
Abstract
Modern artificial intelligence systems based on neural networks need to perform a large number of repeated parallel operations quickly. Without hardware acceleration, they cannot achieve effectiveness and availability. Memristor-based neuromorphic computing systems are one of the promising hardware acceleration strategies. In this paper, we propose a full-size convolution algorithm (FSCA) for the memristor crossbar, which can store both the input matrix and the convolution kernel and map the convolution kernel to the entire input matrix in a full parallel method during the computation. This method dramatically increases the convolutional kernel computations in a single operation, and the number of operations no longer increases with the input matrix size. Then a bidirectional pulse control switch integrated with two extra memristors into CMOS devices is designed to effectively suppress the leakage current problem in the row and column directions of the existing memristor crossbar. The spice circuit simulation system is built to verify that the design convolutional computation algorithm can extract the feature map of the entire input matrix after only a few operations in the memristor crossbar-based computational circuit. System-level simulations based on the MNIST classification task verify that the designed algorithm and circuit can effectively implement Gabor filtering, allowing the multilayer neural network to improve the classification task recognition accuracy to 98.25% with a 26.2% reduction in network parameters. In comparison, the network can even effectively immunize various non-idealities of the memristive synaptic within 30%.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Recently, generative AI has pushed modern artificial intelligence (AI) to a new level, with the ChatGPT chat robot model released by OpenAI, which combines reinforcement techniques, natural language processing, and machine learning to improve its ability to understand and comprehensively respond to users’ needs (Salvagno et al. 2023; Khowaja et al. 2023). Even generative AI can assist in academic research, a combination of large-scale diverse datasets and pre-trained transformers has emerged as a promising approach for developing Single-Cell Multi-omics (Cui et al. 2023). In the medical field, the trained medical AI model can be used to flexibly explain different combinations of medical modalities, including data from imaging, electronic health records, laboratory results, genomics, charts or medical texts. The model will in turn produce expressive output, such as text description, oral recommendation or image annotation showing advanced medical reasoning ability (Moor et al. 2023); at the same time, biomimetic organs based on modern AI technology, such as prostheses and biomimetic eyes, significantly improve the mobility and quality of life of patients with lower limb amputations and blindness (Tran et al. 2022; Kim et al. 2022).
At the same time, modern AI systems have made significant progress and breakthroughs in many intelligent fields. Such as computer vision based on few-shot 3D point cloud (Ye et al. 2023), Parallel Vision Actualization System (PVAS) use in autonomous vehicles (Wang et al. 2022), Neural Structure Search (NAS) has received widespread attention for its ability to design deep neural networks (Ye et al. 2022) automatically. However, the success of AI systems nowadays cannot be achieved without the support of appropriate hardware systems, which in turn determines the availability and effectiveness of AI algorithms (Ivanov et al. 2022). Mapping complex algorithms to various hardware platforms is challenging, especially from embedded systems to mobile smartphones and wearable devices. To achieve this, hardware-efficient algorithms and customised artificial intelligence accelerators are needed to map these algorithms effectively. Some studies focus on designing hardware-friendly algorithms, conducting Quantitative Aware Training (QAT) on networks (Jacob et al. 2018), and Pruning. Other studies focus more on the design of hardware AI accelerators (Seo et al. 2022).
Previous results (Wermter et al. 2014; Zhang et al. 2015) show that 90\(\%\) of the computation during CNN inference comes from the convolutional computation. So, this work will focus on accelerating convolutional operations. The convolution calculation can be described as a multiply and accumulate (MAC) operation. To accelerate computation, convolutional operations are converted into matrix products, such as the Caffe (Chellapilla et al. 2006) architecture-based convolutional computation algorithm, which converts the input matrix into a one-dimensional vector of the same size as the convolutional kernel and then performs vector MAC operations with the stretched convolutional kernel. The high-speed matrix product computation capability of GPUs and FPGAs (Guo et al. 2017; Owens et al. 2008) dramatically accelerates the training and inference of neural networks.
However, current GPUs and FPGAs-based implementations of CNNs are based on the sequential von Neumann architecture; this architecture computation storage is separated, and with the increase of computation, the demand for bandwidth also increases, and the power consumption consumed by data communication also increases, the traditional “von Neumann architecture” is not sufficient for fast training and recognition tasks, such as real-time training and recognition of images and speech information. This challenge is also known as the “von Neumann bottleneck,” which reduces the overall efficiency and performance of the computing system (Von Neumann 1981).
the same time, the emergence of new devices such as memristors and thyristors, with their in-memory computing (IMC) capacity, high speed, low power consumption, and easy integration, has shown great potential for implementing large-scale neural networks in hardware (Chen et al. 2021; Ebong and Mazumder 2011; Vourkas and Sirakoulis 2012). In paper (Merced-Grafals et al. 2016; Afshari et al. 2022), one transistor and one memristor (1T1M) conductance regulation method is proposed, and literature (Zhang et al. 2018; Krestinskaya et al. 2018; Kwon et al. 2020; Owens et al. 2008) offers a hardware implementation of backpropagation algorithms based on 1T1M arrays to implement neural networks in-situ or ex-situ. Meanwhile, to overcome sneak-path current in memristor crossbar (Linn et al. 2010; Ni et al. 2021), Dong et al. (2012) adopts a two-step adjustment method in writing operation; a better approach is to integrate CMOS switches with gate characteristics on the memristor (Li et al. 2018, 2022). A memristor-based CNN with full hardware implementation was reported in Yao et al. (2020); the training speed of the network can reach a considerable 81.92 GOPS and 11,014 GOPS/W energy efficiency.
Although these research reports can realize CNN and have good performance, they have not changed the limitations caused by traditional convolution computing mode (Khan et al. 2020; Wan et al. 2022). For example, the convolution calculation input size is limited by the convolution kernel size, and the number of convolution calculations increases significantly as the input matrix increases due to the need to reshape the input matrix into an input sequence of the same size as the convolutional kernel in most convolutional computation architectures. The convolution result of each layer requires extra off-chip memory, and the memristor array based on 1T1M cannot effectively overcome the sneak path on simultaneously selected rows or columns due to the series characteristics of gate switches. Thus, the convolution calculation method for the memristor cross array needs to be further optimized to maximize its parallel computing capability.
Motivated by this, we propose an optimized convolution algorithm for the memristor crossbar. The number of convolution calculations of this algorithm is no longer affected by the image size. It can take full advantage of the parallel computing of the memristor crossbar. The rest of this paper is organized as follows. Section 2 introduces typical convolution algorithms, including the GPU-oriented Caffe algorithm and a memristor array-oriented algorithm, and then leads to our full-size convolution algorithm. Section 3 maps the designed FSCA algorithm to the memristor array and builds a circuit simulation system based on the physical memristor model for verification. The demonstration of system scalability and flexibility from both the circuit and system aspects is in Sect. 4 and concludes the paper in Sect. 5.
2 Full-size convolution algorithm
2.1 Basic convolution algorithm
Convolution computation accounts for a large proportion of deep convolutional neural networks, and accelerators based on GPU/FPGA and nonvolatile memory still face many challenges. Before introducing the designed full-size convolution algorithm, reviewing the current mainstream deep learning convolution algorithms on GPU/FPGA and nonvolatile memory are necessary.
Figure 1 is the GPU calculation process based on Caffe architecture (Chellapilla et al. 2006). First, the input data is reshaped into a vector of the corresponding size of the convolutional kernel and then multiplied and added to the expanded convolutional kernel.

