) and let \({\overline{X}}=\{i\in [n]: x_i=0\}\) be the complement of X. Observe that in an optimal solution to (22)–(27) we can fix \(\beta _i=[\alpha - {\underline{c}}_iv_i - {\overline{c}}_i(1-v_i)]_{+}\) for each \(i\in [n]\) (we use the notation \([t]_{+}=\max \{0,t\}\)). As \(v_i\in \{0,1\}\), we can set:
Denote \(c^*_i(\alpha )=[\alpha -{\underline{c}}_i]_+ - [\alpha -{\overline{c}}_i]_+\) and, using (28), rewrite (22)–(27) as
Define \({\mathcal {C}}=\{{\underline{c}}_1,\dots ,{\underline{c}}_n\}\cup \{{\overline{c}}_1,\dots ,{\overline{c}}_n\}\).
Lemma 1
There is an optimal solution to (29)–(33) in which \(\alpha \in {\mathcal {C}}\).
Proof
Fix any \((\pmb {u},\pmb {v})\in {\mathcal {Z}}\) to (29)–(33). The optimal value of \(\alpha \ge 0\) can be then found by solving the following problem:
where \({\hat{c}}_i={\underline{c}}_i\) if \(v_i=1\) and \({\hat{c}}_i={\overline{c}}_i\), otherwise. Since \(|{\overline{X}}|\ge p-|X|\), the problem (34) attains a maximum at some \(\alpha \ge 0\). As the objective function of this problem is piecewise linear, the optimal value of \(\alpha \) is at some \({\hat{c}}_k\), \(k\in {\overline{X}}\). Since \({\hat{c}}_k\in {\mathcal {C}}\), the lemma follows. \(\square \)
Theorem 4
The value of \(Z(\pmb {x})\) for a given \(\pmb {x}\in {{\mathcal {X}}}_{{\mathcal {S}}}'\) can be computed in \(O(n^2)\) time.
Proof
Fix \(\alpha \in {\mathcal {C}}\) in (29)–(33). The remaining optimization problem is then
where \({\hat{c}}_i={\underline{c}}_i\) if \(i\notin {\overline{X}}\) and \({\hat{c}}_i={\underline{c}}_i+[\alpha -{\underline{c}}_i]_{+}-[\alpha -{\overline{c}}_i]_{+}\), otherwise. Observe that (35)–(38) is a TSt Selection problem with the first-stage costs \(\pmb {C}\) and the second-stage costs \(\hat{\pmb {c}}\), which can be solved in O(n) time. By Lemma 1 it is enough to try at most 2n values of \(\alpha \) in \({\mathcal {C}}\) to find an optimal solution to (29)–(33). Therefore, one can solve this problem and thus compute \(Z(\pmb {x})\) in \(O(n^2)\) time. \(\square \)
5.2 Compact MIP formulations
Fix \(\alpha \in {\mathcal {C}}\) in (29)–(33). One can easily check that the constraint matrix (30) and (31) is totally unimodular. Hence we can relax the constraints \(u_i, v_i\in \{0,1\}\) with \(u_i, v_i \ge 0\) and write the following dual to the relaxed (29)–(33):
which can be rewritten as:
We can thus construct the following MIP formulation for TStR Selection:
Here, variables \(x_i\in \{0,1\}\) have been added to represent the choice of first-stage solution, along with constraint (44) to model that \(\pmb {x}\in {{\mathcal {X}}}'_{{\mathcal {S}}}\). Taking the minimum over the new variable z gives the maximum over \(\alpha \in {\mathcal {C}}\) by an epigraph reformulation.
In the following we will show how to decompose (40)–(45) into a family of problems of smaller size. The key idea will be to show that it is enough to try at most \(O(n^2)\) cases for the vector of variables \(\pmb {\pi }=(\pi (\alpha ))_{\alpha \in {\mathcal {C}}}\).
Lemma 2
There exist \({\hat{c}}_k\in {\mathcal {A}}=\{C_1,\dots ,C_n\}\cup \{{\underline{c}}_1,\dots ,{\underline{c}}_n\}\) and \({\hat{c}}_l\in {\mathcal {B}}=\{C_1,\dots ,C_n\} \cup \{{\underline{c}}_1,\dots ,{\underline{c}}_n\}\cup \{{\overline{c}}_1,\dots ,{\overline{c}}_n\}\), \( {\hat{c}}_k\le {\hat{c}}_l\) such that
Proof
Let us fix \(\pmb {x}\) and \(\alpha \) in (40)–(45), and define \(r_i(\alpha ,x_i) = \min \{ C_i, {\underline{c}}_i+c_i^*(\alpha )(1-x_i)\}=\min \{C_i, {\underline{c}}_i+([\alpha -{\underline{c}}_i]_+ - [\alpha -{\overline{c}}_i]_+)(1-x_i)\}\). For each \(\alpha \in {\mathcal {C}}\), the values of \(\pi (\alpha )\) and \(\rho _i(\alpha )\) can then be found by solving the following linear programming problem:
By using linear programming duality, one can check that in an optimal solution to this problem, we can set \(\pi (\alpha )\) to the pth smallest value among \(r_i(\alpha ,x_i)\), \(i\in [n]\), meaning that \(\pi (\alpha )\in \{r_i(\alpha ,x_i) : i\in [n]\}\). We now consider all possible shapes of \(r_i(\alpha ,x_i)\).
