
Abstract
Requirement Analysis is the essential sub-field of requirements engineering (RE). From the last decade, numerous automatic techniques are widely exploited in requirements analysis. In this context, requirements identification and classification is challenging for RE community, especially in context of large corpus and app review. As a consequence, several Artificial Intelligence (AI) techniques such as Machine learning (ML), Deep learning (DL) and transfer learning (TL)) have been proposed to reduce the manual efforts of requirement engineer. Although, these approaches reported promising results than traditional automated techniques, but the knowledge of their applicability in real-life and actual use of these approaches is yet incomplete. The main objective of this paper is to systematically investigate and better understand the role of Artificial Intelligence (AI) techniques in identification and classification of software requirements. This study conducted a systematic literature review (SLR) and collect the primary studies on the use of AI techniques in requirements classification. (1) this study found that 60 studies are published that adopted automated techniques in requirements classification. The reported results indicate that transfer learning based approaches extensively used in classification and yielding most accurate results and outperforms the other ML and DL techniques. (2) The data extraction process of SLR indicates that Support Vector Machine (SVM) and Convolutional Neural Network (CNN) are widely used in selected studies. (3) Precision and Recall are the commonly used metrics for evaluating the performance of automated techniques. This paper revealed that while these AI approaches reported promising results in classification. The applicability of these existing techniques in complex and real-world settings has not been reported yet. This SLR calls for the urge for the close alliance between RE and AI techniques to handle the open issues confronted in the development of some real-world automated system.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Requirements Engineering (RE) is concerned with elicitation, analysis, specification, validation and management of requirements (Kotonya and Sommerville 1998). It conceived as sub-discipline of software engineering that contributes to understand customer’s need to improve the quality of software, and decreasing the risk of software failure (Selby 2007). Requirements elicitation phase is concerned with collection of organizational needs, constraints, and facilities required by the system stakeholder. Traditional requirements elicitation takes place through the use of questionnaire, templates, checklists guidelines and inquiring quality issues of stakeholders. The requirements are mainly expressed in natural language and intertwined with each other. So, it is necessary for requirements analysts to identify, understand, prioritize and classify software requirements. Requirements Software requirements analysis considered as critical phase that analyzed the requirements perceived by users or stakeholders. In this phase, high-level requirements statements are analyzed that are collected by using elicitation methods. Besides, requirements analysts establish complete and consistent Software Requirement Specification (SRS) document. In addition, the collected requirements are detect, trace and classify into various categories (Dermeval et al. 2016; Wiegers and Beatty 2013). Software requirements are classified into two types: Functional requirements (FRs), which describe the services, functions or behavior provided by the software, and Non-Functional requirements (NFRs), are the quality attributes (such as quality, usability, security and privacy etc.) or constraint in software development.
Requirements classification is considered as advantageous before architecture and design phase. Because architects need preferential classification of software requirements, so that they can easily implement different types of requirements into different architectural component (Nuseibeh 2001). Early identification of software requirements helps in selection of software, hardware and its configuration. Moreover, later phases of software development depends upon the RE phase in order to implement their tasks. Therefore, manual extraction and classification of requirements is usually time consuming and labor-intensive task (Cleland-Huang et al. 2007). To overcome aforementioned issues, automatic classification methods are exploited by researchers from the last decade. In context of Software development, there is a growing interest in AI techniques to minimize or resolve different types of problems. There are some studies investigate the role of machine learning (ML) in software engineering, specially the role of ML in requirements engineering. However, these studies did not capture all the aspects and evidences that we are interested in. To the best of authors’ knowledge, there is no existing systematic investigation of literature covering AI in RE. Hence, the objective of this work is to conduct a systematic review of literature to find out what AI techniques have been used to extract software requirements from project documents and app stores. It is also important to investigate whether there are real evidences of improvement using AI in extraction of software requirements from documents app reviews. The purpose of this systematic literature is to better understand how AI supports Requirements classification. This paper presents the results from 2012 to 2022 and was conducted following a predefined review protocol (Sect. 3).
The paper is organized is as follows: Sect. 2 discusses the related work. Section 3 presents the research methods. Section 4 includes the research questions. Section 5 performs the results analysis. Active datasets utilized in requirement classification are presented in Sect. 6. Key findings, limitations and open challenges are discussed in Sect. 7. Some of the threats to the validity of this SLR are discussed in Sect. 8. Finally, we conclude this review paper in Sect. 9 with future research directions.
2 Related work
Existing research works have evidently proved the automation of software engineering activities. Most studies related to automatic strategies include machine and deep learning methods. Specifically, these automated techniques are also applied in RE (such as in elicitation, analysis, and specification). For example, Meth et al. (2013) has conducts SLR of existing automated tools for requirements elicitation. They have covered the period from January 1992 to March 2012, and identified requirements from domain documents. Besides, identification of requirements is a small part of their review. By contrast, our review focuses on identification of requirements from documents and app reviews using AI techniques. Mohammad et al. (2019) have discussed the various approaches for security requirements engineering (SRE).
In addition, Binkhonain and Zhao (2019) have also reviewed only 24 studies that adopted machine learning techniques for identification and classification of non-functional requirements (NFRs). In their contribution, they mainly focused on NFRs classification and cover the sub-categories of NFRs. They also discussed the role of natural language processing and data mining techniques in requirements classification. Their review includes 24 published studies from 2007 to 2017. In contrast, our review focuses includes 61 studies from 2012 to early 2023. Moreover, their review explicitly addresses NFRs via ML algorithms, whereas our review focuses on functional as well as NFRs via AI techniques.
Besides, Perez-Verdejo et al. (2020) have found only 13 studies from 2010 to 2019 in requirements classification where different machine and deep learning techniques are used. However, identifying software requirements from app reviews is a small part of that review. By contrast, our review includes 19 studies related to extraction of software requirements from app reviews. Moreover, the authors have restricted to studies employ machine and deep learning, whereas our research addresses the recent studies of transfer learning. Dabrowski et al. (2020) have reviewed the studies related to extraction of NFRs from app reviews using ML approaches. The aim of their SLR is to investigate the role of app reviews in software engineering. Moreover, the authors have included only 10 studies related to identification and classification of software requirements from app reviews. In contrast, our research work includes 19 studies of extraction of requirements from app reviews. The comparison with related work is shown in Table 1.
3 Research method
This section consists of five phases: research questions, search strategy, inclusion and exclusion criteria, snowballing (backward and forward), scrutinizing the data, data extraction, and synthesizing, and quality assessment criteria. In the first phase, research questions are designed to identify to what extend machine and deep learning techniques have been applied to this field. In second phase, PICOC (population, intervention, comparison, outcome and context) search strategy is followed to identify the initial set of related papers. Third phase concerned with the inclusion and exclusion criteria from the start set. In fourth phase, snowballing approach is adopted by this review paper, which is proposed by Wohlin (2014). Snowballing approach is designed to identify relevant studies. Unlike, traditional systematic literature review approach discussed by Kitchenham and Charters (2007), snowballing approach is a way to search the paper from the reference list (backward snowballing), or from the citation to the paper (forward snowballing).Then, extracted papers are scrutinized followed by the fifth phase. Finally, sixth phase is concerned with quality assessment of selected studies.
4 Research questions
The purpose of this SLR is to investigates the role of AI techniques in identification and classification of software requirements. The research questions along with their description and motivation are presented in Table 2.
4.1 Search strategy
For the identification of start set, traditional SLR method is used in which include various electronic literature databases (such as IEEE, Google Scholar, ACM digital Library, IEEE Xplore, Web of Science, Scopus, and ScienceDirect). In order to avoid the biasness toward the publishers, Google scholar is used to create the start set (Wohlin 2014). However, Google scholar returned 13,700 results on (“Software requirements” OR “functional requirements” OR “Non-functional requirements”) AND “Classification” AND “Artificial Intelligence”, that is too general to be useful. Therefore, search string can be breakdown into alternative spellings and synonyms according to PICOC criteria (population, intervention, comparison, outcome, and context) (Kitchenham and Charters 2007). On the basis of PICOC structure, a generic string was constructed to maintain the consistency of the searches across multiple databases. Therefore, alternative and synonym terms are connected with “OR” Boolean operator and Boolean “AND” is used to link the major search terms. The detail description of search terms is shown in Table 3.
