
Abstract
In the inherently hazardous construction industry, where injuries are frequent, the unsafe operation of heavy construction machinery significantly contributes to the injury and accident rates. To reduce these risks, this study introduces a novel framework for detecting and classifying these unsafe operations for five types of construction machinery. Utilizing a cascade learning architecture, the approach employs a Super-Resolution Generative Adversarial Network (SRGAN), Real-Time Detection Transformers (RT-DETR), self-DIstillation with NO labels (DINOv2), and Dilated Neighborhood Attention Transformer (DiNAT) models. The study focuses on enhancing the detection and classification of unsafe operations in construction machinery through upscaling low-resolution surveillance footage and creating detailed high-resolution inputs for the RT-DETR model. This enhancement, by leveraging temporal information, significantly improves object detection and classification accuracy. The performance of the cascaded pipeline yielded an average detection and first-level classification precision of 96%, a second-level classification accuracy of 98.83%, and a third-level classification accuracy of 98.25%, among other metrics. The cascaded integration of these models presents a well-rounded solution for near-real-time surveillance in dynamic construction environments, advancing surveillance technologies and significantly contributing to safety management within the industry.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The construction sector is one of the largest industries and contributes to the economies of developed and emerging countries. Despite its critical role in the economic framework (Khallaf and Khallaf 2021), in construction environments, employees face hazardous conditions that include intense physical labor and significant risks to their safety and health. In this dynamic sector, a significant risk factor is the proximity hazards arising from the interaction of workers with heavy construction equipment and various on-site activities. These factors contribute to poor safety records and increased incidents of both fatal and nonfatal accidents on construction sites (Chen et al. 2023; Rasouli et al. 2023). This is further aggravated by the fact that construction workers constantly face potential dangers, making it one of the most hazardous as well as challenging professions (Seo et al. 2015).
According to the Bureau of Labor Statistics (BLS 2021), construction has had the second most fatal occupational injuries in the USA, a statistic that has remained unchanged from 2017 to 2021. In 2021, out of 1,102 fatalities among construction personnel in America, 170 fatalities resulted from struck-by incidents; 59 were from being caught in, compressed by, or crushed by equipment or objects, as defined by OSHA (Brown et al. 2021, 2020). Furthermore, there were 79,660 nonfatal injuries, with 32.8% resulting from contact with objects or equipment (e.g., loaders, excavators, graders), 31.1% from falling, slipping, or tripping, 25.2% from overexertion or other bodily reactions, and 4.7% from transportation incidents. Struck-by incidents involving heavy construction machinery have been reported as a primary source of injuries in the construction sector since 1992. Considering that a significant 91.8% of construction personnel work around heavy equipment or vehicles, there is a high potential for struck-by or caught-in incidents (Betit et al. 2022; CPWR 2018). The nonfatal injury rate also shows an 8% increase since 2011 (Brown et al. 2020). Choi et al. (2019) conducted an analysis comparing fatal work-related injuries across the USA, South Korea, and China. Their findings revealed that South Korea experiences the highest death rate in the construction sector at 17.9%, with the USA at 9.4% and China at 5.3%. This alarming situation calls for a reevaluation of current safety measures and an exploration of more effective strategies.
The rise of computer and vision-based technologies in construction safety management has the potential to enhance safety monitoring and hazard detection on construction sites (Seo et al. 2015; Alsakka et al. 2023; Lee et al. 2020). Methods based on advanced computer vision (CV) and machine learning (ML) are progressively being utilized to detect unsafe behaviors, track construction vehicles, and monitor activities in real time, offering more precise and proactive safety measures (Guo et al. 2020; Zeng et al. 2021; Martinez et al. 2019; Paneru and Jeelani 2021; Xu et al. 2021).
The need for such advanced detection and classification systems is further emphasized by the evolving nature of construction projects. As these projects become larger and more complex, the use of heavy machinery increases, amplifying the potential risks (Guo et al. 2020; Jung et al. 2022). Additionally, the nature of accidents related to heavy construction machinery tends to be more severe compared to other types of construction-related incidents. Thus, reducing accidents involving heavy machinery is crucial for improving overall safety in the construction industry (Lee et al. 2020; Zeng et al. 2021; Kassemi Langroodi et al. 2021).
Despite the current advancements in these technologies, their applications in CV-based health and safety monitoring in the construction sector are in a nascent stage. There are significant research gaps and technical challenges to be addressed. Issues such as reliability, accuracy, and applicability in diverse construction environments remain to be resolved (Seo et al. 2015; Lee et al. 2020; Guo et al. 2020; Zeng et al. 2021). Furthermore, the construction industry's labor-intensive nature and reliance on manual judgments present additional challenges in integrating these technologies into existing safety management practices (Duan et al. 2022).
Even though the construction industry has made strides in improving safety, adopting smart technologies successfully used in other sectors, such as healthcare, has received only little consideration (Xu et al. 2022). Thus, there is a clear need for more innovative approaches to address the risks associated with heavy machinery (Kassemi Langroodi et al. 2021). The goal of this paper is to explore the potential of advanced detection and classification systems for enhancing safety in the construction industry, with a particular focus on unsafe heavy machinery operations.
The structure of the rest of this document is arranged as follows: Sect. 2 is a summary of the background and related work relevant to the technological advancements related to our methodology. Section 3 offers a comprehensive description of our methodology. Section 4 discusses the computational complexity and cost–benefit analysis of the proposed framework. Section 5 focuses on the performance evaluation of the proposed approach. Finally, Sect. 6 is the concluding section that summarizes the findings of this research.
2 Background and related work
In this section, an overview of the background and related work on CV and ML-based construction safety management is provided, including methods for safety and compliance monitoring, object detection and tracking, and activity recognition and analysis.
2.1 Construction safety management through computer vision and machine learning
There has been notable progress in the field of CV over the last few years, marked by its ability to extract important information from various visual mediums, including videos, digital images, and closed-circuit television (CCTV) systems (IBM 2022). This growth is anticipated to persist going forward, expanding the scope and capabilities of visual data analysis (Martinez et al. 2019; Paneru and Jeelani 2021; Xu et al. 2021; Fang et al. 2019). CV performs a range of visual tasks, for instance, object detection (Guo et al. 2020), image classification (Kim et al. 2017), object and motion tracking (Li et al. 2023), action recognition (Lin et al. 2021), and human pose estimation (Xiong and Tang 2021).
Parallel to these advancements, the integration of CV technology and ML has revolutionized construction safety management, evolving from simple image processing to advanced, automated systems. By simulating human visual perception, CV assists in a variety of construction site operations (Huang 1996). They enhance safety and decision-making by detecting, monitoring, and predicting potential hazards (Martinez et al. 2019; Xu et al. 2021). The early phase of CV for enhancing safety in construction project management focused on the automated monitoring of construction sites through image and video data analysis. These initial efforts employed basic yet crucial methods such as object detection, motion tracking, and activity recognition, all aimed at identifying potential safety hazards. This approach represented a significant improvement compared to traditional, manual safety inspections, offering enhanced accuracy and efficiency. This early stage laid the foundation for a more sophisticated, data-driven methodology for monitoring and ensuring safety in the dynamic, often unpredictable conditions of construction sites (Seo et al. 2015). The continuously advancing integration of CV and ML contributed to construction safety and compliance monitoring, object detection and tracking, as well as activity recognition and analysis in the construction sector.
2.1.1 Safety and compliance monitoring
The integration of ML into construction safety has emerged as a transformative approach to enhancing site safety. It became evident that ML technologies offer robust solutions for hazard detection and risk management. These applications range from predictive modeling of potential safety breaches to the monitoring of construction activities. The integration of ML and deep learning (DL) algorithms with safety management allows for more precise, reliable, and context-sensitive safety interventions (Khallaf and Khallaf 2021; You et al. 2023).
Recent studies in this domain have predominantly focused on leveraging techniques involving ML as well as DL for safety and compliance monitoring. For instance, Lee et al. (2020) developed an event detection system using audio as a basis with the K-Nearest Neighbor (KNN) algorithm and integrating historical accident data along with project schedules for real-time hazard detection in construction sites. The proper detection and monitoring of personal protective equipment (PPE) is also a critical part of construction safety. A significant advancement involved the implementation of MobileNet and shallow Convolutional Neural Network (CNN) classifiers in a pose-guided anchoring scheme for the detection of PPE compliance, which demonstrated high accuracy for the detection of hardhats and safety vests (Xiong and Tang 2021). The exploration of You Only Look Once (YOLO) architecture-based DL models for real-time PPE detection demonstrated substantial accuracy in identifying essential safety gear (Nath et al. 2020). Another study utilized the Faster Region-based Convolutional Neural Network (Faster R-CNN) and Residual Network 50 with Feature Pyramid Networks (ResNet50 + FPN) models for human-object interaction recognition that effectively classifies worker-tool interactions using a specialized dataset to improve safety compliance checks in construction sites (Tang et al. 2020). A novel approach to hazard identification related to improper PPE utilization, combining OpenPose and YOLOv3, was presented, showcasing the effectiveness of DL-based models (Chen and Demachi 2021). Additionally, a framework for real-time hazard detection and worker localization, employing technologies like Mask R-CNN and the Robot Operating System (ROS), was also proposed to enhance safety in dynamic construction environments (Jeelani et al. 2021). The development of a PPE detection system for embedded devices integrated YOLOv5 and YOLOv3-tiny in a Dynamic Neural Network (DNN) architecture with fuzzy logic, optimizing operation in near-real-time with limited training data (Iannizzotto et al. 2021). Lastly, the introduction of the YOLO-EfficientNet model, a two-step approach for safety helmet detection, represented a significant stride in real-time safety management (Lee et al. 2023). While ML applications have been crucial for construction safety and compliance, they have also played a significant role in advancing object detection and tracking in construction.
2.1.2 Object detection and tracking
In the field of construction safety monitoring, object detection and tracking have emerged as critical components for enhancing safety and operational efficiency. An innovative approach was introduced by Guo et al. (2020), utilizing an Orientation-Aware Feature Fusion Single-Stage Detection (OAFF-SSD) network and Unmanned Aerial Vehicle (UAV) imagery. This DL network was able to accurately detect multiple construction vehicles in densely populated areas. The method, which employs techniques for extracting features at multiple levels and integrates them through an innovative fusion process, represents a significant improvement over traditional methods. Furthermore, Zeng et al. (2021) enhanced the detection and localization of machinery in macroscale construction sites through an improved YOLOv3 model coupled with a Grey Wolf Optimizer Improved Extreme Learning Machine (GWO-ELM). This approach has been particularly effective in diverse environmental conditions. For example, the model effectively identifies and localizes construction equipment from far-field videos. Similarly, a DL-based method was developed for multi-object tracking, which significantly improved the tracking performance through deep feature fusion and association analysis, employing techniques like R-CNN and Faster R-CNN for object detection (Li et al. 2023). Son and Kim (2021) integrated YOLOv4 and a Siamese network for real-time personnel detection and tracking, significantly reducing false alarms and enhancing safety in construction machinery operations.
In current years, real-time object detection frameworks often use lightweight models. Chen et al. (2023) introduced a lightweight face-assisted model (WHU-YOLO) for detecting welding masks, integrating a Ghost module with a Bi-directional Feature Pyramid Network (Bi-FPN) for object detection. The model efficiently reduced false positives and enhanced the accuracy of safety management. You Only Look Once and None Left (YOLO-NL) and an Augmented Weighted Bidirectional Feature Pyramid Network (AWBiFPN) were also presented, each offering groundbreaking advancements in object detection, including marine object detection. YOLO-NL employs a global strategy for dynamic label distribution and upgrades the Cross Stage Partial Network (CSPNet) and Path Aggregation Network (PANet) with gradient strategies and self-attention mechanism for enhanced object detection (Zhou 2023; Gao et al. 2023). Finally, Kim et al. (2023) developed a small object detection (SOD) system using YOLOv5, optimized for challenging detection environments, while Angah and Chen (2020) enhanced construction worker tracking through innovative use of Mask R-CNN and gradient-based methods.
