
Abstract
Due to the sparsity, irregularity and disorder of the point cloud, the tasks related to it are full of challenges. Exploring local geometric patterns and multi-scale features is effective for point cloud understanding, and promising results have been achieved. In this paper, we present a Position Adaptive Residual Block, namely PARB, for the first time. It can carry out powerful geometric signal description and feature learning. Starting from this module, we propose two extensions. First, a Position Adaptive Residual Network, called PARNet, is derived by utilizing PARB. Second, PARB can be regarded as a plug-and-play module embedded in MLP-based networks, which can remarkably enhance the performance of the backbone. We also introduce an efficient Knowledge Complement Strategy, which is part of the PARNet architecture, to make the framework perform better. Extensive experimental results on challenging benchmarks demonstrate that our PARNet delivers the new state-of-the-art on ShapeNet-Part and achieves competitive performance on ModelNet40.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
1 Introduction
Recently, with the rapid development of 3D acquisition device, 3D point clouds attract wide discussion and heated attention (Han et al. 2023, 2022; Li et al. 2022; Thomas et al. 2019; Qian et al. 2021). Point clouds are one of the important representations of 3D data, which play an increasingly significant role in a wide range of applications, e.g., intelligent robot technology (Hu et al. 2020), autonomous driving (Xu et al. 2020), virtual reality/augmented reality (Guo et al. 2020), and multimedia interaction (Akhtar et al. 2021). Therefore, how to conduct effective and efficient point cloud analysis is very necessary. In recent years, while remarkable advancements and tremendous success have been obtained in 2D computer vision tasks with deep learning fashions (He et al. 2016; Chen et al. 2017; Redmon and Farhadi 2018; Howard et al. 2019; Dosovitskiy et al. 2020), there are still challenges to performing point cloud processing well due to its nature of sparsity, irregularity, and disorder.
In respond to these problems, researchers have made great efforts and come up with some methods (Thomas et al. 2019; Wang et al. 2018; Milioto et al. 2019; Aksoy et al. 2020; Rethage et al. 2018). Several advanced works attempt to project the point clouds to muti-view images (Aksoy et al. 2020; Cortinhal et al. 2020; Zhao et al. 2021) or transform the point clouds into regular voxel grids (Rethage et al. 2018; Su et al. 2018; Zhou et al. 2020), then applying 2D or 3D convolutional framework to conduct feature learning. Despite promising performances have been acquired, these approaches suffer from valid geometric information loss during data transformation and rendering. Particularly, voxels typically require a large amount of memory and computational costs with the increase of the model (Graham et al. 2018). Another popular stream is to directly deal with point clouds (Ran et al. 2022; Zhao et al. 2021; Qiu et al. 2021; Lai et al. 2022; Park et al. 2023). As the foundational work, both PointNet (Qi et al. 2017) and PointNet++ (Qi et al. 2017) use shared multi-layer perceptrons (MLPs) and symmetric functions to act on the raw points. Subsequent to the cornerstone, the follow-up works mainly focus on the following two aspects: On the one hand, well-designed convolutions are developed (Thomas et al. 2019; Xu et al. 2021; Fan et al. 2021), which operate directly on points to extract local geometric signals and features. On the other hand, some work is committed to revisiting the design of network architecture (Qian et al. 2021; Ma et al. 2022; Qian et al. 2022), e.g., residual structure and multi-scale feature learning, to quest for more comprehensive point representations. The two pipelines of the point-based method mentioned above can establish different learning mechanisms for point clouds and complement each other in the extraction of geometric patterns and features. Nevertheless, to the best of our knowledge, there is no fusion of the above two formulations to process the point cloud.
In this paper, we propose a Position Adaptive Residual Block, namely PARB, for the first time. It integrates local geometrical extractors into the design of residual architecture. PARB has two advantages: it can adaptably model the geometric patterns and spatial variations of 3D point clouds and aggregate point cloud features of different layers. Starting from this effective block, we propose two approaches by leveraging PARB to benefit point cloud analysis.
First, we present a novel Position Adaptive Residual Network termed PARNet, one of its fundamental component is our proposed PARB. In addition, PARNet is equipped with an effective and efficient Knowledge Complement Strategy that we introduce to obtain better generalization ability. Significantly, the Knowledge Complement Strategy merely works on inference-time of the already trained model, which enormously saves the network training cost. Quantitative and qualitative evaluation results demonstrate that our PARNet exhibits strong performance on point cloud classification and better than state-of-the-art models on part segmentation.
Second, PARB can be regarded as a plug-and-play module to improve the performance of MLP-based models. We integrate PARB into classical MLP-based point cloud pipelines by replacing their MLPs without changing other network configurations. On different tasks, our PARB considerably improves the performance of the baseline consistently, e.g., \(+0.7\%\) Inst. mIoU on ShapeNet-Part and \(+3.7\%\) OA on ModelNet40.
To conclude, the main contributions of our work are as follows:
-
A carefully designed Position Adaptive Residual Block, namely PARB, is proposed for fine-grained point cloud understanding.
-
We introduce a Knowledge Complement Strategy, which is training-free and can effectively enhance the performance of our model.