4.2 Inclusion and exclusion criteria
The aim of defining a criterion is to identify those primary studies which provide direct evidence about the research questions and reduce the likelihood of bias (Kitchenham and Charters 2007). It is worth noting that we consider papers as primary studies which present empirical validation of its contribution and secondary papers are those which present the surveys and systematic literature review.
The research papers are included in the review if they presented the primary study, published since January 2012 to June 2023 and also presented the contribution on the use of AI to identify software requirements. If the same research paper is reported by more than one paper, and the paper provides the most detailed description of the study is also included.
Studies were excluded if they were secondary, short-texts, non-peer reviewed, not in English language, papers that do not have any link with research questions, gray paper (i.e. without bibliographic information such as publication date/type, volume, issue number), duplicate papers, and if their focus was not using machine learning and deep learning techniques for RE. The summarization of Inclusion and exclusion criteria is shown in Table 4.
At the end of selection process, 13 studies are identified as relevant papers, which were then included in our start set (shown in Table 5).
4.3 Backward snowballing
From the each paper in start set, backward snowballing is conducted by searching the new study from the reference list of each paper. In the first step, title and reference context of each referenced paper were reviewed. In addition, some referenced papers are evaluated with abstract and keywords. Reference context was based on the text surrounding the reference in the list. In the second step, relevant papers are extracted by applying inclusion and exclusion criteria on full-text reading. New studies should be added in start set, and this process repeat until new study was identified. During the iteration process, 765 of referenced papers were examined and 35 of them were identified as relevant but only 20 were added to start set after inclusion/exclusion criteria. The start set now consists of 36 papers.
4.4 Forward snowballing
From the each paper in start set, forward snowballing is conducted to obtain new studies from the citation of the paper. As discussed by Wohlin (2014), the citation of each paper in start set can be identified on Google Scholar. Relevant studies are extracted by evaluating the paper on the basis of title, abstract, keyword and reference context. These selected papers are added to start set, and this procedure is repeated until no new study was identified. During the five iterations, 954 studies were examined, 47 studies were identified and 24 studies were added to start set based on the inclusion and exclusion criteria. At the end of forward snowballing, 60 numbers of relevant papers were selected as the final set of our review. The graphical representation of both forward and backward snowballing is shown in Fig. 1.

The selection of relevant studies with Wohlin’s snowballing method (Wohlin 2014)
4.5 Extracting and synthesizing the data
After the selection process, the data extraction process was performed by reading the introduction and conclusion and full-text of each paper in start set. During this stage, data were extracted from sixty one relevant studies that are included in systematic literature review according to the predefined extraction form. The extracted data is recorded in excel in two ways: the data required answering the research questions, and data required for showing the bibliographic information of the study. The main aim of data extraction is to enhance the quality of selected studies. The description of extracted data is shown in Table 6.
The 60 studies are distributed according to their year wise publication (shown in Fig. 2). Table 7 presented the number of articles published in different electronic database. Most of the papers are published in conferences and few papers are published in journals such as Requirements Engineering, Empirical Software Engineering and Automated Software Quality etc. Table 19 (in appendix) presents the distribution of selected studies over publication source including the publication name, type and count. Among the 60 studies, 46 publication sources published research related to RE community. The leading venues in RE domain are IREC, IRECW, IEEE Access, and ICASE. These venues indicate the presence of source of RE, Software Engineering and AI areas. In addition, this SLR includes the studies from journal, conference, workshops and book chapter. From Table 19, majority of the studies are presented in conference (23 studies), and followed by journal (17 studies), book chapter (8 studies), workshop (8 studies), thesis (2 studies), symposium (1 study) and seminar (1 study). Figure 5 (in appendix) indicates the country contributing research on requirements classification.

The distribution of 61 studies published from 2012 to 2022
4.6 Quality assessment questions and criteria
The quality assessment criteria assess the creditability, completeness, and relevance of selected studies. All the selected studies addressed to 12 formulated quality assessment questions. The questions are presented in Table 8. All these questions are adopted from literature (Dermeval et al. 2016). Q1, Q3, Q4, Q6, Q9, and Q10 questions have three-grade score. For example, ‘YES’ = 1, ‘NO’ = 0, and ‘PARTLY = 0.5’. If the answer is yes, the corresponding study receives 1 and otherwise 0. If the contribution of study is not strong then it receives 0.5 score. Q2, Q7, Q8, Q11 and Q12 have two grade score. Q11 receives point 1, if the study adds value to software companies and 0.5 points if it is only useful to academic. The authors have Table 9 presents the quality assessment score of studies. The selected studies were reviewed by two independent authors. The authors meticulously executed quality assessment of selected studies. All discrepancies on quality assessment results were discussed among the authors with the aim of reaching consensus. In order to find-rater reliability, we calculated the Kappa coefficient, the value of which turned out to be 0.92 indicating the strong agreement. The reliability of the findings of this review was accomplished by considering only the studies with acceptable quality rate i.e. with quality score greater than 2.5 (50% of the percentage score). As a result, 50* studies were excluded from initial collated studies giving rise to 61 finally collected studies. It is observed that all studies have scored more than 5.0. Q1, Q2, Q3, Q4 and Q12 received highest score and Q7 received the lowest score. It is worth noting that lowest score quality criteria indicate that studies are concerned in developing the tools rather than techniques. From the quality assessment criteria, it can be evidently proved that finding could make valuable contribution to this review (Fig. 3).

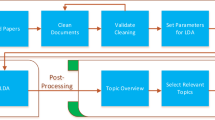
The general process of AI techniques in requirements classification
5 Result analysis
5.1 Text pre-processing
-
RQ1 What natural language processing techniques have been used in requirements classification?
5.1.1 Text pre-processing in machine and deep learning
Text pre-processing is the essential task of natural language processing that follows the set of cleaning operations to filter raw and free ambiguous text into “well defined sequence linguistically meaningful units”. Real-world natural language sentences are often written in short forms, and contain noise, punctuation symbols and typos. This review paper found 11 different NLP techniques in selected studies. Table 10 shows the various techniques used in respective studies.
-
Tokenization The first step of NLP technique is tokenization, also known as text segmentation. It is process of splitting the textual sentence into smaller units called tokens. In this granular operation, tokens are separated by delimiters such as whitespace, punctuations and splitting contraction (Khan et al. 2010).
-
Stopword removal In this step, stop words (non-informative, frequent words (“a”, “an”, and “the” etc.), words having little impact on classification are removed. In addition, removal of stop words reduces the noise and improves the classification accuracy (Khan et al. 2010).
-
Removal of punctuations/symbols/accents: In this process, extra punctuation marks ($, !, ~ , @, #), bad symbols are removed to reduce the dis-ambiguity from the sentence (Younas et al. 2020).
-
Text Normalization Text Normalization is the process of mapping the different variants to standardized linguistic versions. In selected studies, two text normalization operations such as stemming and lemmatization are widely used in text pre-processing. Text reduction techniques, namely, Stemming and Lemmatization are used to reduce the dimensionality of morphological words (such as plural nouns, verb tenses, and pronouns etc.) to their common/root word stem. For example, ‘avail’ can be appearing as ‘available’ and ‘availability’ and with many more variations (Jivani 2011).
-
Part-of-Speech (POS) tagging POS is the process of tagging the verb, pronouns and adjectives in the corpus based on its context (Casamayor et al. 2010).
-
N-gram N-grams are the sequence of words. In this process, words are grouped together into two words (bi-grams), three words (tri-grams) and n-words (n-grams) to extract the semantic meaning of sequence (Cavnar and Trenkle 1994).
-
Case folding This process unifying the case letters (i.e. converting the upper case letters into lower case letters) (Araujo et al. 2022).
-
Regular expression Regular expression consists of specialized notation, such as character (^) means NOT (Gu and Kim 2016).
-
Dependency parsing In this process, grammatical relationship between the words is identified to extract the relevant parts while ignoring the irrelevant parts of the sentence (Marneffe and Manning 2008a, 2008b).
5.1.2 Text preprocessing of BERT
BERT text pre-processing consists of two steps: Tokenization and word embedding.
5.1.2.1 Tokenization
In BERT text representation, special tokens are utilized to encapsulate the raw sequence (Devlin et al. 2018). The details of these tokens are given as follows:
-
(a)
Classification token ([CLS]) The classification token also considered as first token of each sequence. This token indicates the beginning of sentence.