These studies collectively shift toward more precise, efficient, and context-specific object detection methods in complex environments. However, implementing CV for safety management in off-site construction also needs more exploration and development. Current literature indicates that there is a distinct gap in the utilization of this technology for safety applications in off-site settings, especially regarding the risks from moving objects such as forklifts, cranes, and construction vehicles (Alsakka et al. 2023). The developments in object detection and tracking showcase the evolving complexity of construction safety monitoring. However, this progress naturally extends to other domains, including activity recognition and analysis.
2.1.3 Activity recognition and analysis
There has been a notable shift toward leveraging ML and DL to enhance activity recognition and analysis on construction sites. This advancement is evident across several studies. Various studies have focused on ML and semi-supervised learning implementations. Kassemi Langroodi et al. (2021) introduced a method named Fractional Random Forest (FRF) for construction equipment action recognition. This method proved to enhance the traditional Random Forest (RF) classifier through fractional calculus and demonstrated efficacy in smaller datasets. A study explored a semi-supervised learning approach that integrated teacher-student networks with data augmentation, significantly reducing the need for extensive labeled datasets in construction site monitoring (Xiao et al. 2021). Additionally, Sanhudo et al. (2020) utilized ML approaches, particularly KNNs and gradient boosting, in conjunction with wearable accelerometers to classify complex worker activities.
Advanced Neural Network (NN) models are often used for activity recognition. There was an image analytics framework proposed that combined CNNs and Long Short-Term Memory (LSTM) networks for recognizing actions and analyzing operations. The study utilized Faster R-CNN and Simple Online and Realtime Tracking (SORT) networks for object detection and object tracking, respectively (Lin et al. 2021). Jung et al. (2021) developed a 3D CNN-based framework for action detection within videos of heavy equipment, using YOLOv3 for object detection. Similarly, Jeong et al. (2024) presented a contextual multimodal approach, integrating audio-visual, spatial, and cyclical temporal data, to recognize concurrent activities of equipment in tunnel construction.
Other ML-based, innovative detection and estimation techniques were also developed. Ghelmani and Hammad (2022) employed a self-supervised contrastive learning method, Contrastive Video Representation Learning on Limited Dataset (CVRLoLD), for recognizing construction equipment activities on limited datasets. Furthermore, a technique for 3D pose estimation of construction machinery was introduced using single-camera images integrated with virtual models to enhance pose estimation accuracy (Kim et al. 2023).
2.1.4 Limitations of current studies
The field of CV and ML-based construction safety management has witnessed significant advancements in recent years. However, despite the progress made, there are still several limitations and challenges that need to be addressed to enhance the reliability, accuracy, and applicability of these technologies in diverse construction environments (Seo et al. 2015; Lee et al. 2020; Guo et al. 2020; Zeng et al. 2021).
One of the primary challenges is the lack of comprehensive, extensive, and well-annotated datasets specific to the construction domain (Seo et al. 2015; Paneru and Jeelani 2021). This issue adversely impacts the precision and reliability of predictive models, as the absence of construction-specific datasets hinders model training and accuracy in construction settings (Xiong and Tang 2021). Similar dataset limitations have been observed in various applications, such as real-time worker localization and hazard detection (Jeelani et al. 2021), PPE detection (Iannizzotto et al. 2021), and sound recognition accuracy (Lee et al. 2020). The creation of diverse and extensive construction machine image datasets is challenging due to limited online resources and the intensive nature of data collection (Xiao et al. 2021). Moreover, data quality and diversity issues further complicate this research gap, as evidenced by the impact of complex construction environments and reliance on historical data on ML model effectiveness (Lee et al. 2020).
Recent efforts to address these dataset challenges include the development of the Small Object Detection dAtaset (SODA) benchmark (Duan et al. 2022), self-supervised learning methods for equipment activity recognition (Ghelmani and Hammad 2022), and the generation of synthetic datasets (Barrera-Animas and Davila Delgado 2023). However, these approaches still face limitations in scope, annotation depth, and generalizability, and they require further validation in diverse scenarios (Duan et al. 2022; Ghelmani and Hammad 2022; Barrera-Animas and Davila Delgado 2023). Additionally, the Moving Object in Construction Sites (MOCS) dataset, introduced as a new benchmark for object detection in construction sites, is limited by its focus on a limited number of object categories, lack of detailed annotations, and limited diversity (An et al. 2021).
Environmental and site-specific challenges also pose significant obstacles to the deployment of CV and ML technologies in construction safety management. The detection of small objects in surveillance footage is often complicated by their relative size and positioning (Zeng et al. 2021), while varying environmental and lighting conditions directly affect object detection accuracy (Alsakka et al. 2023). Limitations in camera view ranges and the complexity of object detection in diverse settings further emphasize the need for adaptable ML models that can function effectively in different construction environments (Paneru and Jeelani 2021). Real-time processing demands, especially with high-resolution imagery, add operational constraints, necessitating model optimization for different site conditions (Jeong et al. 2024). The complexity of deploying DL models for real-time detection in construction environments, particularly on UAVs, is also acknowledged as a significant limitation (Guo et al. 2020).
Technical and operational challenges, primarily linked to model complexity and integration, also hinder the effective implementation of construction safety monitoring systems. Pose estimation models face accuracy issues when trained on non-specific datasets (Xiong and Tang 2021), while automated detection systems for workers and equipment struggle with object scale and varying environmental conditions (Fang et al. 2018). Lightweight object detection models encounter limitations in generalization and robustness (Chen et al. 2023), and real-time detection models grapple with dataset diversity and environmental constraints (Zhou 2023). Multi-object tracking models require integrated detection and tracking frameworks to enhance accuracy (Li et al. 2023), and models tracking multiple workers on construction sites are hindered by occlusions, environmental factors, and hardware limitations (Angah and Chen 2020). Small object detection systems face challenges in real-time processing and accuracy across different construction sites (Kim et al. 2023), and integrated detection and tracking systems still face limitations in dataset diversity and real-world applicability (Zhu et al. 2017).
Object recognition and tracking in construction safety monitoring are characterized by various technical challenges. Specific datasets are found to limit the effectiveness of identifying irregular construction activities, with performance in diverse environments remaining uncertain (Lin et al. 2021). Automatic hazard identification models face challenges in real-time implementation, scalability, and data diversity (Chen and Demachi 2021), while 3D pose estimation methods using single-camera images are hindered by dataset diversity and sensitivity to equipment color and shape (Kim et al. 2023). Contextual multimodal approaches for equipment activity recognition in tunnel construction are constrained by computational demands and noise in data (Jeong et al. 2024), and challenges are faced in detecting and classifying small objects in crowded images for helmet detection (Lee et al. 2023). Activity analysis methods struggle with environmental variability and real-time processing efficacy (Roberts and Golparvar-Fard 2019), and real-time detection of PPE through DL models faces hurdles in generalizing to diverse construction environments and adapting to varying conditions (Nath et al. 2020).
Data analysis limitations also challenge object recognition and tracking in construction safety monitoring. Temporal analysis reveals variations in accident frequencies, but small sample sizes and outdated datasets limit the applicability of these findings (Jung et al. 2022). Human-object interaction models, while effective, are constrained by dataset variety and real-time application challenges (Tang et al. 2020), and FRF methods for activity recognition are limited by sensor quality and dataset representativeness (Kassemi Langroodi et al. 2021). PPE detection systems for embedded devices face accuracy issues in crowded images and small object detection (Iannizzotto et al. 2021), and sound detection systems are impeded by environmental complexities and reliance on historical data (Lee et al. 2020). Additionally, there are several challenges in classifying construction activities due to data acquisition biases and the complexity of the tasks (Sanhudo et al. 2020).
To address the aforementioned challenges and limitations in the current state of CV and ML applications for construction safety management, this study proposes a novel approach that integrates advanced techniques in a cascaded manner. The proposed framework aims to overcome several limitations of existing studies by utilizing an extensive dataset, incorporating super-resolution techniques, employing temporal and spatial object detection, and implementing a hierarchical classification system.
The paper presents several key contributions to the field of automated safety management within the construction industry. First, the study utilized a diverse range of YouTube videos to create a dataset for detecting unsafe operations of heavy construction machinery. The dataset contains actions from various scenarios and in diverse environments. The meticulous data preparation process ensures that the dataset is standardized and the segments are accurately annotated, thereby enhancing the reliability and applicability of the ML models trained on this dataset.
Second, the use of the Super-Resolution Generative Adversarial Network (SRGAN) marks a significant advancement in the processing of low-resolution surveillance footage, essential for accurate object detection in varying environmental conditions. This approach allows the effective detection of small objects and provides enhanced visual quality of the input data for precise action detection.
Third, temporal and spatial object detection using the RT-DETR model was developed for enhanced object detection in dynamic surveillance environments. This enables the near-real-time processing of the surveillance footage, in addition to the computational efficiency and accuracy of object detection.
Fourth, a cascade learning approach, integrating SRGAN and RT-DETR, was developed for achieving high-resolution object detection in challenging surveillance footage. This methodology enhances detection precision and minimizes false positives, thereby improving surveillance efficacy and resilience in construction environments.
Finally, a detailed hierarchical classification was implemented for effective safety assessment and action-type classification. This system allows for near-real-time monitoring and response, effectively detecting and classifying objects and actions for proactive safety management on construction sites.
3 Methodology
In the methodology section, we primarily elaborate on the methods used for data collection and preparation, focusing on collecting diverse videos from Youtube to create a specialized dataset for unsafe action detection of heavy construction equipment. The section then explains the system architecture of the approach, comprising the SRGAN, RT-DETR, self-DIstillation with NO labels (DINOv2), and Dilated Neighborhood Attention Transformer (DiNAT) models, highlighting their roles in enhancing the image resolution and facilitating temporal and spatial object detection in dynamic surveillance environments.
3.1 Data
3.1.1 Data collection
Our research utilizes a dataset curated from a variety of YouTube videos. This diverse collection of videos showcases a variety of actions in different scenarios performed by five types of heavy construction equipment: backhoe, bulldozer, dump truck, excavator, and wheel loader. These equipment types were deliberately chosen due to their widespread use across various construction sites and their involvement in a wide range of construction activities. Our unsafe action detection dataset aims to encompass a balanced ratio of both safe and unsafe actions, mirroring real-world scenarios where machinery might be utilized correctly or might pose potential safety hazards. The chosen safe and unsafe action categories for each type of construction equipment, including backhoes, bulldozers, dump trucks, excavators, and wheel loaders, are depicted in Table 1. This classification serves as an integral component of the dataset, where actions are distinctly segmented into actions with safe safety status, which describes standard operational procedures such as loading, moving, and grading, and unsafe safety status, which highlights high-risk operations like operating near utilities, operating near power lines, or operating on unsafe terrain. This classification played a crucial role in the annotation process of the study, providing a structured basis for the subsequent training of the cascade learning model aimed at improving on-site safety measures.
In the process of dataset development that could substantiate the effectiveness of our proposed ML model, we adopted a methodical approach to video selection. Each video was carefully examined to ensure it depicted distinct actions, such as grading, hauling, or instances of operation without proper personal protective equipment. Given the niche nature of our research material, our selection process was purely random and without bias, driven by the relevance of the content to our research objectives.
Figure 1 displays a series of actions performed by a backhoe, a piece of construction equipment integral to various operations on a job site. This figure is a compilation of image frames extracted from video clips in our dataset, showcasing the backhoe engaged in diverse tasks such as material handling, digging, and grading. These images help illustrate the backhoe's various functions and give insight into the categorized safety statuses of the maneuvers that have been systematically classified into safe and unsafe action categories within our study.