Caffe architecture convolutional computation
Assuming that the input Matrix is an image with dimension \(m \times m\), convolution kernel size \(d \times d\), and convolution kernel sliding step size s, one MAC operation corresponding to the size of the convolution kernel region is calculated for each sliding. The single operation that can calculate 1-directional kernel convolution \(d \times d\). We can find that the convolutional computation is strongly influenced by the input size \(m \times m\), since each input can only be an amount that matches the convolutional size \(d \times d\), which means that the number of calculations increases significantly as the input image size increases and the time and energy required to unfold the input data into a usable form cannot be ignored.
Another convolution algorithm for memristor arrays appears in the literature (Wen et al. 2020), named convolution kernel first operated (CKFO), as shown in Fig. 2. A \(m \times m\) input matrix and \(d \times d\) kernel, the size of a sliding window of CKFO is \((m-d+1) \times (m-d+1)\), the total number of MAC operations is \(F=((d-1) / s+1) \times ((d-1) / s+1)\), a single operation can calculate 1-directional kernel convolution, the advantage of this algorithm is that it can expand the sliding window, reduce the number of calculations. When the core element is 0, the corresponding matrix can be omitted.

Diagram of convolution kernel first operated algorithm (CKFO)
2.2 New convolution algorithm: full-size convolution algorithm
It can be seen from the Caffe and CKFO algorithm diagram shown in Figs. 1 and 2 that convolution calculation extracts the matrix with the same size as the sliding window from the input matrix and multiplies it with the elements of the convolutional kernel. The total number of convolutional computations is the sum of the number of moves according to the sliding window from the input matrix. Inspired by the parallel calculation of the memristor, we expect to increase the number of sliding windows extracted from the input matrix in a single operation and then rely on the parallelism of the memristor array to achieve the computation.
Assume that the input matrix A is \(m \times m\) dimensional image data, the size of the convolution kernel G is \(d \times d\), and the sliding step is s when satisfying \(m \ge d + s\); then the full-size input convolution algorithm is represented by Eq. (1):
where k, l increasing in step \(d + s - 1\), \(\left\lceil \cdot \right\rceil\) is ceil function, \(*\) which indicates convolution computation.
In order to better show the proposed FSCA algorithm flow, the input matrix in Figs. 1 and 2 is extended to \(5\times 5\), as shown in Fig. 3. First, in the vertical shift-0 (Vshift-0) and horizontal shift-0 (Hshift-0) initial position tile the convolution kernel over the entire input matrix, the result is obtained by calculating all the covered red dotted areas simultaneously (\(2\times 2\) convolution kernel is capable of obtaining four parallel convolutional computation areas on a \(5\times 5\) input matrix) then execute horizontal shift operations (Hshift-1). After performing the horizontal shift, perform the vertical shift (Vshift-1) operation and perform the convolution calculation and horizontal shift as before in Vshift-0. In the Caffe convolution algorithm, it takes 16 times to complete the calculation, and our algorithm only needs four times to get the calculation result, and the larger the size of the input matrix, the more significant computation that is reduced.

FSCA algorithm convolution computation flow
In Table 1, we compare the designed FSCA with Caffe convolutional algorithm and CKFO algorithm in terms of single operation performance. We can find that for a \(m \times m\) input matrix with \(d \times d\) convolution kernels, the FSCA algorithm has obvious advantages in reducing the number of calculations, and the performance of a single calculation can reach \(\left\lceil {{{(m - d + 1)} \mathord{\left/ {\vphantom {{(m - d + 1)} {(d + s - 1)}}} \right. \kern-\nulldelimiterspace} {(d + s - 1)}}} \right\rceil\) directional kernel convolution.
3 FSCA circuit system based on memristor crossbar
3.1 Memristor array
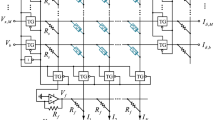
The memristor crossbar has been verified as an effective hardware structure to accelerate convolutional computation; At present, the design of the crossbar is developing towards high integration (Qin et al. 2020); however, with the increase of array size, the sneak path issue is a problem that should not be ignored (Linn et al. 2010; Ni et al. 2021), leakage current will be generated in the adjacent position of the selected cell; the closer the distance from the chosen cell, the more significant the leakage current is. If the leakage current exceeds a certain threshold, the output result will be affected, as shown in Fig. 4a. One solution is to add a transistor to a single memristor to form a 1T1M architecture, a 1T1M cell architecture that only enables read/write to a particular row. The transistor acts as a selector switch, as shown in Fig. 4b, and the leakage current will only be generated in the selected rows, thus reducing the impact of the leakage current on the output result.