-
A newly designed network called PARNet is proposed, which achieves competitive performance on ModelNet40 and outperforms current state-of-the-art methods on ShapeNet-Part.
-
As a plug-and-play module, our PARB enables the network to deliver superior performance.
The remaining structure of our paper is organized as follows. Section 2 provides a summarize of recent work on related point cloud topics. Section 3 introduces the details of our proposed PARB and Knowledge Complement Strategy, and states the construction of our PARNet and the plug-and-play method of our PARB. Comprehensive experiments and analyses are presented in Sect. 4. The conclusion is given in Sect. 5.
2 Related work
Over the years, a number of studies using deep learning on 3D point clouds have made significant progress. Different from the traditional approach (Li et al. 2020; Gao et al. 2020), deep learning methods favor more differentiable amenable structures and achieve very impressive performance. The previous research can be divided into three categories, including projection-based, voxel-based, and point-based methods.
Projection-based methods project 3D LiDAR point clouds into 2D images as deep model inputs, including spherical or top-down Bird-Eye-View images. As the representative work of this method, SalsaNet (Aksoy et al. 2020) proposes a brand-new encoder-decoder architecture to segment road and vehicle points in real-time, which solves the problem of lacking large annotated point cloud data by applying MultiNet (Teichmann et al. 2018) and Mask R-CNN (He et al. 2017). To further improve the performance of SalsaNet, SalsaNext (Cortinhal et al. 2020) proposes a contextual module before the encoder and introduces the dilated convolution and the pixel-shuffle layer into the architecture. However, the RGB-D images obtained by projection-based methods have the problem of information loss.
Voxel-based methods transfer point clouds into voxels for structured data representation, which usually take voxels as input and apply a 3D Convolutional Neural Network to process. FCPN (Rethage et al. 2018) is the first network to operate on point clouds using 3D convolutions and weighted average pooling. In order to alleviate the memory and computational overhead of the voxel-based method, SSCN (Graham et al. 2018) presents a novel sparse convolutional operation to analyze geographically sparse input, while Choy et al. (2019) uses generalized sparse convolution and sparse tensors for spatio-temporal perception. Great efforts have been made to obtain a decent trade-off between resource overhead and prediction accuracy, but voxel-based methods still suffer from excessive hardware costs.
Point-based methods directly work on sparse and unordered point clouds, which is the basis of our research. Different from the above two types of methods, this approach does not introduce redundant transitions of point clouds and has favorable performance while maintaining efficiency. PointNet (Qi et al. 2017) is pioneering work that learns per-point features individually with shared MLPs. It aggregates global features with symmetrical pooling functions. In order to solve the problem that PointNet lacks the ability to capture local structures, PointNet++ (Qi et al. 2017) introduces multi-scale grouping of neighboring points and progressively learns from larger local regions. At present, the most popular branches of point-based methods include constructing point convolution operators that capture local information and designing network architectures with comprehensive representation ability. As an attempt of the point convolution method, KPConv (Thomas et al. 2019) is made up of a set of local 3D filters and can be expanded to deformable convolutions that train their kernel points to conform to the local geometry. PAConv (Xu et al. 2021), which will be discussed in depth in subsequent chapters, is a plug-and-play convolution operator for 3D point cloud understanding. PointNeXt (Qian et al. 2022) and PointMLP (Ma et al. 2022) are the most representative works that focus on network architecture design. The former adapts a set of improved training strategies and introduces separable MLPs and an inverted residual bottleneck architecture into PointNet++ to facilitate effective performance. The latter proposes a simple Residual MLP unit, and is equipped with a geometric affine module to deliver excellent performance on multiple datasets. To further improve the performance of PointMLP on part segmentation, PointStack (Wijaya et al. 2022), which is the backbone of our research, utilizes novel learnable poolings with multi-scale feature learning.
Our work in this paper combines the advantages of point convolution and delicate network architecture to achieve a more comprehensive point cloud feature representation.
3 Methodology
In this section, we first revisit PAConv (Xu et al. 2021), which has limitations in dealing with point clouds with varying numbers and the combining strategy in grouping quantity and weight matrices. Then, we propose an improved PAConv, termed PAConv+, and use it to construct a Positional Adaptive Residual Block called PARB, which can adapt the spatial and geometric information of point clouds and aggregate multi-scale features well. In addition, we introduce an effective Knowledge Complement Strategy that can enhance the ability of already trained models in the inference time. Based on the above, we present a Positional Adaptive Residual Network, namely PARNet. Finally, we also provide plug-and-play usage of PARB.
3.1 Preliminary: revisiting PAConv
Position Adaptive Convolution, namely PAConv, is a plug-and-play operator for point cloud understanding. It defines a Weight Bank \(\mathcal {B} = \{B_{m} \vert m=1,2,..., M\}\), where each \(B_{m}\) is a weight matrix, and M determines the quantity of weight matrices stored. On the top of that, a novel architecture, ScoreNet, is proposed to learn the position relationship between a center point \(p_{i}\) and its neighbor point \(p_{j}\) and output weight coefficients for each weight matrix. We denote the input vector as \((p_{i}, p_{j})\in R^{D_{in}}\). The processing flow of ScoreNet can be formulated as follows:
where \(\mu\) is a multi-layer perceptron and \(\sigma\) denotes Softmax function. The output vector \(S_{ij} = \{S_{ij}^{m} \vert m = 1,..., M\}\), where \(S_{ij}^{m}\) indicates the coefficient of each \(B_{m}\) when building the operator. On this basis, the kernel of PAConv is derived by assembling weight matrices with the corresponding coefficients obtained from ScoreNet.