Action categories of backhoe
Figure 2 presents the visual assortment that illustrates the bulldozer in action. As depicted in Fig. 2, the bulldozer is involved in performing a diverse range of tasks on construction sites. Similar to Fig. 1, the images shown in the figure are carefully selected video frames, capturing the bulldozer as it engages in various operations classified under safe actions like land clearing, grading, and moving, in contrast to unsafe scenarios where the equipment is shown amidst potential hazards such as tipping over or operating in the proximity of falling debris.

Action categories of bulldozer
Figure 3 depicts a collection of the operational spectrum of the dump truck. Through this figure, we exhibit a wide range of activities ranging from the routine, such as transporting materials, to moments that carry an inherent risk, like overheight collisions or unsafe dumping events.

Action categories of dump truck
Excavators, often central to construction and demolition phases, serve a crucial role in versatile construction operations, as presented in Fig. 4. The image frames in Fig. 4 showcase the nuanced dynamics of excavators at work, ranging from digging to demolition. The imagery also shows the unpredictability of emergency response scenarios such as unsafe land clearing, unsafe demolition, or striking underground utilities.

Action categories of excavator
The dynamic range of operations carried out by wheel loaders is encapsulated in Fig. 5, as this equipment is critical in the construction and material handling domains. The figure depicts the wheel loader's actions, divided into safe and unsafe operational procedures such as material handling, loading, grading, and dumping material, as well as inherently risky instances, including vehicle fire, struck-by accidents, and unsafe operation of the equipment.

Action categories of wheel loader
The illustrative content in Figs. 1, 2, 3, 4 and 5 of the manuscript offers a visual reference for the various action categories attributed to each type of construction equipment. These figures are sourced from the actual video clips within our dataset and are intended to provide tangible examples of the actions identified and categorized through our annotation process. They suggest the potential real-world applicability of our dataset for operational recognition and classification in the context of construction equipment usage.
The extraction of video frames was executed with precision, employing manual techniques for cutting videos to isolate the desired segments. We supplemented this manual effort with a Python script specifically designed to automate the frame extraction process at a consistent frame rate. Under standard conditions, frames were extracted at 1 frame per second (fps). However, in instances where the total length of the videos was insufficient to provide a representative sample ratio of a given action category, we adjusted the frame rate to 2 or 3 fps. This ensured that each category was equitably represented in the dataset, thereby facilitating the unbiased training of our model.
3.1.2 Dataset preparation
Once the relevant video clips were isolated, the subsequent stage involved a meticulous data preparation process. The primary goal was to establish uniformity across the dataset, thereby simplifying the model training and validation phases. We standardized the resolution and frame rate of all video segments to create a consistent baseline for input data. This standardization was critical to eliminating any variances that could arise from the diverse origins and formats of the source videos.
The annotation of video segments was executed with the aid of the Computer Vision Annotation Tool (CVAT), a sophisticated tool designed for the task of video annotation. The process began with the delineation of objects within each frame using bounding boxes, followed by the categorization of the safety status of the depicted action, designating it as either safe or unsafe. Subsequently, the specific type of action was labeled, with terms corresponding to the taxonomy of construction equipment operations such as backfilling or material handling. This taxonomy ensures consistency and relevance across the dataset.
Our finalized dataset, after meticulous curation and annotation, comprised approximately 11,064 images reflecting a diverse range of actions and scenarios, which increased to 44,295 images after applying data augmentation techniques. Additionally, the original video dataset included 1,528 videos. To facilitate the development and validation of our ML model, we partitioned the data, creating training, validation, and testing datasets, adhering to the conventional 80–10-10 split ratio. This division was strategically implemented to optimize the model's performance and ensure its robustness.
3.1.3 Data processing
Prior to deploying the chosen ML models, namely SRGAN, RT-DETR, DINOv2, and DiNAT, data processing steps were implemented to ensure optimal input quality and format. The data processing workflow encapsulated several steps, including the preparation of distinct datasets optimized for specific tasks: the SRGAN dataset for image resolution enhancement and the object detection and classification dataset tailored for detecting construction equipment and classifying their safety statuses and specific actions.
The SRGAN dataset, assembled separately from the detection and classification dataset and specifically created from high-resolution construction images of construction machinery, underwent extensive data augmentation. A broad spectrum of augmentation techniques was applied, including horizontal and vertical flipping, rotation, brightness adjustment, contrast enhancement, saturation adjustment, hue modification, affine transformations, grayscale conversion, Gaussian blurring, sharpness adjustment, autocontrast, equalization, and perspective transformations. These augmentations, applied using a Python script leveraging the PIL library and PyTorch's torchvision transforms, significantly expanded the variety of visual conditions the model could learn from, thereby improving its generalizability.
For the object detection and classification tasks, we prepared two separate versions of the dataset, each aligned with its specific use case—object detection or hierarchical classification. The images in the object detection version of the dataset were resized to a uniform dimension of 640 × 640 pixels, and pixel values were normalized to a range of 0 to 1 to minimize input variation and accelerate model training. Auto-orientation adjustments ensured that images were correctly aligned for consistent model input. To further improve the dataset quality and avoid overfitting by enhancing the robustness of the model, image augmentation techniques such as flips, rotations, grayscale conversion, hue adjustment, saturation adjustment, brightness adjustment, and exposure adjustment were applied. These augmentations were designed to produce five augmented outputs per training example, effectively increasing the dataset size and diversity while addressing class imbalance through selective augmentation of underrepresented classes. For the classification version of the dataset, the images were resized to a standard resolution of 224 × 224 pixels, and normalization was applied using predefined mean and standard deviation values to adjust the images' color channels to a consistent scale. For this hierarchical classification dataset version, geometric transformations like random rotations and flips were implemented to mimic the diverse conditions of construction regions while preserving the dataset's hierarchical structure to maintain contextual accuracy for safety statuses and activity types. This augmentation process significantly impacted the model's training and validation phases, leading to reduced misclassification rates and heightened accuracy in distinguishing complex subclass relationships.
Post-augmentation, the annotations, which include bounding boxes and action categories, were converted into a machine-readable vector format. This vectorization is crucial for the RT-DETR model to accurately interpret the location and class of each action within the images. The processed images were then batched into subsets suitable for the model's input requirements. Batching is a crucial step that balances computational efficiency with the model's learning capability, ensuring that each iteration of the training process receives a representative sample of the dataset. Following the batch preparation, the dataset was systematically split to create training, validation, and testing sets. This separation is pivotal for unbiased model evaluation and generalization. The final processed images, now in batches, were fed into the SRGAN and RT-DETR models. SRGAN processed the images first, enhancing the resolution, followed by the RT-DETR model, which performed the near-real-time detection and classification of the actions.
These data processing steps were carefully chosen to align with the objective of our study, ensuring that both of the models used received high-fidelity inputs for effective training and subsequent action detection and classification tasks. The creation of separate versions of the dataset for object detection and classification, along with targeted preprocessing and augmentation techniques, enhances the models' performance and generalizability.
3.2 System Architecture
The cascade learning approach simplifies object detection in low-quality CCTV footage by smartly using four steps involving SRGAN, RT-DETR, DINOv2, and DiNAT models. First, SRGAN helps turn low-resolution images into clearer, high-resolution versions by adding missing details. These clearer images are then passed to the RT-DETR model, which is good at spotting objects in a sequence of frames by understanding their motion and changes over time. Following, the DINOv2 model classifies the action depicted in the image by safety status, and DiNAT further classifies it into specific action categories. By putting these models together in a four-step process, this method improves object detection and hierarchical classification in CCTV footage without using too much computer power. So, the approach aims to deliver better detection and classification accuracy in near-real-time surveillance by cleverly combining the strengths of four specialized DL models, maintaining a practical and straightforward application in various surveillance situations.
3.2.1 SRGAN for resolution enhancement
The SRGAN model (Ledig et al. 2016) is employed in the proposed framework to enhance low-resolution images captured by construction site surveillance systems. SRGAN leverages a DL approach to transform low-resolution images into their high-resolution equivalents while preserving essential textural information and image integrity. The system is divided into two key components: a generator, built upon a ResNet architecture, and a discriminator, structured as an advanced CNN.
The generator's structure is initiated with a 9 × 9 convolutional layer, serving as the entry point for the input image. This is followed by a series of 3 × 3 convolutional layers, augmented with batch normalization and Parametric Rectified Linear Unit (PReLU) activation, forming the core of the generator's upscaling function. Integral to this process are the residual blocks, designed to fine-tune the image's details and incrementally upscale its resolution. The use of PixelShuffle operations, crucial for achieving a 4 × upscaling factor through sub-pixel convolution, ensures the image is upscaled effectively while maintaining its original content integrity. The architecture concludes with a final convolutional layer that outputs the super-resolved image at a resolution of 256 × 256 pixels. The discriminator's function is to distinguish between the generator-produced super-resolved images and genuine high-resolution images. It begins with a 3 × 3 kernel size convolutional layer, progressively increasing in depth and complexity through subsequent layers, each featuring batch normalization. The architecture advances to a fully connected layer and ends with a single neuron that evaluates the authenticity of the input image. Integrating the Visual Geometry Group-19 (VGG-19) model, equipped with pre-trained weights, improves the discriminator's feature extraction capabilities, aligning the training process with perceptual quality standards.
For training our SRGAN model, we chose a two-stage training strategy, spanning 200 epochs, to enhance its capability to upscale images from construction surveillance footage. The first phase involved 100 epochs of training on a generalized, augmented dataset to establish broad feature recognition capabilities. This was followed by a second, more focused phase of another 100 epochs, which concentrated on datasets specifically composed of construction site and equipment imagery, to refine the model's performance for our target application. The batch size was chosen as 32 to balance the computational efficiency and the accuracy of gradient updates. Additionally, our training protocol included saving checkpoints at every epoch, facilitating the preservation of model states for potential resumption of training, and ensuring stability against data loss. The learning rate for both the generator and discriminator was initially set at 0.0001, allowing for substantial model adjustments during the early training phases. As training progressed, particularly during the fine-tuning phase, we decreased the learning rate to 0.00001 to enable more precise weight adjustments. We also introduced a learning rate scheduler that systematically reduced the learning rate by a factor of 0.1 every 30 epochs, enhancing the model’s ability to capture detailed and high-fidelity textures essential for high-quality image output. The Adam optimizer was selected for its adept handling of sparse gradients and effectiveness in large-scale applications, ensuring efficient and effective optimization throughout the training process. The model's loss function was a composite of Binary Cross-Entropy (BCE) for adversarial accuracy, Mean Squared Error (MSE) for content integrity, and a VGG-inspired perceptual loss to ensure the upscaling process retained the original image's texture and quality nuances. To validate SRGAN performance, our construction equipment dataset was employed, assessing the model's ability to enhance low-resolution images to a higher resolution. Quantitative evaluations were conducted using Peak Signal-to-Noise Ratio (PSNR) alongside qualitative visual comparisons to gauge the model's effectiveness in improving image clarity and detail.
The SRGAN model is integrated into the analytical framework to improve the quality of images from construction site CCTV footage, which contributes to the overall performance of the action detection algorithms. The architecture of the SRGAN model is illustrated in Fig. 6.