-
1.
\(r_i(\alpha ,1)= \min \{C_i,{\underline{c}}_i\}\),
-
2.
If \(C_i \le {\underline{c}}_i \le {\overline{c}}_i\), then \(r_i(\alpha ,0)=C_i\).
-
3.
If \({\underline{c}}_i \le C_i \le {\overline{c}}_i\), then
$$\begin{aligned} r_i(\alpha ,0) = {\left\{ \begin{array}{ll} {\underline{c}}_i &{} \text { if }\, \alpha \le {\underline{c}}_i \\ \alpha &{} \text { if } \,\,{\underline{c}}_i< \alpha < C_i \\ C_i &{} \text { if }\,\, C_i \le \alpha \end{array}\right. } \end{aligned}$$ -
4.
If \({\underline{c}}_i \le {\overline{c}}_i \le C_i\), then
$$\begin{aligned} r_i(\alpha ,0) = {\left\{ \begin{array}{ll} {\underline{c}}_i &{} \text { if } \,\alpha \le {\underline{c}}_i \\ \alpha &{} \text { if } \,\,{\underline{c}}_i< \alpha < {\overline{c}}_i \\ {\overline{c}}_i &{} \text { if } \,\,{\overline{c}}_i \le \alpha \end{array}\right. } \end{aligned}$$
The three cases for \(r_i(\alpha ,0)\) are visualized in Fig. 6. All possible shapes have in common that they have a constant value in \(\{C_i,{\underline{c}}_i\}\) up to the diagonal. They then follow the diagonal to leave at another constant value in \(\{C_i, {\underline{c}}_i, {\overline{c}}_i\}\). This means that the function representing the pth smallest value over all \(r_i(\alpha ,x_i)\) is also of this shape.

Shape of \(r_i(\alpha ,0)\) with \({\underline{c}}_i = 3\), \({\overline{c}}_i = 7\)
Hence, we can enumerate all possible combinations of values \(({\hat{c}}_k,{\hat{c}}_l)\) with \({\hat{c}}_k \le {\hat{c}}_l\), \({\hat{c}}_k \in \{C_1,\ldots ,C_n\} \cup \{ {\underline{c}}_i,\ldots ,{\underline{c}}_n\} = {\mathcal {A}}\) and \({\hat{c}}_l \in \{C_1,\ldots ,C_n\} \cup \{ {\underline{c}}_i,\ldots ,{\underline{c}}_n\} \cup \{{\overline{c}}_1,\ldots ,{\overline{c}}_n\}={\mathcal {B}}\) and to define candidate functions \(\pi (\alpha )\) as being equal to \({\hat{c}}_k\) if \(\alpha \le {\hat{c}}_k\), equal to \(\alpha \) if \(\alpha \in [{\hat{c}}_k,{\hat{c}}_l]\), and equal to \({\hat{c}}_l\) if \(\alpha \ge {\hat{c}}_l\), as claimed. Amongst these candidate functions, an optimal choice of \(\pi (\alpha )\) is then contained. \(\square \)
Using Lemma 2 we can enumerate all vectors \(\pmb {\pi }=(\pi (\alpha ))_{\alpha \in {\mathcal {C}}}\) and denote the set of these vectors by \(\Pi \). Notice that \(|\Pi |\) is \(O(n^2)\). For a fixed \(\pmb {\pi }=(\pi (\alpha ))_{\alpha \in {\mathcal {C}}}\in \Pi \), we can rewrite the problem (40)–(45) as follows:
where
and
are constant values. We therefore find that
According to Lemma 2 we enumerate \(O(n^2)\) many candidate vectors \(\pmb {\pi }\in \Pi \). We then solve the resulting problem with n binary variables and O(n) constraints, which is substantially smaller than the MIP formulation (40)–(45). In the next section we will propose a heuristic greedy algorithm, which is based on the decomposition (46).
The computational complexity of the general TStR Selection problem remains open. In the following we will identify some of its special cases which can be solved in polynomial time.
Proposition 2
If \(p=n\), then TStR Selection can be solved in polynomial time.