3.2 Position adaptive residual block
PAConv is data-driven and has shown promising performance on point cloud processing. Nevertheless, the total number of point clouds in the PAConv-modified backbone network remains constant during propagation, so the grouping algorithm in PAConv merely needs to cope with this single situation. It can’t handle the change in the quantity of points, which limits the capability of PAConv to be really plug-and-play. And for specific tasks, e.g., point cloud classification and part segmentation, we find that the full potential of PAConv has yet to be explored. This is due to the sampling number in grouping layer and the quantity of weight matrices. We delve into the above two problems and further propose our Position Adaptive Residual Block, which will be covered later.

The structure of position adaptive residual block (PARB)
First, to accommodate the case where the quantity of points changes at different stages of the network, e.g., PointStack (Wijaya et al. 2022), we extend the implementation of the k-Nearest Neighbors (KNN) algorithm in PAConv. Specifically, for different numbers of point clouds, our KNN algorithm creates new indexes for them to construct diverse ScoreNets to capture the relationships between points in the local region. This is different from the original KNN in PAConv, which uses a constant sampling number. This process can proceed smoothly and can be formulated as:
\(x_{i}\) and \(x_{j}\) represnet the 3D coordinats of the center point and neighbor point position, respectively. \(\mathcal {K}\) denotes our KNN algorithm, which is based on the point-wise Euclidean distance. \(\mathcal {T}\) stands for diversified manipulation of the position relation, e.g., subtraction. \(\mathcal {I}\) refers to inputs of ScoreNet, including the absolute coordinates, relative coordinates, and Euclidean distance of the points in the sample set.
Second, to investigate the entire capacity of PAConv for diverse point cloud assignment, we conduct experiments to figure out the combination relationship between the count of samples and the quantity of weight matrices and gain the best compound fashion. On different tasks, the parameter setting of PAConv is different when the best performance is achieved, as shown in Sect. 4.4.1. On top of the effort, we obtain a fine-tuned PAConv, named PAConv+, for point cloud analysis.
For the first time, we design a simple and effective Position Adaptive Residual Block (PARB) for spatial and geometric information understanding of point clouds, which builds on PAConv+, as illustrated in Fig. 1. It has the merits of both PAConv+ and the residual design. Specifically, PARB can flexibly capture the spatial variation and geometry information of point clouds. The residual connection of PARB can alleviate the problem of gradient vanishing, especially as the network goes deeper. Moreover, it also provides better feature propagation by fusing enrichment point information. In addition, the nonlinear activation operation and Batch Normalization in PARB also enhance the representation ability of this module and accelerate the convergence of point cloud learning, respectively.
PARB takes points with aggregated information as the input and points after nonlinear activation as the output, including two sets of similarly constructed treatment, i.e., each PAConv+ is followed by a Batch Normalization layer and a ReLU activation, which further adds one residual connection in this pipeline. Given N points from a point cloud \(\mathcal {P}\) = \(\{p_{i}\vert i = 1, 2,..., N\in R^{N \times 3}\}\), the input feature map of \(\mathcal {P}\) is represented as \(\mathcal {F} = \{f_{i}\vert i = 1,..., N\}\in R^{N \times C_{in}}\). The extraction of aggregated feature mentioned above can be formulated as:
\(\mathcal {K}(p_{i}, p_{j})f_{i}\) refers to the kernel of fine-tuned PAConv handles the input features, and \(\Lambda\) denotes a aggregation operation in terms of MAX or AVG. The above two steps are the entire treatment of optimized PAConv. \(\beta\) denotes the batch normalization. We define the pipeline of point cloud understanding via PAConv+ and batch normalization as a function \(\Phi\), as shown in formula 3. In equation 4, \(\mathcal {A}\) and \(\mathcal {I}\) denotes a nonlinear activation function(e.g., ReLU) and raw inputs, equivalent to the skip connection in PARB, respectively. \(\mathcal {O}\) represents the outputs in this process.

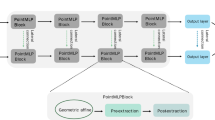
The overall architecture of PARNet for classification. Pre-block refers one geometric affine module and two residual point MLP blocks. Knowledge complement strategy can supplement low-level signals in inference-time
3.3 Knowledge complement strategy
In recent years, the mainstream contextual information learning strategy emploies pyramid structure design (Wijaya et al. 2022; Zhao et al. 2017; Wang et al. 2021). Although it makes the network achieve better performance by aggregating global information of different resolutions, the computing and memory costs are very expensive. Especially for point cloud processing (Wijaya et al. 2022), with the proliferation of models and data, the consumption of hardware resources will be unaffordable.