System architecture: SRGAN and RT-DETR
The SRGAN algorithm (Algorithm 1) presents an approach to enhance low-resolution images into high-resolution counterparts, which is crucial for improving construction site imagery. By employing the generator network to upscale images and the discriminator network to refine the output toward indistinguishability from high-resolution originals, the algorithm achieves remarkable fidelity and detail. In the SRGAN framework, the process begins with the initialization of the two networks: the generator (G) and the discriminator (D), each with their respective weights, θG and θD. Initially, the generator undergoes pre-training, where it learns to upscale low-resolution images (LR) to super-resolution images (SR) by minimizing the content loss between the generated SR images and their high-resolution (HR) counterparts. This phase ensures that the generator can produce visually plausible images. Subsequently, the model enters adversarial training, a phase where the generator and the discriminator iteratively improve through competition: the G network aims to produce increasingly realistic images (minimizing both content loss and adversarial losses), while the D network tries to discern the generated images and the real HR images. This adversarial process is vital for enhancing the perceptual quality of the super-resolved images, making SRGAN an effective tool for our objective.
Algorithm 1

3.2.2 RT-DETR for equipment detection
The Real-Time Detection Transformer (Lv et al. 2023) innovatively advances object detection capabilities, especially for immediate analysis crucial in dynamic settings. This evolution of the DEtection Transformer (DETR) (Carion et al. 2020) framework introduces essential enhancements such as an efficient hybrid encoder, leveraging Attention-based Intra-scale Feature Interaction (AIFI) and CNN-based Cross-scale Feature-Fusion (CCFF) module to efficiently manage multi-scale features. The RT-DETR Extra-Large (RT-DETR-X) version, tailored for swift detection and classification of construction equipment, integrates seamlessly with the SRGAN to significantly improve image resolution and detection accuracy.
RT-DETR-X maintains a sophisticated architecture, beginning with an initial stem (HGStem) that escalates channel depth while ensuring minimal information loss. Hierarchical grouped blocks (HGBlock) further enrich feature maps, optimizing the model for detailed spatial resolution. Incorporating IoU-aware query selection and temporal embedding from preceding frames enhances the model's responsiveness to object motion and temporal changes, crucial for dynamic scene analysis.
The training of RT-DETR-X was conducted over 100 epochs using our carefully annotated equipment detection dataset of 44,295 images to cover a broad range of construction equipment. This phase utilized advanced computational resources, including an NVIDIA GeForce RTX 3090, optimizing the process with the AdamW optimizer for stability and efficiency. Loss functions such as Generalized-IoU (GIoU), classification loss (Cross-Entropy Loss), and L1 loss were employed to refine the model's precision in detection, classification, and localization.
The RT-DETR model's development benefits from the integration with SRGAN, as the upscaled high-definition images provided by SRGAN complement RT-DETR-X's detection capabilities. This synergy allowed RT-DETR-X to process enhanced imagery, thereby improving its accuracy and efficiency in object detection and classification within construction environments. The validation process, involving 1,097 images, demonstrated significant improvements in detection accuracy, as indicated by metrics like mAP50 and mAP50-95.
The RT-DETR-X (Algorithm 2) represents a state-of-the-art approach for real-time object detection within video streams, specifically tailored for dynamic and complex environments. At its core, the algorithm initializes with a model (M), equipped with weights (ω), to sequentially process video frames (F) through temporal feature extraction. This initial step captures the temporal context of each frame, enhancing the accuracy of object detection by considering the continuity inherent in video data. Afterward, the algorithm employs these temporally-rich features to identify and annotate objects across a predefined set of classes (C), leveraging the abilities of the model to accurately detect and annotate objects in real time. Furthermore, the model incorporates a real-time optimization mechanism that allows for the adaptation of its weights in response to new incoming frames. This feature makes sure that the model maintains high detection performance in different environments where conditions may rapidly change.
Algorithm 2

3.2.3 DINOv2 for enhanced safety classification
The DINO (Oquab et al. 2023) model was particularly designed for self-supervised CV applications. The DINO framework itself focuses on leveraging self-distillation, where a model learns to predict its own output under slightly different views of the same image, to enhance the learning of robust and versatile visual features without relying on labeled data. Our DINOv2 implementation was tailored for the nuanced classification of construction actions into safe or unsafe categories.
The architecture of DINOv2 is built on a linear classifier wrapper around the DINO Vision Transformer (ViT) backbone, optimizing self-supervised feature extraction. Its patch embedding layer partitions the input image into a grid of non-overlapping patches, projecting each into a high-dimensional vector space. This facilitates a concentrated analysis of local features within patches, while the self-attention mechanism integrates these details on a global scale. The architecture also features 12 transformer blocks, each with layer normalization and memory-effective attention mechanisms, enhancing the model’s focus and contextual understanding of image patches.
DINOv2's training employs a self-supervised methodology, initiated by resizing images to a uniform dimension (224 × 224) and normalizing them. The safe-unsafe dataset, pivotal for training and validation, ensures the model's capability to generalize from its training data. Customization of the model to match the dataset's unique characteristics involves adjusting the output features of the classification layer to align with the distinct classes present in the dataset. For the dataset division of training, validation, and testing sets, we chose a commonly used 70–20-10 ratio.
The training loop, powered by BCE loss and the Adam optimizer, iteratively refines the model's parameters across 100 epochs. For validation, the validation dataset was employed to monitor the performance and make potential training refinements. This phase provided insights into how accurately our model performs on unseen data.
In the proposed cascaded approach, SRGAN is utilized to upscale low-resolution surveillance imagery, which is then processed by subsequent models in the framework, including RT-DETR and DINOv2, to cooperatively elevate safety classification efficacy. RT-DETR then uses the image to identify and localize construction equipment within dynamic site environments. The localized objects are subsequently passed to DINOv2, which classifies the equipment actions based on operational safety. This integration facilitates a streamlined workflow where each model's output directly influences the subsequent model's input, ensuring precise, near-real-time safety monitoring.
3.2.4 DiNAT for action classification
The DiNAT (Hassani and Shi 2022) model represents an advanced adaptation of the transformer architecture and was made for detailed spatial understanding. The basis of the DiNAT is a Neighborhood Attention module that enables the model to focus on local neighborhood features, thereby capturing finer spatial relationships than traditional global self-attention mechanisms allow.
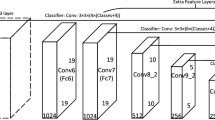
The model architecture begins with an embeddings layer, which employs a sequence of convolutional operations to downsample the input image and create a set of initial feature representations. These features are then normalized using layer normalization and passed through the dropout layer to promote robustness against overfitting. The core of DiNAT is the encoder, which consists of multiple so-called stages, each containing a series of DiNAT layers. Within each of these layers, a layer norm normalizes the input features, preparing them for the attention mechanism. The Neighborhood Attention (NA) module then computes attention within local regions, allowing the model to hone in on specific spatial patterns and details. The intermediate layer within each DiNAT layer performs a feed-forward operation, expanding the feature dimensionality before applying a Gaussian Error Linear Unit (GELU) activation function for non-linearity. Following the attention and feed-forward operations, the features are once again normalized by another layer normalization and passed through the output layer. This layer projects the features back to their original dimensionality and applies dropout to regulate the flow of information. A unique aspect of DiNAT is the drop-path mechanism, a form of structured dropout that randomly drops entire paths in the computational graph to enhance generalization and prevent overfitting. As the information flows through the stages of the encoder, it is progressively downsampled by the downsampler, which uses convolution operations to reduce the spatial resolution while increasing the channel dimension. This hierarchical processing allows DiNAT to operate efficiently on high-resolution inputs by reducing computational complexity while preserving essential information. The model ends with a global layer normalization and a 1D adaptive average pooling layer, which aggregates the features across the spatial dimensions, producing a compact and informative representation suitable for downstream tasks. Both the DiNAT and DINOv2 model architectures are depicted in Fig. 7.

System architecture: DINOv2 and DiNAT
Training the DiNAT model involves preprocessing and normalizing the dataset, followed by the division into batches. The training loop utilizes cross-entropy loss and the Adam optimizer for weight updates over several epochs, with hyperparameters like learning rate and batch size carefully chosen to balance learning speed and stability. Performance metrics are monitored during training to assess the capability of the model to accurately segment and label different regions within the images. During validation, DiNAT's performance is evaluated on unseen data to evaluate its generalization capabilities. The validation phase helps identify overfitting and guides hyperparameter tuning for optimal model performance. The validation metrics provide insights into the model's predictive power, with the primary goal being a balance between low validation loss and high accuracy, indicative of a well-generalized model.
3.2.5 Cascaded SRTransformer framework
The proposed approach, Cascaded SRTRansformer, is built on a four-stage cascade learning model. The cascade learning approach provides high-resolution object detection and classification amidst noisy and often suboptimal CCTV footage. The framework innovatively combines the capabilities of SRGAN, RT-DETR-X, DINOv2, and DiNAT models to address the multifaceted challenge of enhancing image resolution, detecting and classifying construction equipment, and assessing operational safety from CCTV footage of construction sites. This sequential framework is designed to exploit the strengths of each model, thereby providing a detailed analysis of construction equipment actions and their safety implications.
The first step in our framework is SRGAN preprocessing. The framework initiates with SRGAN, tasked with preprocessing low-resolution CCTV images to improve their resolution, thus preparing them for detailed analysis. By upscaling images to a uniform size of 256 × 256 pixels and applying Gaussian blur for noise reduction, SRGAN ensures the retention of crucial textural details, laying a solid foundation for accurate subsequent object detection.
In the second stage, the enhanced images from SRGAN are then processed by RT-DETR-X, which utilizes its real-time detection capabilities to identify and classify construction equipment within the images. The model's ability to detect finer details, thanks to the improved resolution, allows for precise classification of equipment into predefined categories. RT-DETR-X's training on a specialized equipment detection dataset guarantees its effectiveness in recognizing and categorizing equipment accurately. Following the identification and classification of equipment, as the third stage, DINOv2 assesses the operational safety of each detected action of the construction machinery. This model analyzes the equipment's context, usage, and surrounding environment to determine if its action is safe or unsafe. The integration of DINOv2 adds a critical layer of safety analysis, leveraging its training on a dataset specifically labeled for safety features. The cascaded framework ends with DiNAT, which further analyzes the actions performed by the classified equipment. DiNAT's role is to dissect the scene into more granular action categories, informed by inputs pre-classified by DINOv2. This final step utilizes a dataset rich in construction activities to enable DiNAT to distinguish specific actions, enhancing the depth of the framework's analytical capabilities.
The integration of these models into a cascaded system presented challenges such as ensuring data compatibility and maintaining near-real-time processing efficiency. To address these, the framework was optimized through careful parameter tuning and the implementation of lightweight model versions where feasible. The emphasis was placed on reducing latency and enhancing accuracy by selecting efficient architectures and fine-tuning domain-specific datasets. Error management was also a critical component, with robust error-checking and fallback mechanisms implemented at each stage to preserve the integrity of the overall system.
The Cascaded SRTransformer framework (Fig. 8) offers a potential contribution to automated safety management within the construction industry. By systematically enhancing image resolution, detecting and classifying equipment, assessing safety, and identifying specific actions, the framework provides a detailed view of potential hazards on construction sites. As a result, the framework can potentially contribute to the development of more effective safety protocols.