-
(b)
Separation token ([SEP]) Separation token is also considered as delimiter that is used to separate two sentences.
-
(c)
Mask token ([MASK]) This token is used to mask the words in the sequence.
5.1.2.2 Word embedding
Word embedding itself consists of three parts: Token Embedding, Segment Embedding and Position Embedding. The detail description of each embedding is as follows.
-
(a)
Token embedding Token embedding is used to assign vector or vocabulary ID to each token with the help of WordPiece method.
-
(b)
Segment embedding Segment embedding is used to differentiate the two sequences.
-
(c)
Position embedding Position embedding stores the position of each token in the sequence.
The graphical representation of BERT embedding is shown in Fig. 4.

Source adopted from
The visual representation of Embedding layers of BERT. Devlin et al. (2018)
5.2 Feature extraction techniques
-
RQ2 Which word embedding techniques are used for converting text to vectors?
The main aim of feature extraction techniques is to convert the textual sequence into understandable format of AI techniques. In this process, a document is represented in two methods: Binary and non-binary. In binary weighting method, the value of word is 1 if it is present in documents or its value is 0 if it is not present. Only S18 has adopted this method for vector representation. In non-binary methods, vector space is generated on the basis of number of times the word appears in the document. Various word embedding techniques adopted by different studies is shown in Table 11. The detail description of non-binary methods is as follows.
5.2.1 Traditional feature selection methods
-
Bag-of-words (BOW) BoW is the simplest technique of vector representation in NLP. In this word representation model, features are represented as an unordered collection of vectors without retaining the grammatical and syntactic structure of each word. In addition, BoW is frequency-based model, where each word in the document assigns with weight according to its frequency in and between the documents (Khan et al. 2010). S03, S08, S10, S22, S37, S39, and S48: seven studies have adopted this method for vector representation.
-
Term Frequency-Inverse Document Frequency (TF-IDF) TF-IDF is complex type of BoW. In this method, TF computes the frequency of words appears in the document and IDF computes how important the word is. Sometimes, it might possible that a word appear many more times in longer documents than the shorter ones. For this, TF-IDF method assigns the lower score to highly frequent words and high score to rarely occur words (Khan et al. 2010). Fifteen studies S02, S03, S04, S10, S12, S15, S17, S22, S25, S29, S34, S39, S45, S50, and S57 have adopted this method in their study.
5.2.2 Pre-trained word representation
Although traditional word representation methods such as one-hot encoding, BoW and TF-IDF identify important words in text corpus, but these techniques suffers from losing word order problem and syntactic structure. To overcome these issues, pre-trained word embedding methods are explored by recent research works. This sub-section discusses the pre-trained embedding method used in requirements engineering.
-
Word2Vec Word2Vec is the popular distributed word representation technique proposed by Mikolov et al. (2013). Word2Vec is a two layer neural network model that converts text into vector space. These word vectors are trained on English Wikipedia with 300 dimensions. The model creates low-dimensional vector space of semantically similar words. So that similarity of words can be easily calculated. In addition, two methods, namely, Continuous Bag-of-words (CBOW) and Skip-gram are utilized to predict the semantic of two words. CBOW also known as probabilistic model is used to predict the current target word on the basis of its context. Whereas, skip-gram model predict the surrounding words from target words. Word2Vec method is adopted by: S07,S11,S16,S21,S24,S27,S28,S43,S46,S47,S56,S57,S60 and CBOW and Skip-gram are used in only on S57.
-
Doc2Vec Doc2Vec namely, paragraph embedding is an extension of Word2Vec model. Unlike, Word2Vec, Doc2Vec converts the sentence, phrases, paragraphs and documents into vectors (Le and Mikolov 2014). Three studies used Doc2Vec model: S14, S30, and S58.
-
Global Vectors for Word Representation (GloVe) GloVe is an unsupervised learning method that combines the advantages of two models: count-based methods and local context window (same as Word2Vec). GloVe is a log-bilinear regression method, namely count-based method that efficiently captures the co-occurrence of words in a given corpus (Pennington et al. 2014). This method is trained on six billion tokens. GloVe method is adopted in five studies: S35, S51, S53, S44, and S57.
-
FastText FastText is an open-sourced model developed by Facebook’s AI research team in 2016. It uses the same architecture as Word2Vec. The FastText captures subwords representation whereas; Word2Vec captures the whole word for vector representation. Moreover, this model is based on unsupervised approach that converts the large corpus into high dimensional space. The words with similar context meaning are placed close in vector space (Joulin et al. 2016). This method is adopted in two studies: S17 and S46.
-
Embedding from language Model (ELMo) ELMo is a neural language based model that is trained by using LSTM or GRU. It is context based word representation method that converts each input word into feature vector, and same word can have different feature vector depend upon the context. After vectorization, each vector is passed through the LSTM or GRU layers to obtain final word’s embedding (Clark et al. 2018). Only S58 has adopted ELMo as word representation technique.
-
Bidirectional Encoder Representations from Transformers (BERT) Bidirectional Encoder Representation from Transformer (BERT) is type of transfer learning designed by Google (Devlin et al. 2018). BERT, also known as neural language model generate output based on the context of the input, and utilized as word embedding layer to convert the text into vectors. The main purpose of BERT is to learn text from left to right by jointly configuring the context of text. BERT model is trained with two different tasks such as Masked Language Model (MLM) and Next Sentence Prediction (NSP). In MLM, some input tokens are randomly replaced by [MASK] token, then BERT model was trained to predict the masked token on the basis of the context. The NSP technique exhibits the relationship between two sentences for example in question answering (Devlin et al. 2018). In addition, model predict sentence B, that is likely to be adjacent to sentence A. In conclusion, the prominent goal of these tasks is to predict the word based on its contextual meaning. RoBERT, DistilBERT and Multilingual DistilBERT are the variants of BERT model. The main purpose of these variants is to improve the classification accuracy and decrease computational cost. S31, S32, S33, S41, S42, S43, S46, S48, S49, S52, S59 and S61 have utilized BERT for classification purpose.
5.3 Automated techniques
-
RQ3 What are various AI techniques used in identification and classification of requirements?
This section contains the details of AI techniques utilized in requirements classification. Table 12 represents the AI techniques used in requirements and app review classification.
5.3.1 Machine learning techniques
-
Naïve Bayes (NB) NB classifier considered as the kind of probabilistic classifier based on famous bayes’ theorem. It is simplest form of conditional probability that independently evaluates the probability of each input feature and class labels. The probabilities of these input features and class labels are combined to generate the output of the model. Multinomial Naïve Bayes is also a specialized version of simple NB, where multiple class labels are possible. The key difference between NB and MNB is that MNB not only considering presence of feature but also considers the number of features (Lewis 1998).
-
Support Vector Machine (SVM) SVM is a popular supervised machine learning technique for classification and regression tasks. It is the powerful algorithm, capable of performing classification by creating hyperplanes with maximum margins to separate the two different classes. The main aim of SVM classifier is to decide which side of hyperplane the new support vector (data instance) lies. Support Vector classifier (SVC) classifies the input data after fitting the data instances into hyperplanes. Stochastic Gradient Decent (SGD) is an optimization method to improve the performance of linear classifier. In addition, SVM is optimized by SGD optimization method is known as SGD SVM (Burges 1998, Mining et al. 1998).
-
K-Nearest Neighbour (K-NN) K-NN is the most commonly used supervised machine learning algorithm. It is simple and easiest algorithm to find the similarity of new text with already available data instances in training set. The algorithm classified new instances to closest similar category (Alpaydin 2020; Khan et al. 2010).
-
Logistic Regression (LR) LR is probability based supervised machine learning algorithm. It is standardized version of linear regression that evaluates linear and non-linear classification problem. The classifier takes the input value and multiplies with the weight value. LR learns the unique feature that is most suitable to differentiate between the different classes (Hilbe 2016).