Proof
For each \(\pmb {x}\in {\mathcal {X}}'\) and \(\pmb {y}\in {\mathcal {R}}(\pmb {x})\), we get \(\pmb {x}+\pmb {y}=n\). Hence for each \(i\in [n]\), if \(x_i=1\), then the contribution of i to the maximum regret is \(C_i-\min \{C_i,{\underline{c}}_i\}\) and if \(x_i=0\), then the contribution is \({\overline{c}}_i-\min \{C_i, {\overline{c}}_i\}\). Hence we set \(x_i=1\) if \(C_i-\min \{C_i,{\underline{c}}_i\}\le {\overline{c}}_i-\min \{C_i, {\overline{c}}_i\}\) for every \(i\in [n]\). \(\square \)
Proposition 3
The TStR Selection problem can be solved in polynomial time if two out of the following three conditions hold:
-
(1)
The set \(\{ C_i : i\in [n] \}\) is of constant size.
-
(2)
The set \(\{ {\underline{c}}_i : i\in [n] \}\) is of constant size.
-
(3)
The set \(\{ {\overline{c}}_i : i\in [n] \}\) is of constant size.
Proof
We first consider the case in which the conditions (1) and (2) hold. Let the sets \(T_j\), \(j\in [\ell ]\), consist of all \(i\in [n]\) with the same values \(C_i\) and \({\underline{c}}_i\). Due to (1) and (2), \(\ell \) is constant as well. Let \((l_1,\dots ,l_{\ell })\) be a vector of nonnegative integers such that \(l_1+\dots +l_{\ell }=p\). This vector defines a decomposition into subproblems where we pick \(l_j\) many items out of each set \(T_j\). These items \(i\in T_j\) only differ with respect to their upper bounds \({\overline{c}}_i\). An optimal solution is hence to pick those \(l_j\) many items i in the first stage that have the highest second-stage costs \({\overline{c}}_i\). The number of the vectors \(\pmb {l}\) enumerated is \(O(n^{\ell })\) so it remains polynomial. The cases that assumptions (1) and (3) as well as assumptions (2) and (3) hold can be treated in the same way. \(\square \)
5.3 Greedy algorithm
In this section we propose a heuristic algorithm for computing a solution to TStR Selection, which can be applied to larger instances. The first idea consists in applying the mid-point scenario heuristic, i.e. to solve TSt Selection under scenario \(\pmb {c}^m\) such that \(c^m_i=({\underline{c}}_i+{\overline{c}}_i)/2\) for each \(i\in [n]\). Unfortunately, the approximation ratio of this algorithm is unbounded, which can be easily demonstrated by using an instance analogous to that in Fig. 1b. Observe that the TStR Shortest Path instance in this figure can be seen as an instance of TStR Selection with \(n=2\) and \(p=1\). We will now propose a more complex heuristic for the problem, which is based on Eq. (46). Given \(X\subseteq [n]\), let us define
Using (46), we get
Theorem 5
Function \(F^{\pmb {\pi }}\) is supermodular, i.e. for each \(X\subseteq Y\subseteq [n]\) and \(j\in [n]{\setminus } Y\) the inequality \(F^{\pmb {\pi }}(Y\cup \{j\})-F^{\pmb {\pi }}(Y)\ge F^{\pmb {\pi }}(X\cup \{j\})-F^{\pmb {\pi }}(X)\) holds.
Proof
See the “Appendix”. \(\square \)
The greedy algorithm considers all possible \(\pmb {\pi }\in \Pi \). For each fixed \(\pmb {\pi }\) we start with \(X=\emptyset \) and greedily add the elements \(i\in [n]{\setminus } X\) to X as long as an improvement is possible, i.e. if there is \(i\in [n]{\setminus } X\) such that \(F^{\pmb {\pi }}(X\cup \{i\})<F^{\pmb {\pi }}(X)\). For a fixed choice of \(\pmb {\pi }\), the greedy algorithm thus evaluates the objective \(F^{\pmb {\pi }}\) O(np) many times. In total, there are therefore \(O(n^3p)\) calls to \(F^{\pmb {\pi }}\).
Theorem 5 allows us to reduce the search space of the algorithm. Namely, if adding j to X does not decrease the value of \(F^{\pmb {\pi }}\) at some step, then adding j to the current solution in the subsequent steps cannot improve the current solution either. Hence j can be removed from further consideration.

In order to illustrate the algorithm consider an instance of the problem shown in Table 1.