Cascaded SRTransformer object detection and classification pipeline
We introduce a multi-stage framework (Algorithm 3) for enhancing construction site safety and efficiency through advanced video analytics. Initially, the algorithm applies SRGAN to each frame from CCTV footage, improving the image quality and detail, thereby enabling more accurate object detection. Following this, the object detection model, initialized with the trained weights, is deployed for precise detection of various types of construction equipment within these super-resolved frames. Subsequently, the algorithm employs a hierarchical classification approach: initially determining the safety status (safe or unsafe) of detected objects using the DINOv2 model, followed by a more granular analysis of unsafe actions through the DiNAT model, categorizing them into specific types of actions. This classification enables a deeper understanding of safety violations and equipment misuse on construction sites, facilitating immediate and targeted interventions.
Algorithm 3

3.2.6 Experimental setup
The experimental setup employs a combination of state-of-the-art hardware and software to facilitate the intensive data processing and model training tasks. The research was conducted using a high-performance computational environment, as detailed in Table 2.
The experimental framework was powered by an AMD Ryzen Threadripper 3990X CPU with 64 cores, optimized for multi-tasking and efficiency. It featured 256 GB of DDR4 Reg-ECC RAM for robust data handling and a 1 TB Samsung SSD that ensured rapid data access. Visual and ML computations were supported by an RTX 3090 24GB VGA, while the ASUS ROG ZENITH II EXTREME ALPHA motherboard provided necessary high-speed connectivity. The entire system was powered by a reliable FSP HYDRO 1200W 80 + Platinum power supply, ensuring stable performance under high loads.
4 Discussions
In the discussion section, we explore the computational complexity and cost–benefit analysis of the Cascaded SRTransformer, evaluating its operational efficiency and economic impact on enhancing construction site safety through improved object detection and action classification.
4.1 Computational complexity
In the computational complexity analysis of the proposed framework, we assessed each component individually as well as their integration into the entire system. This analysis considers the unique set of computational and memory demands of each component, which influence the overall efficiency of the cascade learning architecture employed in the detection and classification of unsafe operations in construction environments. In the assessment of the proposed framework, several metrics were selected to provide a thorough analysis of the system's performance and resource utilization. These metrics—inference time, resident set size (RSS), virtual memory size (VMS), and giga floating point operations (GFLOPs)—are important for assessing different aspects of computational complexity and operational load within the processing environment.
Inference time measures the duration required to process a single instance through the model. This is fundamental for applications where rapid data processing is critical and provides insight into the responsiveness and speed of the computational framework. Memory utilization of the processes was measured through the RSS and VMS. RSS reflects the amount of memory a process has occupied in the main memory (RAM), excluding the memory that is swapped out. VMS, on the other hand, includes the total amount of virtual memory allocated by the process, which includes both used physical memory and swapped-out space. Both of these metrics help in evaluating the scalability and memory efficiency of the models for deployment in systems with limited memory resources. The GFLOPs quantifies the computational complexity in terms of the number of billion floating-point operations performed per second, which allows for a direct assessment of the processing power required by the framework, providing a basis for comparing the computational demands of different components and configurations within the system.
The evaluation of the framework's computational complexity is summarized in Table 3, which outlines the performance metrics for each component within the system. This table aims to provide a clear overview of the computational and memory demands essential for assessing the efficiency of the framework in practical deployment scenarios.
The data presented in Table 3 reflect the individual and collective computational profiles of the components. The SRGAN, while handling the resolution enhancement, demonstrates significant computational intensity, with an average inference time of 0.80639 s and a GFLOP count indicative of high computational demand. In contrast, the RT-DETR, despite its advanced multi-scale processing capabilities, has a much shorter inference time but uses significantly more memory, both in terms of RSS and VMS. Furthermore, the computational architectures of DINOv2 and DiNAT exhibit significantly reduced resource utilization, as indicated by their minimal RSS and VMS, as well as lower GFLOPs. These attributes highlight the models' capacity to operate efficiently under constraints of reduced computational power while still achieving high levels of processing speed. The overall framework combines these individual components, resulting in a cumulative inference time of 1.00539 s and substantial GFLOPs. The memory requirements, as shown by the RSS and VMS, suggest a heavy reliance on system resources. This is justified by the advanced capabilities and high performance of the integrated framework in operational environments.
Optimizing memory-intensive models like RT-DETR and SRGAN involves implementing memory management strategies that can reduce both RSS and VMS without compromising computational efficacy. Techniques such as memory-efficient programming, optimized caching mechanisms, and advanced data structure management can significantly mitigate high memory demands. Additionally, applying model compression techniques like pruning and quantization can decrease the memory footprint, making the model more amenable to environments with strict resource limitations. The RT-DETR model's extensive resource utilization could be optimized through the refinement of its self-attention mechanisms, potentially reducing computational redundancy. Empirical studies, such as those by Hu et al. (2021), have demonstrated that model pruning, quantization, and the application of knowledge distillation strategies can significantly reduce computational demands without compromising performance. Moreover, enhancing the SRGAN component with a lighter architecture could maintain high-quality image upscaling while reducing GFLOPs.
The system-wide enhancement should also be addressed, focusing on optimizing data throughput to reduce input and output operations that can cause bottlenecks, and the inter-component data flow within the framework can help minimize latency. Employing in-memory computing solutions can accelerate data access speeds, and optimizing the inter-component data flow can substantially reduce processing delays, making it ideal for deployment in real-time settings (Rotem Ben-Hur et al. 2020).
4.2 Cost–benefit analysis
To perform a cost analysis based on the computational complexity of the framework, we must consider several key factors for the estimation. Based on the GFLOPs and memory usage, the cloud computing costs can be estimated. These represent the costs of running this framework on cloud platforms like Amazon Web Services (AWS), Azure, or Google Cloud. Besides the cloud computing costs, operational costs and hardware costs also need to be considered when approximating the total deployment costs. The operational costs include the cost of electricity if run on-premises and the required hardware maintenance. As the deployment of this computational framework necessitates new hardware, the initial acquisition costs must be carefully considered as well.
Cloud services provision computational resources on a pay-as-you-go basis, pricing these services according to the type of compute instance (i.e., GPU or CPU), memory allocation, and storage capacity. The choice of instance is directly influenced by the required computational power, as measured in GFLOPs, and the memory demands of the application. For high-throughput tasks such as those encountered in advanced construction safety monitoring systems, GPU instances are often indispensable. Notable instances include the p3 and p4 series of AWS, equipped with Tesla V100 GPUs, A2 VMs of Google Cloud, and NCas T4 v3 VMs of Azure (AWS 2023a, 2023b). For example, the AWS p3.2xlarge instance, offering a Tesla V100 GPU, is currently priced at $3.06 per hour (AWS 2023a, 2023b), highlighting the financial impact of using state-of-the-art computational resources. In addition, operational expenditures for running these instances are not limited to rental costs alone but also encompass the energy consumption associated with their use. For instance, a Tesla V100 GPU, consuming about 250 watts per hour (NVIDIA 2021), translates to a daily energy usage of 0.25 kWh if operated continuously for an hour. According to the U.S. Energy Information Administration (2024), the average electricity price in February 2024 was approximately $0.128 per kWh. Consequently, the daily operational cost amounts to merely $0.03, which is a minor fraction of the total operational cost. Deploying a system locally necessitates initial capital outlays for purchasing the requisite hardware. High-performance GPUs such as the NVIDIA Tesla V100 or A100 are pivotal for real-time processing tasks involved in monitoring construction sites. The cost of a Tesla V100 is approximately $10,000, whereas the more advanced NVIDIA A100 may exceed $12,000 (NVIDIA 2024), representing a significant investment in computational infrastructure. Considering continuous operation, the monthly cloud computing cost for an instance like the AWS p3.2xlarge can accumulate to approximately $2,197.60, leading to an annual expenditure of around $26,371.20.
However, several risks could affect the projected cost–benefit ratio. Technological risks include the potential obsolescence of hardware and dependency on specific cloud platforms, which could necessitate unforeseen investments and adaptations. Operational risks involve fluctuations in energy prices and potential hardware maintenance issues, especially if the system scales across multiple sites. Economic risks such as inflation and changes in labor costs could alter the cost structure significantly. Additionally, regulatory compliance with data protection laws could introduce further costs. To mitigate these risks, it is recommended to regularly update hardware and software, negotiate flexible contracts with cloud providers, develop comprehensive maintenance schedules, conduct extensive pilot testing, and ensure all operations comply with current data protection and privacy laws.
In spite of these risks, the deployment of such a framework can be justified by the substantial benefits. These benefits include a reduction in accident-related costs, decreased downtime, and insurance premium reductions. Research indicates that the average cost of a workplace accident in the construction industry can exceed $50,000, including medical expenses, legal fees, penalties, and insurance costs (Waehrer et al. 2007; Haupt and Pillay 2016). If we assume that a large construction firm experiences an average of 10 accidents per year, by reducing the accident frequency by 20% through better monitoring and early detection of unsafe operations, the framework could potentially save the firm $100,000 per year. Furthermore, unplanned downtime due to accidents can cost upwards of $1000 per hour when considering halted operations (Gangane and Patil 2018; Deshmukh and Bharat 2021). With real-time monitoring, we can assume a reduction of 50 h of downtime annually. As a result, the framework can save up to $50,000 annually just by reducing downtime. Insurance companies often adjust premiums based on the perceived risk associated with specific operational environments. Implementing advanced safety monitoring systems can lead to lower insurance premiums due to the reduced risk. Based on reports from Allianz Global Corporate & Specialty (2019), large construction projects are typically insured at an annual premium of approximately $200,000. The adoption of the framework could lead to a conservative estimate of a 10% reduction in insurance costs. This adjustment translates into annual savings of $20,000 on insurance premiums alone, thereby reducing operational costs and enhancing the project's overall financial sustainability. By aggregating the savings accrued from reduced accident occurrences, minimized operational downtime, and decreased insurance premiums, the total annual benefits are estimated to be $170,000 each year.
To provide a nuanced perspective, we have introduced the Net Present Value (NPV) analysis to evaluate the long-term financial viability of deploying our computational framework. The NPV calculation takes into account the time value of money, discounting future cash flows to their present value. For this analysis, we assume a discount rate of 10%, which represents the minimum rate of return expected by investors (Gallo 2014). The NPV is calculated over a five-year period, considering the initial hardware investment of $12,000 for an NVIDIA A100 GPU and the annual net savings of $143,628. The resulting NPV is approximately $445,785, indicating that the deployment of our framework is a financially viable investment in the long run. Moreover, we have calculated the Internal Rate of Return (IRR) for further assessment. The IRR represents the discount rate at which the NPV of all cash flows equals zero. In other words, it is the expected compound annual rate of return that will be earned on the investment. Using the same cash flow assumptions as in the NPV analysis, the IRR for deploying our computational framework is estimated to be 198%. This high IRR suggests that the investment in our framework is highly profitable and attractive from a financial standpoint.
We have conducted a sensitivity analysis to explore how changes in key assumptions impact the cost–benefit outcomes. The analysis focuses on three critical variables: the cost of technology (NVIDIA A100 GPU), the annual accident reduction rate, and the insurance premium reduction percentage. We varied each parameter by ± 10% while keeping the others constant to observe the impact on the NPV and IRR. The results show that the NPV remains positive and the IRR stays above 150% in all scenarios, demonstrating the robustness of the financial model. Even in the worst-case scenario, where the cost of technology increases by 10%, the accident reduction rate decreases by 10%, and the insurance premium reduction percentage decreases by 10%, the NPV is still $336,206 and the IRR is 159%.
The annual operating costs for deploying this framework, which include computational expenses and other associated overheads, were previously estimated at approximately $26,371. By comparing these costs against the annual benefits, the net annual savings can reach up to $143,629. This substantial net saving signifies a good return on investment (ROI) from the deployment of such safety monitoring computational frameworks. The significant decrease in both direct and indirect costs related to construction site accidents and inefficiencies, along with the reduced insurance premiums, presents a compelling economic argument for the broad adoption of advanced monitoring technologies. Based on the cost–benefit analysis, financial modeling, and sensitivity analysis, the deployment not only enhances operational safety but also establishes a financially viable solution with quantifiable benefits for the construction industry.
5 Experimental results
In the results section, we present a detailed performance evaluation of the Cascaded SRTransformer, showcasing its effectiveness in enhancing construction site safety through improved object detection and action classification.
5.1 Performance evaluation
5.1.1 Performance evaluation metrics
To estimate the accuracy and precision of the object detection model, several key metrics were used, including the Intersection over Union (IoU), Average Precision (AP), mean Average Precision (mAP), Precision, Recall, and F1-score.
The IoU is a metric that evaluates the overlap between the predicted and actual bounding boxes and varies significantly with different threshold settings. An IoU value of 1 signifies the model's enhanced accuracy in localizing objects. The IoU is calculated as Eq. (1).
Here, the area of overlap represents the intersecting area of the forecasted and actual bounding boxes, and the area of union encompasses the total area covered by both bounding boxes combined.
AP measures the precision of object detection at various threshold levels. This metric is important for assessing the model's performance across various object categories in construction environments. The AP is calculated for each class in Eq. (2).
where t is the threshold, Precision(t) refers to the precision of the model at threshold t, and Recall(t) denotes the recall rate at threshold t. The summation is done over all thresholds.
The mAP calculates the average of the AP values for all categories over various IoU thresholds, as formulated in Eq. (3).
where N represents the number of classes or IoU thresholds, \({AP}_{i}\) is the average precision for the ith class or IoU threshold. This metric provides a holistic view of the performance among multiple object categories.
A variety of metrics are integral to the assessment of the DL models' classification performance. Traditional metrics employed in this study include Precision, Recall, F1-score, and Accuracy, derived from the confusion matrix (Hossin and Sulaiman 2015).
5.2 Performance of the Cascaded SRTransformer
5.2.1 Resolution enhancement
While CCTV footage is a critical tool for safety monitoring on construction sites, its efficacy is often compromised by its low resolution. The Cascaded SRTransformer framework, designed for safety monitoring in construction sites, integrates various advanced techniques, including the SRGAN model, to address the challenges posed by low-resolution CCTV footage and enhance the overall performance of the system. By enhancing the resolution of such images, the SRGAN model improves the granularity and quality of the visual data, facilitating more accurate detection and classification of activities in the subsequent stages of the framework.
The SRGAN model serves as a transformative step in the preprocessing of surveillance data by upscaling images from a lower to a higher resolution without compromising on the integrity of the details within the image. The model operates by upscaling low-resolution images, effectively synthesizing high-frequency details and information, which are often lost in lower-resolution images but are vital for capturing the nuanced environment of construction equipment and construction environments. This upscaling is achieved through the model's capability to transform blurry, pixelated images into clear, high-resolution outputs, which is crucial for the subsequent object detection and hierarchical classification stages.
To demonstrate the effectiveness of our SRGAN model, a comparative analysis is conducted using before-and-after images, as illustrated in Fig. 9 of this section. The low-resolution columns of the figure display a selection of original low-resolution images from our dataset, characteristic of typical CCTV footage in construction environments. The super-resolution columns showcase the corresponding super-resolved images post-processed by the SRGAN model. This analysis provides a clear visual representation of the improvement in image quality achieved through the application of the SRGAN model. The enhanced images exhibit a significant increase in clarity and detail, transforming them from inadequate quality for detailed analysis to a level suitable for accurate and reliable assessment.