-
Decision Trees (DTs) DT is a decision-making method that classifies the text into hierarchical structure by applying decision rules. It is supervised machine learning algorithm that contains series of successive nodes along with root node. The root node is the first node, and all nodes from root node are outgoing nodes that represents the feature of input text. Then, the leaf nodes also known as the decision node represent the class label of input. C4.5 (J48) algorithm is another type of decision tree that allow backtracking with post-pruning feature, hence improve the overall accuracy of classifier (Alpaydin 2020; Khan et al. 2010)
-
Bagging Bagging, namely Bootstrap algorithm is an ensemble-based supervised machine learning model. This model converts weak classifier into strong classifiers in order to avoid misclassification errors. Then, Bootstrap algorithm is utilized to convert these weak classifiers into strong classifier by combining the majority of votes every final predictions. Random Forest (RF) is a creative variant of bagging algorithm. It combines successive trees with additional layer of randomness to bagging mechanism. Unlike decision tree, RF split each node by randomly selecting the features from subset of best features. In addition, the most standardized variants of bagging are Adaptive Boosting (AdaBoost), Gradient Boosting (GBoost) (Quinlan 1996; Llaura and Santi 2017)
-
Interpretable Machine Learning (IML) IML is a supervised machine learning technique that explains and justify the developed machine learning models (Ribeiro and Guestrin 2016).
5.3.2 Deep learning techniques
-
Artificial Neural Network (ANN) ANN, namely Multi-layer perceptron (MLP) is a supervised learning algorithm used for classification tasks. It is feed forward neural network consists of input layer, hidden layer and output layer. These series of layers are connected through edges with weight values. The output layer is also called classification layer, which predict the class of input sequence (Gershenson 2003).
-
Convolutional Neural Network (CNN) CNN is a deep neural network consists of series of convolutional layers to extract local features from NLP applications. The convolution filter is slide on vector space to calculate the dot product between the filter value and word vector. Then, max-pooling layer is used to capture the important feature with maximum value. These features are fed to fully connected layer for classification purpose (Chen 2015).
-
Long-short term Memory (LSTM) LSTM is deep neural network, also considered as the variant of Recurrent Neural Network (RNN). The LSTM memory unit consists of input, forget and output gate used to pass the information and store such information in memory units for further purpose (Hochreiter 1997). Bidirectional-LSTM (BiLSTM) is a variant of LSTM. Unlike LSTM, BiLSTM is used to store both proceeding and succeeding context of input feature (Schuster and Paliwal 1997).
-
Gradient Recurrent Unit (GRU) GRU is deep neural network is another variant of RNNs. It consists of two gates: update gate (combination of input and forget gate of LSTM) and reset gate. The update gate decides what amount information should be passed to current state, and reset gate decides which information should be ignored. Bidirectional-GRU (BiGRU) also utilizes to store the proceeding and succeeding contextual information of input sequence (Nowak et al. 2017).
5.3.3 Transfer learning based techniques
-
BERT Bidirectional Encoder Representation for Transformer is context dependent word representation technique to encode raw sentence. Since the BERT model is employed on raw input. Each word must be embedded into tokens. Therefore, input embedding of BERT model itself consists of three embedding: token embedding, position embedding and segment embedding. The raw input sequence is enclosed with special tokens such as [CLS] and [SEP] tokens indicate the beginning and end of input sequence. BERT model has two variants: Base model (L = 12, H = 768, A = 12, Total parameter = 110 M) and Large (L = 24, H = 1024, A = 16, total parameter = 340 M) is utilized to train the model. Here, L is the transformer blocks, H is the hidden layer and A is the self-attention mechanisms. The output of the BERT model is sequence of vector containing contextual information (Devlin et al. 2018). A Robustly optimized BERT (RoBERT), Distilled BERT (DistilBERT), and Multilingual Distilled BERT (M.DistilBERT) are the standardized derivations of BERT model. Instead of predicting the next sentence in fix order, RoBERT model dynamically predict the next sentence. DistilBERT model utilize the smaller number of parameters than BERT to decrease the computational cost and to save energy. Unlike DistilBERT, M.DistilBERT understands other languages such as Chinese, and Italian etc. (Araujo et al. 2022). Table 13 depicts the brief summary of AI techniques utilized by selected studies.
6 Datasets
RQ4 what are the active datasets utilized in requirements classification?
This section includes the public datasets used to evaluate the effectiveness of AI techniques such as ML, DL and TL in requirements classification.
-
Public datasets: Majority of the studies have utilized public datasets to evaluate their proposed model. Some of studies have created their own truth set. Table 14, out of 61 studies, 48 studies have utilized PROMISE dataset, Electronic Health Record dataset used by three studies. EHR contain natural language requirements of 12 projects. Few of studies have used DOORS, PURE and RE challenge datasets and some of the studies have created their own datasets from the SRS documents. PROMISE dataset is most frequent dataset adopted by most of studies for the sake of comparison.
-
App Review datasets: few papers included in the SLR used natural language app reviews to evaluate the performance of their proposed model. For this purpose, the authors have created truth dataset that contain reviews of iOS and Android apps. These reviews were manually analyzed and labeled by the human annotators and categorize them into bug report, feature request and rating, aspect evaluation, dependability and usability etc. Table 14 presents the number of studies that evaluate the effectiveness of proposed model on identification and classification of software requirements from app reviews. Table 15 presents the type of requirements discussed by each study.
6.1 Evaluation measures
-
RQ5 What measures used for evaluating these AI techniques? (Table 16).
-
Table 17, from the 57 studies, 41 studies have evaluated their classifier with the help of three standard metrics such as precision, recall and f-measure. Precision and recall are often measure together, but there is still a trade-off between them. It is disputable that which metrics value is more important for evaluating the classifier and why. For example, Cleland-Huang et al. (2007) and Stanik et al. (2019) have achieved high recall value than precision, which means that their approach yield more false positive. The authors mentioned that it is easier for the users to discard false positive values than manually detecting the false negative values in large dataset of requirements and reviews. However, Younas et al. (2020) and Henao et al. (2021) have demonstrate that the high recall value overwhelmed developer team with false positive which sometimes frustrate them. In addition, low recall value indicates the risk of missing important information. Consequently, in RE-related tasks, researchers seek acceptable value of precision and recall. It can be observed from the Table 11, only S25 study achieved high recall value than precision, whereas other studies obtained high precision value with acceptable value of recall. In comparison to machine learning, deep learning models achieved higher precision and recall. In addition, pre-trained language model also obtained satisfactory performance with acceptable values of precision and recall.
-
F-Measure is the harmonic mean of precision and recall. Of the 58 studies, 51 studies have evaluated f-measure to evaluate the classification performance of classifier. None of the study has discussed why the authors have considered this metric in their study. In addition, majority of the studies used it as trade-off value of precision and recall.
-
Accuracy is used to measure the performance of the classifier. 18 of the primary studies (S22, S25, S29, S31, S34, S35, S36, S40, S41, S43, S44, S46, S49, S52, S53, S54, S55 and S57) have utilized this metric. Only S55 have mentioned why the authors have not considered accuracy as evaluation criteria. Other than, none of the study has been discussed why and why not they have used accuracy as evaluation measure.
-
Confusion matrix is used to analyze the number of true positive, true negative, false positive and false negative predicted by the classifier. Only S55 has provides the confusion matrix for their classifier.
-
Area under Curve is used to graphically represent the true and false positive rate. More the perpendicular the line, better the performance of classifier is. Only three studies (S17, S19, and S45) have adopted this metric for performance evaluation of classifier.
-
HL measure is specifically used in multi-label classification. Lower the value of HL better the performance of the classifier. Only multi-label classification related studies (S23, S25 and S55) have evaluated this metric.
The selected studies that are added in SLR through inclusion and exclusion criteria are shown in Table 18. Table 18 shows the AI techniques that have been reviewed in paper on requirements and app review classification. However, in paper different methods such as SVM, NB, CNN and BERT yield satisfactory performance in this domain. It is observed that authors have evaluated their approach in precision, recall. Majority of the studies have not considered accuracy because of imbalance nature of datasets. A total of 59 studies have directly discussed the identification and classification of NFRs along with AI techniques, types of pre-processing, word representation technique and evaluation criteria. It is worth mentioning that, the analysis of the results show that though BERT has very less number of papers, but it outperforms both deep and machine learning algorithms in the study related to requirements classification.
It is also observed that SVM, and CNN the frequent algorithms. The datasets and word embedding techniques are also discussed in the table.
7 Key findings, limitations and open challenges
7.1 Key finding
The key finding that are identified from our review are:
-
In general, pre-trained based language model such as BERT, RoBERT, RE-BERT, Distil. Bert and M.DistilBERT performs well and obtained accuracy more than 80% in classification of software requirements.