a Leakage current flow in memristor array. b Leakage current in 1T1M arrays
To further reduce the leakage current on selected rows or columns, one transistor and three memristors (1T3M)-based crossbar structure is to be designed, as shown in Fig. 6. Each cross point consists of one transistor and three memristors, as shown in Fig. 5a. The red memristor M1 is used for calculation and storage, and the other two blue memristors M2 and the NMOS device, form a functional device like a bidirectional pulse-triggered switch; M1 and M2 have different device parameters. To achieve high cell density, we model the cell area of MOS accesses concerning the design rules of DRAM [24], and the area of a MOS access cell is calculated as Eq. (2):
where F is the transistor feature size and is the width-to-length ratio of NMOS. As shown in Fig. 5b, if we set the size of the unit cell to be the same as that of a transistor (10 \(F^2\)) by integrating two memristors monolithically on top of the transistor. This integration does not result in any additional area increase on the two-dimensional plane. In the vertical direction, the additional two memristors (M2) for computation are in parallel with the memristor (M1) used for calculation, so there is no increase in area compared to the 1T1M structure (Fig. 6).

a 1T3M unit structure b 1T3M schematic diagram

1T3M-based memristor crossbar, current flows only along the solid red line through the yellow selected cell. (Color figure online)
3.2 Bidirectional pulse trigger switch
We use two inverted series memristors, M2, to configure the voltage divider circuit to control the NMOS switch. Using two memristors maintains the current switch state until the next opposite-direction pulse control switch arrives and changes the switch state.
For example, assume that the current NMOS in Fig. 5a is in ON state, i.e., (\({R_{OFF}}\) and \({R_{ON}}\) denote the memristor’s high and low resistance states, respectively) and apply a constant 2 V gate voltage to the Vs terminal, if there is an input signal at vin, there will be current flowing through the memristor, as shown in Fig. 7; when a − 10 V (50 ns) switch-off pulse voltage is applied to the Vs side for 50 ns, the NMOS is in the OFF state, i.e., even if there is an input signal at the vin side, no current will flow through the memristor. After applying a switch on pulse voltage of 10 V (50 ns) to the Vs side again, the NMOS has turned on, and the current will flow through the memristor after the input pulse signal at the vin side. The state changes of gate voltage, memristor, and NMOS are shown in Table 2.

Bidirectional pulse triggering characteristics of 1T3M. a Switch on and off trigger signals applied to the Vs side. b The input signal is applied to the Vin terminal. c Current flowing through the memristor
Here we discuss the parameters of the two selected memristors. In the calculation process, M1 is connected in series with the transistor. We choose a high-resistance memristor to reduce the influence of transistors on the calculation results. At the same time, the high \(R_{OFF}/R_{ON}\) ratio of the memristor can help minimize the impact of the leakage current and enable the array’s output to observe a wider voltage range. We use the Voltage-controlled ThrEshold Adaptive Memristor (VTEAM) model (Kvatinsky et al. 2015) realized in SPICE (Radakovits et al. 2020; TaheriNejad et al. 2019) and the differential equation for the state variable of the memristor is:
Where \(k_{off}\), \(k_{on}\), \(\alpha _{off}\), and \(\alpha _{on}\) are constants, \(f_{off}(w)\) and \(f_{on}(w)\) are window functions, which constrain the state variable to bounds of \(w\in \left[ w_{on},w_{off}\right]\), and \(v_{on}\) and \(v_{off}\) are threshold voltages. The memristor M1 uses the memristor model proposed in (TaheriNejad and Radakovits 2019) and shown in Table 3; this model has and is capable of the fastest response in the sub-nanosecond. The memristor M2 is chosen to meet the fast response speed and the need to keep the NMOS ON or OFF state by dividing the voltage in series, analyze the circuit characteristics of the 1T3M structure as shown in Fig. 5a, and the voltage division formula gives:
where \(v_{th}\) denotes the NMOS threshold voltage. When \({\mathrm{{V}}_{gate}}\) is much smaller than \(v_{th}\), the switch is in the \(\text{OFF}\) state. When \({\mathrm{{V}}_{gate}}\) is greater than \(v_{th}\), the switch is in the \(\text{ON}\) state. This needs to meet the appropriate \(R_{OFF}/R_{ON}\) switch ratio, which is usually greater than 10 to meet the condition.
The parameter settings of M2 match the characteristic data of a physical memristor model published in Chanthbouala et al. (2012) and shown in Table 3. In reality, any memristor device that satisfies the requirements outlined in Eqs. (4) and (5) can meet the specified conditions. For instance, considering the 1T3M pulse-triggered switch depicted in Fig. 5a, assuming the trigger voltage of the switch is \(\pm 5\text{V}\), and the threshold voltages of the memristor device M2 are \(v_{off} =2\,\text{V}\) and \(v_{on} =-2\,\text{V}\), with the resistances \(R_{OFF}=10\, {\text{K}}\Omega\) and \(R_{ON}=1\, {\text{K}}\Omega\), the conditions for the pulse-controlled switch can be satisfied.
To elaborate, when the switch needs to transition from the initial ON state to the OFF state, referring to Eq. (5), as long as \(\mathrm {V_{S} }< v_{on} < 0\), the memristor \(\text{M2} _{Left}\) will rapidly shift from \(R_{OFF}\) to \(R_{ON}\), while \(\text{M2} _{Right}\) is initially set to \(R_{ON}\). Subsequently, based on the equation \(\mathrm{{V}}_{gate}= {{\text{Vs}}} \cdot \text{M2}_{Left}/(\text{M2}_{Left}+ \text{M2} _{Right} )\), the condition \({\mathrm{{V}}_{gate}} = |\text{Vs}/2 |> v_{off}\) should be met, where Vs = − 5 V, which satisfies the criteria. Consequently, \(\text{M2} _{Right}\) transitions from \(R_{ON}\) to \(R_{OFF}\), resulting in the switch being in the OFF state. When a conducting voltage of 2 V is reapplied to Vs, \({V_{gate}}\mathrm{{ }} < \mathrm{{ }}{v_{th}}\) and the NMOS enters the cutoff state. A similar analysis can be applied when the switch transitions from OFF to ON.
where \(v_{th}\) denotes the NMOS threshold voltage.
For the leakage current analysis of the 1T3M arrays, assume that all NMOS are initialized to the OFF state. After row selection, we expect to select a cell (such as the yellow area in Fig. 6). First, apply a switch on voltage to the selected cell row address selector, line address selector ground, other row and line suspended, the selected cell NMOS will change to ON state, While the NMOS of other cells remains in OFF state, the 2 V gate voltage is applied to the row line of the selected cell when reading or writing, so that only the current flows through the selected cell, as shown in Fig. 6, the solid red line indicates the current flow direction. In contrast, other cells will not have a current flow, which will further overcome the problem of leakage current in large-scale memristor arrays. We also consider the effect of adding two memristors to the 1T1M structure on the control complexity because these two memristors are in series; only one 50 ns setup signal at Vs terminal is needed to set the two memristors to the desired state (ON or OFF). No additional control signal is needed during the calculation. As with the 1T1M structure, only a constant voltage needs to be applied to the Vs terminal to keep the NMOS on, and the other terminal is grounded.
3.3 Algorithm mapping to memristor array
The current hardware scale of memristor-based chip integration is still challenging to reach and above. Consequently, we design an easily scalable circuit to increase the integration scale. We build the test circuit on LTspice and package the 1T3M cells, represented by rectangular squares, leaving only four pins for connection. The size of the convolution kernel size \(d \times d\) determines the number of columns of the primary array cell, and the number of rows is determined by the dimension of the data to be processed. The n rows and m columns of the input matrix can be extended by the primary array cell, the size of the basic array cell is n rows and d columns, and the number of essential array cells needed is m. We still use the \(5 \times 5\) input and \(2 \times 2\) kernel matrix in Fig. 3 as examples. The primary array cell dimension is \(5 \times 2\), and the number of essential array cells required to compose a \(5 \times 5\) input matrix is 5. So, the structure of the initialized array is shown in Fig. 8.
The circuit implementation flow is divided into three main steps. The first step is the circuit initialization configuration. The purpose is to allow the setting of all memristors by cascading all switches vup and the line switch vset to close. The setting method is to select every first column of all array cells with the column selector. Then apply − 10 V (50 ns) at the end of the row selector of the non-computing cells, which will make all the non-computing cells in the first column of each array cell NMOS to OFF state. Then select the rest column of the array cell to perform the same operation. Because the number of columns of the array cell is the same as the size of the convolutional kernel d, here, \(2 \times 2\) convolutional kernel, the number of settings is only two times. The switches in Fig. 8 are implemented with NMOS, gray fill means the switch is closed, and no fill means it is open.