We get \({\mathcal {A}}=\{1,2,4,6,9,12\}\), \({\mathcal {B}}=\{1,2,4,6,9,12,13\}\) and \({\mathcal {C}}=\{1,2,4,6,9,12,13\}\). For \({\hat{c}}_k=2\) and \({\hat{c}}_l = 6\), we get \(\pi (1)=2\), \(\pi (2)=2\), \(\pi (4)=4\), \(\pi (6)=6\), \(\pi (9)=6\), \(\pi (12)=6\), and \(\pi (13)=6\). For this vector \(\pmb {\pi }\) we compute \(\mathrm{P}(\pmb {\pi })\) by solving the following problem:
An optimal solution to this problem is \(\pmb {x}=(0,1,1,0)\) with \(\mathrm{P}(\pmb {\pi })=2\). In fact, this is an optimal first-stage solution to the sample instance with \(Z(\pmb {x})=2\). Figure 7 shows the search space of the greedy algorithm for the fixed \(\pmb {\pi }\). If 1 is chosen in the first step, then the best achievable regret value is 4 by using the first-stage solution \(X=\{1,2\}\). However, the optimal regret value is 2 by using the first-stage solution \(X=\{2,3\}\). So, the example demonstrates that the approximation ratio of the greedy algorithm is at least 2. We conjecture that the algorithm is indeed a 2-approximation, so the example presented is a worst one. The search space can be reduced by applying Theorem 5. For example, 4 need only be considered in the first step, because \(F^{\pmb {\pi }}(\emptyset )<F^{\pmb {\pi }}(\{4\})\). So adding 4 in the next steps cannot decrease the value of the current solution and 4 can be removed from further considerations. Also we need not to consider adding 3 to \(\{1,2\}\), because by Theorem 5, \(F^{\pmb {\pi }}(\{1,2\}\cup \{3\})-F^{\pmb {\pi }}(\{1,2\})\ge F^{\pmb {\pi }}(\{1\}\cup \{3\})-F^{\pmb {\pi }}(\{1\})>0\).

Greedy search space for the sample problem
The example suggests an improvement of the greedy algorithm. Observe that we can achieve the optimal solution by adding 3 instead of 1 to \(X=\emptyset \). So it may be advantageous to start from all possible subsets of [n] with up to L items. For a small constant L, the algorithm remains polynomial.
6 Experimental results
In this section we show results of some computational tests for the TStR Selection problem discussed in Sect. 5. We will compare various MIP formulations for this problem and the performance of the greedy heuristic described in Sect. 5.3.
6.1 Setup
We conduct computational experiments to answer the following questions:
-
1.
Among the compact formulation (40)–(45), the decomposition formulation (46), and the general iterative row-and-column generation algorithm from Sect. 3, which approach is most efficient for the exact solution of two-stage min-max regret selection problems? How does this comparison depend on the instance size?
-
2.
What is the performance of the greedy algorithm?
To answer these questions, we perform three experiments on instances generated in the following way. For each item i, costs \(C_i\), \({\underline{c}}_i\), and \({\overline{c}}_i\) are uniformly randomly taken from \(\{1,\ldots ,r\}\), where we use \(r=20\) and \(r=100\). If \({\overline{c}}_i < {\underline{c}}_i\), the two values are swapped. For experiments 1 and 2, we use instance sizes \(n\in \{20,40,\ldots ,200\}\) and always set \(p=n/2\). For experiment 3, we use \(n\in \{300,400,\ldots ,1000\}\). We generate 100 instances per choice of n and r, which results in a total of 3600 instances.
For the iterative method, we solve the adversarial problem using the combinatorial algorithm used in the proof of Theorem 4. In preliminary experiments, this was more efficient than employing a MIP approach. For the greedy algorithm, we make use of Theorem 5 to search remaining items more efficiently.
The experiments were performed on a virtual Ubuntu server with ten Xeon CPU E7-2850 processors at 2.00 GHz speed and 23.5 GB RAM. We used CPLEX 12.8 to solve mixed-integer programming formulations, restricted to a single thread. Code is written in C++.
6.2 Experiment 1: exact solution algorithms
We compare the computation times for selection problems using the compact formulation [“Compact”—(40)–(45)], the decomposition formulation [“Decomp”-(46)] and using the general iterative row-and-column generation method (“Iterative”—Sect. 3). We start the row-and-column generation with three cuts, corresponding to three adversary solutions. These are the respective optimal solutions in the following three scenarios: (i) when \(\pmb {c}=\underline{\pmb {c}}\) and \(\pmb {y}^1=\pmb {0}\); (ii) when \(\pmb {y}^2=\pmb {0}\); and (iii) when all item costs are the minimum of \(C_i\) and \({\underline{c}}_i\), and we choose the p items with smallest costs. A time limit of 600 s was used for the iterative method.
In Table 2 we show median, average and maximum computation times (in seconds) for these three methods, as well as the standard deviation.
Overall, we find that Compact is several orders of magnitude faster than Iterative. While instances with \(r=20\) are consistently solved in less than a second using Compact, more than half of instances with size \(n=200\) reach the time limit of 600 s for Iterative. Furthermore, the computation times for Iterative have a high fluctuation, as can be seen in column “Stdev” and in the large difference between average and median times, while the computation times for Compact are stable. For both methods, the instances with \(r=100\) tend to be harder than the instances with \(r=20\). Note that larger values for r increase the size of the set \({\mathcal {C}}\) used in the compact formulation. We also observe that Compact is faster than Decomp on all instance types.