-
Traditional feature extraction techniques BoW, TF-IDF, word2vec and GloVe are widely exploited in existing literature. These techniques suffer from polysemic problem i.e. ignoring syntactic structure of words. However, pre-trained language models overcome this problem by retaining syntactic structure and contextual relationship of words in sequence.
-
It is observed that SVM and CNN are the two frequent algorithms adopted for identification and classification of NFRs from project documents and app reviews. But the best results are achieved by BERT model in requirements classification.
-
Although, ML and DL achieved satisfactory performance in classification of NFRs. But, these methods perform poor on unseen data i.e. these methods suffer from poor generalization problem. BERT based models performed well on unseen data.
-
Few research work such as Binkhonain and Zhao (2019) have discussed 24 studies that have been adopted machine learning techniques in identification and classification of NFRs. Dabrowski et al. (2020) have reviewed the studies related to extraction of NFRs from app reviews using ML approaches. However, utilization of deep learning and pre-trained models in classification of software requirements from formal documents and user reviews is small part of their review. In contrast, this SLR found 61 studies that have extracted software requirements from formal and informal artifacts using AI techniques.
-
Binkhonain and Zhao (2019) conclude that SVM is best algorithms for requirements classification. Perez-Verdejo et al. (2020) found that Naïve Bayes and Decision Tree perform better than other ML techniques. However, our review observed that BERT-based algorithms performed better than SVM algorithms.
From the above mentioned studies, transfer learning based approaches produced promising results in classification of software requirements classification. It is observed that transfer learning models perform well on small or even on large datasets.
7.2 Limitations
During conducting the literature review, number of limitations is observed while reporting and evaluating ML approaches. These limitations are discussed as follows:
7.2.1 Studies are still over old datasets
In the section, Table 14 presents the most commonly used dataset in these studies is PROMISE dataset. This dataset was created by Cleland-Huang in 2006. The dataset contain 625 functional and non-functional requirements. The requirements are labeled by 15 by graduation students. These requirements are manually categorized by annotators and made available on PROMISE repository. This is the well know benchmark dataset widely used in requirements classification domain.
It is observed that majority of the studies still use this dataset to facilitate a comparison of its results to previous studies. Thus, the uses of the datasets tend to be preserved. One way to solve this problem is to expand it by adding new requirements. In this way, it will be possible to compare the results to previous works and evaluate the methods using large benchmarks. Only one study (S48) has add new requirements to PROMISE dataset, hence there dataset contain 6000 requirements.
7.2.2 Scarcity of evaluation and reported results
-
From the selected studies, noted that these supervised learning techniques require labeled dataset to yield satisfactory performance. In addition, input requirements must be in understandable format of supervised learning techniques is known as pre-processing steps. However, most of the studies have presented supervised learning techniques as ‘Black boxes’, and provide no explicit explanation of actual working of these techniques. For example, how they extract features how they retain contextual relationship. As a result, this makes review study fairly difficult. To ensure the consistency of SLR, general process of selected studies is shown in Fig. 3. Moreover, we also assessed the reported results to infer how these approaches works.
-
Out of 61 studies, 48 studies have reported evaluated results. Only S41 nd S55 have explained why the authors have chosen precision, recall and f1-score to evaluate the performance of classifier. Other than that, none of studies have explained why they evaluate precision, recall and which metric value is more important and why. From this it can be concluded that majority of the studies have adopted these metrics for the sake of comparison and did not know why they used specific method. Only S31 have publicly provided their code for reproducibility of results and S25 shared partial code of machine learning techniques. In addition, none of the study provides python code for the reproducibility of results.
7.3 Open challenges
Through the overall assessment, this SLR has identified three open challenges faced by practitioners, elaborated as follows:
7.3.1 Need of new benchmark dataset
From the SLR, it is observed that majority of the studies still use those same datasets (PROMISE, DOORS and EHR) for the sake of comparison with the previous studies. In addition, aforementioned datasets are small in size and contain limited number of requirements. Thus, there is a need for few benchmark dataset in expansion of existing dataset and methods are evaluated using large datasets. In addition, existing benchmark datasets are imbalanced in nature. Therefore, balancing techniques needs more exploration in context of requirements classification. Only S60 has employed Synthetic Minority Over-sampling Technique (SMOTE) technique, and S36 has adopted Undersampling and oversampling techniques for requirements classification.
7.3.2 Computational cost
It is worth mentioning that this SLR focused on AI techniques in requirements classification. The problem with these techniques is the complexity of the model i.e. the output layers require same number of layers for labelling. As a result, model becomes more complex and increase computational cost and time. To mitigate this threat, there is need of optimized neural network models that remove the trade-off between algorithms’ speed and its computational cost.
8 Threats to validity
In this review paper, two most validity threats to requirements classification are discussed as below.
8.1 Construct validity
Construct validity is one of the crucial threats that contain high risks, because search strings are used to extract relevant studies. To mitigate this threat, we are not only restricting our research on “Artificial Intelligence techniques”, but also included the most closely related terms (“Machine Learning”, “Deep Learning”, “Transfer Learning”, and “neural language model”) in PICOC criteria. This enables us to capture more specific techniques in requirements classification.
The other threat to construct validity is inclusion/exclusion criteria. Relevant studies are captured on the basis of review protocol discussed in Sect. 3.3. During the process, some of the relevant studies may be missed out and leads to biasness and ultimately effects the conclusion. To mitigate this threat, authors of this paper have discussed that which study should be included in this review.
8.2 Conclusion validity
It is possible that, some studies included in the review, have not clear information for answering the research questions. To mitigate this threat, details of such studies are analyzed on other resources that is written by same author or on the similar topic. These studies were harmonized by all the authors to mitigate the personal biasness. It is worth noting that, the period for this SLR is from 2012 to 2022. As shown in Table 1, there is currently no SLR on the use of AI techniques in identification and classification of software requirements from SRS documents and from app reviews. Binkhonain and Zhao (2019) have exploited only machine learning techniques in requirement classification. Jivani (2011) has discussed only deep learning techniques in requirements classification. Dąbrowski et al. (2022) have identified software requirements from app reviews. This review paper discussed the studies that utilized AI techniques for identification and classification of software requirements from SRS documents and app reviews.
9 Conclusion
In this research work, SLR is conducted to investigate the use of AI techniques in identification and classification of software requirements. The main goal was to seek the understanding of how these approaches perform in RE. Total sixty one studies have reported in systematic review that adopted automated techniques for requirements classification. Out of 61 studies, 25 studies have used machine learning techniques, 21 studies have adopted deep learning and 9 studies have utilized transfer learning based models. Six studies have proposed ensemble model in integration with two techniques. The review results indicate that transformer based deep learning models outperforms other AI techniques.
The main aim of this SLR is to answer the designed research questions to essence the possible improvement of relevant current studies in AI techniques. In thorough systematic research, 61 studies were examined to answer the research questions by finding the working of AI techniques, what evaluation measures are adopted to evaluate these approaches. On this SLR, a review protocol is designed and some the review protocol describes the aim of this research and how it was achieved. The study selection, inclusion/exclusion, study quality assessment, and data extraction processes are executed in line with protocol. During study selection, a subset of primary studies was achieved. With the help of forward and backward snowballing, other relevant studies are added to the subset. Despite from computational complexity it is concluded that, BERT models outperforms ML and DL approaches.
There are few limitations that are stem from this review. First is, old dataset adopted by the majority of the studies. These existing public datasets consist of limited number of requirements that are sometimes fails to match with the extensive systems and software. Second is the evaluation measure, the standard evaluation measure are required to help developers to report and evaluate their studies. Third is, methodology of proposed model should be clearly explained along with the python code so that readers can easily understand and reproduce the studies.
In this SLR, open challenges are also discussed. The first challenge is to create the new benchmark dataset. The quality and quantity of public dataset needs to be encouraging the research in AI techniques. The findings reveal that shared datasets, tools and codes are the fundamental requirements in RE.
In conclusion, this study reports recent AI advances in RE. More specifically, in collaboration with AI techniques, new decision-support and intelligent systems can be develop to support RE tasks and software engineering processes. In future work, we intend to further investigate the some of the research direction with the emphasis on the integration between the app reviews and software architecture through the use AI techniques. Moreover, we intend to continue this SLR to explain how AI techniques have been supporting the entire software development process.
10 Appendix 1 Distribution of studies across different countries
See Fig. 5

Distribution of selected studies across different countries
11 Appendix 2
See Table 19.