a Two rows of memristor arrays are used to separately store W+ and \(\vert \mathrm W-\vert\). b Fully parallel convolution region, the red solid line squares I are the first convolution calculation area, and the blue dashed line squares II are the second convolution area after moving to the right. (Color figure online)
The second step is to store the input matrix and kernel matrix. Convert the kernel and input matrix to conductance and keep them in the manner mentioned below. For example, the mapping of conductance to the input matrices A can be performed by a linear transformation (Li et al. 2018):
where I is the matrix of ones, and coefficients of the change are determined by:
The convolution calculation results can be recovered from the crossbar measurements by:
where \({v_{in}}\) is the voltage form of the input kernel matrix, \(\mu\) is the scale factor matching the input voltage range, and I is the vector of ones. The second term of the equation contains the sum of all elements of the input voltage and can be easily post-processed by hardware or software.
The third step is to calculate. Before the calculation, we need to select the kernel convolution region for this operation. As in Fig. 8, we show the part chosen by the first two operations, the four red realized squares I are the area of the first convolution calculation, and the four blue dashed squares II are the area of the second convolution calculation after moving to the right.
Now we perform the calculation for the selected area I, a reading voltage with an amplitude of 0.2 V 50 ns pulse width and 50% duty cycle is applied to the W+ input side and connect the output with op-amp circuits after each column as shown in Fig. 9. The amplifier uses LTC6268-10 with a gain bandwidth of 4 G(HZ), and 3.5 ns delay the output after the two op-amps and limits the output voltage to less than the memristor’s threshold voltage M1, here the output voltage range is [0–0.6 V].

A selected kernel convolution region
The kernel elements W+ then enter the corresponding kernel convolution region as voltages. Then close the NMOS switch vup1 connecting the two cell arrays, and use the v-lin4 selector switch to conduct the current in both select rows, and finally use the Output selector switch to connect the calculated results to the output circuit. If an inverting amplifier circuit is connected to the output, as in Fig. 10a, the output result can be expressed as:
We use an integrated circuit to hold the current output; it should be noted that if the current reading is W+, the single pole double throw (SPDT) switch CL1 throw to a terminal. Then the output can be expressed as:
We set the integration time to be the same as the duration of the input signal and make the integration result linear with the output signal by adjusting the RC parameters.
After completing the W+ read and calculation, then execute the above read operation at the \(\vert \mathrm W-\vert\) side; the difference is that here the read voltage needs to be delayed by 100 ns, and the SPDT switch CL1 throw to b terminal, invert the output V1, the result of the calculation is superimposed on the previous W+ result by the RC integration circuit, as shown in Fig. 10b. The delay time generated by the output circuit is about 2.6 ns.