In Table 3 we show the number of cases (out of 100) that method Iterative was able to find an optimal solution for each instance size. Additionally, column “#It” shows how many iterations were performed on average (note that this value can be truncated by the time limit). We also show two gap values to measure the distance to optimality. The value “LB Gap” is the optimum objective value divided by the best lower bound found by Iterative, averaged only over the instances that were suboptimal, and given in percent. The value “UB Gap” is analogous with the best upper bound divided by the optimum objective value. Our results indicate that both LB and UB gap are relevant, i.e. Iterative does not find an optimal solution, and also the lower bound does reach the optimal value.
6.3 Experiment 2: greedy algorithm
In our second experiment, we evaluate the performance of the greedy algorithm. In Table 4 we present both computation times (“Median”, “Average”, “Stdev”, “Max”) as well as the number of instances where an optimal solution was found (“Opt”, note that the greedy method does not prove optimality), the average UB gap on suboptimal solutions, and the maximum UB gap in percent.
We first note that computation times for \(r=100\) tend to be higher than for method Compact. On the one hand, the implementation of the greedy algorithm depends on the skill of the programmer (whereas Compact makes use of CPLEX). On the other hand, the main advantage of the greedy algorithm is the theoretical bound on the computation time, which remains polynomial in the input size, while this guarantee cannot be given for Compact. Note that the algorithm is started for every possible value of \(\pmb {\pi }\), of which there are \(O(\min \{r,n\}^2)\) many.
Considering the quality of solutions, we see that the number of cases where an optimal solution can be identified drops with the instance size. At the same time, the UB gap also becomes smaller with larger n, meaning that more instances are suboptimal, but the relative gap to the optimal objective value becomes smaller. Note that larger instances have a higher objective value, which can explain why wrong decision on very small instances can lead to larger relative differences. Over all 2000 instances, the largest gap we observed was \(21.4\%\), which is well below the gap of \(100\%\) generated by the instance we constructed in Table 1. Overall, the results give numerical evidence that the greedy algorithm may indeed give an approximation guarantee.
6.4 Experiment 3: large-scale instances
In this third experiment, we consider how well methods scale with larger instance sizes. We compare the compact and the decomposition formulations as the most promising exact methods, and two variants of the greedy method. For these variants, we do not enumerate all \(O(n^2)\) candidate functions \(\pi (\alpha )\) (see step 2 of the algorithm), but instead only use a grid to find values of \({\hat{c}}_k\) and \({\hat{c}}_l\) in the possible cost interval. That is, we consider the values \(({\hat{c}}_k,{\hat{c}}_l) \in \{ i\cdot r/X, j\cdot r/X) : i,j = 1,\ldots ,X, i\le j\}\) with grid size X. Recall that only the values \({\hat{c}}_k\le {\hat{c}}_l\) need to be considered on the respective grid. The grid size defines the number of restarts for the greedy method, with a finer grid resulting in more restarts and potentially better solutions. We test the grid sizes of \(10\times 10\) (“G10”) and \(20\times 20\) (“G20”).
We present computation time metrics in Table 5. Several interesting aspects can be noted. While the decomposition approach is slower than the compact formulation for \(r=100\), it is faster for \(r=20\). The compact formulation has a large difference between median and mean computation times on this dataset, which is also reflected in a high standard deviation and large outliers. For \(n=1000\) and \(r=20\), the maximum computation time was over 3100 s for the compact model, while it is less than 4 s for the decomposition model. While the decomposition performs not as strong for \(r=100\), it still gives a reliable performance without outliers. This can be explained with the observation that the number of subproblems does not increase further with n large enough, and each subproblem is relatively easy to solve, scaling roughly linear in n.
We now consider the performance of the greedy heuristics. They are faster than Decomp for \(r=20\), but the difference is particularly pronounced for \(r=100\). Computation times show little deviation and remain below 10 s for G20 and below 3 s for G10. In Table 6, these computation times are complemented with insight into the quality of solutions. For \(r=20\), G10 is on average less than \(5\%\) away from optimality, while this is less than \(3\%\) for G20. The difference between G10 and G20 is less for \(r=100\), where the additional computational effort results in small advantages in solution quality. UB Gaps scale well with instance size. Heuristics show a similar average gap for any size of instance, while maximum gaps tend to decrease due to larger absolute objective values.
Overall, we find that the decomposition model is the exact solution method of choice if there are only few candidate values that need to be checked. For such instances, the compact formulation may fail. For \(r=100\), on the other hand, the compact formulation becomes more robust and gives a better performance than the decomposition model. Greedy heuristics scale well on all types of instances and require very small computation times while being consistently only a few percent away from optimality.