12 Appendix 3 Distribution of selected studies over different venue
See Fig. 6

Distribution of selected studies over different venue
13 Appendix 4 Reference of selected studies
Paper ID | References |
|---|---|
S01 | Rashwan, A., 2012, May. Semantic analysis of functional and non-functional requirements in software requirements specifications. In Canadian Conference on Artificial Intelligence (pp. 388–391). Springer, Berlin, Heidelberg |
S02 | Slankas, J. and Williams, L., 2013, May. Automated extraction of non-functional requirements in available documentation. In 2013 1st International workshop on natural language analysis in software engineering (NaturaLiSE) (pp. 9–16). IEEE |
S03 | Mahalakshmi, K. and Prabhakar, R., 2015. Hybrid Optimization of SVM for Improved Non-Functional Requirements Classification. International Journal of Applied Engineering Research, 10(20) |
S04 | Guzman, E., El-Haliby, M. and Bruegge, B., 2015, November. Ensemble methods for app review classification: An approach for software evolution (n). In 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE) (pp. 771–776). IEEE |
S05 | Panichella, S., Di Sorbo, A., Guzman, E., Visaggio, C.A., Canfora, G. and Gall, H.C., 2015, September. How can i improve my app? classifying user reviews for software maintenance and evolution. In 2015 IEEE international conference on software maintenance and evolution (ICSME) (pp. 281–290). IEEE |
S06 | Gu, X. and Kim, S., 2015, November. " what parts of your apps are loved by users?"(T). In 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE) (pp. 760–770). IEEE |
S07 | Winkler, J. and Vogelsang, A., 2016, September. Automatic classification of requirements based on convolutional neural networks. In 2016 IEEE 24th International Requirements Engineering Conference Workshops (REW) (pp. 39–45). IEEE |
S08 | Maalej, W., Kurtanović, Z., Nabil, H. and Stanik, C., 2016. On the automatic classification of app reviews. Requirements Engineering, 21(3), pp.311–331. Springer |
S09 | Kurtanović, Z. and Maalej, W., 2017, September. Automatically classifying functional and non-functional requirements using supervised machine learning. In 2017 IEEE 25th International Requirements Engineering Conference (RE) (pp. 490–495). Ieee |
S10 | Lu, M. and Liang, P., 2017, June. Automatic classification of non-functional requirements from augmented app user reviews. In Proceedings of the 21st International Conference on Evaluation and Assessment in Software Engineering (pp. 344–353). ACM |
S11 | Navarro-Almanza, R., Juarez-Ramirez, R. and Licea, G., 2017, October. Towards supporting software engineering using deep learning: A case of software requirements classification. In 2017 5th International Conference in Software Engineering Research and Innovation (CONISOFT) (pp. 116–120). IEEE |
S12 | Deocadez, R., Harrison, R. and Rodriguez, D., 2017, September. Automatically classifying requirements from app stores: A preliminary study. In 2017 IEEE 25th international requirements engineering conference workshops (REW) (pp. 367–371). IEEE |
S13 | Johann, T., Stanik, C. and Maalej, W., 2017, September. Safe: A simple approach for feature extraction from app descriptions and app reviews. In 2017 IEEE 25th international requirements engineering conference (RE) (pp. 21–30). IEEE |
S14 | Ezami, S., 2018. Extracting non-functional requirements from unstructured text (Master’s thesis, University of Waterloo) |
S15 | Tóth, L. and Vidács, L., 2018, May. Study of various classifiers for identification and classification of non-functional requirements. In International Conference on Computational Science and Its Applications (pp. 492–503). Springer, Cham |
S16 | Fong, V.L., 2018. Software requirements classification using word embeddings and convolutional neural networks |
S17 | Stanik, C., Haering, M. and Maalej, W., 2019, September. Classifying multilingual user feedback using traditional machine learning and deep learning. In 2019 IEEE 27th international requirements engineering conference workshops (REW) (pp. 220–226). IEEE |
S18 | Baker, C., Deng, L., Chakraborty, S. and Dehlinger, J., 2019, July. Automatic multi-class non-functional software requirements classification using neural networks. In 2019 IEEE 43rd annual computer software and applications conference (COMPSAC) (Vol. 2, pp. 610–615). IEEE |
S19 | Dalpiaz, F., Dell’Anna, D., Aydemir, F.B. and Çevikol, S., 2019, September. Requirements classification with interpretable machine learning and dependency parsing. In 2019 IEEE 27th International Requirements Engineering Conference (RE) (pp. 142–152). IEEE |
S20 | Li, L.F., Jin-An, N.C., Kasirun, Z.M. and Chua, Y.P., 2019. An Empirical comparison of machine learning algorithms for classification of software requirements. International Journal of Advanced Computer Science and Applications, 10(11) |
S21 | Rahman, M.A., Haque, M.A., Tawhid, M.N.A. and Siddik, M.S., 2019, August. Classifying non-functional requirements using RNN variants for quality software development. In Proceedings of the 3rd ACM SIGSOFT International Workshop on Machine Learning Techniques for Software Quality Evaluation (pp. 25–30) |
S22 | Haque, M.A., Rahman, M.A. and Siddik, M.S., 2019, May. Non-functional requirements classification with feature extraction and machine learning: An empirical study. In 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT) (pp. 1–5). IEEE |
S23 | Messaoud, M.B., Jenhani, I., Jemaa, N.B. and Mkaouer, M.W., 2019, August. A multi-label active learning approach for mobile app user review classification. In International Conference on Knowledge Science, Engineering and Management (pp. 805–816). Springer, Cham |
S24 | Younas, M., Wakil, K., Jawawi, D.N., Shah, M.A. and Ahmad, M., 2019. An automated approach for identification of non-functional requirements using word2vec model. International Journal of Advanced Computer Science and Applications, 10(8) |
S25 | Jha, N. and Mahmoud, A., 2019. Mining non-functional requirements from app store reviews. Empirical Software Engineering, 24(6):3659–3695 |
S26 | Dias Canedo, E. and Cordeiro Mendes, B., 2020. Software requirements classification using machine learning algorithms. Entropy, 22(9), p.1057 |
S27 | Sabir, M., Chrysoulas, C. and Banissi, E., 2020, April. Multi-label classifier to deal with misclassification in non-functional requirements. In World Conference on Information Systems and Technologies (pp. 486–493). Springer, Cham |
S28 | Aslam, N., Ramay, W.Y., Xia, K. and Sarwar, N., 2020. Convolutional neural network based classification of app reviews. IEEE Access, 8, pp.185619–185,628 |
S29 | Rahimi, N., Eassa, F. and Elrefaei, L., 2020. An ensemble machine learning technique for functional requirement classification. symmetry, 12(10), p.1601 |
S30 | Tiun, S., Mokhtar, U.A., Bakar, S.H. and Saad, S., 2020, April. Classification of functional and non-functional requirement in software requirement using Word2vec and fast Text. In journal of Physics: conference series (Vol. 1529, No. 4, p. 042077). IOP Publishing |
S31 | Hey, T., Keim, J., Koziolek, A. and Tichy, W.F., 2020, August. NoRBERT: Transfer learning for requirements classification. In 2020 IEEE 28th International Requirements Engineering Conference (RE) (pp. 169–179). IEEE |