Output circuit: a output circuit with two op-amps, b the integrator accumulates positive and negative convolution kernel element calculation results
With the superimposed output results of kernel W+ and \(\vert \mathrm W-\vert\), one kernel operation is considered complete, and the convolution of the four red solid line squares regions I in Fig. 9 is all completed. Next, the algorithm in Eq. (1) can be followed to move and calculate the results of all remaining convolutional regions; due to the parallel nature of the algorithm, the number of such move operations will be minimal, in this case, there are only four operations.
4 Simulation results
4.1 Simulation framework
To simulate the designed FSCA algorithm and the convolutional computing circuit based on the memristor crossbar, a hierarchical simulation framework is used. The circuit layer simulation is performed on the open EDA software LTspice, which provides easy access to ADI’s commercial device libraries, such as the op-amp LTC6268, NMOS devices compatible with standard TSMC 0.18-μm CMOS process. It allows us to build our library of standard devices for memristor. We build SPICE models of voltage threshold memristors that match the characteristic parameters of the physical memristor model. The circuit-level simulation is also used to generate the behavioral models, power consumption, and delay parameters needed for system-level simulation and analysis. We use the MATLAB numerical simulation tool to build the behavioral model of the memristor to verify the flexibility and scalability of the memristor crossbar-based FSCA.
4.2 Circuit-level simulation
The circuit system verification is performed. First, convolution calculation is commonly used for feature extraction, here a \(14 \times 14\) grayscale image is used as the input matrix for full-size convolution calculation to extract edges; the data is used from two randomly selected Modified National Institute of Standards and Technology database (MNIST), the original \(28 \times 28\) image is compressed to \(14 \times 14\) and the edge extraction is performed with a \(3 \times 3\) convolution kernel of Sober operator.
Before storing the pixels, it is necessary to program the voltage and conductance fitting of the memristor, see method (Merced-Grafals et al. 2016). Because the original image MNIST data is an 8-bit gray-scale image, the memristor used to store pixels also needs a stable storage state of 8 bits, program the memristor with voltages of different amplitudes of the same pulse width of 50 ns. To simplify the process, the positive and negative values in the Sober operator are replaced by voltage sources below the threshold voltage of the memristor. Here the basic expansion unit used is \(14 \times 3\), 14 expansion units are required to achieve the full-size convolution of the input matrix, and we build an array of \(14 \times 54\), as shown in Fig. 11.

\(14 \times 54\) arrays made up of fourteen array units
The control signal is simulated using a timing pulse signal source, which can be implemented in the actual circuit using FPGA and microcontrollers. The timing diagram of some of the control signals is shown here, the left part of the red dashed line in Fig. 12 is the storage stage, and the right is the calculation stage. In the storage stage, the uniform pulse signal width is 50ns, and the interval between two adjacent pulses is 5 ns. The input pixel matrix in Fig. 11 is stored in the cross array column by column from left to right, so it takes \(14 \times 55\) ns to keep a \(14 \times 14\) matrix. The control signals V(clin1) and V(clin4) in the storage stage are high level, enabling the data can stored in the first and fourth columns, and V(vset1) and V (vset4) allowed the set operation to be performed on the memristor. V(vup1) and V(vup4) enabling the extended array cells are linked to each other. V(vin13), V(vin14), and V(vin15) are the set voltage values corresponding to the pixel value used to store to the cross array.

Input signal and control signal timing diagram: a The control signals V(clin1), V(clin4), V(vset1) and V(vset4) in the storage stage are high level. b V(vin13), V(vin14), and V(vin15) are the set voltage values corresponding to the pixel value used to store to the cross array. c V(vup1) and V(vup4) enabling the extended array cells are linked to each other. d The corresponding output results of the selected calculation area. (Color figure online)
In the calculation phase, the right half of the red dashed line, the Sober operator is first transformed to voltage as the input, as shown in the partially enlarged view in the right half of Fig. 12b. The V(clin) is kept high and applied to NMOS in the four-pin device to keep the state whether the device participates in the calculation or not, and the V(line) switch controls the current flow between different columns. The V(vup1) and V(vup4) are opened or closed when moving right, making the expansion cells interconnect in the computational order. Figure 12d shows the computational results of each output cell at different moments of the computational stage. We import the calculation results into MATLAB for display.
The simulation results are shown in Fig. 13; we also used MATLAB to perform Sober edge extraction and compared it with the circuit simulation results at the same gradient threshold. Using the FSCA algorithm, the number of convolution operations for \(14 \times 14\) input is \(\left\lceil {d/s} \right\rceil \times \left\lceil {d/s} \right\rceil = 9\). Because the Sober operator we use has two directions of feature extraction template, the actual computation time is \(9 \times 2 \times 100\,\text{ns}\), plus the storage time \(14 \times 55\,\text{ns}\), the total computation time for a \(14 \times 14\) input matrix is 2.6 μs. We use the power consumption calculation function with the LTspice software to estimate the average power consumption of each functional device. The average power consumption of a single NMOS switch is 700 pW, the two M2 memristors in a 1T3M structure is 79.23 nW, and the average power consumption of an M1 memristor is 244.45 nW.

Handwritten digit edge extraction. a Original image. b Circuit simulation result. c Software simulation result
4.3 System-level simulation
The memristor behavioral model is used to simulate FSCA algorithm-based image process. First, we verify the scalability and computational capability of the system. Assuming the system is scaled to an array \(768 \times 256\), it can process a \(256 \times 256\) image. We take a Lena grayscale image as an example and extract its horizontal and vertical directional gradients. The Lena image is stored in a memristor array using the memristor behaviour model in the previous section.
The Sober operator is converted to a below-threshold voltage and fed into the crossover array. It is worth noting here that the positive and negative of the sober operator are calculated separately, both are converted to absolute value voltage for input, and the computed results are inverted for the negative operator and added to the positive results. The weight and pixel mapping scheme are adopted from the literature (Li et al. 2018). We superimpose the horizontal and vertical features and show the results after different numbers of operations, as in Fig. 14. The graph shows that only 9 parallel convolution operations are needed for edge extraction of a Lina image by the FSCA algorithm, which greatly improves the efficiency of image feature extraction. Through the average power consumption of the memristor and transistor during circuit calculation in the previous section, we can estimate the power consumption of a \(768 \times 256\) memristor crossbar in processing a picture is 21.69 mW. Assuming that the time required for one convolution operation in the memristor crossbar circuit in the previous section is used, our convolutional computation system can reach a peak calculation performance of 1.23 tera operations per second (TOPS).