Different from the above multi-scale feature learning methods, we adopt a Knowledge Complement Strategy, which is based on Point-NN (Zhang et al. 2023). It is worth mentioning that this strategy merely works in the test phase of the already trained network, which greatly saves the training cost of the model. Point-NN is the result of re-investigating the basic non-parametric components in existing point cloud representation model. It primarily focuses on low-scale point cloud structural signals due to its peculiar framework architecture pattern, which can be viewed as a plug-and-play module that provides complementary knowledge at low frequency to existing point cloud models with high-scale features and semantic information.
Note that the Knowledge Complement Strategy is not a simple borrowing of the Point-NN, and its specifics are as follows. For part segmentation, the Knowledge Complement Strategy is concretized as a Point-Memory Bank different from that in Point-NN. We use the encoder of our PARNet(vanilla) to replace its inherent Non-Parametric Encoder for global feature extraction and Feature Memory construction. Please note that PARNet(vanilla) refers to PARNet without Knowledge Complement Strategy. Then, we employ our already trained model to extract point cloud features, and interpolate this constructed Point-Memory Bank on top, referring to Zhang et al. (2023), as shown in Fig. 3. We denote the input point cloud representation as \(\{p_{i}, f_{i}\vert p_{i}\in R^{1 \times 3}, f_{i}\in R^{1 \times C}\}_{i=1}^{N}\), where \(p_{i}\) and \(f_{i}\) refer the coordinate and feature of each point i. The pipeline mentioned above can be formulated as:
\(\tau\) denotes the encoder and decoder of PARNet(vanilla). \(\mathcal {F}\) denotes the extracted features. \(\xi\) maps the point feature into logits of K part categories. \(\eta\) refers to the work mechanism of Point-Memory Bank, i.e., calculating the similarity of extracted features, constructed feature memory and label memory. \(\mathcal {S}_{mem}\) and \(\mathcal {L}_{mem}\) represent the feature memory and label memory from training data, respectively. \(\mathcal {C}\) refers to the final logits of our proposed PARNet.
For point cloud classification, the Knowledge Complement Strategy is embodied as a Point-NN for assist prediction. Similarly, the Point-NN used here makes the same changes to its Point-Memory Bank as in the part segmentation task above. We directly fuse the prediction by adding the classification logits of Point-NN and off-the-shelf framework element-wisely, referring to Zhang et al. (2023). This parallel design can produce the ensemble for two different levels of knowledge, as shown in Fig. 2. Same as the definition of input point clouds in part segmentation,the above process is shown in Formula 7. \(\tau\) denotes the global character extractor of PARNet(vanilla). \(\xi\) denotes the last linear projection of PARNet(vanilla). \(\eta\) denotes the encoder and logit-affine of our Point-NN and \(\mathcal {C}\) refers to the final logits of our proposed PARNet.
The Knowledge Complement Strategy for both part segmentation and classification inherits the properties of Point-NN learning in point cloud geometric information and features.

The overall architecture of PARNet for part segmentation. Pre-block refers one geometric affine module and two residual point MLP blocks. Knowledge complement strategy can supplement low-level signals in inference-time
3.4 Architecture of PARNet
Hereon, we present a newly designed network, termed PARNet. The details of its construction will be introduced as follows. We employ PointStack (Wijaya et al. 2022) as the backbone, replacing its posterior residual point MLP block in the second/third (classification/part segmentation) stage with our proposed PARB. For the deployment and assembling of PARB in the point cloud classification task, we set the number of KNN samples in PARB to 20 and the quantity of weight matrices to 16. For the configuration of PARB in the part segmentation task, we set the number of KNN samples in PARB to 20 and the quantity of weight matrices to 8. On top of this, we introduce the Knowledge Complement Strategy mentioned above into the architecture of our network to learn the features and geometrical information of point clouds in parallel. This training-free method can improve the performance of the off-the-shelf network by complementing low-level signals, and it only works in inference-time. All other parts remain the same as PointStack, including the number of stages of feature extraction, the placement and quantity of the geometric affine module, the farthest point sampling configurations, and the arrangement of the multi-resolution feature learning.
As thus, our PARNet integrates the PARB and Knowledge Complement Strategy to abstract both high-dimensional semantic information and low-frequency geometric signals from point clouds, which provides strong support for accurate classification and segmentation. The overall structure of PARNet used for point cloud classification is shown in Fig. 2. The embedding module maps the point cloud into high dimensions. The four-stage feature extraction, Learnable Pooling and Knowledge Complement Strategy construct multi-scale geometric signals and features. The classifier outputs the final result of the point cloud. Among these, the pre-block involves one geometric affine module and two residual point MLP blocks (Ma et al. 2022; Wijaya et al. 2022). For part segmentation, we adopt an encoder similar to classification framework (only the placement and configuration of PARB are different), while the decoder follows the building from PointStack, as shown in Fig. 3. The Feature Mapping and Knowledge Complement Strategy in our PARNet (part segmentation version) work together to predict the result. Section 4 shows that our PARNet can obtain more excellent performance compared to PointStack and achieve state-of-the-art on ShapeNet-Part.