S32 | de Araújo, A.F. and Marcacini, R.M., 2021, March. Re-bert: automatic extraction of software requirements from app reviews using Bert language model. In Proceedings of the 36th Annual ACM Symposium on Applied Computing (pp. 1321–1327) |
S33 | Li, B., Li, Z. and Yang, Y., 2021, September. NFRNet: A Deep Neural Network for Automatic Classification of Non-Functional Requirements. In 2021 IEEE 29th International Requirements Engineering Conference (RE) (pp. 434–435). IEEE |
S34 | López-Hernández, D.A., Mezura-Montes, E., Ocharán-Hernández, J.O. and Sánchez-García, A.J., 2021, November. Non-functional Requirements Classification using Artificial Neural Networks. In 2021 IEEE International Autumn Meeting on Power, Electronics and Computing (ROPEC) (Vol. 5, pp. 1–6). IEEE |
S35 | Kici, D., Malik, G., Cevik, M., Parikh, D. and Basar, A., 2021. A BERT-based transfer learning approach to text classification on software requirements specifications. In Canadian Conference on AI |
S36 | Kici, D., Bozanta, A., Cevik, M., Parikh, D. and Başar, A., 2021, November. Text classification on software requirements specifications using transformer models. In Proceedings of the 31st Annual International Conference on Computer Science and Software Engineering (pp. 163–172) |
S37 | Quba, G.Y., Al Qaisi, H., Althunibat, A. and AlZu’bi, S., 2021, July. Software requirements classification using machine learning algorithm’s. In 2021 International Conference on Information Technology (ICIT) (pp. 685–690). IEEE |
S38 | Shariff, H., 2021. Non-Functional Requirement Detection Using Machine Learning and Natural Language Processing. Turkish Journal of Computer and Mathematics Education (TURCOMAT), 12(3):2224–2229 |
S39 | EzzatiKarami, M. and Madhavji, N.H., 2021, April. Automatically classifying non-functional requirements with feature extraction and supervised machine learning techniques: A research preview. In International Working Conference on Requirements Engineering: Foundation for Software Quality (pp. 71–78). Springer, Cham |
S40 | Sabir, M., Banissi, E. and Child, M., 2021, March. A deep learning-based framework for the classification of non-functional requirements. In World Conference on Information Systems and Technologies (pp. 591–601). Springer, Cham |
S41 | Henao, P.R., Fischbach, J., Spies, D., Frattini, J. and Vogelsang, A., 2021, September. Transfer learning for mining feature requests and bug reports from tweets and app store reviews. In 2021 IEEE 29th International Requirements Engineering Conference Workshops (REW) (pp. 80–86). IEEE |
S42 | Talele, P. and Phalnikar, R., 2021. Software requirements classification and prioritisation using machine learning. In Machine learning for predictive analysis (pp. 257–267). Springer, Singapore |
S43 | Shreda, Q.A. and Hanani, A.A., 2021. Identifying non-functional requirements from unconstrained documents using natural language processing and machine learning approaches. IEEE Access |
S44 | Gnanasekaran, R.K., Chakraborty, S., Dehlinger, J. and Deng, L., 2021. Using Recurrent Neural Networks for Classification of Natural Language-based Non-functional Requirements. In REFSQ Workshops |
S45 | Jindal, R., Malhotra, R., Jain, A. and Bansal, A., 2021. Mining Non-Functional Requirements using Machine Learning Techniques. e-Informatica Software Engineering Journal, 15(1) |
S46 | Mekala, R.R., Irfan, A., Groen, E.C., Porter, A. and Lindvall, M., 2021, September. Classifying user requirements from online feedback in small dataset environments using deep learning. In 2021 IEEE 29th International Requirements Engineering Conference (RE) (pp. 139–149). IEEE |
S47 | Hidayat, T. and Rochimah, S., 2021, December. NFR Classification using Keyword Extraction and CNN on App Reviews. In 2021 4th International Seminar on Research of Information Technology and Intelligent Systems (ISRITI) (pp. 211–216). IEEE |
S48 | Araujo, A.F., Gôlo, M.P. and Marcacini, R.M., 2022. Opinion mining for app reviews: an analysis of textual representation and predictive models. Automated Software Engineering, 29(1), pp.1–30 |
S49 | Li, B. and Nong, X., 2022. Automatically classifying non-functional requirements using deep neural network. Pattern Recognition, 132, p.108948 |
S50 | Dave, D. and Anu, V., 2022, June. Identifying Functional and Non-functional Software Requirements From User App Reviews. In 2022 IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS) (pp. 1–6). IEEE |
S51 | Khayashi, F., Jamasb, B., Akbari, R. and Shamsinejadbabaki, P., 2022. Deep Learning Methods for Software Requirement Classification: A Performance Study on the PURE dataset. arXiv preprint arXiv:2211.05286 |
S52 | Li, G., Zheng, C., Li, M. and Wang, H., 2022. Automatic Requirements Classification Based on Graph Attention Network. IEEE Access, 10, pp.30080–30090 |
S53 | Kaur, K. and Kaur, P., 2022. SABDM: A self-attention based bidirectional-RNN deep model for requirements classification. Journal of Software: Evolution and Process, p.e2430 |
S54 | Handa, N., Sharma, A. and Gupta, A., 2022. Framework for prediction and classification of non functional requirements: a novel vision. Cluster Computing, 25(2), pp.1155–1173 |
S55 | AlDhafer, O., Ahmad, I. and Mahmood, S., 2022. An end-to-end deep learning system for requirements classification using recurrent neural networks. Information and Software Technology, 147, p.106877 |
S56 | Vijayvargiya, S., Kumar, L., Malapati, A., Murthy, L.B. and Misra, S., 2022. Software Functional Requirements Classification Using Ensemble Learning. In International Conference on Computational Science and Its Applications (pp. 678–691). Springer, Cham |
S57 | Vijayvargiya, S., Kumar, L., Murthy, L.B. and Misra, S., 2022, September. Software Requirements Classification using Deep-learning Approach with Various Hidden Layers. In 2022 17th Conference on Computer Science and Intelligence Systems (FedCSIS) (pp. 895–904). IEEE |
S58 | Jp, S., Menon, V.K., Soman, K.P. and Ojha, A.K., 2022. A Non-Exclusive Multi-Class Convolutional Neural Network for the Classification of Functional Requirements in AUTOSAR Software Requirement Specification Text. IEEE Access, 10, pp.117707–117714 |
S59 | Duan, S., Liu, J. and Peng, Z., 2022. RCBERT an Approach with Transfer Learning for App Reviews Classification. In CCF Conference on Computer Supported Cooperative Work and Social Computing (pp. 444–457). Springer, Singapore |
S60 | Kumar, L., Baldwa, S., Jambavalikar, S. M., Murthy, L. B., & Krishna, A. (2022). Software Functional and Non-function Requirement Classification Using Word-Embedding. In International Conference on Advanced Information Networking and Applications (pp. 167–179). Springer, Cham |
S61 | Luo, X., Xue, Y., Xing, Z., & Sun, J. (2023). PRCBERT: Prompt Learning for Requirement Classification using BERT-based Pretrained Language Models. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering (pp. 1–13) |
References
Abad ZSH, Karras O, Ghazi P, Glinz M, Ruhe G, Schneider K (2017) What works better? A study of classifying requirements. In: 2017 IEEE 25th international requirements engineering conference (RE), pp 496–50. IEEE
Alpaydin E (2020) Introduction to machine learning. MIT Press, Cambridge
Anwar Mohammad MN, Nazir M, Mustafa K (2019) A systematic review and analytical evaluation of security requirements engineering approaches. Arab J Sci Eng 44: 8963–8987.