Lena image Sober horizontal and vertical gradient extraction after 3, 6, and 9 operations, respectively
In machine vision, Gabor feature can simulate human visual response well and is widely used in image processing. Some methods use Gabor filters to extract features, which are then fed into the CNN, while others simply use Gabor filters instead of convolutional kernels (Yuan et al. 2022). Data preprocessing plays a crucial role in handling noise, outliers, and duplicate values, ultimately improving the speed and predictive performance of the model. Another work from our team has developed a memristor-based neuromorphic vision system that eliminates the need for complex data conversion (Zhou et al. 2023). This system enables direct optoelectronic sensing and image preprocessing on memristor arrays. In this context, we have designed a novel FSCA that is particularly well-suited for integration into vision processing devices based on image sensors. Previously, we have already validated the significant advantages of our design algorithm in terms of hardware resource utilization through circuit-level simulations. Here, we will proceed to verify the potential of our algorithm in feature extraction and neural network applications at the system level.
Gabor filter is defined as the product of the Gaussian function and sinusoidal function, and the expression is (Grigorescu et al. 2003):
Where \(x' = x\cos \theta + y\sin \theta\), and \(y = - x\sin \theta + y\cos \theta\), and denote the horizontal and vertical coordinates of a pixel in the image, respectively, is the orientation parameter, and refers to the wavelength and is measured in pixels. In addition, is the phase shift, and \(\sigma\) is the standard deviation of the Gaussian coefficient, \(\gamma\) denotes the spatial aspect ratio, which determines the ellipticity of the received field.
Although Gabor filtering with a variety of wavelengths and orientation can extract different features, our main purpose here is to verify our FACA algorithm, so Gabor filters with limited wavelengths and fixed orientation is used to extract features. We refer to the method of converting the Gabor filter into convolution calculation. Perform Gabor filtering at different wavelengths of 0.9, 1.2 and 1.5 by selecting the 0° and 90° orientation parameters, and other parameters are selected as typical values, such as a = 1, which are used to extract the characteristics of the horizontal and vertical directions of the image at different wavelengths. The memristor used to store the input pixel matrix is also simulated using an 8-bit stable state memristor.
Next, we validate the application of design algorithms in deep neural networks for enhanced MNIST data set recognition. First, we build a multilayer neural network; the network structure is 768-100-10, and the MNIST data set is divided into three parts, 50,000 training data, 10,000 validation data, and 10,000 test data. The training algorithm uses mini-batch Stochastic Gradient Descent (Mini-batch SGD), the number of batches is 200, and without other special processing, the recognition accuracy of the 10,000 test set is 97.52%. Next, we add a Gabor filter using the FACA algorithm before the first layer of the network to extract features from the input image to enhance the network performance. Figure 15 illustrates the concept of connecting the output of Gabor filter results to a fully connected neural network using memristor arrays.

Concept diagram of memristive multi-layer neural network using Gabor filter preprocessing
During the preprocessing phase, the input image is sequentially read column-wise into the feature extraction array. The Gabor filter kernel is then applied to the input, and the filtered results are converted using an analog-to-digital converter (ADC) before being inputted into the memristor-based multi-layer fully connected network. The Rectified Linear Unit (ReLU) activation function is used, and the number of neurons in the hidden layer is set to 100.
The output of the hidden layer is processed by an ADC and subsequently inputted into the multi-layer neural network. Notably, the size of the convolution kernel varies depending on the wavelength of filtering. It is important to mention that in the system simulation phase, we did not model or simulate the memristor-based multi-layer neural network. Instead, our modeling and simulation efforts focused solely on the feature extraction array using memristor arrays. For the subsequent multi-layer neural network, we utilized a pre-existing MATLAB programming implementation. Because of the existence of the convolution kernel, the parameters of the next layer input can be reduced, such as the number of parameters of the network filtered by 0.9 Gabor wavelength becomes 676-100-10, and the parameters of the network with 1.2 and 1.5 wavelengths become 576-100-10.
Compared with the network without Gaussian filtering, the network parameters are reduced by 13.6%, 26.2% and 26.2% for wavelengths of 0.9 and 1.2 and 1.5, respectively. And through 20 experiments, the highest average recognition rate was 98.25% on the test sets at the wavelength of 1.2, as shown in Table 4.
However, in practical scenarios, the output of the Gabor filtering process is still a analogy output, as depicted in Fig. 10b. Consequently, to facilitate its utilization in subsequent applications, the output requires conversion and transmission through ADCs. The quantization error of ADCs plays a crucial role in impacting the performance of neural networks. In the circuit design section, our focus is on implementing the FACA algorithm we designed. In the system simulation part, we conduct experiments to examine the influence of ADCs’ quantization error on system applications. The experimental approach involves adding a Gabor filter layer based on the memristor model before the multi-layer neural network in the system simulation. Additionally, we introduce linear ADCs to the output unit, which can simulate the quantization accuracy of ADCs to some extent and positively affect subsequent network performance (Peng et al. 2020). In this study, we only consider the quantitative aspects of the feature extraction layer and directly connect the output from the feature extraction layer to the subsequent multi-layer fully connected network.
We conducted tests to assess the impact of using 2-bit, 4-bit, 6-bit, and 8-bit ADCs under different wavelength conditions. The experimental results are presented in the Table 4. Our findings indicate that the quantization error of ADCs in the feature extraction layer has minimal impact on the performance of the subsequent network. However, when the quantization accuracy of ADCs decreases to 2 bits, there is a significant decrease in network performance. We attribute this observation to the Gabor filter layer, which primarily focuses on extracting image features rather than directly identifying the network. Furthermore, the MNIST recognition task is relatively simple and does not involve complex information such as color and texture. This explains why the network trained on binarized MNIST dataset still achieves high recognition accuracy (Kayumov et al. 2022).
Because of the non-ideal characteristics of the memristor device itself, the performance factor that reduces the memristor network is the device-to-device and cycle-to-cycle variation when writing to memory devices. The device-to-device variation is caused by the fact that the amount of change in conductance is not the same each time when the same set voltage is applied to the same memristor, which can be simulated by adding Gaussian noise to the amount of change in conductance of the memristor and can be expressed as
We test the classification accuracy at different wavelengths, and the results in Fig. 16a show that our network can effectively resist the device-to-device variation within 20% of memristors; after exceeding 30%, the classification accuracy drops obviously.