Resolution enhancement examples
These enhanced-resolution images are fundamental for the precise detection and classification of safe and unsafe actions on construction sites. To quantify the enhancement achieved, we employed the PSNR, a standard measure utilized to evaluate the fidelity of reconstructed images in comparison to their original high-resolution counterparts. The average PSNR value obtained over our test dataset was 35.57 dB, indicating a significant improvement in image quality. This metric, while not the sole indicator of perceptual quality, provides a strong objective basis for the evaluation of our resolution enhancement methodology.
The enhancement of image resolution is an important step in the framework, as it provides a foundation for the subsequent object detection and classification tasks, enabling more accurate and effective construction site monitoring. High-resolution images bypass the limitations posed by pixelated and blurred images, such as the inability to distinguish between similar objects or the misclassification of actions due to obscured details. Subsequently, these enhanced images are processed by our RT-DETR-X object detection model implementation, which benefits from the augmented resolution by achieving more accurate localization of objects. As a consequence, by employing advanced techniques like SRGAN, the study significantly improves the quality of CCTV footage, which yields more accurate and reliable safety analysis, even for footage traditionally deemed unsuitable for detailed analysis.
5.2.2 Object detection
The increasing complexity of construction sites, coupled with the proliferation of CCTV as a tool for remote monitoring, necessitates advanced solutions for object detection. The cascade learning approach, which integrates advanced techniques such as image resolution enhancement and transformer-based object detection, enhances the detection of construction equipment in low-quality CCTV footage. This initial enhancement provided a refined visual input for RT-DETR, enabling identification and localization. Then the object detection model, leveraging its transformer-based architecture, detects the equipment within these complex scenes. The ability of the model to understand the temporal sequence of frames and spatial relationships between objects significantly enhances its detection performance. The capability of the model to process frames in near real-time is also important in the dynamic circumstances of construction sites, where conditions evolve rapidly.
Initial results, illustrated in Fig. 10, show the object detection model's capability to accurately detect and localize individual construction equipment in high-resolution images. This clarity is imperative for identifying specific equipment, such as excavators or dump trucks, against cluttered backdrops and complex backgrounds. The model's refined image processing allows for distinct object boundaries and reduces ambiguity in object localization. Figure 10 presents various types of construction machinery: a backhoe, bulldozer, dump truck, wheel loader, and excavator. In each image, the model successfully detects and localizes the heavy machinery, as indicated by the bounding boxes, corresponding labels, and confidence scores. For instance, in the top-left image, the model accurately identified the operating backhoe, despite the presence of debris and other objects in the background. In Fig. 10, we aim to present a collection of single equipment detection results with different types of construction equipment working in diverse environments and lighting conditions. The figure showcases various settings, from dusty excavation sites and snow-covered areas to urban construction sites.

Single object detection results
High confidence scores are consistently observed across various images, indicating the model's capability to accurately recognize and categorize distinct types of equipment even when scenes are complicated by debris or other obstructions. The performance of the detection system, while effective, requires ongoing evaluation, especially in challenging conditions such as low-light environments or heavily occluded scenes.
Figure 11 provides a visual illustration of the multi-object detection capabilities of the model across various operational scenarios within different construction environments. We aim to showcase images from various settings, including excavation sites, road construction, and material loading areas. The diversity of these settings demonstrates how the model adapts to different environmental and operational contexts.

Multi-object detection results
Each frame in the figure contains multiple pieces of equipment correctly identified and labeled with high confidence scores. The bounding boxes are accurately aligned with the equipment contours, even in crowded scenes, which is important for applications requiring precise localization. The ability to recognize and label equipment, even when partially obscured or in close proximity to other objects, is particularly advantageous in active construction zones where heavy machinery frequently operates in close quarters.
The combination of image resolution enhancement and transformer-based object detection has considerably improved the detection of multiple construction equipment from low-resolution CCTV footage, yielding high accuracy in detecting the presence of objects as well as accurately delineating their boundaries in images.
The preliminary results from the detection model indicate a potential to handle complex construction site environments characterized by varied equipment, diverse activities, and challenging conditions such as changing lighting, occlusions, and the presence of dust and debris. These initial findings suggest that the model may be capable of accurately locating and identifying equipment, which is important for monitoring safety-related actions on sites where precise detection could be critical for determining the safety status of equipment operations and the positioning of personnel.
5.2.3 Hierarchical classification
The hierarchical classification of the detected equipment's actions is a crucial aspect of understanding and categorizing construction site activities. The study encompasses the hierarchical classification of the construction equipment, the safety status of its action, and the specific activity type. This classification is important as it provides deeper understanding and information about the nature of the actions executed by each type of construction machinery, such as backhoe, bulldozer, dump truck, excavator, and wheel loader, categorized previously at level 1 by the RT-DETR model.
The results, illustrated in Fig. 12, display the performance of DINOv2 in accurately categorizing activities into safety classes. Utilizing the transformer-based model for second-level classification, the study distinguishes between the safety status of safe and unsafe activities, offering critical insights for safety monitoring. The accuracy of the DINOv2 model is depicted in the confusion matrix presented in Fig. 12a, which displays minimal false positives and negatives, thus reinforcing the robustness of the Cascaded SRTransformer approach. Figure 12a offers a clear visual representation of the model's ability to differentiate between safe and unsafe operations, a key factor in preemptive measures for accident prevention. The matrix shows impressive fidelity in safe-unsafe classification, as indicated by the predominance of true positive (TP = 0.9878) and true negative (TN = 0.9866) rates, alongside low false negative (FN = 0.0122) and false positive (FP = 0.0134) rates. These results were obtained from evaluations conducted on the test set, ensuring that our assessments reflect the model’s performance in new, unseen conditions. The numbers suggest that the DINOv2 model is highly accurate in distinguishing between safe and unsafe activities. The high level of accuracy observed can be credited to the image quality of the dataset employed during the training process and to the ability of the transformer-based model to capture complex patterns and dependencies within the data, which helps recognize the differences in safety-related activities.

Confusion matrices: a safe-unsafe classification, b backhoe, c bulldozer, d dump truck, e excavator, f wheel loader action classification, where the y-axis and x-axis represent the true and predicted values, respectively
We also introduce the DiNAT model for third-level classification, which focuses on the specific activities of construction equipment. In Fig. 12b–f, the confusion matrices presented provide a quantitative evaluation of the hierarchical capabilities of our DiNAT model implementation, offering detailed performance differentials across various construction equipment activities. These matrices demonstrate the model's high accuracy in categorizing specific equipment actions into predefined classes, a capability that is achieved through the integration of advanced techniques in the Cascaded SRTransformer framework. The evaluations represented in these matrices were specifically conducted using the test set, ensuring that the performance metrics are reflective of the model's ability to generalize to new, unseen data. In these confusion matrices, the diagonal values show the proportion of correctly identified actions, showcasing the sensitivity and specificity of the model in discerning between different activity types. For example, the backhoe (Fig. 12b) shows a predominant true positive rate for actions like backfilling and grading, signifying the adeptness of DiNAT in capturing specific movements. Similarly, the bulldozer (Fig. 12c) exhibits high accuracy in classifying activities such as scraping, with a corresponding true positive rate, which can be attributed to the capability of the model to analyze distinct motion patterns associated with the equipment's operation.
These results showcase minimal false positives and negatives, emphasizing the practical utility of the Cascaded SRTransformer approach in enhancing on-site protocols. The precise and accurate categorization of safe and unsafe actions of these frequently used pieces of construction equipment is instrumental in preemptive safety measures and accident prevention. This detailed hierarchical classification approach enables targeted site interventions and the improvement of site safety protocols.
5.2.4 Overall performance of the Cascaded SRTransformer
The thorough performance evaluation of the Cascaded SRTransformer is presented in Fig. 13 and Tables 4, 5 in this section. For the evaluation of the Cascaded SRTransformer and determining its accuracy as well as reliability, several key performance evaluation metrics were utilized to prove its capabilities and potential in construction safety monitoring. This detailed analysis synthesizes results across various metrics to underscore the model's accuracy, reliability, and effectiveness in real-world safe and unsafe scenarios.