Araujo AF, Gôlo MP, Marcacini RM (2022) Opinion mining for app reviews: an analysis of textual representation and predictive models. Autom Softw Eng 29(1):1–30. https://doi.org/10.1007/s10515-021-00301-1
de Araújo AF, Marcacini RM (2021) Re-bert: automatic extraction of software requirements from app reviews using bert language model. In: Proceedings of the 36th annual ACM symposium on applied computing, pp 1321–1327
Aslam N, Ramay WY, Xia K, Sarwar N (2020) Convolutional neural network based classification of app reviews. IEEE Access 8:185619–185628
Binkhonain, M., & Zhao, L. (2019). A review of machine learning algorithms for identification and classification of non-functional requirements. Expert Systems with Applications: X, 1. https://doi.org/10.1016/j.eswax.2019.100001
Burges CJ (1998) A tutorial on support vector machines for pattern recognition. Data Min Knowl Disc 2(2):121–167
Casamayor A, Godoy D, Campo M (2010) Identification of non-functional requirements in textual specifications: a semi-supervised learning approach. Inf Softw Technol 52(4):436–445. https://doi.org/10.1016/j.infsof.2009.10.010
Cavnar WB, Trenkle JM (1994) N-gram-based text categorization. In: Proceedings of SDAIR-94, 3rd annual symposium on document analysis and information retrieval, vol 161175
Chen Y (2015) Convolutional neural network for sentence classification. Master’s thesis, University of Waterloo
Clark C, Lee K, Zettlemoyer L (2018) Deep contextualized word representations
Cleland-Huang J, Settimi R, Zou X, Solc P (2007) Automated classification of non-functional requirements. Requir Eng 12(2):103–120. https://doi.org/10.1007/s00766-007-0045-1
Dąbrowski J, Letier E, Perini A, Susi A (2022) Analyzing app reviews for software engineering: a systematic literature review. Empir Softw Eng 27(2):1–63
Deocadez R, Harrison R, Rodriguez D (2017) Automatically classifying requirements from app stores: a preliminary study. In: 2017 IEEE 25th international requirements engineering conference workshops (REW), pp 367–371. IEEE
Dermeval D, Vilela J, Bittencourt II, Castro J, Isotani S, Brito P, Silva A (2016) Applications of ontologies in requirements engineering: a systematic review of the literature. Requir Eng 21(4):405–437
Devlin J, Chang MW, Lee K, Toutanova K (2018) Bert: pre-training of deep bidirectional transformers for language understanding. ArXiv preprint arXiv:1810.04805
Duan S, Liu J, Peng Z (2022) RCBERT an approach with transfer learning for app reviews classification. In: Computer supported cooperative work and social computing: 16th CCF conference, ChineseCSCW 2021, Xiangtan, China, pp 444–457, Springer
Gershenson C (2003) Artificial neural networks for beginners. arXiv preprint cs/0308031
Gu X, Kim S (2016) What parts of your apps are loved by users?In: Proceedings-2015 30th IEEE/ACM international conference on automated software engineering, ASE 2015, pp 760–770. https://doi.org/10.1109/ASE.2015.57
Haque MA, Rahman MA, Siddik MS (2019) Non-functional requirements classification with feature extraction and machine learning: An empirical study. In: 2019 1st international conference on advances in science, engineering and robotics technology (ICASERT), pp 1–5. IEEE
Henao PR, Fischbach J, Spies D, Frattini J, Vogelsang A (2021) September. Transfer learning for mining feature requests and bug reports from tweets and app store reviews. In 2021 IEEE 29th International Requirements Engineering Conference Workshops (REW) (pp. 80–86). IEEE
Hey T, Keim J, Koziolek A, Tichy WF (2020) Norbert: transfer learning for requirements classification. In: 2020 IEEE 28th international requirements engineering conference (RE), pp 169–179. IEEE
Hilbe JM (2016) Practical guide to logistic regression. CRC Press, Boca Raton
Hochreiter S (1997) Long short-term memory. 1780:1735–1780
Jha N, Mahmoud A (2019) Mining non-functional requirements from app store reviews. Empir Softw Eng 24:3659–3695
Jivani AG (2011) A comparative study of stemming algorithms. Int J Comp Tech Appl 2(6):1930–1938
Joulin A, Grave E, Bojanowski P, Douze M, Jégou H, Mikolov T (2016) Fasttext. Zip: compressing text classification models. arXiv preprint arXiv:1612.03651
Khan A, Baharudin B, Lee LH, Khan K (2010) A review of machine learning algorithms for text-documents classification. J Adv Inf Technol 1(1):4–20
Kitchenham, B., & Charters, S. (2007). Guidelines for performing systematic literature reviews in software engineering.
Kotonya G, Sommerville I (1998) Requirements engineering: processes and techniques. Wiley, Hoboken
Kurtanović Z, Maalej W (2017) Automatically classifying functional and non-functional requirements using supervised machine learning. In: 2017 IEEE 25th international requirements engineering conference (RE), pp 490–495. IEEE
Laura I, Santi S (2017) Introduction to data science: a python approach to concepts, techniques and applications
Le Q, Mikolov T (2014) Distributed representations of sentences and documents. In: International conference on machine learning, pp 1188–1196. PMLR
Lewis DD (1998) Naive (Bayes) at forty: the independence assumption in information retrieval. In: European conference on machine learning, pp 4–15. Springer, Berlin, Heidelberg
Lu M, Liang P (2017) Automatic classification of non-functional requirements from augmented app user reviews. In: Proceedings of the 21st international conference on evaluation and assessment in software engineering, pp 344–353)
Maalej W, Kurtanović Z, Nabil H, Stanik C (2016) On the automatic classification of app reviews. Requir Eng 21:311–331
De Marneffe MC, Manning CD (2008) The Stanford typed dependencies representation. In: Coling 2008: proceedings of the workshop on cross-framework and cross-domain parser evaluation, pp 1–8
Marneffe MD, Manning CD (2008) The Stanford typed dependencies representation, pp 1–8
Meth H, Brhel M, Maedche A (2013) The state of the art in automated requirements elicitation. Inf Softw Technol 55(10):1695–1709
Mikolov T, Chen K, Corrado G, Dean J (2013) Efficient estimation of word representations in vector space. In: 1st international conference on learning representations, ICLR 2013-workshop track proceedings, pp 1–12
Mining D, Discovery K, Laboratories B, Technologies L (1998) A tutorial on support vector machines for pattern recognition. 167:121–167
Navarro-Almanza R, Juarez-Ramirez R, Licea G (2017) Towards supporting software engineering using deep learning: a case of software requirements classification. In: 2017 5th international conference in software engineering research and innovation (CONISOFT), pp 116–120. IEEE
Nowak J, Taspinar A, Scherer R (2017) LSTM recurrent neural networks for short text and sentiment classification. In: International conference on artificial intelligence and soft computing, pp 553–562. Springer, Cham
Nuseibeh B (2001) Weaving together requirements and architectures. Computer 34(3):115–119. https://doi.org/10.1109/2.910904
Pennington J, Socher R, Manning CD (2014) Glove: global vectors for word representation. In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pp 1532–1543
Pérez-Verdejo JM, Sánchez-García AJ, Ocharán-Hernández JO (2020) A systematic literature review on machine learning for automated requirements classification. In: 2020 8th international conference in software engineering research and innovation (CONISOFT), pp 21–28. IEEE
Quinlan JR (1996) Bagging, boosting, and C4. 5. In: Aaai/Iaai, vol 1, pp 725–730
Rashwan A, Ormandjieva O, Witte R (2013) Ontology-based classification of non-functional requirements in software specifications: a new corpus and svm-based classifier. In: 2013 IEEE 37th annual computer software and applications conference, pp 381–386. IEEE
Ribeiro MT, Guestrin C (2016) “Why should i trust you ?” Explaining the predictions of any classifier. pp 1135–1144
Ribeiro MT, Singh S, Guestrin C (2016) “Why should i trust you?” Explaining the predictions of any classifier. In: Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pp 1135–1144
Schuster M, Paliwal KK (1997) Bidirectional recurrent neural networks. IEEE Trans Signal Process 45(11):2673–2681
Selby RW (2007) Software engineering: Barry W. Boehm’s lifetime contributions to software development, management, and research. Wiley, Hoboken
Slankas J, Williams L (2013) Automated extraction of non-functional requirements in available documentation. In: 2013 1st international workshop on natural language analysis in software engineering (NaturaLiSE), pp 9–16. IEEE
Stanik C, Haering M, Maalej W (2019) September. Classifying multilingual user feedback using traditional machine learning and deep learning. In 2019 IEEE 27th international requirements engineering conference workshops (REW) (pp. 220–226). IEEE
Tóth L, Vidács L (2018) Study of various classifiers for identification and classification of non-functional requirements. In: Computational science and its applications–ICCSA 2018: 18th international conference, Melbourne, Australia, pp 492–503. Springer International Publishing
Wiegers K, Beatty J (2013) Software requirements. Pearson Education, London
Wohlin C (2014) Guidelines for snowballing in systematic literature studies and a replication in software engineering. In Proceedings of the 18th international conference on evaluation and assessment in software engineering, pp 1–10
Younas M, Jawawi DNA, Ghani I, Shah MA (2020) Extraction of non-functional requirement using semantic similarity distance. Neural Comput Appl 32(11):7383–7397. https://doi.org/10.1007/s00521-019-04226-5
Funding
No funding was received for conducting this study.
Author information
Authors and Affiliations
Contributions
Kamaljit Kaur: concept or design of the article; the acquisition, analysis,interpretation of data, Drafted the article Parminder Kaur: revised it critically for important intellectual content; Approved the version to be published
Corresponding author
Ethics declarations
Conflict of interest
The authors have declared that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kaur, K., Kaur, P. The application of AI techniques in requirements classification: a systematic mapping. Artif Intell Rev 57, 57 (2024). https://doi.org/10.1007/s10462-023-10667-1
Published:
DOI: https://doi.org/10.1007/s10462-023-10667-1