Accuracy of identifying MNIST datasets on cycle-to-cycle and device-to-device variation. a Cycle-to-cycle variation. b Device-to-device variation
Device-to-device variation can be simulated by adding Gaussian noise to the coefficients in the differential equation of memristor \(koff \in \mathrm{{N}} (koff,\sigma _{dp}^2)\) and \(kon \in \mathrm{{N}}(kon,\sigma _{dn}^2)\). As shown in Fig. 16b, we find that the recognition rate of the network is unaffected by
device variation up to 20% and decreases significantly above 30%.
5 Conclusion
This work presents a full-scale convolutional computational circuit based on a 1T3M memristor crossbar that can effectively suppress the sneak path issue in the array structure while verifying the significant advantages of the design scheme in terms of computational time and power consumption in spice circuit simulations. Table 5 summarizes the comparison with other state-of-the-art techniques in terms of performance. Our work boasts the most impressive computational power as it manages to complete kernel convolution computations with 7225 directions in a single operation, all without increasing the area of the computational unit. Additionally, our design not only exhibits excellent computational performance but also has the lowest power consumption for single-convolution operations. We also verify that the Gabor filtering implemented based on our design scheme is able to improve the recognition rate on the MNIST dataset to 98.25%, reduce the network parameters by 26.2%, and effectively immunize against various non-idealities of the memristive synaptic devices up to 30%.
References
Abedin M, Roohi A, Liehr M et al (2022) MR-PIPA: an integrated multilevel RRAM (HfOx)-based processing-in-pixel accelerator. IEEE J Explor Solid State Comput Devices Circuits 8:59–67. https://doi.org/10.1109/JXCDC.2022.3210509
Afshari S, Musisi-Nkambwe M, Esqueda IS (2022) Analyzing the impact of memristor variability on crossbar implementation of regression algorithms with smart weight update pulsing techniques. IEEE Trans Circuits Syst I Regul Pap 69:2025–2034
Chanthbouala A, Garcia V, Cherifi RO et al (2012) A ferroelectric memristor. Nat Mater 11:860–864
Chen J, Wu Y, Yang Y et al (2021) An efficient memristor-based circuit implementation of squeeze-and-excitation fully convolutional neural networks. IEEE Trans Neural Netw Learn Syst 33:1779–1790
Dong X, Xu C, Xie Y et al (2012) NVSim: a circuit-level performance, energy, and area model for emerging nonvolatile memory. IEEE Trans Comput Aided Des Integr Circuits Syst 31:994–1007
Ebong IE, Mazumder P (2011) Self-controlled writing and erasing in a memristor crossbar memory. IEEE Trans Nanotechnol 10:1454–1463
Grigorescu C, Petkov N, Westenberg MA (2003) Contour detection based on nonclassical receptive field inhibition. IEEE Trans Image Process 12:729–739
Guo K, Sui L, Qiu J et al (2017) Angel-Eye: a complete design flow for mapping CNN onto embedded FPGA. IEEE Trans Comput Aided Des Integr Circuits Syst 37:35–47
Ivanov D, Chezhegov A, Kiselev M et al (2022) Neuromorphic artificial intelligence systems. Front Neurosci 16:1513. https://doi.org/10.3389/fnins.2022.959626
Khan A, Sohail A, Zahoora U et al (2020) A survey of the recent architectures of deep convolutional neural networks. Artif Intell Rev 53:5455–5516. https://doi.org/10.1007/s10462-020-09825-6
Kim S, Choi YY, Kim T et al (2022) A biomimetic ocular prosthesis system: emulating autonomic pupil and corneal reflections. Nat Commun 13:6760. https://doi.org/10.1038/s41467-022-34448-6
Krestinskaya O, Salama KN, James AP (2018) Learning in memristive neural network architectures using analog backpropagation circuits. IEEE Trans Circuits Syst I Regul Pap 66:719–732
Kvatinsky S, Ramadan M, Friedman EG et al (2015) VTEAM: a general model for voltage-controlled memristors. IEEE Trans Circuits Syst II Express Briefs 62:786–790
Kwon D, Lim S, Bae JH et al (2020) On-chip training spiking neural networks using approximated backpropagation with analog synaptic devices. Front Neurosci 14:423
Li C, Hu M, Li Y et al (2018) Analogue signal and image processing with large memristor crossbars. Nat Electron 1:52–59
Li J, Zhou G, Li Y et al (2022) Reduction 93.7% time and power consumption using a memristor-based imprecise gradient update algorithm. Artif Intell Rev 55:657–677. https://doi.org/10.1007/s10462-021-10060-w
Linn E, Rosezin R, Kügeler C et al (2010) Complementary resistive switches for passive nanocrossbar memories. Nat Mater 9:403–406
Merced-Grafals EJ, Dáivila N, Ge N et al (2016) Repeatable, accurate, and high speed multi-level programming of memristor 1T1R arrays for power efficient analog computing applications. Nanotechnology 27:365202
Moor M, Banerjee O, Abad ZSH et al (2023) Foundation models for generalist medical artificial intelligence. Nature 616:259–265. https://doi.org/10.1038/s41586-023-05881-4
Ni R, Yang L, Huang XD et al (2021) Controlled majority-inverter graph logic with highly nonlinear, self-rectifying memristor. IEEE Trans Electron Devices 68:4897–4902
Owens JD, Houston M, Luebke D et al (2008) GPU computing. Proc IEEE 96:879–899. https://doi.org/10.1109/JPROC.2008.917757
Peng X, Huang S, Jiang H et al (2020) DNN+NeuroSim V2.0: an end-to-end benchmarking framework for compute-in-memory accelerators for on-chip training. IEEE Trans Comput Aided Des Integr Circuits Syst 40(11):2306–2319. https://doi.org/10.1109/TCAD.2020.3043731
Qin YF, Bao H, Wang F et al (2020) Recent progress on memristive convolutional neural networks for edge intelligence. Adv Intell Syst 2:2000114
Radakovits D, TaheriNejad N, Cai M et al (2020) A memristive multiplier using semi-serial imply-based adder. IEEE Trans Circuits Syst I Regul Pap 67:1495–1506
Salvagno M, Taccone FS, Gerli AG et al (2023) Can artificial intelligence help for scientific writing? Crit Care 27:1–5. https://doi.org/10.1186/s13054-023-04380-2