3.5 PARB for plug-and-play
Because of the effective design of PARB, it can flexibly model the spatial and geometric information of the input point cloud and aggregate features at different levels. It is interesting to note that PARB can be viewed as a plug-and-play module, enabling MLP-based networks to deliver superior performance without further changing the backbone architecture.
Recent MLP-based point cloud networks have a wide range of configurations (Qi et al. 2017; Wang et al. 2019; Qian et al. 2021; Ma et al. 2022; Qian et al. 2022). We utilize three classical and straightforward MLP-based networks as the backbone for 3D point cloud tasks to evaluate the efficacy of our PARB and minimize the impact of complex network structures. For object-level segmentation and classification tasks, the networks only need to focus on processing individual 3D objects. PointNet (Qi et al. 2017), DGCNN (Wang et al. 2019), and PointMLP (Ma et al. 2022) are three representatives that are chosen as the backbones for part segmentation and shape classification. We directly replace the MLPs in the encoder of these backbone networks with a certain number of our PARBs without changing other settings. The implementation details and experimental results are described in Sec. 4.3.
4 Experiment
In this section, we first briefly describe the datasets and the evaluation metrics. Subsequently, we introduce the implementation details of our PARNet and conduct quantitative and qualitative experiments on it. Then, extensive experiments on challenging benchmarks evaluate the plug-and-play performance of our PARB. Finally, we present comprehensive ablation studies to validate the effectiveness and reasonability of our method.

Qualitative comparisons of visualization on ShapeNet-Part. The first column indicates the ground truth, while the second column shows the predictions of our network. The third column presents the part segmentation results of PointStack (Wijaya et al. 2022)
4.1 Datasets and metrics
4.1.1 Part segmentation
ShapeNet-Part (Chang et al. 2015) is widely used in object-level part segmentation. It contains 16,881 objects from 16 shape categories with a total of 50 part labels, and each category has 2-6 parts. Following the previous works, We evaluate the performance of our PARNet with the average Intersection over Union (mIoU) over all instances.
4.1.2 Shape classification
The benchmark for point cloud classification that is most frequently used is ModelNet40 (Wu et al. 2015). It is composed of 12,311 CAD-generated meshes in 40 categories, of which 9,843 are utilized for training and the remaining 2,468 are set aside for testing. Following the standard practice in the community, we adopt the class mean accuracy (mAcc) and overall accuracy (OA) to evaluate the performance of our network.
4.2 PARNet
4.2.1 Implementation details
We implement our PARNet architecture based on PyTorch framework and train the network on NVIDIA RTX 3090 GPUs. We train PARNet using SGD optimizer with cosine decay (Loshchilov and Hutter 2016), CrossEntropy loss with label smoothing (Szegedy et al. 2016), an initial learning rate \(lr = 0.01\), and weight decay 0.0002, for all tasks,unless otherwise stated. For ShapeNet-Part part segmentation, we set the input points to 2048, batch size to 16, maximum epoch to 400, and the minimum learning rate to 0.0001. For ModelNet40 classification, we set the input points to 1024, batch size to 48, maximum epoch to 300, and minimum learning rate to 0.005.
4.2.2 Part segmentation
Table 1 compares our proposed PARNet and the previous state-of-the-art models on ShapeNet-Part. In order to focus on evaluating the performance of the model itself, all versions of networks we compare don’t use the voting strategy. It is striking that our method achieves the state-of-the-art in the part segmentation task while obtaining a decent balance of parameters and inference speed. PARNet outperforms the classical networks, PointNet and DGCNN, by 3.71 and 2.21 mIoU, respectively. Also, PARNet surpasses the point cloud representation networks based on transformer, Point Transformer and Stratified Transformer, by 0.81 mIoU. Noticeably, our network has better throughput than the strongest prior model, PointStack, and exceeds it in segmentation accuracy by 0.21 mIoU. We visualize several part segmentation results and compare them with our baseline, as shown in Fig. 4. Intuitively, the predictions of our PARNet demonstrate its excellent performance.
4.2.3 Shape classification
Table 2 compares our proposed PARNet and the previous state-of-the-art models on ModelNet40. For the same purpose as the evaluation of part segmentation, none of the version of the networks we compare employ the voting strategy. It can be observed that our approach achieves very competitive performance while having ideal parameter scale and throughput in the point cloud classification task. Our proposed PARNet outperforms the classical networks, PointNet and PointNet++, by 4.3 and 1.6 OA, respectively. Compared to ASSANet, PARNet performs better in terms of overall accuracy (i.e., +0.6% OA). In addition, PARNet has only about one-tenth of the parameters of ASSANet while being nearly eight times faster than it.
Nevertheless, We notice that the mAcc and OA of PARNet on ModelNet40 are not superior to the state-of-the-art method, which may be related to the quantity of training samples available in ModelNet40. Our analysis is as follows. We can observe that PARNet achieves state-of-the-art performance on ShapeNet-Part, but it is not satisfactory on ModelNet40 for point cloud classification. Consistent with the thoughts mentioned above, We speculate that this is due to the differences in the size of the two datasets. ShapeNet-Part contains 16, 881 objects from just 16 shape categories. In comparison, the ModelNet40 dataset only has 9,843 point clouds but is used to train 40 different classes. Data hunger restricts the optimal capacity of our proposed model. Nevertheless, our method still achieves excellent performance.