7 Conclusions
In this paper we have discussed a class of two-stage combinatorial optimization problems under interval uncertainty representation. We have used the maximum regret criterion to choose the best first-stage solution. The problem has different properties than the corresponding minmax regret single-stage counterpart. In particular, there is no easy characterization of a worst-case scenario for a given first-stage solution and computing its maximum regret can be NP-hard even if the deterministic problem is polynomially solvable. We have proposed a general procedure for solving the problem, which is based on a standard row and column generation technique. This method can be used to compute optimal solutions for the problems with reasonable size. Furthermore, we have provided a characterization of the problem complexity for two variants of TStR shortest Path and proposed compact MIP formulations for TStR Selection. There is a number of open problems concerning the considered approach. The computational complexity of TStR Selection is open. It is also interesting to explore the complexity of more general class of matroidal problems, for which Selection is a special case (another important special case is the Minimum Spanning Tree problem). Finally, no approximation algorithm is known for TStR \({\mathcal {P}}\). We have showed that the mid-point heuristic, used in the single-stage problems, does not guarantee any approximation ratio. We conjecture that the greedy algorithm proposed may be indeed a 2-approximation one for TStR Selection. Proving this (or showing a counterexample) is an interesting open problem.
References
Aissi, H., Bazgan, C., & Vanderpooten, D. (2005). Complexity of the min–max and min–max regret assignment problems. Operations Research Letters, 33, 634–640.
Aissi, H., Bazgan, C., & Vanderpooten, D. (2008). Complexity of the min–max (regret) versions of min cut problems. Discrete Optimization, 5, 66–73.
Aissi, H., Bazgan, C., & Vanderpooten, D. (2009). Min–max and min–max regret versions of combinatorial optimization problems: A survey. European Journal of Operational Research, 197, 427–438.
Aron, I. D., & van Hentenryck, P. (2004). On the complexity of the robust spanning tree problem with interval data. Operations Research Letters, 32, 36–40.
Averbakh, I. (2001). On the complexity of a class of combinatorial optimization problems with uncertainty. Mathematical Programming, 90, 263–272.
Averbakh, I., & Lebedev, V. (2004). Interval data minmax regret network optimization problems. Discrete Applied Mathematics, 138, 289–301.
Chassein, A., Goerigk, M., Kasperski, A., & Zieliński, P. (2018). On recoverable and two-stage robust selection problems with budgeted uncertainty. European Journal of Operational Research, 265, 423–436.
Chassein, A. B., & Goerigk, M. (2015). A new bound for the midpoint solution in minmax regret optimization with an application to the robust shortest path problem. European Journal of Operational Research, 244(3), 739–747.
Conde, E. (2004). An improved algorithm for selecting \(p\) items with uncertain returns according to the minmax regret criterion. Mathematical Programming, 100, 345–353.
Conde, E. (2010). A 2-approximation for minmax regret problems via a mid-point scenario optimal solution. Operations Research Letters, 38, 326–327.
Cormen, T., Leiserson, C., & Rivest, R. (1990). Introduction to algorithms. Cambridge: MIT Press.
Crema, A. (2020). Min max min robust (relative) regret combinatorial optimization. Mathematical Methods of Operations Research,. https://doi.org/10.1007/s00186-020-00712-y.
Doerr, B. (2013). Improved approximation algorithms for the Min–Max selecting Items problem. Information Processing Letters, 113, 747–749.
Garey, M. R., & Johnson, D. S. (1979). Computers and intractability. A guide to the theory of NP-completeness. New York: W. H. Freeman and Company.
Kall, P., & Mayer, J. (2005). Stochastic linear programming. Models, theory and computation. Berlin: Springer.
Karaşan, O. E., Pınar, M. Ç.,Yaman, H. (2001). The robust shortest path problem with interval data. Technical report, Bilkent University, Ankara.
Kasperski, A., Kurpisz, A., & Zieliński, P. (2013). Approximating the min–max (regret) selecting items problem. Information Processing Letters, 113, 23–29.
Kasperski, A., & Zieliński, P. (2006a). An approximation algorithm for interval data minmax regret combinatorial optimization problems. Information Processing Letters, 97, 177–180.
Kasperski, A., & Zieliński, P. (2006b). The robust shortest path problem in series-parallel multidigraphs with interval data. Operations Research Letters, 34, 69–76.
Kasperski, A., & Zieliński, P. (2007). On the existence of an FPTAS for minmax regret combinatorial optimization problems with interval data. Operations Research Letters, 35, 525–532.
Kasperski, A., & Zieliński, P. (2011). On the approximability of robust spanning problems. Theoretical Computer Science, 412, 365–374.
Kasperski, A., Zieliński, P. (2016). Robust discrete optimization under discrete and interval uncertainty: A survey. In M. Doumpos, C. Zopounidis & E. Grigoroudis (Eds.), Robustness analysis in decision aiding, optimization, and analytics (pp. 113–143). Springer, Berlin.
Kasperski, A., & Zieliński, P. (2017). Robust recoverable and two-stage selection problems. Discrete Applied Mathematics, 233, 52–64.
Katriel, I., Kenyon-Mathieu, C., & Upfal, E. (2008). Commitment under uncertainty: Two-stage matching problems. Theoretical Computer Science, 408, 213–223.
Kouvelis, P., & Yu, G. (1997). Robust discrete optimization and its applications. Dordrecht: Kluwer Academic Publishers.