Performance metrics overview by equipment type for object detection and level 1 classification: a Precision, b Recall, c mAP50, d mAP50-95; for level 2 classification: e Precision, f Recall, g Accuracy, h F1-score; for level 3 classification: i Precision, j Recall, k Accuracy, l F1-score
Figure 13 provides a comprehensive overview of the performance evaluation metrics across multiple levels of classification, including object detection, equipment type classification (level 1), safe-unsafe action classification (level 2), and action type classification (level 3). Each metric—Precision, Recall, mAP50, mAP50-95, Accuracy, and F1-score—is meticulously detailed for each equipment class and averaged over all classes. For object detection and level 1 classification, the precision metrics (Fig. 13a) show remarkable results, with the backhoe and wheel loader achieving the highest precisions of 100% and 99.6%, respectively, suggesting that the model is able to accurately identify these equipment types among all detections. In contrast, the dump truck falls behind with a precision of merely 83.3%, potentially due to its features being less distinctive and having more visual similarities with the background or other classes, leading to a high number of false positives. In recall (Fig. 13b), the backhoe (98.7%), bulldozer (98.3%), and wheel loader (98.0%) stand out, indicating fewer false negatives, while the dump truck is observed to have the lowest recall with 67.5%, which may be the result of its features being less discernible in varied conditions as the model missed detecting many positive cases. In Fig. 13, panels (c) and (d) display the object detection metrics mAP50 and mAP50-95, respectively. mAP50 stands for mAP at 50% IoU. It computes the average precision for detections with an IoU of 50% or higher with the ground truth bounding boxes, reflecting the precision at a specific IoU threshold that is often considered a standard for evaluating object detection tasks. mAP50-95 (Fig. 13d) calculates the mean average precision at multiple IoU thresholds, from 50% up to 95%, in steps of 5%. The mAP50 (Fig. 13c) and mAP50-95 (Fig. 13d) metrics follow a similar trend to the precision and recall metrics, with the backhoe, bulldozer, and wheel loader outperforming other equipment types. This reflects not just the model's detection prowess but also its capability to delineate the precise boundaries of this equipment class across different IoU thresholds.
The high IoU values suggest exceptional alignment between the predicted and actual object boundaries, while the AP and mAP values indicate consistent precision across various object categories and confidence thresholds. A higher IoU threshold, such as 0.75 or above, indicates a strict requirement for overlap, thus implying high precision in the model's ability to localize objects accurately. This can be particularly critical in construction settings where precise detection of equipment and personnel is essential. On the other hand, a lower IoU threshold, such as 0.5, though less strict, still offers valuable information, especially in a complex environment where perfect overlap is challenging due to factors like occlusion or rapid movement.
At level 2 classification, precision (Fig. 13e) and recall (Fig. 13f) metrics exhibit substantial proficiency across all classes, with the backhoe and excavator presenting the highest precision, 99.35% and 98.85%, and recall, 99.15% and 99.01%, respectively. The high accuracy (Fig. 13g) and F1-scores (Fig. 13h) across all equipment types suggest that the model is robust in classifying actions as safe or unsafe. Level 3 classification demonstrates consistent performance with precision (Fig. 13i) and recall (Fig. 13j) metrics, where the model maintains high accuracy in identifying specific actions of each equipment type. The accuracy (Fig. 13k) and F1-scores (Fig. 13l) remain high for the bulldozer class, indicating a strong ability to generalize the learned action features to unseen data. These scores, surpassing the traditional models, affirm the Cascaded SRTransformer's proficiency in handling complex environments.
The detailed analysis of the performance of Cascaded SRTransformer's object detection and level 1 classification part is outlined in Table 4, along with several key performance evaluation metrics for object detection within the settings of construction site imagery. To guarantee an equitable evaluation, all models underwent training and testing under identical conditions, such as the number of epochs and the data sets employed for both training and validation purposes. In Table 4, the performance of the Cascaded SRTransformer is compared against other models like the YOLO-NAS, YOLO variants, and DETR. It is evident that the Cascaded SRTransformer outperforms these models across various metrics, including mAP50 of 0.95, mAP50-95 of 0.866, precision of 0.959, and recall of 0.914, particularly in challenging low-quality CCTV footage common in construction sites. While these state-of-the-art models may perform adequately in standard conditions, they are struggling to detect objects in low-resolution images. In contrast, the Cascaded SRTransformer not only performs well with high accuracy in standard-quality images and low-resolution images but also does not show a major decrease in performance when the input image depicts a complex, dynamic environment common in construction sites.
Compared to other models, such as YOLOv8, which is the next best performer with an mAP50 of 0.933 and mAP50-95 of 0.854, the Cascaded SRTransformer's results underscore its robustness in handling varied and challenging detection tasks. While YOLOv8 demonstrates commendable precision and recall scores, the Cascaded SRTransformer's use of cascaded architectures, combining advanced techniques for image enhancement followed by a transformer-based detection mechanism, facilitates a more nuanced understanding of spatial relationships and object features. YOLO-NAS and YOLOv7, though highly efficient, lag behind in mAP50–95, a metric indicative of the model's consistency across different IoU thresholds, highlighting their limitations in detecting objects with high precision across a range of sizes and occlusion levels. DETR, employing a different approach with transformers directly applied to object detection, shows a balanced performance but is still outmatched by the Cascaded SRTransformer. The DETR's performance, with an mAP50 of 0.917 and an mAP50-95 of 0.796, emphasizes the potential of transformer models in object detection, yet also highlights the additional benefits achieved through the cascaded approach and image enhancement techniques utilized by the Cascaded SRTransformer. This approach has shown promising performance outcomes in our experimental setup. The transformer component, known for its capability to capture long-range dependencies and complex patterns within data, is particularly adept at understanding the complex spatial relationships and diverse object types common in construction sites, leading to higher accuracy and fewer false positives or negatives.
In Table 5, three different classification models, such as YOLOv5, ViT, and Resnet34, were compared to the Cascaded SRTransformer classification performance in terms of classifying actions as safe or unsafe and into specific action categories. Several key evaluation metrics were considered for evaluating the performance, for instance, accuracy, precision, recall, and F1-score. Given the advanced hierarchical classification ability, the Cascaded SRTransformer demonstrated higher accuracy (98.8%) in classifying the safety status of the specific activities of each piece of equipment. This can be attributed to its unique architecture, which integrates SRGAN for image enhancement, RT-DETR for object and equipment type detection, and DINOv2 for the binary classification task. The SRGAN model, with image resolution enhancements, enables more accurate feature extraction and subsequent classification by the DINOv2 model. In comparison, ViT, which ranked second in performance, achieved a notable accuracy rate of 97.8% and precision of 98.2%, highlighting the effectiveness of transformer-based models in capturing global dependencies and intricate details within images. YOLOv5 and ResNet34, while still highly effective, demonstrate lower performance metrics, attributable to their architectures' relative limitations in processing the complex, detailed imagery typical of construction sites without the benefit of prior image enhancement.
Additionally, the performance of the approach was also evaluated in classifying the action types for each piece of construction equipment. The hierarchical classification capability of the Cascaded SRTransformer is further evidenced in its performance in level 3 classification, where it achieves an accuracy of 98.2%, precision of 96.7%, recall of 96.4%, and an F1-score of 96.4%. This task, requiring differentiation among various specific actions, benefits from the model's layered approach. The DiNAT component, designed for nuanced action classification, leverages the precise object detection of RT-DETR and the hierarchical classification approach to accurately classify action types. In our experimental setup, the comparative models exhibited lower performance in the action type classification task compared to the proposed Cascaded SRTransformer. YOLOv5, with its object detection origins, and ViT, despite its global perspective capabilities, did not achieve as good results as our approach in level 3 classification. ResNet34, as the foundational CNN model, demonstrates the lowest performance, suggesting the challenges the model faces in capturing the fine-grained details necessary for detailed action classification without the benefit of enhanced input imagery or a hierarchical classification structure.
In conclusion, the Cascaded SRTransformer demonstrates potential as a solution for detecting and classifying unsafe operations in heavy construction machinery. Its advanced resolution enhancement, precise equipment detection, and detailed hierarchical classification provide a multifaceted tool for improving safety standards. The results, as detailed above, suggest that the Cascaded SRTransformer is a promising technology for construction safety monitoring with the potential to address some of the current limitations in the field.
6 Conclusions and future works
This study introduces an innovative cascade learning framework that synergizes SRGAN and RT-DETR-X, DINOv2, and DiNAT models to detect and classify unsafe operations in heavy construction machinery across three levels (equipment type, safety status, and activity type). The developed model significantly enhances the resolution of low-quality CCTV footage, which is important for precise action recognition in dynamic and complex construction environments. The approach demonstrates a significant improvement in detection precision, achieving 96% for both object detection and first-level classification, 98.83% for second-level classification, and 98.25% for third-level classification, marking a substantial contribution to construction safety enhancement.
Despite the good results, there are shortcomings that need to be explored in future research. Future research will be directed toward expanding the model's capabilities by incorporating a wider variety of environmental conditions and equipment types to augment its robustness. Moreover, the integration of multi-modal data streams, including audio and kinesthetic sensors, could yield a multi-faceted detection system, providing a more detailed analysis of unsafe situations. Such advancements could propel the development of intelligent monitoring systems, with the potential to significantly reduce accident rates and enhance safety measures on construction sites. Finally, while our framework currently achieves near-real-time processing, as indicated by an overall inference time of approximately 1.005 s, optimal real-time performance is not yet realized under all operational conditions. This limitation is primarily due to the substantial computational demands of the SRGAN model, which significantly contribute to the total processing time. In our future work, we aim to refine the SRGAN model and optimize the entire framework to enable real-time processing capabilities while maintaining high accuracy, thus presenting a practical solution for construction safety management.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
References
Alsakka F, Assaf S, El-Chami I, Al-Hussein M (2023) Computer vision applications in offsite construction. Autom Constr 154:104803. https://doi.org/10.1016/j.autcon.2023.104980
An X, Li Z, Liu Z, Wang C, Li P, Li Z (2021) Dataset and benchmark for detecting moving objects in construction sites. Autom Constr 122:103482. https://doi.org/10.1016/j.autcon.2020.103482
Angah O, Chen A (2020) Tracking multiple construction workers through deep learning and the gradient based method with re-matching based on multi-object tracking accuracy. Autom Constr 119:103308. https://doi.org/10.1016/j.autcon.2020.103308
Allianz Global Corporate & Specialty (2019) Engineering and Construction claims and insurance trends.
AWS (2023) Amazon EC2 P3—Ideal for Machine Learning and HPC. https://aws.amazon.com/ec2/instance-types/p3/
AWS (2023) Amazon EC2 on-demand pricing. https://aws.amazon.com/ec2/pricing/on-demand/