4.3 Plug-and-play
We employ PointNet, DGCNN and PointMLP as the backbone networks to evaluate the effectiveness of our PARB for plug-and-play. For part segmentation and shape classification tasks, there are certain differences in embedding location and the quantity of PARB. Note that, unless otherwise stated, for part segmentation, we merely replace MLPs in the encoder of backbone networks.
4.3.1 Part segmentation
We utilize two PARBs to replace the MLPs of the encoder in PointNet and EdgeConv of DGCNN. The quantity of input sampling points and feature channels propagated in the encoder tail are consistent with the original network architecture, which is the same as Xu et al. (2021). For PointMLP, we replace the posterior residual point MLP block in the third stage with our PARB, leaving the remaining configurations of the network unchanged. Table 3 summarizes the quantitative comparisons. PARB improves part segmentation accuracy by 0.2 on PointNet, 0.7 on DGCNN, and 0.3 on PointMLP. Especially, the accuracy achieved by PointMLP+PARB is highly competitive.
4.3.2 Shape classification
PARBs are utilized to replace MLPs in PointNet and DGCNN following the above part segmentation task. For PointMLP, we replace the posterior residual point MLP block in the second stage with our PARB, unlike part segmentation. Table 4 shows the comparison results. PARB significantly improves the classification accuracy of the backbone networks. The PointNet with PARBs improved mAcc and OA by 3.2 and 3.7, respectively. The DGCNN equipped with PARBs improved mAcc and OA by 0.2 and 0.5. The OA of PointMLP with PARB has been improved by 0.1. It is worth noting that PointMLP+PARB obtains excellent results compared to state-of-the-art models.
4.4 Ablation study
4.4.1 Combined strategy
We conduct a lot of experiments to explore the influence of the combination of the neighbor query, namely KNN samples, and weight matrices on the performance of PARB in different tasks. We will select the cooperation that achieves the best performance to complete the construction of our PARB and network for point cloud segmentation and classification.

Qualitative analysis of our methods visualized on ShapeNet-Part. a Evaluate the effectiveness of PARB in our network. b Assess the effect of KCS in our network
As shown in Table 5, when the number of PARB neighbor query is 20 and the weight matrices are 8, PARNet(vanilla) achieves the best performance on ShapeNet-Part. On ModelNet40 classification task, when the number of the neighbor query of PARB is 20 and the weight matrices are 8, the mAcc and OA of PARNet(vanilla) are 89.5 and 92.9, respectively. When the combination of neighbor qurey and weight matrices is 20 and 16, PARNet(vanilla) achieves top OA, although the mAcc is 0.1 lower than the combination mentioned above on ModelNet40. Empirically, we choose the neighbor qurey of 20 and weight matrices of 16 to construct our PARB for classification network. The ablation results of PARNet(vanilla) on point cloud classification are shown in Table 6.
We also assess the effect of PARB in our PARNet by visualizing, as shown in Figure 5a. The left column represents the ground truth. The middle and right columns indicate our network with and without PARB, respectively. The experimental results intuitively demonstrate the effectiveness of our design.
4.4.2 Complementary knowledge
To evaluate the effectiveness of the Knowledge Complement Strategy we introduce, we conduct ablation studies on part segmentation and classification tasks. As shown in Table 7, the model with the feature supplement surpasses the vanilla version by 0.02 mIoU on ShapeNet-Part. More intuitively, we select several visualization results to shown in Fig. 5b. The left column represents the ground truth. The middle and right columns indicate our network with and without KCS, respectively. Homoplastically, the model with the knowledge complement outperforms the vanilla network by 0.3 mAcc and 0.4 OA on ModelNet40. The above proves that the Knowledge Complement Strategy can supplement our off-the-shelf model in terms of feature-frequency and geometic information.
5 Conclusion
In this paper, we present a novel and powerful module named PARB for point cloud understanding. Starting from PARB, we present its two use-patterns: the integrating block for our proposed PARNet and the plug-and-play module for performance improvement. We also introduce an efficient and effective Knowledge Complement Strategy for the inference time to enhance the performance of the network, which is part of the PARNet architecture. Numerous evaluations show that our PARNet achieves competitive performance in point cloud classification and outperforms previous state-of-the-art designs on ShapeNet-Part for segmentation. Extensive experiments also demonstrate the efficacy of our PARB for plug-and-play. We hope that this work will inspire the community to explore the cooperation of the point convolution operator and framework design for point cloud feature learning.