Montemanni, R. (2006). A Benders decomposition approach for the robust spanning tree problem with interval data. European Journal of Operational Research, 174, 1479–1490.
Montemanni, R., & Gambardella, L. M. (2004). An exact algorithm for the robust shortest path problem with interval data. Computers and Operations Research, 31, 1667–1680.
Montemanni, R., & Gambardella, L. M. (2005). A branch and bound algorithm for the robust spanning tree problem with interval data. European Journal of Operational Research, 161, 771–779.
Montemanni, R., Gambardella, L. M., & Donati, A. V. (2004). A branch and bound algorithm for the robust shortest path problem with interval data. Operations Research Letters, 32, 225–232.
Papadimitriou, C. H., & Steiglitz, K. (1998). Combinatorial optimization: Algorithms and complexity. Mineola: Dover Publications Inc.
Pereira, J., & Averbakh, I. (2011). Exact and heuristic algorithms for the interval data robust assignment problem. Computers and Operations Research, 38, 1153–1163.
Pereira, J., & Averbakh, I. (2013). The robust set covering problem with interval data. Annals of Operations Research, 207, 217–235.
Poursoltani, M., Delage, E. (2019) Adjustable robust optimization reformulations of two-stage worst-case regret minimization problems. Available at Optimization Online.
Savage, L. J. (1951). The theory of statistical decision. Journal of the American Statistical Association, 46, 55–67.
Yaman, H., Karaşan, O. E., & Pınar, M. Ç. (2001). The robust spanning tree problem with interval data. Operations Research Letters, 29(1), 31–40.
Zeng, B., & Zhao, L. (2013). Solving two-stage robust optimization problems using a column and constraint generation method. Operation Research Letters, 41, 457–461.
Zieliński, P. (2004). The computational complexity of the relative robust shortest path problem with interval data. European Journal of Operational Research, 158, 570–576.
Acknowledgements
The second and third author were supported by the National Science Centre, Poland, Grant 2017/25/B/ST6/00486.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
To prove Theorem 5, we first derive two lemmas.
Lemma 3
The coefficients \(\omega ^{\pmb {\pi }}_i(\alpha )\), \(i\in [n]\), are nonincreasing in \(\alpha \).
Proof
Recall that
where
and
for some fixed \({\hat{c}}_k\in {\mathcal {A}}\) and \({\hat{c}}_l\in {\mathcal {B}}\), \({\hat{c}}_k\le {\hat{c}}_l\). We consider the following cases:
-
1.
\(\alpha \le {\hat{c}}_k\): In this case \(\pi (\alpha )={\hat{c}}_k\) and \({\overline{\rho }}^{\pmb {\pi }}_i(\alpha )={\overline{\rho }}^{\pmb {\pi }}_i\) is constant. Hence
$$\begin{aligned} \omega ^{\pmb {\pi }}_i(\alpha )&= {\left\{ \begin{array}{ll} C_i -\alpha + {\overline{\rho }}^{\pmb {\pi }}_i - \max \{0,{\hat{c}}_k - C_i, {\hat{c}}_k - {\underline{c}}_i\} &{} \text { if } \,\,\alpha \le {\underline{c}}_i \\ C_i -\alpha + {\overline{\rho }}^{\pmb {\pi }}_i - \max \{0,{\hat{c}}_k - C_i, {\hat{c}}_k - \alpha \} &{} \text { if } \,\,{\underline{c}}_i< \alpha < {\overline{c}}_i \\ C_i - {\overline{c}}_i+{\overline{\rho }}^{\pmb {\pi }}_i -\max \{0,{\hat{c}}_k - C_i, {\hat{c}}_k - {\overline{c}}_i\} &{} \text { if } \,\,{\overline{c}}_i \le \alpha \end{array}\right. } \end{aligned}$$and \(\omega ^{\pi }_i(\alpha )\) is nonincreasing in \([0,{\hat{c}}_k]\)
-
2.
\(\alpha \ge {\hat{c}}_l\): This case is analogous to the case 1 with \(\pi (\alpha )={\hat{c}}_l\) and constant \({\overline{\rho }}^{\pmb {\pi }}(\alpha )\), so \(\omega ^{\pmb {\pi }}_i(\alpha )\) is nonincreasing in \([{\hat{c}}_l,\infty )\)
-
3.
\({\hat{c}}_k \le \alpha \le {\hat{c}}_l\): Then \(\pi (\alpha )=\alpha \) and we distinguish further:
-
(a)
\(C_i \le {\underline{c}}_i \le {\overline{c}}_i\): Then
$$\begin{aligned} {\overline{\rho }}^{\pmb {\pi }}_i(\alpha ) - {\underline{\rho }}^{\pmb {\pi }}_i(\alpha ) = [\alpha -C_i]_+ - [\alpha -C_i]_+ = 0 \end{aligned}$$and \(\omega ^{\pmb {\pi }}_i(\alpha )=C_i - \alpha + [\alpha -{\overline{c}}_i]_+\) is nonincreasing in \([{\hat{c}}_k,{\hat{c}}_l]\).