Barrera-Animas A, Davila Delgado M (2023) Generating real-world-like labelled synthetic datasets for construction site applications. Autom Constr 151:104850. https://doi.org/10.1016/j.autcon.2023.104850
Betit E, Barlet G, Bunting J (2022) Struck-by hazards, barriers, and opportunities in the construction industry. CPWR—The Center for Construction Research and Training. https://www.cpwr.com
BLS (2021) Bureau of labor statistics, census of occupational fatalities summary. https://www.bls.gov/news.release/cfoi.nr0.htm
Brown S, Brooks RD, Dong XS (2020) Nonfatal injury trends in the construction industry. CPWR—The Center for Construction Research and Training. https://www.cpwr.com
Brown S, Harris W, Brooks RD, Dong XS (2021) Fatal injury trends in the construction industry. CPWR—The Center for Construction Research and Training. https://www.cpwr.com.
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S. (2020). End-to-End Object Detection with Transformers. European conference on computer vision. Cham: Springer International Publishing https://doi.org/10.1007/978-3-030-58452-8_13
Chen S, Demachi K (2021) Towards on-site hazards identification of improper use of personal protective equipment using deep learning-based geometric relationships and hierarchical scene graph. Autom Constr 125:103619. https://doi.org/10.1016/j.autcon.2021.103619
Chen W, Li C, Guo H (2023) A lightweight face-assisted object detection model for welding helmet use. Expert Syst Appl 221:119764. https://doi.org/10.1016/j.eswa.2023.119764
Choi S, Guo L, Kim J, Xiong S (2019) Comparison of fatal occupational injuries in construction industry in the United States, South Korea, and China. Int J Ind Ergon 71:64–74. https://doi.org/10.1016/j.ergon.2019.02.011
CPWR—The Center for Construction Research and Training (2018) The Construction Chart Book: The U.S. Construction Industry and Its Workers. Sixth Edition. https://www.cpwr.com. pp. 105–108.
Deshmukh DS, Bharat KM (2021) Downtime cost analysis in construction industry. Int J Innov Res Sci Eng Technol 10(5):8
Duan R, Deng H, Tian M, Deng Y, Lin JR (2022) SODA: A large-scale open site object detection dataset for deep learning in construction. Autom Constr. https://doi.org/10.1016/j.autcon.2022.104499
Fang W, Ding L, Zhong B, Luo H (2018) Automated detection of workers and heavy equipment on construction sites: a convolutional neural network approach. Adv Eng Inform. https://doi.org/10.1016/j.aei.2018.05.003
Fang W, Luo H, Ding L (2019) Computer vision for behaviour-based safety in construction: a review and future directions. Adv Eng Inform. https://doi.org/10.1016/j.aei.2019.100980
Gallo A (2014) A refresher on net present value. Harvard Business Review. https://hbr.org/2014/11/a-refresher-on-net-present-value
Gao J, Geng X, Zhang Y, Wang R, Shao K (2023) Augmented weighted bidirectional feature pyramid network for marine object detection. Expert Syst Appl 237:121688. https://doi.org/10.1016/j.eswa.2023.121688
Gangane K, Patil D (2018) A survey on downtime cost of equipment used in a construction industry. 15, 353–359. https://doi.org/10.29070/15/56846.
Ghelmani A, Hammad A (2022) Self-supervised learning approach for excavator activity recognition using contrastive video representation. pp. 350–358. https://doi.org/10.7146/aul.455.c225.
Guo Y, Xu Y, Li S (2020) Dense construction vehicle detection based on orientation-aware feature fusion convolutional neural network. Autom Constr. https://doi.org/10.1016/j.autcon.2020.103124
Haupt TC, Pillay K (2016) Investigating the true costs of construction accidents. J Eng Des Technol 14:373–419
Hassani A, Shi H (2022) Dilated Neighborhood Attention Transformer. https://doi.org/10.48550/arXiv.2209.15001.
Hossin M, Sulaiman MN (2015) A review on evaluation metrics for data classification evaluations. Int J Data Min Knowl Manag Process 5:01–11. https://doi.org/10.5121/ijdkp.2015.5201
Hu Z, Fan C, Song G (2021) A novel quantization method combined with knowledge distillation for deep neural networks. J Phys. https://doi.org/10.1088/1742-6596/1976/1/012026
Huang TS (1996) Computer vision: evolution and promise. In: Proceedings of the 19th CERN School of Computing, pp. 21–25. https://doi.org/10.5170/CERN-1996-008.21.
Iannizzotto G, Lo Bello L, Patti G (2021) Personal protection equipment detection system for embedded devices based on DNN and Fuzzy Logic. Expert Syst Appl 184:115447. https://doi.org/10.1016/j.eswa.2021.115447
IBM (2022) What is computer vision? https://www.ibm.com/topics/computer-vision. Accessed April 19, 2022.
Jeelani I, Asadi K, Ramshankar H, Han K, Albert A (2021) Real-time vision-based worker localization & hazard detection for construction. Autom Constr 121:103448. https://doi.org/10.1016/j.autcon.2020.103448
Jeong G, Jung M, Park S, Park M, Ahn CR (2024) Contextual multimodal approach for recognizing concurrent activities of equipment in tunnel construction projects. Autom Constr 158:105195. https://doi.org/10.1016/j.autcon.2023.105195
Jung S, Jeoung J, Kang H, Hong T (2021) 3D convolutional neural network-based one-stage model for real-time action detection in video of construction equipment. Comput-Aided Civ Infrastruct Eng. https://doi.org/10.1111/mice.12695
Jung H, Choi B, Kang S, Kang Y (2022) Temporal analysis of the frequency of accidents associated with construction equipment. Safety Sci 153:105817. https://doi.org/10.1016/j.ssci.2022.105817
Khallaf R, Khallaf M (2021) Classification and analysis of deep learning applications in construction: a systematic literature review. Autom Constr 129:103760. https://doi.org/10.1016/j.autcon.2021.103760
Kim K, Kim H, Kim H (2017) Image-based construction hazard avoidance system using augmented reality in wearable device. Autom Constr. https://doi.org/10.1016/j.autcon.2017.06.014
Kim S, Hong S, Kim H, Lee M, Hwang S (2023) Small object detection (SOD) system for comprehensive construction site safety monitoring. Autom Constr 156:105103. https://doi.org/10.1016/j.autcon.2023.105103
Kassemi Langroodi A, Vahdatikhaki F, Dorée A (2021) Activity recognition of construction equipment using fractional random forest. Autom Constr 122:103465. https://doi.org/10.1016/j.autcon.2020.103465
Ledig C, Theis L, Huszar F, Caballero J, Aitken A, Tejani A, Totz J, Wang Z, Shi W (2016) Photo-realistic single image super-resolution using a generative adversarial network.
Lee Y, Shariatfar M, Rashidi A, Lee HW (2020) Evidence-driven sound detection for prenotification and identification of construction safety hazards and accidents. Autom Constr 113:103127. https://doi.org/10.1016/j.autcon.2020.103127
Lee JY, Choi WS, Choi SH (2023) Verification and performance comparison of CNN-based algorithms for two-step helmet-wearing detection. Expert Syst Appl 225:120096. https://doi.org/10.1016/j.eswa.2023.120096
Li Y, Luo X, Shi J, Wang X, Yin G, Wang Z (2023) Joint detection and association for end-to-end multi-object tracking. Neural Process Lett 55:1–22. https://doi.org/10.1007/s11063-023-11397-9
Lin ZH, Chen A, Hsieh SH (2021) Temporal image analytics for abnormal construction activity identification. Autom Constr 124:103572. https://doi.org/10.1016/j.autcon.2021.103572
Lv W, Xu S, Zhao Y, Wang G, Wei J, Cui C, Du Y, Dang Q, Liu Y (2023) DETRs beat YOLOs on Real-time object detection.
Martinez P, Al-Hussein M, Ahmad R (2019) A scientometric analysis and critical review of computer vision applications for construction. Autom Constr. https://doi.org/10.1016/j.autcon.2019.102947
Nath N, Behzadan A, Paal S (2020) Deep learning for site safety: Real-time detection of personal protective equipment. Autom Constr 112:103085. https://doi.org/10.1016/j.autcon.2020.103085
NVIDIA (2024) NVIDIA A100 tensor core GPU. https://www.nvidia.com/en-us/data-center/a100/
NVIDIA (2021) NVIDIA Tesla V100 GPU accelerator. https://www.nvidia.com/en-us/data-center/tesla-v100/
Oquab M, Darcet T, Moutakanni T, Vo H, Szafraniec M, Khalidov V, Fernandez P, Haziza D, Massa F, El-Nouby A, Assran M, Ballas N, Galuba W, Howes R, Huang PY, Li SW, Misra I, Rabbat M, Sharma V, Bojanowski P (2023) DINOv2: learning robust visual features without supervision.
Paneru S, Jeelani I (2021) Computer vision applications in construction: current state, opportunities & challenges. Autom Constr. https://doi.org/10.1016/j.autcon.2021.103940
Rasouli S, Alipouri Y, Chamanzad S (2023) Smart personal protective equipment (PPE) for construction safety: a literature review. Safety Sci 170:1–15. https://doi.org/10.1016/j.ssci.2023.106368
Roberts D, Golparvar-Fard M (2019) End-to-end vision-based detection, tracking and activity analysis of earthmoving equipment filmed at ground level. Autom Constr 105:102811. https://doi.org/10.1016/j.autcon.2019.04.006
Rotem Ben-Hur R, Ronen A-A, Bhattacharjee D, Eliahu A, Peled N, Kvatinsky S (2020) SIMPLER MAGIC: synthesis and mapping of in-memory logic executed in a single row to improve throughput. IEEE Trans Comput Aided Des Integr Circuits Syst 39(11):2434–2447
Sanhudo L, Calvetti D, Martins J, Ramos N, Mêda P, Gonçalves M, Sousa H (2020) Activity classification using accelerometers and machine learning for complex construction worker activities. J Build Eng. https://doi.org/10.1016/j.jobe.2020.102001
Seo J, Han S, Lee S, Kim H (2015) Computer vision techniques for construction safety and health monitoring. Adv Eng Inform. https://doi.org/10.1016/j.aei.2015.02.001
Son H, Kim C (2021) Integrated worker detection and tracking for the safe operation of construction machinery. Autom Constr 126:103670. https://doi.org/10.1016/j.autcon.2021.103670
Tang S, Roberts D, Golparvar-Fard M (2020) Human-object interaction recognition for automatic construction site safety inspection. Autom Constr 120:103356. https://doi.org/10.1016/j.autcon.2020.103356
U.S. Energy Information Administration (2024) Electric power monthly. https://www.eia.gov/electricity/monthly/epm_table_grapher.php?t=epmt_5_6_a
Waehrer GM, Dong XS, Miller T, Haile E, Men Y (2007) Costs of occupational injuries in construction in the United States. Accid Anal Prev 39(6):1258–1266. https://doi.org/10.1016/j.aap.2007.03.012
Xiao B, Zhang Y, Chen Y, Yin X (2021) A semi-supervised learning detection method for vision-based monitoring of construction sites by integrating teacher-student networks and data augmentation. Adv Eng Inform 50:101372. https://doi.org/10.1016/j.aei.2021.101372
Xiong R, Tang P (2021) Pose guided anchoring for detecting proper use of personal protective equipment. Autom Constr 130:103828. https://doi.org/10.1016/j.autcon.2021.103828
Xu S, Wang J, Shou W, Ngo T, Sadick A-M, Wang X (2021) Computer vision techniques in construction: a critical review. Arch Computat Methods Eng 28:3383–3397. https://doi.org/10.1007/s11831-020-09504-3
Xu M, Nie X, Li H, Cheng J, Mei Z (2022) Smart construction sites: a promising approach to improving on-site HSE management performance. J Build Eng 49:104007. https://doi.org/10.1016/j.jobe.2022.104007
You K, Zhou C, Ding L (2023) Deep learning technology for construction machinery and robotics. Autom Constr 150:104852. https://doi.org/10.1016/j.autcon.2023.104852
Zeng T, Wang J, Cui B, Wang X, Wang D, Zhang Y (2021) The equipment detection and localization of large-scale construction jobsite by far-field construction surveillance video based on improving YOLOv3 and grey wolf optimizer improving extreme learning machine. Constr Build Mater 291:123268. https://doi.org/10.1016/j.conbuildmat.2021.123268
Zhou Y (2023) A YOLO-NL object detector for real-time detection. Expert Syst Appl 238:122256. https://doi.org/10.1016/j.eswa.2023.122256
Zhu Z, Ren X, Chen Z (2017) Integrated detection and tracking of workforce and equipment from construction jobsite videos. Autom Constr 81:161–171. https://doi.org/10.1016/j.autcon.2017.05.005
Funding
This work is supported by the Korea Agency for Infrastructure Technology Advancement (KAIA) grant funded by the Ministry of Land, Infrastructure and Transport (Grant RS-2023–00251002). This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. 2022R1C1C1005409). This research was supported by Brain Pool program funded by the Ministry of Science and ICT through the National Research Foundation of Korea(NRF-2022H1D3A2A02082296).
Author information
Authors and Affiliations
Contributions
Conceptualization, B. K., and D. L.; methodology, R. L., and E. A.; software, R. L.; validation, B. K., K. R. S. P., R. L., and E. A.; formal analysis, R. L. and K. R. S. P.; investigation, R. L., E. A. and K. R. S. P.; resources, D. L. and B. K.; data curation, R. L. and S. K.; writing—original draft preparation, R. L., K. R. S. P., and E. A.; writing—review and editing, B. K., K. R. S. P., R. L., and E. A.; visualization, R. L.; supervision, D. L. and B. K.; project administration, R. L. K. R. S. P., and E. A.; funding acquisition, D. L., and B. K. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Generative AI in scientific writing
During the preparation of this work the author(s) doesn’t used any AI-assisted technologies in the writing process.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kim, B., An, EJ., Kim, S. et al. SRGAN-enhanced unsafe operation detection and classification of heavy construction machinery using cascade learning. Artif Intell Rev 57, 206 (2024). https://doi.org/10.1007/s10462-024-10839-7
Accepted:
Published:
DOI: https://doi.org/10.1007/s10462-024-10839-7