References
Akhtar A, Gao W, Li L, Li Z, Jia W, Liu S (2021) Video-based point cloud compression artifact removal. IEEE Trans Multimed 24:2866–2876
Aksoy EE, Baci S, Cavdar S (2020) Salsanet: Fast road and vehicle segmentation in lidar point clouds for autonomous driving. In: 2020 IEEE intelligent vehicles symposium (IV), IEEE, pp 926–932
Chang A.X, Funkhouser T, Guibas L, Hanrahan P, Huang Q, Li Z, Savarese S, Savva M, Song S, Su H, et al. (2015) Shapenet: an information-rich 3d model repository. arXiv preprint arXiv:1512.03012
Chen L-C, Papandreou G, Schroff F, Adam H (2017) Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587
Chen G, Wang M, Yang Y, Yu K, Yuan L, Yue Y (2023). Pointgpt: Auto-regressively generative pre-training from point clouds. arXiv preprint arXiv:2305.11487
Choy C, Gwak J, Savarese S (2019) 4d spatio-temporal convnets: Minkowski convolutional neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 3075–3084
Cortinhal T, Tzelepis G, Erdal Aksoy E (2020) Salsanext: fast, uncertainty-aware semantic segmentation of lidar point clouds. In: Advances in visual computing: 15th international symposium, ISVC 2020, San Diego, CA, USA, October 5–7, 2020, Proceedings, Part II 15, pp. 207–222 . Springer
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S, et al. (2020) An image is worth 16x16 words: transformers for image recognition at scale. arXiv preprint arXiv:2010.11929
Fan S, Dong Q, Zhu F, Lv Y, Ye P, Wang F-Y (2021) Scf-net: learning spatial contextual features for large-scale point cloud segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 14504–14513
Gao B, Pan Y, Li C, Geng S, Zhao H (2020) Are we hungry for 3d lidar data for semantic segmentation? A survey and experimental study. arXiv preprint arXiv:2006.04307
Graham B, Engelcke M, Van Der Maaten L (2018) 3d semantic segmentation with submanifold sparse convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 9224–9232
Guo Y, Wang H, Hu Q, Liu H, Liu L, Bennamoun M (2020) Deep learning for 3d point clouds: a survey. IEEE Trans Pattern Anal Mach Intell 43(12):4338–4364
Han X-F, Huang X-Y, Sun S-J, Wang M-J (2022) 3ddacnn: 3d dense attention convolutional neural network for point cloud based object recognition. Artif Intell Rev 55(8):6655–6671
Han X-F, Feng Z-A, Sun S-J, Xiao G-Q (2023) 3d point cloud descriptors: state-of-the-art. Artif Intell Rev 56:1–51
He K, Gkioxari G, Dollár P, Girshick R (2017) Mask r-cnn. In: Proceedings of the IEEE international conference on computer vision, pp 2961–2969
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778
Howard A, Sandler M, Chu G, Chen L-C, Chen B, Tan M, Wang W, Zhu Y, Pang R, Vasudevan V, et al. (2019) Searching for mobilenetv3. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 1314–1324
Hu Q, Yang B, Xie L, Rosa S, Guo Y, Wang Z, Trigoni N, Markham A (2020) Randla-net: Efficient semantic segmentation of large-scale point clouds. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 11108–11117
Lai X, Liu J, Jiang L, Wang L, Zhao H, Liu S, Qi X, Jia, J (2022) Stratified transformer for 3d point cloud segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 8500–8509
Li Y, Bu R, Sun M, Wu W, Di X, Chen B (2018) Pointcnn: convolution on x-transformed points. Adv Neural Inform Process Syst 31:1
Li Y, Ma L, Zhong Z, Liu F, Chapman MA, Cao D, Li J (2020) Deep learning for lidar point clouds in autonomous driving: a review. IEEE Trans Neural Netw Learn Syst 32(8):3412–3432
Li X, Xiao Y, Wang B, Ren H, Zhang Y, Ji J (2022) Automatic targetless lidar-camera calibration: a survey. Artif Intell Rev 56:1–39
Liu Y, Tian B, Lv Y, Li L, Wang F-Y (2023) Point cloud classification using content-based transformer via clustering in feature space. IEEE/CAA J Automatica Sin
Loshchilov I, Hutter F (2016) Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983
Ma X, Qin C, You H, Ran H, Fu Y (2022) Rethinking network design and local geometry in point cloud: a simple residual mlp framework. arXiv preprint arXiv:2202.07123
Milioto A, Vizzo I, Behley J, Stachniss C (2019) Rangenet++: fast and accurate lidar semantic segmentation. In: 2019 IEEE/RSJ international conference on intelligent robots and systems (IROS), IEEE, pp 4213–4220
Park J, Lee S, Kim S, Xiong Y, Kim HJ (2023). Self-positioning point-based transformer for point cloud understanding. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 21814–21823
Qi CR, Su H, Mo K, Guibas LJ (2017) Pointnet: deep learning on point sets for 3d classification and segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 652–660
Qi CR, Yi L, Su H, Guibas LJ (2017) Pointnet++: deep hierarchical feature learning on point sets in a metric space. Adv Neural Inform Process Syst 30:1
Qian G, Hammoud H, Li G, Thabet A, Ghanem B (2021) Assanet: an anisotropic separable set abstraction for efficient point cloud representation learning. Adv Neural Inform Process Syst 34:28119–28130
Qian G, Li Y, Peng H, Mai J, Hammoud H, Elhoseiny M, Ghanem B (2022) Pointnext: revisiting pointnet++ with improved training and scaling strategies. Adv Neural Inform Process Syst 35:23192–23204
Qiu S, Anwar S, Barnes N (2021) Semantic segmentation for real point cloud scenes via bilateral augmentation and adaptive fusion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 1757–1767