-
(b)
\({\underline{c}}_i \le C_i \le {\overline{c}}_i\): Then
$$\begin{aligned} {\overline{\rho }}^{\pmb {\pi }}_i(\alpha ) - {\underline{\rho }}^{\pmb {\pi }}_i(\alpha ) = [\alpha -{\underline{c}}_i]_+ - [\alpha -C_i]_+\end{aligned}$$and therefore
$$\begin{aligned} \omega ^{\pmb {\pi }}_i(\alpha )&= C_i - \alpha + [\alpha -{\overline{c}}_i]_+ + [\alpha -{\underline{c}}_i]_+ - [\alpha -C_i]_+ \\&= {\left\{ \begin{array}{ll} C_i -\alpha &{} \text { if }\,\, \alpha \le {\underline{c}}_i \\ C_i - {\underline{c}}_i &{} \text { if } \,\,{\underline{c}}_i< \alpha \le C_i \\ C_i -{\underline{c}}_i - \alpha + C_i &{} \text { if }\,\, C_i< \alpha \le {\overline{c}}_i \\ C_i -{\overline{c}}_i - {\underline{c}}_i + C_i &{} \text { if }\,\, {\overline{c}}_i <\alpha \\ \end{array}\right. } \end{aligned}$$and \(\omega ^{\pmb {\pi }}_i(\alpha )\) is nonincreasing in \([{\hat{c}}_k,{\hat{c}}_l]\).
-
(c)
\({\underline{c}}_i \le {\overline{c}}_i \le C_i\): Then
$$\begin{aligned} \omega ^{\pmb {\pi }}_i(\alpha )&= C_i - \alpha + [\alpha -{\overline{c}}_i]_+ + [\alpha -{\underline{c}}_i]_+ - [\alpha -{\underline{c}}_i - [\alpha -{\underline{c}}_i]_+ + [\alpha -{\overline{c}}_i]_+ ]_+ \\&= {\left\{ \begin{array}{ll} C_i - \alpha &{} \text { if }\,\, \alpha \le {\underline{c}}_i \\ C_i - {\underline{c}}_i &{} \text { if }\,\, {\underline{c}}_i< \alpha <{\overline{c}}_i \\ C_i + {\underline{c}}_i &{} \text { if }\,\, {\overline{c}}_i \le \alpha \end{array}\right. } \end{aligned}$$
-
(a)
and \(\omega ^{\pmb {\pi }}_i(\alpha )\) is nonincreasing in \([{\hat{c}}_k,{\hat{c}}_l]\). \(\square \)
Lemma 4
For any functions \(f,g, h: [a,b] \rightarrow {\mathbb {R}}\), attaining a maximum in [a, b], where g and h are nonincreasing in [a, b], it holds that
Proof
Let \(u_1\), \(u_2\), \(u_3\) and \(u_4\) be such that
We can assume without loss of generality that \(u_2 \le u_1\) (otherwise, we exchange h and g). Then \(g(u_2)\ge g(u_1)\) by the monotonicity of g, \(f(u_1) \le f(u_3) \), because \(u_3\) maximizes f and \(f(u_1)+g(u_1)+f(u_2)+h(u_2)\le f(u_3)+g(u_2)+f(u_2)+h(u_2)\le f(u_3)+g(u_4)+f(u_4)+h(u_4).\) \(\square \)
We are now in the position to prove that \(F^{\pmb {\pi }}\) is indeed supermodular.
Proof of Theorem 5
Let any \(X\subseteq Y\subseteq [n]\) and \(j\in [n]{\setminus } Y\) be given such that \(|Y|+1\le p\). We need to show that \(F^{\pmb {\pi }}(X\cup \{j\}) - F^{\pmb {\pi }}(X) \le F^{\pmb {\pi }}(Y\cup \{j\}) - F^{\pmb {\pi }}(Y)\). This is the case if and only if
Fix \(f(\alpha )=\nu ^{\pmb {\pi }}(\alpha ) + \sum _{i\in X} \omega ^{\pmb {\pi }}_i(\alpha )\), \(g(\alpha )=\omega ^{\pmb {\pi }}_j(\alpha )\) and \(h(\alpha )=\sum _{i\in Y{\setminus } X} \omega ^{\pmb {\pi }}_i(\alpha )\). The inequality can be rewritten equivalently as
According to Lemma 3, the functions \(g(\alpha )\) and \(h(\alpha )\) are nonincreasing. Applying Lemma 4, the theorem thus follows. \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Goerigk, M., Kasperski, A. & Zieliński, P. Combinatorial two-stage minmax regret problems under interval uncertainty. Ann Oper Res 300, 23–50 (2021). https://doi.org/10.1007/s10479-020-03863-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10479-020-03863-7