Seo JS, Saikia J, Meng J et al (2022) Digital versus analog artificial intelligence accelerators: advances, trends, and emerging designs. IEEE Solid State Circuits Mag 14:65–79. https://doi.org/10.1109/MSSC.2022.3182935
Soliman T, Laleni N, Kirchner T et al (2022) FELIX: a ferroelectric FET based low power mixed-signal in-memory architecture for DNN acceleration. ACM Trans Embed Comput Syst 21:1–25. https://doi.org/10.1145/3529760
TaheriNejad N, Radakovits D (2019) From behavioral design of memristive circuits and systems to physical implementations. IEEE Circuits Syst Mag 19:6–18
Tran M, Gabert L, Hood S et al (2022) A lightweight robotic leg prosthesis replicating the biomechanics of the knee, ankle, and toe joint. Sci Robot 7:eabo3996. https://doi.org/10.1126/scirobotics.abo3996
Von Neumann J (1981) The principles of large-scale computing machines. Ann Hist Comput 3:263–273
Vourkas I, Sirakoulis GC (2012) A novel design and modeling paradigm for memristor-based crossbar circuits. IEEE Trans Nanotechnol 11:1151–1159
Wan W, Kubendran R, Schaefer C et al (2022) A compute-in-memory chip based on resistive random-access memory. Nature 608(7923):504–512. https://doi.org/10.1038/s41586-022-04992-8
Wang J, Wang X, Shen T et al (2022) Parallel vision for long-tail regularization: initial results from IVFC autonomous driving testing. IEEE Trans Intell Veh 7:286–299. https://doi.org/10.1109/TIV.2022.3145035
Wen S, Chen J, Wu Y et al (2020) CKFO: convolution kernel first operated algorithm with applications in memristor-based convolutional neural network. IEEE Trans Comput Aided Des Integr Circuits Syst 40:1640–1647
Yao P, Wu H, Gao B et al (2020) Fully hardware-implemented memristor convolutional neural network. Nature 577:641–646
Ye C, Zhu H, Zhang B et al (2023) A closer look at few-shot 3D point cloud classification. Int J Comput Vis 131:772–795. https://doi.org/10.1007/s11263-022-01731-4
Yuan Y, Wang LN, Zhong G et al (2022) Adaptive gabor convolutional networks. Pattern Recognit 124:108495
Zhang Q, Wu H, Yao P et al (2018) Sign backpropagation: an on-chip learning algorithm for analog rram neuromorphic computing systems. Neural Netw 108:217–223
Zhou G, Li J, Song Q et al (2023) Full hardware implementation of neuromorphic visual system based on multimodal optoelectronic resistive memory arrays for versatile image processing. Nat Commun 14(1):8489. https://doi.org/10.1038/s41467-023-43944-2
Zhu S, Wang L, Dong Z et al (2020) Convolution kernel operations on a two-dimensional spin memristor cross array. Sensors 20:6229
Chellapilla K, Puri S, Simard P (2006) High performance convolutional neural networks for document processing. In: Tenth international workshop on frontiers in handwriting recognition, Suvisoft
Cui H, Wang C, Maan H et al (2023) scGPT: towards building a foundation model for single-cell multi-omics using generative AI. bioRxiv, pp 2023–04. https://doi.org/10.1101/2023.04.30.538439
Jacob B, Kligys S, Chen B et al (2018) Quantization and training of neural networks for efficient integer-arithmetic-only inference. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 2704–2713
Kayumov Z, Tumakov D, Mosin S (2022) An effect of binarization on handwritten digits recognition by hierarchical neural networks. In: Second international conference on image processing and capsule networks: ICIPCN 2021 2. Springer, pp 94–106. https://doi.org/10.1007/978-3-030-84760-9_9
Khowaja SA, Khuwaja P, Dev K (2023) ChatGPT needs spade (sustainability, privacy, digital divide, and ethics) evaluation: a review. arXiv preprint. https://doi.org/10.48550/arXiv.2305.03123
TaheriNejad N, Delaroche T, Radakovits D et al (2019) A semi-serial topology for compact and fast imply-based memristive full adders. In: 2019 17th IEEE international new circuits and systems conference (NEWCAS). IEEE, pp 1–4
Wermter S, Weber C, Duch W et al (2014) Artificial neural networks and machine learning—ICANN 2014: 24th international conference on artificial neural networks, Hamburg, Germany, September 15–19, 2014, proceedings, vol 8681. Springer
Wu Y, Wang Q, Wang Z et al (2023) Bulk-switching memristor-based compute-in-memory module for deep neural network training. arXiv preprint. https://doi.org/10.48550/arXiv.2305.14547
Ye P, Li B, Li Y et al (2022) \(\beta\)-DARTS: beta-decay regularization for differentiable architecture search. In: 2022 IEEE/CVF conference on computer vision and pattern recognition (CVPR). IEEE, pp 10864–10873. https://doi.org/10.1109/CVPR52688.2022.01060
Zhang C, Li P, Sun G et al (2015) Optimizing FPGA-based accelerator design for deep convolutional neural networks. In: Proceedings of the 2015 ACM/SIGDA international symposium on field-programmable gate arrays. pp 161–170
Acknowledgements
This work was supported in part by the National Natural Science Foundation of China (Grant Nos. U20A20227, 62076208, 62076207), Chongqing Talent Plan “Contract System” Project (Grant No. CQYC20210302257), Youth Fund of the National Natural Science Foundation of China (Grant No. 4112300273), Natural Science Foundation of Chongqing (Grant No. cstc2021jcyj-msxmX0565), Fundamental Research Funds for the Central Universities (No.SWU-XDZD22009) and Chongqing Higher Education Teaching Reform Research Project (No.211005).
Author information
Authors and Affiliations
Contributions
Jinpei Tan developed the theoretical formalism, performed the analytic calculations and performed the numerical simulations. Both Siyuan Shen and Shukai Duan authors contributed to the final version of the manuscript. Lidan Wang supervised the project.
Corresponding author
Ethics declarations
Conflict of interest
The author declares that they have no competitive economic interests or personal relationships that affect the work reported in this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tan, J., Shen, S., Duan, S. et al. An efficient full-size convolutional computing method based on memristor crossbar. Artif Intell Rev 57, 158 (2024). https://doi.org/10.1007/s10462-024-10787-2
Accepted:
Published:
DOI: https://doi.org/10.1007/s10462-024-10787-2