Ran H, Liu J, Wang C (2022) Surface representation for point clouds. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 18942–18952
Redmon J, Farhadi A (2018) Yolov3: an incremental improvement. arXiv preprint arXiv:1804.02767
Rethage D, Wald J, Sturm J, Navab N, Tombari F (2018) Fully-convolutional point networks for large-scale point clouds. In: Proceedings of the European conference on computer vision (ECCV), pp 596–611
Su H, Jampani V, Sun D, Maji S, Kalogerakis E, Yang M-H, Kautz J (2018) Splatnet: sparse lattice networks for point cloud processing. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2530–2539
Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z (2016) Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2818–2826
Teichmann M, Weber M, Zoellner M, Cipolla R, Urtasun R (2018) Multinet: real-time joint semantic reasoning for autonomous driving. In: 2018 IEEE intelligent vehicles symposium (IV), IEEE, pp 1013–1020
Thomas H, Qi CR, Deschaud JE, Marcotegui B, Goulette F, Guibas LJ (2019) Kpconv: Flexible and deformable convolution for point clouds. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 6411–6420
Wang Y, Sun Y, Liu Z, Sarma SE, Bronstein MM, Solomon JM (2019) Dynamic graph cnn for learning on point clouds. Acm Trans Graph (tog) 38(5):1–12
Wang Y, Shi T, Yun P, Tai L, Liu M (2018) Pointseg: real-time semantic segmentation based on 3d lidar point cloud. arXiv preprint arXiv:1807.06288
Wang W, Xie E, Li X, Fan D-P, Song K, Liang D, Lu T, Luo P, Shao L (2021) Pyramid vision transformer: a versatile backbone for dense prediction without convolutions. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 568–578
Wijaya KT, Paek D-H, Kong S-H (2022) Advanced feature learning on point clouds using multi-resolution features and learnable pooling. arXiv preprint arXiv:2205.09962
Wu W, Qi Z, Fuxin L (2019) Pointconv: deep convolutional networks on 3d point clouds. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 9621–9630
Wu Z, Song S, Khosla A, Yu F, Zhang L, Tang X, Xiao J (2015) 3d shapenets: a deep representation for volumetric shapes. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1912–1920
Xiang T, Zhang C, Song Y, Yu J, Cai W (2021) Walk in the cloud: learning curves for point clouds shape analysis. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 915–924
Xu M, Ding R, Zhao H, Qi X (2021) Paconv: position adaptive convolution with dynamic kernel assembling on point clouds. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 3173–3182
Xu C, Wu B, Wang Z, Zhan W, Vajda P, Keutzer K, Tomizuka M (2020) Squeezesegv3: Spatially-adaptive convolution for efficient point-cloud segmentation. In: Computer vision–ECCV 2020: 16th European conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXVIII 16, pp 1–19 . Springer
Yan X, Zheng C, Li Z, Wang S, Cui S (2020) Pointasnl: robust point clouds processing using nonlocal neural networks with adaptive sampling. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 5589–5598
Zhang R, Wang L, Wang Y, Gao P, Li H, Shi J (2023) Parameter is not all you need: starting from non-parametric networks for 3d point cloud analysis. arXiv preprint arXiv:2303.08134
Zhao Y, Bai L, Huang X (2021) Fidnet: Lidar point cloud semantic segmentation with fully interpolation decoding. In: 2021 IEEE/RSJ international conference on intelligent robots and systems (IROS), IEEE, pp 4453–4458
Zhao H, Jiang L, Jia J, Torr PH, Koltun V(2021) Point transformer. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 16259–16268
Zhao H, Shi J, Qi X, Wang X, Jia J (2017) Pyramid scene parsing network. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2881–2890
Zhou H, Zhu X, Song X, Ma Y, Wang Z, Li H, Lin D (2020) Cylinder3d: an effective 3d framework for driving-scene lidar semantic segmentation. arXiv preprint arXiv:2008.01550
Acknowledgements
Project supported by the National Natural Science Foundation of China (Grant Nos.62076207, 62076208, U20A20227) and Chongqing Talent Plan“Contract System”Project (Grant No.CQYC20210302257).
Author information
Authors and Affiliations
Contributions
Shichao Zhang conceptualized and designed the algorithm, implemented the initial codebase, and prepared the original manuscript draft. Hangchi Shen contributed to the development of the algorithm, performed substantial debugging and code optimization, and assisted with manuscript writing and revisions. Shukai Duan provided essential theoretical insights, contributed to algorithm improvements, and critically revised the manuscript for important intellectual content. Lidan Wang supervised the project, provided strategic direction in algorithm development and testing, and conducted a thorough review and final approval of the manuscript prior to submission. We confirm that the manuscript has been read and approved by all named authors and that there are no other persons who satisfied the criteria for authorship but are not listed. We further confirm that the order of authors listed in the manuscript has been approved by all of us.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, S., Shen, H., Duan, S. et al. Position adaptive residual block and knowledge complement strategy for point cloud analysis. Artif Intell Rev 57, 129 (2024). https://doi.org/10.1007/s10462-024-10754-x
Accepted:
Published:
DOI: https://doi.org/10.1007/s10462-024-10754-x